
Как Яндекс перепридумал поиск для разработчиков / Хабр
У вас бывало, что открываешь поиск, ищешь что-то по программированию и не находишь ответ? Тогда эта история для вас.
Меня зовут Алексей Степанов, я руковожу службой исследований машинного обучения поиска Яндекса. Сегодня я расскажу непростую историю. Она про проблему, до решения которой у нас слишком долго не доходили руки. Из поста вы узнаете, почему стандартная метрика качества поиска не учитывала интересы разработчиков и как мы её улучшили. Расскажу про новую нейросеть CS YATI, обученную понимать таких же айтишников, как и мы. Ну и про грабли на нашем пути тоже расскажу, куда без них.
Этот пост основан на моём докладе с Data Fest 2022, но не во всём (мой коллега Максим Хурсанов @Maxim2207 существенно расширил историю).
К нам в команду поиска регулярно прилетают жалобы от коллег на качество ранжирования по тем или иным запросам, специфичным для разработчиков. Например, выдача по запросу [C++ list find] ещё недавно выглядела вот так:
Слова все нужные, а ответа нетОднако у нас были продуктовые метрики, которые говорили: ребята, успокойтесь, у вас всё хорошо, вы как минимум не хуже коллег по индустрии. В результате у нас сложилось противоречие. С одной стороны, метрики говорили, что с качеством всё хорошо. А с другой, мы сами пользовались поиском в работе и сами регулярно были недовольны результатами. В один прекрасный день нам надоело это терпеть, и мы решили наконец-то разобраться.
В результате у нас сложилось противоречие. С одной стороны, метрики говорили, что с качеством всё хорошо. А с другой, мы сами пользовались поиском в работе и сами регулярно были недовольны результатами. В один прекрасный день нам надоело это терпеть, и мы решили наконец-то разобраться.
Исправляем метрики
Метрики — это инструмент, с помощью которого мы ставим задачи и контролируем качество их исполнения. Невозможно что-то улучшить в такой сложной системе, как ранжирование, если у вас нет корректных метрик для измерения изменений. Поэтому наша история начинается именно с них.
Больше года назад мы собрались небольшой компанией разработчиков в переговорке, заказали пиццу, начали вводить в поиск реальные запросы пользователей по программированию и оценивать результаты, ориентируясь на свой опыт и знания в предметной области.
В любой непонятной ситуации заказывай пиццуИтак, нам нужно было выяснить, какая из поисковых систем лучше отвечает на специфичные запросы про разработку. Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Что значит «лучше отвечает»? Предположили, что это означает более полезный документ (так мы называем страницы в интернете) в топ-1 результатов выдачи. Мы взяли около 30 программистских запросов и документы в топ-1 Яндекса и Google. Перемешали, чтобы никто не знал, какие ответы откуда. Участникам нужно было сказать, какой из двух документов лучше решает задачу из запроса, или отметить, что они одинаково полезны. Три десятка попарных оценок показали, что Яндекс как минимум не выигрывает. Статистически значимой такую выборку, конечно, не назвать, но этого было достаточно, чтобы начать копать по-крупному.
Мы решили отмасштабировать встречу в переговорке с пиццей на всю компанию: писали посты в этушку (это такие внутренние блоги), выступили с призывом на хурале (еженедельной встрече всех сотрудников). Придумали процесс, в котором участники не только выбирали лучший ответ, но ещё и обсуждали свой выбор с другими разработчиками, если их мнения разошлись. Более того, взяли за привычку каждую пятницу созваниваться с разработчиками из других компаний. Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики. Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
Так нам удалось за несколько недель собрать уже не 30, а 1500 попарных оценок! К сожалению, выводы остались теми же: мы отвечаем существенно хуже, чем говорят нам метрики. Почему? Чтобы понять причину, нужно немного рассказать, как именно оцениваются результаты поиска.
С оценкой качества поиска нам помогают асессоры. Это специалисты, которые умеют отвечать на сложные смысловые вопросы и делают это лучше, чем любой ML-алгоритм. В том числе они оценивают, насколько веб-документ полезен по запросу. И наш процесс разметки не гарантировал, что на вопрос, связанный с программированием, будет отвечать асессор с опытом в программировании. Главная причина в том, что мы таких асессоров-программистов просто не наняли в достаточном количестве.
Представьте, что вас просят оценить пользу от документа на китайском языке. Как вы будете это делать, не зная язык? Правильно, искать иероглифы из запроса в тексте документа. В ряде случаев это нормальная стратегия, но далеко не всегда. К примеру, просим неспециалиста, который никогда не программировал, оценить ответ по запросу [C++ find_if]. Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.
Он видит, что в документе вполне себе есть и C++, и find, и даже if. Этот документ будет отмечен как хороший.
На самом деле среди асессоров мог найтись тот, кто разбирается в программировании. Вот только каждое задание проходит через нескольких асессоров. Если вердикт асессора с опытом не совпадал с ответами других для этого же задания, то оценка просто усреднялась и качество разметки падало.
Как решить эту проблему? Нанять больше людей с опытом в программировании размечать запросы. Так мы и поступили. Непросто найти специалистов, которые смогут разобраться в специфических запросах и прочитать код на веб-страницах. Для этого мы проверили более тысячи кандидатов и наняли сотню лучших. Но оно того стоило: оценки новых асессоров не только были согласованы друг с другом, но и коррелировали с оценками яндексоидов! Метрика, построенная на новых оценках, на порядок лучше подсвечивала проблемы ранжирования. А это значило, что мы наконец-то починили «компас» и теперь знали, куда двигаться. Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов.
Дальше наш взор устремился на модель, которая и отвечает за ранжирование документов.
Улучшаем ранжирование
Задача поиска в интернете довольно сложная. У нас есть сотни миллиардов документов. Нам надо найти среди них десять наиболее релевантных всего за сотню миллисекунд. Поэтому большинство документов отсеиваются простыми, но зато очень быстрыми алгоритмами. А вот дальше начинается самое интересное.
Финальное решение о релевантности каждого документа принимает модель на базе нашей опенсорсной технологии градиентного бустинга CatBoost. На вход модели подаются разные факторы о запросе и документе, на выходе получаем предсказание релевантности документов. Факторов исторически очень много. Но с 2020 года можно однозначно выделить самый главный — тот, что выдаёт текстовая нейросеть YATI. Это огромная сеть с архитектурой Transformer, для работы которой требуются наши суперкомпьютеры. Мой коллега Саша Готманов уже подробно рассказывал о ней на Хабре. Самое главное, что тут надо знать: технология YATI стала самым большим прорывом в истории поиска с момента внедрения Матрикснета в 2009-м. Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
Если убрать все-все остальные факторы, то качество поиска хоть и ухудшится, но не фатально. Ни один другой фактор в одиночку удержать качество не сможет.
Итак, у нас есть модели YATI и CatBoost — два ключевых компонента, от которых зависит качество поиска. Давайте улучшим их для нашей задачи!
Мы решили обучить отдельный трансформер на базе YATI, который будет в первую очередь хорошо решать задачи по программированию. Недолго думая, назвали его CS YATI (Computer Science). Почему отдельный, а не в рамках универсального YATI? Запросов, связанных с программированием, в общем потоке очень мало. Поэтому мы можем позволить себе применять более мощную модель с бóльшим числом параметров. Кроме того, мы можем итеративно обновлять и обучать её без риска что-то поломать в основной модели.
Начали с того, что скормили трансформеру огромное число текстов, связанных с программированием. Так наша новая модель выучила все специализированные словечки и лексику из области компьютерных наук.
Дальше мы собрали поисковые логи программистских запросов и документов, на которые пользователи кликали по этим запросам. И обучили CS YATI именно на них. Правда, не без хитростей.
У нас была проблема: размер документов по программированию часто довольно большой. Это значит, что наша большая модель может отрабатывать на них непростительно долго. Но при этом резать тексты и терять информацию очень не хотелось. Хотелось, наоборот, выжать из неё как можно больше качества при сохранении производительности.
Мы поисследовали различные способы оптимизации модели и пришли к следующему трюку. Вместо того чтобы сокращать число слоёв нейросети, мы стали итеративно уменьшать длину входа каждого слоя. Само по себе это ухудшает качество. Но вся соль в том, что при этом и потребление ресурсов падает, а значит, мы можем подавать больше информации на вход. В результате тонкая оптимизация позволила не только не просадить качество, но и повысить его за счёт увеличения входной информации в полтора раза.
Однако некоторые документы по программированию все равно имеют слишком большой объём. Можно было бы просто брать начало текста, но это слишком грубый способ, снижающий качество. Мы начали выбирать из документов N наиболее релевантных предложений по данному запросу и уже их передавали в трансформер. Причём мера релевантности тоже оптимизировалась под программистские тексты. Финально мы зафайнтюнили CS YATI, ориентируясь на оценки асессоров с опытом в программировании.
Итак, мы создали нейросетевую модель CS YATI, которая может похвастаться пониманием языка программистов и умеет угадывать их выбор в поиске. Осталось придумать, как это всё внедрить в текущий процесс, применить на каждом запросе и не лечь под нагрузкой. Взгляните на схему:
Выглядит логично. Применяем дополнительную нагрузку в виде CS YATI не всегда, а только для узкого среза программистских запросов. Но есть нюанс: кто будет классифицировать каждый запрос перед развилкой?
Решили, что и тут без CS YATI не обойтись. Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Благодаря тем же самым асессорам-программистам мы собрали датасет и с его помощью обучили CS YATI работать ещё и в режиме классификатора запросов — отличать программистские от всех остальных. Но главную проблему это всё равно никак не решало: модель была слишком тяжёлой, чтобы применять её на каждом запросе.
Мы воспользовались уже хорошо зарекомендовавшим себя способом — дистилляцией. Специалисты сразу поймут, о чём я, но для всех остальных скажу: дистилляция — это обучение более лёгкой нейросети «подражать» поведению более тяжёлой. Мы взяли лёгкую DSSM-подобную сеть и обучили её на результатах работы нашего трансформера CS YATI. Понятно, что качество классификации немного просело, но при этом мы сэкономили огромные вычислительные ресурсы и смогли внедрить модель в продакшен.
Схема стала выглядеть так:
Внимательный читатель в этот момент может спросить: если у нас появилась специальная версия YATI, то, может быть, нужна и специальная версия CatBoost, которая будет учитывать специфику? Мы тоже сначала посчитали это хорошей идеей. Но давайте обо всём по порядку.
Но давайте обо всём по порядку.
Мы сделали отдельный CS CatBoost, который, подобно CS YATI, будет обучен ранжировать запросы и документы по программированию. А ещё он будет независим от основного компонента CatBoost — значит, мы сможем обновлять и экспериментировать с ним без оглядки на остальную часть поиска. Для его обучения мы использовали уже собранные нами оценки асессоров-программистов. Звучит хорошо, не правда ли?
Но у такого решения были и минусы. Однажды мы на этом попались. В апреле наши коллеги выпустили в опенсорс технологию YDB и очень громко пошумели об этом (в том числе на Хабре). Настолько, что пользователи пошли в поиск и стали вводить там запрос [YDB]. Наша быстрая нейросетка IS CS QUERY DSSM корректно определяла его как программистский. Дальше правильно отрабатывал трансформер CS YATI. А вот CS-версия CatBoost не показывала ни одной новости о событии.
Чтобы осознать суть беды, нужно добавить немного контекста. В поиске есть особые запросы, которые мы называем «свежими».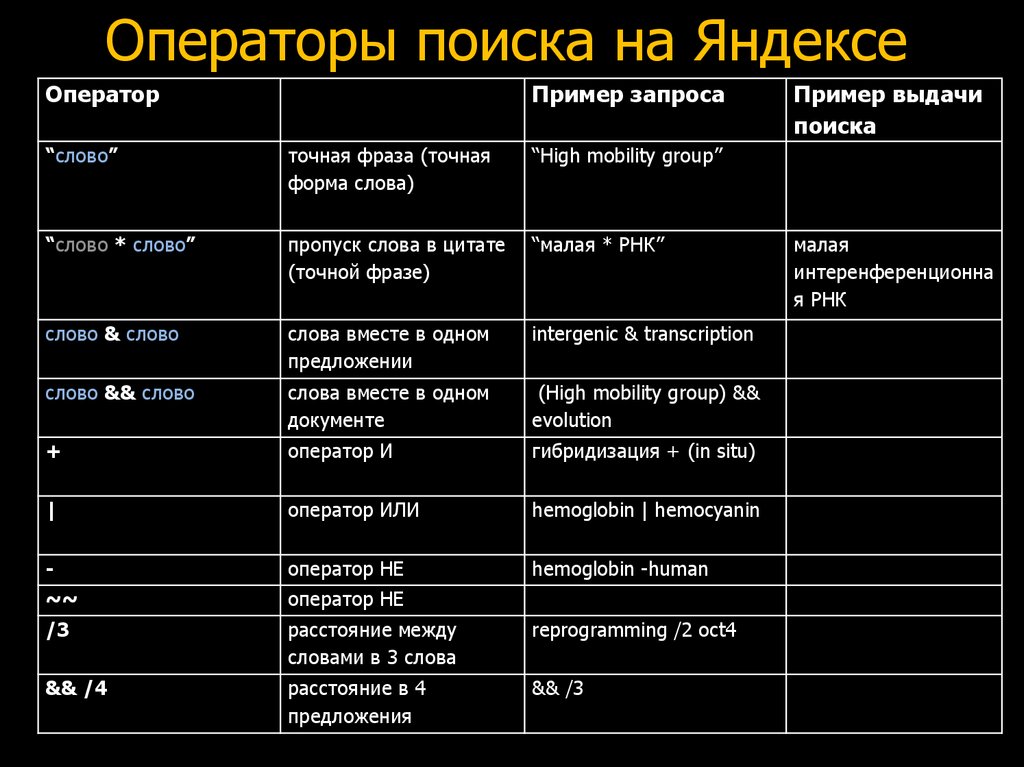 Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Это запросы, ответы на которые появились в интернете совсем недавно — от нескольких минут до нескольких дней назад. Чтобы правильно отвечать на них, недостаточно быстро индексировать интернет. Необходимо обучать модель на примерах запросов, по которым пользователи хотят видеть свежие документы, и на самих свежих документах, которые хорошо на такие запросы отвечают. Если этого не делать, то модель на подобных документах будет вести себя неадекватно. Свежие ответы либо вовсе пропадут из топа выдачи, либо будут нерелевантными.
Мы проверили, что основная версия CatBoost, которая специально обучается на свежих запросах, хорошо справлялась с запросом [YDB]. А в обучении CS CatBoost свежих запросов не было, это и приводило к проблеме. Решение с отдельной версией CatBoost для CS, которое вначале нам показалось простым, привело к тому, что мы сломали ранжирование свежих программистских запросов. Усложнять ими обучение CS CatBoost мы не хотели, и решили, что самый простой способ — объединить две модели в одну. Сейчас это так и работает в проде.
Сейчас это так и работает в проде.
Окей, у нас есть новые метрики, новый CS YATI, обновлённый CatBoost. Что ещё можно было сделать для улучшения качества ранжирования? Например, убедиться, что в данных для обучения моделей ранжирования есть всё, что нужно.
В последнее время я часто читаю новые посты по машинному обучению в телеграме. Часть постов мне потом хотелось перечитать, я шёл в поиск и… не находил их. На самом деле это логично, потому что посты из веб-версии мессенджера плохо оптимизированы для поисковых систем. Начали думать, что же мы можем сделать на своей стороне, чтобы помочь похожим на нас пользователям.
Мы собрались с командой и посмотрели, как асессоры оценивают посты в телеграме. Обнаружили, что в обучающей выборке таких постов почти не было. Мы решили это исправить: намайнили и разметили асессорами-программистами больше документов из телеграма.
Дообучение сработало. Наш поиск научился находить полезные посты в телеграме. Не просто каналы, а конкретные посты из каналов!
Итак, мы починили метрики, улучшили ранжирование и долили новые данные. Но на этом мы не остановились.
Но на этом мы не остановились.
Добавляем быстрые ответы и сниппеты
Цель поиска — не просто ранжировать ссылки, а помогать людям быстро решать свои задачи. Поэтому, помимо работы над ранжированием, мы развиваем и другие форматы. Например, совершенствуем быстрые ответы. Это такие специальные блоки, в которых поиск сразу приводит краткий ответ на запрос. По нашим подсчётам, они экономят пользователям десятки тысяч часов в сутки.
Мы улучшили в поиске быстрые ответы для сайтов, популярных среди разработчиков. Например, теперь там можно встретить ответы на вопросы со Stack Overflow. Поначалу это был просто наиболее рейтинговый ответ с платформы, который выводился в блоке справа. Отзывы коллег помогли усовершенствовать его: появился выбор из нескольких ответов, число оценок, комментариев и даже сам вопрос.
Расширенным стал не только быстрый ответ, но и сниппет в результатах поиска.
Ещё один интересный пример: мы доработали сниппет Гитхаба. Теперь прямо в выдаче можно увидеть рейтинг проекта, число форков и даже дату последнего коммита. Это поможет быстрее сделать правильный выбор.
Это поможет быстрее сделать правильный выбор.
А вот, например, новый сниппет, который помогает быстро найти команду для установки пакетов из npm, brew, pip, Pub и nuget — или сразу получить основную информацию о пакете.
Мы продолжим развивать быстрые ответы, а также добавлять сниппеты и для других сайтов тоже.
Выученные уроки
Если метрика говорит, что мы у пользователей самые лучшие, то стоит проверить эту метрику.
На скорую руку можно только прод поломать (ну или свежие CS-запросы).
Если сделали новую метрику и по ней выиграли, то это не значит, что продукт некуда улучшать. Реальную обратную связь можно получить только от пользователей. Попробуйте наш поиск для запросов по программированию и присылайте фидбэк. Теперь поделиться отзывом просто: внизу выдачи появился пункт «Сообщить об ошибке». Вместе мы можем упростить жизнь огромному числу разработчиков. Спасибо!
App Store: Команды для Яндекс Станция
Описание
Станция – это умная колонка от российской компании Яндекс. В неё встроен голосовой помощник Алиса, который не только позволяет управлять колонкой с помощью голоса, но и может ответить на большое количество различных вопросов. Яндекс.Станция имеет встроенный HDMI-порт, что позволяет подключать этот домашний помощник к телевизору и использовать как ТВ-приставку.
В неё встроен голосовой помощник Алиса, который не только позволяет управлять колонкой с помощью голоса, но и может ответить на большое количество различных вопросов. Яндекс.Станция имеет встроенный HDMI-порт, что позволяет подключать этот домашний помощник к телевизору и использовать как ТВ-приставку.
Вы можете использовать показанные команды для включения музыки, получения информации о погоде, пробках, вызова такси, заказа пиццы и многих других функций.
Это приложение «Команды для Яндекс Станция» не используется для подключения к умной колонке Яндекс.Станция. Также в этом приложении НЕТ встроенной Алисы, для использования голосового помощника вам нужно укупить Яндекс.Станцию или скачать приложение «Яндекс» – голосовой помощник встроен в них. Также Алиса встроена в умные колонки Яндекс.Станция Макс, Яндекс.Станция Мини, JBL Link, JBL Link Portable, Elari SmartBeat, LG XBOOM AI ThinQ WK7Y, Prestigio Smartmate Маяк Edition, Irbis A, Dexp smartbox.
Это приложение «Команды для Яндекс Станция» создано НЕ Яндексом и не связано с компанией.
Версия 1.24
Улучшение дизайна и производительности
Оценки и отзывы
Оценок: 51
Музыка
Минус 1 звезда!
Доработайте пожалуйста плейлист, хочется например включить плейлист и начать его не сначала, а с определённого трека, можно было бы сначала включать плейлист, а походу дела говорить включи трек номер такой. Не выговариваю буквы некоторые чтобы давать команду включать определённый трек.
Часы
Сделайте пожалуйста на большой колонке так, чтоб Часы оставались во время воспроизведения музыки
Назойливая релама при каждом действии
Это не справочник, а каталог рекламы, пользоваться крайне неудобно — при нажатии на любой пункт — всплывает реклама.
Не ставьте, потратите время.
 Не ставьте, потратите время.
Не ставьте, потратите время.Разработчик Sergey Zhizhin указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
Следующие данные могут использоваться для отслеживания информации о пользователе в приложениях и на сайтах, принадлежащих другим компаниям:
- Идентификаторы
- Данные об использовании
Связанные с пользователем данные
Может вестись сбор следующих данных, которые связаны с личностью пользователя:
- Идентификаторы
- Данные об использовании
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Sergey Zhizhin
- Размер
- 29,9 МБ
- Категория
- Справочники
- Возраст
- 4+
- Copyright
- © voiceapp.ru
- Цена
- Бесплатно
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Re: Удаление поиска яндекс.
 — Mozilla Connect
— Mozilla ConnectДа, это нелогично. Убрать Яндекс из-за необъективной системы ранжирования? DuckDuckGo делает буквально то же самое, и это даже публичное заявление: https://twitter.com/yegg/status/1501716484761997318. И если это правда, то Google, скорее всего, делает то же самое (они просто заблокировали все российские каналы YouTube, связанные с политикой).
Информация есть информация, вы учитесь ею пользоваться, а не отталкиваете людей от все другие источники информации. Да, ситуация на Украине ужасная и страшная, но не все черно-белое, и не все так однозначно. Честно говоря, живя в регионе, где сталкиваются 2 потоков пропаганды, я могу сказать, что вижу ложь с обеих сторон, вижу факты с обеих сторон, вижу манипуляции с обеих сторон. Видя все это, я приближаюсь к полной картине, где никто не невиновен, ру и американские потоки показывают факты жестокости, иногда есть доказательства, иногда опровержения, иногда опускают факты или переворачивают их, потому что нет возможности чтобы знать, кто несет ответственность. Я вижу это с обеих сторон.
Я вижу это с обеих сторон.
Честно говоря, я понимаю, почему люди не хотят проводить собственные расследования — тема слишком сложная, и проще и быстрее просто принять мнение, сформированное одной пропагандой, а другую пропаганду просто рассматривать как придирку и необъективность. , только потому, что это противоположно и противоречит вашим сформированным убеждениям. Кто кричит громче всех, тот завоевывает больше сердец, а дальше идет цепная реакция. У меня есть свое мнение, , но здесь я его не проговорюсь, потому что здесь не место.
Увидев все это, я также осознал, что это настоящая информационная война, в которой США используют большую силу цензуры, граничащую с злоупотреблением властью. Ru, возможно, использовал свою власть, чтобы блокировать сайты и в регионе RU, но на самом деле это касается только россиян, а не всего мира, и оно не блокировало крупнейшие сайты СМИ до последнего момента, когда некоторые из местных СМИ решили остановиться. вообще даже без блокировки, и в ход пошли большие пушки вроде гугла (не распространяясь на то, что Россию сейчас отменяют и в рыночной сфере). Ранжирование, цензура, изменение политики разжигания ненависти на более снисходительную, отключение российских граждан от услуг, вроде того, что поможет Украине.
Ранжирование, цензура, изменение политики разжигания ненависти на более снисходительную, отключение российских граждан от услуг, вроде того, что поможет Украине.
И это война, в которой вы приняли участие, добровольно или нет.
Принцип 2 манифеста Mozilla гласит:
Интернет является глобальным общедоступным ресурсом, который должен оставаться открытым и доступным.
И хотя вы по-прежнему разрешаете добавлять Яндекс в качестве поисковой системы вручную, его удаление способствует тому, что интернет становится не таким уж открытым, который формируется правительствами и корпорациями без конкуренции . Это дестабилизировало баланс из Принципа 9
Коммерческое участие в развитии Интернета приносит много преимуществ; баланс между коммерческой прибылью и общественной пользой имеет решающее значение.
, потому что вместо общественной пользы он сместился в сторону коммерческой выгоды (я понимаю, Google является крупным инвестором Firefox, а США — это огромный рынок, который слишком болезненно терять из-за политической позиции правительства США в отношении связей с Россия). Ни слова о политическом нейтралитете, но, думаю, это невыгодно и не совсем исполнимо — когда ты большая Компания, ты либо политический инструмент, либо не более того. Какая жалость.
Ни слова о политическом нейтралитете, но, думаю, это невыгодно и не совсем исполнимо — когда ты большая Компания, ты либо политический инструмент, либо не более того. Какая жалость.
Список 10 лучших поисковых систем (десять самых популярных в мире)
На этой странице вы найдете список 10 лучших поисковых систем за текущий год.
В конце этого руководства вы также найдете диаграмму, в которой представлены 10 самых популярных поисковых систем в сравнении с рейтингом и долей рынка.
Целью этого руководства является дать вам список десяти ведущих поисковых систем в мире, чтобы вы могли понять, какие компании имеют наибольшее влияние в Интернете. А также служить ресурсом для цитирования и ссылок в ваших собственных статьях, сообщениях в блогах и онлайн-публикациях на основе данных маркетинговых исследований.
Содержание
Список 10 ведущих поисковых систем
1. Поисковая система Google
Google занимает первое место в этом списке 10 ведущих поисковых систем, поскольку занимает наибольшую долю рынка поисковых систем, занимая около 92,01%. по состоянию на июнь 2021 года.
по состоянию на июнь 2021 года.
Ссылка: https://www.google.com
Основанное в 1997 году Сергеем Брином и Ларри Пейджем детище этих двоих превратилось в неотъемлемую часть пользовательского опыта. Сообщается, что Google меняет свой поисковый алгоритм примерно 500-600 раз в год. Это, в сочетании с точной аналитикой и тем фактом, что Google имеет наибольшее количество сайтов в своем индексе, позволяет предоставлять точные и подробные результаты конечному пользователю.
Google также является самой предпочтительной и лучшей поисковой системой для бизнеса, потому что ее алгоритм ранжирования оказывает огромное влияние на то, сколько кликов получает веб-сайт. Проще говоря, Google — это бегемот на рынке поисковых систем, которого трудно превзойти.
Прочтите этот пост о том, как найти самые популярные ключевые слова в Google.
2. Поисковая система Bing
На втором месте в десятке поисковых систем находится Bing.
Ссылка: https://www.bing. com
com
Запущен в 2009 г., поисковая система, принадлежащая Microsoft, занимает долю рынка в 2,96% и привлекает более 1 миллиарда посещений в месяц. Хотя Bing не такой большой, как Google, у него есть определенные функции, которые делают его довольно конкурентоспособным.
Например, система поиска изображений Bing известна тем, что демонстрирует четкие высококачественные изображения. Он также позволяет пользователям фильтровать изображения в соответствии с различными макетами изображений — высокими, широкими или квадратными. Отображение Bing результатов поиска видео в виде сетки миниатюр также феноменально.
Кроме того, у Bing есть программа вознаграждений, которая служит стимулом для новых пользователей. Он начисляет баллы пользователям по мере их поиска, и эти баллы можно использовать в различных торговых точках, включая магазины Microsoft, Amazon и Starbucks.
3. Поисковая система Yahoo
Третье место в десятке лучших поисковых систем мира занимает Yahoo, которая на самом деле работает на платформе Microsoft Bing.
Ссылка: https://www.yahoo.com
Поскольку Google является единственным непобедимым игроком в своей лиге, Bing и Yahoo являются самыми яростными конкурентами на рынке поисковых систем. Запущен в 1995, Yahoo — одна из старейших поисковых систем и почтовых сервисов.
Yahoo в настоящее время имеет долю рынка около 1,51% и считается больше интернет-порталом, чем поисковой системой. На самом деле он превосходит Google тем, что предоставляет более обширное предложение популярных элементов и поисковых предложений, помимо того, что пользователь может ожидать.
4. Поисковая система Baidu
Baidu является четвертой по величине поисковой системой в мире с долей рынка 1,17%. Это также самая популярная поисковая система в Китае, к ней обращаются почти 86% интернет-пользователей Китая.
Ссылка: https://www.baidu.com
Baidu получает значительную часть своего дохода от услуг онлайн-маркетинга, что делает его мощной поисковой системой для предприятий, ориентированных на китайский рынок.
5. Поисковая система Яндекса
По состоянию на последний квартал 2021 года Яндекс был пятой по популярности поисковой системой в мире и самой популярной в России с долей рынка 65% в стране. В глобальном масштабе доля рынка Яндекса составляет 1,06%. Его популярность пересекается с другими странами Восточной Европы, включая Украину, Беларусь и Казахстан.
Ссылка: https://yandex.com
Помимо поисковой системы, Яндекс также предоставляет услуги онлайн-карт трафика, онлайн-перевода, музыки и Яндекс-денег. Это особенная сокровищница для обратного поиска изображений. Это технология поисковой системы, которая позволяет пользователям вводить изображение в качестве запроса, а не слова. Он также занимает впечатляющее место как одна из лучших поисковых систем для сопоставления лиц и определения местоположения.
6. Поисковая система DuckDuckGo
Шестая лучшая поисковая система — DuckduckGo. И это одна из 10 самых популярных поисковых систем с самым быстрым ростом доли рынка.
Ссылка: https://duckduckgo.com
С января 2020 года по январь 2021 года среднесуточный объем поиска DuckDuckGo вырос на 73%; однако недавний рост замедлился примерно до 17% с января 2021 года по январь 2022 года. Это все еще значительный рост доли рынка с момента создания поисковой системы в 2008 году. %, причем более половины запросов этой поисковой системы поступают из США. Он также имеет 10 миллионов загрузок из магазина Google Play, что доказывает его популярность среди пользователей Android.
Решительная защита конфиденциальности данных DuckDuckGo отличает ее от других поисковых систем. Если вы хотите рыскать по Интернету без того, чтобы компании взламывали и продавали ваши личные данные, вы можете попробовать мобильное браузерное приложение DuckDuckGo или расширение для настольных компьютеров. Здесь ваши поиски остаются строго конфиденциальными и надежно защищенными от запросов данных или целевой рекламы.
7. Поисковая система Ask.com
Поисковая система Ask. com является седьмой по величине поисковой системой в мире. Его доля на мировом рынке составляет 0,72%, а на рынке США — 6%.
com является седьмой по величине поисковой системой в мире. Его доля на мировом рынке составляет 0,72%, а на рынке США — 6%.
Ссылка: https://www.ask.com
Ask.com — популярный поисковик вопросов и ответов, который получает до 13 миллионов запросов в день. Его пользователи самые разные: от детей, ищущих ответы на домашние задания, профессиональных фотографов, ищущих четкие изображения, университетских ученых, занимающихся академическими вопросами, до миллениалов, ищущих очередной популярный фильм для просмотра.
Поисковая система Naver, вероятно, является причиной того, что Google не может полностью доминировать на рынке поисковых систем Южной Кореи. Он был запущен в 1999 от Naver Corporation, медиа- и технологической компании, которая также владеет 50% акций Yahoo Japan. В настоящее время доля Naver на мировом рынке составляет 0,13%.
Ссылка: https://www.naver.com
Чем Naver отличается от Google?
Хорошо классифицированный интерфейс Naver, похожий на веб-портал, является сильным аргументом в пользу продажи. Если вы ищете поисковую систему с простым единым доступом к целому ряду веб-сервисов, включая новости, музыку и словари, то Naver — это именно то, что вам нужно.
Если вы ищете поисковую систему с простым единым доступом к целому ряду веб-сервисов, включая новости, музыку и словари, то Naver — это именно то, что вам нужно.
Naver также использует так называемую «комплексную службу поиска». Это означает, что когда человек ищет, например, новости о технологиях стартапов, Naver будет собирать и демонстрировать самые последние и наиболее актуальные новостные статьи из основных внутренних и международных источников на одной странице.
9. Поисковая система AOL
Следующей в нашем списке 10 лучших поисковых систем является AOL, что является сокращением от America Online.
Ссылка: https://search.aol.com
Это американский веб-портал и поставщик онлайн-услуг, базирующийся в Нью-Йорке. Основан в середине 19В 80-х годах AOL была пионером в интернет-пространстве и именно так большинство людей, у которых был модем для коммутируемого доступа, подключались к всемирной паутине. К 1995 году у AOL было около трех миллионов активных пользователей, и она была самым узнаваемым брендом в Интернете в Соединенных Штатах.
AOL управляет собственным сайтом поисковой системы, известным как поисковая система AOL. Он предлагает доступ к Интернету, онлайн-покупкам, изображениям, новостям и результатам локального поиска, а его доля на мировом рынке составляет 0,06%.
10. Поисковая система Seznam
Seznam завершает этот список 10 лучших поисковых систем в мире с долей рынка 0,05%.
Ссылка: https://napoveda.seznam.cz/en/seznamcz-web-search/
Это одна из лучших поисковых систем в Чешской Республике, привлекающая миллионы пользователей внутри страны. В настоящее время доля Google на рынке страны составляет 84%, в то время как Seznam и остальные поделили оставшиеся 16%.
Seznam был запущен в 1996 году Иво Лукачовичем как первая поисковая система в Чешской Республике. Сегодня он превратился из простой поисковой системы в поставщика онлайн-услуг с надежным порталом политических, социальных и финансовых новостей, прогнозов погоды, спорта и т. д.
Какая поисковая система №1 используется сегодня?
Google сегодня является поисковой системой №1 с долей мирового рынка 92,01%. Но в некоторых странах другие альтернативы используются чаще, чем Google, например, Яндекс в России, Naver в Южной Корее и Baidu в Китае.
Но в некоторых странах другие альтернативы используются чаще, чем Google, например, Яндекс в России, Naver в Южной Корее и Baidu в Китае.
Таблица 10 самых популярных поисковых систем
66660163 1| Рейтинг | Поисковая система | Доля рынка |
| 92.01% | ||
| 2 | Bing | 2.96% |
| 3 | Yahoo | 1.51% |
| 4 | Baidu | 1.17% |
| 5 | Yandex | 1.06% |
| 6 | DuckDuckGo | 0.68% |
| 7 | Ask.com | 0.42% |
| 8 | Naver | 0.13% |
| 9 | AOL | 0.06% |
| 10 | Seznam | 0.05% |
Data Source: StatCounter Search Engine Market Share
Check out this other page to learn подробнее о 5 лучших поисковых системах или этих страницах, чтобы увидеть 15 лучших поисковых систем, 20 лучших поисковых систем, 50 лучших поисковых систем и 100 лучших поисковых систем, перечисленных по популярности.