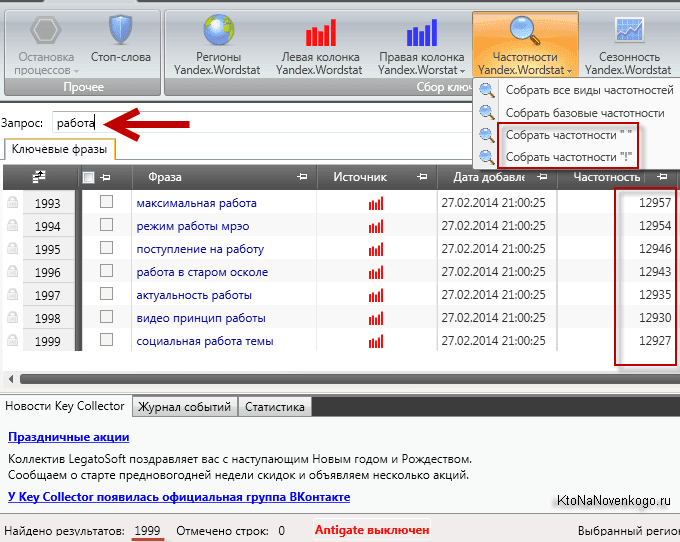
Как собрать семантику и проверить частотность запросов в Google
Когда речь идет о сборе семантического ядра, большинство вебмастеров вспоминают о сервисе подбора ключевых слов от «Яндекса»: о Wordstat. И собирают им фразы для продвижения в обеих поисковых системах, при этом почти не используют планировщик ключевых слов от Google. Разбираемся, правильно ли это и как собрать семантику через «Гугл».
Для начала разберемся в основах. «Вордстат» показывает число запросов в поисковой системе, а планировщик слов от Google «заточен» под контекстную рекламу. В нем тоже можно узнать число запросов в поиске, но есть нюансы, которые немного усложняют сбор семантики. Например, он подходит для сбора СЯ в коммерческих нишах, а информационные запросы будет сложно найти и правильно оценить, потому что по ним почти не показывают рекламу.
1. Кому нужен сбор запросов через сервисы Google
2. Нужно ли собирать семантическое ядро отдельно под Google
3. 3 способа, как собрать семантику для Google 3.
3.2. Как собрать семантику в сервисах Google
3.3. Как собрать семантику для Google в специальных сервисах
Кому нужен сбор запросов через сервисы Google
Очевидно — всем, кто хочет продвигать сайт в этой поисковой системе. И особенно тем, кто планирует получать трафик только из США, стран Европы или других государств, где подавляющее большинство населения использует Google.
В России и странах СНГ тоже стоит собирать ключевые запросы через сервисы «Гугл». Хоть «Яндекс» и пытается монополизировать рынок, доля Google постоянно растет, и им пользуется почти половина пользователей. Уже в 2015 году в браузере Chrome «Гугл» использовали почти в половине случаев.
Посмотрите на ситуацию: два поисковика занимают почти равные доли рынкаТеоретически собирать семантику под Google нужно всем. Практически в некоторых случаях это просто отнимет лишнее время, потому что большинство запросов, которые показывает «Гугл», можно без проблем найти в «Вордстате» с меньшими усилиями.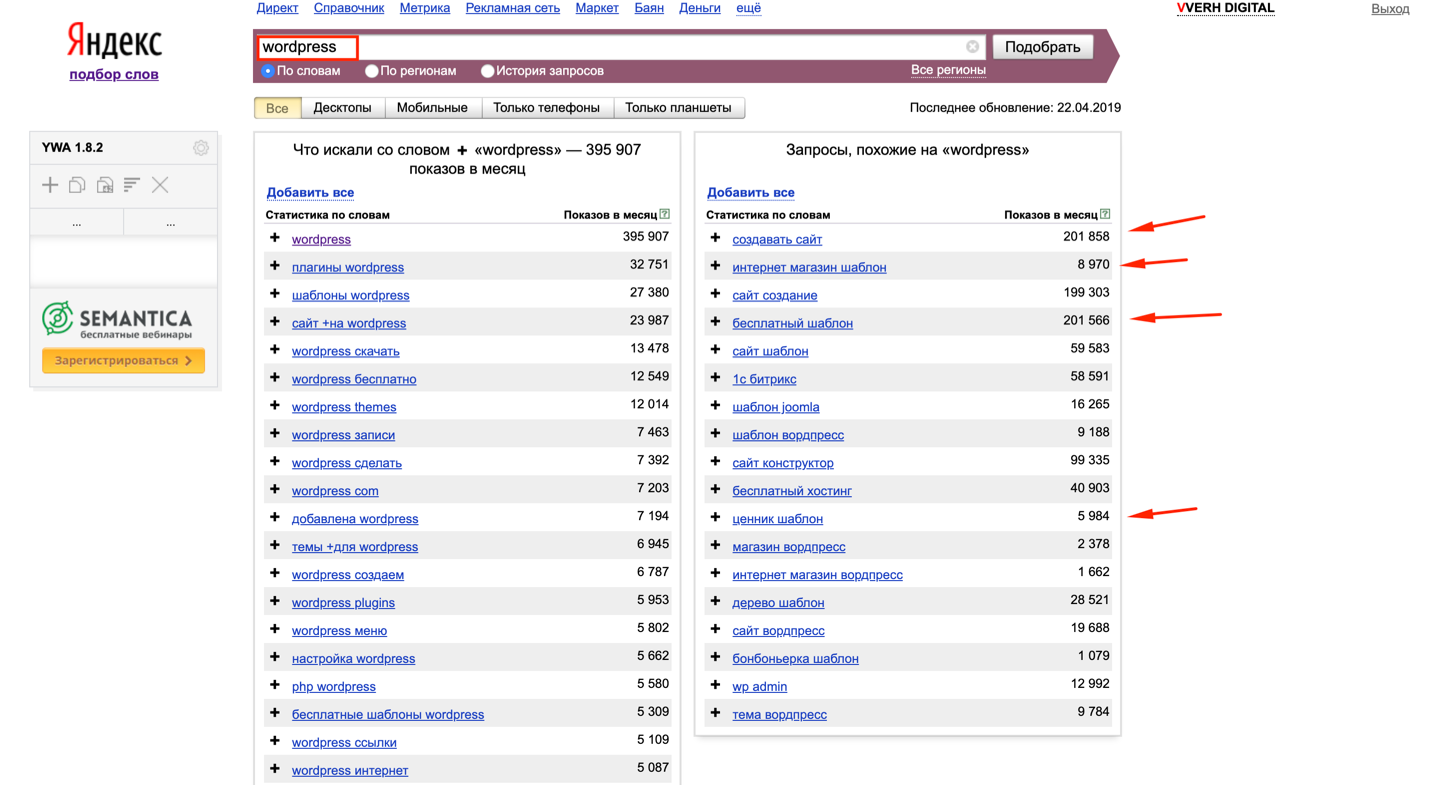
Нужно ли собирать семантическое ядро отдельно под Google
В большинстве случаев вебмастера собирают одно семантическое ядро с помощью «Вордстата» и сторонних планировщиков. Это правильно, потому что такой подход позволяет потратить меньше ресурсов. Но есть нюансы.
Если запускаете контекстную рекламу, отдельное СЯ под Google делать не стоит. Дело в том, что львиную долю переходов там приносит всего 3–10% запросов от общего числа собранных. И если вы будете добавлять в кампанию все низкочастотные ключи, объявления по ним просто не будут показывать.
Если планируете продвижение сайта, лучше собрать отдельное семантическое ядро хотя бы по основным кластерам ключевых слов. Дело в том, что частота ключей в «Яндексе» и Google будет разная, соответственно, будет разная конкуренция. И сравнение двух семантических ядер позволит вам понять, какой запрос выгоднее продвигать в одном поисковике, какой — в другом. В результате потратите на оптимизацию меньше денег и ресурсов.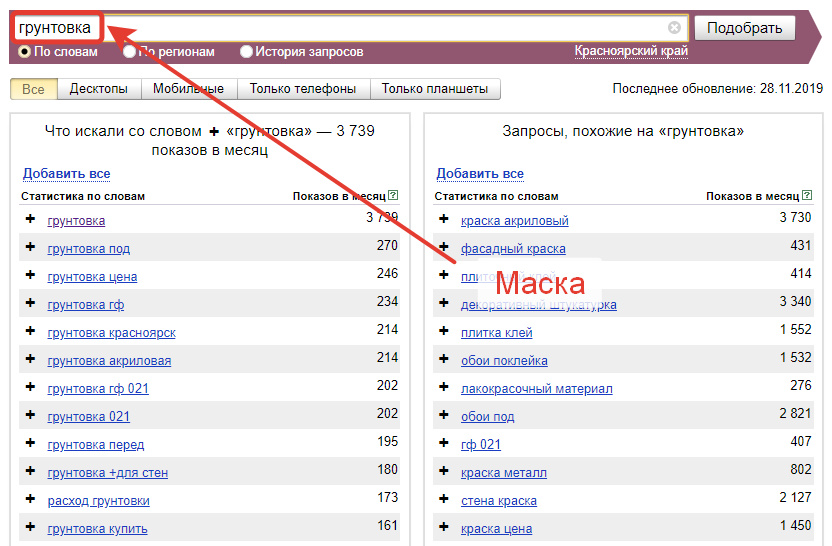
3 способа, как собрать семантику для Google
Собрать ключевые слова для продвижения в «Гугле» можно тремя способами: в планировщике, в сервисах Google и с помощью сторонних планировщиков. Рассмотрим каждый способ подробнее.
Как собрать семантику в планировщике ключевых слов от Google
Сначала нужно зайти в инструмент для запуска рекламной кампании — Google Ads. Авторизуйтесь в нем и зайдите в панель инструментов, а потом — в планировщик.
Нажмите сюда, чтобы попасть в планировщикПотом выберите поиск новых ключевых словЗатем просто впишите основные ключевые фразы. Например, если занимаетесь продажей телефонов — «купить iPhone», «купить смартфон» и так далее. Укажите регион поиска. Также можете добавить домен — это нужно для исключения из результатов выдачи запросов, по которым бессмысленно продвигаться, потому что вы не предоставляете подобных продуктов.
Если у вас уже есть сайт, можете просто указать его в соседней вкладке, и система подберет подходящие фразыВам покажут все найденные запросы, связанные с ключом, который вы указали. Правда, есть нюанс: частоту покажут только усредненную, в диапазоне. Зато сразу покажут статистику по запросам в контекстной рекламе.
Правда, есть нюанс: частоту покажут только усредненную, в диапазоне. Зато сразу покажут статистику по запросам в контекстной рекламе.
Чтобы проверить частотность ключевых слов по Google, нужно найти статистику по ним в отдельном окне. Берем все ключи, найденные ранее, и идем в планировщик, но выбираем не подбор новых фраз, а просмотр количества прогнозов и прогнозов. Указываем интересующие нас ключи и жмем «Начать»
Можно не вводить ключи вручную, а загрузить файл, который вы скачали раньшеЛистаем результаты выдачи вниз, к сводной таблице. Там показаны усредненные данные — примерная цена за клик, число показов объявлений, стоимость продвижения в контексте по запросам. Нас интересует столбец «Показы» — это примерная частотность запроса в Google. Примерная, потому что система планирует показы на следующий месяц, а еще учитывает естественную конкуренцию в контексте.
Как собрать семантику в сервисах Google
Как мы уже говорили, в планировщике данные по информационным запросам могут быть некорректны. Поэтому для проверки наличия запросов в поиске лучше использовать сервисы Google — например, YouTube. Также можно использовать и поисковую строку. Суть способа проста: вводим основной ключ и смотрим на подсказки, которые выдает сервис.
Смотрите: «хвосты» запросов — это популярные ключевые фразы, которые можно использовать для сбора семантикиТак вы сможете собрать ключи, которые по каким-то причинам не показаны в планировщике Google. Или проверить, используют ли их люди. Добыть точную частотность в «Гугл» будет сложно, потому что статистика планировщика может быть искажена из-за того, что запросы информационные. По ним почти не запускают рекламу, поэтому Ads может выдавать меньшее число показов, чем есть на самом деле.
Как собрать семантику для Google в специальных сервисах
Есть сервисы для сбора семантического ядра, которые работают и с «Яндексом», и с Google. Можете пользоваться ими, например, собрать фразы в:
Можете пользоваться ими, например, собрать фразы в:
«Буквариксе». Это бесплатный онлайн-сервис. Может собирать фразы по запросу или домену. Показывает общую частоту на весь мир во всех поисковых системах.
KeywordTool. Условно бесплатный онлайн-сервис. Показывает фразы для каждой поисковой системы по отдельности, также рассчитывает частоту, тенденцию и конкурентность. Правда, за доступ к полным данным придется купить версию PRO — она стоит от 69 $.
KeyCollector. Платное ПО для сбора семантики. Работает со всеми поисковыми системами и показывает общую частотность фраз.
Когда соберете семантику для Google, просто оптимизируйте сайт под нее. Но учитывайте и запросы, которые нашли в «Яндексе», чтобы сайт получал органический трафик с обеих поисковых систем.
Присоединяйтесь к нам:
- Чат Telegram – живое общение, обмен опытом, бесплатные бонусы.
- Канал Telegram – актуальная и полезная информация об арбитраже.

- YouTube – крутой видеоконтент: интервью, гайды и лайфхаки.
- Дайджест в Telegram – топовые подборки кейсов и актуальных статей.

ВЧ, СЧ и НЧ запросы — виды поисковых запросов по частотности, их влияние на продвижение
Поисковые запросы — это фразы, которые люди используют для поиска информации на какую-то тему. По сути они равняются ключевым фразам, которые применяются для продвижения сайта. Именно поэтому каждый владелец сайта должен иметь представление о том, какие словосочетания используют для поиска его потенциальные клиенты.
В статье разберём, что такое высокочастотные, среднечастотные и низкочастотные запросы, а ещё посмотрим, какой из типов лучше выбрать для продвижения своего сайта.
Что такое частотность поисковых запросов?
Самое базовое деление поисковых запросов — по частотности. Все запросы в зависимости от того, как часто их используют люди, можно разделить на три категории: высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ).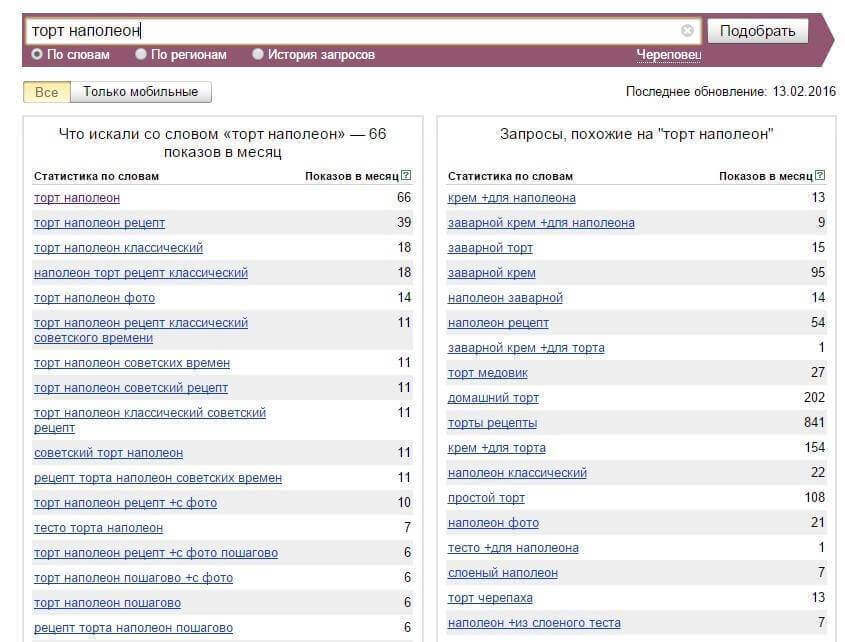
Оценить частоту использования можно с помощью Яндекс.Вордстата. Это бесплатный сервис, где содержится вся статистика по пользовательским вопросам Яндексу за последний месяц. Туда можно вбить любую фразу, и система покажет, сколько раз люди искали её и другие похожие словосочетания.
Что вся эта информация даёт вебмастеру? Самое главное, что можно сделать за счёт частотности — это спрогнозировать трафик на ваш ресурс, если по конкретным фразам он будет находиться в топе. Конечно, не все, кто введёт фразу в поисковую строку в итоге зайдут на сайт, но примерный порядок цифр с помощью такого метода определить можно.
Также если отсортировать все собранные для семантического ядра фразы по частотности, можно понять, какие из них люди используют чаще, а какие не используют вообще. Эти знания очень помогут и в SEO-продвижении, и в контекстной рекламе.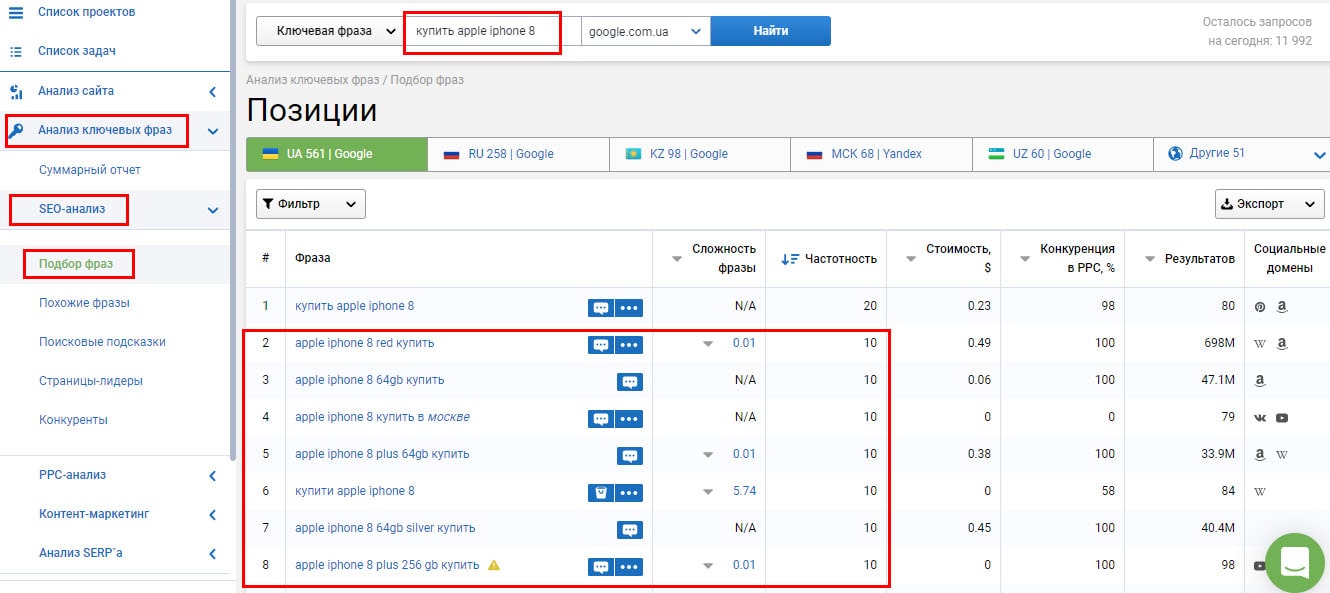
Высокочастотные запросы
Это фразы, которые люди используют максимально часто. Если говорить в цифрах, то это от 10 тысяч раз в месяц. Число примерное, потому что частотность зависит также и от региональности. Запросы, которые в крупных городах относятся к низкочастотным, в маленьких регионах легко могут быть высокочастотными просто потому, что там в принципе живёт меньше людей. Также бывают просто узкие ниши, где люди в целом мало спрашивают что-то у поисковика.
Обычно такие запросы включают в себя одно-два слова и охватывают широкий круг тем. Например, возьмём слово “гитара”. Если человек вбивает его в поисковик, то не совсем понятно, что именно он хочет найти: гитарные магазины, историю возникновения музыкального инструмента, разновидности гитар или что-то другое.
Плюс высокочастотных запросов — широкий охват аудитории. Каждый день эти фразы используют тысячи человек, а значит, если ваш сайт будет отображаться по ним на первой странице, у него есть шанс кратно повысить свою посещаемость. Но отсюда вытекает и минус: большая конкуренция. Ведь каждый владелец сайта хочет, чтобы его ресурс всплывал по запросам вроде “заказать пиццу” или “цветы москва”. Поэтому ресурсы вкладывают огромные бюджеты, чтобы быть в топе выдачи по таким словам. В итоге новичкам или просто небольшим сайтам сложно туда пробиться. Конечно, есть шанс попасть на вторую, третью или десятую страницу, но там аудитории уже гораздо меньше.
Каждый день эти фразы используют тысячи человек, а значит, если ваш сайт будет отображаться по ним на первой странице, у него есть шанс кратно повысить свою посещаемость. Но отсюда вытекает и минус: большая конкуренция. Ведь каждый владелец сайта хочет, чтобы его ресурс всплывал по запросам вроде “заказать пиццу” или “цветы москва”. Поэтому ресурсы вкладывают огромные бюджеты, чтобы быть в топе выдачи по таким словам. В итоге новичкам или просто небольшим сайтам сложно туда пробиться. Конечно, есть шанс попасть на вторую, третью или десятую страницу, но там аудитории уже гораздо меньше.
Другой минус — большой процент нецелевого трафика. Из-за того, что людей здесь очень много, огромная часть из них не будет относиться к вашей целевой аудитории. В итоге даже если они перейдут на сайт, клиентами они не станут, а могут только подпортить поведенческие факторы. Например, если много людей будут слишком быстро закрывать сайт, это увеличит процент отказов. Если большинство будет посещать только одну страницу, это тоже негативно скажется на рейтинге ресурса.
Ещё один минус есть и для пользователя — слишком разнообразная выдача. Из-за того, что поисковик не понимает, что именно хочет найти человек, он может показывать сразу много вариантов. Поэтому часто человеку всё-таки приходится уточнять свой вопрос.
Среднечастотные запросы
Такие фразы люди вводят в поисковую строку реже: примерно от 1 000 до 10 000 раз в месяц. Отличаются они от ВЧ запросов тем, что обычно включают в себя больше слов, из-за чего вопрос становится более конкретным. Пример — фраза “семена гортензии”. Здесь понятно, что человек ищет семена конкретного растения, и, скорее всего, хочет их купить. Поэтому и выдаче уже проще подстроиться под его намерения.
Продвигаться по таким фразам проще: здесь уже нет такой высокой конкуренции, а пользователи знают чего хотят. Но бюджеты на раскрутку здесь всё равно довольно высокие. Например, контекстная реклама — в принципе дорогой инструмент продвижения, поэтому даже по СЧ запросам рекламироваться там довольно затратно.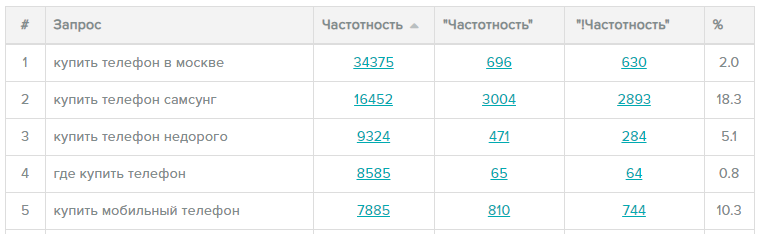
Низкочастотные запросы
Эту группу используют реже всего: от 100 до 1000 раз в месяц. Обычно такие фразы состоят из 3-5 слов, что делает их максимально конкретными. Примеры: “обувная мастерская рядом” или “как правильно просверлить отверстие в плитке”. Конкуренция по таким фразам будет минимальная, потому что далеко не все люди будут заморачиваться и вводить такой подробный вопрос.
Но из этого правила есть и исключения: не все такие запросы низкоконкурентные. Есть тематики, где в принципе мало трафика, зато желающих его получить много. В этом случае за потенциальных клиентов разворачивается настоящая битва, каждый хочет привлечь их именно на свой сайт. Но такие ситуации встречаются довольно редко.
Часто владельцы сайтов игнорируют НЧ запросы, но это ошибка. Да, для того, чтобы собрать и разместить их на своём сайте, нужно гораздо больше времени. Но это даёт свои плюсы: за счёт большого количества таких словосочетаний удаётся привлечь аудиторию, сопоставимую с той, что приходит по СЧ.
Микронизкочастотные запросы
Да, мы говорили, что существует три группы. Но иногда выделяют также микронизкочастотные (МНЧ) запросы. Как можно догадаться из названия, их используют ещё реже, чем низкочастотные запросы. В цифрах это меньше 100 раз в месяц. Обычно такие фразы также называют запросами с длинным хвостом (long tail). Всё потому, что они включают в себя очень много слов. Например, в эту группу можно отнести такие фразы: “фильм где ди каприо играет учителя” или “купить красный чайник для газовой плиты”.
Работа с МНЧ очень актуальна для голосового поиска. Ведь, когда люди ищут информацию голосом, они обычно используют как раз такие длинные фразы. Сейчас это направление развивается всё сильнее, поэтому всё больше ресурсов обращают внимание на эту группу.
Сложность продвижения здесь состоит в том, что их очень и очень много, и каждый месяц появляются всё новые. Поэтому оптимизировать под них страницы трудно, но зато конкуренция тут будет самая минимальная.
Как выбрать запросы для продвижения?
По каким же запросам стоит продвигаться? Только по высокочастотным? Или наоборот полностью избегать их из-за большой конкуренции? Всё зависит от ваших стартовых данных: бюджета и времени на раскрутку, размера сайта, его возраста и т.д.
Например:
- Если бюджет достаточно большой и есть цель повысить узнаваемость и улучшить имидж компании, можно продвигаться по ВЧ и СЧ запросам.
- Если бюджет, наоборот, низкий, лучше остановиться на НЧ.
- Если получить топовые позиции нужно срочно, подойдут низкочастотные фразы. Ведь выход в топ по ВЧ чаще всего занимает годы.
- Интернет-магазинам есть смысл продвигаться по НЧ. Ведь при поиске какого-то товара люди часто используют название его модели, цвет и другие параметры.
- Также НЧ помогут информационным ресурсам и коммерческим сайтам, у которых есть блоги. Такие фразы вполне могут стать темами для статей.
- Новому сайту вряд ли есть смысл сразу выходить на ВЧ запросы для продвижения в поисковой выдаче. Начать лучше со СЧ или НЧ, а уже потом подключать ВЧ.

Но вот один совет, который подойдёт для всех сайтов: в идеале семантическое ядро, по которому продвигается ресурс, должно включать в себя все категории запросов. Да, на первых порах это может быть только один тип фраз, но дальше нужно стремиться сбалансировать стратегию продвижения.
Настройка частоты опроса и сбора данных для облачных интеграций
Наши облачные интеграции получают данные от API облачных провайдеров. В New Relic вы можете изменить некоторые настройки, связанные со сбором данных, для ваших облачных интеграций. Читайте дальше, чтобы узнать, какие изменения вы можете внести, и причины их внесения.
Обзор настроек
Облачные интеграции New Relic получают данные от API облачных провайдеров. Данные обычно собираются из API-интерфейсов мониторинга, таких как AWS CloudWatch, Azure Monitor и GCP Stackdriver, а метаданные инвентаризации собираются из API-интерфейсов конкретных сервисов.
Данные обычно собираются из API-интерфейсов мониторинга, таких как AWS CloudWatch, Azure Monitor и GCP Stackdriver, а метаданные инвентаризации собираются из API-интерфейсов конкретных сервисов.
Вы можете использовать панель мониторинга состояния учетной записи, чтобы увидеть, как ваши облачные интеграции обрабатывают данные от поставщика облачных услуг. Если вы хотите сообщать больше или меньше данных из ваших облачных интеграций или если вам нужно контролировать использование API-интерфейсов облачных провайдеров, чтобы предотвратить достижение лимитов скорости и регулирования в вашей облачной учетной записи, вы можете изменить параметры конфигурации, чтобы изменить количество данных, которые они сообщают. Два основных элемента управления:
- Изменить частоту опроса
- Изменить, какие данные сообщаются
Примеры бизнес-причин для изменения частоты опроса:
- Оплата: Если вам необходимо управлять своим счетом за AWS CloudWatch, вы можете уменьшить частоту опроса. Прежде чем сделать это, убедитесь, что это сокращение не повлияет на любые условия предупреждений, заданные для ваших облачных интеграций.
- Новые службы: Если вы развертываете новую службу или конфигурацию и хотите чаще собирать данные, вы можете временно увеличить частоту опроса.
 Прежде чем сделать это, убедитесь, что это сокращение не повлияет на любые условия предупреждений, заданные для ваших облачных интеграций.
Прежде чем сделать это, убедитесь, что это сокращение не повлияет на любые условия предупреждений, заданные для ваших облачных интеграций.Осторожно
Изменение параметров конфигурации для ваших интеграций может повлиять на условия предупреждений и тенденции диаграммы.
Изменить частоту опроса
Конфигурация частоты опроса определяет, как часто New Relic сообщает данные от вашего облачного провайдера для каждой службы. По умолчанию частота опроса установлена на максимальную частоту, доступную для каждой службы.
Чтобы изменить частоту опроса для облачной интеграции:
- Перейдите по адресу one.newrelic.com > Инфраструктура .
- Выберите вкладку, соответствующую вашему поставщику облачных услуг.
- Выберите Настроить рядом с интеграцией.
- Используйте раскрывающиеся списки рядом с Интервал опроса данных каждые , чтобы выбрать, как часто вы хотите, чтобы New Relic собирала данные интеграции с облаком.
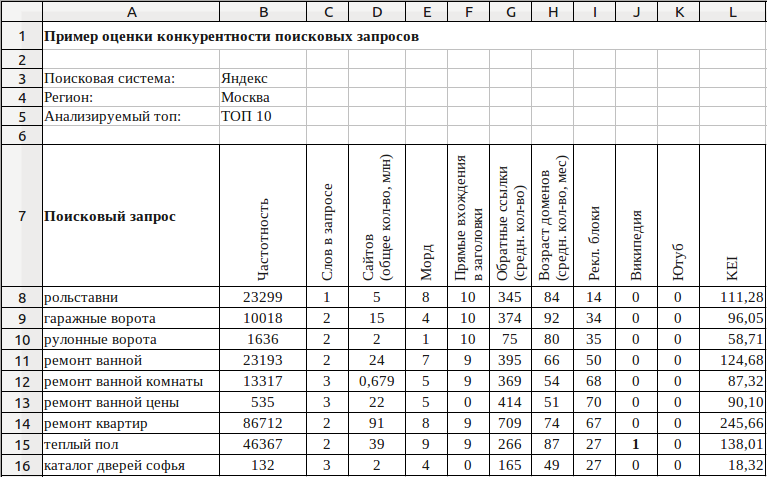
Укажите данные для извлечения
Вы можете указать, какую информацию вы хотите собирать для интеграции с облаком, включив сбор дополнительных данных и применив несколько фильтров к каждой интеграции.
Чтобы изменить эти настройки для интеграции с облаком:
- Перейдите по адресу one.newrelic.com > Инфраструктура .
- Выберите вкладку, соответствующую вашему поставщику облачных услуг.
- Выберите Настроить рядом с интеграцией.
- В разделе Сбор данных и фильтры установите нужные переключатели на .
- Для фильтров выберите или введите значения, которые вы хотите включить в отчетные данные.
Сбор данных
Для некоторых облачных интеграций требуется дополнительное количество вызовов API облачных провайдеров для сбора данных. Например, чтобы получить теги для кластеров AWS Elastic Map Reduce, требуется дополнительный вызов API сервиса.
Например, чтобы получить теги для кластеров AWS Elastic Map Reduce, требуется дополнительный вызов API сервиса.
Чтобы лучше контролировать количество вызовов API, отправляемых в вашу облачную учетную запись для этих интеграций, вы можете указать, когда вам нужно собирать эти типы данных. В зависимости от интеграции доступны различные переключатели сбора данных.
Переключить | Описание |
|---|---|
Собрать теги | Для некоторых интеграций требуются дополнительные вызовы API к облачному провайдеру для создания отчетов о тегах. Сбор тегов включен по умолчанию. Установите для этого параметра значение Off , если вы не хотите, чтобы интеграция собирала теги ваших облачных ресурсов и тем самым уменьшала объем вызовов API. |
Сбор расширенной инвентаризации | Некоторые интеграции могут собирать метаданные расширенной инвентаризации о ваших облачных ресурсах, выполняя дополнительные вызовы API к облачному провайдеру. Расширенный сбор инвентаря отключен по умолчанию . Переключите это на Вкл. , если вы хотите отслеживать расширенные запасы. Это увеличит количество вызовов API. |
Сбор данных сегментов | Доступно для интеграции AWS Kinesis Streams. По умолчанию мы не сообщаем метрики сегментов. Переключите это на On , если вы хотите отслеживать показатели сегмента в дополнение к показателям потока данных. |
Сбор данных Lambda@Edge | Доступно для интеграции с AWS CloudFront. По умолчанию мы не сообщаем данные Lambda@Edge. Переключите это на На , если вы используете Lambda@Edge в AWS CloudFront и хотите получить метаданные местоположения выполнения Lambda. |
Сбор данных узла | Доступно для интеграции с AWS Elasticsearch. По умолчанию мы не сообщаем метрики узла Elasticsearch. Переключите это на On , если вы хотите отслеживать показатели узла в дополнение к показателям кластера. |
Сбор данных шлюза NAT и Сбор данных VPN | Доступно для интеграции с AWS VPC. По умолчанию мы не сообщаем ни о шлюзе NAT, ни о показателях VPN. Переключите их на On , если вы хотите отслеживать показатели и инвентарь шлюза NAT и VPN в дополнение к инвентаризации других объектов, связанных с VPC. |
Сбор IP-адресов | Доступно для интеграции с AWS EC2. По умолчанию мы собираем метаданные экземпляра EC2, которые включают общедоступные и частные IP-адреса и сведения о сетевом интерфейсе. Переключите это на Off , если вы не хотите, чтобы New Relic сохраняла и отображала эти IP-данные. |
 Метаданные, включенные в расширенный перечень для каждой облачной интеграции, описаны в документации по интеграции.
Метаданные, включенные в расширенный перечень для каждой облачной интеграции, описаны в документации по интеграции.
Фильтры
Когда фильтр В вы указываете данные, которые хотите собрать; например, если ограничение для региона AWS равно On , выбранные вами регионы будут теми, для которых будут собираться данные. В зависимости от интеграции доступны различные фильтры:
Фильтр | Описание |
|---|---|
Регион | Выберите регионы, которые включают ресурсы, которые вы хотите отслеживать. |
Префиксы очереди | Доступно для интеграции с AWS SQS. Введите каждое имя или префикс для очередей, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру. |
Префиксы балансировщика нагрузки | Доступно для интеграции с AWS ALB. Введите каждое имя или префикс для балансировщиков нагрузки приложений, которые вы хотите отслеживать. |
Префиксы имен этапов | Доступно для интеграции с AWS API Gateway. Введите каждое имя или префикс для этапов, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру. |
Ключ тега | Введите один ключ тега , связанный с ресурсами, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру, и вы можете использовать этот фильтр в сочетании с фильтром значения тега . |
Значение тега | Введите одно значение тега , связанное с ресурсами, которые вы хотите отслеживать. Значения фильтра чувствительны к регистру, и вы можете использовать этот фильтр в сочетании с ключ тега . |
Группа ресурсов | Выберите группы ресурсов, связанные с ресурсами, которые вы хотите отслеживать. |
 Значения фильтра чувствительны к регистру.
Значения фильтра чувствительны к регистру.
Потенциальное влияние на предупреждения и диаграммы
Изменение конфигурации интеграции может повлиять на условия предупреждений и диаграммы. Вот некоторые вещи, которые следует учитывать:
Если вы измените этот параметр… | Это может иметь следующие последствия… |
|---|---|
Любой параметр конфигурации | и в Лента событий также меняется. |
Любые фильтры | При создании условий оповещения после вы устанавливаете фильтры, убедитесь, что ваши оповещения не инициируются отфильтрованными ресурсами. |
Фильтр для регионов | Если вы фильтруете для определенных регионов, это может уменьшить объем данных, сообщаемых в New Relic, что может вызвать предупреждение. Если вы создадите условие оповещения для определенного региона, а затем отфильтруете этот регион, этот регион больше не будет сообщать данные и никогда не вызовет оповещение. |
Частота опроса | При создании оповещения убедитесь, что вы определили пороговое значение для периода времени, превышающего частоту опроса. |
Теги и расширенный инвентарь | Если вы включите теги и/или расширенный инвентарь, New Relic сделает больше вызовов API к облачному провайдеру, что может увеличить счет за использование API вашего облачного провайдера. |
2 Показатели вовлеченности пользователей
Для большинства веб-сайтов и приложений посетители проходят долгий процесс знакомства, а не секс на одну ночь: они редко конвертируются после первого посещения. Чаще всего первое посещение используется для оценки доверия. Последующие посещения могут включать более сложные взаимодействия и, возможно, конверсии, которые могут произойти через недели или месяцы после первого посещения. Таким образом, чтобы лучше поддерживать наших пользователей, нам необходимо понимать фактический процесс знакомств для посетителей нашего сайта. Люди используют наш сайт каждый день или даже несколько раз в день? Сколько посещений предшествует этой окончательной конверсии? Меняется ли это поведение в зависимости от времени года?
Люди используют наш сайт каждый день или даже несколько раз в день? Сколько посещений предшествует этой окончательной конверсии? Меняется ли это поведение в зависимости от времени года?
Analytics помогут вам ответить на эти вопросы и могут принять решения относительно стратегии контента, графиков маркетинговых рассылок по электронной почте и рекламных акций, а также о том, следует ли разрабатывать дизайн в основном для новичков, впервые посещающих сайт, или для опытных постоянных посетителей.
Определение: Частота посещений сайта указывает общее количество посещений сайта каждым пользователем. Эта метрика позволяет оценить процент новых пользователей на сайте, а также уровень знакомства всех вернувшихся пользователей.
Определение: Недавность измеряет количество дней, прошедших с момента последнего посещения каждого пользователя. Этот показатель позволяет увидеть среднее время между посещениями для вашей пользовательской базы.

В совокупности частота и давность определяют, насколько «прилипчивым» является веб-сайт или приложение — люди регулярно возвращаются к нему или нет? Анализ поведения лояльных клиентов может дать ценную информацию — например, вы можете найти страницы или инструменты, которые часто используются вернувшимися пользователями, но игнорируются случайными посетителями (особенно «посетителями», которые посещают сайт только один раз). Когда вы обнаружите такие тенденции, вы сможете скорректировать дизайн сайта, чтобы повысить доступность тех функций, которые ваши постоянные пользователи считают ценными.
Частота: Сколько посещений?
При использовании инструментов аналитики, таких как Google Analytics или Adobe Analytics, частота описывается гистограммой количества посещений. (Гистограмма — это тип гистограммы, в которой каждый столбец показывает количество точек данных, которые имеют определенное значение или попадают в диапазон значений.) В Google Analytics эта гистограмма называется отчетом о подсчете сеансов .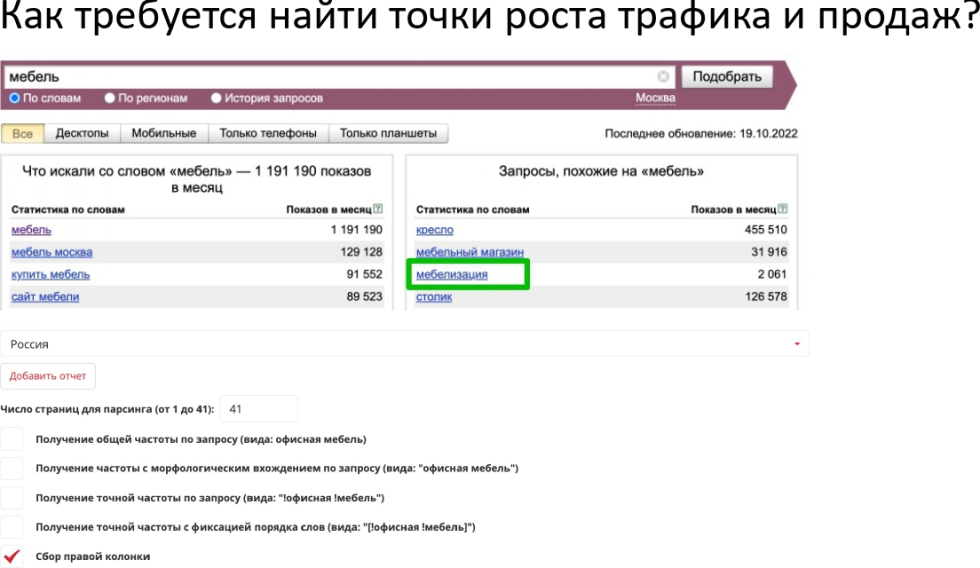 а в Adobe Analytics это отчет о количестве посещений .
а в Adobe Analytics это отчет о количестве посещений .
Вместо того, чтобы просто измерять, являются ли пользователи новыми или вернувшимися, такие отчеты позволяют нам более точно понять уровень знакомства пользователей: сколько посетителей хорошо знакомы с сайтом (скажем, посетили его 6 th или более раз). ) по сравнению с тем, сколько из них относительно недавно появились на сайте?
Отчеты о подсчете сеансов (или посещений) обычно определяются для определенного периода времени T (например, август) и сообщают нам для каждого возможного количества посещений (т. е. количества сеансов) n, сколько у пользователей был n-й визит в течение периода времени T. Так, например, для количества сеансов n=2 и августа гистограмма покажет вам, сколько пользователей совершили свой второй визит в августе. (Обратите внимание, что некоторые из этих пользователей могли совершить свой первый визит до августа, а некоторые — в августе — все они включены в подсчет сеансов для n = 2, так как инструменты аналитики сообщают о количестве посещений как о ценности за все время для каждого пользователь. )
)
Пользователь может быть включен в несколько групп подсчета сеансов: например, пользователи, у которых были первые два посещения в августе, будут включены в подсчет сеансов как для n=1, так и для n=2. Если бы новых посетителей было намного больше, чем вернувшихся, можно было бы ожидать, что первая полоса (для n = 1) будет намного больше, чем остальные.
Для того, чтобы получить более подробные данные о той или иной категории пользователей, нам необходимо создать специальный сегмент (подмножество данных, полученных в результате применения выбранного фильтра).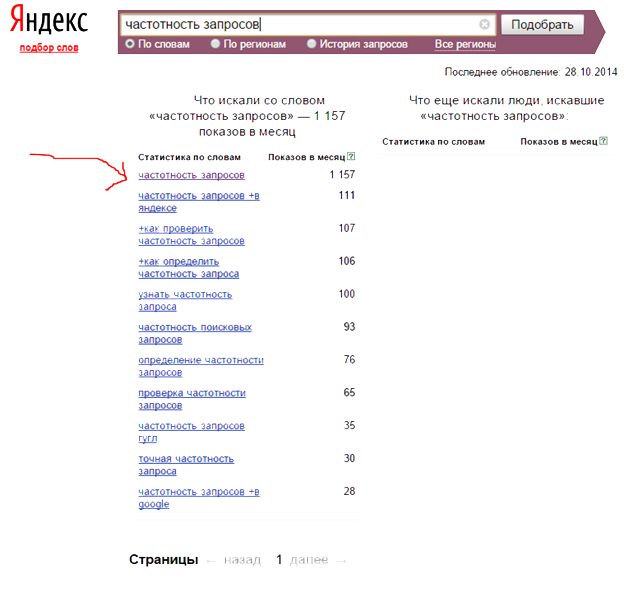 Например, чтобы увидеть график частоты для тех пользователей, которые посетили только один раз в данном месяце, мы бы указали правило «Сеансы = 1» в качестве фильтра для создания сегмента.
Например, чтобы увидеть график частоты для тех пользователей, которые посетили только один раз в данном месяце, мы бы указали правило «Сеансы = 1» в качестве фильтра для создания сегмента.
По отдельности просмотр отчета о частоте не дает многого, потому что строки обычно просто уменьшаются в количестве по мере увеличения счетчика (что неудивительно — по мере повышения уровня лояльности можно ожидать все меньше и меньше пользователей на этом уровне).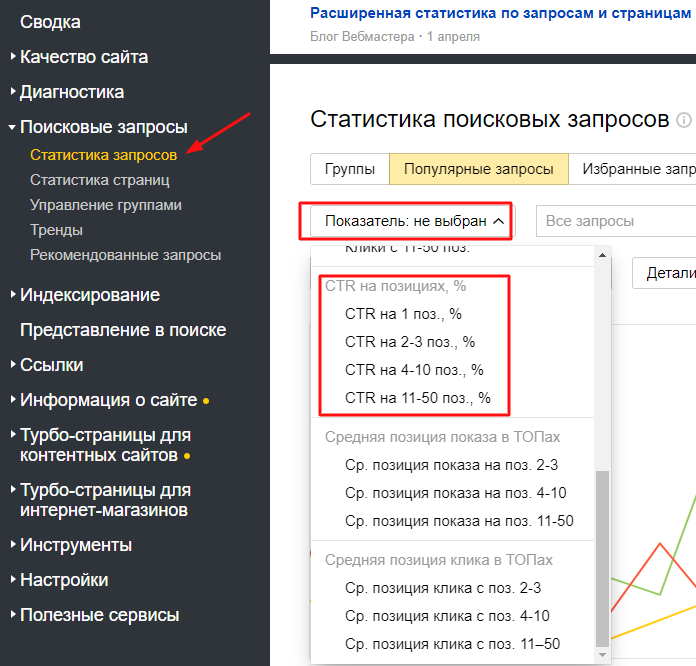 Настоящая ценность возникает при просмотре сегмента посещений, в котором произошли важные события (например, конверсии для достижения определенной цели), и определении того, сколько других посещений предшествовало интересующему событию.
Настоящая ценность возникает при просмотре сегмента посещений, в котором произошли важные события (например, конверсии для достижения определенной цели), и определении того, сколько других посещений предшествовало интересующему событию.
Раскрывая типичное количество посещений, которое пользователь совершил до совершения конверсии, мы можем лучше спроектировать фактические путешествия наших пользователей. Например, если большинство конверсий происходит на странице 5 9 пользователей.0445 th или 6 th , мы можем внедрить инструменты, чтобы напомнить людям, что они делали в прошлом, чтобы помочь им продолжить с того места, на котором они остановились, отправлять электронные письма пользователям только после 3 или 4 посещений, чтобы убедить их вернуться на сайт, и так далее.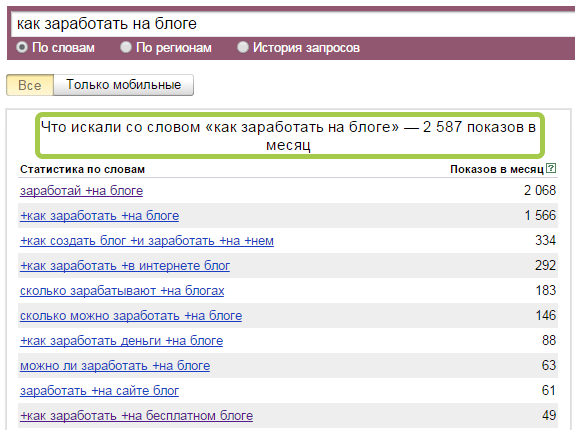 Мы также могли бы запланировать исследование юзабилити или дневниковое исследование, чтобы узнать, какие могут быть барьеры для конверсии: возможно, для конверсии требуется так много посещений, потому что пользователям трудно сравнивать наши предложения с предложениями конкурентов, или потому что они считают, что для конверсии потребуется слишком много времени. зарегистрируйтесь и начните.
Мы также могли бы запланировать исследование юзабилити или дневниковое исследование, чтобы узнать, какие могут быть барьеры для конверсии: возможно, для конверсии требуется так много посещений, потому что пользователям трудно сравнивать наши предложения с предложениями конкурентов, или потому что они считают, что для конверсии потребуется слишком много времени. зарегистрируйтесь и начните.
Недавность: когда люди в последний раз посещали?
Для измерения давности аналитические инструменты сообщают о количестве дней, прошедших с момента предыдущего посещения каждого пользователя.
В Google Analytics для новых пользователей значение давности ( дней с момента последнего сеанса ) записывается как 0 дней — так же, как для пользователей, которые посетили сайт дважды (или более) в течение одного дня. Таким образом, при просмотре отчетов о последних посещениях Google Analytics полезно отфильтровывать новых пользователей, применяя сегмент, включающий только пользователей с несколькими сеансами.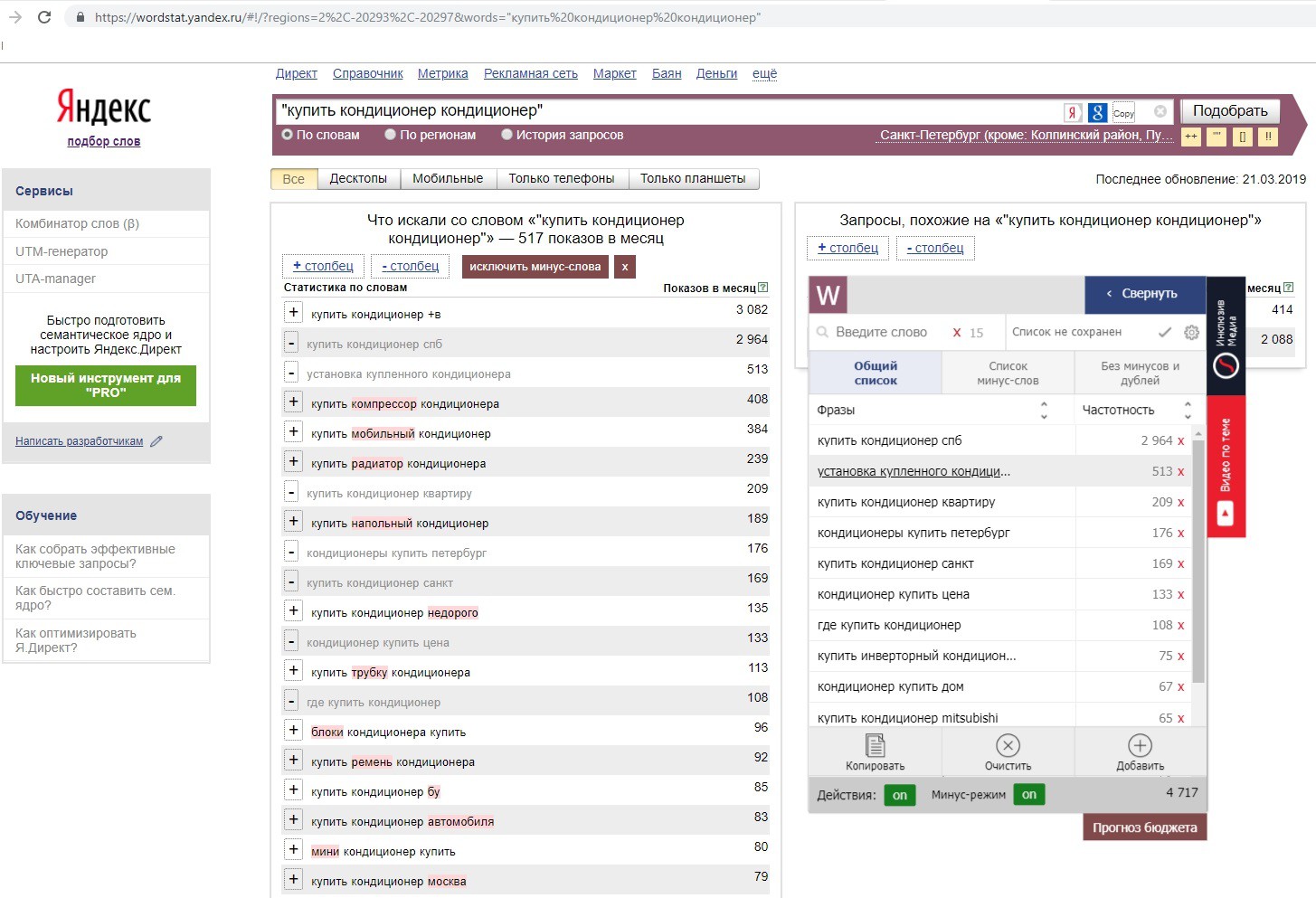 В Adobe Analytics отчет о частоте возврата уже не включает новых посетителей. (Другие инструменты могут сообщать этот тип данных любым методом, поэтому обязательно проверьте, как работает ваш инструмент аналитики.)
В Adobe Analytics отчет о частоте возврата уже не включает новых посетителей. (Другие инструменты могут сообщать этот тип данных любым методом, поэтому обязательно проверьте, как работает ваш инструмент аналитики.)

Данные о давности помогают узнать, насколько регулярно люди посещают сайт, по сравнению с тем, как часто обновляется контент или рекламные акции. Если ваша контент-стратегия изменится, изменится ли также показатель между посещениями? Стоит ли создавать новое изображение баннера каждый день, если большинство пользователей посещают его только раз в несколько недель? (Подсказка: нет.) С другой стороны, если вы видите всплеск посещаемости каждый раз, когда ваш сайт добавляет новый контент, возможно, имеет смысл увеличить частоту ваших обновлений.
Например, на снимке экрана выше мы видим, что большинство многосеансовых пользователей возвращаются на сайт в тот же день, что и при предыдущем посещении (самая длинная полоса — это полоса в строке дней с момента последней сессии = 0) или всего через 1 день. Обратите также внимание на небольшую выпуклость дней с момента последней сессии = 6. В этом случае выпуклость соответствует еженедельному информационному бюллетеню по электронной почте.
Сегменты могут помочь выявить желаемые модели использования — в частности, частых посетителей по сравнению со случайными посетителями. Если люди, которые возвращаются каждый день или через день, как правило, совершают больше конверсий, тогда как менее частые посетители никогда не совершают конверсий, тогда вам следует выяснить, какие другие различия в поведении между двумя группами. Есть ли функция или инструмент, который используют более заинтересованные посетители и который вы могли бы сделать более доступным для всех? Вызваны ли частые посещения определенными рекламными акциями по электронной почте? Есть ли у постоянных посетителей другой опыт из-за того, что они остаются авторизованными в системе? Также можно сравнивать разные времена года, чтобы выявить тенденции использования, основанные на сезонности или конкретных маркетинговых усилиях.
Данные о давности также помогают понять данные о частоте, чтобы лучше понять, когда люди возвращаются на сайт. Например, если в вашем отчете о количестве посещений указано, что большое количество пользователей заходит на сайт 3–4 раза, вы можете создать сегмент для этой группы и посмотреть, происходят ли эти посещения в течение 0–1 дней или в течение несколько недель.