
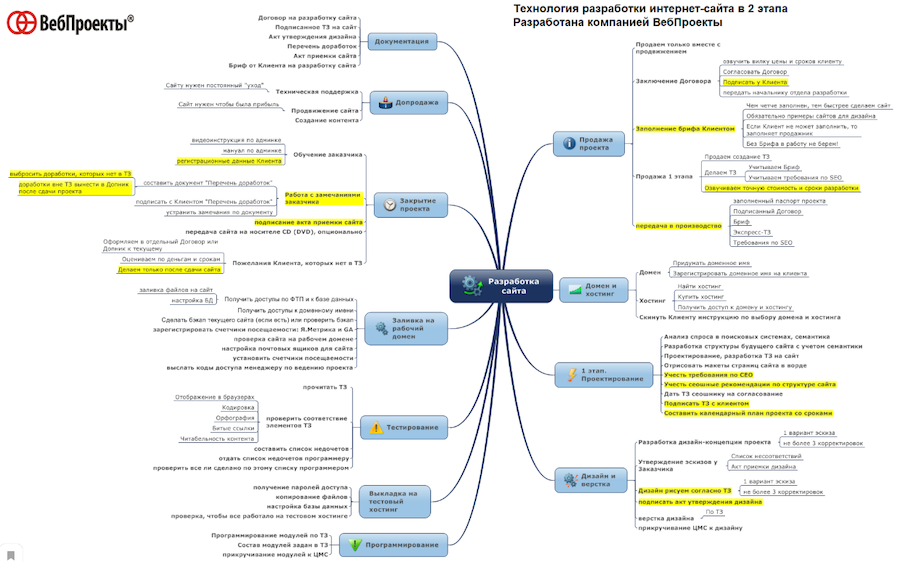
Зачем нужна правильная логика структуры сайта?
Первый шаг к успеху – правильно разработанная структура, ведь это база сайта, первый кирпич в его фундаменте. Каждый проект индивидуален, поэтому подход к структуре под каждый отдельный сайт будет разным. Однако следует учитывать конкретные требования систем поиска, потому что их нужно обязательно соблюдать. Предлагаю сегодня подробно об этом побеседовать.
Что прячется за логической структурой веб-ресурса?
Логической структурой сайта называется такая модель организации сайта, при которой страницы расставлены согласно иерархии. Что мы имеем в виду? Страницы в такой структуре взаимосвязаны и в них прослеживается принадлежность к различным группам, как категории и.т.д.
Структурирование сайта является очень важным этапом, ведь от этого зависит то, будет ли удобно использовать этот интернет-ресурс. Хорошо сложенная структура помогает сэкономить время посетителя и ускорить его поиски. Непонятная организация сайта только оттолкнет пользователя. Поэтому ваша задача – построить структуру так, чтобы посетители сайта могли легко найти среди общей информации именно ту, которую искали.
Поэтому ваша задача – построить структуру так, чтобы посетители сайта могли легко найти среди общей информации именно ту, которую искали.
В чём важность безошибочной структури для систем поиска?
Каждый поисковик имеет свои требования для структуры. Если придерживаться рекомендаций, можно значительно повысить успехи своего сайта. Рассмотрим несколько главных советов.
Рекомендации Google
- Логическая иерархия. Пользователь должен без труда попадать на любые страницы вашего интернет-ресурса. Для удобства используйте навигационную ленту. Этот элемент будет показывать путь в структуре от главной страницы к текущей, на которой находится пользователь. Это похоже на «хлебные крошки», которые помогут не потеряться на сайте и легко вернуться на тот раздел, который нужен.
- Использование текстовых ссылок. В отличие от ссылок-баннеров, текст имеет определенные преимущества. К примеру, поисковые работы смогут лучше оценить релевантность таких источников.

- Создание страницы навигации. Googlebot поможет вам ускорить поиск изменений в вашей структуре. Для этого необходима HTML-карта ресурса и файл Sitemap.xml.
- Создание информационных страниц 404. Когда пользователь случайно перейдёт на страницу, которая не существует, позаботьтесь о том, чтобы он увидел ссылку на основную страницу, а также краткую навигацию. Это поможет ему продолжать поиски, а не покинуть ваш ресурс.
- Прописывайте простые и понятные адреса страниц, так называемые человекопонятные урлы (ЧПУ-URL). Написанные простым форматом страницы более доступны для посетителя.
- Простая структура каталогов. Благодаря этому разобраться на сайте станет легче.
- Для каждого сайта должен быть единственный уникальный адрес.
Рекомендации Yandex
- Соблюдайте четкость в иерархии. Отдельные разделы для каждого из документов.
- Использование карты сайта. Работайте с Яндекс.Вебмастером – добавьте файл Sitemap или ссылку на Robots. txt. Это поможет поисковому роботу работать над индексацией и анализом документов быстро и качественно.
- Ограничение индексирования информации. С этой целью испольуйте файл Robots.txt.
- Уникальность URL.
- Использование ссылок в виде текста. Текст-ссылки лучше воспринимаются поисковиками.
- Правильность symlink. При некорректности этих ссылок можно получить URL, который будет расти в нескончаемой прогрессии (site.com/apple/apple/apple/apple/apple/).
 txt. Это поможет поисковому роботу работать над индексацией и анализом документов быстро и качественно.
txt. Это поможет поисковому роботу работать над индексацией и анализом документов быстро и качественно.Правильная структура веб-сайта: зачем?
Обустроенная по всем правилам структура сайта требуется обеим сторонам: посетителям и поисковикам.
Предлагаю рассмотреть плюсы:
- Рост «юзабилити», то есть эргономичности.
В ваших интересах сделать максимально удобную навигацию для пользователя, что даст ему шанс в кратчайшие сроки найти нужную информацию. Таким образом, вы сможете задержать посетителя на интернет-сайте и повысить ранжирования.
- Сделайте индексацию ещё лучше.
Логика структуры сайта способствуют системе поиска лучше разобраться, в том, что более приоритетно для пользователя. Лучше соблюдать правила 3-х кликов: не размещать важнейшие страницы далеко от основной, максимум 3 клика. Ведь в результате можно получить непроиндексированную страницу или проиндексированную позже, что в конечном счете повлияет на ее приоритет.
- Снижение уровня технических ошибок.
Если ваша структура верна, вы не встретите такую проблему, как множество дубликатов страниц.
- Внутренний вес ссылок.
Вес ссылки рассчитывается исходя из значения страниц. Те, что нужно активно продвигать, должны иметь много внутренних ссылок. А все потому, что поисковики более важными определяют те страницы, на которые есть множество ссылок.
- Охваты запросов.
Если для узких групп запросов создать вспомогательные категории, можно получить ранжирование по ключевым словам, что в свою очередь увеличит трафик, но сделает его более органичным.
Разновидность структур
Давайте попробуем рассмотреть различные виды структур, сравнить плюсы и минусы, чтобы понять, какую лучше применять именно для вас.
Существуют следующие виды:
- Линейная. Страницы размещаются в виде линии. Посетитель такого сайта может перемещаться только по указанному маршруту – сначала начинает с главной странице, а все остальное – перелистывает словно книгу. Здесь иерархия отсутствует, между страницами – равноправие. Такая структура веб-ресурса в основном подойдет для сайтов-визиток или сайтов-презентаций, а привлекать посетителей такой разновидностью структури будет сложно, потому что продвижению подлежит только основная страница.
- Линейная с ответвлениями. Здесь наблюдается тоже структура-линия, однако в цепи появятся дополнительные ветви. Такую структуру можно использовать также для ресурсов-визиток, но с более расширенной информацией, а еще она отлично подойдет для авторских блогов или онлайн-книг.
- Древовидная. В структуре этого типа наблюдаем иерархию – от главной страницы будет достаточно ответвлений на разные категории, подгруппы, карточки товара и т.д. Каждая следующая страница всегда связана с предыдущей и является ее частью. Такая система очень популярна и ее применение можно найти на страницах сайтов-магазинов. Древовидная структура лучшая для успешного продвижения.
- Блочная или «решетка». Система этого типа намного сложнее предыдущих. Страницы находятся в разных ветвях. Пользователь может перемещаться между ними вертикально и горизонтально.Однако структуру блоков обычно используют на сайтах-каталогах или же для какой-либо конкретной услуги или товара. Не часто можно увидеить использование решетчатой структуры, так как есть большая вероятность, что сайт может получиться запутанным и пользователю придется долго искать необходимую информацию.
Основные ошибки
- Различный интент.
Не нужно оптимизировать страницы под разные значения, которые могут возникнуть при запросе пользователя.
- Страницы-дубли.
Если на сайте созданы две и более идентичные страницы, между ними может возникать конкуренция в поисковой системе. Для нее не понятно, какую конкретно страницу нужно показывать, поэтому процесс ранжирования страниц и ее релевантность снижается.
- Высокий уровень вложенности.
Страницы, имеющие такой уровень, плохо поддаются индексации.
Здесь нужно придерживаться правила “трех кликов”.
Если же ваша веб-страница – огромна и такого уровня не избежать, нужно правильно составить навигацию и внутреннюю перелинковку, чтобы можно было увидеть приоритетные страницы.
- Отсутствие навигации.
Карты сайта обязательно должны быть.
Для правильной работы крупных интернет-ресурсов лучше иметь их две:
- для роботов-поисковиков. Здесь пригодится файл Sitemap.xml. Благодаря этому маленький помощник видит все страницы, которым требуется индексация.
- для пользователей создается страница с списком-картой веб-сайта. Это упрощает навигацию.
 Здесь пригодится файл Sitemap.xml. Благодаря этому маленький помощник видит все страницы, которым требуется индексация.
Здесь пригодится файл Sitemap.xml. Благодаря этому маленький помощник видит все страницы, которым требуется индексация.Если ваш веб-ресурс невелик, то по всей вероятности, если карты нет – это не будет критической ошибкой.
- Ошибка в разделе страниц.
При создании новых страниц следует учитывать предыдущие страницы. Например, кровати относятся к разделу Спальня, а не к разделу Кухня.
Запомните и примените
- Логическая структура сайта – база вашего интернет-ресурса. Уделите значительное количество времени для правильной разработки структуры, что принесет успех вам и вашему веб-сайту.
- Принимайте во внимание правила поисковых систем при создании структуры сайта.
- Обратите внимание на виды структур и какие плюсы вы сможете получить для вашего веб-ресурса от правильной структуры.
- Избегайте типичных ошибок.

НАПИШИТЕ НАМ
Ответим за 20 минут!
Основы и принципы работы сайтов
Создание собственного сайта — обязательная мера для обеспечения конкурентоспособности и высокой доходности предприятия. Личная веб страница позволяет стать ближе к потребителю, получать объективную оценку продукции и соответствовать потребностям клиентов. Изучение основных принципов работы сайта поможет окончательно разобраться – как именно собственная веб страница может повысить эффективность работы компании.
Многие из тех, кто смело оперируют понятием «сайт» затрудняются дать ему определение. Любой сайт представляет собой множество файлов, хранящихся не сервере. Эти файлы могут быть графическими, текстовыми или содержать в себе алгоритмы. Каждая веб-страница это текстовый файл, который можно прочитать как и любой другой документ. В нем описано содержание данной страницы на специальном языке HTML.
Главный принцип работы сайта состоит во взаимодействии трех компонентов: компьютера пользователя, DNS – сервера и сервера, на котором хранится запрашиваемый сайт. На первом этапе пользователь вводит адрес сайта в строку браузера на ПК. DNS – сервер, где хранятся все доменные имена, передает браузеру IP адрес запрашиваемого сайта. С помощью полученных сведений ПК связывается с сервером, где хранится необходимый сайт.
На первом этапе пользователь вводит адрес сайта в строку браузера на ПК. DNS – сервер, где хранятся все доменные имена, передает браузеру IP адрес запрашиваемого сайта. С помощью полученных сведений ПК связывается с сервером, где хранится необходимый сайт.
Программа Apache обеспечивает функциональную возможность передачи файлов с компьютера сервера на компьютер пользователя. Такое взаимодействие становится возможным благодаря присвоению каждому серверу собственного IP адреса. Браузер на ПК самостоятельно обрабатывает полученную информацию и преобразует ее к виду веб-страницы.
Роль DNS – сервера в принципах работы сайта
DNS – сервер является промежуточным звеном между ПК и сервером, на котором хранится сайт. Запомнить и ввести в адресную строку доменное имя веб страницы намного проще, чем провести те же операции с IP адресом. DNS находит уникальный набор цифр, соответствующий данному доменному адресу, и передает его браузеру.
Доменный адрес сайта
Доменный адрес — уникальное имя, присвоенное данному сайту. Именно его пользователь вводит в адресную строку для перехода на желаемую веб страницу. В случае с коммерческим сайтом рекомендуется выбирать простое имя, связанное с названием компании или родом оказываемых услуг. Выбор короткого, удобного для запоминания доменного адреса является одним из основных принципов оптимизации сайта.
Именно его пользователь вводит в адресную строку для перехода на желаемую веб страницу. В случае с коммерческим сайтом рекомендуется выбирать простое имя, связанное с названием компании или родом оказываемых услуг. Выбор короткого, удобного для запоминания доменного адреса является одним из основных принципов оптимизации сайта.
Отличительные принципы работы интернет магазина
Схема взаимодействия пользователя с коммерческим сайтом отличается от обыденного поиска информации на других типах веб страниц. Продающие сайты содержат в себе набор целевых действий, которые посетитель должен совершить. Дизайн и функциональное наполнение такого ресурса мотивируют потенциального покупателя на добавление товара в корзину, заказ обратного звонка или оплату покупки.
Основные принципы работы интернет магазина, отличающие этот тип сайта от других, состоят в обеспечении комфортного приобретения товара, его оплаты, доставки и получения. Для этого формируются пошаговые схемы взаимодействия пользователя с веб страницей.
Подтверждение заказа
Следом за оформлением заказа клиент должен получить обратную связь. Главный принцип работы интернет магазина состоит в постоянном взаимодействии с потребителем, поддержании связи и урегулировании всех формальностей.
Функциональные возможности качественной веб страницы должны предоставлять клиенту выбор. Некоторые люди не любят общаться по телефону, в то время как другие не доверяют любого рода сообщениям.
Сотрудники интернет магазина или автоматический клиент поддержки должен уведомить заказчика о наличии товара на складе, технологии оплаты и примерной дате доставки заказа.
Удержание клиента
На основании сделанного выбора и сведений, внесенных в форму обратной связи, следует продолжить работу с клиентом и после получения оплаты. Такое сотрудничество условно делят на две категории:
- получение отзыва о работе интернет магазина;
- ознакомление с акциями и новыми поступлениями с целью повторного оформления заказа.

Сбор объективного мнения об удобстве использования веб страницы поможет повысить показатели эффективности и реорганизовать сайт в будущем. Регулярное уведомление потенциального потребителя о скидках и новых товарах повысит доходность предприятия.
Основные принципы работы интернет магазина не отличаются от тонкостей функционирования любого другого сайта. Тем не менее, при разработке коммерческой веб страницы наши специалисты уделяют особенное внимание формам обратной связи, встроенным виджетам оплаты и простоте достижения целевых действий.
Все аксессуары – Logic
перейти к содержаниюОчистить все
16 товаров
Продажа
Продажа
Продажа
Продажа
Продажа
Распродажа
Продажа
Этот веб-сайт использует JavaScript для предоставления скидок. Чтобы иметь право на скидки, включите JavaScript в своем браузере.
Чтобы иметь право на скидки, включите JavaScript в своем браузере.
Логика в Интернете — Веб-архитектура
Логика в Интернете — веб-архитектура Тим Бернерс-ЛиДата: 1998, последнее изменение: $ Дата: 27.08.2009 21:38:07 $ $Автор: timbl $
Статус: только личный просмотр. Статус редактирования: первый вариант.
До вопросов дизайна
Это немного смотрит на семантический веб-дизайн в свете чтение по формальной логике системы Access Limited Logic, в частности, и в свете логических языков в общий. Проблема здесь в том, что я не логик, и поэтому я я должен вступить в это как очарованный репортер мир, в котором я не обладаю интимным опытом.
Введение
Semantic Web Toolbox обсуждает
шаг из Интернета как хранилища плоских данных
без логики до уровня, на котором можно выразить
логика.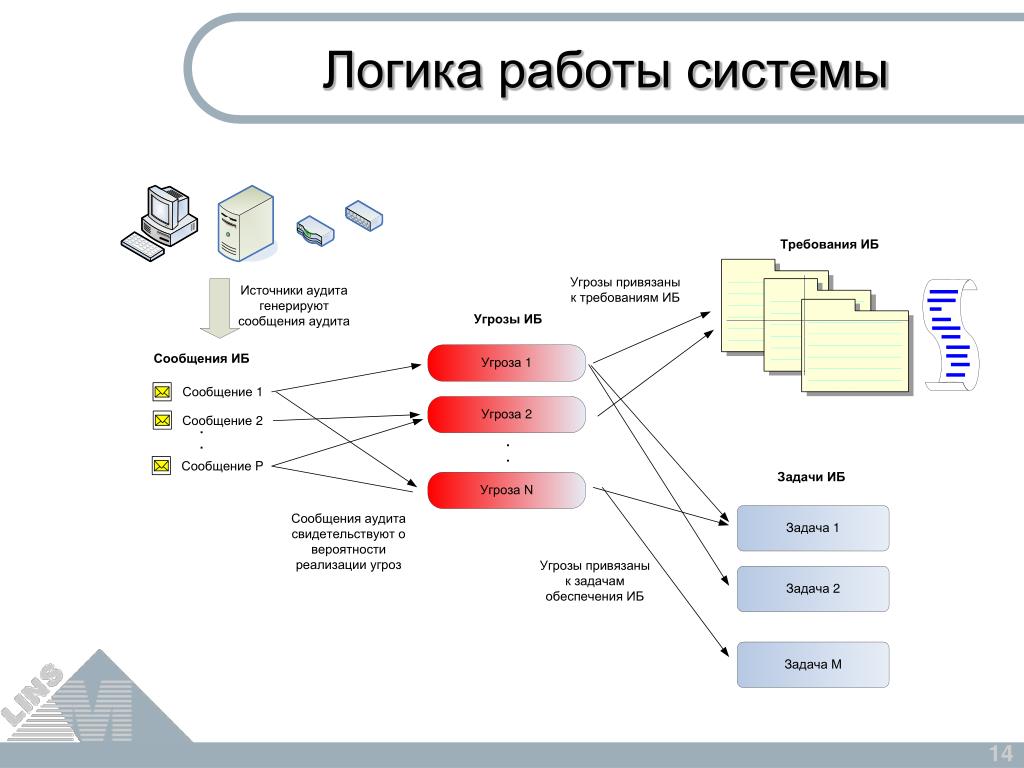 Это то, что представление знаний
системы были осторожны.
Это то, что представление знаний
системы были осторожны.
Семантическая паутина имеет другой набор целей, чем большинство системы логики. Как отметили Кроуфорд и Койперс в [Crawf90],
[…] система представления знаний должна иметь следующие свойства:
- Должен иметь достаточно компактный синтаксис.
- Он должен иметь четко определенную семантику, чтобы можно было сказать точно, что изображается.
- Он должен иметь достаточную выразительную силу, чтобы представить человеческое знание.
- Он должен иметь эффективную, мощную и понятную механизм рассуждения
- Должен использоваться для создания больших баз знаний.
Однако оказалось трудным достичь третьего и четвертые свойства одновременно.
Цель семантической паутины состоит в том, чтобы быть объединяющей системой, которая будет
(подобно сети для человеческого общения) быть таким же безудержным
насколько это возможно, чтобы сложность реальности могла быть
описано.
(Это фундаментальное изменение целей от систем KR к
семантическая сеть во многом аналогична изменению цели с
обычные гипертекстовые системы к оригинальному веб-дизайну
отказ от согласованности ссылок в пользу выразительной гибкости
и масштабируемость.
Если есть семантическая веб-машина , то это валидатор доказательств, а не доказатель теорем. Он не может найти ответы, он даже не может проверить правильность ответа, но может следуйте простому объяснению, что ответ правильный. Семантическая паутина как источник данных должна быть кормом для автоматические системы рассуждений многих видов, но как таковые не система рассуждений.
Большинство систем представления знаний различают
«правила» вывода и другая достоверная информация. В некоторых
случаях это связано с тем, что правила (например, замена в
формулы) не могут быть записаны на языке — они определены
вне языка. На самом деле набор правил, используемых
система часто не только формально достаточно избыточна, но и
произвольный.
Существует много связанных способов, которыми подсистемы могут быть созданный
- Семантический веб-язык может быть подмножеством удаление операций и аксиом и правил;
- Набор операторов может быть ограничен тем, что из конкретные документы или веб-сайты;
- Форма используемых формул может быть ограничена, например использование схем документов;
- Решения по проектированию приложений могут приниматься таким образом, чтобы
специально гарантировать поддающиеся обработке результаты с использованием общих
двигатели рассуждений.
- Доказательства могут быть построены полностью вручную программы для конкретных приложений

Например, Access Limited Logic ограничен (как я понять это) к отношениям r(a,b), доступным, когда r равно доступ, и использует правила вывода, которые только переходят по цепочке по таким ссылкам. Так же есть «разметка» паутины путем разделения правил, чтобы ограничить сложность.
Таким образом, для семантической сети в целом нам требуется сговорчивый
- Непротиворечивость в том, что невозможно вывести противоречие (без указания)
- Сила в том, что все приложения должны быть подмножествами
Заземление в реальности
С философской точки зрения семантическая сеть производит больше, чем набор
правила обращения с формулами. Он определяет документы по
Сеть имеет социально значимое значение. Поэтому
недостаточно просто продемонстрировать, что можно
ограничить семантическую паутину так, чтобы сделать ее изоморфной
конкретной алгебры данной системы, но необходимо обеспечить
что конкретное отображение определено так, что сеть
представление этой конкретной системы передает семантику
таким образом, чтобы его можно было осмысленно сочетать с остальными
семантической паутины. Электронная коммерция нуждается в надежном
таким образом, и развитие семантического
сеть есть (в 1999) необходимо обеспечить жесткую основу в
которые определяют термины электронной коммерции, прежде чем электронные
коммерция расширяется как масса смутно определенной семантики и
специальный синтаксис, который не оставляет места для автоматической обработки,
и в котором суд, а не логический
вывод улаживает аргументы.
Поэтому
недостаточно просто продемонстрировать, что можно
ограничить семантическую паутину так, чтобы сделать ее изоморфной
конкретной алгебры данной системы, но необходимо обеспечить
что конкретное отображение определено так, что сеть
представление этой конкретной системы передает семантику
таким образом, чтобы его можно было осмысленно сочетать с остальными
семантической паутины. Электронная коммерция нуждается в надежном
таким образом, и развитие семантического
сеть есть (в 1999) необходимо обеспечить жесткую основу в
которые определяют термины электронной коммерции, прежде чем электронные
коммерция расширяется как масса смутно определенной семантики и
специальный синтаксис, который не оставляет места для автоматической обработки,
и в котором суд, а не логический
вывод улаживает аргументы.
На практике значение семантических веб-данных основано на
несемантические веб-приложения, которые взаимодействуют с
семантическая сеть. Например, перевод валюты или электронная торговля.
приложения, которые принимают семантический веб-ввод, определяют для
практических целях, какие условия в валютном переводе
инструментальное средство.
Например, перевод валюты или электронная торговля.
приложения, которые принимают семантический веб-ввод, определяют для
практических целях, какие условия в валютном переводе
инструментальное средство.
Аксиоматическая основа
@@I [DanC] думаю, что этот раздел устарел из-за недавнего мысли [2002] о парадоксе и исключенная середина
На уровне логики первого порядка нам действительно не нужно выбрать один набор аксиом в том смысле, что есть эквивалентные варианты которые приводят к очевидно одинаковым результатам.
(Милый на уровне пропозициональной логики кажется [Беррис,
p126] быть набором Никода, в котором nand (в наборе инструментов XML  )
)
Предположим здесь свойства логики первого порядка.
Если мы добавим что-то еще, мы должны быть осторожны, чтобы это не либо быть определимым в терминах множества первого порядка, либо получившийся язык является подмножеством хорошо зарекомендовавшего себя логического системы — иначе нам предстоит проделать большую работу по установлению новая система!
Неразрешимость и неразрешимость
Это две цели, к которым мы явно не стремимся в Semantic Web, чтобы получить взамен выразительную силу. (Мы по-прежнему требуем последовательности!). Мир полон неразрешимые утверждения и неразрешимые проблемы. семантическая сеть должна дать возможность выражать такие вещи.
Кроуфорд и Кейперс То же самое объясняют во введении. их отрицание во ВСЕЙ бумаге,
«Опыт работы с формально заданным представлением знаний системы выявили компромисс между выразительной силой систем представления знаний и их вычислительных сложность.
 Если, например, представление знаний
система так же выразительна, как исчисление предикатов первого порядка,
то проблема решения того, что агент мог бы логически
вывести из своей базы знаний неразрешимо»
Если, например, представление знаний
система так же выразительна, как исчисление предикатов первого порядка,
то проблема решения того, что агент мог бы логически
вывести из своей базы знаний неразрешимо» Должны ли мы на практике решать, какой вывод агент мог бы сделать?
из его логической базы? Нет, не в целом. Агент может иметь
различные виды мыслительных механизмов, а на практике также
различное количество подключений, место для хранения, доступ к
индексы и вычислительная мощность, которая будет определять, что это
на самом деле выведет. Зная, что определенный алгоритм может быть
недетерминированный полином размера всей Сети может
совершенно бесполезна, так как даже линейное время было бы вполне
непрактично. Практическая вычислимость может быть обеспечена
топологические свойства паутины, или существование ноу-хау
ярлыки, такие как предварительно скомпилированные индексы и окончательные
эксклюзивные списки.
Сохранение языка менее мощным, чем предикат первого порядка исчисление вполне разумно в приложении, но не для Интернета.
Разрешимость
Мечта логиков прошлого века найти языки в что все предложения были либо истинными, либо ложными, и доказуемо так. Это включало попытку ограничить язык, чтобы избежать возможности (например) внутренне противоречивого утверждения, которые нельзя классифицировать как истинные или нет истинный.
В семантической паутине это выглядит очень академической проблемой.
когда на самом деле все равно оперируют массой ненадежных
данных в любой момент и ограничивает то, что можно использовать, до ограниченного
подмножество сети. Ясно, что нельзя вывести
противоречивое утверждение, но в этом нет ничего плохого.
язык достаточно силен, чтобы выразить это. Действительно,
системы одобрения должны дать нам возможность сказать, «что
утверждение ложно», и поэтому петли, которые, если верить, доказывают
внутренне противоречивые возникнут случайно или намеренно. А
типичная реакция системы, которая находит внутренне противоречивое
заявление может быть похоже на ответ на обнаружение
противоречие, например, перестать доверять информации
из того же источника (или открытого ключа).
А
типичная реакция системы, которая находит внутренне противоречивое
заявление может быть похоже на ответ на обнаружение
противоречие, например, перестать доверять информации
из того же источника (или открытого ключа).
Рефлексия: цитирование, контекст и/или логика высшего порядка
@@хм… лучше заголовок раздела? может просто цитата или контексты? одно место, где нам действительно нужно больше, чем ХОЛ — это индукция.
Тот факт, что [Баррис п___] «не имеет хорошего набора аксиом
и правила логики высшего порядка» разочаровывает не только в
что это отбивает желание писать здравый смысл
математически, но и потому, что операции, которые кажутся
естественным для электронной коммерции кажется на первый взгляд
логика высшего порядка. Существует также фундаментальная приятность
наличие системы, достаточно мощной, чтобы описать свои собственные правила,
конечно, так же, как кто-то ожидает, что сможет написать компилятор
для языка программирования на том же языке (@@нужно
учиться ссылки от Hayes , особенно «Результаты Тарского
на мета-описания (непротиворечивый язык не может быть одинаковым
выразительная сила как собственная метатеория), парадокс Монтегю
(показывая, что даже довольно слабые языки не могут последовательно
описать свою семантику)» . Когда Фреге попытался
логика второго порядка, как я понимаю, Рассел показал, что его
логика была несовместима. Но можем ли мы создать язык, на котором
непротиворечив (вы не можете вывести противоречие из его
аксиомы) и все же позволяет, например:
Когда Фреге попытался
логика второго порядка, как я понимаю, Рассел показал, что его
логика была несовместима. Но можем ли мы создать язык, на котором
непротиворечив (вы не можете вывести противоречие из его
аксиомы) и все же позволяет, например:
- Реалистичная модель человеческого доверия
- Запишите преобразование XML в логику RDF, чтобы разрешить теорема, которую нужно доказать из необработанного XML (и аналогичным образом определить синтаксис XML в логике, позволяющий доказывать теорему из поток байтов) и его использование;
Заманчиво написать такое правило, которое позволяет вывод тройки RDF из сообщения, семантическая содержания можно алгебраически вывести эту тройку.
всего сообщения,t, r, x, y (
(подписано(сообщение,К)
& производное(t, сообщение)
& тема (т, х)
& предикат (t, r)
& объект(т, у))
-> г (х, у)
)
(где K — конкретный постоянный открытый ключ, t — тройной)
Это разрушает границу между посылками, которые касаются
механика языка и вывод, который
о предмете языка. Нам действительно нужно
для этого, или можно обойтись несколькими независимыми уровнями
машин, позволяя одной машине подготовить «правдоподобное»
поток сообщений и разобрать его на граф, а затем второй
машина, которая не разделяет пространство знаний с первой,
рассуждения о результате? Мне это кажется безнадежным, т.
на практике нужно направить поиск внешнего интерфейса
для новых документов из нужд рассуждений задней
конец. Но это все домыслы.
Нам действительно нужно
для этого, или можно обойтись несколькими независимыми уровнями
машин, позволяя одной машине подготовить «правдоподобное»
поток сообщений и разобрать его на граф, а затем второй
машина, которая не разделяет пространство знаний с первой,
рассуждения о результате? Мне это кажется безнадежным, т.
на практике нужно направить поиск внешнего интерфейса
для новых документов из нужд рассуждений задней
конец. Но это все домыслы.
Перегрин пытается классифицировать потребности и проблемы с логика высшего порядка (HOL) в [Peregrin]. Его описание Хенкинское понимание HOL, в котором предикаты являются подкласс объектов («индивидуумы»), по-видимому, описывает мой текущее понимание отображения RDF в логику, с Предикаты RDF, бинарные отношения, являющиеся подклассом RDF узлы. Конечно в RDF можно вывести тип «свойство» от использования любого URI в качестве предиката:
forall p,x,y p(x,y) -> тип(p, свойство)
и мы предполагаем, что предикат «утвердить» 
для всех p,x,y утверждение(p,x,y) <--> p(x,y)
поэтому мы движемся между формулировкой второго порядка и формулировка первого порядка.
(2000) Опыт работы [ППШ] кажется, демонстрирует, что логика высшего порядка очень реалистичный способ объединения этих систем.
(2001) Обработка контекстов в [CLA] кажется совместимым с дизайном, который мы реализовали.
Кажется очевидным, что ВОЛ недостаточна в том, что какая-то индукция представляется необходимой.
Я согласен с Тейтом (Финитизм, журнал философии, 1981, 78, с. 524-546), что ПРА является НЕОБХОДИМОЙ И ДОСТАТОЧНОЙ логикой для о логике и доказательствах
Роберт С. Бойер, 18 апреля 93
также: пра.n3, N3 транскрипция имени Питер Субер, Теория рекурсивных функций
также: ACL2:
Точное описание логики ACL2 Кауфманн и
Мур 22
апрель 1998 г. ,
запись в блокноте rdf от 26 марта
,
запись в блокноте rdf от 26 марта
(для другого вида индукции, т. е. в отличие от дедукции, см.: Ограничение Маккарти, 1980.)
Еще предстоит решить (1999)
Мне лично нужно понять, на что наложены ограничения логика высшего порядка… и которые являются жесткими ограничениями и которые являются нерешенными областями.
Была ли формулировка Фреге логики второго порядка (которая должна быть конечно формулировкой здравого смысла) глючит в этом Рассел обнаружил, что это может привести к противоречию, или мы действительно найти невозможно представить математическое система, чтобы следовать рассуждениям здравого смысла? Да, Фреге кажется использовали классическую логику, согласно которой любое предложение должно быть истинным или ложным.
Когда мы говорим, что есть действительные предложения, которые не могут быть
производный — что именно мы подразумеваем под «действительным»? В предикате
логике, достоверность может быть определена таблицей истинности, т. е.
оценка для всех оценок истинности переменных
[Беррис]. Фактически этот метод эквивалентен разрешению
алгебраически отображать в непересекающуюся (скажем) нормальную форму, и поэтому
не является операцией «вне» языка. В любой логике с
неограниченные множества это не практично. Обычно мы отступаем
на некоторой логике, такой как здравый смысл вне языка под
обсуждение. В логике высшего порядка интуиция подсказывает, что мы
должны быть в состоянии построить такое доказательство действительности в
сама логика. Теорема Геделя о неполноте
специально рассматривает разницу между валидностью и
выводимость, так что, возможно, хорошее описание этого [DanC
рекомендует The Unknownable@@] содержать необходимые
различия.
е.
оценка для всех оценок истинности переменных
[Беррис]. Фактически этот метод эквивалентен разрешению
алгебраически отображать в непересекающуюся (скажем) нормальную форму, и поэтому
не является операцией «вне» языка. В любой логике с
неограниченные множества это не практично. Обычно мы отступаем
на некоторой логике, такой как здравый смысл вне языка под
обсуждение. В логике высшего порядка интуиция подсказывает, что мы
должны быть в состоянии построить такое доказательство действительности в
сама логика. Теорема Геделя о неполноте
специально рассматривает разницу между валидностью и
выводимость, так что, возможно, хорошее описание этого [DanC
рекомендует The Unknownable@@] содержать необходимые
различия.
Интересно, можно ли найти ответы в Интернете…
После беседы в коридоре с Питером SP-S, собрание DMAL 2001/2/14:
Проблема парадокса заключается не только в возможности выразить
парадокс, но логика такова, что просто рассмотрение
парадокс приводит к тому, что можно вывести ложь. Можно
возражать тогда, либо с возможностью выразить
парадокс, или с аксиомой «р или не р». Логика, которая пытается
получить выше логики первого порядка можно разделить на две группы в
Сюда. Существуют наборы логик, которые используют наборы, но ограничивают
каким-либо образом — например, требуя, чтобы наборы были «хорошо
сформированы», что означает, что они либо пусты, либо содержат по крайней мере
один элемент, который не пересекается с самим множеством. Эти
трюки ограничивают логику, так что вы не можете на самом деле иметь
Множество парадокса Рассела (из всех множеств, не являющихся членами
самих себя), поскольку вы исключаете такие вещи как неправильно сформированные. Как
Питер признался, что в сети этот маршрут кажется глупым.
когда люди будут выражать парадоксы.
Можно
возражать тогда, либо с возможностью выразить
парадокс, или с аксиомой «р или не р». Логика, которая пытается
получить выше логики первого порядка можно разделить на две группы в
Сюда. Существуют наборы логик, которые используют наборы, но ограничивают
каким-либо образом — например, требуя, чтобы наборы были «хорошо
сформированы», что означает, что они либо пусты, либо содержат по крайней мере
один элемент, который не пересекается с самим множеством. Эти
трюки ограничивают логику, так что вы не можете на самом деле иметь
Множество парадокса Рассела (из всех множеств, не являющихся членами
самих себя), поскольку вы исключаете такие вещи как неправильно сформированные. Как
Питер признался, что в сети этот маршрут кажется глупым.
когда люди будут выражать парадоксы.
У другого маршрута также есть много последователей. Некоторые из них,
говорят, сложно. Но кажется, что путь может только
быть в этом направлении.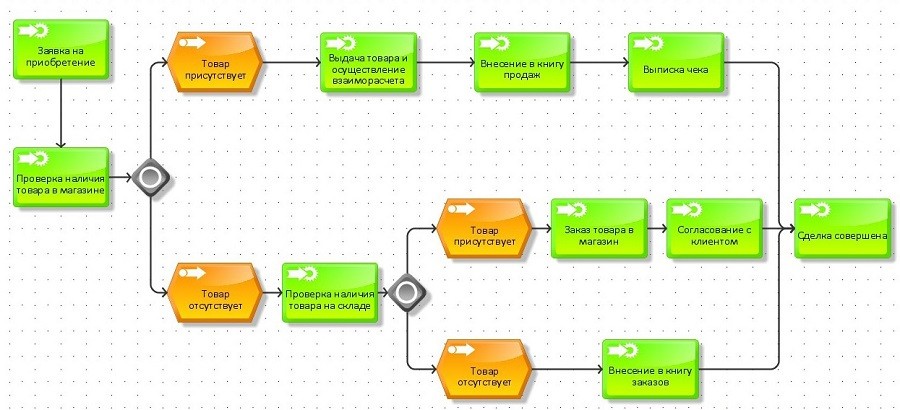 Тем временем на ранчо я замечаю
что большинство семантических веб-приложений, которые я
играя с правилами и аксиомами, которые вовсе не
полный. Каждое приложение имеет свои наборы аксиом и может
быть индивидуально доказано непротиворечивым (или нет). Так что в один конец
вперед для стандартов будет заключаться в том, чтобы создать экземпляр, позволяющий
каждый документ и сообщение в семантической паутине должны иметь
указатель на словарь, который он использует, включая его разновидности
логических связок и связанных с ними аксиом.
Тем временем на ранчо я замечаю
что большинство семантических веб-приложений, которые я
играя с правилами и аксиомами, которые вовсе не
полный. Каждое приложение имеет свои наборы аксиом и может
быть индивидуально доказано непротиворечивым (или нет). Так что в один конец
вперед для стандартов будет заключаться в том, чтобы создать экземпляр, позволяющий
каждый документ и сообщение в семантической паутине должны иметь
указатель на словарь, который он использует, включая его разновидности
логических связок и связанных с ними аксиом.
@@@
Сопоставление моделей RDB и SM — определение URI; нули; и т. д.
@@проза
Пэт Хейс упомянул логику, в которой закон исключенного
среднего не существует — что важно, как всегда
рассмотрим парадокс, который не является ни истинным, ни ложным. Посмотреть электронную почту
01. 09.2000
09.2000
Я думаю, что более подходящей «базовой» логикой могло бы быть обобщенная логика предложения рога. Это похоже на подмножество предложения рога FOL, которое используется в логике программирование, а вместо полного отрицания (которое вычислительно затратный) или отрицание по отказу (что дешевый, но грубый, немонотонный), он использует элегантный промежуточная идея, называемая интуиционистской (или конструктивной) отрицание (которое похоже на полное отрицание, но исключает доказательства от противного: в основном он настаивает на более высоком стандарт доказуемости, чем классическое отрицание. В интуиционистские рассуждения, знаменитый совет Холмса о исключение невозможного не всегда применимо.) вычислительно податлив, полностью монотонен и имеет аккуратная, элегантная семантическая теория, стоящая за этим. Он ускользает от некоторых ограничения логики Хорна, сохраняя при этом многие ее преимущества.
цитируется без разрешения. DanC рекомендует непротиворечивость и «Исключенная середина» в «Логическом» Питера Субера. Заметки к курсу систем как объяснение интуиционистского логика. TimBL отметил то же самое, что и я при первом чтении:
В мире метаматематики интуитивисты не вовсе не экзотика, несмотря на центральное положение PEDC (отсюда PEM) к обычному смыслу непротиворечивости. Их оппоненты не презирают их как иррационалистов, но если ничего, пожалей их за угрызения совести, которые не позволяют чтобы они наслаждались «совершенно хорошей» математикой.

— сократическая полнота, как в [ Crawf90 ], имеет прямое отношение? хммм@@
решения парадоксов вокруг wtr в KIF: сложный в KIFv3, проще, больше ограниченный в более поздней спецификации KIF. (материал KIF/RDF от июля 2000 г.)
Рекомендации
[PCA] Подтверждение переноски Аутентификация . Эндрю В. Аппель и Эдвард В. Фельтен, 6-я конференция ACM по компьютерной и коммуникационной безопасности, 19 ноября99. (фон) Открытие марта 2000 года. на основе [ЛФ]
[Беррис] Стэнли Н. Беррис, Логика для Математика и информатика, Прентис Холл, 1998.
[BurrisSup] Дополнительный текст выше.
[Чэн] Бумага модели ERM, доступная в [Лапланте]
[ConnollySoLREK] Домашняя страница Дэна Коннолли для этого
вид вещи. «Исследование лингвистики: представление и
Обмен знаниями».
«Исследование лингвистики: представление и
Обмен знаниями».
[Crawf90]
ВСЕ: Формализация рассуждений с ограниченным доступом
Дж. М. Кроуфорд [email protected]
Бенджамин Куйперс [email protected]
Департамент компьютерных наук
Техасский университет в Остине
Остин, Техас 78712
25 мая 1990 г.Абстрактный
Логика с ограниченным доступом (ALL) — это язык знаний представление, формализующее ограничения доступа присущие сетевой базе знаний. Где классический дедуктивный метод или логический язык программирования будет извлекать все утверждения, которые удовлетворяют заданному шаблону, логика с ограниченным доступом извлекает все доступные утверждения следуя доступному пути доступа. Сложность Таким образом, вывод не зависит от размера базы знаний и зависит только от ее локальной связи.
 Логика с ограниченным доступом, хотя и неполная, все же
определенная семантика и ослабленная форма полноты, Сократовская полнота , которая гарантирует, что для
любой запрос, являющийся логическим следствием
базе знаний существует ряд запросов после
который исходный запрос будет успешным. Эта глава
представляет обзор ВСЕХ и набрасывает доказательства его
Сократовская полнота и полиномиальная временная сложность.
Логика с ограниченным доступом, хотя и неполная, все же
определенная семантика и ослабленная форма полноты, Сократовская полнота , которая гарантирует, что для
любой запрос, являющийся логическим следствием
базе знаний существует ряд запросов после
который исходный запрос будет успешным. Эта глава
представляет обзор ВСЕХ и набрасывает доказательства его
Сократовская полнота и полиномиальная временная сложность.Алджернон документы
[Crawf91] Дж. М. Кроуфорд и Б.Дж. Койперс, «Отрицание и доказательство противоречием в доступе». Ограниченная логика», в Материалы Девятого национального Конференция по искусственному интеллекту (AAA1-91) , Кембридж, Массачусетс, 1991 г.
[Дата] Введение в базу данных Системы, 6-е изд., Эдисон-Уэсли, 1995 г.
[Дэвис] Рэндалл Дэвис и Ховард Шроб, «6. 871: Основанный на знаниях
Курс «Прикладные системы», информационная поддержка, 1999 г.
871: Основанный на знаниях
Курс «Прикладные системы», информационная поддержка, 1999 г.
[CLA] Контексты: A Формализация и некоторые приложения, Раманатан В. Гуха, 1991 Стэнфордская докторская диссертация. см. также: ContextLogic.lsl, май Транскрипция 2001 г. на лиственницу.
[ХОЛинтро] М. Дж. К. Гордон и Т. Ф. Мелхэм, «Введение в среду для доказательства теорем HOL. для логики высшего порядка», издательство Кембриджского университета, 1 993 ISBN 0 521 44189 7
[Лаплант] Филипп Лаплант (ред.), «Великие статьи по компьютерным наукам», Запад, 1996 г., ISBN: 0-314-06365-X
[Марчиори98] М. Маркиори, Металлог бумага на QL98
[Перегрин] Ярослав Перегрин, «Что Нужна ли, когда ей нужна «логика высшего порядка?» Труды LOGICA’96, FILOSOFIA, Praha, 1997, 75-92
[VLFM] Дж. П. Боуэн, Формальный
Методы в виртуальной библиотеке WWW
П. Боуэн, Формальный
Методы в виртуальной библиотеке WWW
@@
Многое из этого следует за Дэном Коннолли. исследования, и так много ссылок было предоставлено прямо или косвенно со стороны Дэна. Другие указания от Дэна Коннолли
- ДК на необходимость ХОЛ — личное общение
[LF] Харпер, Хонселл, Плоткин «А
Структура определения логики», Журнал ACM,
Январь 1993 г., по-видимому, является основополагающим документом о бумаге ELF.
(АКМ
pdf)
Коннолли (попытка)
транскрипция на лиственнице
Пэт Хейс, Research Interests and Selected Papers содержит информацию о модели времениImpl
Рейтер, Р., О закрытых мировых базах данных, в: Х. Галлер и Дж. Минкер (ред.), Логика и данные Основы , Пленум, 1978, стр. 55-76. Определяет закрытый мир Предположение? Ссылка из CIL
Перлис, Д.