
Удаление дублей страниц на сайте, как найти и удалить дубли
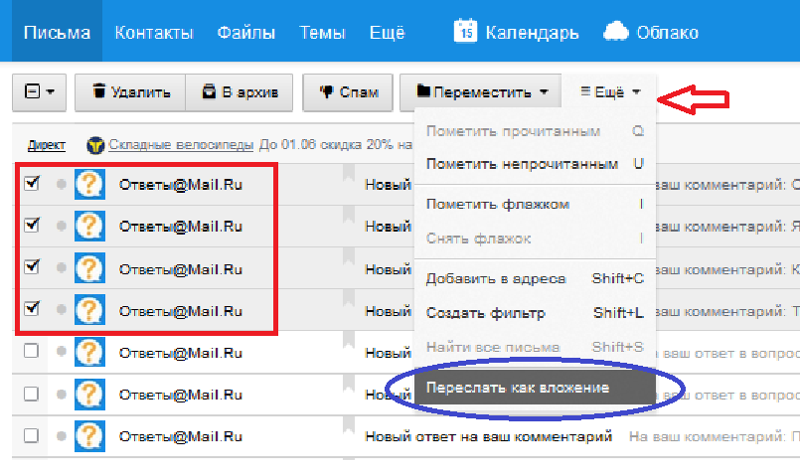
Порядок действий:
- Делаем полный скрининг сайта через программу Seo Screaming Frog (скачать можно с оф. сайта: https://www.screamingfrog.co.uk/seo-spider/ или с торрентов)
- Выгружаем дубли по заголовку h2 в Excel
Теперь разберемся, откуда на сайте появились страницы с одинаковыми заголовками. Вариантов тут немного: либо вы сами создали пачку дублей, либо же они сгенерировались автоматом.
90% дублей страниц я нахожу в следующих местах:
- Товарные фильтры интернет-магазинов
- Страницы пагинации (рубрики товаров, страницы блога, новостей и т.д.)
- Корзины товаров, работающие через URL с параметрами
- Незакрытые от индекса UTM метки (привет директологам)
Я тегирую дубли страниц по характеру их образования и сразу прикидываю, что с ними делать: удалять и склеивать, менять заголовок h2, или же закрывать от индексации.
Удаление явных дублей страниц
- Страницы пагинации нужно клеить через: link rel=»canonical» (каноничные страницы)
- Страницы фильтра закрываем от индексации через атрибут rel=»nofollow»
- Неявные дубли страниц (те, что вы создали сами) удаляем и клеим через 301 редирект
После склейки страниц проверьте, не осталось ли битых ссылок.
Добавляем директивы в robots.txt
В дополнение нужно закрыть дубли в robots.txt
Для того чтобы закрыть от индексации URL, в которых есть знак «?», добавьте в robots.txt следующую строку:
- Disallow: *?*
Вместо знака вопроса можно добавить любой фрагмент дубликата страниц. Например:
Если в дублях страниц встречается фрагмент «filter»: site.ru/category/filter/, то для того, чтобы закрыть все страницы-дубли, нужно добавить фрагмент:
- Disallow: *filter*
Пример:
- https://artameb.ru/catalog/meditsinskie_shirmy/ — оригинальная страница
Дубли из-под фильтра:
- https://artameb.
 ru/catalog/meditsinskie_shirmy/filter/height-from-1676/apply/
ru/catalog/meditsinskie_shirmy/filter/height-from-1676/apply/ - https://artameb.ru/catalog/meditsinskie_shirmy/filter/price-base-from-4914/height-from-1676/apply/
 ru/catalog/meditsinskie_shirmy/filter/height-from-1676/apply/
ru/catalog/meditsinskie_shirmy/filter/height-from-1676/apply/У дублей в примере есть кое-что схожее, в них встречается «apply» и «filter».
Для того чтобы закрыть все возможные дубли страниц в моем случае, нужно добавить сл. директивы в robots.txt:
- Disallow: *filter*
- Disallow: *apply*
Виды дублей страниц
Я разделяю дубли на 2 типа:
- Явные – полный дубль страницы. Их генерируют движки сайтов (Битрикс, WordPress, OpenCart, и др.). Как их искать и удалять мы разобрали выше.
- Неявные – похожая по смыслу страница, воспринимаемая поисковиком как дубль. Такие дубли создают сами пользователи по глупости. Как с ними работать — тема для отдельной статьи.
Владимир Кондрашов
Пишу про SEO и маркетинг, опираясь на 10 летний опыт работы! Более 300 проектов толкнул в ТОП.
Все рекомендации, инструкции, советы проверены мной на пачке проектов.
Автор блога: Кондрашов ВладимирПерейти в услуги
Дубли страниц: как их найти и удалить
ГлавнаяСтатьиSEOДубли страниц: как их найти и удалить
Самые важные новости сферы интернет-маркетинга
Что такое дубли страниц? Это разные страницы одного сайта с идентичным или почти идентичным контентом. С первого взгляда может показаться, что дубли не создают больших проблем. Но это ошибочное мнение. Пользователь действительно не заметит разницы, а вот для ранжирования ресурса в поисковых системах наличие страниц-дублей может иметь негативные последствия.
Какие сложности могут возникнуть при наличии большого числа дублей на сайте:
- Проблемы с индексацией. Поисковые роботы тратят время на индексацию страниц с дублирующим контентом и могут не проиндексировать действительно важные страницы вашего ресурса.
- Потеря внешнего ссылочного веса продвигаемых страниц. Как она возникает? Например, если пользователь поделился ссылкой не на продвигаемую страницу, а на ее дубль.
- Продвижение в поисковике нерелевантной страницы. То есть, когда поисковая система выдает ссылку не на ту страницу, которую вы продвигаете.
- Снижение уникальности контента ресурса.
- Риск попадания под фильтр поисковика из-за неуникального контента.

Дубли страниц бывают полными и частичными. Полные дубли имеют одинаковый контент (например, страницы с www и без www). В частичных дублях контент совпадает не на 100%, существуют отличия в отдельных элементах. Например, идентичный контент на карточках товаров интернет-магазина. Частичные дубли выявляются сложнее, к резким “проседаниям” в ранжировании они не приводят, но понижают позиции постепенно.
Как дубли могут возникнуть на сайте? Например, вследствие изменения структуры сайта, когда старым страницам присвоили новые адреса, но аналогичные страницы со старыми адресами сохранились. Также дубли могут быть сгенерированы CMS автоматически.
Также дубли могут быть сгенерированы CMS автоматически.
Как найти дубли страниц на сайте
Разберем разные способы.
1. С помощью сканирования сайта специальными программами
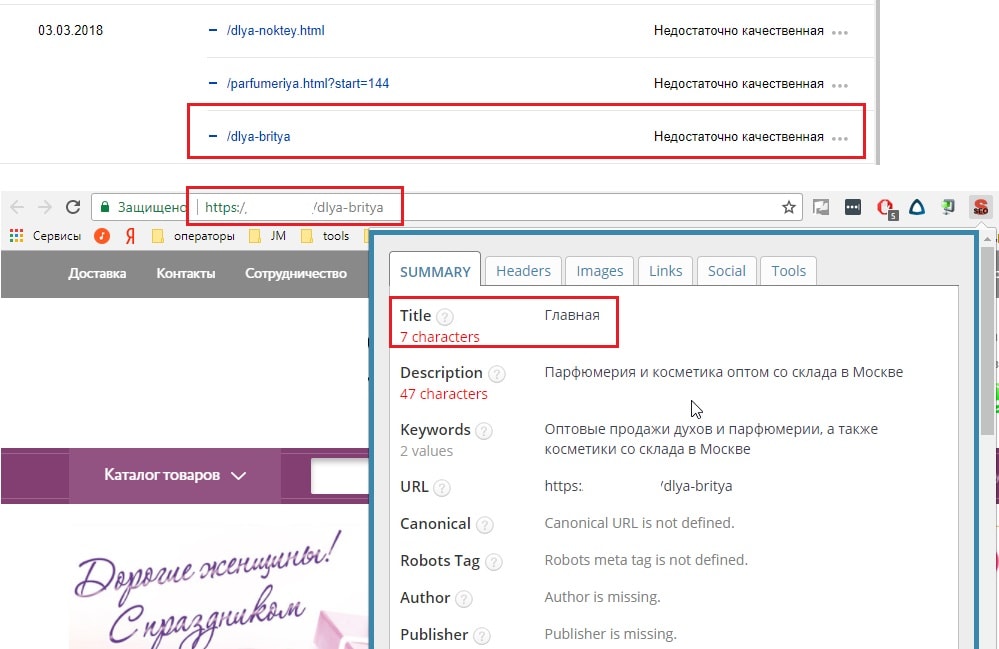
О каких программах идет речь? Например, NetPeak Spider, Xenu Link Sleuth, Screaming Frog SEO Spider. Некоторые из них бесплатные (например, Xenu Link Sleuth), некоторые — частично или полностью платные. После сканирования сайта программой и выгрузки списка URL-ов, вы сможете провести сортировку по совпадению тега «Title» или «Description», обнаружив страницы с совпадающим контентом.
2. С помощью вебмастеров Гугл и Яндекс
Как найти дубли в поисковой консоли Google:
- заходим в панель инструментов;
- выбираем «Вид в поиске»;
- переходим по ссылке «Оптимизация html».
Дубли будут видны в пунктах «Повторяющееся метаописание» и «Повторяющиеся заголовки (теги title)».
В Яндекс Вебмастере дубли страниц на сайте можно обнаружить с помощью раздела «Страницы в поиске». Проходим по пути “Страницы в поиске -> Исключенные страницы -> Сортировка: Дубль -> Применить” и получаем список страниц-дублей. При необходимости данный список вы сможете выгрузить из Яндекс Вебмастера.
В целом первые два способа схожи, однако зачастую с помощью вебмастера можно найти дубли, которые не покажет вам программа, по причине отсутствия ссылок на них на сайте.
3. “Ручной” поиск
Поиск дублей вручную доступен опытным веб-мастерам. Специалист довольно быстро сможет определить наличие страниц с дублирующим контентом, попробовав разные вариации URL-адресов. Например, http://www.apteki.by/ и http://www.apteki.by////////.*
*мы берем условные адреса
4. С помощью оператора «site:»
Чтобы применить этот метод, необходимо ввести запрос «site:mysite.
Как удалить с сайта дубли страниц
Чтобы не приходилось постоянно тратить время на выявление и закрытие от индексации страниц-дублей на сайте, можно избавиться от них. Как?
Существует несколько способов.
1. Настройка 301 редиректа в файле .htaссess.
Этот способ хорошо подойдет в случае, если дубли имеют точечный характер. Например, возникают из-за проблем с использованием слешей в URL. Так, 301 редирект можно использовать для перенаправления со страницы http://mysite.by/catalog///phone на страницу http://mysite.by/catalog/phone.*
2. Запрещение индексации дублей в файле robots.txt.
Вы можете с помощью директивы «Disallow» запретить поисковым роботам доступ к определенным страницам:
User-agent: *
Disallow: /stranica
Этот метод стоит использовать для служебных страниц, которые дублируют контент основных страниц ресурса. Однако данный способ не всегда может сработать. К примеру, если страницы уже попали в индекс, то они все равно могут обнаружиться в выдаче.
Однако данный способ не всегда может сработать. К примеру, если страницы уже попали в индекс, то они все равно могут обнаружиться в выдаче.
3. Установка тега rel=canonical на дубликатах страниц
Этот метод стоит использовать, если страницу необходимо оставить доступной для просмотра. Это характерно, например, для страниц фильтров и сортировок, UTM-страниц.
Указывая данный атрибут, мы обозначаем страницу, которая приоритетна для индексирования. Чтобы задать каноническую страницу, необходимо добавить в теге <link> атрибут rel=canonical в HTML-код текущей страницы.
Так, для страницы http://mysite.by/example/page2 канонической будет страница http://mysite.by/example/. В HTML-коде это будет отображается следующим образом: <link rel=canonical href=http://mysite.by/example/>.
4. Установка мета-тега <meta name=robots content=noindex, nofollow> или <meta name=robots content=noindex, follow>
Метатег <meta name=robots content=noindex, nofollow> дает роботу прямую команду не индексировать документ и не переходить по ссылкам. Метатег <meta name=robots content=noindex, follow> также дает команду не индексировать документ, но разрешает переходить по ссылкам.
Метатег <meta name=robots content=noindex, follow> также дает команду не индексировать документ, но разрешает переходить по ссылкам.
Это решение подойдет, например, для вкладок с отзывами на товары. Тег размещается на страницах-дублях в блоке <head>: <meta name=robots content=noindex, nofollow />.
После удаления дублирующего контента желательно еще раз провести проверку сайта и вообще повторять ее регулярно, чтобы не терять позиции в выдаче и трафик на сайт. Конечно, небольшое число страниц с дублирующим контентом может не привести к неприятным последствиям, но если их много — ситуацию нужно обязательно исправлять.
|
|
Статью подготовил Дмитрий Медведев, ведущий спикер Webcom Academy. |
Поделиться с друзьями:
Самое свежее за последнюю неделю
Как найти и исправить повторяющийся контент на вашем веб-сайте / seo.
 co/
co/Дублированный контент может быть плохим.
Использование одного и того же контента в полной или частичной форме на вашем веб-сайте приводит к ухудшению пользовательского опыта и вызывает красный флажок в алгоритме поиска Google.
В старые времена поисковой оптимизации дублированный контент часто использовался в качестве дешевого трюка, чтобы получить больше ключевых слов и больше контента на веб-сайте, поэтому Google разработал систему для отсеивания спамеров, которые таким образом нарушали передовой опыт.
Сегодня, если вас поймают на использовании дублированного контента, авторитет вашего домена может пострадать, а рейтинг ваших ключевых слов может упасть.
В этом посте мы обсуждаем:
- Что такое дублированный контент? Почему это плохо?
- Распространение контента и дублирование контента
- Какие другие инструменты для создания контента могут привести к дублированию контента?
- Типы дублированного контента. Какие доброкачественные, какие токсичные.
- Как избежать дублирования контента и/или устранить его
 Какие доброкачественные, какие токсичные.
Какие доброкачественные, какие токсичные.Содержание
Определение дублирующегося содержимого
В подавляющем большинстве случаев дублированное содержимое не является вредоносным и является продуктом любой CMS (системы управления содержанием), на которой работает веб-сайт.
Например, WordPress (CMS, являющаяся отраслевым стандартом) автоматически создает страницы «Категории» и дубликаты страниц «тегов», на которых перечислены все сообщения блога в определенных категориях или тегах. Или версия сайта с www или без www может быть неправильно перенаправлена, что приведет к дублированию контента с нескольких URL-адресов.
Это создает несколько страниц или параметров URL в пределах домена, которые содержат один и тот же контент.
1) Google может решить отпустить меня с «предупреждением» и просто не индексировать 99 из 100 моих 100 дубликатов сообщений, а оставить в индексе один из них.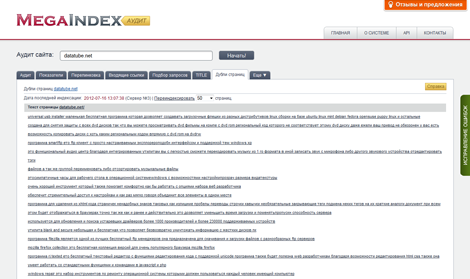 ПРИМЕЧАНИЕ. Это не означает, что дублированный контент каким-либо образом повлияет на рейтинг моего сайта в поиске.
ПРИМЕЧАНИЕ. Это не означает, что дублированный контент каким-либо образом повлияет на рейтинг моего сайта в поиске.
2) Google может решить, что это настолько вопиющая попытка обмануть систему, что он полностью деиндексирует весь мой веб-сайт из всех результатов поиска. Это означает, что даже если вы будете искать напрямую «Example.com», Google не найдет результатов.
Итак, один из этих двух сценариев гарантированно произойдет. Какой именно, зависит от того, насколько вопиющим Google определит вашу ошибку. По словам Google:
Дублирующийся контент на сайте не является основанием для принятия мер на этом сайте, если только не выяснится, что целью страниц с дублирующимся контентом является ввод в заблуждение и манипулирование результатами поисковых систем. Если на вашем сайте возникают проблемы с дублированием контента, а вы не следуете вышеперечисленным советам, мы делаем хорошую работу, выбирая каноническую версию контента для отображения в данном результате поиска.
Этот тип незлонамеренного дублирования довольно распространен, особенно потому, что многие CMS не справляются с этим по умолчанию. Поэтому, когда люди говорят, что такой тип дублированного контента может повлиять на ваш сайт, это происходит не потому, что вас могут оштрафовать; это просто из-за того, как работают веб-сайты и поисковые системы.
Большинство поисковых систем стремятся к определенному уровню разнообразия; они хотят показать вам десять разных результатов на странице результатов поиска, а не десять разных URL-адресов с одинаковым содержанием. С этой целью Google пытается отфильтровать повторяющийся контент и документы, чтобы пользователи сталкивались с меньшей избыточностью.
Итак, что происходит, когда поисковый робот обнаруживает дублированный контент? (с https://searchengineland.com/search-illustrated-how-a-search-engine-determines-duplicate-content-13980)
Как найти повторяющийся контент
Исправить дублированный контент относительно легко. Поиск дублирующегося контента — сложная часть. Как я уже упоминал выше, обнаружение дублированного контента может быть сложным — то, что у вас нет повторяющегося контента с точки зрения взаимодействия с пользователем, не означает, что у вас нет повторяющегося контента с точки зрения поискового алгоритма.
Поиск дублирующегося контента — сложная часть. Как я уже упоминал выше, обнаружение дублированного контента может быть сложным — то, что у вас нет повторяющегося контента с точки зрения взаимодействия с пользователем, не означает, что у вас нет повторяющегося контента с точки зрения поискового алгоритма.
Ваш первый шаг — ручной; просмотрите свой сайт и посмотрите, нет ли очевидных повторений контента. Например, есть ли на вашем сайте одинаковый абзац, завершающий каждую страницу?
Перепишите его.
Вы повторно использовали раздел предыдущего сообщения в новом сообщении? Сделайте различие. После того, как вы завершили это первоначальное ручное сканирование, вы можете использовать два основных инструмента, чтобы найти больше скрытых экземпляров дублированного контента.
Выполните собственный поиск Во-первых, вы можете выполнить поиск, чтобы увидеть глазами Google. Используйте тег Site:, чтобы ограничить поиск только своим сайтом, и используйте тег intitle: для поиска определенной фразы. Это должно выглядеть примерно так:
Это должно выглядеть примерно так:
Site:thisisyoursite.comintitle:”thisisyourtargetphrase”
Этот поиск выдаст все результаты на данном сайте, которые соответствуют выбранной вами фразе. Если вы видите несколько одинаковых результатов, вы знаете, что у вас проблема с дублированным содержимым.
Проверить Google Search Console (GSC)Более простой способ проверить наличие дублирующегося контента — использовать Инструменты Google для веб-мастеров, чтобы просканировать ваш сайт и сообщить о любых ошибках. Создав и подтвердив свою учетную запись Инструментов для веб-мастеров, перейдите на вкладку «Внешний вид в поиске» и нажмите «Улучшения HTML». Здесь вы сможете увидеть и скачать список повторяющихся метаописаний и тегов заголовков. Это распространенные и легко исправимые проблемы, которые просто требуют немного времени для перезаписи.
Чтобы определить, понизит ли образец дублированного контента ваш рейтинг, сначала вам нужно определить, почему вы собираетесь публиковать такой контент.
Все сводится к вашей цели.
Если ваша цель состоит в том, чтобы попытаться напугать систему, используя фрагмент контента, который был опубликован в другом месте, вы обязательно будете оштрафованы. Цель явно обманчива и предназначена для манипулирования результатами поиска.
Вот что говорит Google о таком поведении:
Дублирование контента на сайте не является основанием для принятия мер на этом сайте, если не представляется, что цель дублированного контента состоит в том, чтобы ввести в заблуждение и манипулировать результатами поисковых систем.
Copyscape
За 5 центов за поиск вы можете заказать у Copyscape всю работу для вас. Но если ваш бюджет не позволяет такие расходы, вы все равно можете использовать Copyscape бесплатно. Загвоздка бесплатного Copyscape в том, что вам придется сначала опубликовать контент в Интернете, чтобы получить его URL-адрес.
Скопируйте и вставьте URL вашего недавно опубликованного контента в поле поиска Copyscape. Что делает Copyscape, так это сканирует все сети на наличие копий контента, который вы только что опубликовали.
Что делает Copyscape, так это сканирует все сети на наличие копий контента, который вы только что опубликовали.
Copyscape — это надежный инструмент, от которого зависят многие издатели при проверке качества и оригинальности. Существуют и другие инструменты, очень похожие на Copyscape, которые вы можете использовать для той же цели, такие как Plagiarism Detect и InterNIC.
Проверить наличие дублирующегося содержимого довольно легко и просто. Это незаменимая SEO-задача для начинающих, но никто не должен воспринимать ее как должное. С правильным набором инструментов вы можете с комфортом убедиться, что ваш контент уникален задолго до того, как опубликовать его в Интернете.
Предоставляя своим читателям высококачественный и уникальный контент, вы приносите большую пользу.
Как очистить и удалить повторяющийся контент
После того, как вы определили критические области дублирования на своем сайте, вы можете начать принимать меры по их исправлению. Чем раньше вы предпримете корректирующие действия, тем быстрее вы начнете восстанавливаться от негативных последствий.![]() К счастью, Google также упрощает поиск и исправление дублирующегося контента на вашем сайте. Когда вы войдете в Инструменты Google для веб-мастеров, перейдите к «Внешний вид в поиске», а затем «Улучшения HTML». Это позволит вам составить список любых страниц, на которых Google обнаруживает дублированный контент. Когда у вас есть этот список, вы можете приступить к устранению ошибок дублированного содержимого одну за другой любым из следующих методов:
К счастью, Google также упрощает поиск и исправление дублирующегося контента на вашем сайте. Когда вы войдете в Инструменты Google для веб-мастеров, перейдите к «Внешний вид в поиске», а затем «Улучшения HTML». Это позволит вам составить список любых страниц, на которых Google обнаруживает дублированный контент. Когда у вас есть этот список, вы можете приступить к устранению ошибок дублированного содержимого одну за другой любым из следующих методов:
- Удалите ненужный и повторяющийся контент. Первый шаг самый простой и очевидный, хотя он может занять много времени, если у вас несколько экземпляров. В любой ситуации, когда вы можете переписать часть контента, чтобы устранить дублирование, сделайте это. Облекайте свои идеи в разные слова, используйте разные устройства кадрирования и не бойтесь переписывать с нуля.
- Шаблоны . Длинные шаблоны или уведомления об авторских правах должны быть удалены с разных страниц и вместо этого размещены на одной странице. В тех случаях, когда вам нужно было бы привлечь внимание ваших читателей к шаблону или авторскому праву внизу каждой из ваших страниц или сообщений, вместо этого вставьте ссылку на одну специальную страницу.
- Похожие страницы . Бывают случаи, когда необходимо публиковать похожие или потенциально повторяющиеся страницы, например SEO для малого и крупного бизнеса. Избегайте публикации одной и той же или похожей информации. Вместо этого расширьте возможности обеих служб и сделайте информацию очень специфичной для каждого сегмента бизнеса.
- Без индекса . Люди могут синдицировать ваш контент. Если нет способа избежать этого, добавьте примечание внизу каждой страницы вашего контента, в котором пользователям предлагается включить метатег «noindex» в ваш синдицированный контент, чтобы предотвратить индексацию дублированного контента поисковыми системами.
- 301 переадресация . Сообщите поисковым роботам Googlebot, что страница была перемещена без возможности восстановления, используя переадресацию 301. Это также предупреждает поисковые системы о необходимости удалить старый URL-адрес из своего индекса и заменить его новым адресом.
- Выбор только одного URL-адреса в идентификаторах сеансов . Может быть несколько URL-адресов, которые вы можете использовать для перехода на свою домашнюю страницу, но вам следует выбрать только один. Выбирая лучший URL-адрес для своей страницы, обязательно помните о пользователях. Сделайте URL-адрес удобным для пользователя и будьте осторожны с идентификаторами сеанса. Это облегчает не только вашим пользователям поиск вашей страницы, но и поисковым системам индексацию вашего сайта. Некоторые ошибки дублирования контента не связаны с фактическим дублированием контента. Идентификаторы сеанса связаны со структурой URL, которую видит Google. Например, если у вас есть одна страница, связанная с thisisyoursite.com/, thisisyoursite.com/? и thisisyoursite.com/?sessionid=111, Google увидит эту страницу как повторяющееся содержимое три раза. Во-первых, выберите между форматированием с www или без www и придерживайтесь этого.
- Всегда создавайте уникальный контент . Партнеры почти всегда становятся жертвами удобства готового контента, предоставляемого продавцами. Если вы являетесь аффилированным лицом, обязательно создайте уникальный контент для продуктов продавца, которые вы продвигаете. Не просто копируйте и вставляйте.
 В тех случаях, когда вам нужно было бы привлечь внимание ваших читателей к шаблону или авторскому праву внизу каждой из ваших страниц или сообщений, вместо этого вставьте ссылку на одну специальную страницу.
В тех случаях, когда вам нужно было бы привлечь внимание ваших читателей к шаблону или авторскому праву внизу каждой из ваших страниц или сообщений, вместо этого вставьте ссылку на одну специальную страницу. Это также предупреждает поисковые системы о необходимости удалить старый URL-адрес из своего индекса и заменить его новым адресом.
Это также предупреждает поисковые системы о необходимости удалить старый URL-адрес из своего индекса и заменить его новым адресом. Во-первых, выберите между форматированием с www или без www и придерживайтесь этого.
Во-первых, выберите между форматированием с www или без www и придерживайтесь этого.Как Google наказывает за дублированный контент
Компания Google довольно открыто говорит о своей политике в отношении дублированного контента, в том числе о возможности наложения штрафных санкций за дублирование контента на сайтах в случае их несоблюдения.
Согласно их отчетам, если Google обнаружит две разные версии одной и той же веб-страницы или контент, который заметно похож на контент на сайте в другом месте, он случайным образом выберет каноническую версию страницы для индексации. Вы можете напрямую указать Google, какую страницу вы хотите сделать главной, просто используя тег rel=«canonical» в вашей гиперссылке.
Вот пример, который они приводят: представьте, что у вас есть стандартная веб-страница и версия той же веб-страницы для печати с идентичным содержимым. Google случайным образом выберет одну из этих страниц для индексации и полностью проигнорирует другую версию. При использовании ссылки rel=»canonical» href ничего не подразумевается о наказании, , но в ваших интересах убедиться, что Google правильно индексирует и организует ваш сайт.
Настоящая проблема со ссылкой rel=»canonical» возникает, когда Google подозревает дублированный контент, созданный злонамеренно или манипулятивно. По сути, если Google считает, что ваш дублированный контент был попыткой обмануть их алгоритм ранжирования, даже если включен URL-адрес rel=»canonical», вы столкнетесь с карательными мерами. В ваших же интересах заранее исправить любые ошибки и добавить ссылку rel=»canonical» в ваш HTML-текст, чтобы предотвратить такую судьбу для вашего сайта.
Синдикация: Дублирование контента в разных доменах
Иногда один и тот же фрагмент контента может появляться слово в слово по разным URL-адресам. Вот некоторые примеры:
Вот некоторые примеры:
- Новостные статьи (например, Associated Press)
- Одна и та же статья из каталога статей подбирается разными веб-мастерами
- Веб-мастера, отправляющие один и тот же контент в разные каталоги статей
- Пресс-релизы распространяются через Интернет
- Информация о продукте от производителя, появляющаяся на различных веб-сайтах электронной коммерции
Все эти примеры являются результатом синдикации контента . Сеть полна синдицированного контента. Один пресс-релиз может создать дублированный контент в тысячах уникальных доменов. Но поисковые системы стремятся предоставить пользователям, выполняющим поиск, хороший пользовательский опыт, и предоставление страницы результатов, состоящей из одних и тех же фрагментов контента, не очень многих людей порадует. Так что же должен делать веб-краулер? Каким-то образом он должен решить, какое расположение контента является наиболее релевантным для показа искателю. Так как же это сделать? Прямо из большого G:
Так как же это сделать? Прямо из большого G:
Когда мы сталкиваемся с таким дублирующимся контентом на разных сайтах, мы смотрим на различные сигналы, чтобы определить, какой сайт является оригинальным, что обычно работает очень хорошо. Это также означает, что вам не следует сильно беспокоиться о негативных последствиях для присутствия вашего сайта в Google, если вы заметите, что кто-то очищает ваш контент.
Ну, Google, позволю себе не согласиться. К сожалению, я не думаю, что вы очень хорошо решаете, какой сайт является создателем контента. Как и Майкл Грей, который сетует в своем блоге «Когда Google получает дублированный контент неправильно», что Google часто приписывает исходный контент другим сайтам, на которые он синдицирует свой контент. По словам Майкла:
Однако проблема с Google, их алгоритм ранжирования ИМХО слишком много внимания уделяет доверию и авторитету домена.
И я согласен с Майклом. На протяжении большей части своей карьеры в интернет-маркетинге я синдицировал полные статьи в различные каталоги статей, чтобы расширить охват моего контента, а также использовал его в качестве «топлива для SEO» для получения белых обратных ссылок на мои веб-сайты. По словам Google, пока ваши синдицированные версии содержат обратную ссылку на ваш оригинал, это поможет вам, когда Google решит, какая часть является оригиналом. Вот доказательство:
На протяжении большей части своей карьеры в интернет-маркетинге я синдицировал полные статьи в различные каталоги статей, чтобы расширить охват моего контента, а также использовал его в качестве «топлива для SEO» для получения белых обратных ссылок на мои веб-сайты. По словам Google, пока ваши синдицированные версии содержат обратную ссылку на ваш оригинал, это поможет вам, когда Google решит, какая часть является оригиналом. Вот доказательство:
Во-первых, видео с участием Джона Мюллера, известного блогера и бывшего инженера Google:
Обсуждение синдикации начинается примерно в 2:25. В 2:54 он говорит, что вы можете сказать людям, что вы «хозяин контента», включив ссылку из синдицированного материала обратно на исходный материал.
Дополнительные доказательства:
В тех случаях, когда вы синдицируете свой контент, но также хотите убедиться, что ваш сайт идентифицирован как первоисточник, полезно попросить своих партнеров по синдикации включить ссылку на исходный контент.
И, наконец:
Тщательно распространяйте : Если вы распространяете свой контент на других сайтах, Google всегда будет показывать версию, которую мы считаем наиболее подходящей для пользователей в каждом заданном поиске, которая может быть или не быть вашей версией. предпочел бы. Однако полезно убедиться, что каждый сайт, на котором распространяется ваш контент, содержит ссылку на исходную статью. Вы также можете попросить тех, кто использует ваш синдицированный материал, использовать метатег noindex, чтобы поисковые системы не индексировали их версию контента.
Что мне кажется интересным в этой последней цитате из Google, так это то, что они фактически признают, что выбранный ими контент может быть неправильным. По моему опыту, очень вероятно, что не удастся выбрать правильный сайт, если сайт, создавший контент, относительно молод или имеет низкий PageRank. Таким образом, возникает следующая большая проблема:
Дублирование контента в одном и том же домене
Последнее слово состоит в том, что, если вы действительно откровенно дублируете свой контент на множестве URL-адресов в одном и том же домене, не о чем беспокоиться. Один из ваших URL-адресов, на котором находится повторяющийся контент, будет проиндексирован и выбран в качестве «представителя» этого кластера URL-адресов. Когда пользователи выполняют поисковые запросы в поисковых системах, этот конкретный фрагмент контента будет отображаться в результате соответствующих запросов, а другие URL-адреса в кластере дубликатов не будут отображаться. Просто как тот.
Один из ваших URL-адресов, на котором находится повторяющийся контент, будет проиндексирован и выбран в качестве «представителя» этого кластера URL-адресов. Когда пользователи выполняют поисковые запросы в поисковых системах, этот конкретный фрагмент контента будет отображаться в результате соответствующих запросов, а другие URL-адреса в кластере дубликатов не будут отображаться. Просто как тот.
Однако другой стороной медали является дублирование содержимого в разных доменах . А это совсем другой монстр. Готовы взяться за это? Вот так.
Традиционный «Дублированный контент»
Традиционный дублированный контент — это тип контента, который интуитивно приходит на ум, когда вы слышите эту фразу. Это содержимое, идентичное или очень похожее на содержимое, которое существует в других местах в Интернете (обычно на вашем собственном сайте). Существует несколько причин, по которым сайт намеренно дублирует контент:
- Воспроизведение старого контента, чтобы ваш сайт выглядел более обновленным.
- Повторное копирование материалов для добавления дополнительных страниц на ваш сайт.
- Плагиат материала для выдачи за свой.

Все эти ситуации обманчивы, иногда для пользователей, иногда для Google, и по большей части веб-мастера стараются держаться подальше от таких практик. Если вы участвуете в них, вы, вероятно, заслуживаете наказания.
Дублирование версий страниц
Существует четыре различных версии вашего веб-сайта, каждая из которых рассматривается (или может рассматриваться) поисковыми системами как отдельный веб-сайт:
В серверной части у вас должна быть одна версия, назначенная в качестве основного сайта, и все остальные версии должны быть направлены на этот основной сайт.
Если Google проиндексировал несколько версий вашего сайта, это повлияет на ваш рейтинг. Например, если вы проводите контент-маркетинговую кампанию со ссылками на http://yourdomain.com, только эта версия вашего сайта получит «ссылочный вес». Если ваш основной сайт на самом деле http://www.yoursite.com, вам придется запустить отдельную кампанию для ранжирования страниц в этом домене.
Если ваш основной сайт на самом деле http://www.yoursite.com, вам придется запустить отдельную кампанию для ранжирования страниц в этом домене.
Выполните поиск по сайту в Google для всех 4 форматов доменов, перечисленных выше. Если вы получаете результаты для более чем одного формата домена, поговорите с разработчиком веб-сайта о назначении основной версии и перенаправлении всех остальных на эту основную версию вашего домена.
Скрытый дублированный контент
Я называю это «скрытым» дублированным контентом из-за того, как легко он может подкрасться к вам. Вы не собираетесь создавать дубликаты страниц, но это все равно может произойти. Обычно это происходит из-за технического сбоя или непреднамеренного воспроизведения; например:
- Если у вас есть две версии вашего веб-сайта для https:// и https://, Google может проиндексировать обе версии каждой страницы отдельно, а затем пометить эти страницы как примеры дублирующегося контента.
- Если у вас есть версия веб-страницы для печати, она будет отображаться как отдельный URL-адрес с тем же содержимым.
- Полные и адаптированные для мобильных устройств формы веб-страниц, такие как разделы форума.
К сожалению, большинство из этих случаев могут возникать естественным образом, когда вы создаете и изменяете свой веб-сайт, если только вы специально не предприняли превентивные меры, чтобы остановить их.
«Но я не копирую свой контент»
Вашей первой реакцией на эту оценку может быть увольнение. Вы не копируете свой контент с одной страницы на другую. Вы тщательно следите за тем, чтобы каждая страница вашего сайта была написана оригинально, без повторяющихся фраз или разделов.
К сожалению, для вас все еще существует риск. То, что Google регистрирует как «дублированный контент», не всегда совпадает с тем, что пользователь видит как дублированный контент. Пользователь, просматривающий ваши страницы, может никогда не встретить повторяющуюся фразу, но Google может просканировать ваш сайт и найти десятки повторений в ваших тегах заголовков, или у вас может быть несколько неканонизированных URL-адресов с одинаковым содержимым на странице. Даже если вы уверены, что не повлияли напрямую на какую-либо форму дублированного контента, стоит проверить свой сайт, чтобы быть уверенным.
Даже если вы уверены, что не повлияли напрямую на какую-либо форму дублированного контента, стоит проверить свой сайт, чтобы быть уверенным.
Заключение
Подведем краткие итоги. «Дублированный контент» может относиться к плагиату, скопированному контенту с целью надувания сайта, но, что более важно для обычного пользователя, к страницам, которые Google индексирует дважды. Эти повторяющиеся результаты контента легко отследить с помощью Google Search Console и исправить с помощью настроек канонизации (через rel=»canonical») или перенаправлений, но если они останутся незамеченными, они могут в совокупности снизить ваш рейтинг. Будьте активны и ищите дублированный контент не реже одного раза в несколько месяцев — если ваш процесс управления сайтом не безупречен, вполне вероятно, что дублированный контент появится, когда вы меньше всего этого ожидаете.
В конце концов, все сводится к массовому тестированию, получению достоверных данных и принятию решений на их основе. Итак, вот что я собираюсь сделать. Я собираюсь провести огромный тест, а затем обновить этот пост с моими результатами. В начале поста я упомянул, что скоро запущу огромный веб-сайт с тоннами уникального контента. Я собираюсь синдицировать все это, полностью неотредактированное, насколько это возможно. При этом я буду отслеживать источники органического трафика, чтобы увидеть, по каким ключевым словам люди находят мой контент. Затем я воспроизведу эти ключевые слова в Google и посмотрю, какое место занимает мой сайт в результатах поиска. Это должно стать окончательной проверкой достоинств синдикации.
Итак, вот что я собираюсь сделать. Я собираюсь провести огромный тест, а затем обновить этот пост с моими результатами. В начале поста я упомянул, что скоро запущу огромный веб-сайт с тоннами уникального контента. Я собираюсь синдицировать все это, полностью неотредактированное, насколько это возможно. При этом я буду отслеживать источники органического трафика, чтобы увидеть, по каким ключевым словам люди находят мой контент. Затем я воспроизведу эти ключевые слова в Google и посмотрю, какое место занимает мой сайт в результатах поиска. Это должно стать окончательной проверкой достоинств синдикации.
Спасибо, что остались со мной в этом сумасшедшем посте!
- Автор
- Последние сообщения
Тимоти Картер
Директор по доходам SEO.co
Ветеран отрасли Тимоти Картер является директором по доходам SEO.co. Тим руководит всеми доходами компании и наблюдает за всеми командами, работающими с клиентами, включая продажи, маркетинг и работу с клиентами.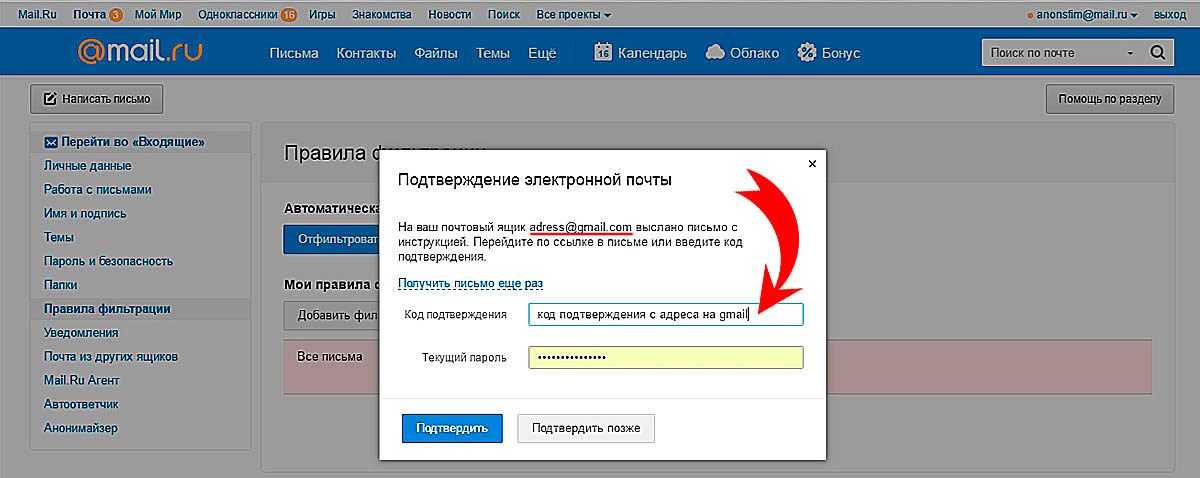 Он провел более 20 лет в мире SEO и цифрового маркетинга, руководя созданием и масштабированием операций по продажам, помогая компаниям повышать эффективность доходов и стимулировать рост веб-сайтов и отделов продаж. Когда он не работает, Тим любит играть в гольф, бегать и проводить время с женой и семьей на пляже… предпочтительно на Гавайях.
Он провел более 20 лет в мире SEO и цифрового маркетинга, руководя созданием и масштабированием операций по продажам, помогая компаниям повышать эффективность доходов и стимулировать рост веб-сайтов и отделов продаж. Когда он не работает, Тим любит играть в гольф, бегать и проводить время с женой и семьей на пляже… предпочтительно на Гавайях.
На протяжении многих лет он писал для таких изданий, как Forbes, Entrepreneur, Marketing Land, Search Engine Journal, ReadWrite и других уважаемых интернет-изданий. Свяжитесь с Тимом в Linkedin и Twitter.
Последние сообщения Тимоти Картера (см. все)
Поисковая оптимизация: как обнаружить и исправить страницы с дублирующимся контентом
Дублированный контент остается распространенным препятствием, когда речь идет об увеличении органического поискового трафика на веб-сайтах розничных продавцов.
Вот некоторые из преимуществ устранения дублированного контента для повышения эффективности SEO по сравнению с другими маркетинговыми мероприятиями, такими как создание ссылок, контент-маркетинг или продвижение контента:
- Консолидация дублированного контента может быть выполнена относительно быстро, так как требует небольшого набора технических изменений;
- Скорее всего, вы увидите улучшение рейтинга в течение нескольких недель после внесения исправления;
- Google быстрее улавливает новые изменения и улучшения вашего сайта, поскольку ему приходится сканировать и индексировать меньше страниц, чем раньше.
Консолидация дублированного контента не позволяет избежать штрафов Google. Речь идет о построении ссылок. Ссылки ценны для эффективности SEO, но если ссылки оказываются на дублирующихся страницах, они вам не помогут. Они идут впустую.
Дублированный контент ослабляет ссылки
Один и тот же контент, доступный по нескольким URL-адресам, ослабляет репутацию. Источник: Google.
Лучшее объяснение этому я нашел много лет назад, когда Google опубликовал SEO-аудит (PDF), который он провел на своих сайтах.
В верхней части рисунка выше три страницы одного и того же продукта. Каждый из них накапливает ссылки и соответствующую репутацию страницы. Google и другие крупные поисковые системы по-прежнему рассматривают качество и количество ссылок со сторонних сайтов как своего рода одобрение. Они используют эти ссылки, чтобы определить, насколько глубоко и часто они посещают страницы сайта, сколько они индексируют, сколько они ранжируют и как высоко они ранжируются.
Репутация главной страницы, также известной как каноническая страница, снижается, потому что две другие страницы получают часть репутации. Поскольку у них одинаковый контент, они будут конкурировать за одни и те же ключевые слова, но большую часть времени в результатах поиска будет отображаться только одно из них. Другими словами, эти ссылки на другие страницы теряются.
Нижняя часть иллюстрации показывает, что простым объединением дубликатов мы увеличиваем количество ссылок на каноническую страницу и ее репутацию. Мы восстановили их.
Результаты могут быть впечатляющими. Я наблюдал 45-процентное увеличение дохода по сравнению с прошлым годом — более 200 000 долларов США менее чем за два месяца — благодаря удалению дублирующегося контента. Дополнительный доход поступает от многих других страниц продуктов, которые ранее не ранжировались и не получали поисковый трафик из-за дублированного контента.
Как обнаружить повторяющийся контент
Чтобы определить, есть ли на вашем сайте дублирующийся контент, введите в Google site:yoursitename. com и проверьте количество страниц в списке.
com и проверьте количество страниц в списке.
Введите в Google «site:yoursitename.com» и проверьте, сколько страниц указано.
Товары должны занимать большую часть страниц на большинстве сайтов розничной торговли. Если Google перечисляет намного больше страниц, чем у вас есть продуктов, ваш сайт, вероятно, содержит дублированный контент.
Если ваши XML-карты сайта являются исчерпывающими, вы можете использовать Google Search Console и сравнить количество страниц, проиндексированных в ваших XML-картах сайта, с общим количеством проиндексированных страниц в Статусе индексирования.
Пример дублирующегося контента
One Kings Lane — розничный продавец мебели и товаров для дома. Используя диагностический инструмент, я вижу, что Google проиндексировал более 800 000 страниц Onekingslane.com. Но, похоже, у него проблема с дублирующимся контентом.
При навигации по сайту я обнаружил страницу продукта — синий коврик — без канонического тега для объединения дублированного контента. Когда я искал в Google название продукта — «Fleurs Rug, Blue», — оказалось, что оно занимает первое место.
Когда я искал в Google название продукта — «Fleurs Rug, Blue», — оказалось, что оно занимает первое место.
One Kings Lane занимает первое место в Google по запросу «Fleurs Rug, Blue», несмотря на отсутствие канонических тегов.
Но когда я нажал на этот список поиска, я перешел на другую страницу. Идентификаторы продуктов разные: 4577674 против 2747242. Я получаю одну страницу при навигации по сайту, другая проиндексирована, и ни одна из них не имеет канонических тегов.
Вероятно, это приводит к снижению репутации, хотя страница занимает первое место в поисковом запросе «Fleurs Rug, Blue». Но большинство страниц продуктов ранжируются по сотням ключевых слов, а не только по названию продукта. В этом случае разбавление, вероятно, приводит к тому, что страница ранжируется по гораздо меньшему количеству терминов, чем могла бы в противном случае.
Однако в этом примере дублирование содержимого — не самая большая проблема. Когда я нажал на этот результат поиска, я перешел на несуществующую страницу.
При нажатии на результат поиска синего коврика открывается страница с ошибкой.
Страница больше не существует. Google, скорее всего, удалит этот продукт из результатов поиска.
Даже если One Kings Lane перестроит страницу продукта, присвоив ей новый идентификатор продукта, Google может пройти несколько недель, чтобы получить его, поскольку Googlebot должен просканировать не менее 800 000 страниц всего сайта.
Исправление дублирующегося контента
Устаревшая тактика решения проблемы дублированного контента – блокировать поисковым системам сканирование дубликатов страниц в файле robots.txt. Но это не закрепляет репутацию дубликатов в канонических страницах. Это позволяет избежать штрафов, но не восстанавливает ссылки. Когда вы блокируете дубликаты страниц через robots.txt, эти дубликаты по-прежнему накапливают ссылки и репутацию страницы, что не помогает сайту.
Вместо этого ниже приведены рецепты решения наиболее распространенных проблем с дублированием содержимого с помощью переадресации 301 в Apache. Но сначала полезно понять варианты использования постоянных перенаправлений и канонических тегов.
Но сначала полезно понять варианты использования постоянных перенаправлений и канонических тегов.
Канонические теги и перенаправления объединяют дубликаты страниц. Но перенаправления, как правило, более эффективны, потому что поисковые системы редко их игнорируют, а перенаправленные страницы не нужно индексировать. Однако вы не можете (или не должны) использовать перенаправления для объединения почти дубликатов, таких как один и тот же продукт в разных цветах или продукты, перечисленные в нескольких категориях.
Лучшая консолидация дублированного контента — это та, которую вам не нужно делать. Например, вместо создания иерархии сайтов с site.com/category1/product1 , просто используйте site.com/product1 . Это устраняет необходимость объединять продукты, перечисленные в нескольких категориях.
Распространенные перенаправления URL
Ниже приведены рецепты перенаправления Apache для решения пяти распространенных проблем с дублированием содержимого.
Я буду использовать mod_rewrite и предполагаю, что он включен на вашем сайте
RewriteEngine On # Это активирует возможности перезаписи
Я также буду использовать программу проверки htaccess для проверки правил перезаписи. 9/?(.*) https://www.webstore.com/$1 [R=301,L]
Это проверяет, что соединение уже не HTTPS.
Обратите внимание, что это правило также относится к редкому случаю дублирования IP-адреса, когда сайт также доступен по IP-адресу.
Это правило также работает в редких случаях дублирования IP-адресов, когда сайт также доступен по IP-адресу.
В следующих примерах мы будем предполагать, что у нас есть полный сайт, использующий HTTPS.
9/]+)/?$ https://www.webstore.com/$1/ [R=301,L]
Это правило добавляет отсутствующие косые черты в конце.
Этот удаляет их:
RewriteEngine On
# Это активирует возможности перезаписи
%{REQUEST_FILENAME} !-f
# Это проверяет, что мы не добавляем слэши к файлам, т. е. /index.html/ будет неправильным
RewriteRule (.+)/$ https://www.webstore.com/$1 [R=301,L]  е. /index.html/ будет неправильным
RewriteRule (.+)/$ https://www.webstore.com/$1 [R=301,L]
е. /index.html/ будет неправильным
RewriteRule (.+)/$ https://www.webstore.com/$1 [R=301,L] Это правило удаляет отсутствующие косые черты в конце.
Дублирование файлов. Распространенным случаем дубликата файла является индексный файл каталога. В системах на основе PHP это index.php . В системах .NET это default.aspx . Мы хотим удалить этот индексный файл каталога, чтобы избежать дублирования.
%{REQUEST_FILENAME} -f
# Это необязательно и проверяет, что мы затрагиваем только файлы
RewriteRule (.*)/?index.php$ https://www.webstore.com/$1 [R=301,L] Это правило удаляет этот индексный файл каталога.
9категория/продукт.php /продукт-%1.html? [Р=301,Л] #Обратите внимание, что на совпадения регулярных выражений из RewriteCond ссылаются с помощью %, а на совпадения в RewriteRule ссылаются с помощью $
Это правило запрещает доступ к недружественным для поисковых систем URL-адресам без перенаправления.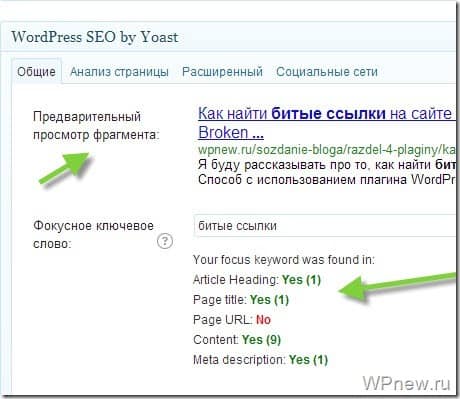
Индивидуальные перенаправления
В приведенных выше примерах я предполагаю, что идентификаторы продуктов одинаковы для обоих URL-адресов — канонической версии и дубликата. Это позволяет использовать одно правило для сопоставления всех страниц продуктов. Однако идентификаторы продуктов часто не совпадают или новые URL-адреса не используют идентификаторы. В таких случаях вам понадобятся сопоставления один к одному.
Но массовые сопоставления и перенаправления один к одному сильно замедляют работу сайта — по моему опыту, в 10 раз медленнее.
Чтобы преодолеть это, я использую приложение под названием RewriteMap. Конкретный MapType , который следует использовать в этом случае, представляет собой тип DBM, который представляет собой хэш-файл, обеспечивающий очень быстрый доступ.
Когда используется MapType DBM, MapSource — это путь в файловой системе к файлу базы данных DBM, содержащему пары ключ-значение, которые будут использоваться в сопоставлении.