
что это такое, для чего нужно, как сделать быстро и по минимальной цене
Здравствуйте!
Разработчики автоматизированного сервиса по управлению контекстной рекламой Click.ru рассказывают, что такое кластеризация и зачем нужна интернет-маркетологам, PPC- и SEO-специалистам, предпринимателям. Как кластеризовать семантическое ядро быстро, качественно и недорого.
Подбор семантики – запросов из «Яндекс.Вордстата», подсказок «Яндекса» и Google, фраз-ассоциаций из блока «Вместе с … ищут» – только первый этап. Итак, вы собрали ключевые слова и фразы. Но перед тем как их использовать, необходимо выполнить кластеризацию.
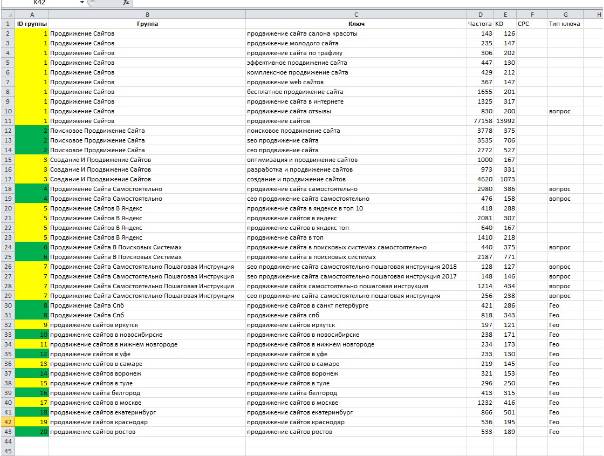
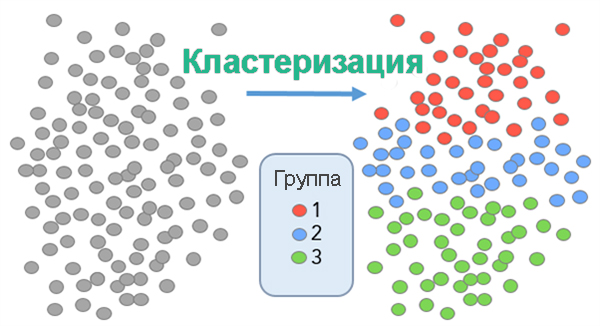
Кластеризация запросов – это …Кластеризация запросов – это группировка, объединение запросов в так называемые кластеры. Процедура позволяет распределить сплошной список ключевых слов и фраз по группам.
Кластеризация помогает превратить такой вот беспорядочный список …
… в подобные упорядоченные группы (кластеры)
Для чего кластеризовать семантическое ядроКластеризация запросов нужна для решения следующих задач:
- Планирование структуры будущего сайта.
 В идеале, сколько кластеров получилось – столько и должно быть страниц. В реальности же ресурсы ограничены, поэтому стоит выбирать наиболее приоритетные. Тип будущей страницы в свою очередь зависит от типа запросов, входящих в кластер. В одну группу попали информационные запросы – планируем написание статьи, если коммерческие запросы – делаем посадочную страницу и т. д.
В идеале, сколько кластеров получилось – столько и должно быть страниц. В реальности же ресурсы ограничены, поэтому стоит выбирать наиболее приоритетные. Тип будущей страницы в свою очередь зависит от типа запросов, входящих в кластер. В одну группу попали информационные запросы – планируем написание статьи, если коммерческие запросы – делаем посадочную страницу и т. д. - Оптимизация имеющихся страниц на сайте. Полученные кластеры распределяются по страницам, которые затем оптимизируются в соответствии со сгруппированными поисковыми запросами.
- Подбор целевых страниц для объявлений в контекстной рекламе. Если ключевые фразы, по которым настраивается реклама, находятся в одном кластере – можно спокойно направлять трафик по всем им на одну целевую страницу.
- Чистка семантического ядра, поиск минус-слов. Нерелевантные, нетематические ключи тоже объединяются в кластеры, поэтому их легко находить и удалять из семантического ядра или же заносить в список минус-слов.
 В идеале, сколько кластеров получилось – столько и должно быть страниц. В реальности же ресурсы ограничены, поэтому стоит выбирать наиболее приоритетные. Тип будущей страницы в свою очередь зависит от типа запросов, входящих в кластер. В одну группу попали информационные запросы – планируем написание статьи, если коммерческие запросы – делаем посадочную страницу и т. д.
В идеале, сколько кластеров получилось – столько и должно быть страниц. В реальности же ресурсы ограничены, поэтому стоит выбирать наиболее приоритетные. Тип будущей страницы в свою очередь зависит от типа запросов, входящих в кластер. В одну группу попали информационные запросы – планируем написание статьи, если коммерческие запросы – делаем посадочную страницу и т. д.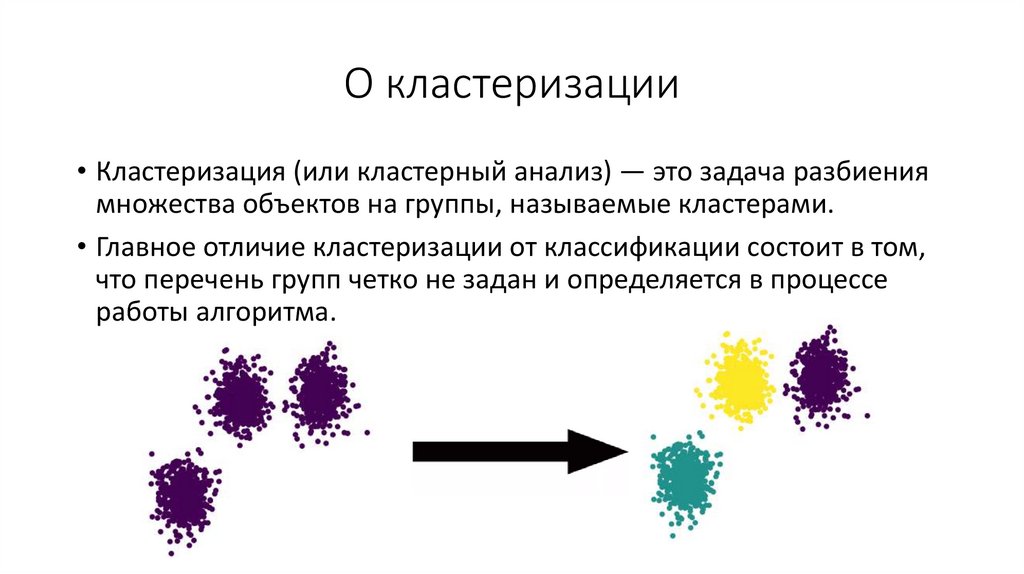
Главное преимущество кластеризации – экономия денег и времени на чистке семантики, разработке дополнительных целевых страниц, оптимизации рекламных кампаний. Также кластеризация предупреждает так называемую каннибализацию.
Каннибализация возникает, когда одни и те же ключи используются и продвигаются на разных страницах. Это приводит к нерелевантной выдаче, неустойчивым позициям в поиске, ухудшению поведенческих факторов.
Методы кластеризацииКластеризация запросов производится по SERP (search engine results page) – странице результатов поиска.
Есть два метода кластеризации:
- Soft-кластеризация – это попарное сравнение выдачи по всем запросам. Запросы объединяются в кластер, если получается заданное количество одинаковых результатов.
- Hard-кластеризация – более сложное сравнение результатов поиска. Выдача сравнивается не только попарно, но и между всеми запросами внутри кластера. Объединение в группы происходит при таком же условии.
Схемы этих двух методов кластеризации запросов
После soft-кластеризации получается слишком широкая семантика, включающая множество нетематических запросов. В итоге такое семантическое ядро нужно дольше чистить и приводить в порядок. Hard-кластеризация же дает более точный результат.
Бесплатная кластеризация запросов?По идее семантическое ядро можно кластеризовать бесплатно и вручную, но:
- Ручная группировка 100 поисковых запросов может занять целый час. Если их 1 000, специалист уже должен потратить пару дней.
- Точную кластеризацию по методу hard сделать почти нереально, так как процесс значительно усложняется.
Чтобы группировать запросы быстро и в полном соответствии с правилами ранжирования поисковиков, необходимо автоматизировать кластеризацию. В этом вам поможет новый инструмент от Click.ru. Он работает в облаке по методу hard, не требует ввода капчи и подключения прокси, справляется с сотней запросов за одну минуту.
В этом вам поможет новый инструмент от Click.ru. Он работает в облаке по методу hard, не требует ввода капчи и подключения прокси, справляется с сотней запросов за одну минуту.
Пошаговая инструкция по работе с кластеризатором Click.ru:
Шаг 1. Зарегистрируйтесь в системе и перейдите на страницу инструмента.
Шаг 2. Укажите название проекта (для удобства) и адрес сайта. Можно оставить URL пустым, если сайт пока в разработке или он работает, но вам не нужен список рекомендованных целевых страниц.
Добавление нового проекта
Шаг 3. Загрузите семантику одним из двух способов: списком в соответствующее поле через копировать-вставить или с помощью файла Excel.
В последнем случае надо учесть, что запросы берутся с каждой заполненной ячейки первого листа. Лишних символов – комментариев, заголовков, частотностей – быть не должно.
Процесс загрузки поисковых запросов для последующей кластеризации
Шаг 4. Установите точность кластеризации – количество совпадений URL в результатах поиска, при котором ключ добавляется в кластер.
Чтобы быстро кластеризовать семантическое ядро и не возиться с настройками, лучше указать точность сравнения топов в диапазоне 3–5. Если поставить цифру от 1 до 3, получатся слишком большие кластеры. При кластеризации с точностью от 6, наоборот, произойдет излишнее дробление семантики. Кстати, в профессиональном режиме можно сделать точность более гибкой, указать максимальный размер кластеров.
Шаг 5. Укажите поисковые системы и регионы, в которых нужно проанализировать топ-10 результатов поиска. Запустите кластеризацию.
Последний шаг настройки кластеризации
Оптимизировать сайт сразу под две поисковые системы не получится: нужно выбрать, что приоритетнее для вашего бизнеса. Если в России оба поисковика примерно одинаково популярны, то Украина, Казахстан и Европа преимущественно используют Google. Также гугл-поиск преобладает среди пользователей Android.
Также гугл-поиск преобладает среди пользователей Android.
Пока идет кластеризация, вы можете закрыть браузер и подождать уведомления на e-mail. Готовый отчет можно открыть в онлайне или скачать на компьютер в формате XLSX.
Пример готового отчета
Стоимость кластеризации зависит от общего числа запросов, выбранных поисковых систем и количества регионов.
Группировка 1 ключа по 1 региону в 1 поисковике обойдется в 1 ТЗ – это внутренняя валюта инструментов Click.ru. Чем больше семантическое ядро, тем дешевле будет стоить кластеризация одного поискового запроса.
Кстати, не нужно сразу платить деньги, если сначала хочется протестировать, как работает кластеризатор Click.ru. Новый пользователь получает в подарок 50 ТЗ при регистрации в системе. Этого хватит на кластеризацию небольшого семантического ядра.
Кластеризация запросов: гибкие настройки
Трекер позиций
Проверка SERP
Трекер КС
Блог
Войти
English
Русский
Español
Deutsch
Français
Italiano
Nederlands
Türkçe
Português
简化字
日本語
Polski
Svenska
Передовой инструмент для анализа вашего SEO и повышения позиций в SERP
Воспользуйтесь кластеризацией ключевых слов от SpySERP для грамотного распределения семантики по страницам вашего сайта. Мы используем особенный алгоритм группировки, что делает результаты более точными.
Мы используем особенный алгоритм группировки, что делает результаты более точными.
Распределяйте ключевые слова правильно
Кластеризация ключевых слов помогает организовать ключевые слова, по которым ранжируется ваш сайт, в отдельные кластеры. Этот процесс необходим для качественного распределения семантического ядра по страницам вашего сайта
ПОПРОБОВАТЬ БЕСПЛАТНО
Учитывайте рейтинг ключевых слов
Используйте высококонкурентные ключевые слова на страницах и в контенте вашего сайта. SpySERP поможет вам определить средний или низкий рейтинг ключей, чтобы вы могли ориентироваться на них создавая новые страницы. Это поможет вам быстрее поднять позиции страниц, для чего и создана кластеризация ключевых слов.
ПОПРОБОВАТЬ БЕСПЛАТНО
Управление несколькими кластерными группами
Создайте несколько кластерных групп с разными настройками и используйте их для более целенаправленного или расширенного распределения ключевых слов по страницам. Вы можете легко перетаскивать слова между кластерами или создавать новые.
Вы можете легко перетаскивать слова между кластерами или создавать новые.
Создание новых кластеров не требует дополнительной оплаты. Инструмент кластеризации можно использовать бесплатно, а с одним снимком SERP можно создать несколько кластерных групп.
ПОПРОБОВАТЬ БЕСПЛАТНО
Кластеры в разных инструментах
Кластерные группы можно использовать в сочетании с различными инструментами SpySERP. Например, в таблице данных SERP они могут выступить в качестве обычных категорий для отображения групп ключевых слов. Все изменения, сделанные в кластерной группе, отображаются везде автоматически.
ПОПРОБОВАТЬ БЕСПЛАТНО
Экспорт кластеров
После создания кластера вы можете экспортировать его в удобный формат или сохранить на Google Диск. Файл экспорта содержит столбцы с ключевыми словами и группами кластеров. При необходимости инструмент может разделять группы на разные файлы.
ПОПРОБОВАТЬ БЕСПЛАТНО
Как работает кластеризация ключевых слов и что она дает SEO вашего сайта
Кластеры используются для группировки целевых условий поиска, относящихся к рассматриваемой странице. Существуют ручные способы кластеризации ключевых слов. Тем не менее, SpySERP автоматически и точнее за вас сделает кластеризацию ключей, после тщательного исследования результатов выдачи.
1
Получение поисковой выдачи
Инструмент начинает работу с выбора ключевых слов и отправки их в поисковые системы в качестве поисковых запросов.
2
Анализ результатов
Инструмент анализирует, совпадают ли одни и те же результаты поисковой выдачи для двух разных ключевых слов. Если это так — такие ключи отправляются в одну группу.
3
Отслеживайте объем и тренды
После кластеризации ключевых слов, вы можете легко отслеживать позиции по группам, анализировать сложность продвижения в Google, сравнить свои результаты с конкурентами и многое другое.
После кластеризации ключевых слов распределите их по страницам вашего сайта. Это поможет сайту получить более высокие позиции в результатах поиска.
ПОПРОБОВАТЬ БЕСПЛАТНО
Тарифные планы
В мес
В годЭкономия 20%
БЕСПЛАТНЫЙ ТАРИФ
Тариф с ограничениями для маленьких проектов
БЕСПЛАТНО
- Один проект (не более 5 ключей)
- Десктопный и мобильный SERP
- Инструменты аналитики
- Максимум 2 поисковика/проект
- Общий доступ к проектам
- Интеграция через API
- Техподдержка
ПОЛУЧИТЬ БЕСПЛАТНЫЙ ТАРИФ
Pro 10k Тарифный план
Для большинства SEO специалистов и агентств
ежемесячная оплатаPro 10kPro 20kPro 50kPro 100kPro 300kPro 1kk
10,000 проверок / месяцДополнительные проверки:$0.79 за 1000
- 10,000 Проверок SERP/мес
- Все возможности бесплатного тарифа
- Безлимит проектов
- До 100 разных поисковиков в проекте
- Интеграция через API
ПОПРОБОВАТЬ БЕСПЛАТНО
Требуется банковская карта
Тариф БИЗНЕС
Персональные настройки для больших компаний и агентств
Персональные расценки
Индивидуальные лимиты, настройки, интеграция с API и т. д.
д.
Инструмент кластеризации ключевых слов: функции и параметры
Специальный алгоритм кластеризации
Инструмент кластеризации ключевых слов SpySERP использует специальный алгоритм группировки для получения более семантически точных результатов. С помощью кластеризации ключей пользователи могут легко отслеживать позицию своего веб-сайта, а также своих конкурентов по каждому кластеру.
Бесплатная версия
Подобно другим функциям SpySERP кластеризация также доступна в бесплатной версии. Пользователи могут использовать полностью бесплатную версию с ограничениями по количеству проектов, и количеству ключевых слов. В бесплатной версии также ограничен доступ к техподдержке.
Гибкая модель оплаты
Кроме того, вы можете подписаться на платную версию SpySERP, которая, конечно же, более продвинутая и выгодная. В платной версии нет ограничений на использование кластеризации ключевых слов, а техподдержка всегда готова помочь. Чтобы проверить эти функциональные возможности, воспользуйтесь 7-дневной пробной версией.
Бренды, отслеживаемые SpySERP
Тысячи бизнесменов, разработчиков, консультантов по SEO и маркетологов уже используют SpySERP для своих SEO-маркетинга, цифрового маркетинга и интернет-рекламы.
Часто задаваемые вопросы
Какая глубина SERP используются для кластеризации?
Вы можете выбрать собственную глубину кластеризации. Доступны Toп 3, Toп 5, Toп 10, Toп 30, Toп 50 и Toп 100.
Что такое SOFT кластеризация?
Для SOFT кластеризации SpySERP выбирает ключевое слово с наибольшим объемом поиска в вашем списке. Инструмент сравнивает результаты, полученные по конкретному ключевому слову, с результатами для других ключевых слов. Если количество общих результатов соответствует заданной точности группировки конкретных ключевых слов, эти ключи группируются.
Используете ли вы кластеризацию MODERATE?
Да, MODERATE кластеризацию можно найти в настройках.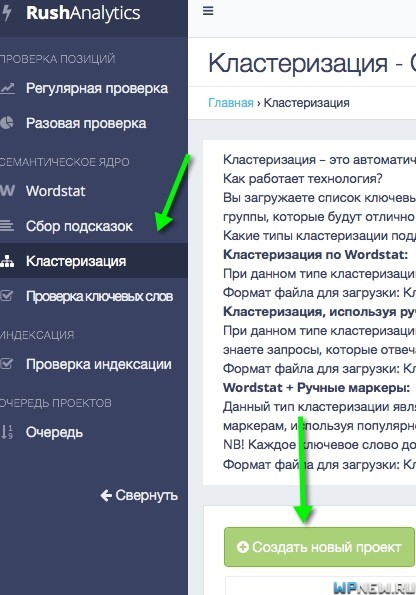 Этот тип группировки — с более сложным алгоритмом, чем SOFT кластеризация. В этом случае ключевые слова в одной группе теснее связаны друг с другом. SEO-специалисты предпочитают использовать именно этот метод для кластеризации ключевых слов.
Этот тип группировки — с более сложным алгоритмом, чем SOFT кластеризация. В этом случае ключевые слова в одной группе теснее связаны друг с другом. SEO-специалисты предпочитают использовать именно этот метод для кластеризации ключевых слов.
Как я могу экспортировать группу кластеров?
Вы можете экспортировать результаты в электронные таблицы Excel или Google. Также для экспорта можно настроить необходимые дополнительные параметры.
Сколько ключевых слов я могу кластеризовать одновременно?
Нет ограничений на количество ключевых слов, которые вы можете сгруппировать. Если объем особенно высок, создание группы может занять немного больше времени, чем обычно. Обязательным условием является наличие хотя бы одного отчета с данными SERP по позициям указанных ключей.
Примеры запросов модели кластеризации | Microsoft Learn
- Статья
- 15 минут на чтение
Применимо к: SQL Server 2019 и более ранние версии служб Analysis Services Службы анализа Azure Power BI Premium
Important
Интеллектуальный анализ данных устарел в службах SQL Server 2017 Analysis Services и больше не поддерживается в службах SQL Server 2022 Analysis Services. Документация не обновляется для устаревших и прекращенных функций. Дополнительные сведения см. в статье обратная совместимость служб Analysis Services.
При создании запроса к модели интеллектуального анализа данных можно получить метаданные о модели или создать запрос содержимого, предоставляющий сведения о шаблонах, обнаруженных в ходе анализа. Кроме того, вы можете создать прогнозный запрос, который использует шаблоны в модели для прогнозирования новых данных. Каждый тип запроса будет предоставлять разную информацию. Например, запрос содержимого может предоставить дополнительные сведения о найденных кластерах, тогда как прогнозный запрос может указать, к какому кластеру с наибольшей вероятностью относится новая точка данных.
В этом разделе объясняется, как создавать запросы для моделей, основанных на алгоритме кластеризации Microsoft.
Запросы содержимого
Получение метаданных модели с помощью DMX
Извлечение метаданных модели из набора строк схемы
Возврат кластера или списка кластеров
Возврат атрибутов процедуры для кластеризации с использованием системного хранения профилей
7 90
Поиск дискриминационных факторов для кластера
Случаи возврата, которые принадлежат кластеру
Запросы прогнозирования
Прогнозируя результаты из модели кластеризации
Определение членства кластера
. Возвращаясь все возможные кластеры с вероятностью и расстояния
. Нахождение на модели
. предоставлять содержимое, полученное алгоритмом, в соответствии со стандартизированной схемой, набором строк схемы модели интеллектуального анализа данных. Вы можете создавать запросы к набору строк схемы модели интеллектуального анализа данных с помощью инструкций расширения интеллектуального анализа данных (DMX). В SQL Server 2017 вы также можете запрашивать наборы строк схемы непосредственно как системные таблицы.
В SQL Server 2017 вы также можете запрашивать наборы строк схемы непосредственно как системные таблицы.
Вернуться к началу
Пример запроса 1. Получение метаданных модели с помощью DMX
Следующий запрос возвращает основные метаданные о модели кластеризации, TM_Clustering , созданной в Учебном руководстве по интеллектуальному анализу данных. Метаданные, доступные в родительском узле модели кластеризации, включают имя модели, базу данных, в которой хранится модель, и количество дочерних узлов в модели. Этот запрос использует запрос содержимого DMX для извлечения метаданных из родительского узла модели:
ВЫБЕРИТЕ КАТАЛОГ_МОДЕЛИ, ИМЯ_МОДЕЛИ, ЗАГЛАВНЫЙ_УЗЕЛ, NODE_SUPPORT, [CHILDREN_CARDINALITY], NODE_DESCRIPTION ИЗ TM_Clustering.CONTENT ГДЕ NODE_TYPE = 1
Примечание
Имя столбца CHILDREN_CARDINALITY необходимо заключить в скобки, чтобы отличить его от зарезервированного ключевого слова многомерных выражений (MDX) с таким же именем.
Пример результатов:
| Строка | Метаданные |
|---|---|
| МОДЕЛЬ_КАТАЛОГ | ТМ_кластеризация |
| ИМЯ_МОДЕЛИ | Приключенческие работы DW |
| NODE_CAPTION | Модель кластера |
| ПОДДЕРЖКА_УЗЛА | 12939 |
| ДЕТИ_КАРДИНАЛЬНОСТЬ | 10 |
| УЗЕЛ_ОПИСАНИЕ | Все |
Определение того, что означают эти столбцы в модели кластеризации, см. в разделе Содержимое модели интеллектуального анализа данных для моделей кластеризации (службы Analysis Services — интеллектуальный анализ данных).
Вернуться к началу
Пример запроса 2. Извлечение метаданных модели из набора строк схемы
Запрашивая набор строк схемы интеллектуального анализа данных, можно найти ту же информацию, которая возвращается в запросе содержимого DMX. Однако набор строк схемы предоставляет некоторые дополнительные столбцы.
В следующем примере возвращается дата создания, изменения и последней обработки модели, а также параметры кластеризации, которые использовались для построения модели, и размер обучающей выборки. Эта информация может быть полезна для документирования модели или для определения того, какие параметры кластеризации использовались для создания существующей модели.
ВЫБЕРИТЕ MODEL_NAME, DATE_CREATED, LAST_PROCESSED, PREDICTION_ENTITY, MINING_PARAMETERS из $system.DMSCHEMA_MINING_MODELS ГДЕ MODEL_NAME = 'TM_Clustering'
Пример результатов:
| Строка | Метаданные |
|---|---|
| ИМЯ_МОДЕЛИ | ТМ_кластеризация |
| ДАТА_СОЗДАНИЯ | 12.10.2007 19:42:51 |
| ПОСЛЕДНЯЯ_ОБРАБОТКА | 12.10.2007 20:09:54 |
| PREDICTION_ENTITY | Покупатель велосипедов |
| MINING_PARAMETERS | cluster_count = 10, cluster_seed = 0, Clustering_Method = 1, Maximum_input_attributes = 255, Maximum_states = 100, Minimum_support = 1, , Minimum_support = 1, , . |
 10
10Вернуться к началу
Наиболее полезные запросы содержимого в моделях кластеризации обычно возвращают тот же тип информации, которую вы можете просматривать с помощью Средство просмотра кластеров . Сюда входят профили кластеров, характеристики кластеров и дискриминация кластеров. В этом разделе приведены примеры запросов, которые извлекают эту информацию.
Пример запроса 3: Возврат кластера или списка кластеров
Поскольку все кластеры имеют тип узла 5, вы можете легко получить список кластеров, запросив содержимое модели только для узлов этого типа. Вы также можете отфильтровать возвращаемые узлы по вероятности или поддержке, как показано в этом примере.
ВЫБЕРИТЕ NODE_NAME, NODE_CAPTION, NODE_SUPPORT, NODE_DESCRIPTION ИЗ TM_Clustering.CONTENT ГДЕ NODE_TYPE = 5 И NODE_SUPPORT> 1000
Пример результатов:
| Строка | Метаданные |
|---|---|
| ИМЯ_УЗЛА | 002 |
| NODE_CAPTION | Кластер 2 |
| ПОДДЕРЖКА_УЗЛА | 1649 |
| УЗЕЛ_ОПИСАНИЕ | Английский Образование=Высшая степень, 32 <=Возраст <=48, Количество автомобилей в собственности=0, 35964. 0771121808 <= Годовой доход <= 97407.7163393957 , Английский Род занятий = Профессиональный , Расстояние до работы = 2-5 миль , Регион = Северная Америка , Покупатель велосипеда = 1 , Количество детей дома = 0 , Количество автомобилей в собственности = 1 , Расстояние до работы = 0- 1 миля, английский язык Образование = бакалавриат, общее количество детей = 1, количество детей дома = 2, английский род занятий = квалифицированное руководство, семейное положение = S, общее количество детей = 0, флаг владельца дома = 0, пол = F, общее количество детей = 2 , Регион=Тихий океан 0771121808 <= Годовой доход <= 97407.7163393957 , Английский Род занятий = Профессиональный , Расстояние до работы = 2-5 миль , Регион = Северная Америка , Покупатель велосипеда = 1 , Количество детей дома = 0 , Количество автомобилей в собственности = 1 , Расстояние до работы = 0- 1 миля, английский язык Образование = бакалавриат, общее количество детей = 1, количество детей дома = 2, английский род занятий = квалифицированное руководство, семейное положение = S, общее количество детей = 0, флаг владельца дома = 0, пол = F, общее количество детей = 2 , Регион=Тихий океан |
Атрибуты, определяющие кластер, можно найти в двух столбцах набора строк схемы интеллектуального анализа данных.
Столбец NODE_DESCRIPTION содержит список атрибутов, разделенных запятыми. Обратите внимание, что список атрибутов может быть сокращен для отображения.
Вложенная таблица в столбце NODE_DISTRIBUTION содержит полный список атрибутов кластера.
Если ваш клиент не поддерживает иерархические наборы строк, вы можете вернуть вложенную таблицу, добавив ключевое слово FLATTENED перед списком столбцов SELECT. Дополнительные сведения об использовании ключевого слова FLATTENED см. в разделе SELECT FROM .CONTENT (DMX).
 Если ваш клиент не поддерживает иерархические наборы строк, вы можете вернуть вложенную таблицу, добавив ключевое слово FLATTENED перед списком столбцов SELECT. Дополнительные сведения об использовании ключевого слова FLATTENED см. в разделе SELECT FROM
Если ваш клиент не поддерживает иерархические наборы строк, вы можете вернуть вложенную таблицу, добавив ключевое слово FLATTENED перед списком столбцов SELECT. Дополнительные сведения об использовании ключевого слова FLATTENED см. в разделе SELECT FROM Вернуться к началу
Пример запроса 4: Возврат атрибутов для кластера
Для каждого кластера Cluster Viewer отображает профиль, в котором перечислены атрибуты и их значения. Средство просмотра также отображает гистограмму, показывающую распределение значений для всей совокупности наблюдений в модели. Если вы просматриваете модель в средстве просмотра, вы можете легко скопировать гистограмму из легенды интеллектуального анализа данных, а затем вставить ее в документ Excel или Word. Вы также можете использовать панель «Характеристики кластера» средства просмотра для графического сравнения атрибутов разных кластеров.
Однако, если вам необходимо получить значения для более чем одного кластера одновременно, проще запросить модель.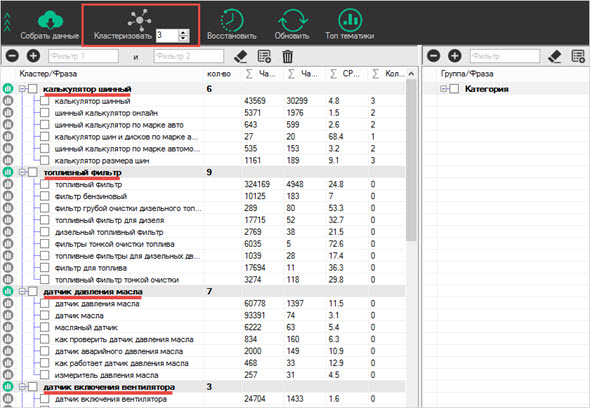 Например, при просмотре модели можно заметить, что два верхних кластера различаются по одному атрибуту,
Например, при просмотре модели можно заметить, что два верхних кластера различаются по одному атрибуту, Количество автомобилей в собственности . Поэтому вы хотите извлечь значения для каждого кластера.
ВЫБЕРИТЕ TOP 2 NODE_NAME, (ВЫБЕРИТЕ ATTRIBUTE_VALUE, [ВЕРОЯТНОСТЬ] ИЗ NODE_DISTRIBUTION, ГДЕ ATTRIBUTE_NAME = «Количество принадлежащих автомобилей») КАК т ИЗ [TM_Clustering].CONTENT ГДЕ NODE_TYPE = 5
Первая строка кода указывает, что вам нужны только два верхних кластера.
Примечание
По умолчанию кластеры упорядочены по поддержке. Поэтому столбец NODE_SUPPORT можно опустить.
Вторая строка кода добавляет вложенный оператор выбора, который возвращает только определенные столбцы из столбца вложенной таблицы. Кроме того, он ограничивает строки из вложенной таблицы теми, которые относятся к целевому атрибуту Количество автомобилей в собственности . Для упрощения отображения вложенная таблица имеет псевдоним.
Примечание
Столбец вложенной таблицы PROBABILITY должен быть заключен в квадратные скобки, поскольку он также является именем зарезервированного ключевого слова MDX.
Пример результатов:
| NODE_NAME | T.ATTRIBUTE_VALUE | Т.ВЕРОЯТНОСТЬ |
|---|---|---|
| 001 | 2 | 0,829207754 |
| 001 | 1 | 0,109354156 |
| 001 | 3 | 0,034481552 |
| 001 | 4 | 0,013503302 |
| 001 | 0 | 0,013453236 |
| 001 | Отсутствует | 0 |
| 002 | 0 | 0,576980023 |
| 002 | 1 | 0,406623939 |
| 002 | 2 | 0,016380082 |
| 002 | 3 | 1.60E-05 |
| 002 | 4 | 0 |
| 002 | Отсутствует | 0 |
Вернуться к началу
Пример запроса 5. Возврат профиля кластера с помощью системных хранимых процедур
В качестве упрощения вместо написания собственных запросов с помощью DMX можно также вызывать системные хранимые процедуры, которые SQL Server Analysis Services использует для работы с кластерами.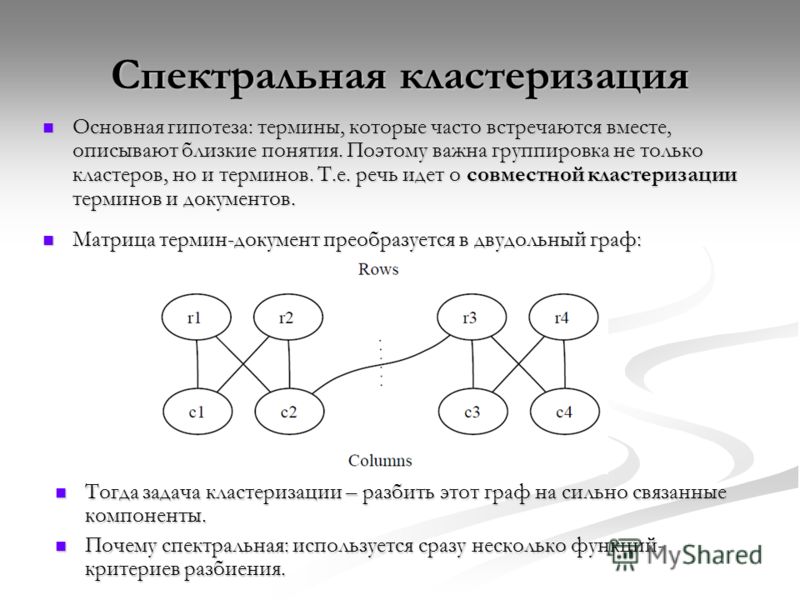 В следующем примере показано, как использовать внутренние хранимые процедуры для возврата профиля для кластера с идентификатором 002.
В следующем примере показано, как использовать внутренние хранимые процедуры для возврата профиля для кластера с идентификатором 002.
ВЫЗОВ System.Microsoft.AnalysisServices.System.DataMining.Clustering.GetClusterProfiles('TM_Clustering", '002',0.0005
Аналогичным образом можно использовать системную хранимую процедуру для возврата характеристик определенного кластера, как показано в следующем примере: ‘, 0,0005
Пример результатов:
| Атрибуты | Значения | Частота | Поддержка | |
|---|---|---|---|---|
| Номер Дети дома | 0 | 0,99999982 | 98 | 899 |
| Регион | Северная Америка | 0,999852875241508 | 899 | |
| Всего детей | 0 | 0,993860958572323 | 893 |
Примечание
Хранимые процедуры системы интеллектуального анализа данных предназначены для внутреннего использования, и Microsoft оставляет за собой право изменять их по мере необходимости. Для производственного использования мы рекомендуем создавать запросы с помощью DMX, AMO или XMLA.
Для производственного использования мы рекомендуем создавать запросы с помощью DMX, AMO или XMLA.
Вернуться к началу
Пример запроса 6. Поиск дискриминационных факторов для кластера
Вкладка Дискриминация кластера средства просмотра кластеров позволяет легко сравнивать кластер с другим кластером или сравнивать кластер со всеми оставшимися случаями (дополнение кластера).
Однако создание запросов для возврата этой информации может быть сложным, и может потребоваться дополнительная обработка на клиенте для сохранения временных результатов и сравнения результатов двух или более запросов. В качестве ярлыка можно использовать системные хранимые процедуры.
Следующий запрос возвращает единственную таблицу, в которой указаны первичные факторы различия между двумя кластерами, имеющими идентификаторы узлов 009 и 007. Атрибуты с положительными значениями отдают предпочтение кластеру 009, тогда как атрибуты с отрицательными значениями отдают предпочтение кластеру 007.
CALL System .Microsoft.AnalysisServices.System.DataMining.Clustering.GetClusterDiscrimination('TM_Clustering','009','007',0.0005,true)
Пример результатов:
| Атрибуты | Значения | Оценка |
|---|---|---|
| Регион | Северная Америка | 100 |
| Английский Род занятий | Квалифицированный ручной | 94. 03898654 |
| Регион | Европа | -72,5041051379789 |
| Английский Род занятий | Руководство | -69.6503163202722 |
Это та же информация, которая представлена в таблице Дискриминация кластера средство просмотра, если вы выберете Кластер 9 из первого раскрывающегося списка и Кластер 7 из второго раскрывающегося списка. Чтобы сравнить кластер 9 с его дополнением, вы используете пустую строку во втором параметре, как показано в следующем примере:
CALL System.
 Microsoft.AnalysisServices.System.DataMining.Clustering.GetClusterDiscrimination('TM_Clustering','009', '', 0,0005, правда)
Microsoft.AnalysisServices.System.DataMining.Clustering.GetClusterDiscrimination('TM_Clustering','009', '', 0,0005, правда)
Примечание
Хранимые процедуры системы интеллектуального анализа данных предназначены для внутреннего использования, и Microsoft оставляет за собой право изменять их по мере необходимости. Для производственного использования мы рекомендуем создавать запросы с помощью DMX, AMO или XMLA.
Вернуться к началу
Пример запроса 7. Возврат наблюдений, принадлежащих кластеру
Если в модели интеллектуального анализа данных включена детализация, можно создавать запросы, возвращающие подробные сведения о наблюдениях, используемых в модели. Кроме того, если для структуры интеллектуального анализа данных включена детализация, вы можете включить столбцы из базовой структуры с помощью функции StructureColumn (DMX).
В следующем примере возвращаются два столбца, которые использовались в модели, Возраст и Регион, и еще один столбец, Имя, который не использовался в модели. Запрос возвращает только случаи, которые были отнесены к Кластеру 1.
Запрос возвращает только случаи, которые были отнесены к Кластеру 1.
ВЫБЕРИТЕ [Возраст], [Регион], StructureColumn('Имя')
ИЗ [TM_Clustering].CASES
ГДЕ находится в узле ('001')
Чтобы вернуть обращения, принадлежащие кластеру, необходимо знать идентификатор кластера. Вы можете получить идентификатор кластера, просмотрев модель в одном из средств просмотра. Или вы можете переименовать кластер для удобства поиска, после чего вы можете использовать имя вместо идентификационного номера. Однако знайте, что имена, которые вы назначаете кластеру, будут потеряны при повторной обработке модели.
Вернуться к началу
Создание прогнозов с использованием модели
Хотя кластеризация обычно используется для описания и понимания данных, реализация Microsoft также позволяет прогнозировать членство в кластере и возвращать вероятности, связанные с прогнозом. В этом разделе приведены примеры того, как создавать прогнозирующие запросы для моделей кластеризации. Вы можете делать прогнозы для нескольких случаев, указав источник табличных данных, или вы можете предоставлять новые значения одновременно, создавая одноэлементный запрос. Для ясности все примеры в этом разделе представляют собой одноэлементные запросы.
Вы можете делать прогнозы для нескольких случаев, указав источник табличных данных, или вы можете предоставлять новые значения одновременно, создавая одноэлементный запрос. Для ясности все примеры в этом разделе представляют собой одноэлементные запросы.
Дополнительные сведения о том, как создавать прогнозирующие запросы с помощью DMX, см. в разделе Инструменты запросов интеллектуального анализа данных.
Вернуться к началу
Пример запроса 8: Прогнозирование результатов с помощью модели кластеризации
Если созданная вами модель кластеризации содержит предсказуемый атрибут, вы можете использовать эту модель для прогнозирования результатов. Однако модель обрабатывает предсказуемый атрибут по-разному в зависимости от того, установлен ли предсказуемый столбец как Predict или PredictOnly 9.0016 . Если вы установите использование столбца на Predict , значения для этого атрибута добавляются в модель кластеризации и отображаются как атрибуты в готовой модели.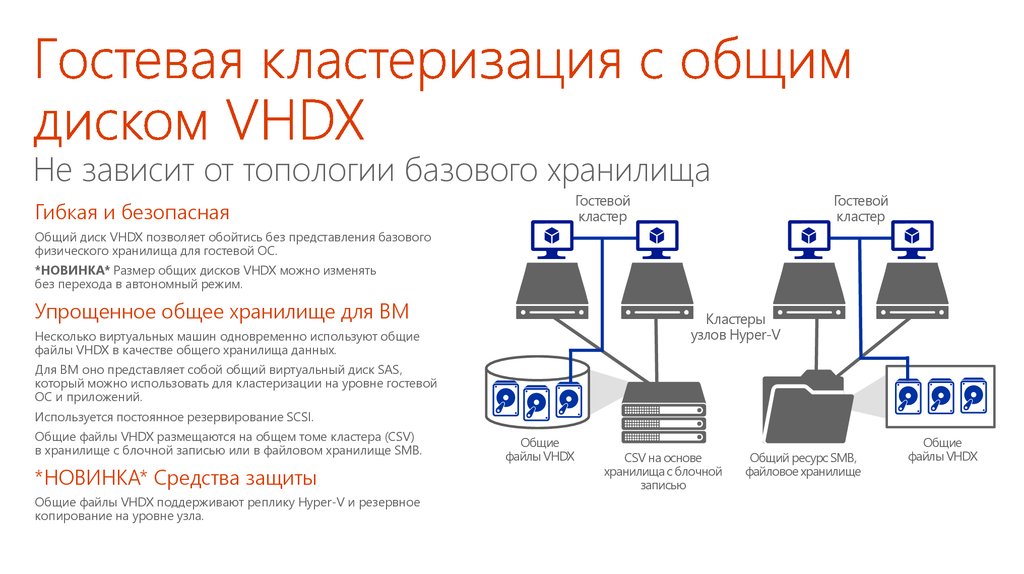 Однако если для использования столбца установлено значение PredictOnly , значения не используются для создания кластеров. Вместо этого после завершения режима алгоритм кластеризации создает новые значения для атрибута PredictOnly на основе кластеров, к которым принадлежит каждый случай.
Однако если для использования столбца установлено значение PredictOnly , значения не используются для создания кластеров. Вместо этого после завершения режима алгоритм кластеризации создает новые значения для атрибута PredictOnly на основе кластеров, к которым принадлежит каждый случай.
Следующий запрос предоставляет модели один новый случай, где единственной информацией о случае является возраст и пол. Оператор SELECT определяет интересующую вас предсказуемую пару атрибут/значение, а функция PredictProbability (DMX) сообщает вам вероятность того, что случай с этими атрибутами будет иметь целевой результат.
ВЫБОР [TM_Clustering].[Покупатель велосипеда], PredictProbability([Покупатель велосипеда],1) ОТ [TM_кластеризация] ЕСТЕСТВЕННОЕ ПРОГНОЗИРОВАНИЕ ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ 40 КАК [Возраст], 'F' AS [Пол]) AS t
Пример результатов, когда использование установлено на Predict :
| Покупатель велосипеда | Выражение |
|---|---|
| 1 | 0,592924735740338 |
Пример результатов, когда использование установлено на PredictOnly и модель переработана:
| Покупатель велосипеда | Выражение |
|---|---|
| 1 | 0,55843544003102 |
В этом примере разница в модели несущественна. Однако иногда может быть важно обнаружить различия между фактическим распределением значений и тем, что предсказывает модель. Функция PredictCaseLikelihood (DMX) полезна в этом сценарии, поскольку она сообщает вам, насколько вероятен случай, учитывая модель.
Однако иногда может быть важно обнаружить различия между фактическим распределением значений и тем, что предсказывает модель. Функция PredictCaseLikelihood (DMX) полезна в этом сценарии, поскольку она сообщает вам, насколько вероятен случай, учитывая модель.
Число, возвращаемое функцией PredictCaseLikelihood, является вероятностью и, следовательно, всегда находится в диапазоне от 0 до 1, а значение 0,5 соответствует случайному результату. Таким образом, оценка менее 0,5 означает, что прогнозируемый случай маловероятен с учетом модели, а оценка более 0,5 указывает на то, что прогнозируемый случай скорее соответствует модели, чем не соответствует ей.
Например, следующий запрос возвращает два значения, которые характеризуют вероятность появления нового образца. Ненормализованное значение представляет вероятность с учетом текущей модели. При использовании ключевого слова NORMALIZED показатель вероятности, возвращаемый функцией, корректируется путем деления «вероятности с моделью» на «вероятность без модели».
ВЫБОР PredictCaseLikelihood(NORMALIZED) AS [NormalizedValue], PredictCaseLikelihood(NONNORMALIZED) AS [NonNormalizedValue] ОТ [TM_Clustering_PredictOnly] ЕСТЕСТВЕННОЕ ПРОГНОЗИРОВАНИЕ ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ 40 КАК [Возраст], 'F' AS [Пол]) AS t
Пример результатов:
| NormalizedValue | Ненормализованное значение |
|---|---|
| 5.56438372679893E-11 | 8.65459953145182E-68 |
Обратите внимание, что числа в этих результатах выражены в экспоненциальном представлении.
Вернуться к началу
Пример запроса 9: Определение членства в кластере
В этом примере используется функция Cluster (DMX) для возврата кластера, к которому, скорее всего, принадлежит новый случай, и функция ClusterProbability (DMX) для возврата вероятность членства в этом кластере.
ВЫБЕРИТЕ Кластер(), Вероятность Кластера() ОТ [TM_кластеризация] ЕСТЕСТВЕННОЕ ПРОГНОЗИРОВАНИЕ ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ 40 КАК [Возраст], 'F' AS [Пол], 'S' AS [Семейное положение]) AS t
Пример результатов:
| $CLUSTER | Выражение |
|---|---|
| Кластер 2 | 0,397918596951617 |
Примечание По умолчанию функция ClusterProbability возвращает вероятность наиболее вероятного кластера. Однако вы можете указать другой кластер, используя синтаксис
Однако вы можете указать другой кластер, используя синтаксис ClusterProbability('имя кластера') . Если вы сделаете это, имейте в виду, что результаты каждой функции прогнозирования не зависят от других результатов. Следовательно, оценка вероятности во втором столбце может относиться к кластеру, отличному от кластера, указанного в первом столбце.
Вернуться к началу
Пример запроса 10. Возврат всех возможных кластеров с вероятностью и расстоянием
В предыдущем примере показатель вероятности был не очень высоким. Чтобы определить, существует ли лучший кластер, вы можете использовать функцию PredictHistogram (DMX) вместе с функцией Cluster (DMX), чтобы вернуть вложенную таблицу, включающую все возможные кластеры, вместе с вероятностью того, что новый случай, принадлежащий каждому кластеру . Ключевое слово FLATTENED используется для преобразования иерархического набора строк в плоскую таблицу для более удобного просмотра.
ВЫБЕРИТЕ ПЛАСКИЙ PredictHistogram(Cluster()) От [TM_кластеризация] ЕСТЕСТВЕННОЕ ПРОГНОЗИРОВАНИЕ ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ 40 КАК [Возраст], 'F' AS [Пол], 'S' AS [Семейное положение])
Выражение. $CLUSTER $CLUSTER | Выражение.$DISTANCE | Выражение.$ВЕРОЯТНОСТЬ | |
|---|---|---|---|
| Кластер 2 | 0,602081403048383 | 0,397918596951617 | |
| Группа 10 | 0,719691686785675 | 0,280308313214325 | |
| Кластер 4 | 0,8677725 | 7910,132227409621209 | |
| Группа 5 | 0,931039872200985 | 0,06896012779 | |
| Кластер 3 | 0,942359230072167 | 0,0576407699278328 | |
| Кластер 6 | 0,958973668972756 | 0,0410263310272437 | |
| Кластер 7 | 0,97 | ||
| 0,0209187240732763 | |||
| Кластер 1 | 0,99916 | 186240,000830955181376364 | |
| Кластер 9 | 0,999831227795894 | 0,000168772204105754 | |
| Группа 8 | 1 | 0 |
По умолчанию результаты ранжируются по вероятности. Результаты говорят вам, что, хотя вероятность для Кластера 2 довольно низка, Кластер 2 по-прежнему лучше всего подходит для новой точки данных.
Результаты говорят вам, что, хотя вероятность для Кластера 2 довольно низка, Кластер 2 по-прежнему лучше всего подходит для новой точки данных.
Примечание Дополнительный столбец $DISTANCE представляет расстояние от точки данных до кластера. По умолчанию алгоритм кластеризации Microsoft использует масштабируемую кластеризацию EM, которая назначает несколько кластеров каждой точке данных и ранжирует возможные кластеры. Однако если вы создаете модель кластеризации с использованием алгоритма K-средних, каждой точке данных может быть назначен только один кластер, и этот запрос вернет только одну строку. Понимание этих различий необходимо для интерпретации результатов функции PredictCaseLikelihood (DMX). Дополнительные сведения о различиях между кластеризацией EM и кластеризацией K-средних см. в Техническом справочнике по алгоритму кластеризации Microsoft.
Вернуться к началу
Список функций
Все алгоритмы Microsoft поддерживают общий набор функций. Однако модели, построенные с использованием алгоритма кластеризации Microsoft, поддерживают дополнительные функции, перечисленные в следующей таблице.
Однако модели, построенные с использованием алгоритма кластеризации Microsoft, поддерживают дополнительные функции, перечисленные в следующей таблице.
| Функция прогнозирования | Использование |
|---|---|
| Кластер (DMX) | Возвращает кластер, который, скорее всего, будет содержать входной вариант. |
| Расстояние до кластера (DMX) | Возвращает расстояние входного наблюдения от указанного кластера или, если кластер не указан, расстояние входного наблюдения от наиболее вероятного кластера. Возвращает вероятность того, что входной вариант принадлежит указанному кластеру. |
| Вероятность кластера (DMX) | Возвращает вероятность того, что входной вариант принадлежит указанному кластеру. |
| Является потомком (DMX) | Определяет, является ли один узел дочерним элементом другого узла в модели. |
| IsInNode (DMX) | Указывает, содержит ли указанный узел текущий случай. |
| PredictAdjustedProbability (DMX) | Возвращает взвешенную вероятность. |
| PredictAssociation (DMX) | Прогнозирует принадлежность к ассоциативному набору данных. |
| PredictCaseLikelihood (DMX) | Возвращает вероятность того, что входной случай будет соответствовать существующей модели. |
| Прогностическая гистограмма (DMX) | Возвращает таблицу значений, связанных с текущим предсказанным значением. |
| PredictNodeId (DMX) | Возвращает Node_ID для каждого случая. |
| PredictProbability (DMX) | Возвращает вероятность предсказанного значения. |
| PredictStdev (DMX) | Возвращает предсказанное стандартное отклонение для указанного столбца. |
| PredictSupport (DMX) | Возвращает значение поддержки для указанного состояния. |
| PredictVariance (DMX) | Возвращает дисперсию указанного столбца. |
Синтаксис конкретных функций см. в справочнике по функциям расширений интеллектуального анализа данных (DMX).
См. также
Запросы интеллектуального анализа данных
Технический справочник по алгоритму кластеризации Microsoft
Алгоритм кластеризации Microsoft
Оптимизация BigQuery: кластеризация таблиц | Фелипе Хоффа
BigQuery только что объявил о возможности кластеризации
таблиц — о чем я расскажу здесь. Если вы ищете значительную экономию средств и времени на запросы, этот пост для вас.Важное обновление : Я покинул Google и присоединился к Snowflake в 2020 году, поэтому я не могу обновлять свои старые сообщения. Если вы хотите попробовать Snowflake, присоединяйтесь к нам — мне очень весело ❄️.
tl;dr:
- Кластеры обеспечивают высокую производительность и снижение затрат
- Кластеризация бесплатна, поэтому есть огромный стимул для кластеризации ваших таблиц.
- Кластеризация таблиц может повлиять на скорость загрузки. — есть процесс постоянной перекластеризации и оптимизации таблиц без простоев и бесплатно.
- Нет ограничений на количество значений, которые может иметь кластеризованный столбец (с другой стороны, есть ограничения на разделы).

Внимание! Этот пост воспроизводит несколько терабайт данных. Настройте контроль затрат BigQuery, пристегнитесь, сохраняйте спокойствие и продолжайте запрашивать.
Можете ли вы заметить огромную разницу между запросом слева и справа?
Один и тот же запрос почти к тем же таблицам — одна кластеризована, другая нет. Быстрее и эффективнее.Что мы видим здесь:
- Kubernetes был популярной темой в Википедии в 2017 году — с более чем 400 000 просмотров на англоязычных сайтах Википедии.
- Kubernetes получает намного меньше просмотров страниц на мобильном сайте Википедии, чем на традиционном настольном (90 тыс. против 343 тыс. ).
 ).
).Но что действительно интересно:
- Запрос слева смог обработать 2,2 ТБ за 20 секунд. Впечатляет, но дорого.
- Запрос справа прошёлся по аналогичной таблице — но дал результаты всего за 5,4 секунды и за одну десятую стоимости (227 ГБ ).
В чем секрет?
Теперь вы можете указать BigQuery хранить ваши данные, «отсортированные» по определенным полям — и когда ваши запросы будут фильтроваться по этим полям, BigQuery будет достаточно умным, чтобы открывать только соответствующие кластеры. Другими словами, вы получите более быстрый и дешевый результат.
Ранее я объяснял свою ленивую загрузку представлений Википедии в секционированные ежегодные таблицы BigQuery. Напоминаем, что только в 2017 году мы будем запрашивать более 190 миллиардов просмотров страниц, более 3927 сайтов Википедии, охваченных более чем 54 миллиардами строк (2,2 ТБ данных в год).
Чтобы переместить существующие данные в новую кластеризованную таблицу, я могу использовать DDL:
CREATE TABLE `fh-bigquery.
, require_partition_filter=true
)
AS SELECT * FROM `fh-bigquery.wikipedia_v2. просмотры страниц_2017`
WHERE datehour > '1990-01-01' # nag-- Прошло 4724,8 с, обработано 2,20 ТБ. оптимизирует эти запросы. Эти запросы будут оптимизированы еще больше, если пользователь также отфильтрует поtitle. Если пользователь фильтрует только поtitle, кластеризация не сработает, так как важен порядок (представьте себе коробки внутри коробок).
 wikipedia_v3.pageviews_2017` description="Просмотры страниц Википедии - разделены по дням, сгруппированы по (вики, названию). Контакт https://twitter.com/felipehoffa"
wikipedia_v3.pageviews_2017` description="Просмотры страниц Википедии - разделены по дням, сгруппированы по (вики, названию). Контакт https://twitter.com/felipehoffa"  Обратите внимание, что вы можете выполнить ту же операцию бесплатно с комбинацией
Обратите внимание, что вы можете выполнить ту же операцию бесплатно с комбинацией bq export/load , но мне нравится гибкость, которую поддерживает DDL. В пределах SELECT * FROM Я мог бы отфильтровать и преобразовать свои данные или добавить больше столбцов только для целей кластеризации. SELECT * LIMIT 1
SELECT * LIMIT 1 — известный антишаблон BigQuery. Вы платите за полное сканирование таблицы, в то время как вы могли бы получить те же результаты бесплатно с предварительным просмотром таблицы. Давайте попробуем это на нашей таблице v2 :
SELECT *
FROM `fh-bigquery.wikipedia_v2.pageviews_2017`
WHERE DATE(datehour) МЕЖДУ '2017-06-01' И '2017-06-30'
LIMIT 11,7 с истекло, 180 ГБ обработано
Ой. Обработано 180 Гб — но по крайней мере разбивка даты на покрытие только июня сработала. Но то же самое в v3 , наша кластеризованная таблица:
SELECT *
FROM `fh-bigquery.
ГДЕ ДАТА(datehour) МЕЖДУ '2017-06-01' И '2017-06-30'
LIMIT Прошло 11,8 с, 112 МБ обработано
 wikipedia_v3.pageviews_2017`
wikipedia_v3.pageviews_2017` Да!!! Теперь с кластеризованной таблицей мы можем выполнить
SELECT * LIMIT 1, и он отсканировал только 0,06% данных (в данном случае).
Базовый запрос: Barcelona, English, 180->10GB
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v2.pageviews_2017` '2017-06-30'
И wiki LIKE 'en'
AND title = 'Barcelona'
СГРУППИРОВАТЬ ПО wiki ORDER BY wiki18.1s истекло, 180 ГБ обработано
Любой запрос, подобный этому, будет стоить 180 ГБ на нашем v2 табл. Тем временем в v3 :
ВЫБЕРИТЕ вики, СУММ(просмотров) просмотров
ИЗ `fh-bigquery.wikipedia_v3.pageviews_2017`
ГДЕ ДАТА(datehour) МЕЖДУ '2017-06-01' И '2017-06-30' И
LIKE 'en'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wikiПрошло 3,5 с, обработано 10,3 ГБ
В кластеризованной таблице мы получаем результаты в 1/6 случаев за 5% затрат.
ВЫБЕРИТЕ вики, СУММ(просмотры) просмотры
ИЗ `fh-bigquery.wikipedia_v3.pageviews_2017`
ГДЕ DATE(datehour) МЕЖДУ '2017-06-01' И '2017-06-30'
-- AND wiki = 'en'
AND title = 'Барселона'
ГБ обработано
Если я не воспользуюсь своей стратегией кластеризации (в данном случае: фильтруя по тому, какая из кратных вики в первую очередь), то я не получу всей возможной эффективности, но все равно лучше, чем раньше.
Меньшие кластеры, меньше данных
В английской Википедии больше данных, чем в албанской. Проверьте, как ведет себя запрос, когда мы смотрим только на этот:
ВЫБЕРИТЕ вики, СУММА(просмотров) просмотров
ИЗ `fh-bigquery.wikipedia_v3.pageviews_2017`
ГДЕ ДАТА(datehour) МЕЖДУ '2017-06-01' И '2017-06-30'
AND wiki = 'sq'
AND title = 'Barcelona'
GROUP BY wiki ORDER BY wiki Прошло 2,6 с, 3,83 ГБ
Кластеры могут LIKE и REGEX
Давайте запросим все вики, которые начинаются с r , и названия, соответствующие Bar . :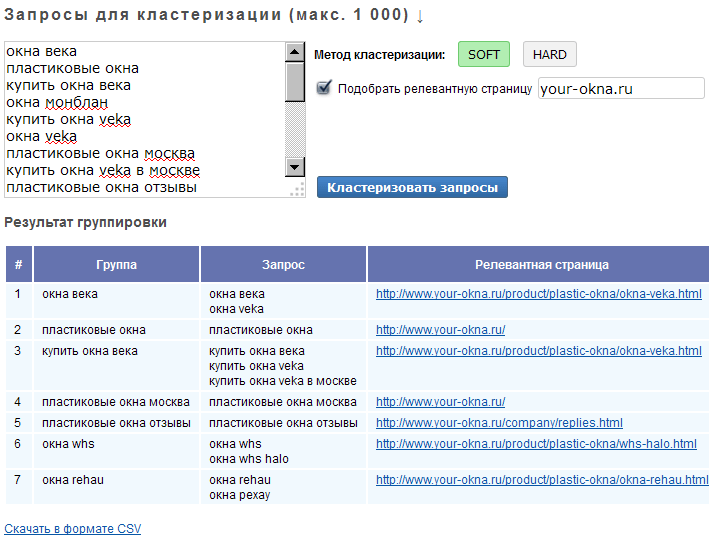 *na
*na
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017` 9Bar.*na')
GROUP BY wiki ORDER BY wikiПрошло 4,8 с, обработано 14,3 ГБ
Это хорошее поведение — кластеры могут работать с выражениями LIKE и REGEX , но только при поиске префиксов.
Если вместо этого искать суффиксы:
SELECT wiki, SUM(views) views
FROM `fh-bigquery.wikipedia_v3.pageviews_2017`
WHERE DATE(datehour) МЕЖДУ '2017-06-01' И '2017-06- 30'
И вики КАК '%m'
И REGEXP_CONTAINS(title, '.*celona')
GROUP BY wiki ORDER BY wiki(прошло 5,1 с, обработано 180 ГБ
Это возвращает нас к 180 ГБ — этот запрос вообще не использует кластеры.
JOIN и GROUP BY
диапазон времени, независимо от того, какую таблицу я использую:
ВЫБЕРИТЕ вики, заголовок, СУММ(просмотры) просмотры
ИЗ `fh-bigquery.wikipedia_v2.pageviews_2017`
ГДЕ ДАТА(datehour) МЕЖДУ '2017-06-01' И '2017 -06-30'
СГРУППИРОВАТЬ ПО вики, название
ОРДЕНИРОВАТЬ ПО просмотрам DESC
LIMIT 1064,8 с истекло, 180 ГБ обработано
Это довольно впечатляющий запрос — мы группируем 185 миллионов комбинаций (wiki, title) и выбираем 10 лучших. Непростая задача для большинства баз данных, но здесь это выглядит так. был. Могут ли кластеризованные таблицы улучшить это?
Непростая задача для большинства баз данных, но здесь это выглядит так. был. Могут ли кластеризованные таблицы улучшить это?
ВЫБЕРИТЕ вики, название, СУММ(просмотров) просмотров title
ORDER BY просмотры DESC
LIMIT 1022.1 истек, обработано 180 ГБ
Как вы можете видеть здесь, с v3 запрос занял треть времени: поскольку данные кластеризованы, требуется гораздо меньше перетасовки для группировки всех комбинаций перед их ранжированием.
Мои данные не могут быть разделены по дате, как мне использовать кластеризацию?
Два варианта:
1. Использовать секционированную таблицу времени приема с кластеризацией по интересующим полям. Это предпочтительный механизм, если у вас есть> ~ 10 ГБ данных в день.
2. Если у вас есть меньшие объемы данных в день, используйте таблицу, разделенную на столбцы, с кластеризацией, секционированную по необязательному столбцу «фальшивой» даты. Просто используйте для него значение NULL (или оставьте его неуказанным, и BigQuery будет считать, что оно равно NULL). Укажите интересующие столбцы кластеризации.
Укажите интересующие столбцы кластеризации.
Мы обсуждали кластеризацию по идентификатору без разделения по дате в Stack Overflow.
Средство оценки запросов не показывает каких-либо преимуществ кластеризации
BigQuery предоставляет оценку того, сколько данных будет запрашивать каждый запрос перед выполнением запроса. Без кластеризации указанная оценка является точной. При кластеризации оценка является верхней границей, и запрос может оказаться намного меньше запросов, как показано выше.
Какой баланс подходит для принятия решения о разделении таблицы в BigQuery?
См.:
Каков хороший баланс, чтобы решить, когда разбивать таблицу в BigQuery?
При секционировании таблицы необходимо иметь достаточно данных для каждой секции. Думайте о каждом разделе как…
stackoverflow.com
- Кластеризируйте свои таблицы — это бесплатно и может оптимизировать многие ваши запросы.
- Основные издержки кластеризации — увеличение времени загрузки, но оно того стоит.
