что это такое и зачем он нужен
Понимание метода машинного обучения «Матрикснет» дает возможность разобраться, каким образом нужно подбирать семантику и совершенствовать сайт, почему эффект оптимизации может проявиться не сразу или отсутствовать совсем.
Понимание метода машинного обучения «Матрикснет» дает возможность разобраться, каким образом нужно подбирать семантику и совершенствовать сайт, почему эффект оптимизации может проявиться не сразу или отсутствовать совсем.
Яндекс начал использовать новый алгоритм, учитывающий большое количество факторов ранжирования, в 2009 году. «Матрикснет» продемонстрировал выдающиеся способности к переобучению без опасности выявить несуществующие закономерности и увеличения количества асессорских оценок.
В качестве примера возьмем два устройства. Одно из них — машина с единственным рычагом, нажатие которого позволяет запустить или завершить процесс. Второе устройство — сложный механизм с множеством кнопок, с их помощью можно изменять параметры процесса. Именно таким является созданный Яндексом «Матрикснет». Этот алгоритм позволяет задавать отдельные настройки для каждого класса запросов.
Именно таким является созданный Яндексом «Матрикснет». Этот алгоритм позволяет задавать отдельные настройки для каждого класса запросов.
1.png
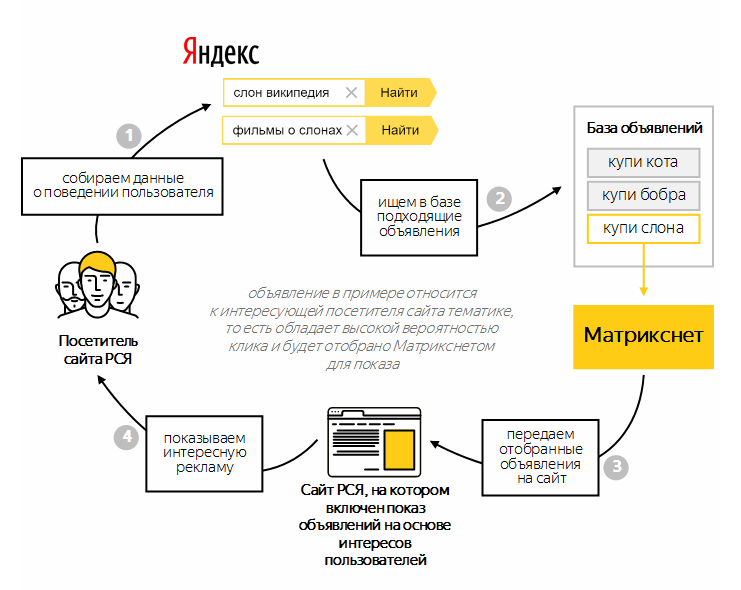
1.pngСуществует большое количество факторов, способных по отдельности или в комплексе определять тип сайта с учетом конкретных условий. Так, избыток продвигаемых запросов в тексте на странице результатов поиска может отрицательно отразиться на репутации ресурса в глазах поисковика. При этом если страница является каталогом товаров, большое количество повторений ключа оправданно и допустимо.
Запуск алгоритма «Матрикснет» дал возможность создать сложную и длинную формулу ранжирования, включающую десятки тысяч коэффициентов. Такой метод машинного обучения за короткое время проверяет множество параметров, причем для этого не приходится существенно увеличивать число обслуживающих серверов и другого оборудования.
Архитектура
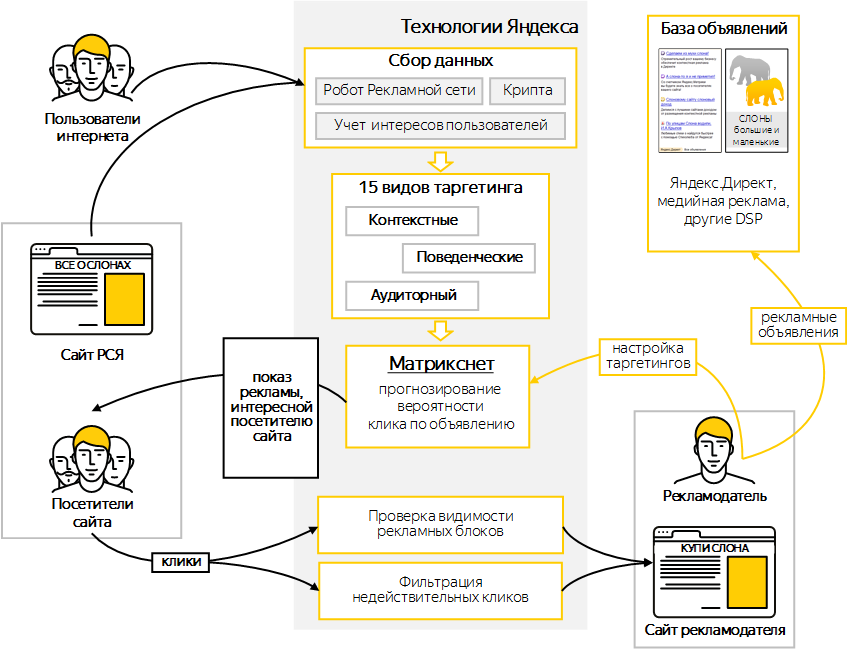
Для формирования списка релевантных ответов поисковая система использует несколько серверов. Каждый из них создает собственный список сайтов, отвечающих запросу пользователя. Результаты работы всех серверов — множество потенциально релевантных страниц. Они проходят проверку по формуле, созданной «Матрикснетом». Ее основные составляющие: класс запроса, тип элемента и другие характеристики. Благодаря этой технологии на первых позициях выдачи оказываются наиболее релевантные ресурсы, следовательно, пользователь получает максимально полный ответ на интересующий вопрос.
Каждый из них создает собственный список сайтов, отвечающих запросу пользователя. Результаты работы всех серверов — множество потенциально релевантных страниц. Они проходят проверку по формуле, созданной «Матрикснетом». Ее основные составляющие: класс запроса, тип элемента и другие характеристики. Благодаря этой технологии на первых позициях выдачи оказываются наиболее релевантные ресурсы, следовательно, пользователь получает максимально полный ответ на интересующий вопрос.
Перед обработкой поискового запроса:
составляется список факторов — описание страницы, сайта, ссылок и запроса по множеству различных признаков;
происходит процесс обучения — «Матрикснет» определяет характеристики ресурсов, которые занимают высокие позиции в выдаче. На этом этапе выполняется асессорская оценка обучающей выборки, на основе которой и создается формула ранжирования.
Алгоритм поисковика быстро совершенствуется: в течение последних лет добавилась возможность прямого взаимодействия с веб-мастерами (переписка), разработаны четкие инструкции для асессоров, а также новые критерии оценки ресурсов.
Процесс обучения
Этот процесс базируется на схеме взаимодействия машины и человека. В качестве входных данных берется множество подобранных факторов, а также подготовленная асессорами обучающая выборка. В ней представлены не только высоко оцененные, но и нерелевантные запросу ресурсы.
2.png
2.pngВходные данные загружаются в систему. Затем она обрабатывает информацию, выделяет характеристики сайтов, которые имеют высокую и низкую релевантность. Данные факторы представлены в числовом виде, так что расчет формулы сводится к подбору коэффициентов. Это делается путем решения математической системы уравнений.
3.png
3.pngТаким же образом можно представить создание формулы ранжирования:
20 и 29 — асессорские оценки;
2 и 5 — показатели двух факторов одного ресурса;
3 и 7 — характеристики другого сайта;
k1 и k2 — коэффициенты, отражающие вклад факторов в оценку релевантности.


На самом деле подходы к выявлению значимых факторов и алгоритмы их определения значительно сложнее. Названия: «метод Ньютона для классификации», gradient boosting и «регуляризация в листьях» — говорят сами за себя.
Сегодня вместо технологии «Матрикснет» Яндекс использует новый метод машинного обучения — CatBoost. Он дает более точные результаты в задачах по ранжированию, регрессии и классификации, а также учитывает данные в нечисловой форме. Пользоваться библиотекой машинного обучения CatBoost могут все желающие: она выложена в открытом доступе. Более подробную информацию о методе вы найдете в блоге Яндекса.
ЧИТАЙ ТАКЖЕ
Фильтры поисковой системы Google
Фильтры «Яндекса»
Календарь инфоповодов. Март 2019
(Рейтинг: 4.33, Голосов: 6) |
У тебя есть нерешенные задачи?
В этом блоге мы делимся знаниями, но если у тебя есть серьезные цели, которые требуют вмешательства настоящих профи, сообщи! Перезвоним, расскажем, решим любые задачи из области digital
Находи клиентов.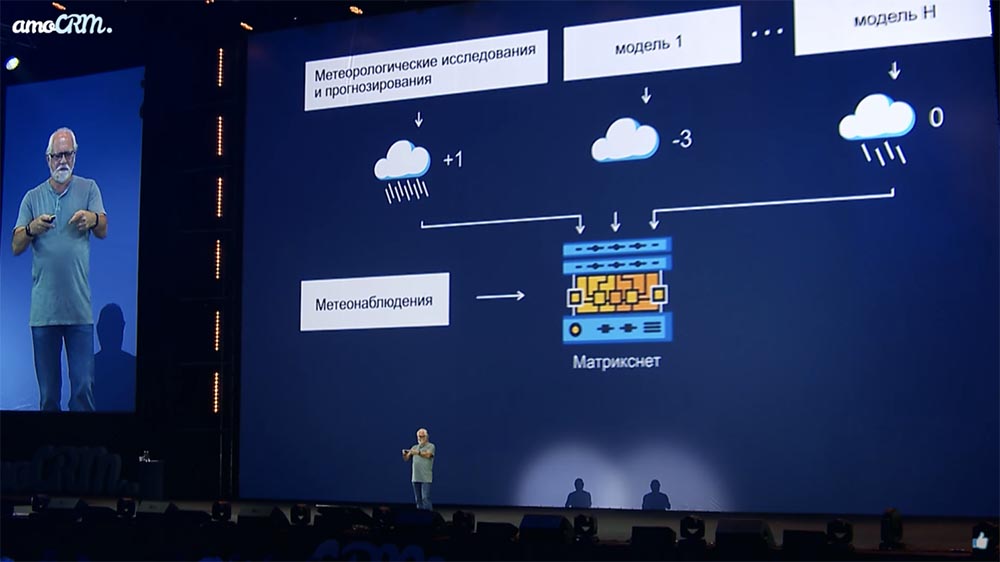 Быстрее!
Быстрее!
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Приложи файл или ТЗ
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
наверх
Как сеошники Матрикснет вскрывали / Хабр
wolfВремя на прочтение 2 мин
Количество просмотров 2.5KПоисковая оптимизация *
Мнение
Сергей Людкевич, SEO-консультант, автор канала SEalytics
Наверное, только совсем далекий от интернета человек еще не слышал о недавней утечке данных из Яндекса. Естественно, такое событие не могло не поднять ажиотаж на рынке SEO. Многие сеошники начали искать, чем бы можно поживиться в 40+ гигабайтах утекших данных. Первым объектом стал файл factors_gen.txt со списком 1922 факторов ранжирования. Добыча была, прямо сказать, не слишком жирная, так как кроме краткого описания факторов в списке ничего не было. И понять, насколько важен тот или иной фактор, не представлялось возможным. Можно было только порефлексировать типа «Гляди-ка, догадались учитывать наличие цифр в URL, наверное, в минус» или «Надо же, они считают количество заглавных букв в теге title».
Многие сеошники начали искать, чем бы можно поживиться в 40+ гигабайтах утекших данных. Первым объектом стал файл factors_gen.txt со списком 1922 факторов ранжирования. Добыча была, прямо сказать, не слишком жирная, так как кроме краткого описания факторов в списке ничего не было. И понять, насколько важен тот или иной фактор, не представлялось возможным. Можно было только порефлексировать типа «Гляди-ка, догадались учитывать наличие цифр в URL, наверное, в минус» или «Надо же, они считают количество заглавных букв в теге title».
Но потом один въедливый иностранец по имени Michael King опубликовал статью, в которой продемонстрировал некий файлик nav_linear.h. В нём некоторым факторам были сопоставлены некоторые коэффициенты, как положительные, так и отрицательные. Вот тут уже у сеошников образовалось широкое пространство для творчества. И постепенно этот мутный список с непонятной развесовкой факторов начал завладевать их умами. Почему-то они решили, что эти коэффициенты и есть самые что ни на есть настоящие веса факторов ранжирования и начали на их основе разрабатывать рекомендации по покорению топов поисковой выдачи Яндекса. И уже на полном серьезе от разных лиц зазвучали призывы отказываться от доменов в зоне .ru, так как в списке это отрицательный фактор. И менять их на домены в зоне .com, так как этот фактор обозначен, как положительный. Правда совсем уж неудобные нестыковки комментаторы старались обходить стороной, и пока еще никто не призывал отказаться, к примеру, от использования в тексте всех слов запроса подряд, хотя в файле этот фактор имеет отрицательный коэффициент.
И уже на полном серьезе от разных лиц зазвучали призывы отказываться от доменов в зоне .ru, так как в списке это отрицательный фактор. И менять их на домены в зоне .com, так как этот фактор обозначен, как положительный. Правда совсем уж неудобные нестыковки комментаторы старались обходить стороной, и пока еще никто не призывал отказаться, к примеру, от использования в тексте всех слов запроса подряд, хотя в файле этот фактор имеет отрицательный коэффициент.
Списочек факторов с развесовками упорядочили и выложили на Github, однако вдруг в комментариях там отметился не кто иной, как Ден Расковалов, бывший сотрудник отдела качества поиска Яндекса. Он заявил, что «nav_linear.h has nothing to do with ranking web search results in Yandex search.»
Ну, а окончательно паззл складывается, если сопоставить название взбудоражившего сеошные умы файла с коэффициентами – nav_linear.h– с названием одного из факторов – FI_NAV_linear, отвечающим за классификацию неких «полунавигационных» запросов. Вот так вот. То есть весовые коэффициенты для расчета одного составного фактора приняли за весовые коэффициенты всего алгоритма. Вскрытие Матрикснета отменяется. Можно менять домены .com обратно на .ru )
Вот так вот. То есть весовые коэффициенты для расчета одного составного фактора приняли за весовые коэффициенты всего алгоритма. Вскрытие Матрикснета отменяется. Можно менять домены .com обратно на .ru )
- яндекс
- seo
- Поисковая оптимизация
Всего голосов 31: ↑3 и ↓28 -25
Комментарии 1
Сергей Людкевич @wolf
SEO-консультант
rep.estimators.matrixnet — документация REP (воспроизводимая экспериментальная платформа) 0.6.7
""" :class:`MatrixNetClassifier` и :class:`MatrixNetRegressor` — это оболочки для веб-сервиса MatrixNet — проприетарный BDT. разработан в Яндексе. Думайте об этом как о конкретном алгоритме Boosted Decision Tree, который доступен как услуга. На данный момент MatrixMet доступен только для **пользователей CERN**. Чтобы использовать MatrixNet, сначала приобретите токен:: * Перейдите на https://yandex-apps.cern.ch/ (войдите под своей учетной записью CERN) * Нажмите «Добавить токен» на левой панели..utils импортировать take_last __author__ = 'Татьяна Лихоманенко, Алексей Рогожников' __all__ = ['MatrixNetBase', 'MatrixNetClassifier', 'MatrixNetRegressor'] регистратор = getLogger (__ имя__) РАЗМЕР = 1000 SYNC_SLEEP_TIME = 10 DEFAULT_CONFIG_PATH = "$HOME/.rep-matrixnet.config.json" @contextlib.contextmanager определение make_temp_directory(): temp_dir = tempfile.mkdtemp() выход temp_dir Shutil.rmtree(temp_dir) [документы]класс MatrixNetBase(объект): """Базовый класс для MatrixNetClassifier и MatrixNetRegressor. Это оболочка вокруг технологии **MatrixNet (специально BDT)**, разработанной в **Яндексе**, который доступен для сотрудников CERN, использующих авторизацию. Обученный оценщик загружается и хранится на вашем компьютере, поэтому вы можете использовать его в любое время. :param features: функции, используемые в обучении Особенности :type: list[str] или None :param str api_config_file: путь к файлу с удаленной конфигурацией API в формате json:: {"url": "https://ml. api_config_file = API_config_file self.iterations = итерации саморегуляция = регуляризация self.intervals = интервалы self.auto_stop = авто_стоп self.max_features_per_iteration = max_features_per_iteration self.features_sample_rate_per_iteration = features_sample_rate_per_iteration self.training_fraction = тренировочная_фракция self.sync = синхронизировать self.random_state = случайное_состояние self._initialisation_before_fit() def _initialisation_before_fit(я): self.formula_mx = Нет self.mn_cls = Нет self._api = Нет self._feature_importances = Нет self._pool_hash = Нет self._fit_status = Ложь def _configure_api (я, config_file_path): config_file_path = os.path.expandvars(config_file_path) с open(config_file_path, 'r') как conf_file: config = json.load(conf_file) self._api = MatrixNetClient(config['url'], token=config['token']) если self. read(128 * md5.block_size), b''): md5.update(чанк) вернуть md5.hexdigest() def _save_df_to_file(self, df, labels, sample_weight, outfile): """ сохранить DataFrame для отправки на сервер """ заголовок = Истина режим = 'ш' для строки в диапазоне (0, len (df), CHUNKSIZE): df_ef = df.iloc[строка: строка + CHUNKSIZE, :].copy() df_ef['is_signal'] = метки[строка: строка + CHUNKSIZE] df_ef['вес'] = sample_weight[строка: строка + CHUNKSIZE] df_ef.to_csv(outfile, sep='\t', index=False, header=header, mode=mode) заголовок = Ложь режим = 'а' def _upload_training_to_bucket(self, X, y, sample_weight): с make_temp_directory() как temp_dir: data_local = os.path.join (temp_dir, 'data.csv') self._save_df_to_file(X, y, sample_weight, data_local) self._pool_hash = self._md5 (data_local) self._configure_api(self. api_config_file) mn_bucket = self._api.bucket (bucket_id = self._pool_hash) если 'data.csv' не в наборе (mn_bucket.ls()): mn_bucket.upload (data_local) вернуть mn_bucket def _train_formula (я, mn_bucket, функции): """ подготовить параметры и вызвать _train_sync """ если self.random_state равно None: семя = нет elif isinstance (self.random_state, int): семя = self.random_state еще: seed = check_random_state(self.random_state).randint(0, 10000) mn_options = {'итерации': int(self.iterations), 'регуляризация': float(self.regularization), 'max_features_per_iteration': int(self.max_features_per_iteration), 'features_sample_rate_per_iteration': поплавок (self.features_sample_rate_per_iteration), 'training_fraction': поплавок (self.training_fraction), «семя»: нет, «интервалы»: нет, 'auto_stop': нет, 'train_type': self. [документы] def training_status(self): """ Проверить, закончилось ли обучение на сервере :rtype: бул """ self._configure_api(self.api_config_file) утверждать, что self._fit_status и self.mn_cls не равны None, 'Вызвать подгонку до' печать (я.mn_cls) assert self.mn_cls.get_status() != 'сбой', 'Ошибка оценщика, запустить функцию повторной отправки, идентификатор задания {}'.format( self.mn_cls.classifier_id) если self.
[документы] определение синхронизации (самостоятельно): """ Синхронизировать асинхронное обучение: дождитесь окончания процесса обучения на сервере """ assert self._fit_status, 'Подходит, модель не обучена' если self.formula_mx не равно None и self._feature_importances не равно None: возвращаться пока не self.training_status(): время.сон (SYNC_SLEEP_TIME) утверждать (self.formula_mx не равно None и self._feature_importances не равно None), \ "Классификатор не был подогнан, сначала позвоните "подходит""
деф _download_formula (я): """ Скачать формулу с сервера """ если self.formula_mx не None: возвращаться с tempfile.NamedTemporaryFile() в качестве внешнего файла: self.[документы] def get_feature_importances(self): """ Получить важность характеристик: `эффект`, `эффективность`, `информационные` характеристики :rtype: pandas.DataFrame с `index=self.features` """ самосинхронизировать() вернуть self._feature_importances
@свойство определение feature_importances_(я): """Sklearn-способ вернуть важность функции. Это возвращается как numpy.array, столбец «эффект» используется среди важностей MatrixNet. """ вернуть numpy.array(self.get_feature_importances()['effect'].ix[self.features])[документы] def get_iterations(self): """ Возвращает количество уже построенных деревьев во время обучения :return: целое или None """ self._configure_api(self.api_config_file) если self.
[документы] def resubmit(self): """ Повторно отправить процесс обучения на сервер в случае сбоя задания. """ если self.mn_cls не None: self._configure_api(self.api_config_file) self.mn_cls.resubmit()
[документы] класс MatrixNetClassifier (MatrixNetBase, Classifier): __doc__ = 'Модель классификации MatrixNet. \n' + remove_first_line(MatrixNetBase.__doc__) def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH, итерации = 100, регуляризация = 0,01, интервалы = 8, max_features_per_iteration=6, features_sample_rate_per_iteration=1,0, training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42): MatrixNetBase.__init__(self, api_config_file=api_config_file, итерации=итерации, регуляризация=регуляризация, интервалы=интервалы, max_features_per_iteration=max_features_per_iteration, features_sample_rate_per_iteration=features_sample_rate_per_iteration, training_fraction=training_fraction, auto_stop=auto_stop, sync=синхронизация, random_state=random_state) Классификатор.[документы] def fit(self, X, y, sample_weight=None): self._initialisation_before_fit() X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False) self._set_classes_special(y) X = self._get_features(X) mn_bucket = self._upload_training_to_bucket (X, y, sample_weight) self._train_formula (mn_bucket, список (X.columns)) если self.sync: самосинхронизировать() вернуть себя
fit.__doc__ = Классификатор.fit.__doc__[документы] def predict_proba(self, X): вернуть take_last (self.staged_predict_proba (X, шаг = 100000))
Predict_proba.__doc__ = Classifier.predict_proba.__doc__[документы] def staged_predict_proba(self, X, step=10): """ Прогнозировать вероятности данных для каждой метки класса на каждом этапе.
[документы] класс MatrixNetRegressor (MatrixNetBase, регрессор): __doc__ = 'MatrixNet для регрессионной модели. \n' + remove_first_line(MatrixNetBase.__doc__) def __init__(self, features=None, api_config_file=DEFAULT_CONFIG_PATH, итерации = 100, регуляризация = 0,01, интервалы = 8, max_features_per_iteration=6, features_sample_rate_per_iteration=1,0, training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42): MatrixNetBase.[документы] def fit(self, X, y, sample_weight=None): self._initialisation_before_fit() X, y, sample_weight = check_inputs(X, y, sample_weight=sample_weight, allow_none_weights=False) X = self._get_features(X) mn_bucket = self._upload_training_to_bucket (X, y, sample_weight) self._train_formula (mn_bucket, список (X.columns)) если self.sync: самосинхронизировать() вернуть себя
fit.[документы] определение предсказать (я, X): вернуть take_last (self.staged_predict (X, шаг = 100000))
прогноз.__doc__ = Классификатор.predict.__doc__[документы] def staged_predict(self, X, step=10): """ Прогнозировать вероятности данных для каждой метки класса на каждом этапе. :param pandas.DataFrame X: данные формы [n_samples, n_features] :param int step: шаг возвращаемых итераций (по умолчанию 10). :возврат: итератор """ самосинхронизировать() X = self._get_features(X) данные = X.astype (с плавающей запятой) данные = pandas.DataFrame(данные) mx = MatrixNetApplier (BytesIO (self.formula_mx)) для этапа прогнозирование в enumerate(mx.staged_apply(data)): если этап % шаг == 0: прогноз урожайности если этап % шаг != 0: прогноз урожайности
 * Выберите сервис `MatrixNet` и нажмите `Создать токен`
* Создайте файл `~/.rep-matrixnet.config.json` со следующим содержимым
(при создании объекта-обертки можно указать собственный путь к файлу конфигурации)::
{
"url": "https://ml.cern.yandex.net/v1",
"токен": "<ваш_токен>"
}
"""
from __future__ import Division, print_function, absolute_import
импортировать контекстную библиотеку
импортировать хеш-библиотеку
импортировать json
импортировать номера
импорт ОС
импортный шутил
импортировать временный файл
время импорта
из abc импортировать ABCMeta
из коллекций импортировать defaultdict
из копии импортировать глубокую копию
из лога импортировать getLogger
импортировать numpy
импортировать панд
из шести импортных BytesIO
из sklearn.utils импортировать check_random_state
из ._matrixnetapplier импортировать MatrixNetApplier
из ._mnkit импортировать MatrixNetClient
из .interface импорта Классификатор, Регрессор
из .utils импортировать check_inputs, score_to_proba, remove_first_line
из .
* Выберите сервис `MatrixNet` и нажмите `Создать токен`
* Создайте файл `~/.rep-matrixnet.config.json` со следующим содержимым
(при создании объекта-обертки можно указать собственный путь к файлу конфигурации)::
{
"url": "https://ml.cern.yandex.net/v1",
"токен": "<ваш_токен>"
}
"""
from __future__ import Division, print_function, absolute_import
импортировать контекстную библиотеку
импортировать хеш-библиотеку
импортировать json
импортировать номера
импорт ОС
импортный шутил
импортировать временный файл
время импорта
из abc импортировать ABCMeta
из коллекций импортировать defaultdict
из копии импортировать глубокую копию
из лога импортировать getLogger
импортировать numpy
импортировать панд
из шести импортных BytesIO
из sklearn.utils импортировать check_random_state
из ._matrixnetapplier импортировать MatrixNetApplier
из ._mnkit импортировать MatrixNetClient
из .interface импорта Классификатор, Регрессор
из .utils импортировать check_inputs, score_to_proba, remove_first_line
из .
 cern.yandex.net/v1", "токен": "<ваш_токен>"}
:param int iterations: количество построенных деревьев (по умолчанию=100)
:param float Regularization: номер регуляризации (по умолчанию = 0,01)
:param intervals: количество бинов для дискретизации функций или dict с границами
список для каждой функции для ее дискретизации (по умолчанию = 8)
:тип интервалы: int или dict(str, list)
:param int max_features_per_iteration: depth (по умолчанию = 6, поддерживает 1 <= .. <= 6)
:param float features_sample_rate_per_iteration: выборка обучающих признаков (по умолчанию = 1.0)
:param float training_fraction: укладка обучающих строк (по умолчанию = 0,5)
:param auto_stop: значение ошибки для предварительной остановки обучения
:type auto_stop: нет или с плавающей запятой
:param bool sync: синхронное или асинхронное обучение на сервере
:param random_state: состояние псевдослучайного генератора
:type random_state: None или int или RandomState
"""
__metaclass__ = ABCMeta
_model_type = Нет
def __init__(self, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
self.
cern.yandex.net/v1", "токен": "<ваш_токен>"}
:param int iterations: количество построенных деревьев (по умолчанию=100)
:param float Regularization: номер регуляризации (по умолчанию = 0,01)
:param intervals: количество бинов для дискретизации функций или dict с границами
список для каждой функции для ее дискретизации (по умолчанию = 8)
:тип интервалы: int или dict(str, list)
:param int max_features_per_iteration: depth (по умолчанию = 6, поддерживает 1 <= .. <= 6)
:param float features_sample_rate_per_iteration: выборка обучающих признаков (по умолчанию = 1.0)
:param float training_fraction: укладка обучающих строк (по умолчанию = 0,5)
:param auto_stop: значение ошибки для предварительной остановки обучения
:type auto_stop: нет или с плавающей запятой
:param bool sync: синхронное или асинхронное обучение на сервере
:param random_state: состояние псевдослучайного генератора
:type random_state: None или int или RandomState
"""
__metaclass__ = ABCMeta
_model_type = Нет
def __init__(self, api_config_file=DEFAULT_CONFIG_PATH,
итерации = 100, регуляризация = 0,01, интервалы = 8,
max_features_per_iteration=6, features_sample_rate_per_iteration=1,0,
training_fraction=0,5, auto_stop=Нет, sync=True, random_state=42):
self.
 mn_cls не None:
self.mn_cls.requests_kwargs['заголовки']['X-Yacern-Token'] = self._api.auth_token
защита __getstate__(я):
результат = глубокая копия (self.__dict__)
если '_api' в результате:
результат результата['_api']
если результат['mn_cls'] не равен None:
результат['mn_cls'].requests_kwargs['заголовки']['X-Yacern-Token'] = ""
вернуть результат
def __convert_borders (я, границы, особенности):
"""
конвертировать границы объектов в правильный формат для отправки на сервер
"""
convert_borders = ""
для i функция в enumerate(features):
если нет в границах:
продолжать
для границы в границах [функция]:
convert_borders += "{}\t{}\t0\n".format(i, граница)
вернуть convert_borders
def _md5 (я, имя файла):
"""
вычислить хэш md5 для файла
"""
md5 = hashlib.md5()
с открытым (имя файла, 'rb') как file_d:
для чанка в iter(lambda: file_d.
mn_cls не None:
self.mn_cls.requests_kwargs['заголовки']['X-Yacern-Token'] = self._api.auth_token
защита __getstate__(я):
результат = глубокая копия (self.__dict__)
если '_api' в результате:
результат результата['_api']
если результат['mn_cls'] не равен None:
результат['mn_cls'].requests_kwargs['заголовки']['X-Yacern-Token'] = ""
вернуть результат
def __convert_borders (я, границы, особенности):
"""
конвертировать границы объектов в правильный формат для отправки на сервер
"""
convert_borders = ""
для i функция в enumerate(features):
если нет в границах:
продолжать
для границы в границах [функция]:
convert_borders += "{}\t{}\t0\n".format(i, граница)
вернуть convert_borders
def _md5 (я, имя файла):
"""
вычислить хэш md5 для файла
"""
md5 = hashlib.md5()
с открытым (имя файла, 'rb') как file_d:
для чанка в iter(lambda: file_d.

 _model_type}
если семя не None:
mn_options['seed'] = int(seed)
если isinstance (self.intervals, numbers.Number):
mn_options['интервалы'] = int(self.intervals)
еще:
assert set(self.intervals.keys()) == set(features), 'интервалы должны содержать границы для всех признаков'
с make_temp_directory() как temp_dir:
borders_local = os.path.join (temp_dir, 'границы')
с open(borders_local, "w") как file_b:
file_b.write(self.__convert_borders(self.intervals, features))
суффикс = '.{}.baseline'.format (self._md5 (borders_local))
borders_name = borders_local + суффикс
os.rename (borders_local, borders_name)
если borders_name не в наборе (mn_bucket.ls()):
mn_bucket.upload(имя_границы)
mn_options['интервалы'] = 'границы' + суффикс
если self.auto_stop не None:
mn_options['auto_stop'] = float(self.
_model_type}
если семя не None:
mn_options['seed'] = int(seed)
если isinstance (self.intervals, numbers.Number):
mn_options['интервалы'] = int(self.intervals)
еще:
assert set(self.intervals.keys()) == set(features), 'интервалы должны содержать границы для всех признаков'
с make_temp_directory() как temp_dir:
borders_local = os.path.join (temp_dir, 'границы')
с open(borders_local, "w") как file_b:
file_b.write(self.__convert_borders(self.intervals, features))
суффикс = '.{}.baseline'.format (self._md5 (borders_local))
borders_name = borders_local + суффикс
os.rename (borders_local, borders_name)
если borders_name не в наборе (mn_bucket.ls()):
mn_bucket.upload(имя_границы)
mn_options['интервалы'] = 'границы' + суффикс
если self.auto_stop не None:
mn_options['auto_stop'] = float(self. auto_stop)
дескриптор = {
'мн_параметры': мн_параметры,
'мн_версия': 1,
«поля»: список (функции),
'дополнительный': {},
}
self._configure_api(self.api_config_file)
self.mn_cls = self._api.classifier(
параметры = дескриптор,
description="Классификатор, представленный REP",
ведро_id = mn_bucket.bucket_id,
)
self.mn_cls.upload()
self._fit_status = Истина
auto_stop)
дескриптор = {
'мн_параметры': мн_параметры,
'мн_версия': 1,
«поля»: список (функции),
'дополнительный': {},
}
self._configure_api(self.api_config_file)
self.mn_cls = self._api.classifier(
параметры = дескриптор,
description="Классификатор, представленный REP",
ведро_id = mn_bucket.bucket_id,
)
self.mn_cls.upload()
self._fit_status = Истина
 mn_cls.get_status() == 'завершено':
self._download_formula()
self._download_features()
вернуть Истина
еще:
вернуть Ложь
mn_cls.get_status() == 'завершено':
self._download_formula()
self._download_features()
вернуть Истина
еще:
вернуть Ложь 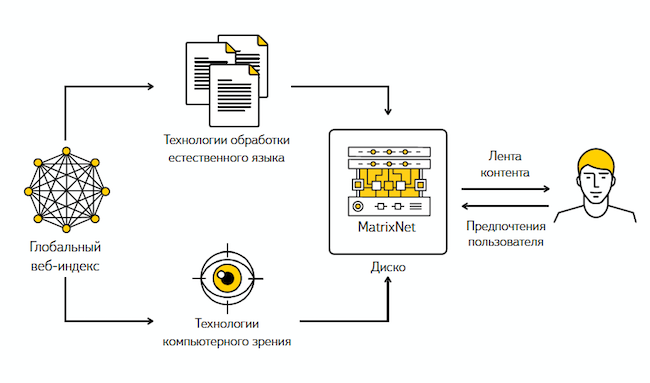 _configure_api(self.api_config_file)
self.mn_cls.save_formula(outfile.name)
с открытым (outfile.name, 'rb') как файл_формулы:
self.formula_mx = файл_формулы.read()
утверждать len(self.formula_mx) > 0, "Формула пуста"
защита _download_features (я):
если self._feature_importances не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self.mn_cls.save_stats(outfile.name)
статистика = json.loads(open(outfile.name).read())['факторы']
важности = defaultdict (список)
столбцы = ["имя", "эффект", "информация", "эффективность"]
для данных в статистике:
для ключа в столбцах:
важности [ключ]. добавить (данные [ключ])
df = pandas.DataFrame (важность)
df_result = {'эффект': df['эффект'].values / max(df['эффект']),
'информация': df['info'].values / max(df['info']),
'эффективность': df['эффективность'].
_configure_api(self.api_config_file)
self.mn_cls.save_formula(outfile.name)
с открытым (outfile.name, 'rb') как файл_формулы:
self.formula_mx = файл_формулы.read()
утверждать len(self.formula_mx) > 0, "Формула пуста"
защита _download_features (я):
если self._feature_importances не None:
возвращаться
с tempfile.NamedTemporaryFile() в качестве внешнего файла:
self.mn_cls.save_stats(outfile.name)
статистика = json.loads(open(outfile.name).read())['факторы']
важности = defaultdict (список)
столбцы = ["имя", "эффект", "информация", "эффективность"]
для данных в статистике:
для ключа в столбцах:
важности [ключ]. добавить (данные [ключ])
df = pandas.DataFrame (важность)
df_result = {'эффект': df['эффект'].values / max(df['эффект']),
'информация': df['info'].values / max(df['info']),
'эффективность': df['эффективность'].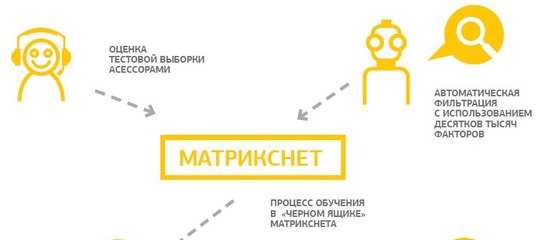 values / max(df['эффективность'])}
self._feature_importances = pandas.DataFrame (df_result, index = df ['имя']. значения)
values / max(df['эффективность'])}
self._feature_importances = pandas.DataFrame (df_result, index = df ['имя']. значения)
 mn_cls не None:
вернуть self.mn_cls.get_iterations()
еще:
return None
mn_cls не None:
вернуть self.mn_cls.get_iterations()
еще:
return None  __init__(self, features=features)
self._model_type = 'классификация'
защита _set_classes_special (я, у):
self._set_classes(y)
assert self.n_classes_ == 2, "Поддержка только 2 классов (данные содержат {})".format(self.n_classes_)
__init__(self, features=features)
self._model_type = 'классификация'
защита _set_classes_special (я, у):
self._set_classes(y)
assert self.n_classes_ == 2, "Поддержка только 2 классов (данные содержат {})".format(self.n_classes_)
 :param pandas.DataFrame X: данные формы [n_samples, n_features]
:param int step: шаг возвращаемых итераций (по умолчанию 10).
:возврат: итератор
"""
самосинхронизировать()
X = self._get_features(X)
данные = X.astype (с плавающей запятой)
данные = pandas.DataFrame(данные)
mx = MatrixNetApplier (BytesIO (self.formula_mx))
для этапа прогнозирование в enumerate(mx.staged_apply(data)):
если этап % шаг == 0:
доходность score_to_proba(прогноз)
если этап % шаг != 0:
доходность score_to_proba(прогноз)
:param pandas.DataFrame X: данные формы [n_samples, n_features]
:param int step: шаг возвращаемых итераций (по умолчанию 10).
:возврат: итератор
"""
самосинхронизировать()
X = self._get_features(X)
данные = X.astype (с плавающей запятой)
данные = pandas.DataFrame(данные)
mx = MatrixNetApplier (BytesIO (self.formula_mx))
для этапа прогнозирование в enumerate(mx.staged_apply(data)):
если этап % шаг == 0:
доходность score_to_proba(прогноз)
если этап % шаг != 0:
доходность score_to_proba(прогноз)  __init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop, sync=sync,
random_state = случайное_состояние)
Регрессор.__init__(self, features=features)
self._model_type = 'регрессия'
__init__(self, api_config_file=api_config_file,
итерации=итерации, регуляризация=регуляризация, интервалы=интервалы,
max_features_per_iteration=max_features_per_iteration,
features_sample_rate_per_iteration=features_sample_rate_per_iteration,
training_fraction=training_fraction, auto_stop=auto_stop, sync=sync,
random_state = случайное_состояние)
Регрессор.__init__(self, features=features)
self._model_type = 'регрессия'
 __doc__ = Классификатор.fit.__doc__
__doc__ = Классификатор.fit.__doc__
CatBoost — библиотека повышения градиента с открытым исходным кодом
CatBoost — высокопроизводительная библиотека с открытым исходным кодом для повышения градиента на деревьях решений
Как установитьУчебники
Сегодня мы открываем исходный код нашей библиотеки повышения градиента CatBoost. Он хорошо подходит для обучения моделей машинного обучения задачам, в которых данные разнородны, т. е. описываются различными входными данными, такими как содержимое, историческая статистика и выходные данные других моделей машинного обучения. Новый алгоритм повышения градиента теперь доступен на GitHub под лицензией Apache License 2.0.
Он хорошо подходит для обучения моделей машинного обучения задачам, в которых данные разнородны, т. е. описываются различными входными данными, такими как содержимое, историческая статистика и выходные данные других моделей машинного обучения. Новый алгоритм повышения градиента теперь доступен на GitHub под лицензией Apache License 2.0.
Разработанный учеными и инженерами Яндекса, он является преемником алгоритма MatrixNet, который используется внутри компании для решения широкого круга задач, начиная от ранжирования результатов поиска и рекламы и заканчивая прогнозом погоды, обнаружением мошенничества и рекомендациями. В отличие от MatrixNet, который использует только числовые данные, CatBoost может работать с нечисловой информацией, такой как типы облаков или штат/провинция. Он может использовать эту информацию напрямую, не требуя преобразования категориальных признаков в числа, что может дать лучшие результаты по сравнению с другими алгоритмами повышения градиента, а также сэкономить время.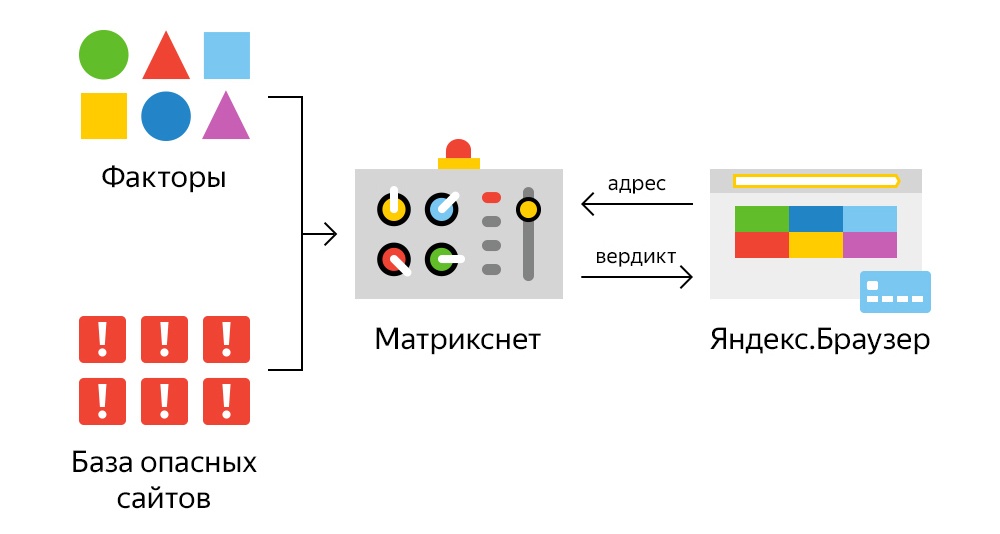 Спектр приложений CatBoost охватывает самые разные сферы и отрасли, от банковского дела и прогнозирования погоды до рекомендательных систем и производства стали.
Спектр приложений CatBoost охватывает самые разные сферы и отрасли, от банковского дела и прогнозирования погоды до рекомендательных систем и производства стали.
CatBoost поддерживает Linux, Windows и macOS, а также им можно управлять из командной строки или через удобный API для Python или R. В дополнение к открытому исходному коду нашего алгоритма повышения градиента мы выпускаем наш инструмент визуализации CatBoost Viewer , что позволяет отслеживать процессы обучения в iPython Notebook или в автономном режиме. Мы также предоставляем всем пользователям CatBoost инструмент для сравнения результатов популярных алгоритмов повышения градиента.
«Яндекс имеет долгую историю машинного обучения. У нас работают лучшие специалисты в этой области. Открывая CatBoost с открытым исходным кодом, мы надеемся, что наш вклад в машинное обучение будет оценен экспертным сообществом, которое поможет нам продвигать его дальнейшее развитие», — говорит Миша Биленко, руководитель отдела машинного интеллекта и исследований Яндекса.