
HTML/Элемент noindex
Синтаксис
Валидный
Невалидный
<!--noindex--> ... <!--/noindex-->
Описание
Элемент noindex (от англ. «no index» ‒ «не индексировать») устанавливает запрет на индексирование текста расположенного внутри данного элемента. Запрет распознаётся такими поисковыми системами как Яндекс и Rambler. Как правило, noindex используют для запрета индексации частей скопированного (не оригинального) текста, текста с использованием нецензурных выражений, а так же кодов всевозможных счётчиков (тИЦ, PR, liveinternet и прочие). Для того, что бы контент не индексировался ещё и Google, дополнительно используется мета-тег «noindex».
Примечание
Действие тега распространяется только на текст. Ссылки, а так же такие объекты как видео, аудио, изображения и прочее попав внутрь данного элемента, индексируются, как и прежде.
Условия использования
noindex может располагаться в любом месте HTML документа.
Поддержка браузерами
Chrome
Поддерж.
Firefox
Поддерж.
Opera
Поддерж.
Maxthon
Поддерж.
IExplorer
Поддерж.
Safari
Поддерж.
iOS
Поддерж.
Android
Поддерж.
Спецификация
| Верс. | Раздел |
|---|---|
| HTML | |
| 2.0 | |
| 3.2 | |
| 4.01 | |
| 5.0 | |
| 5.1 | |
| XHTML | |
1. 0 0 | |
| 1.1 | |
Атрибуты
Данный элемент не имеет параметров / атрибутов.
Пример использования
Листинг кода
<!DOCTYPE html>
<html>
<head>
<meta charset=»utf-8″>
<title>Элемент noindex</title>
</head>
<body>
<h2>Пример использования элемента «noindex»</h2>
<p>В этом примере показано использование валидной версии элемента «noindex» для сокрытия части текста от некоторых поисковиков.</p>
<!—noindex—>
<p>Данный текст не будет проиндексирован поисковыми системами <u>Яндекс</u> и <u>Rambler</u>.</p>
</body>
</html>
Элемент noindex
как, зачем и для чего используют в SEO
Noindex nofollow: как, зачем и для чего используют в SEOStarting a new project?
получить консультациюЧитайте наш Telegram 👈
Заказать
звонок
Оставьте свои контактные данные, наш менеджер перезвонит вам.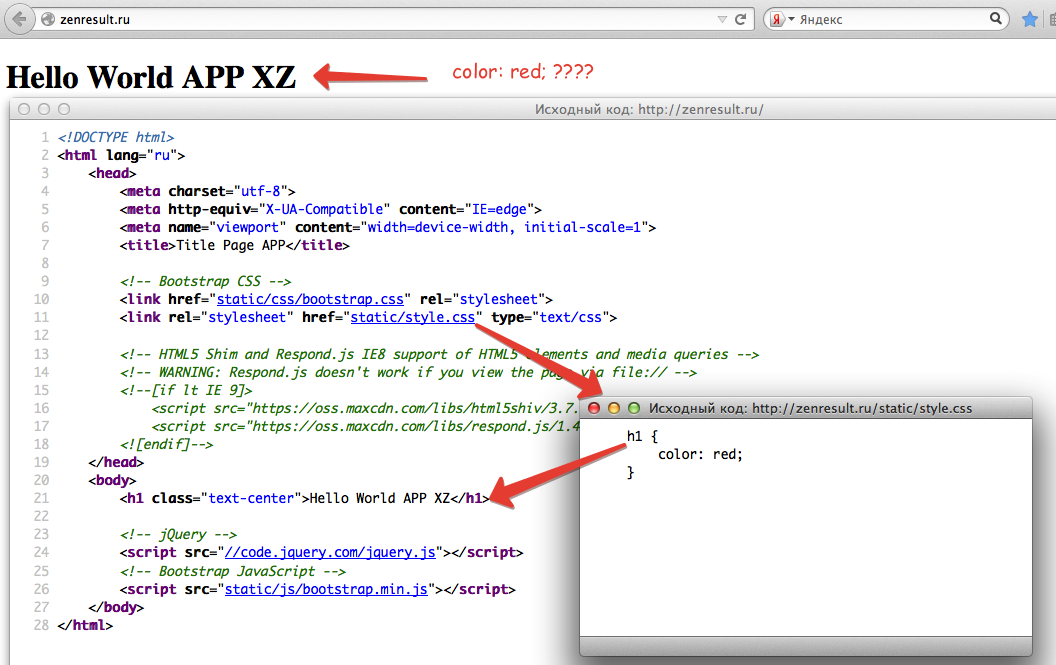
Спасибо! Скоро с Вами свяжется наш менеджер.
Получить
консультацию
Спасибо! Скоро с Вами свяжется наш менеджер.
POWER IS IN TRUST
Прокачайте свой сайт!
Подписывайтесь и получайте советы по оптимизации сайта и повышению продаж
Заказать обратный звонок
Подтвердите свой Email для завершения подписки.
Вы уже подписаны на нашу рассылку!
1289
10
Поделиться:
Noindex nofollow имеют несколько разных понятий, и в зависимости от значений выполняют определенные функции.
- метатег <meta name=»robots» content=»noindex, nofollow» />;
- тег <noindex>;
- атрибут rel=”nofollow”.
Для чего же созданы эти элементы и в каких случаях их стоит применять? Давайте разберемся вместе.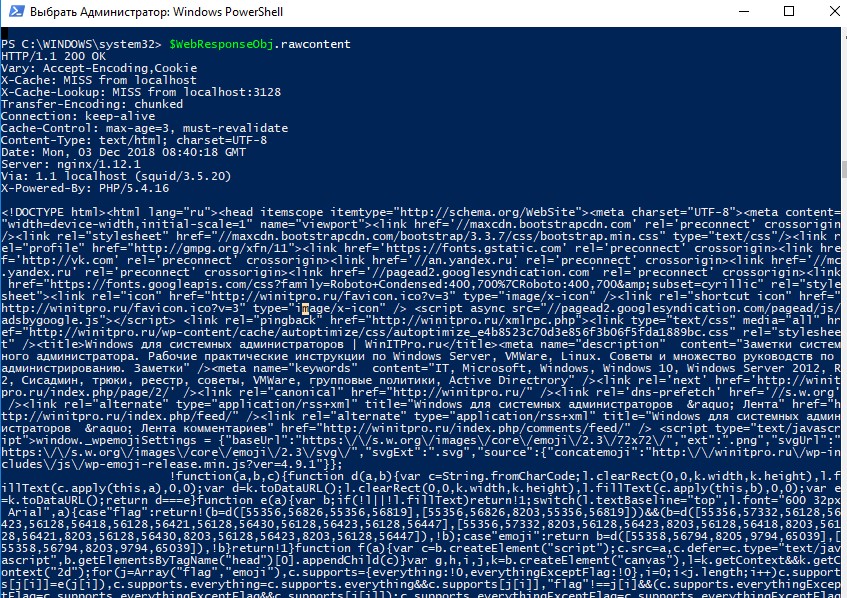
1. Метатег robots
Поисковая выдача формируется из документов, просканированных и проиндексированных поисковым роботом. Но не вся информация должна попадать в индекс. И тогда на помощь приходит метатег robots, благодаря которому можно скрыть страницу от индексации поисковыми роботами.
Тег необходимо установить в секцию <head> для того, чтобы страница не попала в индекс.
Пример:
<head> <meta name = “robots” content = “noindex”/> </head> |
Большинство поисковых роботов понимают этот метатег. А при необходимости можно закрыть страницу только от определенного робота.
Например, от Google:
<meta name=«googlebot» content=«noindex»/>
Что же тогда означает комбинация значений «noindex, nofollow»?
Как вы уже поняли, noindex запрещает индексировать страницу, включая весь контент, который на ней находится.
А nofollow запрещает поисковым роботам переходить как по внутренним, так и по внешним ссылкам, размещенным на странице.
Рассмотрим различные варианты значений метатега robots:
| <meta name=“robots” content=“noindex, nofollow”> | Запрещает индексировать страницу и переходить по ссылкам |
| <meta name=“robots” content=“index,follow”> | Разрешает индексировать страницу и переходить по ссылкам на ней. Но в этой комбинации нет необходимости, т. к. по умолчанию поисковые роботы выполняют те же действия |
| <meta name=“robots” content=“index,nofollow”> | Можно индексировать страницу, но нельзя переходить по ссылкам |
| <meta name=“robots” content=“noindex,follow”> | Нельзя индексировать страницу, но можно переходить по URL-адресам. Используется для того, чтобы страница не попала в индекс, но поисковые роботы могли посещать ссылки, размещенные на ней. Эта комбинация встречается чаще всего. Вы можете увидеть ее на второй и последующих страницах пагинации, т. к. данные страницы не должны попадать в индекс, но поисковые роботы должны иметь возможность переходить по ссылкам товаров |

Очень часто для запрета индексирования используют файл robots.txt. Но для поисковых роботов условия, написанные в нем, скорее служат рекомендациями и могут быть проигнорированы. Более надежным способом запрета от индексирования считается метатег <meta name=«robots» content=«noindex»/>.
Довольно часто для удаления уже проиндексированной страницы используют директиву Disallow в файле robots.txt. Это ошибка, ведь в таком случае вы запрещаете доступ к странице, и поисковый робот не удалит ее из индекса.
В выдаче поисковой системы вместо описания страницы вы увидите сообщение о том, что доступ к данной странице заблокирован с помощью файла robots.txt.
 Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.
Поисковый робот просканирует страницу, увидит атрибут noindex, и исключит страницу из индекса.3. Атрибут rel=”nofollow”
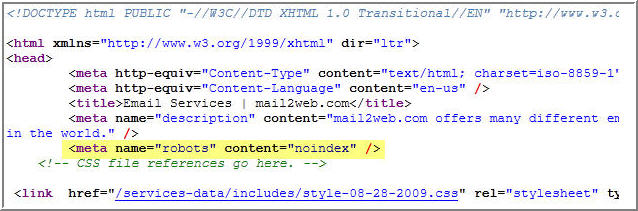
rel=”nofollow” применим к тегу <а> и относится только к гиперссылке, для которой он прописан.
Как он выглядит:
| <a href=»http://site.com/» rel=»nofollow»>текст ссылки</a> |
Вид в коде страницы:
Рис. 1 — nofollow в коде страницы
История атрибута очень интересна. Изначально Google позиционировал nofollow как инструмент для борьбы со спамом в комментариях. Но это было в далеком 2005.
Затем шла борьба с накруткой PageRank. Все пытались манипулировать внутренним весом, чтобы у продаваемых страниц был самый высокий PageRank. Ведь ссылочный вес делился одинаково между всеми гиперссылками на странице, не учитывая rel=«nofollow». И поэтому в 2009 Google внес поправки, согласно которым ссылочный вес не передавался по ссылкам, к которым применим атрибут rel=«nofollow».
Более того, изменились правила передачи ссылочного веса. Например, если на странице Х размещены 3 ссылки (2 dofollow и 1 nofollow), а вес страницы Х равен 6 “баллам”, то до внесения изменений Гуглом каждая ссылка без nofollow получила бы по 3 “балла”. А сейчас такие ссылки получат по 2 “балла”. Это означает, что ссылочный вес разделяется между всеми внутренними ссылками, но передается только по dofollow.
Когда специалисты стали меньше заморачиваться над передачей ссылочного веса, Google заявил, что все купленные ссылки должны иметь атрибут rel=«nofollow», утверждая, что некоторые проплаченные ссылки ничем не отличаются от тех, что были получены естественным путем (когда люди просто делятся тем, что по их мнению может быть интересным и полезным для других). Таким образом Google стимулирует получать естественные ссылки путем создания качественного контента.
В каких случаях сейчас стоит использовать ссылки с атрибутом «nofollow»?
Могу порекомендовать вам использовать nofollow ссылки для того, чтобы:
- сделать ссылочный профиль сайта разнообразным;
- обезопасить себя от санкций, применив атрибут к некачественным ссылкам.


Все об аутрич: что это и как построить
Как оптимизировать YouTube для поиска
Что такое тег canonical?
Подпишитесь на наши обновления
Больше полезных статей и мануалов еще впереди.
Вы уже подписаны на нашу рассылку!
Подтвердите свой Email для завершения подписки.
Заказать
продвижение
Больше полезных статей и мануалов еще впереди. Будьте в курсе!
Соглашаюсь на обработку данныхСпасибо! Скоро с Вами свяжется наш менеджер.
×
Индексирование поиска блоков с помощью noindex | Центр поиска Google | Документация
noindex — это набор правил с тег или заголовок ответа HTTP и используется для предотвращения индексации контента поисковыми системами, которые
поддерживают правило noindex , например Google. Когда робот Googlebot сканирует эту страницу и
извлекает тег или заголовок, Google полностью удалит эту страницу из результатов поиска Google,
независимо от того, ссылаются ли на него другие сайты.
Когда робот Googlebot сканирует эту страницу и
извлекает тег или заголовок, Google полностью удалит эту страницу из результатов поиска Google,
независимо от того, ссылаются ли на него другие сайты.
noindex было эффективным, страница
или ресурс не должен быть заблокирован файлом robots.txt, и он должен быть в противном случае
доступным для поискового робота. Если страница заблокирована
robots.txt или сканер не сможет получить доступ к странице, сканер никогда не увидит noindex правило, и страница все еще может отображаться в результатах поиска, например
если на него ссылаются другие страницы. Использование noindex полезен, если у вас нет root-доступа к вашему серверу, так как
позволяет контролировать доступ к вашему сайту на постраничной основе.
Есть два способа реализовать noindex : как тег и
как заголовок ответа HTTP. Они имеют тот же эффект; выбрать метод, который больше
удобно для вашего сайта и соответствует типу контента. Указание
Они имеют тот же эффект; выбрать метод, который больше
удобно для вашего сайта и соответствует типу контента. Указание правило noindex в файле robots.txt не поддерживается Google.
Вы также можете комбинировать правило noindex с другими правилами, управляющими индексацией. Для
Например, вы можете объединить подсказку nofollow с правилом noindex : .
<мета> тег Чтобы запретить индексацию всеми поисковыми системами , которые поддерживают правило noindex странице вашего сайта, разместите следующие тег в раздел вашей страницы:
Чтобы запретить только поисковым роботам Google индексировать страницу:
Имейте в виду, что некоторые поисковые системы могут интерпретировать noindex правила разные. В результате возможно, что ваша страница может
по-прежнему появляются в результатах других поисковых систем.
В результате возможно, что ваша страница может
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о теге noindex .
Если вы используете CMS, например Wix, WordPress или Blogger , возможно, вы не сможете редактировать
ваш HTML напрямую, или вы можете предпочесть этого не делать. Вместо этого ваша CMS может иметь поисковую систему.
страницу настроек или какой-либо другой механизм, сообщающий поисковым системам о мета-тегах .
Если вы хотите добавить на свой веб-сайт метатег , выполните поиск инструкций.
о модификации вашей страницы на вашей CMS (например,
найдите «wix добавить метатеги»).
Вместо тега вы можете вернуть X-Robots-Tag Заголовок HTTP со значением noindex или none в вашем ответе.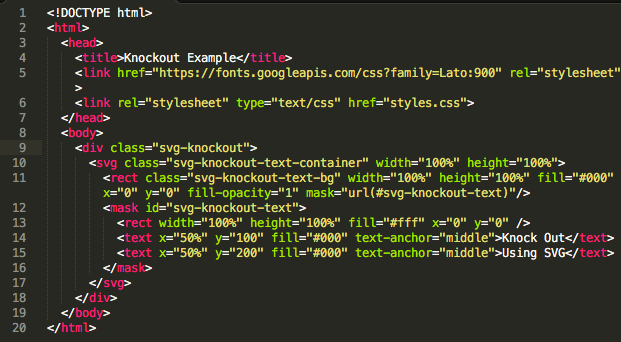 Заголовок ответа можно использовать для ресурсов, отличных от HTML, таких как PDF-файлы, видеофайлы и изображения.
файлы. Вот пример HTTP-ответа с
Заголовок ответа можно использовать для ресурсов, отличных от HTML, таких как PDF-файлы, видеофайлы и изображения.
файлы. Вот пример HTTP-ответа с X-Robots-Tag 9.0004 заголовок
указание поисковым системам не индексировать страницу:
HTTP/1.1 200 ОК (...) X-Robots-Tag: noindex (...)
Узнайте больше о заголовке ответа noindex .
Отладка
noindex проблемы Нам нужно просканировать вашу страницу, чтобы увидеть тега и заголовки HTTP. Если
страница по-прежнему отображается в результатах, возможно, это связано с тем, что мы не сканировали страницу с
вы добавили noindex правило. В зависимости от важности страницы на
Интернет, роботу Googlebot может потребоваться несколько месяцев, чтобы повторно посетить страницу. Вы можете запросить, чтобы Google
пересканировать страницу с помощью
Инструмент проверки URL.
Вы можете запросить, чтобы Google
пересканировать страницу с помощью
Инструмент проверки URL.
Если вам нужно быстро удалить страницу вашего сайта из результатов поиска Google, см. документация об увольнении.
Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google. сканеры, поэтому они не могут видеть тег. Чтобы разблокировать свою страницу от Google, вы должны отредактируйте файл robots.txt. Вы можете редактировать и тестировать файл robots.txt с помощью robots.txt Тестер инструмент.
Наконец, убедитесь, что правило noindex видно Googlebot. Чтобы проверить, если ваш noindex реализация правильная, используйте
Инструмент проверки URL
чтобы увидеть HTML-код, полученный роботом Googlebot при сканировании страницы.
Вы также можете использовать
Отчет об индексации страниц
в Search Console, чтобы отслеживать страницы вашего сайта, с которых робот Googlebot извлек noindex правило.
Технические характеристики метатегов роботов | Центр поиска Google | Документация
В этом документе подробно описывается, как можно использовать настройки уровня страницы и текста для настройки того, как Google
представляет ваш контент в результатах поиска. Вы можете задать настройки на уровне страницы, включив
Мета-тег на страницах HTML или в заголовке HTTP. Вы можете задать настройки уровня текста с помощью атрибут data-nosnippet для элементов HTML на странице.
Имейте в виду, что эти настройки можно прочитать и использовать только в том случае, если сканерам разрешено получить доступ к страницам, которые включают эти настройки.
К поисковой системе применяется правило .
гусеницы. Чтобы заблокировать поисковые роботы, такие как AdsBot-Google , вам может потребоваться добавить правила, ориентированные на конкретный
поисковый робот (например, ).
Использование тега robots
meta Метатег robots позволяет вам
отдельная страница должна быть проиндексирована и показана пользователям в результатах поиска Google. Поместите
роботы метатег в разделе данной страницы, например
этот:
<заголовок> (…) <тело> (…)
Если вы используете CMS, например Wix, WordPress или Blogger , возможно, вы не сможете редактировать
ваш HTML напрямую, или вы можете предпочесть этого не делать. Вместо этого ваша CMS может иметь поисковую систему.
страница настроек или какой-либо другой механизм, сообщающий поисковым системам о метатегов .
Если вы хотите добавить на свой веб-сайт метатег , выполните поиск инструкций.
об изменении вашей страницы на вашей CMS (например,
найдите «wix добавить метатеги»).
В этом примере тег robots meta указывает поисковым системам не показывать страницу в
результаты поиска. Значение атрибута name ( robots )
указывает, что правило применяется ко всем сканерам. К
обратиться к конкретному сканеру, замените роботов значение имя атрибут с именем искателя, которым вы являетесь
адресация. Определенные сканеры также известны как пользовательские агенты (сканер использует свой пользовательский агент для
запросить страницу.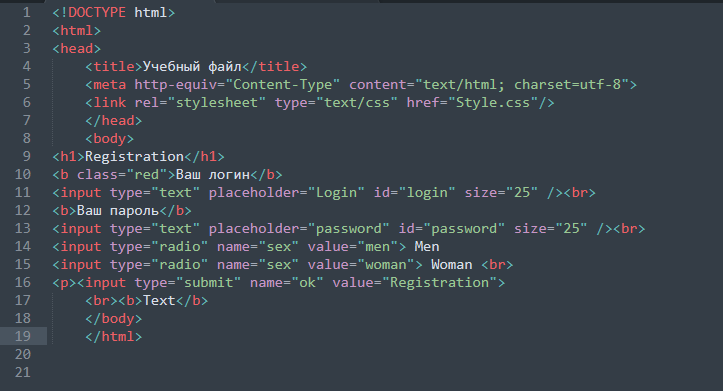 ) Стандартный поисковый робот Google имеет имя пользовательского агента
) Стандартный поисковый робот Google имеет имя пользовательского агента Гуглбот . Чтобы предотвратить индексацию вашей страницы только Google,
обновите тег следующим образом:
Этот тег теперь предписывает Google не показывать эту страницу в результатах поиска. Оба имя и содержимое атрибуты
не чувствительны к регистру.
Поисковые системы могут иметь разные сканеры для разных целей. См.
полный список поисковых роботов Google.
Например, чтобы показать страницу в результатах веб-поиска Google, но не в Новостях Google, используйте
следующий метатег :
Чтобы указать несколько поисковых роботов по отдельности, используйте несколько robots мета теги:
Чтобы заблокировать индексирование ресурсов, отличных от HTML, таких как файлы PDF, видеофайлы или файлы изображений,
вместо этого используйте заголовок ответа X-Robots-Tag .
Использование
X-Robots-Tag HTTP-заголовка X-Robots-Tag можно использовать как элемент HTTP-заголовка
ответ для заданного URL. Любое правило, которое можно использовать в robots 9Метатег 0003 также может быть
указан как X-Robots-Tag . Вот пример HTTP
ответ с X-Robots-Tag , указывающим поисковым роботам не индексировать
страница:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: noindex (…)
Несколько заголовков X-Robots-Tag могут быть объединены в HTTP-заголовке.
ответ, или вы можете указать список правил, разделенных запятыми. Вот пример
Ответ заголовка HTTP, который имеет без архива X-Robots-Tag в сочетании с недоступен_после X-Robots-Tag .
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Метка: нет в архиве X-Robots-Tag: unavailable_after: 25 июня 2010 г. 15:00:00 PST (…)
X-Robots-Tag может дополнительно указывать пользовательский агент перед
правила. Например, следующий набор из X-Robots-Tag HTTP
заголовки могут использоваться для условного разрешения показа страницы в результатах поиска для разных
поисковые системы:
HTTP/1.1 200 ОК Дата: вторник, 25 мая 2010 г., 21:42:43 по Гринвичу (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: otherbot: noindex, nofollow (…)
Правила, заданные без пользовательского агента, действительны для всех сканеров. Заголовок HTTP,
имя пользовательского агента, а указанные значения не чувствительны к регистру.
Конфликтующие правила роботов: В случае конфликтующих роботов
правил, применяется более строгое правило. Например, если на странице есть оба max-snippet:50 и nosnippet правила, будет применяться правило nosnippet .
Действительные правила индексации и обслуживания
Следующие правила, также доступные в
машиночитаемый формат, может использоваться для
управлять индексацией и показом сниппета с помощью
роботы метатег и X-Robots-Tag . Каждое значение представляет определенный
правило. Несколько правил могут быть объединены через запятую.
списке или в отдельных мета-тегах . Эти правила нечувствительны к регистру.
| Правила | |
|---|---|
все | Нет никаких ограничений для индексации или обслуживания. Это правило является значением по умолчанию и не имеет никакого эффекта, если явно указан. |
без индекса | Не показывать эту страницу, медиа или ресурс в результатах поиска. Если вы не укажете это правило, страница, медиа или ресурс могут быть проиндексированы и показаны в результатах поиска. Чтобы удалить информацию из Google, следуйте нашим
пошаговое руководство. |
nofollow | Не переходите по ссылкам на этой странице. Если вы не укажете это правило, Google может использовать
ссылки на странице, чтобы обнаружить эти связанные страницы. Узнать больше о nofollow . |
нет | Эквивалентно noindex, nofollow . |
без архива | Не показывать
кешированная ссылка
в результатах поиска. Если вы не укажете это правило, Google может создать кешированную страницу.
и пользователи могут получить к нему доступ через результаты поиска. |
nositelinkssearchbox | Не показывать окно поиска дополнительных ссылок в результатах поиска для этой страницы. Если вы не укажете это правило, Google может создать поле поиска, относящееся к вашему сайту, в результатах поиска вместе с другими прямыми ссылками на ваш сайт. |
нет фрагмента | Не показывать фрагмент текста или предварительный просмотр видео в результатах поиска для этой страницы. А
миниатюра статического изображения (если она доступна) все еще может быть видна, когда это приводит к лучшему
Пользовательский опыт. Это относится ко всем формам результатов поиска (в Google: веб-поиск,
Google картинки, Откройте для себя). Если вы не укажете это правило, Google может создать фрагмент текста и видео. предварительный просмотр на основе информации, найденной на странице. |
indexifembedded | Google разрешено индексировать содержимое страницы, если оно встроено в другую страницу.
через |
макс-фрагмент: [число] | Используйте не более [число] символов в текстовом фрагменте для этого результата поиска. Если вы не укажете это правило, Google выберет длину фрагмента. Специальные значения:
Примеры: Чтобы остановить отображение фрагмента в результатах поиска: Чтобы во фрагменте отображалось до 20 символов: Чтобы указать, что нет ограничений на количество символов, которые могут отображаться в фрагмент: |
максимальный предварительный просмотр изображения: [настройка] | Установить максимальный размер предварительного просмотра изображения для этой страницы в результатах поиска. Если вы не укажете правило Принятые значения [настройки]:
Это относится ко всем формам результатов поиска (таким как веб-поиск Google, изображения Google,
Откройте для себя, помощник). Однако это ограничение не применяется в случаях, когда издатель
отдельно предоставленное разрешение на использование контента. Если вы не хотите, чтобы Google использовал большие эскизы изображений на своих AMP-страницах
и каноническая версия статьи отображаются в Поиске или Обнаружении, укажите Пример: |
макс-видео-превью: [число] | Используйте максимум [число] секунд в качестве фрагмента видео для видео на этой странице в поиске
Результаты. Если вы не укажете правило Специальные значения:
Это относится ко всем формам результатов поиска (в Google: веб-поиск, изображения Google, Google Видео, Discover, Ассистент). Это правило игнорируется, если нет анализируемого [число] указано. Пример: |
без перевода | Не предлагать перевод этой страницы в результатах поиска. Если вы не укажете это
правило, Google может предоставлять
перевод заглавной ссылки и сниппета
результатов поиска для результатов, которые не на языке
поискового запроса. Если пользователь щелкает переведенную ссылку заголовка, все дальнейшие пользовательские
взаимодействие со страницей осуществляется через Google Translate, который будет автоматически переводить
любые ссылки. Если вы не укажете это
правило, Google может предоставлять
перевод заглавной ссылки и сниппета
результатов поиска для результатов, которые не на языке
поискового запроса. Если пользователь щелкает переведенную ссылку заголовка, все дальнейшие пользовательские
взаимодействие со страницей осуществляется через Google Translate, который будет автоматически переводить
любые ссылки. |
индекс индекса изображения | Не индексировать изображения на этой странице. Если не указать это значение, изображения на странице могут быть проиндексированы и показаны в результатах поиска. |
недоступен_после: [дата/время] | Не показывать эту страницу в результатах поиска после указанной даты/времени. Если вы не укажете это правило, эта страница может отображаться в результатах поиска. на неопределенный срок. Робот Googlebot значительно снизит скорость сканирования URL-адреса после указанного Дата и время. Пример: |

 (Примечание
что URL-адрес может отображаться как несколько результатов поиска на странице результатов поиска.) Это
не влияет на предварительный просмотр изображений или видео. Это относится ко всем формам результатов поиска
(например, веб-поиск Google, Google Images, Discover, Assistant). Однако этот предел
не применяется в случаях, когда издатель отдельно предоставил разрешение на использование
содержание. Например, если издатель предоставляет контент в виде встроенных
структурированные данные или имеет лицензионное соглашение с Google, этот параметр не прерывает
более конкретное разрешенное использование. Это правило игнорируется, если нет анализируемого [число]
указано.
(Примечание
что URL-адрес может отображаться как несколько результатов поиска на странице результатов поиска.) Это
не влияет на предварительный просмотр изображений или видео. Это относится ко всем формам результатов поиска
(например, веб-поиск Google, Google Images, Discover, Assistant). Однако этот предел
не применяется в случаях, когда издатель отдельно предоставил разрешение на использование
содержание. Например, если издатель предоставляет контент в виде встроенных
структурированные данные или имеет лицензионное соглашение с Google, этот параметр не прерывает
более конкретное разрешенное использование. Это правило игнорируется, если нет анализируемого [число]
указано.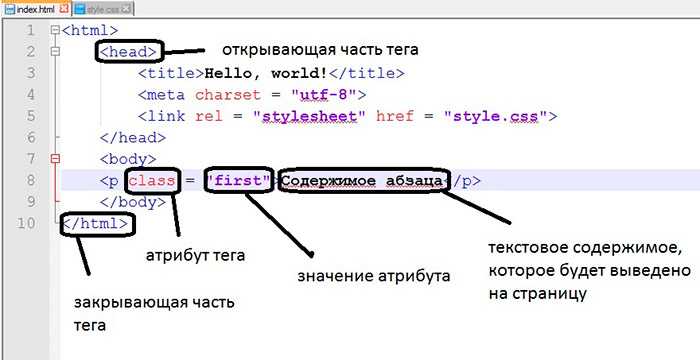 Эквивалентно
Эквивалентно 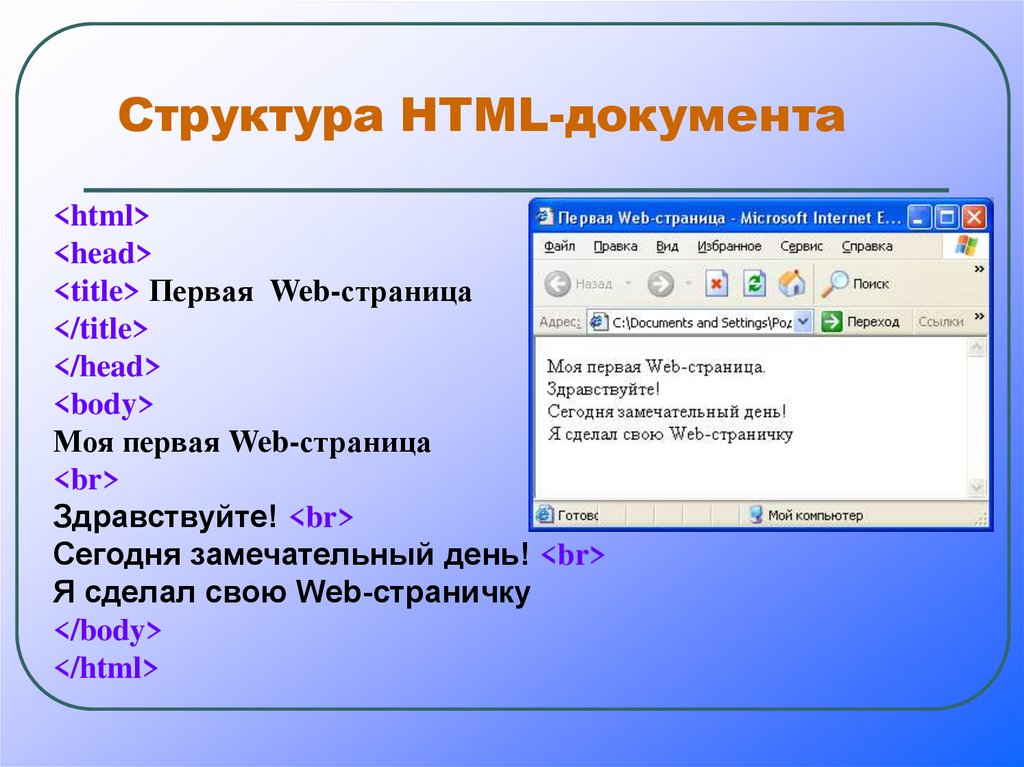
 Например, если издатель
предоставляет контент в виде структурированных данных на странице (таких как AMP и канонические
версии статьи) или имеет лицензионное соглашение с Google, этот параметр не будет
прерывать эти более конкретные разрешенные виды использования.
Например, если издатель
предоставляет контент в виде структурированных данных на странице (таких как AMP и канонические
версии статьи) или имеет лицензионное соглашение с Google, этот параметр не будет
прерывать эти более конкретные разрешенные виды использования.
 Дата/время
должны быть указаны в общепринятом формате, включая, но не ограничиваясь
RFC 822,
RFC 850 и
ИСО 8601.
Правило игнорируется, если не указаны допустимые дата/время. По умолчанию нет
срок годности контента.
Дата/время
должны быть указаны в общепринятом формате, включая, но не ограничиваясь
RFC 822,
RFC 850 и
ИСО 8601.
Правило игнорируется, если не указаны допустимые дата/время. По умолчанию нет
срок годности контента.Обработка комбинированных правил индексации и обслуживания
Вы можете создать инструкцию с несколькими правилами, объединив роботов мета правила тегов с запятыми или с использованием нескольких мета-тегов . Вот пример метатега robots
Вот пример метатега robots , который предписывает поисковым роботам не индексировать
страницу и не сканировать ни одну из ссылок на странице:
Список, разделенный запятыми
Несколько
метатегов Вот пример, который ограничивает текстовый фрагмент до 20 символов и позволяет использовать большое изображение. предварительный просмотр:
В ситуациях, когда несколько искателей указаны вместе с разными правилами,
поисковая система будет использовать сумму отрицательных правил. Например:
Например:
Страница, содержащая эти метатега , будет интерпретироваться как имеющая noindex, правило nofollow при сканировании роботом Googlebot.
Использование HTML-атрибута
data-nosnippet Вы можете определить текстовые части HTML-страницы, которые не будут использоваться в качестве фрагмента. Это можно сделать
на уровне HTML-элемента с HTML-атрибутом data-nosnippet на диапазон , раздел и раздел элементов.
data-nosnippet считается
логический атрибут.
Как и для всех логических атрибутов, любое указанное значение игнорируется. Чтобы обеспечить машиночитаемость,
раздел HTML должен быть действительным HTML, и все соответствующие теги должны быть соответствующим образом закрыты.
Примеры:
Этот текст можно отобразить во фрагменте и эта часть не будет отображаться.
не во фрагментетоже не во фрагментетоже не во фрагментекакой-то тексткакой-то текст Google обычно отображает страницы для их индексации, однако обработка не гарантируется.
data-nosnippetможет произойти как до и после рендеринга. Во избежание неопределенности при рендеринге не добавляйте и не удаляйтеdata-nosnippetатрибут существующих узлов через JavaScript. При добавлении элементов DOM через JavaScript включитеатрибут data-nosnippetпо мере необходимости при первоначальном добавлении элемент в DOM страницы. Если используются пользовательские элементы, оберните их или визуализируйте с помощьюраздел,интервалилиразделэлементов, если вам нужно использоватьdata-nosnippet.Использование структурированных данных
Метатеги Robots
регулируют объем контента, который Google автоматически извлекает из Интернета.мета тегограничения не влияют на использование этих структурированных данных, за исключениемартикул.описаниеи т.д.описаниезначения для структурированных данных, указанные для других творческие работы. Чтобы указать максимальную продолжительность предварительного просмотра на основе этихописаниезначения, используйтеmax-snippetправило. Например,рецептструктурированные данные на странице подходят для включения в карусель рецептов, даже если в противном случае предварительный просмотр текста был бы ограничен.max-snippet, но этот тег robotsmetaне применяется, когда информация предоставляется с использованием структурированных данных для расширенных результатов.Чтобы управлять использованием структурированных данных для ваших веб-страниц, измените типы структурированных данных и сами значения, добавляя или удаляя информацию, чтобы предоставить только те данные, которые вам нужны сделать доступным. Также обратите внимание, что структурированные данные остаются пригодными для использования в результатах поиска, когда объявлено в
data-nosnippetэлемент.Практическая реализация
X-Robots-TagВы можете добавить
X-Robots-Tagв HTTP-ответы сайта через файлы конфигурации программного обеспечения веб-сервера вашего сайта.X-Robots-Tagс ответами HTTP заключается в том, что вы можете указать сканирование правила, которые применяются глобально на сайте. Поддержка регулярных выражений позволяет высокий уровень гибкости.Например, чтобы добавить noindex
, nofollowX-Robots-Tagна ответ HTTP для всехфайлов .PDFв весь сайт, добавьте следующий фрагмент в корневой файл сайта.htaccessили файлhttpd.confна Apache или файл.confсайта на NGINX.Апач
<Файлы ~ "\.pdf$"> Набор заголовков X-Robots-Tag "noindex, nofollow"НГИНКС
расположение ~* \.Вы можете использовать
X-Robots-Tagдля файлов, отличных от HTML, таких как файлы изображений. где использование тегов robotsmetaв HTML невозможно. Вот пример добавленияnoindexX-Robots-Tagправило для файлы изображений (.png,.jpeg,.jpg,.gif) по всему сайту:Апач
<Файлы ~ "\.(png|jpe?g|gif)$"> Набор заголовков X-Robots-Tag "noindex"НГИНКС
расположение ~* \.(png|jpe?g|gif)$ { add_header X-Robots-Tag "noindex"; }Вы также можете установить заголовки
X-Robots-Tagдля отдельных статических файлов:Апач
# файл htaccess должен быть помещен в каталог соответствующего файла.
 Из-за этого извлечение
Из-за этого извлечение  страницы для отображения в качестве результатов поиска. Но многие издатели также используют структурированные данные schema.org.
сделать конкретную информацию доступной для
поисковое представление. Роботы
страницы для отображения в качестве результатов поиска. Но многие издатели также используют структурированные данные schema.org.
сделать конкретную информацию доступной для
поисковое представление. Роботы  Вы можете ограничить длину
предварительного просмотра текста с
Вы можете ограничить длину
предварительного просмотра текста с  Например, в Интернете на основе Apache
серверах вы можете использовать файлы .htaccess и httpd.conf. Преимущество использования
Например, в Интернете на основе Apache
серверах вы можете использовать файлы .htaccess и httpd.conf. Преимущество использования  pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
} 