
как проверить и найти дубли страниц на сайте
Одной из частых проблем, мешающих SEO-продвижению, являются дубли страниц. Они содержат одинаковое с оригиналом содержание, но при этом у них отличаются URL. Почему они возникают, как их искать – читайте в этой статье.
Что такое дублированный контент и его виды
Под данным термином подразумевается идентичное наполнение страниц с разными урлами. Они могут быть расположены как на одном, так и на нескольких доменных именах. Появляются они не только из-за копирования содержимого. Дубли страниц также возникают в результате невозможности исключения тестовой версии сайта из индексации или невыполненной переадресации.
В зависимости от объема скопированного контента их делят на:
- полные;
- частичные.
Первые содержат 100 % идентичного материала. Обычно к полным относятся зеркала ресурсов, адрес которых может содержать или не содержать www, дубли main page и реферальных программ. Еще сюда относятся веб-страницы, связанные с некорректной иерархией, содержащие в URL множественные символы // или ///. Возникают полные дубли и по причине неправильно выполненного переезда на протокол SSL. Их обязательно нужно удалить и как можно быстрее.
Возникают полные дубли и по причине неправильно выполненного переезда на протокол SSL. Их обязательно нужно удалить и как можно быстрее.
Частичные дублируют контент не полностью, а только какую-то его часть. Это web-страницы пагинации, сортировки. Чаще всего их возникновение обусловлено нюансами CMS. Узнать такие можно по параметру get. К частичным дублям могут относиться и другие типы страниц: отзывов, свойств товара, фильтрации или копии, созданные при помощи AJAX.
Проблемы внутреннего и внешнего дублирования
Особенность страниц с идентичным содержанием в том, что они могут возникать не только на каком-то одном сайте, но и сразу на нескольких. Называются они, соответственно, внутренними и внешними. Остановимся на нюансах детальнее.
Внутреннее дублирование
Так называют страницы, содержащие идентичное наполнение, расположенные на одном ресурсе, но по разным адресам.
Внутреннее дублирование приводит к каннибализации фраз. При такой ситуации минимум пара подстраниц одного доменного имени может отображаться для одного ключа.
Если внутреннее дублирование не устранить, то позиции начнут «прыгать» в выдаче. Почему? Все просто – поисковая система не сможет определить, какую из страниц показать, поэтому демонстрироваться они будут по очереди. Из-за этого алгоритмы Google расценят их как некачественные, и приоритет в ранжировании будет отдаваться другим сайтам.
Рекомендуем также почитать о том, как выполняется продвижение сайта, и принципах ранжирования.
Хотите получить комплексный анализ вашего сайта?Адрес сайта
Внешнее дублирование
Так называют идентичный контент, который расположен на разных веб-ресурсах. Случается такое в основном по двум причинам:
- воровство;
- размещение контента-копии со своего сайта на других площадках.
Дубли страниц в поддоменах тоже относятся к этой категории. Если же одинаковый текст размещен на нескольких доменных именах, то поисковик Google на высокой позиции будет отображать ту страницу, оптимизация которой выполнена лучше, создана ранее или линк на нее размещен на большом количестве площадок-доноров.
Причины внутреннего дублирования
Рассмотрим причины, которые наиболее часто приводят к проблеме. Это важно, поскольку такое дублирование контента на сайте случается буквально у каждого владельца ресурса. Чтобы понимать, почему так произошло, читайте дальше.
Дубль товара по разным URL
Варианты продукта, которые размещены на нескольких подстраницах, – явление нередкое. Если бы постоянно использовались уникальные описания, то проблема не возникла. Но далеко не всегда соблюдается это правило, особенно если в продаже есть много позиций товара с небольшими отличиями (модель туфель в разных цветах, к примеру) и тратиться на оригинальные описания нет времени и лишних средств. Это, кстати, один из частых приемов маркетинга. Из-за такого подхода и возникает дублирование контента на сайте, влекущее за собой проблемы с продвижением.
Оставлять ситуацию так нельзя, нужно устранить проблему. Это необходимо, чтобы интернет-ресурс не потерял позиции в рейтинге.
Поиск дублированных страниц
Найти проблему можно несколькими способами. Расскажем детальнее, как найти дубли страниц на сайте.
Расскажем детальнее, как найти дубли страниц на сайте.
С помощью специальных программ и сервисов
Обнаружить дубли страниц можно при помощи:
- Xenu;
- NetPeak Spider;
- Screaming Frog SEO Spider.
Эти и подобные им программы находят веб-страницы с идентичным содержимым, проверяя совпадение метатегов.
Еще можно применить инструмент Гугл Search Console. Он поможет выявить на сайте дубли и даст рекомендации, как их устранить.
Использование поисковых операторов
К таким относятся «inurl» и «site». Операторы анализируют URL и при обнаружении адресов с одинаковым контентом выдают их списком.
Как найти дубли страниц при помощи поисковых операторов? Нужно просто в поле поиска ввести оператора перед адресом сайта. Например:
site:https:// название ресурса.com — site:https:// название ресурса.com/&
В этой формуле первое определение показывает страницы вашего веб-ресурса, которые содержатся в общем индексе системы Google. Второе – странички, которые задействованы в поиске.
Второе – странички, которые задействованы в поиске.
Как бороться с проблемой дублирования контента
Бывает, что писать уникальные тексты для однотипных товаров не всегда есть возможность. Но и дублирование контента – не выход. Избежать проблемы поможет специальный тег, который ведет к базовой версии – rel=canonical. Такая ссылка указывает роботам поисковика предпочтительные страницы для подстраниц похожего типа. Прибегать к нему нужно, если тексты повторяются на нескольких урлах.
Еще один способ, который поможет избежать такой проблемы, как дублированный контент – создавать на похожие товары уникальные карточки с опцией выбора нужного варианта. Но следует учесть, чтобы при таком подходе URL не менялся. Прочие подстраницы нужно перенаправить на главную.
В ситуациях, если на каждый тип товара уже подобраны ключи и создан контент, необходимо создать индивидуальные адреса URL. Таким образом, получится добиться оптимизации товара под отличительные черты, что улучшит видимость в выдаче.![]() Ключи с хвостами помогут привлечь большее количество клиентов – состоявшихся или потенциальных.
Ключи с хвостами помогут привлечь большее количество клиентов – состоявшихся или потенциальных.
Сайт доступен по многим адресам
Причин такого явления довольно много. Среди наиболее распространенных:
- Индексирование тест-версии ресурса. Процесс создания или редактирования имеющегося сайта влечет за собой появление версии, которая при правильном раскладе должна оставаться доступной лишь разработчикам. Но если от индексации она не скрыта, то робот просканирует и ее, в результате появятся дубли страниц на сайте.
- Отображение home page сразу по нескольким урлам. Некоторые из движков могут создавать адреса в разных версиях с небольшими отличиями в написании: со слешем или без, с «index.php» или «index.html». Подобное указывает, что одинаковые тексты отображаются на нескольких страницах, возникает дублирование контента. Подобного результата можно избежать, если указать поисковику на оригинал сайта, перенаправив на него адреса-копии.

- Неправильное подключение SSL-стандарта. Дублирование контента на сайте может возникать и по причине отсутствия редиректа. Его обязательно следует настроить подключением SSL. Поисковик страницы http и https воспринимает как разные, то есть будет считать их за две версии ресурса. Чтобы не возникло дублей, следует выполнить несколько действий:

- настроить редирект для подстраниц;
- удалить внутренние ссылки, содержащие http без подключенного стандарта SSL. Сделать это можно, если проверить канонические ссылки, а также файлы с графическим изображением;
- выполнить обновление sitemap.xml. Но перед этим следует создать файл по текущему адресу.
Еще нужно позаботиться о добавлении версии ресурса с SSL в Search Controle поисковой системы Google, отправить sitemap.xml обновленного типа.
Неоптимизированные страницы сортировки и фильтрации
Дубли страниц на сайте еще могут возникать и по причине неправильно выполненной оптимизации таких функций, как фильтрация и сортировка. Почему? Дело в том, что настройка данных функций меняет лишь определенную часть ресурса, ту, на которой размещены товары. При этом содержимое не меняется. А вот когда в процессе перезагрузки добавляются параметры фильтра и сортировки, то появляются копии.
Почему? Дело в том, что настройка данных функций меняет лишь определенную часть ресурса, ту, на которой размещены товары. При этом содержимое не меняется. А вот когда в процессе перезагрузки добавляются параметры фильтра и сортировки, то появляются копии.
Решить эту проблему поможет тег, о котором мы уже упоминали – rel=canonical. Но даже так странички будут отображаться в выдаче. Чтобы удалить их, потребуется метатег – noindex.
Можно еще позаботиться о том, чтобы не отображался процесс индексирования фильтрации и сортировки в robots.txt. Помочь в этом может директива, блокирующая доступ поисковику к ряду страниц. Подобный метод также эффективно экономит бюджет, выделенный на краулинг.
Но прежде чем применять способ, следует проверить, как он скажется на трафике, не упадет ли посещаемость? Если снизится, то можно попробовать оптимизировать эту часть аудитории под ключи с хвостами.
Внутренний поиск и копии
Проблемы могут возникать и по причине плохой реализации опции поиска на ресурсе. Ее применение порой провоцирует появление новой веб-страницы, которая по сути будет копией. Решить такую проблему можно добавлением в robots.txt несколько директив, закрывающих доступ для роботов к страничкам внутреннего поиска.
Ее применение порой провоцирует появление новой веб-страницы, которая по сути будет копией. Решить такую проблему можно добавлением в robots.txt несколько директив, закрывающих доступ для роботов к страничкам внутреннего поиска.
Неоптимизированные страницы пагинации
Пагинация помогает разделять содержимое и размещать эти части на подстраницах. В качестве контента могут использоваться список категорий, товары и пр.
Если пагинация выполнена неверно, она сопровождается рядом проблем:
- копия первой страницы;
- отсутствие различия в заголовках тегов;
- идентичное наполнение.
Работая над пагинацией, сразу нужно мониторить, чтобы не образовывались дубли страничек.
Неправильная реализация языковых версий
Отсутствие переводов на каждой странице тоже является причиной возникновения дублей. Избежать рисков можно, если выполнить перевод текстов на тот язык, который соответствует стране продвижения. Еще поможет указание на страницах атрибутов hreflang. Так, поисковики поймут, что на ресурсе реализовано несколько языковых версий.
Так, поисковики поймут, что на ресурсе реализовано несколько языковых версий.
Как создается внешнее дублирование
Такие ситуации не всегда возникают из-за воровства контента. Причины могут быть разными.
Копирование описаний товаров с сайтов производителей
Так называемый копипаст используется широко. Но не все в курсе, что подобные методы влекут за собой проблемы. Если есть множество товаров, и нет возможности для каждого создать уникальный контент, то необходимо подготовить тексты хотя бы для позиций, которые определены приоритетными.
Оригинальность наполнения ценится поисковиками. Поэтому шансы подняться в рейтинге у ресурса с уникальным контентом тоже выше.
Создание нескольких похожих или одинаковых сайтов
Дубли на сайте появляются, если есть субдомен. Так называют версии ресурса, созданные под определенные регионы. Чтобы не допускать появления дублей, при разработке субдоменов следует уделить внимание написанию новых текстов.
Выводы
Дублирование контента на сайте – проблема распространенная. Порой к ее появлению приводят неожиданные факторы, поэтому важно мониторить ресурс, чтобы выявить их как можно раньше и быстро устранить. Также следует принять меры по предотвращению появления дублей. Для этого необходимо каждую страницу наполнить полезным и уникальным контентом.
Порой к ее появлению приводят неожиданные факторы, поэтому важно мониторить ресурс, чтобы выявить их как можно раньше и быстро устранить. Также следует принять меры по предотвращению появления дублей. Для этого необходимо каждую страницу наполнить полезным и уникальным контентом.
Мы, команда Elit-Web, при продвижении сайтов уделяем особое внимание этому аспекту. Чтобы снизить риски образования дублей, веб-ресурс клиента наполняется только уникальным оптимизированным контентом, который создают наши авторы. Ответственный подход к созданию текстов позволяет обеспечивать гарантированный результат и успешное поисковое продвижение сайтов.
КОМПЛЕКСНЫЙ АУДИТ САЙТА
Профессиональный комплексный аудит сайта — глобальный анализ вашего проекта ✔ Подробный отчет с перечнем ошибок и рекомендаций для улучшения ✔ Увеличение конверсий
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Что такое дубли страниц?
Дубли — веб-страницы с одинаковым содержанием, но разными адресами. Данная проблема возникает как из-за недоработки или ошибки вебмастера, так и в результате автоматической генерации.
Данная проблема возникает как из-за недоработки или ошибки вебмастера, так и в результате автоматической генерации.
Почему стоит избегать дублей?
Дубликаты негативно влияют на продвижение сайтов из-за того, что уникальность контента на этих страниц равна нулю.
Допустим, вы на своем сайте опубликовали статью, поисковики проиндексировали ее. Буквально через неделю по результатам анализа обратных ссылок вы обнаруживаете, что на эту статью ссылаются в других блогах.
Благодаря этому профиль ссылок растет, но позиции статьи по ключевым запросам никак не меняются. А все потому, что авторы других блогов ссылаются на дубль страницы.
Дубли приводят к:
- Неправильной идентификации релевантной страницы — той, что наиболее точно отражает информацию по поисковому запросу. Допустим, у продвигаемой страницы есть дубликат. Вы вкладываете средства, благодаря чему она появилась в Топ-10 поисковой выдаче, но в какой-то момент робот исключает ее из индекса и заменяет на дубликат. Из-за этого оригинальная страница привлечет меньше трафика.
- Увеличению времени, которое тратится на переобход сайта поисковыми роботами. У робота ограниченное время на сканирование сайта. Если дублей будет много, то он не сможет дойти до оригинальной страницы, что приведет к более длительной индексации.
- Наложению санкций поисковыми системами. Поисковой алгоритм может посчитать, что дубли создаются намеренно, чтобы манипулировать результатами выдачи.
- Увеличению трудозатрат. Особенно это актуально, если не удалять дубли сразу после обнаружения. Если их накопиться слишком много, то физически устранить все будет сложно. А это приведет к появлению ошибок.
 Из-за этого оригинальная страница привлечет меньше трафика.
Из-за этого оригинальная страница привлечет меньше трафика.Виды дублей страниц
Дубли могут быть полными и частичными. Последние сложнее обнаружить, однако они влияют на ранжирование сайта.
Полные дубли
Они имеют идентичное содержание, однако доступны по разным URL-адресам. Примеры полных дублей:
- Адреса могут содержать слэши и быть без них, например: https://site-name. ru/catalog или https://site-name.ru//////catalog.
- Наличие двух протоколов: https://site-name.ru/catalog и http://site-name.ru/catalog.
- Наличие www или его отсутствие: https://site-name.ru/catalog и https://www.site-name.ru/catalog/
- Адрес с одним из окончаний: index.htm, index.php, index.html, home, default.asp, default.aspx, например, https://site-name.ru/home.
- Использование букв разного регистра, например, https://site-name.ru/catalog и https://site-name.ru/Catalog.
- Изменение иерархической структуры URL-адреса, например, https://site-name.ru/catalog/igrushki_dlya_devochek и https://site-name.ru/igrushki_dlya_devochek/catalog
- Наличие в адресе utm-меток (дают аналитическую информацию) и других, реферальных ссылок, например, https://site-name.ru/?yclid=321.
 ru/catalog или https://site-name.ru//////catalog.
ru/catalog или https://site-name.ru//////catalog.Частичные дубли
На них размещен одинаковый контент, но с некоторыми отличиями в элементах. Примеры:
- Дубликаты на карточках товаров и страницах категорий.
Чтобы предупредить образование дублей, рекомендуется использовать разные описания товаров. - Дубликаты могут появляться на страницах для печати, скачивания или поиска.

Как найти дубли страниц?
- Проверить, доступен ли сайт сразу по двум протоколам: HTTP (http://site-name.ru/) и HTTPS (https://site-name.ru/). Если в окне браузера открываются обе версии, то проблема с дублями точно существует.
- Проверить доступность сайта со слэшем в конце (https:/site-name.ru/) и без него (https://site-name.ru).
- Проверить, доступен ли сайт с WWW (https://www.site-name.ru/) и без этих букв (https://site-name.ru/).
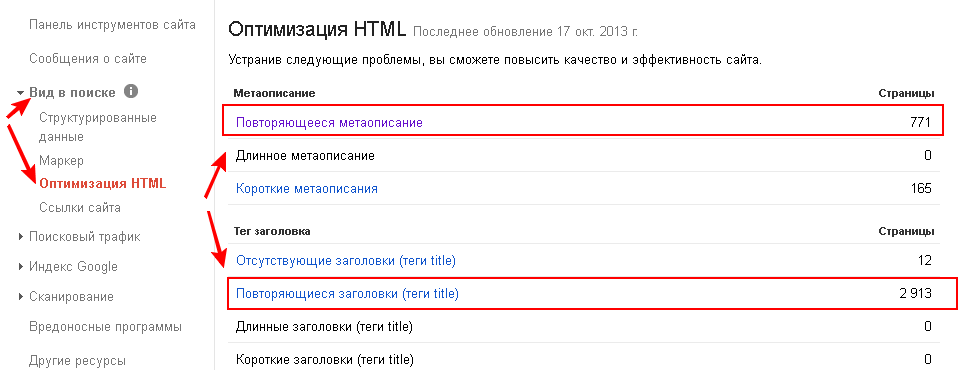
- Воспользоваться специальными инструментами для вебмастеров Яндекс и Google. Наличие дубликатов можно увидеть в разделе «Оптимизация HTML» в Google Search Console:
Или «Индексирование — Проверить статус URL», если работа проводится в Яндекс.Вебмастер. Для поиска дубликата страницы, нужно ввести ее адрес в специальное поле.В появившемся результате нужно нажать кнопку «Подробнее», после чего можно увидеть адрес дубликата: - Выполнить расширенный поиск Google, для чего в расширенном поиске нужно ввести адрес главной страницы сайта. Система предоставит общий список страниц в индексе. Если же указать адрес не главной страницы, а той конкретной, которая проверяется на наличие дублей, то в списке будут все дубликаты в индексе. Выглядит это так.
- Воспользоваться бесплатной версией инструмента Screaming Frog SEO Spider, которая дает возможность просканировать до 500 URL, чего вполне достаточно для небольшого веб-проекта. Доступна и платная версия. Оба варианта ищут не только дубликаты по адресам, но и идентичные title и description.
- Воспользоваться программой Netpeak Spider. Она легко находит дубли страниц, текста, метатег и даже заголовков Н1.
- Воспользоваться программой Xenu Link Sleuth, которая способна найти полные дубли и выполнить аудит сайта.
- Посетить seo-платформу Serpstat, там есть блок анализа дублированного контента на сайте.
 Система предоставит общий список страниц в индексе. Если же указать адрес не главной страницы, а той конкретной, которая проверяется на наличие дублей, то в списке будут все дубликаты в индексе. Выглядит это так.
Система предоставит общий список страниц в индексе. Если же указать адрес не главной страницы, а той конкретной, которая проверяется на наличие дублей, то в списке будут все дубликаты в индексе. Выглядит это так.Удаление дублей страниц
301 редирект
Это автоматическое перенаправление старой страницы на новую. После настроек редиректа боты видят, что по данному URL страница не доступна и перенесена на другой адрес. Благодаря этому удается передать ссылочный вес с дубликата на оригинал.
Благодаря этому удается передать ссылочный вес с дубликата на оригинал.
Данный метод эффективен в том случае, если дубли появились из-за:
- проблем с использованием слэшей в адресе;
- наличия букв разного регистра;
- изменения иерархической структуры адреса.
Например, 301 редирект способен перенаправить бота с https://site-name.ru////catalog на https://site-name.ru/catalog.
Файл robots.txt
С помощью этого файла вебмастер может рекомендовать ботам те страницы, которые лучше посетить и те, что не стоит сканировать. Для этого используется директива «Disallow».
User-agent: * Disallow: /stranica
Если дубль был проиндексирован или на него есть ссылки, то страница все равно будет в поисковой выдаче. Инструкции в robots.txt имеют рекомендательный характер, поэтому гарантии удаления дублей нет.
Метатеги
Чтобы этот метод сработал, нужно на дублях в блоке <head> разместить один из этих тегов:
- Метатег
<meta name="robots" content="noindex, nofollow> - Метатег
<meta name="robots" content="noindex, follow>запрещает роботу только индексировать документ, а переход по ссылкам — нет.
 В отличие от файла robots.txt этот метатег является прямой командой, поэтому поисковой робот не будет ее игнорировать.
В отличие от файла robots.txt этот метатег является прямой командой, поэтому поисковой робот не будет ее игнорировать.Атрибут rel=«canonical»
Атрибут поддерживается только поисковой системой Google, в то время как Яндекс этот тег проигнорирует.
Данный метод используется в том случае, если страницу удалять нельзя и ее нужно оставить доступной для просмотра, например, на страницах сортировок или фильтров.
Также этот тег используется для удаления дубликатов, в адресе которых имеются utm-метки, или если на странице контент представлен на нескольких языках.
Указывать нужно адрес той страницы, которая должна индексироваться. Например, на сайте интернет-магазина есть категория «Игрушки для девочек». В ней можно выполнить фильтрацию товаров по бренду, цене, возрасту, типу.
Для них канонической является общая страница категории. Чтобы сделать ее такой, в ее HTML-коде необходимо разместить атрибут rel=«canonical» между тегами<head>…</head>. Например, <link rel=«canonical» href=»https://puzat.ru/» />.
Чтобы сделать ее такой, в ее HTML-коде необходимо разместить атрибут rel=«canonical» между тегами<head>…</head>. Например, <link rel=«canonical» href=»https://puzat.ru/» />.
Что нужно знать о дублях страниц?
- Дубли — разные страницы сайта с одинаковым контентом.
- Возникают дубликаты из-за ошибок вебмастера, изменения структуры сайта или автоматической генерации.
- Наличие дублей на сайте может привести к ухудшению индексации, изменению позиций в выдаче поисковой системы, уменьшению ссылочной массы.
- Найти дубли помогут программы Screaming Frog SEO Spider и Netpeak Spider, инструменты для вебмастеров от Яндекса и Google.
- Удалить дубликаты можно с помощью 301 редирект, файла robots.txt и прямых команд роботу поисковиков.
Как исправить повторяющееся содержимое главной страницы и index.html | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- Дом
- SEO-тактика
- Оптимизация страницы
- Как исправить повторяющийся контент для домашней страницы и index.html
Эта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Хорошо, Пол, я слышу, что ты говоришь. Это очень открытый и очевидный дисс.
Я не уверен, что то, что вы говорите, имеет значение для аргумента, что канонический путь здесь не подходит. Я объяснял самым простым образом, я бы не хотел, и я уверен, что вы тоже не хотели бы такую живую страницу — домашнюю страницу, живую и канонизированную.
(Учитывается, что канонический работает как 301, передавая сок ссылок на предпочтительную версию.
)Так что спасибо, но это не имеет значения — каждый раз удаляйте & 301.
Google усиливает свое недоверие к каноническим – новый инструмент Seach Console показывает, какие страницы являются предпочтительными каноническими, и это является неожиданностью для SEO-специалистов!
Если вы хотите снова сыграть в козыри, почему бы не написать мне в личку? — так намного лучше и непосвященным не нужно это видеть!
Приветствую Найджела
-
Надлежащий канонический тег делает намного больше, чем просто говорит Google не ранжировать его. При правильном использовании (т. .
Я согласен с Кристиной — хотя 301 было бы предпочтительнее (это директива, а канонические теги рассматриваются как рекомендации), канонический тег был бы намного лучше, чем ничего не предпринимать для решения проблемы.
По крайней мере, до тех пор, пока разработчик не решит проблему с переадресацией 301 должным образом.Пол
Лучше всего использовать перенаправление, но если это невозможно, канонический маршрут должен сильно решить проблему! Вы, вероятно, потеряете часть ссылочного веса с этим маршрутом, но он должен устранить проблемы с дублированием контента со стороны Google.
-
Hi Dre
Если вы просто сделаете каноническую страницу, то страница все еще будет жить, вы просто скажете Google не ранжировать ее.
Лучше всего удалить все вместе и 301. Плохая практика — иметь более одной версии вашей домашней страницы (любой страницы) в прямом эфире!С уважением Найджел
-
Большое спасибо за ответы. Таким образом, похоже, что редирект 301 через htaccess — это то, что вам нужно. В чем разница между использованием 301 через htaccess и использованием rel=canonical в моем случае? Обеспечивает ли 301 лучший ссылочный вес по сравнению с rel=canonical или канонический просто неприменим в данном случае? Еще раз спасибо всем за ответы и полезные советы!
РЕДАКТИРОВАТЬ: я поговорил со своим разработчиком (который сейчас размещает и поддерживает мой сайт).. он сказал, что пытался сделать 301 через htaccess, но, похоже, это приводит к сбою сайта (и поверьте мне, он очень хорош в том, что он делает ).
Часть проблемы заключается в том, что мой сайт ОЧЕНЬ старый (первоначально он был создан около 10 лет назад и с тех пор НЕ обновлялся ни разу). site и не работает, но в то же время насколько безопасно использовать rel=canonical вместо 301?Еще раз спасибо!
-
Hi dre
Ваш сайт действительно не должен создавать index.html в первую очередь, но если это так, вы должны убедиться, что в файле htaccess есть 301, направляющий весь трафик на единственный URL-адрес главной страницы как Lynn правильно указывает, что это будет постоянное перенаправление.
Это очень просто сделать. Обе версии рассматриваются как отдельные страницы (как http и https), поэтому вы, по сути, показываете Google дубликат сайта, поэтому ваш рейтинг будет ужасным, пока вы не измените его.
9(.*)/index.html$ /$1/ [R=301,L]После того, как вы добавили эти правила, вы также должны исправить все свои внутренние ссылки, убедитесь, что они ссылаются на URL-адрес без .html
Надеюсь, это поможет,
Джозеф Яп
-
«В настоящее время у меня есть настройка 301 для моей страницы с http на https» — отлично! Кроме того, вы должны проверить, не перенаправляются ли ваши внутренние страницы с HTTP-версий на HTTPS.
index.html должен перенаправлять на главную версию главной страницы с постоянным перенаправлением 301.
 org/Comment»>
org/Comment»> Здравствуйте,
Я знаю, что об этом, вероятно, спрашивают довольно много, но я не нашел недавней публикации об этом в 2018 году на Moz Q&A, поэтому я решил проверить и посмотреть, какой лучший маршрут/решение для этой проблемы возможно. Я всегда очень беспокоюсь о любых (потенциально плохих/неправильных) изменениях на сайте, так как это мой источник средств к существованию, поэтому я надеюсь, что кто-то может указать мне правильное направление.
Moz, SEMRush и несколько других инструментов SEO сообщают, что у меня есть дублированный контент для моей домашней страницы и index.html (одна и та же идентичная страница).
Согласно Moz, моя домашняя страница (без index.html) имеет PA 29, а index.html имеет PA 15. Они оба показывают статус 200. Я читал, что вы можете либо сделать переадресацию 301, либо добавить rel=canonical
I в настоящее время у меня есть настройка 301 для моей страницы с http на https, и на сайт/страницу не добавлены никакие rel=canonical.![]() Каков наилучший и безопасный способ избавиться от дублированного контента и объединить мои домашние страницы без индекса и index.html вместе? Я читал, что и 301, и канонический передаются по ссылочному весу, но я не знаю, какой лучший маршрут для меня, учитывая то, что я сказал выше.
Каков наилучший и безопасный способ избавиться от дублированного контента и объединить мои домашние страницы без индекса и index.html вместе? Я читал, что и 301, и канонический передаются по ссылочному весу, но я не знаю, какой лучший маршрут для меня, учитывая то, что я сказал выше.
Спасибо за прочтение, мы очень ценим любой отзыв!
 )
) По крайней мере, до тех пор, пока разработчик не решит проблему с переадресацией 301 должным образом.
По крайней мере, до тех пор, пока разработчик не решит проблему с переадресацией 301 должным образом. Лучше всего удалить все вместе и 301. Плохая практика — иметь более одной версии вашей домашней страницы (любой страницы) в прямом эфире!
Лучше всего удалить все вместе и 301. Плохая практика — иметь более одной версии вашей домашней страницы (любой страницы) в прямом эфире! Часть проблемы заключается в том, что мой сайт ОЧЕНЬ старый (первоначально он был создан около 10 лет назад и с тех пор НЕ обновлялся ни разу). site и не работает, но в то же время насколько безопасно использовать rel=canonical вместо 301?
Часть проблемы заключается в том, что мой сайт ОЧЕНЬ старый (первоначально он был создан около 10 лет назад и с тех пор НЕ обновлялся ни разу). site и не работает, но в то же время насколько безопасно использовать rel=canonical вместо 301? 9(.*)/index.html$ /$1/ [R=301,L]
9(.*)/index.html$ /$1/ [R=301,L] org/Comment»>
org/Comment»>Google считает HTTP и HTTPS двумя отдельными протоколами. Поскольку содержание одинаково в обеих версиях, боты Google рассматривают его как дублированный контент. Добавление канонического URL решит эту проблему. Если у вас есть какие-либо сомнения, не стесняйтесь спрашивать.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией All CategoriesAffiliate MarketingAlgorithm UpdatesAPIBrandingCommunityCompetitive ResearchContent DevelopmentConversion Rate OptimizationDigital MarketingFeature RequestsGetting StartedImage & Video OptimizationIndustry EventsIndustry NewsIntermediate & Advanced SEOInternational SEOJobs and OpportunitiesKeyword ExplorerKeyword ResearchLink BuildingLink ExplorerLocal ListingsLocal SEOLocal Website OptimizationMoz BarMoz LocalMoz NewsMoz ProMoz ToolsOn-Page OptimizationOther SEO ToolsPaid Search MarketingProduct SupportReporting & AnalyticsResearch & TrendsReviews and RatingsSearch BehaviorSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>Здравствуйте! наши веб-сайты предлагают время молитвы в США и Великобритании. Проблема в том, что у нас есть близлежащие города, где время молитвы и страницы совпадают (пример: https://prayer-times.us/prayer-times-lake-michigan-12258-en и https://prayer-times). .us/prayer-times-lake-12147-en) дублируются. Та же проблема с этой страницей https://prayer-time.uk/prayer-times-wallsend-411-en Как мы можем решить эту проблему
Оптимизация страницы | | Закиро
0
 org/ListItem»> Проблемы с индексированием
org/ListItem»> Проблемы с индексированием Одна из главных страниц моего сайта, http://www.waikoloavacationrentals.com/kolea-rentals/condos, мне было трудно заставить Google индексировать ее правильно или вообще. Это одна из первых страниц моего сайта, и она должна быть в моих подссылках в Google, но она даже не отображается в результатах поиска. Мы будем признательны за любой вклад. Единственная проблема с красной полосой — это количество исходящих ссылок, но именно такой должна быть страница. Я бы предположил, что большинство страниц с объявлениями о недвижимости очень похожи. В конечном счете, когда вы смотрите на трафик, время на странице, входящие ссылки и т. д., это одна из лучших страниц на моем сайте во всех этих категориях. Мы будем очень признательны за любой вклад.
Оптимизация страницы | | РобДалтон
0
 org/ListItem»> Решает ли постоянная переадресация проблему дублированного контента?
org/ListItem»> Решает ли постоянная переадресация проблему дублированного контента? Привет! У меня есть страница продукта на моем сайте, как показано ниже. www.mysite.com/Main-category/SubCatagory/product-page.html Эта страница была доступна в обоих случаях, как показано ниже. 1. www.mysite.com/Main-category/SubCatagory/product-page.html 2. www.mysite.com/Main-category/product-page.html. Это вызывало проблему с дублированием заголовков. Поэтому я постоянно перенаправлял один на другой. Но по прошествии более месяца и после многих сканирований, улучшение html инструментов для веб-мастеров по-прежнему показывает проблему с дублированием заголовков. Мой вопрос в том, что постоянное перенаправление решает проблему дублирования контента или что-то, что мне здесь не хватает?
Оптимизация страницы | | Кашиф-Амин
0
 org/ListItem»> Html to wordpress
org/ListItem»> Html to wordpress У меня есть html-сайт, и большинство моих страниц хорошо ранжируются. Я хочу перейти на WordPress, но боюсь, что потеряю рейтинг на своих внутренних страницах. Какие-нибудь мысли? И я должен сделать перенаправление или использовать плагин html
Оптимизация страницы | | БенджаминМарцинк
0
Привет, сообщество Moz,
Новичок здесь. На моей второй неделе Moz, и мне это нравится, но у меня есть пара вопросов относительно ошибок сканирования. У меня есть два вопроса:
1. У меня есть несколько страниц с повторяющимся контентом, но там написано 0 повторяющихся URL. Как узнать, что дублируется в этом экземпляре?
2. Я не уверен, что кто-то здесь знаком с IDX для веб-сайта по недвижимости. Но у меня есть эта настройка на моем сайте, и кажется, что все ссылки, которые она генерирует для разных домов для продажи, отображаются как дубликаты страниц.
Например, http://www.handyrealtysa.com/idx/mls…tonio_tx_78258 отмечено как дублирующее содержание страницы по сравнению с 7 повторяющимися URL-адресами:
http://www.handyrealtysa.com/idx/mls…tonio_tx_78247
На моей второй неделе Moz, и мне это нравится, но у меня есть пара вопросов относительно ошибок сканирования. У меня есть два вопроса:
1. У меня есть несколько страниц с повторяющимся контентом, но там написано 0 повторяющихся URL. Как узнать, что дублируется в этом экземпляре?
2. Я не уверен, что кто-то здесь знаком с IDX для веб-сайта по недвижимости. Но у меня есть эта настройка на моем сайте, и кажется, что все ссылки, которые она генерирует для разных домов для продажи, отображаются как дубликаты страниц.
Например, http://www.handyrealtysa.com/idx/mls…tonio_tx_78258 отмечено как дублирующее содержание страницы по сравнению с 7 повторяющимися URL-адресами:
http://www.handyrealtysa.com/idx/mls…tonio_tx_78247
http://www.handyrealtysa.com/idx/mls…tonio_tx_78253
http://www.handyrealtysa.com/idx/mls…tonio_tx_78245
http://www.handyrealtysa.com/idx/mls …tonio_tx_78261
http://www.handyrealtysa.com/idx/mls…tonio_tx_78258
http://www.handyrealtysa.com/idx/mls. ..tonio_tx_78260
..tonio_tx_78260
http://www.handyrealtysa.com /idx/mls…tonio_tx_78260
Я прикрепил снимок экрана, на котором показаны 2 страницы с повторяющимся содержимым страницы, но не имеющие повторяющихся URL-адресов. Также вы можете увидеть кое-что о дублирующихся страницах idx.
rel=»canonical» работает на этих страницах, или так кажется, когда я просматриваю исходный код со страницы.
Любая помощь приветствуется.
Скетч.png
Оптимизация страницы | | HandyRealtySA
0
Привет всем,
Прогнал мой веб-сайт через кампании SEOMOZ, и диагностика сканирования выдала мне повторяющуюся ошибку для этих URL-адресов. http://www.mysite.com/cat1/статья
http://www.mysite.com/cat1/article/
поэтому URL-адрес с «/» является дубликатом URL-адреса без «/»
Может ли кто-нибудь указать мне решение для решения этой проблемы?
С уважением,
Фредерик
http://www.mysite.com/cat1/статья
http://www.mysite.com/cat1/article/
поэтому URL-адрес с «/» является дубликатом URL-адреса без «/»
Может ли кто-нибудь указать мне решение для решения этой проблемы?
С уважением,
Фредерик
Оптимизация страницы | | frdrik123
0
Привет, у нас есть эта страница продуктов, например целевая страница:
http://www.redwrappings.com.au/australian-made/gift -идеи
а затем у нас есть ссылка на страницу 2,3,4 и так далее:
http://www.redwrappings. com.au/products.php?c=australian-made&p=2
com.au/products.php?c=australian-made&p=2
http://www.redwrappings.com.au/products.php?c=australian-made&p=3
В SEOmoz они распознаются как повторяющееся содержимое страницы.
Как лучше всего решить эту проблему?
Я могу придумать один простой способ: назначить первую целевую страницу главной страницей (http://www.redwrappings.com.au/australian-made/gift-ideas) и добавить на нее канонические мета-ссылки. 2,3 и так далее.
Любые другие предложения?
Спасибо 🙂
Оптимизация страницы | | Эссенция
0
Привет, кто-нибудь может помочь решить проблему «дубликата заголовка страницы, дублирования контента страницы»? это сайт электронной коммерции, в каждой категории есть сотни продуктов, поэтому есть более 10 страниц, но отчет сканирует ошибки, я понятия не имею, может ли кто-нибудь помочь? Большое спасибо! Анна
Оптимизация страницы | | Анна-294451
0
Дублирование страниц или разделов в Pages на iPhone
Страницы
Искать в этом руководстве
- Добро пожаловать
- Введение в страницы
- Текстовый редактор или верстка?
- Знакомство с изображениями, диаграммами и другими объектами
- Создайте свой первый документ
- Введение в создание книги
- Используйте шаблоны
- Найти документ
- Откройте документ
- Сохранить и назвать документ
- Распечатать документ или конверт
- Отменить или повторить изменения
- Предотвращение случайного редактирования
- Быстрая навигация
- Введение в символы форматирования
- Показать линейку
- Просмотр страниц рядом
- Быстрое форматирование текста и объектов
- Просмотр оптимизированной версии документа
- Копировать текст и объекты между приложениями
- Основные жесты сенсорного экрана
- Создайте документ с помощью VoiceOver
- Используйте VoiceOver для предварительного просмотра комментариев и отслеживания изменений
- Выберите текст и поместите точку вставки
- Добавить и заменить текст
- Скопируйте и вставьте текст
- Добавить, изменить или удалить поле слияния
- Управление информацией об отправителе
- Добавление, изменение или удаление исходного файла в Pages на iPhone
- Заполнение и создание настраиваемых документов
- Форматирование документа для другого языка
- Используйте фонетические справочники
- Использовать двунаправленный текст
- Используйте вертикальный текст
- Добавить математические уравнения
- Закладки и ссылки
- Добавить ссылки
- Изменить внешний вид текста
- Установить шрифт по умолчанию
- Изменить заглавные буквы текста
- Используйте стили текста
- Копировать и вставлять стили текста
- Автоматически форматировать дроби
- Лигатуры
- Добавить буквицы
- Сделать символы надстрочными или подстрочными
- Форматирование китайского, японского или корейского текста
- Формат дефисов и кавычек
- Установить интервалы между строками и абзацами
- Установить поля абзаца
- Форматировать списки
- Установить позиции табуляции
- Выравнивание и выравнивание текста
- Добавить разрывы строк и страниц
- Форматировать столбцы текста
- Связать текстовые поля
- Установите размер и ориентацию бумаги
- Установить поля документа
- Настройка разворота страниц
- Шаблоны страниц
- Добавить страницы
- Добавляйте и форматируйте разделы
- Изменение порядка страниц или разделов
- Дублирование страниц или разделов
- Удалить страницы или разделы
- Оглавление
- Сноски и концевые сноски
- Заголовки и колонтитулы
- Добавьте номера страниц
- Изменить фон страницы
- Добавить рамку вокруг страницы
- Добавляйте водяные знаки и фоновые объекты
- Добавить изображение
- Добавить галерею изображений
- Редактировать изображение
- Добавить и изменить фигуру
- Объединяйте или разбивайте фигуры
- Сохранение фигуры в библиотеке фигур
- Добавление и выравнивание текста внутри фигуры
- Добавьте линии и стрелки
- Добавляйте и редактируйте рисунки
- Добавить видео и аудио
- Запись видео и аудио
- Редактировать видео и аудио
- Установите формат фильма
- Размещение и выравнивание объектов
- Размещайте объекты с текстом
- Используйте направляющие для выравнивания
- Слой, группировка и блокировка объектов
- Изменить прозрачность объекта
- Заполнение фигур и текстовых полей цветом или изображением
- Добавить границу к объекту
- Добавить подпись или заголовок
- Добавьте отражение или тень
- Используйте стили объектов
- Изменение размера, поворот и отражение объектов
- Добавить или удалить таблицу
- Выбор таблиц, ячеек, строк и столбцов
- Добавление или удаление строк и столбцов таблицы
- Переместить строки и столбцы таблицы
- Изменение размера строк и столбцов таблицы
- Объединить или разъединить ячейки таблицы
- Изменение внешнего вида текста таблицы
- Показать, скрыть или изменить заголовок таблицы
- Изменение линий сетки и цветов таблицы
- Используйте стили таблиц
- Изменение размера, перемещение или блокировка таблицы
- Добавлять и редактировать содержимое ячейки
- Форматирование дат, валюты и т.
- Форматирование дат, валюты и т.
