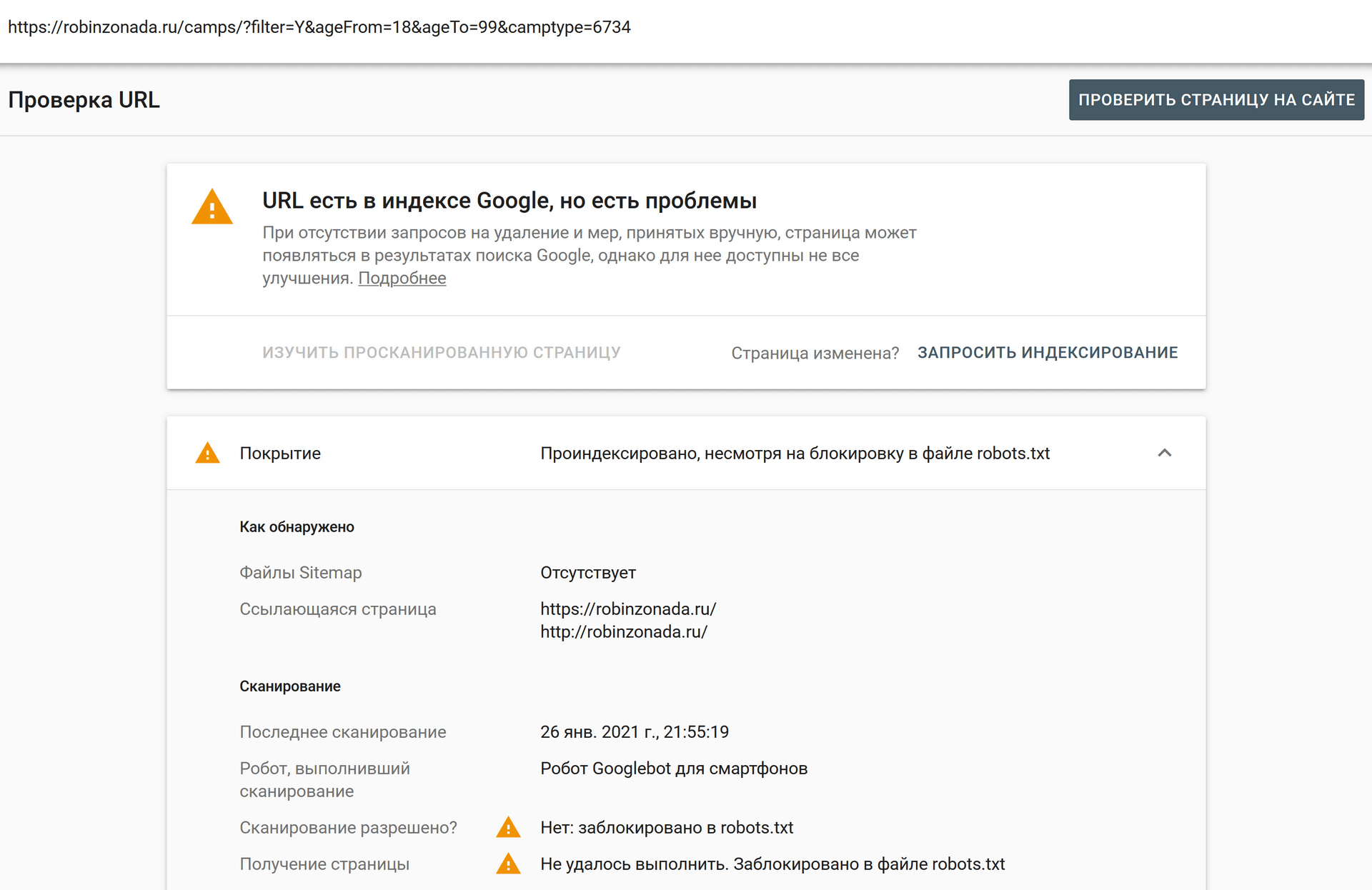
какие данные нужно скрывать и как проверить работу запрета. — Топвизор–Журнал
В статье о том, зачем и как закрыть сайт от индексации в robots.txt, что можно скрыть и как проверить, что вы всё сделали правильно.
Эта статья — часть нашего бесплатного курса по SEO для начинающих, с ней помогал главный эксперт курса Александр Сопоев. Если хотите разобраться, как продвигать сайты в ТОП поисковых систем, заходите на курс. В конце — сертификат от Топвизора!
Зачем закрывать сайт от индексации
Когда поисковые роботы просканировали и проиндексировали страницы сайта, они начинают показываться в поисковых системах. Это значит, что пользователи могут находить сайт по конкретным поисковым запросам в Google, Яндексе и других поисковых системах.
Это значит, что пользователи могут находить сайт по конкретным поисковым запросам в Google, Яндексе и других поисковых системах.
При этом сайт может состоять из множества разных страниц, и некоторые из них пользователям и поисковым системам видеть не нужно. Например, служебные страницы, дубли страниц и другой малополезный контент. Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Кроме того, стоит учитывать и краулинговый бюджет сайта — лимит на количество страниц сайта, которые поисковые роботы смогут обойти за сутки. И этот лимит может тратиться на неважные страницы сайта, в то время как важные целевые страницы могут долго быть непроиндексированными. Подробнее об этом мы писали в статье «Как оптимизировать краулинговый бюджет».
Что можно закрыть от индексации
Дубль
Это страницы сайта, которые отличаются URL‑адресом, но содержат одинаковый или практически одинаковый контент.
снижение скорости индексирования новых страниц. Индексирующий робот может медленнее доходить до новых страниц, из‑за того что будет обходить дубли;
поисковая система «склеит» дубли и сама выберет среди них основную страницу. При этом есть риск, что эта выбранная страница не будет вашей целевой;
в индексе останутся все дубли. Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
Подробнее про дубли в Яндекс.Справке
Документ для скачивания
В некоторых случаях может быть нужно закрыть от индексации документы, например в формате pdf, docx и т. п. С помощью robots.txt это можно сделать.
С одной стороны, когда документы можно скачать из выдачи, не переходя на сайт, это может приводить к потере трафика, с другой стороны, может, наоборот, положительно повлиять на посещаемость сайта. Исходите из стратегии и пользы для вашего проекта.
Исходите из стратегии и пользы для вашего проекта.
Страницы, которые находятся в разработке
Если на странице нет контента или есть, но он дублирует другую страницу, если на странице идёт редизайн или доработка и мы пока не хотим её выкатывать и в других подобных случаях можно запретить её индексацию.
Если оставить такие страницы доступными для индексации, то ПС может сама понизить или исключить их из индекса, что может сказаться на оценке сайта в целом.
Техническая страница
Все служебные, технические страницы не содержат полезного контента для пользователей или вовсе могут быть пустыми. Поэтому их стоит закрыть от индексации.
Такими страницами, в зависимости от конкретного сайта и особенностей проекта, могут быть: страницы регистрации, авторизации, результаты поиска по страницам сайта, Личный кабинет, Корзина, Избранное и т. д.
Папка
Файлы сайта обычно распределяются по папкам, например по категориям, каталогам, разделам, подразделам и т. д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
Картинка
Помимо закрытия страниц сайта, можно также закрыть от индексации отдельный тип контента, например все картинки определённого формата или фотографии.
Если вы размещаете информативные и полезные изображения, закрывать их от индексации нежелательно.
Ссылка
С помощью robots.txt мы не можем запретить индексацию одной ссылки. Чтобы робот не переходил по ссылкам на странице, мы можем закрыть от индексации страницу, на которой размещена ссылка, или страницу, на которую она ведёт.
Чтобы скрыть от индексирования конкретную ссылку, Яндекс рекомендует использовать атрибут rel.
Блок на сайте
Мы не можем закрывать в robots.txt отдельные блоки на странице.
Запретить индексирование части текста в Яндексе можно с помощью тега noindex, но Google данный тег не поддерживает.
Как запретить индексацию в robots.
 txt
txtФайл robots.txt — это текстовый документ формата .txt, в котором прописаны специальные правила (директивы) для поисковых роботов. Они помогают управлять индексацией сайта.
С помощью этих правил можно указать поисковым роботам, какие страницы и файлы сайта не должны присутствовать в поисковой выдаче, а какие, наоборот, должны.
В файле robots.txt можно:
разрешить или запретить индексацию страниц или разделов сайта;
указать ссылку на карту сайта Sitemap.xml;
заблокировать показ изображений, видеороликов и аудиофайлов в результатах поиска.
В robots.txt мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
Если у сайта есть robots.txt, то обычно он хранится он в корневой папке сайта — там, куда загружаются каталоги и другие файлы.
Кроме того, на некоторых сайтах robots.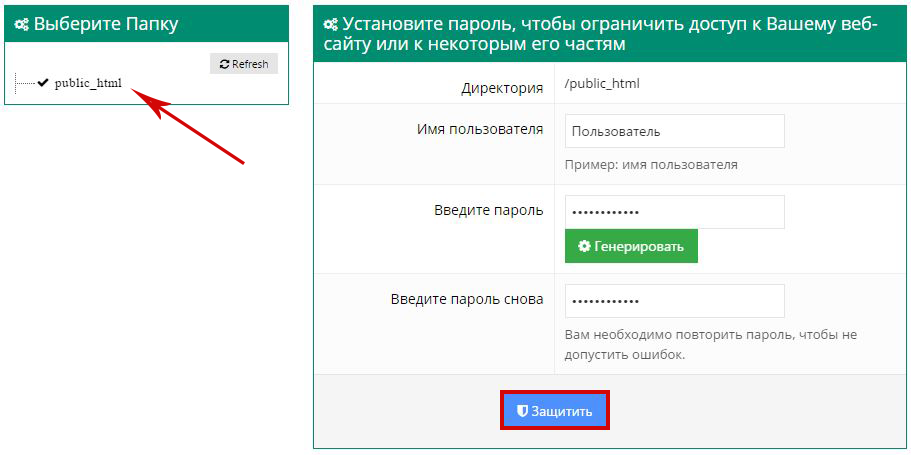 txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
Если файла нет, значит, скорее всего, сейчас для индексации доступны все страницы сайта и у поисковых роботов нет специальных указаний.
Поэтому файл нужно создать самостоятельно. Сделать это можно в Блокноте или другом текстовом редакторе. В файле нужно прописать специальные директивы, о которых расскажем ниже.
После этого сохраняем документ в формате .txt с названием robots и загружаем в корневую папку сайта.
Основные директивы robots.txt
User‑Agent — обязательная директива, которая говорит, какому именно поисковому роботу адресуются указанные ниже правила. В документе эта директива может повторяться несколько раз — с неё начинается каждая новая группа правил для конкретного бота.
В файле эта строка будет выглядеть так:
User‑agent:
После двоеточия мы прописываем название бота, к которому будут обращены последующие правила.
Чаще всего используем такие:
- * — когда обращаемся ко всем поисковым роботам;
- Googlebot — когда обращаемся к роботам Google;
- Yandex — когда обращаемся к роботам Яндекса.
Записи в файле будут выглядеть так:
User‑agent: * или: User‑agent: Yandex или: User‑agent: Googlebot
Список User‑agent поисковых роботов Google
Список User‑agent поисковых роботов Яндекса
Перед каждой новой директивой User‑agent, которую вы прописываете в документе, необходимо ставить дополнительный пропуск строки.
Например, если бы нам нужно было закрыть весь сайт от индексации для Яндекса и Google, мы бы написали так:
User‑agent: Googlebot Disallow: / User‑agent: Yandex Disallow: /
Disallow — этой директивой мы можем запретить роботу индексировать определённые разделы сайта, страницы или файлы. Здесь могут закрываться от индексации, например:
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;страницы сортировок, которые изменяют вид отображения информации;
страницы внутреннего поиска и т. д.
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;Правила указания директивы такие:
Сначала указываем саму директиву и двоеточие. Например: Disallow:
После этого указываем раздел или страницу в корневой папке текущего сайта без указания самого домена. Например: /ru/marketing/.
Например, чтобы запретить роботам Яндекса индексацию всего раздела «Маркетинг» в Топвизор‑Журнале, мы бы написали в robots.txt так:
User‑agent: Yandex Disallow: /ru/marketing/
Allow — директива указывает поисковому роботу, какие разделы сайта можно индексировать. Обычно используется для указания подправила директивы Disallow, например, когда мы хотим разрешить сканирование какой‑то страницы или каталога внутри закрытого директивой Disallow раздела.

User‑agent: Yandex Disallow: /catalog/ Allow: /catalog/auto/ # запрещает скачивать страницы, начинающиеся с '/catalog/', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto/'
Если в документе одновременно указаны директивы Allow и Disallow для одного и того же элемента, то предпочтение отдаётся директиве Allow — элемент будет проиндексирован.
О директиве Disallow и Allow у Яндекса
О директиве Disallow и Allow у Google
Дополнительно
При указании пути к разделу, странице или файлам может использоваться спецсимвол «*».
Он означает любую (в том числе пустую) последовательность символов. Может ставиться как префикс в начале адреса или как суффикс в конце.
Например:
Disallow: /catalog/*/shopinfo — запрещает индексацию любых страниц в разделе catalog, в URL которых есть shopinfo.
Disallow: *shopinfo — запрещает индексацию всех страниц, содержащих в URL “shopinfo”, например: /ru/marketing/shopinfo.
Подробнее о спецсимволах и правилах их использования в Яндексе
Спецсимволы работают в том числе и с директивой Allow.
Путь указывается через директиву Sitemap, а сам путь должен быть полным, с указанием домена, как в браузере:
Sitemap: https://site.com/sitemaps1.xml
Если карт сайта несколько, директиву можно повторять несколько раз с новой строки.
Директива считается межсекционной: поисковые роботы увидят путь к карте сайта вне зависимости от места в файле robots.txt, где он указан.
О директиве Sitemap в Яндекс.Справке
О директиве Sitemap в Google Справке
Яндекс предупреждает, что если не закрыть страницы с параметрами через Clean‑param, то в поиске могут появиться многочисленные дубли страниц, что может негативно отразиться на ранжировании.
Синтаксис и правила оформления:
файл должен называться robots.txt;
размер файла не больше 500 КБ;
на сайте должен быть только один такой файл;
файл размещён в корневом каталоге сайта, но не в подкаталоге.
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;файл отдаёт ответ сервера 200 OK.
 Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;Подробные правила оформления robots.txt у Яндекса.
Подробные правила оформления robots.txt у Google.
Дополнительно про файл robots.txt:
есть директивы, которые одни ПС воспринимают, а другие нет. Например, Clean‑param для Яндекса;
те страницы, которые вы запретили в файле, всё равно могут быть проиндексированы. Например, Google говорит, что страницы могут попасть в индекс, если поисковый робот нашёл их по ссылке с других сайтов или страниц. Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
Как проверить запрет
После создания из загрузки файла на сайт убедитесь, что он существует, размещён в корневом каталоге сайта и без проблем открывается. Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
После этого можно проверить файл в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Яндекс.Вебмастер
В Вебмастере открываем «Инструменты» → «Анализ robots.txt». Обычно содержимое файла сразу будет отображаться в строке. Если нет, копируем из браузера и вставляем сюда. Затем нажимаем кнопку «Проверить»:
Проверка файла в ВебмастереЕсли в файле будут ошибки, Вебмастер подскажет, как их исправить.
Google Search Console
Для того чтобы проверить файл robots.txt с помощью валидатора Google, необходимо:
1. Зайти в аккаунт Google Search Console.
2. Перейти в инструмент проверки robots.txt.
3. В открывшемся окне вы увидите уже подгруженную информацию из файла. Если нет, вставьте её из браузера.
GSC покажет, есть ли в файле ошибки и как их исправить.
Проверка файла в GSCКраткий конспект
На сайте может быть необходимо скрыть некоторые страницы, например:
Закрывать от индексации можно как сайт полностью, так и отдельные страницы, файлы, изображения.
В robots.txt с помощью специальных директив мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
После создания правил для индексирования сайта в robots.txt важно его проверить. Сделать это можно бесплатно в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Как закрыть сайт от индексации?
Категория: Полезное, Сайтостроение, Опубликовано: 2018-07-09
Автор: Юлия Гусарь
Приветствую вас, посетители сайта Impuls-Web!
Когда вы только приступили к созданию сайта и не хотите, что бы поисковые системы индексировали его до завершения работ, вы может закрыть сайт от индексации в поисковых системах.
Навигация по статье:
- Как закрыть сайт от индексации в WordPress?
- Как закрыть сайт от индексации name=»robots»?
- Как закрыть сайт от индексации в robots.txt?
Так же такая необходимость может возникнуть для тестового сайта, или для сайта, который предназначен для закрытого пользования определенной группой лиц, и вам не нужно, чтобы внутренние ссылки попали в выдачу поисковиков.
Я хочу вам сегодня показать несколько достаточно простых способов, как можно закрыть сайт от индексации.
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
- 2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:
- 3.Сохраняем изменения.
Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:
Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)
Как закрыть сайт от индексации name=»robots»?
Данный способ заключается в самостоятельном добавлении записи, показанной на предыдущем скриншоте. Данный вариант подойдет для тех сайтов, которые создаются без использования CMS.
Вам всего лишь нужно в начале каждой страницы, перед закрытием тега </head> добавить эту запись:
<meta name=’robots’ content=’noindex,follow’ />
<meta name=’robots’ content=’noindex,follow’ /> |
В поле content можно задать следующие условия:
Запрещающие условия:
- none – запрет для страниц и ссылок;
- noindex – запрет для страниц;
- nofollow – запрещает индексацию ссылок на странице;
Разрещающие условия:
- all – разрешает индексацию страниц и ссылок;
- index — разрешает индексацию страниц;
- follow – разрешает индексацию ссылок на странице;
Зная данный набор условий, мы можем составить альтернативную запись для полного запрета для сайта и ссылок на нем. Выглядеть она будет вот так:
Выглядеть она будет вот так:
<meta name=’robots’ content=’none’ />
<meta name=’robots’ content=’none’ /> |
Как закрыть сайт от индексации в robots.txt?
Показанные выше варианты закрытия сайта от индексации работают для всех поисковиков, а это бывает не всегда нужно. Так же, предыдущий способ достаточно неудобен в случае, если ваш ресурс состоит из большого количества страниц, и каждую из них нужно закрыть от индексации.
В этом случае лучше воспользоваться еще одним способом закрытия сайта от индексации. Данный вариант дает нам возможность более гибко закрывать от индексации не только сайт в целом, но и отдельные страницы, медиафайлы и папки.
Для полного закрытия от индексации вам нужно создать в редакторе кода NotePad++ файл с названием robots.txt и разместить в нем такую запись:
User-agent: * Disallow: /
User-agent: * Disallow: / |
User-agent со значением * означает, что данное правило предназначено для всех поисковых роботов. Так же вы можете запретить индексацию для какой-то поисковой системы в отдельности. Для этого в User-agent указываем имя конкретного поискового робота. Например:
Так же вы можете запретить индексацию для какой-то поисковой системы в отдельности. Для этого в User-agent указываем имя конкретного поискового робота. Например:
User-agent: Yandex
User-agent: Yandex |
В этом случае запись будет работать только для Яндекса.
Обратите внимание. В строке User-agent может быть указан только один поисковый робот, и соответственно директивы Disallow, указанные ниже будут работать только для него. Если вам нужно запретить от индексацию в нескольких ПС, то вам нужно это сделать по отдельность для каждой. Например:User-agent: Googlebot Disallow: / User-agent: Yandex Disallow: /
User-agent: Googlebot Disallow: /
User-agent: Yandex Disallow: / |
Так же, директива Disallow позволяет закрывать отдельные элементы. Данная директива указывается отдельно для каждого закрываемого элемента. Например:
Например:
User-agent: Yandex Disallow: *.jpg Disallow: /about-us.php
User-agent: Yandex Disallow: *.jpg Disallow: /about-us.php |
Здесь для поискового робота Yandex закрыты для индексации все изображение с расширением .jpg и страница /about-us.php.
Каждый из показанных приемов удобен по своему в зависимости от сложившейся ситуации. Надеюсь у меня получилось достаточно подробно рассказать вам о способах закрытия сайта от индексации, и данный вопрос у вас не вызовет трудностей в будущем.Если данная информация была для вас полезно, обязательно оставьте свой комментарий под статьей и поделитесь ею в социальных сетях.
Желаю вам успехов в создании сайтов. До встречи в следующих статьях!
С уважением Юлия Гусарь
Как удалить проиндексированные страницы и файлы из поиска Google
Большинство владельцев сайтов считают, что чем больше страниц на вашем сайте и в индексе Google, тем больше трафика вы получаете. Это может быть правдой, если вы владеете качественным контентом только на своем сайте. Что делать, если есть много некачественных страниц и файлов, которые не приносят никакой пользы и делают ваш сайт беспорядочным? Они не только создадут дублированный контент, но и повлияют на ваш SEO-рейтинг.
Это может быть правдой, если вы владеете качественным контентом только на своем сайте. Что делать, если есть много некачественных страниц и файлов, которые не приносят никакой пользы и делают ваш сайт беспорядочным? Они не только создадут дублированный контент, но и повлияют на ваш SEO-рейтинг.
Пришло время удалить проиндексированные файлы и контент из поиска Google, чтобы очистить ваш сайт и улучшить рейтинг. В этой статье мы обсудим 3 причины и 4 способа удаления проиндексированных страниц и файлов WordPress из поиска Google.
- Зачем удалять проиндексированные страницы
- Как проверить проиндексированные страницы в Google
- Удалить проиндексированные страницы из поиска Google
- Удалить проиндексированные файлы из поиска Google
Причины удаления проиндексированных страниц
Существует 3 распространенных причины, по которым вы можете захотеть удалить проиндексированные страницы из результатов поиска:
1. SEO-эффекты
SEO-эффекты
Некачественные проиндексированные страницы могут нанести вред вашему SEO. Google наложит штрафы и понизит рейтинг вашего сайта, если обнаружит много страниц с очень небольшим содержанием.
2. Частные страницы
Частное содержимое, такое как страницы с политикой конфиденциальности или страницы с конфиденциальными данными, оказывается важным для вашего веб-сайта и бизнеса. Если они проиндексированы, посетители могут найти их и украсть вашу информацию.
3. Взломанные веб-сайты
Хакерам удалось войти на ваш сайт и создать множество нежелательных для вас страниц. Эти страницы, если они будут перечислены в результатах поиска, создадут плохой пользовательский опыт и повлияют на репутацию вашего бренда.
Как проверить проиндексированные страницы в Google
Прежде чем удалять какие-либо страницы из результатов поиска Google, вам нужно знать, какие страницы вашего сайта были проиндексированы. Чтобы проверить эти страницы, вы можете использовать Google site:-query или инструмент Google Search Console.
Чтобы проверить эти страницы, вы можете использовать Google site:-query или инструмент Google Search Console.
Google site:-query
Googlebot сканирует каждую страницу вашего веб-сайта и обновляет URL-адреса страниц в базе данных поиска Google. Чтобы узнать количество проиндексированных страниц, вы можете:
- Перейти на google.com
- Введите «site:your-domain.com» в строке поиска Google. Не забудьте заменить «ваш домен» фактическим URL-адресом домена сайта 9.0008
- Получить общее количество проиндексированных страниц, отображаемых вверху результатов
Консоль поиска Google
Консоль поиска Google предлагает еще один вариант отображения обзора проиндексированных страниц. Не забудьте активировать Search Console на своем веб-сайте, если вы еще не использовали ее. Затем вам необходимо:
- Войти в Google Search Console и выбрать нужный сайт
- Выберите Индекс Google в левой панели навигации
- Нажмите на Статус индекса в подменю
Теперь вы можете увидеть график, показывающий «Статус индекса» вашего домена за последние несколько месяцев. На графике есть 3 разные линии, представляющие числа
На графике есть 3 разные линии, представляющие числа
- проиндексированных страниц .
- Страницы заблокированы роботами
- Удалены страницы
Как удалить проиндексированные страницы из поиска Google
После того, как вы узнали все проиндексированные страницы сайта, пришло время решить, какие из них удалить из поиска Google. Вы можете выбрать один из нескольких методов, таких как удаление страниц непосредственно с веб-сайта, использование инструмента «Удалить устаревшее содержимое» или инструмента «Удалить URL-адреса».
1. Удалить прямо с веб-сайта
Если ваши страницы не приносят никакой пользы посетителям и вашему веб-сайту, удалите их. Это самый простой способ, так как вам не нужно использовать какие-либо инструменты вне сайта WordPress.
Все, что вам нужно сделать, это перейти в раздел Pages на панели управления WordPress. Затем выберите страницу, которую хотите удалить. После этого нажмите Удалить под заголовком страницы. Не забудьте зайти в Корзину, чтобы навсегда удалить страницу.
Не забудьте зайти в Корзину, чтобы навсегда удалить страницу.
После удаления ваши страницы все еще существуют в поисковых системах. После повторного сканирования вашего сайта несколько раз и проверки того, что эти страницы полностью исчезли, Google начнет удалять их из результатов поиска.
2. Средство удаления устаревшего содержимого
Хотя ваши страницы удалены, они по-прежнему отображаются в результатах поиска. Вы не хотите ждать, пока Google просканирует много раз и уберет эти страницы из результатов. Итак, используйте инструмент «Удалить устаревшее содержимое».
Три следующих шага помогут вам удалить устаревшее содержимое:
- Перейти к странице Удалить устаревшее содержимое
- Введите URL нужной страницы
- Выберите Запрос на удаление
3. Инструмент удаления URL-адресов
Инструмент удаления URL-адресов, предоставляемый Google Search Console, является решением ВРЕМЕННОГО удаления страниц из результатов поиска. Выполните 6 шагов ниже:
Выполните 6 шагов ниже:
- Откройте инструмент удаления URL-адресов
- Выбрать Временно скрыть
- Введите URL страницы и нажмите Продолжить
- Выберите одно из двух действий: очистить URL только из кеша или очистить URL из кеша и временно удалить из поиска Google.
- Отправить Запрос
- Отправьте дополнительные запросы на удаление любых других URL-адресов этой страницы
Обратите внимание, что:
- Запрос на удаление действует только 90 дней. По истечении этого периода времени ваши страницы могут снова появиться в результатах поиска. Чтобы навсегда удалить страницу, вы должны воспользоваться одним из этих 3 способов:
- Удалите контент с вашего сайта и убедитесь, что страница переходит на страницу 404 (не найдена) или 410 (исчезла)
- Использовать пароль для защиты страницы
- Используйте инструмент «Удалить URL-адреса», чтобы запретить Google индексировать страницу. Этот метод не так безопасен, как другие.
- Несмотря на очистку кэша и скрытие URL-адреса, робот Googlebot все равно будет сканировать ваши страницы. Если вы не заблокируете свою страницу тегом «без индекса» или паролем, она может снова появиться в результатах поиска через 90 дней.
 Этот метод не так безопасен, как другие.
Этот метод не так безопасен, как другие.Как удалить проиндексированные файлы из поиска Google
В некоторых случаях вы можете сосредоточиться на том, чтобы скрыть содержимое от глаз Google, но забыть проинструктировать сканеры Google о файлах, которые не следует индексировать. Затем ваши файлы отображаются публично в результатах поиска.
В такой ситуации лучше всего убрать цифровой контент/файлы из веб-поиска и поиска на мобильных страницах.
Существуют различные способы удаления уже проиндексированных файлов из Google, в том числе:
- Использовать инструмент удаления URL Google
- Использовать средство удаления авторских прав
1. Инструмент удаления URL-адресов
Инструмент удаления URL-адресов Google обеспечивает самый простой способ удалить URL-адрес сайта из результатов поиска.
Люди находят этот инструмент простым в использовании, так как для него требуется только новая учетная запись почты Google. Если у вас уже есть учетная запись Google, выполните следующие 4 шага:
- Перейдите в консоль поиска Google .
- Перейти к разделу «Удалить URL-адреса» в меню навигации слева
- Введите URL-адрес файла в текстовое поле для удаления URL-адреса
- Добавьте на страницу тег no-index, чтобы поисковые роботы Google или другие боты больше не индексировали такую страницу
2. Инструмент для удаления авторских прав
Google также удаляет все ссылки на ваши материалы, отображаемые при поиске в Интернете или на мобильных устройствах. Это сработает для тех, чьи файлы, DOC, PDF, видео и аудио файлы находятся в Google, тем самым нарушая их авторские права.
Вы должны знать свои права в отношении изображений и письменного контента. Google удалит материалы, защищенные авторским правом, после того, как они хорошо зарекомендовали себя, из своего индекса. Этот шаг соответствует Закону об авторском праве в цифровую эпоху (текст которого можно найти на веб-сайте Бюро регистрации авторских прав США) и другим применимым законам об интеллектуальной собственности.
Этот шаг соответствует Закону об авторском праве в цифровую эпоху (текст которого можно найти на веб-сайте Бюро регистрации авторских прав США) и другим применимым законам об интеллектуальной собственности.
Это работает, когда цифровое содержимое определенного сайта было изменено или распространено по сети без надлежащего разрешения.
Деиндексация страниц и файлов WordPress — краткое изложение
Существует множество способов удалить проиндексированные страницы и файлы из поиска Google. Используйте инструмент «Удалить URL-адреса», чтобы временно деиндексировать страницы из результатов поиска. Чтобы навсегда удалить страницы, вам нужно использовать другие методы, такие как защита паролем или добавление метатега «без индекса».
Хотя средство удаления URL-адресов также помогает удалить проиндексированные файлы, в качестве крайней меры можно использовать средство удаления авторских прав. Этот инструмент по-прежнему будет работать, даже если ваши файлы будут распространены.
Пожалуйста, оставьте комментарий, если у вас есть вопросы о том, как удалить проиндексированный контент и файлы из результатов поиска Google.
Как удалить страницу из индекса Google
Как SEO-гуру, мы тратим много времени, пытаясь выяснить, как лучше всего поднять наши веб-страницы в рейтинге поисковых систем, таких как Google. Мы нечасто рассматриваем возможность удаления страниц с нашего веб-сайта или намеренно запрещаем Google индексировать наши страницы. Но должны ли мы? Мы расскажем, почему иногда удаление страницы из индекса Google может быть полезным, и как вы можете скрыть свои страницы от роботов Google.
Почему вы можете удалить страницу из индекса Google
Пользователи нажимают на веб-сайт со страницы результатов поисковой системы (SERP), чтобы взаимодействовать с контентом, который отвечает или информирует их поисковый запрос. Однако иногда Google индексирует страницы, которые вы не хотите показывать в поисковой выдаче. Скорее всего, вы захотите удалить эти страницы из индекса Google. Давайте поговорим о том, как могут выглядеть эти страницы и как сделать так, чтобы пользователям было удобно пользоваться вашим сайтом.
Давайте поговорим о том, как могут выглядеть эти страницы и как сделать так, чтобы пользователям было удобно пользоваться вашим сайтом.
Некачественный контент
В мире SEO публикация высококачественного контента на вашем веб-сайте является основным компонентом маркетинга. Когда мы говорим «качественный», мы имеем в виду контент, который действительно отвечает на запрос пользователя и соответствует релевантным ключевым словам.
К низкокачественному контенту обычно относятся страницы с недостаточным содержанием, устаревшей или дублирующейся информацией или даже с большим количеством грамматических ошибок. Если на вашем веб-сайте есть контент, который не отвечает на поисковый запрос пользователя или не предоставляет ему релевантную информацию, может быть лучше удалить страницу из индекса Google или запретить Google индексировать ее.
Частная информация
Время от времени нам может понадобиться разместить в сети более конфиденциальную информацию по той или иной причине. Однако это не означает, что мы хотим, чтобы наша личная информация отображалась на первой странице Google, чтобы ее мог найти весь мир. Вы спросите, что считается частной информацией? Частное или конфиденциальное содержимое может относиться к контактной информации, медицинской или финансовой информации, а также к содержимому с возрастными ограничениями. Хотя эти типы страниц могут быть менее распространены, важно удалить страницы из индекса Google, если у вас есть опасения по поводу их появления в поисковой выдаче.
Однако это не означает, что мы хотим, чтобы наша личная информация отображалась на первой странице Google, чтобы ее мог найти весь мир. Вы спросите, что считается частной информацией? Частное или конфиденциальное содержимое может относиться к контактной информации, медицинской или финансовой информации, а также к содержимому с возрастными ограничениями. Хотя эти типы страниц могут быть менее распространены, важно удалить страницы из индекса Google, если у вас есть опасения по поводу их появления в поисковой выдаче.
Мало того, что информация на частных или некачественных страницах не имеет отношения к пользователям, она также может перегрузить ваш веб-сайт и замедлить его скорость и производительность. Кроме того, поисковые роботы тратят больше времени на анализ ненужных страниц вместо того, чтобы искать на вашем сайте ценный контент. Сочетание этих факторов может отрицательно сказаться на пользовательском опыте и привести к тому, что посетители будут уходить с вашего сайта быстрее, чем они нажимали на него.
Удаление страницы из индекса Google
Если вы оказались в одной из вышеперечисленных ситуаций, вам повезло! Google предлагает различные шаги, которые вы можете предпринять, чтобы удалить свой контент из Интернета и исключить его из поисковой выдачи. Мы углубимся в эти методы ниже.
Запрос на удаление URL
Перейдите в Google Search Console и войдите в систему, чтобы запросить удаление URL. Процесс удаления — идеальное решение для страниц, которые вы хотите временно скрыть или которые больше не существуют. Первоначальное удаление URL-адреса продлится примерно 90 дней, поэтому, если вы хотите навсегда удалить страницу из индекса Google, вам нужно будет предпринять дополнительные шаги.
Тег Noindex
Googlebots — это крошечные поисковые роботы, которые перемещаются по сети, анализируя и индексируя ваш сайт для Google. Лучше всего они работают, когда им дается набор инструкций, и именно здесь пригодится тег noindex. Тег noindex создает эквивалент гигантского красного знака остановки в вашем HTML-коде. Добавление этого тега в ваш мета-заголовок сообщит роботу Googlebot, что не следует сканировать, и запретит Google индексировать определенную страницу. Лучше всего включить этот тег во время первоначального создания страницы, но добавление его позже также может помочь предотвратить повторное сканирование и обновление страницы.
Добавление этого тега в ваш мета-заголовок сообщит роботу Googlebot, что не следует сканировать, и запретит Google индексировать определенную страницу. Лучше всего включить этот тег во время первоначального создания страницы, но добавление его позже также может помочь предотвратить повторное сканирование и обновление страницы.
Защита паролем
Пароли являются ключом к защите с помощью различных технологий, поэтому неудивительно, что их можно использовать для защиты ваших страниц. Вы даже можете зайти так далеко, что потребуется полное имя пользователя и пароль для входа на определенную страницу и просмотра содержимого. Это может быть полезной тактикой для защиты личной информации, такой как медицинские документы, которые могут вам понадобиться в Интернете, но не должны отображаться в поисковой выдаче.
Удалить содержимое
Последним вариантом удаления страницы из индекса Google является ее полное удаление из Интернета. Роботы Google не могут найти URL-адрес, если он больше не существует.