
Как использовать noindex и nofollow — Сollaborator
Как использовать noindex и nofollow
Noindex и nofollow — разные по функционалу элементы. Их часто путают, и как только не называют: тегами, метатегами, атрибутами. Расставим все точки и расскажем, чем отличается noindex от nofollow и в каких случаях их целесообразно использовать.
Теги и атрибутыТеги и атрибуты еще называют дескрипторами — это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфические визуальные характеристики.
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
Noindex (ноиндекс) – это тег и атрибут HTML-страницы, который закрывает от индексации часть страницы, которая в него заключена. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов или машин, анализирующих и индексирующих веб-сайты. Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
Какой контент помечается этим тегом?Важно! На самом деле, робот посмотрит все, что есть на сайте. Но это правило говорит ему, что не стоит индексировать конкретную часть документа.

Любой контент. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.
Тег можно вставить в разделе <head> страницы как мета (атрибутом), увеличив область его действия на всю страницу.
1. С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
2. А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
3. Такое правило можно указать для конкретного робота. Например, поискового бота Google:
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
4. Еще один способ — встраивание тегов в текст.
<noindex> кусок текста, который хотелось бы скрыть от индексации поисковиками </noindex>
Правда, такая разметка может нагородить кучю ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится использовать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow?
Nofollow — это атрибут, который вставляется перед ссылками, запрещающий по ним переходить и отдавать вес страницы.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Как использовать nofollow?Атрибутом нофолов помечаются ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Например, добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?1. С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
2. Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
3.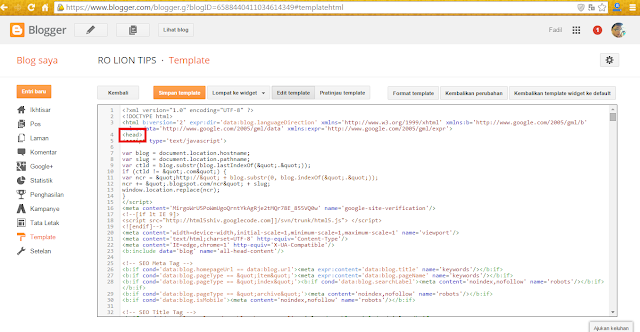 Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки:
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки:
<a href="page.html" rel="nofollow"> Гиперссылка </a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше:
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, снижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Мы уже упомянули выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснили зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.

- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.

Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за “исключение” страниц из индексации.
Важно! Способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Использование одного из вышеупомянутых элементов (или обоих сразу) зависит от условий, которые преследуются (сокрытие части текста, ссылки или всей страницы при использовании с мета-тегом robots).
Если нужно скрыть от робота Яндекса отдельный текст, noindex это сделает, но когда закрывается ссылка, noindex не поможет. В этом случае следует выбрать атрибут rel=nofollow.
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.

Похожие вопросы
- Что такое аутрич?
- 20 главных метатегов для сайта и как их заполнять
Ольга Горбенко
Практикующий SEO-специалист
что такое, как и где использовать
Игорь СеровSEO Googlenofollow, noindex, исходящая ссылка, мета тег robots, ссылка, ссылки на сайт, учет ссылок, файл robots.txt
От автора: В мета тегах robots нет ничего нового. На практике, есть много случаев, когда вы можете захотеть использовать некоторые атрибуты мета тега robots, например атрибут noarchive или noindex или nofollow. Использование мета тегов robots с различными атрибутами позволит осуществлять контроль, как Google видит и индексирует страницы сайта.
Про атрибут noarchive
Давайте посмотрим на атрибут noarchive и посмотрим, что он может сделать.
Атрибут noarchive показывает ботам поисковика, существует ли кэшированная копия этой страницы.
Когда вы создаёте веб страницу, вы обычно хотите, чтобы страница была максимально доступна и открыта. Однако со временем ценность страницы может меняться, и вы можете захотеть ограничивать возможности этой страницы.
Например, по какой-то причине вы не хотите, чтобы Google кэшировал страницу. Особенно, если вы скоро обновите её. Используя атрибут noarchive, вы сможете сказать Google, что «я не хочу, чтобы вы это кешировали».
Использование тега noarchive не оказывает существенного влияния на ранжирование поиска.
Как создать атрибут noarchive?
Вы можете использовать следующие фрагменты кода:
<meta name = ”robots” content = ”noarchive”>
Или вы можете использовать прямое обращение к Google ботам:
<meta name = ”googlebot” content = ”noarchive”>
Первая реализация мета тега применяется ко всем роботам, вторая только к Googlebot.
Значение кеширования ваших страниц
Кеширования страниц вашего сайта неплохой инструмент. Например. Он позволит получить доступ к вашим страницам, даже если ваш сайт не работает.
Из кеша Google предоставит «только текстовую» версию страницы, которая даст представление о том, как он «видит» вашу страницу.
Когда следует использовать атрибут noarchive?
На сайте всегда есть контент, который вы не захотите и не должны кешировать. К такому контенту можно отнести:
- Рекламу, которую вы не хотите, чтобы Google кэшировал.
- Любые целевые страницы для контекстной рекламы (PPC).
- Внутренние документы которые не должны быть публичными.
- Любая другая конфиденциальная документация, для которой вам не нужна история кэширования.
Можете ли вы получить наказание используя атрибут noarchive?
Нет. В прошлом люди беспокоились о том, что Google может негативно оценивать использование noarchive, решив, что сайт скрывается..png) Однако официально, Google заявил, что нет ничего плохого в использовании атрибута
Однако официально, Google заявил, что нет ничего плохого в использовании атрибута noarchive.
Этот тег удаляет только «кэшированную» ссылку для страницы. При этом Google продолжит индексировать эту страницу и отображать её сниппет.
Какие другие теги вы можете использовать?
Приведенные выше теги – не единственные, которые можно использовать для ограничения активности сканера.
Существует ряд других тегов, которые вы можете использовать, когда дело доходит до объявления директив сканера.
Nofollow: рекомендация (уже не директива) роботу не обходить ссылки с этим атрибутом. Реализация:
Для ссылки: rel=nofollow
Для страницы:
<meta name="robots" content="nofollow">
Noindex: запрещает поисковым системам показывать страницу в результатах поиска. Реализация для ссылки: rel=noindex
Для страницы:
<meta name="robots" content="noindex">
Sponsored: сообщает поисковику, что это рекламная ссылка или ссылка спонсоров.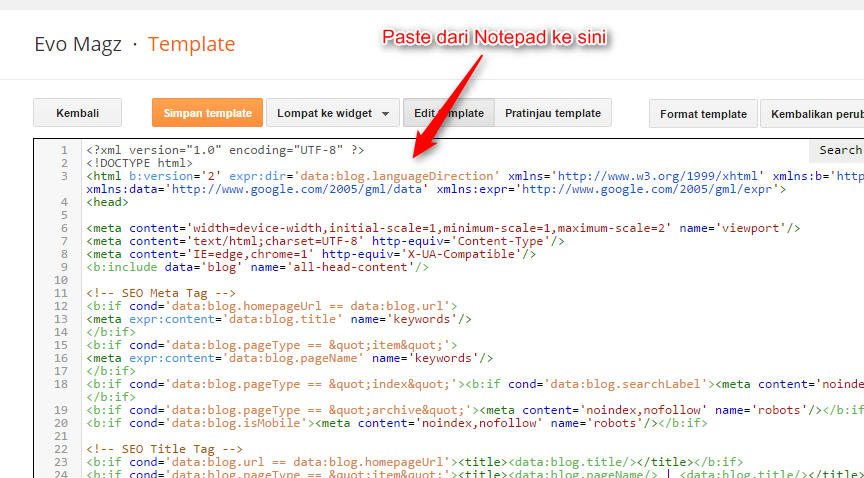 Реализация для ссылки:
Реализация для ссылки: rel=sponsored
Google рекомендует больше не использовать nofollow для коммерческих ссылок, а рекомендует помечать коммерческие ссылки как sponsored.
UGC: для ссылок, размещаемых пользователями в комментариях, форумах и т.п. Реализация для ссылки: rel=ugc
Заключение
Сканерами поисковых систем, управлять несложно. Атрибут noarchive этому хороший пример. Однако трудно оценить вашу общую стратегию и куда вам следует идти дальше.
©seojus.ru
Еще статьи
Похожие записи:
Мета-теги роботов — возможности Yoast SEO • Yoast
Как добавить метатеги роботов с помощью Yoast SEO
Yoast SEO позволяет вам общаться с поисковыми системами. С помощью переключателя вы можете указать им, какие URL следует исключить из результатов поиска (noindex). Кроме того, вы можете запретить поисковым системам оценивать ссылки на странице (nofollow).
Получите подписку Yoast SEO Premium
Зачем мне указывать поисковым системам, что делать?
Вы хотите порадовать свою аудиторию и поисковые системы, верно? Вы можете сделать это, критически оценив свои страницы и исключив бесполезные из результатов поиска. В Yoast SEO вы получаете право решать, какой поисковый индекс будет напрямую влиять на опыт вашей аудитории!
Получите полный контроль сайта над отображением вашего контента в поиске
Выберите, какие таксономии включить или исключить
Архивы категорий и тегов могут служить целевыми страницами и способствовать вашему рейтингу. На самом деле, добавление богатого контента на эти типы страниц может сделать их одними из ваших лучших страниц! Но иногда вы можете захотеть не индексировать эти страницы. Yoast SEO позволяет вам сделать это одним щелчком переключателя.
Хранить архивы дат вне поисковых систем
Если на вашем веб-сайте в URL-адресах используются даты, возможно, лота малоценных страниц. Каждая страница архива даты, месяца и года содержит в значительной степени повторяющийся контент и не представляет большой ценности для пользователя в качестве целевой страницы. Они могут быть полезны для навигации и поиска, но обычно не должны индексироваться поисковыми системами. С Yoast SEO вы можете оставить эти страницы для навигации пользователей, но запретить Google их индексировать.
Каждая страница архива даты, месяца и года содержит в значительной степени повторяющийся контент и не представляет большой ценности для пользователя в качестве целевой страницы. Они могут быть полезны для навигации и поиска, но обычно не должны индексироваться поисковыми системами. С Yoast SEO вы можете оставить эти страницы для навигации пользователей, но запретить Google их индексировать.
Исправление веб-сайтов с одним автором
Если на вашем веб-сайте есть только один автор или пользователь, то, скорее всего, страницы архива вашего автора являются просто копией вашей домашней страницы. Поисковые системы могут воспринять это как дублированный контент, и это может повредить вашему рейтингу. Yoast SEO позволяет вам не индексировать ваши авторские архивы, чтобы они были вне поля зрения поисковых систем и пользователей!
Noindex для других типов контента
В Yoast SEO вы можете установить noindex по умолчанию для постов, страниц или других типов контента. Например, если вы используете WooCommerce или некоторые другие наши плагины, у вас могут быть дополнительные типы контента, такие как страницы продуктов или местоположений.
Например, если вы используете WooCommerce или некоторые другие наши плагины, у вас могут быть дополнительные типы контента, такие как страницы продуктов или местоположений.
Решите, что произойдет с отдельными сообщениями и страницами
Что общего между страницей входа и страницей благодарности? Они оба не имеют значения для SEO. Лучше всего удалить такие страницы из поисковых систем.
Как насчет сообщений? Возможно, вы захотите не индексировать старые записи, над которыми нужно доработать. Тег noindex может пригодиться, пока вы не обновите публикацию и не подготовите ее к гордому размещению на странице результатов поиска.
Позвольте Yoast SEO управлять техническими вещами в фоновом режиме
Yoast SEO усердно работает за кулисами, чтобы облегчить диалог между вашим сайтом и поисковыми системами. В нашей документации для разработчиков вы можете узнать больше о том, как мы управляем метатегами роботов и генерируем их.
Как noindex и nofollow работают в Yoast SEO?
Если вы уверены, что хотите добавить директивы noindex или nofollow на страницу, Yoast SEO позволяет сделать это в несколько кликов.
Элементы управления на уровне сайта
В настройках внешнего вида при поиске Yoast SEO (в разделе «Тип контента») вы можете получить доступ к настройкам на уровне сайта, которые позволяют вам управлять значениями индексации по умолчанию для каждого из ваших типов контента. Это вопрос включения или выключения тумблера!
Отдельные сообщения и страницы
Чтобы запретить подписку или не индексировать отдельные сообщения или страницы, перейдите на вкладку «Дополнительно» в окне Yoast SEO Meta. Опять же, здесь все, что вам нужно сделать, это выбрать несколько переключателей, и все готово!
Итак, если вы хотите контролировать, куда поисковые системы попадают на ваш сайт и что им разрешено индексировать, вам поможет плагин Yoast SEO! Конечно, это не все, что делает наш плагин. Обязательно ознакомьтесь с другими функциями, которые он может предложить.
Получите подписку Yoast SEO Premium
Как контролировать качество тегов Noindex в тестовой среде | по коду | Руководствуясь кодом
Автор: Харрисон ДеСантис
Повышение эффективности сканирования и индексации Google — один из важнейших столпов успешной программы технического SEO, особенно для такого крупного корпоративного сайта, как TrueCar. Одной из основных технических проблем SEO является контроль индексируемых страниц, поскольку мы не хотим отправлять в Google лишние страницы, которые не заслуживают индексации. Однако природа промежуточных сред затрудняет проверку того, будет ли ваша стратегия индексации работать, как запланировано, в реальной среде. В этом посте мы рассмотрим некоторую историю стратегии индексирования TrueCar и подробно расскажем о том, как мы разработали процесс контроля качества для тестирования мета-тегов noindex перед продвижением изменений на работающем сайте.
Одной из основных технических проблем SEO является контроль индексируемых страниц, поскольку мы не хотим отправлять в Google лишние страницы, которые не заслуживают индексации. Однако природа промежуточных сред затрудняет проверку того, будет ли ваша стратегия индексации работать, как запланировано, в реальной среде. В этом посте мы рассмотрим некоторую историю стратегии индексирования TrueCar и подробно расскажем о том, как мы разработали процесс контроля качества для тестирования мета-тегов noindex перед продвижением изменений на работающем сайте.
Метатег robots — это HTML-фрагмент, помещаемый в заголовок URL-адреса. Он контролирует, как поисковые системы обрабатывают эту страницу. Это может выглядеть примерно так:
Одним из наиболее распространенных вариантов использования метатега robots является «noindex. ” Выглядит это так:
A meta robots content=”NOINDEX, NOFOLLOW” 9Тег 0076 говорит Google не индексировать эту страницу и не переходить ни по одной из закодированных на ней ссылок.
Перед внедрением каких-либо изменений в TrueCar.com наша команда проверяет код в промежуточной среде, чтобы убедиться в отсутствии ошибок. Тем не менее, QA-обработка ошибок мета-роботов была невозможна, потому что наш промежуточный сайт имеет номер 
В промежуточной среде TrueCar мы включаем дополнительный тег заголовка, который очень похож на заголовок мета-роботов, но с небольшим отличием. В то время как обычный заголовок будет читать name=”ROBOTS” перед директивой, мы добавляем name=”TC-PROD-ROBOTS” , чтобы отразить, какой будет директива , когда промежуточное изменение будет объединено. Поскольку этот заголовок не читается как name="ROBOTS" , это не настоящий метатег robots. Поэтому Google не признает это какой-либо инструкцией по индексации. Это совершенно не имеет значения для индексируемости промежуточного сайта.
Тег настоящих метароботов: Тег искусственных метароботов:
Добавив этот тег в HTML, у нас теперь есть поле, которое мы можем извлечь, чтобы увидеть, каким будет статус индексации/отслеживания страницы.
Теперь, когда в промежуточном коде есть фальшивый метатег robots, нам просто нужно запустить сканирование, чтобы извлечь этот «TC-PROD-ROBOTS» значение. Вот как это сделать.
- Соберите список примеров URL-адресов, где, как мы ожидаем, произойдут изменения мета-роботов. Поместите эти URL-адреса в текстовый файл. Назовем его List.txt.
- Возьмите те же URL-адреса, скопируйте их в отдельный файл текстового редактора и найдите/замените их доменное имя на промежуточное доменное имя. Убедитесь, что они разрешаются в браузере Chrome. Затем добавьте эти промежуточные URL-адреса в тот же текстовый файл. List.txt теперь содержит две версии каждого URL-адреса: рабочую версию и тестовую версию.
- Создайте специальный проект сканирования в Botify.
- В разделе «Настройки» > «Сканер» загрузите наш недавно созданный файл List.txt.
- В разделе «Разрешенные домены» введите два домена: промежуточный и рабочий сайты.
 Затем добавьте эти промежуточные URL-адреса в тот же текстовый файл. List.txt теперь содержит две версии каждого URL-адреса: рабочую версию и тестовую версию.
Затем добавьте эти промежуточные URL-адреса в тот же текстовый файл. List.txt теперь содержит две версии каждого URL-адреса: рабочую версию и тестовую версию.- Создайте еще одно правило регулярного выражения извлечения HTML, которое ищет поле faux meta robots и возвращает строку. Назовите правило как-нибудь запоминающимся (например, «Фальшивые метароботы»).
- Создайте еще одно правило регулярного выражения HTML, которое ищет реальное мета-поле robots и возвращает строку. Назовите правило как-нибудь запоминающимся (например, «Prod Meta Robots»).
- После проверки правила, чтобы убедиться, что оно извлекает строку, запустите сканирование!
После завершения обхода Botify выберите Site Crawler > URL Explorer (на платформе Botify) и создайте отчет из трех столбцов. Можно выбрать только следующие столбцы:
Можно выбрать только следующие столбцы:
- URL-карта
- Prod Meta Robots
- Faux Meta Robots
Экспорт этого отчета с тремя столбцами в Excel.
Чтобы не делать этот пост слишком тяжелым для Excel, мы просто опишем желаемый результат этого экспорта. Получите URL-адрес без домена (или «ключ») для функции ВПР в столбцах Prod и Faux Meta Robots. Когда это будет завершено, будет приятное параллельное сравнение состояния тегов как в рабочей, так и в тестовой среде. На выходе должен получиться простой отчет с тремя столбцами, который очень похож на исходный экспорт (но с вдвое меньшим количеством строк и «URL Slug» без домена вместо полной «URL-карты»):
- URL Slug
- Prod Meta Robots
- Faux Meta Robots
Теперь у нас есть список того, что находится на URL-адресе и сайте prost, показывающем слаг URL-адреса и URL-адрес сайта prost. . Последнее, что нужно сделать, это добавить еще один столбец с простой формулой: ячейка Faux meta robots = ячейка Prod meta robots.