Что такое файл robots.txt и как его настроить
- Что такое robots.txt
- Директивы и структура robots.txt
- Как настроить robots.txt: советы
- Как проверить robots.txt онлайн
- Проверка в Яндекс.Вебмастер
- Проверка в Google Search Console
Читайте нашу статью, если хотите узнать, как сделать анализ robots txt. Мы расскажем, что это за файл и как его настроить, а также покажем, как делается проверка robots txt по правилам Яндекс и Google.
Что такое robots.txt
Файл robots.txt — это инструкция для поисковых роботов, в которой указано, какие разделы и страницы сайта они могут посещать, а какие должны пропускать.
Поисковые роботы — это программы, которые с определенной периодичностью просматривают содержимое сайтов и заносят информацию о них в базы поисковых систем (например, Яндекс и Google). Этот процесс называют индексацией сайта.
Если не настроить robots.txt, можно столкнуться, как минимум, с двумя проблемами:
- каждый раз сайт будет индексироваться очень долго (и, возможно, редко),
- роботы увидят нежелательное содержимое (например, служебные файлы или временную информацию) и страницы сайта будут “оценены” некорректно.


Всё это негативно скажется на позициях сайта в поисковой выдаче.
Если файл присутствует на сайте и настроен корректно, роботы будут действовать строго по указанным в нём правилам. Так они поймут, на какие страницы или разделы стоит обратить внимание в первую очередь, а какие скрыты от индексации.
Как правило, файл robots.txt создают и настраивают на сайте веб-разработчики. Но при должном желании это может сделать и любой владелец сайта. Для этого нужно знать структуру файла и его основные директивы.
Директивы и структура robots.txt
Как выглядит правильная структура файла, предлагаем рассмотреть на следующем простом примере:
User-agent: *
Disallow: /wp-admin
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
Allow: /*.jpg
Sitemap: http://site.ru/sitemap.xml А теперь объясним, за что в структуре отвечает каждая из директив:
- User-agent (для кого прописаны правила): помогает указать, что правила адресованы конкретным роботам (например, Yandex, Googlebot или другим) либо отметить (с помощью символа «*»), что они относятся к роботам из всех поисковых систем сразу;
- Disallow (запрет индексации): сообщает, какие разделы не должны обходить роботы. Эту директиву нужно прописывать обязательно, даже если на сайте нет служебных файлов (просто не указывайте значение). Без неё поисковые роботы не смогут корректно прочитать robots.txt.
- Allow (разрешение): сообщает, какие разделы или файлы роботы должны просканировать обязательно. Здесь стоит указывать только исключения из правила Disallow. Не нужно прописывать все разделы сайта — роботы автоматически обойдут все, что не запрещается правилами к обходу.
- Sitemap (карта сайта): должна содержать список всех страниц, доступных для индексации (следует указывать полную ссылку на файл в формате .xml.), а также время и частоту их обновления.
 Эту директиву нужно прописывать обязательно, даже если на сайте нет служебных файлов (просто не указывайте значение). Без неё поисковые роботы не смогут корректно прочитать robots.txt.
Эту директиву нужно прописывать обязательно, даже если на сайте нет служебных файлов (просто не указывайте значение). Без неё поисковые роботы не смогут корректно прочитать robots.txt. Как настроить robots.txt: советы
Чтобы поисковые роботы правильно выполняли указанные в файле условия, соблюдайте следующие основные правила:
1. Группируйте директивы. Если вы хотите указать разные правила для поисковых роботов каждой системы, создайте несколько групп с правилами и разделите их пустой строкой.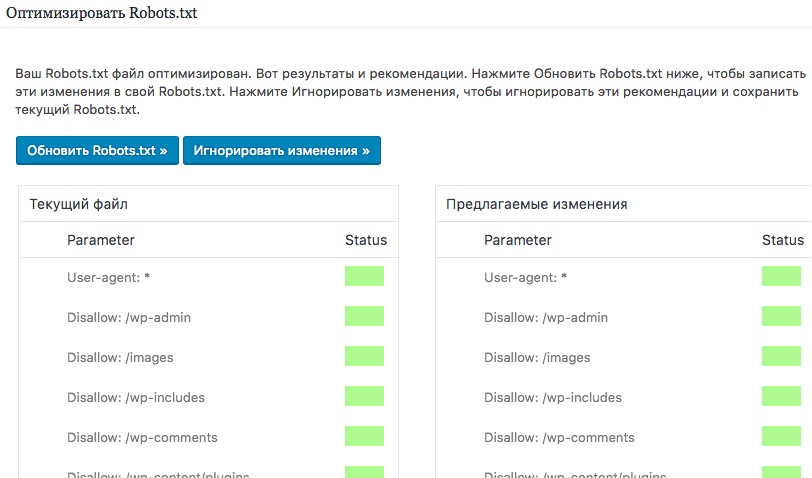 Пример:
Пример:
User-agent: Yandex # правила только для ПС Яндекс
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
# пустая строка
User-agent: Googlebot # правила только для ПС Google
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
Sitemap: # адрес файлаТак роботы не будут путаться и им не придется искать нужную инструкцию во всём документе.
2. Учитывайте регистр. Для некоторых поисковых систем принципиально, чтобы название файла было указано только строчными или прописными. Например, Google правильно прочитает файл только в том случае, если вы укажите название файла строчными — robots.txt. Если этого не сделать, работы проиндексируют сайт некорректно.
4. Удаляйте лишние директивы. После создания файла в нём будут директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов) и Clean-param (ограничение дублирующегося контента). Они считаются устаревшими, поэтому их лучше сразу удалить. Так роботам будет проще ориентироваться в правилах.
Как проверить robots.txt онлайн
Для этих целей существуют сервисы онлайн-проверки, например, Website Planet или PR.CY. Однако, если вы указывали правила специально для роботов Яндекс и Google, то проверять настройки нужно через их сервисы.
Обратите внимание: сервисы позволяют вносить правки в режиме онлайн — так вы сразу сможете понять, какие изменения помогут исправить ошибки. Однако эти изменения не вносятся в robots.txt автоматически. Код нужно поправить вручную (на хостинге или в административной панели CMS), а затем сохранить изменения.
Проверка в Яндекс.Вебмастер
 Вебмастер, перед началом работы добавьте свой сайт и подтвердите права на него. Без этого у вас не будет доступа к инструментам анализа SEO-показателей и продвижения в поисковых системах Яндекс.
Вебмастер, перед началом работы добавьте свой сайт и подтвердите права на него. Без этого у вас не будет доступа к инструментам анализа SEO-показателей и продвижения в поисковых системах Яндекс.Чтобы проверить robots txt:
- Авторизуйтесь в личном кабинете Яндекс.Вебмастер.
- Перейдите в раздел Инструменты — Анализ robots.txt.
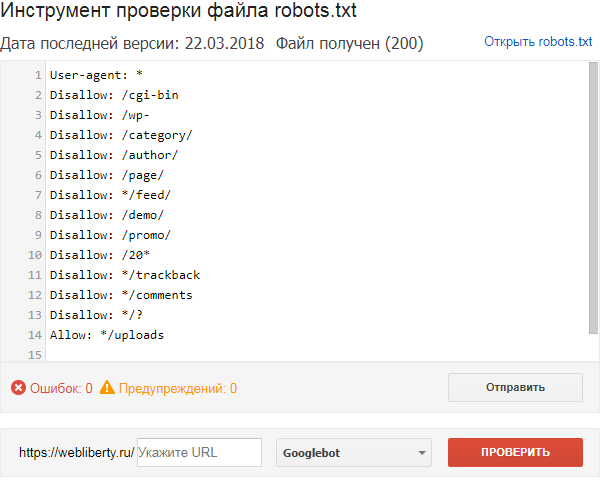
- Содержимое файла должно подтянуться в форму автоматически. Если этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
Готово, вы увидите результаты проверки. Если в директивах есть ошибки, сервис покажет, в какой строке, и опишет проблему:
Проверка в Google Search Console
- Чтобы сделать анализ robots txt:
- Перейдите в сервис проверки.
- Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и действуйте по инструкции Google:
- Подождите несколько минут. Затем обновите страницу, чтобы увидеть актуальные директивы. Если система найдет ошибки, они будут перечислены под кодом.
 Затем обновите страницу, чтобы увидеть актуальные директивы. Если система найдет ошибки, они будут перечислены под кодом.
Затем обновите страницу, чтобы увидеть актуальные директивы. Если система найдет ошибки, они будут перечислены под кодом.Готово, в нашем примере проверка показала, что ошибок нет:
Как сделать правильный Robots.txt для Битрикс, WordPress, Joomla, ModX и других систсем управления
Файл Robots.txt – это текстовый документ в формате .txt, служащий вспомогательным элементом для поисковых роботов и указывающий им какие команды нужно сделать по сайту. Как правило – это: закрытие от индексации не нужных страниц, закрытие от индексации дублей страниц, указание главного зеркала сайта, указания пути адреса к карте сайта.
Так же при первичной разработке сайта, если мы не хотим, что его видели поисковые машины, в файле Robots.txt можно закрыть весь сайт от индексации.
Пример части файла Robots.txt
User-agent: *
Disallow: /nenugnaya-stranica
Host: vashsait.ru
Sitemap: http:// vashsait /sitemap.xml
В данном случае робот разрешает индексацию сайта, но запрещает к индексации одну из страниц «Disallow: /nenugnaya-stranica».
По мимо этого указано главное зеркало сайта «Host: vashsait.ru» и указан путь к карте сайте «Sitemap: http:// vashsait /sitemap.xml».
Основные команды в robots.txt:
Disallow: / — запрещает индексацию всего сайта
Disallow: /nenugnii-razdel — запрещает индексацию к страницам начинающимся с /nenugnii-razdel и все что после
Allow: / — разрешает индексацию всего сайта
Allow: /nenugnii-razdel — разрешает индексацию к страницам начинающимся с /nenugnii-razdel
Host: Директива указывающая поисковым системам, какое зеркало у Вашего сайта считается главным.
Sitemap: Директива указывает путь к карте sitemap.xml сайта
Правильный Robots.txt для системы управления сайтом Битрикс
Ниже представлен стандартный файл для сайтов на движке Битрикса:
User-agent: *
Disallow: /bitrix/
Disallow: /upload/
Disallow: /search/
Allow: /search/map.
Disallow: /club/search/
Disallow: /club/group/search/
Disallow: /club/forum/search/
Disallow: /communication/forum/search/
Disallow: /communication/blog/search.php
Disallow: /club/gallery/tags/
Disallow: /examples/my-components/
Disallow: /examples/download/download_private/
Disallow: /auth/
Disallow: /auth.php
Disallow: /personal/
Disallow: /communication/forum/user/
Disallow: /e-store/paid/detail.php
Disallow: /e-store/affiliates/
Disallow: /club/$
Disallow: /club/messages/
Disallow: /club/log/
Disallow: /content/board/my/
Disallow: /content/links/my/
Disallow: /*/search/
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=yes
Disallow: /*forgot_password=yes
Disallow: /*change_password=yes
Disallow: /*login=yes
Disallow: /*logout=yes
Disallow: /*auth=yes
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*print_course=Y
Disallow: /*bitrix_*= Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*index.
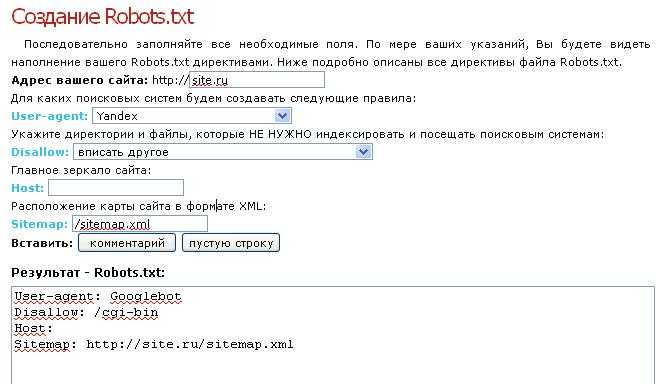 php
php php$
php$Правильный Robots.txt для wordpress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: /wp-comments
Disallow: */trackback
Disallow: */feed
Disallow: */comments
Правильный Robots txt для Joomla
Вот так выглядит стандартный robots.txt сайтов на движке Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/Disallow: /components/
Disallow: /component/*
Disallow: /component/search/
Disallow: /component/content/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Правильный Robots txt для ModX
User-agent: *
Disallow: /assets/cache/
Disallow: /assets/docs/
Disallow: /assets/export/
Disallow: /assets/import/
Disallow: /assets/modules/
Disallow: /assets/plugins/
Disallow: /assets/snippets/
Disallow: /install/
Disallow: /manager/
Disallow: /?
Disallow: /*?
Disallow: /index.
php Host: seoshpargalka.ru
Sitemap: http://seoshpargalka.ru/sitemap.xml
Правильный Robots txt для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Allow: /*?page=
Disallow: /*?
Host: sait.
Sitemap: http://sait.ru/sitemap.xml
 ru
ruRobots.txt: Руководство для начинающих
Содержание
Robots.txt:
Простой файл, содержащий компоненты, используемые для указания страниц веб-сайта, которые нельзя сканировать (или в некоторых случаях необходимо сканировать). поисковыми ботами. Этот файл необходимо поместить в корневой каталог вашего сайта. Стандарт для этого файла был разработан в 1994 году и известен как стандарт исключения роботов или протокол исключения роботов.
Некоторые распространенные заблуждения о robots.txt:
- Блокирует индексацию контента и его отображение в результатах поиска.
Если вы перечислите определенную страницу или файл в файле robots.txt, но URL-адрес страницы будет найден во внешних ресурсах, роботы поисковых систем все равно могут сканировать и индексировать этот внешний URL-адрес и отображать страницу в результатах поиска.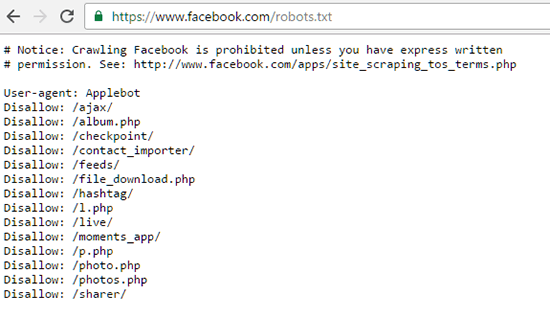 Кроме того, не все роботы следуют инструкциям, данным в файлах robots.txt, поэтому некоторые боты все равно могут сканировать и индексировать страницы, упомянутые в файле robots.txt. Если вам нужен дополнительный блок индексации, метатег robots со значением «noindex» в атрибуте контента будет служить таковым при использовании на этих конкретных веб-страницах, как показано ниже:
Кроме того, не все роботы следуют инструкциям, данным в файлах robots.txt, поэтому некоторые боты все равно могут сканировать и индексировать страницы, упомянутые в файле robots.txt. Если вам нужен дополнительный блок индексации, метатег robots со значением «noindex» в атрибуте контента будет служить таковым при использовании на этих конкретных веб-страницах, как показано ниже:
Подробнее об этом читайте здесь.
- Защищает частное содержимое.
Если у вас есть частный или конфиденциальный контент на сайте, который вы хотите заблокировать от ботов, пожалуйста, не полагайтесь только на robots.txt. Желательно использовать защиту паролем для таких файлов или вообще не публиковать их в сети.
- Гарантирует отсутствие дублирования индексации контента.
Поскольку файл robots.txt не гарантирует, что страница не будет проиндексирована, использовать его для блокировки дублирующегося контента на вашем сайте небезопасно. Если вы используете robots.txt для блокировки дублированного контента, убедитесь, что вы также используете другие надежные методы, такие как тег rel=canonical.
Если вы используете robots.txt для блокировки дублированного контента, убедитесь, что вы также используете другие надежные методы, такие как тег rel=canonical.
- Гарантирует блокировку всех роботов.
В отличие от ботов Google, не все боты являются законными и поэтому могут не следовать инструкциям файла robots.txt, чтобы заблокировать определенный файл от индексации. Единственный способ заблокировать этих нежелательных или вредоносных ботов — заблокировать их доступ к вашему веб-серверу с помощью конфигурации сервера или сетевого брандмауэра, при условии, что бот работает с одного IP-адреса.
Использование robots.txt:
В некоторых случаях использование robots.txt может показаться неэффективным, как указано в предыдущем разделе. Однако у этого файла есть причина, и это его важность для SEO на странице.
Ниже приведены некоторые практические способы использования файла robots.txt:
- Для предотвращения посещения краулерами личных папок.
- Чтобы роботы не сканировали менее примечательный контент на веб-сайте. Это дает им больше времени для сканирования важного контента, который должен отображаться в результатах поиска.
- Чтобы разрешить сканирование вашего сайта только определенным ботам. Это экономит пропускную способность. Поисковые боты по умолчанию запрашивают файлы robots.txt. Если они не найдут его, они сообщат об ошибке 404, которую вы найдете в файлах журнала. Чтобы избежать этого, вы должны как минимум использовать файл robots.txt по умолчанию, то есть пустой файл robots.txt.
- Для предоставления ботам местоположения вашего файла Sitemap. Для этого введите в файле robots.txt директиву, в которой указано местоположение вашего файла Sitemap:
- Карта сайта: http://yoursite.com/sitemap-location.xml

Вы можете добавить это в любом месте файла robots.txt, потому что директива не зависит от строки пользовательского агента. Все, что вам нужно сделать, это указать местоположение вашего файла Sitemap в части sitemap-location. xml URL-адреса. Если у вас несколько файлов Sitemap, вы также можете указать расположение файла индекса Sitemap. Узнайте больше о файлах Sitemap в нашем блоге XML Sitemaps.
xml URL-адреса. Если у вас несколько файлов Sitemap, вы также можете указать расположение файла индекса Sitemap. Узнайте больше о файлах Sitemap в нашем блоге XML Sitemaps.
Ознакомьтесь с нашим Руководством по поисковой оптимизации Robots.txt, чтобы узнать, как работают файлы robots.txt и как их можно использовать для SEO.
Примеры файлов robots.txt:
В файле robots.txt есть два основных элемента: User-agent и Disallow.
Агент пользователя: Агент пользователя чаще всего представлен подстановочным знаком (*), который представляет собой знак звездочки, означающий, что инструкции по блокировке предназначены для всех ботов. Если вы хотите, чтобы определенные боты были заблокированы или разрешены на определенных страницах, вы можете указать имя бота в директиве пользовательского агента.
Disallow: если ничего не указано в disallow, это означает, что боты могут сканировать все страницы на сайте. Чтобы заблокировать определенную страницу, вы должны использовать только один префикс URL для каждого запрета. Вы не можете включать несколько папок или префиксов URL-адресов в элемент disallow в файле robots.txt.
Вы не можете включать несколько папок или префиксов URL-адресов в элемент disallow в файле robots.txt.
Ниже приведены некоторые распространенные варианты использования файлов robots.txt.
Чтобы разрешить всем ботам доступ ко всему сайту (по умолчанию robots.txt) используется следующее:
User-agent:* Disallow:
Чтобы заблокировать весь сервер от ботов, используется этот robots.txt:
User-agent:* Disallow: /
Разрешить одного робота и запретить другим роботам:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Чтобы заблокировать сайт от одного робота:
Агент пользователя: XYZbot Запретить: /
Чтобы заблокировать некоторые части сайта:
Агент пользователя: * Запретить: /tmp/ Запретить: /junk/
Используйте этот файл robots.txt для блокировки всего содержимого определенный тип файла. В этом примере мы исключаем все файлы, которые являются файлами Powerpoint. (ПРИМЕЧАНИЕ: знак доллара ($) указывает на конец строки):
User-agent: * Disallow: *.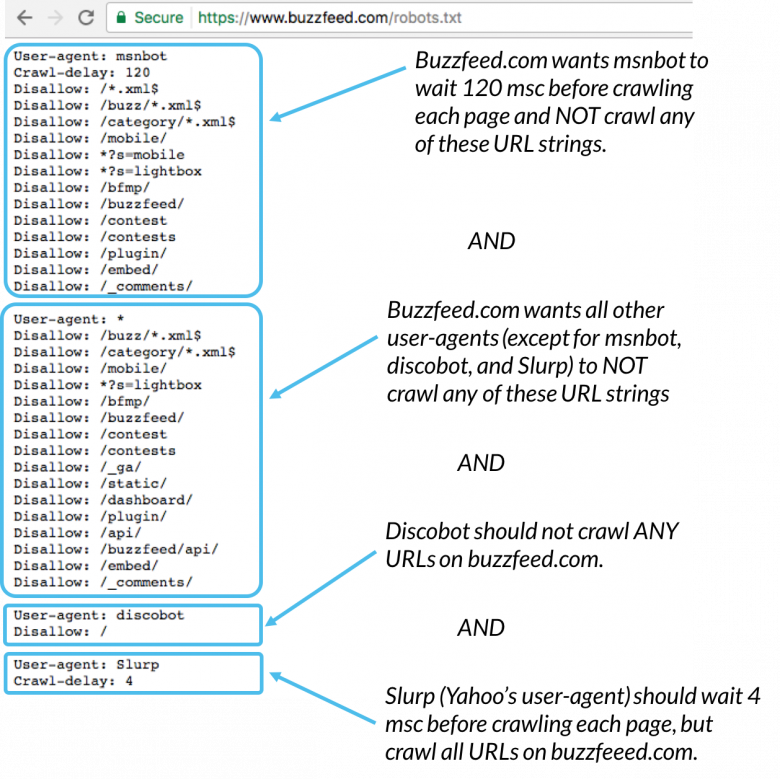 ppt$
ppt$
Блокировать ботов из определенного файла:
User-agent: * Disallow: / каталог/файл.html
Для сканирования определенных HTML-документов в каталоге, который заблокирован от ботов, вы можете использовать директиву Allow. Некоторые основные поисковые роботы поддерживают директиву Allow в файле robots.txt. Пример показан ниже:
User-agent: * Disallow: /folder/ Allow: /folder1/myfile.html
Чтобы заблокировать URL-адреса, содержащие определенные строки запроса, которые могут привести к дублированию содержимого, используется приведенный ниже файл robots.txt. В этом случае любой URL, содержащий вопросительный знак (?), блокируется:
User-agent: * Disallow: /*?
Иногда страница будет проиндексирована, даже если вы включите ее в файл robots.txt по таким причинам, как внешняя ссылка. Чтобы полностью заблокировать отображение этой страницы в результатах поиска, вы можете добавить метатеги robots noindex на эти страницы по отдельности. Вы также можете включить тег nofollow и указать ботам не переходить по исходящим ссылкам, вставив следующие коды:
Чтобы страница не индексировалась:
Для того, чтобы страница не индексировалась и по ссылкам не переходили:
ПРИМЕЧАНИЕ: Если вы добавите эти страницы в файл robots. txt, а также добавить указанный выше метатег на страницу, она не будет сканироваться, но страницы могут отображаться в списках результатов поиска только по URL-адресам, поскольку ботам было специально заблокировано чтение метатегов на странице.
txt, а также добавить указанный выше метатег на страницу, она не будет сканироваться, но страницы могут отображаться в списках результатов поиска только по URL-адресам, поскольку ботам было специально заблокировано чтение метатегов на странице.
Еще один важный момент: вы не должны включать URL-адреса, заблокированные в файле robots.txt, в карту сайта XML. Это может произойти, особенно если вы используете отдельные инструменты для создания файла robots.txt и XML-карты сайта. В таких случаях вам, возможно, придется вручную проверить, включены ли эти заблокированные URL-адреса в карту сайта. Вы можете проверить это в своей учетной записи Google Webmaster Tools, если ваш сайт отправлен и проверен в инструменте, а также отправлена ваша карта сайта.
Перейдите на страницу Инструменты для веб-мастеров > Оптимизация > Карты сайта , и если инструмент покажет какую-либо ошибку сканирования в отправленных картах сайта, вы можете дважды проверить, включена ли эта страница в robots. txt.
txt.
Кроме того, в GWT есть инструмент тестирования robots.txt. Он находится в разделе Инструменты для веб-мастеров > Здоровье > Заблокированные URL-адреса .
Этот инструмент — отличный способ научиться пользоваться файлом robots.txt. Вы можете увидеть, как роботы Google будут обрабатывать URL-адреса после того, как вы введете URL-адрес, который хотите протестировать.
Наконец, есть несколько важных моментов, о которых следует помнить, когда дело доходит до robots.txt:
- Если вы используете косую черту после каталога или папки, это означает, что robots.txt заблокирует каталог или папку и все, что в ней , как показано ниже:
- Запретить: /junk-directory/
- Убедитесь, что файлы CSS и коды JavaScript, отображающие расширенное содержимое, не заблокированы в файле robots.txt, так как это будет препятствовать предварительному просмотру фрагментов.
- Проверьте свой синтаксис с помощью Google Webmaster Tool или поручите это кому-то, кто хорошо разбирается в robots. txt, иначе вы рискуете заблокировать важный контент на своем сайте.
- Если у вас есть два раздела пользовательского агента, один для всех ботов и один для определенного бота, скажем, Googlebots, вы должны иметь в виду, что поисковый робот Googlebot будет следовать только инструкциям в пользовательском агенте для Googlebot и не для общего с подстановочным знаком (*). В этом случае вам, возможно, придется повторить операторы запрета, включенные в общий раздел пользовательского агента, в раздел, относящийся к роботам Google. Взгляните на текст ниже:
- User-agent: * Disallow: /folder1/ Disallow: /folder2/ Disallow: /folder3/ User-agent: googlebot Задержка сканирования: 2 Disallow: /folder1/ Disallow: /folder2/ Запретить: /folder3/ Запретить: /folder4/ Запретить: /folder5/
 txt, иначе вы рискуете заблокировать важный контент на своем сайте.
txt, иначе вы рискуете заблокировать важный контент на своем сайте.Опубликовано
Категория
Подпишитесь на регулярные обновления
Спасибо! Мы отправили вам электронное письмо для подтверждения подписки.
К сожалению, что-то пошло не так. Пожалуйста, попробуйте еще раз
Пожалуйста, попробуйте еще раз
Как создать файл robots.txt в cPanel
ИскатьСодержание
Если вы когда-либо создавали свой веб-сайт, возможно, вы слышали о файле robotx.txt и задавались вопросом, для чего этот файл? Ну, вы в правильном месте! Ниже мы рассмотрим этот файл и его важность.Что такое файл robots.txt?
Во-первых, robots.txt — это не что иное, как обычный текстовый файл (ASCII или UTF-8), расположенный в корневом каталоге вашего домена , который блокирует (или разрешает) поисковым системам доступ к определенным областям. вашего сайта. robots.txt содержит простой набор команд (или директив) и обычно применяется для ограничения трафика сканера на ваш сервер, что предотвращает нежелательное использование ресурсов.
Поисковые системы используют так называемые сканеры (или боты) для индексации частей веб-сайта и возврата их в качестве результатов поиска. Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска. Файл robots.txt поможет вам сделать это.
Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска. Файл robots.txt поможет вам сделать это.
Примечание. Файлы или страницы на вашем веб-сайте не удаляются полностью из поисковых роботов, если эти файлы проиндексированы или на них есть ссылки с других веб-сайтов. Чтобы ваш URL не отображался в поисковых системах Google, вы можете защитить файлы паролем прямо с вашего сервера.
Как создать файл robots.txt
Чтобы создать файл robots.txt (если он еще не существует), выполните следующие действия:
1. Войдите в свою учетную запись cPanel05 2. Перейдите в раздел ФАЙЛЫ и нажмите Диспетчер файлов
cPanel > Файлы > Диспетчер файлов 3. Перейдите в Диспетчер файлов в каталог веб-сайта (например, public_html), затем нажмите « Файл 9».0015 » >> Введите «robots. txt» >> Нажмите « Создать новый файл ».
txt» >> Нажмите « Создать новый файл ».
4. Теперь вы можете редактировать содержимое этого файла, дважды щелкнув по нему.
Примечание: вы можете создать только один r файл obots.txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или поддомен должен содержать собственный файл robots.txt .
Примеры правил использования и синтаксиса
Обычно файл robots.txt содержит одно или несколько правил, каждое из которых находится в отдельной строке. Каждое правило блокирует или разрешает доступ данному сканеру к указанному пути к файлу или ко всему веб-сайту.
- Запретить всем сканерам (пользовательским агентам) доступ к каталогам журналов и ssl .
Агент пользователя:* Запретить: /журналы/ Запретить: /ssl/
- Заблокировать все поисковые роботы для индексации всего сайта.

Агент пользователя: * Disallow: /
- Разрешить всем пользовательским агентам доступ ко всему сайту.
Агент пользователя: * Разрешить: /
- Запретить индексацию всего сайта от определенного поискового робота.
Агент пользователя: Bot1 Disallow: /
- Разрешить индексирование для определенного поискового робота и предотвратить индексирование другими.
Агент пользователя: Googlebot Запретить: Пользовательский агент: * Запретить: /
- Под User-agent : вы можете ввести имя конкретного сканера. Вы также можете включить все поисковые роботы, просто введя символ звездочки (*). С помощью этой команды вы можете отфильтровать все поисковые роботы, кроме сканеров AdBot, которые необходимо перечислить явно. Вы можете найти список всех сканеров в Интернете.