
Ключевые слова
Ключевые слова (словосочетания) – это слова, соответствующие тем запросам, которые вводят пользователи в строку поиска. Используются эти слова для продвижения веб-сайтов на высокие позиции в выдаче поисковиков.
Чтобы продвижение было эффективным, SEO-оптимизаторам нужно выполнить целый комплекс действий, позволяющих добиться высокого качества сайта и его соответствия всем требованиям поисковых систем. Но главное, без чего продвижение совершенно невозможно – это наличие уникальных, полезных для пользователей и грамотно оптимизированных текстов.
При написании SEO-текстов очень важно помнить: в первую очередь они предназначаются для потенциальных посетителей сайта, и только во вторую – для поисковых роботов. Поэтому SEO-копирайтер должен уметь вписывать в тексты ключевые слова так, чтобы они выглядели естественно.
Да, нелегко вписать ключевые слова вида «свадьбы организация торжеств». Но если заказчик требует точное вхождение, постарайтесь придумать что-нибудь более оригинальное, чем рассказ о пользователях, которые вводят в строку поиска эти слова именно в таком виде.
Помните о том, что текст должен быть не только оптимизированным под ключевые слова, но и легкочитаемым!
Вхождения ключевых фраз в текст
Точное вхождение ключевого слова показано в примере выше. В ключевую фразу не было внесено никаких изменений. Такой вариант использования «ключевика» может ещё называться «чистым вхождением».
Прямое вхождение – это использование в ключевой фразе знаков препинания (при этом сами слова остаются в той же форме), например:
Чтобы остались прекрасные впечатления от свадьбы, организация торжеств должна быть поручена профессионалам.
Разбавленное вхождение – в этом варианте ключевое словосочетание используется вместе с другими словами, например:
При подготовке ко дню свадьбы организация запланированных торжеств начинается задолго до праздника.
Морфологическое вхождение – слова ключевой фразы могут быть использованы в другом падеже, числе, роде. Даже могут стать другой частью речи:
Ради проведения незабываемой свадьбы организовывать торжества поручите event-агентству.
Это основные виды вхождений ключевых слов в текст. Об остальных вариантах использования «ключевиков» в SEO-копирайтинге вы сможете узнать в процессе более глубокого изучения секретов оптимизации.
Использование синонимов
Часто заказчики просят использовать в SEO-текстах синонимы ключевых слов. Это помогает не только избежать так называемого переспама (слишком большого числа вхождений слов из запроса), но и сделать текст более привлекательным и для пользователей, и для поисковых роботов.
Слова-синонимы Яндекс считает соответствующими запросу и подсвечивает их, обращая внимание пользователя не только на слово из запроса, но и на его синоним.
Вот наглядный пример:
Знаки препинания в ключевых фразах
Чтобы страница сайта хорошо ранжировалась в поиске Яндекса, ключевая фраза должна быть использована в рамках одного пассажа.
Пассаж – это фраза, которая начинается с прописной буквы и заканчивается точкой, вопросительным или восклицательным знаком. Но если после этих символов нет пробела или следующее предложение начинается с маленькой буквы, то всё объединяется в один пассаж. Однако мы же понимаем, что нормальные тексты так не пишутся.
Робот Яндекса может воспринимать как пассаж максимум 63-64 слова (мнения оптимизаторов насчет их количества различаются). Но это не значит, что можно использовать части ключевой фразы, располагая их на большом расстоянии в очень длинных предложениях. Не забывайте: текст должен быть читабельным!
Верстка текста тоже влияет на его разделение: теги, обозначающие абзац, список или перенос строки также разбивают пассаж. Поэтому можно использовать ключевую фразу в рамках только одного абзаца.
Поэтому можно использовать ключевую фразу в рамках только одного абзаца.
Резюмируем:
- в ключевых фразах можно использовать тире, запятые, двоеточия, точку с запятой, если слова из запроса не переносятся в следующий абзац (и если заказчик не требует чистого вхождения, разрешив прямое).
- Нельзя разбивать ключевую фразу точкой, вопросительным или восклицательным знаком.
В SEO-оптимизированных текстах важно также соблюдать допустимую плотность ключевых слов, но подробнее об этом мы расскажем в другом уроке курса.
Ключевые слова
Введение
Ключевые слова – это слова, на которых строится произведение. Задача данной работы – показать, что, анализируя ключевые слова в произведении, можно полнее понять его идейное содержание. Разобраться в том, какие слова являются ключевыми, помогает название произведения, обозначающее его тему. Подробно об этом в основной части работы.
Ещё одной задачей данного
исследования является попытка опровергнуть
бытующее мнение, что критики оценивают
литературные произведения с чисто
субъективной точки зрения, выдвигая
необоснованные предположения.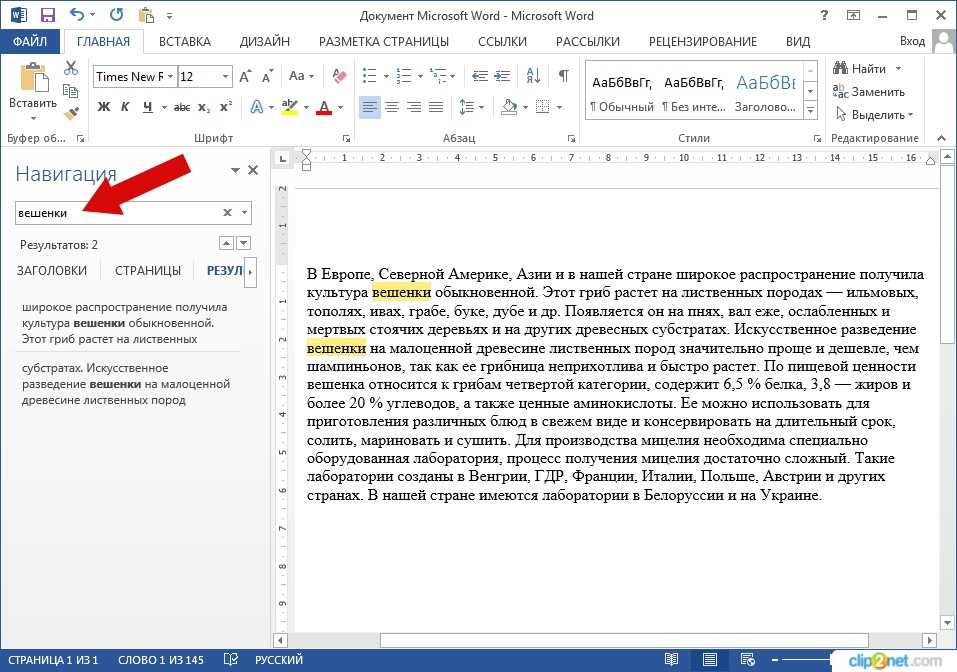 На самом
деле анализ языка действительно
помогает найти скрытые пружины
в произведении и увидеть, как
развивается мысль автора. К настоящему
времени назрела необходимость обобщения,
систематизации интеграции всех существующих
точек зрения на феномен ключевых слов
для уточнения терминологического статуса
этого понятия, выявления его теоретической
сущности, определения функциональной
природы и роли ключевых слов как особых
лексико-семантических единиц текста.
Этим и определяется актуальность
темы выпускной квалификационной работы.
На самом
деле анализ языка действительно
помогает найти скрытые пружины
в произведении и увидеть, как
развивается мысль автора. К настоящему
времени назрела необходимость обобщения,
систематизации интеграции всех существующих
точек зрения на феномен ключевых слов
для уточнения терминологического статуса
этого понятия, выявления его теоретической
сущности, определения функциональной
природы и роли ключевых слов как особых
лексико-семантических единиц текста.
Этим и определяется актуальность
темы выпускной квалификационной работы.
Научная новизна нашей работы заключается в том, что впервые предпринята попытка семантического и функционального анализа ключевых слов в рамках нескольких текстов.
Объектом исследования выступают ключевые слова как компоненты семантической структуры текста.
Предмет изучения: текстообразующая
функция ключевых слов в тексте. Цель
работы — с учетом актуальных
исследований в области лингвистики
текста последних лет рассмотреть проблему
ключевых слов в теоретическом
аспекте и определить роль этих лексических
единиц в семантической структуре художественного
текста на материале рассказов
у Л.
Достижение поставленной цели предполагает решение следующих задач:
- Описать специфику художественного текста как объекта лингвистических исследований.
- Опираясь на различные исследовательские подходы, уточнить содержание понятия «ключевые слова художественного текста», охарактеризовать основные текстовые функции этих лексико-семантических единиц.
- Выполнить контекстуально-смысловой анализ ключевых слов, выделенных в рассказах Л.Петрушевской.
Глава 1.Из истории вопроса.
1.1.Текст как объект исследования ключевых слов
В последние десятилетия
в лингвистике заметно 
Как отмечает Ю. А. Сорокин, существует около 250 различных определений понятия «Текст». «По-видимому, понятие « текст » не может быть передано только лингвистическим путем. Текст есть, прежде всего, понятие коммуникативное…» [ Сорокин , 1985].
Нельзя не согласиться с Л. Г. Бабенко и
ее соавторами, которые в специальной
работе о лингвистическом анализе художественного
текста (Бабенко и др., 2000) признают, что
общепризнанного определения текста до
сих пор не существует и что, отвечая на
этот вопрос, разные авторы указывают
на разные стороны этого явления: Д. Н.
Лихачев — на существование его создателя,
реализующего в тексте некий замысел;
О. Л. Каменская — на основополагающую роль
текста как средства вербальной коммуникации;
А. А. Леонтьев — на функциональную завершенность
этого речевого произведения и т. д. В заключение
ими приводится определение И. Р. Гальперина,
данное в 1981 г. как «емко раскрывающее
природу текста и наиболее часто цитирующееся
в литературе по вопросу».
 п. так и не
был опубликован»), а также тексты, записанные
на звукозаписывающей аппаратуре и предназначенные
для прослушивания. Далеко не у всех текстов
есть заголовки (отдельные стихотворения,
рекламные тексты, объявления, анонсы).
Наконец, не все тексты могут быть представлены
в виде последовательности сверхфразовых
единств — во всяком случае, если признавать,
что и надписи типа «Вход воспрещен»
или «Рвать цветы категорически запрещается»
тоже являют собой особые тексты.
п. так и не
был опубликован»), а также тексты, записанные
на звукозаписывающей аппаратуре и предназначенные
для прослушивания. Далеко не у всех текстов
есть заголовки (отдельные стихотворения,
рекламные тексты, объявления, анонсы).
Наконец, не все тексты могут быть представлены
в виде последовательности сверхфразовых
единств — во всяком случае, если признавать,
что и надписи типа «Вход воспрещен»
или «Рвать цветы категорически запрещается»
тоже являют собой особые тексты.
Между тем текст относится к наиболее
очевидным реальностям языка, а способы
его интуитивного выделения не менее укоренены
в сознании современного человека, чем
способы отграничения и выделения слова,
и основаны они на разумном предположении
о том, что любое завершенное и записанное
вербальное сообщение может идентифицироваться
как текст, если, конечно, и сама завершенность
текста подсказана нам тем или иным формальным
способом. Одновременно не может не поразить
то разнообразие и многообразие самих
речевых произведений, по отношению к
которым мы легко используем обозначение
«текст», и не случайно лексикографы
довольствуются указанием на то, что текстом
является «всякая записанная речь»,
и перечисляют в качестве примеров документы,
сочинения, литературные произведения
и т. п.
п.
По данным специалистов, 75 % своей жизни мы проводим в общении, где нам и необходимы те самые, заложенные в нас с детства, коммуникативные умения. С возрастом эти умения мы развиваем, наполняя знаниями о языке, о средствах выразительности, о законах текстообразования и восприятия текста.
Как отмечает Е.Н.Левинтова, текст изучается сегодня 17 науками: психологией и социологией, философией и историей, лингвистикой и литературоведением и др. «Согласно современным научным представлениям, текст понимается как феномен реальной действительности и как способ отражения ее с помощью языка; как основная единица коммуникации, способ хранения и передачи информации, как отражение психической жизни индивида и манифестация менталитета автора текста, как письменная форма фиксации языкового сознания субъекта и т.д. Все это создает основу для множественности описания текста и для его многочисленных определений».
Итак, что же такое-текст?
С позиции семиотики, текст-это
осмысленная последовательность любых
знаков. (Энциклопедия культурологи.) Это
широкая трактовка текста.
(Энциклопедия культурологи.) Это
широкая трактовка текста.
В узком смысле, (по определению Болотновой Н. С.), текст определяется как речевое произведение, концептуально-обусловленное и коммуникативно-ориентированное в рамках определенной сферы общения, имеющее информативно смысловую и прагматическую сущность.
Большой Энциклопедический словарь дает несколько трактовок данного понятия:
ТЕКСТ (от лат. Textus — ткань, соединение), 1) последовательность предложений, слов (в семиотике — знаков), построенная согласно правилам данного языка, данной знаковой системы и образующая сообщение. 2) Словесное произведение; в художественной литературе — законченное произведение либо его фрагмент, составленный из знаков естественного языка (слов) и сложных эстетических знаков (слагаемых поэтического языка, сюжета, композиции и т. д.). 3) Авторское сочинение без комментариев и приложений к нему.
Очень развернутое определение
текста представлено в «Словаре-справочнике
по методике русского языка» М. Р.Львова:
Р.Львова:
« Текст-это продукт, результат речевой деятельности, произведение речи -устного или письменного, обладающего единством темы и замысла и относительной законченностью.»
Гуманитарный словарь дает следующее определение:
«Текст (от лат. textus «ткань; сплетение, связь, сочетание») — в общем плане связная и полная последовательность знаков».
Л.В. Щерба писал, что на языке лингвистов тексты – “совокупность всего говоримого и понимаемого в определенной конкретной обстановке в ту или другую эпоху жизни данной общественной группы”.
Текст — явление, феномен употребления языка. Текст возникает как результат употребления языка, и наиболее характерные свойства, признаки текста обусловлены именно этим обстоятельством.
Существуют две основных
трактовки понятия «текст»: «имманентная»
(расширенная, философски нагруженная)
и «репрезентативная» (более частная).
Имманентный подход подразумевает отношение
к тексту как к автономной реальности,
нацеленность на выявление его внутренней
структуры. Репрезентативный — рассмотрение
текста как особой формы представления
знаний о внешней тексту действительности.
Репрезентативный — рассмотрение
текста как особой формы представления
знаний о внешней тексту действительности.
В лингвистике
термин текст используется в широком значении,
включая и образцы устной речи. Восприятие
текста изучается в рамках лингвистики
текста и психолингвистики.
Текст состоит из некоторого количества
предложений. Одно предложение, даже очень
распространённое, сложное, текстом назвать
нельзя, поскольку текст можно расчленить
на самостоятельные предложения, а части
предложения сочетаются по законам синтаксиса
сложного предложения, но не текста.
Главный тезис — текст состоит из двух
или нескольких предложений.
Некоторыми
исследователями замечено, что текст может
состоять и из одного предложения. Будь
оно распространенное или простое, ничем
не осложненное предложение. Так, предложение:
«Осень», — является текстом, так как оно
обладает одним из главных признаков текста
— информативностью.
В смысловой цельности текста
отражаются те связи и зависимости, которые
имеются в самой действительности (общественные
события, явления природы, человек, его
внешний облик и внутренний мир, предметы
неживой природы и т. д.).
д.).
Единство
предмета речи — это тема высказывания.
Тема — это смысловое ядро текста, конденсированное
и обобщённое содержание текста.
Понятие «содержание высказывания» связано
с категорией информативности речи и присуще
только тексту. Оно сообщает читателю
индивидуально-авторское понимание отношений
между явлениями, их значимости во всех
сферах жизни. Здесь может быть два вида
информации:
*содержательно-фактуальная
*содержательно-концептуальная
Эти две разновидности информации называют
темой и основной мыслью текста. Весь отбор
материала подчинён задаче передать основную
мысль высказывания. Другими словами,
не только тема, но и основная мысль объединяют
предложения текста и придают ему смысловую
цельность.
В большом тексте ведущая тема распадается
на ряд составляющих подтем; подтемы членятся
на более дробные, на абзацы (микротемы).
Завершённость высказывания связана со
смысловой цельностью текста. Показателем
законченности текста является возможность
подобрать к нему заголовок, отражающий
его содержание.
Показателем
законченности текста является возможность
подобрать к нему заголовок, отражающий
его содержание.
Таким образом, из смысловой цельности
текста вытекают следующие признаки текста:
* Текст — это высказывание на определённую
тему;
* В тексте реализуется замысел говорящего,
основная мысль;
* Текст любого размера — это относительно
автономное (законченное) высказывание;
* К тексту можно подобрать заголовок;
* Правильно оформленный текст обычно
имеет начало и конец.
Вся наша речь — это текст.
Поэтому важно знать, что такое
текст. В тексте собрано несколько
предложений. Но нужно помнить, что
не любой набор предложений  А из предложений,
как уже было сказано, получается текст.
А из предложений,
как уже было сказано, получается текст.
Таким образом, текст — это самая высшая единица языка. У этой единицы, как и у других, есть свои свойства. Главное из них в том, что все предложения должны быть связаны между собой общей темой.
У текста есть свои функции. Самая главная —воздействие на человека. Это сможет сделать только связный текст.
Что же касается современных собственно-научных работ по теории текста, то их обзор позволяет сделать вывод о доминировании синтаксического подхода к нему. Это связанно с интенсивной разработкой такого направления, как лингвистика текста. В лингвистике текста: текст -организованный на основе языковых связей и отношений отрезок речи, содержательно объединяющий синтаксические единицы в некое целое.(«Русская грамматика»)
На основе всех вышеперечисленных определений
хочется сделать вывод, что текст – это,
во –первых, речевое произведение. Во-вторых,
текст всегда имеет идею, отражающую авторский
замысел и формирующую целостность текста.
В-третьих, текст обладает стилистической
окраской, отражающий определенную сферу
общения. В-четвертых, текст всегда ориентирован
на адресата, в-пятых, текст несет информацию.
В-шестых, текст обладает эффектом воздействия
— и это главный его признак.
Во-вторых,
текст всегда имеет идею, отражающую авторский
замысел и формирующую целостность текста.
В-третьих, текст обладает стилистической
окраской, отражающий определенную сферу
общения. В-четвертых, текст всегда ориентирован
на адресата, в-пятых, текст несет информацию.
В-шестых, текст обладает эффектом воздействия
— и это главный его признак.
1.2.Ключевые слова.
Ключевые слова — слова, которые используются, чтобы показать внутреннюю структуру рассуждения автора. В то время как они используются прежде всего для риторики, они также используются в строго грамматическом смысле для структурного состава, рассуждения, и понимания. Действительно, они — основная часть любого языка.(Ю.Н. Караулов.)
Сочетания «ключевые слова»,
«ключевое слово» общеизвестны и
широко используются в школьной и
вузовской практике преподавания филологических
дисциплин, прежде всего на занятиях
по лингвистическому анализу текста
. Несмотря на это, работы теоретического
характера, посвященные непосредственно
исследованию феномена ключевых слов
текста, отсутствовали фактически до
середины XX столетия. Причину этого довольно
точно могут объяснить слова Ю. Н. Караулова:
«Дать определение тому, что обычно метафорически
именуют ключевыми словами, довольно непросто…»
[Караулов: 1992, с. 155]. Действительно, сочетание
«ключевые слова» или «слова-ключи» — это
скорее метафора, нежели научный термин
в точном понимании этого слова. Традиционно
всеми принималось мнение, что ключевые
слова — это по сути слова, помогающие понять
и описать некий общий смысл текста.
Несмотря на это, работы теоретического
характера, посвященные непосредственно
исследованию феномена ключевых слов
текста, отсутствовали фактически до
середины XX столетия. Причину этого довольно
точно могут объяснить слова Ю. Н. Караулова:
«Дать определение тому, что обычно метафорически
именуют ключевыми словами, довольно непросто…»
[Караулов: 1992, с. 155]. Действительно, сочетание
«ключевые слова» или «слова-ключи» — это
скорее метафора, нежели научный термин
в точном понимании этого слова. Традиционно
всеми принималось мнение, что ключевые
слова — это по сути слова, помогающие понять
и описать некий общий смысл текста.
Ключевые слова
Ключевое слово — это уникальное слово или фраза, которую клиенты отправляют на ваш рабочий номер телефона, чтобы подписаться на конкретную информацию.
Ключевые слова не чувствительны к регистру и будут работать независимо от заглавных букв, если слово или фраза точны. Например, если вы создадите ключевое слово «Купон», кто-то может написать «Купон» или «купон» и ожидать получения информации о купонах и подобных предложениях. Если вам нужно более длинное ключевое слово, вы можете создать фразу, например «Бесплатные купоны». Однако, чтобы ключевое слово работало, вам нужно не может иметь пробелов между словами .
Если вам нужно более длинное ключевое слово, вы можете создать фразу, например «Бесплатные купоны». Однако, чтобы ключевое слово работало, вам нужно не может иметь пробелов между словами .
Ключевые слова в основном используются по двум причинам:
а) Чтобы отправить предустановленное сообщение всем, кто отправляет текстовое сообщение по ключевому слову необходимо
Чтобы создать ключевое слово:
1. Перейдите к Ключевые слова в разделе Настройки меню Текстовый запрос.
2. Нажмите + Новое ключевое слово .
3. Назовите ключевое слово. Это будет слово или фраза, которую люди отправляют вам.
4. Введите сообщение, которое клиенты получают при отправке текстовых сообщений, в ключевое слово.
5. Решите, следует ли включать подтверждение подписки, когда клиент вводит текстовое сообщение в ключевое слово в первый раз. Это включено по умолчанию.
Это включено по умолчанию.
6. Нажмите Добавить ключевое слово , чтобы создать ключевое слово.
Редактирование и удаление ключевых слов
Хотя вы не можете изменить название ключевого слова, вы можете изменить ответ, который люди получают, когда они пишут его.
Чтобы отредактировать ответ ключевого слова:
1. Перейдите к Ключевые слова в разделе Настройки меню текстового запроса
2. Выберите из списка ключевое слово, которое хотите изменить.
3. Введите новый ответ, который должен отображаться, когда люди вводят ключевое слово.
4. Выбрать Сохранить .
Чтобы удалить ключевое слово:
1. Перейдите к ключевому слову в разделе Настройки меню запроса текста.
2. Найдите ключевое слово, которое вы хотите удалить из списка.
3. Нажмите на три точки в разделе Действия .
4. Выберите Удалить ключевое слово из списка вариантов.
5. Нажмите Да, Удалить , чтобы подтвердить удаление.
Примечание: Удаление ключевого слова не удаляет группу ключевых слов или контакты в ней.
Подписчики ключевых слов для обмена сообщениями
При создании ключевого слова автоматически создается группа с именем Ключевое слово: [Имя ключевого слова] . Например, если вы создаете ключевое слово под названием «Купон», создается группа с именем Ключевое слово: купон .
Отправка сообщения списку подписчиков ключевых слов аналогична отправке любого другого группового сообщения. Просто найдите эту новую группу под своим Контакты и выберите Написать .
Если вы создали ответ для своего ключевого слова, это сообщение автоматически отправляется всем новым подписчикам.
Контакты Отказ от ключевых слов
Любой контакт, который отправляет сообщение « СТОП [ключевое слово] », отписывается от вашего списка ключевых слов. Однако они по-прежнему могут получать сообщения с вашего номера.
Если контакт отправляет только текст « STOP », вы больше не сможете отправлять текстовые сообщения этому контакту, и он будет автоматически заархивирован.
В целях соблюдения всем контактам отправляется сообщение об отказе, когда вы в первый раз отправляете им текстовое сообщение.
Отчет по ключевым словам
Хотите узнать, какие ключевые слова наиболее эффективны и сколько контактов отправляют текстовые сообщения? Посетите нашу справочную статью «Отчет по ключевым словам», чтобы узнать, как запускать эти отчеты и максимально эффективно использовать ключевые слова.
Методы извлечения ключевых слов из документов в НЛП
Эта статья была опубликована в рамках блога по науке о данных.
Введение
Извлечение ключевых слов обычно используется для извлечения ключевой информации из ряда абзацев или документов. Извлечение ключевых слов — это автоматизированный метод извлечения наиболее релевантных слов и фраз из введенного текста. Это метод анализа текста, который включает автоматическое извлечение наиболее важных слов и выражений со страницы. Это помогает обобщить содержание текста и определить ключевые обсуждаемые вопросы — например, протокол собрания (MOM).
Источник: https://towardsdatascience.com/textrank-for-keyword-extraction-by-python-c0bae21bcec0 Предположим, вы хотите найти в Интернете большое количество оценок продуктов (возможно, сотни тысяч). Чтобы просмотреть все данные и найти термины, которые лучше всего определяют каждый обзор, можно использовать извлечение ключевых слов. Вы сможете увидеть, какие темы вызывают наибольшее обсуждение среди ваших потребителей, а автоматизация процесса сэкономит вашим сотрудникам много времени. В этом блоге я покажу вам, как извлекать ключевые слова из документов с помощью обработки естественного языка. Это те.
В этом блоге я покажу вам, как извлекать ключевые слова из документов с помощью обработки естественного языка. Это те.
- Грабли_NLTK
- Спаси
- Текстранг
- Word облако
- КейБерт
- Яке
- API-интерфейс MonkeyLearn
- Текстразор API
Рейк_NLTK
RAKE (быстрое автоматическое извлечение ключевых слов) — это хорошо известный метод извлечения ключевых слов, который находит наиболее релевантные слова или фразы в фрагменте текста, используя набор стоп-слов и разделителей фраз. Rake nltk — это расширенная версия RAKE, поддерживаемая NLTK. Шаги для быстрого автоматического извлечения ключевых слов следующие:
- Разделить вводимое текстовое содержимое по точкам
- Создать матрицу совпадений слов
- Оценка слова — эта оценка может быть рассчитана как степень слова в матрице, как частота слова или как степень слова, деленная на его частоту
- ключевых фраз также можно создать, комбинируя ключевые слова
- Ключевое слово или ключевая фраза выбраны тогда и только тогда, когда их оценка относится к числу лучших T оценок, где T — количество ключевых слов, которые вы хотите извлечь
Реализация Python для извлечения ключевых слов с использованием алгоритма Rake
Для установки
pip3 установить rake-nltk
Для извлечения ключевых слов
Прочтите этот официальный документ, чтобы узнать больше об алгоритме RAKE.
Спэйси
Еще одна фантастическая библиотека Python NLP — spaCy. Этот пакет, более новый, чем NLTK или Scikit-Learn, направлен на то, чтобы максимально упростить глубокое обучение для анализа текстовых данных. Ниже приведены процедуры, связанные с извлечением ключевых слов из текста с использованием спайса.
- Разделение входного текстового содержимого по токенам
- Извлечь популярные слова из списка токенов.
- Установите горячие слова как слова с почтовым тегом « PROPN », « ADJ » или « NOUN ». (список POS-тегов настраивается)
- Найдите наиболее распространенное количество T горячих слов из списка
- Распечатать результаты
Реализация Python для извлечения ключевых слов с использованием Spacy
Для установки
pip3 установить пробел
Для извлечения ключевых слов
импортировать пространство из коллекций импорт Счетчик пунктуация импорта строки nlp = spacy.load ("en_core_web_sm") деф get_hotwords (текст): результат = [] pos_tag = ['PROPN', 'ADJ', 'СУЩЕСТВИТЕЛЬНОЕ'] документ = нлп (текст.нижний ()) для токена в документе: if(token.text в nlp.Defaults.stop_words или token.text в пунктуации): продолжать если (токен.pos_ в pos_tag): результат.добавление(токен.текст) вернуть результат новый_текст = """ Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения. они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега. К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE. """ вывод = установить (get_hotwords (новый_текст)) most_common_list = Счетчик(выход).most_common(10) для элемента в most_common_list: печать (элемент [0])
 load ("en_core_web_sm")
деф get_hotwords (текст):
результат = []
pos_tag = ['PROPN', 'ADJ', 'СУЩЕСТВИТЕЛЬНОЕ']
документ = нлп (текст.нижний ())
для токена в документе:
if(token.text в nlp.Defaults.stop_words или token.text в пунктуации):
продолжать
если (токен.pos_ в pos_tag):
результат.добавление(токен.текст)
вернуть результат
новый_текст = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения. они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE.
"""
вывод = установить (get_hotwords (новый_текст))
most_common_list = Счетчик(выход).most_common(10)
для элемента в most_common_list:
печать (элемент [0])
load ("en_core_web_sm")
деф get_hotwords (текст):
результат = []
pos_tag = ['PROPN', 'ADJ', 'СУЩЕСТВИТЕЛЬНОЕ']
документ = нлп (текст.нижний ())
для токена в документе:
if(token.text в nlp.Defaults.stop_words или token.text в пунктуации):
продолжать
если (токен.pos_ в pos_tag):
результат.добавление(токен.текст)
вернуть результат
новый_текст = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения. они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE.
"""
вывод = установить (get_hotwords (новый_текст))
most_common_list = Счетчик(выход).most_common(10)
для элемента в most_common_list:
печать (элемент [0]) Выход
точность точность способный частичный прогноз счет правильный экстракторы Матчи идеально
Текстовый рейтинг
Textrank — это инструмент Python, который извлекает ключевые слова и обобщает текст. Алгоритм определяет, насколько тесно связаны слова, просматривая, следуют ли они друг за другом. Затем наиболее важные термины в тексте ранжируются с использованием алгоритма PageRank. Textrank обычно совместим с конвейером Spacy. Вот основные процессы, которые Textrank выполняет при извлечении ключевых слов из документа.
Алгоритм определяет, насколько тесно связаны слова, просматривая, следуют ли они друг за другом. Затем наиболее важные термины в тексте ранжируются с использованием алгоритма PageRank. Textrank обычно совместим с конвейером Spacy. Вот основные процессы, которые Textrank выполняет при извлечении ключевых слов из документа.
Шаг – 1: Чтобы найти релевантные термины, алгоритм Textrank создает сеть слов (граф слов). Эта сеть создается путем просмотра того, какие слова связаны друг с другом. Если два слова часто встречаются в тексте рядом друг с другом, между ними устанавливается связь. Ссылка получает больший вес, если два слова чаще появляются рядом друг с другом.
Шаг – 2 :Для определения релевантности каждого слова к сформированной сети применяется алгоритм PageRank. Верхняя треть каждого из этих терминов сохраняется и считается важной. Затем, если релевантные термины появляются в тексте один за другим, создается таблица ключевых слов путем их группировки.
TextRank — это реализация Python, которая обеспечивает быстрое и точное извлечение фраз, а также резюмирование для использования в рабочих процессах spaCy. Метод графа не зависит от какого-либо конкретного естественного языка и не требует знания предметной области. Инструмент, который мы будем использовать для извлечения ключевых слов, — это PyTextRank (версия TextRank для Python в качестве плагина конвейера spaCy). Пожалуйста, ознакомьтесь с базовым документом здесь, чтобы узнать больше о Textrank.
Реализация Python для извлечения ключевых слов с использованием Textrank
Для установки
pip3 установить pytextrank
скачать spacy en_core_web_sm Для извлечения ключевых слов
импортировать пространство импортировать pytextrank # пример текста text = "Совместность систем линейных ограничений на множество натуральных чисел. Рассмотрены критерии совместности системы линейных диофантовых уравнений, строгих неравенств и нестрогих неравенств.
 Верхние оценки компонент минимального множества решений и алгоритмы построения даны минимальные порождающие множества решений для всех типов систем. Эти критерии и соответствующие им алгоритмы построения минимального опорного множества решений могут быть использованы при решении всех рассматриваемых типов систем и систем смешанных типов».
# загрузить модель spaCy в зависимости от языка, масштаба и т.д.
nlp = spacy.load ("en_core_web_sm")
# добавить PyTextRank в конвейер spaCy
nlp.add_pipe ("textrank")
документ = нлп (текст)
# проверить самые популярные фразы в документе
для фразы в doc._.phrases[:10]:
печать(фраза.текст)
Верхние оценки компонент минимального множества решений и алгоритмы построения даны минимальные порождающие множества решений для всех типов систем. Эти критерии и соответствующие им алгоритмы построения минимального опорного множества решений могут быть использованы при решении всех рассматриваемых типов систем и систем смешанных типов».
# загрузить модель spaCy в зависимости от языка, масштаба и т.д.
nlp = spacy.load ("en_core_web_sm")
# добавить PyTextRank в конвейер spaCy
nlp.add_pipe ("textrank")
документ = нлп (текст)
# проверить самые популярные фразы в документе
для фразы в doc._.phrases[:10]:
печать(фраза.текст) Выход
смешанные типы минимальные порождающие наборы системы нестрогие неравенства строгие неравенства натуральные числа линейные диофантовы уравнения решения линейные ограничения минимальный вспомогательный набор
Облако слов
Величина каждого слова представляет его частоту или релевантность в облаке слов, которое является инструментом визуализации данных для визуализации текстовых данных. Облако слов можно использовать для выделения важных текстовых данных. Данные с веб-сайтов социальных сетей часто анализируются с использованием облаков слов.
Облако слов можно использовать для выделения важных текстовых данных. Данные с веб-сайтов социальных сетей часто анализируются с использованием облаков слов.
Чем крупнее и жирнее термин появляется в облаке слов, тем больше раз он появляется в источнике текстовых данных (например, речи, записи в блоге или базе данных) (также известном как облако тегов или текстовое облако). Облако слов — это набор слов разных размеров. Чем чаще термин встречается в документе и чем он важнее, тем он крупнее и жирнее. Это отличные способы извлечения наиболее важных частей текстовых данных, таких как сообщения в блогах и базы данных.
Реализация Python для извлечения ключевых слов с помощью Wordcloud
Для установки
pip3 установить wordcloud pip3 установить matplotlib
Для извлечения ключевых слов и демонстрации их релевантности с помощью Wordcloud
коллекции импорта импортировать numpy как np импортировать панд как pd импортировать matplotlib.
 cm как см
импортировать matplotlib.pyplot как plt
из matplotlib импортировать rcParams
из wordcloud импортировать WordCloud, СТОП СЛОВА
all_headlines = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE.
"""
стоп-слова = СТОП-СЛОВА
wordcloud = WordCloud(stopwords=stopwords, background_color="white", max_words=1000).generate(all_headlines)
rcParams['figure.figsize'] = 10, 20
plt.imshow (облако слов)
плт.ось("выкл")
plt.show()
filtered_words = [слово в слово в all_headlines.split(), если слово не входит в стоп-слова]
counted_words = collections.Counter(отфильтрованные_слова)
слова = []
количество = []
для буквы подсчитайте в counted_words.
cm как см
импортировать matplotlib.pyplot как plt
из matplotlib импортировать rcParams
из wordcloud импортировать WordCloud, СТОП СЛОВА
all_headlines = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
К счастью, есть и другие метрики, способные фиксировать частичные совпадения. Примером этого является ROUGE.
"""
стоп-слова = СТОП-СЛОВА
wordcloud = WordCloud(stopwords=stopwords, background_color="white", max_words=1000).generate(all_headlines)
rcParams['figure.figsize'] = 10, 20
plt.imshow (облако слов)
плт.ось("выкл")
plt.show()
filtered_words = [слово в слово в all_headlines.split(), если слово не входит в стоп-слова]
counted_words = collections.Counter(отфильтрованные_слова)
слова = []
количество = []
для буквы подсчитайте в counted_words. most_common(10):
слова.добавлять(буква)
counts.append(количество)
цвета = см.радуга(np.linspace(0, 1, 10))
rcParams['figure.figsize'] = 20, 10
plt.title('Лучшие слова в заголовках по сравнению с их количеством')
plt.xlabel('Счетчик')
plt.ylabel('Слова')
plt.barh(слова, количество, цвет=цвета)
plt.show()
most_common(10):
слова.добавлять(буква)
counts.append(количество)
цвета = см.радуга(np.linspace(0, 1, 10))
rcParams['figure.figsize'] = 20, 10
plt.title('Лучшие слова в заголовках по сравнению с их количеством')
plt.xlabel('Счетчик')
plt.ylabel('Слова')
plt.barh(слова, количество, цвет=цвета)
plt.show() Выход
Источник: Автор Источник: Автор
КейБерт
KeyBERT — это базовый и простой в использовании метод извлечения ключевых слов, который генерирует ключевые слова и фразы, наиболее похожие на данный документ, с использованием встраивания BERT. Он использует BERT-эмбеддинги и базовое косинусное сходство для поиска поддокументов в документе, которые наиболее похожи на сам документ.
BERT используется для извлечения вложений документов, чтобы получить представление на уровне документа. Затем извлекаются вложения слов для N-граммных слов/фраз. Наконец, он использует косинусное сходство, чтобы найти слова/фразы, наиболее похожие на документ. Затем наиболее сопоставимые термины могут быть идентифицированы как те, которые лучше всего описывают весь документ.
Затем наиболее сопоставимые термины могут быть идентифицированы как те, которые лучше всего описывают весь документ.
Поскольку KeyBert построен на основе BERT, он генерирует вложения с использованием предварительно обученных моделей на основе Huggingface Transformer. По умолчанию для встраивания используется модель all-MiniLM-L6-v2 .
Реализация Python для извлечения ключевых слов с использованием KeyBert
Для установки
pip3 установить ключ
Для извлечения ключевых слов и демонстрации их релевантности с помощью KeyBert
из импорта ключей KeyBERT
документ = """
Обучение с учителем — это задача машинного обучения по обучению функции, которая
сопоставляет ввод с выводом на основе примеров пар ввода-вывода. Это предполагает
функцию из размеченных обучающих данных, состоящих из набора обучающих примеров.
В обучении с учителем каждый пример представляет собой пару, состоящую из входного объекта
(обычно вектор) и желаемое выходное значение (также называемое контрольным сигналом).
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_model = KeyBERT()
ключевые слова = kw_model.extract_keywords(doc)
печать(ключевые слова)  Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_model = KeyBERT()
ключевые слова = kw_model.extract_keywords(doc)
печать(ключевые слова)
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_model = KeyBERT()
ключевые слова = kw_model.extract_keywords(doc)
печать(ключевые слова) Выход
[('под наблюдением', 0,6676), ('помеченный', 0,4896), ('обучение', 0,4813), ('обучение', 0,4134), ('метки', 0,3947)] Еще один экстрактор ключевых слов (Yake)
Для автоматического извлечения ключевых слов в Yake функции текста используются неконтролируемым образом. YAKE — это базовый неконтролируемый автоматический метод извлечения ключевых слов, который определяет наиболее релевантные ключевые слова в тексте с использованием текстовых статистических данных из отдельных текстов. Этот метод не зависит от словарей, внешних корпусов, размера текста, языка или домена и не требует обучения на определенном наборе документов. Основные характеристики алгоритма Яке следующие:
Этот метод не зависит от словарей, внешних корпусов, размера текста, языка или домена и не требует обучения на определенном наборе документов. Основные характеристики алгоритма Яке следующие:
- Неконтролируемый подход
- Независимо от корпуса
- Независимо от домена и языка
- Один документ
Реализация Python для извлечения ключевых слов с использованием Yake
Для установки
pip3 установить яке
Для извлечения ключевых слов и демонстрации их релевантности с помощью Yake
импортный яке
документ = """
Обучение с учителем — это задача машинного обучения по обучению функции, которая
сопоставляет ввод с выводом на основе примеров пар ввода-вывода. Это предполагает
функцию из размеченных обучающих данных, состоящих из набора обучающих примеров.
В обучении с учителем каждый пример представляет собой пару, состоящую из входного объекта
(обычно вектор) и желаемое выходное значение (также называемое контрольным сигналом).
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_extractor = yake.KeywordExtractor()
ключевые слова = kw_extractor.extract_keywords(doc)
для кВт в ключевых словах:
печать (кВт)  Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_extractor = yake.KeywordExtractor()
ключевые слова = kw_extractor.extract_keywords(doc)
для кВт в ключевых словах:
печать (кВт)
Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.
которые можно использовать для отображения новых примеров. Оптимальный сценарий позволит
алгоритм для правильного определения меток класса для невидимых экземпляров. Это требует
алгоритм обучения для обобщения обучающих данных на невидимые ситуации в
«разумным» способом (см. индуктивное смещение).
kw_extractor = yake.KeywordExtractor()
ключевые слова = kw_extractor.extract_keywords(doc)
для кВт в ключевых словах:
печать (кВт) Выход
(«задача машинного обучения», 0,022703501568910843) («Обучение с учителем», 0,06742808121232775) («обучение», 0,072457069999) («данные для обучения», 0,07557730010583494) («сопоставляет ввод», 0,07860851277995791) («на основе вывода», 0,08846540097554569) («пары ввода-вывода», 0,08846540097554569) («машинное обучение», 0,09853013116161088) («учебная задача», 0,09853013116161088) («обучение», 0,10592640317285314) («функция», 0,11237403107652318) («обучающие данные, состоящие из», 0,12165867444610523) («алгоритм обучения», 0,1280547892393491) («Под наблюдением», 0.
 120398758118)
(«алгоритм обучения под наблюдением», 0.13060566752120165)
("данные", 0,1454043828185849)
(«помеченные данные обучения», 0,15052764655360493)
(«алгоритм», 0,15633092600586776)
(«вход», 0,17662443762709562)
(«состоящая пара», 0,172807220248)
120398758118)
(«алгоритм обучения под наблюдением», 0.13060566752120165)
("данные", 0,1454043828185849)
(«помеченные данные обучения», 0,15052764655360493)
(«алгоритм», 0,15633092600586776)
(«вход», 0,17662443762709562)
(«состоящая пара», 0,172807220248) API-интерфейс MonkeyLearn
MonkeyLearn — это удобный инструмент для анализа текста с предварительно обученным экстрактором ключевых слов, который можно использовать для извлечения важных фраз из ваших данных с помощью API MonkeyLearn. API-интерфейсы доступны на всех основных языках программирования, и разработчики могут извлекать ключевые слова с помощью всего нескольких строк кода и получать файл JSON с извлеченными ключевыми словами. У MonkeyLearn также есть бесплатный генератор облаков слов, который работает как простой «извлекатель ключевых слов», позволяя вам создавать облака тегов из ваших самых важных терминов. После того, как вы создадите учетную запись Monkeylearn, вам будет присвоено 9Ключ API 0186 и идентификатор модели для извлечения ключевых слов из текста.
Дополнительные сведения см. в официальной документации по API Monkeylearn.
Преимущества автоматизации извлечения ключевых слов
- Описания продуктов, отзывы клиентов и другие источники можно использовать для извлечения ключевых слов.
- Определите, какие термины чаще всего используются клиентами.
- Мониторинг упоминаний брендов, продуктов и услуг в режиме реального времени
- Можно автоматизировать и ускорить извлечение и ввод данных.
Реализация Python для извлечения ключевых слов с использованием MonkeyLearn API
Для установки
pip3 установить обезьяну узнать
Для извлечения ключевых слов с помощью Monkeylearn API
от monkeylearn импортировать MonkeyLearn
мл = MonkeyLearn('your_api_key')
мой_текст = """
Когда дело доходит до оценки производительности экстракторов ключевых слов, вы можете использовать некоторые стандартные показатели машинного обучения: точность, достоверность, полнота и оценка F1. Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
"""
данные = [мой_текст]
model_id = 'ваш_model_id'
результат = ml.extractors.extract (id_модели, данные)
dataDict = результат.тело
для элемента в dataDict[0]['extractions'][:10]:
печать (элемент ['parsed_value'])  Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
"""
данные = [мой_текст]
model_id = 'ваш_model_id'
результат = ml.extractors.extract (id_модели, данные)
dataDict = результат.тело
для элемента в dataDict[0]['extractions'][:10]:
печать (элемент ['parsed_value'])
Однако эти показатели не отражают частичные совпадения; они учитывают только идеальное совпадение между извлеченным сегментом и правильным прогнозом для этого тега.
"""
данные = [мой_текст]
model_id = 'ваш_model_id'
результат = ml.extractors.extract (id_модели, данные)
dataDict = результат.тело
для элемента в dataDict[0]['extractions'][:10]:
печать (элемент ['parsed_value']) Выход
эффективность ключевого слова стандартная метрика счет f1 частичное совпадение правильный прогноз извлеченный сегмент машинное обучение экстрактор ключевых слов идеальное совпадение метрика
API Textrazor
Другой API для извлечения ключевых слов и других полезных элементов из неструктурированного текста — Textrazor. Доступ к Textrazor API можно получить с помощью различных компьютерных языков, включая Python, Java, PHP и другие. Вы получите ключ API для извлечения ключевых слов из текста после того, как создадите учетную запись в Textrazor. Посетите официальный сайт для получения дополнительной информации.
Посетите официальный сайт для получения дополнительной информации.
Textrazor — хороший выбор для разработчиков, которым нужны инструменты быстрого извлечения с широкими возможностями настройки. Это служба извлечения ключевых слов, которую можно использовать локально или в облаке. TextRazor API может использоваться для извлечения смысла из текста и может быть легко подключен к нашему необходимому языку программирования. Мы можем создавать собственные экстракторы и извлекать синонимы и отношения между объектами в дополнение к извлечению ключевых слов и объектов на 12 различных языках.
Реализация Python для извлечения ключевых слов с использованием Textrazor API
Для установки
pip3 установить textrazor
Для извлечения ключевых слов с релевантностью и доверием с веб-страницы с помощью Textrazor API
импортировать текстразор textrazor.api_key = "ваш_api_key" client = textrazor.
Выход
Документ 0,1468 2,734 Отладка 0,4502 6,739 Прикладное ПО 0,256 1,335 Высокая доступность 0,4024 5,342 Передовая практика 0,3448 1,911 Коробка 0,03577 0,9762 Прикладное ПО 0,256 1,343 Эксперимент 0,2456 4,424 Устаревание 0,1894 2,876 Объект (грамматика) 0,2584 1,039 Ложноположительные и ложноотрицательные 0,09726 2,222 Система 0,3509 1,251 Алгоритм 0,3629 17,14 Документ 0,1705 2,741 Точность и прецизионность 0,4276 2,089Конкатенация 0,4086 3,503 Твиттер 0,536 6,974 Новости 0,2727 1,43 Система 0,3509 1,251 Документ 0,1705 2,691 Клавиша интерфейса прикладного программирования 0,1133 1,795 ... ... ...
Заключение
Извлечение ключевых слов — это автоматизированный метод извлечения наиболее релевантных слов и фраз из введенного текста. Важные моменты, которые следует помнить, приведены ниже.
- Извлечение ключевых слов обычно используется, когда нам нужно извлечь ключевую информацию из пакета документов.
- В этой статье я попытался представить вам некоторые из самых популярных инструментов для задач автоматического извлечения ключевых слов в НЛП.
- Рейбл NLTK , SPACY , TEXTRANK , Word Cloud , Keybert, и Yake — это инструменты и Meninglearn и .
- Каждый из этих инструментов имеет свои преимущества и особенности использования.
- Это наиболее эффективные методы извлечения ключевых слов, используемые в настоящее время в области науки о данных.
Примечания
Целью извлечения ключевых слов является автоматический поиск фраз, которые лучше всего описывают содержание документа. Ключевые фразы, ключевые термины, ключевые сегменты или просто ключевые слова — это термины, используемые для определения терминов, обозначающих наиболее релевантную информацию, содержащуюся в документе.