
что это, виды, как устроена
Поисковая система (ПС) — это набор алгоритмов, позволяющих проводить поиск в интернете. Характерная особенность ПС — мгновенное нахождение информации по конкретной фразе или определенному слову. Благодаря процессу индексирования она способна сканировать и затем извлекать данные из миллионов документов. И все это — за считанные миллисекунды.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
История поисковых систем
Первой ПС принято считать W3Catalog — она появилась в 1993 году. W3Catalog представлял из себя не классическую поисковую машину (ПМ), а скорее обычный каталог, содержащий списки сайтов / адресов. Полноценная ПМ в интернете появилась в 1994 году: и это была вовсе не Google, а Aliweb 🙂
 Пример сайтов — в разделе Media and Entertainment
Пример сайтов — в разделе Media and Entertainment
Aliweb первой в мире начала обрабатывать контент сайтов: сканировать, индексировать его, перемещая в собственный индекс.
Так выглядел Aliweb в 1995 годуНо даже у Aliweb еще не было краулеров в привычном для нас понимании, т. е. для автоматического сканирования всех новых страниц. Информацию о новых сайтах добавляли сами вебмастеры: они указывали названия и ключевые слова для каждой страницы в общую базу данных (БД), которую позже и сканировал Aliweb.
За несколько десятилетий было создано свыше тысячи разнообразных ПС. Лишь десятки из них сумели дойти до наших дней и остаются работоспособными сегодня. Самыми популярными поисковыми системами в России уже долгие годы остается Google и «Яндекс».
Самые популярные ПС в мире. Динамика с 2014 по 2021 годыКак устроены поисковые системы
Если проводить аналогию с нецифровым миром, ПС — это картотека в библиотеке, где у каждой книги есть свой уникальный номер.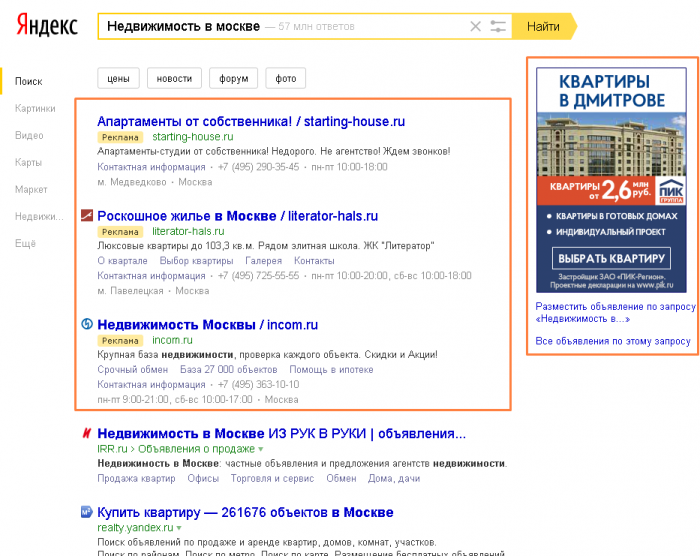
Упрощенный алгоритм работы таков:
- Пользователь указывает поисковый запрос.
- ПС анализирует весь ранее собранный индекс и находит документы, которые ему максимально релевантны.
- Наиболее релевантные документы сортируются: от наиболее близких поисковому запросу к наименее.
- Результаты выводятся на странице поисковой выдачи.
Что такое краулер поисковой системы
Краулер — это специальная программа, используемая ПС для перехода по URL, которые он обнаруживает на веб-странице. Затем краулер помечает такие ссылки специальным образом.
Благодаря найденным URL поисковый робот находит все новые и новые страницы (о которых ПС не знала ранее)Последовательность работы ПС: этапы обработки документа
Поисковая система состоит из трех компонентов:
Далее поговорим о том, как индексирование документов помогает функционировать поисковым системам.
Зачем поисковым системам нужен индекс
Индекс по своей сути — это просто база данных, необходимая для ускорения поискового процесса: извлечения данных о документах, обработки и представлении результатов поиска пользователю. Любые данные из индексной БД «вынимаются» за миллисекунды, ведь в индексе ПС уже хранится информация обо всех страницах в интернете.
Индексация — извлечение важных для ПС данных и дальнейшая их конвертация в понятные поисковой системе форматы
Кэш поисковой системы нужен для ускорения экстракции данных (по аналогии, например, с разархивированием архива в WinRar) с ранее посещенных веб-страниц.
ПС хранят индекс не просто так: они обращаются к нему в дальнейшем, при работе с запросами. Так что хранить эту базу данных где-то, в любом случае, нужно.
Читайте также:
Индексация в поисковых системах: что это простыми словами
Как поисковые системы хранят индекс на своей стороне
Google хранит документы фрагментарно или полностью на своих серверах. Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Как ПС обновляют свой индекс и базы данных
В среде SEO-специалистов обновления индекса систем называются апдейтами выдачи. У каждой поисковой системы такие апдейты происходят по-разному. Google добавляет новые документы в свой индекс ежедневно, причем несколько раз в сутки. «Яндекс» действует по-другому — новые страницы попадают в индекс произвольно (апдейт происходит 2 раза в неделю, например).
Самыми важными факторами является суммарная релевантность ключевой фразы и подобранного документа, проработанность индекса и особенности морфологических параметров языка пользователя.
Виды поисковых систем
Выделим три классификации:
- По особенностям использования индекса.
- По типу индекса.
- По области поиска.
I По особенностям использования индекса
Безиндексные ПС
Это мультипотоковые системы, которые функционируют через крупные поисковые системы. Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Примеры: Bing (Microsoft Bing), AskNet, Quintura, Ixuick, MetaCrawler.
«Нигма» — самая известная российская метапоисковая система (ныне не существует)Классические поисковые машины
Еще говорят «поисковый движок», «поисковые машины с индексом». Пауки ПС сканируют все страницы в интернете, затем формируют собственный индекс (базы данных) с информацией о веб-документах. Поиск по БД в случае классической поисковой машины, условно, состоит из трех этапов:
- Нахождение наиболее релевантного поисковой фразе документа.
- Ранжирование остальных документов исходя из их суммарной релевантности.
- Кластеризация документов.
Кроме этих функций, маркер классической ПМ — разные методы поиска ссылок в ручном и автоматическом режимах. В первом случае их добавляют в поисковую машину сами вебмастеры, во втором — краулеры сканируют сеть самостоятельно.
Примеры: Google и «Яндекс».
Гибридные ПС
Относятся к классическим поисковым машинам, однако с неким допущением можно выделить их и в отдельную категорию.
Индекс здесь собирается не только за счет сканирования краулером ПС, но и благодаря пользовательским источникам данных: реестрам документов, каталогам, справочникам.
Примеры: Yahoo, «Яндекс», Google.
«Яндекс» — поисковая машина гибридного типаЧитайте также:
Отличия SEO под Яндекс и Google
Каталожные поисковые системы
Это пользовательские БД, где все данные добавляются вручную. Качество результатов поиска в таких ПС в теории должно быть заметно выше, чем в автогенерируемых системах.
Они могут выглядеть как рубрикатор заданной иерархии с большим количеством категорий и подкатегорий. Для каждого сайта указывается описание контента, заголовок и ссылка на страницу.
Примеры: Russia on the Net, AtRus, Yahoo!, Directory (сейчас некоторые уже не существуют).
II По типу индекса
В 2022 году массово распространены два типа ПС: с инвертированным индексом и с индексом, имеющим предопределенное расположение ключевых слов. Разница между ними легко прослеживается.
Инвертированный индекс (ИИ)
Для слов в наборе документов указаны все страницы в реестре, где они упоминались. В свою очередь, сам ИИ может быть двух видов:
- Лист документов для каждого слова.
- Лист документов для каждого слова + позиция слова в каждом веб-документе.
Пример: Google.
Индекс с предопределенным расположением ключевых слов (устаревший)
Все фразы упорядочены и отсортированы уже изначально по иерархическому принципу. В настоящий момент не известно ни одной крупной поисковой машины с этим типом индекса.
III По области поиска
Локальная ПС
Отдельностоящее ПО либо веб-приложение, которое разворачивается на компьютере пользователя и позволяет искать информацию, например, на жестком диске или в в пределах домашней сети.
Примеры: Tracker, Copernic Desktop Search.
Глобальная ПС
Веб-сайт / веб-приложение / сервис для поиска документов во всем интернете (или, например, в пределах конкретной доменной зоны).
«Спутник» — национальная поисковая система. Ныне закрытаПримеры: Google, Bing, Yandex, Baidu.
При этом они могут содержать в себе элементы локальных поисковых систем: например, поиск в определенной доменной зоне или поддержка китайского языка по умолчанию, как Baidu. Есть также национальные ПС, созданные для использования в конкретной стране — наши «Спутник» и «Поиск Mail.ru».
Также существуют поисковые системы для поиска информации только в определенных каналах. Например:
- на новостных сайтах;
- внутри FTP-хранилищ.
- в RSS-каналах;
- в библиотечных ресурсах;
- в интернет-магазинах;
- в юзнете.
Юзнет — это глобальная компьютерная сеть для интернет-дискуссий и публикации файлов, состоит из набора групп новостей, организованных по темам. Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Что нужно знать о поисковых системах вебмастеру и пользователю
Поисковая система — это сложный набор алгоритмов, которые работают внутри единой компьютерной программы.
Чтобы новая страница сайта отображалась в результатах поиска, она должна попасть в индекс. Краулеры ПС автоматически обходят все страницы в интернете, добавляя их в специальную базу данных. Обрабатывается также и содержимое страниц.
Читайте также:
Факторы ранжирования Google и Яндекс: что это и как работает
Поисковая выдача зависит от суммарной релевантности документа по отношению к запросу. У каждой ПС свои методы определения релевантности, и подробно о них узнать нельзя. Известно лишь об общих принципах оценки:
- Семантический анализ слов в запросе, включая слова в поисковых фразах вместе и по отдельности.

- Идентифицирование типа запроса.
- Интерпретация орфографических ошибок.
- Определение синонимичности запроса.
- Сопоставление поисковой фразы с особенностями языковой модели.
- Определение актуальности информации.
- Определение региональности запроса.

СДЕЛАЕМ САЙТ, КОТОРЫЙ НРАВИТСЯ ПОИСКОВЫМ СИСТЕМАМ
Сайт
Телефон
Поисковая система «Яндекс» – существующие преимущества и недостатки, отличия от системы Google
Осталось мало людей, которые хотя бы раз не искали ответ на вопросы в интернете. Одной из популярных платформ является поисковая система «Яндекс», которая благодаря особому алгоритму работы помогает решить много задач и за непродолжительное время найти нужную информацию.
Что такое поисковая система «Яндекс»?
Доминирующая русскоязычная система поиска и одновременно группа сервисов, работающая в России и странах СНГ. Первоначально это был только поиск «Яндекс», но в настоящее время в дополнение идет большое количество полезных сервисов востребованных среди русскоязычной аудитории. Девиз компании «Найдется все» и сотрудники делают все, чтобы воплотить в жизнь свои обещания. Использование давно переросло из обычного «погуглить» до уровня «заказа еды и других услуг», а также «отправки писем» и «просмотра статистики сайта».
Первоначально это был только поиск «Яндекс», но в настоящее время в дополнение идет большое количество полезных сервисов востребованных среди русскоязычной аудитории. Девиз компании «Найдется все» и сотрудники делают все, чтобы воплотить в жизнь свои обещания. Использование давно переросло из обычного «погуглить» до уровня «заказа еды и других услуг», а также «отправки писем» и «просмотра статистики сайта».
Как работает поисковая система «Яндекс»?
Функционирование представляет собой не что иное, как действие поисковых роботов. Они переходят по нужным ссылкам, индексируют сайты и сохраняют страницы в своей базе без их полной загрузки на ПК пользователя. Поиск Yandex наделен четким порядком ранжирования, в результате которого сайты располагаются в определенной последовательности. В общем, работа поисковой системы «Яндекс» – набор сложных программ и баз данных, действующих по определенному алгоритму. Упрощенно он разделяется на три этапа:
- Поиск новых страниц.
- Индексация. Процесс попадания информации в индекс поисковой системы «Яндекс». Страницы с бесполезной информацией автоматически отсеиваются системой.
- Определение релевантности и ранжирование. Этап действует только под воздействием человека. После вбивания в поисковую строку запроса, система проводит подбор подходящих ссылок. Ранжирование происходит по количеству совпадений, чем их больше, тем сайт выше.
Поисковая система «Яндекс» – история
Первая версия начала свою работу в 1997 году. Поисковая система «Яндекс. ру» изначально называлась индекс («index» — индексация, индексировать). После творческих переработок получилось «Yet Another iNDEXer» или «YANDEX». Потом первый слог заменили буквой «Я». Современное название появилось в 2008 году. В то время поисковая система «Яндекс» была монополистом в России. После прихода «Гугл» доли постепенно уравнялись. Сегодня происходит постоянная работа по усовершенствованию алгоритмов поиска, индексации и анализа объемов данных, чтобы отвоевать свои позиции.
После прихода «Гугл» доли постепенно уравнялись. Сегодня происходит постоянная работа по усовершенствованию алгоритмов поиска, индексации и анализа объемов данных, чтобы отвоевать свои позиции.
Поисковая система «Яндекс» – плюсы и минусы
К достоинствам можно отнести следующие характеристики:
- Большое количество сервисов, значительно превосходящие главных конкурентов.
- Создание блоков новостей на основной странице.
- Высокий уровень информативности.
- Комфортное и при этом компактное размещение результатов поиска.
- Поисковая система Yandex каждый результат поиска создается индивидуально.
- Система исправляет орфографические ошибки или предлагает подходящий вариант написания.
- Отсутствие спама в поиске и небольшое количество коммерческой информации.
- Удобный поиск по сервисам.
Среди недостатков можно выделить следующие моменты:
- Систематически появляющаяся CAPTCHA.
- Трудности с раскруткой новых сайтов, система подозрительно их воспринимает.
- Сбои в поиске приводят к потере популярности сайтами, которые потом неожиданно возвращаются на свои места.

Чем отличается поисковая система «Яндекс» от «Гугла»?
Платформы разработаны для проведения похожих действий, но при этом имеют некоторые различия. Рассмотрим самые явные:
- Google начинает индексировать новые сайты только спустя 4 мес. Yandex проводит сортировку на начальном этапе.
- Поисковая система «Яндекс точка ру» имеет гибкий таргетинг и поэтому выдает при узких запросах самую точную информацию.
- Мощности Google выше, чем у Яндекс, даже при его локальности.
- Техподдержка Yandex легче выходит на связь.
- Google начал раньше использовать базы знаний их доверенных источников.
- «Яндекс» – главная поисковая система, которая имеет большую зависимость от местного законодательства.
- «Гугл» внедряет в поиск много дополнительных сервисов.
- «Яндекс» имеет мягкую политику по отношению к мусорным запросам.

Похожие статьи
Что такое ID – для чего нужен Айди и чем он отличается от IP? Многие люди не знают, что такое ID, хотя всем пользователям всемирной паутины доводилось сталкиваться с этим понятием при регистрации в социальных сетях. Между тем важно понимать значение Айди компьютера и отличие от IP. |
Как сделать репост – что это такое, особенности разных социальных сетей и Ютуба Информация о том, как сделать репост, будет полезной для пользователей социальных сетей, потому что эта функция позволяет делиться с другими интересными материалами – фото, видео, статьями, текстовыми записями. |
|
Как сделать загрузочную флешку – что это такое, использование разных программ, как из загрузочной сделать обычную флешку? Как сделать загрузочную флешку, должен знать любой пользователь персонального компьютера. | Как поднять ФПС в КС ГО – что это такое, как узнать, почему падает, способы увеличения Как поднять ФПС в КС ГО должен знать каждый геймер, ведь от этого показателя напрямую зависит качество игры. Существуют несколько методов увеличения кадровой частоты, которые всегда лучше применять в комплексе |
 Этот маленький девайс влияет на удобство использования некоторых программ и помогает восстановить операционную систему в случае экстренной необходимости.
Этот маленький девайс влияет на удобство использования некоторых программ и помогает восстановить операционную систему в случае экстренной необходимости.Новый алгоритм поиска Яндекса на основе искусственного интеллекта Палех
Недавно Яндекс объявил о своем новом алгоритме поиска Палех, который улучшает то, как Яндекс понимает значение каждого поискового запроса, используя свои глубокие нейронные сети в качестве фактора ранжирования среди других. В конечном счете, новый алгоритм помогает Яндексу улучшить результаты поиска по всем направлениям, но особенно для поисковых запросов с длинным хвостом.
Как известно большинству читателей State of Digital, поисковые запросы с длинным хвостом классифицируются по запросам, которые поисковая машина обрабатывает очень редко. Существует корреляция между редкостью запроса и его длиной. Как правило, чем короче запрос, тем он чаще встречается, а чем длиннее, тем реже. Такие запросы часто бывают разговорными и подробно описывают что-то, когда пользователь не знает точную фразу или слово, но пытается объяснить поисковику. Например, написать описание фильма, не зная названия, например, «фильм о парне, выращивающем картошку на какой-то планете».
Эти длинные запросы заставляют поисковые системы полностью понять цель запроса, чтобы предлагать наиболее релевантные результаты поиска. Поисковые системы более легко предлагают результаты поиска на основе сходства слов в запросе схожести и релевантности слов в результатах. Проблема запросов с более длинным хвостом заключается в том, что они не так легко совпадают для релевантных синонимов слов, и по этим редким запросам гораздо меньше данных.
Однако запросы с длинным хвостом и результаты поиска можно лучше всего сопоставить, найдя и соединив сходство значений. Яндекс решил внедрить передовой искусственный интеллект, чтобы улучшить поиск совпадений между запросами и результатами, лучше понимая цель запроса, а не сходство самих слов.
Как компания, специализирующаяся на машинном обучении, Яндекс исторически встраивал машинное обучение в 70% своих продуктов и услуг, начиная с поиска. Совсем недавно с Палехом поисковая команда Яндекса научила свои нейронные сети видеть связи между запросом и документом, даже если они не содержат общих слов.
Этот новый алгоритм был назван в честь российского города Палех из-за жар-птицы на его гербе с длинным хвостом. Яндекс назвал все свои поисковые алгоритмы именами российских городов и выбрал Палех, основываясь на символе длинного хвоста и влиянии этого алгоритма на запросы с длинным хвостом.
В этом блоге рассказывается о динамике машинного обучения, лежащей в основе новейшего поискового алгоритма Яндекса Палех, и о том, что отличает его от других способов использования глубоких нейронных сетей для ранжирования веб-поиска.
Машинное обучение — это именно то, что оно самообучается, создавая связи из шаблонов входных данных. Как говорит Яндекс, «машина, которая может учиться, — это машина, которая может принимать собственные решения на основе входных алгоритмов, эмпирических данных и опыта». Как только цель поставлена, модели обучаются для достижения этой цели на основе обучающих образцов. Машина учится создавать правила, которые со временем улучшаются по мере того, как она обрабатывает больше данных. На результаты алгоритма влияют миллионы факторов, которые оказываются гораздо более сложными, чем способность человека обрабатывать или программировать.
Нейронные сети — это метод машинного обучения, созданный по образцу нейронов в человеческом мозгу и предназначенный для решения задач, подобных человеческому мозгу. Нейронные сети основаны на реальных числах и могут быть обучены находить отношения в наборе данных после обработки входных данных и распознавания закономерностей. Их можно обучить анализировать изображения, звук или текст, и они применяются для различных целей, таких как распознавание изображений, перевод текста или ранжирование в веб-поиске.
Их можно обучить анализировать изображения, звук или текст, и они применяются для различных целей, таких как распознавание изображений, перевод текста или ранжирование в веб-поиске.
Яндекс обучил свои нейронные сети с помощью модели семантического отображения, которая сводит информацию к числам, группирует их на основе значения содержания, проецирует группы на семантическую карту, а затем находит совпадения между группами на основе их близости на карте. Как правило, семантическое отображение находит связи между двумя разными объектами, помещая их в одно и то же семантическое пространство и подтверждая их связи на основе их близости друг к другу. В этом случае ранжирования веб-страниц два объекта, которые проверяются на наличие соединений, — это поисковые запросы и документы или заголовки просканированных страниц.
Прежде чем что-то случилось с сопоставлением, поисковая группа сначала должна была обучить алгоритм, предоставив ему примеры пар запросов и соответствующих заголовков веб-страниц. Этот обучающий набор предоставил нейронным сетям базовое понимание связей, которые поисковая команда Яндекса хотела установить.
Этот обучающий набор предоставил нейронным сетям базовое понимание связей, которые поисковая команда Яндекса хотела установить.
Поскольку компьютеры лучше работают с числами, а не со словами, Яндекс затем преобразовал миллиарды поисковых запросов и просканированных страниц в числа. Затем эти числа нужно было организовать так, чтобы за ними стоял смысл. Произвольный набор слов не имеет реального понятия или значения. Только очень определенные наборы слов имеют смысл вместе, и существуют миллионы возможных контекстов. Алгоритм находит небольшие подмножества слов, которые заполнены по смыслу, но это по-прежнему приводит к миллионам возможностей, поэтому числа должны быть сгруппированы. Таким образом, используя метод, называемый уменьшением размерности, матрица сжимает длинный список слов в группу из 300, а затем помещает ее в 300-мерный вектор. Слова могут быть совершенно разными, но если они попадают в один и тот же вектор, то и значение у них похожее. То же самое делается для заголовков просканированных страниц.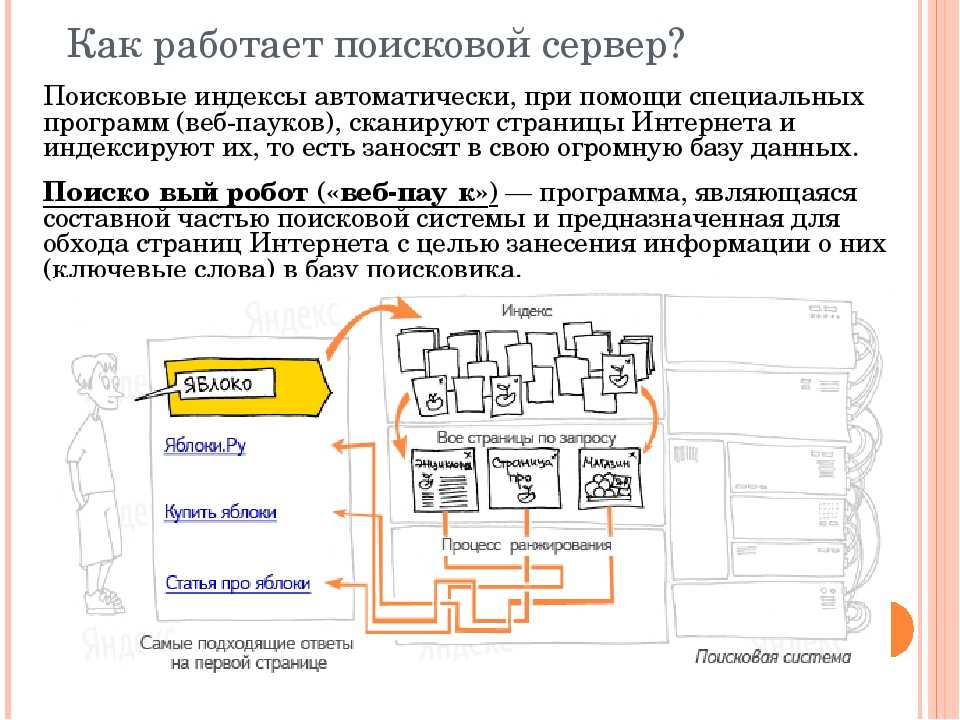
Затем эти семантические векторы используются для поиска совпадений на основе их близости. Каждый запрос и заголовок проверяются, чтобы увидеть, насколько близка проекция размерности заголовка к запросу на карте. Точно так же, как слова выглядят в поисковой системе, векторы тоже.
Для упрощения объяснения предположим, что мы имеем дело с двумерным пространством, поэтому числа рассматриваются как точки на координатной плоскости. Затем заданный запрос и заголовок веб-страницы отображаются на координатной плоскости. Затем можно измерить расстояние между точками запроса и заголовком веб-страницы, чтобы решить, насколько документ релевантен запросу. Чем ближе две точки, тем более релевантен запрос документу.
Почему это особенно полезно для длинных запросов? Помещая запрос в семантический вектор с заголовком веб-страницы, поисковая система понимает, что запрос и заголовок веб-страницы имеют смысл, даже если они не имеют похожих слов. Раньше алгоритмы были более ограничены поиском сходства на основе синонимов и понятий. Например, обувь и ботинки или концепция бренда Kayak и настоящего каяка. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, совпадающие с похожими словами или понятиями. Используя нейронные сети, поисковая система может найти сходство не только слов, но и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов меньше данных, семантическое сопоставление заполняет пробел.
Раньше алгоритмы были более ограничены поиском сходства на основе синонимов и понятий. Например, обувь и ботинки или концепция бренда Kayak и настоящего каяка. Однако, как люди, мы знаем, что запросы с длинным хвостом могут не включать слова, совпадающие с похожими словами или понятиями. Используя нейронные сети, поисковая система может найти сходство не только слов, но и значений. Из-за того, что запросы с длинным хвостом обычно требуют результатов, основанных на значении, и для этих редких запросов меньше данных, семантическое сопоставление заполняет пробел.
Яндекс также включает другие цели для обучения своих нейронных сетей. Эти цели включают предсказание длинных кликов, CTR и модели «кликать или не кликать». Вместо того, чтобы просто использовать одну из своих лучших моделей нейронных сетей, Яндекс включает пять. Сравнивая преимущества включения всех своих моделей, поисковая команда Яндекса отмечает гораздо более точные результаты поиска.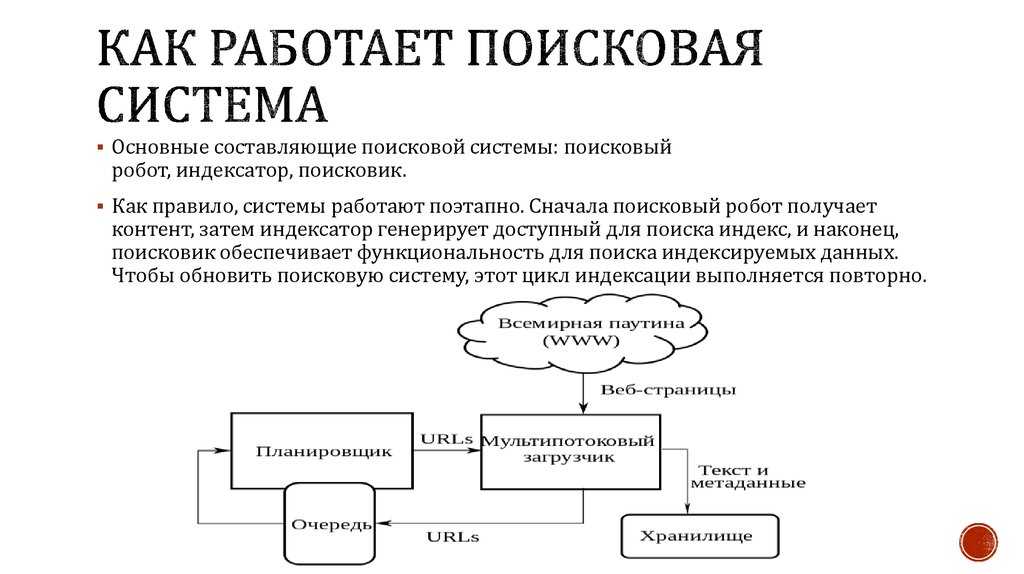 Используя все свои предыдущие факторы ранжирования плюс свою лучшую модель нейронной сети, Яндекс добился улучшения на 1% по длинным хвостовым запросам. Применяя все свои предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к повышению точности запросов с длинным хвостом на 2%.
Используя все свои предыдущие факторы ранжирования плюс свою лучшую модель нейронной сети, Яндекс добился улучшения на 1% по длинным хвостовым запросам. Применяя все свои предыдущие факторы ранжирования и пять моделей нейронных сетей, это улучшение удваивается и приводит к повышению точности запросов с длинным хвостом на 2%.
Яндекс научил свои нейросети видеть заголовки документов, но поисковая команда в настоящее время работает над проверкой текстового содержания. При этом поисковая система Яндекса сможет выдавать еще более точные результаты после более детального изучения того, соответствует ли содержание просканированных страниц заданному запросу. На сегодняшний день другие поисковые системы с аналогичной технологией проверяют только заголовки.
Яндекс также работает над внедрением модели с большим количеством просканированных страниц. В настоящее время модель просматривает сотни документов, которые уже отфильтрованы в топ результатов поиска Яндекса. Поисковая команда Яндекса работает над оптимизацией модели на более ранней стадии поиска, чтобы в конечном итоге она охватила миллиарды документов. Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
Поисковая команда Яндекса работает над оптимизацией модели на более ранней стадии поиска, чтобы в конечном итоге она охватила миллиарды документов. Чем больше документов сможет включить Яндекс, тем точнее будут результаты поиска.
Помимо общего повышения точности результатов поиска Яндекса, это в целом поможет Яндексу лучше понимать разговорные запросы в будущем.
Что это означает для SEO? По мере того, как Яндекс совершенствует свою способность обрабатывать диалоговые запросы, остальным SEO-специалистам и онлайн-маркетологам также придется адаптироваться к этому. Как всегда в SEO, несколько факторов ранжирования имеют значение, и трудно сказать, какие из них имеют наибольшее значение. Однако в конечном итоге качественный контент для пользователя всегда был в центре внимания поисковой команды Яндекса. Палех этого не изменит. SEO-специалисты по-прежнему должны учитывать, что нужно пользователю, не сосредотачиваясь на отдельных ключевых словах и не практикуя наполнение ключевыми словами.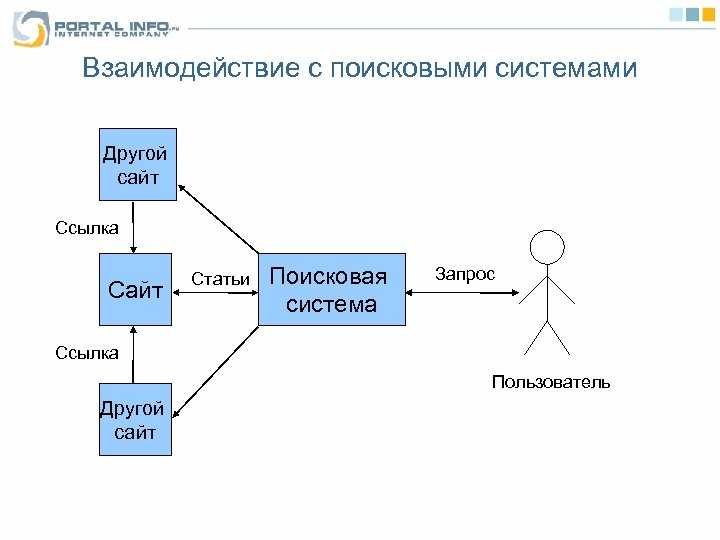 Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса распознает его.
Пока веб-мастера предоставляют контент, который поможет пользователям Яндекса, машинное обучение Яндекса распознает его.
Пользователи Яндекса могут быть уверены, что передовая технология машинного обучения Яндекса будет предоставлять им все более и более релевантные результаты поиска по мере того, как будет обрабатываться больше данных. Поскольку поисковая команда Яндекса успешно обучила Палеха, пользователи могут рассчитывать на взаимодействие с окном поиска Яндекса с гораздо более сложными запросами.
Теги
AI (10) искусственный интеллект (6) поисковая система (5) SEO (451) yandex (26)
Утечка Яндекса включает исходный код популярной российской поисковой системы
TechSpot скоро отметит свое 25-летие. TechSpot — это технический анализ и советы, которым вы можете доверять.
Facepalm: Являясь четвертой по величине поисковой системой в мире, Яндекс является настоящим технологическим гигантом, предлагающим множество цифровых услуг или услуг с цифровыми дополнениями.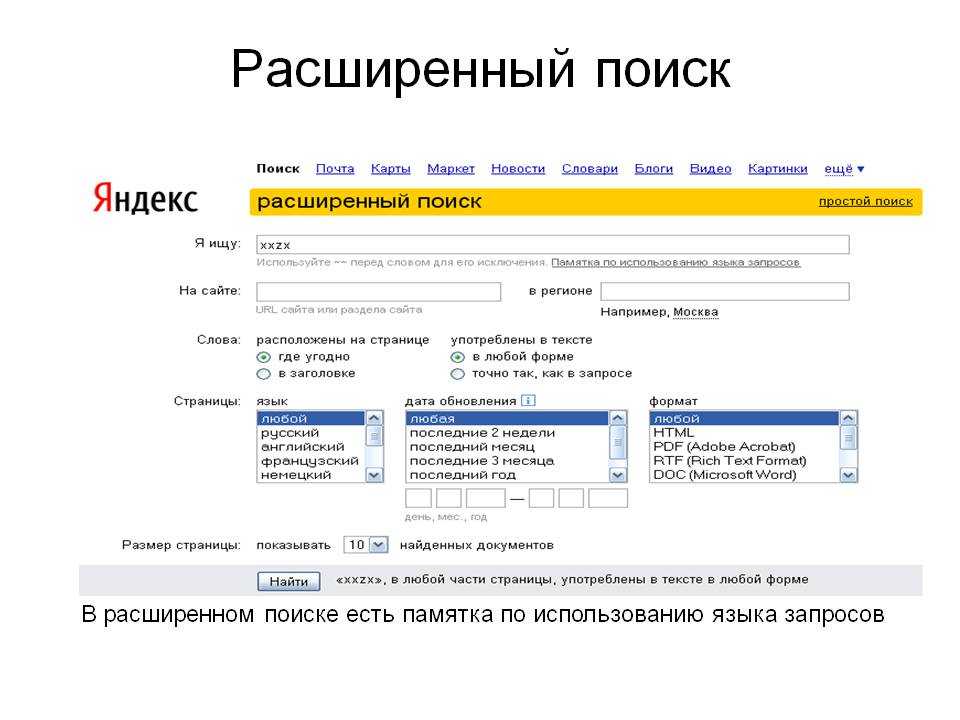 Компания была вовлечена в недавний инцидент с безопасностью, который даст интересные результаты, по крайней мере, для рынка SEO.
Компания была вовлечена в недавний инцидент с безопасностью, который даст интересные результаты, по крайней мере, для рынка SEO.
Почти 50 гигабайт украденных данных из сервисов Яндекса недавно выложили в сеть. Компания пытается преуменьшить утечку, но исходный код, распространяемый через торрент, может раскрыть много полезной информации о том, как на самом деле работают ее сервисы — и, в частности, поисковая система.
Утечка произошла 25 января и касалась списка файлов, которые, по-видимому, были украдены в июле 2022 года из хранилища, относящегося к февралю 2022 года — месяцу, когда Россия начала полномасштабное вторжение в Украину. Торрент, похоже, не содержит никаких данных (или готовых двоичных файлов), кроме исходного кода всех основных сервисов Яндекса, включая поисковую систему с ее ботом-индексатором, Карты (российская версия Google Maps и Street View), Uber- как сервис Такси, Почта, Маркет (альтернатива Amazon), облачная платформа и многое другое.
По словам инженера-программиста Арсения Шестакова, утечка — это серьезно. «Представьте себе одну компанию», способную разом заменить Google, Uber, Amazon, Netflix и Spotify, — сказал кодер. Утечка также реальна, так как Шестаков говорил с разными людьми, которые работали в компании (или до сих пор работают там), и сказал, что некоторые из архивов содержат «современный исходный код» для сервисов Яндекса и документацию, указывающую на реальные URL-адреса интрасети.
«Представьте себе одну компанию», способную разом заменить Google, Uber, Amazon, Netflix и Spotify, — сказал кодер. Утечка также реальна, так как Шестаков говорил с разными людьми, которые работали в компании (или до сих пор работают там), и сказал, что некоторые из архивов содержат «современный исходный код» для сервисов Яндекса и документацию, указывающую на реальные URL-адреса интрасети.
Одним из наиболее интересных и потенциально опасных аспектов утечки является исходный код поисковой системы Яндекс, а именно факторы ранжирования, используемые алгоритмом для предоставления результатов по поисковым запросам пользователей. Утечка перечисляет 1,922 уникальных фактора ранжирования, большинство из которых помечены как «устаревшие» и, вероятно, были заменены в последних версиях кода Яндекса.
Первым фактором ранжирования, используемым российской поисковой системой, является «PAGE_RANK», что является явной отсылкой к наиболее важному алгоритму, используемому Google для ранжирования веб-страниц.