Правильный robots.txt для MODX Revo
Главная » MODX Revo
MODX Revo
Автор Алексей На чтение 3 мин Просмотров 5.9к. Опубликовано Обновлено
Содержание
- Как создать robots.txt для MODX Revo
- Краткий разбор нестандартного «роботс» для CMS MODX
- Использование кириллицы
- Проверка корректности robots.txt
Сегодня мы составим правильный robots.txt для MODX Revo. Данный файл в первую очередь создается для того что бы закрыть дубли страниц и системный файлы от индексации в поисковых системах.
Как создать robots.
 txt для MODX Revo
txt для MODX RevoПеред тем как начать вы должны включить ЧПУ MODX в настройках сайта.
robots.txt можно создать 2-мя способами:
Первый — прямо на компьютере при помощи блокнота создать текстовый документ с именем robots и расширением txt.
Второй — непосредственно в самом modx (создать документ — и в настройках выбрать тип содержимого txt)
Выбирайте любой способ, который больше нравится. Ну а теперь самое главное.
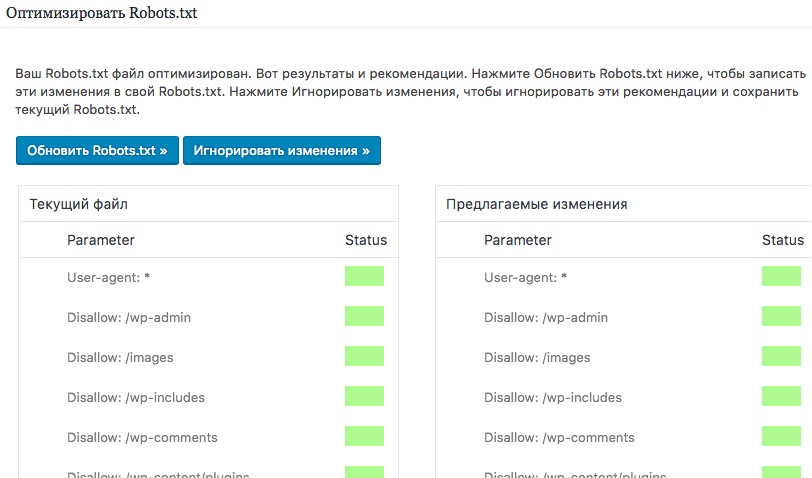
Правильный стандартный robots.txt для MODX Revo и Evo
User-agent: * # правила для всех роботов Disallow: /manager/ # авторизация Disallow: /assets/components/ # папка с файлами modx пакетов Disallow: /core/ # папка с системными файлами modx Disallow: /connectors/ # папка с системными файлами modx Disallow: /index.php # дубль главной страницы index.php Disallow: *?* # удаляем дубли для всех страниц (с параметрами) Disallow: *openstat= # ссылки с метками openstat Disallow: *from= # ссылки с метками from Disallow: *utm*= # ссылки с utm-метками Allow: /*.jpg # здесь и далее открываем для индексации изображения, скрипты и прочие файлы Allow: /*.jpeg Allow: /*.gif Allow: /*.png Allow: /*.pdf Allow: /*.doc Allow: /*.docx Allow: /*.xls Allow: /*.xlsx Allow: /*.ppt Allow: /*.pptx Allow: /*.css Allow: /*.js Allow: *?page= # открываем для индексации страницы пагинации (и проверьте, чтобы для них был настроен canonical) # Укажите один или несколько файлов Sitemap Sitemap: http://site.ru/sitemap.xml
 jpg # здесь и далее открываем для индексации изображения, скрипты и прочие файлы
Allow: /*.jpeg
Allow: /*.gif
Allow: /*.png
Allow: /*.pdf
Allow: /*.doc
Allow: /*.docx
Allow: /*.xls
Allow: /*.xlsx
Allow: /*.ppt
Allow: /*.pptx
Allow: /*.css
Allow: /*.js
Allow: *?page= # открываем для индексации страницы пагинации (и проверьте, чтобы для них был настроен canonical)
# Укажите один или несколько файлов Sitemap
Sitemap: http://site.ru/sitemap.xml
jpg # здесь и далее открываем для индексации изображения, скрипты и прочие файлы
Allow: /*.jpeg
Allow: /*.gif
Allow: /*.png
Allow: /*.pdf
Allow: /*.doc
Allow: /*.docx
Allow: /*.xls
Allow: /*.xlsx
Allow: /*.ppt
Allow: /*.pptx
Allow: /*.css
Allow: /*.js
Allow: *?page= # открываем для индексации страницы пагинации (и проверьте, чтобы для них был настроен canonical)
# Укажите один или несколько файлов Sitemap
Sitemap: http://site.ru/sitemap.xmlТакже часто на хостингах в директориях сайта, есть папка cgi-bin, ее тоже закрываем от индексации: Disallow: /cgi-bin
Если вы используете модуль pThumb (phpThumbOf или phpThumbOn), то желательно открыть для индексации обрезанные изображения:
Allow: /core/cache/phpthumb/*.jpeg
Allow: /core/cache/phpthumb/*.png
Allow: /core/cache/phpthumb/*.svg
Раньше еще указывали директиву host (Host: сайт.ru) но ее сейчас поисковые боты не учитывают — она устарела)
Краткий разбор нестандартного «роботс» для CMS MODX
Использование кириллицы
Использование кириллицы запрещено в файле robots. txt и HTTP-заголовках сервера.
txt и HTTP-заголовках сервера.
Для указания имен кириллических доменов и папок с русскими именами используйте Punycode. Названия указывайте в кодировке, соответствующей кодировке текущей структуры сайта. Пример для указания сайтмапа для http://сайт.рф:
Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
Проверка корректности robots.txt
Анализ robots.txt от Yandex (нужна авторизация).
Анализ robots.txt от Google (нужна авторизация).
Если у вас есть какие либо вопросы или предложения по правильному составлению robots.txt для CMS MODX пишите в комментариях.
modx robots.txt robots txt modx revo
Поделиться с друзьями
Оцените автора
( 1 оценка, среднее 5 из 5 )
Создание и настройка robots.txt для MODX Revolution
Главная » CMS »
После создания файла sitemap.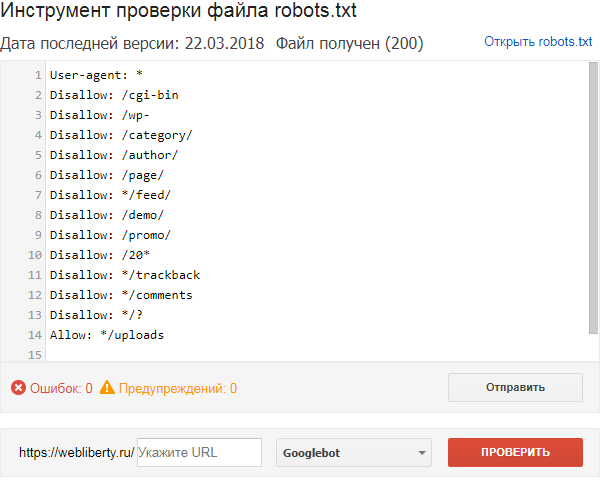
Самый простой и универсальный способ создания файла robots.txt это создать его непосредственно на своём компьютере, а затем загрузить в корень сайта. Просто откройте текстовый редактор, создайте файл с именем robots и задайте ему расширение txt.
Другой способ создать robots.txt для MODX Revolution — создать его непосредственно из «админки». Сразу скажу, что «универсального» или «правильного» файла robots.txt не существует. Вы наполняете его в соответствии с вашими потребностями. Ниже я приведу пример такого файла и прокомментирую его содержимое.
User-agent: * Disallow: /cgi-bin/ Disallow: /manager/ Disallow: /assets/components/ Disallow: /core/ Disallow: /connectors/ Disallow: /index.
 php
Disallow: *?
Allow: /core/cache/phpthumb/*.jpeg
Allow: /core/cache/phpthumb/*.png
Allow: /core/cache/phpthumb/*.svg
Host: [URL-сайта]
Sitemap: [URL-сайта]/sitemap.xml
php
Disallow: *?
Allow: /core/cache/phpthumb/*.jpeg
Allow: /core/cache/phpthumb/*.png
Allow: /core/cache/phpthumb/*.svg
Host: [URL-сайта]
Sitemap: [URL-сайта]/sitemap.xmlПервая строчка (User-agent: *) говорит нам о том, что настройки применяются ко всем поисковым роботам.
Строки, начинающиеся с Disallow, запрещают индексирование указанных каталогов. Какие каталоги мы закрыли?
cgi-bin — папка для CGI-скриптов, может содержать файлы конфигурации;
manager — каталог админ-панели MODX;
assets/components — каталог с дополнениями;
core — каталог ядра CMS;
connectors — каталог точек входа для AJAX-запросов;
index.php — дубль главной страницы сайта;
Ну а *? поможет избавиться от дублей страниц.
Отметим, что даже если вы не собираетесь ничего закрывать, оставьте в файле строку
Disallow:
Дело в том, что инструкция Disallow является обязательной в robots. txt, и без неё робот может «не понять» файл.
txt, и без неё робот может «не понять» файл.
Строки, которые начинаются с Allow, открывают доступ к определенным частям сайта. На самом деле, поисковый робот сканирует всё, что не помечено Disallow, но что делать, если нужно открыть доступ к определенным файлам или подкаталогам в закрытом каталоге? Тогда и используется Allow. Так, хотя мы и закрыли доступ к папке core, но разрешаем сканирование изображений в /core/cache/phpthumb/.
Директива Host нужна для поискового робота Яндекса. Если вы используете протокол HTTPS, то URL сайта в этой строке нужно указать с ним. При использовании HTTP протокол указывать не нужно. Однако, в свете последних событий, использование директивы Host выглядит не обязательным.
Наконец, мы указываем поисковым работам точное расположение файла sitemap.xml.
После окончания редактирования положите файл robots.txt в корень сайта (обычно каталог public_html).
Рубрики CMS, MODX
Опубликовано Автор Евгений
Новый элемент управления robots.txt в MODX Cloud
Сегодня мы объявляем о новой функции в облаке, которая упрощает обработку файлов robots.txt, добавляя новые возможности для уникальных файлов robots.txt для каждого имени хоста для многосайтовых установок.
Райан Трэш, Майк Шелл
19 октября 2017 г. | 3 мин чтения
Облачная версия MODX
Сегодня мы анонсируем новую функцию в облаке, которая упростит обработку файлов robots.txt, предоставив новую возможность для уникальных файлов robots.txt для каждого имени хоста для многосайтовых установок.
Что такое robots.txt?
Файл /robots.txt — это необязательный файл, который позволяет веб-мастеру явно сообщать хорошо работающим веб-роботам, таким как пауки поискового индекса, о том, как им следует сканировать веб-сайт. Если файл robots.txt отсутствует, большинство роботов должны продолжить сканирование и индексацию сайта.
Это полезно, когда владельцы сайтов используют сайт разработки или промежуточный сайт для текущей работы, а также изолированный рабочий сайт, на котором развертываются изменения и обновления. Вы можете указать веб-роботам игнорировать сайт разработки, разрешив при этом индексирование рабочего сайта.
Robots.txt в MODX Cloud
Ранее MODX Cloud предоставлял пользователям контроль над поведением, разрешая обслуживание пользовательского файла robots.txt на основе переключателя на панели управления. Хотя это было полезно, можно было случайно разрешить индексирование на промежуточных/разрабатываемых сайтах, переключив параметр на панели инструментов. Точно так же можно было легко запретить индексацию на рабочем сайте.
Сегодня мы полностью удаляем этот интерфейс и полагаемся на наличие файлов robots.txt в файловой системе со следующим исключением: любой домен, оканчивающийся на modxcloud.com будет обслуживаться директивой Disallow: / для всех пользовательских агентов, независимо от наличия или отсутствия файла robots. txt.
txt.
Для рабочих сайтов (тех, которые получают реальный трафик посетителей) вам нужно будет использовать собственный домен, если вы хотите, чтобы ваш сайт был проиндексирован.
Подавать уникальные файлы robots.txt для каждого имени хоста в MODX Cloud
Некоторые организации используют MODX Revolution для запуска нескольких веб-сайтов из одной установки с использованием контекстов . Случаи, когда это может применяться, могут быть общедоступными маркетинговыми сайтами в сочетании с микросайтами целевых страниц и, возможно, закрытым интранетом.
Большинство владельцев сайтов хотят, чтобы их сайты были проиндексированы. В MODX Cloud все сайты с пользовательскими именами хостов будут возвращаться к обслуживанию любого загруженного файла robots.txt в корневом каталоге веб-сайта, обычно со следующим содержимым:
User-agent: * Disallow:
Однако для гипотетической интрасети, использующей intranet.example.com в качестве имени хоста, вы бы не хотели, чтобы она индексировалась. Традиционно это было сложно сделать при многосайтовых установках, потому что они использовали один и тот же веб-корневой каталог. Однако в MODX Cloud это просто. Просто загрузите дополнительный файл в свой веб-каталог с именем 9.0025 robots-intranet.example.com.txt со следующим содержимым, и он заблокирует индексирование роботами с хорошим поведением, а все остальные имена хостов вернутся к стандартному файлу robots.txt, если не существует другого файла, специфичного для имени хоста:
Традиционно это было сложно сделать при многосайтовых установках, потому что они использовали один и тот же веб-корневой каталог. Однако в MODX Cloud это просто. Просто загрузите дополнительный файл в свой веб-каталог с именем 9.0025 robots-intranet.example.com.txt со следующим содержимым, и он заблокирует индексирование роботами с хорошим поведением, а все остальные имена хостов вернутся к стандартному файлу robots.txt, если не существует другого файла, специфичного для имени хоста:
Пользовательский агент: * Disallow: /
Нужно ли что-то делать?
Все новые облака будут работать, как описано выше, начиная с этого момента. См. наше примечание о поведении robots.txt для облаков, созданных до 19 октября 2017 г.
Подробнее
Понимание того, как robots.txt влияет на ваши сайты в поисковых системах, является важным аспектом управления сайтом. Узнайте больше о robots.txt на robotstxt.org. Также добавьте в закладки нашу документацию по обработке robots. txt в облаке MODX. И если вы хотите начать использовать эту новую возможность в MODX Cloud, войдите в свою панель инструментов или создайте учетную запись сегодня.
txt в облаке MODX. И если вы хотите начать использовать эту новую возможность в MODX Cloud, войдите в свою панель инструментов или создайте учетную запись сегодня.
Подпишитесь на MODX Cloud!
Что такое robots.txt и как им правильно пользоваться?
Начнем с краткого определения: robots.txt — текстовый файл, размещенный на сервере, отвечающем за взаимодействие с индексирующими роботами. Основная функция robots.txt — предоставить или запретить доступ к файлам в папке сайта.
Узнайте о некоторых распространенных конфигурациях файла robots.txt, о которых я расскажу ниже:
# Доступ ко всему сайту.
User-Agent: *
Disable:
# Нет доступа к сайту.
User-Agent: *
Disable: /
# Одна папка исключена.
Агент пользователя: *
Запретить: /folder/
# Исключена одна подстраница.
Агент пользователя: *
Отключить: /file.html
Зачем нам знать, что такое robots.txt?
- Незнание того, что такое robots. txt, и неправильное его использование могут негативно сказаться на рейтинге вашего сайта.
- Файл robots.txt определяет, как сканеры сканируют ваш сайт.
- Robots.txt упоминается в нескольких руководствах, предоставленных самим Google.
- Этот файл и индексирующие боты являются фундаментальными элементами, влияющими на работу всех поисковых систем.
 txt, и неправильное его использование могут негативно сказаться на рейтинге вашего сайта.
txt, и неправильное его использование могут негативно сказаться на рейтинге вашего сайта.Боты для обхода Интернета
Первое, что сделает такой робот при посещении вашего сайта — заглянет в файл robots.txt. Для чего? Робот хочет знать, есть ли у него права доступа к данной странице или файлу. Если файл robots.txt разрешает вход, то он продолжит работу. Если нет, он покинет указанный сайт. В связи с этим, если у вас есть инструкция по индексации роботов, то файл robots.txt для этого подходит.
Примечание. При работе с файлом robots.txt каждый веб-мастер должен сделать две важные вещи:
- определить, существует ли robots.txt
- , если он существует, убедиться, что он не повлияет на позицию вашего сайта в поиске. двигатели
 двигатели
двигателиКак проверить, есть ли на сайте файл robots.txt?
Robots.txt можно просмотреть в любом веб-браузере. Этот файл необходимо поместить в корневую папку каждого сайта, чтобы мы могли определить, есть ли на сайте robots.txt. Просто добавьте «robots.txt» в конец вашего доменного имени, как показано в примере ниже:
www. domain.pl/robots.txt
Если файл существует или пуст, браузер отобразит его содержимое. Если он не существует, вы получите ошибку 404.
Нужен ли нам файл robots.txt?
Если вы уже знаете, что такое robots.txt, возможно, он вам вообще не нужен на вашем сайте.
Причины, по которым на вашем сайте должен быть файл robots.txt:
- У вас есть данные, которыми вы не хотите делиться с поисковыми системами.
- Вы используете платные ссылки или объявления, требующие специальных инструкций для поисковых роботов.
- Вы хотите, чтобы ваш сайт посещали только авторитетные боты, такие как Googlebot.
- Вы создаете сайт и модифицируете его «вживую», поэтому не хотите, чтобы роботы индексировали незаконченную версию.
- Robots.txt поможет вам следовать рекомендациям, опубликованным Google.

Причина, по которой файл robots.txt не обязательно должен быть на вашем сайте:
- Не имея файла robots.txt, вы исключаете возможные ошибки, которые могут негативно повлиять на позиции вашего сайта в поисковых системах.
- У вас нет файлов, которые вы хотите скрыть от поисковой системы.
В связи с этим, если у вас нет файла robots.txt, поисковые системы имеют полный доступ к вашему сайту. Это, конечно, нормально и распространено, поэтому не о чем беспокоиться.
Как создать файл robots.txt?
Создание файла robots.txt — детская игра.
Такой файл представляет собой простой текстовый файл, что означает, что вы можете использовать самый обычный блокнот в вашей системе или любой другой текстовый редактор. Так что вы можете посмотреть на это так: я не создаю файл robots.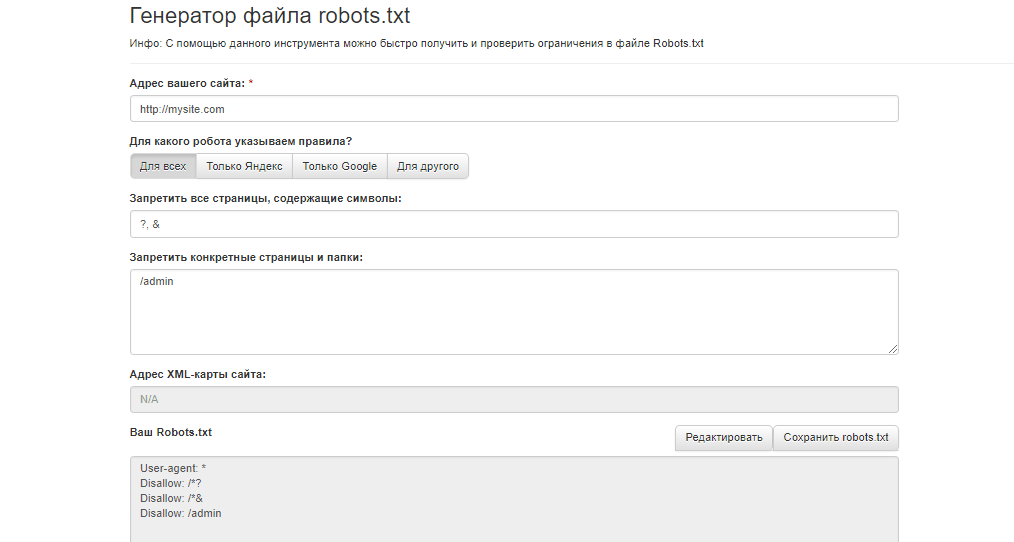 txt, я просто пишу простую заметку.
txt, я просто пишу простую заметку.
Инструкции robots.txt и их важность
Теперь, когда вы знаете, что такое robots.txt, вам нужно научиться правильно его использовать.
Агент пользователя
Агент пользователя:
#lub
Агент пользователя: *
#lub
Агент пользователя: Googlebot
Описание:
индексирующие роботы перемещаются — если нужно, конечно. Это можно сделать двумя способами. Если вы хотите сообщить обо всех роботах, добавьте «*» (звездочка).
Запретить
Инструкция «Запретить» используется для предотвращения доступа роботов к указанным папкам или файлам. Это означает, что если вы не хотите, например, чтобы Google индексировал изображения на вашем сайте, вы помещаете их все в одну папку и исключаете ее.
Это означает, что если вы не хотите, например, чтобы Google индексировал изображения на вашем сайте, вы помещаете их все в одну папку и исключаете ее.
Как ты это делаешь? Допустим, вы уже переместили все свои фотографии в папку с названием «pics». Теперь нужно запретить роботам посещать эту папку для индексации.
Вот что в robots.txt в этой ситуации:
User-agent: *
Disable: /photos
Приведенные выше две строки текста в файле robots.txt будут держать роботов подальше от папки с фотографиями.
Примечание. Если вы забыли знак «/» после оператора Disallow, например….
User-Agent: *
Disable:
…тогда робот-индексатор посетит ваш сайт, посмотрит первую строку, затем прочитает вторую (т.е. «Disallow:»). Что случится? После этого робот будет чувствовать себя как рыба в воде, ведь вы ему запретили… ничего. Так он начнет индексировать все страницы и файлы.
Разрешить
Только несколько роботов-индексаторов понимают эту конкретную инструкцию, одним из которых является, например, Googlebot.
Разрешить:
Оператор «Разрешить» позволяет роботу определить, может ли он просматривать файл в папке, заблокированной с помощью команды «Запретить». Чтобы проиллюстрировать это, давайте посмотрим на предыдущий пример.
User-Agent: *
Disable: /photos
Мы сохранили все фотографии в одной папке под названием «fotki» и благодаря функции «Disallow: /photos» мы заблокировали полный доступ к ее содержимому. Однако через некоторое время мы пришли к выводу, что хотим сделать доступной для поисковика только одну фотографию, которая находится именно в папке «фотографии». Позиция «Разрешить» позволяет нам сказать роботу Google, что, несмотря на то, что мы заблокировали доступ к папке, он все равно может искать в ней и индексировать фото с именем, например, «bike.jpg». В связи с этим нам необходимо создать для него инструкцию, которая будет выглядеть так:
Агент пользователя: *
Отключить: /photos
Разрешить: /photos/bike.jpg
Такие инструкции сообщают роботу Googlebot, что он может найти «bicycle.