
KeyClusterer 2.3 — Многопоточность, интеграция с Key Collector / Хабр
Всем привет! В новой версии KeyClusterer нами была проведена работа над оптимизацией импорта данных, добавлена многопоточность с возможностью сбора данных в поисковой системе Google, добавлено отображение ТОП сайтов по видимости. Ниже детали о новой версии.
Основные изменения
1. Добавлен импорт данных из Key Collector 4
В новой версии KeyClusterer добавлена возможность импорта данных из программы Key Collector 4-й версии.
Теперь можно производить импорт запросов, частотностей, позиций, посадочных и SERP напрямую из файлов формата *.kc4, без промежуточного экспорта данных в CSV или Excel.
Сам импорт происходит все также через специальную форму, в которой после сопоставления полей (по умолчанию поля сопоставляются автоматически) происходит непосредственный импорт данных.
2. Добавлена возможность сбора данных для кластеризации в поисковой системе Google
В настройках сбора данных добавлен сервис SERPRiver (Googe), позволяющий собирать SERP в поисковой системе Google, на основе чего можно осуществлять кластеризацию запросов.
В отличие от Яндекса, для которого указывается лишь регион выдачи, для Google необходимо указывать более подробное местоположение:
- домен (google.com, google.ru, google.com.ua…)
- язык (Russian, English, Ukrainian…)
- страна (Russian Federation, United States, Ukraine…)
- место («Moscow,Russia», «New York,United States», «Kyiv city,Ukraine»…)
Например, при указании в поисковой системе Google домена «google.com.ua», поисковик будет производить поиск только в украинском сегменте интернета, а при дополнительном указании региона «Kyiv city,Ukraine», будет получать данные с учетом указанного местоположения.
3. Добавлено отображение ТОП сайтов по видимости
Данный функционал поможет выявить наиболее популярные сайты в вашей тематике (сайты в списке отсортированы по числу запросов, входящих в ТОП-10 по каждому сайту).
Данные для анализа берутся из поисковой выдачи, собранной по каждому запросу, соответственно, для отображения статистики, данные SERP должны изначально присутствовать (должны быть собраны тем или иным способом).
4. В быстром фильтре добавлена возможность выбора параметров фильтрации
Таким образом, фильтрацию данных теперь можно осуществить по трем различным параметрам:
- По кластерам и фразам.
- По кластерам.
- По фразам.
Это позволит более гибко проводить манипуляции семантическими ядрами больших размеров.
Прочие изменения
- Добавлен многопоточный сбор данных (до 10 потоков одновременно).
- Восстановлена возможность импорта списка прокси из файла и буфера обмена.
- Исправлено зависание программы, возникающее при сборе данных поисковой выдачи на большом числе запросов.
Будем рады любым замечаниям и предложениям по доработкам и улучшению функционала программы.
Как группировать СЯ в Key Collector для Директа
Главная » Контекстная реклама » Как группировать семантическое ядро в Кей Коллектор
Продолжаем обучаться работе с Key Collector. Из всей массы функций это программы мы разбираем только те, которые нам нужны для работы с контекстной рекламой. Конечно, SEO-специалистам это тоже пригодится, но упор в моих материалах на директологов.
Из всей массы функций это программы мы разбираем только те, которые нам нужны для работы с контекстной рекламой. Конечно, SEO-специалистам это тоже пригодится, но упор в моих материалах на директологов.
Напомню, что в прошлых статьях мы уже разобрали где скачать и как настроить Кей Коллектор, а так же как собрать минус-слова для нашей РК через эту программу. Так же я писал о том, как получить бесплатно Кей Коллектор и какие у него аналоги.
Как кластеризировать семантику через Key Collector
Кластеризация или другими словами группировка — это процесс объединения фраз в группы по определенным параметрам.
Для SEO-специалистов всегда объединяются запросу по интенту, то есть по намерениям пользователя, а для директологов бывают и другие типы кластеризации.
На мой взгляд, наиболее правильно объединять именно по интенту.
Например, запросы вида «купить еду в макдаке» и «заказать еду в макдональдс» будут разные, но ищут по ним одну и ту же информацию и намерение пользователей не отличается.
Можно еще группировать по ключевым словам, которые указаны в запросе. Таким образом директологи пытаются добиться максимально релевантных заголовков, чтобы как можно больше слов подсвечивалось в вашем объявлении и был выше CTR.
Дело в том, что часто именно во втором варианте допускаются ошибки и CTR ниже, потому что мы не всегда можем понять у всех ли запросов одинаковый интент, если запросы похожи, но часто даже похожие запросы имеют совершенно разный интент.
Итак. Для начала создаем проект
Заказать настройку рекламы
Напоминаю, что лучше в названии указывать на каком этапе ваше СЯ, дата создания и для какого проекта. Таким образом вы не запутаетесь в файлах со временем.
Затем добавляем фразы в программу.
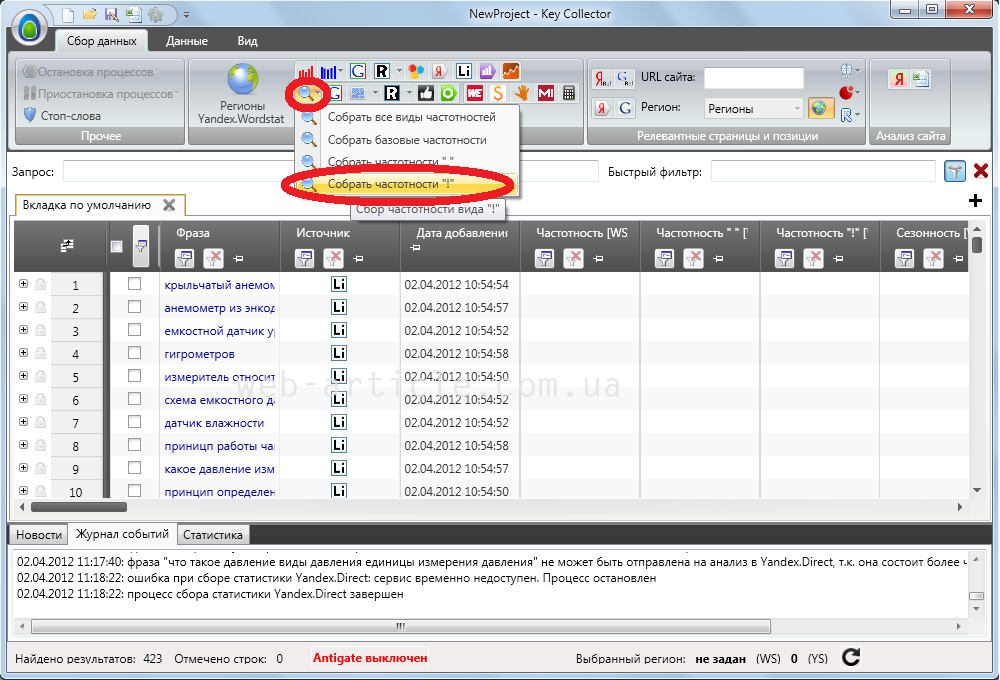
Фразы можно взять из Вордстата, специальных сервисов по сбору СЯ, собрать напрямую в Кей Коллекторе через стартовые фразы или любым другим способом.
Если у вас очень маленькая семантика (до 100 запросов), то можно собрать и в Вордстате, а если больше, то надо сначала собрать базисы (стартовые запросы) в Вордстате, затем спарсить СЯ по этим запросам через КейКоллектор.
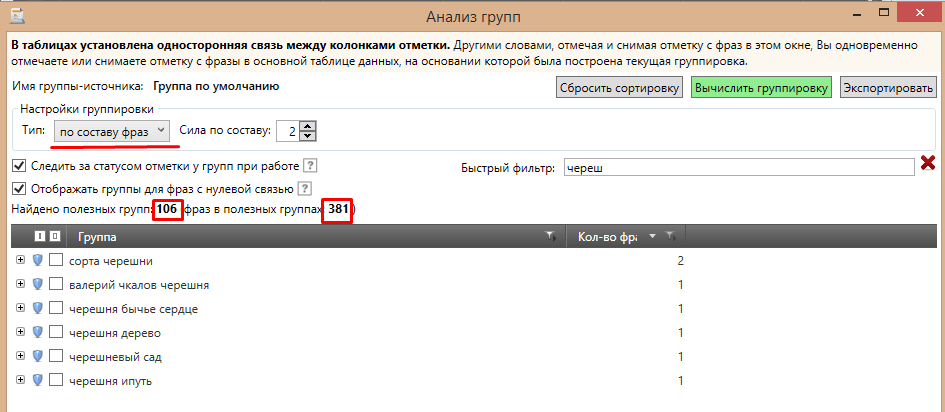
Далее переходим на вкладку «данные», выбираем «анализ групп» и настраиваем группировку по вашим параметрам. Если по интенту, то выбираете пункт «по поисковой выдаче», а если по отдельным словам или по составу фраз, то тоже выбираете соответствующий пункт. Затем эту таблицу можно выгрузить в Эксель.
Выглядят группированные запросы следующим образом:
Это группировка по составу фраз. То есть фразы объединяются по нескольким наиболее часто встречающимся словам.
Если группируете по поисковой выдаче, то есть по интенту, то выбираете поискову систему и силу SERP. Сила SERP — это то, как часто запросы пересекаются в выдаче между собой. А поисковую систему выбирайте ту, по которой настраиваете рекламу. Разница между интентами запросов у Гугла и Яндекса редко, но бывает.
Для кластеризации по интенту лучше всего использовать сервис Кулакова или Арсенкина, а для большой семантики программу KeyAssort. Перед началом работы рекомендую сначала настроить Кей Коллектор.
Заказать настройку рекламы
Управление кластерами и коллекторами

- Хост развертывания под управлением поддерживаемой операционной системы версии Opsview
- Корневой доступ к хосту развертывания
- SSH-доступ с хоста развертывания ко всем хостам Opsview (включая новые серверы, добавляемые в качестве хостов-сборщиков)
- Аутентификация должна использовать открытые ключи SSH
- Удаленный пользователь должен быть «root» или иметь доступ «sudo» без пароля и без TTY
Чтобы добавить новые серверы-сборщики в существующую систему Opsview Monitor с одним сервером, откройте файл /opt/opsview/deploy/etc/opsview_deploy.yml
Примечание: Не изменять существующие строки в opsview_deploy.yml:
collect_clusters:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
Замените «opsview-de-1» и «10.12.0.9» на имя хоста и IP-адрес вашего нового коллектора и дайте имя кластеру коллекторов, изменив «collectors-de».
Вы можете добавить несколько кластеров коллекторов и несколько коллекторов в каждый кластер, например:
кластеры_коллекторов:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
opsview-de-2: {ip: 10.12.0.19}
opsview-de-3: {ip: 10.12.0.29}
коллекторы-fr:
коллектор_хост:
opsview-fr-1: {ip: 10.7.0.9}
opsview-fr-2: {ip: 10.7.0.19}
opsview-fr-3: {ip: 10.7.0.10}
opsview-fr-4: {ip: 10.7.0.20}
opsview-fr-5: {ip: 10.7.0.30}
🚧
Размер кластера
В кластере сборщиков всегда должно быть нечетное количество узлов: 1, 3, 5 и т. д. Это необходимо для повышения отказоустойчивости и предотвращения проблем с разделением мозгов.
В кластере с четным числом, если половина узлов выйдет из строя, другая половина перестанет функционировать, поскольку кластер внутри opsview-datastore и opsview-messagequeue не будет иметь кворума и не будет принимать обновления, пока не будут восстановлены другие элементы кластера.
Мы не поддерживаем кластеры только с двумя коллекторами по вышеуказанной причине.

В приведенном выше примере конфигурации создаются два новых кластера коллекторов с именами «collectors-de» и «collectors-fr».
«collectors-de» требует минимум 3 узла-коллектора, а «collectors-fr» имеет 5 узлов-коллекторов с указанными именами хостов и IP-адресами.
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy ./bin/opsview-deploy lib/playbooks/check-deploy.yml ./bin/opsview-deploy lib/playbooks/setup-hosts.yml ./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy lib/playbooks/setup-opsview.yml
После запуска opsview-deploy проверьте раздел «Регистрация новых серверов Collector в Opsview Web».
Если вы хотите автоматически зарегистрировать коллектор и добавить предлагаемые шаблоны хостов и связанные с ними переменные, необходимые для этих шаблонов, запустите setup-monitoring.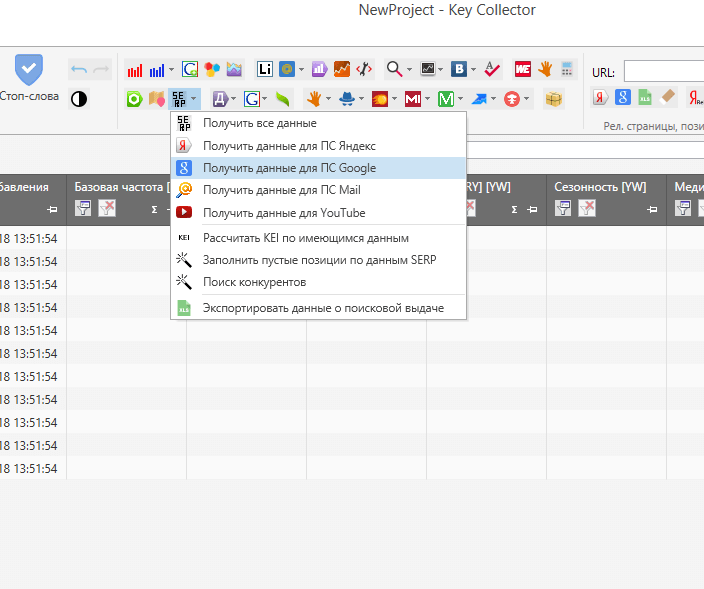 yml.
yml.
корень:~# cd /opt/opsview/deploy корень:/opt/opsview/deploy# ./bin/opsview-deploy lib/playbooks/setup-monitoring.yml
Пожалуйста, примените изменения в пользовательском интерфейсе после успешного завершения, чтобы этот шаг вступил в силу.
КРИТИЧЕСКИЙ: Не удалось подключиться к локальному хосту Код ответа: 401 Неавторизованный
Если у вас уже есть несколько сборщиков и вы хотите добавить новые сборщики, откройте /opt/opsview/deploy/etc/opsview_deploy.yml на сервере развертывания (обычно это хост opsview с оркестратором и opsview-web) и добавьте новые кластеры коллекторов или хосты коллекторов после существующих, например:
коллектор_кластеров:
существующий-коллектор1:
коллектор_хост:
существующий хост1: {ip: 10. 12.0.9}
новый хост1: {ip: 10.12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.29}
 12.0.9}
новый хост1: {ip: 10.12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.29}
12.0.9}
новый хост1: {ip: 10.12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.29}
В приведенном выше примере существует 5 новых хостов-сборщиков (новый-хост1, новый-хост2, новый-хост3, новый-хост4 и новый-хост5) и добавлен 1 новый кластер сборщиков (новый-сборщик-кластер1).
- new-host1 и 2 добавляются в существующий кластер сборщиков (existing-collector1)
- new-host3, 4 и 5 добавляются в новый кластер сборщиков (new-collector-cluster1).
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy ./bin/opsview-deploy lib/playbooks/check-deploy.yml ./bin/opsview-deploy lib/playbooks/setup-hosts.yml ./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy lib/playbooks/datastore-reshard-data.yml ./bin/opsview-deploy lib/playbooks/setup-opsview.yml

Если вы хотите ускорить этот процесс, вы можете указать кластер сборщиков, который вы обновляете или создаете.
Наилучший способ сделать это — указать кластер сборщиков, используя минус строчную букву «-l» (l для Lima). правильно
компакт-диск /opt/opsview/развернуть ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/check-deploy.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/setup-hosts.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/datastore-reshard-data.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/setup-opsview.yml
Вы также можете использовать имена сборщиков в двойных кавычках, если это новые кластеры сборщиков
Это также рекомендуется для удаления коллектора из кластера.
После запуска opsview-deploy проверьте раздел «Регистрация новых серверов Collector в Opsview Web».
Если вы хотите автоматически зарегистрировать коллектор и использовать предложенные шаблоны хостов и связанные с ними переменные, необходимые для этих шаблонов, запустите setup-monitoring.yml.
./bin/opsview-deploy lib/playbooks/setup-monitoring.yml
Вы можете настроить конкретную конфигурацию компонента для любого коллектора. Настройки можно развернуть для отдельных или для всех коллекторов с помощью /opt/opsview/deploy/etc/user_vars.yml
/opt/opsview/deploy/etc/opsview_deploy.yml . В этом примере мы рассмотрим настройку конкретных примеров для конфигурации opsview-executor для всех сборщиков, а затем для существующего-сборщика1 9.0020 сервер. Чтобы передать конфигурацию всем сборщикам при развертывании, вам потребуется указать раздел «ov_component_overrides» и применимый раздел компонента, например «opsview_executor_config» — это устанавливается в /opt/opsview/deploy/etc. /user_vars.yml . Эти изменения применяются к компонентам .yaml конфигурационный файл, поэтому для исполнителя это /opt/opsview/executor/etc/executor.yaml . Приведенное ниже изменит системные настройки по умолчанию для initial_worker_count от до 4 (системное значение по умолчанию 2) и max_concurrent_processes от до 10 (системное значение по умолчанию 25).
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
Затем запустите развертывание с помощью playbook setup_everything.yaml, чтобы распространить эту конфигурацию на все коллекторы.
Если конфигурация требуется только для одного сборщика, измените файл /opt/opsview/deploy/etc/opsview_deploy.yml , чтобы добавить переопределения в раздел vars: для конкретного сборщика следующим образом:
collect_clusters:
кластер коллекторов:
коллектор_хост:
существующий-коллектор1:
IP-адрес: 10. 12.0.9
вары:
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
Вместо того, чтобы запускать весь процесс развертывания, используйте плейбук collect-install.yml для конкретного сборщика (как подробно описано в разделе выше). Если несколько сборщиков в одном и том же кластере изменены, убедитесь, что вы запускаете playbook для всех из них одновременно, используя опцию 9.0019 -l коллектор1,коллектор2,коллектор3
. /user_vars.yml
/user_vars.yml  12.0.9
вары:
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
12.0.9
вары:
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
Войдите в пользовательский интерфейс Opsview Monitor и перейдите на страницу Configuration > Monitoring Collectors .
Вы должны увидеть желтое сообщение «Ожидание регистрации» справа, как показано ниже:
Щелкните значок меню справа от имени хоста вашего коллектора и нажмите «Зарегистрировать», как показано ниже:
появится другое окно для регистрации коллектора. :
:
Нажмите «Отправить изменения и далее». Появится новое окно для создания «Нового кластера мониторинга»:
Дайте новому кластеру мониторинга то же имя, которое вы добавили в opsview_deploy.yml, например «collectors-de». Выберите сборщики, которые должны быть в этом кластере мониторинга, из списка сборщиков, затем щелкните Отправить изменения.
После добавления первого кластера мониторинга вы можете зарегистрировать коллектор в существующем кластере мониторинга, выбрав «Существующий кластер» и выбрав кластер мониторинга из раскрывающегося списка:
После регистрации новых коллекторов вы должны увидеть свои кластеры и количество коллекторов под каждым кластером на вкладке «Кластеры»:
Вы даже можете щелкнуть числа в столбце «COLLECTORS», чтобы увидеть имена хостов сборщиков:
После регистрации новых сборщиков перейдите в «Конфигурация» > «Применить изменения», чтобы запустить сборщики в работу.
Убедитесь, что коллекторы работают правильно, проверив вкладку «Обзор системы» в разделе «Конфигурация» > «Моя система»:
На странице «Конфигурация» > «Мониторинг коллекторов» отображаются сведения о работоспособности как отдельных узлов коллекторов, так и каждого кластера.
- Статус ONLINE/OFFLINE напрямую связан с обработкой очереди работоспособности кластера, показанной во время вывода команды
/opt/opsview/messagequeue/sbin/rabbitmqctl list_queues. Если вы видите здесь накопление, то последние статусы не будут отображаться, и эту очередь нужно будет очистить, прежде чем они будут. - Это можно сделать с помощью команды rabbitmqctl
purge_queue cluster-health-queue; обычно необходимо запускать только на сервере оркестратора. - Если очередь не очищается, остановите и запустите компоненты
opsview-schedulerиopsview-orchestrator
В столбце Состояние показано текущее состояние кластера. Возможные значения:
- ОНЛАЙН — Кластер работает нормально
- DEGRADED — Проблемы с кластером. Наведите курсор на статус, чтобы получить список тревог
- OFFLINE — Кластер не ответил в течение заданного периода времени, поэтому предполагается, что он находится в автономном режиме
В таблице ниже описаны возможные сигналы тревоги, которые будут отображаться, когда пользователи наводят указатель мыши на состояние кластера DEGRADED. Эти аварийные сигналы относятся к состояниям следующих компонентов Opsview:
Эти аварийные сигналы относятся к состояниям следующих компонентов Opsview:
- opsview-schedulers
- opsview-исполнители
- отправитель результатов opsview
| Тревоги | Описание | Предложения/Действия |
|---|---|---|
| Все компоненты [Имя компонента] недоступны напр. Все компоненты opsview-executor недоступны. | Главный сервер/сервер Orchestrator не может обмениваться данными с какими-либо компонентами [Имя компонента] в кластере сборщика. Это может быть из-за проблемы с сетью/связью или из-за того, что в кластере не запущены компоненты [Имя компонента]. Примечание. Этот аварийный сигнал срабатывает только тогда, когда все компоненты [Имя компонента] в кластере коллекторов недоступны, поскольку кластер может быть сконфигурирован так, чтобы эти компоненты работали только на подмножестве коллекторов. Кроме того, кластер может продолжать мониторинг с остановкой некоторых (хотя и не всех) компонентов [Имя компонента]. | Чтобы решить эту проблему, убедитесь, что главный сервер/оркестратор может обмениваться данными с кластером коллекторов (т. е. разрешать любые сетевые проблемы) и что по крайней мере один планировщик работает. т. е. SSH для сбора и запуска /opt/opsview/watchdog/bin/opsview-monit start [Имя компонента] |
| Получено недостаточно сообщений ([Имя компонента 1] → [Имя компонента 2]): [Период времени ] [Процент полученных сообщений]%. напр. Получено недостаточно сообщений (opsview-scheduler → opsview-executor): [15m] 0%. | Менее 70% сообщений, отправленных [Имя компонента 1], были получены [Имя компонента 2] в течение периода времени. Это может указывать на проблемы со связью между компонентами в кластере сборщиков или на то, что [Имя компонента 2] перегружен и не может своевременно обрабатывать получаемые сообщения. напр. 0% сообщений, отправленных планировщиком, были получены исполнителем в течение 15-минутного периода. | Если 0% отправленных сообщений было получено [Имя компонента 2] и нет других аварийных сигналов, это может означать сбой связи в кластере. Чтобы решить эту проблему, убедитесь, что все сборщики в кластере могут взаимодействовать через все порты (см. https://knowledge.opsview.com/docs/ports#collector-clusters) и что opsview-messagequeue выполняется на всех сборщиках без ошибок. В качестве альтернативы это может указывать на то, что не все необходимые компоненты работают на сборщиках в кластере. Запустите /opt/opsview/watchdog/bin/opsview-monit summary на каждом сборщике, чтобы убедиться, что все компоненты находятся в рабочем состоянии. Если какие-либо из них остановлены, запустите /opt/opsview/watchdog/bin/opsview-monit start [имя компонента], чтобы запустить их. Если > 0 % отправленных сообщений были получены [Имя компонента 2], это, вероятно, указывает на проблему с производительностью в кластере. Чтобы решить эту проблему, вы можете: Уменьшите нагрузку на кластер, т. |


 е.
е. Примечание. Для нового коллектора/кластера, который только что был настроен или активность которого минимальна, предупреждение «Недостаточно сообщений получено» будет подавлено, чтобы избежать ненужного беспокойства администратора/пользователя. Это не влияет на аварийный сигнал «Все компоненты [Имя компонента] недоступны», который по-прежнему будет выдаваться для автономного коллектора.
Если ваша подписка включает функцию топологии сети, на странице Конфигурация > Мониторинг коллекторов можно включить или отключить регулярное определение топологии сети для каждого кластера.
В столбце «Топология сети» показано, включено ли обычное определение топологии сети для каждого кластера. Чтобы включить, щелкните значок меню и «Включенные функции»:
Затем щелкните переключатель «Топология сети»:
. щелкнув значок меню для этого кластера, а затем «Просмотреть топологию»:
Для получения дополнительной информации о содержимом карты топологии сети см. Просмотр карт топологии сети
В столбце Состояние отображается текущее состояние коллектора. Возможные значения:
- ОНЛАЙН — Сборщик работает нормально, судя по статусу opsview-scheduler .
- OFFLINE — Collector не ответил в течение заданного периода времени, поэтому предполагается, что он находится в автономном режиме
Чтобы удалить коллектор из кластера, нажмите «КОНФИГУРАЦИЯ > МОНИТОРИНГ КОЛЛЕКТОРОВ» в верхнем меню, а затем перейдите на вкладку «Кластеры». Затем щелкните значок меню и «Изменить»:
Затем отмените выбор коллектора, который вы хотите удалить, и нажмите кнопку «Отправить изменения». Теперь вы можете перейти в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение и завершить работу коллектора.
Теперь вы можете перейти в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение и завершить работу коллектора.
Чтобы добавить коллектор в кластер, отредактируйте кластер, а затем выберите коллектор (используйте Cntrl в Windows или Cmd в Mac OS, чтобы выбрать в дополнение к существующим выборам). Перейдите в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение.
Шаги немного отличаются в зависимости от размера кластера.
Примечание: Если вы удалили коллектор, но затем хотите зарегистрировать его снова, вы не увидите, что он станет доступным в сетке незарегистрированных коллекторов, пока вы не остановите планировщик на этом коллекторе хотя бы на целую минуту, а затем перезапустите это.
1. Отключите кластер (Конфигурация > Мониторинг коллекторов > Кластеры).
Отредактируйте кластер, затем снимите флажок «Активировано» и нажмите Отправить изменения . Затем вам нужно будет Применить изменения .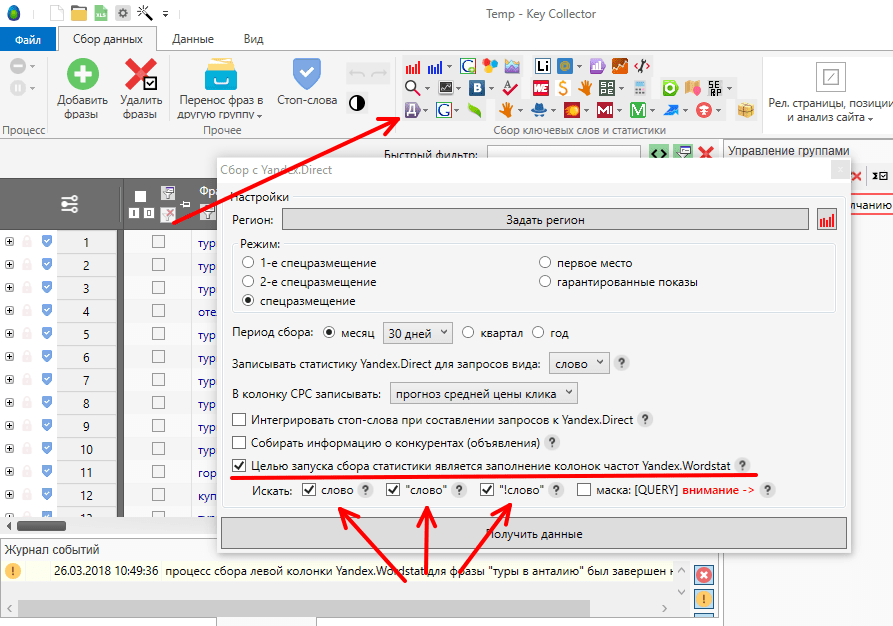
2. Удалить кластер (Конфигурация > Мониторинг коллекторов > Кластеры).
3. Удалить коллектор (Конфигурация > Мониторинг коллекторов > Коллекторы).
4. Удалить коллектор как отслеживаемый хост (Конфигурация > Хосты).
5. Выполнить Применить изменения .
6. Отредактируйте файлы развертывания (opsview_deploy.yml, user_vars.yml и другие в зависимости от ситуации), закомментировав или удалив строки для удаленного Collector.
1. Удалить коллектор из его кластера (Конфигурация > Мониторинг коллекторов > Кластеры).
Отредактируйте кластер и отмените выбор коллектора, который вы хотите удалить, чтобы были выделены только те коллекторы, которые вы хотите оставить в кластере, затем нажмите Отправить изменения .
2. Удалить коллектор (Конфигурация > Мониторинг коллекторов > Коллекторы).
3. Удалить Collector как отслеживаемый хост (Конфигурация > Хосты).
4. Выполнить Применить изменения .
5. Отредактируйте файлы развертывания (opsview_deploy.yml, user_vars.yml и другие в зависимости от ситуации), закомментировав или удалив строки для удаленного Collector.
6. Запустите полное развертывание в кластере, например. /opt/opsview/deploy/bin/opsview-deploy -l collection1,collector2,collector3 /opt/opsview/deploy/lib/playbooks/setup-everything.yml .
Обновить Collector так же просто, как обновить все пакеты Opsview на сервере Collector. Чтобы избежать простоев, отключите соединение от Collector к главному серверу MessageQueue, обновите все пакеты и перезагрузите систему. Как только соединение будет восстановлено, коллектор автоматически присоединится к кластеру, и теперь вы сможете выполнить обновление других коллекторов.
В распределенной системе Opsview Monitor сценарии мониторинга в Collectors могут не синхронизироваться со сценариями в Orchestrator, если:
- новые пакеты Opspack, сценарии мониторинга или подключаемые модули были импортированы в Orchestrator.
- сценариев мониторинга были обновлены непосредственно в Orchestrator.
В таких случаях папку сценариев мониторинга ( /opt/opsview/monitoringscripts ) в Оркестраторе необходимо синхронизировать со всеми коллекторами с помощью доступного плейбука под названием 9.0019 sync_monitoringscripts.yml .
Playbook sync_monitoringscripts.yml использует rsync для отправки соответствующих обновлений каждому сборщику (при необходимости он будет установлен автоматически), исключая определенные наборы файлов.
Следующие каталоги и файлы (относительно /opt/opsview/monitoringscripts ) не синхронизируются:
.
 ../lib/*
.../tmp/*
.../делиться/*
.../перл/*
.../плагины/utils.pm
.../вар/*
.../opspacks/*
.../etc/notificationmethodvariables.cfg
.../etc/plugins/check_snmp_interfaces_cascade
../lib/*
.../tmp/*
.../делиться/*
.../перл/*
.../плагины/utils.pm
.../вар/*
.../opspacks/*
.../etc/notificationmethodvariables.cfg
.../etc/plugins/check_snmp_interfaces_cascade
Например, при использовании приведенного выше списка исключений файлы в каталоге /opt/opsview/monitoringscripts/lib/ и определенные файлы, такие как /opt/opsview/monitoringscripts/etc/notificationmethodvariables.cfg , не будут синхронизированы. .
Кроме того, если у Collector не та же версия ОС, что и у Orchestrator, будут синхронизированы только статически связанные исполняемые файлы и текстовые файлы. Это делается для того, чтобы двоичные файлы, используемые в Orchestrator, не синхронизировались с несовместимым Collector. Например, двоичный файл AMD64 не будет отправлен в коллектор на базе ARM32.
- Интерпретируемые файлы сценариев, такие как сценарии Python, Perl и Bash и файлы конфигурации, являются текстовыми файлами, и будут синхронизированы.
- Динамически связанные исполняемые файлы не будут синхронизироваться, поскольку они могут работать неправильно из-за зависимостей во время выполнения. Такие динамически связанные исполняемые файлы необходимо устанавливать на сборщики вручную, если у сборщиков другая версия ОС, чем у Orchestrator.
Ключи SSH настроены между Orchestrator и коллекторами (это уже должно быть на месте, если Opsview Deploy ранее использовался для установки или обновления системы).
Выполните следующие команды от имени пользователя root в Orchestrator:
cd /opt/opsview/deploy/ bin/opsview-deploy lib/playbooks/sync_monitoringscripts.yml
Если ваш сервер развертывания не является Orchestrator, вы можете выполнять те же команды на своем сервере развертывания, но ключи SSH должны быть настроены между Orchestrator и сборщиками для пользователей SSH, определенных для ваших сборщиков в вашем файле opsview_deploy.yml.
Обновлено 2 месяца назад
sos.
 collector.clusters — Профили кластеров — Документация SoS 4.0 sos.collector.clusters — Профили кластеров — Документация SoS 4.0
collector.clusters — Профили кластеров — Документация SoS 4.0 sos.collector.clusters — Профили кластеров — Документация SoS 4.0- class
sos.collector.clusters.Кластер( общие )[источник] Базы:
объектЭто класс, подклассом которого должны быть профили кластера, чтобы добавить поддержку различных технологий кластеризации и сред для sos-коллектор.
Профиль должен как минимум определять пакет, указывающий, что узел настроен для типа кластера, для обслуживания которого предназначен профиль, и затем дополнительно иметь возможность возвращать список пронумерованных узлов через
get_nodes()методПараметры: commons (
dict) — общий словарь, содержащий системную информацию. Такой же как что переданоPlugin()Переменные: - option_list (
списокизкортежей) — параметры, поддерживаемые профилем и устанавливаемые –cluster-option cmdline аргумент - упаковки (
tuple) — Какие пакеты должен включить этот профиль на - sos_plugins (
список) — Какие плагины принудительно включить для отчетов узлов - sos_plugin_options (
dict) — параметры плагина для принудительной установки для узлов - sos_preset (
str) — пресет SoSReport для принудительного включения на узлах - cluster_name (
str) — Имя кластера типа
-
add_default_ssh_key( ключ ) [источник] Некоторые кластеры генерируют и/или развертывают общеизвестные и согласованные Ключи SSH в разных средах.
В этом случае профиль кластера
может вызвать эту команду, чтобы последующие соединения узлов использовали эту
ключ, а не запрашивать у пользователя один или пароль.Обратите внимание, что это будет работать только в том случае, если сборщик запущен локально на главный узел.
-
check_enabled()[источник] Это может быть переопределено кластерами
Это вызывается sos collect для каждого существующего типа кластера, и предназначен для возврата True, когда тип кластера соответствует критерию это указывает на то, что тип кластера используется.
Запускается только первый тип кластера для определения соответствия
Возвращает: True, если следует использовать профиль кластера, илиЛожьТип возвращаемого значения: bool
-
exec_master_cmd( cmd , need_root = False ) [источник] Используется для получения выходных данных команды от (главного) узла в кластере
Параметры: - cmd (
str) — Команда для запуска - need_root (
bool) — Требуются ли для команды привилегии root
Возвращает: Вывод и статус cmd
Тип возврата: dict- cmd (
-
format_node_list()[источник] Форматировать возвращенный список узлов из кластера в известный формат.
Это список, не содержащий дубликатовВозвраты: Список узлов, без посторонних записей из вывода cmd Тип возврата: список
-
get_node_label( узел )[источник] Используется
SosNode()для извлечения соответствующей метки из кластер, установленный с помощьюset_node_label()в профиле кластера.Параметры: узел ( str) — Имя узла для получения метки дляВозвраты: Метка для отчета узла Тип возврата: стр
-
get_nodes()[источник] Это ДОЛЖНО быть переопределено профилем кластера, подклассом этого класса
Кластер должен использовать этот метод для возврата списка или строки, содержит все узлы, из которых должен быть собран отчет
Возвраты: Список полных доменных имен узлов или IP-адресов Тип возврата: списокилиНет
-
get_option(опция ) [источник] Используется кластерами для проверки того, был ли выбран параметр кластера.
поставляется в sos collectПараметры: опция ( str) — Имя опции для полученияВозвращает: Значение запрашиваемой опции, если она существует, или False
-
log_debug( сообщение )[источник] Используется для печати отладочных сообщений
-
log_error( сообщение )[источник] Используется для печати сообщений об ошибках
-
log_info( сообщение )[источник] Используется для печати информационных сообщений
-
log_warn( сообщение )[источник] Используется для печати предупреждающих сообщений
- classmethod
имя()[источник] Возвращает имя кластера в виде строки.
- option_list (
 В этом случае профиль кластера
может вызвать эту команду, чтобы последующие соединения узлов использовали эту
ключ, а не запрашивать у пользователя один или пароль.
В этом случае профиль кластера
может вызвать эту команду, чтобы последующие соединения узлов использовали эту
ключ, а не запрашивать у пользователя один или пароль. Это список, не содержащий дубликатов
Это список, не содержащий дубликатов поставляется в sos collect
поставляется в sos collect