
Справка по работе инструмента Кластеризация фраз по группам
С введением в Яндекс.Директ статуса «мало показов» работа с данной платформой немного усложнилась, так как часто рекламодатели использовали большой пул низкочастотных запросов с небольшой ценой за клик и за счет этого обеспечивали низкую стоимость конверсии. Теперь рекламодателям приходится искать обходные пути.
Одним из способов обхода статуса является кластеризация фраз.
Она формирует группы, в которых находятся фразы как высокочастотные, так и низкочастотные.
В этом случае среднее количество показов всей группы выше минимально допустимого и Яндексе не присваивает этой группе статус «Мало показов».
Сервис PPC help предлагает удобный и быстрый кластеризатор. Для того, чтобы кластеризировать фразы, необходимо выполнить следующие шаги:
Шаг 1
Создаем новый проект в сервисе:
Шаг 2
Вводим название проекта, нажимаем «продолжить»
Шаг 3
Загружаем ключевые фразы в сервис
Загрузить их можно двумя способами — скопировать в поле для ввода или загрузить файлом. Для загрузки текстом можно просто скопировать фразы в поле ввода.
Для загрузки текстом можно просто скопировать фразы в поле ввода.
Для загрузки файлом список фраз обязательно должен быть в excel формате xls или xlsx. Пример фала для загрузки можно сказать в подсказке спарва.
В колонке слева должны быть ключевые фразы, справа частотность.
Данный файл, загружаем в сервис, нажимаем кнопку «продолжить».
Шаг 4
Устанавливаем настройки
Разберем подробнее.
Удалять строки длиной более 53 символов – если в систему будет загружена фраза более 53 символов, то такая фраза будет игнорироваться при обработке. Если снять галку, то такое ограничение для длины снимается.
Удалять строки со словами длиной более 23 символов — если слово в фразе имеет более 23 символов, система при обработке будет его игнорировать. Если снять галку с настройки, то такое ограничение больше не будет использоваться
Удалить строки, содержащие более 7 слов – система будет игнорировать ключевые фразы, которые содержат больше 7 слов. Если снять галку, то такое ограничение не будет использоваться.
Если снять галку, то такое ограничение не будет использоваться.
Не учитывать предлоги при разбивке – кластеризатор не будет учитывать в работе такие части предложения как предлоги. Если будет снята галка напротив настройки, то ограничение будет снято.
Не учитывать цифры при разбивке – система не будет учитывать цифры при работе с фразами. Если снять галку напротив данной настройки, то цифры начнут учитываться.
Сначала группировать по городам – система изначально будет разбивать фразы по городам, а потом по всем остальным признакам. Если снять галку с настройки, то порядок кластеризации будет стандартным.
База слов – база, из какой будут браться данные для кластеризации. Mystem является наиболее оптимальной базой, но есть возможность выбрать другие варианты.
Глубина кластеризации – отвечает за объем групп. Чем более глубокая кластеризация, тем меньше групп.
Чтобы настроить данный параметр необходимо нажать на обведенную область и выбрать необходимую глубину.
Когда все загружено и настроено, нажимаем на кнопку «Отправить проект на обработку».
Откроется следующая панель управления
Шаг 5
Скачиваем результат
После окончания процесса обработки файла, можно будет скачать фразы разделенные по группам.
Как сделать кластеризацию запросов семантического ядра hard и soft методами
Привет, друзья!
В этой статье хотелось бы поговорить о качественной кластеризации семантического ядра.
Кластеризация – это автоматическое объединение ключевых слов в группы на основании данных поисковой выдачи.
Зачем это нужно? После сбора семантики, ключевые слова надо объединить в группы по одинаковому смыслу. Так, чтобы при распределении этих групп по сайту, определённые страницы отвечали одному желанию (интенту) пользователя. Если это делать «вручную», то seo-специалисту нужно досконально знать анализируемую тематику, чтобы ориентироваться в синонимах и поведении пользователей. Например, слова «алоэ» и «столетник» несут один и тот же смысл, но без этого знания сделать качественную кластеризацию не получится.
Методы и алгоритмы кластеризации
В данный момент у большинства инструментов для кластеризации есть 2 основных алгоритма: hard и soft. У некоторых инструментов, таких как KeyAssort, есть ещё middle – нечто среднее между hard и soft, поэтому на его примере мы и будем рассматривать кластеризацию.
Чем эти методы отличаются и когда применять тот или иной алгоритм?
Все методы кластеризации используют один и тот же алгоритм – для каждой фразы собирают топ поисковой системы и сравнивают url всех фраз между собой. Но отличия всё же есть в методах сравнения.
Soft кластеризация
При этом методе сравниваются url у всех фраз между собой. У запроса А может быть общий набор url с запросом Б, а у запроса Б – общий набор url с запросом В. При этом запрос А и В могут не иметь общих URL. Софт метод подходит для информационных сайтов с низким уровнем конкуренции в тематике.
У запроса А может быть общий набор url с запросом Б, а у запроса Б – общий набор url с запросом В. При этом запрос А и В могут не иметь общих URL. Софт метод подходит для информационных сайтов с низким уровнем конкуренции в тематике.
Middle кластеризация
При этом методе берётся один центральный запрос А и с ним сравниваются остальные фразы на предмет совпадения URL. Этот метод подходит для информационных сайтов с высоким уровнем конкуренции либо для коммерческих сайтов с низким уровнем конкуренции.
Hard кластеризация
При этом методе фразы будут объединены в группу только при совпадении общего для всех фраз набора URL. Хард метод характеризуется высокой точностью и подходит коммерческим сайтам с высоким уровнем конкуренции.
Сила (порог) кластеризации
Точность или порог кластеризации (сила по SERP) — это параметр, который отвечает за то, сколько одинаковых URL нужно в топ-10 поисковой системы, чтобы ключевые слова попали в один кластер, т.е. отвечает за то, как сильно должны быть похожи запросы для попадания в одну группу. Чем выше этот параметр – тем точнее получаются группы, но при этом меньше в размерах.
Чем выше этот параметр – тем точнее получаются группы, но при этом меньше в размерах.
Инструменты для кластеризации запросов
В данный момент на рынке кластеризации свои услуги предлагают онлайн сервисы и десктопные программы. Из основных сервисов, основываясь на экспериментах и отзывах seo-специалистов можно выделить:
- TopVisor;
- Rush Analytics;
- Just-Magic;
- Serpstat;
- SemParser.
Из программ для качественной кластеризации можно отметить только KeyAssort.
Учитывая, что KeyAssort выигрывает в цене кластеризации, а часто и в качестве, для этой статьи был выбран именно этот инструмент.
Пошаговая кластеризация на реальном примере
После сбора семантического ядра, его надо распределить по группам и составить структуру будущего сайта, если мы делаем семантику для нового сайта.
В самом начале нам надо принять решение, будем ли мы составлять структуру на основании распределённого по группам семантического ядра или на основании логики/конкурентов. Если второй вариант, то загружаем в программу готовую структуру, которую предварительно составили.
Если второй вариант, то загружаем в программу готовую структуру, которую предварительно составили.
Если же первый вариант, то импортируем ядро, а структуру будем составлять после кластеризации, глядя на готовые группы. В данном примере мы импортируем файл с параметрами, т.к. нам важна частота запросов для дальнейшего принятия решения относительно того, какие группы мы будем использовать в первую очередь, а какие не будем использовать вообще.
Вот как это будет выглядеть после импорта:
Т.к. последнее время Google становится всё популярнее и популярнее Яндекса, принимаем решение собирать данные именно с google.
После регистрации на сервисе XMLRiver, пополняем счёт (1), в разделе «Покупка запросов» (2) копируем ссылку для запросов (3):
Эту ссылку нам надо вставить в окно настроек программы (1), установить топ10 (2) и другие настройки, связанные с местоположением:
Относительно топ10 – больше ставить нет никакого смысла, у Гугла в подавляющем большинстве случаев достаточно качественная выдача и увеличение количества собранных данных не приведёт к улучшению качества кластеризации.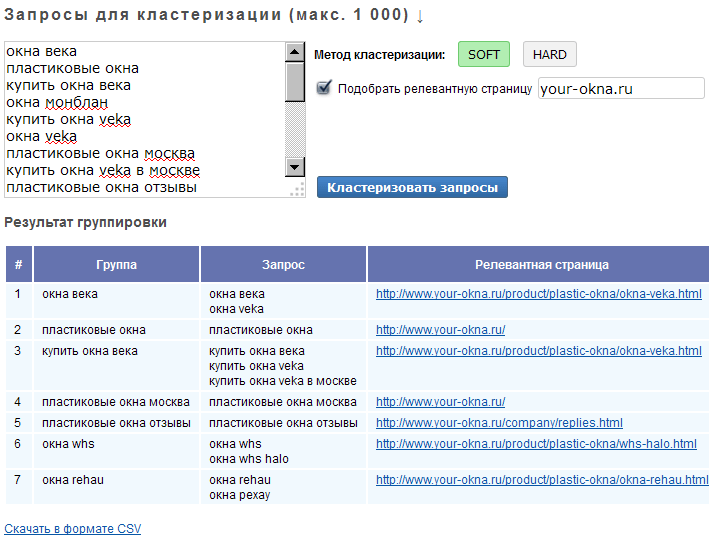
Региональность можно указать как в софте, так и в настройках сервиса. Однако обратите внимание, что если эти данные указаны и в одном и во втором месте, приоритет будет у указанных в программе.
Если указываете местоположение в программе, числовое значение этого местоположения надо брать из файла на скриншоте.
Также стоит упомянуть, что если вы хотите собрать данные, например, по Москве, то домен надо выбирать ru, язык — Russian, страну – Russia. Иначе данные могут быть не точны.
После описанных выше настроек и сбора данных переходим непосредственно к процессу кластеризации. Тематика у нас не самая конкурентная, поэтому выбираем вид кластеризации Middle с миграцией (это можно сделать горячими клавишами ctrl+Tab) и попробуем силу группировки 3. Если в результате получится слишком много групп с одним поисковым интентом, надо уменьшить силу кластеризации, если же фразы в группах будут слишком разнородными – увеличить и снова провести процесс кластеризации. Для этого заново собирать данные не требуется, достаточно нажать на кнопку «Восстановить», при этом семантическое ядро вернётся в первоначальное состояние до процесса кластеризации.
В нашем случае результат был достаточно хорошим, и, после небольших ручных правок, вырисовалась картина по структуре сайта, которая сразу была создана, а группы распределены по своим категориям.
Дружественное введение в кластеризацию текста | Корбиниан Кох
Огромное количество методов, используемых для кластеризации слов и документов, поначалу может показаться ошеломляющим, но давайте рассмотрим их поближе.
Темы, затронутые в этой статье, включают k-средние, кластеризацию Брауна, tf-idf, тематические модели и скрытое распределение Дирихле (также известное как LDA).
Кластеризация — одна из самых больших тем в науке о данных, настолько обширная, что вы легко найдете тонны книг, в которых обсуждается каждая ее деталь. Подтема кластеризации текста не является исключением. Поэтому эта статья не может дать исчерпывающий обзор, но она охватывает основные аспекты. При этом давайте начнем с того, что выясним, что такое кластеризация и чем она не является.
Вы только что прокрутили по кластерам!
По сути, кластеры — это не что иное, как группы, содержащие похожие объекты. Кластеризация — это процесс, используемый для разделения объектов на эти группы.
Объекты внутри кластера должны быть максимально похожи. Объекты в разных кластерах должны быть максимально непохожими. Но кто определяет, что значит «похожий»? Мы вернемся к этому позже.
Возможно, вы слышали о классификации ранее. При классификации объектов вы также распределяете их по разным группам, но есть несколько важных отличий. Под классификацией понимается объединение новых, ранее невиданных объектов в группы на основе объектов, групповая принадлежность которых уже известна, так называемых обучающих данных. Это означает, что у нас есть что-то надежное для сравнения новых объектов — при кластеризации мы начинаем с чистого листа: все объекты новые! Из-за этого мы называем классификацию методом контролируемых , группируя неконтролируемый один.
Это также означает, что для классификации известно правильное количество групп, тогда как при кластеризации такого количества нет. Обратите внимание, что это не просто неизвестно — это просто не существует . Мы сами должны выбрать подходящее количество кластеров для нашей цели. Во многих случаях это означает опробовать несколько, а затем выбрать тот, который дал наилучшие результаты.
Прежде чем мы углубимся в конкретные алгоритмы кластеризации, давайте сначала установим некоторые способы их описания и различения. Есть несколько способов, как это возможно:
В жесткой кластеризации каждый объект принадлежит ровно одному кластеру . В soft кластеризация объект может принадлежать одному или нескольким кластерам . Членство может быть частичным, то есть объекты могут принадлежать к одним кластерам больше, чем к другим.
В иерархической кластеризации кластеры итеративно объединяются в иерархическом порядке, в конечном итоге заканчиваясь одним корнем (или суперкластером, если хотите). Вы также можете рассматривать иерархическую кластеризацию как двоичное дерево. Все методы кластеризации, не следующие этому принципу, можно просто описать как плоская кластеризация , но иногда их также называют неиерархическими или раздельными . Вы всегда можете преобразовать иерархическую кластеризацию в плоскую, «разрезав» дерево по горизонтали на выбранном вами уровне.
Вы также можете рассматривать иерархическую кластеризацию как двоичное дерево. Все методы кластеризации, не следующие этому принципу, можно просто описать как плоская кластеризация , но иногда их также называют неиерархическими или раздельными . Вы всегда можете преобразовать иерархическую кластеризацию в плоскую, «разрезав» дерево по горизонтали на выбранном вами уровне.
Иерархические методы можно разделить на две подкатегории. Методы агломерации («снизу вверх») начинают с помещения каждого объекта в отдельный кластер, а затем продолжают их объединение. Методы деления («сверху вниз») делают обратное: они начинают с корня и продолжают его деление до тех пор, пока не останутся только отдельные объекты.
Должно быть понятно, как выглядит процесс кластеризации, верно? Вы берете некоторые данные, применяете выбранный вами алгоритм кластеризации и та-да, все готово! Хотя теоретически это возможно, обычно это не так. Особенно при работе с текстом необходимо выполнить несколько шагов до и после кластеризации. На самом деле процесс кластеризации текста часто бывает запутанным и отмечен множеством неудачных попыток. Однако, если вы попытаетесь изобразить его в идеализированной линейной манере, это может выглядеть так:
Особенно при работе с текстом необходимо выполнить несколько шагов до и после кластеризации. На самом деле процесс кластеризации текста часто бывает запутанным и отмечен множеством неудачных попыток. Однако, если вы попытаетесь изобразить его в идеализированной линейной манере, это может выглядеть так:
Несколько дополнительных шагов, верно? Не волнуйтесь — вы, вероятно, интуитивно сделали бы это в любом случае правильно. Однако полезно рассматривать каждый шаг отдельно и иметь в виду, что могут существовать альтернативные варианты решения проблемы.
Поздравляем! Вы прошли введение. В следующих нескольких абзацах мы рассмотрим методы кластеризации для слов . Давайте посмотрим на следующий их набор:
Нам сразу становится ясно, какие слова принадлежат друг другу. Очевидно, должен быть один кластер с животными, содержащий слова Трубкозуб и Зебра и один с наречиями, содержащими на и под . Но так ли это очевидно для компьютера?
Говоря о словах со схожим значением, вы часто читаете о гипотезе распределения в лингвистике. Эта гипотеза утверждает, что слова, имеющие сходное значение, будут появляться в похожих контекстах слов. Вы можете сказать «Коробка на полке», но также и «Коробка под полкой». и по-прежнему производить осмысленное предложение. На и под до определенной степени взаимозаменяемы.
Эта гипотеза утверждает, что слова, имеющие сходное значение, будут появляться в похожих контекстах слов. Вы можете сказать «Коробка на полке», но также и «Коробка под полкой». и по-прежнему производить осмысленное предложение. На и под до определенной степени взаимозаменяемы.
Эта гипотеза используется при создании встраивания слов . Вложения слов отображают каждое слово словаря в n-мерное векторное пространство. Слова с похожим контекстом будут появляться примерно в одной и той же области векторного пространства. Одно из таких вложений было разработано Weston, Ratle & Collobert в 2008 году. Здесь вы можете увидеть интересный сегмент векторов слов (уменьшенный до двух измерений с помощью t-SNE):
Источник: Джозеф Туриан, полную картину смотрите здесь. Обратите внимание, как аккуратно сгруппированы месяцы, имена и места. Это пригодится для их кластеризации на следующем шаге. Чтобы узнать больше о том, как именно создаются вложения слов и какими интересными свойствами они обладают, взгляните на эту статью на Medium Хантера Хайденрайха. Он также включает информацию о более сложных вложениях слов, таких как word2vec.
Он также включает информацию о более сложных вложениях слов, таких как word2vec.
Теперь мы рассмотрим самый известный векторный алгоритм кластеризации: k-средних. Что делает k-means, так это возвращает назначение кластера одному из k возможных кластеров для каждого объекта. Подводя итог тому, что мы узнали ранее, это жесткая, плоская кластеризация метод. Давайте посмотрим, как выглядит процесс k-средних:
Источник: Chire, через Википедию (CC-BY-SA)K-средних назначает k случайных точек в векторном пространстве в качестве начальных виртуальных средних k кластеров. Затем он присваивает каждой точке данных ближайшее среднее значение кластера. Затем пересчитывается фактическое среднее значение каждого кластера. На основе смещения средних точек данных переназначаются. Этот процесс повторяется до тех пор, пока средства кластеров не перестанут двигаться.
Чтобы получить более интуитивное и наглядное представление о том, что делает k-means, посмотрите это короткое видео Джоша Стармера.
K-означает, что это не единственный векторный метод кластеризации. Другие часто используемые методы включают DBSCAN, метод, отдающий предпочтение густонаселенным кластерам, и метод максимизации ожидания (EM), который предполагает базовое вероятностное распределение для каждого кластера.
Существуют также методы кластеризации слов, не требующие, чтобы слова уже были доступны в виде векторов. Вероятно, наиболее цитируемой такой техникой является кластеризация Брауна, предложенная в 1992, Браун и др. (не связан с коричневым корпусом, названным в честь Университета Брауна, Род-Айленд).
Кластеризация по Брауну — это метод иерархической кластеризации . Если срезать на правильном уровне дерева, это также приводит к красивым, плоским гроздьям, таким как следующие:
адаптировано из: Brown et al. (1992) Вы также можете просмотреть небольшие поддеревья и найти кластеры, содержащие пары слов, близкие к синонимам, такие как оценка и оценка или разговор и обсуждение .
Как это достигается? Опять же, этот метод опирается на гипотезу распределения. Он вводит функцию качества, описывающую, насколько хорошо слова окружающего контекста предсказывают появление слов в текущем кластере (так называемая взаимная информация). Затем следует следующая процедура:
- Инициализировать , назначая каждому слову свой собственный уникальный кластер.
- До тех пор, пока не останется только один кластер (корень) : Объединить два кластера, из которых произведенное объединение имеет наилучшее значение функции качества.
По этой причине оценка и оценка так рано объединены. Поскольку оба они появляются в очень похожих контекстах, функция качества, описанная выше, по-прежнему дает очень хорошее значение. Тот факт, что мы начинаем с одноэлементных кластеров, которые постепенно объединяются, означает, что этот метод агломерат .
Кластеризация Брауна используется до сих пор! В этой публикации Owoputi et al. (2013) коричневая кластеризация использовалась для поиска новых групп слов в разговорном онлайн-языке, заслуживающих своего собственного тега части речи. Результаты интересные, но точные:
Источник: Owoputi et al. (2013)Если вам интересно узнать больше о том, как работает коричневая кластеризация, я настоятельно рекомендую посмотреть эту лекцию, прочитанную Майклом Коллинзом в Колумбийском университете.
Хотя этот абзац завершает наш раздел о кластеризации слов, существует множество других подходов, которые не обсуждаются в этой статье. Одним из очень многообещающих и эффективных способов кластеризации слов является кластеризация на основе графа, также называемая спектральной кластеризацией . Используемые методы включают кластеризацию на основе минимального связующего дерева, кластеризацию цепей Маркова и китайский шепот.
Как правило, кластеризация документов также может быть выполнена путем просмотра каждого документа в векторном формате. Но документы редко имеют контексты. Вы можете представить себе книгу, стоящую рядом с другими книгами на аккуратной полке, но обычно это не то, что делают большие коллекции цифровых документов (т.н. корпуса ) выглядят так.
Но документы редко имеют контексты. Вы можете представить себе книгу, стоящую рядом с другими книгами на аккуратной полке, но обычно это не то, что делают большие коллекции цифровых документов (т.н. корпуса ) выглядят так.
Самый быстрый (и, пожалуй, самый тривиальный) способ векторизации документа — дать каждому слову в словаре собственное векторное измерение, а затем просто подсчитать вхождения для каждого слова и каждого документа. Этот способ просмотра документов без учета порядка слов называется подходом мешка слов . Оксфордский словарь английского языка содержит более 300 000 основных статей, не считая омографов. Это много измерений, и большинство из них, вероятно, получат нулевое значение (или как часто вы читаете слова апатазисный , перистеронический и аматорный ?).
В определенной степени вы можете противодействовать этому, удалив все измерения слов, которые не используются в вашей коллекции документов (корпусе), но вы все равно получите много измерений. И если вы вдруг увидите новый документ, содержащий слово, ранее не использовавшееся, вам придется обновить каждый отдельный вектор документа, добавив это новое измерение и нулевое значение для него. Итак, для простоты предположим, что наша коллекция документов не растет.
И если вы вдруг увидите новый документ, содержащий слово, ранее не использовавшееся, вам придется обновить каждый отдельный вектор документа, добавив это новое измерение и нулевое значение для него. Итак, для простоты предположим, что наша коллекция документов не растет.
Посмотрите на следующий игрушечный пример, содержащий только два коротких документа d1 и d2 и результирующий пакет векторов слов:
Как видите, не очень конкретные слова, такие как I и love , получают награду то же значение, что и слова, фактически различающие два документа, такие как пицца и шоколад . Способ противодействия такому поведению состоит в использовании tf-idf , числовой статистики, используемой в качестве весового коэффициента, смягчающего влияние менее важных слов.
Tf-idf обозначает частоту термина и обратную частоту документа, два фактора, используемые для взвешивания. Частота термина — это просто количество вхождений слова в конкретном документе. Если наш документ «Я люблю шоколад, а шоколад любит меня» , то частота термина слова любовь будет равна двум. Это значение часто нормализуется путем деления его на самую высокую частоту терминов в данном документе, в результате чего значения частоты терминов находятся между 0 (для слов, не встречающихся в документе) и 1 (для наиболее часто встречающихся слов в документе). Частота терминов рассчитывается для каждого слова и документа.
Если наш документ «Я люблю шоколад, а шоколад любит меня» , то частота термина слова любовь будет равна двум. Это значение часто нормализуется путем деления его на самую высокую частоту терминов в данном документе, в результате чего значения частоты терминов находятся между 0 (для слов, не встречающихся в документе) и 1 (для наиболее часто встречающихся слов в документе). Частота терминов рассчитывается для каждого слова и документа.
Обратная частота документа , с другой стороны, рассчитывается только для каждого слова. Он показывает, как часто слово встречается во всем корпусе. Это значение инвертируется путем его логарифмирования. Помните вездесущее слово I , от которого мы хотели избавиться? Поскольку логарифм единицы равен нулю, его влияние полностью исключается.
На основе этих формул мы получаем следующие значения для нашего игрушечного примера:
Глядя на последние два столбца, мы видим, что только самые релевантные слова получают высокое значение tf-idf. Так называемый стоп-слова , то есть слова, повсеместно встречающиеся в нашей коллекции документов, получают значение, равное или близкое к 0.
Так называемый стоп-слова , то есть слова, повсеместно встречающиеся в нашей коллекции документов, получают значение, равное или близкое к 0.
Полученные векторы tf-idf по-прежнему имеют такую же большую размерность, как и исходный набор векторов слов. Поэтому методы уменьшения размерности, такие как латентное семантическое индексирование (LSI), часто используются для упрощения работы с ними. Алгоритмы, такие как k-means, DBSCAN и EM, также могут использоваться для векторов документов, как описано ранее для кластеризации слов. Возможные меры расстояния включают евклидово и косинусное расстояние.
Часто просто иметь группы документов недостаточно.
Тематическое моделирование Алгоритмы представляют собой статистические методы, которые анализируют слова исходных текстов, чтобы обнаружить темы, которые проходят через них, как эти темы связаны друг с другом и как они меняются с течением времени (Blei, 2012).
Все тематические модели основаны на одном и том же основном предположении:
- каждый документ состоит из распределения по теме и
- каждая тема состоит из распределения по словам.


Помимо других тематических моделей, таких как вероятностный латентный семантический анализ (pLSA), латентное распределение Дирихле (LDA) является наиболее известным и широко используемым. Просто взглянув на его название, мы уже можем многое узнать о том, как он работает.
Латентное относится к скрытым переменным, распределение Дирихле является распределением вероятностей по другим распределениям вероятностей и распределение означает, что некоторые значения распределяются на основе двух. Чтобы лучше понять, как работают эти три аспекта, давайте посмотрим, какие результаты дает нам LDA. Следующие темы представляют собой выдержку из 100 тем, раскрытых путем подгонки модели LDA к 17 000 статей из журнала Science .
адаптировано из: Blei (2012) Как следует интерпретировать эти темы? Тема — это распределение вероятностей по словам. Какие-то слова чаще появляются в теме, какие-то меньше. То, что вы видите выше, — это 10 наиболее часто встречающихся слов по теме, исключая стоп-слова. Важно отметить, что темы на самом деле не имеют названий Генетика или Эволюция . Это всего лишь термины, которые мы, люди, использовали бы, чтобы обобщить суть темы. Вместо этого попробуйте взглянуть на темы как распределения вероятностей слов 1 или распределения вероятностей слов 23 .
То, что вы видите выше, — это 10 наиболее часто встречающихся слов по теме, исключая стоп-слова. Важно отметить, что темы на самом деле не имеют названий Генетика или Эволюция . Это всего лишь термины, которые мы, люди, использовали бы, чтобы обобщить суть темы. Вместо этого попробуйте взглянуть на темы как распределения вероятностей слов 1 или распределения вероятностей слов 23 .
Но это далеко не все, что нам предоставляет LDA. Кроме того, он сообщает нам для каждого документа, какие темы появляются в нем и в каком процентном соотношении. Например, статья о новом устройстве, которое может определять распространенность определенного заболевания в вашей ДНК, может состоять из смеси тем 48% Болезни , 31% Генетика и 21% Компьютеры .
Чтобы понять, как мы можем заставить компьютер знать, как выглядят хорошие темы и как их найти, мы снова создадим небольшой игрушечный пример. Давайте представим, что наш словарный запас состоит всего из пары эмодзи.
Возможные темы или распределения вероятности слов в этом словаре могут выглядеть следующим образом:
Как люди, мы можем идентифицировать эти темы как Еда, Смайлики и Животные . Предположим, темы заданы. Чтобы понять основные предположения, которые делает LDA, давайте рассмотрим процесс создания документов. Даже если они кажутся не очень реалистичными, предполагается, что автор предпримет следующие шаги:
- Выберите, сколько слов вы хотите написать в своем тексте.
- Выберите сочетание тем, которые должен охватывать ваш текст.
- Для каждого слова в документе:
- нарисуйте тему, к которой слово должно относиться из смеси
- нарисовать слово из выбранной темы распределение слов
На основании этих шагов результатом может стать следующий документ: возможно исходить из него. Теперь, когда у нас есть желаемый результат, нам нужно только найти способ обратить этот процесс вспять. Только? В реальности мы сталкиваемся с этим:
Теоретически мы могли бы заставить наш компьютер перепробовать все возможные комбинации слов и тем. Помимо того факта, что на это, вероятно, уйдет вечность, как мы узнаем, в конце концов, какая комбинация имеет смысл, а какая нет? Для этого пригодится распределение Дирихле. Вместо того, чтобы рисовать распределение, как на изображении выше, давайте нарисуем наш документ на симплексе темы в соответствующей позиции.
Помимо того факта, что на это, вероятно, уйдет вечность, как мы узнаем, в конце концов, какая комбинация имеет смысл, а какая нет? Для этого пригодится распределение Дирихле. Вместо того, чтобы рисовать распределение, как на изображении выше, давайте нарисуем наш документ на симплексе темы в соответствующей позиции.
Помимо этого, мы можем нарисовать множество других документов из нашего корпуса. Это могло бы выглядеть так:
Или, если бы мы заранее выбрали другие темы, вот так:
Если в первом варианте документы четко различимы и сопереживают разные темы, то во втором варианте все документы более-менее одинаковый Выбранные здесь темы не смогли осмысленно разделить документы. Эти два возможных распределения документов есть не что иное, как два разных Распределения Дирихле ! Это означает, что мы нашли способ описать, как выглядят «хорошие» распределения по темам!
Тот же принцип применяется к словам в темах. В хороших темах будет различное распределение слов, в то время как в плохих темах слова будут примерно такими же, как и в других.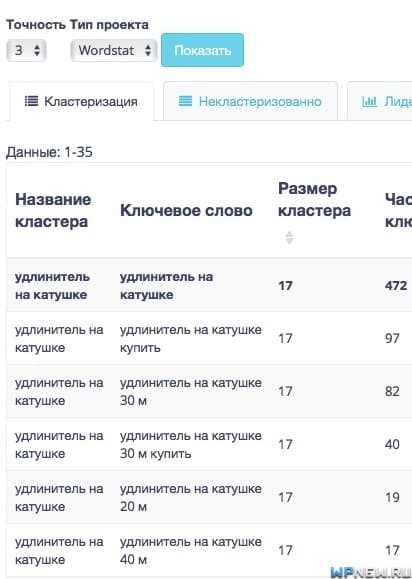 Эти два вида распределения Дирихле описываются в модели LDA двумя гиперпараметрами, альфа и бета. Как правило, вы хотите, чтобы ваши параметры Дирихле были ниже единицы. Посмотрите, как различные значения меняют распределение в этой великолепной анимации, созданной Дэвидом Леттье.
Эти два вида распределения Дирихле описываются в модели LDA двумя гиперпараметрами, альфа и бета. Как правило, вы хотите, чтобы ваши параметры Дирихле были ниже единицы. Посмотрите, как различные значения меняют распределение в этой великолепной анимации, созданной Дэвидом Леттье.
Распределение хороших слов и тем обычно аппроксимируется с помощью таких методов, как свернутая выборка Гиббса или распространение ожиданий. Оба метода итеративно улучшают случайно инициализированные распределения слов и тем. Однако «идеальное» распределение может никогда не быть найдено.
Если вы хотите попробовать, что LDA делает с выбранным вами набором данных в интерактивном режиме, пройдитесь по этой замечательной демонстрации в браузере, созданной Дэвидом Мимно.
Помните блок-схему кластеризации, представленную во введении? Особенно последний шаг, называемый окончательной оценкой? При использовании методов кластеризации вы всегда должны помнить, что даже если конкретная модель может привести к наименьшему среднему векторному движению или наименьшему значению распределения вероятности, это не означает, что она «правильна». Есть много наборов данных, k-средние не могут правильно кластеризоваться, и даже LDA может создавать темы, которые не имеют никакого смысла для людей.
Есть много наборов данных, k-средние не могут правильно кластеризоваться, и даже LDA может создавать темы, которые не имеют никакого смысла для людей.
Вкратце: Все модели ошибочны, но некоторые из них полезны. Получайте удовольствие от кластеризации ваших текстов и будьте осторожны!
Анастасиу, округ Колумбия, Тагарелли, А., Карипис, Г. (2014). Кластеризация документов: следующий рубеж. В Aggarwal, CC & Reddy, CK (Eds.), Кластеризация данных, алгоритмы и приложения (стр. 305–338). Миннеаполис: Чепмен и Холл.
Блей, Д.М., Нг, А.Ю., и Джордан, М.И. (2003). Скрытое распределение Дирихле. Журнал исследований машинного обучения, 3 (январь), 993–1022.
Блей, Д. М. (2012). Вероятностные тематические модели: обзор набора алгоритмов, предлагающих решение для управления большими архивами документов. Связь АКМ, 55 (4), 77–84.
Браун, П. Ф., Пьетра, В. Дж., Соуза, П. В., Лай, Дж. К., и Мерсер, Р. Л. (1992). N-граммные модели естественного языка на основе классов. Компьютерная лингвистика , 18, 467–479.
Компьютерная лингвистика , 18, 467–479.
Фельдман, Р., и Сангер, Дж. (2007). Кластеризация, Справочник по интеллектуальному анализу текста. Передовые подходы к анализу неструктурированных данных. Кембридж: Издательство Кембриджского университета.
Ле, К. и Миколов, Т. (2014). Распределенные представления предложений и документов. Материалы 31-й Международной конференции по машинному обучению, в PMLR 32 (2), 1188–1196.
Мэннинг, К., и Шютце, Х. (1999). Кластеризация, Основы статистической обработки естественного языка . Кембридж, Массачусетс: MIT Press.
Овопути, О., О’Коннор, Б., Дайер, К., Гимпель, К., Шнайдер, Н., и Смит, Н. А. (2013). Улучшенная маркировка частей речи для разговорного онлайн-текста с кластерами слов. Технологии человеческого языка: конференция Североамериканского отделения Ассоциации компьютерной лингвистики, Труды, 9–14 июня 2013 г., Атланта, Джорджия, США (стр. 380–390).
кластерный анализ — Кластеризация слов в группы
спросил
Изменено 4 года назад
Просмотрено 12 тысяч раз
Это вопрос домашнего задания.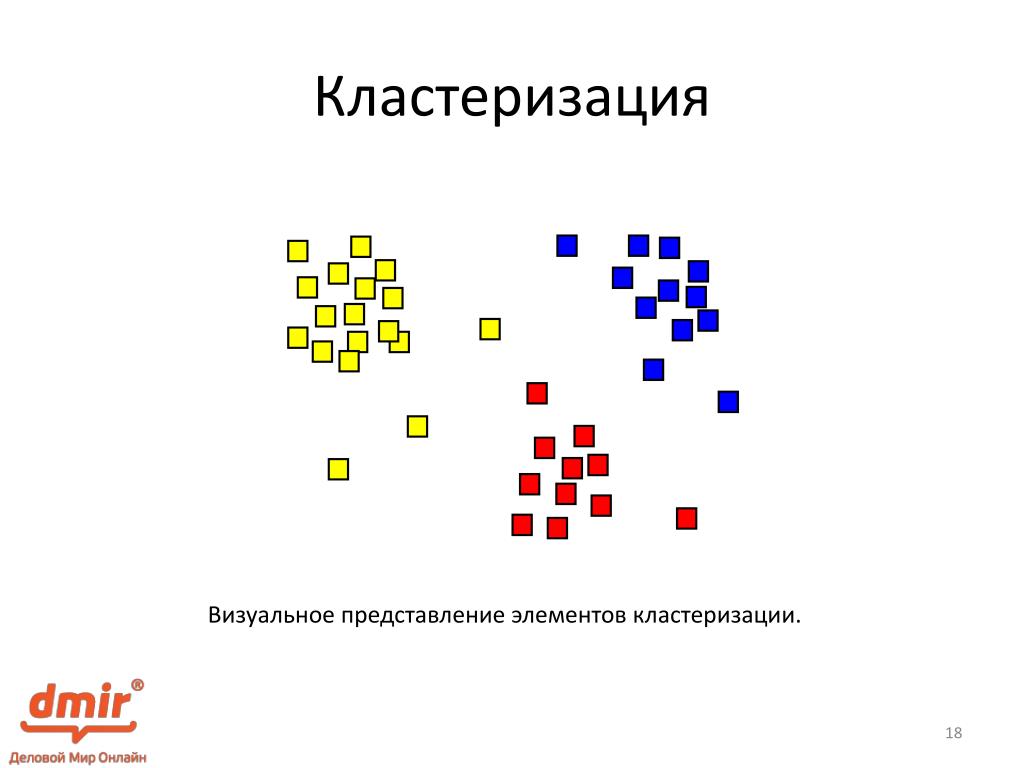 У меня есть огромный документ, полный слов. Моя задача состоит в том, чтобы классифицировать эти слова по разным группам/кластерам, которые адекватно представляют слова. Моя стратегия борьбы с этим заключается в использовании алгоритма K-средних, который, как вы знаете, выполняет следующие шаги.
У меня есть огромный документ, полный слов. Моя задача состоит в том, чтобы классифицировать эти слова по разным группам/кластерам, которые адекватно представляют слова. Моя стратегия борьбы с этим заключается в использовании алгоритма K-средних, который, как вы знаете, выполняет следующие шаги.
- Создать k случайных средних для всей группы
- Создайте K кластеров, связав каждое слово с ближайшим средним значением
- Вычислить центр тяжести каждого кластера, который становится новым средним значением
- Повторяйте шаги 2 и 3 до тех пор, пока не будет достигнута определенная точка отсчета/конвергенция.
Теоретически вроде понимаю, но не совсем. Я думаю, что на каждом этапе у меня есть вопросы, которые ему соответствуют, а именно:
Как мне выбрать k случайных средств, технически я мог бы сказать 5, но это не обязательно может быть хорошим случайным числом. Так является ли это k чисто случайным числом или на самом деле оно определяется эвристикой, такой как размер набора данных, количество задействованных слов и т.
Как вы связываете каждое слово с ближайшим средним значением? Теоретически я могу заключить, что каждое слово связано своим расстоянием до ближайшего среднего, поэтому, если есть 3 средних, любое слово, принадлежащее определенному кластеру, зависит от того, до какого среднего оно имеет кратчайшее расстояние. Однако как это вычисляется на самом деле? Между двумя словами «группа», «текстовое слово» и предположим среднее слово «карандаш», как мне создать матрицу подобия.
Как вычислить центр тяжести?
Когда вы повторяете шаги 2 и 3, вы принимаете каждый предыдущий кластер как новый набор данных?

Много вопросов, и я явно не разобрался. Если есть какие-либо ресурсы, которые я могу прочитать, было бы здорово. Википедии не хватило 🙁
- кластерный анализ
- k-means
- текстовый анализ
Поскольку вы не знаете точное количество кластеров — я предлагаю вам использовать своего рода иерархическую кластеризацию :
- Представьте, что все ваши слова просто точки в неевклидовом пространстве. Используйте расстояние Левенштейна для вычисления расстояния между словами (отлично работает, если вы хотите, чтобы обнаруживал кластеры лексикографически похожих слов )
- Построить минимальное остовное дерево , содержащее все ваши слова
- Удалить ссылки , длина которых превышает некоторый порог
- Связанные группы слов представляют собой кластеры похожих слов
 Используйте расстояние Левенштейна для вычисления расстояния между словами (отлично работает, если вы хотите, чтобы обнаруживал кластеры лексикографически похожих слов )
Используйте расстояние Левенштейна для вычисления расстояния между словами (отлично работает, если вы хотите, чтобы обнаруживал кластеры лексикографически похожих слов ) Вот небольшая иллюстрация:
P.S. в сети можно найти много статей, где описывается кластеризация на основе построения минимального остовного дерева
P.P.S. Если вы хотите обнаружить кластеры из семантически похожих слов, вам потребуются некоторые алгоритмы автоматического построения тезауруса
2
То, что вы должны выбрать «k» для k-средних, является одним из самых больших недостатков k-средних. Однако, если вы воспользуетесь здесь функцией поиска, вы найдете ряд вопросов, касающихся известных эвристических подходов к выбору k. В основном путем сравнения результатов многократного запуска алгоритма.
Однако, если вы воспользуетесь здесь функцией поиска, вы найдете ряд вопросов, касающихся известных эвристических подходов к выбору k. В основном путем сравнения результатов многократного запуска алгоритма.
Что касается «ближайшего». K-means фактически не использует расстояний . Некоторые люди считают, что он использует евклидово, другие говорят, что это евклидов в квадрате. Технически, то, что интересует k-means, это дисперсия . Он минимизирует общую дисперсию, назначая каждый объект кластеру таким образом, чтобы дисперсия была минимизирована. По совпадению, сумма квадратов отклонений — вклад одного объекта в общую дисперсию — по всем измерениям является в точности определением квадрата евклидова расстояния. А так как квадратный корень монотонный, вместо него можно также использовать евклидово расстояние.
В любом случае, если вы хотите использовать k-средних со словами, вам сначала нужно представить слова в виде векторов, где квадрат евклидова расстояния имеет смысл.