
Как пользоваться Yandex Wordstat, как работать с Вордстатом
Один из самых полезных и популярных – Яндекс Wordstat. Он позволяет анализировать частоту запросов, которые вводят пользователи поисковика.
При этом доступен анализ не только по словам, но и с учетом географического положения или же с точки зрения сезонности. Сегодня мы разберемся, как пользоваться wordstat Яндекс для продвижения сайтов.
Для чего нужен Wordstat
Сервис принято использовать при составлении семантического ядра – то есть сбора тех ключевых запросов, которые нужно вписывать в статьи на сайте, чтобы обеспечить эффективную оптимизацию под сам поисковик.
Но он также пригодится и для разработки контекстной рекламы, поскольку позволяет в сезонном бизнесе оценить колебания спроса, а также оценить емкость рынка.
Основы работы с Wordstat
Обратите внимание: работа с сервисом доступна любому пользователю Яндекс почты. Если у вас нет аккаунта, можно за минуту зарегистрироваться.
Интерфейс у Wordstat’а простой: сверху расположено поле для ввода ключевых фраз, под ним переключатели режима поиска, ниже фильтры по категориям и результаты поиска.
Для найденных фраз (левый столбец) отображается число показов в месяц. Это не фактическая величина, а примерная оценка Яндексом на основании собранной статистике. Результаты сортируются по частоте, страницы можно прокручивать.
Теперь разберемся, как работать с Яндекс Вордстатом. В поле поиска нужно ввести слово или фразу, которая описывают раскручиваемый сайт или продвигаемую услугу. В режиме по умолчанию («по словам») сервис будет подбирать любые словосочетания, в которые входит искомая фраза, в том числе с вариациями по падежу или числу, с добавлением других слов и так далее.
Любой из результатов является ссылкой, если нажать на нее – откроются результаты уже для запроса с данной фразой. Таким способом можно уточнять свой выбор. Также для перехода к низкочастотным запросам можно прокрутить страницы, пока оценка числа показов не достигнет желаемых значений.
В правом столбце отображаются похожие запросы. Их можно использовать для расширения семантического ядра. Очень полезно, поскольку так можно найти более выгодные фразы для продвижения или такие синонимы, которые даже не приходят в голову.
Фильтр по устройствам позволяет быстро переключаться между общими результатами или отдельными категориями. Например, можно отобразить данные исключительно для телефонов.
Поиск по регионам
Крайне важна возможность указать регион для поиска фразы. Если нужно продвинуть сайт в Москве – логично проверить именно частоту именно по столице. Впрочем, можно указывать и более крупные регионы.
Анализ сезонности
В Вордстат сезонность отображается при переключении в режим истории запросов.
По умолчанию показываются результаты за последний год с разбивкой по месяцам. Однако можно просмотреть изменение спроса и по неделям. При этом фильтры можно гибко комбинировать. Например, провести поиск по истории для Москвы и области с мобильных устройств, разбивка по неделям.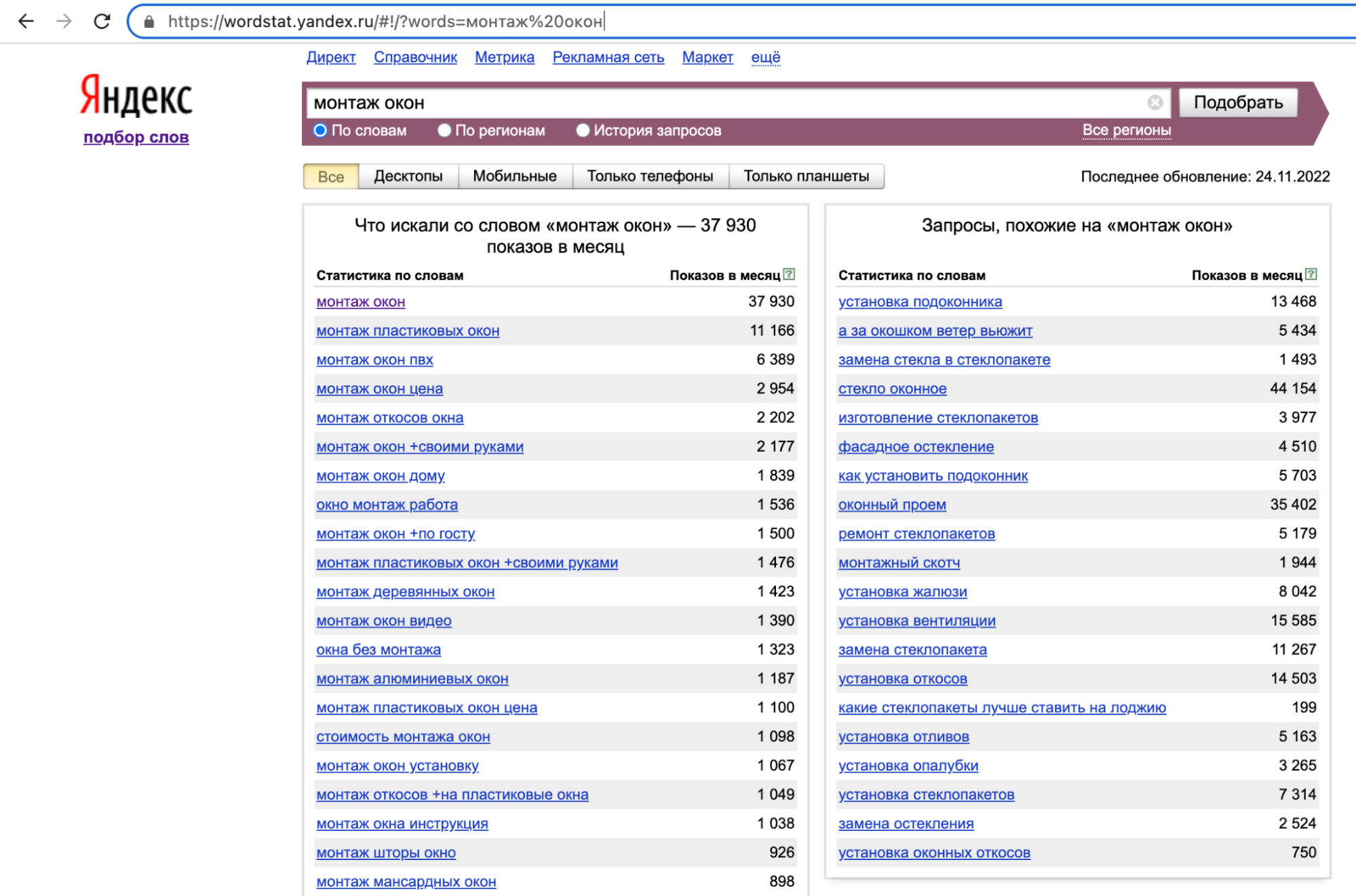
В результате сервис позволяет анализировать тенденции и прогнозировать изменение спроса по разным регионам, а также различным сегментам пользователей.
Операторы для профессионального поиска
Больше возможностей дают различные операторы поиска. Каждый из них представляет собой правило или инструкцию, в соответствии с которой будут отфильтрованы результаты.
Если никаких операторов не указано, Вордстат выдаст все доступные варианты. Обратите внимание, что короткие предлоги и союзы (“и”, “в”) сервис игнорирует, то есть они могут как входить, так и отсутствовать.
Знак “-” используется для исключения слова. Например, если хочется найти информацию об упоминаниях Магадана, но без ссылки на песню, можно дописать с минусом слово «песня».
При обратной ситуации, когда слово обязательно должно присутствовать в результатах, нужно использовать оператор “+”.
Важно: если добавить плюс к предлогу, предлог будет в выдаче.
Двойные кавычки используются для указания конкретных слов, которые должны входить в запрос – все прочие варианты при этом отсекаются. Обратите внимание, что при этом учитываются все доступные окончания.
Обратите внимание, что при этом учитываются все доступные окончания.
Чтобы зафиксировать вхождение слова в нужной форме, нужно указать его с восклицательным знаком.
Также есть возможность указать альтернативные слова, записав их в скобках и разделив вертикальной чертой “|”. В таком случае в выдачу попадут запросы, в которых есть хотя бы один из вариантов.
Комбинацией операторов можно очень точно указать запрос. В дальнейшем собранные варианты можно использовать для продвижения по низкочастотным запросам или для получения наиболее низкой стоимости клика в Яндекс Директ.
Типичные ошибки при использовании
Вордстат настолько функциональный инструмент, что при его использовании можно даже навредить себе. Например, подобрать такую форму запроса, для которой нет конкуренции, но нет и показов. Поэтому не стоит гнаться только за цифрами, нужно и здравый смысл применять.
Также не стоит использовать слишком расплывчатые запросы, особенно если в них можно добавить слова, которые с почти 100% вероятностью напишут целевые пользователи. Сравните, например, «магазин одежды» и «интернет магазин одежды» при продвижении онлайн-магазина.
Сравните, например, «магазин одежды» и «интернет магазин одежды» при продвижении онлайн-магазина.
Игнорирование географии опасно размытием целевой аудитории. Если 99% клиентов находятся в одном городе, едва ли будет полезно показывать рекламу на весь мир.
Но и чрезмерная фокусировка на одном регионе может быть невыгодной. Например, если рекламировать сервис проката авто исключительно по Москве, можно упустить всех гостей столицы, которым автомобиль нужен на пару дней. Поэтому экспериментируйте и находите лучшие варианты для своего сайта.
Как пользоваться Яндекс Wordstat – подробная инструкция работы
Однозначно, это самый полезный сервис от Яндекса. Именно благодаря Вордстату мы можем узнать, что ищут люди в сети.
Однозначно, это самый полезный сервис от Яндекса. Именно благодаря Вордстату мы можем узнать, что ищут люди в сети.
Яндекс.Вордстат:
- Демонстрирует популярность запроса;
- Показывает технические возможности людей, которые совершают запрос;
- Отображает сезонность конкретных запросов;
- Показывает географические данные (в каком регионе определенный запрос пользуется большим спросом).

Используя данные Вордстата, вы можете определить долгосрочные тренды в поисковых системах, а также лучше понять свою целевую аудиторию.
Основные определения
Для начала разберем основные определения:
- Правая колонка – демонстрирует ключевые фразы по заданному запросу.
- Левая колонка – включает фразы ключевого запроса с прямыми или непрямыми вхождениями.
- Прямое вхождение – неизменный запрос пользователя, который он ввел в поисковую строку.
- Не прямое вхождение – фраза, с разными окончаниями, синонимами, измененным порядком слов.
Знакомимся с сервисом
- Войдите в свою почту на Яндексе
- Введите в поисковой строке Яндекс Вордстат и перейдите на сайт.
- Для старта потребуется авторизация через почту Яндекса.
- Скачайте приложение Yandex Wordstat Assistant для своего браузера.
Первое что вы увидите, войдя на сайт – это поисковую строку с минимальным набором настроек, а также кнопку «ПОДОБРАТЬ». Интерфейс прост и интуитивно понятен. В поисковую строку мы пишем интересующий нас запрос. Выбираем регион (выбирайте только тот, который вам интересен. Если это вся Россия, то оставьте данную графу без изменений). Нажимаем кнопку «Подобрать».
Интерфейс прост и интуитивно понятен. В поисковую строку мы пишем интересующий нас запрос. Выбираем регион (выбирайте только тот, который вам интересен. Если это вся Россия, то оставьте данную графу без изменений). Нажимаем кнопку «Подобрать».
Практически сразу перед вами откроется две колонки, в которых будут отражены данные по запросу.
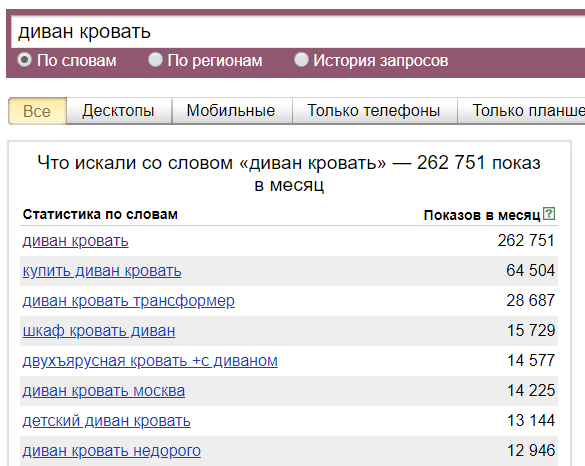
Интерфейс Яндекс Вордстат. Обзор правой и левой колонкиСлева – запросы в прямом виде, слева – синонимы и измененные запросы. Из левой колонки вы можете создать интересные ключи, которые подходят как для СЕО продвижения, так и для контекстной рекламы. Правее запросов находятся числа – это показы в месяц. Выделяют запросы высокочастотные (10 тыс. и более), среднечастотные (от 1000 до 100000) и низкочастотные (1000 и менее). СЕО-специалисты рекомендуют использовать разные варианты для работы.
Также Вордстат позволяет изучить статистику отдельно для мобильных устройств, планшетов, десктопов. Переключайте категории и изучайте.
Если вам требуется узнать, в каком городе услуга/товар/продукт пользуется большим спросом, используйте раздел «ПО РЕГИОНАМ».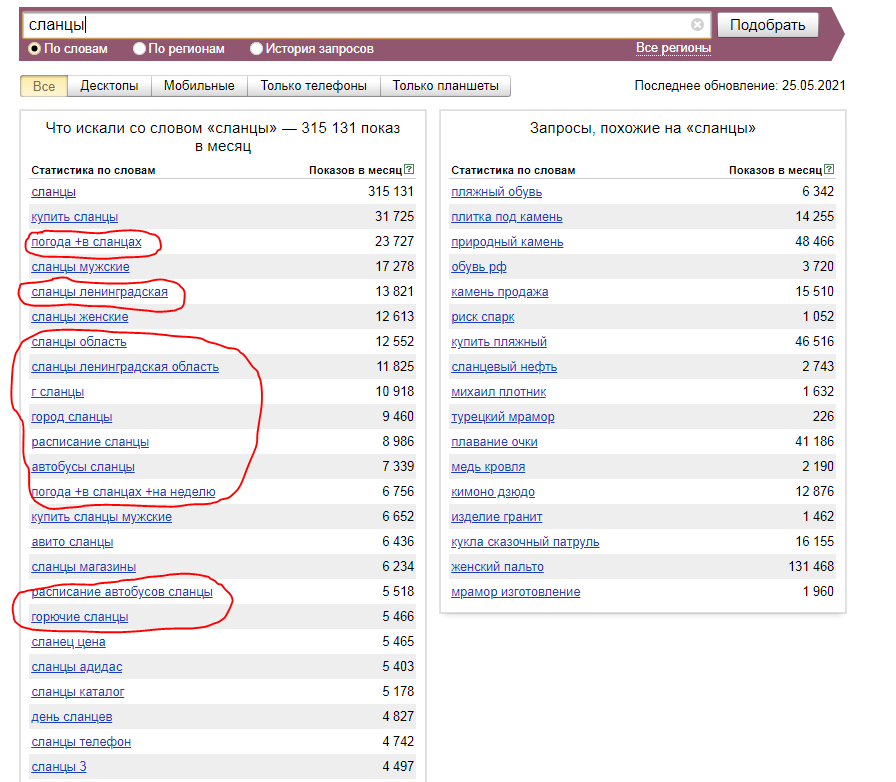
Как смотреть историю запросов
Просмотр истории запросов через Яндекс ВордстатПерейдите в категорию «ИСТОРИЯ ЗАПРОСОВ».
Система расскажет, как вела себя статистика по заданному запросу на конкретных отрезках времени (год, месяц, неделя). Зачем это нужно? Тут вы можете определить сезонность вашей услуги.
Сезонные запросы – это поисковые фразы, которые люди ищут в определенное время. Так, фраза «купить самокат» будет чаще использоваться в летний-весенний период, нежели в зимний.
А вы знали, что стать владельцем сайта можно за 1 день? Нет? Смотрите какой сайт для платной рыбаки мы разработали за 24 часа.
Операторы для Яндекс Вордстат
Для формирования типа сбора ключевых запросов используются операторы. Они помогают отсортировать мусор от действительно нужных и полезных запросов.
| Оператор | Пример использования | Значение |
|---|---|---|
| – | -авито –самому –своими -руками | Позволяет удалить фразу из списков поисковых запросов (указанные в примере слова будут удалены из общего списка Вордстата) |
| + | Создание сайтов +в Москве | Показываются только те фразы, которые содержат слово с «+».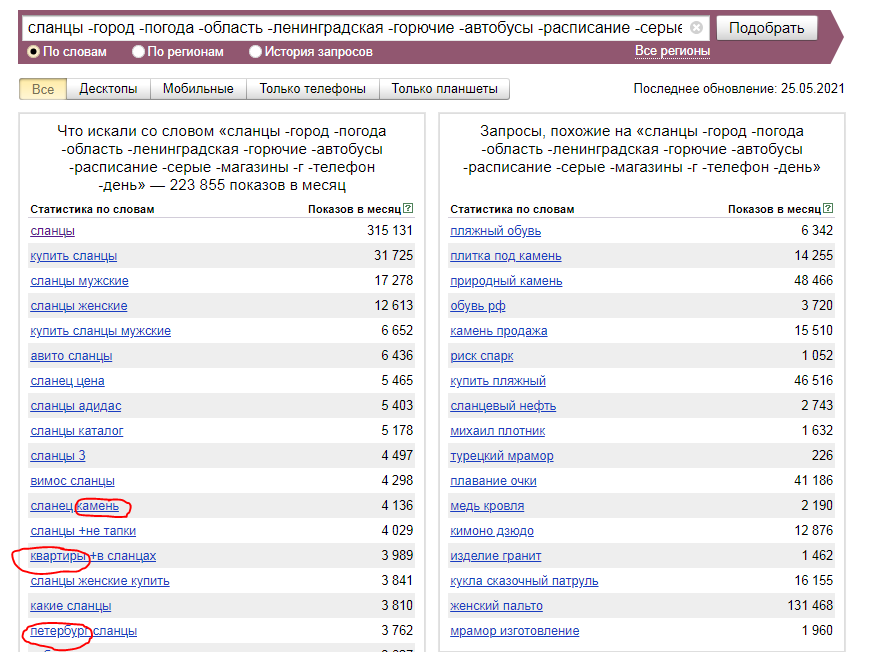 Запрос будет включать предлог в. Запрос будет включать предлог в. |
| «» | «создание сайтов» | Фиксирует ключевую фразу, но не показывает данные с измененной словоформой |
| ! | !создание !сайтов | Точное вхождение |
Например, вы ремонтируете только квартиры в новостройках. Решили создать сайт по ремонту квартир, но хотели бы узнать каким спросом пользуется услуга. В поисковой строке Вордстата вы вбиваете «ремонт квартир -дома». Все фразы, содержащие «дома» будут исключены из списка, а, следовательно, поиск нужной статистики и фраз будет идти гораздо быстрее.
Как установить Yandex Wordstat Ассистент?
Сбор ключевых запросов без этого расширения – мартышкин труд. Поэтому мы решили выделить вопросу установки отдельный подраздел в статье.
Для установки потребуется всего пара минут. Плагин можно уставить из магазина приложений. Если вы пользуетесь Яндекс Браузером зайдите в Меню – Дополнения. Найдите Yandex Wordstat Ассистент и нажмите переключатель на «ВКЛ».
Найдите Yandex Wordstat Ассистент и нажмите переключатель на «ВКЛ».
Расширение автоматически начнет установку.
Как установить Yandex Wordstat АссистентЕсли у вас другой браузер скачать расширение вы также можете. Перейдите в поисковую систему. Введите Yandex Wordstat Ассистент. В выдаче появится сайт от GOOGLE. Заходим. Нажимаем установить.
Устанавливаем.
Установка расширения Yandex Wordstat АссистентВот и все. Сразу после установки вы можете пользоваться возможностями Ассистента.
Кстати, есть и другие расширения. Например, от сайта be1. Удобная программка, которая позволяет разделять ключевые запросы на несколько страниц. Так, вы можете уже на предварительной стадии сбора ключевиков выполнить минимальное разделение и кластеризацию. Очень удобно. Установить данное расширение можно на официальном сайте платформе be1.
Установка плагина для подбора слов от be1Как выбрать запросы для продвижения сайта
Итак, обещанные фишки.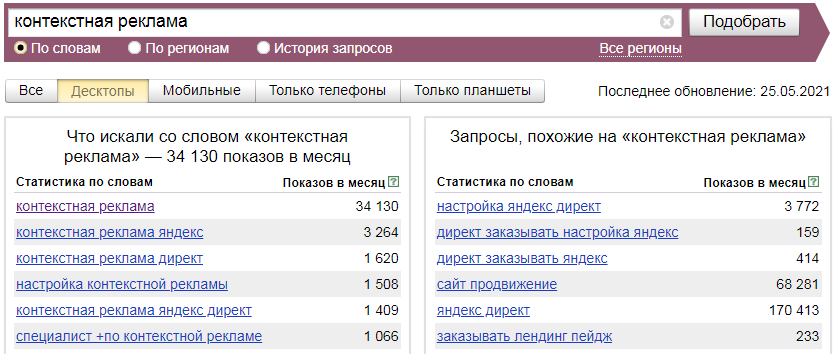 Рассказываем о том, как подобрать аппетитные запросы для быстрого продвижения информационного портала или блога в ТОП поисковиков.
Рассказываем о том, как подобрать аппетитные запросы для быстрого продвижения информационного портала или блога в ТОП поисковиков.
- Соберите близкие к вашей теме запросы (основные ключи).
- Установите Ассистент. Он потребуется для сбора сразу нескольких ключевых фраз.
- Копируйте фразы. Перенесите их в таблицу Excel.
- Проанализируйте фразы, а после оставьте самые «горячие» и интересные по вашему мнению.
- Используйте операторы «!». Это необходимо, чтобы определить популярность фраз. Только что созданным сайтам подойдут запросы, частотность которых не превышает 100 (низкочастотные).
- Полученный список проанализируйте через сервис Мутаген. Если уровень конкуренции менее 15 – используйте фразу! Она подходит для статьи.
- Далее самое интересное. Переходим в поисковик. Анализируем конкурентов, которые уже написали материал по вашей фразу. Смотрим на объем текста, количество изображений, видео. Опираясь на эти данные пишем статью намного объемнее, интереснее и полезнее.

Выводы и заключение
Маркетологам, таргетологам, SEOспециалистам, веб-мастерам, блогерам, тем, кто планирует открыть свое дело, но не знает, какая услуга пользуется большим спросом. Wordstat незаменимый помощник при сборе семантического ядра.
Зарегистрированная почта в Яндексе. Для детального сбора необходимо установить расширение Yandex Wordstat Assistant.
Это платно?
Нет. Яндекс.Вордстат – бесплатный сервис статистики, воспользоваться которым может каждый.
Что дает сервис?
Позволяет собрать семантическое ядро для сайта. Определить запросы для написания продающих статей. Подобрать ключевые фразы для настройки контекстной рекламы. Понять сезонность товара, услуги.
словарей тональности — Provalis Research
Посмотреть PDF-версию
Что такое анализ настроений?
Автоматический анализ настроений — это применение методов анализа текста для выявления субъективных мнений в текстовых данных. Обычно это включает в себя классификацию текста по категориям, таким как «положительный», «отрицательный» и в некоторых случаях «нейтральный». За последние пять лет мы наблюдаем огромный рост спроса на инструменты анализа настроений со стороны компаний, желающих отслеживать мнения людей о компании, ее продуктах и услугах, а также со стороны исследователей в области социальных наук. Чтобы удовлетворить растущий спрос на такие инструменты, все больше и больше исследователей и компаний выпускают продукты для анализа тональности, многие из которых заявляют, что могут выполнять анализ тональности любого типа документа в любой области. К сожалению, опыт показал нам, что «готовых» инструментов анализа тональности, работающих в разных областях, еще не существует. Основная причина, по которой анализ настроений настолько сложен, заключается в том, что слова часто принимают разные значения и связаны с разными эмоциями в зависимости от области, в которой они используются. Использование такого слова, как «отпечатки пальцев», может означать крупный прорыв в уголовном расследовании, но большую головную боль для производителей смартфонов.
Обычно это включает в себя классификацию текста по категориям, таким как «положительный», «отрицательный» и в некоторых случаях «нейтральный». За последние пять лет мы наблюдаем огромный рост спроса на инструменты анализа настроений со стороны компаний, желающих отслеживать мнения людей о компании, ее продуктах и услугах, а также со стороны исследователей в области социальных наук. Чтобы удовлетворить растущий спрос на такие инструменты, все больше и больше исследователей и компаний выпускают продукты для анализа тональности, многие из которых заявляют, что могут выполнять анализ тональности любого типа документа в любой области. К сожалению, опыт показал нам, что «готовых» инструментов анализа тональности, работающих в разных областях, еще не существует. Основная причина, по которой анализ настроений настолько сложен, заключается в том, что слова часто принимают разные значения и связаны с разными эмоциями в зависимости от области, в которой они используются. Использование такого слова, как «отпечатки пальцев», может означать крупный прорыв в уголовном расследовании, но большую головную боль для производителей смартфонов. «Замораживание» хорошо для холодильника, но плохо для программного обеспечения. Вы хотите, чтобы фондовый рынок или ваша машина были «предсказуемыми», но не обязательно фильмом, который вы собираетесь смотреть. Бывают даже ситуации, когда разные формы одного слова будут связаны с разными чувствами. Например, в отзывах клиентов мы обнаружили, что слово «улучшенный» ассоциировалось с положительными комментариями, а «улучшить» чаще использовалось с отрицательными.
«Замораживание» хорошо для холодильника, но плохо для программного обеспечения. Вы хотите, чтобы фондовый рынок или ваша машина были «предсказуемыми», но не обязательно фильмом, который вы собираетесь смотреть. Бывают даже ситуации, когда разные формы одного слова будут связаны с разными чувствами. Например, в отзывах клиентов мы обнаружили, что слово «улучшенный» ассоциировалось с положительными комментариями, а «улучшить» чаще использовалось с отрицательными.
Все инструменты анализа настроений в той или иной степени полагаются на списки слов и фраз с положительными и отрицательными коннотациями или эмпирически связаны с положительными или отрицательными комментариями. Мы использовали такой список в прошлом для задач анализа настроений, но мы никогда не делали наш словарь настроений доступным по нескольким причинам. Такие списки нельзя использовать как есть, их необходимо настроить для определенных доменов, чтобы обеспечить надежные результаты. Требуется много усилий, чтобы разработать словарь настроений для конкретной области и определить правильный словарь, связанный с выражением положительных и отрицательных чувств. Многие люди не обязательно готовы тратить время на выполнение таких задач по настройке и проверке. Им нужно что-то, что, по их мнению, будет работать сразу, и они готовы много платить за такой инструмент.
Многие люди не обязательно готовы тратить время на выполнение таких задач по настройке и проверке. Им нужно что-то, что, по их мнению, будет работать сразу, и они готовы много платить за такой инструмент.
Мы полагаем, что существует риск того, что некоторые люди могут использовать наш словарь настроений как есть, не пытаясь проверить его или настроить для своего типа данных. Те, кто знает об ограничениях таких списков, возможно, до сих пор не имеют ни малейшего представления о том, как можно добиться такой настройки, и нуждаются в некотором руководстве. Однако, несмотря на возможное неправильное использование списков слов для анализа тональности, мы решили сделать наш словарь тональности WordStat общедоступным. Одной из причин, заставивших нас передумать, стала публикация двух статей. В первом из них, написанном Лограном и Макдональдом (2011), подчеркивается опасность использования словарей, подобных нашему, без какой-либо попытки адаптировать их к предполагаемой области, в их случае к бухгалтерским и финансовым новостям. Эти исследователи разработали свои собственные словари настроений для конкретной предметной области и довольно подробно описали процесс, с помощью которого они отбирали слова и подтверждали свои результаты. Во второй статье, опубликованной Янгом и Сорокой (2011), также представлен процесс создания и проверки словаря настроений, но на этот раз адаптированного для анализа политических новостей. Обе статьи представляют собой похвальные усилия, и их стоит прочитать всем, кто хотел бы научиться создавать контекстно-зависимый словарь анализа настроений.
Эти исследователи разработали свои собственные словари настроений для конкретной предметной области и довольно подробно описали процесс, с помощью которого они отбирали слова и подтверждали свои результаты. Во второй статье, опубликованной Янгом и Сорокой (2011), также представлен процесс создания и проверки словаря настроений, но на этот раз адаптированного для анализа политических новостей. Обе статьи представляют собой похвальные усилия, и их стоит прочитать всем, кто хотел бы научиться создавать контекстно-зависимый словарь анализа настроений.
Словарь финансовых настроений Loughran and McDonald
Статья Loughran and McDonald (2011) наглядно демонстрирует, что применение общего списка слов для настроений к темам бухгалтерского учета и финансов может привести к высокому уровню ошибочной классификации. Они обнаружили, что около трех четвертей отрицательных слов в словаре отрицательных слов Harvard IV TagNeg обычно не являются отрицательными в финансовом контексте. Например, такие слова, как «шахта», «рак», «шина» или «капитал», часто используются для обозначения определенного сегмента отрасли. Эти слова не предсказывают тон документов или финансовых новостей, а просто добавляют шум к измерению настроений и ослабляют его прогностическую ценность. Эти авторы создали собственные списки из отрицательных и положительных слов, относящихся к области бухгалтерского учета и финансов. Еще одно преимущество словаря, который они предлагают, заключается в том, что он показывает, как количественный контент-анализ может выйти за рамки простой дихотомической дифференциации, типичной для анализа настроений, и может также использоваться для измерения дополнительных аспектов интереса. Двумя примечательными дополнениями являются список слов Uncertainty , в котором делается попытка измерить общее понятие неточности (без явного указания на риски), и Спорность список слов, который можно использовать для выявления потенциальных юридических проблемных ситуаций. Они также включали слабых модальных и сильных модальных списков слов.
Эти слова не предсказывают тон документов или финансовых новостей, а просто добавляют шум к измерению настроений и ослабляют его прогностическую ценность. Эти авторы создали собственные списки из отрицательных и положительных слов, относящихся к области бухгалтерского учета и финансов. Еще одно преимущество словаря, который они предлагают, заключается в том, что он показывает, как количественный контент-анализ может выйти за рамки простой дихотомической дифференциации, типичной для анализа настроений, и может также использоваться для измерения дополнительных аспектов интереса. Двумя примечательными дополнениями являются список слов Uncertainty , в котором делается попытка измерить общее понятие неточности (без явного указания на риски), и Спорность список слов, который можно использовать для выявления потенциальных юридических проблемных ситуаций. Они также включали слабых модальных и сильных модальных списков слов. В следующей таблице показаны различные категории словаря финансовых настроений Loughran и McDonald.
В следующей таблице показаны различные категории словаря финансовых настроений Loughran и McDonald.
Словарь финансовых настроений Loughran and McDonald
Весы |
| Образцы слов |
|---|---|---|
Отрицательный | 2 337 | прекращение, прекращение, штрафы, неправомерное поведение, серьезное, несоблюдение, ухудшение, уголовное преступление |
Положительный | 353 | достижение, достижение, эффективность, улучшение, прибыльность |
Неопределенность | 285 | приблизительный, случайный, зависящий, колеблющийся, неопределенный, неопределенный, изменчивый |
Спорность | 731 | истец, показания, промежуточные показания, деликт |
Слабые модальные слова | 27 | может, в зависимости, может, возможно |
Сильные модальные слова | 19 | всегда, высший, должен, будет |
Загрузка словаря
Оригинальную версию словаря настроений, а также его версию WordStat можно скачать здесь. Обратите внимание, что словарь нельзя использовать в коммерческих целях без разрешения. Для получения дополнительной информации об этом словаре настроений или для получения разрешения на коммерческое использование, пожалуйста, свяжитесь с авторами на указанной выше веб-странице.
Обратите внимание, что словарь нельзя использовать в коммерческих целях без разрешения. Для получения дополнительной информации об этом словаре настроений или для получения разрешения на коммерческое использование, пожалуйста, свяжитесь с авторами на указанной выше веб-странице.
Словарь настроений WordStat 2.0
(26.01.2018) Словарь WordStat Sentiment был фактически разработан путем сочетания негативных и положительных слов Гарвард IV, словарь регрессивных образов (Martindale, 2003) и Словарь лингвистики и подсчета слов (Pennebaker, 2007). Затем была использована служебная программа создания словаря WordStat для расширения списка слов путем автоматического определения потенциальных синонимов и родственных слов, а также любых флективных форм. У нас получилось больше 9526 отрицательных и 4669 положительных словоформ. На самом деле настроение измеряется не этими двумя списками слов и словосочетаний, а двумя наборами правил, которые пытаются учитывать отрицания, которые могут предшествовать этим словам.
- Отрицательные слова, которым не предшествует отрицание (нет, не никогда) в пределах четырех слов в одном предложении.
- Положительные слова, которым предшествует отрицание, в пределах четырех слов в одном предложении.
Позитивное настроение измеряется аналогичным образом путем поиска положительных слов, которым не предшествует отрицание, а также отрицательных слов, следующих за отрицанием. Однако наш собственный опыт показывает, что это последнее правило имеет меньшую прогностическую ценность и может даже немного ухудшить измерение настроений. Но могут быть ситуации, когда такое правило может помочь предсказать положительные настроения. Мы решили сохранить это последнее правило и позволить пользователю решать, применять его или отключать.
Загрузка Словаря
Вы можете загрузить последнюю версию словаря настроений WordStat отсюда. Чтобы использовать словарь в WordStat, распакуйте его в папку My Provalis Research Projects\Dictionaries , расположенную в основной папке «Документы».
Рекомендуемое использование
МЫ НЕ РЕКОМЕНДУЕМ ИСПОЛЬЗОВАТЬ ЭТОТ СЛОВАРЬ КАК ЕСТЬ. Мы твердо верим, что это не даст очень точных результатов. Мы рекомендуем вместо этого настраивать этот словарь, применяя следующие процедуры:
УДАЛИТЬ СЛОВА, СВЯЗАННЫЕ С ДОМЕНОМ. Выявите и удалите часто встречающиеся слова, которые могут относиться к интересующей вас области и обычно не имеют положительных или отрицательных коннотаций. Просмотр всех этих слов может занять много времени, поэтому более эффективный способ сделать это — применить этот словарь к большому набору документов в вашей доменной области и определить слова, которые часто встречаются. Затем вы должны использовать функции WordStat по ключевым словам в контексте, чтобы оценить, как эти слова используются.
ВЫЯВЛЕНИЕ ОШИБОЧНЫХ ПРОГНОЗОВ. Если у вас есть набор документов, которые уже были классифицированы как положительные или отрицательные, или содержат оценки удовлетворенности или любой другой индикатор настроения автора, мы предлагаем использовать функцию кросс-таблицы WordStat для оценки корреляции между частыми положительные и отрицательные слова и те индикаторы. В таком списке обратите пристальное внимание на любое слово, которое кажется вам обратно связанным с ожидаемым предсказанием. Используя функцию ключевого слова в контексте, изучите, как используются эти слова. Если им обычно предшествует отрицание (в пределах трех слов), вы можете оставить эти слова в словаре, поскольку WordStat содержит правила, которые будут учитывать их.
В таком списке обратите пристальное внимание на любое слово, которое кажется вам обратно связанным с ожидаемым предсказанием. Используя функцию ключевого слова в контексте, изучите, как используются эти слова. Если им обычно предшествует отрицание (в пределах трех слов), вы можете оставить эти слова в словаре, поскольку WordStat содержит правила, которые будут учитывать их.
ДОБАВЬТЕ СЛОВА И ФРАЗЫ, ОТНОСЯЩИЕСЯ К ДОМЕНУ. Довольно часто в вашей доменной области есть определенные слова, которые используются для обозначения положительных или отрицательных аспектов или характеристик. Например, если вы продаете смартфоны, такие элементы, как «отпечаток пальца», «шум», «падение» или «качество звука», могут быть тесно связаны с положительными или отрицательными отзывами. Для производителей автомобилей «слепое пятно», «жесткий пластик», «пыхтение», «хлыстовая волна», «подпрыгивание» или любое упоминание о «ветре» или «ногах» также может быть связано с конкретным мнением о конкретном автомобиле. Если у вас есть доступ к набору положительных и отрицательных оценок, одним из простых способов определить эти специфичные для предметной области слова будет сопоставление наиболее часто встречающихся слов с оценками удовлетворенности и выявление тех, которые с высокой вероятностью дают отрицательные и положительные оценки. Однако существует ловушка, которую следует избегать при выборе этих предикторов на основе их высокой корреляции с показателями удовлетворенности: полученная мера настроений может стать нечувствительной к изменениям. Например, если многие люди жалуются на плохое качество звука мобильного телефона, то фраза «качество звука», скорее всего, будет предсказывать негативные комментарии. Если в ответ на эти оценки производитель выпустит новую версию с улучшенным качеством звука, то любые новые положительные отзывы об этом улучшенном качестве звука могут быть ошибочно классифицированы как отрицательные. Это отсутствие чувствительности к изменениям также является ловушкой многих подходов машинного обучения к анализу настроений.
Если у вас есть доступ к набору положительных и отрицательных оценок, одним из простых способов определить эти специфичные для предметной области слова будет сопоставление наиболее часто встречающихся слов с оценками удовлетворенности и выявление тех, которые с высокой вероятностью дают отрицательные и положительные оценки. Однако существует ловушка, которую следует избегать при выборе этих предикторов на основе их высокой корреляции с показателями удовлетворенности: полученная мера настроений может стать нечувствительной к изменениям. Например, если многие люди жалуются на плохое качество звука мобильного телефона, то фраза «качество звука», скорее всего, будет предсказывать негативные комментарии. Если в ответ на эти оценки производитель выпустит новую версию с улучшенным качеством звука, то любые новые положительные отзывы об этом улучшенном качестве звука могут быть ошибочно классифицированы как отрицательные. Это отсутствие чувствительности к изменениям также является ловушкой многих подходов машинного обучения к анализу настроений.
Мы будем время от времени обновлять словарь настроений WordStat . Если вы считаете, что слова или фразы отсутствуют, или если вы обнаружите какие-либо ошибки, которые необходимо исправить для повышения точности словаря, сообщите нам об этом. Кроме того, если вы разработали какую-либо индивидуальную версию этого словаря, мы очень хотели бы узнать о ваших усилиях.
Нажмите здесь для получения дополнительной информации о WordStat
Загрузите бесплатные пробные версии
Ссылки
Лофран, Т. и Макдональд, Б. (2011). Когда обязательство не является обязательством? Анализ текста, словари и 10-ки. Журнал финансов, 66 (1), 35-66.
Что нового в WordStat 6 — Provalis Research
Новые функции WordStat 6.1
- Новый многоязычный пользовательский интерфейс (английский, французский и испанский)
- Улучшенная лингвистическая поддержка со встроенными словарями и тезаурусами для пяти языков (английский, французский, испанский, немецкий и португальский) для помощи в разработке таксономий и словарей для контент-анализа
- Повышение скорости обработки на 50 % по сравнению с предшественником, что позволяет анализировать до 30 миллионов слов в минуту
Новые функции WordStat 6
1.
 НОВАЯ ФУНКЦИЯ АВТОМАТИЧЕСКИХ ПРЕДЛОЖЕНИЙ
НОВАЯ ФУНКЦИЯ АВТОМАТИЧЕСКИХ ПРЕДЛОЖЕНИЙНа странице частоты дополнительная панель (справа) автоматически показывает для выбранных элементов (слов или категорий контента) все связанные оставшиеся слова (синонимы, антонимы, гипонимы). , гиперонимы, слова с одинаковым основанием и т. д.), что позволяет выбрать релевантные слова и отнести их к категории. Обратите внимание, что эта функция полностью функциональна только при анализе документа на английском языке. При анализе документов на других языках на панели будут отображаться слова с похожей корневой формой.
2. ВСТРОЕННОЕ ПЕРЕТАСКИВАНИЕ В СЛОВАРЬ
Редактор словаря с перетаскиванием был заменен новой панелью перетаскивания, доступной в левой части страниц «Частоты», «Кросс-таблица» и «Поиск фраз», что упрощает назначение словарь категорий, список исключений и новый список замещения. Назначения в новую категорию можно выполнить, перетащив один или несколько элементов на значок дерева НОВАЯ КАТЕГОРИЯ.

3. КЛАСТЕРИЗАЦИЯ И АНАЛИЗ СООТВЕТСТВИЙ ФРАЗ
Теперь можно выполнять кластерный анализ и анализ соответствия фраз без необходимости сохранять их в словарь категорий. Диалог также позволяет добавлять в этот список часто встречающиеся слова и сохранять извлеченные фразы в новый словарь.
4. Гистограмма с накоплением и пузырьковая диаграмма
Две новые диаграммы были добавлены для отображения связи между кодами и переменными: 9Гистограмма с накоплением 0013 позволяет отображать относительную или абсолютную частоту кодирований путем их суммирования для каждого класса категориальной или числовой переменной. Он позволяет быстро показать отношение частей к целому или подчеркнуть сумму нескольких кодов.
Пузырьковая диаграмма представляет собой графическое представление кросс-таблиц, в которых относительные частоты представлены кружками разного диаметра. Этот тип диаграммы позволяет быстро идентифицировать высокочастотные и низкочастотные ячейки и, таким образом, особенно полезен для презентационных целей.
 Многие функции диаграммы можно настроить, чтобы выделить конкретные результаты. Строки и столбцы можно свободно перемещать или удалять, и можно настроить цвет каждой ячейки, а также используемые шрифты.
Многие функции диаграммы можно настроить, чтобы выделить конкретные результаты. Строки и столбцы можно свободно перемещать или удалять, и можно настроить цвет каждой ячейки, а также используемые шрифты.5. ИЗМЕНЕННЫЙ ДИАГРАММ БЛИЗОСТИ
График близости теперь создает графику высокой четкости и теперь может использоваться для отображения близости от более чем одного ключевого слова с помощью двойных и столбчатых гистограмм.
6. УЛУЧШЕННЫЕ МНОГОМЕРНЫЕ ГРАФИКИ МАСШТАБИРОВАНИЯ
Теперь можно отображать частоту терминов в 2D- и 3D-графиках MDS, используя пузырьковых диаграмм . Кроме того, новый алгоритм ограниченной кластеризации теперь позволяет сохранять структуру кластеризации на многомерных графиках масштабирования, что значительно упрощает интерпретацию 2D- и 3D-карт MDS и делает ее более согласованной с решениями кластеризации.
7.
 УЛУЧШЕННЫЕ ДЕНДРОГРАММЫ
УЛУЧШЕННЫЕ ДЕНДРОГРАММЫТеперь можно отображать частоты терминов вместе с дендрограммами, используя гистограмму.
8. ПЕРЕКРЕСТНАЯ СТАБИЛИЗАЦИЯ ПО ДВУМ ПЕРЕМЕННЫМ
Страница КРОССТАБИЛЬНАЯ СТАБИЛИЗАЦИЯ теперь позволяет исследовать взаимосвязь между словами или категориями контента и комбинированными значениями двух переменных (например: пол x возраст).
9. АВТОМАТИЧЕСКИЙ ПОИСК И КОДИРОВАНИЕ КАТЕГОРИЙ СОДЕРЖАНИЯ
Новая кнопка на странице ЧАСТОТЫ позволяет получить все абзацы или предложения, соответствующие любой из категорий контента, и прикрепить к ним соответствующий код QDA Miner. Если у определенной категории контента нет соответствующих кодов в кодовой книге проекта, автоматически будет создана новая.
10. НОВАЯ ФУНКЦИЯ ЗАМЕНЫ
Функция предварительной обработки лемматизации была заменена более гибким процессом замены.
 Этот новый процесс не только поддерживает существующие процедуры лемматизации, но и позволяет пользователям создавать собственный процесс замены для лемматизации текста на языке, который в настоящее время не поддерживается WordStat, или автоматически исправлять орфографические ошибки без изменения исходных документов. Процесс замены может также использоваться для предварительной категоризации и использоваться в сочетании со словарем категоризации.
Этот новый процесс не только поддерживает существующие процедуры лемматизации, но и позволяет пользователям создавать собственный процесс замены для лемматизации текста на языке, который в настоящее время не поддерживается WordStat, или автоматически исправлять орфографические ошибки без изменения исходных документов. Процесс замены может также использоваться для предварительной категоризации и использоваться в сочетании со словарем категоризации.11. ФУНКЦИЯ ОТМЕНЫ РЕДАКТИРОВАНИЯ СЛОВАРОВ
Все изменения, внесенные в список исключений, словарь категорий и новый процесс замены, теперь отслеживаются и могут быть отменены.
12. УЛУЧШЕННЫЕ ЛИНГВИСТИЧЕСКИЕ РЕСУРСЫ
13. ПОДДЕРЖКА МЕНЕДЖЕРА ОТЧЕТОВВнутренние лингвистические ресурсы для английского языка были значительно улучшены благодаря обновлению до WordNet 3 и добавлению третьего тезауруса.
WordStat теперь объединяет функции диспетчера отчетов, представленные в QDA Miner 3.
Подобные кнопки были добавлены во многие диалоговые окна для автоматического сохранения таблиц, диаграмм и текста в диспетчере отчетов. Удерживая нажатой клавишу Shift при нажатии этой кнопки, откроется диалоговое окно, в котором можно настроить заголовок и ввести описание сохраненного элемента.
 0, что позволяет хранить в одном месте документы, таблицы, графику и текстовые результаты, созданные QDA Miner и WordStat. Менеджер отчетов структурирован как планировщик (аналогично средству просмотра выходных данных SPSS), что позволяет легко просматривать элементы, редактировать их, реорганизовывать и создавать черновые версии отчетов.
0, что позволяет хранить в одном месте документы, таблицы, графику и текстовые результаты, созданные QDA Miner и WordStat. Менеджер отчетов структурирован как планировщик (аналогично средству просмотра выходных данных SPSS), что позволяет легко просматривать элементы, редактировать их, реорганизовывать и создавать черновые версии отчетов. 14. УЛУЧШЕННОЕ ИЗВЛЕЧЕНИЕ ФРАЗ
Реализован новый алгоритм удаления избыточных или лишних последовательностей слов.
15. УЛУЧШЕННАЯ ПАНЕЛЬ ПЕРЕКРЫТИЯ ФРАЗ
Теперь можно выполнять операции над фразами, перечисленными в панели перекрытия (перетаскивание в словарь, получение списка KWIC или удаление их)
16.
 УЛУЧШЕННЫЙ ЭКСПОРТ СТАТИСТИЧЕСКИХ ДАННЫХ ИСТИКА
УЛУЧШЕННЫЙ ЭКСПОРТ СТАТИСТИЧЕСКИХ ДАННЫХ ИСТИКАДиалоговое окно для экспорта статистики данных на диск было улучшено за счет новых опций выбора переменных для добавления в отчет и возможности экспорта вхождений категорий контента в полиномиальные переменные. Панель параметров также позволяет предварительно просмотреть данные для экспорта.
17. СТАТИСТИКА ПОКРЫТИЯ ДОКУМЕНТОВ И СЛОВАРОВ
На странице ЧАСТОТЫ появилась новая кнопка, позволяющая получить различную статистику документа (количество слов, предложений, абзацев, слов в предложении и т.д.) и оценить охват словарь контент-анализа (процент слов, предложений, абзацев, документов и дел, содержащих элементы по категориям).
18. ЭКСПОРТ ДАННЫХ СОВМЕСТНОСТИ В ПРОГРАММУ ДЛЯ АНАЛИЗА СОЦИАЛЬНЫХ СЕТЕЙ
Данные о совпадениях теперь можно экспортировать в популярные программы анализа социальных сетей, такие как UCINET, Pajek, NetDraw и NetMiner.

19. ЭКСПОРТ В ФАЙЛЫ SPSS
Все таблицы и матрицы данных теперь можно экспортировать непосредственно в файлы данных SPSS .SAV.
20. ВЕРТИКАЛЬНЫЕ МЕТКИ НА ТАБЛИЦАХ И ГРАФИКАХ
В различные диаграммы и таблицы добавлена новая кнопка для отображения меток столбцов или на нижней оси вертикально, а не горизонтально.
21. СОЗДАНИЕ КАТЕГОРИЙ QDA MINER CODEBOOK
В диалоговом окне поиска ключевых слов с помощью WordStat 5.1 можно было назначить существующий код QDA Miner извлеченным текстовым сегментам. Также можно было добавлять новые коды, но нельзя было создавать новые категории в кодовой книге. WordStat 6 теперь позволяет добавлять категории в существующую кодовую книгу QDA Miner или создавать новую кодовую книгу.
22. СПИСОК KWIC ДЛЯ НЕСКОЛЬКИХ ЗАПИСЕЙ
Определяемое пользователем поле редактирования в диалоговом окне «Ключевое слово в контексте» теперь поддерживает спецификацию нескольких записей (разделенных точкой с запятой).
 Выбор нескольких строк таблицы и вызов списка KWIC также приведет к созданию списка KWIC для всех выбранных элементов.
Выбор нескольких строк таблицы и вызов списка KWIC также приведет к созданию списка KWIC для всех выбранных элементов.23. ПОДДЕРЖКА ДИСКРИПТОРОВ КЕЙСОВ QDA MINER
Поддержка дескрипторов кейсов QDA Miner позволяет определять более подробные метки кейсов на основе нескольких переменных.
24. ВЫБОР НЕЗАВИСИМЫХ ПЕРЕМЕННЫХ
Новая опция теперь позволяет выбирать новые независимые переменные без необходимости возвращаться в QDA Miner или Simstat.
25. ВЫБОР ПО КОЛИЧЕСТВУ ЭЛЕМЕНТОВ
Новая опция позволяет ограничить количество извлекаемых элементов до определенного числа (например, выбрать 100 наиболее часто встречающихся слов или 200 элементов с наибольшим значением TFxIDF.
26. ВОЗМОЖНОСТЬ УКАЗАНИЯ СПЕЦИАЛЬНЫХ ВСТРОЕННЫХ СИМВОЛОВ
Новая опция позволяет идентифицировать специальные символы, которые будут распознаваться как неотъемлемая часть слова (или токена) при условии, что они непосредственно окружены с обеих сторон другими допустимые символы.
 Например, ввод точки и знака @ в этом списке сохранит адреса электронной почты нетронутыми и извлечет их. При вводе точки и запятых в этом списке и знака $ в другом списке допустимых символов будут получены такие элементы, как 1000 долларов или 3,1415. Слова в конце предложений по-прежнему будут извлекаться без знака точки, поскольку за этой точкой, вероятно, будет следовать пробел или возврат каретки (таким образом, они не будут окружены буквенно-цифровыми символами).
Например, ввод точки и знака @ в этом списке сохранит адреса электронной почты нетронутыми и извлечет их. При вводе точки и запятых в этом списке и знака $ в другом списке допустимых символов будут получены такие элементы, как 1000 долларов или 3,1415. Слова в конце предложений по-прежнему будут извлекаться без знака точки, поскольку за этой точкой, вероятно, будет следовать пробел или возврат каретки (таким образом, они не будут окружены буквенно-цифровыми символами).27. ВОЗМОЖНОСТЬ ПОВТОРНОГО ПРИМЕНЕНИЯ ПРЕДЫДУЩИХ ОРФФОРМАЦИОННЫХ ИСПРАВЛЕНИЙ
Все замены орфографических ошибок, выполненные в тексте с помощью функции «неизвестные слова», автоматически сохраняются. При использовании этой же функции в новой текстовой коллекции программа автоматически предложит повторно применить исправления, сделанные ранее.
28. НОВЫЙ АЛГОРИТМ ДЛЯ УСКОРЕННОГО АНАЛИЗА СООТВЕТСТВИЙ
Мы реализовали гораздо более быстрый алгоритм анализа соответствий.
РАЗМЕР
ВРЕМЯ ВЫЧИСЛЕНИЙ
WORDSTAT 5.1ВРЕМЯ ВЫЧИСЛЕНИЙ
WORDSTAT 6.0283 случая x 10 переменных
1,28 секунды
0,00 секунды
854 случая x 10 переменных
34,1 секунды
0,03 секунды
1377 случаев x 10 переменных
2 минуты 28 секунд
0,05 секунды
2027 случаев x 10 переменных
20 минут 2 секунды
0,06 секунды
3089 случаев x 10 переменных
1 час 34 минуты 8 секунд
0,11 секунды
 См. результаты синхронизации ниже.
См. результаты синхронизации ниже.29. УЛУЧШЕННЫЙ КОНСТРУКТОР СЛОВАРОВ
Конструктор словарей был улучшен несколькими способами.
 Теперь он использует последнюю версию WordNet 3.0 (предыдущая версия использовала WordNet 1.7). Добавлена новая опция для отображения только слов, присутствующих в вашей текстовой коллекции (остаточные слова). Это также примерно в два раза быстрее, чем предыдущие версии.
Теперь он использует последнюю версию WordNet 3.0 (предыдущая версия использовала WordNet 1.7). Добавлена новая опция для отображения только слов, присутствующих в вашей текстовой коллекции (остаточные слова). Это также примерно в два раза быстрее, чем предыдущие версии.30. УЛУЧШЕННОЕ ДИАЛОГОВОЕ ОКНО ОСНОВНЫХ ПРЕДЛОЖЕНИЙ
Функция «Основные предложения» была переработана. Теперь он предоставляет больше предложений и позволяет фильтровать предложения, чтобы отображать только слова, которые в настоящее время находятся в текущей коллекции документов. Скорость этой функции также значительно улучшилась.
31. ИНТЕРАКТИВНЫЙ ДВУХМЕРНЫЙ ДИАГРАММА СООТВЕТСТВИЙ
Теперь можно щелкнуть правой кнопкой мыши ключевое слово в корреспонденции и создать список ключевых слов в контексте или поиск ключевых слов. Можно также использовать щелчок правой кнопкой мыши, чтобы удалить ключевое слово или класс категориальной переменной и пересчитать анализ соответствия, что позволяет легко удалить выбросы и отобразить взаимосвязь между оставшимися элементами.

32. УЛУЧШЕННАЯ ОБРАБОТКА ДАТ
При выборе переменной даты на странице кросс-таблицы появляется диалоговое окно, позволяющее сгруппировать все даты по десятилетиям, годам, месяцам, кварталам или дням недели.
33. УЛУЧШЕННАЯ КОМАНДА «ДОБАВИТЬ В КАТЕГОРИИ»
При выборе нескольких слов или фраз в таблице и последующем выборе команды ДОБАВИТЬ В СЛОВАРЬ КАТЕГОРИИ теперь предлагается добавить их все сразу в одну категорию.
34. УЛУЧШЕННОЕ ДИАЛОГОВОЕ ОКНО ДЛЯ ДОБАВЛЕНИЯ ЭЛЕМЕНТОВ В СЛОВАРЬ
Новое диалоговое окно позволяет назначать элементы новой категории за один шаг (пользователям больше не нужно сначала создавать категорию, а затем назначать слова или фразы). в эту вновь созданную категорию).
35. ИЗМЕНЕННЫЙ ДИЗАЙН СТРАНИЦЫ СЛОВАРОВ
Упрощенная для изучения и использования страница словаря.
36.
