
Поиск страниц с rel=»canonical» на сайте
Что такое атрибут rel=»canonical»
Атрибут rel=»canonical» применяется для указания поисковым системам канонической страницы. Каноническая страница — это страница на сайте, которая является предпочтительной для индексации в поисковых системах. Поисковый робот, обнаружив атрибут rel=»canonical» на какой-либо странице, вместо нее проиндексирует ту страницу, адрес которой указан в данном атрибуте. В отличие от редиректа, rel=»canonical» переадресует на другую страницу не пользователей, а только поисковые системы.
Как прописать атрибут rel=»canonical» в коде страницы
Задается он с помощью тега LINK с атрибутом rel=”canonical” в блоке HEAD страницы. Для этого необходимо поместить в HEAD следующую запись:
<link rel=”canonical” href=”канонический URL” />
Где «канонический URL» – это полный адрес страницы, которую вы считаете предпочтительной для индексации.
Пример употребления атрибута:
<link rel=”canonical” href=”http://site.ru/razdel/document/"/>
Обязательно использовать относительный (полный) путь на страницу!
В каких случаях применяют этот атрибут?
Этот атрибут применяется в тех случаях, когда на сайте имеются страницы с идентичным или очень похожим контентом. Чтобы поисковая система не расценивала такие страницы как дубли, необходимо разместить на них ссылку на предпочтительную для индексации каноничную страницу. Это один из самых простых способов борьбы с дублями страниц. Более подробно изучить информацию про дубли страниц и способы борьбы с ними вы сможете в нашей статье Дубли страниц на сайте.
Почему это важно для поисковых систем
Информация от Яндекс о поддержке поисковыми роботами rel=»canonical» появилась еще в 2011 году – https://yandex.ru/blog/webmaster/10371.
Кроме того, вы можете ознакомиться с рекомендациями от Яндекс по употреблению rel=»canonical» в разделе Яндекс.Помощь.
Google также официально рекомендует использовать rel=»canonical» для борьбы с повторяющимися URL. Об этом можно прочитать в руководстве Консолидация повторяющихся URL.
Почему нужно знать, на каких страницах сайта есть rel=»canonical»
Очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку в некоторых случаях канонические страницы могут быть указаны неверно или ссылка может вести не ту страницу, на которую нужно. Это может обернуться для вас ошибками в индексации — одни страницы вашего сайта могут не проиндексироваться, а другие URL будут ошибочно указаны каноническими.Как обнаружить на сайте страницы с rel=»canonical»
Это можно сделать с помощью сервиса Labrika. Отчет «Страницы с rel=»canonical» вы можете найти в разделе «Технический аудит» левого бокового меню.
Страница с отчетом выглядит следующим образом:
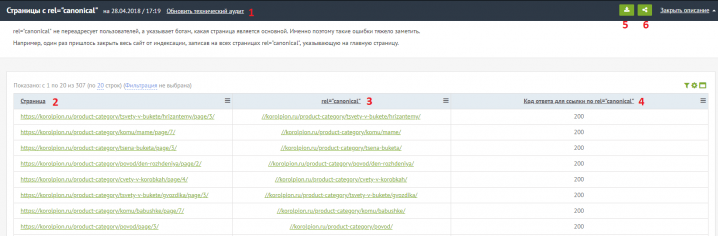
Цифрами на странице обозначены:
- Кнопка для обновления технического аудита, чтобы получить актуальные данные по страницам с rel=»canonical».
- Страница, на которой прописан атрибут rel=»canonical».
- URL, который прописан в атрибуте, то есть, указан в качестве канонического для поисковых систем.
- Код ответа ссылки, которая размещена в rel=»canonical». Код ответа 200 говорит об успешной обработке запроса (страница доступна).
- При нажатии на эту кнопку вы скачаете отчет в формате Excel.
- Ссылка, с помощью которой можно скопировать отчет и отправить другому пользователю. Отчет будет доступен даже тем, кто не имеет аккаунта в Labrika.
После получения данных о канонических страницах на сайте вы сможете увидеть ошибки, если они есть, и исправить их, чтобы избежать проблем с индексацией сайта.
Что такое канонические ссылки и адреса страниц
Здравствуйте, дорогие читатели! Вы когда-нибудь задумывались, почему некоторые веб-ресурсы несмотря на большие усилия по SEO-продвижению так и не занимают лидирующих позиций в выдаче? Вроде и контент уникальный, и верстка корректная, а все стоит на месте. Причина – дубли страниц, о которых владелец ресурса даже не подозревает. Сегодня расскажу, что такое канонические ссылки и адреса веб-страниц, и как они уничтожают вредные копии интернет-страниц сайта.
Откуда взялись эти дубли
Дубли – это копии веб-страниц сайта. Если один и тот же пост доступен с разных адресов, то имеет место разговор о дублированном контенте.
«Какие копии? У меня все тексты уникальные в единственном экземпляре» — скажете вы. Однако они могут появиться не только из-за невнимательности или недобросовестности владельца веб-ресурса.
Существует ряд причин образования этих ненужных повторов, которые не видны с первого взгляда.
- Часто генерацией дублей грешат сами CMS-движки, на которых расположены веб-сайты. Это их особенность. Подчас CMS создает огромное количество дублированных страниц.
- Причиной может быть и то, что статья входит сразу в несколько категорий. Следовательно она будет доступна с разных url-адресов.
- Еще одна причина – склейка доменов. Не выбрано главное зеркало сайта. Результат – пост доступен с адреса www.myblog.ru/post и с myblog.ru/post. Из-за неправильной настройки для поисковика это два разных интернет-адреса.
- Интернет-страница содержит мало контента в основной части. Например, небольшое описание товара в интернет-магазине. Это неявные дубли. Такие web-страницы будут обладать низкой уникальностью. Для поискового робота они очень похожи друг на друга. Для таких страничек нужно писать более длинный уникальный контент.
Каноническая страница веб-сайта
Посмотрите на следующие адреса веб-страниц.
http://myblog.ru/seo
http://myblog.ru/zametki/seo
http://myblog.ru/zametki?id=7
http://www.myblog.ru/seo
Все они приведут на один и тот же пост. Но для поисковика – это будут четыре разные странички с одинаковым содержимым. Даже если вы новичок в SEO, то все равно понимаете, что для продвижения это очень большая проблема. Поисковые машины не любят копипаст и нещадно понижают такой сайт в выдаче.
Необходимо выбрать каноничную веб-страницу и, пометив ее специальным атрибутом, указать на нее роботу. О том, как это сделать читайте далее.
Каноническая страница – значит первостепенная, предпочтительная при индексировании.
Как отыскать все дубли
Прежде, чем бороться с копиями, их нужно найти. Существует несколько способов. Ниже кратко расскажу о каждом.
- Для начала обратимся к инструментам для веб-мастеров от Яндекс и Google. Обратите внимание на количество проиндексированных каждым сервисом страниц. Если это число сильно отличается в каждом из сервисов, то есть большая вероятность присутствия дублей. Также сопоставьте количество опубликованных постов и проиндексированных веб-страниц. Если постов только 50, а интернет-страниц в индексе 250, то стоит задуматься.
- Найти страницы-дубли можно при помощи специальных программ. Одной из них является XENU. Проводя хороший аудит сайта, она поможет найти дубли. Еще одна программа называется «ComparseR».
- Также в сети можно найти онлайн-сервисы для поиска страниц-дублей.
- Если самому разбираться с техническими моментами нет времени, то можно заказать полный аудит сайта с исправлением всех нюансов, мешающих SEO-продвижению. В этом случае компания, предоставляющая услуги проведет аудит и даст отчет о проделанной работе.
Как использовать канонические ссылки
Отыскав все страницы-дубли можно приступать к избавлению от них. Для этого используют канонические ссылки со специальным атрибутом rel=”canonical” и url-адресом на первоисточник. Сейчас расскажу, как это работает.
Сначала определяете каноническую веб-страницу – то есть, страницу первоисточник. Допустим, она имеет следующий адрес: http://myblog.ru/seo-post.
В теге head первоисточника помещаем запись следующего вида: .
Атрибут rel=”canonical” – определяет каноничность страницы, а url-адрес, написанный в атрибуте href указывает, что это за интернет-страница.
Вроде бы все просто, но стоит уточнить некоторые нюансы.
- Указывайте в атрибуте href абсолютный, а не относительный адрес веб-страницы.
- Указанный url должен быть открыт для индексации, то есть не закрыт в файле robots.txt.
- Ссылка обязательно ведет на сайт в том же домене (без поддоменов).
- На одной интернет-странице может быть использована только одна каноническая ссылка.
- Нельзя создавать «цепь» из каноничных ссылок. Например, одна каноничная страница содержит ссылку на другую и т.д.
Правильное использование очень благотворно влияет на SEO-продвижение ресурса в сети. Указывая основную страницу, вы даете понять поисковому роботу, где первостепенный контент, а какие url-адреса следует игнорировать.
Алгоритм действий по устранению копий
Давайте подведем итоги и пропишем основной алгоритм действий по устранению дублей.
- Проводим аудит веб-сайта на предмет дублирующих страниц.
- Проверяем склейку доменов и настроено ли основное зеркало сайта.
- Выявляем основную страничку и проставляем каноническую ссылку.
- Используем переадресацию 301 для неканонических url-адресов.
- После этого ждем изменений, постоянно анализируя веб-сайт на предмет дублирующих страниц.
Стоит достаточно серьезно отнестись к данной проблеме, ведь эти технические нюансы могут свести на нет все усилия по продвижению веб-ресурса. Поисковые машины будут считать такой ресурс неуникальным, а вы будете терять свое время и деньги. Обязательно проверяйте сайт на дублирование и ставьте канонические ссылки.
Вот вы и узнали что такое канонические ссылки. Желаю скорейшего продвижения вашему интернет-ресурсу.
Не забывайте делиться постом в социальных сетях.
Подписывайтесь на обновления блога и будьте в курсе самого важного. До новых встреч.
Повышение рейтинга одинакового контента c каноническим URL — Netpeak Blog
Причин возникновения дублей контента может быть много: особенности CMS сайта, страницы с динамическими параметрами URL, сайт доступен по https://www.site.com/ и по https://site.com/, http://site.com/ и так далее. Если не указать поисковику приоритетную — каноническую страницу с дублирующимся контентом, робот выберет ее на свое усмотрение и последствия могут быть неприятными, особенно для владельцев сайтов.
В этом выпуске «Азбуки SEO» поговорим о понятии каноничности страниц и атрибуте rel=»canonical».
Что такое атрибут rel=»canonical»?
Атрибут rel=»canonical» указывает роботам поисковых систем, какую страницу необходимо считать приоритетной. Он присваивается тегу link и располагается в <head></head> страницы. Страница, указанная в атрибуте rel=»canonical», начинает восприниматься поисковыми роботами как приоритетная (каноническая).
Например: <link rel=»canonical» href=»http://[url]» />, где [url] — адрес канонической страницы.
Допустим, для страницы «http://site.com/?get=12345» канонической является «http://site.com/». В таком случае на странице «http://site.com/?get=12345
Google поддерживает этот атрибут с 2009, Яндекс — с 2011 года.
Зачем указывать canonical?
- Устранить полные или частичные дубли контента на сайте.
- Защитить контент от дублирования на ресурсах, которые частично или полностью могут кешировать сайт (например, веб-архивы).
В каких случаях нужно определять каноничность?
Страницы пагинации
Для страниц пагинации есть два решения вопроса с каноническими страницами. Выбор варианта зависит от того, есть ли в каждой категории сайта страница «Показать все», например, «http://site.com/category-1/show-all», на которой доступны все товары из категории.
Если такая страница есть, Google рекомендует на каждой из страниц пагинации указать канонической страницу «Показать все».
Например, «http://site.com/category-1/page-2» должна содержать каноническую ссылку: <link rel=»canonical» href=»http://site.com/category-1/show-all» />.
Если страницы «Показать все» нет и мы имеем дело с классической пагинацией, следует в качестве канонических указывать эти же страницы.
Например, страница «http://site.com/category-1/page-2» должна содержать каноническую ссылку: <link rel=»canonical» href=»http://site.com/category-1/page-2″ />.
О том, как мы используем rel=»canonical» для оптимизации страниц интернет-магазина, читайте здесь.
Страницы с UTM-метками
Необходимо настроить сервер так, чтобы при нахождении UTM-параметров в адресе страницы, отдавался код «200 ОК» и страница содержала абсолютную каноническую ссылку на URL этой страницы без UTM-метки.
Речь о следующих UTM-параметрах:
- gclid;
- utm_medium;
- utm_source;
- utm_campaign;
- utm_content;
- utm_term;
- _openstat.
Так, страница «http://site.com/?utm_source=testk&utm_medium=test&utm_campaign=test» должна содержать каноническую ссылку: <link rel=»canonical» href=»http://site.com/» />.
Читайте, как правильно создавать и проставлять UTM-метки.
Страницы фильтрации
На страницах фильтрации следует в качестве канонических указывать сами страницы фильтрации.
Например, для страницы «http://site.com/category-1/filter-1/» нужна ссылка: <link rel=»canonical» href=»http://site.com/category-1/filter-1/» />.
Дублирование контента на разных доменах
Иногда при переходе на новое доменное имя используется сервер, который не поддерживает переадресацию на своей стороне. В таком случае можно использовать междоменный атрибут rel=»canonical» в элементе link.
Просто нужно указать канонические ссылки со всех доменов, на которых есть дублирующийся контент, на основной — предпочтительный для индексирования.
Важно: на данный момент междоменный каноникал понимает только Google.
О чем следует помнить при простановке rel=»canonical»?
- Ссылки в атрибуте следует ставить абсолютные — с http:// или https://. Так сокращается риск появления ошибок.
- Если на странице с дублирующимся контентом указываете на другую страницу как каноническую, не забудьте в <head></head> той страницы также прописать ее как каноническую.
- Если на странице указаны несколько канонических адресов, поисковый робот проигнорирует их и определит каноническую страницу самостоятельно.
- Если канонической указана страница, отдающая код ответа 404, поисковый робот не сможет использовать данную рекомендацию.
- Чтобы избежать ошибок, не стоит использовать цепочки канонических страниц.
- Поисковые роботы воспринимают атрибут rel=»canonical» не как строгую директиву, а как рекомендацию, то есть указанный URL может быть проигнорирован.
- При самостоятельном определении канонических страниц поисковая система Google отдает предпочтение страницам на https.
Выводы
В нашей практике бывали случаи, когда контент с сайта копировали полностью, вместе с внутренней текстовой перелинковкой и каноническими адресами. Поэтому атрибут rel=»canonical» стоит указывать на всех страницах.
Особенно важно определять каноничность для:
- страниц пагинации;
- страниц с UTM-метками;
- страниц фильтрации.
Это помогает бороться с дублированием контента и обезопасить сайт от копирования.
Узнайте больше о продвинутых способах использования rel=»canonical».
Google объяснил, как выбираются канонические URL

В последнем выпуске серии справочных видео #AskGoogleWebmasters сотрудник Google Джон Мюллер объяснил, как поисковик выбирает канонические URL.
Вопрос к Google звучал так:
«Мы можем указывать свои предпочтения, используя определённые техники, но Google может выбрать как каноническую совсем другую страницу, по разным причинам. Почему это так?».
В ответ Мюллер рассказал, что довольно часто на сайтах имеется несколько уникальных URL, ведущих на один и тот же контент. Например, это могут быть версии страниц с префиксом www и без него.
Другая распространенная конфигурация – это когда главная страница доступна как index.html или когда URL с прописными и строчными буквами ведут на одни и те же страницы.
В идеале на сайте не должно быть альтернативных версий URL, но иногда они всё же имеются. Поэтому при выборе канонического URL для показа в результатах поиска Google обычно учитывает следующие два аспекта:
- Какой URL отмечен как канонический для Google;
- Какая версия URL будет наиболее полезной для пользователей.
Владельцы сайтов могут указать, какой URL они считают предпочтительным. Чем более последовательны сигналы, передаваемые сайтом, тем выше вероятность того, что Google также выберет этот URL.
Эти сигналы включают:
- Атрибуты rel=canonical, используемые для одного и того же формата URL по всему сайту;
- Редиректы;
- Внутренние ссылки с использованием предпочтительного формата URL;
- URL-адреса в файле Sitemap.
Мюллер также отметил, что Google отдаёт предпочтение HTTPS перед HTTP и склонен выбирать как канонические те URL-адреса, которые «лучше выглядят».
Главная рекомендация для того, чтобы Google выбирал определённую версию URL, – убедиться, что она последовательно используется.
Чем более согласованным будет сайт, тем выше вероятность, что Google выберет предпочтительную версию URL.
При этом Мюллер подчеркнул, что если Google выберет другую версию страницы, это не будет иметь негативного влияния на ранжирование. Указывать канонический URL необязательно. Вполне нормально не обозначать такие предпочтения вообще.
Напомним, что в апреле Search Console начал привязывать данные об эффективности к каноническим страницам.
Добавим также, что для Google канонические страницы в Sitemap – это менее значимый сигнал, чем rel=canonical.