
Как часто вам приходится что-либо оценивать? Наверное, каждый день. Хорошая или плохая сегодня погода, сносно ли ведет себя кот, нравится ли вам эта футболка. На работе вы оцениваете свои задачи и результаты: это сделано хорошо, а тут можно было лучше. Такие оценки часто основаны на субъективном ощущении. Но эти оценки не могут повысить эффективность процессов, и нужна более высокая детализация. Тогда на помощь приходят метрики. Как вы можете охарактеризовать свои рабочие процессы и практики? Они хорошие? Плохие? Насколько? Почему вы так решили? Не удержусь и процитирую слова лорда Кельвина: «Если вы можете измерить то, о чем говорите, и выразить это в цифрах – значит, вы что-то об этом предмете знаете. Но если вы не можете выразить это количественно, ваши знания крайне ограничены и неудовлетворительны». Никакой процесс не может считаться зрелым пока не станет прозрачным и управляемым. Я видел две крайности:
Истина, как всегда, посередине. Чтобы к ней приблизиться, нужно понимать принципиальную вещь: метрики — это не дань моде и не панацея от плохих процессов. Метрики — это просто инструмент, и результаты работы этого инструмента — не самоцель, а лишь какое-то основание для дальнейших шагов. Метрики нужны для:
Правильно запилить метрики непросто. Во-первых, нужно четко расписать причинно-следственные связи, выявить все факторы, влияющие на процесс, и раздать им свои веса. Во-вторых, технически реализовать сам сбор. Собираясь вводить метрики в автотесты, вы должны понимать, для чего это вам. Специфика наших автотестов:
Мы тратили много сил на на поддержку стабильности и скорости, даже назначили дежурного по автотестам. Когда мы перестали понимать насколько все хорошо или плохо, сколько ресурсов мы тратим на это, мы начали окутывать нашу систему метриками.
Метрики дежурного по автотестам Мы начали обращать внимание не только на стабильность теста и время прогона, но и на:
Плюс, учли ряд специфичных для нас особенностей:
Поиск испорченных виртуальных машин Большинство команд могут собирать метрики с помощью CI. Нам этого не хватило — слишком хитро мы настроили свои категории и запускалки. Пришлось написать небольшую оберточку, которая в TearDown’е отправляла в БД мету билда со всеми показателями. Наши цели:
Метрики позволили понять по каким показателям мы проседаем. Дальше расставляем веса, ориентиры и вырабатываем порядок достижения цели. Раз в две недели на летучке с дежурным мы:
Эти метрики собираем автоматически каждое утро после ночных прогонов, состоящих из множества повторных запусков тестов. Еще одной большой задачей является оценка покрытия. Еще ни один вариант расчета этого показателя не устраивал меня полностью. А как покрытие считаете вы? Делитесь в комментариях. Кто-то считает покрытие по написанным вручную кейсам. Здесь есть ряд минусов. Во-первых, это человеческий фактор. Хорошо, если задачей займется грамотный аналитик, который будет опираться на репрезентативную статистику. Но и в этом случае можно что-то пропустить, не учесть. Во-вторых, по мере роста тестируемой системы, такой подход становится слишком дорог в поддержке. Кто-то считает покрытие кода. Но здесь не учитывается с какими параметрами мы вызываем тот или иной метод. Действительно, зайдя в метод, который делит А на В с какими-нибудь «безопасными» аргументами, мы не можем сказать, что метод покрыт и протестирован. А если деление на ноль? А если переполнение? Также не учитывается критичность непокрытого кода, а поэтому неясна мотивация это покрытие увеличивать. Идеальный для нас вариант — считать покрытие популярных пользовательских юзкейсов. Причем считать мы будем состояния системы и атомарные переходы между ними. Главное отличие от первого варианта расчета — отсутствие человеческого фактора. Кейсы будут генериться скриптом. Т.е. переход на определенную страницу или какое-то действие на ней отправляет запрос в наш сервис метрик. Это особенность нашей тестируемой системы, так статистика собирается автоматически. Дальше принцип простой:
Этот алгоритм перезапускается раз в месяц, чтобы актуализировать топ. На все недостающие тесты заводятся задачки в бэклог и разгребаются отдельным потоком. Еще одним местом применения метрик послужил наш релизный цикл. Не знаю как у вас, но в нашей команде ресурс тестировщиков ограничен. Поэтому готовые к тестированию обновления берем не сразу, а с задержкой. В какой-то момент этот временной лаг стал вызывать дискомфорт, и мы решили оценить ситуацию. Мы стали считать сколько времени задача находится на каждой стадии релизного цикла.
Сбор метрик релизного цикла на базе YouTrack Из всего этого мы сумели:
Сейчас у нас соотношение пишущих разработчиков к выпускающим их тестировщикам в районе 3 (± 0.1), комфортным считается 2.5. С учетом проводимой автоматизации релизного цикла мы хотим выйти на соотношение 3.5 и 3. Наша реализация сбора метрик основывалась на редакторе правил внутрикомандного багтрекера. Это YouTrack Workflow. В своей команде вы можете использовать аналогичные возможности ваших трекеров, либо писать велосипеды с веб-хуками. Мы завели для таска приватные поля-счетчики и каждый час инкрементировали значение в них. Учли при этом, что счетчик должен тикать только в рабочие часы и только по будням — такой уж у нас рабочий график. Все по-хитрому! =) Типичным антипаттерном являются «метрики ради метрик». Как я уже отмечал выше, метрики — это лишь инструмент, который помогает количественно оценить, насколько хорошо вы достигаете целей. Допустим, никогда не понимал такую метрику как количество тестов. Нафига? Что вам скажет показатель, что в какой-то команде 12345 тестов? Они хорошо тестируют? Не факт. Их автотестам можно доверять? Вряд ли ребята даже знают что они проверяют. Это показывает эффективность работы автотестера? Возможно, там минусов от поддержки больше, чем какого-либо профита — о какой эффективности речь? На самом деле, под этой метрикой подразумевают покрытие и доверие к вашей тестовой системе. Но, блин, это не одно и то же. Если хотите поговорить о покрытии, то им и оперируйте. Всегда помните, что сбор метрик требует от вас определенных усилий и времени. Цените его и подходите к этой практике с умом! Нам очень интересно, а какие метрики используете вы, а от каких, наоборот, отказались. Пишите в комментариях! Обсудить в форуме |
 Кирилл Раткин, тестировщик Контур.Экстерна, расскажет как повысить эффективность тестирования с их помощью и не уйти в крайности.
Кирилл Раткин, тестировщик Контур.Экстерна, расскажет как повысить эффективность тестирования с их помощью и не уйти в крайности.

Как оценить качество системы A/B-тестирования / HeadHunter corporate blog / Habr
Вот уже более полугода в компании используется единая система для проведения A/B-экспериментов. Одной из самых важных частей этой системы является процедура проверки качества, которая помогает нам понять, насколько мы можем доверять результатам A/B-тестов. В этой статье мы подробно опишем принцип работы процедуры проверки качества в расчете на тех читателей, которые захотят проверить свою систему A/B-тестирования. Поэтому в статье много технических деталей.
Несколько слов про A/B-тестирование
Рисунок 1. Схема процесса A/B-тестирования.
В целом процесс A/B-тестирования можно разделить на следующие шаги (показанные на рисунке):
- Распределение пользователей по двум группам A и B.
- Представление двум группам пользователей двух различных вариантов.
- Сбор данных и вычисление значения метрики для каждой группы.
- Сравнение с помощью статистического теста значений метрики в обеих группах и принятие решения, какой из двух вариантов выиграл.
В принципе, с помощью A/B-тестов можно сравнивать любые два варианта, но мы, для определенности, будем считать, что группе A показывается текущий вариант, работающий в продакшене, а группе B — экспериментальный вариант. Таким образом, группа A — контрольная группа, а группа B — экспериментальная. Если пользователям в группе B показывается такой же вариант, как и в группе A (то есть между вариантами A и B нет никакой разницы), то такой тест называют A/A-тестом.
Если в A/B-тесте победил один из вариантов, то говорят, что тест прокрасился.
История A/B-тестирования в компании
A/B-тестирование в компании HeadHunter началось, можно сказать, стихийно: команды разработчиков произвольно делили аудиторию на группы и проводили эксперименты. При этом общего пула проверенных метрик не было — каждая команда вычисляла свои собственные метрики из логов действий пользователей. Общей системы определения победителя тоже не было: если один вариант сильно превосходил другой, то он признавался победителем; если разница между двумя вариантами была небольшой, то для определения победителя применялись статистические методы. Хуже всего было то, что разные команды могли проводить эксперименты на одной и той же группе пользователей, тем самым влияя на результаты друг друга. Стало понятно, что нам нужна единая система для проведения A/B-тестов.
Такая система была создана и запущена в июле 2016 года. С помощью этой системы в компании уже проведено 77 экспериментов. Количество A/B-экспериментов по месяцам показано на рисунке 2.
Рисунок 2. Число A/B-экспериментов по месяцам с момента запуска системы A/B-тестирования. Число экспериментов за март 2017 неполное, т.к. на момент публикаций этот месяц еще не закончился.
При создании системы A/B-тестирования мы уделили наибольшее внимание статистическому тесту. В первую очередь нас интересовал ответ на следующий вопрос:
Как убедиться в том, что статистический тест нас не обманывает и мы можем доверять его результатам?
Вопрос вовсе не праздный, поскольку вред от некорректных результатов стат. теста может быть даже больше, чем от отсутствия результатов.
Почему у нас могут быть причины не доверять стат. тесту? Дело в том, что статистический тест предполагает вероятностную интерпретацию измеряемых величин. Например, мы считаем, что у каждого пользователя есть «вероятность» совершить некое успешное действие (успешными действиями могут быть регистрация, покупка товара, лайк и т. д.). При этом мы считаем действия разных пользователей независимыми. Но изначально мы не знаем, насколько хорошо действия пользователей соответствуют вероятностной модели стат. теста.
Чтобы оценить качество системы A/B-тестирования, мы проводили большое количество A/A-тестов и измеряли процент прокрасившихся тестов, то есть процент случаев, в которых стат. тест ошибался, утверждая о статистически значимом превосходстве одного варианта над другим. О пользе A/A-тестов можно прочитать, например, здесь. Измеренный процент ошибок стат. теста сравнивался с заданным теоретическим значением: если они примерно совпадали, значит, все хорошо; если измеренный процент ошибок сильно меньше или сильно больше теоретического, значит, результаты такого стат. теста ненадежны.
Чтобы рассказать подробнее о методе оценки качества системы A/B-тестирования, следует сначала рассказать про уровень значимости и про другие понятия, возникающие при проверке статистических гипотез. Читатели, знакомые с данной темой, могут пропустить следующий параграф и перейти к параграфу Оценка качества системы A/B-тестирования.
Статистический тест, доверительные интервалы и уровень значимости
Давайте для начала рассмотрим простой пример. Пусть у нас всего 6 пользователей и мы разбили их на 2 группы по 3 человека, провели A/B-тест, подсчитали значение метрики для каждого отдельного пользователя и получили в результате такие таблицы:
| Пользователь |
Значение метрики |
|---|---|
| А. Антонов | 1 |
| П. Петров | 0 |
| С. Сергеев | 0 |
| Пользователь |
Значение метрики |
|---|---|
| Б. Быстров | 0 |
| В. Вольнов | 1 |
| У. Умнов | 1 |
Среднее значение метрики в группе A равно , в группе B — , а среднее значение разности между двумя группами равно . Если мы ограничимся только средними значениями, то получается, что вариант, показанный группе B, выиграл (т. к. разность больше нуля). Но в каждой группе только 3 значения — значит, истинное значение разности мы оценили по 6 числам, то есть с большой погрешностью. Поэтому полученный результат может быть случайным и может ровным счетом ничего не значить.
То есть, кроме разности средних значений метрики в двух группах, нам еще хотелось бы оценить и доверительный интервал для истинного значения разности , то есть интервал в котором, «скорее всего», лежит истинное значение. Фраза «скорее всего» имеет интуитивное значение. Чтобы его формализовать, используют понятие уровня значимости . Уровень значимости связан с доверительным интервалом и отражает степень нашей уверенности, что истинное значение находится внутри данного доверительного интервала. Чем меньше уровень значимости, тем мы более уверены.
Представить себе, что означает уровень значимости, можно так. Если мы много раз будем повторять A/A-тест, то процент случаев, в которых A/A-тест прокрасится, будет примерно равен . То есть в случаев мы отклоняем гипотезу о равенстве вариантов, хотя оба варианта действительно равны (иными словами, в случаев мы совершим ошибку первого рода). Мы выбрали уровень значимости равным .
Собственно, статистический тест как раз и занимается оценкой доверительного интервала для разности при заданном уровне значимости. Если доверительный интервал известен, то процедура определения победителя проста:
- Если обе границы доверительного интервала больше 0, значит, выиграл вариант B.
- Если 0 внутри интервала, значит, ничья — ни один из вариантов не выиграл.
- Если обе границы меньше 0, значит, выиграл вариант A.
Например, предположим, что мы как-то смогли узнать, что для уровня значимости доверительный интервал для разности в нашем примере равен . То есть, истинное значение разности скорее всего лежит внутри интервала . Ноль принадлежит этому интервалу — значит, у нас нет оснований предполагать, что один из вариантов лучше, чем другой (в действительности один из вариантов может быть лучше, чем другой, у нас просто недостаточно данных, чтобы утверждать об этом с уровнем значимости 5%).
Нам осталось понять, как статистический тест из уровня значимости и экспериментальных данных оценивает доверительные интервалы для разности значений метрики между группами A и B.
Определение доверительных интервалов
Рисунок 3. Оценка доверительных интервалов для разности с помощью бутстрэпа (левый график, 10 000 итераций бутстрэпа) и аналитически (правый график). Зеленой линией показаны границы доверительного интервала, черной линией — положение нуля. На среднем графике оба способа совмещены для сравнения.
Для определения доверительных интервалов мы пользовались двумя способами, показанными на рисунке 3:
- Аналитически.
- С помощью бутстрэпа.
Аналитическая оценка доверительных интервалов
В аналитическом подходе мы опираемся на утверждение центральной предельной теоремы (ЦПТ) и ожидаем, что разность средних значений метрик в двух группах будет иметь нормальное распределение, с параметрами и . Точных значений и мы не знаем, но можем подсчитать приближенные оценки и :
Где средние значения () и дисперсии средних значений () вычисляются по стандартным формулам.
Зная параметры нормального распределения и уровень значимости, мы можем вычислить доверительные интервалы. Формулы для вычисления доверительных интервалов мы не приводим, но идея показана на рисунке 3 на правом графике.
Одним из минусов такого подхода является тот факт, что в ЦПТ случайные величины предполагаются независимыми. В реальности это предположение часто нарушается, в частности, из-за того, что действия одного пользователя зависимы. Например, пользователь «Амазона», купивший одну книгу, скорее всего, купит и еще одну. Будет ошибкой считать две покупки одного пользователя независимыми случайными величинами, потому что мы можем в результате получить слишком оптимистичную оценку на доверительный интервал. А это означает, что в реальности процент ложно прокрасившихся A/A-тестов может быть в разы больше, чем заданное значение. Именно это мы и наблюдали на практике. Поэтому мы попробовали другой метод оценки доверительных интервалов, а именно бутстрэп.
Оценка доверительных интервалов с помощью бутстрэпа
Бутстрэп — это один из методов непараметрической оценки доверительных интервалов, в котором не делается никаких предположений о независимости случайных величин. Применение бутстрэпа для оценки доверительных интервалов сводится к следующей процедуре:
- Повторять раз:
- выбрать с помощью бутстрэпа случайные подвыборки значений из групп A и B;
- подсчитать разность средних значений в этих подвыборках;
- Упорядочить по возрастанию значения, полученные на каждой итерации
- С помощью упорядоченного массива определить доверительный интервал так, чтобы точек лежали внутри интервала. То есть, левой границей интервала будет число с индексом
, а правой границей — число с индексом в упорядоченном массиве.
На рисунке 3 на левом графике показаны гистограмма для массива значений разности, полученного после 10 000 итераций бутстрэпа, и доверительные интервалы, вычисленные по описанной здесь процедуре.
Оценка качества системы A/B-тестирования
Итак, мы разбили всех пользователей на групп, подготовили статистический тест и выбрали метрику, которую хотим улучшать. Теперь мы готовы оценивать качество системы A/B-тестирования. В HeadHunter нас интересовало, как часто стат. тест будет совершать ошибку первого рода, то есть какой процент A/A-тестов будет прокрашиваться (обозначим эту величину ) при фиксированном уровне значимости .
Вычислить мы можем проведя много A/A-тестов. В итоге мы можем получить три варианта:
- Если , то либо стат. тест, либо выбранная метрика слишком консервативны. То есть у A/B-тестов заниженная чувствительность («стойкий оловянный солдатик»). И это плохо, т. к. в процессе эксплуатации такой системы A/B-тестирования мы будем часто отклонять изменения, которые действительно что-то улучшили, т. к. мы не почувствовали улучшения (т. е. мы будем часто совершать ошибку второго рода).
- Если , то либо стат. тест, либо выбранная метрика слишком чувствительны («принцесса на горошине»). Это тоже плохо, т. к. в процессе эксплуатации мы будем часто принимать изменения, которые в действительности ни на что не влияли (т. е. мы будем часто совершать ошибку первого рода).
- Наконец, если , значит, стат. тест вместе с выбранной метрикой показывают хорошее качество и такой системой можно пользоваться для проведения A/B-тестирования.
Итак, нам нужно провести много A/A-тестов, чтобы лучше оценить процент ошибок стат. теста . Для этого нам нужно большое число пар групп пользователей. Но откуда можно взять большое число пар, если все пользователи распределены по небольшому числу групп (мы распределяли пользователей по 64 группам). Первое, что приходит в голову, — это составить всевозможные пары групп. Если число групп пользователей у нас равно , то мы сможем из них составить различных пар (схема разбиения на пары для 4 групп показана на рисунке 4 (a)).
Однако такой подход обладает серьезным недостатком, а именно: мы получаем большое число зависимых пар. Например, если в одной группе среднее значение метрики очень мало, то большинство A/A-тестов для пар, содержащих эту группу, прокрасится. Поэтому мы остановились на подходе, показанном на рисунке 4 (б), в котором все группы разбиваются на непересекающиеся пары. То есть число пар равно . Пар получилось значительно меньше, чем в первом способе, но зато теперь они все независимы.
Результаты применения A/A-теста к 64 группам пользователей, которые разбились на 32 независимые пары, показаны на рисунке 5. Из этого рисунка видно, что из 32 пар прокрасились только 2, то есть .
Рисунок 5. Результаты A/A-тестов для 64 групп пользователей, случайно разбитых на 32 пары. Доверительные интервалы вычислялись с помощью бутстрэпа, уровень значимости — 5%.
Гистограммы значений , полученных бутстрэпом, показаны синим для непрокрасившихся пар, желтым для прокрасившихся; распределение Гаусса с вычисленными аналитически параметрами показано красным. Черная линия показывает положение нуля.
В принципе, на этом можно было бы и остановиться. У нас есть способ вычислить реальный процент ошибок стат. теста. Но в этом способе нас смущало небольшое число A/A-тестов. Кажется, что 32 A/A-теста — это маловато для надежного измерения величины . Значит, нам осталось ответить на следующий вопрос:
Если число пар невелико, то как нам надежно измерить ?
Мы использовали такое решение: давайте много раз случайно перераспределять пользователей по группам. И после каждого перераспределения мы сможем измерять процент ошибок . Среднее всех измеренных значений даст оценку величины .
В итоге мы получили следующую процедуру для оценки качества системы A/B-тестирования:
- Повторять раз:
- вычислить как среднее по всем итерациям:
$$display$$ \begin{equation*} \alpha^{\textrm{real}} =\dfrac{1}{N_\textrm{iterations}} \sum_{i=1}^{N_\textrm{iterations}}\alpha^\textrm{real}_i \end{equation*} $$display$$
Если в процедуре оценки качества системы A/B-тестирования мы зафиксируем стат. тест (например, всегда будем использовать бутстрэп) и поверим, что сам стат. тест непогрешим (или незаменим), то у нас получится система оценки качества метрик.
Пример оценки качества одной из метрик показан на рисунке 6. Из этого графика видно, что средний процент ошибок стат. теста (т.е. значение ) практически идеально совпадает с заданным значением . Стоит отметить, что такое хорошее совпадение мы видели нечасто. Мы считаем хорошим совпадением, если .
Рисунок 6. Результат оценки качества для метрики успешных действий пользователей. Синим показана гистограмма для массива чисел , зеленым — среднее значение массива, черным — заданный уровень значимости для бутстрэпа (число итераций бутстрэпа — 10 000). Количество пар групп пользователей равно 32. Число итераций процедуры оценки качества .
Результаты оценки качества метрик
| |
|
|
| (a) |
(б) |
(в) |
| Рисунок 7. Результаты оценки качества для метрики успешности поисковых сессий: (а) — для исходной метрики и бутстрэпа по значениям, (б) — для исходной метрики и бутстрэпа по пользователям, (в) — для модифицированной метрики и бутстрэпа по значениям. |
||
Когда мы применили процедуру оценки качества к метрике успешности поисковых сессий, то получили такой результат, как на рисунке 7 (а). Стат. тест в теории должен ошибаться в 5% случаев, а в реальности ошибается в 40% случаев! То есть, если мы будем использовать данную метрику, то 40% A/B-тестов будут прокрашиваться, даже если вариант А ничем не отличается от варианта Б.
Данная метрика оказалась «принцессой на горошине». Однако мы все же хотели использовать эту метрику, так как ее значение имеет простую интерпретацию. Поэтому мы стали разбираться, в чем может быть проблема и как с этим можно справиться.
Мы предположили, что проблема может быть связана с тем, что от одного пользователя в метрику попадает несколько значений, которые зависимы. Пример ситуации, когда от одного пользователя (Иван Иванович) в метрику попадает два числа, показан в таблице 3.
| Пользователь |
Значение метрики |
|---|---|
| Иван Иванович | 0 |
| Иван Никифорович | 0 |
| Антон Прокофьевич | 1 |
| Иван Иванович | 1 |
Ослабить влияние зависимости значений одного пользователя мы можем либо модификацией стат. теста, либо изменением метрики. Мы попробовали оба этих варианта.
Модификация стат. теста
Поскольку значения от одного пользователя зависимы, то мы выполняли бутстрэп не по значениям, а по пользователям: если пользователь попал в бутстрэпную выборку, то используются все его значения; если не попал, то не используется ни одно из его значений. Применение такой схемы привело к значительному улучшению (рисунок 7 (б)) — реальный процент ошибок стат. теста на 100 итерациях оказался равным , что очень близко к теоретическому значению .
Модификация метрики
Если нам мешает, что от одного пользователя в метрику попадает несколько зависимых значений, то можно сначала усреднить все значения внутри пользователя, чтобы от каждого пользователя в метрику попадало бы только одно число. Например, таблица 3 после усреднения значений внутри каждого пользователя перейдет в следующую таблицу:
| Пользователь |
Значение метрики |
|---|---|
| Иван Иванович | 0.5 |
| Иван Никифорович | 0 |
| Антон Прокофьевич | 1 |
Результаты оценки качества метрики после данной модификации показаны на рисунке 7 (в). Процент случаев, в которых стат. тест ошибался, оказался почти в 2 раза ниже теоретического значения . То есть, для данной метрики и неидеально совпадают, но это гораздо лучше, чем исходная ситуация на рисунке 7 (а).
Какой из двух подходов лучше
Мы применяли оба подхода (модификация стат. теста и модификация метрики) для оценки качества различных метрик, и для подавляющего большинства метрик оба подхода показывали хорошие результаты. Поэтому использовать можно тот способ, который проще реализовать.
Выводы
Главный вывод, который мы сделали при оценке качества системы A/B-тестирования: нужно обязательно выполнять оценку качества системы A/B-тестирования). Перед тем как использовать новую метрику, ее нужно проверить. Иначе A/B-тесты рискуют превратиться в одну из форм гадания и повредить процессу разработки.
В этой статье мы постарались, насколько это возможно, привести всю информацию о устройстве и принципах работы процедуры оценки качества системы A/B-тестирования, используемой в компании. Но если у Вас остались вопросы, не стесняйтесь задавать их в комментариях.
P.S.
Я хотел бы выразить благодарность lleo за систематизацию процесса A/B-тестирования в компании и за проведение proof-of-concept экспериментов, развитием которых является данная работа, и p0b0rchy за передачу опыта, терпеливые многочасовые разъяснения и за генерацию идей, которые легли в основу наших экспериментов.
Полезные метрики для оценки проектов / Habr
В октябре я уже рассказывала о способах оценки тестирования, все страждующие и сочувствующие могут посмотреть запись здесь. А сегодня мне захотелось затронуть тему метрик проекта в целом, причём метрик не «длягалочных», а метрик «пользуприносящих» и «проектыулучшающих». Именно поэтому, вместо сухих формул и перечня метрик, я расскажу 3 истории из опыта о внедрении и использовании строго определённых метрик в строго определённых условиях — и о результатах, которые с их помощью удалось достичь.Зачем что-либо измерять?
Есть проект. Ваш любимый, родной, которому вы желаете расти и процветать.
Но как вы оцените его процветание, если нет критериев этого самого процветания?
Как вы сможете оперативно среагировать на проблемы до того, как они стали неисправимыми, если не будете использовать «датчик грядущей Ж»?
Как вы поймёте, что именно следует улучшать, если вам неизвестен источник проблем?
Если вкратце, то метрики нужны, чтобы эффективно управлять проектом: диагностировать проблемы, локализовывать их, исправлять и проверять, правда ли выбранные вами способы решения проблемы помогают.
Я поделюсь разными типами метрик, каждые из которых проверены и принесли немалую пользу. Каждый раз, внедряя их, любой команде очень лень и некомфортно: приходится сохранять дополнительную информацию, что-то там мерять, разводить бюрократию. Но когда мы впервые получаем от какой-либо метрики пользу, на смену лени приходят дисциплина и глубокое понимание важности той или иной метрики.
А если не приходят, значит метрику можно смело выбросить 😉
История 1: Кто впустил его сюда??
В одной замечательной компании руководство жаловалось на «некачественный продукт», виной чему — тестирование. Моей задачей было проанализировать причины этого досадного недоразумения и каким-либо образом их решить, причём естественно вчера.
Задача #1 для меня стала очевидной: оценка % пропущенных ошибок: а правда ли, что тестировщики что-то пропускают? Для этого мы ввели в баг-трекере поле «сообщил клиент», пометили таким образом старые баги и посчитали. Процент составил чуть больше 5%, причём далеко не все из них были критическими.
Много это или мало? По моему опыту это достаточно хороший процент. Откуда тогда мнение, что тестировщики много пропускают?
Мы ввели ещё одно поле: «воспроизводится на релизной версии». Каждый раз, регистрируя новую ошибку с тестового стенда, тестировщики проверяли, есть ли она в последней пользовательской версии: возможно, пользователи просто не сообщают конкретные ошибки? Результат за первый месяц — около 40% ошибок, зарегистрированных в баг-трекер, воспроизводятся в релизной версии.
Получается, пропускаем мы действительно много, но пользователи не сообщают о конкретных ошибках, а вот мнение «ваш софт — отстой!» у них явно формируется. Таким образом мы сформировали метрики-датчики: что не так:
- % пропущенных в релизную версию ошибок
- % ошибок, сообщённых пользователем
Ставим цель (а иначе зачем что-то вообще мерять?)! Хотим не больше 10% ошибок, попавших в релизную версию. Но как это обеспечить? Непомерно расширять ресурсы? Увеличивать сроки?
Для ответа на этот вопрос нам нужно копать дальше, и искать новые метрики, которые дадут ответ на этот вопрос.
В данном случае, мы для всех пропущенных ошибок добавили ещё одно поле: «Причина пропуска». И на выбор указываем, почему не завели эту багу раньше:
- неизвестное требование (не знали или не поняли, что это было нужно)
- не учли тест (не додумались тестировать это ТАК)
- не протестировали (тест был, его проверили, но потом функционал сломался, а повторно эту область не проверяли)
По этому алгоритму я уже во многих компаниях исследовала причины пропусков, и результаты всегда разные. В рассматриваемом мной случае более 60% ошибок оказались пропущенными потому, что тестировщики не учли какой-либо тест, то есть даже не подумали, что это нужно тестировать. Конечно, нам нужно работать по всем фронтам, но начали мы с 60%, опираясь на закон Парето.
Брейншторминг «как решить эту загадку» привёл к различным решениям: еженедельное обсуждение пропущенных дефектов в группе тестирования, согласование тестов с аналитиками и разработчиками, прямое общение с пользователями для исследования их окружений и условий и т.д. Внедряя потихоньку эти новые процедуры, мы снизили всего за 2 месяца % пропущенных ошибок до 20%. НЕ расширяя команду, НЕ увеличивая сроки.
До 10% мы пока что не дошли, но в июле было 14% — мы уже совсем близки к цели, и судя по уверениям внедренцев, клиенты уже заметили изменения в качестве. Неплохо, да?
История 2: Откуда дровишки?
Эта история касается одного из моих собственных проектов. Мы разрабатываем некий ужасно нужный и полезный сервис, и сроки разработки не очень-то грели мою душу. Естественно, у меня на проекте всё ну очень хорошо с тестированием, но почему разработка еле плетётся?
Естественно, я начала с попыток измерить свои субъективные ощущения «медленно». Как это понять? С чем сравнить? KLOC в месяц? Фич в итерацию? Средние срывы сроков относительно плана? Естественно, первые 2 метрики ничего полезного не принесут, поэтому я стала смотреть % срывов сроков по фичам (итерации у нас не имеют фиксированного набора фич, поэтому серьёзно припоздниться не могут — что за 2 недели успели сделать и протестировать, то и выкладываем). Но фичи!
Оказалось, что по ним мы срываем сроки в среднем в 1,5-2 раза! Я не буду рассказывать, чего мне стоило добыть эту информацию из редмайна, но вот, она есть. И я хочу копать дальше, используя принцип «пяти „почему“». Почему так? Мы плохо планируем? Я слишком быстро хочу результат? Или низкая квалификация? На что уходит время?
Я стала анализировать: в среднем на 1 небольшую фичу приходится от 15 до 40 багов, а время на их фикс уходит больше, чем на разработку самой фичи. Почему? Много это или мало? Разработчики жалуются, что очень много просьб на изменение уже разработанного функционала — правда ли это или субъективная ошибочная оценка?
Копаем дальше. Я ввожу в бедный несчастный разбухший от дополнительных полей баг-трекер поле: «Причина появления ошибки». Не пропуска, как в Истории #1, а именно ПОЯВЛЕНИЯ. Это поле заполняет разработчик в момент коммита, когда он уже точно знает, что и как он исправлял. И варианты ответа следующие:
- Код (вот взяли и накосячили)
- Непонимание требований («ах я ж не понял, что именно это было нужно!»)
- Изменение требований (product owner посмотрел на результат и сказал «э не, на самом деле нужно по-другому, а не так, как я изначально просил»)
Ошибок в коде у нас оказалось около 30%. Изменений требований — меньше 5% (разработчики удивились, но признали — это ведь они указывают причину!). А почти 70% ошибок оказались вызваны непониманием требований. В нашем случае, когда багфикс занимает больше разработки, это ПОЛОВИНА ВРЕМЕНИ, ЗАТРАЧИВАЕМОГО НА РАЗРАБОТКУ ФИЧИ.
Что делать?
Вариантов решения проблемы мы нашли много, начиная от найма технического писателя, который будет вызнавать требования у product owner’а и документировать подробно всё то, что мы описываем в пару строк и заканчивая product owner’ом, переведённым в секретари, круглые сутки документирущим новые фичи. Ни один из этих вариантов нам не понравился, слишком они бюрократичны для команды из 4 разработчиков, сидящих в одном кабинете. Поэтому мы сделали следующее:
- Product owner вкратце, как и всегда, описывает новую фичу
- Разработчик, когда доходит до неё, тщательно обдумывает способ реализации, как это будет выглядеть, что с этой фичей ему вообще делать
- После этого разработчик и РО садятся вместе, и разработчик подробно рассказывает свои мысли на тему
светлого будущегоразрабатываемой фичи - Разработчик ни при каких условиях не начинает работу над новой фичей, не пройдя вышеописанный алгоритм действий и не согласовав своё видение с РО
- Тестировщик чаще всего участвует в этом процессе, заранее подсказывая сложные моменты, которые он будет тестировать
Теперь у нас есть около 3-7 таких ~часовых «болталок» в неделю, на которые отрывается 2-3 человека. Количество заводимых багов снизилось, из них ошибок кода стало больше 50% — поэтому нашей следующей задачей будет внедрение code review, т.к. теперь у нас новая «главная проблема».
Но от метрики-анализатора мы вернулись к метрике-датчику и поняли, что ни разу с весны не сорвали сроки по фиче больше чем на 50%, хотя до этого среднее значение срыва было от 50% до 100%, а иногда и больше.
И это только начало! 😉
История #3: Кто тормозит разработчиков?
Ещё одна история касается моего совсем недавнего опыта в сторонней компании. Настоящий-пренастоящий Agile, еженедельные итерации… И еженедельные срывы сроков!
Причина, заявленная руководством компании: «Разработчики допускают слишком много багов».
Я начала анализировать, как это происходит. Я просто участвовала в процессе и наблюдала со стороны, как это очень здорово описано в книге Имаи «Гемба Кайдзен». И вот что я увидела: Релизы по четвергам, пятница подготовительный к новой итерации день. Во вторник-среду появляется сборка на тестирование. В среду-четверг заводятся дефекты. В пятницу, вместо подготовки к новой итерации, разработчики экстренно исправляют баги и так каждую неделю.
Я попросила в таск-трекере, где дублируются фичи с доски, проставлять статусы по фиче: фича принята в разработку, фича отдана на тестирование, фича протестирована и отправлена на доработку, фича протестирована и принята в релиз.
И как вы думаете, какой средний срок между «фича отдана на тестирование» и «фича протестирована и отправлена на доработку»? 1,5 дня!
Причём иногда — с ЕДИНСТВЕННЫМ блокирующим дефектом.
Разработчики в этой компании жаловались на тормозных тестировщиков, но тестировщики и руководство были против разработчиков: «вы сами должны тестировать и не отдавать сырой продукт». Но ведь кесарю кесарево!
Итак, метрика есть, 1,5 дня недопустимо много, хотим сократить минимум втрое — это должно ускорить релизы на день. Как это сделать? Опять брейншторм, опять куча идей, 90% участников процесса настаивают что «разработчики должны тестировать сами».
Но в итоге мы решили попробовать по-другому: как только фича, по мнению разработчика, готова, тестировщик садится с ним за один компьютер, берёт блокнот с ручкой и начинает проверять, комментировать, выписывать замеченные косяки в блокнот, не тратя время на баг-трекинг. Больше половины багов разработчики в таком режиме исправляют на лету! Ведь фича только написана, всё ещё держится в голове!
Срок с 1,5 до 0,5 дней мы сократили очень быстро, но на практике мы достигли другого, более серьёзного изменения: % переведённых в статус «отправлено на доработку» фич снизился с почти 80 до почти 20! То есть в 4 раза! То есть 80% фич теперь сразу принимался после переведения в статус «тестирование», потому что незадолго до перевода в этот статус проходило тестирование «на лету», так сильно сокращающее и время регистрации ошибок, и стоимость их исправления.
Кстати, история 3 — единственная, где мы сразу достигли поставленную цель. Срывы итераций всё ещё бывают, но теперь это исключение, и почти каждый четверг команда разработки уходит домой вовремя, а в пятницу правда начинается подготовка к следующей итерации.
Бинго!
Выводы
Я очень не хотела рисовать сухие формулы, философствовать и теоретизировать. Я рассказала конкретные истории из свежего (2012!) опыта. Истории, в которых мы сокращали сроки и повышали качество, не меняя бюджет.
Вы всё ещё не готовы использовать метрики с пользой?
Тогда мы идём к вам! 🙂
виды тестов, метрики и советы от профессионалов
 Сегодня, когда рост вычислительных мощностей снизился, а объемы обрабатываемых данных, количества пользователей и запросов к системам продолжают расти, вопросы производительности и ее тестирования широко обсуждаются в профессиональной среде.
Сегодня, когда рост вычислительных мощностей снизился, а объемы обрабатываемых данных, количества пользователей и запросов к системам продолжают расти, вопросы производительности и ее тестирования широко обсуждаются в профессиональной среде.
В данной статье команда по тестированию производительности A1QA освещает основные виды тестов и рассказывает, что нужно учесть при их выполнении для получения релевантных результатов.
Перед вами самые распространенные виды тестирования производительности.
1. Стресс-тестирование (Stress Test)
Этот тест проводится первым. Нагрузка постепенно увеличивается до тех пор, пока приложение не перестанет работать корректно. В конце теста фиксируется количество пользователей, которое приложение выдерживало, соответствуя требованиям производительности, и сколько выдержать не смогло. Первое значение и будет пределом производительности вашего приложения. Часто этот вид тестирования проводится, если заказчик предвидит резкое увеличение нагрузки на систему. Например, для e-commerce это могут быть дни распродаж.
2. Нагрузочный тест (Load Test)
Нагрузка на систему подается на протяжении 4-8 часов. В это время собираются метрики производительности: количество запросов в секунду, транзакций в секунду, время отклика от сервера, процент ошибок в ответах, утилизация аппаратных ресурсов и т д. Собранные метрики проходят проверку на соответствие заданным требованиям. В результате получаем ответ на вопрос: соответствует ли система требованиям производительности?
Также на выходе имеем локализацию узких мест в производительности приложения и дефектов, подробное профилирование всех компонентов системы и утилизацию аппаратных ресурсов под целевой нагрузкой.
- 3. Тестирование на больших объемах данных (Volume Test)
Данный вид тестирования помогает сделать прогноз относительно работоспособности приложения. Форма подаваемой нагрузки та же, что и при нагрузочном тестировании. Задача теста – узнать, какое влияние окажет увеличение объема данных на систему. Таким образом, можем найти ответ на вопрос: как изменится производительность приложения спустя X лет, если аудитория приложения вырастет в Y раз?
- 4. Тестирование отказоустойчивости (Stability Test)
Продолжительность нагрузки может варьироваться в зависимости от целей и возможностей проекта, доходя до семи дней и более. В результате получаем представление о том, как изменится производительность системы в течение длительного периода времени под нагрузкой, например, в течение недели. Снизится ли уровень производительности? Способно ли приложение выдерживать стабильную нагрузку без критических сбоев?
- 5. Тестирование масштабируемости (Scalability Test)
Профиль нагрузки тот же, что и при нагрузочном тестировании. Что получаем в результате? Ответы на следующие вопросы:
- Увеличится ли производительность приложения, если добавить дополнительные аппаратные ресурсы?
- Увеличится ли производительность пропорционально количеству добавленных аппаратных средств?
О видах тестирования поговорили, теперь коснемся такого важного аспекта их проведения как нагрузка.
Подаваемая нагрузка
Нагрузка во время тестов должна базироваться исключительно на основе реального поведения пользователей. Только в таком случае вы сможете получить результат, соответствующий реальной производительности системы. Запуск любых других форм нагрузки – это пустая трата ресурсов и времени.
Для защиты от ошибок в поведении скриптов мы настоятельно рекомендуем дважды проверять сетевой трафик, который генерируют нагрузочные скрипты и реальные пользователи. Структура запросов и ответов всегда должна быть идентичной.
Чтобы избежать неожиданных проблем во время запуска тестов, генераторы нагрузки необходимо располагать как можно ближе к тестовому окружению.
Например, нагрузка на окружение подается равной 1000 пользователей, а действительная нагрузка во время теста составляет только 200 пользователей. Разница обусловлена «узким местом» в сети между клиентами и сервером.
В этом случае вы не сможете получить точную информацию о времени отклика и оценить производительность системы в целом. Так, например, во время теста вы получили среднее время отклика равное 10 секундам, но лишь транспортировка пакета от клиента к серверу и обратно занимало 9.5 секунд, а формирование ответа уложилось в 0.5 секунды. Сервер способен оперативно обрабатывать запросы, но мы его не догрузили из-за сетевых условий.
При правильном подходе мы тестируем производительность системы, а не сети. Для этого тестовое окружение и генератор должны быть расположены в одной локальной сети.
В таком случае мы избежим проблемы производительности сети и будем уверены в том, что время отклика соответствует реальной производительности приложения.
Какие же метрики собираются во время тестирования производительности?
Время отклика измеряется с момента отправки запроса к серверу до получения последнего байта от сервера.
Запросы в секунду. Клиентское приложение формирует HTTP-запрос и отправляет его на сервер. Серверное ПО данный запрос обрабатывает, формирует ответ и передает его обратно клиенту. Общее число запросов в секунду и есть интересующая нас метрика.
Транзакции в секунду. Пользовательские транзакции – это последовательность действий пользователя в интерфейсе. Сравнивая реальное время прохождения транзакции с ожидаемой (или количество транзакций в секунду), вы сможете сделать вывод о том, насколько успешной системой было пройдено нагрузочное тестирование.
Число виртуальных пользователей в единицу времени также позволяет выяснить, отвечает ли производительность приложения заявленным требованиям. Если вы все делаете правильно и ваши сценарии максимально приближены к поведению пользователя, то один виртуальный пользователь будет равен одному реальному пользователю.
Процент ошибок рассчитывается как отношение невалидных ответов к валидным за промежуток времени.
Желаемые показатели данных метрик указываются в требованиях к программному обеспечению. Но это в идеале. Если эти данные не прописаны, руководитель команды по тестированию должен прояснить этот момент с заказчиком.
Советы для тестировщиков и аналитиков по тестированию производительности
- Корреляция динамических параметров и построение скриптов должны быть основаны на реальном поведении пользователей. Иначе тестирование будет больше напоминать DDOS-атаку.
- Перед разработкой и запуском скриптов необходимо провести большую аналитическую работу, чтобы понять и подготовить детализированную методологию тестирования производительности.
- Важно принимать во внимание временные задержки между действиями пользователей и корректно размещает их в скриптах согласно поведению реальных пользователей.
- Функция кэширования должна воспроизводиться как для каждого виртуального пользователя, так и для реальных пользователей в промышленной эксплуатации системы.
- Виртуальные пользователи должны использовать заранее подготовленные тестовые данные и взаимодействовать с системой в поведенческой манере. Каждое действие должно иметь предварительно заданную вероятность и выполняться только определенным количеством пользователей.
- Чтобы найти функциональные дефекты, которые проявляются только при нагрузке, следует создавать скрипты с такими же наборами действий, как и у реальных пользователей. Это даст возможность проанализировать и воспроизвести запросы.
Итак, мы рассказали, в чем состоит разница между различными тестами производительности и на какие вопросы они помогают ответить; какие метрики позволяют сравнивать ожидаемый и реальный уровень производительности. Надеемся, данная информация будет вам полезной и поможет в работе.
Обсудить в форуме
Автор: Баз Дийкстра (Bas Dijkstra) Перевод: Ольга Алифанова Неплохая идея – определить и отслеживать метрики, чтобы держать автоматизационные усилия под контролем и принять меры, если метрики скажут вам, что ваши действия не приносят нужных результатов. Еще важнее возможность купаться в славе, если они-таки их приносят! Но что такое хорошие метрики тест-автоматизации? В этой статье я рассмотрю некоторые метрики, которые считаю полезными, и некоторые, без которых мир автоматизаторов вполне может обойтись. Отмечу, что я не собираюсь перечислять ВСЕ метрики, которые используются в автоматизации, но надеюсь, что упомянутые мной укажут вам верное направление. Итак, что, с моей точки зрения, может быть полезной метрикой для отслеживания эффективности и/или результатов усилий по автоматизации? Снижение длительности петли обратной связи Первая метрика, которую я бы предположил, не связана с качеством приложения – скорее она относится к качеству процесса разработки. Сама суть тест-автоматизации (по крайней мере, в идеале) – это повышение эффективности усилий тестирования. Один из способов отследить это – замерять время, которое проходит между моментом, когда разработчик коммитит изменение, и моментом, когда ему сообщают о том, как эти изменения повлияли на качество приложения. Это время, также известное как время петли обратной связи, в идеале должно быть как можно короче. Если разработчик узнает об ужасных последствиях своего коммита спустя две недели – он давно уже переключился на другие задачи. Или проекты. Или вообще сменил работу. Если же обратная связь приходит в течение нескольких минут (или секунд), поправить дело куда проще. Один из способов сократить длительность петли обратной связи – эффективно использовать автоматизацию, поэтому подходите к ней с умом и отслеживайте, как она влияет на петлю обратной связи. Процент завершения пользовательских сценариев Возможно, кого-то это удивит, но автотесты, тестирование, разработка ПО в целом – это все еще деятельность, посвященная высшему благу: счастью пользователя. В этом ключе имеет смысл разработать метрику, которая напрямую относится к способности пользователя использовать ваше приложение. Примером такой метрики может служить количество предопределенных критических пользовательских сценариев, которые (все еще) могут быть завершены при помощи автотеста после того, как в код были внесены правки. Под «критическими» я имею в виду сценарии, которые напрямую относятся к генерированию дохода, привлечению потребителей и другим маркетинговым штукам. Чем проще и чаще вы можете убедиться (при помощи автоматизации), что эти сценарии работают, тем больше веры у вас будет в ваше новое прекрасное приложение, которое вот-вот увидит свет. Ложноположительные и ложноотрицательные срабатывания Автотесты ценны, только если вы можете полностью доверять той обратной связи, которую они вам дают. Если автотест падает, то это должно происходить из-за дефекта (или незамеченных изменений) в приложении, а не потому, что ваш автотест плох (зачем вам ложноотрицательные срабатывания?). С другой стороны, если автотест прошел, вы должны быть полностью уверены, что компонент или приложение, которое тестировалось, действительно работает так, как должно (ложноположительные срабатывания нужны вам еще меньше). Ложноотрицательные срабатывания раздражают, но как минимум не проходят незамеченными. Исправляем их причину и идем дальше. Если она не может быть исправлена, удаляем сам тест – если ему нельзя верить, в нем нет смысла. Ложноположительные срабатывания – куда большая проблема, потому что их не так-то просто заметить. Если в мире автоматизации все вокруг зеленое, очень легко (и по-человечески понятно) доверять результатам, даже если все, что вы проверяли – это то, что единица равна единице (см. ниже). Один из подходов по определению ложноположительных срабатываний, по крайней мере в области юнит-тестирования – это использование мутационного тестирования. Если это невозможно, регулярно проверяйте ваши автотесты, чтобы убедиться, что они все еще послушно ищут баги. Помимо полезных метрик, есть и такие, ценность которых сомнительна (или вовсе отсутствует). Покрытие кода Метрика, которая часто используется для выражения покрытия сьюта юнит-тестов. Основная проблема с этой метрикой в том, что, теоретически, она очень логична (каждая строчка кода запускалась как минимум один раз, когда мы прогоняли наши тесты), но на практике она ровным счетом ничего не говорит о качестве и эффективности тестов, а также качестве самого приложения. К примеру, очень даже возможно написать юнит-тесты, которые затронут абсолютно все строки кода и убедятся, что единица равна единице. Или что яблоки равны яблокам. Эти тесты пройдут без сучка, без задоринки. Они будут проходить каждый божий раз (ну или до тех пор, пока единица не перестанет равняться единице, но я думаю, что в обозримом будущем все будет хорошо). Инструменты покрытия кода покажут блестящий 100% результат. Который будет означать ровным счетом ничего в смысле качества приложения. Процент тест-кейсов, которые уже автоматизированы Экспонента феномена «автоматизируйте все на свете!». В теории, выглядит круто: «Мы автоматизировали 83,56% наших тестов!» Во-первых (особенно в плане исследовательского тестирования – это не моя сильная сторона, могу ошибаться), нет такого понятия, как фиксированное количество тест-кейсов. Следовательно, выражать количество автотестов как процент от переменной, которая вовсе не существует – это бессмысленно. Или вы просто врете сами себе (выберите сами, что именно). Есть только одна метрика, которая заслуживает внимания в этом ключе, цитируя Алана Пейджа: Вы должны автоматизировать 100% тестов, которые должны быть автоматизированы. Снижение количества тестировщиков Да-да, на дворе 2016. И да, некоторые организации все еще думают именно так. Я даже не буду тратить время на объяснения, почему мысль «если мы автоматизируем наши тесты, мы можем обойтись меньшим количеством тестировщиков» – идиотская. Однако я планировал упомянуть хорошие, плохие и дурацкие метрики автоматизации, и эту конкретную никак нельзя обойти стороной. В заключение хочется сказать, что я смотрю на метрики автоматизации так: они должны говорить вам что-то полезное о качестве вашего приложения или процесса разработки. Метрики, связанные непосредственно с автоматизацией или чем-то, для чего автоматизация не может быть использована (например, тестирование), возможно, не имеют смысла и не нужны никому. Обсудить на форуме |
 Оригинал статьи: http://www.ontestautomation.com/not-so-useful-metrics-in-test-automation/
Оригинал статьи: http://www.ontestautomation.com/not-so-useful-metrics-in-test-automation/Как получить сертификат по Яндекс.Метрике?
Сертификат по Яндекс.Метрике – официальный документ, подтверждающий высокую квалификацию специалистов в области веб-аналитики. Знание инструментов Метрики, умение собирать информацию о работе сайта и строить отчёты, выявлять существующие проблемы и анализировать успешность рекламных кампаний помогут вам успешно пройти тестирование даже с первого раза.
Сертификат по Яндекс.Метрике могут получить:
- отдельные специалисты;
- рекламные агентства.
Порядок сертификации агентства
Для получения статуса сертифицированного агентства Яндекс выдвигает ряд требований:
- В штате компании должны работать не менее 3-ёх специалистов, каждый из которых является владельцем именного сертификата по Яндекс.Метрике. Вместе с этим, хотя бы один из сотрудников должен подтвердить опыт публичных выступлений на конференциях в соответствующей сфере.
- Дополнительно необходимо предоставить утверждённый клиентом кейс, в котором используются «продвинутые» инструменты сервиса для реализации различных задач бизнеса.
Процедура сертификации разделена на 2 этапа – рассмотрение кейса и собеседование с представителем агентства. При положительном результате выдаётся статус сертифицированного агентства по Яндекс.Метрике, действительный в течение 6 месяцев. Дальнейшее подтверждение статуса проводится каждые 3 месяца и требует выполнения установленных условий. Все сертифицированные агентства указаны на сайте Яндекс, что однозначно помогает привлечь потенциальных клиентов.
Порядок сертификации специалистов
К сертификации допускается специалист любого уровня квалификации, владеющий навыками работы в системе веб-аналитики Яндекс. Тестирование бесплатное и проходит в режиме онлайн. При успешной сдаче вам выдаётся именной сертификат, действительный на протяжении 12 месяцев. По истечению срока необходимо повторно пройти тест.
Что вас ждёт на экзамене?
- 50 вопросов по 6-ти темам;
- лимит по времени 60 минут.
Число попыток не ограничивается. При отрицательном результате вы допускаетесь к повторной сертификации через 7 дней. Далее интервал между попытками составляет 3 месяца. Точные даты будут прописаны в вашем Личном кабинете.
При 80 % и более верных ответов вы становитесь обладателем именного сертификата — минимальный порог касается каждой темы. Если хотя бы по одной теме вы дадите менее 80 % верных ответов, итог тестирования засчитывается, как отрицательный.
Приостанавливать тестирование, сохранять промежуточные итоги вы не можете. Единственный момент, в процессе решения задач разрешается пропускать вызывающие у вас сложности вопросы, чтобы вернуться к ним позже (при условии, что время теста ещё не истекло). Если вы случайным образом закрыли страницу с активным тестированием, не беда. Время идёт, но при повторном открытии страницы вы возвращаетесь на то место, где остановились.
Как подготовиться к тестированию?
Перед сертификацией полезно пройти небольшой пробный тест, где показана методика подсчёта результатов и представлен интерфейс основного тестирования. В этой версии нет ограничений по времени между попытками сдачи теста.
Новичкам Яндекс предлагает изучить «Базовый курс» , который состоит из уроков:
- Чем полезна Метрика бизнесу.
- Основные понятия Метрики.
- Как работает система.
- Как устанавливается код счетчика на веб-ресурс.
- Обзор инструментов Метрики.
Уроки представлены в видео роликах и текстовом формате с картинками. В конце каждого раздела выдаётся задание для проверки усвоения знаний.
Для тех, кто уверенно работает в сервисе веб-аналитики целесообразно изучить обучающие видео от Яндекс, выложенные на YouTube канале. Много полезной информации можно почерпнуть в разделе «Материалы для подготовки к сертификации по Метрике».
Конечно, вы уже видели, сколько ресурсов выкладывают и даже продают готовые ответы к тестированию. Нужны ли вам они? Вопрос спорный. Во-первых, стоит задуматься о верности данных ответов. Во-вторых, для чего вы сдаёте тестирование? Если вы стремитесь получить опыт для повышения своей квалификации, то вам однозначно необходимо самостоятельно ориентироваться в каждой теме. Первоклассным специалистом может стать только тот, кто постоянно совершенствует свои личные знания и навыки.
Правила сертификации: это нужно знать!
Логин для сертификации
Проходите тест под собственным именем и фамилией, проверив корректность данных в Яндекс.Паспорте, так как после выдачи сертификата вам не удастся внести какие-либо изменения. При обнаружении некорректно указанных сведений руководство Яндекс оставляет за собой право аннулировать действующий сертификат. Причём допуск к сертификации вы получите только тогда, когда истечёт срок действия аннулированного документа.
Сотрудникам рекламных агентств рекомендуется проходить тест под логином агентского представителя. В противном случае, при сертификации вашей компании результаты тестирования засчитаны не будут.
Порядок присвоения именного сертификата
Полученный вами сертификат будет действительным в течение 1 года. За месяц до окончания его срока действия сотрудники Яндекс высылают уведомление на почту, соответствующую вашему логину. С этого момента вы можете приступать к повторному тестированию.
Все сертификаты Яндекс, включая Метрику, хранятся в Личном кабинете. Вы можете использовать их несколькими способами:
- скачать документ в формате pdf и сделать распечатку;
- разместить сертификат на сайте путём копирования кода баннера;
- «поделиться» личными медиа страницами с именным сертификатом.
Возможно ли проверить сертификат на подлинность?
Да, такая возможность есть у всех пользователей системой Яндекс. На странице «Проверка подлинности сертификата» вводится номер и фамилия его владельца.
Сертификация по Метрике: инструкция
- Откройте (https://yandex.ru/adv/expert/exam/metrika) и войдите под своим логином.
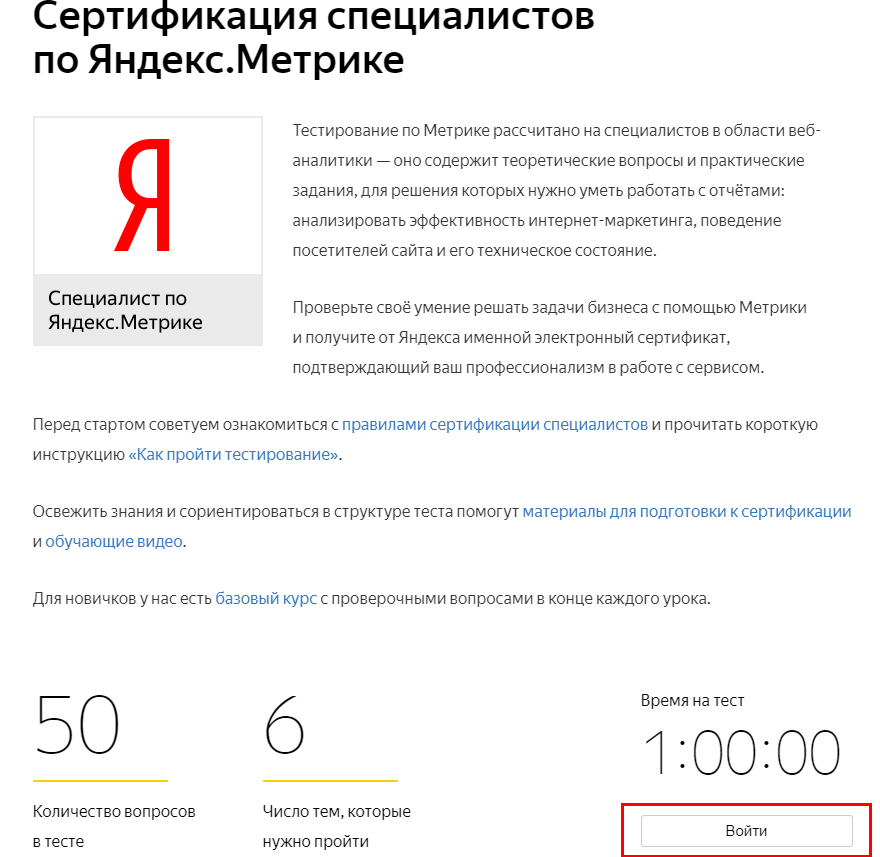
- Подтвердите правильность указанных вами данных и кликайте «Начать тестирование». На этом этапе у вас есть возможность внести изменения. Дальше этого права у вас не будет!

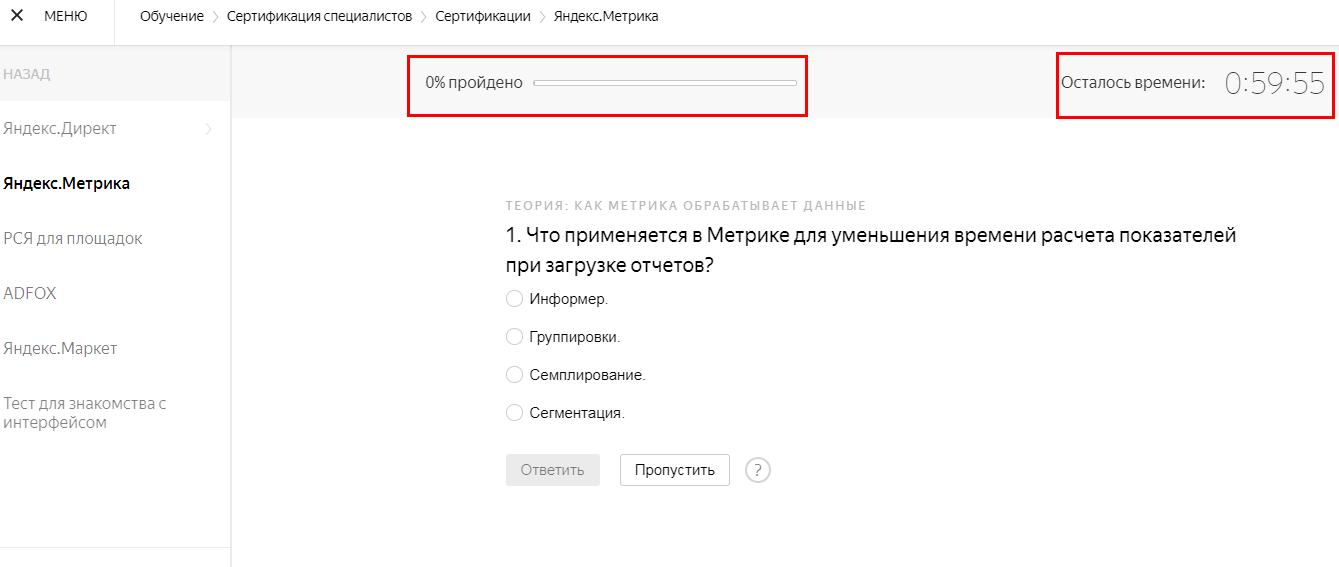
Время пошло. Вот так выглядит интерфейс страницы сертификации. В правом верхнем углу отображается текущее время, слева – процент пройденных заданий. Это позволит вам рационально распоряжаться временным ресурсом. Не теряйте ценные минуты на сложные вопросы — в конце теста вы сможете к ним вернуться.
Тестирование содержит теорию и практические задачи, требующие решения.
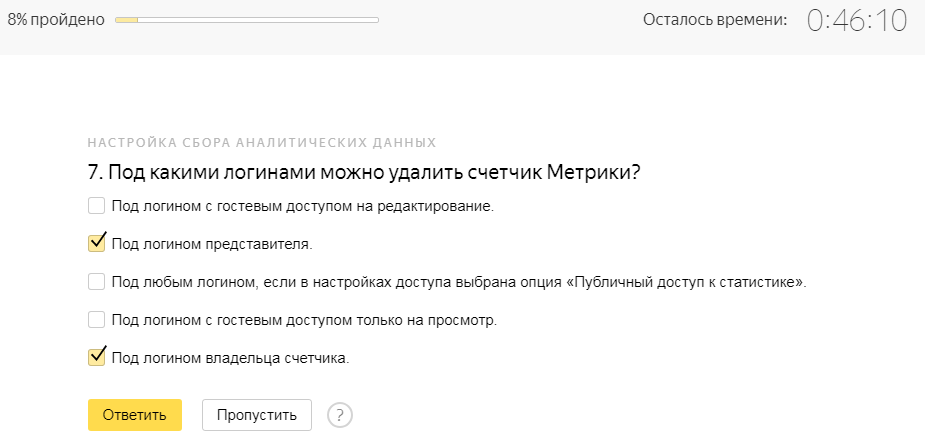
Обращаю ваше внимание, теоретические вопросы могут содержать как один, так и несколько правильных ответов.
Второй тип заданий – изучение отчётов Метрики, на основе которых даётся ответ. Статистика открывается в новой вкладке.
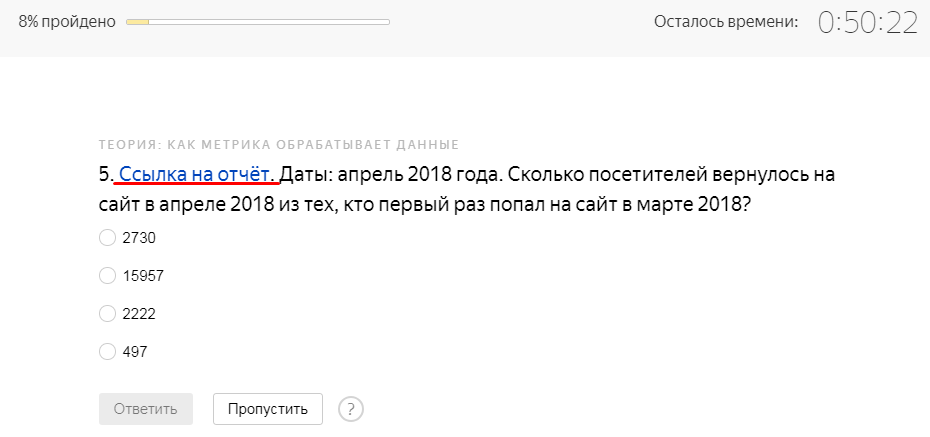
Пример заданий, в которые включены скриншоты.
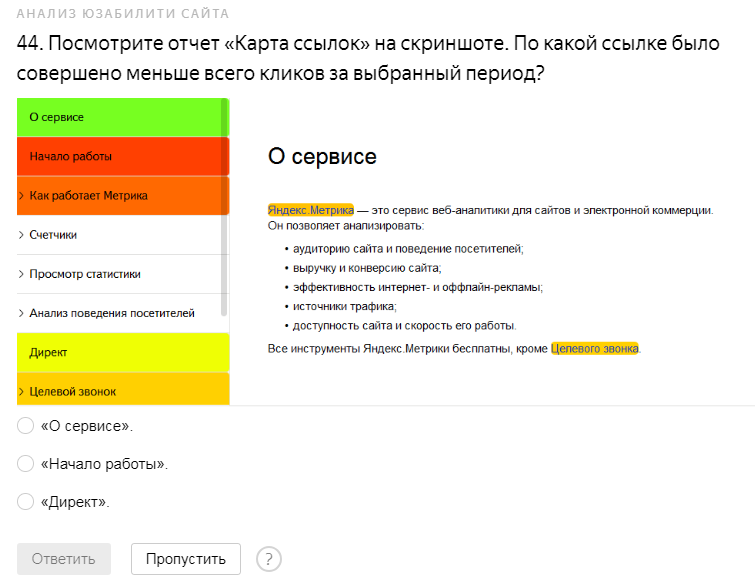
По истечению времени или ответов на все указанные вопросы система сразу же подсчитывает результаты в процентах по каждой теме. Такой подход даёт вам информацию о том, какие разделы следует повторить. Красным выделяются темы, где не был преодолён минимальный показатель верных ответов (80 %).
Если вы смогли дать 80 % и более правильных ответов по каждой теме, результат тестирования положительный. Вы становитесь владельцем именного сертификата.
Вывод
На самом деле, успешно сдать тестирование несложно. Хорошо изучите теорию, освойте функциональные возможности Метрики и потренируйте знания на практике. И ещё, следите за модернизацией сервиса – его возможности постоянно расширяются. Если вы какое-то время не работали с Метрикой, то обязательно просмотрите обучающие материалы и интерфейс сервиса.
Получив именной сертификат по Яндекс.Метрике, вы существенно повысите свой статус, как специалиста. Смело используйте официальный документ при трудоустройстве в рекламное агентство или поиске потенциальных клиентов, если занимаетесь ведением проектов самостоятельно.
Желаю вам удачи!
виды тестов, метрики и советы от профессионалов
Сегодня, когда рост вычислительных мощностей снизился, а объемы обрабатываемых данных, количества пользователей и запросов к системам продолжают расти, вопросы производительности и ее тестирования широко обсуждаются в профессиональной среде.
В данной статье команда по тестированию производительности A1QA освещает основные виды тестов и рассказывает, что нужно учесть при их выполнении для получения релевантных результатов.
Перед вами самые распространенные виды тестирования производительности.
1. Стресс-тестирование (Stress Test)
Этот тест проводится первым. Нагрузка постепенно увеличивается до тех пор, пока приложение не перестанет работать корректно. В конце теста фиксируется количество пользователей, которое приложение выдерживало, соответствуя требованиям производительности, и сколько выдержать не смогло. Первое значение и будет пределом производительности вашего приложения. Часто этот вид тестирования проводится, если заказчик предвидит резкое увеличение нагрузки на систему. Например, для e-commerce это могут быть дни распродаж.
2. Нагрузочный тест (Load Test)
Нагрузка на систему подается на протяжении 4-8 часов. В это время собираются метрики производительности: количество запросов в секунду, транзакций в секунду, время отклика от сервера, процент ошибок в ответах, утилизация аппаратных ресурсов и т д. Собранные метрики проходят проверку на соответствие заданным требованиям. В результате получаем ответ на вопрос: соответствует ли система требованиям производительности?
Также на выходе имеем локализацию узких мест в производительности приложения и дефектов, подробное профилирование всех компонентов системы и утилизацию аппаратных ресурсов под целевой нагрузкой.
3. Тестирование на больших объемах данных (Volume Test)
Данный вид тестирования помогает сделать прогноз относительно работоспособности приложения. Форма подаваемой нагрузки та же, что и при нагрузочном тестировании. Задача теста – узнать, какое влияние окажет увеличение объема данных на систему. Таким образом, можем найти ответ на вопрос: как изменится производительность приложения спустя X лет, если аудитория приложения вырастет в Y раз?
4. Тестирование отказоустойчивости (Stability Test)
Продолжительность нагрузки может варьироваться в зависимости от целей и возможностей проекта, доходя до семи дней и более. В результате получаем представление о том, как изменится производительность системы в течение длительного периода времени под нагрузкой, например, в течение недели. Снизится ли уровень производительности? Способно ли приложение выдерживать стабильную нагрузку без критических сбоев?
5. Тестирование масштабируемости (Scalability Test)
Профиль нагрузки тот же, что и при нагрузочном тестировании. Что получаем в результате? Ответы на следующие вопросы:
- Увеличится ли производительность приложения, если добавить дополнительные аппаратные ресурсы?
- Увеличится ли производительность пропорционально количеству добавленных аппаратных средств?
О видах тестирования поговорили, теперь коснемся такого важного аспекта их проведения как нагрузка.
Подаваемая нагрузка
Нагрузка во время тестов должна базироваться исключительно на основе реального поведения пользователей. Только в таком случае вы сможете получить результат, соответствующий реальной производительности системы. Запуск любых других форм нагрузки – это пустая трата ресурсов и времени.
Для защиты от ошибок в поведении скриптов мы настоятельно рекомендуем дважды проверять сетевой трафик, который генерируют нагрузочные скрипты и реальные пользователи. Структура запросов и ответов всегда должна быть идентичной.
Чтобы избежать неожиданных проблем во время запуска тестов, генераторы нагрузки необходимо располагать как можно ближе к тестовому окружению.
Например, нагрузка на окружение подается равной 1000 пользователей, а действительная нагрузка во время теста составляет только 200 пользователей. Разница обусловлена «узким местом» в сети между клиентами и сервером.
В этом случае вы не сможете получить точную информацию о времени отклика и оценить производительность системы в целом. Так, например, во время теста вы получили среднее время отклика равное 10 секундам, но лишь транспортировка пакета от клиента к серверу и обратно занимало 9.5 секунд, а формирование ответа уложилось в 0.5 секунды. Сервер способен оперативно обрабатывать запросы, но мы его не догрузили из-за сетевых условий.
При правильном подходе мы тестируем производительность системы, а не сети. Для этого тестовое окружение и генератор должны быть расположены в одной локальной сети.
В таком случае мы избежим проблемы производительности сети и будем уверены в том, что время отклика соответствует реальной производительности приложения.
Какие же метрики собираются во время тестирования производительности?
Время отклика измеряется с момента отправки запроса к серверу до получения последнего байта от сервера.
Запросы в секунду. Клиентское приложение формирует HTTP-запрос и отправляет его на сервер. Серверное ПО данный запрос обрабатывает, формирует ответ и передает его обратно клиенту. Общее число запросов в секунду и есть интересующая нас метрика.
Транзакции в секунду. Пользовательские транзакции – это последовательность действий пользователя в интерфейсе. Сравнивая реальное время прохождения транзакции с ожидаемой (или количество транзакций в секунду), вы сможете сделать вывод о том, насколько успешной системой было пройдено нагрузочное тестирование.
Число виртуальных пользователей в единицу времени также позволяет выяснить, отвечает ли производительность приложения заявленным требованиям. Если вы все делаете правильно и ваши сценарии максимально приближены к поведению пользователя, то один виртуальный пользователь будет равен одному реальному пользователю.
Процент ошибок рассчитывается как отношение невалидных ответов к валидным за промежуток времени.
Желаемые показатели данных метрик указываются в требованиях к программному обеспечению. Но это в идеале. Если эти данные не прописаны, руководитель команды по тестированию должен прояснить этот момент с заказчиком.
Советы для тестировщиков и аналитиков по тестированию производительности
- Корреляция динамических параметров и построение скриптов должны быть основаны на реальном поведении пользователей. Иначе тестирование будет больше напоминать DDOS-атаку.
- Перед разработкой и запуском скриптов необходимо провести большую аналитическую работу, чтобы понять и подготовить детализированную методологию тестирования производительности.
- Важно принимать во внимание временные задержки между действиями пользователей и корректно размещает их в скриптах согласно поведению реальных пользователей.
- Функция кэширования должна воспроизводиться как для каждого виртуального пользователя, так и для реальных пользователей в промышленной эксплуатации системы.
- Виртуальные пользователи должны использовать заранее подготовленные тестовые данные и взаимодействовать с системой в поведенческой манере. Каждое действие должно иметь предварительно заданную вероятность и выполняться только определенным количеством пользователей.
- Чтобы найти функциональные дефекты, которые проявляются только при нагрузке, следует создавать скрипты с такими же наборами действий, как и у реальных пользователей. Это даст возможность проанализировать и воспроизвести запросы.
Итак, мы рассказали, в чем состоит разница между различными тестами производительности и на какие вопросы они помогают ответить; какие метрики позволяют сравнивать ожидаемый и реальный уровень производительности. Надеемся, данная информация будет вам полезной и поможет в работе.
Данный материал является частной записью члена сообщества Club.CNews.
Редакция CNews не несет ответственности за его содержание.