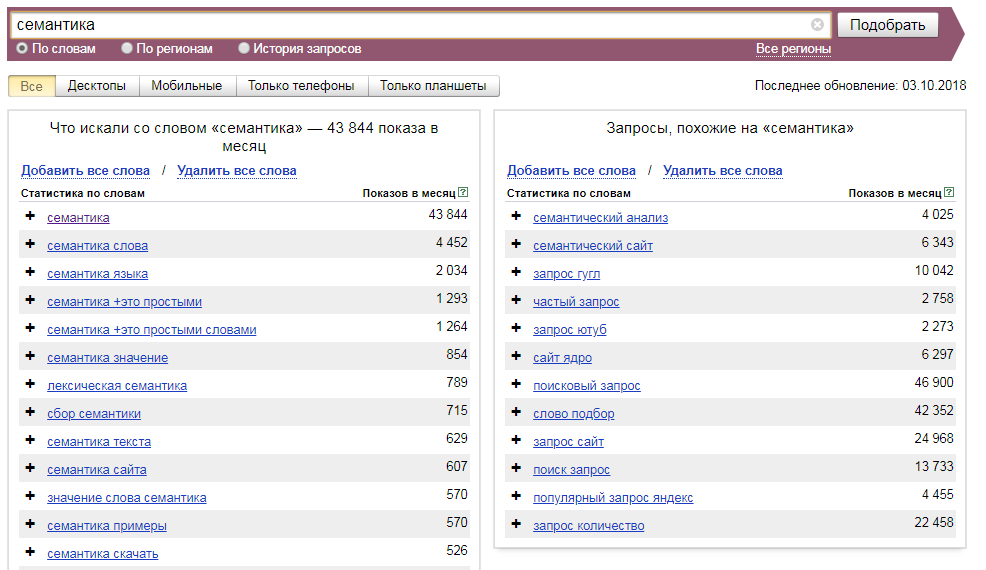
Google назвал самые популярные запросы россиян в 2021 году
Впечатления
Автор Николь Зонтах
08 декабря 2021
Google представил «Год в Поиске» — видео с событиями, которые больше всего волновали россиян и рождали горячие дискуссии в 2021 году. Саундтрек к ролику написала певица Манижа
Google подвел итоги года в России, собрав самые главные и волнующие россиян темы в видеоролике. Саундтреком к «Году в Поиске» послужила новая песня Манижи «Неделимые», которую она написала специально для проекта, сообщается в блоге компании.
Google представил «Топ-10 самых быстрорастущих запросов» в шести основных категориях: «События», «Что такое», «Выставки», «Мультфильмы», «Российские сериалы» и «Книги».
В этом году российские пользователи следили за событиями, которые из-за пандемии не случились в 2020 году: Олимпиадой в Токио, «Евровидением», чемпионатом Европы по футболу и чемпионатом мира по хоккею. Переживали трагические события — стрельбу в Казани и конфликт в Афганистане.
Реклама на РБК www.adv.rbc.ru
Топ быстрорастущих запросов в категории «События»
- Чемпионат Европы по футболу.
- Олимпиада в Токио.
- «Евровидение».
- Чемпионат мира по хоккею 2021.
- Учреждение Дня отца.
- Конфликт в Афганистане.
- Стрельба в Казани.
- Выборы в Госдуму.
- Блокировка Суэцкого канала.
- Масштабный сбой в работе социальных сетей.
В категории «Что такое» пользователи пытались разобраться с разницей между симпл-димплами и поп-итами, и соскучившись по личному общению, активно разбирались с приложением Clubhouse и понятием «Дружба».
Топ быстрорастущих запросов в категории «Что такое»
- Симпл-димпл.
- Митинг.
- Поп-ит.
- Формалин.
- Clubhouse.
- Аквадискотека.

- Дружба.
- Феминизм.
- Эквайринг.
- ПЦР-тест.

В этом году мы снова проводили много времени дома за просмотром сериалов и чтением книг, хотя и стали чаще выбираться на выставки и интересоваться миром искусства. Так, в первую пятерку популярных выставок вошла скандальная экспозиция анатомических экспонатов «Мир тела», масштабная выставка Михаила Врубеля, концептуальная экспозиция «Я, Энди Уорхол», проект «Lady Dior as seen by» и выставка Роберта Фалька.
Топ быстрорастущих запросов в категории «Российские сериалы»
- «Ивановы-Ивановы».
- «Трудные подростки».
- «Миллионер с Рублевки».
- «Отпуск».
- «Девушки с Макаровым».
- «Содержанки».
- «Вампиры средней полосы».
- «Мир! Дружба! Жвачка!»
- «Жуки».
- «Бывшие».
Среди популярных книг — роман «Угрюм-река» Вячеслава Шишкова, «Дюна» Дени Вильнева, экранизированная автобиография «Кто-нибудь видел мою девчонку?» Карины Добротворской, детская сказка «Мойдодыр», а также классика фантастики от Рэя Бредбери «451 градус по Фаренгейту», «И грянул гром» и другие.
Полные списки по всем категориям опубликованы здесь.
Теги: итоги года
Google подвел итоги 2021 года в России
Россиян волновали спортивные события, конфликты, выборы, мультфильмы, симпл-димпл и поп-ит, сериалы, книги и многое другое.
Редакция «Правил жизни»
Теги:
россия
итоги
Google подвел итоги года в России, проанализировав поисковые запросы россиян в 2021 году.
«2021 стал годом контрастов. Одни и те же события вызывали у людей противоположные эмоции и рождали горячие дискуссии», — говорится в блоге компании.
В рамках проекта «Год в Поиске 2021» Google представил ролик под песню Манижи «Неделимые», которую она написала специально для проекта.
Google представил «Топ-10 самых быстрорастущих запросов» в категориях: «События», «Что такое», «Выставки», «Мультфильмы», «Российские сериалы» и «Книги».
События:
- Чемпионат Европы по футболу.
- Олимпиада в Токио.
- «Евровидение».
- Чемпионат мира по хоккею 2021.
- Учреждение Дня отца.
- Конфликт в Афганистане.
- Стрельба в Казани.
- Выборы в Госдуму.
- Блокировка Суэцкого канала.
- Масштабный сбой в работе социальных сетей.
Что такое:
- Симпл-димпл.
- Митинг.
- Поп-ит.
- Формалин.
- Clubhouse.
- Аквадискотека.
- Дружба.
- Феминизм.
- Эквайринг.
- ПЦР-тест.

Мультфильмы:
- «Душа».
- «Лука».
- «Семейка Адамс».
- «Ледниковый период».
- «Красавица и чудовище».
- «Дарья».
- «Жихарка».
- «Князь Владимир».
- «Мулан».
- «Головоломка».
Российские сериалы:
- «Ивановы-Ивановы».
- «Трудные подростки».
- «Миллионер с Рублевки».
- «Отпуск».
- «Девушки с Макаровым».
- «Содержанки».
- «Вампиры средней полосы».
- «Мир! Дружба! Жвачка!».
- «Жуки».
- «Бывшие»
Книги:
- «Угрюм-река».
- «Дюна».
- «Убить сталкера».
- «Канон Андрея Критского».
- «Кто-нибудь видел мою девчонку?»
- «Тень и кость».
- «Игра вслепую».
- «Мойдодыр».
- «451 градус по Фаренгейту».
- «И грянул гром».

Отмечается, что в этом году россияне стали чаще ходить на выставки и интересоваться миром искусства. В первую пятерку популярных выставок вошла скандальная выставка анатомических экспонатов «Мир тела», масштабная выставка Михаила Врубеля, концептуальная экспозиция «Я, Энди Уорхол», проект «Lady Dior as seen by» и выставка Роберта Фалька.
Вы согласны с итогами Google?
Помимо SQL: 8 новых языков для запросов данных
SQL десятилетиями доминировал в запросах данных. Новые языки запросов предлагают больше элегантности, простоты и гибкости для современных вариантов использования.
Питер Уэйнер
Соавтор, Информационный Мир |
В течение последних трех десятилетий базы данных и язык структурированных запросов (SQL) были почти синонимами. Любой, кто хотел получить информацию из базы данных, должен был изучить SQL. Любой, кто хотел заботиться о базе данных или устроиться на работу администратором базы данных, должен был освоить ее нюансы.
Любой, кто хотел получить информацию из базы данных, должен был изучить SQL. Любой, кто хотел заботиться о базе данных или устроиться на работу администратором базы данных, должен был освоить ее нюансы.
Сам язык является возвратом, возможностью думать и программировать, как это делали пользователи мэйнфреймов. В то время как остальной мир принял строчные буквы, пользователи SQL продолжали вводить такие слова, как SELECT или WHERE. Даже сегодня мало кого волнует, что некоторые пользователи Tik Tok издеваются над ними или спрашивают, почему они кричат. Если ВСЕ ЗАГЛАВНЫЕ буквы были достаточно хороши для жокеев с перфокартами в галстуках и рубашках с короткими рукавами, то они все еще достаточно хороши для сегодняшнего удаленного работника в пижаме с плюшевым мишкой.
Но возможности SQL при извлечении данных ослабевают. Появляются новые базы данных, и некоторые из них говорят на совершенно новых языках. Дело не в том, что SQL становится менее популярным. Во всяком случае, SQL пишется больше, чем когда-либо.
В этой статье представлены восемь новых подходов к извлечению данных. В некоторых случаях нововведения носят чисто косметический характер. Разработчики обновили синтаксис SQL, чтобы сделать его более четким и удобным для чтения, чтобы было проще переключаться между написанием кода для браузера и получением данных. Создатели этих инструментов подчеркивают, что базовая структура по существу такая же, как у SQL. Учиться все равно будет легко. Не волнуйся.
Другие инструменты побуждают нас мыслить совершенно иначе. Базы данных, которые хранят свои биты в виде графиков или временных рядов, предлагают новые парадигмы того, как программисты определяют, что они хотят найти.
Не все из этих вариантов будут лучше, чем SQL для того, что вам нужно сделать. Не все из них охватят возможности, которые вы ищете. Но все они дают возможность по-новому взглянуть на это море байтов на каком-то сервере, ожидая, когда вы найдете способ изложить то, что вам нужно.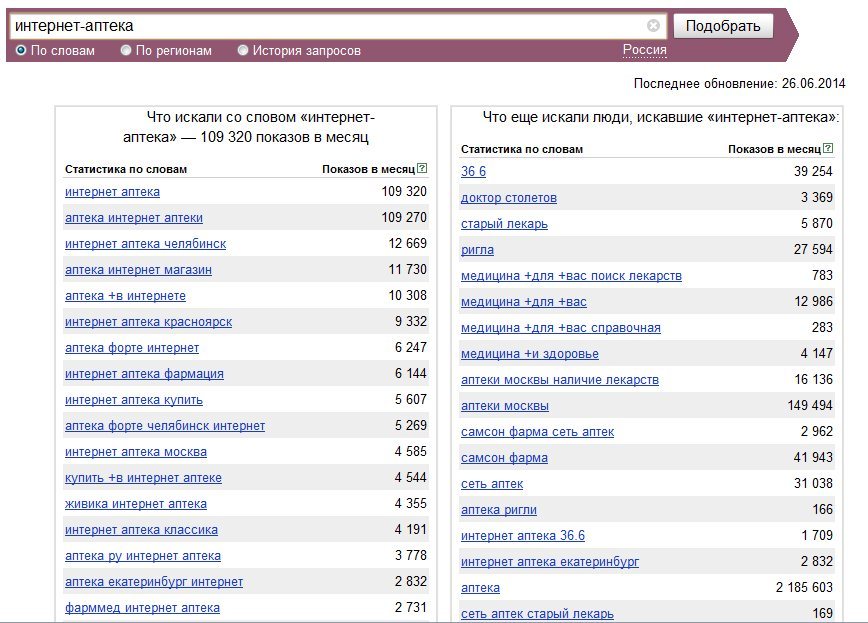
GraphQL
Название GraphQL немного сбивает с толку, потому что на самом деле это не язык, предназначенный для использования всех возможностей графовых баз данных. Это больше похоже на элегантное сокращение для запроса данных, которые хранятся во вложенном формате, похожем на JSON. Запрос — это просто краткое описание того, как должны выглядеть результаты. Серверная часть просматривает этот список полей, которые могут иметь ограничения на значения, и пытается найти совпадающие результаты. Где SQL указывает как база данных должна выполнить запрос, пользователи GraphQL просто предоставляют список полей. Некоторые называют это «запросом на примере».
Этот язык естественным образом подходит для некоторых баз данных JSON, но GraphQL также становится все более популярным для поиска в реляционных базах данных с табличной схемой. Интеллектуальные серверные части могут преобразовывать вложенные запросы в шаблон JOIN, соответствующий схеме.
Исходный язык начинался как внутренний проект Facebook, но после того, как он был выпущен как независимый проект с открытым исходным кодом, другие начали разработку серверной части GraphQL. В настоящее время существуют версии, написанные на всех основных языках, а также на многих современных экспериментальных языках.
В настоящее время существуют версии, написанные на всех основных языках, а также на многих современных экспериментальных языках.
PRQL
Если вы обычно думаете о программном обеспечении как о конвейере или языке ассемблера, то вам может понравиться PRQL, что означает конвейерный реляционный язык запросов (произносится как «приквел»). Запросы в этом языке структурированы как цепочка небольших команд. В совокупности команды дают результат только с теми данными, которые вам нужны.
Подобно многим современным языкам программирования, ментальная модель запроса использует функциональный подход. Простые функции, такие как переменные, уменьшают количество повторений и упрощают процесс. Результаты из одной строки передаются в следующую строку в длинной цепочке. Если вы хотите удалить один шаг, вы часто можете просто закомментировать эту строку, и остальная часть конвейера по-прежнему будет работать.
Код PRQL написан на Rust как транспилятор для преобразования PRQL в SQL. Базовая структура предназначена для расширения, поэтому вы можете добавлять дополнительные абстракции в соответствии со своим вариантом использования. Эта простота экспериментирования гарантирует, что язык будет быстро развиваться.
Базовая структура предназначена для расширения, поэтому вы можете добавлять дополнительные абстракции в соответствии со своим вариантом использования. Эта простота экспериментирования гарантирует, что язык будет быстро развиваться.
WebAssembly
Многие разработчики считают WebAssembly (сокращенно Wasm) инструментом для создания быстрых приложений, которые запускаются в веб-браузерах. Когда Redpanda начала создавать инструмент потоковой передачи данных, чтобы заменить Kafka, они хотели добавить механизм не только для доставки данных, но и для периодического их преобразования. WebAssembly был их выбором.
Redpanda действует как бухгалтерская книга, создавая неизменяемый и упорядоченный поток данных. События добавляются, и программисты могут подключиться к потоку в любой момент в прошлом. Большинство из них начинаются с вновь созданных событий, но некоторые могут начинаться в прошлом для создания исторических агрегаций.
WebAssembly, конечно, намного более функционален и низкоуровнев, чем даже хранимые процедуры, являющиеся частью некоторых баз данных. Не все разработчики хотят писать побитовый код на уровне байтов. Но эта опция открывает поток данных для сложных преобразований, которые выходят далеко за рамки того, что возможно с помощью SQL.
Не все разработчики хотят писать побитовый код на уровне байтов. Но эта опция открывает поток данных для сложных преобразований, которые выходят далеко за рамки того, что возможно с помощью SQL.
GQL
Язык запросов Graph, или GQL, является предлагаемым стандартом, объединяющим аналогичные декларативные языки, такие как Cypher, PGQL и GSQL. Разработчики создают запросы, указывая конкретную модель для набора узлов, а затем база данных отвечает за поиск совпадений. GQL работает с более сложными графами свойств, которые позволяют парам узлов использовать несколько разных соединений.
Стандарт находится в активной разработке. В настоящее время лучшими реализациями являются исследовательские инструменты, не предназначенные для долгосрочного развертывания.
Gremlin
Один из исходных языков для поиска по графу, Gremlin запрашивает набор шагов для поиска соединений между узлами. Некоторые называют его языком «на основе пути» или «обхода графа». Каждый запрос состоит из шагов, и каждый шаг может включать отображение текущего узла, фильтрацию списка или каким-либо образом табулирование результатов.
Язык часто является лишь отправной точкой. Некоторые, например, расширяют Gremlin, встраивая в него интерпретатор Python, чтобы запросы могли включать код Python. Другие встраивают Gremlin в стандартный язык программирования, такой как Java, чтобы программисты могли использовать мощь Gremlin изнутри этого языка.
Gremlin был впервые создан для проекта Apache TinkerPop и был принят основными базами данных транзакционных графов, такими как Amazon Neptune, и платформами обработки графов, использующими Apache Spark или Hadoop.
N1QL
На протяжении многих лет Couchbase искала лучший способ запрашивать общие документы. Вначале запрос был написан как функция JavaScript, которая передавалась базе данных для выполнения. Это было хорошее общее решение, иногда для получения результата требовалась целая вечность, но оно требовало от программистов мыслить немного по-другому.
N1QL (произносится как «никель») предназначен для упрощения работы пользователей SQL с объектами JSON, которые могут храниться в Couchbase. Базовый запрос имеет несколько разделов, определяемых ключевыми словами SELECT, FROM и WHERE, как и SQL. Детали указания пути в структуру данных, из которого будут поступать данные, корректируются и адаптируются к вложенному миру объектов JSON.
Базовый запрос имеет несколько разделов, определяемых ключевыми словами SELECT, FROM и WHERE, как и SQL. Детали указания пути в структуру данных, из которого будут поступать данные, корректируются и адаптируются к вложенному миру объектов JSON.
Для поощрения экспериментов N1QL предлагает рабочую среду запросов с визуальным интерфейсом для тестирования и уточнения запросов. Couchbase также предлагает общий вариант полнотекстового поиска, который работает независимо для запросов, ищущих текстовые слова вместо структурированных данных.
Malloy
Проблема с SQL, по мнению создателей Malloy, кроется в синтаксических деталях. Выражение даже самого простого запроса требует времени, потому что язык многословен и полон скрытых ловушек производительности. Итак, они создали современный язык программирования с естественными значениями по умолчанию и более простым синтаксисом, который можно скомпилировать в SQL, поэтому никому не нужно модифицировать стандартную базу данных.
Результатом является синтаксис, напоминающий более мощный GraphQL. Запрос больше похож на модель или видение результата, включая любые ограничения, совпадения или значения по умолчанию. Маллой выполняет некоторую оптимизацию в фоновом режиме. Например, более интеллектуальные соединения JOIN могут генерироваться автоматически, чтобы избежать ловушек пропасти и производительности вентилятора. Подзапросы можно объединять для экономии времени. Индексы также добавляются по мере необходимости. В результате написание запросов больше похоже на написание современного кода, а пунктуация служит для сохранения краткости структуры.
Ядро Malloy с открытым исходным кодом построено на TypeScript для включения в код Node.js. Плагин VS Code упрощает разработку.
Базис
Большинство языков запросов привязаны непосредственно к конкретной базе данных. Basis строит больше конвейера, который может использовать различные источники, прежде чем фильтровать их с помощью смеси SQL и Python. В конце конвейера находятся экспортеры, которые доставляют данные в различные стандартные варианты, которые варьируются от работающего кода до алгоритмов ИИ, диаграмм и информационных панелей.
В конце конвейера находятся экспортеры, которые доставляют данные в различные стандартные варианты, которые варьируются от работающего кода до алгоритмов ИИ, диаграмм и информационных панелей.
Разработчики уже создают подобные конвейеры в своем собственном коде, и многие проекты зависят от подобных структур. Basis предлагает готовый вариант, который можно настроить более сложным образом. Входные данные варьируются от стандартных запросов к базе данных до касаний API и пользовательского кода Python. Преобразователи не ограничены базовыми предложениями SQL WHERE, потому что вы можете написать код Python, который делает больше, чем просто фильтрует данные, протекающие по конвейеру.
Basis — это лишь один из примеров новых инструментов конвейера данных, которые открывают процесс запросов для извлечения из более чем одного источника, фильтрации с использованием более чем одного языка и предоставления данных более чем в одной форме. Это видение возможности брать данные практически из любого источника и доставлять их практически любому потребителю.
Связанный:
- Разработка программного обеспечения
- SQL
- База данных
- Средства разработки
Copyright © 2022 IDG Communications, Inc.
Как выбрать платформу разработки с низким кодом
Что такое NoSQL? Описание баз данных NoSQL
Базы данных NoSQL (также известные как «не только SQL») не являются табличными базами данных и хранят данные не так, как реляционные таблицы. Базы данных NoSQL бывают разных типов в зависимости от их модели данных. Основными типами являются документ, ключ-значение, широкий столбец и график. Они обеспечивают гибкие схемы и легко масштабируются при больших объемах данных и высокой пользовательской нагрузке.
В этой статье вы узнаете что такое база данных NoSQL, почему (и когда!) вы должны использовать один, и как начать работу.
Обзор
В этой статье рассматриваются:
- Что такое база данных NoSQL?
- Краткая история баз данных NoSQL
- Особенности базы данных NoSQL
- Типы баз данных NoSQL
- Различия между РСУБД и NoSQL
- Почему NoSQL?
- Когда следует использовать NoSQL?
- Неправильные представления о базе данных NoSQL
- Учебное пособие по запросам NoSQL
- Сводка
- Часто задаваемые вопросы
Что такое база данных NoSQL?
Когда люди используют термин «база данных NoSQL», они обычно используют его для обозначения любой нереляционной базы данных.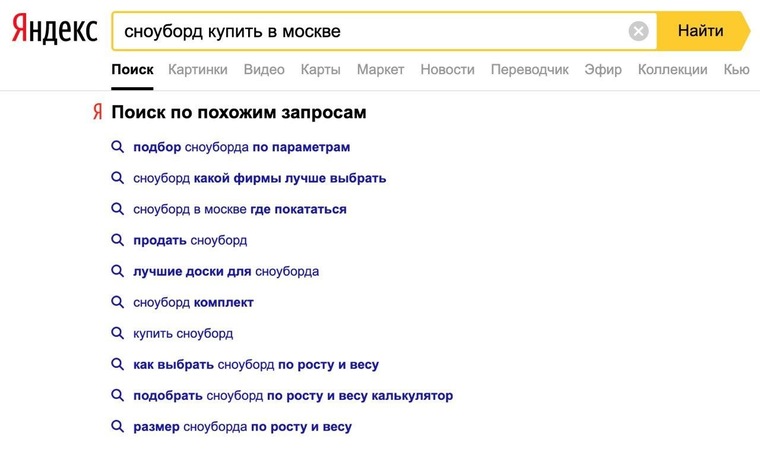 Некоторые говорят, что термин «NoSQL» означает «не SQL», в то время как другие говорят, что он означает «не только SQL». В любом случае, большинство согласны с тем, что базы данных NoSQL — это базы данных, которые хранят данные в формате, отличном от реляционных таблиц.
Некоторые говорят, что термин «NoSQL» означает «не SQL», в то время как другие говорят, что он означает «не только SQL». В любом случае, большинство согласны с тем, что базы данных NoSQL — это базы данных, которые хранят данные в формате, отличном от реляционных таблиц.
Краткая история баз данных NoSQL
Базы данных NoSQL появились в конце 2000-х, когда резко снизилась стоимость хранения. Прошли те времена, когда нужно было создавать сложную, трудноуправляемую модель данных, чтобы избежать дублирования данных. Разработчики (а не хранилище) становились основной статьей расходов при разработке программного обеспечения, поэтому базы данных NoSQL были оптимизированы для повышения производительности разработчиков.
Поскольку затраты на хранение быстро снижались, объем данных, которые приложения должны были хранить и запрашивать, увеличивался. Эти данные были самых разных форм и размеров — структурированные, полуструктурированные и полиморфные — и заранее определить схему стало практически невозможно. Базы данных NoSQL позволяют разработчикам хранить огромные объемы неструктурированных данных, что дает им большую гибкость.
Базы данных NoSQL позволяют разработчикам хранить огромные объемы неструктурированных данных, что дает им большую гибкость.
Кроме того, популярность Agile Manifesto росла, и инженеры-программисты переосмысливали свои методы разработки программного обеспечения. Они признавали необходимость быстрой адаптации к изменяющимся требованиям. Им нужна была возможность быстро выполнять итерации и вносить изменения в свой программный стек — вплоть до базы данных. Базы данных NoSQL предоставили им такую гибкость.
Популярность облачных вычислений также возросла, и разработчики начали использовать публичные облака для размещения своих приложений и данных. Им нужна была возможность распределять данные между несколькими серверами и регионами, чтобы сделать их приложения отказоустойчивыми, масштабировать, а не увеличивать, и интеллектуально распределять данные по географическому положению. Некоторые базы данных NoSQL, такие как MongoDB, предоставляют эти возможности.
Функции базы данных NoSQL
Каждая база данных NoSQL имеет свои уникальные функции. На высоком уровне многие базы данных NoSQL имеют следующие функции:
На высоком уровне многие базы данных NoSQL имеют следующие функции:
- Гибкие схемы
- Горизонтальное масштабирование
- Быстрые запросы благодаря модели данных
- Простота использования для разработчиков
Ознакомьтесь с преимуществами баз данных NoSQL? чтобы узнать больше о каждой из функций, перечисленных выше.
Типы баз данных NoSQL
Со временем появилось четыре основных типа баз данных NoSQL: базы данных документов, базы данных ключей-значений, хранилища с широкими столбцами и базы данных графов.
- Базы данных документов хранить данные в документах, аналогичных объектам JSON (нотация объектов JavaScript). Каждый документ содержит пары полей и значений. Значения обычно могут быть различных типов, включая такие вещи, как строки, числа, логические значения, массивы или объекты.
- Базы данных «ключ-значение» — это более простой тип базы данных, где каждый элемент содержит ключи и значения.
- Хранилища с широкими столбцами хранят данные в таблицах, строках и динамических столбцах.
- Базы данных графов хранить данные в узлах и ребрах. Узлы обычно хранят информацию о людях, местах и вещах, а ребра хранят информацию об отношениях между узлами.
Дополнительные сведения см. на странице Общие сведения о различных типах баз данных NoSQL.
Разница между РСУБД и базами данных NoSQL
Хотя между реляционными системами управления базами данных (RDBMS) и базами данных NoSQL существует множество различий, одно из ключевых различий заключается в способе моделирования данных в базе данных. В этом разделе мы рассмотрим пример моделирования одних и тех же данных в реляционной базе данных и базе данных NoSQL. Затем мы выделим некоторые другие ключевые различия между реляционными базами данных и базами данных NoSQL.
RDBMS vs NoSQL: пример моделирования данных
Рассмотрим пример хранения информации о пользователе и его увлечениях. Нам нужно сохранить имя пользователя, фамилию, номер мобильного телефона, город и увлечения.
Нам нужно сохранить имя пользователя, фамилию, номер мобильного телефона, город и увлечения.
В реляционной базе данных мы, скорее всего, создадим две таблицы: одну для пользователей и одну для хобби.
Пользователи
| ID | имя | фамилия | сотовый | город |
|---|---|---|---|---|
| 1 | Leslie | Yepp | 8125552344 | Pawnee |
Hobbies
| ID | user_id | hobby |
|---|---|---|
| 10 | 1 | scrapbooking |
| 11 | 1 | Еда вафли |
| 12 | 1 | Работа | . таблицу нужно будет соединить вместе. Модель данных, которую мы разрабатываем для базы данных NoSQL, будет зависеть от типа выбранной нами базы данных NoSQL. {
"_id": 1,
"first_name": "Лесли",
"last_name": "Да",
"ячейка": "8125552344",
"город": "Пауни",
"хобби": ["скрапбукинг", "поедание вафель", "работа"]
} Чтобы получить всю информацию о пользователе и его увлечениях, из базы данных можно получить один документ. Соединения не требуются, что приводит к более быстрым запросам. Чтобы увидеть более подробную версию этого примера моделирования данных, прочтите статью Сопоставление терминов и понятий из SQL в MongoDB. Другие различия между РСУБД и реляционными базами данныхХотя в приведенном выше примере показаны различия в моделях данных между реляционными базами данных и базами данных NoSQL, существует много других важных различий, в том числе:
Чтобы узнать больше о различиях между реляционными базами данных и базами данных NoSQL, посетите страницу NoSQL и базы данных SQL. Почему NoSQL?Базы данных NoSQL используются практически во всех отраслях. Варианты использования варьируются от крайне важных (например, хранение финансовых данных и медицинских записей) до более забавных и легкомысленных (например, хранение показаний IoT из умного кошачьего туалета). В следующих разделах мы рассмотрим, когда следует использовать базу данных NoSQL, и распространенные заблуждения о базах данных NoSQL. Когда следует использовать NoSQL?При принятии решения о том, какую базу данных использовать, лица, принимающие решения, обычно обнаруживают, что один или несколько из следующих факторов приводят их к выбору базы данных NoSQL:
Дополнительные сведения о причинах, перечисленных выше, см. Неправильные представления о базах данных NoSQLЗа прошедшие годы в сообществе разработчиков распространилось множество неправильных представлений о базах данных NoSQL. В этом разделе мы обсудим два наиболее распространенных заблуждения:
Чтобы узнать больше о распространенных заблуждениях, прочитайте «Все, что вы знаете о MongoDB, неверно». Заблуждение: данные об отношениях лучше всего подходят для реляционных баз данныхРаспространенным заблуждением является то, что базы данных NoSQL или нереляционные базы данных плохо хранят данные об отношениях. Базы данных NoSQL могут хранить данные об отношениях — просто они хранят их иначе, чем реляционные базы данных. На самом деле, по сравнению с реляционными базами данных, многие считают моделирование данных взаимосвязей в базах данных NoSQL проще, чем в реляционных базах данных, поскольку связанные данные не нужно разбивать между таблицами. Заблуждение: базы данных NoSQL не поддерживают транзакции ACIDДругое распространенное заблуждение состоит в том, что базы данных NoSQL не поддерживают транзакции ACID. Некоторые базы данных NoSQL, такие как MongoDB, действительно поддерживают транзакции ACID. Обратите внимание, что способ моделирования данных в базах данных NoSQL может устранить необходимость в транзакциях с несколькими записями во многих случаях использования. Рассмотрим предыдущий пример, в котором мы хранили информацию о пользователе и его увлечениях как в реляционной базе данных, так и в базе данных документов. Чтобы обеспечить совместное обновление информации о пользователе и его увлечениях в реляционной базе данных, нам потребуется использовать транзакцию для обновления записей в двух таблицах. Чтобы сделать то же самое в базе данных документов, мы могли бы обновить один документ — транзакция с несколькими записями не требуется. Руководство по запросам NoSQLСуществует множество баз данных NoSQL. Сегодня мы попробуем MongoDB, самую популярную в мире базу данных NoSQL по версии DB-Engines. В этом руководстве вы загрузите образец базы данных и научитесь делать запросы к ней, не устанавливая ничего на свой компьютер и ничего не платя. Аутентификация в MongoDB AtlasСамый простой способ начать работу с MongoDB — MongoDB Atlas. Atlas — это полностью управляемая база данных как услуга MongoDB. У Atlas есть бессрочный бесплатный уровень, который вы будете использовать сегодня.
Для получения дополнительной информации о том, как выполнить описанные выше шаги, посетите официальную документацию MongoDB по созданию учетной записи Atlas. Создайте кластер и базу данных Кластер — это место, где вы можете хранить свои базы данных MongoDB. Когда у вас есть кластер, вы можете начать хранить данные в Atlas. Вы можете вручную создать базу данных в Atlas Data Explorer, в MongoDB Shell, в MongoDB Compass или с помощью вашего любимого языка программирования. Вместо этого в этом примере вы импортируете образец набора данных Atlas.
Загрузка примера набора данных займет несколько минут. Хотя в этом руководстве нам не нужно думать о проектировании базы данных, обратите внимание, что проектирование базы данных и моделирование данных являются основными факторами производительности MongoDB. Узнайте больше о передовых методах моделирования данных в MongoDB:
Запрос к базе данных Теперь, когда у вас есть данные в кластере, давайте сделаем запрос! Точно так же, как у вас было несколько способов создать базу данных, у вас есть несколько вариантов запроса к базе данных: в Atlas Data Explorer, в оболочке MongoDB, в MongoDB Compass или с помощью вашего любимого языка программирования. В этом разделе вы будете запрашивать базу данных с помощью Atlas Data Explorer. Это хороший способ начать работу с запросами, так как он не требует настройки.
Два документа с названием «Гордость и предубеждение» возвращены. Результаты поиска фильмов с названием «Гордость и предубеждение». Поздравляем! Вы успешно запросили базу данных NoSQL! Продолжить изучение ваших данных В этом руководстве мы лишь немного коснулись того, что вы можете делать в MongoDB и Atlas. Когда вы будете готовы попробовать более сложные запросы, объединяющие ваши данные, создайте конвейер агрегации. Платформа агрегации — невероятно мощный инструмент для анализа ваших данных. Чтобы узнать больше, пройдите бесплатный университетский курс MongoDB M121 The MongoDB Aggregation Framework. Если вы хотите визуализировать свои данные, ознакомьтесь с диаграммами MongoDB. Диаграммы — это самый простой способ визуализации данных, хранящихся в Atlas и Atlas Data Lake. Диаграммы позволяют создавать информационные панели, заполненные визуализацией ваших данных. РезюмеБазы данных NoSQL предоставляют множество преимуществ, включая гибкие модели данных, горизонтальное масштабирование, молниеносные запросы и простоту использования для разработчиков. Базы данных NoSQL бывают разных типов, включая базы данных документов, базы данных ключей и значений, хранилища с широкими столбцами и базы данных графов. MongoDB — самая популярная в мире база данных NoSQL. Узнайте больше о MongoDB Atlas и попробуйте бесплатный уровень. Хотите узнать больше, теперь у вас есть собственная учетная запись Atlas? Отправляйтесь в Университет MongoDB, где вы сможете пройти бесплатное онлайн-обучение у инженеров MongoDB и получить сертификат MongoDB. Учебники по быстрому запуску — еще одно отличное место для начала; они помогут вам быстро начать работу с вашим любимым языком программирования. Следуйте этому руководству с MongoDB AtlasОцените преимущества использования MongoDB, первоклассной базы данных NoSQL, в облаке.Каковы преимущества NoSQL?Многие базы данных NoSQL имеют следующие преимущества:
Ознакомьтесь с преимуществами базы данных NoSQL? Больше подробностей. Что такое окончательная согласованность?Согласованность в конечном итоге является свойством распределенных баз данных. Согласованность в конечном счете гарантирует, что при обновлении базы данных все узлы в распределенной базе данных будут отражать это обновление. Что такое теорема CAP? Теорема CAP утверждает, что распределенная вычислительная система может обеспечить максимум два из следующих трех свойств: согласованность, доступность и устойчивость к разделению. Для чего используется NoSQL?Базы данных NoSQL используются почти во всех отраслях для самых разных целей. Тип базы данных NoSQL определяет типичный вариант использования. Например, базы данных документов, такие как MongoDB, являются базами данных общего назначения. Базы данных «ключ-значение» идеально подходят для больших объемов данных с простыми поисковыми запросами. Хранилища с широкими столбцами хорошо подходят для случаев использования с большими объемами данных и предсказуемыми шаблонами запросов. Базы данных Graph отлично подходят для анализа и отслеживания взаимосвязей между данными. Дополнительную информацию см. в разделе Общие сведения о различных типах баз данных NoSQL. Что такое база данных NoSQL?База данных NoSQL — это база данных, в которой данные хранятся в формате, отличном от реляционных таблиц. Как написать запрос NoSQL? Каждая база данных NoSQL будет иметь собственный подход к написанию запросов. Посетите интерактивную документацию MongoDB, чтобы узнать больше о запросах к базе данных MongoDB. Сложно ли освоить NoSQL?Нет, базы данных NoSQL несложно изучить. Фактически, многие разработчики считают данные моделирования в базах данных NoSQL невероятно интуитивно понятными. Например, документы в MongoDB сопоставляются со структурами данных в большинстве популярных языков программирования, что делает программирование быстрее и проще. Обратите внимание, что тем, кто прошел обучение и имеет опыт работы с реляционными базами данных, скорее всего, придется немного поучиться, поскольку они приспосабливаются к новым способам моделирования данных в базах данных NoSQL. Является ли JSON NoSQL?Базы данных документов — это тип базы данных NoSQL, в которой данные хранятся в документах JSON или BSON. Какой язык используется для запросов NoSQL? Базы данных NoSQL охватывают множество типов и реализаций. В результате к базам данных NoSQL можно обращаться с помощью различных языков запросов и API. К MongoDB, самой популярной в мире базе данных NoSQL, можно обращаться с помощью языка запросов MongoDB (MQL). |
 Давайте рассмотрим, как хранить ту же информацию о пользователе и его увлечениях в базе данных документов, такой как MongoDB.
Давайте рассмотрим, как хранить ту же информацию о пользователе и его увлечениях в базе данных документов, такой как MongoDB.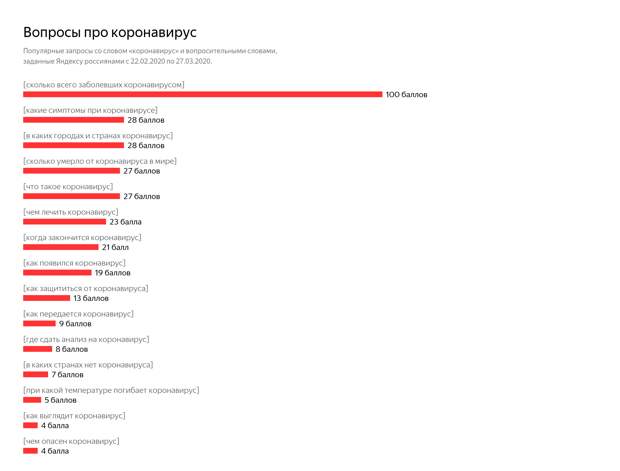
 в разделах «Когда использовать базы данных NoSQL» и «Изучение примеров баз данных NoSQL».
в разделах «Когда использовать базы данных NoSQL» и «Изучение примеров баз данных NoSQL». Модели данных NoSQL позволяют вкладывать связанные данные в единую структуру данных.
Модели данных NoSQL позволяют вкладывать связанные данные в единую структуру данных.
 В этом разделе вы создадите бесплатный кластер.
В этом разделе вы создадите бесплатный кластер.
 Давайте запросим фильм Гордость и предубеждение. В строке запроса введите
Давайте запросим фильм Гордость и предубеждение. В строке запроса введите