какие бывают и 3 способа избавится от них
Словосочетания «дубликаты страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов
Из многочисленных проблем в SEO, дубли страниц на сайте одна из проблем, которую решить проще всего.
Словосочетания «дубли страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов. Но правда в том, что не каждый дубликат контента является негативным фактором при оптимизации сайта, а вернее сказать, существуют разные типы дубликатов и они не равны!
Почему нужно обратить внимание на дубли страниц?
Дубли страниц с точки зрения поисковых систем
- Они не знают какую страницу следует индексировать, а какую страницу выкидывать из индекса. Вследствие чего, не редки такие случаи, когда то одна страница влетает в поиск, а остальные вылетают, то наоборот. Как следствие, позиции для этой страницы могут существенно изменятся.
- Они не знают какой странице передавать траст и вес, а вернее сказать, они не могут определить, каким образом эти параметры должны передаваться, для каждой страницы, в отдельности или только для одной из них.


Дубли страниц с точки зрения владельца сайта
- Поисковые системы крайне редко ставят в выдачу две страницы с одинаковым содержимым (дубли страницы на сайте), поэтому они вынуждены самостоятельно выбирать, какую из страниц нужно показывать в результатах поиска. Это разбавляет видимость каждого из документов. Как следствие потеря трафика.
- На разные адреса страниц могут быть ссылки внутри сайта или из внешних источников, а поскольку ссылочный вес является одним из факторов ранжирования, то очевидна потеря «веса» остальных страниц.
О неуникальном контенте
Поскольку контент является ключевым элементом хорошего SEO, многие пытались манипулировать результатом поисковой выдачи с помощью старого доброго метода “копировать и вставить”, т.е. забирали контент на свой сайт с других сайтов. Поисковые системы, как правило, наказывают за такой метод, поэтому он должен использоваться с осторожностью, а лучше не использоваться вовсе.
Но, если вы создали не уникальный контент на сайте, не сходите с ума! Ниже мы рассмотрим, как поисковые системы относятся к дубликату контента, и я поделюсь несколькими советами, которые вы можете применить, чтобы убедиться, что содержание вашего сайта свежее и уникальное.
Чтобы лучше понимать как, например, Google обрабатывает дублированный контент, вам нужно ознакомится с их мануалом https://support.google.com/webmasters/answer/66359?hl=ru Если вы боитесь получить фильтр за дублированный контент, позвольте я вас успокою и приведу цитату из данной справки
Наличие на сайте повторяющегося контента не является основанием для принятия каких-либо мер по отношению к нему. Такие меры применяются только в том случае, если это сделано с целью ввести пользователей в заблуждение или манипулировать результатами поиска.
Вот и все, Google сообщает, что сайт не попадет под фильтр за дублированный контент, если вы не вводите пользователей в заблуждение. Но, если на сайте присутствуют дубли, то нужно разобраться, что это за дубли и решить эту проблему. Существует несколько типов дублированного контента:
- Полный дубль – два разных URL’а имеют одинаковый контент
- Частичный дубль – контент на разных страницах имеет мало отличий друг от друга
- Дубли с других доменов – полный или частичный дубль с другими сайтами (доменами).

Дублированный контент может получится в связи с разными ситуациями. Неправильная структура сайта, которая порождает полные или частичные дубли на разных страницах, лицензионное соглашение выбранной CMS, которое может находиться на разных сайта, шаблонные страницы, такие как публичная оферта, тексты законов и так далее.
Каждая из этих проблем имеет свои пути решения. Прежде чем приступить к решению этой проблемы, рассмотрим последствия наличие дублей страниц для сайта.
Последствия дублированного контента
Если вы разместили на сайте кусок дублированного контента по недосмотру или другим случайным причинам, то поисковые алгоритмы могут просто зафильтровать эту часть текста и отобразят в ТОП лучшие, по их мнению материалы.
Иногда они могут отобразить в ТОП и ваш сайт, даже с не уникальном контентом. Пользователи хотят видеть вверху результатов поиска, сайты с лучшим контентом и поисковые алгоритмы оценивая страницы сайтов, так или иначе могут подмешивать в выдачу страницы состоящие из частично неуникального контента.
- Краулинговый бюджет. У каждого сайта есть так называемый краулинговый бюджет. Это количество страниц, которые поисковый робот обходит при очередном посещении сайта. При большом количестве дублей контента (фильтра, сортировки в интернет-магазинах, доступные по разным адресам) поисковый алгоритм заходит на эти URL’ы и как только заканчивается краулинговый бюджет, он покидает сайт, из-за большого количества дублей не доиндексировав сайт.
- Потеря ссылочного веса. На внутренних страницах сайта может быть хороший ссылочный вес, но поисковые алгоритмы могут выкинуть из индекса эти страницы.
- Неправильные страницы в выдаче. Никто точно не знает, как работаю поисковые алгоритмы. Поэтому в поисковую выдачу они могут поставить совсем не ту страницу которую следовало бы из пула дубликатов.
Почему появляются дубли страниц?
Существует несколько основных путей появления таких станиц:
1.
 Параметрические URL
Параметрические URLПараметры URL, такие как фильтра, UTM-метки и прочее создают дубль страницы.
Например, адрес этой страницы : https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya , но она также доступна по следующим адресам:
- https://ex-pl.com/index.php?option=com_content&Itemid=682&catid=11&id=102&lang=ru&view=article;
- https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya?utm
Однако в первом случае происходит 301 редирект, во-втором, в коде страницы есть тег rel=canonical, но об этом ниже.
2. Домен с www и без www, с http и(или) https
Если ваш сайт доступен по двум адресам «site.ru» и «www.site.ru», один и тот же контент представлен на обоих версиях сайта, т.е. каждая страница сайта имеет полный дубликат. Такая же ситуация и с http:// и https:// если сайт доступен по обоим протоколам, то у каждой страницы также есть свой дубликат.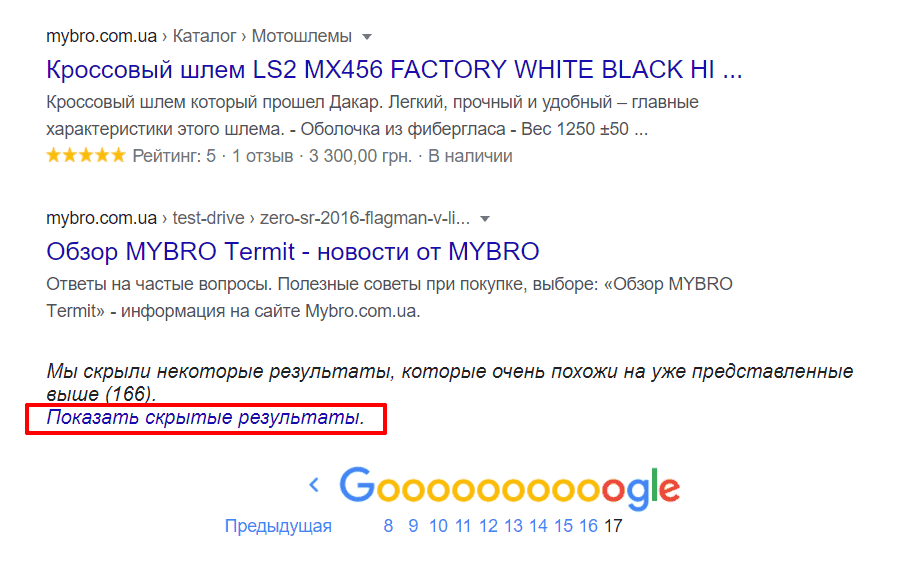
3. Неуникальный контент
Контент страницы состоит не только из обычного текста или записей в блогах, сюда же можно отнести и графику, и документы в docx, pdf, итд, а также и характеристики и описания продуктов или товаров, если мы говорим о интернет-магазинах. Если множество разных интернет-магазинов продают один и тот же товар и для описания товара используют данные производителя, то такой контент, наверняка, будет использован на множестве других сайтов.
Как найти дубли страниц на сайте?
Существует несколько методов поиска дублей страниц.
Google WebMaster
В Google Search Console вы можете посмотреть, у каких страниц есть повторяющиеся заголовки, проверить эти страницы и сделать вывод о том, являются ли эти страницы дублями.
Программа Xenu Link Sleuth
Xenu Link Sleuth – одна из необходимых программ для любого SEO-оптимизатора, которая помогает провести технический аудит сайта и выявить одинаковые заголовки (titles).
Просто просканируйте сайт этой программой, отсортируйте результаты в алфавитном порядке по заголовку и вы увидите одинаковые заголовки. Скорее всего страницы с одинаковыми заголовками являются дубликатами.
Скорее всего страницы с одинаковыми заголовками являются дубликатами.
Воспользоваться операторами в поисковой системе
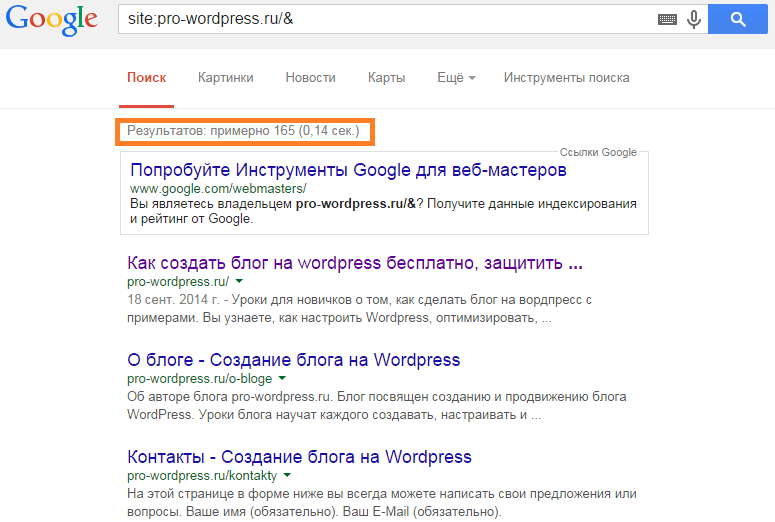
В поисковых системах можно произвести поиск не только в глобальной сети, но и на одном отдельно взятом сайте. Например, для того, чтобы в Google найти дубликаты на сайте, нужно сделать специальный запрос, который выглядит следующим образом: site:test.ru -site:test.ru/&.
- site:test.ru – вывод всех проиндексированных страниц
- site:mysite.com/& — вывод страниц участвующих в поиске
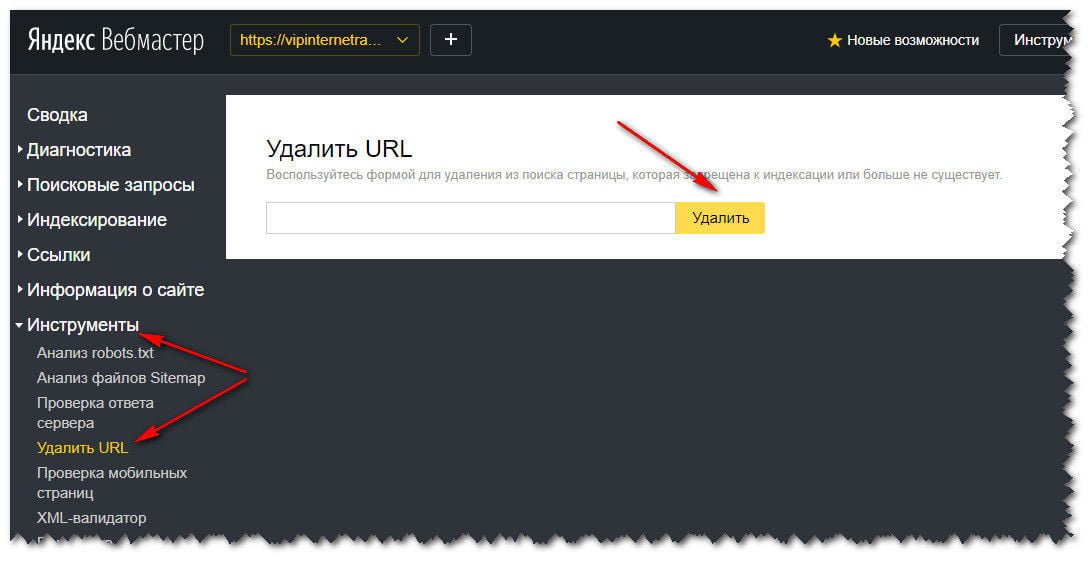
Как бороться с дублями страниц на сайте
Наличие не уникального контента на сайте, как в пределах сайта, так и в пределах интернета, не самое полезное явление для поисковых алгоритмов и пользователей сайта. Проще говоря, дублированный контент может негативно сказаться на продвижении сайта, поэтому, желательно от него избавиться. Есть несколько путей решения данной проблемы:
Использование 301 редиректов. Это один из подходов для того, чтобы избавиться от дубликатов. Если один из дублей страниц внутри сайта имеет наибольший ссылочный вес, то решением является сделать 301 редирект из пула дубликатов именно на эту страницу.
Если один из дублей страниц внутри сайта имеет наибольший ссылочный вес, то решением является сделать 301 редирект из пула дубликатов именно на эту страницу.
Использование файла robots.txt. Еще один выход это использование директив в файле robots.txt, который позволит запретить индексировать дубликаты страниц. В зависимости от ситуации, такое решение может быть не самым лучшим, т.к. директивы в файле robots.txt имеют рекомендательный характер.
Использование rel=“canonical”. Если вы хотите избавиться от дублированного контента, использование rel=“canonical” прекрасный выбор. Данный тег сообщает поисковым алгоритмам, какая страница из пула дубликатов является главной. Этот тег используется в <head></head> и выглядит следующим образом:
<link href="https://ex-pl.com/blog/kak-perejti-na-https-gotovyj-kejs" rel="canonical" />
Хотя дубликаты контента являются проблемой и могут помешать в поисковом продвижении сайта, они не так уж и страшны. Если вы намеренно не пытаетесь манипулировать поисковой выдачей, то поисковые системы, как правило, не наказывают вас.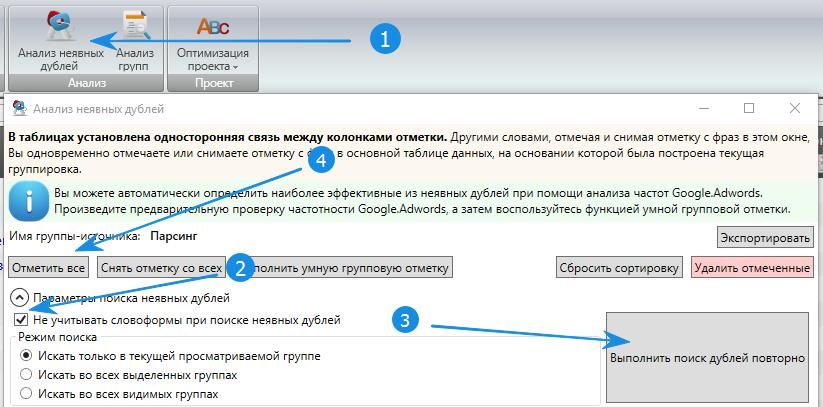 Но, как и говорилось выше, существуют и другие негативные последствия за дублированный контент. Я рекомендую избавиться от дублированного контента, это первый шаг к улучшению позиций сайта.
Но, как и говорилось выше, существуют и другие негативные последствия за дублированный контент. Я рекомендую избавиться от дублированного контента, это первый шаг к улучшению позиций сайта.
Дубли страниц сайта — поиск и удаление
Что такое дубли страниц
В рамках одного доменного имени очень может такое быть, что один и тот же контент доступен по разным адресам.
Вполне вероятно, что на разных страницах сайта опубликован очень похожий или же полностью дублированный контент. Это может быть одинаковые (или очень похожие) описания meta name="description" content="", заголовки h2, title страницы. Если после проверки на наличие дубликатов выяснилось, что они присутствуют в вашем приложении, то необходимо устранить ненужные дубли страниц.
Дубли — это страницы, которые или очень похожи или являются полной копией (дублем) основной (продвигаемой вами) страницы.
Причины появления дублей страниц на сайте
- Не указано главное зеркало сайта. Одна и та же страница доступна по разным URL (с www. и без | с http и с https).
- Версии страниц сайта для печати, не закрытые от индексации.
- Генерация страниц с одними и теми же атрибутами, расположенными в разном порядке. Например,
/?id=1&cat=2и/?cat=2&id=1. - Автоматическая генерация дубликатов движком приложения (CMS). Из-за ошибок в системе управления контентом (CMS), так же могут появляются дубли страниц.
- Ошибки веб-мастера при разработке (настройке) приложения.
- Дублирование страницы (статьи, товара…) веб-мастером или контент-маркетологом.
- Изменение структуры сайта, после которого страницам присваиваются новые адреса, а старые не удаляются.
- На сайте используются «быстрые» мобильные версии страниц, с которых не выставлен
Canonicalна основные версии. - Сознательное или несознательное размещение ссылок третьими лицами на ваши дубли с других ресурсов.
 Одна и та же страница доступна по разным URL (с www. и без | с http и с https).
Одна и та же страница доступна по разным URL (с www. и без | с http и с https).
Виды дублей
Дубликаты различают на 3 вида:
- Полные — с полностью одинаковым контентом;
- Частичные — с частично повторяющимся контентом;
- Смысловые, когда несколько страниц несут один смысл, но разными словами.
Полные
Полные дубли ухудшают факторы всего сайта и осложняют его продвижение в ТОП, поэтому от них нужно избавиться сразу после обнаружения.
- Версия с/без
www. Возникает, если пользователь не указал зеркало в панели Яндекса и Google. - Различные варианты главной страницы:
- site.com
- site.com/default/index
- site.com/index
- site.com/index/
- site.com/index.html
- Страницы, появившиеся вследствие неправильной иерархии разделов:
- site.com/products/apple/
- site. com/products/category/apple/
- site.com/category/apple/
- UTM-метки. Метки используются, чтобы передавать данные для анализа рекламы и источника переходов. Обычно они не индексируются поисковиками, но бывают исключения.
- GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес страницы:
- site.com/products/apple/page.php?color=green
- Страницы, сгенерированные реферальной ссылкой. Обычно они содержат специальный параметр, который добавляется к URL. С такой ссылки должен стоять редирект на обычный URL, однако часто этим пренебрегают.
- Неправильно настроенная страница с ошибкой 404, которая провоцирует бесконечные дубли. Любой случайный набор символов в адресе сайта станет ссылкой и без редиректа отобразится как страница 404.
 com/products/category/apple/
com/products/category/apple/Избавиться от полных дубликатов можно, поставив редирект, убрав ошибку программно или закрыв документы от индексации.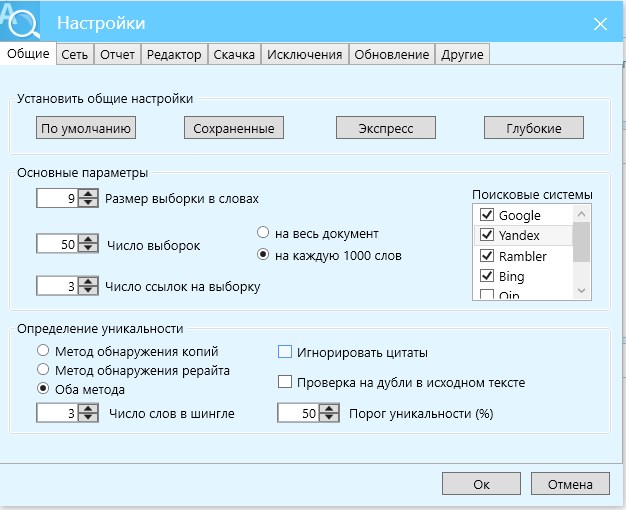
Частичные
Частичные дубликаты не так страшны для на сайта, как полные. Однако, если их много — это ухудшает ранжирование веб-приложения. Кроме того, они могут мешать продвижению и по конкретным ключевым запросам. Разберем в каких случаях они возникают.
Характеристики в карточке товара
Нередко, переключаясь на вкладку в товарной карточке, например, на отзывы, можно увидеть, как это меняет URL-адрес. При этом большая часть контента страницы остаётся прежней, что создает дубль.
Если CMS неправильно настроена, переход на следующую страницу в категории меняет URL, но не изменяет Title и Description. В итоге получается несколько разных ссылок с одинаковыми мета-тегами:
- site.com/fruits/apple/
- site.com/fruits/apple/?page=2
Такие URL-адреса поисковики индексируют как отдельные страницы. Чтобы избежать дублирования, проверьте техническую реализацию вывода товаров и автогенерации.
Также на каждой странице пагинации необходимо указать каноническую страницу, которая будет считаться главной.
Подстановка контента
Часто для повышения видимости по запросам с указанием города в шапку сайта добавляют выбор региона. При нажатии которого на странице меняется номер телефона. Бывают случаи, когда в адрес добавляется аргумент, например city_by_default=. В результате, у каждой страницы появляется несколько одинаковых версий с разными ссылками. Не допускайте подобной генерации или используйте 301 редирект.
Версия для печати
Версии для печати полностью копируют контент и нужны для преобразования формата содержимого. Пример:
- site.com/fruits/apple
- site.com/fruits/apple/print – версия для печати
Поэтому необходимо закрывать их от индексации в robots.txt.
Смысловые
Смысловые дубли — контент страниц, написанный под запросы из одного кластера. Чтобы их обнаружить (смысловые дубли страниц), нужно воспользоваться результатом парсинга сайта, выполненного, например, программой Screaming Frog. Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Чем опасны дубли страниц на сайте
Наличие дубликатов на сайте — один ключевых факторов внутренней оптимизации (или её отсутствия), который крайне негативно сказывается на позициях сайта в органической поисковой выдаче. Дубли служат причиной нескольких проблем, связанных с оптимизацией:
- Индексация сайта. При большом количестве дублей поисковые роботы в силу ограниченного краулингового бюджета могут не проиндексировать нужные страницы. Также есть риск того, что сайт будет пессимизирован, а его краулинговый бюджет — урезан.
- Проблемы с выдачей приоритетной страницы в органическом поиске. За счет дублей в поисковую выдачу может попасть не та страница, продвижение которой планировалось, а её копия. Есть и другой вариант: обе страницы будут конкурировать между собой, и ни одна не окажется в выдаче.
- «Распыление» ссылочного веса. Вес страницы сайта — это своеобразный рейтинг, выраженный в количестве и качестве ссылок на неё с других сайтов или других страниц внутри этого же сайта. При наличии дублей ссылочный вес может переходить не на единственную версию страницы, а делиться между ее дубликатами. Таким образом, все усилия по внешней оптимизации и линкбилдингу оказываются напрасными.

Инструменты для поиска
Как найти дублирующиеся страницы? Это можно сделать с помощью специальных программ и онлайн сервисов. Часть из них платные, другие – бесплатные, некоторые – условно-бесплатные (с пробной версией или ограниченным функционалом).
Яндекс Вебмастер
Чтобы посмотреть наличие дубликатов в панели Яндекса, необходимо зайти: Индексирование -> Страницы в поиске -> Исключённые.
Страницы исключаются из индекса по разным причинам, в том числе из-за повторяющегося контента (дублирования). Обычно конкретная причина прописана под ссылкой.
Обычно конкретная причина прописана под ссылкой.
Google Search Console
Посмотреть наличие дублей страниц в панели Google Search Console можно так: Покрытие -> Исключено.
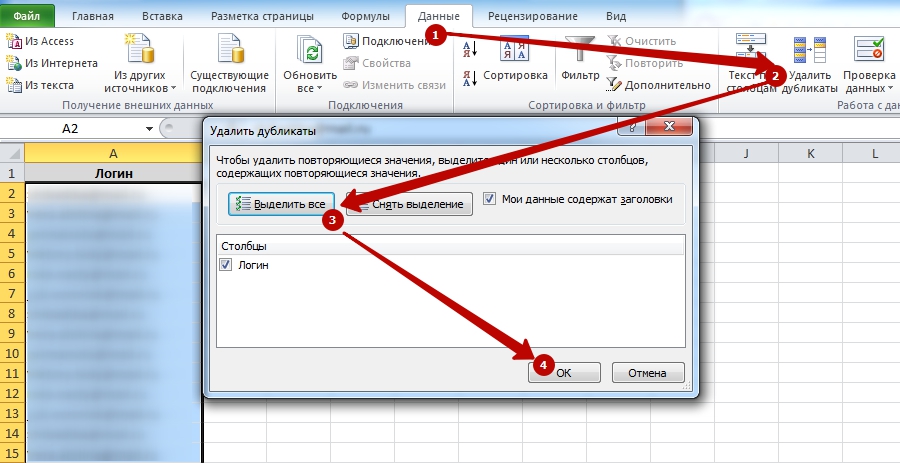
Netpeak Spider
Netpeak Spider – платная программа с 14-дневной пробной версией. Если провести поиск по заданному сайту, программа покажет все найденные ошибки и дубликаты.
Xenu
Xenu — бесплатная программа, в которой можно проанализировать даже не проиндексированный сайт. При сканировании программа найдет повторяющиеся заголовки и мета-описания.
Сайт Репорт
Сайт Репорт — это неплохой сервис, предоставляющий пользователю инструмент диагностики внутренних и внешних факторов с целью оптимизации сайта. Поиск дубликатов — это один из множества инструментов сервиса по оптимизации сайта или другого приложения. Сервис предоставляет бесплатный анализ до 25 страниц. Если у вас на сайте большее количество страниц, то (при необходимости) придётся немного потратиться. Но оно того стоит.
Но оно того стоит.
Screaming Frog Seo Spider
Screaming Frog Seo Spider является условно-бесплатной программой. До 500 ссылок можно проверить бесплатно, после чего понадобится платная версия. Наличие дублей программа определяет так же, как и Xenu, но быстрее и эффективнее.
Как начать пользоваться бесплатно:
- Скачать программу Screaming Frog Seo Spider и установить её на свой ПК. Скачать ключ-активатор для программы. Пароль к архиву:
prowebmastering.ru - Запустить
keygen.exe, задать имя пользователя и ключ (ключ можно сгенерировать) - В самой программе Screaming Frog Seo Spider выбрать вкладку «Licence» -> «Enter Licence»
- В появившемся окне указать то, что указали (или сгенерировали) при запуске
keygen.exe, жмём «OK», перезапускаем программу.
Документация по работе с программой Screaming Frog Seo Spider здесь.
Поисковая выдача
Результаты поиска могут отразить не только нужный нам сайт, но и некое отношение поисковой системы к нему. Для поиска дублей в Google можно воспользоваться специальным запросом.
Для поиска дублей в Google можно воспользоваться специальным запросом.
site:mysite.ru -site:mysite.ru/&
site:mysite.ru — показывает страницы сайта mysite.ru, находящиеся в индексе Google (общий индекс).
site:mysite.ru/& — показывает страницы сайта mysite.ru, участвующие в поиске (основной индекс).
Таким образом, можно определить малоинформативные страницы и частичные дубли, которые не участвуют в поиске и могут мешать страницам из основного индекса ранжироваться выше. При поиске обязательно кликните по ссылке «повторить поиск, включив упущенные результаты», если результатов было мало, чтобы видеть более объективную картину.
Варианты устранения дубликатов
При дублировании важно не только избавиться от копий, но и предотвратить появление новых.
Физическое удаление
Самым простым способом было бы удалить повторяющиеся страницы вручную. Однако перед удалением нужно учитывать несколько важных моментов:
- Источник возникновения. Зачастую физическое удаление не решает проблему, поэтому ищите причину
- Страницы можно удалять, только если вы уверены, что на них не ссылаются другие ресурсы
 Зачастую физическое удаление не решает проблему, поэтому ищите причину
Зачастую физическое удаление не решает проблему, поэтому ищите причинуНастройка 301 редиректа
Если дублей не много или на них есть ссылки, настройте редирект на главную или продвигаемую страницу. Настройка осуществляется через редактирование файла .htaccess либо с помощью плагинов (в случае с готовыми CMS). Старый документ со временем выпадет из индекса, а весь ссылочный вес перейдет новой странице.
Создание канонической страницы
Указав каноническую страницу, вы показываете поисковым системам, какой документ считать основным. Этот способ используется для того, чтобы показать, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Для этого на всех дублях в теге прописывается следующая строчка со ссылкой на оригинальную страницу:
<link rel="canonical" href="http://site.
 com/original.html">
com/original.html">Например, на странице пагинации главной должна считаться только одна страница: первая или «Показать все». На остальных необходимо прописать атрибут rel="canonical", также можно использовать теги rel=prev/next:
// Для 1-ой страницы: <link rel="next" href="http://site.com/page/2"> <link rel="canonical" href="http://site.com"> // Для второй и последующей: <link rel="prev" href="http://site.com"> <link rel="next" href="http://site.com/page/3"> <link rel="canonical" href="http://site.com">
Запрет индексации в файле Robots.txt
Файл robots.txt — это своеобразная инструкция по индексации для поисковиков. Она подойдёт, чтобы запретить индексацию служебных страниц и дублей.
Для этого нужно воспользоваться директивой Disallow, которая запрещает поисковому роботу индексацию.
Disallow: /dir/ – директория dir запрещена для индексации Disallow: /dir – директория dir и все вложенные документы запрещены для индексации Disallow: *XXX – все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
Внимательно следите за тем какие директивы вы прописываете в robots.txt. При некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
Запрет индексировать страницы действует для всех роботов. Но каждый из них реагирует на директиву Disallow по-разному: Яндекс со временем удалит из индекса запрещенные страницы, а Google может проигнорировать правило, если на данный документ ведут ссылки..
Вывод
Дублирующиеся h2, title, description, а также некоторые части контента вроде отзывов и комментариев очень нежелательны и осложняют продвижение сайта. Поэтому обязательно проверяйте ресурс на дубликаты, как сгенерированные, так и смысловые и применяйте описанные в статье методы для их устранения.
Как быстро идентифицировать повторяющийся контент с помощью обхода сайта
В этой статье кратко рассказывается, как использовать поисковый робот сайта для быстрого выявления дублирующегося контента. Существует много инструментов, но Screaming Frog, безусловно, является одним из самых популярных/мощных парсеров, и именно его мы выбрали для этого урока.
Существует много инструментов, но Screaming Frog, безусловно, является одним из самых популярных/мощных парсеров, и именно его мы выбрали для этого урока.
Первым шагом к любому обходу сайта является настройка. Ограничьте количество сканируемых страниц любым способом, который вы считаете нужным, поскольку, как правило, в интересах каждого избежать очистки всего Интернета.
Показанные выше параметры были выбраны для этого примера сканирования Costco.com. Ограничив «Общий лимит поиска», Screaming Frog будет сканировать только первые 100 URL-адресов, которые встретится.
Указав параметры, введите адрес сайта и нажмите «Старт». В большинстве инструментов сканирования URL-адреса отображаются по мере их запроса. Когда прогресс завершится, нажмите «Экспорт».
Пока Screaming Frog использовался для получения списка результатов, показанных ниже, можно использовать любой инструмент, который может запрашивать, анализировать и экспортировать эти данные:
- Адрес
- Код состояния
- Название страницы
- Метаданные
- Метаобновление
- Канонический
Красота в простоте, и этот отчет определенно прост, но эффективен. Справа от кодов состояния находится заголовок страницы, отсортированный по возрастанию, с выделенными повторяющимися значениями (с использованием условного форматирования в Excel). Столбцы справа от заголовков страниц показывают, содержат ли эти страницы директивы, которым будут следовать поисковые системы.
Справа от кодов состояния находится заголовок страницы, отсортированный по возрастанию, с выделенными повторяющимися значениями (с использованием условного форматирования в Excel). Столбцы справа от заголовков страниц показывают, содержат ли эти страницы директивы, которым будут следовать поисковые системы.
- Метаданные: Будут отображаться любые теги Meta Robots Noindex
- Meta Refresh: Иногда используется для перенаправления пользователей
- Канонический: Используется на дублирующихся (или подмножественных) страницах для указания на авторитетный или рейтинговый URL-адрес
Продолжая использовать методологию выявления дублированного контента, просматривая столбец «Названия страниц» и ища дубликаты, выделенные розовым цветом, мы обнаруживаем то, что выглядит как дубликаты страниц обслуживания клиентов на изображении, показанном выше.
http://www.costco.com/customer-service.html
http://www. costco.com/customer-service.html?cm_re=Common-_-Top_Nav-_-Customer_Service
costco.com/customer-service.html?cm_re=Common-_-Top_Nav-_-Customer_Service
Ресурсы
Глядя вправо, видно, что метаданные и метаобновление не используется, но оба содержат канонический адрес:
http://www.costco.com/customer-service.html
Это отличная новость! Это означает, что они используют самореферентные канонические символы, чтобы справиться хотя бы с частичным дублированием.
Теперь, просматривая оставшуюся часть этих данных, мы знаем, что может быть много случаев одного и того же, поэтому может быть проще искать случаи, когда есть дублирующиеся заголовки страниц, но канонический пуст. Для больших наборов данных было бы неплохо использовать для этого фильтры, но, поскольку это всего лишь пример сканирования, вы можете видеть ниже, что это довольно очевидно.
Подождите, что это там, Costco? Похоже, они забыли использовать свою каноническую стратегию для главной страницы!
http://www.costco.com/
http://www.costco. com/?cm_re=Common-_-Top_Nav-_-Home
com/?cm_re=Common-_-Top_Nav-_-Home
http://www.costco.com/TopCategories?langId=-1&storeId=10301&catalogId=10701
Throw Включение этих дубликатов страниц в Open Site Explorer и Majestic SEO не выявило обратных ссылок, но, поскольку эти страницы имеют внутренние ссылки и на них можно перемещаться, у пользователей определенно есть возможность ссылаться на них и возможность разделения ссылок. Лучшие практики предполагают, что они добавляют каноническую ссылку на себя на домашнюю страницу, чтобы убедиться, что любые свойства индексации URL-адресов, содержащих параметры отслеживания, объединены на их законном месте, странице ранжирования.
Поисковые роботы следует использовать с осторожностью! Сайт может выйти из строя, если он сканируется слишком быстро. При этом они играют ключевую роль в выявлении проблем на сайте, имеющих отношение к SEO, а также в понимании масштабов конкретной проблемы.
Подробнее:
Как обнаружить дубликаты веб-сайтов
Киберпреступники будут копировать ваш контент, чтобы нанести ущерб репутации вашего бренда, переманить клиентов от вашего бизнеса к их нелегальному бизнесу или просто удовлетворить требования к контенту, которые они не могут удовлетворить самостоятельно. Копирование вашего контента для создания поддельного, похожего на веб-сайт (также называемого фишинговым сайтом) не только наносит ущерб репутации вашего бренда и влияет на вашу прибыль, но дублирование или «удаление» контента негативно влияет на ваш SEO-рейтинг и может привести к тому, что ваша страница будет деиндексирована Google.
Копирование вашего контента для создания поддельного, похожего на веб-сайт (также называемого фишинговым сайтом) не только наносит ущерб репутации вашего бренда и влияет на вашу прибыль, но дублирование или «удаление» контента негативно влияет на ваш SEO-рейтинг и может привести к тому, что ваша страница будет деиндексирована Google.
Только в 2020 году Google обнаружил 2,11 миллиона фишинговых сайтов, что на 25% больше, чем годом ранее, и с тех пор уровень киберпреступности фактически вырос! Узнайте, как обнаружить дубликаты веб-сайтов и контента в этой статье. Вы также узнаете:
- Почему люди дублируют веб-сайты и контент
- Какое влияние дублирующий веб-сайт оказывает на ваш бренд и SEO-рейтинг
- Как мошенники дублируют сайт?
- Что делать, если вы обнаружили, что ваш сайт был скопирован
- Как предотвратить кражу и дублирование вашего контента веб-сайтами
Дублирование веб-сайтов: почему это происходит?
Дублированные веб-сайты также известны как подделка домена, фишинговые сайты и даже похожие веб-сайты-подражатели. Киберпреступники копируют некоторые идентифицирующие элементы вашего веб-сайта, такие как логотип, доменное имя и письменный контент, чтобы обмануть клиентов, заставив их поверить в то, что они делятся своими личными данными для входа или тратят свои деньги в надежной компании. По сути, киберпреступник питается уважением, которое создал ваш бренд.
Киберпреступники копируют некоторые идентифицирующие элементы вашего веб-сайта, такие как логотип, доменное имя и письменный контент, чтобы обмануть клиентов, заставив их поверить в то, что они делятся своими личными данными для входа или тратят свои деньги в надежной компании. По сути, киберпреступник питается уважением, которое создал ваш бренд.
В общем, у мошенника, дублирующего ваш сайт, есть три варианта выхода:
- Продажа контрафактных товаров
- Для создания фишинговых веб-сайтов
- Для разработки поддельных веб-сайтов безопасности, которые устанавливают вредоносные программы на компьютеры пользователей.
При этом контент в целом не дублируется исключительно киберпреступниками, желающими обмануть представителей общественности. Создание контента — это крысиные бега, в которые онлайн-компании должны вступить, если они собираются размещать свои сайты выше на страницах результатов поисковых систем. Таким образом, контент иногда может быть скопирован законными, хотя и недобросовестными компаниями или блогерами, которые ищут простой способ повысить рейтинг своей страницы в Google.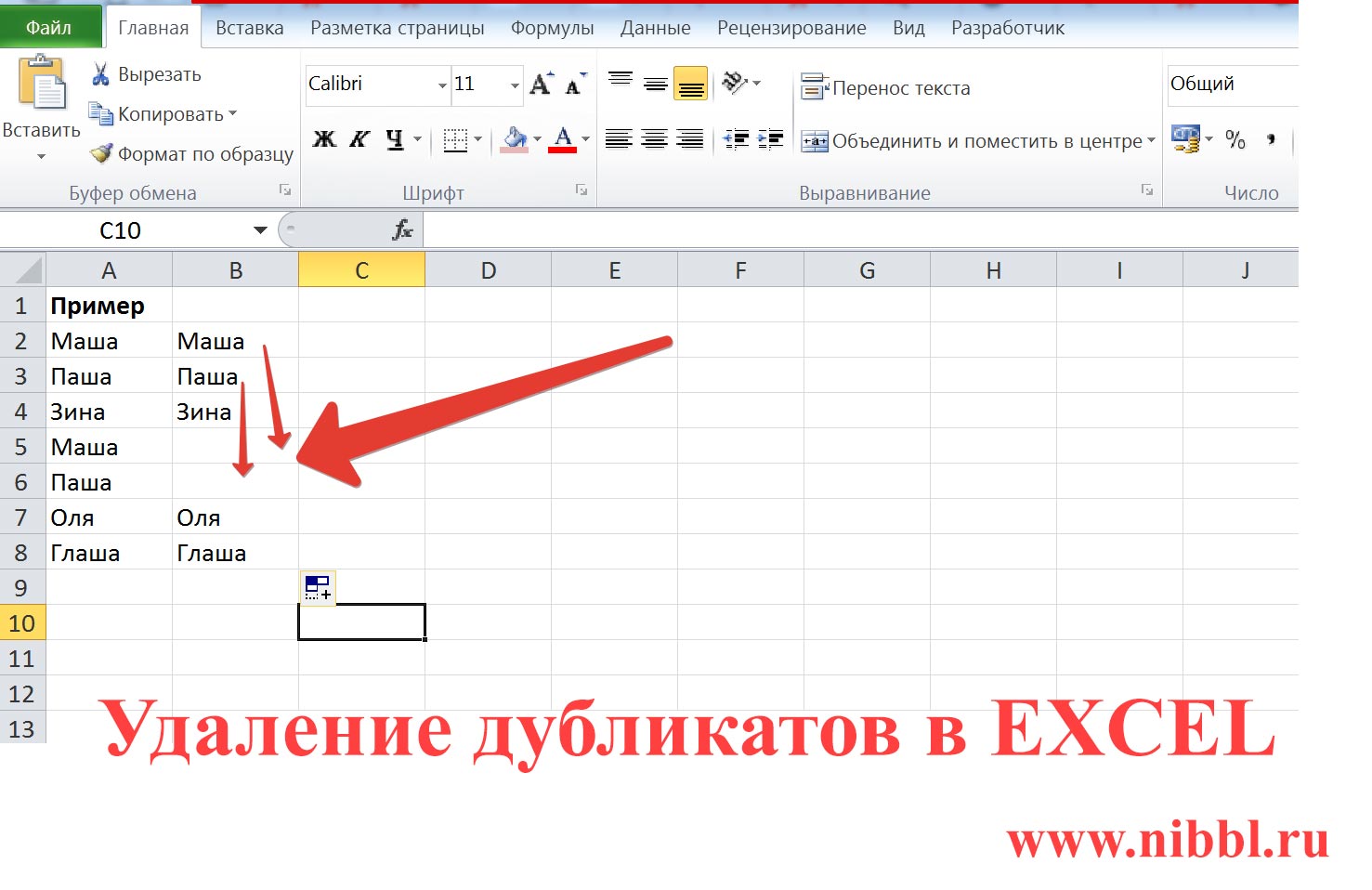
Чем авторитетнее ваш бизнес в определенных темах, тем выше вероятность того, что ваш контент будет скопирован ленивыми владельцами веб-сайтов и блогерами. Копирование контента всегда является нарушением ваших авторских прав и должно сопровождаться уведомлением DMCA или письмом о прекращении действия.
Как мошенники дублируют сайт?
- Скопируйте идентифицирующие элементы вашего веб-сайта
Вам не нужно быть техническим экспертом, чтобы создать дубликат веб-сайта. Мошенник начнет с копирования идентифицирующих элементов вашего веб-сайта, таких как ваш логотип, макет, списки ваших продуктов, если вы являетесь сайтом электронной коммерции, и ваш контент. Это заставит пользователей поверить, что они попали на ваш законный веб-сайт, а не на мошеннический сайт.
Это серьезное нарушение авторских прав и товарных знаков вашего веб-сайта. Убедитесь, что вы зарегистрировали свой веб-сайт для защиты авторских прав и товарных знаков, чтобы иметь больше шансов наказать злоумышленников в суде.
- Подмена вашего доменного имени
Чтобы дубликат веб-сайта выглядел как ваш, мошенники подделывают ваше доменное имя. Они делают это разными способами. Например, они могут создать версии вашего доменного имени с опечатками, например amzon.com вместо amazon.com. Или они будут использовать ваше доменное имя с измененным окончанием. Таким образом, вместо amazon.com они зарегистрируют веб-сайт как amazon.net. Опечатки легко допустить, и невольные клиенты будут привлечены к домену, который выглядит так же, но на самом деле является подделкой. Это называется «типосквоттинг».
Киберсквоттинг похож на типосквоттинг. Киберпреступники будут создавать слегка отличающиеся версии исходного доменного имени, например, g00gle.com вместо google.com. Один из лучших способов предотвратить такие атаки с подменой домена — зарегистрировать опечатку в вашем доменном имени при регистрации основного доменного имени.
- Привлекайте людей на свой сайт с помощью поисковой оптимизации, социальных сетей, электронной почты и текстовых сообщений
Мошенники могут использовать различные способы, чтобы заставить вас нажать на их дубликаты веб-сайтов. Возможно, они отправят вам текстовое сообщение или электронное письмо с поддельной ссылкой на их веб-сайт. Или они создают поддельные учетные записи в социальных сетях, которые работают в тандеме с их веб-сайтом. Киберпреступники также следят за тем, чтобы их страницы ранжировались в поисковых системах, используя черные методы SEO. Сам факт того, что они находятся на первой или второй странице Google, означает, что они кажутся заслуживающими доверия компаниями.
Возможно, они отправят вам текстовое сообщение или электронное письмо с поддельной ссылкой на их веб-сайт. Или они создают поддельные учетные записи в социальных сетях, которые работают в тандеме с их веб-сайтом. Киберпреступники также следят за тем, чтобы их страницы ранжировались в поисковых системах, используя черные методы SEO. Сам факт того, что они находятся на первой или второй странице Google, означает, что они кажутся заслуживающими доверия компаниями.
Каковы последствия дублирования вашего веб-сайта?
Узнаваемость торговой марки
Идентичность торговой марки компании является одним из ее наиболее ценных активов. Владельцы бизнеса тратят бесчисленное количество времени, денег и ресурсов на создание идентичности своего бренда, чтобы создать что-то, что клиенты смогут узнавать и которым доверяют.
К сожалению, этот ценный актив используется мошенниками для обмана клиентов с помощью скопированных логотипов, доменных имен, контента, продуктов, профилей в социальных сетях и так далее. Клиенты либо будут сбиты с толку тем, какой бренд является вашим законным, либо просто свяжут ваш бренд с жульничеством и мошенничеством и, по всей вероятности, никогда больше не будут покупать у вас. Вот почему так важно защитить идентичность вашего бренда от дублирующих веб-сайтов.
Клиенты либо будут сбиты с толку тем, какой бренд является вашим законным, либо просто свяжут ваш бренд с жульничеством и мошенничеством и, по всей вероятности, никогда больше не будут покупать у вас. Вот почему так важно защитить идентичность вашего бренда от дублирующих веб-сайтов.
Упущенная выгода
Каждая продажа, осуществленная через веб-сайт-дубликат, означает потерю вашего бизнеса. Не только это, но и то, что одна продажа могла привести к повторному покупателю. Конечно, если их первое знакомство с тем, что они считают вашим брендом, было негативным, они не вернутся. По сути, злоумышленники перенаправляют невольных клиентов на свой веб-сайт и уводят их от вашего бизнеса, а это означает, что ваш доход постепенно утекает.
Отрицательное SEO
Когда Google увидит, что страница была продублирована, он покажет только одну из страниц. Google ясно заявляет, что они могут не знать, какой URL-адрес размещать выше в результатах поиска, поэтому оба URL-адреса наказываются и получают более низкую важность. Они могут даже деиндексировать дублированные веб-сайты. Это означает не только то, что вы будете менее заметны в Google, но и то, что ваши конкуренты будут более заметны, что позволит им увеличить продажи, которые мог бы сделать ваш бизнес.
Они могут даже деиндексировать дублированные веб-сайты. Это означает не только то, что вы будете менее заметны в Google, но и то, что ваши конкуренты будут более заметны, что позволит им увеличить продажи, которые мог бы сделать ваш бизнес.
Очень важно, если вы обнаружите дублирующийся веб-сайт или контент, вы должны сообщить об этом в Google, чтобы они не наказали ваш веб-сайт.
Как обнаружить повторяющиеся веб-сайты
Автоматизированное программное обеспечение, которое обнаруживает и удаляет повторяющиеся веб-сайты Чем успешнее ваш бренд, тем больше вам придется бороться с мошенниками, пытающимися выдать себя за ваш бизнес. Киберпреступники могут действовать из любой точки мира в любое время, и преследовать их — работа 24/7. Служба удаления доменов Red Points автоматически обнаруживает и запрашивает удаление оскорбительных и дублирующих веб-сайтов до того, как мошенники успеют начать выкачивать вашу прибыль и ухудшать имидж вашего бренда.
Проведите поиск домена
Чтобы узнать, был ли дублирован ваш сайт, вы можете провести поиск похожего доменного имени. Есть два способа сделать это. Во-первых, вы можете использовать инструмент поиска доменных имен ICANN. Введите свое доменное имя и аналогично написанные доменные имена (например, yourdomain.com и yourdomain.net). Изучите все домены, похожие на ваш.
Другой способ — просто ввести разные URL-адреса в строку поиска. Как и выше, введите, например, yourdomain.com и yourdomain.net. Попробуйте версии с опечатками, например yourdoman.com. Если вы что-то найдете, это может быть дубликат веб-сайта.
Используйте поисковую систему Google.
Для обнаружения дубликатов веб-сайтов Google вам в помощь. Найдите сообщение в блоге или другой контент на своем веб-сайте, скопируйте около десяти слов из начала предложения.
Вставьте десять слов в строку поиска Google, заключив их в кавычки.
Выберите ввод. Если отображается более одного результата, скорее всего, это дублированный контент.
Конечно, этот дублированный контент может появиться откуда-то еще на вашем собственном веб-сайте, поэтому всегда важно создавать оригинальный контент, иначе ваше SEO пострадает.
Если на странице результатов есть другие веб-сайты, Google считает исходным контентом тот результат, который окажется первым.
Отслеживание обратных ссылок и использование инструментов Google для веб-мастеров
Часто, когда вы пишете статьи, оптимизированные для поисковых систем, вы включаете ссылки на другие статьи или страницы на своем веб-сайте. Каждый раз, когда внешний источник ссылается на ваш сайт, вы должны получать уведомление об обратной ссылке. Вы также можете использовать инструменты Google для веб-мастеров. Обязательно проверьте эти трекбэки, потому что иногда они могут исходить от людей, которые просто копируют и вставляют ваш контент. Однако это не является надежным. Многие мошенники удалят ссылки в тексте, чтобы вы не были предупреждены.
Настройка Google Alerts
Google Alerts — это бесплатный инструмент, с помощью которого Google будет оповещать вас об интересующем вас контенте. Вы также можете получать оповещения, если какие-либо заголовки ваших сообщений в блоге появляются в сети после того, как ваш контент уже был создан. Это может быть совпадением, а может быть и более коварным.
Вы также можете получать оповещения, если какие-либо заголовки ваших сообщений в блоге появляются в сети после того, как ваш контент уже был создан. Это может быть совпадением, а может быть и более коварным.
Что делать, если ваш веб-сайт дублируется
Если вы обнаружите дубликат веб-сайта, который нарушает ваши авторские права и товарный знак, вы можете сообщить об этом несколькими способами. Ниже приведена подборка руководств Red Points по удалению повторяющихся веб-сайтов:
- В этом пошаговом руководстве объясняется, как закрыть поддельный веб-сайт с помощью писем о прекращении действий.
- Вы можете сообщить о дублирующихся веб-сайтах в Google
- Хотя ваша интеллектуальная собственность автоматически получает товарный знак при создании, всегда имеет смысл официально зарегистрировать свой бренд, чтобы у вас было достаточно законных оснований для уничтожения материала, нарушающего авторские права.
- То же самое касается авторского права: если другие веб-сайты копируют ваш контент, вы будете лучше защищены, если официально защитите свой веб-сайт авторскими правами.
- Если ваш бизнес связан с электронной коммерцией, из этого руководства вы можете узнать, как сообщить о поддельном интернет-магазине.
- Если веб-сайт просто скопировал сообщение в блоге, и это успешный бизнес, используйте это как маркетинговую возможность для своего бренда. Вместо того, чтобы просить их удалить контент (на что вы имеете полное право), попросите кредит и ссылку на ваш сайт.

Как предотвратить кражу вашего контента дублирующими сайтами
1. Зарегистрируйте свою интеллектуальную собственность (IP): Как подчеркивалось выше, если вы зарегистрируете свой веб-сайт в отношении авторских прав и товарных знаков, это обеспечит дополнительную защиту вашего бренда, особенно с юридической точки зрения. Эти дополнительные средства защиты также ускоряют процесс закрытия веб-сайта, а время имеет решающее значение, когда речь идет о мошенничестве.
2. Отображение уведомлений о товарных знаках и авторских правах: Вы можете отображать на своем веб-сайте информацию об авторских правах и защите товарных знаков, чтобы отпугнуть злоумышленников.
3. Шифрование: Вы можете зашифровать код на своем сайте. Это означает, что мошенники не могут просматривать ваш код, и обеспечивает дополнительный уровень защиты.
4. Отключите функцию копирования/вставки: Хотя это не является надежным, отключение копирования и вставки является дополнительным барьером для недобросовестных подражателей.
5. Следите за Интернетом: Убедитесь, что ваш бизнес всегда открыт для подражателей. Лучший и самый надежный способ сделать это — установить службу удаления доменов. Программное обеспечение для мониторинга доменов Red Points — это простая альтернатива без стресса, которая активно сканирует сеть, выявляет злоумышленников и устраняет их до того, как будет нанесен ущерб вашему бренду.
Что дальше?
Дублирование веб-сайтов и копирование контента — методы, используемые киберпреступниками для введения клиентов в заблуждение. Клиенты думают, что они покупают у вашего надежного бренда, хотя на самом деле они вступают на опасную территорию, где их данные и деньги находятся под угрозой.