
Плагин отнесен в категорию nofollow | Страница 2 из 4
Ultimate NoFollow SEO
(1 общий рейтинг)If you are looking to build your site’s rank in a natural and Google approved…
HeyGoTo 300+ активных установок Протестирован с 4.7.26 Обновлен 6 лет назад
Ultimate Noindex Nofollow Tool
(0 общий рейтинг)Improves your blog’s search engine optimization by «noindexing» pages you choose.
Jonathan Kemp 300+ активных установок Протестирован с 2.7.1 Обновлен 14 лет назад
Nofollow Internal Links
(3 общий рейтинг)Nofollow internal links: read more link, tag cloud, post tags, archive links, category list, post…
pandasilk 200+ активных установок Протестирован с 4.8.22 Обновлен 6 лет назад
NoIndex NoFollow All Posts
(1 общий рейтинг)This plugin lets you Noindex Nofollow All Posts in a category.
DigitalChef.in — Madhu Ramrakhyani 200+ активных установок Протестирован с 4.7.26 Обновлен 6 лет назад
Nofollow External Links (SEO)
(0 общий рейтинг)It automatically set all external links to «nofollow» in website content.
Mitali, Viitorcloud 200+ активных установок Протестирован с 6.2.2 Обновлен 2 месяца назад
Noindex Links
(1 общий рейтинг)Плагин заключает любые ссылки в комментариях в теги <noindex></noindex>.
Flector 200+ активных установок Протестирован с 6.1.3 Обновлен 7 месяцев назад
WP Better SEO Links
(1 общий рейтинг)Adds a checkbox in the insert link popup box for including rel=»nofollow», rel=»sponsored», and rel=»ugc»…
WP Help 200+ активных установок Протестирован с 5.2.18 Обновлен 4 года назад
New Page Link
(4 общий рейтинг)New Page Link plugin converts all your external or internal links in the body to…
Zeeshan Aslam Durrani 100+ активных установок Протестирован с 5.
 8.7
Обновлен 2 года назад
8.7
Обновлен 2 года назадSmart DoFollow
(1 общий рейтинг)The «Smart DoFollow» plugins lets you automatically give DoFollow links to authors of comments that…
Łukasz Więcek 100+ активных установок Протестирован с 3.3.2 Обновлен 11 лет назад
SMu Manual DoFollow
(3 общий рейтинг)SMu DoFollow has many DoFollow Options (Manual or Automatism) and included URL Validator (Manual, WP-Cron…
Stefan Murawski 100+ активных установок Протестирован с 4.1.38 Обновлен 7 лет назад
Follow My Links
(0 общий рейтинг)Do not automatically add the rel=nofollow attribute to links in authorial comments, strip nofollow from…
Everfluxx 100+ активных установок Протестирован с 3.1.4 Обновлен 12 лет назад
WordPress Countdown
(2 общий рейтинг)Add JQuery Countdown easily to your page/post with one shortcode only
Ivan Kristianto 100+ активных установок Протестирован с 3.
 3.2
Обновлен 8 лет назад
3.2
Обновлен 8 лет назадNofollow for External Link TAP
(1 общий рейтинг)Just simple, if you use this plugins, rel=nofollow and target=_blank will be insert automatically, for…
Alain Sanchez 80+ активных установок Протестирован с 4.1.38 Обновлен 8 лет назад
WPF Force External Nofollow
(0 общий рейтинг)Automatically inserts rel="nofollow" into all the external links on your wordpress posts or pages.
Mike Johnson (AfterDarkMike) 80+ активных установок Протестирован с 3.7.41 Обновлен 9 лет назад
WPMU Automatic Links
(2 общий рейтинг)This plugin will automatically create links from words.
Benjamin Santalucia ([email protected]) 60+ активных установок Протестирован с 4.0.38 Обновлен 9 лет назад
Noindex/Nofollow links
(0 общий рейтинг)This plugin can add rel=»noindex,nofollow» to archive, tag, and category links. You can configure exactly…
You can configure exactly…
John Syrinek 40+ активных установок Протестирован с 2.7.1 Обновлен 14 лет назад
BBP DoFollow
(1 общий рейтинг)A helpful tool to makes your bbpress internal links dofollow and external links nofollow.
4Games 40+ активных установок Протестирован с 5.0.19 Обновлен 4 года назад
(2 общий рейтинг)
Plugin makes all or specified links in the footer rel=nofollow. Use of Genesis Theme Framework…
Mike Hale 40+ активных установок Протестирован с 4.9.23 Обновлен 5 лет назад
Nofollow External Link
(1 общий рейтинг)Insert ‘rel=nofollow’ and ‘target=_blank’ to all the external links automatically into your website posts or…
Dinesh Panchal 40+ активных установок Протестирован с 3.
 7.41
Обновлен 9 лет назад
7.41
Обновлен 9 лет назадLionScripts: Site Maintenance & Noindex Nofollow Plugin
(1 общий рейтинг)LionScripts’ Site Maintenance & Noindex Nofollow is a very useful Site Maintenance plugin, which provides…
LionScripts.com 30+ активных установок Протестирован с 4.7.26 Обновлен 6 лет назад
Seo оптимизация страниц пагинации
На сегодняшний день seo-оптимизаторы используют разные методы при работе со страницами пагинации. Какого-то универсального или на 100% правильного метода в данном случае быть не может – всё зависит от ресурса и целей данных страниц.
Для начала немного терминологии:
В веб-дизайне под пагинацией понимают постраничный вывод информации, показ ограниченной части информации на одной (веб)-странице.
Страницы с пагинацией – это страницы с параметрами, которые ограничивают вывод количества результатов по умолчанию. Например, 10 результатов поиска на странице или вывод 30 карточек товаров на странице категории интернет-магазина.
Для чего нужна пагинация?
Пагинация способствует юзабилити сайта и упрощает его использование. Представим себе ситуацию, когда на странице каталога интернет-магазина представлен весь ассортимент, то есть десятки тысяч товаров. Технически это возможно, но насколько данная страница будет юзабельна? Будет ли пользователю удобно «работать» с данной страницей? Ответ – определенно нет. Также не стоит забывать, что скорость интернет-соединения на данный момент ограничена, следовательно, чем больше товаров на странице, тем дольше она будет прогружаться в браузере пользователя.
Какие проблемы могут возникнуть при неправильной настройке пагинации?
- Дублирование контента.
- Смена релевантных страниц в поисковой выдаче.
- Присутствие в выдаче нерелевантных или неактуальных страниц.
- Затруднение индексирования и расход краулингового бюджета сайта.
- Увеличение нагрузки на сервер сайта при его сканировании поисковыми ботами.

Давайте рассмотрим некоторые пути решения данных проблем:
Метод 1. Закрытие страниц пагинации в файле robots.txt
К примеру, Disallow: /*?
Минусы данного метода: в случае отсутствия карты сайта возможны проблемы с индексированием контента. Также теряем ссылочный вес с внешних ресурсов (в случае их наличия). Передача некоторых показателей, важных для поисковой системы Яндекс, со страниц пагинации не будет производиться.
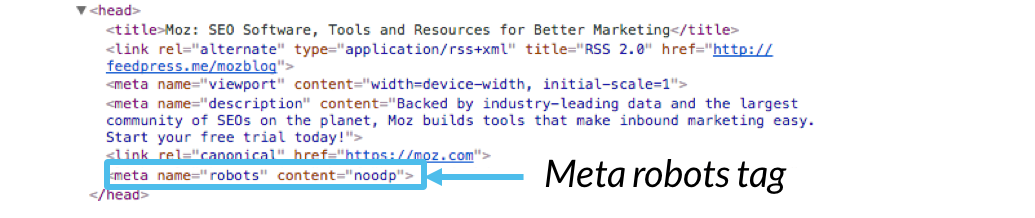
Метод 2. Закрытие страниц пагинации через метатег name=»robots»
Варианты:
- <meta name=»robots» content=»noindex, nofollow» /> Минусы данного метода все те же, что и при закрытии страниц через robots.txt
- <meta name=»robots» content=»noindex, follow» /> Минусы – потеря ссылочного веса с внешних ресурсов в случае их наличия на странице пагинации, передача некоторых показателей (важных для поисковых систем) со страниц пагинации не будет производиться, с индексированием контента в данном случае проблем не будет.
- <meta name=»robots» content=»noindex» /> = <meta name=»robots» content=»noindex, follow» />
- <meta name=»robots» content=»none» /> = <meta name=»robots» content=»noindex, nofollow» />

В данных метатегах параметр noindex запрещает к индексации содержимое страницы. Параметр nofollow запрещает переходить по ссылкам на данной странице.
Метод 3. Уникализация страниц пагинации через теги, метатеги и написание для данных страниц дополнительных уникальных текстов
Минусы метода: заточка разных страниц пагинации под разные запросы работала лет 5 назад. На данный момент, по нашим наблюдениям, это неэффективно и может привести к пессимизации ресурса. Также для выполнения данного метода необходимы большие объемы дополнительных работ, которые в будущем не принесут нужного результата.
Как в таком случае поступать с данными страницами? Давайте посмотрим, что нам рекомендуют поисковые системы:
- Google: рекомендации для вебмастеров тут и тут.
- Яндекс: к сожалению, в справке нет данных о том, как поступать со страницами пагинации. Но зато есть информация в официальном блоге для интернет-магазинов тут и общая информация в справке об атрибуте rel=»canonical» тут.

Ознакомившись с данной информацией, мы сделали вывод, что Яндекс рекомендует нам настроить атрибут rel=»canonical» на первую страницу сайта. А Google же говорит, что так делать не совсем верно – и у них есть для этого специальный атрибут rel=»next» и rel=»prev», который поможет поисковой системе определить, что данные страницы связаны между собой.
И если мы внимательно прочитаем комментарии в блоге Яндекса от Платона Щукина, то узнаем:
Похоже, что это наиболее подходящий вариант как для Яндекса, так и для Google.
Исходя из вышесказанного, получаем четвертый вариант оптимизации:
Метод 4. Настроить атрибут rel=»canonical» на страницы «Показать всё»
Это идеальный вариант, который подойдет и для Яндекс, и для Google.
Но вновь он не устроит многих вебмастеров и пользователей сайтов с большим количеством подборок (статей, товаров, объявлений), так как подобные страницы будут загружаться крайне долго, а желательная загрузка страницы должна быть не более 5-7 секунд. И чем быстрее, тем лучше (не путать с временем ответа сервера – оно должно быть не более 0,2 секунд). Есть вариант – подключить бесконечную прокрутку, но вновь могут возникнуть проблемы со стороны поисковых систем. До сих пор ПС сложно обрабатывают js и ajax-элементы, периодически возникают проблемы с индексацией содержимого и при сборе данных систем аналитики.
Метод 5. Отдача разного содержимого в зависимости от заходящего поискового бота
Подробного описания данного метода предоставлять не буду, так как он попадает под определение «маскировка» у Google (подробнее) и под определение «клоакинг» у Яндекса (подробнее).
Но реализация предоставляет что-то наподобие следующего:
<?php
if ( strstr($_SERVER[‘HTTP_USER_AGENT’], ‘Yandex’) )
{echo ‘Выводим канонический url’;}
elseif ( strstr($_SERVER[‘HTTP_USER_AGENT’], ‘Googlebot’) )
{echo ‘Выводим rel=»next» и rel=»prev»‘;}
else
{
{echo ‘Можно ничего не выводить’;}
}
?>
В результате получаем:
Вариант составлен по первой рекомендации в справке Google:
P. S. Не рекомендую использовать данный метод.
S. Не рекомендую использовать данный метод.
Метод 6. Выбрать приоритетную поисковую систему Яндекс или Google и следовать её рекомендациям
По опыту замечено, если ставить rel=»canonical» на первую страницу, ничего критичного с Google не происходит: позиции, приходящиеся на данные страницы, либо не проседают, либо восстанавливаются в течение 2-3 недель. Поэтому на этом методе остановимся более подробно.
Кстати, при реализации на сайте rel=»canonical» с тегом <base href=»»> производить никаких действий не надо, хотя многие рекомендуют. Это совершенно два разных тега с разными функциями. Тег Base предназначен для браузеров с управлением контентом, в которых используется относительный адрес. Никакого отношения к индексации или поисковым системам он не имеет.
Реализация canonical на первую страницу без параметров на MODX Revolution (для Yandex)
Вариант № 1:
Установить Canonical snippet.
Вариант № 2:
Вручную проставить канонические адреса.
Для начала необходимо проверить, что [<!— —>[*alias]<!— —>] отрабатывает нормально, дружественные Url у нас включены.
Далее переходим на главную страницу, смотрим поле «Псевдоним» на главной странице. Как правило, это будет либо index, либо glavnaya по умолчанию.
Данный канонический адрес для главной страницы нас не устраивает.
Самое простое решение – это скопировать шаблон и подменить в нем чанк head.
Копируем код шаблона (html) в Шаблон для главной, создаем чанк с содержимым [<!— —>[$headg]<!— —>], заменяем в шаблоне для главной [<!— —>[$head]<!— —>] на [<!— —>[$headg]<!— —>], назначаем созданный шаблон для главной страницы.
В чанк [<!— —>[$headg]<!— —>] добавляем <link rel»canonical» href=»[<!— —>[!++site_url]<!— —>]»/>
В чанк для [<!— —>[$head]<!— —>] добавляем
<link rel=»canonical» href=»[<!— —>[++site_url]<!— —>][<!— —>[*uri]<!— —>]»/> если ваш url имеет окончание / или . html
html
В случае если закрывающий слеш отсутствует или производится редирект средствами .htaccess, то можно использовать конструкцию
<link rel=»canonical» href=»[<!— —>[++site_url]<!— —>][<!— —>[~[<!— —>[*parent:is=`0`:then=«:else=`[<!— —>[*parent]<!— —>]`]<!— —>]]<!— —>][<!— —>[*alias]<!— —>]»/>
После произведенных действий проверяем канонический адрес на всех страницах сайта.
Если страниц у сайта много, рекомендую воспользоваться программой для ПК ComparseR. В деморежиме она позволяет отпарсить до 150 страниц сайта – как правило, для большинства сайтов этого хватает.
После проверки удаляем из файла robots.txt правила, если они есть:
Disallow: /?
Disallow: /*?
Disallow: /index.php
За удаление дублированного контента теперь будет ответственен атрибут rel=»canonical»
Настройка атрибутов тега link rel=»canonical», rel=»prev» и rel=»next»
В данном случае canonical у нас должен вести на страницу, на которой находится поисковый бот, к примеру, https://site. com/podborka/?page=3 – это избавляет нас от дублирования контента с доп. параметрами.
com/podborka/?page=3 – это избавляет нас от дублирования контента с доп. параметрами.
rel=»prev» https://site.com/podborka/?page=2 говорит поисковому боту о том, что есть предыдущая часть этой страницы.
rel=»next» https://site.com/podborka/?page=4 подает сигнал поисковому боту о том, что есть продолжение этой страницы (в случае её существования).
Заключение
В данной статье мы постарались рассмотреть все возможные плюсы и минусы реализации оптимизации страниц пагинации. Сказать, что какой-то из случаев именно ваш, нельзя. Каждый сайт индивидуален, у каждого сайта свои цели, и исходя из этих целей будет зависеть, какой вид реализации подойдет именно вашему сайту. Если хотите, чтобы наши специалисты посмотрели ваш сайт, то вам сюда.
Оценок: 720 (средняя 5 из 5)
Seo оптимизация страниц пагинации {descr}- Главная
- Seo оптимизация страниц пагинации
php — добавить «noindex» в ссылку на pdf
У меня есть веб-сайт, на котором есть ссылки на php-скрипт , где я генерирую pdf с библиотекой mPdf, и он отображается в браузере или загружается, в зависимости от конфигурация.
Проблема в том что я не хочу чтобы он индексировался в гугл . Я уже поставил ссылку rel="nofollow" с тем, что больше не индексируется, но как мне dexindexe то, что уже есть?
С rel="noindex, nofollow" не работает.
Придется это делать только по php или какой-нибудь html тег
- php
- html
- mpdf
Как Google должен что-то деиндексировать, если вы запретили его роботу доступ к ресурсу? 😉 Сначала это может показаться нелогичным.
Удалите rel="nofollow" в ссылках, а в сценарии, обслуживающем PDF-файлы, включите X-Robots-Tag: нет заголовка . Google сможет зайти на ресурс, и увидит, что индексировать данный конкретный ресурс запрещено и удалит запись из индекса.
Когда деиндексация завершена, добавьте правило Disallow в файл robots.txt , как упоминает @mtr. web, чтобы роботы больше не истощали ваш сервер.
web, чтобы роботы больше не истощали ваш сервер.
Если у вас есть файл robots.txt, вы можете запретить Google индексировать какой-либо конкретный файл, добавив к нему правило. В вашем случае это будет примерно так:
Агент пользователя: * запретить: /path/to/PdfIdontWantIndexed.pdf
После этого все, что вам нужно сделать, это убедиться, что вы отправляете файл robots.txt в Google, и вскоре после этого Google прекратит его индексацию.
Примечание:
Также может быть целесообразно удалить ваш URL-адрес из существующего индекса Google, потому что это будет быстрее в случае, если он уже был просканирован Google.
Самый простой способ: Добавьте robots.txt в корень и добавьте это:
Агент пользователя: * Запретить: /*.pdf$
Примечание. Если к URL-адресу добавлены параметры (например, ../doc.pdf?ref=foo ), то этот подстановочный знак не будет препятствовать сканированию, поскольку URL-адрес больше не заканчивается на «. pdf»
pdf»
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но никогда не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
seo — разница между « и `rel=»nofollow»`
спросил
Изменено 7 лет, 4 месяца назад
Просмотрено 1к раз
Является метатегом
То же, что и rel="nofollow" в ссылке (за исключением того факта, что метатег будет распространяться на всю страницу, а не на ссылку)
Или версия метатега относится к тому, должны ли роботы сканировать ссылки на странице, а не передавать «ссылочный вес»?
- SEO
- мета-теги
- nofollow
- мета-роботы
То же, что и rel=»nofollow» в ссылке (кроме того факта, что метатег будет распространяться на всю страницу, а не на ссылку)
Да, то же, что и rel="nofollow" , за исключением того, что nofollow в метатеге применяется ко всем ссылкам на странице.
Или версия метатега относится к тому, должны ли роботы сканировать ссылки на странице, а не к тому, передают ли они «ссылочный вес»?
То же самое делает атрибут rel="nofollow" в ссылке. Он говорит ботам не переходить по этой ссылке. т.е. Не ползайте по нему. Побочным продуктом этого является то, что он также не пропускает «ссылочный вес».
Из справки Google Search Console «Используйте rel=»nofollow» для определенных ссылок»:
Первоначально атрибут
nofollowпоявлялся в метатеге уровня страницы и предписывал поисковым системам не переходить (т. е. не сканировать) любые исходящие ссылки на странице.До того, как
nofollowиспользовался для отдельных ссылок, предотвращение перехода роботов по отдельным ссылкам на странице требовало больших усилий (например, перенаправление ссылки на URL-адрес, заблокированный в robots.txt). Вот почемуСоздано значение атрибута nofollowдля атрибутаrel.
 Это дает веб-мастерам более детальный контроль : вместо того, чтобы указывать поисковым системам и ботам не переходить ни по каким ссылкам на странице, вы можете легко указать роботам не сканировать конкретную ссылку.
Это дает веб-мастерам более детальный контроль : вместо того, чтобы указывать поисковым системам и ботам не переходить ни по каким ссылкам на странице, вы можете легко указать роботам не сканировать конкретную ссылку.Они означают то же самое, если следовать определениям HTML5:
Определение типа ссылки HTML5
nofollow:Ключевое слово
nofollowуказывает на то, что ссылка не одобрена первоначальным автором или издателем страницы или что ссылка на документ, на который делается ссылка, была включена главным образом из-за коммерческих отношений между людьми, связанными с двумя страницами.HTML5 ссылается на MetaExtensions для регистрации имен метаданных, в котором говорится о значении
nofollowдляrobotsname:[…] «nofollow» работает как значение ссылки с тем же именем.
(Добавлено Aleksandersen 30.
06.2007.)
 06.2007.)
06.2007.) (Обратите внимание, что поиск Google, похоже, не следует определению HTML5, но поиск Google также не делает различий между nofollow как имя метаданных и как тип ссылки.)
Однако в HTML 4.01 определение значения nofollow в элементе meta — robots отличается (выделено жирным шрифтом):
Элемент
METAпозволяет авторам HTML сообщать посещающим роботам, может ли документ быть проиндексирован или использоваться для сбора дополнительных ссылок . […]В следующем примере робот не должен ни индексировать этот документ, ни анализировать его на наличие ссылок .
Кажется, это соответствует определению на robotstxt.org, где говорится о мета — роботов :
Не путайте NOFOLLOW с атрибутом ссылки rel=»nofollow».
И в связанной записи часто задаваемых вопросов говорится:
Судя по этому описанию, это влияет только на ранжирование, а робот Google все еще может переходить по ссылкам и индексировать их.
