
Управление метатегами роботов с помощью плагина метаданных
С помощью нашего бесплатного SEO-расширения Joomla под названием Плагин метаданных вы можете массово добавлять noindex, nofollow и другие метатеги роботов на указанные вами страницы, тем самым избавляясь от этих уродливых нестандартные части URL-адреса и параметры запроса URL-адреса легко из Google SERP.
В результате правильной настройки плагина метатеги будут меняться в зависимости от URL:
http://example.com/computer-parts/keyboards.html — Индексированный и отслеживаемый URL. Все плохие URL-адреса теперь не индексируются и не отслеживаются роботами.Конфигурация
- Статус
- Чтобы ваши правила работали, вы должны их включить.
- Проверка URL
- Ваша страница (URL) будет проверена на основе выбранного метода, который может быть:
- Часть(и) URL
- Параметр(ы) запроса URL 9002 4
- Регулярное выражение
- Все

- Проверка URL: Параметры запроса URL
- Параметры запроса URL всегда следуют за «?» символ. В URL-адрес можно включить несколько параметров, если они указаны после символа «&». Плагин не проверяет значения запроса, только параметры запроса . Если после символа «&» есть еще параметры запроса, их тоже можно проверить.
Если вы назначаете несколько параметров запроса для одного правила, разделяйте их следующим символом:
|
Примеры распространенных параметров запроса URL для noindex, nofollow SEO-сигналов:tmpl|id|Itemid|phocaslideshow|do_pdf|кнопки|подробности|задача|тип|всплеск|опция|catid|просмотр|action_object_map|ключевое слово|язык 13 URL-адрес части в основном между косыми чертами, например: /68-uncategorized/ или /virtuemart/ и т. д.
Если вы используете несколько частей для одного правила, разделите их следующим символом:|
Например:68-uncategorized|virtuemart
Общие части URL-адресов, назначаемые для noindex, nofollow SEO-сигнализации:добродетельmart|component|by,mf_name|detail|68-uncategorized|
В некоторых случаях необходимо проверить конец URL-адреса. В этом случае, если параметр в глобальной конфигурации ➙ Добавить суффикс к URL-адресу установлен на Да , вам необходимо использовать .html для части. Пример здесь. - Проверка URL: Регулярное выражение
- Вы можете назначать URL-адреса правилам с помощью правила REGEX. Это полезно, когда некоторые части URL-адреса являются вариантами или имеют шаблон (например, нумерацию страниц).
example.com/products/results,1321-1350
Допустим, у вас есть больше разбитых на страницы URL-адресов, как в приведенном выше примере, которые уже проиндексированы Google, что нецелесообразно. В этом случае вы можете использовать специальный синтаксис регулярного выражения для частей, которые включают такие элементы:результатов, 1321-1350. результаты, 76-135 results,1081-1140
Правило регулярного выражения для этого примера будет следующим:results,\d*-\d*
или/results,\d*-\d*/
- Проверка URL: ВСЕ
- не проверять URL-адреса специально.
- Метаимя
- В списке есть разные мета-имена, но с точки зрения поисковой выдачи Google эти три являются важными:
- robots
Мета-тег robots позволяет вам использовать детальный, специфичный для страницы подход к управлению тем, как должна выглядеть отдельная страница. индексируется и показывается пользователям в результатах поиска Google. - googlebot
Стандартным поисковым роботом Google является Googlebot. Поэтому, чтобы предотвратить индексацию вашей страницы только Google, вы должны выбрать это в правиле. - google
Тег запрещает Google показывать окно поиска дополнительных ссылок. Какие мета-имена поддерживает Google. - Google Search Central Docs
Метатег Robots позволяет вам давать практически всем типам поисковых систем информацию о том, как вы хотите, чтобы они обрабатывали страницу.
Однако, если вы хотите проинструктировать роботов Google или Google о том, как они обрабатывают или индексируют ваши страницы, вы можете использовать мета-имена googlebot или Google. - robots
- Метаконтент
- Вы можете выбрать следующее метасодержимое из списка:
- noindex, nofollow
- noindex
- nofollow
- noindex, follow
- index, nofollow
- notrans поздно
- nopagereadaloud
- custom

 В этом случае, если параметр в глобальной конфигурации ➙ Добавить суффикс к URL-адресу установлен на Да , вам необходимо использовать .html для части. Пример здесь.
В этом случае, если параметр в глобальной конфигурации ➙ Добавить суффикс к URL-адресу установлен на Да , вам необходимо использовать .html для части. Пример здесь.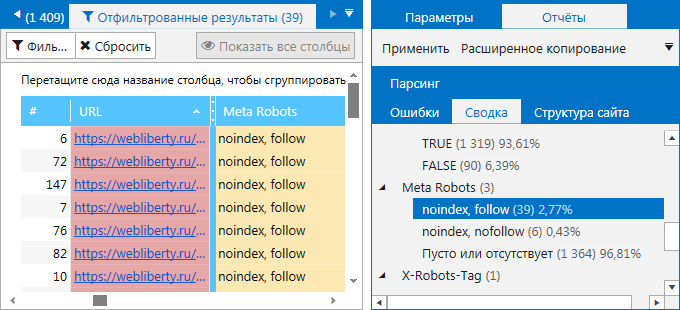
 Однако, если вы хотите проинструктировать роботов Google или Google о том, как они обрабатывают или индексируют ваши страницы, вы можете использовать мета-имена googlebot или Google.
Однако, если вы хотите проинструктировать роботов Google или Google о том, как они обрабатывают или индексируют ваши страницы, вы можете использовать мета-имена googlebot или Google.Другие пункты к сведению
Противоречивые правила
Если в вашей конфигурации имеется более одного правила, вы можете применять их несколько раз. Однако это, конечно, зависит от правил. Вы можете получить следующую мета::
Есть несколько шансов получить это. Например, для одного из правил вы устанавливаете часть URL для «noindex, nofollow», в другом правиле вы устанавливаете «index, follow». Будьте осторожны при использовании правил, всегда проверяйте результаты своей конфигурации в плагине. (В этом конкретном случае Google принимает во внимание теги «noindex, nofollow».
Будьте осторожны при использовании правил, всегда проверяйте результаты своей конфигурации в плагине. (В этом конкретном случае Google принимает во внимание теги «noindex, nofollow».
Плагин переопределяет глобальные настройки
. site для «nofollow, noindex» в плагине. Все, что вам нужно сделать, это создать правило, выбрать «Все» при проверке URL-адреса и установить метаимя «роботов» для «noindex, nofollow». Это может быть легко сделано по ошибке, поэтому всегда проверяйте результаты.0003
Использование суффикса .html в частях URL-адреса
Если ваш URL-адрес также содержит суффикс .html в конце URL-адреса, вы должны использовать эту часть вместе с этим суффиксом .html при вводе его в части URL-адреса. поле, например:
Это URL-адрес:
/computer-parts/keyboards/17-computer-parts.html
Таким образом, вы вводите его следующим образом:
17-computer-parts.html
Вариант использования
Мы исправили проблему SEO с внезапной потерей трафика для одного из наших клиентов, и для некоторых частей мы использовали это расширение.
 Для лучшего понимания мы сделали об этом сообщение в блоге Use case.
Для лучшего понимания мы сделали об этом сообщение в блоге Use case.Средство проверки исключения роботов — Интернет-магазин Chrome
Активные проверки URL-адресов на наличие robots.txt, meta robots, x-robots-tag и канонических тегов. Простой красный, янтарный и зеленый статус. SEO-расширение.
Средство проверки исключения роботов предназначено для визуального определения того, не препятствуют ли какие-либо исключения роботов сканированию или индексированию вашей страницы поисковыми системами. ## Расширение сообщает о 5 элементах: 1. Роботы.txt 2. Метатег роботов 3. X-роботы-тег 4. Отн.=канонический 5. Значения атрибутов UGC, Sponsored и Nofollow - Роботы.txt Если URL-адрес, который вы посещаете, находится под действием «Разрешить» или «Запретить» в robots.txt, расширение покажет вам конкретное правило в расширении, упрощая копирование или посещение активного файла robots.txt. также будет показан полный файл robots.txt с выделенным конкретным правилом (если применимо).Каноническая информация собирается на каждой странице из ответа заголовка HTML и HTTP. - UGC, Sponsored и Nofollow Новое дополнение к расширению дает вам возможность выделять любые видимые ссылки, которые используют значение атрибута «nofollow», «ugc» или «sponsored» rel. Вы можете контролировать, какие ссылки будут выделены, и установить предпочтительный цвет для каждой из них. Я бы предпочел, чтобы это было отключено, вы можете полностью отключить. ## Пользовательские агенты В настройках вы можете выбрать один из следующих пользовательских агентов для имитации того, к чему имеет доступ каждая поисковая система: 1. Гуглбот 2. Новости Googlebot 3. Бинг 4. Яху ## Преимущества Этот инструмент будет полезен всем, кто занимается поисковой оптимизацией (SEO) или цифровым маркетингом, поскольку он дает четкое визуальное представление о том, блокируется ли страница файлом robots.txt (многие существующие расширения не отмечают это). Проблемы со сканированием или индексацией напрямую влияют на то, насколько хорошо ваш сайт работает в органических результатах, поэтому это расширение должно быть частью вашего набора инструментов SEO-разработчика для Google Chrome. 1.0.3: Различные исправления ошибок, в том числе улучшенная обработка URL-адресов с закодированными символами. Функция расширения robots.txt, позволяющая просматривать очень длинные правила. Теперь JavaScript совместим с history.pushState(). 1.0.4: Различные улучшения. Добавлено обнаружение канонических тегов (заголовки HTML и HTTP) с оповещениями о желтых значках. Robots.txt теперь отображается полностью с выделенным соответствующим правилом. Тег X-robots теперь выделяется в полной информации заголовка HTTP. Различные улучшения UX, такие как ссылки «Копировать в буфер обмена» и «Просмотр исходного кода». Добавлены значки социальных сетей. 1.0.5: Принудительно вызывает фоновый вызов HTTP-заголовка, когда расширение обнаруживает изменение URL-адреса, но не обнаруживает новую информацию в заголовке HTTP — в основном для сайтов, сильно зависящих от JavaScript. 1.0.6: Исправлена проблема с хеш-частью URL при выполнении канонической проверки. 1.0.7: Принудительно вызывает фоновый вызов основного текста в дополнение к заголовкам HTTP, чтобы обеспечить некэшированное представление URL-адреса для сайтов с большим количеством JavaScript.
 - Тег мета-роботов
Любые метатеги роботов, которые направляют роботов на «index», «noindex», «follow» или «nofollow», будут отмечены соответствующими красными, желтыми или зелеными значками. Директивы, которые не повлияют на индексацию поисковой системы, такие как «nosnippet» или «noodp», будут отображаться, но не будут учитываться в предупреждениях. Расширение позволяет легко просматривать все директивы, а также полностью показывать любые HTML-мета-теги robots, которые появляются в исходном коде.
- X-роботы-тег
Обнаружение каких-либо директив robots в заголовке HTTP в прошлом было проблемой, но теперь это не так. Любые конкретные исключения будут хорошо видны, как и полный HTTP-заголовок — с выделенными конкретными исключениями!
- Канонические теги
Хотя канонический тег не влияет напрямую на индексацию, он все же может повлиять на поведение ваших URL-адресов в SERPS (страницах результатов поисковой системы). Если страница, которую вы просматриваете, разрешена для ботов, но было обнаружено несоответствие Canonical (текущий URL-адрес отличается от URL-адреса Canonical), тогда расширение пометит желтый значок.
- Тег мета-роботов
Любые метатеги роботов, которые направляют роботов на «index», «noindex», «follow» или «nofollow», будут отмечены соответствующими красными, желтыми или зелеными значками. Директивы, которые не повлияют на индексацию поисковой системы, такие как «nosnippet» или «noodp», будут отображаться, но не будут учитываться в предупреждениях. Расширение позволяет легко просматривать все директивы, а также полностью показывать любые HTML-мета-теги robots, которые появляются в исходном коде.
- X-роботы-тег
Обнаружение каких-либо директив robots в заголовке HTTP в прошлом было проблемой, но теперь это не так. Любые конкретные исключения будут хорошо видны, как и полный HTTP-заголовок — с выделенными конкретными исключениями!
- Канонические теги
Хотя канонический тег не влияет напрямую на индексацию, он все же может повлиять на поведение ваших URL-адресов в SERPS (страницах результатов поисковой системы). Если страница, которую вы просматриваете, разрешена для ботов, но было обнаружено несоответствие Canonical (текущий URL-адрес отличается от URL-адреса Canonical), тогда расширение пометит желтый значок.
 Альтернатива некоторым из распространенных онлайн-тестеров robots.txt.
Это расширение полезно для:
- Обзор и оптимизация фасетной навигации (полезно видеть управление роботом за сложными/наложенными фасетами)
- Обнаружение проблем со сканированием или индексацией
- Общий обзор SEO и аудит в вашем браузере
## Избегайте необходимости в нескольких SEO-расширениях
В области роботов и индексации нет лучшего расширения. На самом деле, установив Robots Exclusion Checker, вы избежите запуска нескольких расширений в Chrome, которые замедлят его работу.
Подобные плагины включают в себя:
Не следует
https://chrome.google.com/webstore/detail/nofollow/dfogidghaigoomjdeacndafapdijmiid
сироботы
https://chrome.google.com/webstore/detail/seerobots/hnljoiodjfgpnddiekagpbblnjedcnfp
NoIndex, проверка метатегов NoFollow
https://chrome.google.com/webstore/detail/noindexnofollow-meta-tag/aijcgkcgldkomeddnlpbhdelcpfamklm
ИЗМЕНЕНИЙ:
1.0.2: Исправлена ошибка, препятствовавшая обновлению мета-роботов после обновления URL.
Альтернатива некоторым из распространенных онлайн-тестеров robots.txt.
Это расширение полезно для:
- Обзор и оптимизация фасетной навигации (полезно видеть управление роботом за сложными/наложенными фасетами)
- Обнаружение проблем со сканированием или индексацией
- Общий обзор SEO и аудит в вашем браузере
## Избегайте необходимости в нескольких SEO-расширениях
В области роботов и индексации нет лучшего расширения. На самом деле, установив Robots Exclusion Checker, вы избежите запуска нескольких расширений в Chrome, которые замедлят его работу.
Подобные плагины включают в себя:
Не следует
https://chrome.google.com/webstore/detail/nofollow/dfogidghaigoomjdeacndafapdijmiid
сироботы
https://chrome.google.com/webstore/detail/seerobots/hnljoiodjfgpnddiekagpbblnjedcnfp
NoIndex, проверка метатегов NoFollow
https://chrome.google.com/webstore/detail/noindexnofollow-meta-tag/aijcgkcgldkomeddnlpbhdelcpfamklm
ИЗМЕНЕНИЙ:
1.0.2: Исправлена ошибка, препятствовавшая обновлению мета-роботов после обновления URL.
 1.0.8: Исправлена ошибка, возникающая при обнаружении нескольких ссылок на один и тот же пользовательский агент в файле robots.txt.
1.0.9: исправлена проблема с предупреждением о каноническом несоответствии.
1.1.0: Различные обновления пользовательского интерфейса, в том числе предупреждение JavaScript, когда расширение обнаруживает изменение URL-адреса без нового HTTP-запроса.
1.1.1: Добавлена дополнительная логика мета-роботов конфликтов правил пользовательского агента.
1.1.2: Добавлен интерфейс на немецком языке.
1.1.3: Добавлено выделение UGC, Sponsored и Nofollow ссылок.
1.1.4: отключена подсветка ссылки nofollow по умолчанию при новых установках и исправлена ошибка, связанная с каноническими несоответствиями HTTP-заголовка.
1.1.5: Исправлены ошибки для улучшения парсера robots.txt.
1.1.6: Расширение теперь помечает ошибки 404 красным цветом.
1.1.7: Не отправляются файлы cookie при выполнении фонового запроса на получение страницы, на которую вы перешли с помощью pushstate.
1.0.8: Исправлена ошибка, возникающая при обнаружении нескольких ссылок на один и тот же пользовательский агент в файле robots.txt.
1.0.9: исправлена проблема с предупреждением о каноническом несоответствии.
1.1.0: Различные обновления пользовательского интерфейса, в том числе предупреждение JavaScript, когда расширение обнаруживает изменение URL-адреса без нового HTTP-запроса.
1.1.1: Добавлена дополнительная логика мета-роботов конфликтов правил пользовательского агента.
1.1.2: Добавлен интерфейс на немецком языке.
1.1.3: Добавлено выделение UGC, Sponsored и Nofollow ссылок.
1.1.4: отключена подсветка ссылки nofollow по умолчанию при новых установках и исправлена ошибка, связанная с каноническими несоответствиями HTTP-заголовка.
1.1.5: Исправлены ошибки для улучшения парсера robots.txt.
1.1.6: Расширение теперь помечает ошибки 404 красным цветом.
1.1.7: Не отправляются файлы cookie при выполнении фонового запроса на получение страницы, на которую вы перешли с помощью pushstate.