
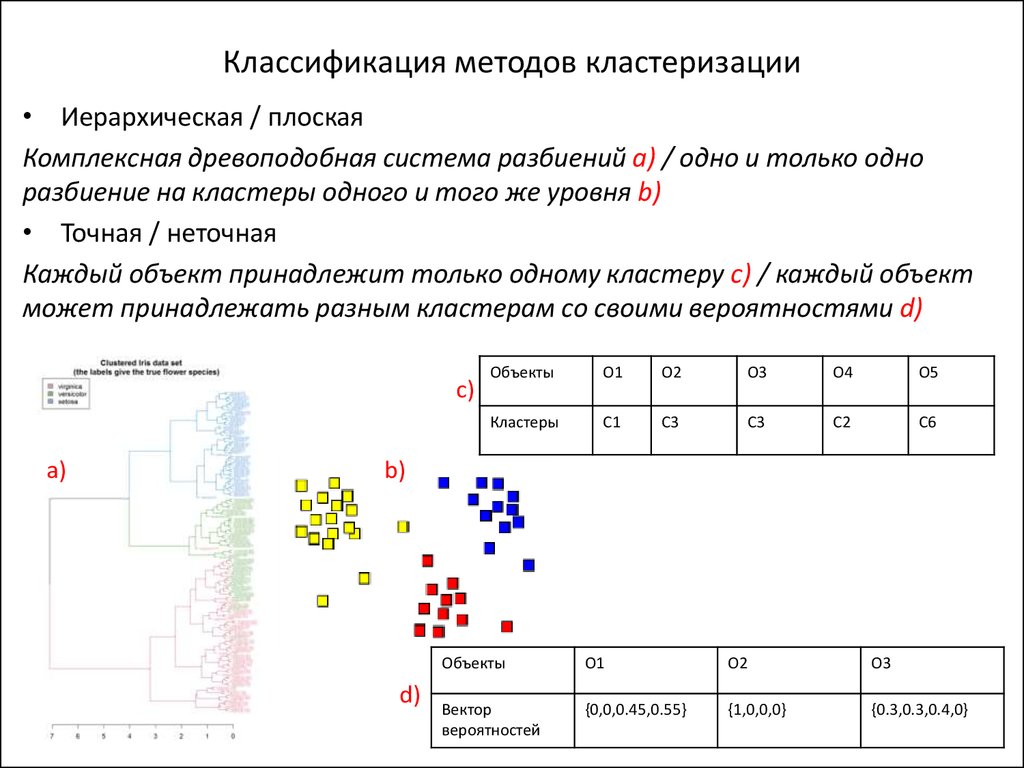
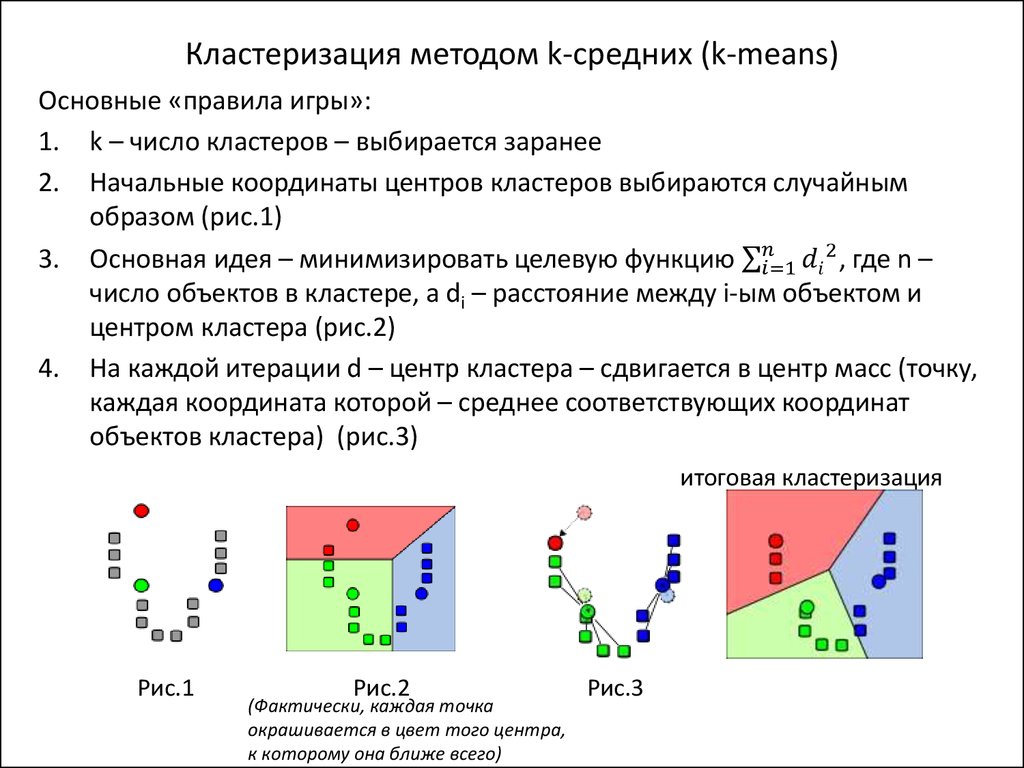
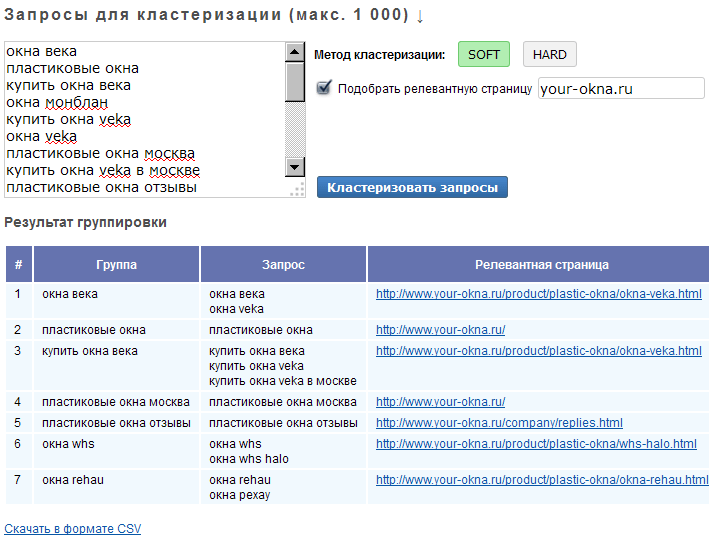
Группировка запросов семантического ядра онлайн
X
- Новости Be1.ru
- Новости SEO
Be1 Вконтакте
1251 подписчиков
Be1 Facebook
1567 подписчиков
Новости
Сообщить о проблеме
0 / 400
Все регионыРоссияМоскваСанкт-ПетербургЕкатеринбургКазаньНижний НовгородНовосибирскОмскРостов-на-ДонуСамараУфаЧелябинскВолгоградВоронежКрасноярскПермьЗеленоградКрасногорскОдинцовоХимкиАбаканАбхазияАкмолинская областьАктобеАктюбинская областьАлександровАлматинская областьАлматыАлтайский крайАлуштаАльметьевскАмурская областьАнадырьАнапаАнгарскАпатитыАрзамасАрмавирАрменияАрхангельскАрхангельская областьАстанаАстраханская областьАстраханьАтырауская областьАчинскБалаковоБалашихаБарнаулБеларусьБелая ЦерковьБелгородБелгородская областьБелогорскБельцыБендерыБердскБийскБиробиджанБлаговещенскБратскБрестБрестская областьБрянскБрянская областьБугульмаВеликие ЛукиВеликий НовгородВидноеВинницаВинницкая областьВитебскВитебская областьВладивостокВладикавказВладимирВладимирcкая областьВолгоградская областьВолгодонскВолжскийВологдаВологодская областьВолынская областьВоронежcкая областьВосточно-Казахстанская областьГатчинаГейдельбергГеленджикГлазовГомельГомельская областьГорно-АлтайскГродненская областьГродноГрозныйГрузияГусь-ХрустальныйДзержинскДимитровградДмитровДнепропетровскДнепропетровская областьДолгопрудныйДомодедовоДонецкДонецкая областьДругие города регионаДубнаЕвпаторияЕврейская автономная областьЕйскЕлабугаЕссентукиЖамбылская областьЖелезногорскЖелезнодорожныйЖигулевскЖитомирЖитомирская областьЖодиноЖуковскийЗабайкальский крайЗакарпатская областьЗападно-Казахстанская областьЗапорожская областьЗапорожьеЗеленодольскЗлатоустИвано-ФранковскИвано-Франковская областьИвановоИвановская областьИжевскИркутскИркутская областьИшимЙошкар-ОлаКазахстанКайерканКалининградКалининградская областьКалугаКалужская областьКаменск-УральскийКаменск-ШахтинскийКамчатский крайКарагандаКарагандинская областьКарачаево-Черкесская РеспубликаКемеровоКемеровская областьКерчьКиевКиевская областьКипрКиргизияКировКирово-ЧепецкКировоградКировоградская областьКировская областьКисловодскКишиневКлинКовровКокшетауКоломнаКомратКомсомольск-на-АмуреКоролёвКостанайская областьКостромаКостромская областьКраматорскКраснодарКраснодарский крайКрасноярский крайКременчугКривой РогКрымКрымский федеральный округКстовоКузнецкКурганКурганская областьКурскКурская областьКызылКызылординская областьЛатвияЛипецкЛипецкая областьЛос-АнджелесЛуганскЛуганская областьЛуцкЛьвовЛьвовская областьЛюберцыМагаданМагаданская областьМагнитогорскМайкопМакеевкаМальтаМангистауская областьМариупольМахачкалаМеждуреченскМексикаМелитопольМиассМинеральные ВодыМинскМинская областьМогилевМогилевская областьМолдоваМосква и областьМурманскМурманская областьМуромМытищиНабережные ЧелныНазраньНальчикНаходкаНевинномысскНенецкий АОНефтекамскНидерландыНижегородская областьНижневартовскНижнекамскНижний ТагилНиколаевНиколаевская областьНовый УренгойНовгородская областьНовокузнецкНовомосковскНовороссийскНовосибирская областьНовоуральскНовочеркасскНогинскНорильскОбнинскОбщероссийскиеОдессаОдесская областьОзерскОмская областьОрелОренбургОренбургская областьОрехово-ЗуевоОрловская областьОрскПавловский ПосадПавлодарПавлодарская областьПензаПензенская областьПервоуральскПереславльПермский крайПетрозаводскПетропавловск-КамчатскийПоволжьеПодольскПолтаваПолтавская областьПриморский крайПрокопьевскПрочееПсковПсковская областьПушкиноПущиноПятигорскРаменскоеРеспублика АдыгеяРеспублика АлтайРеспублика БашкортостанРеспублика БурятияРеспублика ДагестанРеспублика ИнгушетияРеспублика Кабардино-БалкарияРеспублика КалмыкияРеспублика КарелияРеспублика КомиРеспублика Марий ЭлРеспублика МордовияРеспублика Саха (Якутия)Республика Северная Осетия-АланияРеспублика ТываРеспублика ХакасияРеутовРжевРовенская областьРовноРостовРостовская областьРубцовскРыбинскРязанская областьРязаньСалаватСалехардСамарская областьСанкт-Петербург и Ленинградская областьСаранскСарапулСаратовСаратовская областьСаровСатисСаткаСахалинская областьСаяногорскСвердловская областьСевастопольСеверный КавказСеверо-ЗападСеверо-Казахстанская областьСеверодвинскСеверскСемейСербияСергиев ПосадСерпуховСибирьСимферопольСловакияСловенияСмоленскСмоленская областьСНГ (исключая Россию)СнежинскСоликамскСолнечногорскСортавалаСочиСтавропольСтавропольский крайСтарый ОсколСтерлитамакСтраны БалтииСтупиноСуздальСумская областьСумыСургутСызраньСыктывкарТаганрогТаджикистанТаиландТалдыкорганТамбовТамбовская областьТатарстанТверская областьТверьТернопольТернопольская областьТираспольТобольскТольяттиТомскТомская областьТроицкТуапсеТулаТульская областьТуркменияТурцияТындаТюменская областьТюменьУгличУдмуртская республикаУжгородУзбекистанУкраинаУлан-УдэУльяновскУльяновская областьУралУссурийскУсть-ИлимскУсть-КаменогорскУхтаФеодосияХабаровскХабаровский крайХайфаХанты-МансийскХанты-Мансийский АОХарьковХарьковская областьХерсонХерсонская областьХмельницкая областьХмельницкийЧебоксарыЧелябинская областьЧереповецЧеркасская областьЧеркассыЧеркесскЧерниговЧерниговская областьЧерновицкая областьЧерновцыЧерноголовкаЧеховЧеченская РеспубликаЧимкентЧистопольЧитаЧувашская республикаЧукотский автономный округШахтыШтутгартЩелковоЭлектростальЭлистаЭнгельсЮжная ОсетияЮжно-Казахстанская областьЮжно-СахалинскЯкутскЯлтаЯмало-Ненецкий АОЯрославльЯрославская областьАвстралияАвстралия и ОкеанияАвстрияАзербайджанАзияАргентинаАрктика и АнтарктикаАтлантаАфрикаБеер-ШеваБельгияБерлинБлижний ВостокБолгарияБостонБразилияВашингтонВеликобританияВенгрияВыборгВыксаГамбургГерманияГрецияДальний ВостокДанияДетройтЕвропаЕгипетИерусалимИзраильИндияИспанияИталияКанадаКельнКитайКореяЛитваМюнхенНовая ЗеландияНорвегияНью-ЙоркОбъединенные Арабские ЭмиратыПольшаПортугалияРумунияСан-ФранцискоСеверная АмерикаСиэтлСШАТель-АвивУниверсальноеФинляндияФранкфурт-на-МайнеФранцияХорватияЦентрЧерногорияЧехияШвейцарияШвецияЭстонияЮгЮжная АмерикаЯпония
Кластеризация запросов сортирует (разбивает) список семантического ядра (СЯ), на группы по схожести, что дает возможность в дальнейшем оптимизировать под них страницы сайта.
Инструмент анализирует выдачу Яндекс по каждому запросу и сравнивает ее с выдачей остальных запросов из списка. Если в ТОП-10 по разным запросам находятся те же релевантные страницы, то эти запросы определяются как схожие и помещаются в одну группу. Это значит что под них можно оптимизировать одну страницу.
Порог кластеризации запросов это количество совпавших релевантных страниц в выдаче, по разным запросам. Проще говоря, если ввести в Яндекс два запроса и в выдаче ТОП-10 будет две одинаковые страницы (две из десяти), то при выставлении «порога кластеризации 2» эти два запроса будут помещены в одну группу.
Минусы ручной группировки запросов
Группировка ключевых запросов, известная также как разбивка, выполняется SEO оптимизаторами непосредственно после сбора СЯ.
- При наличии большого количества запросов сложно в ручном режиме определить их схожесть между собой, приходится либо вводить каждый запрос в поиск, либо полагаться на интуицию/опыт, что может сыграть злую шутку при продвижении и не дать нужных результатов.

- Высокая стоимость, которая сформировалась за счет длительности процесса. На качественную разбивку семантики с 500 запросами на борту уходит в среднем 4..16 часов. Необходимо вычитать каждый запрос, определить его группу (наличие которой необходимо держать в голове), при необходимости перепроверить поиском или сервисами…бррр.

Плюсы автоматической группировки запросов
- Скорость выполнения разбивки примерно равна скорости звука. Система проверит выдачи каждого из запросов, сравнит их и даст возможность поправить возможные мелкие исключения вручную, после чего результат можно выгрузить в CSV файл (эксель).
- Точность результата, достигаемая за счет исключения человеческого фактора. Человек может отвлечься и потерять мысль, забыть, недопонять или просто не уметь делать разбивку правильно, с программой такие сложности не наблюдаются.
- Инструмент предоставляется полностью на бесплатной основе; он не требует помесячной заработной платы, отпусков, больничных; также у него нет графика работы: работает 24/7.

Разбивка является очень важным процессом при продвижении, она задает цели для оптимизации каждой страницы проекта и всего сайта в целом.
Be1.ru рекомендует оптимизировать страницы сайта по 3…10 запросам максимум. В противном случае есть опасность перемудрить и не продвинуться ни по одному из них, попав под фильтр за переспам.
Отзывы об инструменте
Оценка:
4.9 5 18
04.11.2022 15:37
Очень полезный сервис много бесплатных приколюшек!
Ответить
04.06.2021 14:32
От души хочу оставить отзыв! ОГРОМНЕЙШЕЕ СПАСИБО Вам за бесплатный доступ
Это как никогда помогает начинающим арбитражникам, SEOшникам и т.д
Так как начинающие пробуют и пока не разбираются надо ли это им или нет
С вашими бесплатными сервисами можно как раз начать пробовать себя в рекламе
ОГРОМНЕЙШЕЕ СПАСИБО еще раз! Лучшие!!!
P. S Люди, возьмите в привычку оставлять хорошие отзывы, а не только плохие, так как никогда нигде нельзя найти нормальный продукт или услугу, так как отзывов либо нет, либо только плохие. Оставляйте хорошие отзывы тоже. Например как для этой компании. Разве так сложно
S Люди, возьмите в привычку оставлять хорошие отзывы, а не только плохие, так как никогда нигде нельзя найти нормальный продукт или услугу, так как отзывов либо нет, либо только плохие. Оставляйте хорошие отзывы тоже. Например как для этой компании. Разве так сложно
Ответить
12.02.2021 08:24
Очень хорошая группировка запросов, спасибо за такой хороший и бесплатный продукт! Хотелось бы делать большие объёмы, но естественно на платной основе, к примеру, по подписке.
Ответить
03.02.2020 23:07
Лучший инструмент кластеризации что видел — отзыв не покупной)
Порог кластеризации — вообще вышка!
14.10.2019 12:00
Отличный инструмент! Жаль, что уже давно не работает. Наверное, достали нытики… Для них стараются, что-либо полезное / актуальное сделать, да еще и «за бесплатно». Но, не тут то было )) Дай палец, руку откусят.
Ответить
05.01.2019 01:56
Редко оставляю отзывы, здесь не удержалась.
Первое впечатление — что за … все висит, ничего не происходит. аааа, оказалось потом сервер упал. Ну что ж, с кем не бывает:))
Тестила много разных сервисов, имея представление о том, как должны быть качественно сгруппированы ключевые слова.
Могу сделать такое резюме: удивили и очень порадовали. Серьезно!
Даже некоторые платные проги рядом не стоят!
Огромное спасибо разработчикам. Конечно, приходится частично вручную докидывать, но это уже такие мелочи по сравнению с получаемым в целом отличным результатом.
Ответить
06.07.2018 20:18
Спасибо! еще и бесплатно)))
Ответить
17.11.2017 06:43
Сделайте анализ выдачи по региону, когда собираешь ядро по Новосибу, все запросы с городом идут в отдельную группу, так как скорей всего парсится выдача Москвы. в Остальном все ок.
в Остальном все ок.
______________________
Учтём Ваше пожелание)
Ответить
08.08.2017 09:16
Прогресс идёт и чем больше автоматизации, тем проще жить. Благодарен за эту простоту в использовании и качественный результат. Юзаю на постоянной основе теперь!
Ответить
29.11.2021 16:10
Спасибо за ваш сайт и шикарные инструменты, которыми вы делитесь бесплатно.
Ответить
04.05.2021 14:03
а можно подобное платно до 50 тысяч запросов?
03.03.2020 10:36
Это лучше кекса
Ответить
19.01.2020 21:58
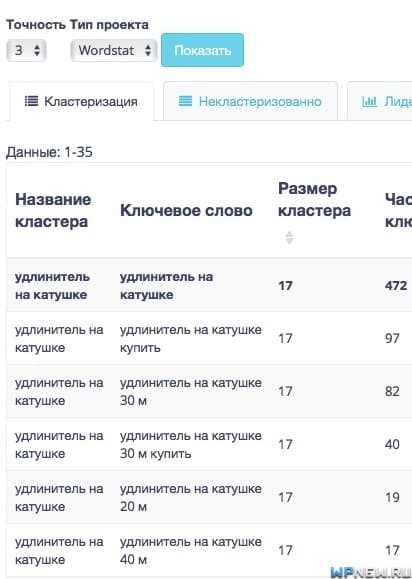
Отличный инструмент для группировки запросов, особенно порадовала опция с порогом кластеризации.
Ответить
01. 06.2019 12:37
06.2019 12:37
Сперва не понял как работает данный инструмент, а когда получилось подобрать ключи по группам, я был очень приятно впечатлен. Большое спасибо разработчикам!
Ответить
18.07.2018 21:16
По какому региону идет кластеризация?
_________________________
По выбранному Вами.
Ответить
04.06.2018 10:40
Поистине отличный сайт главный помощник в продвижении , спасибо огромное
Ответить
01.11.2017 16:24
Ну что тут сказать.. Вы просто спасаете наше время! Я в восторге! 🙂
Ответить
27.07.2017 15:46
Опробовал данный инструмент по группировке запросов и очень впечатлен результатами его работы. Группирует отчасти даже лучше, чем известные мне платные инструменты кластеризации. Удивили, честное слово. Разработчики просто молодцы! Так держать!!!
Удивили, честное слово. Разработчики просто молодцы! Так держать!!!
Ответить
\n’ + ‘
\n’ + ‘
\n’ + ‘ 0\n’ + ‘ \n’ + ‘
\n’ + ‘
\n’ + ‘ 0\n’ + ‘ \n’ + ‘
\n’ + ‘
\n’ + ‘ ‘+item.author+’\n’ + ‘
KeyClusterer 2.
 2 — бесплатная кластеризация поисковых запросов — Трибуна на vc.ru
2 — бесплатная кластеризация поисковых запросов — Трибуна на vc.ruВсем привет! Представляю вашему вниманию новую версию программы KeyClusterer, предназначенной для группировки семантического ядра методами Hard и Soft.
1274 просмотров
В новой версии мы постарались максимально оптимизировать скорость импорта и кластеризации запросов, что на порядок ускорило работу в программе и позволило кластеризовать семантические ядра на 100 и более тысяч запросов за минимально короткое время. Также, были расширены возможности интерфейса программы. Расскажем обо всем подробнее.
Основные изменения
1. Оптимизирована скорость импорта и кластеризации запросов.
Скорость импорта запросов из CSV-файлов на некоторых проектах выросла до 20 раз. Даже для 100 000 запросов импорт теперь занимает менее 3-х минут.
Скорость кластеризации также была качественно улучшена – в среднем кластеризация 5 000 запросов теперь занимает менее минуты, а семантические ядра на десятки тысяч запросов программа стала обрабатывать за вполне адекватное время, нежели это было в прошлой версии.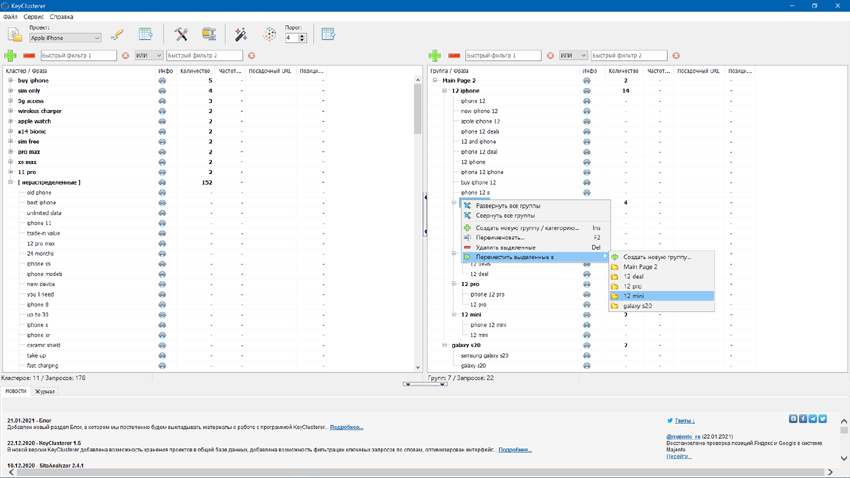
Скорость кластеризации зависит от числа пересечений URL. Для среднестатистического семантического ядра мы получили такие тестовые значения по скорости кластеризации запросов (данные приблизительные, исследования проводились на тестовых семядрах).
Для метода Soft (порог 4):
Для метода Hard (порог 3):
Примечание: если, к примеру, для текущего семядра было добавлено несколько ключевых запросов без собранных данных поисковой выдачи, то такие запросы автоматически попадут в группу [ нераспределенные ]. После сбора отсутствующих данных для этих запросов, они будут кластеризованы на общих основаниях.
2. Добавлено диалоговое окно импорта данных из CSV.
По вашим просьбам мы добавили форму для облегчения импорта проектов из CSV-файлов, в том числе из программы Key Collector.
Таким образом, после указания имени импортируемого файла программа KeyClusterer сама автоматически пытается определить наличие нужных полей в CSV-файле для импорта данных. При необходимости, можно вручную указать поля из которых будут взяты данные для импорта. Все остальные несопоставленные поля в импортируемом файле будут проигнорированы.
При необходимости, можно вручную указать поля из которых будут взяты данные для импорта. Все остальные несопоставленные поля в импортируемом файле будут проигнорированы.
3. Добавлена возможность отмены последних действий при работе с семантическим ядром.
Как известно, автоматическая кластеризация позволяет сделать лишь 40-60% всей работы по группировке ключевых запросов. И зачастую ручная кластеризация занимает немалое время для качественной проработки и догруппировки семантического ядра.
Поэтому, для более удобной ручной работы с ключевыми словами мы добавили возможность отмены последних действий. Будь это перемещение запросов или кластеров, создание групп, переименование или удаление запросов – все это теперь можно отменить и вернуться на тот или иной момент ручной кластеризации без необходимости начинать все сначала. История запоминает последние 100 действий.
4. Добавлена возможность вырезки и вставки групп и ключевых запросов.
Теперь, помимо переноса групп и запросов методом Drag & Drop, можно вырезать и вставлять запросы и группы при помощи контекстного меню и комбинаций клавиш Ctrl-X и Ctrl-V. Это является более удобным способом манипуляции группами и запросами на больших семантических ядрах.
Это является более удобным способом манипуляции группами и запросами на больших семантических ядрах.
Также мы добавили возможность перемещения запросов и групп в пределах групп. Теперь можно поменять местами интересующие группы или запросы, расположить их в нужном порядке (через контекстное меню).
5. Добавлена возможность использования списка стоп-слов для манипуляции ключевыми запросами.
Было добавлено отдельное окно для хранения стоп-слов и манипуляций ими.
При помощи данного функционала можно выделять ключевые слова в левой или правой панели по определенным правилам и проводить над ними дальнейшие действия: удаление, перемещение и т.п.
Параметры действий при поиске запросов:
- Полное вхождение (ищем «я пил молоко», находим «молоко я пил вчера»).
- Частичное соответствие (ищем «ил моло», находим «я пил молоко»).
- Точное соответствие (ищем «я пил молоко», находим «я пил молоко»).
Это бывает удобно, например, для удаления ключевых слов из семантического ядра по списку стоп-слов, либо для поиска ключевых фраз по вхождению определенного слова, которые затем можно переместить в ту или иную группу.
6. Добавлена подсветка найденных слов и частей слова при фильтрации данных.
При фильтрации данных, найденные части слова из первого фильтра теперь выделяются желтым цветом, а из второго – зеленым.
7. Добавлена возможность работы со списком прокси.
Была добавлена поддержка работы программы через прокси с возможностью проверки списка прокси-серверов на работоспособность.
8. Оптимизирована работа с сайтами-исключениями в интерфейсе основных настроек программы.
Список сайтов исключений теперь редактируется в отдельном окне основных настроек программы.
Прочие изменения
- Добавлена возможность добавления запросов в текущее семантическое ядро проекта.
- Добавлена возможность перемещения групп и фраз в любое место в списке.
- Добавлено автоопределение кодировки импортируемых файлов.
- Добавлена расширенная форма выбора региона Яндекс.
- Добавлена возможность экспорта данных из левой панели.
- При кластеризации запросы без собранных данных помещаются в папку [ нераспределенные ].
- Размер шрифта теперь меняется только на панелях с запросами, а не во всем интерфейсе.

Скачать KeyClusterer и протестировать работу программы можно по этой ссылке >>
Введение в кластеризованные таблицы | BigQuery
Кластеризованные таблицы в BigQuery — это таблицы, содержащие пользовательский столбец. порядок сортировки с использованием сгруппированных столбцов . Кластеризованные таблицы могут улучшить запросы производительность и снизить затраты на запросы.
В BigQuery кластеризованный столбец — это определяемая пользователем таблица.
свойство, которое сортирует
блоки хранения
на основе значений в кластеризованных столбцах. Блоки хранения адаптивно
размер зависит от размера стола. Кластеризованная таблица поддерживает сортировку
свойства в контексте каждой операции, которая их изменяет. Запросы, которые
фильтровать или агрегировать по сгруппированным столбцам, сканировать только соответствующие блоки на основе
в кластеризованных столбцах, а не во всей таблице или разделе таблицы. Как
В результате BigQuery не сможет точно оценить
байтов для обработки запросом или затраты на запрос, но он пытается
уменьшить общее количество байтов при выполнении.
Кластеризованная таблица поддерживает сортировку
свойства в контексте каждой операции, которая их изменяет. Запросы, которые
фильтровать или агрегировать по сгруппированным столбцам, сканировать только соответствующие блоки на основе
в кластеризованных столбцах, а не во всей таблице или разделе таблицы. Как
В результате BigQuery не сможет точно оценить
байтов для обработки запросом или затраты на запрос, но он пытается
уменьшить общее количество байтов при выполнении.
При кластеризации таблицы с использованием нескольких столбцов порядок столбцов определяет какие столбцы имеют приоритет, когда BigQuery сортирует и группирует данные в блоки хранения. В следующем примере сравнивается логическое хранилище блочный макет некластеризованной таблицы с макетом кластеризованных таблиц, иметь один или несколько кластеризованных столбцов:
Когда вы запрашиваете кластеризованную таблицу, вы не получаете точную стоимость запроса
оценить перед выполнением запроса, потому что количество блоков памяти, которые должны быть
scanned неизвестно до выполнения запроса.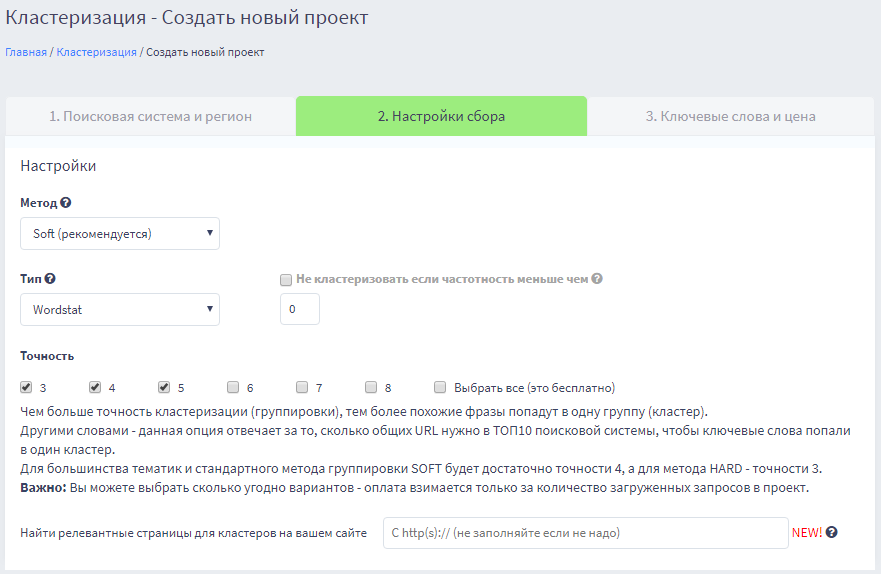 Окончательная стоимость определяется после
выполнение запроса завершено и основано на конкретных блоках памяти, которые
были отсканированы.
Окончательная стоимость определяется после
выполнение запроса завершено и основано на конкретных блоках памяти, которые
были отсканированы.
Когда использовать кластеризацию
Кластеризацию можно рассмотреть в следующих сценариях:
- Ваши запросы обычно фильтруются по определенным столбцам. Кластеризация ускоряется запросы, потому что запрос сканирует только те блоки, которые соответствуют фильтру.
- Ваши запросы фильтруются по столбцам, которые имеют много различных значений (высокая кардинальность). Кластеризация ускоряет эти запросы, предоставляя BigQuery с подробными метаданными о том, откуда брать входные данные.
- Перед выполнением запроса не требуется строгая оценка затрат.
Вы можете рассмотреть альтернативы кластеризации в следующих случаях:
- Перед выполнением запроса необходимо провести строгую оценку стоимости запроса. Цена
запросов к кластерным таблицам можно определить только после выполнения запроса.
- Размер ваших таблиц запросов меньше 1 ГБ. Как правило, кластеризация не обеспечивают значительный прирост производительности для таблиц размером менее 1 ГБ.

Поскольку кластеризация решает вопрос о том, как хранится таблица, в первую очередь рекомендуется параметр для повышения производительности запросов. Если вам нужны другие или дополнительные методы, вы можете подумать о секционировании таблицы.
Как и при кластеризации, при разбиении на разделы используются определяемые пользователем столбцы разделов для указания
как данные разделены и какие данные хранятся в каждом разделе. В отличие от
кластеризации, секционирование обеспечивает детализированную оценку стоимости запросов перед запуском
запрос. Подобно кластеризации, секционирование не обязательно уменьшает объем
данные, которые сканируются в запросе. Громкость зависит от того, что вы установили в качестве
столбцы разделов и то, как эти столбцы используются в качестве фильтров запросов во время
исполнение.
Другой метод заключается в объединении кластеризации и секционирования таблиц. В этом подход, вы сначала сегментируете данные на разделы, а затем кластеризуете данные в каждом разделе по столбцам кластеризации. Для получения дополнительной информации см. Кластеризованные и секционированные таблицы в этом документ.
Типы и порядок столбцов кластера
В этом разделе описываются типы столбцов и порядок столбцов в таблице. кластеризация.
Типы столбцов кластера
Столбцы кластера должны быть неповторяющимися столбцами верхнего уровня, которые являются одним из следующих типов:
-
STRING -
INT64 -
ЦИФРОВОЙ -
ДВУХЦИФРОВОЙ -
ДАТА -
ДАТАВРЕМЯ -
ВРЕМЕННАЯ МЕТКА -
Логический -
ГЕОГРАФИЯ
Дополнительные сведения о типах данных см. Стандартные типы данных Google SQL.
Стандартные типы данных Google SQL.
Порядок столбцов в кластере
Порядок столбцов в кластере влияет на производительность запросов. Чтобы извлечь выгоду из кластеризация, порядок фильтра запроса должен соответствовать порядку кластеризованного столбца и должен включать по крайней мере первый кластеризованный столбец.
В следующем примере таблица заказов группируется с использованием сортировки по столбцам.
порядок Дата_Заказа , Страна и Статус . Запрос, который фильтрует Order_Date и Страна оптимизирован для кластеризации, но запрос, который фильтрует
только на Страна и Статус не оптимизирован. Чтобы оптимизировать кластеризацию
результаты, вы должны фильтровать по сгруппированным столбцам в порядке, начиная с первого
кластерный столбец.
Объединение кластеризованных и секционированных таблиц
Кластеризацию таблиц можно комбинировать с секционированием таблиц. для достижения мелкозернистой сортировки для дальнейшей оптимизации запросов.
В многораздельной таблице данные хранятся в физических блоках, каждый из которых содержит один раздел данных. Каждая секционированная таблица поддерживает различные метаданные о свойства сортировки во всех операциях, которые ее изменяют. Метаданные позволяют BigQuery более точно оценивает стоимость запроса перед запросом работает. Однако разделение требует, чтобы BigQuery поддерживал больше метаданных, чем с неразделенной таблицей. По мере увеличения количества разделов количество поддерживаемых метаданных увеличивается.
Когда вы создаете кластеризованную и секционированную таблицу, вы можете добиться большего мелкозернистая сортировка, как показано на следующей диаграмме:
Автоматическая повторная кластеризация
По мере добавления данных в кластеризованную таблицу новые данные организуются в блоки,
которые могут создавать новые блоки хранения или обновлять существующие блоки. Блокировать
требуется оптимизация для оптимальной производительности запросов и хранилища, поскольку новые
данные могут быть не сгруппированы с существующими данными, имеющими одинаковые значения кластера.
Блокировать
требуется оптимизация для оптимальной производительности запросов и хранилища, поскольку новые
данные могут быть не сгруппированы с существующими данными, имеющими одинаковые значения кластера.
Чтобы сохранить характеристики производительности кластеризованной таблицы, BigQuery выполняет автоматическую повторную кластеризацию в фоновом режиме. Для секционированные таблицы, кластеризация поддерживается для данных в рамках каждой раздел.
Примечание. Автоматическая повторная кластеризация не влияет на емкость запросов.Ограничения
- Для запросов кластеризованных таблицы и для записи результатов запроса в кластеризованные таблицы.
- Можно указать не более четырех столбцов кластеризации. Если тебе надо дополнительные столбцы, рассмотрите возможность объединения кластеризации с секционированием.
- При использовании столбцов типа
STRINGдля кластеризации BigQuery использует только первые 1024 символа для кластеризации данных. Значения в
сами столбцы могут быть длиннее 1024 символов. - Если изменить существующую некластеризованную таблицу на кластеризацию, существующие данные не кластеризуются. Сохраняются только новые данные кластеризованных столбцов и подлежит автоматической повторной кластеризации.
 Значения в
сами столбцы могут быть длиннее 1024 символов.
Значения в
сами столбцы могут быть длиннее 1024 символов.Квоты и ограничения для кластеризованных таблиц
BigQuery ограничивает использование общих ресурсов Google Cloud с квоты и лимиты, в том числе ограничения на определенный стол операций или количество заданий, выполняемых в течение дня.
При использовании функции кластеризованной таблицы с секционированной таблицей с учетом ограничений на секционированные таблицы.
Квоты и ограничения также применяются к различным типам заданий, которые вы можете выполнять против кластерных таблиц. Для получения информации о квотах на работу, которые применяются к свои таблицы, см. Задания в разделе «Квоты и лимиты».
Стоимость кластерных таблиц
Когда вы создаете и используете кластерные таблицы в BigQuery, ваши
плата зависит от того, сколько данных хранится в таблицах и от запросов
которые вы запускаете против данных.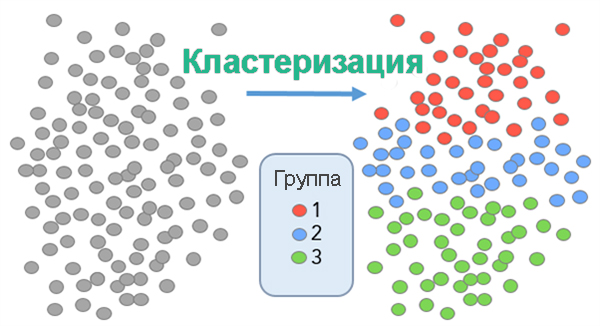 Для получения дополнительной информации см.
Цены на хранение и
Стоимость запроса.
Для получения дополнительной информации см.
Цены на хранение и
Стоимость запроса.
Как и другие операции с таблицами BigQuery, операции с кластерными таблицами воспользоваться бесплатными операциями BigQuery, такими как пакетная загрузка, копирование таблицы, автоматическая рекластеризация и экспорт данных. Эти операции с учетом квот и ограничений BigQuery. Информацию о бесплатных операциях см. Бесплатные операции.
Подробный пример ценообразования кластеризованной таблицы см. Оцените затраты на хранение и запросы.
Безопасность таблиц
Чтобы контролировать доступ к таблицам в BigQuery, см. Введение в управление доступом к таблицам.
Что дальше
- Чтобы узнать, как создавать и использовать кластеризованные таблицы, см. Создание и использование кластерных таблиц.
- Сведения о запросах к кластерным таблицам см. Запрос кластеризованных таблиц.
Краткое руководство: запрос данных в веб-интерфейсе Azure Data Explorer
- Статья
- 10 минут на чтение
Azure Data Explorer — это быстрая, полностью управляемая служба анализа данных для анализа больших объемов данных в режиме реального времени. Azure Data Explorer предоставляет веб-интерфейс, который позволяет подключаться к кластерам Azure Data Explorer, а также писать, выполнять и совместно использовать команды и запросы Kusto Query Language. Веб-интерфейс доступен на портале Azure и в виде отдельного веб-приложения, веб-интерфейса Azure Data Explorer. Веб-интерфейс Azure Data Explorer также может размещаться на других веб-порталах в iframe HTML. Дополнительные сведения о размещении веб-интерфейса Azure Data Explorer и используемого редактора Monaco см. в разделе Интеграция Monaco IDE. В этом кратком руководстве вы будете работать в автономном веб-интерфейсе Azure Data Explorer.
Предварительные условия
- Учетная запись Microsoft или удостоверение пользователя Azure Active Directory. Подписка Azure не требуется.
- Кластер и база данных Azure Data Explorer. Вы можете создать бесплатный кластер, создать полный кластер или воспользоваться справочным кластером. Чтобы решить, что лучше для вас, проверьте сравнение функций.
 Подписка Azure не требуется.
Подписка Azure не требуется.Войдите в приложение.
Добавить кластеры
При первом открытии приложения отсутствуют подключения к кластеру.
Перед запуском запросов необходимо добавить подключение к кластеру. В этом разделе вы добавите подключения к кластеру Azure Data Explorer help и к тестовому кластеру, который вы создали в предварительных условиях (необязательно).
Добавить кластер справки
В меню слева выберите Запрос .
В левом верхнем углу приложения выберите Добавить кластер .
В В диалоговом окне Добавить кластер введите URI
https://help.kusto.windows.net, затем выберите Добавить .В области подключения к кластеру теперь должен отображаться кластер справки . Разверните базу данных Samples и откройте папку Tables , чтобы просмотреть образцы таблиц, к которым у вас есть доступ.
Мы используем таблицу StormEvents далее в этом кратком руководстве и в других статьях Azure Data Explorer.
Добавьте свой кластер
Теперь добавьте созданный вами тестовый кластер.
Выберите Добавить кластер .
В диалоговом окне Добавить кластер введите URL-адрес тестового кластера в формате
https://, затем выберите Добавить . Например,. .kusto.windows.net/ https://mydataexplorercluster.westus.kusto.windows.net, как на следующем изображении:В приведенном ниже примере вы видите кластер help и новый кластер docscluster.
westus (полный URL-адрес: https://docscluster.westus.kusto.windows.net/).
Выполнение запросов
Теперь вы можете выполнять запросы в обоих кластерах (при условии, что у вас есть данные в тестовом кластере). В этой статье мы сосредоточимся на кластере help .
На панели Кластерное соединение в разделе help кластер, выберите базу данных Samples .
Скопируйте и вставьте следующий запрос в окно запроса. В верхней части окна выберите Выполнить .
StormEvents | сортировать по описанию StartTime | возьми 10
Этот запрос возвращает 10 новейших записей в таблице StormEvents . Результат должен выглядеть, как в следующей таблице.
На следующем изображении показано состояние приложения с добавленным кластером и запрос с результатами.
Скопируйте и вставьте следующий запрос в окно запросов под первым запросом.
Обратите внимание, что он не отформатирован в отдельных строках, как первый запрос.Штормовые события | сортировать по описанию StartTime | проект StartTime, EndTime, State, EventType, DamageProperty, EpisodeNarrative | возьми 10
Выберите новый запрос. Нажмите Shift+Alt+F , чтобы отформатировать запрос, чтобы он выглядел следующим образом.
Выберите Выполнить или нажмите Shift+Enter , чтобы выполнить запрос. Этот запрос возвращает те же записи, что и первый, но включает только столбцы, указанные в инструкции
проекта. Результат должен выглядеть, как в следующей таблице.Совет
Выберите Вызов в верхней части окна запроса, чтобы отобразить набор результатов из первого запроса без повторного выполнения запроса. Часто во время анализа вы запускаете несколько запросов, и Recall позволяет получить результаты предыдущих запросов.
Давайте запустим еще один запрос, чтобы увидеть другой тип вывода.
StormEvents | суммировать event_count=count(), mid = avg(BeginLat) по состоянию | сортировать по середине | где количество событий > 1800 | Состояние проекта, event_count | отображать столбчатую диаграмму
Результат должен выглядеть следующим образом.
Примечание
Пустые строки в выражении запроса могут повлиять на то, какая часть запроса будет выполнена.
- Если текст не выбран, предполагается, что запрос или команда разделены пустыми строками.
- Если выделен текст, выполняется выделенный текст.

Работа с сеткой результатов
Теперь, когда вы увидели, как работают базовые запросы, вы можете использовать сетку результатов для настройки результатов и дальнейшего анализа.
Расширить ячейку
Расширяемые ячейки полезны для просмотра длинных строк или динамических полей, таких как JSON.
Дважды щелкните ячейку, чтобы открыть расширенное представление. Это представление позволяет читать длинные строки и обеспечивает форматирование JSON для динамических данных.
Выберите значок в правом верхнем углу таблицы результатов, чтобы переключить режимы области чтения. Выберите один из следующих режимов области чтения для расширенного представления: встроенный, под панелью и правой панели.
Развернуть строку
При работе с таблицей с десятками столбцов разверните всю строку, чтобы можно было легко просмотреть обзор различных столбцов и их содержимого.
Щелкните стрелку > слева от строки, которую вы хотите развернуть.
В расширенной строке некоторые столбцы развернуты (стрелка, указывающая вниз), а некоторые столбцы свернуты (стрелка, указывающая вправо). Нажмите на эти стрелки для переключения между этими двумя режимами.
Сгруппировать столбец по результатам
В результатах можно сгруппировать результаты по любому столбцу.
Выполните следующий запрос:
StormEvents | сортировать по описанию StartTime | возьми 10
Наведите указатель мыши на столбец State , выберите меню и выберите Group by State .
В сетке дважды щелкните Калифорния , чтобы развернуть и просмотреть записи для этого штата. Этот тип группировки может быть полезен при проведении исследовательского анализа.
Наведите указатель мыши на столбец Группа , затем выберите Сбросить столбцы . Этот параметр возвращает сетку в исходное состояние.
Использовать агрегирование значений
После группировки по столбцу можно использовать функцию агрегирования значений для расчета простой статистики по группам.
Выберите меню для столбца, который вы хотите оценить.
Выберите Агрегирование значений , а затем выберите тип функции, которую вы хотите выполнить в этом столбце.
Скрыть пустые столбцы
Вы можете скрыть/отобразить пустые столбцы, переключив значок глаза в меню сетки результатов.
Фильтрация столбцов
Для фильтрации результатов столбца можно использовать один или несколько операторов.
Чтобы отфильтровать определенный столбец, выберите меню для этого столбца.
Выберите значок фильтра.
В построителе фильтров выберите нужного оператора.
Введите выражение, по которому вы хотите отфильтровать столбец. Результаты фильтруются по мере ввода.
Примечание
Фильтр не чувствителен к регистру.
Чтобы создать фильтр с несколькими условиями, выберите логический оператор, чтобы добавить еще одно условие
Чтобы удалить фильтр, удалите текст из первого условия фильтра.

Выполнить статистику ячеек
Выполните следующий запрос.
StormEvents | сортировать по описанию StartTime | где DamageProperty > 5000 | время начала проекта, состояние, тип события, свойство повреждения, источник | возьми 10
В таблице результатов выберите несколько числовых ячеек. Сетка таблицы позволяет выбрать несколько строк, столбцов и ячеек и вычислить по ним агрегирование. Веб-интерфейс Azure Data Explorer в настоящее время поддерживает следующие функции для числовых значений: Среднее , Подсчет , Минимум , Максимум и Сумма .
Фильтр для запроса из сетки
Еще один простой способ фильтрации сетки — добавить оператор фильтра к запросу непосредственно из сетки.
Выберите ячейку с содержимым, для которого вы хотите создать фильтр запроса.
Щелкните правой кнопкой мыши, чтобы открыть меню действий с ячейкой.
Выберите Добавить выделение как фильтр .Предложение запроса будет добавлено к вашему запросу в редакторе запросов:
 Выберите Добавить выделение как фильтр .
Выберите Добавить выделение как фильтр .Сводная таблица
Функция режима сводной таблицы аналогична сводной таблице Excel, что позволяет выполнять расширенный анализ в самой сетке.
Сводка позволяет брать значения столбцов и превращать их в столбцы. Например, можно выполнить поворот по , штат , чтобы создать столбцы для Флориды, Миссури, Алабамы и т. д.
В правой части сетки выберите Столбцы , чтобы увидеть панель инструментов таблицы.
Выберите Pivot Mode , затем перетащите столбцы следующим образом: EventType в Группы строк ; DamageProperty от до Значения ; и Состояние от до Метки столбцов .
Результат должен выглядеть как следующая сводная таблица:
Поиск в сетке результатов
Вы можете искать конкретное выражение в таблице результатов.
Выполните следующий запрос:
StormEvents | где DamageProperty > 5000 | возьми 1000
Нажмите кнопку Search справа и введите «Wabash»
Все упоминания искомого выражения теперь выделяются в таблице. Вы можете перемещаться между ними, нажимая , Enter , чтобы идти вперед, или Shift+Enter , чтобы идти назад, или вы можете использовать вверх, и 9.0003 вниз кнопки рядом с окном поиска.
Совместное использование запросов
Много раз вы хотите поделиться созданными вами запросами.
В окне запроса выберите первый скопированный запрос.
В верхней части окна запроса выберите Поделиться .
В раскрывающемся списке доступны следующие параметры:
- Ссылка на буфер обмена
- Связать запрос с буфером обмена
- Ссылка, запрос, результаты в буфер обмена
- Штифт к приборной панели
- Запрос к Power BI
Укажите прямую ссылку
Вы можете предоставить прямую ссылку, чтобы другие пользователи, имеющие доступ к кластеру, могли выполнять запросы.
В Поделиться выберите Ссылка, запрос в буфер обмена .
Скопируйте ссылку и запрос в текстовый файл.
Вставьте ссылку в новое окно браузера. Результат должен выглядеть следующим образом
Закрепление на панели мониторинга
Когда вы завершите исследование данных с помощью запросов в веб-интерфейсе Azure Data Explorer и найдете нужные данные, вы можете закрепить их на панели мониторинга для непрерывного мониторинга.
Чтобы закрепить запрос:
В разделе Share выберите Закрепить на приборной панели .
На панели Пин для приборной панели :
- Введите имя запроса .
- Выберите Использовать существующий или Создать новый .
- Укажите Имя информационной панели
- Установите флажок Просмотр панели мониторинга после создания (если это новая панель мониторинга).
- Выберите Штифт
Примечание
Закрепление на приборной панели закрепляет только выбранный запрос. Чтобы создать источник данных панели мониторинга и преобразовать команды рендеринга в визуальный элемент панели мониторинга, необходимо выбрать соответствующую базу данных в списке баз данных.
Экспорт результатов запроса
Чтобы экспортировать результаты запроса в файл CSV, выберите Файл > Экспорт в CSV .
Настройки
На вкладке Настройки вы можете:
- Экспортировать настройки среды
- Импорт параметров среды
- Подсветка уровней ошибок
- Очистить локальное состояние
- Изменить дату и время на определенный часовой пояс
Выберите значок настроек в правом верхнем углу, чтобы открыть Окно настроек .
Экспорт и импорт параметров среды
Действия по экспорту и импорту помогают защитить рабочую среду и перенести ее в другие браузеры и устройства. Действие экспорта экспортирует все ваши настройки, подключения к кластеру и вкладки запросов в файл JSON, который можно импортировать в другой браузер или устройство.
Действие экспорта экспортирует все ваши настройки, подключения к кластеру и вкладки запросов в файл JSON, который можно импортировать в другой браузер или устройство.
Экспорт настроек среды
- В окне Настройки > Общие выберите Экспорт .
- Файл adx-export.json будет загружен в ваше локальное хранилище.
- Выберите Очистить локальное состояние , чтобы вернуть среду в исходное состояние. Этот параметр удаляет все подключения к кластеру и закрывает открытые вкладки.
Примечание
Экспорт экспортирует только данные, относящиеся к запросу. Данные сводной панели не будут экспортированы в файл adx-export.json .
Импорт параметров среды
В окне Настройки > Общие выберите Импорт . Затем во всплывающем окне Warning выберите Import .
Найдите файл adx-export.json в локальном хранилище и откройте его.
Ваши предыдущие подключения к кластеру и открытые вкладки теперь доступны.

Примечание
Импорт переопределяет любые существующие настройки и данные среды.
Уровни ошибок выделения
Kusto пытается интерпретировать серьезность или уровень детализации каждой строки на панели результатов и соответствующим образом окрашивать их. Это достигается путем сопоставления различных значений каждого столбца с набором известных шаблонов («Предупреждение», «Ошибка» и т. д.).
Включить выделение уровня ошибки
Чтобы включить выделение уровня ошибки:
Выберите значок Настройки рядом с вашим именем пользователя.
Выберите Внешний вид и переключите параметр Включить уровень ошибки с выделением справа.
| Цветовая схема уровня ошибки в режиме Light | Цветовая схема уровня ошибки в режиме Dark |
|---|---|
Требования к столбцу для выделения
Для выделенных уровней ошибок столбец должен иметь тип int, long или string.
- Если столбец имеет тип
longилиint:- Имя столбца должно быть Уровень
- Значения могут включать только числа от 1 до 5.
- Если столбец имеет тип
, строка:- Имя столбца может быть опционально Уровень для повышения производительности.
- Столбец может содержать только следующие значения:
- критический, критический, фатальный, утвердительный, высокий
- ошибка, е
- предупреждение, w, монитор
- информация
- подробный, глагол, д
Изменение даты и времени для определенного часового пояса
Вы можете изменить отображаемые значения даты и времени, чтобы они отражали определенный часовой пояс.