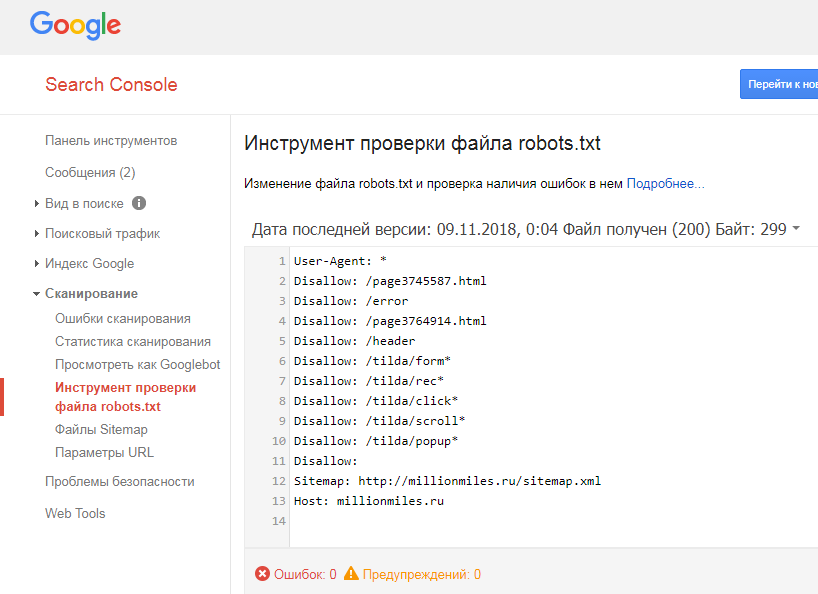
WordPress, Modx. Какая директива может закрыть страницу сайта от индексации
Поисковые роботы индексируют сайт независимо от наличия robots.txt и sitemap.xml, с помощью файла robots.txt можно указать поисковым машинам, что исключить из индекса, и настроить другие важные параметры.
Стоит учесть, что краулеры поисковых машин игнорируют определенные правила, например:
- Google Bot не использует директиву host и Crawl-Delay полный список поисковых роботов Google.
- Yandex Direct, YandexDirectDyn, Yandex Video Parser и другие специфичные роботы: обходят общие директивы, если они не написаны специально для них.
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года.
Основные — часто используемые директивы
User-agent: директива, с которой начинается Robots.txt.
Пример:
User-agent: * # указания для всех поисковых роботов.User-agent: Yandex
# указания для робота Яндекса. User-agent: GoogleBot # указания для робота Google. Disallow: # запрещающая директива, запрет индексции того, что указанно после /. Allow: # разрешающая директива, для указания на индексацию URL. Disallow: # не работает без спецсимвола /. Allow: / # игнорируются, если после / не указан URL.
 User-agent: Yandex
User-agent: Yandex Спецсимволы, которые используются в robots.txt
/, * , $.Обратите внимание на символ /, можно допустить крупную ошибку прописав например:
User-agent:* Disallow: / # таким образом можно закрыть весь сайт от индексации.
Спецсимвол * означает любую, в том числе и пустую, последовательность символов, например:
Disallow: /cart/* # закрывает от индексации все страницы после URL: site.ru/cart/
Спецсимвол $ ограничивает действие символа *, дает строгое ограничение:
User-agent:* Disallow: /catalog$ # при таком символе не будет индексироваться catalog, но в индексе будет catalog.
 html
htmlДиректива sitemap — указывает путь к карте сайта и выглядит так:
User-agent:* Allow: / Sitemap: http://www.site.ru/sitemap.xml # ее необходимо указывать с http:// или https://, https:// - указывается если подключён SSL сертификат
Директива Host — указывает главное зеркало сайта с www или без www.
User-agent:* Allow: / Sitemap: http://www.site.ru/sitemap.xml Host: www.site.ru # следует писать путь к домену без http и без слэшей, убедитесь, что домен склеен. Без правильной склейки домена, одна и та же страница может попасть в индекс поисковых систем более одного раза, что может повлечь пессимизацию.
Директива Crow-Delay — ограничивает нагрузку на сервер, задает таймаут для поисковых машин:
User-agent: * Crawl-delay:2 # задает таймаут в 2 секунды. User-agent: * Disallow: /search Crawl-delay: 4.5 # задает таймаут в 4.5 секунды.
Директива Clean-Param необходима, если адреса страниц сайта содержат динамические параметры, которые не влияют на содержимое, например: идентификаторы сессий, пользователей, рефереров и т. п.
п.
Робот Яндекса, используя значения директивы Clean-Param, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, страницы с таким адресом:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить, с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Также стоит отметить, что для этой директивы есть несколько вариантов настройки
Кириллические символы в robots.
 txt
txtИспользование символов русского алфавита запрещено в robots.txt, для этого необходимо использовать Punycode (стандартизированный метод преобразования последовательностей Unicode-символов в так называемые ACE-последовательности)
#Неверно: User-agent: * Disallow: /корзина Host: интернет-магазин.рф #Верно: User-agent: * Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Host: xn----8sbalhasbh9ahbi6a2ae.xn--p1aiРекомендации по тому, что нужно закрывать в файле robots.txt
- Административную панель — но при этом учтите, что путь к вашей административной панели будет известен, убедитесь в надежности пароля в панели управлением сайтом.
- Корзину, форму заказа, и данные по доставке и заказам.
- Страницы с параметрами фильтров, сортировки, сравнения.
- Пустая строка — недопустимо делать пустую строку в директиве user-agent, которая по правилам robots. txt считается «разделительной» (относительно блоков описаний). Это значит, что спрогнозировать применимость следующих за пустой строкой директив — нельзя.
- При конфликте между двумя директивами с префиксами одинаковой длины, приоритет отдается директиве Allow.
- Для каждого файла robots.txt обрабатывается только одна директива Host. Если в файле указано несколько директив, робот использует первую.
- Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
- Шесть роботов Яндекса не следуют правилам Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Чтобы запретить им индексацию на сайте, следует сделать отдельные параметры user-agent для каждого из них.
- Директива User-agent всегда должна писаться выше запрещающей директивы.
- Одна строка, для одной директории. Нельзя писать множество директорий на одной строке.
- Имя файла должно быть только таким: robots.txt. Никаких Robots.txt, ROBOTS.txt, и так далее. Только маленькие буквы в названии.
- В директиве host следует писать путь к домену без http и без слешей. Неправильно: Host: http://www.site.ru/, Правильно: Host: www.site.ru (или site.ru)
- При использовании сайтом защищенного протокола https в директиве host (для робота Яндекса) нужно обязательно указывать именно с протоколом, так Host: https://www.site.ru
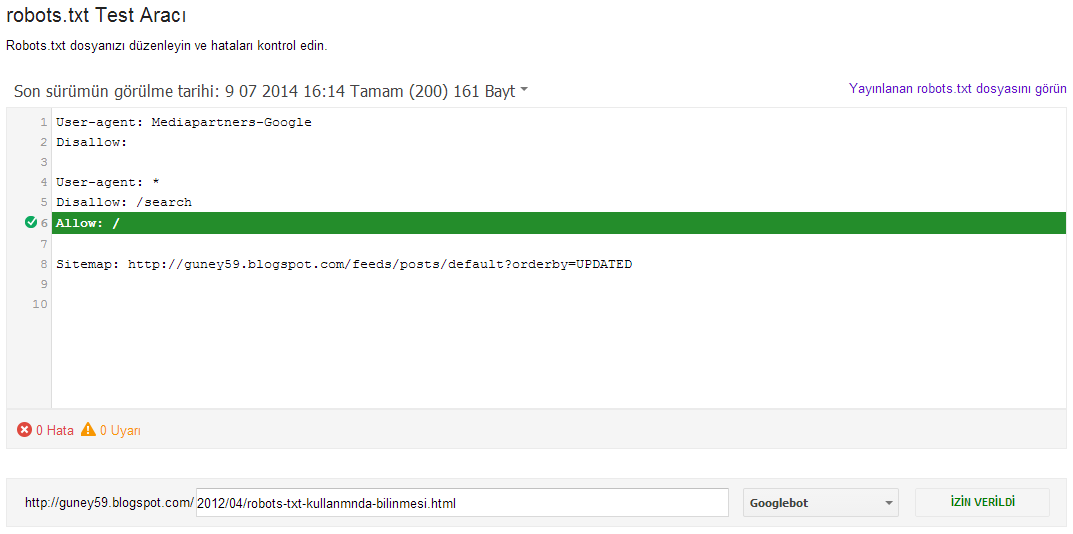 txt считается «разделительной» (относительно блоков описаний). Это значит, что спрогнозировать применимость следующих за пустой строкой директив — нельзя.
txt считается «разделительной» (относительно блоков описаний). Это значит, что спрогнозировать применимость следующих за пустой строкой директив — нельзя. 
labrika→в левом меню Технический аудит→в выпадающем меню→Ошибки robots.txt→перепроверить robots.txt
Необходимо учесть, что файл размером больше 32кб считывается как полностью разрешающий, вне зависимости от того, что написано.
Избыточное наполнение robots. txt. Начинающие веб-мастера впечатляются статьями, где сказано, что все ненужное необходимо закрыть в robots.txt и начинают закрывать вообще все, кроме текста на строго определенных страницах. Это, мягко говоря, неверно. Во-первых, существует рекомендация Google не закрывать скрипты, CSS и прочее, что может помешать боту увидеть сайт так же, как видит его пользователь. Во-вторых, очень большое количество ошибок связано с тем, что закрывая одно, пользователь закрывает другое тоже. Безусловно, можно и нужно проверять доступность страницы и ее элементов. Как вариант ошибки — путаница с последовательностью Allow и Disallow. Лучше всего закрывать в robots.txt только очевидно ненужные боту вещи, вроде формы регистрации, страницы перенаправления ссылок и т. п., а от дубликатов избавляться с помощью canonical. Обратите внимание: то, что вы поправили robots.txt, совсем не обозначает, что Yandex- bot и Google-bot его сразу перечитают. Для ускорения этого процесса достаточно посмотреть на robots.
txt. Начинающие веб-мастера впечатляются статьями, где сказано, что все ненужное необходимо закрыть в robots.txt и начинают закрывать вообще все, кроме текста на строго определенных страницах. Это, мягко говоря, неверно. Во-первых, существует рекомендация Google не закрывать скрипты, CSS и прочее, что может помешать боту увидеть сайт так же, как видит его пользователь. Во-вторых, очень большое количество ошибок связано с тем, что закрывая одно, пользователь закрывает другое тоже. Безусловно, можно и нужно проверять доступность страницы и ее элементов. Как вариант ошибки — путаница с последовательностью Allow и Disallow. Лучше всего закрывать в robots.txt только очевидно ненужные боту вещи, вроде формы регистрации, страницы перенаправления ссылок и т. п., а от дубликатов избавляться с помощью canonical. Обратите внимание: то, что вы поправили robots.txt, совсем не обозначает, что Yandex- bot и Google-bot его сразу перечитают. Для ускорения этого процесса достаточно посмотреть на robots. txt в соответствующем разделе вебмастера.
txt в соответствующем разделе вебмастера.
Примеры правильно настроенного robots.txt для разных CMS:
WordPressUser-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /tag Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: site.ru Sitemap: http://site.ru/sitemap.xmlModX
User-agent: * Disallow: /manager/ Disallow: /assets/components/ Disallow: /core/ Disallow: /connectors/ Disallow: /index.php Disallow: *? Host: example.ru Sitemap: http://example.ru/sitemap.xmlOpenCart
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /export Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Disallow: /*?page= Disallow: /*&page= Disallow: /wishlist Disallow: /login Disallow: /index.Joomla
 php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
BitrixUser-agent:* Allow: /index.php?option=com_xmap&sitemap=1&view=xml Disallow: /administrator/ Disallow: /cache/ Disallow: /components/ Disallow: /go.php Disallow: /images/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Disallow: /*com_mailto* Disallow: /*pop=* Disallow: /*lang=ru* Disallow: /*format=* Disallow: /*print=* Disallow: /*task=vote* Disallow: /*=watermark* Disallow: /*=download* Disallow: /*user/* Disallow: /.html Disallow: /index.php? Disallow: /index.html Disallow: /*? Disallow: /*% Disallow: /*& Disallow: /index2.php Disallow: /index.php Disallow: /*tag Disallow: /*print=1 Disallow: /trackback Host: Ваш сайт
User-agent: * Disallow: /*index.ru Sitemap: http://www.sitename.ru/sitemap.xml
 php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all= Host: sitename.
php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all= Host: sitename.
В данных примерах, в указании User-Agent указан параметр * , разрешающий доступ всем поисковым роботам, для настройки robots.txt под отдельные поисковые системы вместо спецсимвола указывается название робота Yandex, GoogleBot, StackRambler, Slurp, MSNBot, ia_archiver.
MODX — Карта сайта и Robots.txt — OLDESIGN.RU
Разработка и ведение стартапов, изготовление сайтов, дизайн печатной и сувенирной продукции, продвижение.
КАРТА САЙТА для MoDx:
- Создайте ресурс с именем sitemap
Во вкладке настроек ресурса выберите:
Тип содержимого (Content Type) — XML,
Шаблон документа — Пустой (Blank template)
- Установите дополнение GoogleSiteMap
- В настройках Ресурса отключите «использовать html-редактор»
- В содержимое поле контента вставьте вызов сниппета [ [ !GoogleSiteMap? ] ], убрав пробелы.
- Cохраните ресурс.

Карта сайта готова!
ROBOTS.TXT для MoDx
- Создайте ресурс с именем robots
Во вкладке настроек ресурса выберите:
Тип содержимого — text,
Шаблон документа — Пустой
- В настройках Ресурса отключите «использовать html-редактор»
- В содержимое поле контента вставьте код ниже
- Замените«domen.ru» на адрес домена вашего сайта.
- Cохраните ресурс.
User-agent: * Disallow: /manager/ Disallow: /assets/components/ Disallow: /core/ Disallow: /connectors/ Disallow: /index.php Disallow: *? Host: domen.ru Sitemap: http://domen.ru/sitemap.xml
Ваш правильный robots.txt для MoDx Revo готов, и карта сайта теперь находится по адресу:
http://вашдомен/sitemap. xml
xml
Комментарии (0)
Оставьте ваш комментарий:
- Все статьи блога
- Яндекс.Карты для MoDx Revo
Mapex — Лучшее дополнение для MODX Revolution…
- Эффект цвета в маркетинге
Цветовые схемы и психологические реакции клиентов…
- Центрирование в CSS
Центрирование элементов — самая популярная причина…
- Цветовой профиль Photoshop для верстальщика
Простыми словами о том как грамотно настроить…
- Цветовая схема для сайта
Коллекция сервисов для подбора или коррекции…
- Функция Php для удаления лишних символов из строки
Здесь представлена функция, которая вычищает…
- Стилизация всплывающих сообщений в AjaxForm
Стандартный и нестандартные методы изменения…
- Список HTML шрифтов
Таблица как показываются шрифты Web в разных…
- Скрипт для Instagram
Предлагаем вам 1 раз приобрести недорогой скрипт,…
- Сервисы для тестирования сайта на разных гаджетах
Список сервисов для тестирования и презентации…
- Сервисы для визуализации данных
Коллекция сервисов для подбора или коррекции…
- Разноплановые и необычные CSS и SVG меню
На данной странице мы собираем красивые и необычные…
- Перевод аудио в текст
Как перевести речевой аудио-файл в текст с помощью…
- Нейросети для создания и обработки изображений
Сервисы для обработки и создания изображений…
- Настройка Nic ru — сайт modx revo на ру-центре
Описание корректной установки системы Modx на…
- Минимальная Seo-настройка сайта
Статья по первоначальной и основной сео-оптимизации…
- Метки по углам — макрос для расставления меток в CorelDraw
Бесплатный, удобный и простой макрос, который…
- Маркетинг ручной работы
Эта краткая статья поможет тем, кто хочет увеличить…
- Макрос для CorelDraw — Curve info
Удобный и практичный макрос площади, периметра…
- Лучшая адаптивная галерея Fotorama
Fotorama — мощная и многофункциональная галерея,…
- Как избежать штрафа о хранении и обработке персональных данных
С 1 июля 2017 года вступают в силу поправки к…
- Как вставить Google forms на сайт
Как сделать из обычной формы гугл — точную копию…
- Горячие клавиши браузеров
Горячие клавиши при работе с браузером, которые…
- Всплывающие окна popup при загрузке страницы
2 простейших рабочих варианта всплывающих окон…
- Все meta-tags на вашем сайте
Метатеги, которые используются для хранения информации…
- ReCaptchaV2 для MoDx Revolution
Описание установки ReCaptcha 2 от Google на сайт…
- PrintNCut — макрос для печати и резки в CorelDraw
Удобный и практичный макрос, который ускорит…
- Open Server и Dr. Web — разрешаем файл Hosts
Как разрешить на запись файл HOSTS для настройки…
- MoDx обновление 2.6.5
С 19 июля 2018 года произошла большая атака на…
- MODX Revolution с http на https
Статья, кратко и по делу, описывающая правильных…
- MODX — Карта сайта и Robots.txt
В этой статье простым языком написано как установить…
- meta — теги для сайта MoDx Revo
Для того чтобы у каждой страницы вашего сайта…
- LESS на стороне клиента
Использование на стороне клиента (в самом браузере)…
- Iconogen — сервис автоматической генерации Favicon
Это сервис поможет вам быстро сгенерировать favicon…
- HTML5 аудио-плеер с плейлистом
Аудио-плеер на основе технологии HTML5. Он состоит…
- HSL — цветовая палитра и прозрачность
Значения цвета HSLA являются расширением значений…
- FormIt на MoDx Revolution
FORMIT — это приложение для обработки формы в…
- Eurowebcart — CMS для создания магазина
Система управления сайтом Eurowebcart позволяет…
 Web — разрешаем файл Hosts
Web — разрешаем файл HostsMade in Russia 2005-2021
КОНТАКТЫ / Политика конфиденциальности
ModX — как сделать Sitemap.
 xml, robots.txt; как убрать ‘.html’ расширение у страниц сайта
xml, robots.txt; как убрать ‘.html’ расширение у страниц сайтаСоздание sitemap.xml
Sitemap – это карта сайта. В основном она нужна для поисковых ботов, чтобы они могли зайти по адресу
site.ru/sitemap.xml и увидели все ссылки на все ресурсы, которые есть на вашем сайте. Например, если у
вас 100 страниц, то в sitemap также будет отображено 100 страниц. Формат данных представлен в виде
XML (eXtensible Markup Language) структуры.
Также на некоторых веб ресурсах Вы можете встретить страницы вида site.ru/sitemap.html. Такие страницы
делаются для оптимизации ссылочных масс. Здесь отображают основные страницы вашего сайта, а также ставят ссылки на
партнеров ресурса. Таким образом вы делитесь своим «весом» с другими сайтами сети, тем самым продвигая друг друга.
В случае отсутствия sitemap на сайте, поисковым роботам будет очень трудно найти все страницы вашего
веб ресурса, как следствие ваши страницы будут медленнее появляться в поисковой выдаче.
Sitemap на ModX создается очень просто. В прошлой статье про установку плагинов мы
поставили расширение под название pdoTools, которое нам пригодится:
- Во вкладке ресурсы нажимаем на «+» и создаем новую страницу
- Во вкладке «Документ» в заголовок пишем «Sitemap»
-
Во вкладке «Настройки» убираем галочку
«Использовать HTML редактор»а тип содержимого выставляем «XML» -
В самом содержимом пишем простую инструкцию
[[!pdoSitemap]] - Сохраняем и можем перейти в ресурс и убедиться в правильности отображения контента.
Создание robots.txt
Robots.txt – это текстовый файл, который обычно находится в корне сайта и доступен по адресу:
site.ru/robots.txt.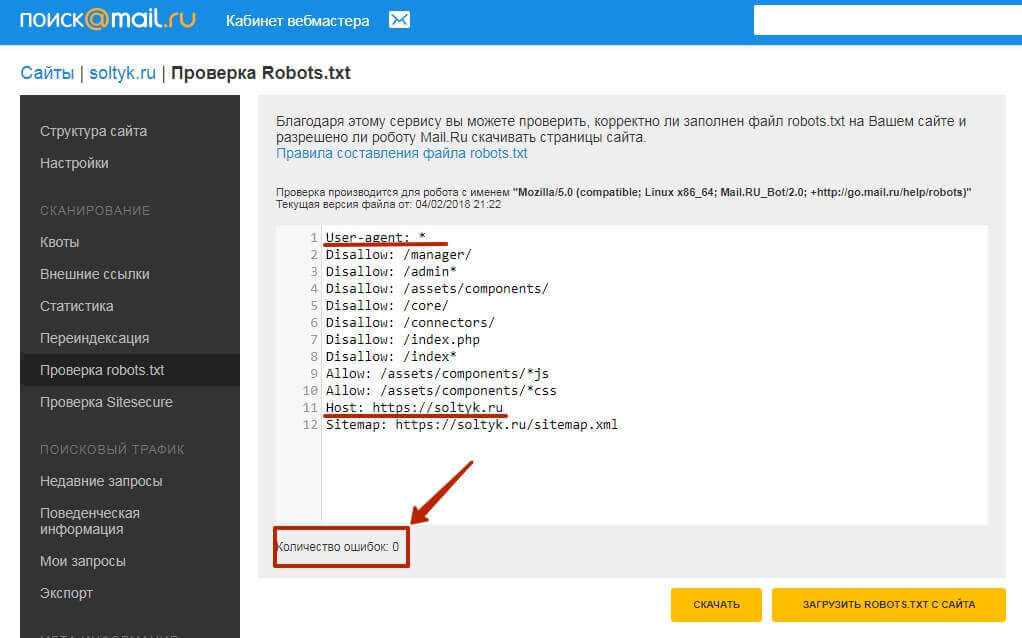 Данный файл нужен поисковым роботам, чтобы они могли проанализировать сайт и узнать
какие ресурсы им можно и нужно индексировать, а какие трогать нельзя. Также в этом файле указывается ссылка на хост
вашего сайта и ссылка на карту, т.к. robots.txt – это первая страница, куда попадет бот на вашем
сайте.
Данный файл нужен поисковым роботам, чтобы они могли проанализировать сайт и узнать
какие ресурсы им можно и нужно индексировать, а какие трогать нельзя. Также в этом файле указывается ссылка на хост
вашего сайта и ссылка на карту, т.к. robots.txt – это первая страница, куда попадет бот на вашем
сайте.
Robots.txt также создается в ModX несложно:
-
Переходим во вкладку «Элементы» и создаем новый сниппет нажатием на
«+». -
Называем сниппет «host» а в код сниппета вставляем следующее:
<?php echo $_SERVER['HTTP_HOST']; -
После сохранения сниппета переходим обратно в ресурсы и нажатием на
«+»(создать новый ресурс). -
Обзываем его robots. Во вкладке настройки также снимаем галку с
«Использовать HTML редактор», а тип содержимого выбираем text.
-
В код содержимого вставляем следующие строчки:
User-agent: * Disallow: /core/ Disallow: /manager/ Disallow: /connectors/ Disallow: /index.php Disallow: /index.html Host: https://[[host]] Sitemap: https://[[host]]/sitemap.xml -
Сохраняем ресурс и можем проверять его, перейдя по
site.ru/robots.txt

Как видно из кода, в последней строчке мы указываем [[host]], что вызовет наш сниппет
host и вернет текущее имя хоста, например localhost или site.ru.
No-html ресурсы
Многие страницы в интернете выглядят так: site.ru/ochen-interesnaya-statia.html. Как видно из ссылки
включены дружественные URL, которые транслитерируют текст (как включить дружественные URL читайте в этой
статье), но в конце все портит «.». В modx очень просто отключить отображение расширения, чтобы
ссылки на ваши ресурсы были красивыми и приятными.
 html
html
П.с. данную процедуру можно также выполнить через .htaccess, но мы рассмотрим встроенные
в движок метод.
- Во вкладке вверху выбираем Содержимое → Типы содержимого.
- Создаем «Новый тип содержимого» по кнопке и с ПКМ по «HTML» выбираем «Редактировать тип содержимого».
-
У вас получится 2 открытых окна и из типа HTML копируем все, кроме «Названия» и
«Расширения файла». Расширение оставляем пустым, а в названии вписываем, например,
no-HTML. -
Теперь в настройках нам нужно сделать так, чтобы данный тип содержимого автоматически присваивался каждому
созданному ресурсу. Для этого переходим в Шестеренку → Системные настройки.
-
В фильтрах выставляем Core → Сайт и находи пункт «
default_content_type». Кликаем 2 раза и выбираем вновь созданный тип содержимого
 Для этого переходим в Шестеренку → Системные настройки.
Для этого переходим в Шестеренку → Системные настройки.
MODX Revolution — Базовый туториал. MODX Революция
Головна / Построю уборкуОфициальный сайт MODX
http://modx.com/
Первичные материалы о создании сайтов на MODx
Параметры сниппетов
http://wiki.modxcms.com/index.php/Category:Фрагменты
Остальной дистрибутив можно скачать по адресу http://modx.com/download/evolution/
Последовательность создания сайта на MODx эволюция
- Создайте базу данных с тем же префиксом, который назначает хостер, чтобы не редактировать файл config.inc.php.
- Установить MODx. Зробити налаштування.
- Скопируйте шаблон на сайт в папку assets/templates.
- Скопируйте код шаблона index.html из шаблона «Минимальные шаблоны».
- Все посередине напишите путь
.
- Написать пути к скриптам, картинкам, стилям (img, ссылка, scrypts). Например,
- Назначение шаблонов ссылок на сайте.
- Увидев спальни, со всех сторон часть смрада будет кусками. Кусочки появляются на косточках фигурных висков. Например, ((ГОЛОВА))
- Грязное меню сайта можно списать на окремый кусок. .
- Меню сайта Эта карта сайта отображается в виде фрагмента Wayfinder. Описание фрагмента Wayfinder.
- Список ресурсов для этого номера с описаниями, картинками, сообщениями… отображается вместе с сниппетом Ditto. Опишите и прикрепите фрагмент Ditto.
- Навигационный фонарь «Хлебные крошки» отображается во фрагменте «Хлебные крошки». Описание фрагмента хлебных крошек.
- Поиск по сайту осуществляется с помощью сниппета AjaxSearch. Описание сниппета AjaxSearch.
- Форма зв’азку- Сниппет eForm. Приклад складной формы зворотной звязки с использованием сниппета eForm.
- Плагин Phx назначения для перепроверки наличия изображения в ТВ-параметрах с указанием полномочий отца и внутр.
- Необходимо дополнительно прописать кильку стилей.
- После переноса сайта на хостинг:
 Приклад складной формы зворотной звязки с использованием сниппета eForm.
Приклад складной формы зворотной звязки с использованием сниппета eForm.http://www.xml-sitemaps.com
# Исключения modx по умолчанию
Агент пользователя: *# права индексирования распространяются на любого робота
Запретить: /assets/cache/
Запретить: /assets/docs/
Запретить: /assets/export/
Запретить: / assets/import/
Запретить: /assets/modules/
Запретить: /assets/plugins/
Запретить: /assets/snippets/
Запретить: /assets/packages/
Запретить: /assets/tvs/
Запретить: /install/
Disallow: /manager/
# Для автообнаружения sitemaps. xml. Раскомментируйте, если он у вас есть.
xml. Раскомментируйте, если он у вас есть.
хост: веб-сайт
Карта сайта: http://site/sitemap.xml
Всем привет, друзья! Это основной урок решения CMF MODX Revo Насколько мы знаем из системы MODX, мы установим необходимые плагины и установим базовую структуру.
Хлопок
Запинити
Ресурсы для базового урока MODX:
- Документация по pdoTools: docs.modx.pro/components/pdotools/
Установка и настройка плагинов MODx
Installable Advanced Версия MODx, при установке указано, что папка будет называться по имени администратора super .
Обязательный плагин MODx
Самые популярные и чаще всего злые дополнения для MODx:
- Ace — Редактор кода MODx;
- Коллекции — введение и управление коллекциями ресурсов;
- pdoTools — Набор базовых инструментов MODx;
- FormIt — робот с формами в MODx;
- phpThumbOf — робот с изображениями в MODx;
- TinyMCE/CKEditor (опционально) — текстовый редактор WYSIWYG для MODx;
- translit — Транслитерация URL для MODX;
- MIGX — Добавлены поля для добавления в MODx;
- autotemplate — «Интеллектуальное» автоматическое распознавание шаблонов ресурсов.

Основные настройки MODx Revolution
Перейти к «Системной настройке».
Общий: Дружественный URL
- Транслитерация псевдонимов: русский;
- Подходит для взбивания URL: So;
- Suvory дружественный режим URL: So;
- Изменить на дублирование URI во всех контекстах: Итак;
- URL избранных материалов: So;
- Не забудьте также изменить имя ht.access в .htaccess в корне сайта.
Раздел: Панель керування
- Показать описание в верхнем меню: Ni.
Роздол: Веб-сайт
- Сторинка помилования 404 «Документ не найден»: Идентификатор ресурса 404;
- Для изоляции: Итак;
- Имя сайта: Назовите свой проект.
Розділ: Система и сервер
- Заголовок Nadsilati X-Powered-By: Ni.
- Заголовок Nadsilati X-Powered-By: Ni.
Пространство имен: туз
- Размер шрифта: 18px;
- Мягкая таблица: Привет;
- Розмир таблица: 2;
- Тема редактора (необязательно): атмосфера, хаос, хром, облака, облака_полночь, кобальт, малиновый_редактор, рассвет, мечтатель, затмение, github, idle_fingers, katzenmilch, kr, kuroir, merbivore, merbivore_soft, mono_indrk, завтра_ночь, завтра_ночь_синий, завтра_ночь_яркий, завтра_ночь_восьмидесятые, сумерки, яркие_чернила, xcode ;
- Кроме того, вы можете изменить тему на материал с помощью редактора Ace. Инструкция:
MODx Ace Material Theme 1. Настройка системы > «ace» Пространство имен: Размер шрифта: 15px Высота области редактирования: 560 Невидимые символы: Tak Soft Tab: N Размер вкладки: 2 Тема редактора: Завтра_ночь 2. Файлы: super > default > css > index.css: (Добавить в css) !важно) .ace_gutter(color:#666E79!важно) .ace_active-line,.ace_gutter-active-line(цвет фона: #2A2F38!важно) .
ace_scroller,.ace_gutter (цвет фона: #272B33!важно) . ace_meta.ace_tag(цвет:#A6B2C0!важно) .ace_meta.ace_tag.ace_tag-name(цвет:#DF6A73!важно) .ace_entity.ace_other.ace_attribute-name(цвет:#D2945D!важно) !важно) 3. Очистить кэш через меню.

 ace_scroller,.ace_gutter (цвет фона: #272B33!важно) . ace_meta.ace_tag(цвет:#A6B2C0!важно) .ace_meta.ace_tag.ace_tag-name(цвет:#DF6A73!важно) .ace_entity.ace_other.ace_attribute-name(цвет:#D2945D!важно) !важно) 3. Очистить кэш через меню.
ace_scroller,.ace_gutter (цвет фона: #272B33!важно) . ace_meta.ace_tag(цвет:#A6B2C0!важно) .ace_meta.ace_tag.ace_tag-name(цвет:#DF6A73!важно) .ace_entity.ace_other.ace_attribute-name(цвет:#D2945D!важно) !важно) 3. Очистить кэш через меню.Создание базовых ресурсов
- Сторинка 404 — сторона для фиксации документа не найдена. Не показывать в меню;
- карта сайта — ресурс для видения [] . Пустой шаблон. Не отображать в меню. Введите вместо: XML. Недоступно для розыгрыша. Не помечайте HTML-редактор;
- robots — ресурс для зрения robots.txt . Пустой шаблон. Не отображать в меню. Введите на месте: Текст. Недоступно для розыгрыша. Не помечайте HTML-редактор.
На прошлых уроках мы установили и исправили modx, а также установили пакеты, которые будут необходимы для создания сайта. Сегодняшний урок посвящен переносу отличного HTML/CSS/JS в дизайн MODX Revo. Где взять дизайн, я писал в статье: Шаблоны MODX — что это такое, что это такое? Для своего сайта я выбрал готовый платный адаптивный бутстрап шаблон на theforest за 17$ под названием Brightbox (кликните по названию, чтобы просмотреть демонстрацию йоги и описание). Обыграть можно абсолютно все, это все равно без каких-либо затрат — так вы понимаете весь принцип растяжки все быстрее и быстрее.
Обыграть можно абсолютно все, это все равно без каких-либо затрат — так вы понимаете весь принцип растяжки все быстрее и быстрее.
HTML-структура темы
Практичная тема скина может иметь html, css, js и файлы изображений + иметь больше файлов php- Обробник формы.
На мой взгляд, в папке assets лежат css и js файлы (в отдельных директориях), в папке images — картинки и красные файлы (можно и не красные — все хранится в установленном за замком браузере ) — это html-файлы.
Портирование шаблона на Modx
Самый простой способ — просто залить все файлы с папками (кремовый html) в корень сайта. Але, я пойду по складной тропе. Поскольку у меня нет файлов modx и каталогов ресурсов, я буду загружать ресурсы (подпапки css и js) в корень сайта и изображения в корень.
Ранее я создал директорию шаблонов и закачал из нее все файлы — вы можете сделать это сами.
Редактирование базового шаблона
В дереве языков перейдите на вкладку «Элементы» и откройте шаблон початка (можно просто нажать ЛКМ или ПКМ и выбрать редактирование).
Можем посмотреть и заменить на код из index.html (в корень сайта не клали).
HTML файл можно открыть с помощью отличного блокнота, а еще лучше написать специальный редактор например
Перейдем на главную страницу сайта.
Основная сторона при этом выглядит криво.
Случилось тому, кто поменял пути к скриптам и css.
Исправление путей
Так сразу выглядят пути.
До речи троха, тема замечательная, озвучьте путь через косую черту /, и \, исправьте.
Если вы уже установили пакет ace, вы можете легко и просто найти замену, для чего можно нажать на код и далее нажать на клавиши Ctrl+H (работает в Linux и windows), в верхнее поле ввести \, а внизу / я нажимаю все.
Нужна помощь с Robots.txt | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
- SEO-тактика
- Средний и продвинутый SEO
- Нужна помощь с robots.txt
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
- Я бы добавил канонический тег, а затем обрабатывал его с помощью раздела «Параметры» Search Console. Вот почему он там, именно для этого типа сайта именно с этой проблемой.
https://support.google.com/webmasters/answer/6080550?hl=ru
- Нахид, прежде чем использовать запрет файла robots.txt для этих URL-адресов, вы можете пересмотреть свое решение. Вместо этого вы можете использовать тег canonical. Если у вас разные размеры, цвета и т. д., мы обычно рекомендуем использовать тег Canonical, а не запрет в robots.txt.
В любом случае, если вы хотите использовать запрет, вы можете использовать один из этих:
Запретить: / ?
или
Запретить: / ?cat=
 org/Comment»>
org/Comment»> Сайт электронной коммерции, созданный с помощью Modx CMS. Я обнаружил много проблем с автоматически сгенерированными дубликатами страниц на этом сайте. Теперь мне нужно запретить некоторые страницы из этой категории. Вот фактический URL-адрес страницы продукта выглядит как
product_listing.php?cat=6857
А вот автоматически сгенерированная структура URL-адреса
product_listing.php?cat=6857&cPath=dropship&size=19
Может ли кто-нибудь предложить, как запретить эту конкретную категорию через robots.txt. Я не так хорошо знаком с Modx и такой структурой ссылок.
Мы будем признательны за вашу помощь.
Спасибо
 Вот почему он там, именно для этого типа сайта именно с этой проблемой.
Вот почему он там, именно для этого типа сайта именно с этой проблемой.У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От За все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»> Привет!
Google готовится к массовой рассылке спама, последняя ссылка на отчет Enhancements > Breadcrukbs , сообщение такое:
«…Системы Google показывают, что на ваш сайт влияют 24 экземпляра проблем с разметкой хлебных крошек. Это означает, что ваши страницы хлебных крошек могут не отображаться как расширенные результаты в поиске Google. Консоль поиска создала новый отчет только для этого типа расширенных результатов. ..»
Я использовал их инструмент тестирования структурированных данных, никаких ошибок не было выделено. Кто-нибудь может понять, что они имеют в виду, пожалуйста?
Кто-нибудь может понять, что они имеют в виду, пожалуйста?
Средний и продвинутый SEO | | джасонмкмахон
0
У меня есть два существующих сайта электронной коммерции. Старая версия построена на платформе Yahoo и имеет ограничения в отношении взаимодействия с пользователем. Новый сайт построен на платформе Magento 2. Мы собираемся использовать поиск SLI для нашего поиска и навигации на новой платформе Magento. SLI хочет, чтобы мы 301 перенаправляли все наши категории на размещенные страницы категорий, которые они создадут, которые будут иметь структуру URL, аналогичную site. com/shop/category-name.html.
Проблема в том, что если я хочу объединить два сайта, мне придется выполнить 301 для страниц категорий нового сайта, которые будут иметь 301 для страниц категорий, размещенных SLI. Я надеюсь это имеет смысл!
Как я это вижу, у меня есть два варианта:
Сделайте 301 из старого домена в категории нового домена, а категории нового домена 301 в категории SLI;
или же,
Я могу сделать свои 301 прямо на страницах категорий, размещенных в SLI.
Недостатком № 1 является то, что я буду делать два 301, и я знаю, что в результате потеряю больше ссылочного веса. Преимущество № 1 заключается в том, что если вы решите не использовать SLI в будущем, одной проблемой станет меньше. Недостатком № 2 является то, что я буду направлять все страницы категорий со старого сайта на сайт, который я в конечном итоге не контролирую.
Я ценю любые отзывы.
com/shop/category-name.html.
Проблема в том, что если я хочу объединить два сайта, мне придется выполнить 301 для страниц категорий нового сайта, которые будут иметь 301 для страниц категорий, размещенных SLI. Я надеюсь это имеет смысл!
Как я это вижу, у меня есть два варианта:
Сделайте 301 из старого домена в категории нового домена, а категории нового домена 301 в категории SLI;
или же,
Я могу сделать свои 301 прямо на страницах категорий, размещенных в SLI.
Недостатком № 1 является то, что я буду делать два 301, и я знаю, что в результате потеряю больше ссылочного веса. Преимущество № 1 заключается в том, что если вы решите не использовать SLI в будущем, одной проблемой станет меньше. Недостатком № 2 является то, что я буду направлять все страницы категорий со старого сайта на сайт, который я в конечном итоге не контролирую.
Я ценю любые отзывы.
Средний и продвинутый SEO | | Х3017
1
 org/ListItem»> Совет robots.txt
org/ListItem»> Совет robots.txt Привет, ребята!
Вы когда-нибудь видели подобный код в файле robots.txt? Я никогда раньше не видел правила noindex в файле robots.txt, а вы?
пользовательский агент: AhrefsBot
Агент пользователя: trovitBot
Агент пользователя: Nutch
Агент пользователя: Baiduspider
Запретить: /
User-agent: *
Disallow: /WebServices/
Disallow: /*?notfound=
Disallow: /?list=
Noindex: /?*list=
Noindex: /local/
Disallow: /local/
Noindex: / handle/
Disallow: /handle/
Noindex: /Handle/
Disallow: /Handle/
Noindex: /localsites/
Disallow: /localsites/
Noindex: /search/
Disallow: /search/
Noindex: /Search/
Запретить: /Поиск/
Запретить: ?
Я никогда раньше не видел правила noindex в файле robots. txt, а вы?
txt, а вы?
Любые указатели?
Средний и продвинутый SEO | | eLab_Лондон
0
Привет, Моззерс!
Я провожу аудит сайта для клиента, и меня смущает то, что они делают со своим файлом robot.txt. Он показывает в GWT, что есть файл, и он блокирует около 12 тыс. URL-адресов (изображение прилагается). Он также показывает в GWT, что файл был успешно загружен 10 часов назад. Однако, когда я перехожу по ссылке на файл robot.txt, страница пуста.
Будут ли они делать что-то продвинутое, чтобы блокировать URL-адреса, чтобы скрыть их от пользователей? Похоже, он правильно блокирует вход в систему, но я хотел бы знать наверняка, что он работает правильно. Любые советы по этому поводу будут высоко оценены. Спасибо!
Джаред
ihgNxN7
Любые советы по этому поводу будут высоко оценены. Спасибо!
Джаред
ihgNxN7
Средний и продвинутый SEO | | Джей-Банз
0
В Magento была небольшая ошибка.
У нас было расширение Yoast Canonical Links, которое работало хорошо, но затем мы установили Mageworx SEO Suite… что сломало Canonical Links.
К сожалению, он начал указывать www.mysite.com/catalog/product/view/id/516/ в качестве канонической ссылки, а все URL-адреса с /catalog/productview/* заблокированы в Robots.txt.
Так что, к сожалению, Мы сказали Google, что правильная страница также является заблокированной страницей. Насколько я вижу, они не были удалены, но трафик, безусловно, упал.
У нас также в то же время были некоторые изменения сайта, группирующие некоторые страницы и имеющие переадресацию 301.
Повторно отправил карту сайта и сделал выборку как Google.
Любые другие идеи? И идея, сколько времени потребуется, чтобы стать разблокированным?
Насколько я вижу, они не были удалены, но трафик, безусловно, упал.
У нас также в то же время были некоторые изменения сайта, группирующие некоторые страницы и имеющие переадресацию 301.
Повторно отправил карту сайта и сделал выборку как Google.
Любые другие идеи? И идея, сколько времени потребуется, чтобы стать разблокированным?
Средний и продвинутый SEO | | s_EOgi_Bear
0
Всем привет…
Я разрабатываю структуру для веб-сайта с 53 страницами. Можете ли вы взглянуть на прилагаемую диаграмму и убедиться, что структура веб-сайта в порядке?
На прилагаемой диаграмме я пронумеровал страницы от 1 до 53, где 1 самая важная домашняя страница — 2,3,4,5, следующие 4 важные страницы — 6,7,8. .. 15,16, 17 — это 3-й набор важных страниц, а 18,19,20….. 51,52,53 — последний набор страниц, которые проще всего ранжировать.
У меня есть два вопроса:
Правильна ли структура веб-сайта для этого? Я удостоверился, что все страницы на веб-сайте доступны.
Учитывая, что домашняя страница и номер страницы 2,3,4,5 являются наиболее важными страницами — я ссылаюсь на эти страницы из последнего набора страниц (18,29,20…51,52,53) . В последнем наборе 36 страниц — и из этих 36, из них 24 я ссылаюсь на домашнюю страницу и страницы номер 2,3,4,5. Оставшиеся 8 страниц из 36 будут ссылаться на страницы 6,7,8…15,16,17.
Суммарно самая важная страница будет иметь следующее количество внутренних входящих ссылок:
Домашняя страница : 25
Страницы 2,3,4,5 : 25
Страницы 6,7,8…15,16,17 : 4
Страницы 18,19,20…51,52,53 : 1
Это нормально, учитывая главную страницу, а страницы 2,3,4,5 самые важные? Или вы думаете, что я должен разделить и дать больше внутренних ссылок на другие страницы?
Если вы можете поделиться какими-либо отзывами или предложениями о том, как я могу улучшить это, это очень поможет мне.
.. 15,16, 17 — это 3-й набор важных страниц, а 18,19,20….. 51,52,53 — последний набор страниц, которые проще всего ранжировать.
У меня есть два вопроса:
Правильна ли структура веб-сайта для этого? Я удостоверился, что все страницы на веб-сайте доступны.
Учитывая, что домашняя страница и номер страницы 2,3,4,5 являются наиболее важными страницами — я ссылаюсь на эти страницы из последнего набора страниц (18,29,20…51,52,53) . В последнем наборе 36 страниц — и из этих 36, из них 24 я ссылаюсь на домашнюю страницу и страницы номер 2,3,4,5. Оставшиеся 8 страниц из 36 будут ссылаться на страницы 6,7,8…15,16,17.
Суммарно самая важная страница будет иметь следующее количество внутренних входящих ссылок:
Домашняя страница : 25
Страницы 2,3,4,5 : 25
Страницы 6,7,8…15,16,17 : 4
Страницы 18,19,20…51,52,53 : 1
Это нормально, учитывая главную страницу, а страницы 2,3,4,5 самые важные? Или вы думаете, что я должен разделить и дать больше внутренних ссылок на другие страницы?
Если вы можете поделиться какими-либо отзывами или предложениями о том, как я могу улучшить это, это очень поможет мне. Кроме того, если вы знаете какие-либо ссылки на хорошие руководства по внутренней перелинковке веб-сайтов объемом более 50 страниц, пожалуйста, поделитесь ими в ответах.
Спасибо вам всем!
С уважением,
P.S. URL изображения находится по адресу http://imgur.com/XqaK4.
Кроме того, если вы знаете какие-либо ссылки на хорошие руководства по внутренней перелинковке веб-сайтов объемом более 50 страниц, пожалуйста, поделитесь ими в ответах.
Спасибо вам всем!
С уважением,
P.S. URL изображения находится по адресу http://imgur.com/XqaK4.
Средний и продвинутый SEO | | Арджун Раджкумар81
0
Веб-сайт будет содержать ссылку на видео YouTube, связанное с моим каналом. Получает ли мой веб-сайт также кредит SEO, даже если этот веб-сайт не ссылается непосредственно на мой сайт, а скорее на видео на моем канале YouTube. Видео с YouTube также загружено на мой веб-сайт, но этот веб-сайт хочет разместить ссылку на видео непосредственно на YouTube.
Веб-сайт «www.hawaiijobengine.com», а канал на YouTube — «hawaiijobegnine.com» — откуда Google знает, что эти 2 принадлежат одному и тому же владельцу?
благодарю вас
Видео с YouTube также загружено на мой веб-сайт, но этот веб-сайт хочет разместить ссылку на видео непосредственно на YouTube.
Веб-сайт «www.hawaiijobengine.com», а канал на YouTube — «hawaiijobegnine.com» — откуда Google знает, что эти 2 принадлежат одному и тому же владельцу?
благодарю вас
Средний и продвинутый SEO | | кильсен
0
При деиндексации страниц из Google, каковы плюсы и минусы каждого из двух следующих вариантов:
robots.txt и запрос на удаление URL из веб-мастеров Google
Используйте noindex, следите за метатегом на всех страницах профиля врача. Сохраните URL-адреса в файле Sitemap, чтобы Google повторно просканировал их и нашел метатег noindex.
убедитесь, что они не запрещены файлом robots.txt
Сохраните URL-адреса в файле Sitemap, чтобы Google повторно просканировал их и нашел метатег noindex.
убедитесь, что они не запрещены файлом robots.txt
Средний и продвинутый SEO | | Николь Healthline
0
Robots.txt Генератор для создания robots.txt за несколько шагов
Создать файл robots.txt с нуля
или
Выберите один из предложенных вариантов
Создать файл robots.txt с нуля
- 2 создать с нуля
предложения
AlliveDisallow
Удалить
AllingDisallow
DELETE
Добавить еще одну строку
Копировать все необходимые файлы
Скопируйте все изображения
. Все
. Запретить все для наиболее часто блокируемых ботов
Запретить для всех ботов Google, кроме Google
Разрешить для всех ботов Google
Robots.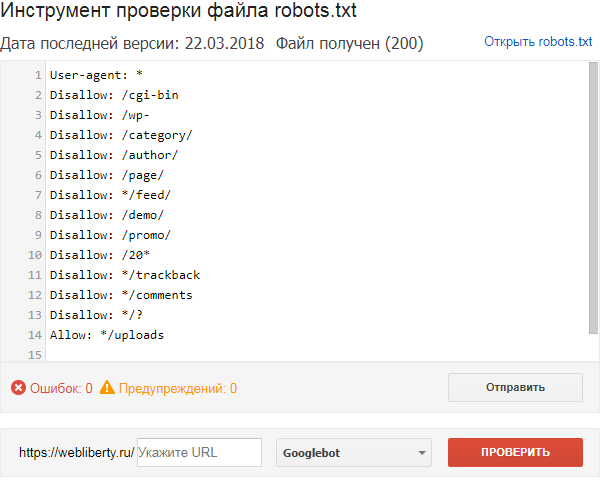 txt для WordPress
txt для WordPress
robots.txt для Joomla
robots.txt для MODX
Robots.txt для Drupal
Robots.txt для Magento
Robots.txt для Opensart
Robots.txt For Woocommerce
robots.txt
Сброс
Ваш файл robots.txt
Нажмите, чтобы скопировать
Я знаю, что использую генератор robots.txt на свой страх и риск. SE не несет никакой ответственности Ранжирование на предмет ошибок или отсутствия индексации веб-сайта.
Скачать файл robots.txt
Проверить файл robots.txt, sitemap.xml и другие проблемы со сканированием
Посмотреть подробные и простые советы
Проанализировать
Как прочитать файл robots.
 txt?
txt?- Агент пользователя
- Разрешить
- Запретить
- Карта сайта
Агент пользователя
Эта директива определяет сканеры, для которых в файле прописаны рекомендации. У каждой поисковой системы есть свои сканеры. Здесь вам нужно выбрать бота (или ботов), которому запрещено или разрешено сканировать страницы и файлы вашего сайта.
Разрешить
С помощью директивы Разрешить вам необходимо определить, какие файлы или страницы доступны для поисковых роботов. Он используется для противодействия директиве Disallow, которая сообщает поисковым системам, что они могут получить доступ к определенному файлу или странице в каталоге, который в противном случае запрещен.
Запретить
С помощью этой директивы вы можете запретить поисковым системам доступ к определенным файлам, страницам или разделам вашего веб-сайта, которые вы не хотите индексировать, например, страницы поиска и входа, дубликаты, служебные страницы, и т. д.
д.
Карта сайта
Это необязательная директива, предназначенная для уведомления поисковых систем о наличии карты сайта в формате XML. Из карты сайта сканеры получают дополнительную информацию об основных страницах вашего сайта и его структуре. При необходимости вы можете добавить URL-адрес карты сайта в этот инструмент.
Как использовать наш генератор Robots.txt?
Мы разработали этот генератор файлов robots.txt, чтобы помочь веб-мастерам, специалистам по поисковой оптимизации и маркетологам быстро и легко создавать файлы robots.txt.
Вы можете создать файл robots.txt с нуля или использовать готовые предложения. В первом случае вы настраиваете файл, устанавливая директивы (разрешить или запретить сканирование), путь (конкретные страницы и файлы) и ботов, которые должны следовать директивам. Либо вы можете выбрать готовый шаблон robots.txt, содержащий набор наиболее распространенных общих и CMS-директив. Вы также можете добавить карту сайта в файл.
В результате вы получите готовый файл robots.txt, который вы сможете отредактировать, а затем скопировать или скачать.
Часто задаваемые вопросы
Что делает файл robots.txt?
Файл robots.txt сообщает поисковым системам, какие страницы сканировать и какие боты имеют доступ для сканирования содержимого веб-сайта.
Насколько важен файл robots.txt?
С помощью robots.txt можно решить две проблемы:
- 1. Уменьшить вероятность сканирования определенных страниц, включая индексацию и появление в результатах поиска.
- 2. Сохранить краулинговый бюджет.
С помощью robots.txt можно заблокировать информацию, не имеющую ценности для пользователя и не влияющую на ранжирование сайта, а также конфиденциальные данные.
Что такое User-agent* в robots.txt?
User-agent * указывает, что рекомендации, содержащиеся в файле robots.txt, будут применяться ко всем поисковым роботам без исключения.
Что означает User-agent: * Disallow: /?
User-agent: * Disallow: / сообщает всем ботам, что им запрещен доступ к сайту.
Что нужно заблокировать в файле robots.txt, а что разрешить?
Какой контент чаще всего блокируется?
Страницы, не подходящие для отображения в поисковой выдаче или контент, который пользователи видят при знакомстве с ресурсом: сообщения об успешном заказе, регистрационные формы и т. д.
Разрешить доступ к важным файлам для ранжирования: скрипты, стили, изображения.
При каких условиях файл robots.txt будет работать правильно?
Файл robots.txt будет корректно работать при трех условиях:
- 1. Правильно указанный User-agent и директивы. Например, каждая группа начинается со строки User-agent, по одной директиве в строке.
- 2. Файл должен быть только в формате .txt.
- 3. Файл robots.txt должен находиться в корневом каталоге узла веб-сайта, к которому он относится.
Имеет ли значение порядок в файле robots.txt?
Да, порядок в файле robots.txt имеет значение, но не для всех элементов. Каждая группа должна начинаться со строки User-agent, затем необходимо указать директивы Allow и Disallow (порядок этих полей можно изменить), а затем, при необходимости, добавить файл Sitemap.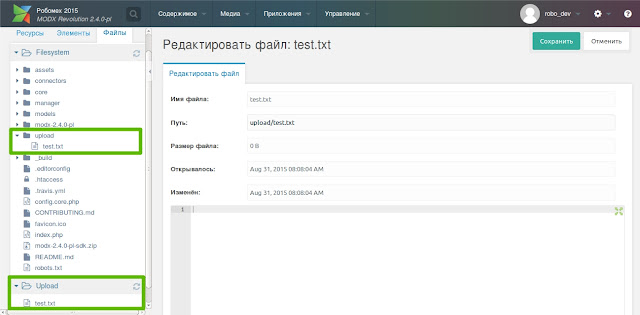 Например:
Например:
Агент пользователя: Google
Запретить: /folder2/
Карта сайта: https://seranking.com/sitemap.xml
Могу ли я использовать регулярное выражение в файле robots.txt?
Чтобы создать robots.txt с более гибкими инструкциями, вы можете использовать два регулярных выражения, распознаваемых поисковыми системами:
- * — используется для указания любого варианта значения
- $ — используется для указания того, что путь URL должен заканчиваться таким образом
Например:
User-agent: *
Disallow: /*page$
Это означает, что вы хотите заблокировать все URL-адреса, в конце которых есть страница.
Как заблокировать поисковый робот в robots.txt?
Для этого в директиве User-agent укажите бота, а затем в строке Disallow укажите путь к файлу, обход которого запрещен. Например:
User-agent: Google
Disallow: /folder2/
Как заблокировать все поисковые системы?
Чтобы заблокировать доступ к контенту вашего сайта для всех поисковых роботов, используйте User-agent: * Disallow: / Например:
User-agent: * — блокирует всех ботов
Disallow: /folder1/ — блокирует определенные страницы или папки
или
Disallow: / — блокирует весь сайт
Как использовать файл robots. txt?
txt?
После создания файла robots.txt добавьте его в корневой каталог веб-сайта. И тогда следует проверить, все ли работает должным образом. Вы можете сделать это с помощью нашего тестера robots.txt.
Как долго действует файл robots.txt?
Google обычно проверяет файл robots.txt каждые 24–36 часов.
Дополнительные функции для изучения
Мониторинг изменений страницы
- Получение немедленных уведомлений при внесении изменений на веб-страницу
- Сравнение изменений с двумя датами сканирования
- Понимание причин колебаний ранжирования Checker
- Анализ целевого URL для целевого ключевого слова
- Обеспечивает технический, контентный, ссылочный и многие другие виды анализа
- Просмотр таких анализируемых параметров, как «пройдено», «предупреждения» и «ошибки»
- Используйте практические советы для решения проблем и устранения предупреждений
Лидогенератор
- Добавьте настраиваемый виджет на свой веб-сайт
- Предложите своим посетителям бесплатный SEO-аудит на странице
- Соберите информацию о посетителях, чтобы превратить их в клиентов
Группировщик ключевых слов
- Анализ и группировка поисковых запросов, соответствующих URL-адресу одного и того же веб-сайта
- Группировка ключевых слов независимо от местоположения
- Проверка объема поиска прямо на месте
- Простая группировка поисковых запросов с длинным хвостом
Проверка обратных ссылок
- Анализ каждой ссылки 15 SEO-параметры
- Узнайте профили обратных ссылок у себя и своих конкурентов
- Экспортируйте обратные ссылки в инструмент мониторинга обратных ссылок
- Создайте структуру профиля обратных ссылок на ценных SEO-факторах
Управление социальными сетями
- Планирование автоматических публикаций в социальных сетях
- Анализ ключевых показателей
- Управление Facebook и Twitter
- Анализ демографических данных пользователей социальных сетей
Белая метка, настраиваемый цвет шапки, доменный логотип 5
- и многое другое
- Настройка автоматических или ручных фирменных отчетов
- Пользовательский доступ к различным средствам SEO
- Использование собственного домена через отдельный персональный доступ
Маркетинговый план
- Полный контрольный список с указаниями и советами
- Регулярно обновленные материалы
- Пользовательские задачи могут быть добавлены
- Отслеживайте свой прогресс
SEO/PPC конкурентные конкуренты
9018 SEO/PPC.