
Где и как изучать машинное обучение? / Habr
Всем привет!
Ни для кого не секрет, что интерес к машинному обучению и искусственному интеллекту растет в лучшем случае по экспоненте. Тем временем мой Яндекс Диск превратился в огромную свалку пейперс, а закладки в Google Chrome превратились в список, длина которого стремится к бесконечности с каждым днем. Таким образом, дабы упростить жизнь себе и вам, решил структурировать информацию и дать множество ссылок на интересные ресурсы, которые изучал я и которые рекомендую изучать вам, если вы только вначале пути (буду пополнять список постоянно).
Путь для развития новичка я вижу примерно так:
Попробуйте для начала начать с малого, если у вас нет за спиной 6 лет специалитета ВМК по методам прогнозирования, не стоит сразу скачивать архив лекций Е. Соколова или К. Воронцова, возможно статьи на Medium будут для вас оптимальнее. Также сложности могут возникнуть с понимаением алгоритмов, если вы плохо ориентируетесь в теории вероятностей, теории оптимизации и статистике, поэтому советую заглянуть на Ozon, в Московский Дом Книги и запастись курсами лекций по математике. Далее, ознакомившись с теорией будет проще применять знания в решении задач. Далее я приведу для вас список интересных ресурсов, которые я сам когда-то изучал. Желаю успехов 🙂
Новичку:
Лайфхак по быстрому выбору моделей от команды Sklearn
Data Science Glossary (англ.)
Crash-Course по базовым статьям по deep learning на Medium
Туториал TensorFlow
Python vs. R — различия (англ.)
Видеолекции открытого курса от Open Data Science на Хабре
Отличный ML CheatSheet (англ.)
Арифметика сверточных нейронных сетей от команды Theano (англ.)
Отличные видеоуроки по анализу данных и эконометрике на языке R
Наивный байессовский классификатор своими руками с Хабра
Хорошие объяснения того, как работает ROC-AUC
www.youtube.com/watch?v=21Igj5Pr6u4
www.youtube.com/watch?v=vtYDyGGeQyo
Machine Learning Basics (англ.)
Продолжающему:
GitHub Евгения Соколова с лекциями по Machine Learning в НИУ ВШЭ
Блог организации Open Data Science на Хабре (рекомендую)
Отбор и оценка моделей — основы (Себастьян Рашка, англ.)
Математические методы обучения по прецедентам (теория обучения машин), К. Воронцов (рекомендую)
Книга по natural language toolkit (nltk, англ.)
Машины опорных векторов на практике (англ.)
Keras.js — машинное обучение в браузере, можно потрогать руками работу алгоритмов машинного обучения, помогает при изучении
Алгоритмы Data Mining с использованием R — интерактивная книга по изучению машинного обучения на R
Преимущества и недостатки AUC и accuracy (англ.)
Нейронные сети для перенося стиля на фото (англ) (рекомендую)
Перенос стиля с помощью TensorFlow (англ.)
Ritchie Ng — собрание ресурсов по машинному обучению (англ.)
Обзор методов оптимизации градиентным спуском на практике (англ.)
Лекции по машинам опорных векторов от университета Utah (англ.)
Функции потерь для задачи классификации (англ.)
15 книг по машинному обучению для начинающих / Habr
Сделал подборку книг по Machine Learning для тех, кто хочет разобраться, что да как.Добавляйте в закладки и делитесь с коллегами!
Книги по машинному обучению на русском
1. «Математические основы машинного обучения и прогнозирования» Владимир Вьюгин.
О чем
Сначала изучите азы статистической теории машинного обучения, игр с предсказаниями и прогнозирования с применением экспертной стратегии. Их основы прекрасно объясняет автор книги, доктор физико-математических наук Владимир Вьюгин. Пособие рассчитано на студентов и аспирантов и в доступной форме излагает математические основы, необходимые для дальнейшей работы с машинным обучением.
2. «Верховный алгоритм» Педро Домингос.
О чем
Книга, благодаря которой даже ничего не смыслящие в математике и статистике люди поймут, что такое алгоритмы машинного обучения и каково их применение в жизни. Профессор Педро Домингос рассказывает о пяти основных школах Machine Learning и о том, как они используют идеи из различных областей научного знания — нейробиологии, физики, статистики, биологии, — чтобы помогать людям решать сложные задачи и упрощать рутину с помощью алгоритмов.
3. «Машинное обучение» Хенрик Бринк, Джозеф Ричардс, Марк Феверолф.
О чем
Эта книга 2017 года издания доступно рассказывает о Machine Learning — для тех, кто ничего не слышал об этих технологиях. В ней нет заумной статистики, математики или углубленного и подробного объяснения, как использовать тот или иной алгоритм. Авторы с легкостью объясняют, что такое машинное обучение и как его применять в повседневной жизни. Примеры в книге приводятся на языке программирования Python, который используется в том числе и в этой сфере.
4. «Крупномасштабное машинное обучение вместе с Python» Бастиан Шарден, Лука Массарон, Альберто Боскетти.
О чем
Еще одна отличная книга для начинающих свой путь в программировании и анализе больших данных. Авторы утверждают, что благодаря ей читатель научится самостоятельно строить модели машинного обучения и развертывать крупномасштабные приложения для прогнозирования. В книге рассказывается о том, какие алгоритмы входят в семейство масштабируемых, что они из себя представляют и как с их помощью обрабатывать большие файлы. Также вы узнаете, что такое вычислительная парадигма MapReduce и как работать с машинными алгоритмами на платформах Hadoop и Spark на языке Python.
5. «Python и машинное обучение» Себастьян Рашка.
О чем
Книга для новичков, осваивающих Python и машинное обучение. Издание содержит подробные мануалы даже по таким нюансам, как установка специализированного приложения Jupyter Notebook.
В книге рассматриваются основы Machine Learning, возможности самых мощных библиотек Python для анализа данных и дается ответ на вопрос, почему этот язык — один из лидеров в Data Science.
6. «Методы обработки и распознавания изображений лиц в задачах биометрии» Георгий Кухарев, Екатерина Каменская, Юрий Матвеев, Надежда Щеголева
О чем
Несмотря на то что эта книга рассчитана на начинающих и знакомит с основными принципами искусственного интеллекта — в частности, технологии распознавания лиц, — для полного понимания терминологии и комфортного погружения в чтение все же требуется некоторый бэкграунд. В ней рассматриваются такие вопросы биометрии, как методы анализа изображений лиц, получение исходных данных из реальных сцен, структуры систем распознавания и другие. Примеры в монографии приводятся на языке машинного обучения MATLAB. Если техническими фоновыми знаниями вы не обладаете, но книгу прочитать все же хочется — незнакомые термины можно гуглить, этого вполне достаточно, чтобы не испытывать при чтении никакого дискомфорта.
7. «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петер Флах.
О чем
Это цветное издание с иллюстрациями также предназначено для новичков и рассматривает широкие вопросы машинного обучения. По мере погружения читателя в тему автор раскрывает все больше деталей, но книга не слишком сложна для восприятия: вся новая терминология объясняется, а статистические и логические модели описываются понятным неподготовленному читателю языком.
8. «Обучение с подкреплением» Ричард С. Саттон, Эндрю Г. Барто.
О чем
Обучение с подкреплением — это одно из направлений искусственного интеллекта. Кратко и в самом общем виде его суть можно изложить так: машина учится действовать в окружающей среде, нарабатывая интуитивный опыт, а затем наблюдает свои результаты. В книге исчерпывающе излагается концепция обучения с подкреплением — от основополагающих идей до современных достижений в этой сфере.
Книги по машинному обучению на английском
Все книги рассчитаны на новичков без опыта работы с технологиями искусственного интеллекта либо специалистов с небольшим техническим бэкграундом. Цель большинства — познакомить с основными принципами, концепциями, идеями и некоторыми алгоритмами машинного обучения.
9. «Bayesian Reasoning and Machine Learning» David Barber.
О чем
Книга Дэвида Барбера написана для студентов и выпускников с минимальными знаниями алгебры и математического анализа — то есть отлично подходит для начала изучения машинного обучения. Как видно по названию, она сосредоточена вокруг байесовского статистического вывода. Книга позволяет развить аналитические навыки и найти новые способы решения проблем в работе с алгоритмами машинного обучения. Каждая глава сопровождается примерами, практическими и теоретическими заданиями.
10. «Introduction to Machine Learning» Nils J. Nilsson
О чем
Эта книга — не учебное пособие, сборник практических задач или теоретических изысканий. Это своеобразный «мостик» от теории к практике машинного обучения. С ее помощью читатель может подготовиться к дальнейшему изучению темы Machine Learning и науки о данных.
11. «The Elements of Statistical Learning. Data Mining, Inference and Prediction» Trevor Hastie, Robert Tibshirani, Jerome Friedman.
О чем
В этом пособии концептуально описываются идеи науки о данных, то есть без сложных математических формул и понятий. В ней множество иллюстративных примеров, которые еще больше раскрывают суть написанного. Охват книги широк: от контролируемого обучения (прогнозирования) до обучения без учителя. Рассматриваемые темы включают нейронные сети, методы опорных векторов, деревья классификации и бустинг. Авторы книги — преподающие профессора, создатели учебных пособий и инструментов интеллектуального анализа данных.
12. «Machine Learning, Neural and Statistical Classification» D. Michie, D.J. Spiegelhalter, C.C. Taylor.
О чем
В этом издании обзорно излагаются основные современные подходы к проблемам классификации: машинное обучение, статистика и нейронные сети. Авторы сравнили эффективность методов по различным показателям и сделали выводы о том, для решения каких коммерческих и промышленных задач каждый из них больше подходит.
13. «Make Your Own Neural Network» Tariq Rashid.
О чем
Преимущество книги — невысокие требования к фоновым математическим знаниям читателя. Даже со школьным курсом в голове вы сможете ее прочесть, понять, освоить основные концепции и научиться программировать собственные алгоритмы распознавания изображений на Python. Все математические идеи в основе устройства нейронных сетей поданы под соусом из большого количества иллюстраций и примеров, что упрощает восприятие.
14. «Artificial Intelligence: A Modern Approach» Stuart Russell, Peter Norvig.
О чем
Учебное пособие для студентов первого курса. Его часто используют в роли введения в Data Science во множестве обучающих университетских программ. Если вам интересно проектирование нейросетей именно для создания искусственного интеллекта, рекомендуем ее как первую книгу на эту тему.
15. «Learning From Data» Yaser S. Abu-Mostafa, Malik Magdon-Ismail, Hsuan-Tien Lin.
О чем
Книга носит подзаголовок «A short course» и кратко знакомит читателя с основами машинного обучения. Если вы только начали вникать, что происходит в мире Data Science, и прочли несколько статей в интернете, то это идеальный вариант, чтобы разобраться в предмете чуть глубже.
как работает машинное обучение / «Лаборатория Касперского» corporate blog / Habr
В последнее время все технологические компании твердят о машинном обучении. Мол, столько задач оно решает, которые раньше только люди и могли решить. Но как конкретно оно работает, никто не рассказывает. А кто-то даже для красного словца машинное обучение называет искусственным интеллектом.Как обычно, никакой магии тут нет, все одни технологии. А раз технологии, то несложно все это объяснить человеческим языком, чем мы сейчас и займемся. Задачу мы будем решать самую настоящую. И алгоритм будем описывать настоящий, подпадающий под определение машинного обучения. Сложность этого алгоритма игрушечная — а вот выводы он позволяет сделать самые настоящие.
Задача: отличить осмысленный текст от белиберды
Текст, который пишут настоящие люди, выглядит так:
- Могу творить, могу и натворить!
- У меня два недостатка: плохая память и что-то еще.
- Никто не знает столько, сколько не знаю я.
Белиберда выглядит так:
- ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ
- Йцхяь длваополц ыадолцлопиолым бамдлотдламда
Наша задача — разработать алгоритм машинного обучения, который бы отличал одно от другого. А поскольку мы говорим об этом применительно к антивирусной тематике, то будем называть осмысленный текст «чистым», а белиберду — «зловредной». Это не просто какой-то мысленный эксперимент, похожая задача на самом деле решается при анализе реальных файлов в реальном антивирусе.
Алгоритм
Наш алгоритм будет считать, как часто в нормальном тексте одна конкретная буква следует за другой конкретной буквой. И так для каждой пары букв. Например, для первой чистой фразы — «Могу творить, могу и натворить!» — распределение получится такое:
| ат 1 | мо 2 | ри 2 |
| во 2 | на 1 | тв 2 |
| гу 2 | ог 2 | ть 2 |
| ит 2 | ор 2 |
Что получилось: за буквой в следует буква о — два раза, — а за буквой а следует буква т — один раз. Для простоты мы не учитываем знаки препинания и пробелы.
На этом этапе мы понимаем, что для обучения нашей модели одной фразы мало: и сочетаний недостаточное количество, и разница между частотой появления разных сочетаний не так велика. Поэтому надо взять какой-то существенно больший объем данных. Например, давайте посчитаем, какие сочетания букв встречаются в первом томе «Войны и мира»:
| то 8411 | на 6236 | на 6236 |
| ст 6591 | не 5199 | оу 31 |
| на 6236 | по 5174 | мб 2 |
| оу 31 | ен 4211 | тж 1 |
Разумеется, это не вся таблица сочетаний, а лишь ее малая часть. Оказывается, вероятность встретить «то» в два раза выше, чем «ен». А чтобы за буквой т следовало ж — такое встречается лишь один раз, в слове «отжившим».
Отлично, «модель» русского языка у нас теперь есть, как же ее использовать? Чтобы определить, насколько вероятно исследуемая нами строка чистая или зловредная, посчитаем ее «правдоподобность». Мы будем брать каждую пару букв из этой строки, определять по «модели» ее частоту (по сути реалистичность сочетания букв) и перемножать эти числа:
F(мо) * F(ог) * F(гу) * F(тв) *… = 2131 * 2943 * 474 * 1344 *… = правдоподобность
Также в финальном значении правдоподобности следует учесть количество символов в исследуемой строке — ведь чем она была длиннее, тем больше чисел мы перемножили. Поэтому из произведения извлечем корень нужной степени (длина строки минус один).
Использование модели
Теперь мы можем делать выводы: чем больше полученное число — тем правдоподобнее исследуемая строка ложится в нашу модель. Стало быть, тем больше вероятность, что ее писал человек, то есть она чистая.
Если же исследуемая строка содержит подозрительно большое количество крайне редких сочетаний букв (например, ёё, тж, ъь и так далее), то, скорее всего, она искусственная — зловредная.
Для строчек выше правдоподобность получилась следующая:
- Могу творить, могу и натворить! — 1805 баллов
- У меня два недостатка: плохая память и что-то еще. — 1535 баллов
- Никто не знает столько, сколько не знаю я. — 2274 балла
- ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ — 44 балла
- Йцхяь длваополц ыадолцлопиолым бамдлотдламда — 149 баллов
Как видите, чистые строки правдоподобны на 1000-2000 баллов, а зловредные не дотягивают и до 150. То есть все работает, как задумано.
Чтобы не гадать, что такое «много», а что — «мало», лучше доверить определение порогового значения самой машине (пусть обучается). Для этого скормим ей некоторое количество чистых строк и посчитаем их правдоподобность, а потом скормим немного зловредных строк — и тоже посчитаем. И вычислим некоторое значение посередине, которое будет лучше всего отделять одни от других. В нашем случае получится что-то в районе 500.
В реальной жизни
Давайте осмыслим, что же у нас получилось.
1. Мы выделили признаки чистых строк, а именно пары символов.
В реальной жизни — при разработке настоящего антивируса — тоже выделяют признаки из файлов или других объектов. И это, кстати, самый важный шаг: от уровня экспертизы и опыта исследователей напрямую зависит качество выделяемых признаков. Понять, что же на самом деле важно — это все еще задача человека. Например, кто сказал, что надо использовать пары символов, а не тройки? Такие гипотезы как раз и проверяют в антивирусной лаборатории. Отмечу, что у нас для отбора наилучших и взаимодополняющих признаков тоже используется машинное обучение.
2. На основании выделенных признаков мы построили математическую модель и обучили ее на примерах.
Само собой, в реальной жизни мы используем модели чуть посложнее. Сейчас наилучшие результаты показывает ансамбль решающих деревьев, построенный методом Gradient boosting, но стремление к совершенству не позволяет нам успокоиться.
3. На основе математической модели мы посчитали рейтинг «правдоподобности».
В реальной жизни мы обычно считаем противоположный рейтинг — рейтинг вредоносности. Разница, казалось бы, несущественная, но угадайте, насколько неправдоподобной для нашей математической модели покажется строка на другом языке — или с другим алфавитом?
Антивирус не имеет права допустить ложное срабатывание на целом классе файлов только по той причине, что «мы его не проходили».
Альтернатива машинному обучению
20 лет назад, когда вредоносов было мало, каждую «белиберду» можно было просто задетектить с помощью сигнатур — характерных отрывков. Для примеров выше “сигнатуры” могли бы быть такими:
ОРПорыав аоырОрпаыор ОрОРАыдцуцзущгкгеуб ыватьыивдцулвдлоадузцщ
Йцхяь длваополц ыадолцлопиолым бамдлотдламда
Антивирус сканирует файл, если встретил «зущгкгеу», говорит: «Ну понятно, это белиберда номер 17». А если найдет «длотдламд» — то “белиберда номер 139”.
15 лет назад, когда вредоносов стало много, преобладать стало «дженерик»-детектирование. Вирусный аналитик пишет правила, что для осмысленных строк характерно:
- Длина слов от одного до двадцати символов.
- Заглавные буквы очень редко встречаются посередине слова, цифры тоже.
- Гласные обычно более-менее равномерно перемежаются с согласными.
- И так далее. Если много критериев нарушено — детектируем эту строку как зловредную.
По существу это примерно то же самое, только вместо математической модели в этом случае набор правил — которые аналитик должен вручную написать. Это хорошо работает, но требует времени.
И вот 10 лет назад, когда вредоносов стало ну просто очень много, начали робко внедряться алгоритмы машинного обучения. Поначалу по сложности они были сопоставимые с описанным нами простейшим примером, но мы активно нанимали специалистов и наращивали уровень экспертных знаний.
Сейчас без машинного обучения не работает ни один нормальный антивирус. Если оценивать вклад в защиту пользователей, то с методами на основе машинного обучения по статическим признакам могут посоперничать разве что методы на основе анализа поведения. Но только при анализе поведения тоже используется машинное обучение. В общем, без него уже никуда.
Недостатки
Преимущества понятны, но неужели это серебряная пуля, спросите вы. Не совсем. Этот метод хорошо справляется, если описанный выше алгоритм будет работать в облаке или в инфраструктуре, постоянно обучаясь на огромных количествах как чистых, так и вредоносных объектов.
Также очень хорошо, если за результатами обучения присматривает команда экспертов, вмешивающихся в тех случаях, когда без опытного человека не обойтись.
В этом случае недостатков действительно немного, а по большому счету только один — нужна эта дорогостоящая инфраструктура и не менее дорогостоящая команда специалистов.
Другое дело, когда кто-то пытается радикально сэкономить и использовать только математическую модель и только на стороне продукта, прямо у клиента. Тогда могут начаться трудности.
1. Ложные срабатывания.
Детектирование на базе машинного обучения — это всегда поиск баланса между уровнем детектирования и уровнем ложных срабатываний. И если нам захочется детектировать побольше, то ложные срабатывания будут. В случае машинного обучения они будут возникать в непредсказуемых и зачастую труднообъяснимых местах. Например, эта чистая строка — «Мцыри и Мкртчян» — распознается как неправдоподобная: 145 баллов в модели из нашего примера. Поэтому очень важно, чтобы антивирусная лаборатория имела обширную коллекцию чистых файлов для обучения и тестирования модели.
2. Обход модели.
Злоумышленник может разобрать такой продукт и посмотреть, как работает модель. Он человек и пока, если не умнее, то хотя бы креативнее машины — поэтому он подстроится. Например, следующая строка считается чистой (1200 баллов), хотя ее первая половина явно вредоносная: «лоыралоыврачигшуралорыловарДобавляем в конец много осмысленного текста, чтобы обмануть машину». Какой бы умный алгоритм ни использовался, его всегда может обойти человек (достаточно умный). Поэтому антивирусная лаборатория обязана иметь продвинутую инфраструктуру для быстрой реакции на новые угрозы.
Один из примеров обхода описанного нами выше метода: все слова выглядят правдоподобно, но на самом деле это бессмыслица. Источник.
3. Обновление модели.
На примере описанного выше алгоритма мы упоминали, что модель, обученная на русских текстах, будет непригодна для анализа текстов с другим алфавитом. А вредоносные файлы, с учетом креативности злоумышленников (смотри предыдущий пункт) — это как будто постепенно эволюционирующий алфавит. Ландшафт угроз меняется довольно быстро. Мы за долгие годы исследований выработали оптимальный подход к постепенному обновлению модели прямо в антивирусных базах. Это позволяет дообучать и даже полностью переобучать модель «без отрыва от производства».
Заключение
Итак.
- Мы рассмотрели реальную задачу.
- Разработали реальный алгоритм машинного обучения для ее решения.
- Провели параллели с антивирусной индустрией.
- Рассмотрели с примерами достоинства и недостатки такого подхода.
Несмотря на огромную важность машинного обучения в сфере кибербезопасности, мы в «Лаборатории Касперского» понимаем, что лучшую киберзащиту обеспечивает именно многоуровневый подход.
Все в антивирусе должно быть прекрасно — и поведенческий анализ, и облачная защита, и алгоритмы машинного обучения, и многое-многое другое. Но об этом “многом другом” — в следующий раз.
10 курсов по машинному обучению на лето / ITMO University corporate blog / Habr
За последние десятилетия с помощью машинного обучения создали самоуправляемые автомобили, системы распознавание речи и эффективный поиск. Сейчас это одна из самых быстроразвивающихся и перспективных сфер на стыке компьютерных наук и статистики, которая активно используется в искусственном интеллекте и data science. Методы машинного обучения используются в науке, технике, медицине, ритейле, рекламе, генерации мультимедиа и других областях.Команда Университета ИТМО собрала десять курсов по машинному обучению, которые можно успеть пройти до конца лета. Одним они помогут войти в профессию, а другим — углубиться в нее.
1. «Введение в машинное обучение»
Площадка: Coursera
Автор: Высшая школа экономики, Школа анализа данных Яндекс
Длительность: 7 недель, 3-5 часов в неделю
Стоимость: бесплатно
Язык: русский
На курсе рассказывает преимущественно про основные типы задач машинного обучения: классификацию, регрессию и кластеризацию. Преподаватели из Яндекса и Высшей школы экономики объясняют основные методы и рассказывают про их особенности, учат оценивать качество моделей и понимать, для решения какой задачи подходит каждая из них. Программа рассчитана на семь недель, но если постараться, то можно закончить курс до 1 сентября. Курс ориентирован на слушателей, которые знакомы с Python, так как используются его библиотеки numpy, pandas и scikit-learn.
2. Введение в машинное обучение от GL4G
Площадка: Great Learning
Автор: Great Learning
Длительность: 1,5 часа
Стоимость: бесплатно
Язык: английский
Короткий курс предназначен для тех, кто интересуется машинным обучением, но пока еще не знает, с чего начать. Программа состоит из 12 видеоуроков и объясняет, что такое машинное обучение и как алгоритм может учиться, рассказывает основную терминологию и методы, а также дает практические упражнения.
3. Машинное обучения от А до Я: применение Python и R в науке о данных
Площадка: Udemy
Автор: Кирилл Еременко,, Хаделин де Понтевес, команда SuperDataScience
Длительность: 41 час видеолекций
Стоимость: $10,99
Язык: английский
Курс разработан двумя дата-сайентистами, чтобы объяснить сложную теорию, алгоритмы и программирование с использованием библиотек машинного обучения. Программа состоит из десяти частей, в которых рассматривается обработка данных, регрессия, классификация, кластеризация, обучение с подкреплением, обработка естественного языка и глубокое обучение. На курсе есть практические упражнения и шаблоны кода для Python и R. Большое внимание уделяется выбору правильной модели для каждого типа задач.
4. Bootcamp-тренировка: Python для науки о данных и машинного обучения
Площадка: Udemy
Автор: Хосе Портилья
Длительность: 21,5 часов видеолекций
Стоимость: $10,99
Язык: английский
Программа курса помогает понять, как использовать Python для анализа данных, создания визуализации и использования алгоритмов машинного обучения. На курсе используются NumPy, Seaborn, Matplotlib, Pandas, Scikit-Learn, Machine Learning, Plotly, Tensorflow и другие инструменты. Также слушателям расскажут про обработку естественного языка, искусственный интеллект и глубокое обучение.
5. Наука о данных, глубокое обучение и машинное обучение с помощью Python
Площадка: Udemy
Автор: Фрэнк Кейн
Длительность: 12 часов видеолекций
Стоимость: $10,99
Язык: английский
На курсе рассказывается об использовании искусственного интеллекта и машинного обучения для решения бизнес-задач. Преподаватель Фрэнк Кейн девять лет работал в Amazon и IMDb, создавая рекомендательные системы. Каждая концепция описывается на простом языке без сложных математических терминов. После вводной части демонстрируется использование кода на Python. Основное внимание уделяется практическому пониманию и применению алгоритмов машинного обучения. В конце курса слушателям предлагают работу над итоговым проектом, чтобы применить новые знания.
6. Курс машинного обучения от Google
Площадка: Google
Автор: Google
Длительность: 15 часов видеолекций
Стоимость: бесплатно
Язык: английский
Компания предлагает быстрое и практическое введение в машинное обучение с использованием API TensorFlow. Курс включает серию уроков с видеолекциями, реальными задачами и практическими упражнениями. Всего слушателям необходимо прослушать 25 уроков и выполнить 40 упражнений. Для всех алгоритмов предлагается интерактивная визуализация.
7. Структурирование проектов по машинному обучению
Площадка: Coursera
Автор: deeplearning.ai
Длительность: две недели
Стоимость: подписка на Coursera 3 039 ₽ в месяц
Язык: английский
Преподаватели курса из Стэнфордского университета расскажут, как построить работу команды по машинному обучения. За две недели слушатели научатся находить ошибки в системе машинного обучение, расставлять приоритеты в направлении работы и понимать сложные детали машинного обучения, например, невалидные обучающие наборы данных.
8. Использование глубокого обучения в творчестве с помощью TensorFlow
Площадка: Kadenze
Автор: Google Magenta
Длительность: пять сессий по 12 часов
Стоимость: бесплатно
Язык: английский, русские субтитры
Курс создан при поддержке проекта Magenta от Google, в рамках которого компания пытается создать «творческий компьютер». Преподаватели рассказывают про основные компоненты глубокого обучения, которые необходимы для построения алгоритмов: сверточные сети, вариационные автокодеры, генеративные состязательные сети и рекурсивные нейросети. Внимание уделяется творчеству нейросетей. Например, работе с изображением и созданию контента, который будет соответствовать эстетике или содержимому другого изображения.
9. Статистическое машинное обучение
Площадка: YouTube
Автор: Университет Карнеги — Меллона
Длительность: 24 лекции по 1,5 часа
Стоимость: бесплатно
Язык: английский, русские субтитры
На YouTube есть запись цикла лекций профессора Департамента статистики и факультета машинного обучения Университета Карнеги-Меллона Ларри Вассермана. Курс рассчитан на людей с продвинутыми знаниями математики и программирования, так как ориентирован на интеграцию статистики и машинного обучения. Предпосылкой к курсу служат лекции «Промежуточная статистическая теория» и «Введение в машинное обучение».
10. «Принципы машинного обучения»
Площадка: EdX
Автор: Microsoft
Длительность: 6 недель, 2–4 часа в неделю
Стоимость: бесплатно, сертификат $99
Язык: английский
Курс входит в сертификацию Microsoft в области науки о данных. На нем рассказывают, как создавать и работать с моделями машинного обучения с использованием Python, R и Azure Machine Learning. Преподаватели рассказывают о классификации, регрессии в машинном обучении, контролируемых моделях, системах нелинейного моделирования, кластеризации и разработке рекомендаций.
Для тех, кому ближе оффлайн-встречи, Университет ИТМО со 2 по 15 августа проводит в Санкт-Петербурге Летнюю школу машинного обучения на базе Центра речевых технологий. Слушатели получат практический опыт применения методов и алгоритмов глубокого обучения для анализа аудиовизуальных данных для распознавания эмоций.
Требования к участникам:
— студенты старших курсов;
— владение Python;
— имеют опыт применения современных методов машинного обучения;
— огромное желание развиваться в области аудио- и видеоаналитики.
Прием заявок продлится до 23 июля. Зарегистрироваться можно на сайте. Участие в Школе бесплатное. Также организаторы оплачивают проживание в общежитии Университета ИТМО. А за лучшее решение тестового задания — и транспортные расходы.
Введение в машинное обучение — Основы и Примеры
Перевод статьи разработчика алгоритмов машинного обучения, бизнес-консультанта и популярного автора Ганта Лаборде «Machine Learning: from Zero to Hero».
Начнешь c “Зачем?”, придешь к “Я готов!”
Если вы мало знаете об основах машинного обучения, то эта статья как раз для вас. Я буду постепенно излагать введение в машинное обучение, склеивая дружелюбный текст с вдохновляющими примерами. Присядь и расслабься, это займет некоторое время.
Почему машинное обучение сейчас в тренде
Искусственный интеллект (далее ИИ) всегда имел применение, начиная от перемещения ракетки в пинг понге и заканчивая выполнением комбо в Street Fighter.
ИИ опирается на представление программиста о том, как программа должна себя вести. Но как часто становится понятно, не все программисты талантливы в программировании искусственного интеллекта. Стоит только погуглить “эпичные фейлы в играх” и наткнуться на глюки в физике, даже у опытных разработчков.
Несмотря на это, компьютер поддается обучению для игры в видеоигры, понимания языка и распознавания людей и предметов. Этот навык исходит из старой концепции, которая только недавно получила необходимые вычислительные мощности для существования вне теории. Я имею в виду машинное обучение (ML, Machine learning).
Не продумывайте сложные алгоритмы самостоятельно — обучите компьютер создавать собственные сложные алгоритмы. Как это будет работать? Алгоритм не столько написан, сколько выведен. Посмотри это короткое видео, с помощью анимации оно должно дать понимание общего принципа создания ИИ.
И как возможно такое, что мы даже не понимаем устройство рабочего алгоритма? Прекрасным визуальным примером был ИИ, написанный для прохождения игр Марио. Люди хорошо знают, как нужно играть в сайд-скроллеры, но это безумие пытаться определить стратегию игры для ИИ.
Впечатлены? Как это возможно? К счастью, Элон Маск представил некоммерческую компанию, которая предоставляет возможность подключения ИИ к любым играм и задачам с помощью дюжины строк кода. Посмотрите, как это работает.
Зачем следует использовать машинное обучение?
У меня два ответа на вопрос, почему вас должно это заботить. Во-первых, с помощью машинного обучения компьютеры выполняют задачи, которые раньше они не выполняли. Если хотите создать что-то новое для всего мира, вы можете сделать это, используя машинное обучение.
Во-вторых, если не влияете на мир, мир повлияет на вас. Компании инвестируют в ML, и эти инвестиции уже меняют мир. Лидеры мысли предупреждают, что нельзя позволить алгоритмам машинного обучения быть в тени. Представьте себе, если бы монополия из нескольких корпораций контролировала Интернет. Если мы не “возьмемся за оружие”, наука не будет нашей.
Christian Heilmann высказал правильную мысль в беседе о машинном обучении:
“Можно надеяться, что остальные будут использовать эту мощь только в мирных целях. Я, например, не рассчитываю на эту милость. Предпочитаю играть и быть частью этой революции. И вы присоединяйтесь”.
Хорошо, теперь я заинтересован…
Концепт полезный и веселый. Но что за дичь там в действительности творится? Как это работает? Если хочешь сразу погрузиться, советую пропустить раздел и перейти к следующему “С чего мне начать?”. Если вы уже мотивированы делать модели ML, эти видео не понадобятся.
Если ты все еще пытаешься понять, как такое вообще возможно, следующее видео проведет тебя через логику работы алгоритмов, используя классическую задачу ML — проблему распознавания рукописного текста.
Классно, не правда ли? Видео демонстрирует, что каждый новый слой становится проще, а не сложнее. Будто бы функция пережевывает данные в более мелкие кусочки, которые потом выстраиваются в задуманный концепт. Поиграйтесь с этим процессом здесь.
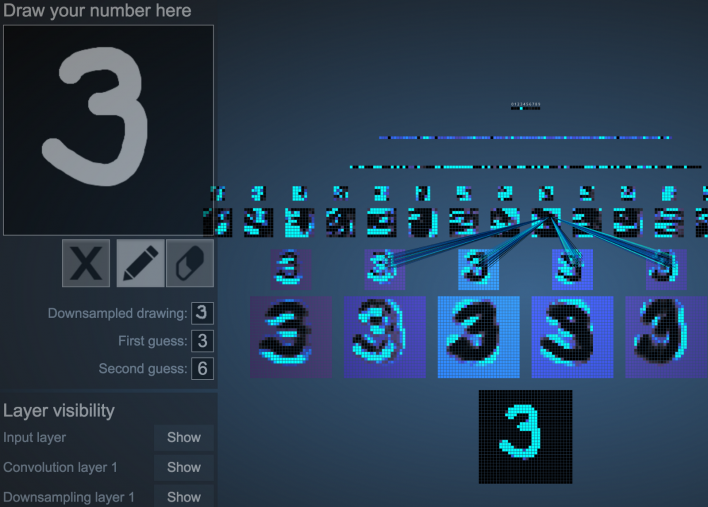
Занятно наблюдать, как данные проходят через натренированную модель, но ты также можешь пронаблюдать тренировку собственной нейронной сети.
Классический пример машинного обучения в действии — датасет прямиком из 1936-го года, называемый ирисами Фишера. На презентации эксперта JavaFX, посвященной машинному обучению, я узнал, как использовать этот инструмент, чтобы визуализировать прикрепление и обратное распространение весов к нейронам в нейронной сети. Понаблюдайте за тем, как тренируется нейронная сеть.
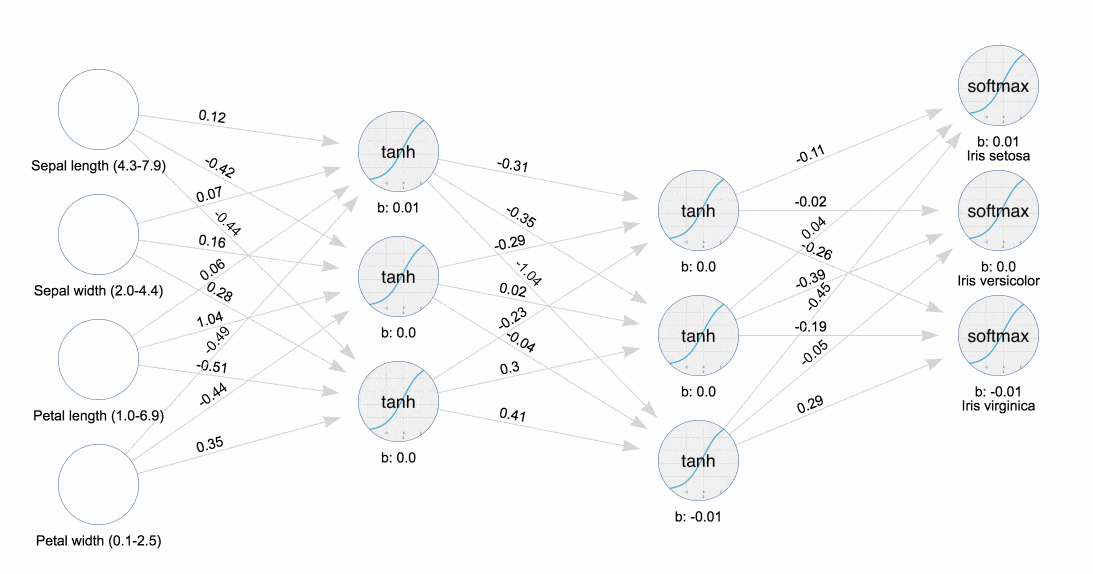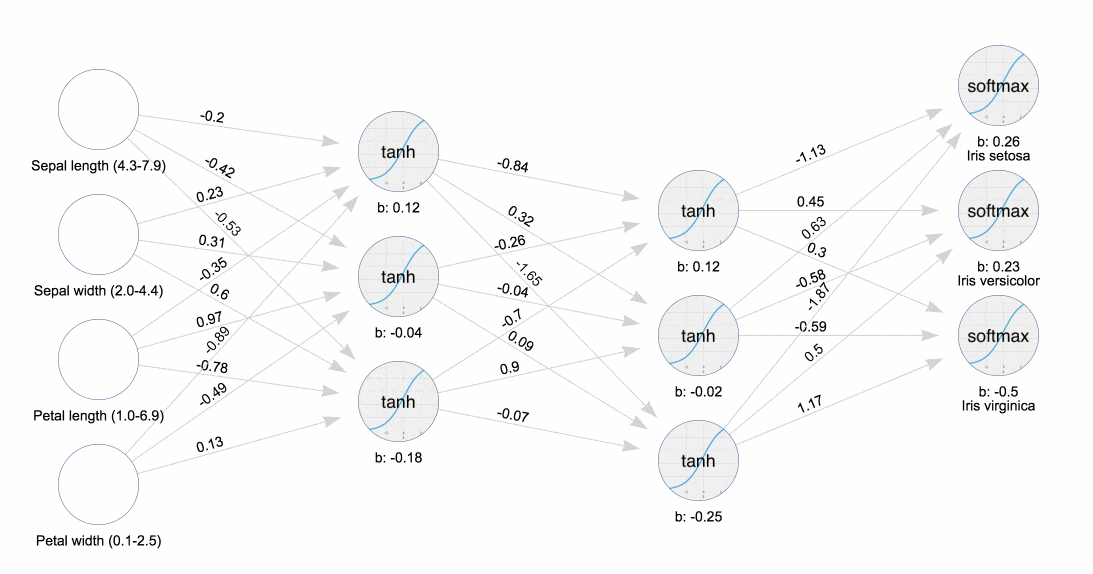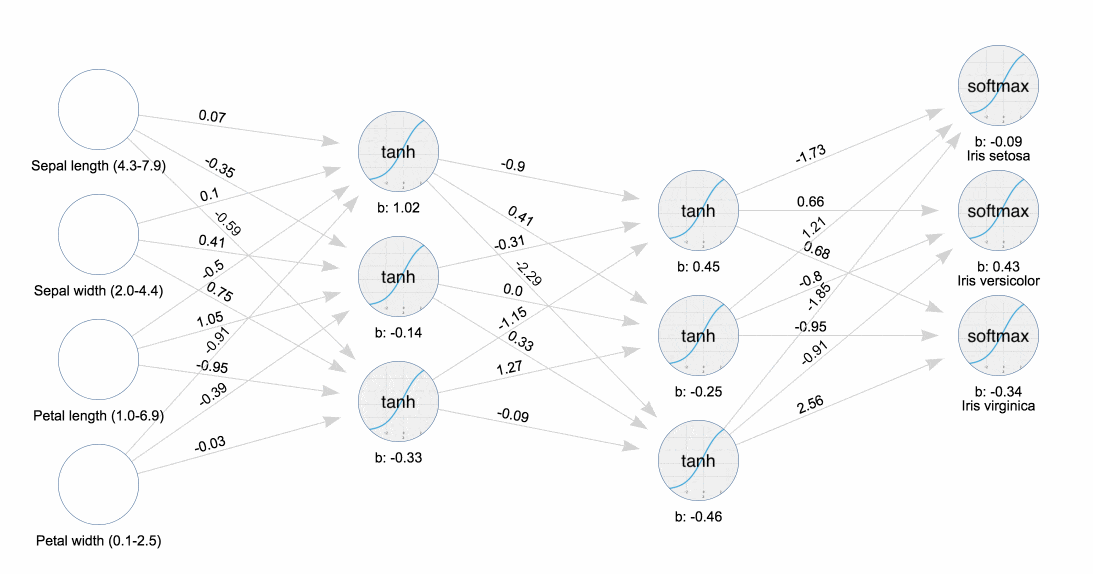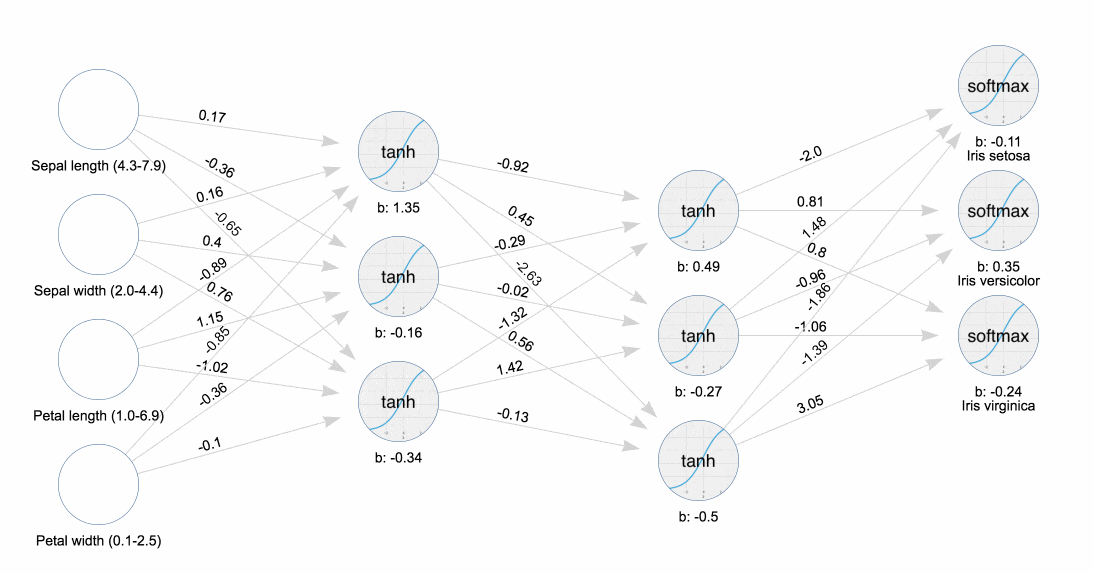 Обучение нейронной сети Ирисы
Обучение нейронной сети ИрисыГотовы стать Эйнштейном новой эры? Прорывы происходят каждый день, поэтому начинайте сейчас.
С чего мне начать?
Доступных ресурсов много. Я рекомендую два подхода.
Основы
С этим подходом вы поймете машинное обучение вплоть до алгоритмов и математики. Знаю, этот путь кажется тяжким, но зато как круто будет по-настоящему проникнуться в детали и кодить с нуля!
Если хочешь получить силу в этой сфере и вести серьезные обсуждения о ML, то этот путь для тебя. Советую пройти курс по искусственным нейронным сетям. Этот подход позволит вам изучать ML на вашем телефоне, убивая время, например, в очереди. Одновременной проходите курс о машинном обучении.

Курсы могут показаться слишком сложными. Для многих это причина не начинать, но для других это повод пройти это испытание и получить сертификат о том, что вы справились. Все вокруг будут впечатлены, если справитесь, потому что это действительно не просто. Но если вы это сделаете, получите понимание о работе ML, которое позволит вам успешно применять его.
Гонщик
Если вы не заинтересованы в написании алгоритмов, но хотите использовать их для создания сайтов и приложений, то используйте TensorFlow и погрузитесь в crash course.
TensorFlow — это библиотека с открытым исходным кодом для машинного обучения. Ее можно использовать любым способом, даже с JavaScript. А вот crash source.
Услуги ML
Если проходить курсы не ваш стиль, то пользуйтесь ML как услугой. Технические гиганты владеют натренированными моделями, а сектор услуг по машинному обучению растет.
Предупреждаю, что нет гарантии, что ваши данные будут в безопасности или вообще останутся вашими, но предложения услуг по ML очень привлекательны, если вы заинтересованы в результате и имеете возможность загрузить данные на Amazon/Microsoft/Google.
Давайте быть созидателями
Я все еще новичок в мире ML и счастлив осветить путь для других, путь, который даст нам возможность завоевать эру, в которой мы оказались.
Курсы по data science
Крайне важно быть на связи со знающими людьми, если изучаете это ремесло. Без дружеских лиц и ответов, любая задача покажется трудной. Возможность спросить и получить ответ кардинально облегчает ситуацию. Дружелюбные люди всегда помогут дельными советами.
Надеюсь, эта статья вдохновила вас и ваше окружение изучать ML!
Различия между искусственным интеллектом, машинным обучением и глубоким обучением
Искусственный интеллект, машинное обучение и глубокое обучение уже сейчас являются неотъемлемой частью многих предприятий. Часто эти термины используются как синонимы.Искусственный интеллект движется огромными шагами — от достижений в области беспилотных транспортных средств и способности обыгрывать человека в такие игры, как покер и Го, к автоматизированному обслуживанию клиентов. Искусственный интеллект — это передовая технология, которая готова произвести революцию в бизнесе.
Часто термины искусственный интеллект, машинное обучение и глубокое обучение используются бессистемно как взаимозаменяемые, но, на самом деле, между ними есть различия. Чем именно различаются эти термины будет рассказано далее.
Искусственный интеллект (ИИ)
Искусственный интеллект — широкое понятие, касающееся передового машинного интеллекта. В 1956 году на конференции по искусственному интеллекту в Дартмуте эта технология была описана следующим образом: «Каждый аспект обучения или любая другая особенность интеллекта могут быть в принципе так точно описаны, что машина сможет сымитировать их.»
Искусственный интеллект может относиться к чему угодно — от компьютерных программ для игры в шахматы до систем распознавания речи, таких, например, как голосовой помощник Amazon Alexa, способный воспринимать речь и отвечать на вопросы. В целом системы искусственного интеллекта можно разделить на три группы: ограниченный искусственный интеллект (Narrow AI), общий искусственный интеллект (AGI) и сверхразумный искусственный интеллект.
Программа Deep Blue компании IBM, которая в 1996 году обыграла в шахматы Гарри Каспарова, или программа AlphaGo компании Google DeepMind, которая в 2016 году обыграла чемпиона мира по Го Ли Седоля, являются примерами ограниченного искусственного интеллекта, способного решать одну конкретную задачу. Это его главное отличие от общего искусственного интеллекта (AGI), который стоит на одном уровне с человеческим интеллектом и может выполнять много разных задач.
Сверхразумный искусственный интеллект стоит на ступень выше человеческого. Ник Бостром описывает его следующим образом: это «интеллект, который намного умнее, чем лучший человеческий мозг, практически во всех областях, в том числе в научном творчестве, общей мудрости и социальных навыках.» Другими словами, это когда машины станут намного умнее нас.
Машинное обучение
Машинное обучение является одним из направлений искусственного интеллекта. Основной принцип заключается в том, что машины получают данные и «обучаются» на них. В настоящее время это наиболее перспективный инструмент для бизнеса, основанный на искусственном интеллекте. Системы машинного обучения позволяют быстро применять знания, полученные при обучении на больших наборах данных, что позволяет им преуспевать в таких задачах, как распознавание лиц, распознавание речи, распознавание объектов, перевод, и многих других. В отличие от программ с закодированными вручную инструкциями для выполнения конкретных задач, машинное обучение позволяет системе научиться самостоятельно распознавать шаблоны и делать прогнозы.
В то время, как обе программы — и Deep Blue, и DeepMind, являются примерами использования искусственного интеллекта, Deep Blue была построена на заранее запрограммированном наборе правил, так что она никак не связана с машинным обучением. С другой стороны, DeepMind является примером машинного обучения: программа обыграла чемпиона мира по Го, обучая себя на большом наборе данных ходов, сделанных опытными игроками.
Заинтересован ли Ваш бизнес в интеграции машинного обучения в свою стратегию? Amazon, Baidu, Google, IBM, Microsoft и другие уже предлагают платформы машинного обучения, которые могут использовать предприятия.
Глубокое обучение
Глубокое обучение является подмножеством машинного обучения. Оно использует некоторые методы машинного обучения для решения реальных задач, используя нейронные сетей, которые могут имитировать человеческое принятие решений. Глубокое обучение может быть дорогостоящим и требует огромных массивов данных для обучения. Это объясняется тем, что существует огромное количество параметров, которые необходимо настроить для алгоритмов обучения, чтобы избежать ложных срабатываний. Например, алгоритму глубокого обучения может быть дано указание «узнать», как выглядит кошка. Чтобы произвести обучение, потребуется огромное количество изображений для того, чтобы научиться различать мельчайшие детали, которые позволяют отличить кошку от, скажем, гепарда или пантеры, или лисицы.
Как уже упоминалось выше, в марте 2016 года искусственным интеллектом была достигнута крупная победа, когда программа AlphaGo DeepMind обыграла чемпиона мира по Го Ли Седоля в 4 из 5 игр с использованием глубокого обучения. Как объясняют в Google, система глубокого обучения работала путем комбинирования «метода Монте-Карло для поиска в дереве с глубокими нейронными сетями, которые прошли обучение с учителем на играх профессионалов и обучения с подкреплением на играх с собой».
Глубокое обучение также имеет бизнес-приложения. Можно взять огромное количество данных — миллионы изображений, и с их помощью выявить определенные характеристики. Текстовый поиск, обнаружение мошенничества, обнаружения спама, распознавание рукописного ввода, поиск изображений, распознавание речи, перевод — все эти задачи могут быть выполнены с помощью глубокого обучения. Например, в Google сети глубокого обучения заменили много «систем, основанных на правилах и требующих ручной работы».
Стоит отметить, что глубокое обучение может быть весьма «предвзятым». Например, когда была первоначально развернута система распознавания лиц Google, она помечала много черных лиц как гориллы. «Это пример того, что произойдет, если у вас нет афроамериканских лиц в вашем наборе обучения», сказала Anu Tewary, главный специалист по работе с данными Mint at Intuit. «Если у вас нет афроамериканцев, работающих над системой, если у вас нет афроамериканцев, тестирующих систему, то, когда ваша система сталкивается с афроамериканскими лицами, она не будет знать, как вести себя.»
Существует мнение, что тема глубокого обучения сильно раздута. Система Sundown AI, например, предоставляет автоматизированные взаимодействия с клиентами с использованием комбинации машинного обучения и policy graph алгоритмов без использования глубокого обучения.
Оригинал статьи — «Understanding the differences between AI, machine learning, and deep learning».
«Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science
Ранее в моей прошлой статье, посвящённой обучению Data Science с нуля, я обещал записаться на специализацию «Машинное обучение и анализ данных», на Coursera и поделиться моими впечатлениями о доступности этих знаний для практически абсолютного новичка в области науки о данных. Сказано – сделано! Хотя безусловно, на Хабре уже есть упоминания об этой и аналогичных специализациях, но думаю мои «пять копеек» не помешают.Цитата из известного фильма в названии статьи и картинка, взяты не случайно, местами мне кажется, что эта специализация доставляла мне почти физическую боль, и было колоссальное желание все бросить, но интерес в итоге взял верх. Поэтому если вам интересно как я с минимально возможными финансовыми затратами прошел эту серию курсов — милости прошу под кат.
Часть 1. «Вспомнить все…» — немного о навыках
Думаю, в самом начале будет уместно напомнить с чего все начиналось, чтобы читатель мог примерить мой опыт на себя.
Итак, данная статья является завершающей в спонтанно возникшем цикле статей, о том, как я осваивал азы Data Science с нуля (статьи ниже приведены в порядке появления):
Каждую из этих статей я начинал с краткого описания своих навыков, поскольку освоение указанных выше материалов суммарно умещалось примерно в одну неделю (без учета времени написания статей), то не могу сказать, что я сильно прогрессировал, поэтому к началу обучения на Coursera мой бэкграунд был следующим:
- Самые начальные представления о Data Science (зачем нужна, что входит, немного о методах работы)
- Почти нулевые познания в мат. анализе и статистике (матрицы от руки перемножал с ошибками, принцип доказательства статистических гипотез не воспринимал почти на генетическом уроне)
- Почти нулевое знание Python, немного минимальных навыков программирования в других языках (например, C#), которые похоже только мешали освоить логику Питона.
- Шило в «пятой точке» которое заставляло убить целый месяц на сверхинтенсивное прохождение курса
Именно с такой базой я подошел к началу обучения. В описании специализации честно сказано: «Intermediate Specialization. Some related experience required.» и признаться это меня настораживало, но поскольку в разработчиках специализации числится МФТИ и Яндекс я решил рискнуть.
Кстати, доложен отметить, что курс действительно заставил меня вспомнить все, в особо трудные минуты неожиданно начали всплывать в памяти, давно «прошедшие мимо ушей» знания, казалось бы, забытые за ненадобностью. Правда, как мне кажется, эта специализация в части статистики и мат. анализа все равно отложила у меня в голове больше чем предметы из программы специалитета и магистратуры ВУЗа вместе взятые.
Ну не буду вас больше томить, перейдем ближе к делу.
Часть 2 — «Начало» — знакомство с курсом
«Какой самый живучий паразит? Бактерия? Вирус? Кишечный глист? Идея. Она живучая и крайне заразная. Стоит идее завладеть мозгом, избавиться от нее практически невозможно. Я имею в виду сформировавшуюся идею, полностью осознанную, поселившуюся в голове» — Inception
Пока писал эту статью и вспоминал прохождение курсов, задумался, что единственной здравой причиной, по которой я вообще заинтересовался Data Science может быть, только то что мне эту идею внедрили во сне, или даже во сне внутри сна во сне внутри сна…
Причем это была не просто идея — пройти курс по Data Science на Coursera, это была идея пройти курс максимально быстро потому что лишних денег, да и времени растягивать на полгода не было.
Если кто-то не знаком с новой политикой Coursera, то сейчас на данный курс действует система подписки, а именно 7 бесплатных дней пробной подписки, потом каждый месяц платно.
Специализация рассчитана примерно на 6 месяцев. Один месяц мне обошелся в 4 576 руб (сейчас стоит немного больше).
Таким образом система давала 1 месяц + 1 неделю, и я решил, что именно за этот отрезок должен пройти специализацию. Забегая вперед, скажу, что задача вполне посильная.
Перейдем к описанию программы специализации. Она состоит из 6 курсов, пять из них теоретические, а шестой это курсовой проект (Capstone Project), доступ к нему откроется только после прохождения первых пяти. Курсы желательно проходить в прямом порядке, вас конечно никто не заставляет, но очень настоятельно рекомендуют. Если вы решите в сжатый срок пройти специализацию, то иногда будет смысл немного проходить курсы не в прямом порядке (об этом позже), но скорей всего это вам «аукнется» и будет необходимо возвращаться к ранее пройденному.
Пять курсов специализации плавно подводят вас к возможности самостоятельного применения знаний, особенно ценны они во взаимосвязи, но в принципе курсы могут быть полезны и по отдельности. Так некоторые курсы (точнее их части) похоже были сделаны несколько в отрыве от основного контекста, но в любом случае генеральная линия прослеживается и требования к уровню вашего мастерства будут возрастать постепенно от курса к курсу.
Начнете вы с основ Питона, азов мат. анализа и теории вероятностей, потом рассмотрите обучение с учителем и без учителя (от базовых моделей из scikit learn до нейронных сетей), потом статистика, потом практическое применение. В принципе похоже, что это общераспространённый подход к обучению в области Data Science.
Может быть, для кого-то станет критичным, что курс заточен под Python 2, причем я бы от греха не советовал бы даже некоторые вещи импортировать «из будущего», ибо в некоторых задачах «грейдер», очень чуткий и могут возникать проблемы из-за, например, разницы в библиотеках, в том числе и при применении Python 3 (по крайней мере судя по отзывам на форумах).
На мой взгляд удобней всего настроить Anaconda. Если у вас уже установлена анаконда с окружением под Python 3, то не расстраивайтесь настроить второе окружение с Python 2 достаточно просто (я ставил через консоль conda по этой инструкции). Ставится она и под Windows и под Linux, под Mac OSX не пробовал, но думаю тоже ставится без проблем.
Кстати, судя по форумам специализации многие проходили этот курс пользуясь OS Windows, я рекомендую на всякий случай накатить второй системой Linux, но безусловно это не обязательно, хотя может быть полезно.
Я накатил себе Linux Mint второй системой, чисто для этой специализации, и не пожалел. Субъективно мне кажется, что местами расчёты под ним проходят быстрей, также было меньше проблем с установкой некоторых библиотек, которые требовались при прохождении курса.
Первый курс для новичка выглядит вполне дружелюбно: по-своему харизматичные ребята из МФТИ и Яндекс расскажут зачем это нужно и поначалу не будут вас пугать зубодробительными заданиями. А вот потом, уровень фрустрации зависит от вашей подготовки. У меня, и у некоторых людей на форуме бывали случаи, когда целыми днями не удавалось подобрать решении задачи или теста, с другой стороны если у вас есть способности и хорошая «база», то думаю вам все будет просто и понятно.
Для каждого курса есть своя сессия (примерно месяц), в которую подразумевается его изучение, курс состоит из недель, неделя состоит из 2-4 занятий (обычно), в каждом занятии (уроке), как правило есть необязательный материал (лекции, пробные тесты) и контрольный материал, тесты с оценками, задания по программированию, задания для взаимной проверки и т.п. Сдача этих оценочных материалов, обязательна для завершения курса.
Если вы что-то не сдали в срок, за это не штрафуют, однако если это завязано на других людей, например, задания взаимной проверки, то могут возникнуть трудности (все убегут вперед и им будет не до проверки вашей работы). Если не уложились в одну сессию всегда можете перейти на другую, результат сохранится.
Отдельное слово надо сказать о лекторах курса и заданиях. Над курсом работала большая команда и соответственно есть свои плюсы и есть свои минусы, большую часть курса читают 4 ключевые специалиста, у каждого похоже своя специализация. По лекторам видно, что они опытные и толковые люди, но к некоторым по началу привыкнуть трудно. Я не буду раскрывать персоналии, чтобы никого не обидеть. Просто отмечу, что есть лекторы, которым хочется просто поклонится в ноги, за то, что они стараются разжевать материал даже новичкам, некоторые же лекторы могут немного нервировать и вызывать на первых порах жгучее желание совершить насильственные действия агрессивного характера. Это безусловно моя субъективная реакция, вызванная плохими базовыми знаниями и личным восприятием, в любом случае к концу специализации привыкаешь к манере каждого из лекторов и даже как-то жалко становится с ними заочно расставаться.
С лекторами также непосредственно связаны контрольные материалы уроков, вы заметите, что в чьих-то уроках задания (в целом) более зубодробительные, например, где-то тесты простые как «три копейки», а в задачах на статистику и теорию вероятности заставляют изрядно попотеть.
Ну и отдельно задания по программированию (и/или по взаимной проверке), тоже разрабатывали разные люди, поэтому в некоторых случаях формулировки могут вызывать у неподготовленного человека чувства полного непонимания и беспросветной паники.
Что касается приглашённых лекторов, они люди грамотные, ну а если что-то не нравится, то они не успевают сильно надоесть, да и моментов таких не очень много, как правило приглашенные лекторы читают материал, немного оторванный от основного контекста, но безусловно полезный для общего развития.
Я не хочу вдаваться в подробности обучения по каждому из курсов, думаю вы все постигните в процессе обучения перейду к полезным советам. Ну и еще раз повторюсь есть статьи на Хабре про эту специализацию, например, от самого МФТИ).
Часть 3 «Автостопом по галактике» — что делать чтобы не было мучительно больно.
«Галактика суровая штука. Чтобы в ней выжить, надо знать, где твое полотенце» — Автостопом по галактике
Ниже я постараюсь расписать пару моментов, которые мне стоили выпавших на клавиатуру волос и бессонных ночей, надеюсь это вас хоть немного убережет, пусть это будет вашим «полотенцем».
1. Моя большая ошибка, это отсутствие структурированного подхода к фиксации процесса обучения. В некоторых вопросах я вполне себе «пенсионер» и популярными хорошими практиками не пользуюсь. Ближе к 4-му курсу специализации я понял, что с самого начала надо было завести что-то вроде Mind map (или любой аналог). Основная проблема начинается в тот момент, когда курс перестает вас вести за ручку и требует, чтобы вы вернулись в ранее пройденный материал и откопали реализацию функции или кусок теории, рассмотренный ранее. Не стоит полагаться на память, она скорей всего вас местами подведет. Слава богу есть способы, позволяющие скомпенсировать отсутствие Mind map, но я все же рекомендую вам как-то структурировать то что вы учите.
2. Также не смотря на основной посыл статьи, я не рекомендую проходить специализацию галопом как я. Да может быть 6 месяцев это объективно, много, но думаю месяца три это вполне комфортные условия для размеренного поглощения знаний. Изучение же курса за месяц + одну неделю помимо бессонных ночей и отсутствия нормальных выходных приведет к тому, что возможно ваш мозг просто не переварит то что вы, выучили. Так, например, я обнаружил забавный эффект к моменту, когда я уже проходил 4-й курс, я вдруг, не осознанно просто так занимаясь совсем другими делами начал понимать некоторые моменты из первых курсов. К моменту прохождения финального проекта специализации у меня ни с того ни с сего в голове начало возникать понимание самых основ статистики из 4-го курса, видимо мозгу нужно время. В качестве совета частично компенсирующего недостаток времени на прохождение курса при быстром изучении, рекомендую через пару курсов после начала обучения начать параллельно читать, какой-нибудь самоучитель по теме. Я, например, выбрал книгу: А. Мюллер, С. Гвидо —«Введение в машинное обучение с помощью Python. Руководство для специалистов по работе с данными» — 2017 г. Там мало теории, но зато материал книги наглядно повторяет приемы, освоенные в рамках курса.
Или еще, как вариант «Python и машинное обучение» Себсатьян Рашка (подсказал Metsur )
3. Используйте форумы курсов и slack, вы удивитесь, сколько людей столкнулись с теми же проблемами, что и вы. Поскольку я очень спешил, то практически каждое задание я начинал сразу с изучения тем на форуме связанных с трудностями, которые возникают во время его решения. Не редко на форуме можно встретить, прям куски кода, или формат ответов, которые ждет «грейдер», а в особо сложных случаях прям целые инструкции от пользователей, в которых разжевано, что же хотел от вас автор задачи (у которого видимо есть трудности в общении с неспециалистами). Slack меня выручил на самом последнем этапе, когда было необходимо скооперироваться с людьми для взаимной проверки заданий, народу на шестом курсе мало и чтобы не ждать долго, полезно искать людей которые уже прошли этот этап и просить их об оценке или наоборот помогать советом (в рамках правил) людям которые вас догоняют, чтобы они быстрее вас догнали и смогли оценить работу. Также маленький «лайф хак», если вы не наберёте достаточно заданий для того чтобы оценить сокурсников и не хотите ждать, то всегда можете поискать ссылки от людей на форуме, где люди просят их проверить (пусть и пару месяцев назад), правда из чувства солидарности я все же советую не останавливаться на трех минимально необходимых оцененных работах, а помочь с проверкой большему числу людей. Кроме форума на первых курсах помогает просто поиск в Интернет, там вы вполне можете найти подсказки для решения ваших задач (например, одна из задачек в первых курсах базируется на научной статье, которую можно найти и подглядеть куски кода), а вот дальше Интернет уже менее полезен.
4. Рассмотрим следующий момент, который для некоторых может стать «камнем преткновения». На всякий случай рекомендую в заданиях для проверки «грейдером» формировать ответы через функции записи файла в Питон, а не вручную через блокнот, это убережет вас от «невидимых» символов которые система признает ошибочным ответом.
5. Запись на сессии. Тщательно прикиньте ваш прогресс. Если вы хотите закончить в сжатые сроки, то не имеете права ждать впустую. Некоторые задания невозможно сдать, пока не начнется сессия, ну, например, вы закончили 2й курс 14 числа, а сессия не третий курс начнется только 21 числа, это значит, что вы 7 дней не сможете сдавать некоторую часть заданий (как правило связанную со взаимной оценкой). Поэтому есть смысл записываться на сессии чуть раньше, чем вы закончили прошлый курс.
Приведу пример, допустим какой-то курс уже начался, но первые 3 недели не содержат заданий с проверкой другими пользователями, тогда есть смысл записаться на эту сессию и потом наверстать, чем ждать пока начнется новая сессия и пока ваши сокурсники дойдут до третей недели. Второй пример на один из курсов мне пришлось записаться с опережением графика, получилось, что я закончил второй курс и сразу записался на пятый, быстро сдал задание, оцениваемое пользователями на самой первой неделе и вернулся спокойно к третьему и четвертому курсу по порядку. Таким образом я не потерял момент, когда люди были готовы оценить работу и потом наверстал упущенное. Из минусов первую неделю пятого курса потом пришлось учить заново потому что из головы все вылетело.
6. Не все знают и явно это похоже не прописано, так что на всякий случай напишу — Coursera по крайней мере на текущий момент на Capstone проект дает полгода, то есть срок моей подписки (месяц + бесплатная неделя ) истекали 08.08.17, но как сказала поддержка доступ к Capstone проекту сохранится полгода с момента начала 6 курса в моем случае до конца января, ибо начал я в конце июля. Так что зная это, вы можете сберечь себе нервы.
7. Capstone проект делится на 4 ветки, для завершения специализации достаточно пройти одну из них, при этом местами системы оценок не очень справедливые. Ну, например, в 5-м задании 1-го проекта (идентификация интернет пользователей) будет очень тяжело достигнуть высокой оценки в связи с необходимостью попасть в топ соревнования на kagle, с другой стороны в 5-м задании проекта по сантимент анализу, предлагают написать примитивный парсер сайта, задание можно сделать за пол часа даже не вдаваясь в предыдущие задачи курса, а оценку хорошую получить проще (учтут в итоге лучший бал). Таким образом вы можете в каких-то моментах где владеете навыками лучше, кроме основной ветки выполнить еще здания и в других, совместите приятное с полезным.
8. Не ленитесь писать нормальный код и хорошо оформлять блокнот, я спешил (ну и знаний не хватало) и мой код был жуткий, я с трудом могу его сам разобрать, другим людям это тоже тяжело (это иногда влияет на оценки пользователей). Я думаю не зазорно посмотреть, как делают другие и чуть-чуть себя поправить, безусловно не переходя границу с плагиатом. Так же рекомендую включать в блокнот текст из описания заданий, я вот сейчас уже не вспомню, что именно я делал в каждой ячейке, а доступ к зданиям закрыт по истечению подписки, так что и не посмотришь. Хотя на самом деле многие задачи есть на GitHub, так что это не очень критично.
9. Ну и пусть это банально, но рассчитайте свои силы, серьезно, за прошедший месяц мне порой приходилось спать за ночь по 2 часа, не видеть друзей и близких, забывать поесть, все выходные гробить на решение задач, да и много еще чего. Поэтому если вы действительно хотите, не имея спецподготовки осилить курс за месяц подумайте готовы ли вы на это.
Кстати, фраза из Автостопом по галактике вспомнилась по тому что в курсе периодически предлагают выставить random seed в значение = 42
Ну думаю есть смысл подводить итоги.
Часть 4 «I’ ll be back» — заключение.
Давайте по порядку ответим на вопросы:
1. Пригодились ли мне навыки, которые я получил из обучения до этого (см. первые три статьи цикла)?
— Да, но не сильно, с одной стороны хорошо, когда имеешь представление о том что примерно тебя ждет (Курсы от Cognitive Class), также местами пригодился и самоучитель про «Data Science с нуля» там я перечитывал теорию вероятности (там немного материала, но то что есть написано понятней), ну и опыт с kagle вам тоже пригодится, когда будете делать Capstone проект, Однако суммарно все три прошлые статьи по навыкам с точки зрения практики и близко не лежат с прохождением специализации, так что если вы уже твердо решили что хотите, можете начинать «без прелюдий».
2. Страдал ли я от недостатка базовых знаний?
— Да, местами очень, особенно когда 2.5 дня не мог написать простейшую функцию, или тупо не мог воспринять какие-то моменты статистики и теории вероятности. К счастью есть форум и slack там много таких же людей, и можно найти помощь, ну и менторы курса, а иногда и сами разработчики стараются помочь. Если все совсем плохо, можете взять персонального тьютора, но думаю, что любой человек в состоянии справится сам.
3. Узнал ли я что-то новое?
— Да, во-первых, я первый раз в жизни написал программу, которая работала 9.5 часов подряд, потом накрылась выдав memory error (потом я конечно это все поправил), у меня несильный компьютер, но даже игрушки с нормальной графикой не могли конкурировать с моим творением в части пожирания ресурсов. Это очень хороший опыт, я навсегда теперь запомнил о важности и пользе разряженных матриц. Ну и во-вторых другие моменты полезные тоже есть: это курс все же немного учит Python(у), я по прежнему его знаю очень плохо и не освоил «Pythonic way», но это намного лучше чем вообще никак, курс неплохо объясняет базовые принципы высшей математики и статистики (не вдаваясь в подробности), фактически я их для себя открыл заново. Курс действительно показывает многие интересные фишки, часть из которых при желании можно перенести в свою повседневную жизнь. Да, есть проблемы с усвоением информации думаю 3/4 материала прошли мимо моего осознания, но даже оставшегося хватит, чтобы догадываться в каком направлении копать, если где-то понадобится анализ данных.
4. Может ли этот курс освоить каждый?
— Думаю да, лишь бы было желание, возможно не за месяц, но точно освоит каждый, кто решит для себя что он действительно хочет. Контингент на курс подбирался разный и молодые парни и девушки и люди в возрасте, как с хорошим знанием материала, так и не очень.
Еще в качестве бонуса, авторы на на сайте специализации пишут о возможности содействия в трудоустройстве после её прохождения, я пока еще не пробовал, но сама возможность радует.
Подводя итог, специализацию однозначно рекомендую, там многие моменты еще шероховаты, но думаю по соотношению цена качество — это более чем приемлемый вариант.
Что же дальше? Ну может применю полученные навыки для своего хобби и потом скину материал на Хабр, может быть посмотрю, как обстоят дела с машинным обучением на .net и тоже отпишусь. Но это всё будет сильно позже.
Так что желаю всем удачи в освоение данной интересной области знаний!
Ну а, чтобы статья не казалось совсем уж серьезной ловите «бонус»:
В качестве бонуса
Еще одним крутым плюсом этой специализации, стало то, что я выучил слово корреляция и теперь буду его везде пихать к месту и не очень.
Итак, ваши письма и комментарии к прошлым статьям подвели меня к знанию о том, что мои прошлые статьи в рамках цикла, читаются более ли менее легко и содержат немного юмора (ну надеюсь это действительно так), однако судя по ощущениям эта статья читается тяжелее, да и писал я её с серьезной рожей вглядываясь в монитор.
Если так задуматься, то можно найти некоторую взаимосвязь между тем насколько легко давалось обучение по материалам в каждой из статей всего цикла и количеством условных «шуток» в статье.
Давайте посмотрим, а есть ли какая-то КОРРЕЛЯЦИЯ?!
Давайте посчитаем соотношение числа слов в статье и числа «шуток» в ней, а также сложность освоения (затраченные на обучение дни).
Статьи нумеруются в том порядке как я их указал в начале статьи, эта соответственно будет четвертой, при расчёте количества шуток и слов, бонусный раздел в выборку не включался.
Под шутками понимаются хоть какие-то намеки на юмор (с учетом картинок вначале статьи), цитаты в заголовках за шутки не считались. Итак:
1. Статья №1: слов = 2575, шуток =5, дней обучения — 2
2. Статья №2: слов = 2098, шуток =3, дней обучения — 3
3. Статья №3: слов = 2667, шуток =4, дней обучения — 2
4. Статья №4: слов = 3051, шуток =2, дней обучения — 37
Далее код на Python 3, для Python 2 уберите скобки перед print и убедитесь, что делите на float, также можно убрать list () перед zip()
import pandas as pd
humor_rate=[(5/2575),(3/2098), (4/2667),(2/3051)]
days=[2,3,2,37]
df=pd.DataFrame(list(zip(humor_rate, days)), index=None, columns=['Humor rate', 'Days of study'])
print ('Таблица данных: \n', df)
print ('Корреляция между humor rate и days of study = ', df.corrwith(df['days of study'])[0])
вывод:
Таблица данных:
.....Humor rate.....Days of study
0....0.001942............2
1....0.001430............3
2....0.001500............2
3....0.000656............37
Корреляция между humor rate и days of study = -0.912343823382
Ну что в итоге? А в итоге мы имеем ярко выраженную отрицательную КОРРЕЛЯЦИЮ (коэф. КОРРЕЛЯЦИИ Пирсона), которая говорит нам что, как правило, чем меньше число дней, потраченных на обучение тем больше юмора в статье.
Конечно это шуточный пример КОРРЕЛЯЦИИ. Данных безусловно мало, да и у меня возникли сложности с определением однозначного количества шуток в статье, но будем считать это маленьким примером того, как вы сможете применить полученные после специализации навыки на практике, в том числе и для расчёта КОРРЕЛЯЦИИ.
P.S. сколько раз я упомянул это слово в бонусном фрагменте статьи? Правильно — восемь с учетом, вывода print ().