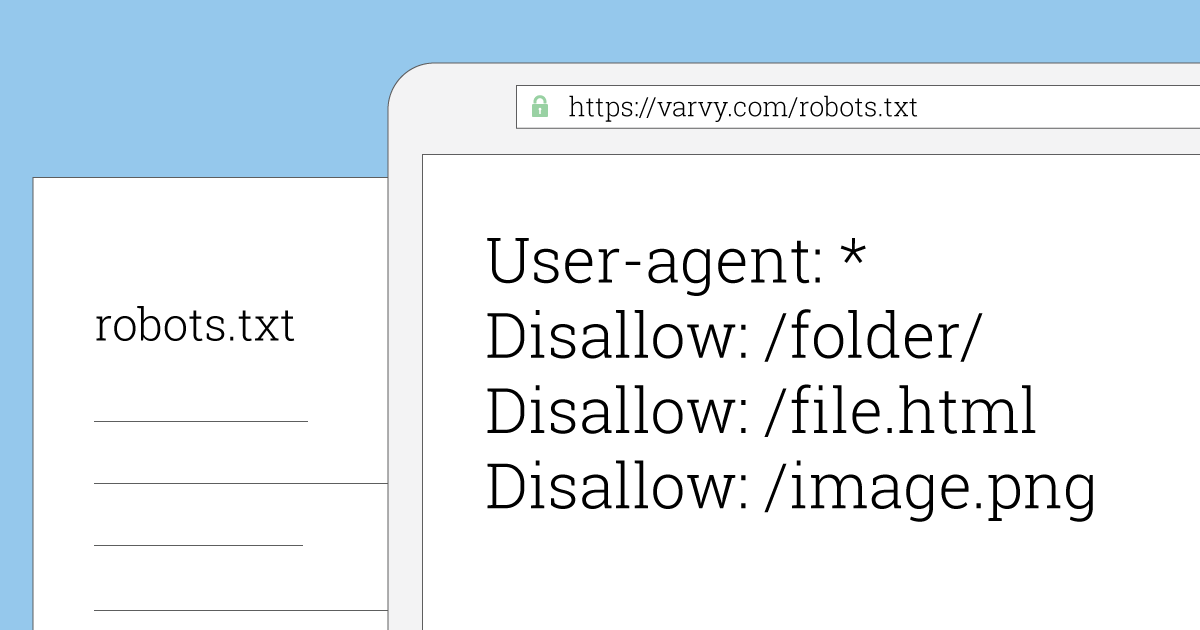
составляем правильный роботс для WordPress и других систем
Содержание статьи
- Что такое robots.txt
- Зачем закрывают какие-то страницы? Не проще ли открыть всё?
- Где находится Robots
- Для чего нужен этот файл
- Как работают поисковые роботы и как они обрабатывают данный файл
- По-разному ли Яндекс и Google воспринимают этот файл
- Чем может грозить неправильно составленный роботс
- Как создать файл robots.txt
- Пример правильного robots.txt для WordPress
- «Универсальный» роботс
- Роботс для Joomla
- Robots для Битрикса
- Как правильно составить роботс
- Что нужно закрывать в нем
- Как закрыть страницы от индексации и использовать Disallow
- Нужно ли использовать директиву Allow?
- Регулярные выражения
- Для чего нужна директива Host
- Что такое Crawl-delay
- Нужно ли указывать Sitemap в роботсе
- Прочие рекомендации к составлению
- Как запретить индексацию всего сайта
- Как проверить, правильно ли составлен файл
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате . txt, который сможет открыть даже компьютер вашего деда.
txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
User-agent: * Allow: /
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.
Это корневой каталог, и в нем лежит роботс.
Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории.
 Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта; - чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
 Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.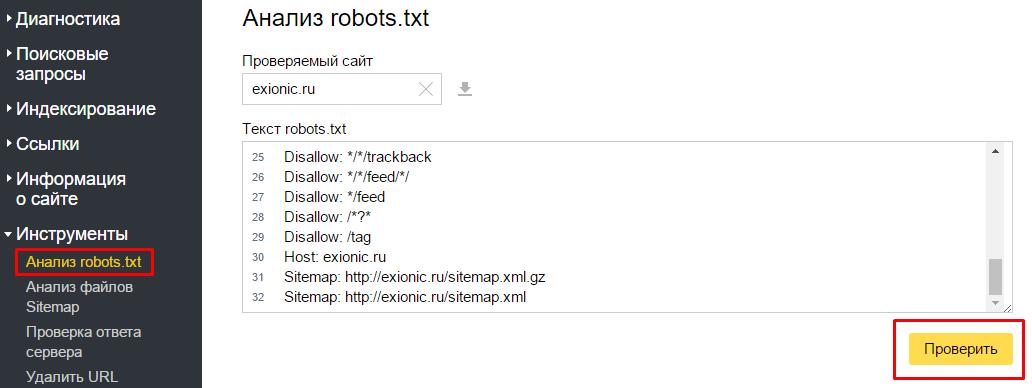
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
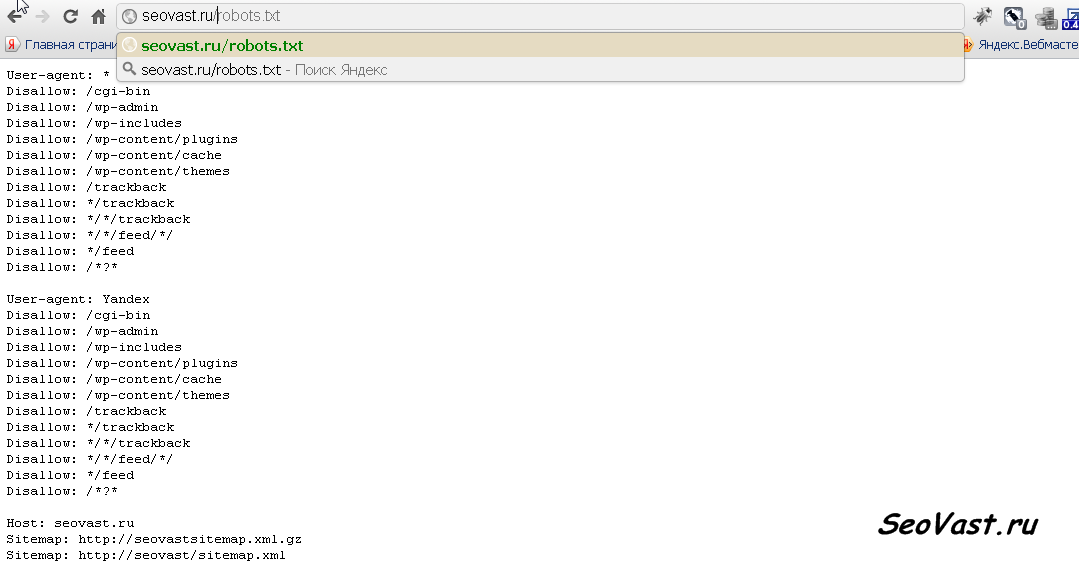
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: https://znet.ru/sitemap.xml
 php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
Host: znet.ru
User-agent: Googlebot
Disallow: /wp-admin
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.
php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
Host: znet.ru
User-agent: Googlebot
Disallow: /wp-admin
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: Mail.Ru
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /search
Disallow: */trackback/
Disallow: */feed
Disallow: */comments/
Disallow: *?*
Disallow: */comment
Disallow: */attachment/*
Disallow: */print/
Disallow: *?print=*
Allow: /wp-content/uploads/
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-login.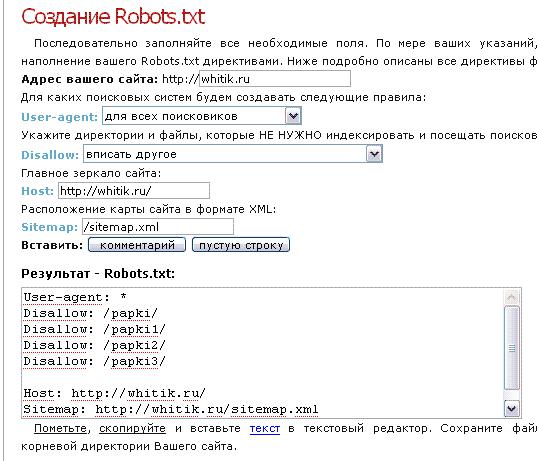
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
User-agent: * Allow: /
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml

Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php$ Host: znet.ru Sitemap: https://znet.ru/sitemap.xml
 php
Disallow: /e-store/affiliates/
Disallow: /club/$
Disallow: /club/messages/
Disallow: /club/log/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /*/search/
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*print_course=Y
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.
php
Disallow: /e-store/affiliates/
Disallow: /club/$
Disallow: /club/messages/
Disallow: /club/log/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /*/search/
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*print_course=Y
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: Googlebot
Мэйл.ру: Mail.Ru
Yahoo!: Slurp
MSN: MSNBot
Рамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильных
Googlebot-Image — это для картинок
Mediapartners-Google — этот робот сканирует содержание обьявлений AdSense
Adsbot-Google — это для качества целевых страниц AdWords
MSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
User-agent: Yandex
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
А вот обращение ко всем роботам всех систем сразу:
User-agent: *
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: https://znet.ru/sitemap.xml
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
Disallow: /page.html
А если мне нужно закрыть все страницы, которые начинаются с https://znet.ru/instrumenty/? То есть страницы https://znet.ru/instrumenty/1.html, https://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Disallow: /instrumenty/
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу https://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.
 html
htmlВ таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx
/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example. html и другие. Только конкретную страницу /example.
html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
То таймаут между загрузками двух страниц составит две секунды.
Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: https://znet.ru/sitemap.xml
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.

А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
Как правильно создать и настроить robots.txt для сайта? FAQ
X
- Новости Be1.ru
- Новости SEO
Be1 Вконтакте
1251 подписчиков
Be1 Facebook
1567 подписчиков
Новости
Не нашли ответа на свой вопрос?
Напишите, что бы Вы хотели узнать, и мы ответим Вам
Robots.txt — текстовый документ, который размещается в корневом каталоге сайта и содержит запреты для поисковых роботов на индексацию технических страниц ресурса, с целью недопущения попадания них в поисковую выдачу.
Поисковые роботы используют сессионный принцип, во время каждой сессии робот формирует список страниц сайта, которые планирует загрузить. При заходе на сайт, робот первым делом смотрит файл robots. txt, чтобы знать что можно смотреть на сайте, а что нет.
txt, чтобы знать что можно смотреть на сайте, а что нет.
Предлагаем посмотреть короткое видео от Яндекс, где при помощи простых сравнений наглядно рассказывается о задачах документа robots.txt:
Создание robots txt
01 При помощи любого текстового редактора (к примеру стандартного блокнота), создайте файл вида robots.txt.02 Пропишите в нем индивидуальные настройки, инструкция как это сделать описанная ниже. 03 Проверьте файл при помощи сервиса Яндекс Анализ robots.txt, все технические страницы должны быть под запретом, обязательно должны быть прописаны директивы Host и Sitemap. 04 Загрузите составленный файл robots.txt в корневую директорию сайта и проверьте его доступность по адресу yoursite.ru/robots.txt.
Как правильно составить robots txt?
01Директива User-agent: содержит название поискового робота, к которому будут применены описанные ниже нее ограничения. Если использовано несколько разных директив User-agent, то перед каждой рекомендуется вставлять пустой перевод строки. Примеры User-agent: User-agent: YandexBot # для основного индексирующего робота Яндекс User-agent: Googlebot # для поискового робота компании Google User-agent: * #для всех роботов-индексаторов02Директивы Disallow и Allow: используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры Disallow: Disallow: / # запрет на индексацию всего сайта
Примеры User-agent: User-agent: YandexBot # для основного индексирующего робота Яндекс User-agent: Googlebot # для поискового робота компании Google User-agent: * #для всех роботов-индексаторов02Директивы Disallow и Allow: используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры Disallow: Disallow: / # запрет на индексацию всего сайта
Disallow: /admin #для запрета индексации всех страниц на сайте, которые начинаются с «/admin» Примеры использования Disallow и Allow: User-agent: YandexBot
Disallow: / # запрещает индексировать весь сайт
Allow: /katalog # но разрешено индексировать страницы, которые начинаются с «/katalog» 03 Спецсимволы * и $ — используются для задавания определенных регулярных выражений при указании путей директив Allow и Disallow: используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры использования: User-agent: YandexBot
Disallow: /profile/*.aspx # запрещает «/profile/example.aspx» и «/profile/private/test. aspx»
aspx»
Disallow: /*private # запрещает не только «/private», но и «/profile/private»
Disallow: /admin* # запрещает индексировать страницы начинающиеся с «/admin»
Disallow: /example$ # запрещает «/example», но не запрещает «/example.html» 04 Директива Sitemap — указывает местоположение xml карты сайта, которая содержит URL адреса всех допустимых к индексированию страниц сайта. используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры использования: User-agent: YandexBot
Allow: Sitemap: http://site.com/sitemap.xml 05 Директива Host — указывает на главное зеркало сайта, которое и будет впоследствии участвовать в поиске. Если основным зеркалом является сайт, который доступен по защищенному протоколу HTTPS, это обязательно необходимо указать. Примеры использования: User-agent: YandexBot
Allow: /
Sitemap: http://www.site.com/sitemap.xml
Host: www.site.com 06 Директива Crawl-delay — используется для минимизации нагрузок на сервер, с ее помощью можно задать период времени в секундах, который должен быть между запросами роботами страниц сайта. Примеры использования: User-agent: YandexBot
Примеры использования: User-agent: YandexBot
Crawl-delay: 2 # задает таймаут в 2 секунды
Рекомендуем проанализировать в ручном режиме страницы Вашего сайта, которые попали в индекс поисковых систем, сделать это можно при помощи нашего инструмента по анализу сайтов, в разделе “индексация сайта”, это поможет максимально быстро и эффективно найти все технические страницы и закрыть их посредством файла robots.txt и директивы Disallow.
Наши инструменты для продвижения сайтов
Robots.txt в WordPress, объяснение
Когда мы говорим о «посетителях» веб-сайта в нашем блоге, мы почти всегда говорим о людях, заходящих на ваш веб-сайт через браузер. Там ничего удивительного.
Но есть еще один важный посетитель, о котором вам следует подумать при запуске веб-сайта WordPress: боты. Согласно отчету за 2020 год, трафик ботов составляет около 40% всего трафика веб-сайта, включая 25% «плохих ботов» и 15% «хороших ботов».
Источник изображения
Чтобы справиться с плохими ботами, ознакомьтесь с нашим руководством по безопасности WordPress. В этом посте мы сосредоточимся на хороших ботах, а именно на тех, которые используются поисковыми системами для сканирования ваших страниц и индексации вашего контента, чтобы ваш сайт отображался в результатах поиска.
В этом посте мы сосредоточимся на хороших ботах, а именно на тех, которые используются поисковыми системами для сканирования ваших страниц и индексации вашего контента, чтобы ваш сайт отображался в результатах поиска.
Существует много способов поддерживать и оптимизировать ваш сайт WordPress для хороших ботов, один из которых — понять, как работает ваш файл robots.txt. Этот файл может указывать ботам переходить к некоторым частям вашего веб-сайта, игнорируя части, которые вы хотите скрыть от поиска. Таким образом, только ваш релевантный контент сканируется и отображается в результатах обычного поиска.
В этом руководстве мы познакомим вас с файлом robots.txt в WordPress. Вы узнаете, для чего он предназначен, где его найти, что он содержит и как адаптировать его содержимое к вашим потребностям SEO.
Что такое robots.txt в WordPress?
В WordPress robots.txt — это файл, содержащий специальные команды для ботов, сканирующих веб-страницы. Он предназначен для того, чтобы проинструктировать роботов поисковых систем о том, как индексировать ваш сайт. По умолчанию robots.txt находится в корневом каталоге вашего сайта и может быть легко изменен для целей SEO.
По умолчанию robots.txt находится в корневом каталоге вашего сайта и может быть легко изменен для целей SEO.
Чтобы отображать ваши веб-страницы в результатах поиска, поисковые системы должны понимать структуру и содержание вашего веб-сайта — какую информацию содержат ваши веб-страницы и как эти страницы связаны между собой. Они делают это, развертывая поисковых ботов, также называемых «сканерами», для индексации ваших веб-страниц. С помощью этой проиндексированной информации поисковая система определяет рейтинг вашего сайта по заданному запросу.
Однако вы можете не захотеть, чтобы поисковые роботы посещали определенные части вашего веб-сайта WordPress, такие как страницы, находящиеся на обслуживании, тестовую область, ваш плагин, тему и папки администратора, а также другие страницы, которые вы не хотите, чтобы пользователи находили через поисковые системы.
Вот где robots.txt имеет значение: перед сканированием вашего сайта бот поисковой системы сначала ищет файл robots. txt, чтобы сообщить ему, какие страницы и/или области вашего сайта следует игнорировать. Если вы его включили, бот будет сканировать ваш сайт на основе инструкций, приведенных в этом файле. В противном случае он будет сканировать ваш сайт как обычно.
txt, чтобы сообщить ему, какие страницы и/или области вашего сайта следует игнорировать. Если вы его включили, бот будет сканировать ваш сайт на основе инструкций, приведенных в этом файле. В противном случае он будет сканировать ваш сайт как обычно.
Что в robots.txt?
WordPress автоматически создает простой файл robots.txt для новых веб-сайтов и помещает его в корневой каталог. Вы можете просмотреть содержимое файла robots.txt, добавив «/robots.txt» в конец основного URL-адреса вашего веб-сайта. Например, если URL-адрес вашей домашней страницы «https://example.com», URL-адрес «https://example.com/robots.txt» отобразит файл robots.txt в окне браузера. Наверное, это выглядит примерно так:
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Карта сайта: https://www.example.com/wp-sitemap.xml
Распаковываем содержимое этого файла. Файл robots.txt состоит из одного или нескольких блоков кода, каждый из которых содержит инструкции для одного или нескольких ботов.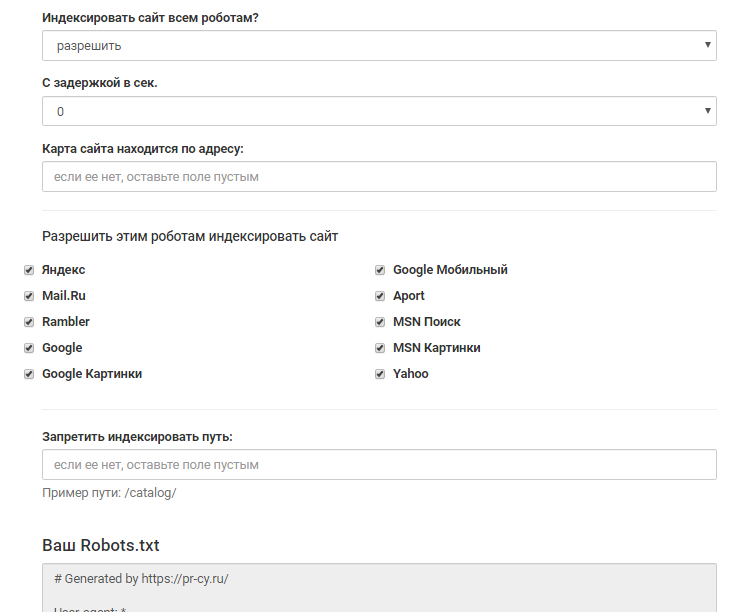 Блок кода состоит из:
Блок кода состоит из:
- агента пользователя , который идентифицирует бота, на которого распространяется правило. В приведенном выше примере пользовательский агент — это звездочка (*), означающая, что блокировка применяется к любому пользовательскому агенту, который посещает веб-сайт. Однако вы можете настроить таргетинг на конкретного бота с помощью его пользовательского агента. Например, пользовательский агент Google — 9.0045 Гуглбот . Замена звездочки на Googlebot приведет к тому, что блокировка будет применяться только к Google.
- Одна или несколько из следующих команд, за которыми следует соответствующий файл или каталог:
- Запретить указывает роботам поисковых систем игнорировать указанный файл или файлы. В приведенном выше примере robots.txt не позволяет ботам сканировать содержимое каталога wp-admin .
- Разрешить разрешает поисковым роботам доступ к указанному файлу или файлам. В этом нет необходимости, если только вы не хотите разрешить доступ к файлу или подкаталогу в запрещенном родительском каталоге. В приведенном выше примере боты могут сканировать файл admin-ajax.php , даже если он находится внутри каталога wp-admin .
- Crawl-delay указывает, сколько времени бот поисковой системы должен ждать между загрузками страницы. Он связан с числовым значением в секундах.
 В этом нет необходимости, если только вы не хотите разрешить доступ к файлу или подкаталогу в запрещенном родительском каталоге. В приведенном выше примере боты могут сканировать файл admin-ajax.php , даже если он находится внутри каталога wp-admin .
В этом нет необходимости, если только вы не хотите разрешить доступ к файлу или подкаталогу в запрещенном родительском каталоге. В приведенном выше примере боты могут сканировать файл admin-ajax.php , даже если он находится внутри каталога wp-admin .Вы также можете поместить косую черту (/) рядом с Запретить вместо имени файла или каталога, чтобы запретить все страницы на вашем веб-сайте.
После этих блоков файл robots.txt может также включать один или несколько Карта сайта s, каждая из которых связана с URL-адресом карты сайта для веб-сайта. Это не требуется и не нужно, если вы регулярно отправляете карты сайта в поисковые системы через такие сервисы, как Google Search Console.
Подводя итог, вот пример того, как может выглядеть файл robots. txt:
txt:
User-agent: [user-agent]
Disallow: [URL, который не должен сканироваться user-agent]
Агент пользователя: [имя агента пользователя]
Запретить: [URL-адрес, который не должен сканироваться агентом пользователя]
Разрешить: [URL-адрес, который должен сканировать агент пользователя]Карта сайта: [URL карты сайта]
Зачем использовать robots.txt в WordPress?
Если у вас небольшой веб-сайт WordPress с минимальным контентом, который можно проиндексировать, вам, скорее всего, не придется беспокоиться о файле robots.txt. На больших веб-сайтах измененный файл robots.txt потенциально может улучшить ваш рейтинг и скорость страницы.
Для каждого веб-сайта, который они индексируют, поисковые системы устанавливают краулинговый бюджет, который представляет собой количество страниц на веб-сайте, которые поисковая система просматривает за определенный период времени. Если количество проиндексированных страниц превышает ваш краулинговый бюджет, весь ваш сайт не будет проиндексирован до следующего сеанса сканирования. Это имеет негативные последствия для вашего рейтинга в органическом поиске, если боты тратят свой краулинговый бюджет на нерелевантные или частные разделы вашего сайта и пропускают самые важные страницы.
Это имеет негативные последствия для вашего рейтинга в органическом поиске, если боты тратят свой краулинговый бюджет на нерелевантные или частные разделы вашего сайта и пропускают самые важные страницы.
Ваш файл robots.txt позволяет указать поисковым системам, какие области следует пропускать, тем самым отдавая приоритет основному контенту. Внеся небольшие изменения в этот файл, вы помогаете поисковым роботам каждый раз указывать на контент, который вы хотите проиндексировать.
robots.txt также может повысить производительность вашего сайта и, как следствие, его удобство для пользователей. Поисковые боты похожи на посетителей-людей в том смысле, что они запрашивают страницы с вашего сервера и расходуют ресурсы. Указав сканерам поисковых систем избегать больших разделов вашего сайта, вы освободите ресурсы сервера для посетителей-людей. Вы даже можете полностью отключить определенных ботов от своего сайта. Даже если это незначительная разница в скорости, в результате вы можете ожидать большей вовлеченности на свой сайт.
Обратите внимание, что боты не обязаны следовать всем или каким-либо правилам в вашем файле robots.txt. Боту решать, подчиняться ли вашим инструкциям, хотя поисковые роботы для популярных поисковых систем обычно следуют большинству команд, которые вы указываете в файле robots.txt. Но «плохие» боты, как вы можете предположить, проигнорируют ваш файл robots.txt. По этой причине вы никогда не должны полагаться на robots.txt как на средство защиты личной информации.
Кроме того, только потому, что вы запретили страницу или группу страниц, это не исключает возможности индексации этих страниц поисковой системой. Если сканер найдет обратную ссылку на другом веб-сайте, которая ведет на вашу запрещенную страницу, он все равно может проиндексировать эту страницу. Чтобы предотвратить индексацию страницы, рекомендуется использовать метатег noindex, защитить страницу паролем или удалить страницу из файлов вашего сервера.
Как создать и отредактировать файл robots.txt в WordPress
Чтобы отредактировать файл robots. txt WordPress, у вас есть возможность использовать плагин или отредактировать файл вручную и загрузить его на свой сервер через FTP. Первый способ лучше подходит для новичков, а второй не требует установки дополнительного плагина для внесения изменений.
txt WordPress, у вас есть возможность использовать плагин или отредактировать файл вручную и загрузить его на свой сервер через FTP. Первый способ лучше подходит для новичков, а второй не требует установки дополнительного плагина для внесения изменений.
Создание и редактирование robots.txt с помощью плагина
Многие плагины SEO для WordPress позволяют изменять файл robots.txt без непосредственного редактирования файла. All in One SEO (AIOSEO) — один из таких плагинов. Он также хорошо принят, его скачали более трех миллионов раз. Бесплатная версия AIOSEO позволяет легко добавлять правила в robots.txt.
Чтобы отредактировать файл robots.txt в AIOSEO:
1. Установите и активируйте плагин All in One SEO.
2. Вы попадете в мастер настройки AIOSEO. Вы можете продолжить настройку с помощью мастера или вернуться на панель управления.
3. На панели инструментов перейдите к Все в одном SEO > Инструменты .
4. На вкладке Редактор Robots.txt включите Enable Custom Robots.txt .
5. Ниже под Robots.txt Preview вы увидите текущий файл robots.txt. Он будет содержать правила, добавленные WordPress. По умолчанию это удерживает поисковых ботов от вашего ядра WordPress, за исключением вашего файла ajax-admin.php .
6. Чтобы добавить правило, добавьте своего пользователя агента и путь к каталогу в соответствующие поля и выберите Разрешить или Запретить при необходимости.
При добавлении этой информации вы увидите изменение предварительного просмотра файла robots.txt.
7. Чтобы добавить другое правило, нажмите Добавить правило и заполните поля, как на предыдущем шаге.
8. По завершении нажмите Сохранить изменения в правом нижнем углу.
Создание и редактирование robots.txt вручную
Если вы не хотите использовать плагин SEO для изменения файла, вы также можете изменить robots.txt напрямую с помощью клиента протокола передачи файлов (FTP). Вот как:
1. В выбранном вами текстовом редакторе создайте файл с именем robots.txt .
2. Добавьте нужные правила в этот файл в надлежащем формате — указанном ниже — и сохраните файл:
User-agent: [user-agent]
Disallow: [URL -agent для сканирования]
Агент пользователя: [имя агента пользователя]
Запретить: [URL, который не должен сканироваться агентом пользователя]
Разрешить: [URL, который должен сканировать агент пользователя]Карта сайта: [URL карты сайта]
3. Используя FTP-клиент, подключитесь к вашему хостингу WordPress.
4. Загрузите robots.txt на свой сервер и поместите его в корневой каталог вашего сайта. Если в этом каталоге уже есть файл robots.txt, новый файл должен заменить его.
5. Чтобы изменить этот файл в будущем, загрузите его со своего сервера, внесите изменения в текстовом редакторе, а затем повторно загрузите файл на свой сервер. Или вы можете вносить изменения непосредственно через ваш FTP-клиент.
Проверьте свой новый файл robots.txt
После внесения изменений вручную или с помощью подключаемого модуля вы должны протестировать новый файл robots.txt, чтобы убедиться, что ваши инструкции работают правильно. Опечатка в этом файле может отвлечь ботов от вашего важного контента и нанести вред SEO.
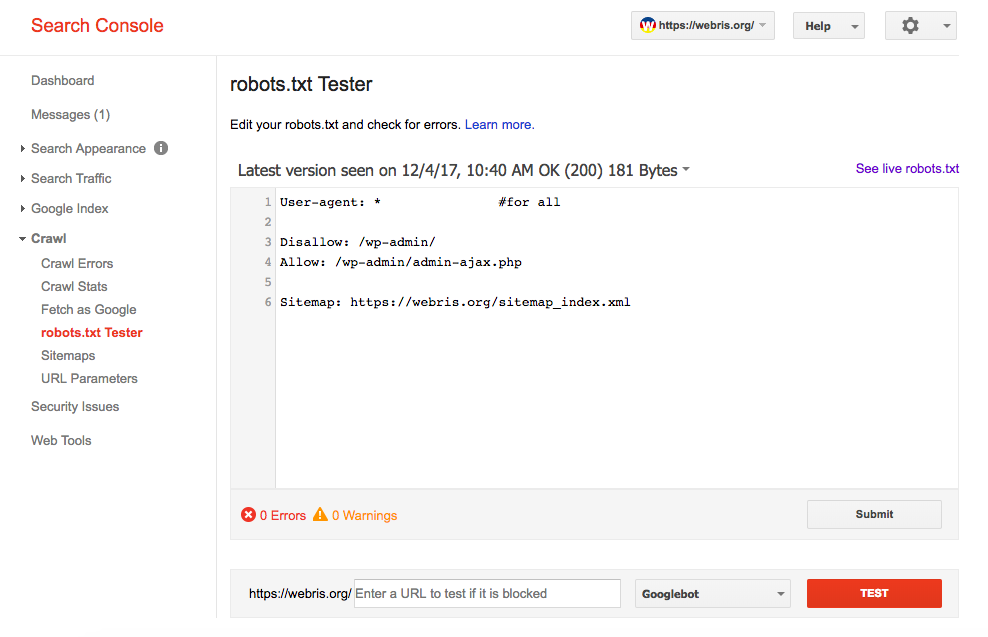
Чтобы оценить файл robots.txt, вы можете использовать инструмент тестирования в Google Search Console. После того, как вы подключили свой сайт к Google Search Console, откройте тестер robots.txt и выберите свой домен из раскрывающегося списка. Google сканирует ваш файл и предупреждает вас о любых ошибках или предупреждениях. Если инструмент показывает ноль ошибок и ноль предупреждений, все готово:
Google сканирует ваш файл и предупреждает вас о любых ошибках или предупреждениях. Если инструмент показывает ноль ошибок и ноль предупреждений, все готово:
Примеры правил WordPress robots.txt
Вот несколько простых примеров того, как может выглядеть блок robots.txt, который вы можете добавить в свой собственный файл в соответствии с вашими потребностями.
Разрешить файл в запрещенной папке
Возможно, вы захотите запретить ботам сканировать все файлы в каталоге, кроме одного файла. В этом случае выполните следующее правило:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Замените указанные выше имена каталогов и файлов своими собственными.
Запретить одного или всех ботов
Чтобы бот не сканировал ваши страницы, используйте следующее правило:
Агент пользователя: [агент пользователя]
Запретить: правила) от сканирования ваших страниц со следующим:
User-agent: *
Disallow: /
Запретить всем ботам, кроме одного
Эти правила ограничивают доступ к вашему сайту для всех ботов, кроме одного:
User-agent: [user agent]
Disallow:
User-agent: *
Disallow: /
Add Crawl Delay
Еще один способ уменьшить трафик поисковых роботов на вашем сайте — добавить правило задержки сканирования на robots.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Crawl-delay: 60
Обратите внимание, что боты могут не подчиняться вашей задержке сканирования. Если эти боты продолжают влиять на вашу производительность, обратитесь к документации службы или обратитесь в службу поддержки (для хороших ботов) или установите брандмауэр (для плохих ботов).
Направьте ботов в правильном направлении.
По мере масштабирования вашего веб-сайта и увеличения количества страниц файл robots.txt становится ценным активом для оптимизации вашей поисковой системы. Он может направить поисковых ботов к вашему наиболее ценному контенту, что приведет к увеличению органического трафика и потенциально более быстрому времени загрузки.
Кроме того, файл robots.txt прост для понимания, поэтому любой администратор WordPress может внести пару основных изменений, расслабиться и наслаждаться результатами (то есть результатами поиска).
Темы: Веб-сайт WordPress
Не забудьте поделиться этим постом!
файлов robots.txt | Search.gov
Файл
/robots.txt— это текстовый файл, который дает автоматизированным веб-ботам инструкции о том, как сканировать и/или индексировать веб-сайт. Веб-команды используют их для предоставления информации о том, какие каталоги сайта следует или не следует сканировать, как быстро следует получать доступ к контенту и какие боты приветствуются на сайте.Как должен выглядеть мой файл robots.txt?
Подробную информацию о том, как и где создать файл robots.txt, см. в протоколе robots.txt. Ключевые моменты, о которых следует помнить:
 txt. Crawl-delay устанавливает количество времени (в секундах), которое бот должен ждать, прежде чем сканировать следующую страницу. В приведенном ниже примере я добавил задержку сканирования в одну минуту (60 секунд):
txt. Crawl-delay устанавливает количество времени (в секундах), которое бот должен ждать, прежде чем сканировать следующую страницу. В приведенном ниже примере я добавил задержку сканирования в одну минуту (60 секунд):
- Файл должен находиться в корне домена, и для каждого поддомена нужен свой файл.
- Протокол robots.txt чувствителен к регистру.
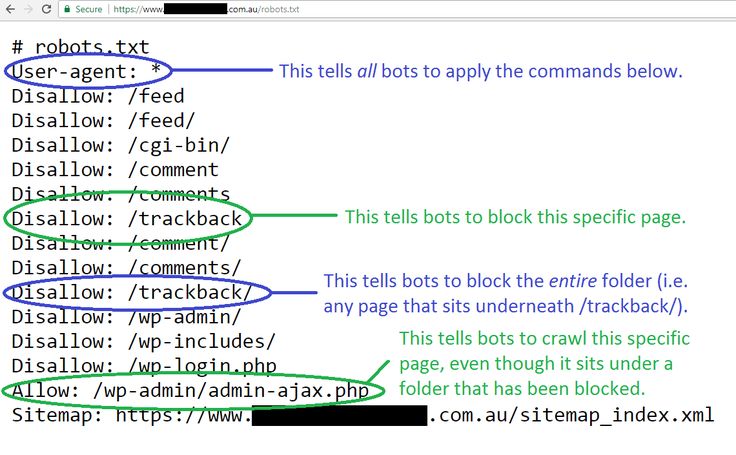
- Легко случайно заблокировать сканирование всего:
-
Запретить: /означает запретить все. -
Disallow:означает ничего не запрещать, то есть разрешать все. -
Разрешить: /означает разрешить все. -
Разрешить:означает ничего не разрешать, что запрещает все.
-
- Инструкции в файле robots.txt являются руководством для ботов, а не обязательными требованиями — вредоносные боты могут игнорировать ваши настройки.

Как оптимизировать файл robots.txt для Search.gov?
Задержка сканирования
В файле robots.txt может быть указана директива «задержка сканирования» для одного или нескольких пользовательских агентов, которая сообщает боту, как быстро он может запрашивать страницы с веб-сайта. Например, задержка сканирования, равная 10, означает, что сканер не должен запрашивать новую страницу чаще, чем каждые 10 секунд.
500 000 URL-адресов
x 10 секунд между запросами
5 000 000 секунд на все запросы
5 000 000 секунд = 58 дней, чтобы проиндексировать сайт один раз.
Мы рекомендуем задержку сканирования в 2 секунды для нашего ussearch и установить более высокую задержку сканирования для всех остальных ботов. Чем меньше задержка сканирования, тем быстрее Search.gov сможет проиндексировать ваш сайт. В файле robots.txt это будет выглядеть так:
Агент пользователя: usasearch Задержка сканирования: 2 Пользовательский агент: * Задержка сканирования: 10
XML-файлы Sitemap
В файле robots.txt также должны быть перечислены одна или несколько ваших XML-карт сайта. Например:
Карта сайта: https://www.example.gov/sitemap.xml Карта сайта: https://www.example.gov/independent-subsection-sitemap.xml
- Список карт сайта только для домена, в котором находится файл robots.txt. Карта сайта другого субдомена должна быть указана в файле robots. txt этого субдомена.
 txt этого субдомена.
txt этого субдомена.Разрешить только тот контент, который вы хотите найти
Мы рекомендуем запретить любые каталоги или файлы, которые не должны быть доступны для поиска. Например:
Запретить: /архив/ Запретить: /news-1997/ Запретить: /reports/duplicative-page.html
- Обратите внимание: если вы запретите каталог после того, как он был проиндексирован поисковой системой, это может не привести к удалению этого содержимого из индекса. Вам нужно будет зайти в инструменты поисковой системы для веб-мастеров, чтобы запросить удаление.
- Также обратите внимание, что поисковые системы могут индексировать отдельные страницы в запрещенной папке, если поисковая система узнает об URL-адресе из метода, не связанного со сканированием, например, по ссылке с другого сайта или из вашей карты сайта. Чтобы данная страница не была доступна для поиска, установите на этой странице метатег robots.
Настройка параметров для разных ботов
Вы можете установить разные разрешения для разных ботов.