
БЕСПЛАТНАЯ КЛАСТЕРИЗАЦИЯ семантического ядра автоматически онлайн СЕМАНТИСТ® — онлайн-сервис группировки ключевых фраз обработает до 2000 строк запросов
SEMANTIST.RU
Крупная семантика для сбора 80% трафика вашей ниши Только под ключ от 95 000₽
ТОП выдача поисковика «Яндекс» служит основой для группировки, объединяющая наиболее похожие по смыслу ключевые слова в семантические кластеры. Группировка поисковых запросов семантического ядра для сайта по смыслу один из самых ответственных этапов продвижения. Кластеризация семантического ядра в инструменте СЕМАНТИСТ® позволяет бесплатно в онлайн любому пользователю получить сгруппированные ключи для написания SEO-текстов или для контекстной рекламы.
Предыдущая
Следующая
Сервис, с помощью которого осуществляется кластеризация семантики на этой странице бесплатно способен объединить в семантические кластера до 2000 фраз. Чтобы программа для кластеризации семантического ядра обработала ваши запросы, необходимо выполнить следующие действия:
Чтобы программа для кластеризации семантического ядра обработала ваши запросы, необходимо выполнить следующие действия:
- Выбрать в строке «Регион проверки» интересующую географическую область, регион или город, чтобы кластеризация поисковых запросов происходила с привязкой к указанному региону.
- Фразы, которые необходимо кластеризовать вставьте в пустое поле «Запросы». Общее количество ключевиков не должно превышать 2000, а каждый поисковый запрос должен размещаться в отдельной строке.
- Порог кластеризации запросов по словам можно изменить от 1 до 10 в зависимости от Ваших потребностей, по умолчанию установлено среднее значение 5.
- Когда все вышеперечисленные действия были выполнены, для осуществления кластеризации нажмите на кнопку «Сгруппировать», находящуюся под полем «Запросы».
* Когда SERP плохого качества, нужна ручная SEO-кластеризация ключевых слов с последующим группировкой по страницам в Excel по смыслу, по типу или по леммам через базу или вручную.


Если сервисы бесплатной кластеризации запросов, не полностью удовлетворяет вашим потребностям, попробуйте полную версию кластеризатора семантики.
При превышении лимита в бесплатном кластеризаторе SEMANTIST.RU®, мы можем предоставить услуги создания семантического ядра на платной основе объемом до 46 000 000 ключевых фраз. Мы осуществляем группировку СЯ в Яндексе и Google, по запросу вы можете получить пример.
При создании семантического ядра важно выбрать методику с помощью которого будет происходить кластеризация ключевых слов. Ручная группировка специалистом (самый простой) может быть эффективна лишь при малом объеме поисковых фраз, не ориентированном на поисковую выдачу. Однако автоматическая кластеризация запросов не только экономит время, но и целенаправленно ориентирует сформированные кластеры на дальнейшее продвижение по СЕО. Не важно, предназначена она для директа или будет использована в написании статей, алгоритм данного кластеризатора можно использовать для группировки фраз в любых целях.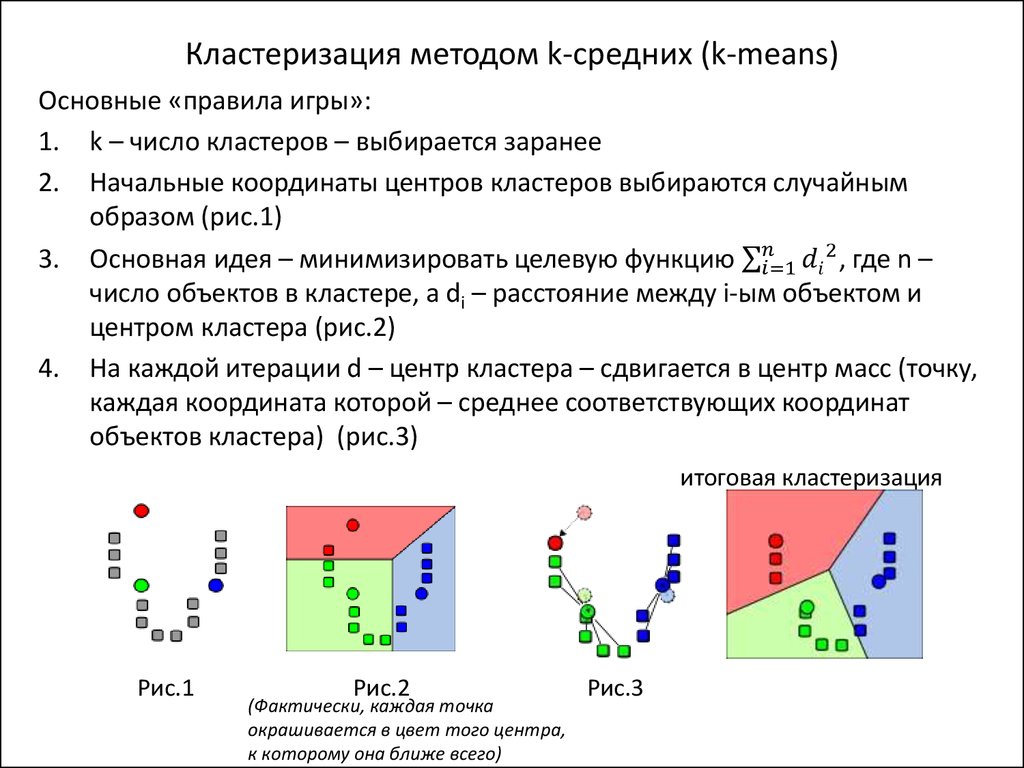
Группировка запросов онлайн — бесплатная кластеризация поисковых фраз из семантического ядра в сервисе — Пиксель Тулс
Инструмент «Группировка запросов по ТОПу выдачи Яндекса и Google» незаменим для формирования файла распределения запросов по URL, построения оптимальной структуры сайта с точки зрения SEO.
Что умеет инструмент?
Основное его предназначение — кластеризация семантического ядра и автоматизация процесса формирования файла распределения.
Кроме того, инструмент имеет следующие полезные функции:
-
Определение текущих позиций сайта по запросам (ТОП-100).
-
Сбор частот запросов: общая и точная.
-
Поиск для каждой фразы наиболее релевантного URL на сайте.
-
Определение количества главных страниц в ТОП-10 выдачи.
-
Вспомогательная статистика: число поисковых фраз в группе, порядковый номер каждой при загрузке.
-
Хранение истории кластеризации предыдущих ключевых фраз (до 40 файлов).

Как пользоваться группировкой?
Для определения релевантных страниц нужно ввести доменное имя сайта, список поисковых запросов, который требуется кластеризовать, и поисковую систему.
Далее — выбрать метод обработки, регион, степень группировки, в чек-боксах проставляются необходимые галочки и нажимается кнопка «Проверить».
Список поисковых запросов (ключевых слов), которые можно кластеризовать по ТОПу бесплатно за один раз, достаточно велик — до 5000 фраз.
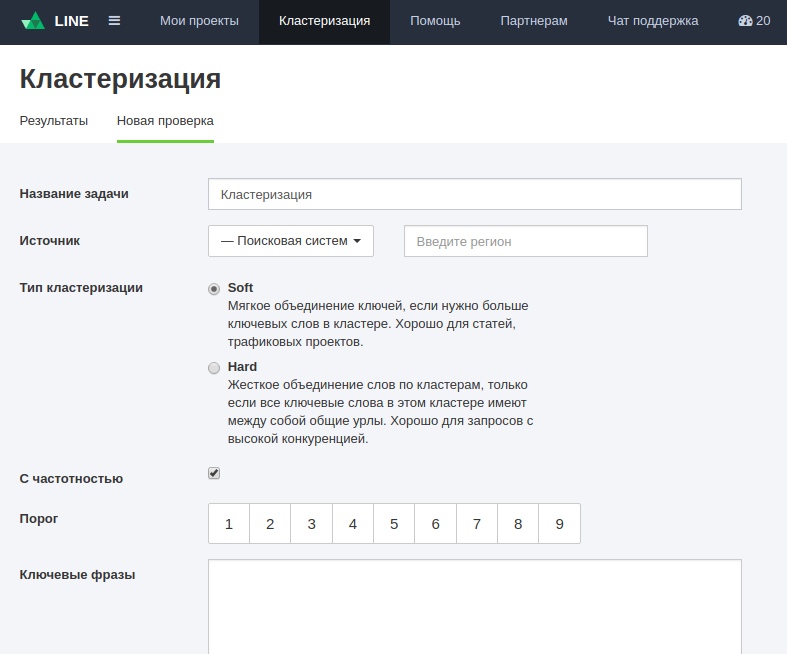
При работе доступно четыре метода кластеризации. Первые три — вполне традиционные и привычные для SEO-специалистов, четвертый — авторская разработка:
-
Сильная связь в группах (так называемый Hard-метод).
-
Средняя связь в группах (Middle).
-
Слабая связь в группах (Soft).
-
Метод «Пиксель Тулс» — уникальный алгоритм, который умеет классифицировать запросы и обеспечивает более точную группировку, так как результаты выдачи по каждой фразе подвергаются предварительной фильтрации — удалению крупных справочников («Википедия» и прочие из «чёрного списка»), витальных URL, результатов, полученных с помощью алгоритма СПЕКТР и прочих примесей, которые не являются органической выдачей поисковой системы Яндекс и искажают исходные данные.

При продвижении по трафику можно использовать Soft-метод, так как в этом случае не требуется 100% выводимость запросов в группах, а ставка идёт на их количество.
Если же задача вывести максимум фраз из семантического ядра проекта на первые строчки выдачи — рекомендуется использовать метод группировки «Пиксель Тулс».
В кластеризаторе доступно быстрое определение релевантных URL сайта и возможность получения количества главных страниц в выдаче по запросу, что позволяет в дальнейшем скорректировать распределение.
Степень или сила группировки ключей может варьироваться. Рекомендуемая степень равна трем, она введена по умолчанию.
Обычно её достаточно для получения оптимальных результатов. Если группы получаются довольно малочисленные, а список достаточно обширный — число можно снизить до двух.
Сила / степень — количество одинаковых URL, которые должны встретиться в выдаче по двум запросам, чтобы алгоритм мог ассоциировать их в группу.
Сервис бесплатно хранит предыдущие результаты в таблице, которую можно скачать в CSV, переименовать, либо удалить.
Видео: советы и нюансы распределения запросов на сайте
Как это работает?
Сервис в режиме онлайн производит сканирование результатов выдачи в выбранной поисковой системе, определяет, по каким запросам находятся одинаковые URL-адреса. В методе «Пиксель Тулс» — дополнительно исключает из анализа ресурсы, которые, скорее всего, не соответствуют вашему сайту и ранжируются не по общей формуле релевантности, будут исключены и результаты, найденные с помощью алгоритма «Спектр».
Время обработки зависит от количества поисковых запросов, но в целом, результат получается довольно быстро.
При автоматическом скачивании в предложенном названии файла указывается метод обработки, сила группировки и дата.
В файле результатов доступна нумерация фраз в той очередности, в которой они были добавлены, что позволяет в любой момент отсортировать файл как в исходном варианте.
Также в нем присутствуют столбцы «Группа» и «Релевантный URL на сайте». Релевантный документ определяется даже в случаях, когда сайт находится за пределами ТОП-100 результатов выдачи, и он часто является оптимальной посадочной страницей для данной группы.
Дополнительно выводится количество главных страниц в выдаче Яндекса или Google, что позволяет понять, какую страницу лучше продвигать. Если по большому количеству разных запросов много главных страниц в выдаче, то для оптимального продвижения рекомендуется создавать поддомены.
Еще один столбец — текущая позиция вашего сайта, которая показывает, насколько осмысленно менять релевантную страницу по данному поисковому запросу. Если сайт уже в ТОП-3, то понятно, что менять стратегию продвижения на текущий момент нет необходимости.
Столбец «Количество запросов в группе» позволяет быстро понять, какие группы требуется дополнительно разбить, а какие — наоборот, объединить.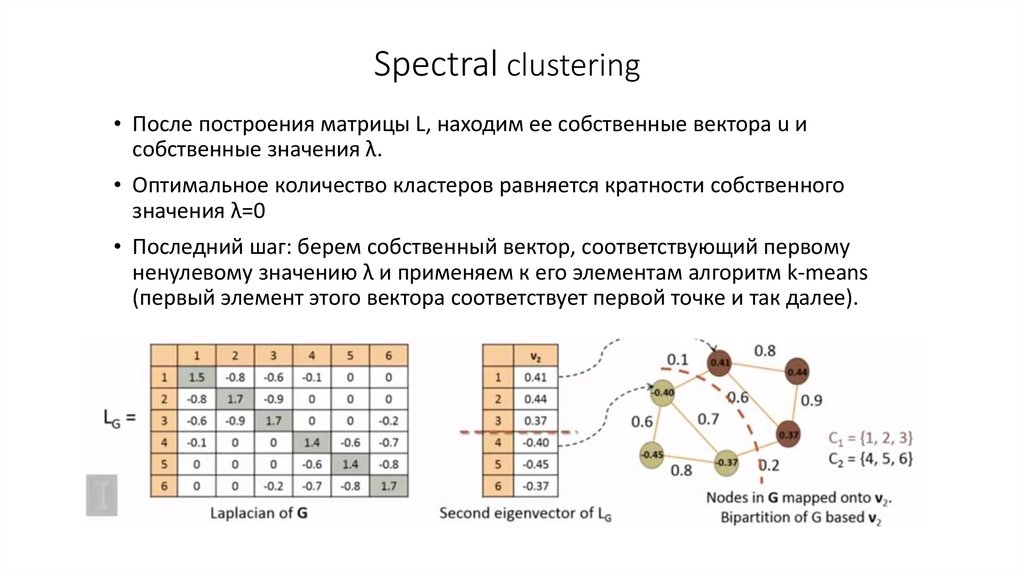
Путем простого форматирования в Excel можно преобразовать файл в таблицу и отсортировать по любым интересующим нас свойствам: релевантному URL, ключевым словам, количеству главных страниц либо по количеству запросов в группе.
Это позволяет довольно быстро понять, как классифицировать запросы. Например, если два запроса ассоциированы в одну группу, при этом у них разные релевантные страницы и по ним обоим по 9 или даже 10 из 10 главных страниц в выдаче, соответственно, по обоим запросам желательно продвигать именно главную.
С помощью этого инструмента файл оптимального распределения по посадочным страницам формируется буквально в несколько кликов.
Лимиты
Независимо от выбора метода обработки запросов и степени их группировки, инструмент автоматически списывает всего 2 лимита за один запрос. Проверка позиций при этом включена. Для парсинга частоты WordStat также потребуется 2 лимита за каждую фразу. В итоге максимальная сумма лимитов за один запрос при всех активных чек-боксах — 4. Инструмент предварительно рассчитывает необходимое количество лимитов для проверки.
Инструмент предварительно рассчитывает необходимое количество лимитов для проверки.
Удачи в использовании и онлайн-группировке запросов по ТОПу!
значений кластера — Power Query
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 3 минуты на чтение
Значения кластера автоматически создают группы с похожими значениями с помощью алгоритма нечеткого сопоставления, а затем сопоставляют значение каждого столбца с наиболее подходящей группой. Это преобразование очень полезно, когда вы работаете с данными, которые имеют много разных вариантов одного и того же значения, и вам нужно объединить значения в согласованные группы.
Рассмотрим образец таблицы со столбцом id , который содержит набор идентификаторов, и столбец Person , содержащий набор версий имен Miguel, Mike, William и Bill, написанных по-разному и с заглавной буквы.
В этом примере результат, который вы ищете, представляет собой таблицу с новым столбцом, который показывает правильные группы значений из столбца Person , а не все различные варианты одних и тех же слов.
Примечание
Функция значений кластера доступна только для Power Query Online.
Создать столбец кластера
Чтобы сгруппировать значения, сначала выберите столбец Person , перейдите на вкладку Добавить столбец на ленте, а затем выберите параметр Кластеризировать значения .
В диалоговом окне Значения кластера подтвердите столбец, который вы хотите использовать для создания кластеров, и введите новое имя столбца.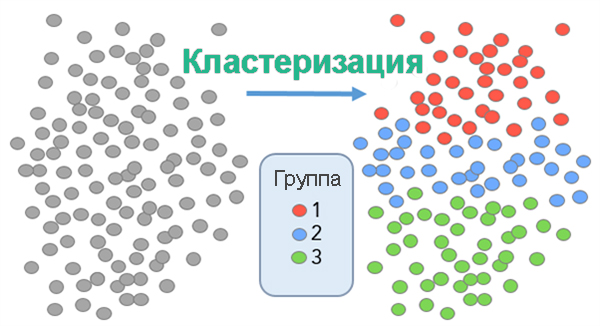 В этом случае назовите этот новый столбец Кластер .
В этом случае назовите этот новый столбец Кластер .
Результат этой операции дает результат, показанный на следующем рисунке.
Примечание
Для каждого кластера значений Power Query выбирает наиболее часто встречающийся экземпляр из выбранного столбца в качестве «канонического» экземпляра. Если несколько экземпляров происходят с одинаковой частотой, Power Query выбирает первый.
Использование параметров нечеткой кластеризации
Следующие параметры доступны для кластеризации значений в новом столбце:
- Порог подобия (необязательно) : Этот параметр указывает, насколько похожими должны быть два значения, чтобы их можно было сгруппировать вместе. Минимальное значение 0 приводит к тому, что все значения группируются вместе. Максимальное значение 1 позволяет сгруппировать только точно совпадающие значения. По умолчанию 0,8.
- Игнорировать регистр : При сравнении текстовых строк регистр игнорируется.
- Группировка путем объединения текстовых частей : Алгоритм пытается объединить текстовые части (например, объединение Micro и soft в Microsoft) для группировки значений.
- Показать оценки сходства : Показывает оценки сходства между входными значениями и вычисленными репрезентативными значениями после нечеткой кластеризации.
- Таблица преобразования (необязательно) : Вы можете выбрать таблицу преобразования, которая сопоставляет значения (например, сопоставление MSFT с Microsoft), чтобы сгруппировать их вместе.
В этом примере новая таблица преобразования с именем Моя таблица преобразования используется для демонстрации того, как значения могут быть сопоставлены. Эта таблица преобразования имеет два столбца:
- From : текстовая строка для поиска в таблице.
- To : Текстовая строка, используемая для замены текстовой строки в столбце From .

Важно
Важно, чтобы таблица преобразования имела те же столбцы и имена столбцов, что и на предыдущем изображении (они должны быть названы «От» и «Кому»), иначе Power Query не распознает эту таблицу. как таблицу преобразования, и никакого преобразования не произойдет.
Используя ранее созданный запрос, дважды щелкните шаг Кластеризованные значения , затем в диалоговом окне Кластерные значения разверните Параметры нечеткого кластера . В разделе Опции нечеткого кластера включите параметр Показать оценки сходства . Для таблицы преобразования (необязательно)
После выбора таблицы преобразования и включения параметра Показать оценки сходства выберите OK . В результате этой операции вы получите таблицу, которая содержит те же столбцы id и Person , что и исходная таблица, но также включает два новых столбца справа, называемых Cluster и Person_Cluster_Similarity . Столбец Cluster содержит правильно написанные и написанные с заглавной буквы имена Miguel для версий Miguel и Mike и William для версий Bill, Billy и William. Столбец Person_Cluster_Similarity содержит оценки сходства для каждого из имен.
Столбец Cluster содержит правильно написанные и написанные с заглавной буквы имена Miguel для версий Miguel и Mike и William для версий Bill, Billy и William. Столбец Person_Cluster_Similarity содержит оценки сходства для каждого из имен.
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
6.12 Онлайн-операции с ALTER TABLE в кластере NDB
MySQL NDB Cluster 7.3 и 7.4 поддерживают изменения онлайн-схемы таблиц
с использованием ИЗМЕНИТЬ
ТАБЛИЦА ... АЛГОРИТМ=ПО УМОЛЧАНИЮ|НА МЕСТЕ|КОПИЯ . Кластер NDB
ручки КОПИРОВАТЬ и ВСТАВИТЬ как
описано в следующих нескольких абзацах.
Для АЛГОРИТМ=КОПИРОВАНИЕ mysqld Обработчик кластера NDB выполняет
следующие действия:
Указывает узлам данных создать пустую копию таблицы и чтобы внести необходимые изменения схемы в эту копию.
Читает строки из исходной таблицы и записывает их в копировать.
Сообщает узлам данных удалить исходную таблицу, а затем переименовать копию.
Иногда мы называем это «копированием» или
«офлайн» ИЗМЕНИТЬ ТАБЛИЦУ .
Операции DML не допускаются одновременно с копированием ИЗМЕНИТЬ ТАБЛИЦУ .
mysqld , на котором выполняется копирование ALTER
Выдается оператор TABLE , который блокирует метаданные, но
это действует только на этом mysqld . Другой Клиенты NDB могут изменять данные строк во время
копирование ALTER TABLE , в результате чего
непоследовательность.
Для ALGORITHM=INPLACE обработчик кластера NDB
говорит узлам данных внести необходимые изменения и не
выполнять любое копирование данных.
Мы также называем это «некопированием» или
«онлайн» ИЗМЕНИТЬ ТАБЛИЦУ .
Некопируемый ALTER TABLE разрешает параллельный DML
операции.
Независимо от используемого алгоритма, mysqld берет глобальную блокировку схемы (GSL) при выполнении ИЗМЕНИТЬ
ТАБЛИЦА ; это предотвращает выполнение любого (другого) DDL или
резервные копии одновременно на этом или любом другом узле SQL в кластере.
Обычно это не проблематично, если только ALTER
ТАБЛИЦА занимает очень много времени.
Примечание
В старых версиях NDB Cluster использовался синтаксис, специфичный для NDB , который устарел в NDB 7.3
и 7.4, и больше не поддерживается в NDB 7.5 или более поздних версиях. (Этот
синтаксис не поддерживается никаким другим механизмом хранения MySQL,
в том числе InnoDB . ) MySQL NDB
Кластер 7.3 и более поздние версии поддерживают
) MySQL NDB
Кластер 7.3 и более поздние версии поддерживают ALTER.
Синтаксис TABLE , используемый сервером MySQL
( АЛГОРИТМ = ПО УМОЛЧАНИЮ | НА МЕСТЕ | КОПИРОВАТЬ ) и
описано в другом месте в этом разделе. По этим причинам вы
настоятельно рекомендуется конвертировать любые приложения, использующие старый
Синтаксис ONLINE и OFFLINE как можно быстрее.
Операции, которые добавляют и удаляют индексы для столбцов переменной ширины Таблицы NDB появляются в сети. онлайн
операции некопирующие; то есть они этого не требуют
индексы создаются заново. Они не блокируют изменяемую таблицу
от доступа других узлов API в кластере NDB (но см.
Ограничения онлайн-операций NDB, далее в этом
раздел). Такие операции не требуют однопользовательского режима для NDB изменения таблицы, сделанные в NDB
кластер с несколькими узлами API; транзакции могут продолжаться
непрерывно во время онлайн-операций DDL.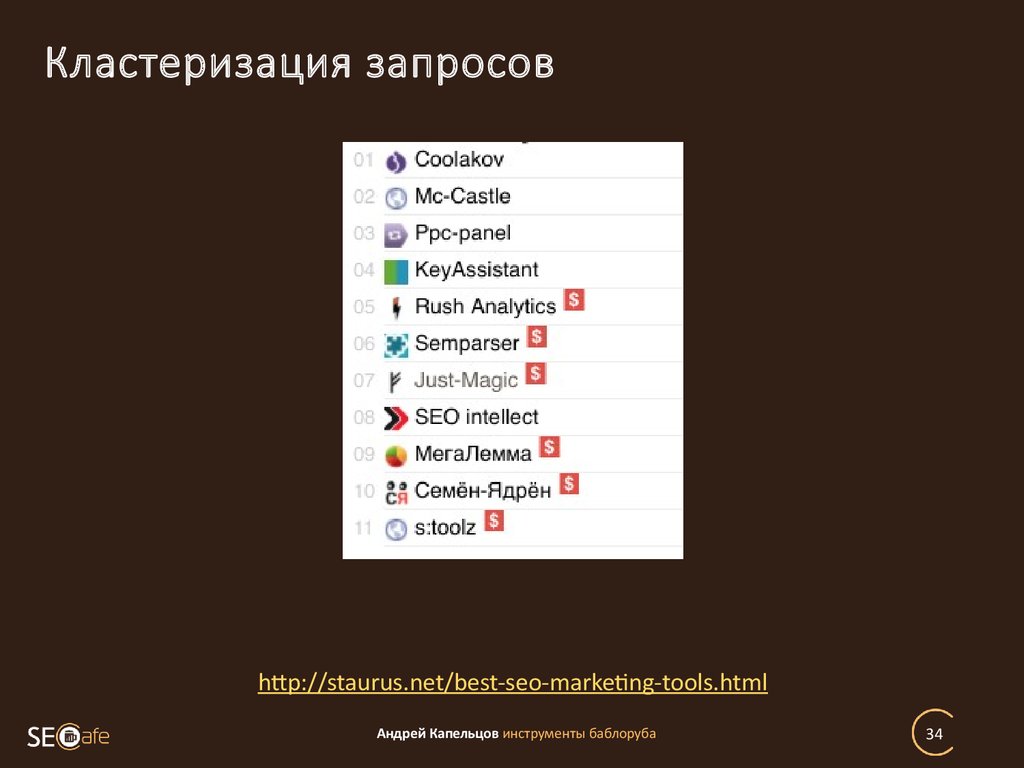
ALGORITHM=INPLACE можно использовать для выполнения онлайн ДОБАВИТЬ СТОЛБЦ , ДОБАВИТЬ ИНДЕКС (включая операторы CREATE INDEX ) и DROP INDEX операции на NDB таблицы. Онлайн переименование
Также поддерживаются таблицы NDB .
В настоящее время вы не можете добавлять столбцы на основе диска в NDB таблицы онлайн. Это означает, что,
если вы хотите добавить столбец в памяти к Таблица NDB , которая использует уровень таблицы STORAGE DISK вариант, вы должны объявить новый
столбец как явно использующий хранилище в памяти. За
пример — предполагается, что вы уже создали табличное пространство ts1 — допустим, вы создаете таблицу т1 следующим образом:
mysql> СОЗДАТЬ ТАБЛИЦУ t1 (
> c1 INT NOT NULL ПЕРВИЧНЫЙ КЛЮЧ,
> c2 ВАРЧАР(30)
> )
> ДИСК ДЛЯ ХРАНЕНИЯ TABLESPACE ts1
> ДВИГАТЕЛЬ НДБ;
Запрос выполнен успешно, затронуто 0 строк (1,73 сек. )
Записей: 0 Дубликатов: 0 Предупреждений: 0  )
Записей: 0 Дубликатов: 0 Предупреждений: 0
)
Записей: 0 Дубликатов: 0 Предупреждений: 0 Вы можете добавить новый столбец в памяти в эту таблицу онлайн, как показано ниже. здесь:
mysql> ИЗМЕНИТЬ ТАБЛИЦУ t1
> ДОБАВИТЬ КОЛОННУ c3 INT COLUMN_FORMAT DYNAMIC STORAGE MEMORY,
> АЛГОРИТМ=НА МЕСТЕ;
Запрос выполнен успешно, затронуто 0 строк (1,25 сек.)
Записей: 0 Дубликатов: 0 Предупреждений: 0 Это утверждение не выполняется, если STORAGE MEMORY вариант опущен:
mysql> ИЗМЕНИТЬ ТАБЛИЦУ t1
> ДОБАВИТЬ КОЛОННУ c4 INT COLUMN_FORMAT DYNAMIC,
> АЛГОРИТМ=НА МЕСТЕ;
ОШИБКА 1846 (0A000): ALGORITHM=INPLACE не поддерживается. Причина:
Добавление столбцов или добавление/реорганизация раздела не поддерживается онлайн. Пытаться
АЛГОРИТМ=КОПИРОВАНИЕ. Если вы опустите параметр COLUMN_FORMAT DYNAMIC ,
динамический формат столбца используется автоматически, но предупреждение
выдается, как показано здесь:
mysql> ALTER ONLINE TABLE t1 ADD COLUMN c4 INT STORAGE MEMORY; Запрос выполнен успешно, затронуто 0 строк, 1 предупреждение (1,17 сек.
 )
Записей: 0 Дубликатов: 0 Предупреждений: 0
mysql> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ\G
*************************** 1-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: ДИНАМИЧЕСКИЙ столбец c4 с STORAGE DISK не поддерживается, столбец будет
стать ИСПРАВЛЕННЫМ
mysql> ПОКАЗАТЬ СОЗДАТЬ ТАБЛИЦУ t1\G
*************************** 1-й ряд ********************** *******
Таблица: т1
Создать таблицу: CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` varchar(30) ПО УМОЛЧАНИЮ NULL,
`c3` int(11) /*!50606 STORAGE MEMORY */ /*!50606 COLUMN_FORMAT DYNAMIC */ DEFAULT NULL,
`c4` int(11) /*!50606 ПАМЯТЬ ДЛЯ ХРАНЕНИЯ */ ПО УМОЛЧАНИЮ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (`c1`)
) /*!50606 TABLESPACE ts_1 STORAGE DISK */ ENGINE=ndbcluster DEFAULT CHARSET=latin1
1 ряд в сет (0,03 сек)
)
Записей: 0 Дубликатов: 0 Предупреждений: 0
mysql> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ\G
*************************** 1-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: ДИНАМИЧЕСКИЙ столбец c4 с STORAGE DISK не поддерживается, столбец будет
стать ИСПРАВЛЕННЫМ
mysql> ПОКАЗАТЬ СОЗДАТЬ ТАБЛИЦУ t1\G
*************************** 1-й ряд ********************** *******
Таблица: т1
Создать таблицу: CREATE TABLE `t1` (
`c1` int(11) NOT NULL,
`c2` varchar(30) ПО УМОЛЧАНИЮ NULL,
`c3` int(11) /*!50606 STORAGE MEMORY */ /*!50606 COLUMN_FORMAT DYNAMIC */ DEFAULT NULL,
`c4` int(11) /*!50606 ПАМЯТЬ ДЛЯ ХРАНЕНИЯ */ ПО УМОЛЧАНИЮ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (`c1`)
) /*!50606 TABLESPACE ts_1 STORAGE DISK */ ENGINE=ndbcluster DEFAULT CHARSET=latin1
1 ряд в сет (0,03 сек) Примечание
ХРАНЕНИЕ и COLUMN_FORMAT ключевые слова поддерживаются только в
Кластер NDB; в любой другой версии MySQL, пытаясь использовать
любое из этих ключевых слов в CREATE
ТАБЛИЦА или ИЗМЕНИТЬ ТАБЛИЦУ заявление приводит к ошибке.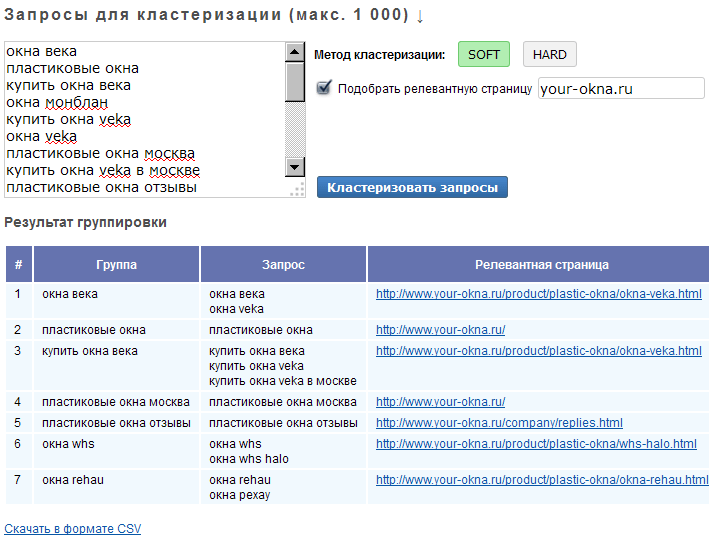
Также можно использовать оператор ALTER TABLE ...
РЕОРГАНИЗОВАТЬ РАЗДЕЛ, АЛГОРИТМ=НА МЕСТЕ без опция для таблиц имена разделов INTO
( раздел_определения ) NDB . Это может быть
используется для перераспределения данных NDB Cluster между новыми узлами данных, которые
были добавлены в кластер онлайн. Это делает , а не выполнить любую дефрагментацию, которая
требуется OPTIMIZE TABLE или null Оператор ALTER TABLE . Для большего
информацию см. в Разделе 6.7, «Добавление узлов данных кластера NDB в режиме онлайн».
Ограничения онлайн-операций NDB
Онлайн DROP COLUMN операции не
поддерживается.
Онлайн ИЗМЕНИТЬ ТАБЛИЦУ , СОЗДАТЬ ИНДЕКС или DROP INDEX операторов, которые добавляют
столбцы или индексы добавления или удаления подлежат следующим
ограничения:
Данный онлайн
ALTER TABLEможет используйте только один изДОБАВИТЬ СТОЛБЦ,ДОБАВИТЬ ИНДЕКСилиИНДЕКС СБРОСА. Один или больше
столбцы могут быть добавлены онлайн в одном заявлении; только один
index может быть создан или удален онлайн в одном операторе.Изменяемая таблица не заблокирована по отношению к API узлы, отличные от того, на котором
ИЗМЕНИТЬ ТАБЛИЦУДОБАВИТЬ СТОЛБЦ,ДОБАВИТЬ ИНДЕКС, илиИНДЕКС ПАДЕНИЯоперация (илиСОЗДАТЬ ИНДЕКСилиОператор DROP INDEX). Однако таблица заблокирована от любых других операций. исходящий из того же API-узла , в то время как выполняется онлайн-операция.Изменяемая таблица должна иметь явный первичный ключ; в скрытый первичный ключ, созданный
Механизм хранения NDBне достаточно для этой цели.Механизм хранения, используемый таблицей, нельзя изменить в режиме онлайн.
Табличное пространство, используемое таблицей, не может быть изменено онлайн. (Ошибка № 99269, Ошибка № 31180526)
При использовании с таблицами NDB Cluster Disk Data это не можно изменить тип хранилища (
ДИСКилиПАМЯТЬ) столбца онлайн. Это означает, что когда вы добавляете или удаляете индекс таким образом, что операция будет выполняться онлайн, и вы хотите, чтобы хранилище тип столбца или столбцов, которые необходимо изменить, необходимо использоватьALGORITHM=COPYв инструкции, которая добавляет или сбрасывает индекс.
 Один или больше
столбцы могут быть добавлены онлайн в одном заявлении; только один
index может быть создан или удален онлайн в одном операторе.
Один или больше
столбцы могут быть добавлены онлайн в одном заявлении; только один
index может быть создан или удален онлайн в одном операторе.
Столбцы, добавляемые онлайн, не могут использовать BLOB или TEXT и должен соответствовать
следующие критерии:
Столбцы должны быть динамическими; то есть должна быть возможность создайте их, используя
COLUMN_FORMAT DYNAMIC. Если
вы опускаете параметр COLUMN_FORMAT DYNAMIC, динамический формат столбца используется автоматически.Столбцы должны разрешать 90 161 NULL 90 162 значений, а не иметь какое-либо явное значение по умолчанию, отличное от
НУЛЕВОЕ. Колонки, добавленные онлайн, автоматически создается какDEFAULT NULL, как можно увидеть здесь:mysql> СОЗДАТЬ ТАБЛИЦУ t2 ( > c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY > ) ДВИГАТЕЛЬ=NDB; Запрос выполнен успешно, затронуто 0 строк (1,44 сек.) mysql> ИЗМЕНИТЬ ТАБЛИЦУ t2 > ДОБАВИТЬ КОЛОННУ c2 INT, > ДОБАВИТЬ КОЛОННУ c3 INT, > АЛГОРИТМ=НА МЕСТЕ; Запрос выполнен успешно, затронуто 0 строк, 2 предупреждения (0,93 сек) mysql> ПОКАЗАТЬ СОЗДАТЬ ТАБЛИЦУ t1\G *************************** 1-й ряд ********************** ******* Таблица: т1 Создать таблицу: CREATE TABLE `t2` ( `c1` int(11) NOT NULL AUTO_INCREMENT, `c2` int(11) ПО УМОЛЧАНИЮ NULL, `c3` int(11) ПО УМОЛЧАНИЮ NULL, ПЕРВИЧНЫЙ КЛЮЧ (`c1`) ) ENGINE=ndbcluster НАБОР ШИМОВ ПО УМОЛЧАНИЮ=latin1 1 ряд в наборе (0,00 сек)Столбцы должны быть добавлены после любых существующих столбцов.
Если
вы пытаетесь добавить столбец онлайн перед любыми существующими столбцами
или с помощью FIRSTключевое слово, инструкция вылетает с ошибкой.Существующие столбцы таблицы не могут быть переупорядочены онлайн.
 Если
вы опускаете параметр
Если
вы опускаете параметр  Если
вы пытаетесь добавить столбец онлайн перед любыми существующими столбцами
или с помощью
Если
вы пытаетесь добавить столбец онлайн перед любыми существующими столбцами
или с помощью Для онлайн-операций ALTER TABLE на таблицах NDB , столбцы фиксированного формата
преобразуются в динамические, когда они добавляются онлайн или когда
индексы создаются или удаляются онлайн, как показано здесь (повторяющиеся CREATE TABLE и ALTER
ТАБЛИЦА заявления только что показаны для ясности):
mysql> СОЗДАТЬ ТАБЛИЦУ t2 (
> c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY
> ) ДВИГАТЕЛЬ=NDB;
Запрос выполнен успешно, затронуто 0 строк (1,44 сек.)
mysql> ИЗМЕНИТЬ ТАБЛИЦУ t2
> ДОБАВИТЬ КОЛОННУ c2 INT,
> ДОБАВИТЬ КОЛОННУ c3 INT,
> АЛГОРИТМ=НА МЕСТЕ;
Запрос выполнен успешно, затронуто 0 строк, 2 предупреждения (0,93 с)
mysql> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
*************************** 1-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: преобразовано ИСПРАВЛЕННОЕ поле 'c2' в ДИНАМИЧЕСКОЕ, чтобы включить ДОБАВИТЬ СТОЛБЦУ онлайн.
*************************** 2-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: Преобразованное ИСПРАВЛЕННОЕ поле 'c3' в ДИНАМИЧЕСКОЕ, чтобы включить онлайн ДОБАВИТЬ СТОЛБЦ
2 ряда сетом (0,00 сек)  *************************** 2-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: Преобразованное ИСПРАВЛЕННОЕ поле 'c3' в ДИНАМИЧЕСКОЕ, чтобы включить онлайн ДОБАВИТЬ СТОЛБЦ
2 ряда сетом (0,00 сек)
*************************** 2-й ряд ********************** *******
Уровень: Предупреждение
Код: 1478
Сообщение: Преобразованное ИСПРАВЛЕННОЕ поле 'c3' в ДИНАМИЧЕСКОЕ, чтобы включить онлайн ДОБАВИТЬ СТОЛБЦ
2 ряда сетом (0,00 сек) Только столбец или столбцы, которые будут добавлены онлайн, должны быть динамическими.
Существующие столбцы не должны быть; это включает в себя таблицу
первичный ключ, который также может быть FIXED , как показано
здесь:
mysql> СОЗДАТЬ ТАБЛИЦУ t3 ( > c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY COLUMN_FORMAT FIXED > ) ДВИГАТЕЛЬ=NDB; Запрос выполнен успешно, затронуто 0 строк (2,10 сек.) mysql> ALTER TABLE t3 ADD COLUMN c2 INT, ALGORITHM=INPLACE; Запрос выполнен успешно, затронуто 0 строк, 1 предупреждение (0,78 сек.) Записей: 0 Дубликатов: 0 Предупреждений: 0 mysql> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; *************************** 1-й ряд ********************** ******* Уровень: Предупреждение Код: 1478 Сообщение: преобразовано ИСПРАВЛЕННОЕ поле 'c2' в ДИНАМИЧЕСКОЕ, чтобы включить ДОБАВИТЬ СТОЛБЦУ онлайн.
