
Дубли главной страницы сайта — неявная угроза продвижению
Практически все CMS, доступные в настоящее время, создают дубли главной страницы сайта, как и внутренних. Кроме того, еще и хостинг способен генерировать дубликаты страниц. Эта не видимая для многих веб-мастеров проблема в продвижении тормозит развитие их веб-ресурсов.

Что такое дубли страниц на сайте?
Дубли страниц на сайте — это страницы, содержащие тот же контент, что и основная, но обладающие дополнительными символами в их адресах. На дубле главной страницы сайта, как и на остальных, отображаются сайдбары, шапка и подвал со всем их содержимым, включая баннеры и рекламные блоки, но что недопустимо — и контент основной страницы.
Существует два вида дублей:
1. Полные дубли страниц — это абсолютные копии. Они значительно ухудшают ранжирование сайта.
2. Неполные дубли — это когда не сайте дублируются части и отдельные фрагменты контента. Частичное дублирование наблюдается обычно на главной, в рубриках, архивах и RSS-ленте. Ведь там публикуются анонсы — первые абзацы статей.
Каким бывает дубль главной?
1. Если сайт размещен на хостинге по тарифу, где допускается привязка только 1 домена, дубли главной страницы могут быть такими, как на изображении, размещенном ниже.

Не в каждом случае создаются дубли главной с index.php. Как и те, что заканчиваются на index.html.
2. В случае когда сайт является аддоном (дополнительным) на хостинге и если он располагается под главным доменом, его вторым адресом является поддомен главного. Например, если основное доменное имя — домен.com, а аддона — сайт.com, то дублями главной сайт.com будут сайт.домен.com и www.сайт.домен.com.
3. IP-адрес, по которому располагается сайт, может быть дублем главной страницы, если:
— у веб-ресурса выделенный IP-адрес;
— сайт является первым из размещенных на сервере.
Этот дубль главной содержит в своем адресе IP-адрес, как например, http://123.456.789.120.
4. Сейчас все больше сайтов переезжает на защищенный протокол. В связи с этим многие хостеры подключают к каждому сайту бесплатный сертификат и не уведомляют об этом владельцев веб-ресурсов. А потому в поиске появляются дубли. Поэтому важно проверить их наличие и удалить каждый.
Их адреса обычно такого вида: https://веб-сайт.net, https://www.веб-сайт.net. А если сайт — аддон, то дублирование страницы может быть еще и таким: https://веб-сайт.domen.net и https://www.веб-сайт.domen.net.
5. Движки сайтов тоже создают дубли главной страницы. WordPress среди всех CMS выделяется обильной генерацией одинаковых интернет-страничек. Он может создавать дубли главной с адресами вида:
— веб-ресурс.ru/?;
— веб-ресурс.ru/?page2;
— веб-ресурс.ru/index/1.
Это далеко не весь список возможных дубликатов главной. Существуют и другие. После «/?» может указываться, вообще, чужой домен. Такое безобразие вытворяют конкуренты и создатели дорвеев.
Чем опасны дубли страниц?
Повторяющийся на разных страничках сайта контент считается неуникальным. А потому поисковые роботы понижают их в выдаче. Google и «Яндекс» усиленно борются за чистоту интернета. И их разработчикам все равно, опытный веб-мастер создал веб-площадку или новичок.
Роботы находят в сети очередной сайт, устанавливают, что на его разных страницах одинаковый контент и выкидывают дубли вместе с оригиналом из выдачи или отправляют на последние места. Хуже всего на SEO сайта влияет дублирование главной. Разные URL одного веб-ресурса — худший вариант дублей. Поэтому нужно время от времени проверять адрес и затем убирать похожие страницы, чтобы они не попали в индекс.
Ниже по пунктам разъясняется, в чем заключается опасность дублирования страниц:
1. Ухудшается индексация сайта. Вместо 100 страничек веб-ресурс может обладать сразу 1 000, 90 % из которых — дубли.
2. Неправильно распределяется внутренний ссылочный вес. Страницы-дубли могут определяться роботами, как наиболее значимые.
3. Неверно выбирается роботом релевантная страница. Пример: вместо главной — ресурс.com релевантной может показываться в поиске ресурс.com/?page2/page5/page3/.
4. Теряется естественный внешний ссылочный вес. Если интернет-пользователь перейдет по дублю, анонс он запостит на свою стену в соцсети либо на форуме, указав адрес странички-дубля, содержащей тот же контент, что размещен и на основной.
Как проверить дубль главной страницы?
Выявить большую часть альтернативных адресов сайта помогает этот сервис проверки качества сертификата SSL. На его странице напротив Hostname надо указать домен сайта, а затем нажать на кнопку Submit. В результате появится список альтернативных адресов.
Другой способ определить дубли главной — прописывать в строке браузера свой домен, дополняя его теми символами, что указаны в предыдущей части статьи. На дублях станет отображаться главная страница сайта со всем ее содержимым.
Как убрать дубли главной?
1. Борьба с разными адресами веб-площадки далеко не настолько сложна, как может показаться. Хотя отнимает она много времени и требует определенных знаний. Главное — найти все альтернативные названия интернет-ресурса. Тогда удастся их удалить из поиска. Проще всего убрать дубли главной страницы через .htaccess.
Применяя новый код в файле .htaccess, рекомендуется предварительно создать его резервную копию, чтобы в случае допущения ошибки быстро восстановить работоспособность сайта.
Ниже представлен код, который делает 301 редирект всех страниц с https на http (если у сайта еще нет сертификата). А также добавляет слэш в конце URL каждой страницы. Это код для файла .htaccess на WordPress, как и все остальные, представленные на этой странице:
RewriteEngine On
RewriteCond %{HTTPS} on
RewriteRule (.*) http://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
RewriteCond %{REQUEST_URI} !/$
Скопировать код
Другое правило позволяет указать в .htaccess разрешенные хосты. В данном случае приоритетным указывается домен с www. Данный код запрещает обращаться к сайту по IP. Вместо «сайт.ru» нужно указать доменное имя своей площадки:
SetEnvIfNoCase Host ^(?:www\.)?сайт\.ru$ allow_host
Order Deny,Allow
Deny from env=!allow_host
Скопировать код
Следующее правило позволяет создать переадресацию с адреса вида название-сайта.ru/index.php на основное зеркало:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index\.php\ HTTP/
RewriteRule ^index\.php$ http://название-сайта.ru/ [R=301,L]
Скопировать код
Данное правило убирает дубли страниц, делая редирект со страницы без «/» на страницу о слешем:
RewriteCond %{REQUEST_URI} !\?
RewriteCond %{REQUEST_URI} !\&
RewriteCond %{REQUEST_URI} !\=
RewriteCond %{REQUEST_URI} !\.
RewriteCond %{REQUEST_URI} !\/$
RewriteRule ^(.*[^\/])$ /$1/ [R=301,L]
Скопировать код
Это правило делает переадресацию с http://www.домен.ru на http://домен.ru:
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.домен.ru$ [NC]
RewriteRule ^(.*)$ http://домен.ru/$1 [R=301,L]
Скопировать код
Данный код позволяет сделать переадресацию с http://интернет-страница.ru/index.html на http://интернет-страница.ru. Тут также подключается обработка 404 ошибки:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index.html\ HTTP/
RewriteRule ^index.html$ http://интернет-страница/ [R=301,L]
RewriteRule ^index.html/ http://интернет-страница.ru/ [L,R=301]
ErrorDocument 404 /err404.html
Скопировать код
2. Следует отметить, что robots.txt тоже позволяет справиться с адресами вида:
— веб-страница.ru/?;
— веб-страница.ru/?page2;
— веб-страница.ru/index/1.
В файле robots.txt надо указать все дубли запрещенными к индексации. При этом они не исчезнут с веб-ресурса, однако, не появятся в поиске. Ведь роботы поисковых систем не станут их индексировать.
Запрет на индексацию дублей в файле robots.txt должен быть такого вида:Disallow: /?
Disallow: /*?page
Disallow: /index/1
Скопировать код
3. Если сайт является аддоном и подчинятся всем правилам родительского домена, его дублем будет домен третьего уровня. То есть, поддомен основного. В этом случае надо убрать public_html/ на хостинге в настройках домена напротив Document Root. После этих изменений нужно перенести в новую папку (расположенную по адресу без public_html/) все файлы сайта.
Другой способ удалить поддомен из индекса — настроить 301 редирект. В этом случае он уже не попадет в поиск, а потому не станет дублем. Важно, чтобы только главное зеркало веб-ресурса появлялось в поиске. В этом случае можно ожидать на страницы трафик из поисковых систем. А потому — и ежемесячный доход.
Copyright © kak-sarabotatj.ru
что это такое и как их удалить
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
![]()
Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т. д. Поэтому дубли нужно быстро удалять и стараться не допускать их появления.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом (CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи. В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические разделы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y - Человеческий фактор. Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
site.ru/tools/tools/tools/…/…/…
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.
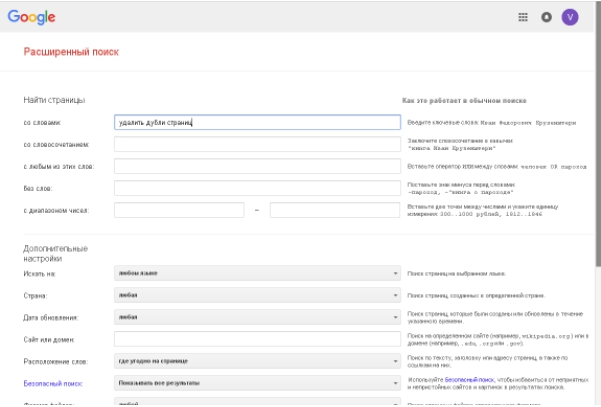
- Нахождение дублей на сайте с помощью расширенного поиска Google. Укажите в расширенном поиске адрес главной страницы. Система выдаст общий список проиндексированных страниц. А если указать адрес конкретной страницы, то поисковик покажет весь перечень проиндексированных дублей. В отличие от Google, в Яндексе копии страниц сразу видны.
Например, такой вид имеет расширенный поиск Google:
На сайте может быть много страниц. Разбейте их на категории — карточки товара, статьи, блога, новости и ускорьте аналитический процесс. - Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли. Чтобы получить аудит и произвести фильтрацию по заголовку требуется в специальную строку ввести URL сайта. Программа поможет найти полные совпадения. Однако через данную программу невозможно найти неполные дубли.
- Обнаружение дублей при помощи web – мастерской Google. Зарегистрируйтесь, и тогда в мастерской, разделе «Оптимизация Html», будет виден список страниц с повторяющимся контентом, тегами <Title>. По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.
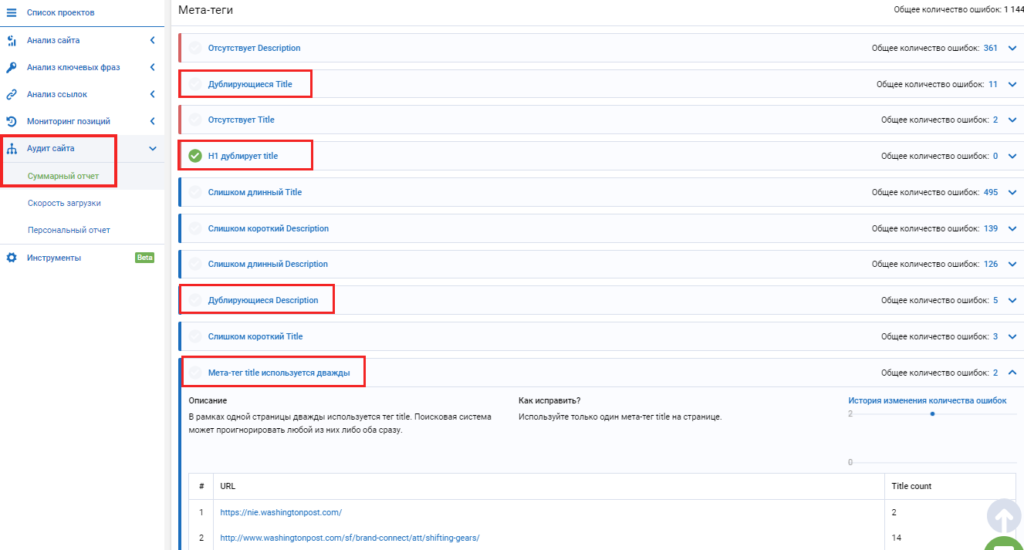
- Онлайн seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. Среди них есть блок для анализа дублируемого контента на сайте. Так сервис найдет дублирующиеся Title, Description, h2 на двух и больше страницах. Также видит случаи, когда h2 дублирует Title, на одной странице по ошибке прописаны два мета-тега Title и больше одного заголовка Н1.
Чтобы сделать технический аудит в Serpstat, нужно зарегистрироваться в сервисе и создать проект для аудита сайта.
Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel=»canonical». В код каждого дубля внедряется тег в виде <link=»canonical» href=»http://site.ru/cat1/page.php»>, который указывает на главную страницу, которую нужно индексировать.
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.
Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
Похожие, дублированные страницы. Ищем дубли контента
Здравствуйте Уважаемые читатели SEO-Mayak.com. В статье — «Файл robots.txt — запрет индексации для Яндекса и Google» я уже касался темы дублированных страниц и сегодня поговорим об этом более подробно.
Что такое дубли страниц? Это страницы с похожим или одинаковым текстом доступные по разным URL адресам. Например, очень часто встречающиеся дубли главной страницы ресурса
Ниже мы рассмотрим несколько распространенных вариантов дублирования контента, а сейчас давайте поговорим о том, как влияют
Поисковые системы давно научились определять уникальность текста по последовательности символов, т.е по одинаково составленным предложениям, откуда берется последовательность букв и пробелов. Если контент не уникальный (ворованный), то робот без труда это выяснит, а когда не уникальный текст встречается часто, то перспектива попадания такого ресурса под фильтр АГС довольно высока.

Давайте представим себе работу поискового робота. Зайдя на сайт он в первую очередь смотрит на файл robots.txt и от него получает инструкции: что нужно индексировать и что для индексации закрыто. Следующим его действием будет обращение к файлу sitemap.xml, который покажет роботу карту сайта со всем разрешенными маршрутами. Почитайте статью — «Файл sitemap.xml для поисковиков Google и Яндекс.» Получив всю необходимую информацию, робот отправляется выполнять свои привычные функции.
Зайдя на определенную страницу он «впитывает» ее содержимое и сравнивает с уже имеющейся в его электронных мозгах информацией, собранной со всего бескрайнего простора интернета. Уличив текст в не уникальности поисковик не станет индексировать данную страницу и сделает пометку в своей записной книжке, в которую он заносит «провинившиеся» URL адреса. Как Вы наверное уже догадались на эту страницу он больше не вернется, дабы не тратить свое драгоценное время.
Допустим, страница имеет высокую уникальность и робот ее проиндексировал, но пройдя по следующему URL того же ресурса он попадает на страницу с полностью или частично похожим текстом. Как в такой ситуации поступит поисковик? Конечно он тоже не станет индексировать похожий тест, даже если оригинал находиться на том же сайте, но по другому URL. Робот наверняка останется недоволен бесполезно потраченным временем и обязательно сделает пометочку в своем блокноте. Опять же, если такой инцидент будет неоднократно повторяться, то ресурс может пасть в немилость к поисковой системе.
Вывод №1. Похожие страницы расположенные по разными URL отнимают время, которое отводится роботу для индексации сайта. Дубли страниц он все равно индексировать не будет, но потратит часть временного лимита на ознакомление с ними и возможно не успеет добраться до действительно уникального контента.
Вывод№ 2. Дублированный контент отрицательно скажется но продвижении сайта в поисковой системе. Не любят поисковики не уникальные тексты!
Вывод №3. Надо обязательно проверять свой проект на дубли страниц, чтобы избежать проблем перечисленных выше.
Многие совершенно не заботятся об «чистоте» своего контента. Ради интереса я проверил несколько сайтов и был несколько удивлен положению дел с дублями страниц. На блоге одной женщины я вообще не обнаружил файла robots.txt.
Необходимо со всей серьезность бороться с дублями контента и начинать надо с их выявления.
Примеры часто встречающихся дублей контента и способы устранение проблемы
Дубль главной страницы. Пример:
- http://сайт.com
- http://сайт.com/index.php.
В этом случаи вопрос решается с помощью 301 редиректа — «командой» для сервера через файл .htaccess. Как сделать 301 редирект (перенаправление) через файл .htaccess
Еще один пример дубля главной страницы:
- http://сайт.com
- http://www.сайт.com
Чтобы избежать подобного дублирования можно прописать основное зеркало сайта в файле robots.txt в директиве — «Host» для Яндекс:
А также воспользоваться 301 редиректом и указать поисковикам Яндекс и Google на главное зеркало сайта посредством инструментов для веб-мастеров.
Пример дубля главной страницы, который чуть не взорвал мне мозг при поиске решения выглядит так:
- http://сайт.com
- http://сайт.com/
Я где-то прочитал, что слеш в конце ссылки на главную страницу, создает дубль и поисковики воспринимают ссылки со слешом и без, как разные URL, ведущие на страницу с одинаковым текстом. Меня забеспокоила даже не сама возможность дублирования, сколько потеря веса главной страницы в такой ситуации.
Я начал копать. По запросу к серверу по вышеупомянутым URL я получил ответ код 200. Код 200 означает — » Запрос пользователя обработан успешно и ответ сервера содержит затребованные данные». Из этого следует, что все-таки дубль на лицо.
Я даже попытался сделать 301 редирект (перенаправление), но команды не действовали, и желанного ответного кода 301 я так и получил. Решение проблемы состояло в отсутствии самой проблемы. Каламбур такой получился. Оказывается, современные браузеры сами подставляют символ «/» в конце строки, делая его невидимым, что автоматически делает дубль невозможным. Вот так!
Ну и еще один пример дубля главной страницы:
- http://сайт.com
- https://сайт.com
Бывают случаи, что по ошибке веб-мастера или глюка поисковика или при других обстоятельствах в индекс попадает ссылка под защищенным протоколом https://. Что же делать в таком случаи и как избежать этого в будущем? Конечно надо удалить ссылки с протоколом https://из поиска, но делать придется в ручную средствами инструментов для веб-мастеров:
В поисковой системе Яндекс, веб- мастер — мои сайты — удалить URL:

В Google инструменты для веб мастеров — Оптимизация — Удались URL адреса:

И в файле .htaccess прописать 301 редирект.
Теперь пройдемся по дублям встречающимся при не правильном составлении файла robots.txt . Пример:
- http://сайт.com/page/2
- http://сайт.com/2012/02
- http://сайт.com/category/название категории
- http://сайт.com/category/название категории/page/2
На первый взгляд не чего особенного, но это и есть классический пример частичного дублирования.
Что такое частичное дублирование? Это когда в индекс попадают страницы с анонсами постов. Причем размер таких анонсов бывают чуть ли не в половину всей статьи. Не делайте объемных анонсов! Решение проблемы простое. В файле robots.txt прописываем следующее:
- Disallow: /page/
- Disallow: /20*
- Disallow: /category/
Пример полного дублирования:
- http://сайт.com/tag/название статьи
- http://сайт.com/название статьи/comment-page-1
Решение опять же находиться в файле robots.txt
- Disallow: /tag/
- Disallow: /*page*
Я не веду речь про интернет магазины и другие сайты на коммерческой основе, там ситуация другая. Страницы с товарами, содержащие частично повторяющийся текст с множеством изображений, также создают дубли, хотя визуально выглядит все нормально. В таких случаях в основном применяется специальный тег:
rel="canonical"
Который указывает поисковику на основную страницу, подробнее читайте тут.
Важно! Директивы, прописанные в файле robots.txt, запрещают поисковым роботам сканировать текст, что уберегает сайт от дублей, но те же директивы не запрещают индексировать URL страниц.
Подробнее читайте в статьях:
Supplemental index. Дополнительный (сопливый) индекс Google
Мета-тег robots. Правильная настройка индексации сайта
Как определить похожие страницы по фрагменту текста
Есть еще один довольно действенный способ определения «клонов» с помощью самих поисковых систем. В Яндексе в поле поиска надо вбить: link.сайт.com «Фрагмент теста». Пример:

Яндекс нашел 2 совпадения потому, что я не закрыл от индексации категории и поэтому есть совпадение с анонсом на главной странице. Но если для кулинарного блога участие рубрик в поиске оправдано, то для других тематик, таких как SEO такой необходимости нет и категории лучше закрыть от индексации.
С помощью поиска Google проверить можно так: site:сайт.com «Фрагмент текста». Пример:

Программы и онлайн сервисы для поиска внутренних и внешних дублей контента по фрагментам текста
Я не буду в этой статье делать подробный обзор популярных программ и сервисов, остановлюсь лишь на тех, которыми сам постоянно пользуюсь.
Для поиска внутренних и внешних дублей советую использовать онлайн сервис www.miratools.ru. Помимо проверки текста сервис включает еще различные интересные возможности.
Программа для поиска дублей — Advego Plagiatus. Очень популярная программа, лично я ей пользуюсь постоянно. Функционал программы простой, чтобы проверить текст достаточно скопировать его и вставить в окно программы и нажать на старт.

После проверки будет представлен отчет об уникальности проверяемого текста в процентах с ссылками на источники совпадений:

Также, будут выделены желтым фоном конкретные фрагменты текста, по которым программы нашла совпадения:

Очень хорошая программа, пользуйтесь и обязательно подпишитесь на обновления блога.
До встречи!
С уважением, Кириллов Виталий
Совет 3. Настраиваем файл .htaccess для правильной индексации сайта
 Всем привет, сегодня хочу поговорить о том, как настроить сайт для правильной индексации поисковыми системами. Наверно некоторые уже встречали файл, представленный ниже, на своих серверах.
Всем привет, сегодня хочу поговорить о том, как настроить сайт для правильной индексации поисковыми системами. Наверно некоторые уже встречали файл, представленный ниже, на своих серверах.
.htaccess — это служебный файл для дополнительной настройки веб-сервера. Давайте рассмотрим на примерах, что он дает и как им воспользоваться.
Каждый раз, когда приходится провести технический аудит сайтов клиентов, я начинаю смотреть, что попало в индекс поисковых систем. Зачастую в поиск попадают дубли страниц, а Яндекс и Google видят один и тот же сайт, как два разных.
Что бы активно заняться продвижением, покупкой ссылочной массы и сэкономить бюджет вашей компании, необходимо заранее привести сайт в порядок и настроить служебный файл .htaccess.
Рассмотрим по порядку, что нам необходимо прописать. Есть множество всяких настроек, я расскажу о том, что я использую. Со временем, буду дополнять новые проверенные настройки.
Настраиваем основное зеркало сайта
Основной ошибка, когда сайт доступен по двум адресам, с www или без:
Точной информации, что лучше использовать, я не нашел. Но чаще склонен использовать название домена без www. Считаю, что использование www в названии, чаще актуально в off-лайне, для рекламы, баннерах, визитках. Визуальное видение названия с www подразумевает, что речь идет о сайте в интернете.
Смотрим, что нужно прописать:
- главное зеркало с www
RewriteEngine On
RewriteCond %{HTTP_HOST} ^site.ru
RewriteRule (.*) http://www.site.ru/$1 [R=301,L]
- главное зеркало без www
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www\.site\.ru$ [NC]
RewriteRule ^(.*)$ http://site.ru/$1 [R=301,L]
Убираем дубль главной страницы /index.php
Далее, сайт может быть доступен как:
Убираем /index.php из индексации:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index\.php\ HTTP/
RewriteRule ^index\.php$ http://site.ru/ [R=301,L]
Исправляем слэш в URL адресе
Например страница доступна со слэшем и без него:
- site.ru/catalog
- site.ru/catalog/
Необходимо выбрать что-то одно. Честно, не уверен насколько это серьезно для продвижения сайта, будет ли вес страницы разбиваться пополам? Но есть один отрицательный момент, когда страница без слэша на конце, или наоборот, отдает ответ сервера 404. Посмотрим решение.
- Убираем слэш на конце URL адреса:
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^(.+)/$ /$1 [R=301,L]
- Добавляем слэш в конец URL адреса:
RewriteCond %{REQUEST_URI} (.*/[^/.]+)($|\?)
RewriteRule .* %1/ [R=301,L]
301 Редирект с одной страницы на другую
Если адрес вашей страницы поменялся и вам необходимо сделать перенаправление на новую, используем следующий формат записи:
Redirect /old.php http://site.ru/new.php
Как проверить ответ сервера?
В процессе настройки файла .htaccess или после всех проделанных операций на сайте, необходимо убедиться в правильности работы вашего ресурса. Есть различные интернет-сайты для проверки, я использую сервис Яндекса — «Проверка ответа сервера». Для проверки необходимо добавить сайт в панель Яндекс.Вебмастер.

Надеюсь данная статья поможет вам с помощью служебного файла .htaccess добиться правильной индексации сайта. Не забывайте включать директиву модуля RewriteEngine On!