
Список минус слов для Яндекс Директ в 2022, как использовать минус-слова в Яндекс.Директ
- Что такое минус-слова и для чего они нужны?
- В чем разница между минус-словами и минус-фразами?
- Где найти минус-фразы для Директа?
- Как добавить минус-слова в Яндекс.Директ?
- Некоторые особенности
- Что такое кросс-минусовка?
Что такое минус-слова и для чего они нужны?
В сети один запрос может предполагать разные аспекты, по которым пользователю нужна информация. В SEO это называется Подробнее…»>интентом поискового запроса, и его нужно учитывать при создании контента, чтобы получать только целевой конверсионный трафик. Но SEO — это условно бесплатный трафик, и нецелевые посещения грозят разве что сниженным показателем отказов, а это исправимо. А в контекстной рекламе нецелевые клики стоят рекламодателю реальных денег, которые уходят безвозвратно. Поэтому так важно еще на этапе настройки отсекать ненужные смыслы и варианты использования. В этом специалистам по рекламе в Директе помогают минус-слова.
В этом специалистам по рекламе в Директе помогают минус-слова.
Резюмируем.
Минус-слова — это слова и словосочетания, по которым объявления показываться не будут.
В чем разница между минус-словами и минус-фразами?
Рассмотрим на примере. Допустим, фирма оказывает юридическую помощь при оформлении банкротства физических лиц. Смотрим, какие есть запросы по этой теме в Wordstat:
В этом списке запросы, которые не подходят услуге данной компании, — частично или целиком:
Единичные слова, которые не относятся к услуге данной компании, — это минус-слова.
А запросы из двух и более слов, которые полностью не подходят, — минус-фразы.
Мы исключаем их из ключевых фраз контекстной рекламы.
Где найти минус-фразы для Директа?
Один из вариантов мы уже показали выше — это сервис Вордстат. Он принадлежит Яндексу, поэтому данные из него достоверны и релевантны для кампаний в Директе..png)
Второй вариант — универсальные минус-слова. Они экономят время, потому что большинство из них одинаковы для разных бизнесов. Например, это бесплатные варианты или раскрывающие информационный аспект темы:
- бесплатно;
- видео;
- фото;
- рисунок;
- скачать;
- реферат;
- самостоятельно;
- инструкция;
- самому;
- дома.
Все эти примеры из запросов не помогают рекламодателям получать целевые клики, потому что в Директе рекламные кампании работают преимущественно по продающим запросам (купить, заказать и другие).
Такие списки часто выкладывают в интернете, но никто не гарантирует, что они подойдут вашей кампании. Значит ли это, что они бесполезны? Нет, их можно и нужно использовать, особенно, когда нет доступа к профессиональной настройке контекстной рекламы. Главное, внимательно перечитывать и безжалостно выбрасывать ненужное.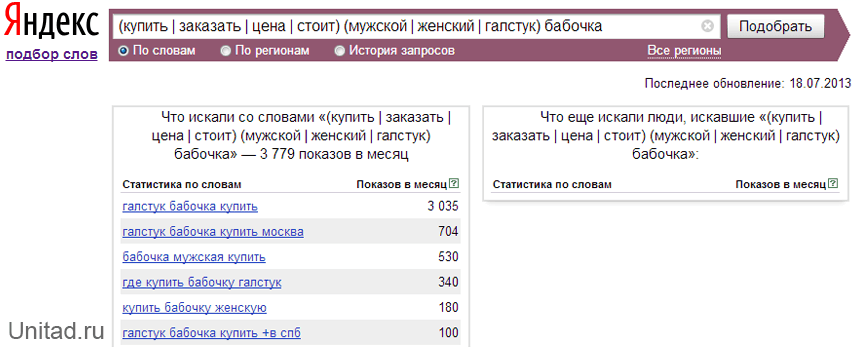
- другими тематиками, но пересекающимися по названию к вашей услуге или товару. Например, вы продаете наклейки на автомобили, а не наклейки на окна, ногти или ноутбуки;
- другими товарами и услугами, которые есть на рынке, но не относятся к деятельности вашей компании. Допустим, ваша компания поставляет запчасти для корейских авто, а не китайских или японских;
- другими регионами и странами, куда у вас нет доставки.
Есть еще третий источник подбора исключений, но о нем уместнее рассказать чуть позже — уже после того, как мы настроили и запустили кампанию.
Как добавить минус-слова в Яндекс.Директ?
Настроить минус-слова и минус-фразы можно в личном кабинете Директа в дополнительных настройках кампании:
Часто используемые исключения можно сохранять в наборах. Вся совокупность таких наборов — это библиотека минус-фраз. В одном личном кабинете может быть до 30 наборов, максимальное общее количество символов на один набор — 4096.
Применять набор можно сразу к нескольким группам объявлений. К одной группе объявлений можно добавить максимум 3 набора минус-фраз — и это выручает, потому что объем минус-фраз к кампании ограничен 20 000 символов. Когда исключений много и этот список постоянно пополняется, этот лимит быстро исчерпывается.
Минус-слова можно добавлять на всех уровнях: в ключевых фразах, группах, кампаниях и библиотеке. Минус-фразы — для групп объявлений, кампании и в библиотеке.
Здесь мы возвращаемся к упомянутому выше третьему варианту, раскрывающему, как подобрать минус-слова для Яндекс.Директ. Этот инструмент — вкладка в статистике по работе кампании в Директе, содержащая статистические данные по рекламе. Перед стартом кампании специалисты по контекстной рекламе собирают максимально возможное множество исключений, но в 100% случаев их рано или поздно становится недостаточно. Поэтому нужно просматривать отчет «Поисковые запросы» в Директе для их пополнения. Сразу исключить все неподходящее невозможно, так как всегда найдутся люди, которые придумают что-то новое, или могут возникнуть медийные тренды, которые будут вести на сайт нецелевой трафик.
Сразу исключить все неподходящее невозможно, так как всегда найдутся люди, которые придумают что-то новое, или могут возникнуть медийные тренды, которые будут вести на сайт нецелевой трафик.
Некоторые особенности
- По умолчанию слово исключается в любом числе, падеже, роде. Например, вместе с колесо уходят колеса, колесами и так далее. Если нужна фиксация только конкретной формы, нужно использовать оператор ! при вводе: — !колесо.
- Если ключевой запрос и исключение совпадают, побеждает ключевой. Яндекс.Директ не будет учитывать минус-слово искусственные, если в объявлении кампании есть ключевой запрос искусственные цветы. И объявление будет показываться.
- Отдельно нужно работать с минус-словами для РСЯ. Именно за счет ключевых запросов рекламодатель подбирает тематику площадки, где будет демонстрироваться объявление, поэтому отсекая слова, вы отсекаете и сайты. При неправильном составлении списка исключений можно невольно отказаться от площадок с целевой аудиторией.
 Директ в целом рекомендует создавать для Рекламной сети Яндекса самостоятельные кампании.
Директ в целом рекомендует создавать для Рекламной сети Яндекса самостоятельные кампании.
 Директ в целом рекомендует создавать для Рекламной сети Яндекса самостоятельные кампании.
Директ в целом рекомендует создавать для Рекламной сети Яндекса самостоятельные кампании.Что такое кросс-минусовка?
Кросс-минусовка — это перекрестное исключение запросов, которая исключает пересечения ключевых фраз и ограничивает показ объявлений по запросу, нерелевантному этой ключевой фразе.
Кросс-минусовку нужно проводить, чтобы по одному высокочастотному запросу не показывались средне- и низкочастотные.
Например, есть запросы купить квартиру и купить квартиру москва. К фразе купить квартиру добавляется минус-слово москва. Таким образом показываться будут только релевантные ключевой фразе объявления, и внутри рекламной кампании запросы не будут конкурировать между собой.
Как правильно подобрать и добавить минус-слова для контекста
То, как вы подбираете поисковые фразы, напрямую влияет на качество трафика с контекстной рекламы. Мусорные запросы съедают бюджет и размывают показатели кампании. Минус-слова помогают настроить рекламу так, чтобы клики и просмотры с рекламы были целевыми, а эффект от контекста – максимальным.
Минус-слова помогают настроить рекламу так, чтобы клики и просмотры с рекламы были целевыми, а эффект от контекста – максимальным.
В статье показываем, как собрать список минус-слов для контекста в Яндекс.Директе и Google Ads и разбираемся в нюансах и отличиях работы минусов в двух рекламных системах.
Содержание:
-
Зачем использовать минус-слова
- Что будет, если не использовать минус-слова в контекстной рекламе
Особенности работы с минус-словами в Яндекс.Директ
Особенности работы с минус-словами в Google Ads
Минус-слова в сетях РСЯ и КМС и на поиске: отличия
Как собрать минус-слова для контекстной рекламы: пошаговый алгоритм
- С помощью Яндекс.Wordstat
- В интерфейсе Яндекс. Директ
- С помощью планировщика Google Ads
 Директ
ДиректСтатья будет полезна также тем, кто задается вопросом – использовать операторы соответствия (например, кавычки) или собирать список минус-слов. Тут вопрос во временных затратах – если «мусорных» запросов слишком много, то проще заключить ключевое слово в кавычки, чем собрать минуса. В других случаях целесообразней собирать минуса, чтобы не отсекать целевой трафик. Оценить временные затраты вы сможете после прочтения статьи.
Зачем использовать минус-слова
Минус-слова блокируют показ объявлений по ключевым запросам, которые не относятся прямо к вашим товарам или услугам. Так вы отсекаете нецелевую аудиторию и сокращаете рекламные расходы.
Использование подходящих минус-слов позволяет:
- повысить релевантность показов,
- увеличить CTR (кликабельность) объявлений,
- снизить расходы на рекламу.
Что будет, если не использовать минус-слова
- Вашу рекламу видят люди с нерелевантными, «мусорными» запросами.
- CTR кампании снижается: пользователи из нецелевой аудитории не кликают на объявления, которые не соответствуют их запросам.
- Из-за нецелевого трафика растет доля отказов на сайте: люди быстро покидают сайт, не отвечающий их потребностям.
- Цена за клик растет из-за низкого CTR и высокого процента отказов. Эти показатели напрямую влияют на ставки, которые формирует Яндекс.Директ при автоматических стратегиях.
- Рекламный бюджет расходуется впустую. Вы не просто сливаете деньги, а делаете это все быстрее и быстрее из-за роста цены за клик.
Читайте также Что такое CTR?
Пример:
Вы запускаете кампанию для продажи арматурной сетки. Ключевой запрос для вас – «арматурная сетка». При этом вы не продаете сетку с ПВХ-покрытием. Если не «отминусить» слово «пвх», объявления увидят пользователи с запросом «арматурная сетка пвх». И, как итог – нецелевой трафик, слив бюджета, низкая конверсия в продажу, грусть и тоска.
Ключевой запрос для вас – «арматурная сетка». При этом вы не продаете сетку с ПВХ-покрытием. Если не «отминусить» слово «пвх», объявления увидят пользователи с запросом «арматурная сетка пвх». И, как итог – нецелевой трафик, слив бюджета, низкая конверсия в продажу, грусть и тоска.
Поэтому мы рекомендуем тщательно прорабатывать минус-слова для каждой вашей рекламной кампании.
Особенности работы с минус-словами в Яндекс.Директ
-
Добавляйте минус-слова на уровне рекламной кампании, группы объявлений или отдельной ключевой фразы.
-
Используйте как отдельные слова, так и целые фразы. Максимальная длина минус-фразы – 7 слов.
-
Максимальное количество символов без пробелов для минус-слов на уровне рекламной кампании – 20 000, на уровне отдельной группы объявлений – 4 096.
-
Вам не нужно склонять слова, Яндекс сам понимает и не показывает объявления по всем словоформам минус-слов.
-
При пересечении ключевого запроса и минус-слова последнее игнорируется, и Яндекс показывает объявление по ключевой фразе.
Пример:
При использовании минус-слова «оцинкованная», показов объявлений не будет также по запросам со словами «оцинкованной», «оцинкованную», «оцинкованных» и т. д.
Пример:
В рекламной кампании есть ключевой запрос «арматурная сетка 100х100» и минус-слово «100х100», то есть показы по запросу «арматурная сетка 100х100» будут.
Особенности работы с минус-словами в Google Ads
-
Добавляйте минус-слова на уровне аккаунта, рекламных кампаний или групп объявлений.
-
На уровне аккаунта минус-слова добавляются только списками. Максимальное количество списков в аккаунте – 20.
Максимальное число элементов в списке – 5 000. Ограничение по количеству минус-слов на кампанию или группу объявлений – 10 000.
-
Показ объявления может произойти по запросам длиной более 10 слов.
Пример:
В рекламной кампании есть минус-слово «недорого», а пользователь вводит запрос «сетка арматурная сварная для железобетонных конструкций 150х150 диаметр 4 миллиметра доставка монтаж недорого». Минус-слово находится на позиции после 10 слова и, соответственно, не сработает. Учитывайте это свойство при добавлении минус-фраз: в каждой не более 10 слов.
-
Учитывайте склонение слов.
Пример:
Чтобы не показывать объявления по всем ключевым запросам, связанным с оцинкованной сеткой, необходимо отминусить все варианты: «оцинкованная», «оцинкованной», «оцинкованную», «оцинкованных» и так далее.
-
При полном пересечении ключевого запроса и минус-слова приоритет будет у последнего и показа объявлений не будет.
 Максимальное число элементов в списке – 5 000. Ограничение по количеству минус-слов на кампанию или группу объявлений – 10 000.
Максимальное число элементов в списке – 5 000. Ограничение по количеству минус-слов на кампанию или группу объявлений – 10 000.

Минус-слова в сетях РСЯ и КМС и на поиске: отличия
Минус-слова для рекламы в сетях РСЯ и КМС работают не так, как на поиске. Это справедливо и для Яндекс.Директ, и для Google Ads. Использование минус-слов в сетевой рекламной кампании исключает показы объявлений не по ключевым запросам, а по площадкам. То есть, добавляя минус-слово, вы исключите показ объявлений на всех площадках этой тематики. В этом случае используйте минус-слова с осторожностью, чтобы не отсечь площадки, которые потенциально могут приводить целевой трафик.
Существуют универсальные списки «плохих» площадок, но для вашей ниши они могут оказаться эффективными. Поэтому для рекламы в сетях рекомендуем анализировать и исключать отдельные площадки вручную.
Ограничения по количеству минус-слов в РСЯ такие же, как и в рекламе на поиске: 20 000 символов без учета пробелов. В КМС – не более 5 000 минус-слов на кампанию.
Читайте также Как правильно настроить рекламу в РСЯ
Как собрать минус-слова для контекстной рекламы: пошаговый алгоритм
Начинать сбор минус-слов лучше всего на этапе создания семантического ядра. Собирать минус-слова можно как вручную, так и автоматически. Для парсинга ключевых запросов вручную используйте инструменты подбора ключевых слов от Яндекса или от Google Ads. Для автоматического парсинга воспользуйтесь программой KeyCollector (требуется платная лицензия) или ее бесплатным аналогом – программой Словоеб.
Читайте также
Как правильно подобрать ключевые слова для «Яндекс. Директ» и Google Ads
Директ» и Google Ads
Подбор минус-слов с помощью Яндекс.Wordstat
Зайдите в Вордстат, укажите интересующий регион и тип устройств и введите запрос – перед вами появится статистика похожих запросов.
В левой колонке отображаются все вложенные запросы, а в правой – похожие. Минус-слова можно найти в обеих колонках. В Wordstat существует ограничение по количеству отображаемых страниц – 41. Поэтому все ключевые запросы вручную охватить не получится.
В каждой тематике минус-слова будут уникальными, но есть группы маркеров, которые подходят большинству ниш. Рассмотрим на примере арматурных сеток:
Маркеры нерелевантных категорий товаров:
- оцинкованная
- ПВХ
Маркеры нерелевантных услуг:
- установка
- монтаж
- сварщик
Маркеры вторичного рынка:
- бу
- авито
- юла
Маркеры низкокачественного спроса:
- бесплатно
- даром
- халява
Маркеры нерелевантного контента:
- видео
- фото
- отзывы
Маркеры обучающего контента:
- диплом
- курсовая
- реферат
- ргр
- инструкция
- своими
- руками
- что
- такое
- википедия
Маркеры поиска работы:
- вакансии
- резюме
Совет:
Используйте сервисы для подбора синонимов, чтобы максимально дополнить список минус-слов, например от Text.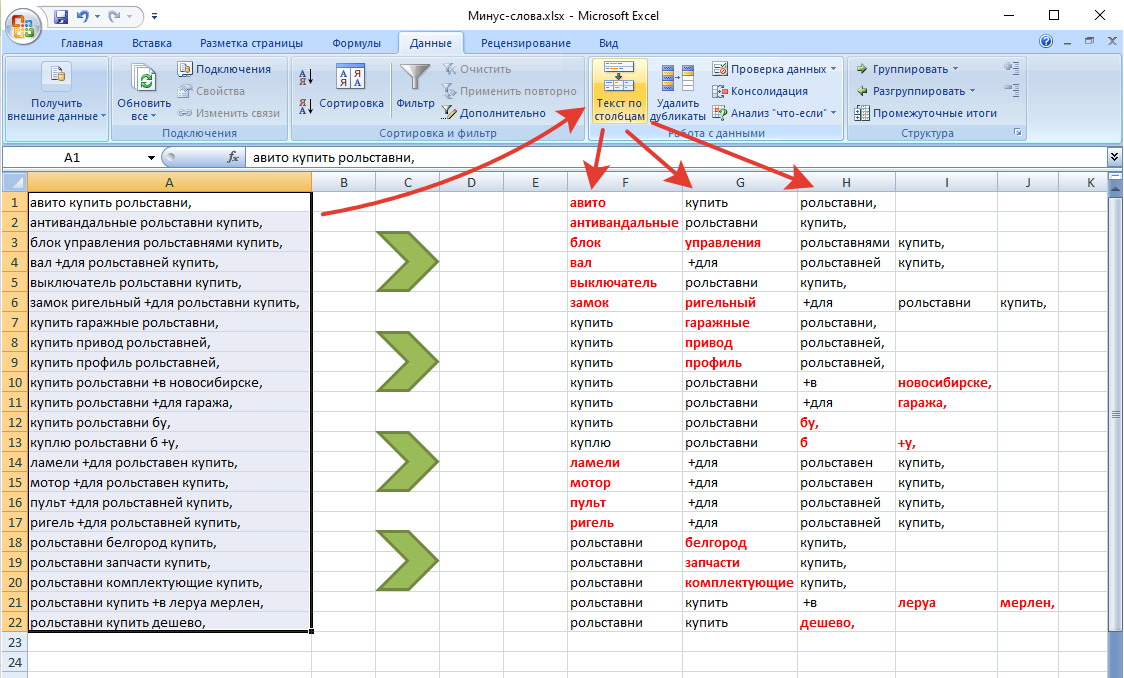 ru или Sinonim.org.
ru или Sinonim.org.
Подбор минус-слов в интерфейсе Яндекс.Директ и кросс-минусовка
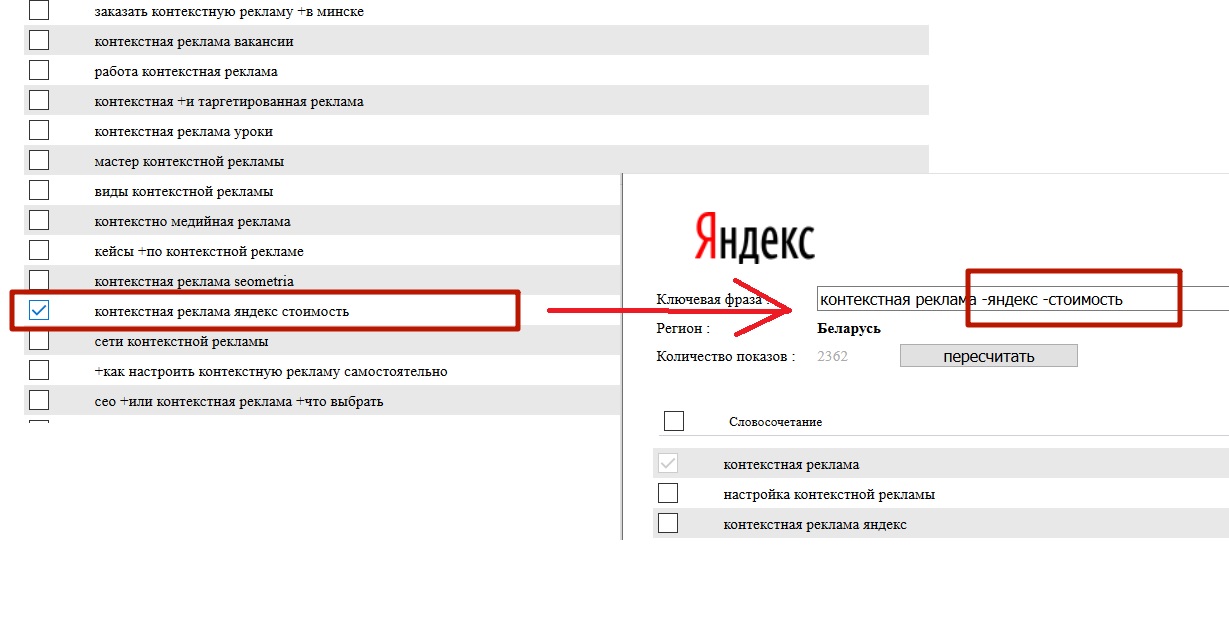
Также можно подобрать минус-слова к каждому ключевому запросу напрямую в интерфейсе Яндекс.Директа. Для этого кликните на интересующую ключевую фразу и нажмите кнопку «Уточнить»:
Подобранные минус-слова можно сразу же добавить к ключевому запросу – это пригодится для кросс-минусовки
Кросс-минусовка – добавление дополнительных минус-слов к ключевым запросам, чтобы исключить пересечения между ними. Это необходимо, чтобы исключить конкуренцию ключевых запросов между собой и показывать релевантные объявления по каждому запросу.
Пример:
Есть два ключевых запроса: «арматурная сетка цена» и «арматурная сетка 150х150 цена», для которых вы создали разные объявления. Одно объявление ведет на страницу со всеми доступными товарами, а второе – на конкретную страницу с арматурной сеткой 150х150. При отсутствии кросс-минусовки для обоих ключевых запросов может быть показано, например, первое объявление. Это снижает релевантность объявления для пользователей, которые ищут конкретный товар. Избежать этого можно, добавив к первому ключевику минус-слово «150х150».
При отсутствии кросс-минусовки для обоих ключевых запросов может быть показано, например, первое объявление. Это снижает релевантность объявления для пользователей, которые ищут конкретный товар. Избежать этого можно, добавив к первому ключевику минус-слово «150х150».
Подбор минус-слов с помощью планировщика Google Ads
Зайдите в кабинет Google Ads и выберите в инструментах «Планировщик ключевых слов»:
Введите запрос и укажите домен сайта, чтобы система проанализировала его и не подбирала ключевые запросы, связанные с товарами или услугами, которые вы не предлагаете.
Планировщик ключевых слов предоставит варианты запросов, среди которых можно подобрать минус-слова.
Просматривая поисковые запросы, копируйте минус-слова в отдельный файл в Excel, Word, Блокнот или куда вам удобно, чтобы затем добавить их в рекламную кампанию.
Для того, чтобы облегчить работу, воспользуйтесь генератором минус-слов.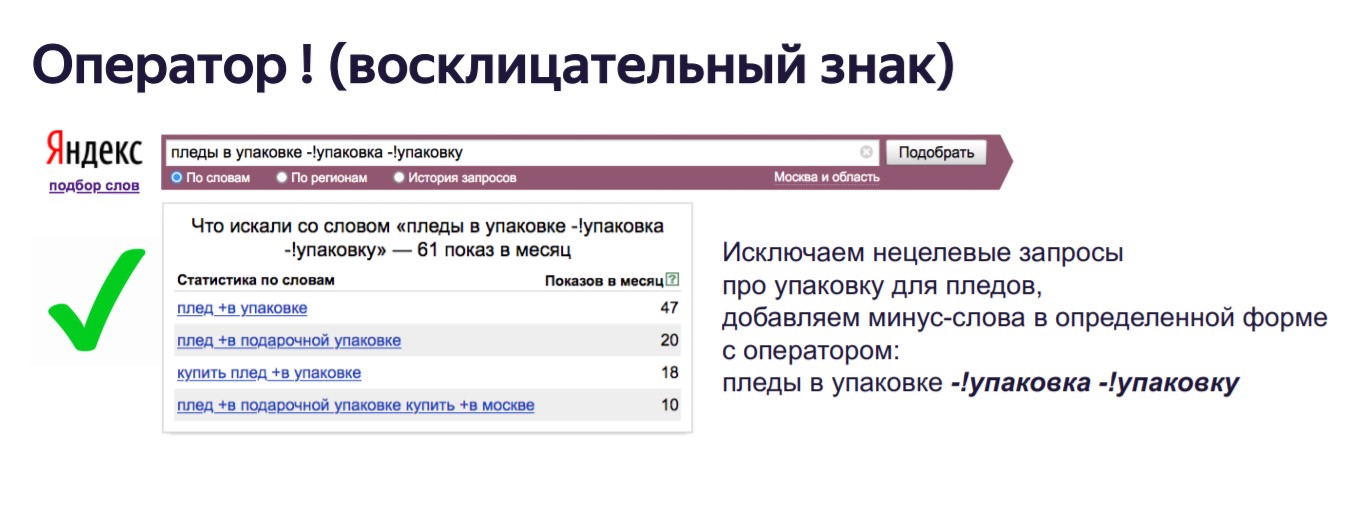 Введите ваши ключевые запросы и нажмите кнопку «Начать сбор минус слов»:
Введите ваши ключевые запросы и нажмите кнопку «Начать сбор минус слов»:
В появившемся списке справа отметьте минус-слова и нажмите кнопку «Получить список минус слов»:
После этого можете копировать минус-слова и добавлять их в рекламные кампании.
Просклонять слова для Google Ads также можно с помощью специального инструмента Склонятор слов.
Как добавить минус-слова в Яндекс.Директ
Для добавления минус-слов на уровне кампании:
Зайдите в кампанию и выберите пункт «Единый набор минус-фраз». В выпадающем окне добавьте все собранные минус-слова с новой строки или через запятую и сохраните.
Для добавления минус-слов на уровне группы объявлений:
Зайдите в кампанию, найдите нужную группу, выберите пункт «Минус-фразы на группу» и в выпадающем окне добавьте минус-слова с новой строки или через запятую. Не забудьте сохранить.
Шпаргалка по операторам для минус-слов в Яндекс.Директе
! – закрепляет словоформу
Пример:
!сетку; объявление не будет показываться по запросу «купить арматурную сетку», но будет показано по запросу «арматурная сетка купить».
+ – учитывает стоп-слова (предлоги, союзы, частицы)
Пример:
+для стяжки; объявление не будет показываться по запросу «арматурная сетка для стяжки», но будет показано по запросу «арматурная сетка стяжка».
“” – фиксирует фразу
Пример:
“арматурная сетка 50х50”; по запросу «арматурная сетка 50х50» объявление не будет показываться, а по запросу «сетка арматурная» будет.
[ ] – соблюдает порядок слов
Пример:
[сетка для стяжки]; по запросу «сетка для стяжки» объявление не показывается; по запросу «сетка арматурная для стяжки» показывается.
Как добавить минус-слова в Google Ads
Для добавления минус-слов на уровне аккаунта:
Зайдите в аккаунт и выберите пункт меню «Списки минус-слов»:
Нажмите на «+», дайте название списку, добавьте слова и сохраните.
Для добавления минус-слов на уровне кампании или группы объявлений:
Зайдите в интересующую кампанию и выберите раздел «Минус-слова»:
Нажмите на «+» и введите минус-слова по одному в строке. Выберите в какую кампанию или группу объявлений их добавить и сохраните изменения. Вы можете добавить ранее созданный список минус-слов.
Шпаргалка по операторам для минус-слов в Google Ads
Широкое соответствие (используется по умолчанию) – объявления не будут показаны по запросам, содержащим все минус-слова в любом порядке.
Пример:
кладочная сетка; по запросу «кладочная сетка» или «сетка кладочная» объявление не будет показываться, а по запросу «арматурная сетка» будет.
Фразовое соответствие (оператор “”) – объявления не будут показаны по запросам, содержащим все минус-слова в заданном порядке, даже если в запросе есть другие слова.
Пример:
композитная сетка”; по запросам «композитная сетка» или «композитная сетка для армирования» объявление не будет показываться, а по запросу «сетка композитная» будет.
Точное соответствие (оператор []) – объявления не будут показаны по запросам, содержащим все минус-слова в заданном порядке без дополнительных слов. Показы по запросу будут, если запрос будет содержать дополнительные слова.
Пример:
[пвх сетка]; по запросу «пвх сетка» объявление не будет показываться, а по запросу «забор пвх сетка» будет.
Читайте также 10 причин, почему контекстную рекламу нужно настраивать постоянно, а не только в момент запуска
Библиотека минус-слов
Существуют стандартные списки минус-слов, подходящие для всех случаев или для рекламы определенных тематик. Списки обычно разделяют на:
-
универсальные,
-
списки городов,
-
специальные списки для конкретных ниш.
Ниже вы найдете универсальный список минус-слов для контекстной рекламы. Крайне рекомендуем все равно добавлять списки в свою кампанию обдуманно. Кликайте на подходящую тему, просмотрите каждое слов и проанализируйте, будет ли оно минусом для вашего случая или нет. Без этого вы рискуете отсечь целевой трафик.
Универсальный
Скорей всего
Продажа чего-либо
Если продаете только новое
Если не занимаетесь установкой и монтажом
Если нет кредита и рассрочки
Если только в розницу
Если только оптом
Автодилер
Аренда квартир
Если только долгосрочно
Если только посуточно
Продажа квартир
Места в Москве
ТОП 20 городов РФ
ТОП 10 городов Украины
Универсальный
Этот список минус-слов подходит практически для любых рекламных кампаний.
!что
!это
!как
бесплтно
бесплатно
безкоштовно
!даром
!free
!бесплтно
руками
самостоятельно
самодельный
скачать
download
драйвер
прошивка
порно
порнушка
вконтакте
доклад
porn
porno
sex
форум
реферат
статья
блог
хитрости
уловки
хабр
хабра
хабрхабр
faq
инструкция
википедия
!вики
!wikipedia
!wiki
схема
состав
способ
методы
технология
торрент
торент
torrent
torent
torents
torrents
сонник
приснилось
прикол
смешно
юмор
анекдот
эротика
эротический
Скорей всего
Этот список минус-слов подходит для большинства рекламных кампаний.
сделать
!дома
домашних
книга
работа
вакансия
курсовая
курсовик
дипломная
диссертация
дисертация
учебник
шпоры
шпоргалка
контрольная
!оквэд
онлайн
online
!самому
!самой
!самим
!гост
рисунок
фото
фотка
фотографию
картинка
!видео
!видио
видяшки
video
смотреть
посмотреть
фильм
кино
сериал
doc
pdf
dju
3d
3д
ютуб
ютуба
ютубе
рутуб
ролики
ролик
ролика
ролику
роликов
фотогалерея
фотогаллерея
недостатки
описание
изготовление
запчасти
устройство
секс
кряки
кряк
взлом
crack
крякнутый
крякнутая
крякнутые
крякнутых
крякнуть
крек
крэк
креки
крэки
avi hd
jpeg
mp3
mpeg4
png
играть
игра
слушать
Продажа чего-либо
Также смотрите список «Универсальный»
чистка
ремонт
починка
починить
ремнт
рмонт
ремонтировать
отремонтировать
аренда
арендовать
снять
бронировать
забронировать
бронирование
прокат
напрокат
впрокат
обслуживание
сломалась
поломка
неисправности
мастер
Если продаете только новое
!бу
!б
подержанные
подержаные
!рук
старые
Если не занимаетесь установкой и монтажом
установка
установить
монтаж
монтажник
Если нет кредита и рассрочки
кредит
рассрочка
расрочка
Если только в розницу
опт
оптовый
склад
оптовик
прайс
Если только оптом
розничные
розница
Автодилер
Также смотрите список «Продажа чего-либо»
обои
фотообои
тюнинг
мотоциклы
игра
gta
!гта
ошибки
разборка
реклама
страховка
запчасти
Аренда квартир
Также смотрите список «Универсальный»
купить
покупка
продажа
дизайн
ремонт
новостройка
новострой
какая
документы
субсидия
отделка
Если только долгосрочно
посуточно
подобово
!сутки
!суток
почасово
час
Если только посуточно
длительно
доглосрочно
долго
помесячно
месяц
Продажа квартир
Также смотрите список «Продажа чего-либо»
какая
ремонт
дизайн
субсидия
посуточно
подобово
!сутки
!суток
почасово
час
длительно
доглосрочно
долго
помесячно
месяц
Места в Москве
Без склонения в AdWords. Взято у Александра Сухорукова.
Взято у Александра Сухорукова.
академическая
аннино
балашиха
беляево
битцевский парк
бутово
вао
видное
внуково
воробьевы горы
воскресенск
дмитров
дмитрова
долгопрудный
домодедово
дубна
железнодорожный
жуковский
звенигород
зеленоград
зуево
ивантеевка
калужская
каховская
клин
коломна
коньково
королев
красногорск
лесопарковая
лобне
люберцы
марьино
мытищи
новоясеневская
новые черемушки
ногинск
одинцово
орехово
парк культуры
подмосковье
подольск
подольске
посад
поселок московский
пражская
профсоюзная
пушкино
раменское
раменском
реутов
свао
севастопольская
сергиев
серпухов
солнечногорск
солнцево
строгино
теплый стан
троицк
университет
фоминск
химки
чертановская
чехов
шаболовская
щелково
электросталь
юго-западная
южная
ясенево
Топ 20 городов РФ
Москва
мск
Петербург
спб
питер
Новосибирск
Екатеринбург
Новгород
Казань
Самара
Челябинск
Омск
Ростов
Уфа
Красноярск
Пермь
Волгоград
Воронеж
Саратов
Краснодар
Тольятти
Тюмень
Ижевск
Топ 10 городов Украины
Киев
київ
Харьков
харків
Одесса
Одеса
Днепропетровск
дніпропетровськ
Донецк
Запорожье
Львов
Львів
Николаев
Мариуполь
Резюмируем
Несмотря на то, что проработка минус-слов – это долгий и трудоемкий процесс, мы рекомендуем обратить на него внимание, поскольку это сильно влияет на успех рекламных кампаний и помогает расходовать бюджет рационально.
Удачи в ведении ваших рекламных кампаний!
-
Хотите запустить прибыльную и эффективную рекламу? Поручите это дело профессионалам.
Если вам помог наш материал – обязательно подписывайтесь на наш блог, чтобы не пропустить другие полезные материалы. А еще у нас есть Телеграм-канал.
Что такое минус-слова и как их подбирать для Яндекс Директ
07 апреля 2022 Контекстная реклама
Минус-слова — это составляющие запросов, показ объявлений по которым невыгоден, так как это не будет способствовать росту числа конверсий: если добавить их в настройках, количество переходов станет больше, а стоимость клика — ниже.
Сегодня мы поговорим о механизмах сбора минус-слов для рекламных кампаний в Яндекс.Директ: сейчас этот сервис в связи с уходом с рынка аналогичных сервисов Google является важнейшим для e-commerce.
«В сложившейся ситуации мы видим увеличение количества запросов от малого и среднего бизнесе в отношении покупки клиентов в Яндекс.Директ. Ушла часть крупных игроков с рынка, но на их место сразу пришли наши игроки со своими товарами и услугами. В данный момент мы наблюдаем высокий спрос на рекламу в Яндекс. Сейчас мы видим, что старые маркетинговые связки перестают работать на отлично, приходится менять стратегию и пробовать новые маркетинговые комбинации. Качество рекламы выходит на первое место».
Таисия Мешкова,
Маркетинговое агентство «BUSINESS MARKETING»
Рекламные бюджеты экономить стоит всегда, и сбор минус-слов играет здесь важную роль.
Что такое минус-словаПриведем пример минус-слов. У вас есть интернет-магазин, который продает мебель в Москве, но только в пределах МКАД. Соответственно, запросы формата «мебель Балашиха» или «купить мебель в Подольске» будут нецелевыми, и названия городов-спутников Москвы в таком случае будут минус-словами и не принесут продаж.
Либо, например, вы занимаетесь продажами бижутерии ручной работы и у вас есть собственный бренд, пусть даже начинающий и не особо известный широкой аудитории. Запросы, включающие в себя наименования производителей бижутерии других торговых марок (в том числе известных и популярных — вряд ли вы будете конкурировать с Sokolov или Sunlight), уже станут нецелевыми и их надо минусовать.
Читайте также: Как оценить эффективность ключевых слов в контекстной рекламе
Группы минус-словДля работы с минус-словами используются специальные программы, такие как KeyCollector. В нем минус-слова можно объединять в группы — глобальные (для всех проектов) или локальные (для конкретного проекта). Список групп можно редактировать, упорядочивая или переименовывая их, выгружать и импортировать. Удалять ненужные группы можно только предварительно их скрыв.
Инструменты для отбора минус-словСоставлять список минус-слов можно с помощью нескольких инструментов. Если у вашей компании есть бриф, описывающий вашу работу, аудиторию и ассортимент, то часть минус-слов уже можно вычленить, исходя из этой информации. Если указан режим работы магазина (например, с 10-00 до 18-00 по будням), то сразу можно добавить минус-слово «круглосуточно». Если вы торгуете товарами премиум-класса, предназначенных для платежеспособной аудитории, то минус-словами будут «дешево», «недорого» и «скидка» (хотя во многих других случаях именно эти слова привлекают посетителей). Если вы работаете только в Санкт-Петербурге в пределах городской черты, то названия городов Ленинградской области сразу можно минусовать.
Если у вашей компании есть бриф, описывающий вашу работу, аудиторию и ассортимент, то часть минус-слов уже можно вычленить, исходя из этой информации. Если указан режим работы магазина (например, с 10-00 до 18-00 по будням), то сразу можно добавить минус-слово «круглосуточно». Если вы торгуете товарами премиум-класса, предназначенных для платежеспособной аудитории, то минус-словами будут «дешево», «недорого» и «скидка» (хотя во многих других случаях именно эти слова привлекают посетителей). Если вы работаете только в Санкт-Петербурге в пределах городской черты, то названия городов Ленинградской области сразу можно минусовать.
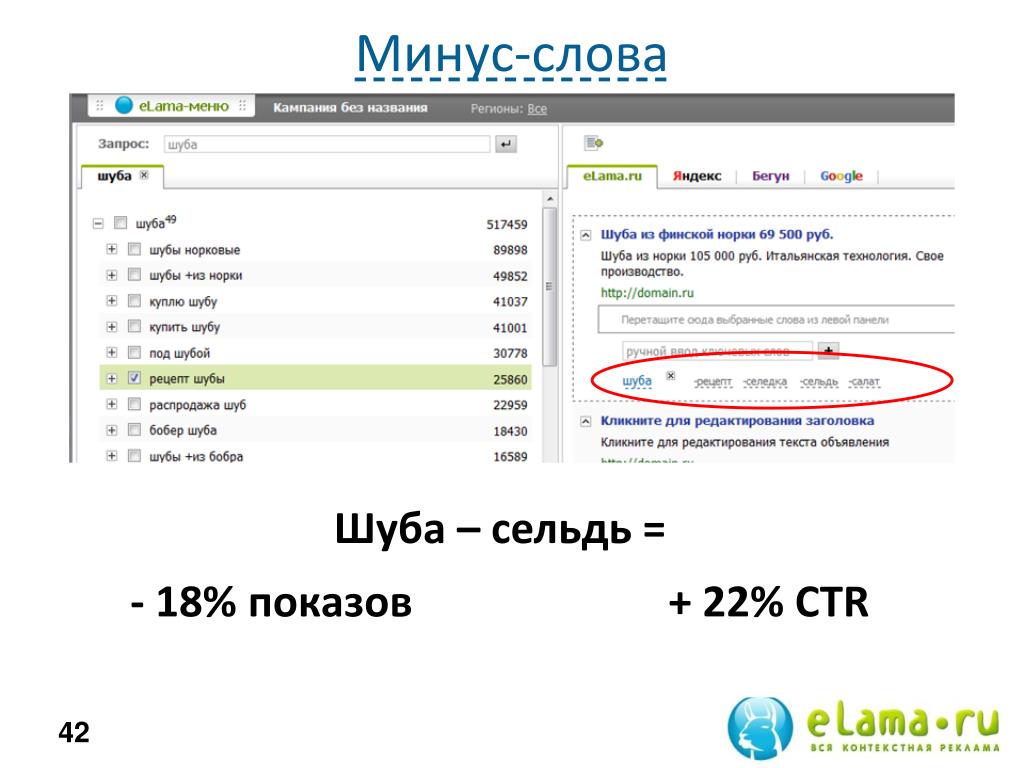
Основные запросы легко собрать, используя Wordstat, и тогда можно сразу заминусовать те слова и словосочетания, что являются для вас нецелевыми. К примеру, вы торгуете детской одеждой, соответственно, слова «мужская», «женская», «свадебная» уже идут в минус.
Пример работы с Yandex. Wordstat
Wordstat
Можно искать ключи с помощью Wordstat.Assistant, копируя нерелевантные для вас запросы, разделяя их знаком + и отправляя в список минус-слов.
Готовые спискиЕсть вариант и заминусовать имеющиеся списки ключевых фраз, касающиеся вашей сферы деятельности, но не релевантные для вашего бизнеса. Чтобы подобрать минус-слова, можно использовать и специализированные сервисы, такие как Prodalet. Но списки все равно стоит время от времени просматривать, чтобы не пропустить и не отправить в минус релевантные для вас ключи.
Пример списка минус-слов в Prodalet
KeyCollectorДля сбора семантического ядра и составления списков минус-слов существует специальная программа KeyCollector — о ней мы уже говорили выше. Перед тем, как начать парсинг, надо добавить очевидно нерелевантные слова и фразы в раздел «Стоп-слова». Затем в разделе «Анализ групп» отметьте нерелевантные для вас фразы, по которым конверсии точно не будет, и отправьте их в окно со стоп-словами. Список того, что получилось, можно копировать в разделе «Стоп-слова».
Список того, что получилось, можно копировать в разделе «Стоп-слова».
Добавление стоп-слов в KeyCollector
Опцией минус-слов лучше не злоупотреблять, лучше пусть их будет меньше, но в списках будут явно нецелевые фразы: так вы с меньшей вероятностью будете терять конверсии и заказы. Используйте сразу несколько инструментов, тогда список будет более точным, время от времени минус-слова можно пересматривать, если у вас меняется ассортимент или условия работы. В конечном итоге, ваши рекламные кампании станут эффективнее при меньших бюджетах и большем числе конверсий.
Создание своего интернет-магазина — процесс довольно трудоемкий. Если вам нужна помощь в выполнении какой-то задачи — мы подскажем, где найти исполнителей.
Наши партнеры приготовили для вас специальные предложения, которые помогут вам решить любую задачу в создании своего онлайн-проекта:
-Настроить интернет-магазин «под ключ».
-Настроить визуальное оформление магазина.
-Запустить контекстную рекламу.
-Написать тексты и описания товаров.
И много других задач.
Чтобы заказать нужную вам услугу перейдите по ссылке и выберите подходящего исполнителя.
Делегируя задачи профессионалам, вы сможете реализовать ваш проект за короткие сроки.
Создать аккаунт на AdvantShop
На платформе вы сможете быстро создать интернет-магазин, лендинг или автоворонку.
Воспользоваться консультацией специалиста
Ответим на любые ваши вопросы и поможем выйти на маркетплейсы.
СвязатьсяЧто почитать еще
Контекстная реклама 13.09.2022
Как настроить ретаргетинг в Яндекс Директ
Контекстная реклама
11. 08.2022
08.2022
Виртуальная визитка в Яндекс Директе: как ее заполнять
Контекстная реклама 30.05.2022
Как пользоваться Yandex.Wordstat
Контекстная реклама 12.04.2022
Контекстная реклама теперь только в «Директе»: новое на площадке и перенос кампаний
Контекстная реклама 26.02.2022
Как оценить эффективность ключевых слов в контекстной рекламе
Контекстная реклама
24. 01.2022
01.2022
Что такое контекстно-медийная сеть Google
Минус-слова – Key Collector
Инструмент «Минус-слова» расположен на вкладке «Данные».
Он позволяет выполнять поиск вхождений отдельных слов, их наборов или фраз целиком среди добавленных в таблицу запросов. Также поддерживается функция кросс-минусации фраз.
Вообще говоря, инструмент выполняет универсальный поиск заданных слов или фраз. Нет требования, чтобы они являлись минус-словами или минус-фразами, и потом браковались. Однако для удобства повествования в дальнейшем мы будем упоминать искомые выражения как «минус-слова».
- Описание
- Группы минус-слов
- Составление списка минус-слов
- Режимы поиска
- Борьба с погрешностями поиска и операторы
- Выполнение поиска и работа с результатами
- Кросс-минусация фраз
Окно поиска содержит таблицу минус-слов, панель настроек выбранного режима поиска, а также панель инструментов со вспомогательными функциями.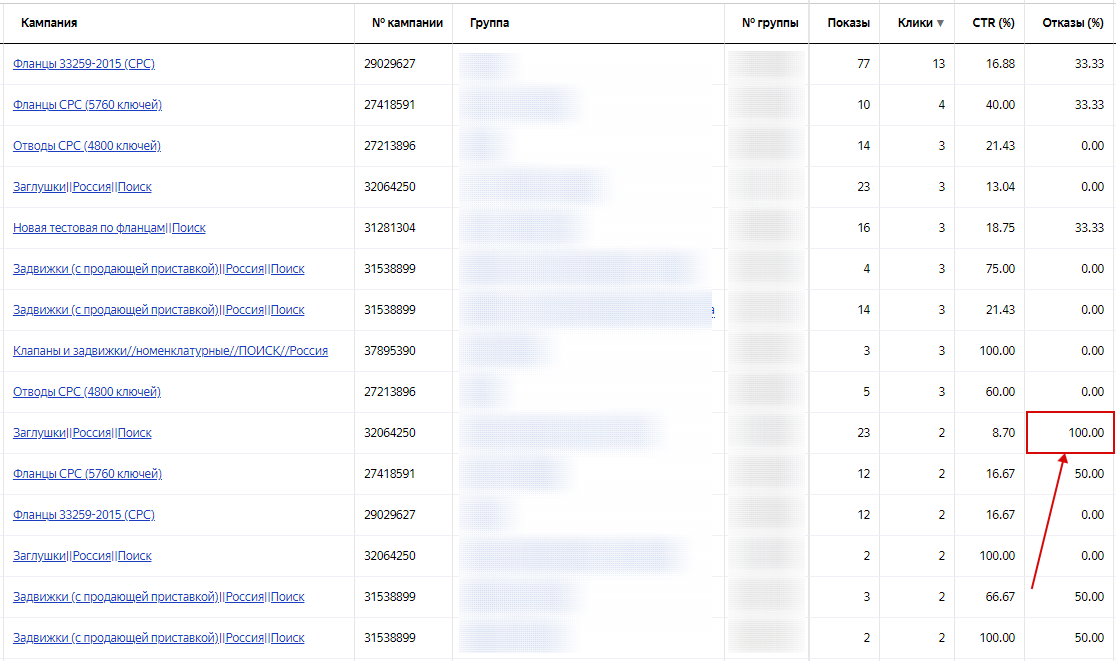
Программа поддерживает несколько режимов поиска:
- независимый от словоформы
- быстрый
- улучшенный
- зависимый от словоформы
- полное вхождение
- частичное вхождение
- полное соответствие целиком
Заданные минус-слова хранятся в файле проекта.
Окно поиска минус-слов
Группы минус-слов
Перед началом поиска необходимо определить список искомых минус-слов. Для удобства работы инструмент поддерживает ведение независимых групп минус-слов.
Группы могут быть глобальными (доступны для использования из любого проекта) и локальными (доступны только в том проекте, где они определены; по умолчанию в каждом проекте создаются 2 локальные группы минус-слов).
Для выбора текущей группы воспользуйтесь выпадающем списком в верхнем левом углу окна.
Для редактирования списка групп нажмите кнопку справа от выпадающего списка выбора групп.
Здесь вы можете создавать, упорядочивать и переименовывать группы.
Список групп вместе с минус-словами можно выгрузить во внешний файл, а потом импортировать обратно (выбрать формат выгрузки можно в панели настроек).
Из соображений безопасности функция удаления групп удаляет только предварительно скрытые группы. Поэтому для удаления группы необходимо отметить ее, нажать кнопку «Скрыть», а лишь потом — «Удалить».
Редактор групп минус-слов
Здесь также можно включить режим «Только чтение», который будет блокировать функцию добавления и удаления минус-слов из группы. Для его активации нажмите напротив заголовка группы.
Составление списка минус-слов
Теперь можно поговорить о процессе наполнения списков для минусации.
Первым способом является непосредственный ввода данных в таблицу минус-слов с клавиатуры или из файлов (импортирование из произвольных или ранее выгруженных списком минус-слов).
Вторым способом является отправка фраз из основной таблицы с данными в окно инструмента минус-слов. Для этого выделите или отметьте фразы и выберите «Отправить выделенные/отмеченные фразы в минус-слова» в контекстном меню таблицы. Удобно пользоваться горячей клавишей F11.
Для точечной отправки отдельных слов в настройках можно включить отображение кнопки отправки фразы в минус-слова.
Третьим способом является точечная отправка предварительно помеченных слов или фраз. Этот режим удобнее предыдущего, т.к. вы можете пометить только нужные слова («как», «куда», «можно» в пред. примере) и упростить работу на следующем шаге.
Для пометки слов зажмите клавишу W и начинайте кликать мышкой по нужным словам.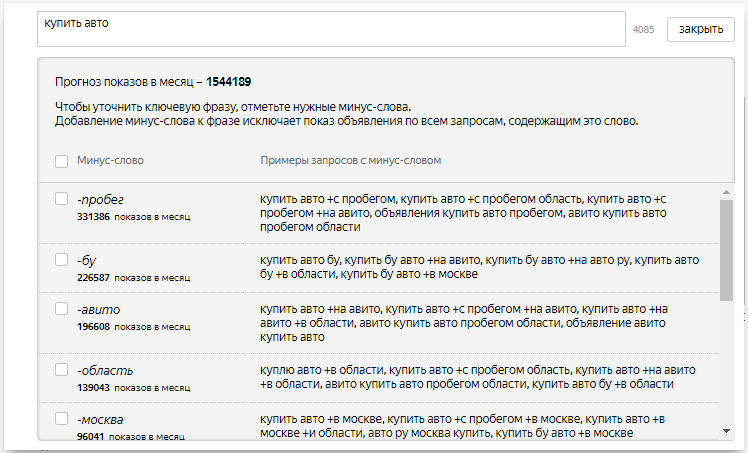 Помеченные слова окрашиваются в альтернативный цвет.
Помеченные слова окрашиваются в альтернативный цвет.
Речь идет о пометке отдельных слов: каждый клик включает или отключает пометку для конкретного слова.
Если по каким-то причинам вы не хотите удерживать клавишу W, режим пометки отдельных слов можно зафиксировать, нажав на кнопку в панели статуса.
В контекстном меню этой кнопки можно включить или выключить формонезависимую подсветку помеченных слов в таблице.
Если формонезависимый режим подсветки включен, то после пометки слова «колбасы», визуально в таблице поменяют цвет в том числе все варианты написания этого слова: «колбаса», «колбасу» и т.д.
Если требуется пометить наборную фразу, а не отдельные слова, зажмите и удерживайте Ctrl+W, а затем начинайте кликать по составным словам нужной фразы. При пометке наборных слов они не будут визуально выделяться до тех пор пока вы не отпустите и снова не зажмете Ctrl+W.
После завершения пометки отдельных слов или наборных фраз для отправки помеченных элементов в минус-слова выберите «Отправить помеченные слова в минус-слова» в контекстном меню таблицы. Удобно пользоваться горячей клавишей F12.
Четвертым способом составлять списки минус-слов является работа с инструментом анализа групп.
Отправка в минус-слова- Выберите режим: отправка фраз целиком (в том виде, в котором они были отправлены) или отправка отдельных слов (отправленные фразы разбиваются на уникальные слова).
- Отметьте нужные элементы в таблице.
- Последняя колонка отвечает за нормализацию текста ячейки в таблице. Если включить опцию для строки в таблице, фраза или слово примут начальную форму (единственное число, именительный падеж).
- Укажите целевую группу, куда добавить отмеченные в п. 2 элементы (этот пункт можно пропустить; элементы можно не добавлять, а просто выполнить экспресс-поиск).
- При условии выполнения п.4 нажмите «Добавить», чтобы добавить элементы в указанную группу.
- Для выполнения поиска по отмеченным в п.2 элементам (только по ним) нажмите «Показать найденные фразы».
- Перед запуском поиска в п.6 необходимо задать его параметры.
 2 элементы (этот пункт можно пропустить; элементы можно не добавлять, а просто выполнить экспресс-поиск).
2 элементы (этот пункт можно пропустить; элементы можно не добавлять, а просто выполнить экспресс-поиск).Отправка в минуса-слова
Режимы поиска
Программа поддерживает несколько видов поиска.
Независимый от словоформы: быстрый
Поиск выполняется в формонезависимом режиме: искомые слова и слова исследуемых фраз приводятся к начальной форме и сравниваются.
Например, во фразе «копченые колбасы» будет найдено слово «колбаса».
Независимый от словоформы: улучшенный
Поиск выполняется в формонезависимом режиме: искомые слова и слова исследуемых фраз приводятся к начальной форме и сравниваются.
В отличие от быстрого улучшенного поиска, в этом случае анализ выполняется точнее, с меньшими погрешностями. Это занимает чуть больше времени, но разницу можно почувствовать только на миллионных проектах.
Например, во фразе «копченые колбасы» будет найдено слово «колбаса».
Зависимый от словоформы: полное вхождение
Исследуемая фраза разбивается на отдельные слова, и поиск выполняется среди ее составных частей (слов) в полном вхождении.
Режим подходит при поиске сложных слов или в условиях поиска точных вариантов написания слов.
Например, в фразе «купить авто б/у» будет найдено слово «купить», но не будет найдено «купил».
Зависимый от словоформы: частичное вхождение
Выполняется частичный поиск указанных искомых частей в исследуемых фразах.
Например, во фразе «купить ноутбук E102AC» будет найдена часть «102», чего не произошло бы в режиме полного вхождения.
Зависимый от словоформы: полное вхождение фразы целиком
Выполняется поиск минус-слова/минус-фразы целиком от начала до конца среди фраз в исследуемых группах.
Например, минус-фраза «купить авто недорого» будет найдена только для такой же фразы «купить авто недорого» (все символы с точностью до знака совпадают).
При этом фраза «купить авто» не будет считаться подходящей (отсутствуют некоторые слова).

 При этом фраза «купить авто» не будет считаться подходящей (отсутствуют некоторые слова).
При этом фраза «купить авто» не будет считаться подходящей (отсутствуют некоторые слова).В базовой варианте мы рекомендуем использовать улучшенный формонезависимый режим.
- Он обеспечивает приемлемую гибкость поиска, не требует дублирования одних и тех слов в списке минусации. Достаточно указать один вариант «колбаса» вместо перечисления всех склонений: «колбасы», «колбасу» и т.д. как в случае с полным вхождением.
- Минус-слова можно задавать в естественном виде целиком: «колбаса» вместо «колбас» в случае поиска в частичном вхождении.
Борьба с погрешностями и операторы поиска
К сожалению, при работе в формонезависимых режимах возможны погрешности. Иногда программа считает близкие по смыслу слова одинаковыми, а иногда наоборот не улавливает связи между одним и тем же словом в разных склонениях.
Специальными операторы поиска позволяются исправить ошибки или уточнить его критерии.
Фиксация словоформы (точный поиск)Если программа ошибочно принимает какое-то слово за искомое, вы можете зафиксировать проблемное минус-слово оператором !
- !Киев
- !кий
- !как
- !тянули !репку
Например, «Киев» и «кий» в упрощенном быстром режиме могут считаться равными, т.к. их неизменяемая часть «ки» совпадает в обоих словах. Или же «как» и «почему» может быть приняты за равнозначные слова в улучшенном режиме.
Для фиксации минус-фразы необходимо использовать оператор ! перед каждым словом фразы. Фиксировать отдельные слова минус-фразы не допускается.
Фиксировать отдельные слова минус-фразы не допускается.
При поиске минус-фраз, состоящих из нескольких слов, по умолчанию программа разрешает присутствие посторонних слов между словами искомой фразы. Оператор » « локально запрещает эту возможность.
- «заказать торт»
- «в банке»
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «заказать свадебный бисквитный торт с кремом». Если добавить оператор » «, то минус-фраза будет найдена только в запросах вида «заказать торт на праздник» (слова искомой фразы не разделены посторонними словами).
Фиксация порядка слов- заказать торт
- в банке
Например, минус-фраза заказать торт (без кавычек) будет найдена в запросе «торт на праздник заказать». Если добавить оператор , то минус-фраза будет найдена только в запросах вида «заказать праздничный торт» (слова искомой фразы следуют строго в заданном порядке).
Если добавить оператор , то минус-фраза будет найдена только в запросах вида «заказать праздничный торт» (слова искомой фразы следуют строго в заданном порядке).
Допускается использование различных операторов сразу, однако важен порядок их применения.
- Фразовая фиксация » «
- Точная фиксация !
- «заказать торт«
- !вкусные !пельмени
- «!чайник !бош«
Выполнение поиска и работа с результатами
Итак, после выбора группы минус-слов, формирования списка минусации и установки настроек вы можете выполнить поиск.
По завершении поиска открывается временная мультигруппа с результатами.
В ленте инструментов при этом будет добавлена контекстная вкладка «Предпросмотр», которая позволит управлять временной мультигруппой.
Таблица результатов содержит колонку подсветки, где отображается подсказка по найденному минус-слову в исходной фразе, а само найденное минус-слово отображается в колонке «Минус-слово».
Вы можете работать с результатами поиска в мультигруппе как с обычной мультигруппой: сортировать данные, применять фильтры, отмечать и удалять строки, запускать парсинг и т.д.
В колонке «Группа» отображается название целевой группы, где была найдена фраза из указанных групп-источников. Вы можете перейти внутрь этой целевой группы, зажав клавишу Ctrl и кликнув по ее названию.
Для возврата к результатам поиска воспользуйтесь кнопкой «Показать временную группу» в «Предпросмотр» или пунктом «Назад» контекстным меню в панели управления групп.
Кросс-минусация фраз
В раскрывающемся меню кнопки «Минус-слова»доступна функция кросс-минусации фраз.
Инструмент ориентирован на опытных пользователей, которые используют механизм кросс-минусация для тонкой настройки рекламных кампаний.
Комментарии
Оставляйте заметки к запросам, используйте их при дальнейшей обработке данных. Это возможно при помощи модуля комментариев.
Узнать больше
как подобрать минус слова для контекстной рекламы
Содержание
Что такое минус слова в контекстной рекламе
Минус слова в поисковых рекламных кампаниях — это метод исключения таргетинга. С помощью минус слов можно урезать охват объявлений, в первую очередь, для оптимизации рекламных расходов. Например, при рекламе контактных линз, добавив в список минус слова такие слова, как «фотоаппарат» или «объектив» мы исключим возможные показы наших объявлений по поисковым запросам: «линзы для объектива» или «линза на фотоаппарат».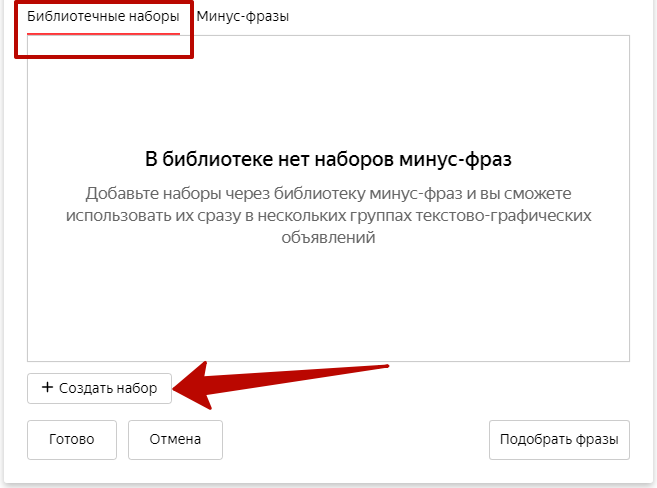
В отличие от ключевых слов, минус-слова не охватывают близкие варианты. Например, если задать минус-слово цветы с широким соответствием, то реклама не будет показываться по поисковому запросу красные цветы, но может появиться по запросу красный цветок.
Источник
Зачем добавлять минус слова
Кроме того, что с помощью минус слов можно ограничить таргетинг и исключить показы рекламы по нерелевантным поисковым запросам, добавление минус слов помогает повысить CTR объявлений, тем самым поднять показатель качества.
Мы экономим рекламный бюджет, исключая нецелевые клики. Следует отметить, что составление списка минус слов производится не только на этапе первичного сбора семантического ядра, но и в процессе открутки рекламы, поскольку всё равно в процессе работы появляются поисковые запросы, которые мы либо не предусмотрели, либо их не было на момент сбора ключей.
Повышаем конверсию. Иногда бывает даже так, что какое-то отдельное слово или словосочетание, на первый взгляд является целевым, однако по мере сбора статистики, можно увидеть, что оно не приносит ни прямых ни ассоциированных конверсий.
Минус слова типы соответствия в Google Ads
В поисковых кампаниях можно использовать минус-слова с широким, фразовым или точным соответствием. Однако, минус-слова работают не так, как ключевые слова. Главное отличие состоит в том, что минус-слова не охватывают близкие варианты, поэтому нужно вручную добавлять все синонимы, словоформы и ошибочные варианты написания, которые требуется исключить.
В кампаниях в контекстно-медийной сети для минус-слов используется точное соответствие. Объявления не будут показываться, даже если точное ключевое слово или фраза явно не указаны на странице, но ее тема тесно связана с набором минус-слов.
Например, добавление минус-слова «женские брюки» приведет к исключению страницы про женские джинсы, даже если на ней не встречается фраза «женские брюки». При этом страницы про другие предметы женской одежды (например, юбки) или мужские брюки не затрагиваются. Обычные ключевые слова действуют по-другому (например, ключевое слово «ботинки» относится к более широкой категории «обувь»).
Минус-слова с широким соответствием
По умолчанию для минус-слов используется широкое соответствие. Если добавить минус-слово с широким соответствием, то реклама не будет показываться по запросам, содержащим все части минус-слова в любом порядке. Однако она может появляться, если запрос содержит лишь некоторые компоненты минус-слова.
ПримерМинус-слово с широким соответствием: беговые кроссовки
| Поисковый запрос | Может ли отображаться объявление? |
|---|---|
| синие теннисные кроссовки | |
| беговой кроссовок | |
| синие беговые кроссовки | |
| кроссовки беговые | |
| беговые кроссовки |
Минус-слова с фразовым соответствием
Если вы добавите минус-слово с фразовым соответствием, ваша реклама не будет показываться по запросам, содержащим все части минус-слова в заданном порядке, даже если в поисковом запросе есть и другие слова.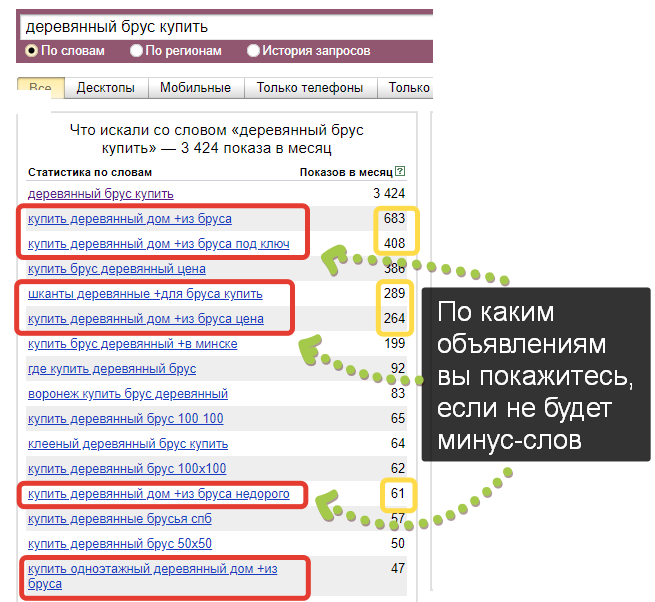 Кроме того, слова в поисковых запросах могут содержать дополнительные символы. В таких случаях объявление будет показываться в результатах поиска, даже если остальные слова указаны в заданном порядке.
Кроме того, слова в поисковых запросах могут содержать дополнительные символы. В таких случаях объявление будет показываться в результатах поиска, даже если остальные слова указаны в заданном порядке.
Пример
Минус-слово с фразовым соответствием: «беговые кроссовки»
| Поисковый запрос | Может ли отображаться объявление? |
|---|---|
| синие теннисные кроссовки | |
| беговой кроссовок | |
| синие беговые кроссовки | |
| кроссовки беговые | |
| беговые кроссовки |
Минус-слова с точным соответствием
Если вы добавите минус-слово с точным соответствием, ваша реклама не будет показываться по запросам, содержащим все части минус-слова в заданном порядке без дополнительных слов. Однако если в поисковом запросе есть ещё другие слова, пользователь может увидеть ваше объявление.
Однако если в поисковом запросе есть ещё другие слова, пользователь может увидеть ваше объявление.
Пример
Минус-слово с точным соответствием: [беговые кроссовки]
| Поисковый запрос | Может ли отображаться объявление? |
|---|---|
| синие теннисные кроссовки | |
| беговой кроссовок | |
| синие беговые кроссовки | |
| кроссовки беговые | |
| беговые кроссовки |
Источник
Как подобрать минус слова
Простейший и бесплатный способ собрать список минус слов.
Шаг 1. Выгружаем сырую семантику в Excel или любой другой табличный редактор.
Шаг 2. Добавляем рядом пустой столбец.
Шаг 3. Отмечаем в ячейке рядом с фразой цифрой 1 целевую фразу. Цифрой 2 нецелевую.
Шаг 4. Сортируем столбец с цифрами по убыванию
Шаг 5. С помощью инструмента «Считалка слов» разбиваем нецелевые фразы на отдельные слова
Шаг 6. Собранные минус слова добавляем на новый лист в табличный редактор и повторяем Шаг 3.
Важно! Предлоги не нужно добавлять в минус слова
Шаг 7. Cклонение минус слов для адвордс. Полученные слова желательно ещё просклонять перед добавлением в рекламный аккаунт.
Готово.
Сервисы и инструменты для подбора минус слов
Бесплатный сервис от Prodalet
https://prodalet.ru/module/tools/listminus/
Всё, что нам нужно — это добавить в сервис собранную семантику, а дальше он разобьет её на составляющие слова. Нам всего лишь останется отметить нецелевые слова, а затем скачать в нужно виде: или списком, где каждое слово с новой строки, либо в одну строку с проставлением «-» перед каждым словом.
Утилита для фильтрации ключевых слов
https://tools.yaroshenko.by/filter.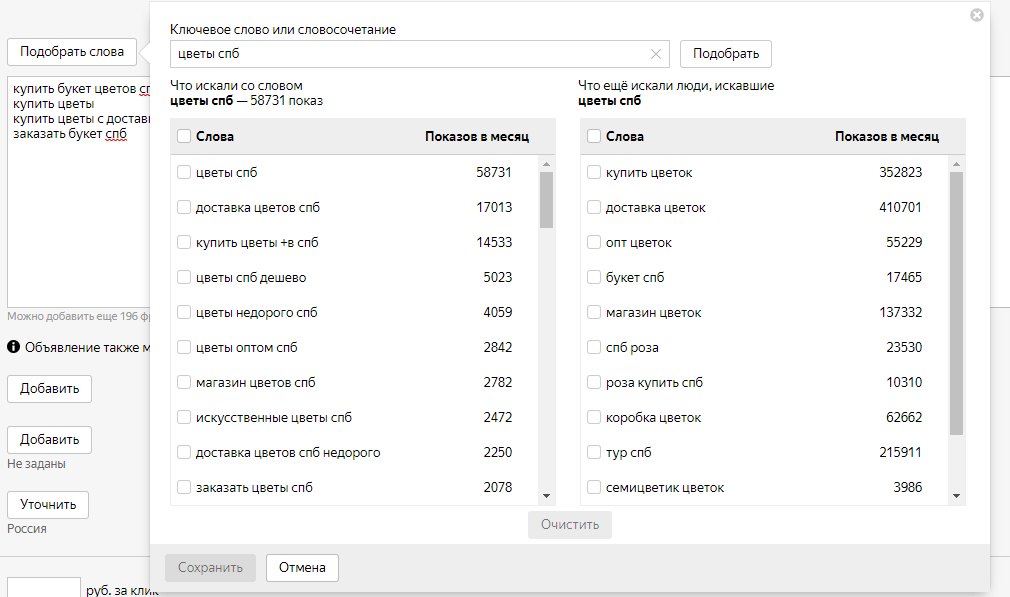 php
php
Бесплатный аналог фильтра ключевых слов в KeyCollector. Скопируйте и добавьте ключевые слова из wordstat или другого источника. После этого вводите в строку фильтра часть ключевого слова для поиска.
Генератор минус-слов
https://livepage.pro/tools/keys/
Бесплатный онлайн инструмент. Добавьте семантическое ядро в окно «Ваши запросы». Затем нажмите «Получить список минус слов». Справа в окне кликните на нецелевое слово. После того, как окончили отметку минус слов, нажмите «Получить список минус слов». Скопируйте и вставьте в текстовый документ. Чтобы получить очищенную семантику нажмите «Получить список рабочих слов»
Подбор минус слов Serpstat
https://serpstat.com/ru/keywords/suggestions/
С помощью инструмента «Поисковые подсказки» можно найти много разных вариантов, как для дальнейшего исследования семантического ядра, так и быстро составить список минус слов.
Вот один из примеров, как можно найти минус слова по тематике. Введите однословный маркерный запрос.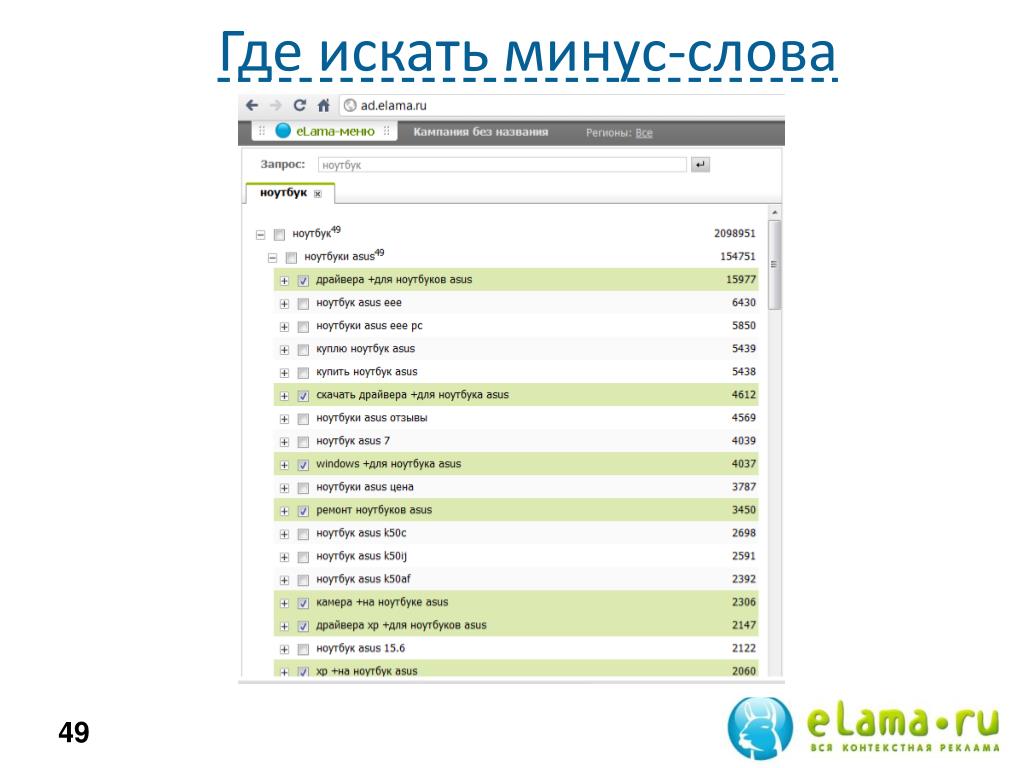 Например, «реклама». Отметьте галочку «Только вопросы». Скачайте документ.
Например, «реклама». Отметьте галочку «Только вопросы». Скачайте документ.
Сразу скопируйте и перенесите на отдельный лист столбец «Вопрос». Нажмите на вкладке «Данные» кнопку «Удалить дубликаты». Мы получили список из слов, которые практически всегда встречаются в информационных запросах.
На этом сбор минус слов с помощью serpstat не заканчивается. Выгруженные запросы почистите на предмет минус слов любым из вышеперечисленных методов.
Как собрать минус слова с помощью Key Collector
В Key Collector есть удобный инструмент, который можно использовать, как для чистки, так и для группировки семантического ядра. Называется он «Анализ групп»
Выберите тип группировки «По отдельным словам». Затем, зажмите клавишу CTRL на клавиатуре и отмечайте нецелевые слова мышкой.
После того, как завершили этот этап, нажмите клавишу F3. Откроется окно добавления фраз в стоп слова. Проследите, чтобы были активны чек боксы «Запомнить отмеченные слова» и «Выполнить отметку фраз по данным стоп словам/ стоп фразам».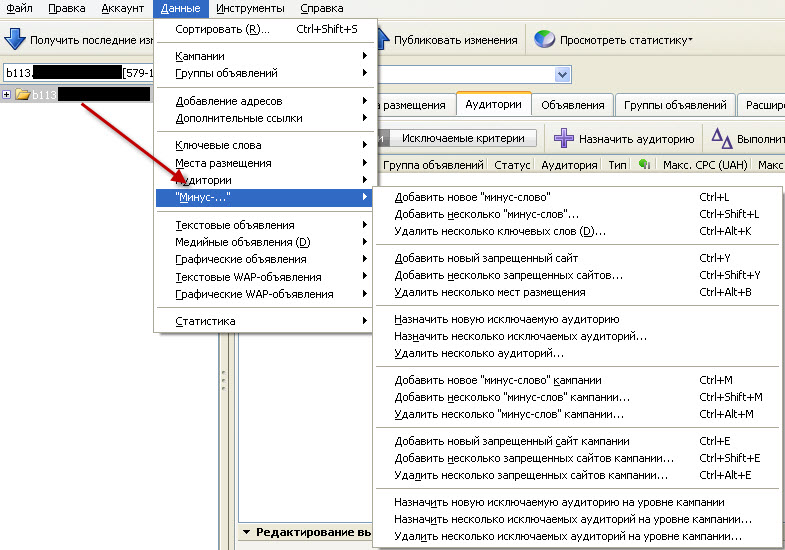 Так вы в одно действие и чистите список ключевых слов от нецелевых запросов и составляете список минус слов, который потом можете скачать и добавить в рекламный кабинет.
Так вы в одно действие и чистите список ключевых слов от нецелевых запросов и составляете список минус слов, который потом можете скачать и добавить в рекламный кабинет.
Как добавить минус слова в Google Ads
В Google Ads минус слова могут использоваться на нескольких уровнях:
- Аккаунт;
- кампания;
- группа объявлений.
Для добавления минус слов на уровень всего аккаунта откройте меню «Инструменты и настройки», затем перейдите в раздел «Общая библиотека» и откройте ссылку «Списки минус слов». На 1 рекламный аккаунт доступно создание 20 списков минус слов. В каждый список можно добавить до 5000 минус слов.
Чтобы добавить минус слова на уровень кампании или группы объявлений, перейдите в левом меню в раздел «Ключевые слова» затем выберите «Минус слова». В появившемся меню появится возможность добавления минус слов. Там же можно выбрать и уровень, на который будут добавляться минус слова.
Как добавить минус слова в Adwords Editor
Перейдите в раздел «Ключевые слова и таргетинг». Затем кликните на «Ключевые слова, Исключаемый критерий». В центральном окне нажмите «Внести несколько изменений», если нужно добавить несколько минус слов одновременно. Там выберите на какой уровень нужно их добавить (кампания или группа объявлений). Рекомендую предварительно отметить все кампании, чтобы они появились в списке и вы могли выбрать нужные.
Затем кликните на «Ключевые слова, Исключаемый критерий». В центральном окне нажмите «Внести несколько изменений», если нужно добавить несколько минус слов одновременно. Там выберите на какой уровень нужно их добавить (кампания или группа объявлений). Рекомендую предварительно отметить все кампании, чтобы они появились в списке и вы могли выбрать нужные.
Откроется окно «Внести несколько изменений». Выберите чек-бокс «Использовать выбранные места назначения». Отметьте нужный уровень добавления: кампания или группа объявлений». Затем отметьте нужные кампании или группы объявлений в списке внизу. После чего, предварительно скопированные в буфер обмена минус слова вставьте через кнопку «Вставить из буфера обмена». Минус слова добавятся в столбик. Название столбца будет «Не импортировать». Нажмите на него и выберите из выпадающего списка «Keyword (Ключевое слово).
На данный момент через редактор Google Ads Editor нельзя создавать списки минус слов. Этот функционал доступен только в самом рекламном кабинете. Однако, вы можете назначать уже созданные списки минус слов к нужным кампаниям в Ads Editor. Перед этим не забудьте скачать в программу последние данные из рекламного аккаунта.
Однако, вы можете назначать уже созданные списки минус слов к нужным кампаниям в Ads Editor. Перед этим не забудьте скачать в программу последние данные из рекламного аккаунта.
Готовые списки минус слов
Все списки минус слов по ссылке: Папка на Google Диск
Отдельно выделю наиболее универсальные списки:
Универсальный список минус слов
Аренда
Бу
Для электронной коммерции
Информационные
Кросс минусовка в Google Ads
Кросс-минусовка — это когда ключи из одной группы добавляются как минус-слова в другую. Это обеспечивает показ объявления из максимально релевантной группы.
Например:
| Группа с ключевыми словами | Минус-слова |
| Купить кота | днепр, днепре, недорого |
| Купить кота в Днепре | недорого |
| Купить кота недорого | днепр, днепре |
| Купить кота Днепр недорого |
Кросс-минусовка — отличный метод. И, кажется, с ним все отлично: обеспечиваешь показ более релевантных объявлений в группе → получаешь выше вероятность конверсии. Но есть нюанс…
И, кажется, с ним все отлично: обеспечиваешь показ более релевантных объявлений в группе → получаешь выше вероятность конверсии. Но есть нюанс…
В одной группе у ключа может быть слишком маленькая ставка или низкое качество. Соответственно, объявление не покажется. А вот во второй группе со ставкой и рейтингом проблем нет! Но показа все равно не будет, потому что ключ, вызывающий его, окажется внесенным в минус-слова.
Мораль: не переусердствуйте с кросс-минусовкой, чтобы не заблокировать самому себе возможность показов.
Источник
Как сделать перекрестную минусовку и не урезать себе трафик
Для этого необходимо сделать удобную структуру аккаунта по воронке продаж.
Например, рекламируем керамические обогреватели. Будут созданы кампании на основе осведомленности. Идём от общего к частному.
- Общая кампания (обогреватели)
- Коммерческие запросы (обогреватели купить)
- Дальше сужаем (керамические обогреватели)
- Коммерческие запросы (керамические обогреватели купить)
- Брендовые кампании (керамические обогреватели + бренд)
- Коммерческие брендовые кампании (керамические обогреватели + бренд купить)
Как производить перекрестную минусовку? Из общего исключаем частное. На уровне кампании добавляем минус слова. К общей кампании добавляем минус слова:
На уровне кампании добавляем минус слова. К общей кампании добавляем минус слова:
- купить
- керамические
- бренд
Из общей кампании по коммерческим запросам исключаем
- керамические
- бренд
И так далее. Таким образом, кампании не будут пересекаться по условиям таргетинга и будут выбраны наиболее релевантные ключи.
Как работать с поисковыми запросами и обновлять списки минус слов
Кроме исследования поисковых запросов по ключевым словам на предмет явно не целевых запросов, необходимо анализировать такие показатели, как CTR, коэффициент конверсии и цена за конверсию.
Если обнаруживаются поисковые запросы, по которым CTR явно ниже среднего по аккаунту, кампании или группе, то добавляем этот поисковый запрос в качестве минус слова на необходимый уровень. Точно так же ислледуем поисковые запросы на предмет цены за конверсию и коэффициент конверсии.
Продвинутый способ
Для этого понадобится воспользоваться скриптом N-грамм анализ.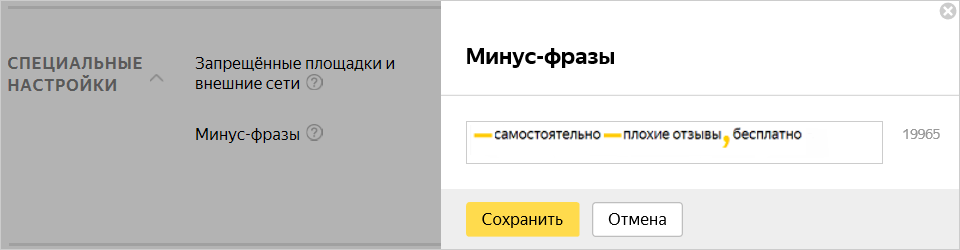 Данный скрипт выгружает все поисковые запросы по нужным кампаниям и представляет отчёт в виде таблицы. Где мы можем видеть данные в разрезе всего аккаунта на уровне, как отдельных слов, так и словосочетаний (биграммы, триграммы). Если обнаруживаются слова или словосочетания, которые явно проигрывают всем остальным в пределах отчета, то можно добавить их в список, чтобы в дальнейшем не получать трафик по запросам, не приносящим конверсии или с дорогими конверсиями.
Данный скрипт выгружает все поисковые запросы по нужным кампаниям и представляет отчёт в виде таблицы. Где мы можем видеть данные в разрезе всего аккаунта на уровне, как отдельных слов, так и словосочетаний (биграммы, триграммы). Если обнаруживаются слова или словосочетания, которые явно проигрывают всем остальным в пределах отчета, то можно добавить их в список, чтобы в дальнейшем не получать трафик по запросам, не приносящим конверсии или с дорогими конверсиями.
Join @sandyrievcom on Telegram
как добавить, настроить минус фразы, операторы в 2022 году
Содержание
- Определения и требования
- Преимущества использования минус-слов в Директе
- Как добавить минусовки в Яндекс.Директ
- Работа с библиотекой минус-фраз в Яндекс.Директ
- Как использовать готовые наборы минус-фраз в группах объявлений
- Как настроить минус-слова в Яндекс.Директ и фразы в Яндекс Коммандере
- Операторы минус-слов в Яндекс. Директ
- Как подобрать список минус-слов и минус-фраз для Яндекс.Директ
- Как собрать минус-слова для Яндекс.Директ: инструменты и сервисы
 Директ
Директ Статья обновлена 16.06.2022
По данным Responsify, почти 50% рекламодателей не задают «минусовки» для своих кампаний, и впоследствии это им дорого обходится. Один из простых способов сэкономить бюджет и убрать нерелевантные клики — использование минус-фраз. Как работают минусовки в Яндекс.Директ и где их искать, расскажем в этой статье.
Определения и требования
Что значат минус-слова в Яндекс.Директ
В цифровом маркетинге есть тенденция: задавать таргетинг на все типы ключевых слов, связанных с бизнесом. Но это не лучший способ использовать возможности Яндекс.Директ. Ведь нужно, чтобы реклама показывалась только по релевантным поисковым запросам, привлекающим только целевых пользователей. Тогда те перейдут на сайт и совершат конверсию.
Люди заходят в поисковик, чтобы найти информацию или найти товар, услугу, организацию. Иногда они получают результаты, которые никак не связаны с их задачей. Так бывает, если рекламодатель вообще не использует минус-слова. Это часто ведет тому, что автор кампании переплачивает за рекламу, а объявления еще и приносят нерелевантный трафик, который не конвертируется в продажи.
Иногда они получают результаты, которые никак не связаны с их задачей. Так бывает, если рекламодатель вообще не использует минус-слова. Это часто ведет тому, что автор кампании переплачивает за рекламу, а объявления еще и приносят нерелевантный трафик, который не конвертируется в продажи.
Минус-слова — это ключевые слова, которые препятствуют показу ваших объявлений по определенным поисковым запросам.
Пример
У вас есть сайт, где продаются фигурки из популярных аниме. Вы размещаете рекламу в Директе по поисковому запросу «аниме». Когда человек набирает эту фразу в строке поиска, он может просто искать новые сериалы в этом жанре. Поэтому наверняка будет разочарован, увидев в поисковой выдаче вашу ссылку. Ведь всё, что вы делаете, — это продаете фигурки, которые ему не нужны. Таким образом, вы потратите платный клик впустую.
Минус-слова помогают различать релевантные тематики запросов для показа. Также они облегчают людям поиск информации по теме, которая их интересует.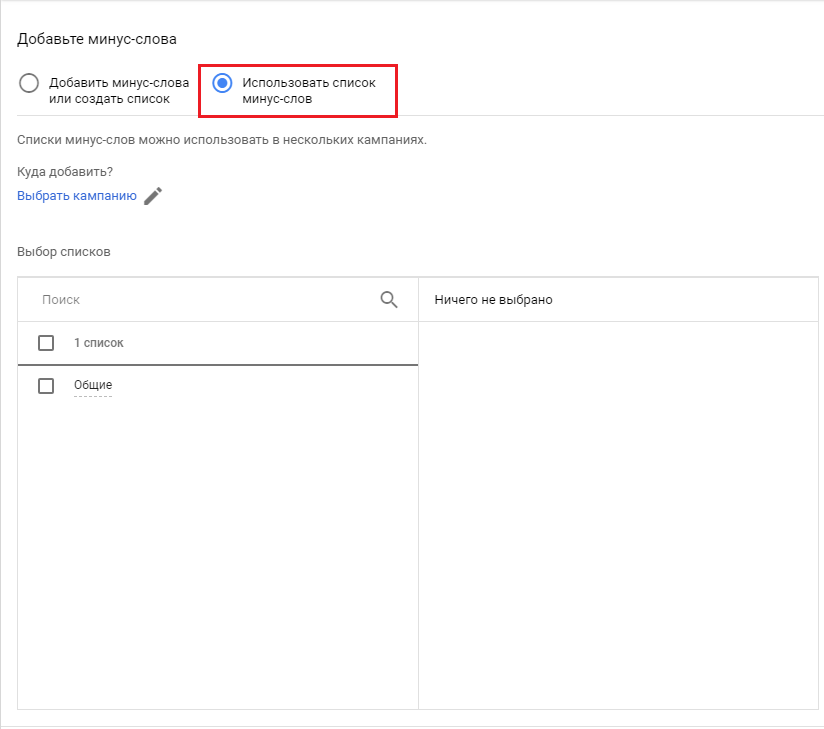 За счет минус-слов вы предотвращаете показ объявления с оплатой по модели CPM, поэтому минимизируете показатель отказов и увеличиваете ROI.
За счет минус-слов вы предотвращаете показ объявления с оплатой по модели CPM, поэтому минимизируете показатель отказов и увеличиваете ROI.
Чем минус-слово отличается от минус-фразы
Перед разбором отличий рассмотрим принцип обработки рекламных объявлений в Яндексе.
- Система приоритетно работает ключевиками, которые вы задали в настройках кампании.
- При выборе, показывать объявление или нет, сначала проверяются заданные ключевые слова. Если есть совпадение, алгоритм добавляет объявление в выдачу.
- Но если у вас дополнительно заданы минус-слова или минус-фразы, то искусственный интеллект сверяет их с запросом на предмет совпадений. Если такое минус-слово или фраза содержатся, объявление будет исключено из показов.
Минус-слова работают, только когда задана ключевая фраза.
Пример
Вы задали ключевик «купить кофемашину», а минус-слово — «дешево», то объявление не будет показываться по запросу «купить кофе-машину дешево». Такая настройка кампании подойдет производителям кофе-машин премиум-сегмента.
Такая настройка кампании подойдет производителям кофе-машин премиум-сегмента.
Минус-фраза работает по-другому. Она исключает для показов запросы, где есть полное или частичное совпадение всех слов. То есть поисковый запрос содержит все перечисленные в минус-фразе слова или целое словосочетание. Но если в запросе есть только часть минус-слов, то он исключаться не будет.
Пример
Вы задали ключевик «купить кофемашину», а минус-фразу — «кофемашина с зерновым кофе». Ваше объявление всё равно будет показываться по запросу «кофемашина с молотым кофе». То есть система понимает, что изменение «зернового» на «молотый» меняет смысл фразы, и в итоге запрос уже не относится к минусовкам.
Если минус-фраза и ключевик полностью совпадают, показы всё равно будут идти. Более значимым для запуска показов является заданный ключевик.
Особенности минус-слов и фраз при показе в РСЯ и на поиске
Работают «минусовки» не только на поиске, но и в РСЯ. На основе заданных ключевых слов Яндекс сам выбирает, на каких площадках РСЯ показывать объявления. Если дополнительно указать минус-фразы и слова, можно исключить объявление из показов на нерелевантных сайтах. Такая опция действует для всех рекламных форматов, кроме смарт-баннеров.
На основе заданных ключевых слов Яндекс сам выбирает, на каких площадках РСЯ показывать объявления. Если дополнительно указать минус-фразы и слова, можно исключить объявление из показов на нерелевантных сайтах. Такая опция действует для всех рекламных форматов, кроме смарт-баннеров.
При показе в РСЯ минус-слова и фразы также позволяют точнее сегментировать целевую аудиторию. Они максимально уточняют рекламную тематику, которая будет интересна только определенным пользователям.
Обычно рекламодатели используют разные списки минусовок на поиске и в РСЯ. Это связано со спецификой мест размещения соответствующих объявлений.
Особенности работы с минусовками в РСЯ по сравнению с поиском:
- используется меньше минус-слов, иначе можно потерять охваты;
- крайне важно проводить минусовку неподходящих площадок;
- минусуются только те площадки, которые очевидно не относятся к тематике бизнеса, например, через используемые на сайте фразы «игры», «рефераты», «казино», «купонаторы и акции», если такая аудитория не нужна рекламодателю;
- часто не минусуют слово «отзывы», так как при цене за клик в РСЯ это не критично.

Важно подбирать для показов те площадки, которые действительно приведут «горячую» аудиторию, готовую к конверсии. То есть сайт должен соответствовать вашей тематике и предполагать, что люди могут заинтересоваться здесь товаром, а не просто скачать фильм или листать картинки. Исключение неэффективных площадок поможет вам сохранить бюджет для тех партнерских сайтов, которые действительно принесут прибыль.
Технические требования к «минусовкам» в Директе
Правила таковы:
- не больше 7 слов в одной минус-фразе;
- до 4096 знаков без пробелов на весь перечень в группе, всего не более 200 фраз;
- до 20 000 знаков без пробелов на весь перечень в кампании.
Преимущества использования минус-слов в Директе
Добавление «минусовок» поможет вам экономить рекламный бюджет. Но их использование дает и другие преимущества.
Более релевантные объявления
Удалив ключевики, не относящиеся к вашему бизнесу, вы повысите релевантность своей рекламы.
Пример
Вы продаете варенье из земляники. Как показывает Вордстат, формулировку «варенье из земляники» искали более 100 тысяч раз за последний месяц.
Но если взять формулировку «варенье из земляники сварить», то Вордстат показывает 7754 показа за месяц.
Это значит, что если вы включите минус-слово «сварить», то исключите почти 8000 нерелевантных показов. То есть показов тем пользователям, которые не заинтересованы в покупке, а хотят сделать варенье сами.
Повышение CTR
Когда релевантность ваших объявлений повысится, целевая аудитория будет считать их более привлекательными. Это означает, что процент людей, которым будет интересна ваша реклама, станет выше. Когда этот показатель увеличивается, повышается и CTR рекламы — ее кликабельность.
Метрика считается по формуле:
CTR = (количество кликов / количество показов) × 100%
Рекламодатели стремятся увеличить кликабельность, показывая объявление более заинтересованной аудитории и исключая нерелевантные показы. В этом и помогают минусовки.
В этом и помогают минусовки.
Повышение коэффициента конверсий
Использование минус-слов гарантирует, что ваши объявления не будут показаны в Яндексе по определенным поисковым запросам. Значит, реклама начнет отображаться только для тех ключевиков, которые потенциально способны привести к конверсиям.
Уменьшение процента отказов
Когда ваша реклама не соответствует содержанию лендинга, на который она ведет, это часто вызывает раздражение. Например, пользователь ввел запрос «купить пластиковые окна для дачи». Увидел объявление с таким же заголовком и кликнул по нему. Но на сайте увидел только окна сегмента премиум, которые на дачу не ставят. Пользователь сразу закроет сайт — такое предложение ему не подходит.
Это влияет на показатель отказов — он увеличивается, раз люди немедленно покидают сайт. Если предотвратить такую ситуацию с помощью минус-слов, гарантированно уменьшится значение показателя отказов — Bounce Rate, BR.
Поэтому рекламодатели используют минус-слова вроде «бесплатно», «своими руками», «в домашних условиях», чтобы не показываться тем, у кого нет намерения приобрести их продукт.
Повышение показателя качества и доходов
Если увеличивается CTR рекламы, то растет и качество объявлений в Директе. Это позволяет снизить стоимость каждого клика и общую стоимость рекламной кампании.
Показатель качества демонстрирует, насколько ваш бизнес полезен и актуален для людей. Он влияет как на позицию в поисковой выдаче, так и на стоимость ваших объявлений CPC в Яндексе.
Реклама будет видна только целевой аудитории, которая может быть заинтересована в продуктах или услугах. Они не только с большей вероятностью перейдут на ваш сайт, но и совершат конверсию. Таким образом, минус-слова могут не только снизить ваши расходы, но и увеличить доходы.
Как добавить минусовки в Яндекс.Директ
Минус-слова работают только на уровне ключевых фраз. Минус-фразы можно как писать для конкретной кампании, так и задавать для группы объявлений. Покажем на примере, как это делается.
Минус-слова для ключевика
- Зайдите в раздел «Ставки и фразы» и в общем списке нажмите на иконку редактирования.
- Во всплывающем окне вы увидите поле для записи фразы с минус-словами. Здесь вы можете использовать операторы либо ввести словосочетание целиком.
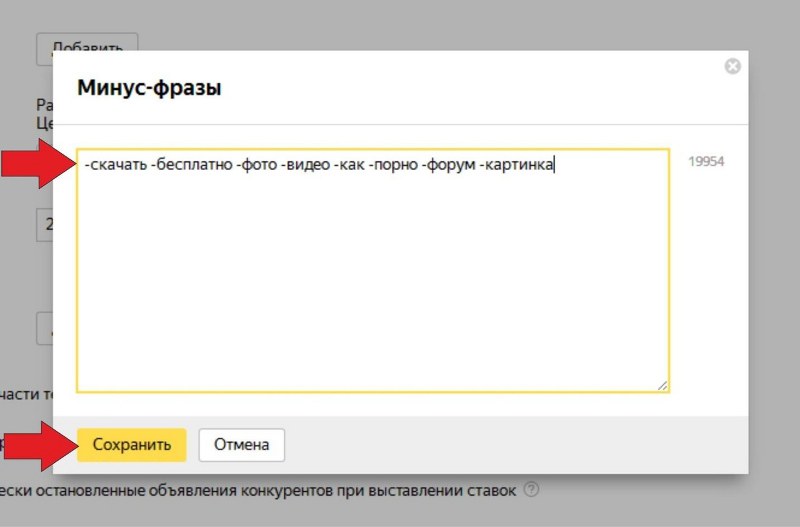
- При нажатии на кнопку «Уточнить» Яндекс выдаст ежемесячный прогноз показов для такой фразы и примеры запросов. С помощью этой информации вы можете скорректировать свой список.
- Для сохранения нажмите «Готово».
Минус-фразы для группы
- Зайдите на страницу групп объявлений, отметьте галочкой нужную. В нижнем меню «Действия» выберите пункт «Минус-фразы».
- В открывшемся текстовом поле введите все необходимые слова и нажмите на кнопку «Применить».
Минус-фразы для кампании
- Перейдите на вкладку кампаний, отметьте галочкой нужную и в нижнем меню «Действия» выберите пункт «Минус-фразы».
- В открывшемся окне добавьте список фраз для кампании и нажмите «Применить».
Работа с библиотекой минус-фраз в Яндекс.
 Директ
ДиректМожно создавать наборы минусовок, чтобы использовать их в любых рекламных кампаниях.
- В основном меню зайдите в раздел «Библиотека» и выберите пункт «Минус-фразы».
- Во всплывающем окне нажмите на кнопку «Добавить набор». Задайте название и введите через запятую или тире фразы, которые хотите «отминусовать». Яндекс отформатирует их сам.
- Если у вас уже есть готовый набор минус-фраз, вы можете создать на его основе новый. Для этого в библиотеке готовых наборов нажмите на иконку настроек рядом с нужным названием. Во всплывающем меню выберите пункт «Создать на основе». Здесь же можно отредактировать имеющийся набор минус-фразы или удалить его.
Как использовать готовые наборы минус-фраз в группах объявлений
Если вы составили список минусовок, который хотите сохранить в готовом виде для будущих кампаний, зайдите на страницу редактирования группы.
- В разделе «Условия показа» перейдите в раздел «Минус-слова и фразы».

- Откройте вкладку «Библиотечные наборы» и отметьте галочкой нужный перечень.
- Нажмите кнопку «Готово» и набор будет привязан к конкретной группе объявлений.
Чтобы посмотреть, в каких группах используется готовый перечень, зайдите в библиотеку в раздел «Минус-фразы». Напротив нужного названия нажмите на иконку «В группах». Яндекс откроет ту группу объявлений, где используется конкретный набор.
Чтобы привязать или отвязать набор от группы, нужно выделить на вкладке группу и в нижнем выпадающем меню «Действие» выбрать «Библиотеки минус-фраз».
Здесь вы можете отметить нужный набор и нажать на кнопку «Отвязать». Таким же образом можно привязать группе набор, не заходя непосредственно на страницу редактирования.
Как настроить минус-слова в Яндекс.Директ и фразы в Яндекс Коммандере
Яндекс Коммандер — специальная десктопная программа. Она позволяет управлять рекламной активностью гибко и без необходимости заходить в рекламный аккаунт. Здесь можно массово задать минус-фразы на уровне кампании либо группы объявлений.
Здесь можно массово задать минус-фразы на уровне кампании либо группы объявлений.
- Для редактирования минус-фраз на уровне кампании перейдите в соответствующую вкладку «Компании» и в открывшемся окне справа прокрутите до раздела «Минус-фразы на кампанию». Здесь их можно уточнить, добавить, отредактировать и нажать на кнопку «Сохранить».
- Чтобы управлять минус-фразами в группе, перейдите на вкладку «Группы» и в правом окне найдите раздел «Минус-фразы на группу». Вы можете отредактировать их точно так же, как и для кампании, затем сохранить изменения.
Операторы минус-слов в Яндекс.Директ
Чтобы упростить работу с минус-фразами, в Яндексе можно использовать следующие операторы: +, !, «», [].
Что они означают?
| Оператор | Что делает | Пример | Показы будут | Показов не будет |
| + | Добавляет стоп-слова в Яндекс. Директ: служебные части речи, дополнительные слова и местоимения в поиск, закрепляет их Директ: служебные части речи, дополнительные слова и местоимения в поиск, закрепляет их | кофемашина +на дом | Кофемашина на дом | кофемашина дома кофемашина в доме |
| ! | Закрепляет словоформу: склонение, падеж, число и время | купить кофемашину в !москве | купить кофемашину в москве | купить кофемашину в москву |
| «» | Закрепляет число слов во фразе, обеспечивает показы только по тем запросам, которые такую фразу содержат | «купить кофемашину» | купить кофемашину кофемашину купить | купить кофемашину в москве |
| [] | Закрепляет порядок слов во фразе, принимая во внимание список стоп-слов в Яндекс.Директ и словоформ | кофемашина [с зерновым кофе] | кофемашина с зерновым кофе кофемашина с зерновым кофе купить | кофемашина зерновой кофе кофемашина на зерновом кофе |
При использовании операторов в минус-фразах учитывайте, как они будут пересекаться с ключевиками. Приведем примеры того, как это работает на практике.
Приведем примеры того, как это работает на практике.
| Ключевик | Минус-фраза в группе | Показы будут | Показов не будет |
| Кофемашина | -профессиональная с зерновым кофе | кофемашина профессиональная кофемашина с зерновым кофе кофе для кофемашины кофемашина для дома с зерновым кофе профессиональная кофемашина с кофе | хорошая кофемашина с зерновым кофе |
| Кофемашина | — профессиональная + с !зерновым кофе | кофемашина без зернового кофе кофе для профессиональной кофемашины кофемашина для дома с зерновым кофе кофемашина с зерновым кофе | профессиональная кофемашина с зерновым кофе |
| Профессиональная кофемашина | -+с ! зерновым кофе | профессиональная кофемашина с молотым кофе хорошая профессиональная кофемашина | профессиональная кофемашина с зерновым кофе купить профессиональная кофемашина с зерновым кофе |
| Кофемашина | -[со встроенной кофемолкой] | кофемолка со встроенной кофемашиной | кофемашина со встроенной кофемолкой |
| Кофемашина | -«кофемашина профессиональная с зерновым кофе» | кофемашина для профессионалов профессиональная кофемашина | профессиональная кофемашина с зерновым кофе |
Как подобрать список минус-слов и минус-фраз для Яндекс.
 Директ
ДиректКогда вы нашли нерелевантные ключевики, оцените, стоит ли их «минусовать». Разберем виды «минусов» для размещения рекламы в Директе с оплатой CPC.
Товары, услуги или темы, не относящиеся к бизнесу
Если товар, услуга или тема запроса не имеют отношения к вашему сайту — «минусуйте» их.
Пример
Вы продаете надувные матрасы. Но ваша реклама появляется для тех, кто интересуется матрасами для кровати. Поэтому нужно заминусовать варианты словосочетаний со словом «кровать».
Названия маркетплейсов
Новым компаниям сложно конкурировать с крупными маркетплейсами — такими как Wildberries или Ozon. Пользователи часто ищут название товара вместе с наименованием платформы, и это — не ваши клиенты.
Отфильтруйте поисковые запросы, добавьте в список «минусов» все названия маркетплейсов, на которых продаются похожие товары. Если вы, конечно, не продаете на них сами.
Это может показаться нелогичным. Но лучше заблокировать клик пользователя, который с 90% вероятностью купит товар не у вас и потратит ваш рекламный бюджет впустую. В конце концов, он же включил название крупного розничного продавца в свой поисковый запрос.
В конце концов, он же включил название крупного розничного продавца в свой поисковый запрос.
Общие термины
Это правило относится ко всем областям. Но оно особенно важно, если вы продаете на своем сайте дорогие или нишевые товары.
Блокировать показ объявления по общим терминам — значит, перестать платить за сотни кликов людей, которые на самом деле не знают, чего они хотят.
Пример
Фритюрница — общий термин. А фритюрница Philips — уже конкретика. Как вы думаете, кто больше готов к покупке? Человек, знающий бренд, который он ищет? Или тот, кто всё еще собирает информацию по всем фритюрницам?
Конечно, применять это правило всегда и всюду нельзя. Обязательно рассматривайте каждый товар и ситуацию отдельно. Не стоит минусовать термин «книги», если вы их продаете. И обязательно нужно, если у вас на повестке «книга бухгалтерского учета».
Как собрать минус-слова для Яндекс.Директ: инструменты и сервисы
Существует несколько способов.
1. Посмотрите минус-слова из готовых списков
Вы можете сформулировать для себя универсальный список минус-слов Яндекс.Директ. То есть перечень, который подойдет практически к любой кампании. Для большинства рекламодателей, которые продают в Сети товары или услуги, универсальный список может включать такие минусовки:
- бесплатно;
- даром;
- б/у;
- что это;
- сделать самому;
- в домашних условиях;
- дешево/дорого — в зависимости от сегмента — бюджетный или премиум.
Подобные стандартные минус-слова применимы многих видов электронной коммерции Яндекс.Директ. Можете найти их на специальных онлайн-сервисах — генераторах.
Но не все они сработают — нужно внимательно читать каждое слово и «примерять» к собственной бизнес-ситуации. Существуют списки разной тематики — например, список городов для минус-слов Яндекс.Директ или фразы, отсекающие любителей халявы.
Если вы готовы проверять их все вручную, какие-то основные мысли из таких списков взять можно.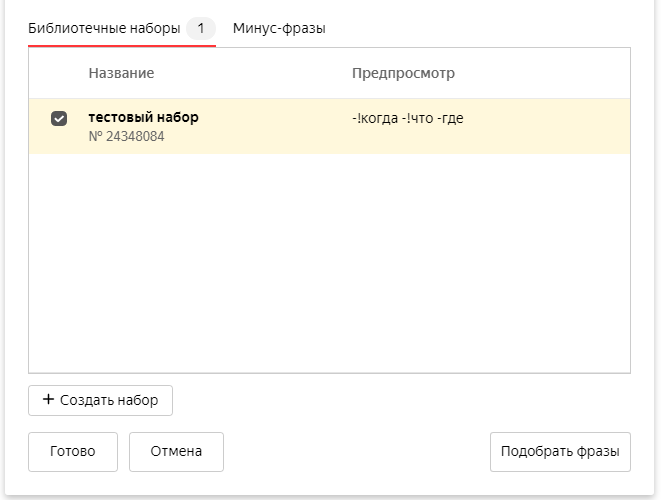 Главное — не использовать их «как есть».
Главное — не использовать их «как есть».
2. Опирайтесь на автофокус Яндекс.Директ
Так называется инструмент, который изучает статистику показов рекламы и «запоминает» неэффективные слова и фразы. Раньше эту опцию можно было включить выборочно. Но в 2017 году Яндекс.Директ сообщил, что автофокус исчезнет из интерфейса и просто станет одним из алгоритмов системы. Так что теперь рекламодателям не ходится каждый раз включать эту полезную опцию.
Автофокус Яндекс.Директ работает очень аккуратно, деликатно и не считает неэффективными фразы, для которых не хватает статистики.
3. Анализируйте отчеты по поисковым запросам
Лучшие данные по минус-словам в Яндекс.Директе — ваши собственные данные. Поэтому обязательно изучите отчеты, чтобы выявить утечки рекламного бюджета и внести эти запросы в «черный список».
Такой подбор для списка минус-фраз для Яндекс.Директ основан на сборе нерелевантных запросов от пользователей с вашего сайта. Как его сделать?
- Зайдите в раздел «Статистика по всем кампаниям» и перейдите на вкладку «Поисковые запросы».
- Задайте нужный период и отметьте столбец отказов в табличном отчете.
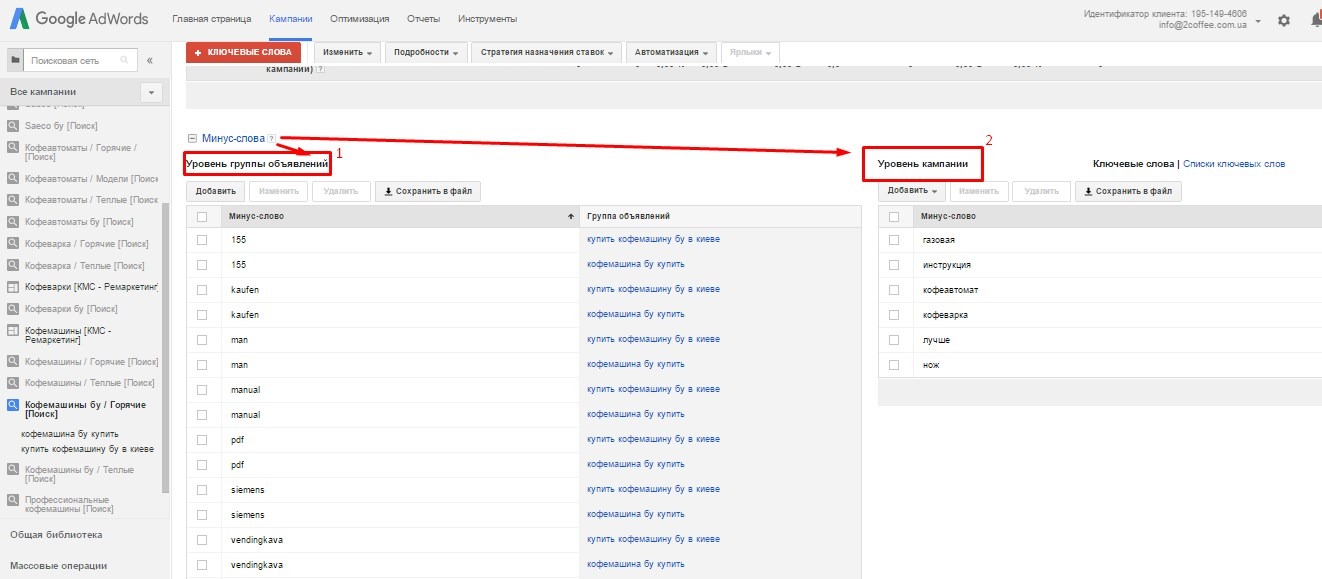
- Если процент отказов выше 80%, данный запрос лучше сразу занесите в «минусы».
Также доступна оценка количества отказов через отчетность Яндекс.Метрики. Типовой отчет «Директ сводка» с настройкой по кампаниям и поисковым фразам можно отсортировать по количеству отказов и также выделить те запросы, которые показывают высокие значения BR.
Свести всю информацию воедино и не собирать ее по разным отчетам поможет сквозная аналитика. Подключите Яндекс.Метрику в качестве одного из источников данных — и увидите в режиме реального времени, какие ключевики сливают бюджет. Выявленные нерелевантные запросы можно тут же добавить в свой перечень.
4. Используйте автозаполнение Яндекса
Когда вы набираете в Яндекс какой-то запрос, срабатывает функция автозаполнения, которая подсказывает популярные варианты, как заполнять поле дальше. Например, если ввести «купить кофемашину», то можно увидеть такие варианты:
Это релевантные запросы, если вы продаете кофемашины. Но следующими в списке идут запросы, связанные с брендами Nivona и Philips, а также конкретными городами. Если это не про вас, добавьте такие формулировки в список минус-фраз.
Но следующими в списке идут запросы, связанные с брендами Nivona и Philips, а также конкретными городами. Если это не про вас, добавьте такие формулировки в список минус-фраз.
Поиск вручную позволяет быстро обнаружить нерелевантные запросы. Но чем объемнее рекламная кампания, тем больше времени на это уходит. Автоматизировать процесс сбора можно с помощью специальных сервисов подбора минус-фраз для Яндекс.Директ онлайн — Mangools KWFinder, SEMrush, Key Collector или SEO PowerSuite.
5. Используйте сервис Wordstat
Wordstat обычно используется для корректного ключевых слов. Но он работает и в обратную сторону. Как найти минус-слова в Яндекс.Директ через Вордстат?
- Зайдите на главную страницу сервиса.
- Введите ключевое слово, для которого хотите изучить связанные запросы. Например, «купить кофемашину».
Просмотрите не только левый, но и правый столбец, который содержит связанную информацию. Для этого примера можно с уверенностью отсекать запросы типа «миксер цена», «духовой шкаф электрический цена» и другие нерелевантные словосочетания.
Сбор минус-слов Яндекс.Директ на этом не заканчивается. В основных запросах, которые искали со словами «купить кофемашину» также можно найти нерелевантные примеры. Например, с упоминанием конкурентов «кофемашина ecam купить» или «nespresso кофемашина купить». Также вы можете уточнить тип кофемашин: если не продаете аппараты для зернового кофе, то исключите соответствующие формулировки.
6. Исследуйте результаты поиска
Хороший способ дополнить свой список минус-слов — провести мини-исследование в поиске. Просто выполните запрос в Яндексе по нужным ключевикам.
Результаты, которые появятся на первых нескольких страницах, будут релевантными по мнению Яндекса. Просматривая их, ищите строки в заголовках, которые явно не относятся к теме, затем добавляйте их в свою подборку минусовок.
Частые вопросы
Что такое минус-слова?Минус-слова — ключевые слова, по которым вы не хотите показывать свою рекламу. Они — полная противоположность ключевикам. Их использование позволяет исключить поисковые запросы от людей, которым неинтересны ваши продукты или услуги.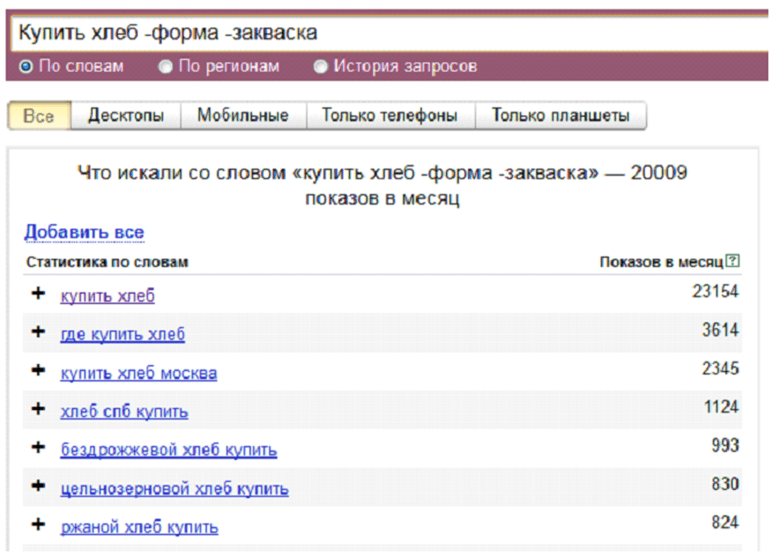
Минус-слово — это одна словоформа, а минус-фраза включает несколько слов. Им можно задавать определенный род, падеж, число, использовать их со служебными и другими частями речи — стоп-словами. Минус-слово работает только когда задан ключевик. Оно исключает показы, где есть и минус-слово, и ключ. Минус-фраза же отсекает все показы с похожим содержанием запроса.
Какие есть сервисы для сбора списка минус-слов и фраз?К ним относятся минус-слова из готовых списков в Сети, анализ отчетов по поисковым запросам, автозаполнение Яндекса и изучение результатов поиска, а также сервис Wordstat.
Следующая статья: « ТОП-15 лайфхаков для настройки эффективной рекламной кампании в Яндекс.Директ
Содержание
- Определения и требования
- Преимущества использования минус-слов в Директе
- Как добавить минусовки в Яндекс.Директ
- Работа с библиотекой минус-фраз в Яндекс. Директ
- Как использовать готовые наборы минус-фраз в группах объявлений
- Как настроить минус-слова в Яндекс.Директ и фразы в Яндекс Коммандере
- Операторы минус-слов в Яндекс.Директ
- Как подобрать список минус-слов и минус-фраз для Яндекс.Директ
- Как собрать минус-слова для Яндекс.Директ: инструменты и сервисы
 Директ
ДиректОцените статью:
Средняя оценка: 4.5 Количество оценок: 998
Понравилась статья? Поделитесь ей:
Подпишитесь на рассылку ROMI center: Получайте советы и лайфхаки, дайджесты интересных статей и новости об интернет-маркетинге и веб-аналитике:
Вы успешно подписались на рассылку. Адрес почты:
Читать также
Как увеличить продажи в несколько раз с помощью ROMI center?
Закажите презентацию с нашим экспертом. Он просканирует состояние вашего маркетинга, продаж и даст реальные рекомендации по её улучшению и повышению продаж с помощью решений от ROMI center.
Запланировать презентацию сервиса
Попробуйте наши сервисы:
Импорт рекламных расходов и доходов с продаж в Google Analytics
Настройте сквозную аналитику в Google Analytics и анализируйте эффективность рекламы, подключая Яндекс Директ, Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Попробовать бесплатно
Импорт рекламных расходов и доходов с продаж в Яндекс Метрику
Настройте сквозную аналитику в Яндекс.Метрику и анализируйте эффективность рекламы, подключая Facebook Ads, AmoCRM и другие источники данных за считанные минуты без программистов
Попробовать бесплатно
Система сквозной аналитики для вашего бизнеса от ROMI center
Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Попробовать бесплатно
 Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Сквозная аналитика для Google Analytics позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
Сквозная аналитика для Яндекс.Метрики позволит соединять рекламные каналы и доходы из CRM Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете. Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Подробнее → Попробовать бесплатно
Сквозная аналитика от ROMI позволит высчитывать ROMI для любой модели аттрибуции Получайте максимум от рекламы, объединяя десятки маркетинговых показателей в удобном и понятном отчете.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Подробнее → Попробовать бесплатно
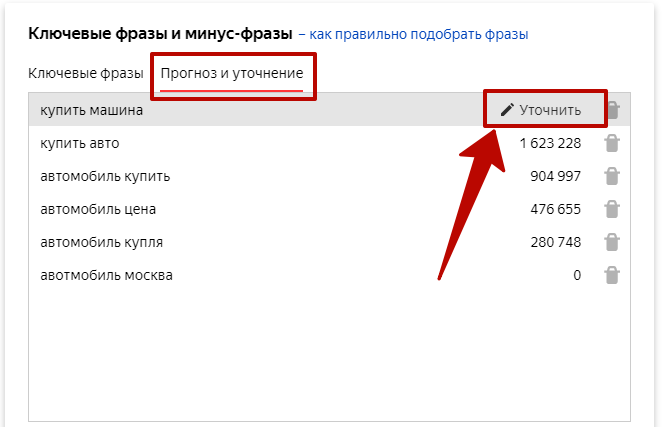 Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.
Отслеживайте окупаемость каждого рекламного канала и перестаньте сливать бюджет.Как находить, добавлять и использовать минус-слова с максимальной выгодой
Каждый маркетолог с оплатой за клик знает, что платные поисковые кампании не могут быть эффективными без всестороннего списка гипертаргетированных ключевых слов. Не менее важны минус-слова, которые позволяют рекламодателям уточнить таргетинг своих объявлений, предотвращая показ объявлений незаинтересованным поисковым пользователям. В свою очередь, это помогает цифровым рекламодателям экономить бюджет, направляя свои рекламные доллары на ключевые слова, которые с большей вероятностью принесут рентабельность инвестиций.
Что такое минус-слова?
Минус-слова (также известные как «минус-соответствие») — это определенные слова или фразы, которые предотвращают показ объявлений тем, кто ищет это ключевое слово или фразу. Маркетологи PPC определяют эти фразы после тщательного анализа кампании, чтобы определить, какие ключевые слова генерируют клики и, в конечном итоге, лиды или доход. Эти ключевые фразы можно добавить на уровне группы объявлений или на уровне кампании (подробнее об этом позже).
Маркетологи PPC определяют эти фразы после тщательного анализа кампании, чтобы определить, какие ключевые слова генерируют клики и, в конечном итоге, лиды или доход. Эти ключевые фразы можно добавить на уровне группы объявлений или на уровне кампании (подробнее об этом позже).
Рассмотрим поисковый запрос «бесплатная служба CRM». Если ваше программное обеспечение CRM , а не бесплатно, вы бы хотели, чтобы эта фраза была включена в список минус-слов. Скорее всего, они не заинтересованы в том, чтобы платить за ваши услуги, так зачем тратить свой бюджет на показ своей рекламы?
Чем минус-слова отличаются от других ключевых слов?
Разница заключается в том, появляются ли ваши объявления в результатах поиска или нет. Назначая минус-слова, ваши кампании больше фокусируются на поисковых запросах, которые вы считаете релевантными для вашего продукта или услуги, и дадут положительные результаты. Короче говоря, выбирая то, что , а не для таргетинга делает кампанию более целенаправленной, т. е. повышает вероятность увеличения рентабельности инвестиций.
е. повышает вероятность увеличения рентабельности инвестиций.
Типы соответствия минус-слов
Существует три типа соответствия: широкое соответствие, фразовое соответствие и точное соответствие.
Широкое соответствие
Отрицательное широкое соответствие позволяет исключить ваше объявление из результатов поиска, в которых каждое слово вашей ключевой фразы в любом порядке появляется в результатах поиска. Это означает, что ваше объявление не будет показываться всякий раз, когда в поисковом запросе используется весь термин, но может показываться, если поиск содержит только одно или несколько ключевых слов. Этот тип соответствия используется Google по умолчанию в поисковых кампаниях PPC, если не указано иное.
Вот пример Google для «кроссовки» в качестве отрицательного ключевого слова с широким соответствием:
Фразовое соответствие
Минус-ключевое слово с фразовым соответствием позволяет исключить ваше объявление из поисковых запросов, включающих точную ключевую фразу со словами в тот же порядок. Поисковый запрос может содержать дополнительные слова, но объявление все равно не будет показываться, если все ключевые слова включены в поиск в том же порядке. Тем не менее, если кто-то ищет только одно или несколько слов из минус-слова, ваше объявление все равно будет отображаться.
Поисковый запрос может содержать дополнительные слова, но объявление все равно не будет показываться, если все ключевые слова включены в поиск в том же порядке. Тем не менее, если кто-то ищет только одно или несколько слов из минус-слова, ваше объявление все равно будет отображаться.
Давайте посмотрим, как меняются результаты по одной и той же поисковой фразе «кроссовки:»
Точное соответствие
Минус-ключевое слово с точным соответствием звучит именно так: оно позволяет исключить ваше объявление из поисковых запросов точную ключевую фразу, в том же порядке, без дополнительных слов. Если поисковый запрос содержит какие-либо дополнительные слова или все ключевые термины расположены в другом порядке, ваше объявление все равно может показываться. Этот тип соответствия устранит минимальный трафик, поскольку он очень специфичен.
В этом же примере обратите внимание, что слово «кроссовки» — единственная фраза, которая не будет отображаться в объявлении:
Примечание: Минус-слова не распознают близкие варианты, такие как опечатки, единственное или множественное число, аббревиатуры, стемминги или аббревиатуры. Чтобы гарантировать, что ни один из этих вариантов не появится, вы должны добавить их как отдельное минус-слово.
Чтобы гарантировать, что ни один из этих вариантов не появится, вы должны добавить их как отдельное минус-слово.
Поиск минус-слов
При создании списка минус-слов начните с определения поисковых запросов, которые похожи на ваши целевые ключевые слова, но могут обслуживать клиентов, которые на самом деле ищут совершенно другой продукт или услугу — продукты или услуги, которые вы могли бы быть ошибочно приняты за определенные условия поиска.
Например, продавец, продающий мужские рабочие ботинки, может захотеть добавить минус-слова для таких поисковых запросов, как «резиновые сапоги» и «ковбойские сапоги», чтобы не привлекать нерелевантную аудиторию «ботинок».
Идентификация минус-слов может быть сложной и трудоемкой задачей. К счастью, есть много инструментов, которые могут помочь. Начиная с отчета по поисковым запросам Google, вы увидите конкретные поисковые запросы людей, которые вызвали показ вашего объявления:
Этот инструмент следует использовать не только для того, чтобы увидеть, какие ключевые слова генерируют клики, но и для того, чтобы определить, какие поисковые запросы люди используют. использование которых не связано с вашим продуктом или услугой. Это термины/поисковые запросы, которые следует добавить в список минус-слов.
использование которых не связано с вашим продуктом или услугой. Это термины/поисковые запросы, которые следует добавить в список минус-слов.
Добавление минус-слов
Из отчета по поисковым запросам Google:
- Перейдите на вкладку Ключевые слова.
- Установите флажок рядом с ключевым словом, для которого вы хотите создать отчет о поиске, и нажмите кнопку Условия поиска.
- Выберите любые нерелевантные условия поиска и нажмите «Добавить как минус-слово:»
На этом этапе у вас есть возможность применить выбор ко всей кампании или к определенным группам объявлений. И Google, и Bing позволяют применять минус-слова на уровне кампании и группы объявлений. Однако при использовании нескольких уровней минус-слова самого низкого уровня имеют приоритет над ключевыми словами более высокого уровня.
Кроме того, не забывайте, что ваш выбор будет автоматически соответствовать минус-словам с широким соответствием , потому что это то, что Google использует по умолчанию. Если вы хотите, чтобы они были другого типа соответствия, вам придется изменить их вручную.
Если вы хотите, чтобы они были другого типа соответствия, вам придется изменить их вручную.
Без запуска отчета по поисковым запросам
Для этого выполните следующие действия:
- Нажмите «Ключевые слова» в меню слева.
- Нажмите «Минус-слова».
- Нажмите синюю кнопку с плюсом.
Отсюда вы можете добавить новые минус-слова в свои кампании или группы объявлений, создать новый список минус-слов или использовать существующий список минус-слов.
Добавление новых ключевых слов в кампании, группы объявлений или создание нового списка:
- Выберите «Добавить минус-слова или создать новый список».
- Выберите кампанию или группу объявлений, а затем выберите конкретную кампанию или группу объявлений.
- Добавьте ключевые слова (по одному в строке) и убедитесь, что ваши минус-слова не перекрываются с целевыми ключевыми словами, так как это предотвратит показ вашего объявления вообще.
- Если вы добавляете минус-слова в кампанию, вы можете сохранить ключевые слова в новый или существующий список и применить этот список к кампании. Просто установите флажок «Сохранить в новый или существующий список», введите имя нового списка или выберите существующий список, затем нажмите «Сохранить».
 Просто установите флажок «Сохранить в новый или существующий список», введите имя нового списка или выберите существующий список, затем нажмите «Сохранить».
Просто установите флажок «Сохранить в новый или существующий список», введите имя нового списка или выберите существующий список, затем нажмите «Сохранить».Чтобы использовать существующий список минус-слов:
- Выберите «Использовать список минус-слов».
- Выберите кампанию, к которой нужно применить списки минус-слов.
- Установите флажки в списках минус-слов, которые вы хотите использовать.
- Нажмите «Сохранить».
Получите максимальную отдачу от своих расходов на рекламу
В рекламе с оплатой за клик целевые ключевые слова — это только одна часть уравнения — минус-слова также оказывают значительное влияние на ваши рекламные кампании. Хотя рекламные платформы, такие как Google и Bing, отлично справляются с фильтрацией вашей аудитории, самостоятельное определение конкретных поисковых запросов может помочь еще больше.
Создайте список минус-слов сегодня, чтобы повысить релевантность своего объявления.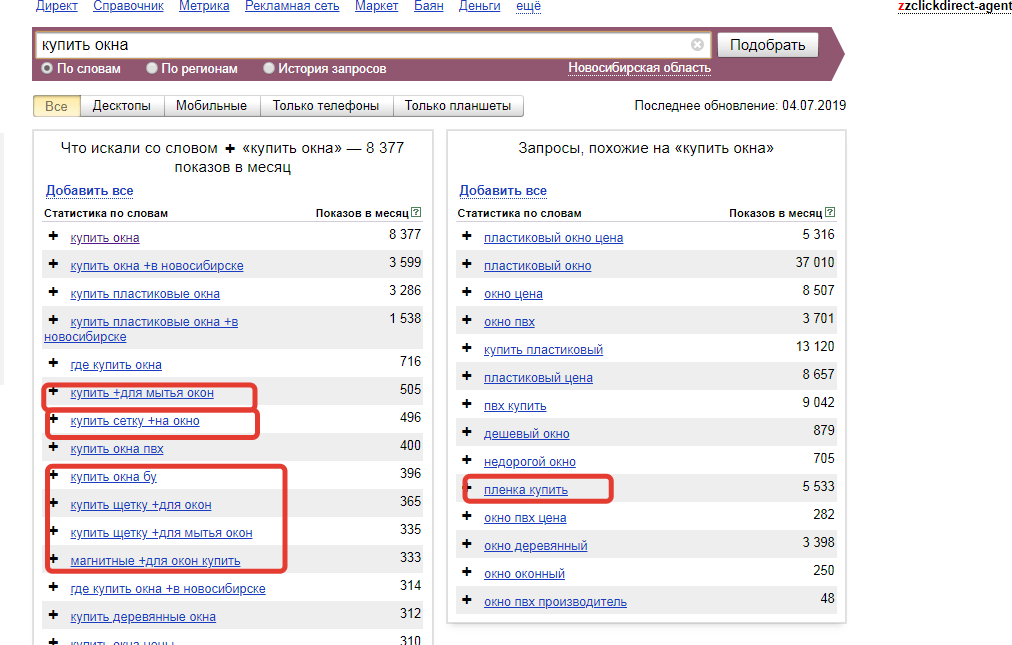 Затем завершите свою рекламную кампанию, предоставив оптимальную целевую страницу после клика от объявления до целевой страницы после клика с Instapage — самой надежной платформой оптимизации после клика, подпишитесь на демоверсию Instapage Enterprise сегодня.
Затем завершите свою рекламную кампанию, предоставив оптимальную целевую страницу после клика от объявления до целевой страницы после клика с Instapage — самой надежной платформой оптимизации после клика, подпишитесь на демоверсию Instapage Enterprise сегодня.
AdWords: 3 способа найти минус-слова
В каждой учетной записи AdWords есть отчет, который показывает точные слова («запрос»), которые пользователи ввели в Google, прежде чем нажать на определенное объявление. Он называется «Отчет о поисковых запросах». Иногда его называют SQR (отчет о поисковых запросах). Это один из самых полезных и действенных отчетов в AdWords.
Чтобы открыть отчет в текущем интерфейсе AdWords, перейдите к кампании или группе объявлений, щелкните вкладку Ключевые слова и выберите «Поисковые запросы».
Чтобы перейти к отчету о поисковых запросах, щелкните вкладку Ключевые слова и выберите Поисковые запросы.
В новом интерфейсе AdWords (если использовать термин Google) перейдите к определенной кампании или группе объявлений, нажмите «Ключевые слова» в левой панели навигации, а затем выберите «Поисковые условия» вверху.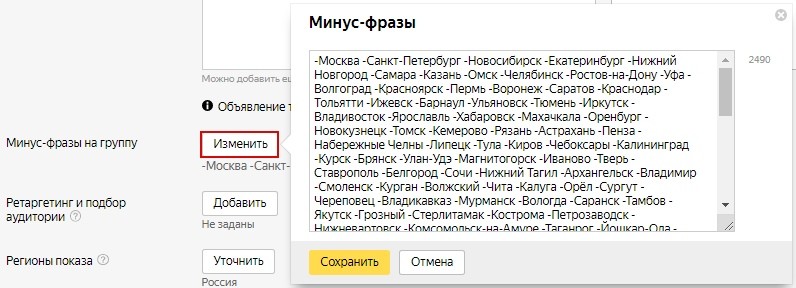 Этот путь аналогичен текущему интерфейсу.
Этот путь аналогичен текущему интерфейсу.
В новом интерфейсе AdWords нажмите «Ключевые слова» слева, а затем выберите «Поисковые запросы» вверху. Щелкните изображение, чтобы увеличить его.
Ключевые слова обычно раскрывают намерения искателя. Например, кто-то, кто ищет «лучшие суши рядом со мной», вероятно, хочет поесть вне дома, и скоро. Однако тот, кто ищет «лучшие ингредиенты для суши», скорее всего, готовит суши дома.
Таким образом, если ваше ключевое слово «лучшие суши», ваша реклама может быть показана обоим этим людям. Ближайший суши-ресторан, вероятно, потребует первого человека, а японский продуктовый магазин, вероятно, потребует второго человека. Введите минус-слова.
Почему минус-слова?
Ключевые слова сообщают AdWords, когда вы хотите, чтобы ваши объявления появлялись рядом с результатами поиска. Минус-слова, однако, сообщают AdWords, когда , а не , показывать ваши объявления.
В приведенном выше примере ресторан может добавить «лучшие ингредиенты для суши» в качестве минус-слова с точным соответствием, чтобы его объявление не отображалось в результатах поиска по этому поисковому запросу. Ресторан также может со временем заметить, что многие запросы со словом «ингредиенты» не очень релевантны. Таким образом, он может добавить «ингредиенты» в качестве минус-слова, чтобы исключить любой запрос , содержащий это слово.
Ресторан также может со временем заметить, что многие запросы со словом «ингредиенты» не очень релевантны. Таким образом, он может добавить «ингредиенты» в качестве минус-слова, чтобы исключить любой запрос , содержащий это слово.
Минус-слова, как и обычные поисковые ключевые слова, могут иметь широкое, фразовое и точное соответствие. (Я рассматривал типы соответствия в статье «Объявления с оплатой за клик: понимание типов соответствия ключевых слов».) AdWords анализирует только первые 10 слов запроса. Таким образом, если ваше минус-слово появляется после первых 10 слов, ваше объявление все равно может показываться в результатах поиска.
Например, наш гипотетический суши-ресторан все еще может показывать рекламу, когда поисковый запрос звучит так: «Где в Беверли-Хиллз я могу найти магазин с лучшими ингредиентами для суши». Это ограничение, вероятно, будет приобретать все большее значение с ростом популярности голосового поиска.
Короче говоря, рекламодатели часто платят за клики по несвязанным запросам.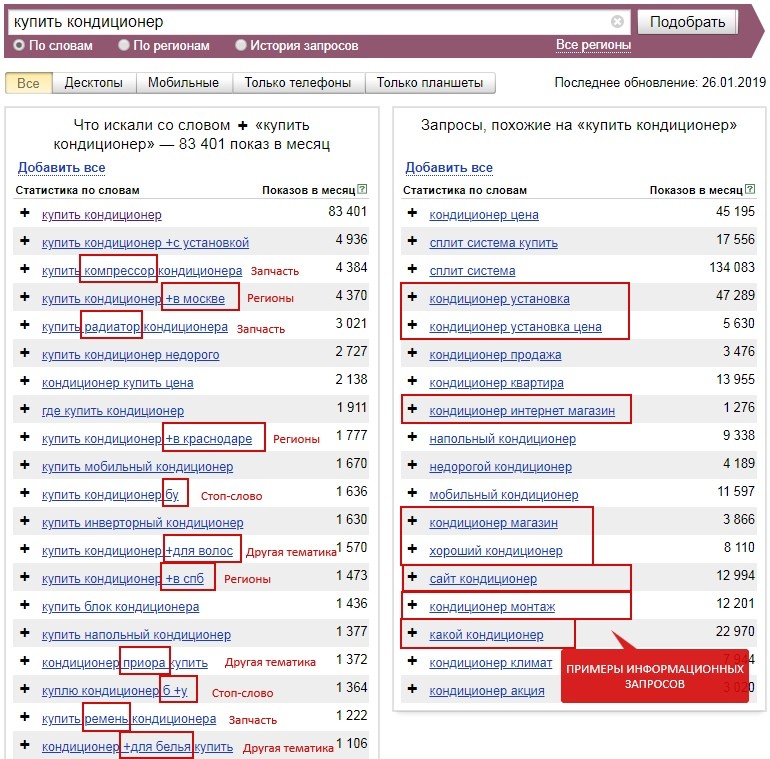 Для отраслей с высокой стоимостью клика даже один квалифицированный клик может снизить прибыльность. Так как же рекламодатели могут найти потенциальные минус-слова и исключить их?
Для отраслей с высокой стоимостью клика даже один квалифицированный клик может снизить прибыльность. Так как же рекламодатели могут найти потенциальные минус-слова и исключить их?
Вот три способа.
3 способа найти минус-слова
Ручной поиск. Составьте список примерно из 10 ключевых слов, по которым вы размещаете рекламу или которые рассматриваете. Зайдите в Google и начните поиск. Посмотрите, что еще рекламируют. Что отображается в органических списках? Вы видите некоторые результаты, которые не связаны? Почему они не связаны?
Рассмотрим этот пример поиска по запросу «ремонт обогревателя».
Пример результатов поиска по запросу «ремонт обогревателя». Щелкните изображение, чтобы увеличить его.
Скажем, подрядчик по отоплению и вентиляции жилых помещений рекламирует «ремонт обогревателей». Некоторые результаты появляются быстро.
- Первое объявление из автомагазина. Подрядчик по отоплению и вентиляции жилых домов не ремонтирует обогреватели в автомобилях или грузовиках. Таким образом, «автомобили», «грузовики» и связанные термины будут хорошими минус-словами.
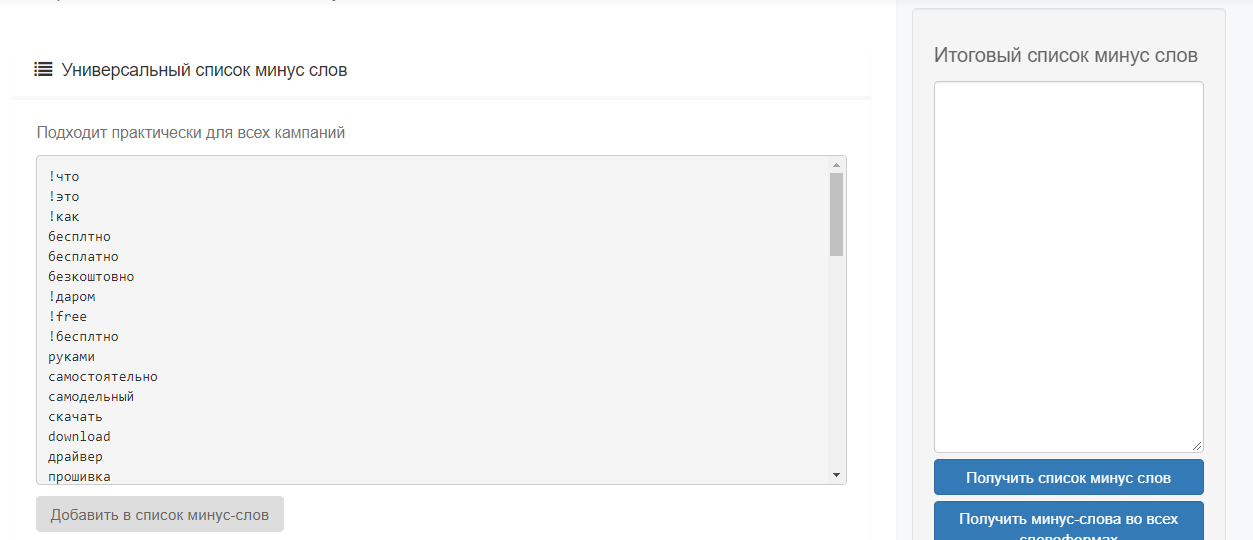 Таким образом, «автомобили», «грузовики» и связанные термины будут хорошими минус-словами.
Таким образом, «автомобили», «грузовики» и связанные термины будут хорошими минус-словами.- Третье объявление предназначено для сантехника, а пара органических объявлений под картой — для ремонта водонагревателя. Подрядчик из нашего примера не продает и не ремонтирует водонагреватели. Таким образом, «водонагреватель» также является хорошим минус-словом.
- Второй органический результат под картой касается плинтусных обогревателей, настенных обогревателей и систем лучистого обогрева полов. Если наш подрядчик сосредоточится на крупных системах центрального отопления и установках с принудительной подачей воздуха, «обогреватели плинтуса», «настенные обогреватели» и «системы лучистого обогрева пола» также будут хорошими минус-словами.
После выполнения этого упражнения с 5-10 ключевыми словами у вас должно появиться несколько хороших идей.
Подсказка Google. При ручном поиске обратите внимание на предложения от Google. Это также потенциальные минус-слова. Вот несколько предложений, которые появились во время моего поиска «ремонт обогревателя».
Используйте результаты автозаполнения Google для выявления потенциальных минус-слов.
Обратите внимание, что каждая буква, которую вы добавляете в свой поисковый запрос, меняет предложения автозаполнения, генерируя массу потенциальных идей. На приведенном выше снимке экрана наш подрядчик по отоплению и кондиционированию воздуха может рассмотреть минус-слова для «аренды», «резистора» и «отзывов».
Исследование ключевых слов. Существует множество инструментов для исследования ключевых слов, таких как SEMrush и Планировщик ключевых слов в AdWords. Идея состоит в том, чтобы увидеть, какие другие ключевые слова не связаны буквально, оценить их релевантность и добавить минус-слова, прежде чем они будут стоить чего-либо. Каждый рекламодатель AdWords имеет доступ к Планировщику ключевых слов Google в AdWords. Найдите его в новом интерфейсе, щелкнув значок гаечного ключа в правом верхнем углу, а затем выберите «Планировщик ключевых слов».
В новом интерфейсе AdWords щелкните значок гаечного ключа в правом верхнем углу и выберите Планировщик ключевых слов.
Чтобы использовать Планировщик ключевых слов, введите свое ключевое слово, чтобы просмотреть список вариантов ключевых слов, а также предполагаемую конкуренцию со стороны других рекламодателей и предлагаемые суммы ставок.
Чтобы использовать Планировщик ключевых слов, введите ключевое слово (в данном примере «ремонт обогревателя»), чтобы просмотреть список предлагаемых ключевых слов, а также предполагаемую конкуренцию со стороны других рекламодателей и предлагаемые суммы ставок. Щелкните изображение, чтобы увеличить его.
Для этого примера я ограничил свой поиск в Планировщике ключевых слов результатами в Чикаго. Цифры будут отличаться в зависимости от вашего местоположения. На скриншоте выше этого не видно, но результатов 677 — у вас большой потенциал.
По моему опыту, Планировщик ключевых слов фокусируется на конкурентоспособных ключевых словах (что имеет смысл, учитывая их объем) и не так полезен для длинных фраз. Одно интересное наблюдение по поводу моего поиска «ремонт обогревателя»: пик объема поиска приходится на июнь, который обычно не является холодным временем года. Это может указывать на то, что люди в Чикаго не используют слово «ремонт обогревателей» для обогревателей, но также и для кондиционеров, возможно, «ремонт отопления и воздуха».
Экономия денег
Минус-слова — это отличный инструмент для экономии средств рекламодателей AdWords. Однако вам не нужно полагаться на отчеты по поисковым запросам, чтобы найти эти ключевые слова. Проведите собственное исследование, чтобы отсеять пожирателей денег до того, как они вам обойдутся.
Обзор инструментов анализа настроений, часть 1. Базы данных положительных и отрицательных слов | Дата Монстры | Продукт AI
Ольги Давыдовой
Инструменты анализа настроений основаны на списках слов и фраз с положительной и отрицательной коннотацией. Уже было разработано множество словарей слов положительного и отрицательного мнения. В этой статье мы рассмотрим наиболее известные базы данных слов.
Лексикон мнений Лю и Ху содержит около 6800 положительных и отрицательных слов-мнений или слов-эмоций для английского языка [1]. Этот список составлялся на протяжении многих лет.
SentiWordNet
SentiWordNet — это лексический ресурс для сбора мнений, который присваивает каждому синсету WordNet три оценки тональности: позитивность, негативность и объективность [2]. Он имеет графический пользовательский веб-интерфейс и находится в свободном доступе для исследовательских целей. Развитие ресурса основано на количественном анализе глосс, связанных с синсетами, и на использовании полученных представлений векторных терминов для полуконтролируемой классификации синсетов. Положительность, отрицательность и объективность получаются путем объединения результатов, полученных комитетом из восьми троичных классификаторов [3].
Обработка естественного языка (SentiWords)
Следующим ресурсом, содержащим примерно 155 000 английских слов, является SentiWords [4]. Слова связаны с оценкой тональности от -1 до 1. Слова имеют форму lemma#PoS и выровнены со списками WordNet, которые включают прилагательные, существительные, глаголы и наречия.
AFINN — это вручную помеченный Финном Арупом Нильсеном в 2009–2011 годах список английских слов, оцененных по валентности с целым числом от минус пяти (отрицательное) до плюс пять (положительное) [5]. Попробовать можно на этом сайте [6].
WordStat
Словарь настроений WordStat включает более 9164 отрицательных и 4847 положительных словесных шаблонов, но настроения не измеряются с помощью этих двух списков [7]. Негативное настроение измеряется с помощью следующих двух правил. Первое правило — отрицательные слова, которым не предшествует отрицание в пределах трех слов в одном предложении. Второе правило — положительные слова, которым предшествует отрицание в пределах трех слов в одном предложении. Правила для положительного настроения те же: положительные слова не предшествуют отрицанию, а отрицательные слова следуют за отрицанием.
SenticNet
SenticNet обеспечивает полярность, связанную с 50 000 понятий естественного языка [8]. Полярность — это плавающее число от -1 до +1. Минус один — крайний негатив, плюс один — крайний позитив. База знаний бесплатна. Его можно скачать в виде XML-файла. Его последняя версия также доступна как API.
The Affective Norms for English Words (ANEW) представляет собой набор нормативных оценок эмоциональных слов с точки зрения удовольствия, возбуждения и доминирования [9].]. Он был разработан для создания стандарта для использования в исследованиях эмоций и внимания.
The Whissell Dictionary of Affect in Language
The Whissell Dictionary of Affect in Language — бесплатное программное обеспечение для статистического анализа отдельных слов не в соответствии с их значением, а в соответствии с тем, как они «ощущаются» [10]. Включая 348 000 слов, он охватывает 90% разговорного английского языка. Десятки добровольцев оценивали слова в зависимости от того, насколько они приятны на ощупь, насколько активными они казались и насколько хорошо слово вызывало в уме образ.
Pattern
В Pattern письменный текст делится на два типа: факты и мнения [11]. Мнения могут выражать отношение людей к слову. В пакете есть файл sense.xml, который включает 2888 слов, оцениваемых по полярности, субъективности, интенсивности и надежности. Слова в основном прилагательные. Есть две полезные функции: sentient() и Positive(). Функция mind() возвращает кортеж (полярность, субъективность), упорядоченный набор значений для данного предложения. Полярность — это значение от -1,0 до +1,0 и субъективность от 0,0 до 1,0. Функция Positive() возвращает True, если полярность данного предложения выше порогового значения.
Лексикон Sentiment140 был создан из корпуса смайликов Sentiment140 из 1,6 миллиона твитов и содержит список слов и их ассоциаций с положительными и отрицательными эмоциями [12].
Linguistic Inquiry and Word Count (LIWC)
Linguistic Inquiry and Word Count (LIWC) — компьютерная программа для языкового анализа [13]. Он поддерживает английский, немецкий, испанский, голландский и итальянский языки. Этот коммерческий список слов позволяет выделить около 60 различных категорий слов, включая положительные эмоции, отрицательные эмоции, агрессию, аффективные процессы, тревогу, гнев, ненормативную лексику и так далее.
Лексикон субъективности MPQA (мультиперспективные ответы на вопросы)
Лексикон субъективности MPQA (мультиперспективные ответы на вопросы) представляет собой список подсказок субъективности, который является частью OpinionFinder [14]. Это помогает определить полярность текста.
Список на этой странице содержит более 6000 положительных слов и фраз, что делает его одним из самых длинных и лучших списков положительных слов [15].
Другими примерами баз данных являются список положительных слов [16] и список отрицательных слов [17].
Резюме
Были описаны наиболее популярные базы данных положительных и отрицательных слов, которые могут помочь в проведении анализа настроений: словарь мнений Лю и Ху, SentiWordNet, SentiWords, AFINN, WordStat Sentiment Dictionary, SenticNet, аффективные нормы для английских слов, словарь Whissell Affect in Language, Pattern, Sentiment140 Lexicon, Linguistic Inquiry and Word Count, MPQA Subjectivity Lexicon.
Ресурсы
1. https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html#lexicon
2. http://sentiwordnet.isti.cnr.it/
3. http://nmis.isti.cnr.it/sebastiani/Publications/LREC06.pdf
4. https://hlt-nlp .fbk.eu/technologies/sentiwords
5. http://www2.imm.dtu.dk/pubdb/views/publication_details.php?id=6010
6. http://darenr.github.io/afinn /#
7. https://provalisresearch.com/products/content-analysis-software/wordstat-dictionary/sentiment-dictionaries/
8. http://sentic.net/
9. http:// csea.phhp.ufl.edu/media/anewmessage.html
10. https://www.god-helmet.com/whissel-dictionary-of-affect/index.htm
11. http://www.clips.ua.ac.be/pages/pattern-ru #sentiment
12. https://github.com/felipebravom/StaticTwitterSent/tree/master/extra/Sentiment140-Lexicon-v0.1
13. http://liwc.wpengine.com/
14. http ://mpqa.cs.pitt.edu/lexicons/subj_lexicon/
15. http://positivewordsresearch. com/positive-words-that-start-with-letters-from-a-to-z/
16 . https://github.com/jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English/positive-words.txt
17. https://github.com/jeffreybreen/twitter-sentiment-analysis-tutorial-201107/blob/master/data/opinion-lexicon-English/negative-words.txt
Руководство по анализу настроений
Анализ настроений (или анализ мнений) — это метод обработки естественного языка (НЛП), используемый для определения того, являются ли данные положительными, отрицательными или нейтральными. Анализ настроений часто выполняется на текстовых данных, чтобы помочь компаниям отслеживать отношение к бренду и продукту в отзывах клиентов и понимать потребности клиентов.
Начните анализировать свой текст на предмет тональности
ПОПРОБУЙТЕ СЕЙЧАС
Узнайте больше о том, как работает анализ тональности, о его проблемах и о том, как вы можете использовать анализ тональности для улучшения процессов, принятия решений, повышения удовлетворенности клиентов и многого другого.
Ознакомившись с основами, приступайте к работе с простыми в использовании инструментами анализа настроений, готовыми к использованию сразу же.
- Что такое анализ настроений?
- Типы анализа настроений
- Почему важен анализ настроений?
- Примеры анализа настроений и анализ отзывов Trustpilot
- Как работает анализ настроений?
- Проблемы анализа настроений
- Приложения для анализа настроений
- Инструменты и учебные пособия по анализу настроений
- Исследования и курсы по анализу настроений
Что такое анализ настроений?
Анализ тональности — это процесс определения положительных или отрицательных тональностей в тексте. Он часто используется предприятиями для определения настроений в социальных данных, оценки репутации бренда и понимания клиентов.
Типы анализа настроений
Анализ настроений фокусируется на полярности текста ( положительный, отрицательный, нейтральный ), но он также выходит за пределы полярности для обнаружения конкретных чувств и эмоций ( злой, счастливый, грустный и т. д.), срочность ( срочно, не срочно ) и даже намерения ( интересно против не интересно ).
В зависимости от того, как вы хотите интерпретировать отзывы и запросы клиентов, вы можете определить и настроить категории в соответствии с вашими потребностями в анализе настроений. А пока вот некоторые из самых популярных типов анализа настроений:
Градированный анализ тональности
Если точность полярности важна для вашего бизнеса, вы можете рассмотреть возможность расширения категорий полярности, включив в нее разные уровни положительного и отрицательного:
- Очень положительное
- Положительное
- Нейтральное
- Очень отрицательное0
Это обычно называется градуированным или детальным анализом настроений и может использоваться для интерпретации 5-звездочных оценок в обзоре, например:
- Очень положительное = 5 звезд
- Очень отрицательное = 1 звезда
Обнаружение эмоций
Анализ настроений при обнаружении эмоций позволяет выйти за пределы полярности и обнаружить такие эмоции, как счастье, разочарование, гнев и печаль.
Многие системы обнаружения эмоций используют лексиконы (то есть списки слов и эмоций, которые они передают) или сложные алгоритмы машинного обучения.
Одним из недостатков использования словарей является то, что люди выражают эмоции по-разному. Некоторые слова, которые обычно выражают гнев, например плохой или убить (например, ваш продукт такой плохой или ваша служба поддержки меня убивает ) может также выражать радость (например, это круто или вы его убиваете ).
Анализ тональности на основе аспектов
Обычно при анализе тональности текстов вам нужно знать, какие конкретные аспекты или особенности люди упоминают в положительном, нейтральном или отрицательном ключе.
Вот где может помочь анализ настроений на основе аспектов, например, в этом обзоре продукта: «Слишком короткое время автономной работы этой камеры» , классификатор на основе соотношения сторон сможет определить, что предложение выражает негативное мнение о времени автономной работы рассматриваемого продукта.
Многоязычный анализ тональности
Многоязычный анализ тональности может быть затруднен. Это требует много предварительной обработки и ресурсов. Большинство этих ресурсов доступны в Интернете (например, лексиконы настроений), в то время как другие необходимо создавать (например, переведенные корпуса или алгоритмы обнаружения шума), но вам нужно знать, как их использовать.
Кроме того, вы можете автоматически определять язык в текстах с помощью языкового классификатора, а затем обучать пользовательскую модель анализа тональности для классификации текстов на выбранном вами языке.
Почему важен анализ настроений?
Поскольку люди выражают свои мысли и чувства более открыто, чем когда-либо прежде, анализ настроений быстро становится важным инструментом для отслеживания и понимания настроений во всех типах данных.
Автоматический анализ отзывов клиентов, таких как мнения в ответах на опросы и разговоры в социальных сетях, позволяет брендам узнавать, что делает клиентов счастливыми или разочарованными, чтобы они могли адаптировать продукты и услуги для удовлетворения потребностей своих клиентов.
Например, использование анализа настроений для автоматического анализа более 4000 открытых ответов в ваших опросах об удовлетворенности клиентов может помочь вам понять, почему клиенты довольны или недовольны на каждом этапе взаимодействия с клиентом.
Может быть, вы хотите отслеживать отношение к бренду, чтобы сразу выявлять недовольных клиентов и реагировать как можно скорее. Может быть, вы хотите сравнить настроения из одного квартала в другой, чтобы увидеть, нужно ли вам что-то делать. Затем вы можете глубже изучить свои качественные данные, чтобы понять, почему настроения падают или растут.
Общие преимущества анализа тональности включают :
- Сортировка данных в масштабе
Можете ли вы представить себе ручную сортировку тысяч твитов, разговоров со службой поддержки или опросов? Слишком много бизнес-данных, чтобы обрабатывать их вручную. Анализ настроений помогает предприятиям эффективно и экономично обрабатывать огромные объемы неструктурированных данных.
- Анализ в реальном времени
Анализ настроений может выявлять критические проблемы в режиме реального времени, например, обостряется ли PR-кризис в социальных сетях? Разгневанный клиент вот-вот уйдет? Модели анализа настроений могут помочь вам немедленно определить такие ситуации, чтобы вы могли сразу же принять меры.
- Согласованные критерии
Подсчитано, что люди соглашаются только в 60-65% случаев при определении настроения конкретного текста. Пометка текста по настроению очень субъективна и зависит от личного опыта, мыслей и убеждений.
Используя централизованную систему анализа тональности, компании могут применять одни и те же критерии ко всем своим данным, что помогает им повысить точность и получить лучшее представление.
Применения анализа настроений безграничны. Итак, чтобы помочь вам понять, как анализ тональности может принести пользу вашему бизнесу, давайте рассмотрим несколько примеров текстов, которые вы могли бы проанализировать с помощью анализа тональности.
Затем мы перейдем к реальному примеру того, как Chewy, компания по производству товаров для животных, смогла получить гораздо более тонкое (и полезное!) понимание своих отзывов с помощью анализа настроений.
Примеры анализа настроений
Чтобы понять цель и проблемы анализа настроений, вот несколько примеров:
Основные примеры данных анализа настроений
- У Netflix лучший выбор фильмов
- У Hulu отличный пользовательский интерфейс
- Мне не нравится новый криминальный сериал
- Я ненавижу ждать выхода следующего сериала
Более сложные примеры анализа настроений
- Я не люблю фильмы ужасов. (фраза с отрицанием)
- Нелюбовь к фильмам ужасов , а не редкость. (отрицание, обратный порядок слов)
- Иногда Я действительно ненавижу это шоу. (наречие изменяет настроение)
- Я люблю ждать два месяца до выхода следующей серии! (сарказм)
- Финальный эпизод удивил ужасным поворотом в конце (отрицательный термин используется в положительном смысле)
- Фильм смотреть было легко, но друзьям я бы его не рекомендовал. (трудно классифицировать)
- I LOL’d в конце сцены с тортом (часто трудно понять новые термины)
Теперь давайте посмотрим на некоторые реальные обзоры на Trustpilot и посмотрим, как инструменты анализа настроений MonkeyLearn плата за проезд, когда дело доходит до распознавания и классификации чувств.
Практический пример: анализ настроений на TrustPilot Reviews
Chewy — компания по производству товаров для животных, в которой нет недостатка в конкуренции, поэтому обеспечение превосходного клиентского опыта (CX) для своих клиентов может иметь огромное значение.
По этой причине онлайн-обзоры могут быть чрезвычайно ценным источником информации, позволяющей получить представление о клиентах для улучшения их клиентского опыта. Chewy имеет тысячи отзывов в TrustPilot, вот как выглядит их архив отзывов:
Via TrustPilot
Легко сделать общий вывод об относительном успехе Chewy только из этого — 82% ответов «отлично» — это «отлично» стартовое место.
Но одних результатов TrustPilot недостаточно, если целью Chewy является улучшение своих услуг. Этот поверхностный обзор не дает практического понимания, краеугольного камня и конечной цели эффективного анализа настроений.
Если бы Chewy захотела распаковать что и почему за своими обзорами, чтобы еще больше улучшить свои услуги, им нужно было бы анализировать каждый негативный отзыв на детальном уровне.
Но с инструментами анализа настроений Chewy могла подключить свои 5 639 (на тот момент) обзоров TrustPilot, чтобы получить мгновенную информацию об анализе настроений.
Мы загрузили и проанализировали обзоры Chewy в комплексную студию анализа и визуализации данных MonkeyLearn, чтобы создать следующую панель инструментов:
Chewy TrustPilot Reviews Sample
Не стесняйтесь щелкнуть эту ссылку, чтобы ознакомиться с результатами на досуге — поскольку этот пример панели управления является общедоступной демонстрацией, вы можете щелкнуть и изучить входные данные и фильтры в действии самостоятельно.
Несмотря на то, что есть еще много всего, что нужно изучить, в этой разбивке мы сосредоточимся на четырех результатах визуализации данных анализа настроений, которые визуализировала для нас панель мониторинга.
- Общее отношение
- Изменение настроения во времени
- Настроение по рейтингу
- Настроение по теме
1. Общее настроение
Мы начнем с извлечения соответствующего графика из приведенной выше панели инструментов.
Вы заметите, что эти результаты сильно отличаются от обзора TrustPilot (82% отлично и т. д.). Это связано с тем, что искусственный интеллект для анализа настроений MonkeyLearn выполняет расширенный анализ настроений, анализируя каждый отзыв предложение за предложением, слово за словом.
Вам останется только точная оценка всего, что написали клиенты, а не простая таблица звездочек. Этот анализ может указать вам точки трения гораздо точнее и подробнее.
Ознакомьтесь с механизмом работы анализа настроений ниже.
2. Настроения в зависимости от времени
Вот наш удобный график изменения настроений во времени, увеличенный:
Этот пример визуализации данных представляет собой классическую временную визуализацию данных, которая отслеживает результаты и отображает их в течение определенного периода времени.
Этот график дополняет наши данные об общем настроении — он отслеживает общую долю положительных, нейтральных и отрицательных настроений в отзывах с 2016 по 2021 год.
Этот график показывает постепенное изменение содержания их письменных отзывов за этот пятилетний период. Например, в период с 2019 по 2020 год количество негативных ответов снизилось, а затем снова подскочило до прежнего уровня в 2021 году.
Взяв каждую категорию TrustPilot от 1-плохо до 5-отлично и разбив текст письменных обзоров на баллы, вы можете получить приведенный выше график.
Глядя на результаты и внимательно изучая обзоры с помощью анализа настроений, мы сразу можем сделать несколько интересных выводов.
- Результаты TrustPilots не бесполезны — в более качественных отзывах выше доля положительных отзывов, а в худших — больше негативных. Но все обзоры содержат немного всех типов настроений — мы узнали, что наши обзоры имеют нюансы и, следовательно, могут иметь для нас еще больше скрытой информации!
- Наши мнения поляризованы. Они смещаются в сторону 5 и 1.
Эти быстрые выводы указывают нам на золотые прииски для будущего анализа. А именно, положительные разделы отрицательных отзывов и отрицательные разделы положительных отзывов, а также 2-4 отзыва (почему они чувствуют себя так, как они, как мы можем улучшить их оценки?).
4. Настроения по темам
Наконец, мы можем взглянуть на настроения по темам, чтобы начать иллюстрировать, как анализ настроений может продвинуть нас еще глубже в наши данные.
На приведенной выше диаграмме применяется классификация текста, связанная с продуктом, в дополнение к анализу тональности, чтобы связать заданную тональность с конкретными функциями продукта/услуги, это известно как анализ тональности на основе аспектов.
Это означает, что мы можем знать, что наши клиенты думают о том, что, помогая нам сосредоточиться и решить конкретные болевые точки или проблемы.
Все это отличные отправные точки, предназначенные для наглядной демонстрации ценности анализа настроений, но они лишь слегка касаются его истинной силы.
Прочтите пошаговое руководство о том, как работает анализ тональности.
Как работает анализ настроений?
Анализ настроений, также известный как анализ мнений, работает благодаря обработке естественного языка (NLP) и алгоритмам машинного обучения для автоматического определения эмоционального тона онлайн-разговоров.
Существуют различные алгоритмы, которые можно реализовать в моделях анализа тональности, в зависимости от объема данных, которые необходимо проанализировать, и от того, насколько точной должна быть ваша модель. Мы рассмотрим некоторые из них более подробно ниже.
Алгоритмы анализа тональности делятся на три группы:
- На основе правил: эти системы автоматически выполняют анализ тональности на основе набора правил, созданных вручную.
- Автоматически: системы используют методы машинного обучения для изучения данных.
- Гибридные системы сочетают в себе как основанный на правилах, так и автоматический подходы.
Подходы, основанные на правилах
Обычно система, основанная на правилах, использует набор правил, созданных человеком, чтобы помочь идентифицировать субъективность, полярность или предмет мнения.
Эти правила могут включать в себя различные методы НЛП, разработанные в компьютерной лингвистике, такие как:
- Stemming , токенизация , тегирование частей речи и синтаксический анализ .
- Лексиконы (т.е. списки слов и выражений).
Вот базовый пример того, как работает система, основанная на правилах:
- Определяет два списка поляризованных слов (например, отрицательные слова, такие как плохие , худшие , уродливый и т. д. и положительные слова, такие как хороший , лучший , красивый и т. д.).
- Подсчитывает количество положительных и отрицательных слов в заданном тексте.
- Если количество появлений положительных слов больше, чем количество появлений отрицательных слов, система возвращает положительное значение, и наоборот. Если числа четные, система вернет нейтральный тон.
Системы, основанные на правилах, очень наивны, поскольку не учитывают, как слова объединяются в последовательности. Конечно, можно использовать более продвинутые методы обработки и добавлять новые правила для поддержки новых выражений и словарного запаса. Однако добавление новых правил может повлиять на предыдущие результаты, и вся система может стать очень сложной. Поскольку системы, основанные на правилах, часто требуют тонкой настройки и обслуживания, им также потребуются регулярные инвестиции.
Автоматические подходы
Автоматические методы, в отличие от систем, основанных на правилах, полагаются не на созданные вручную правила, а на методы машинного обучения. Задача анализа тональности обычно моделируется как задача классификации, когда классификатор получает текст и возвращает категорию, например. положительный, отрицательный или нейтральный.
Вот как можно реализовать классификатор машинного обучения:
Процессы обучения и прогнозирования
В процессе обучения (а) наша модель учится связывать определенный ввод (т. е. текст) с соответствующим выводом (тегом) на основе на тестовых образцах, используемых для обучения. Средство извлечения признаков переносит введенный текст в вектор признаков. Пары векторов признаков и тегов (например, положительный , отрицательный или нейтральный ) передаются в алгоритм машинного обучения для создания модели.
В процессе прогнозирования (b) экстрактор признаков используется для преобразования невидимых входных текстовых данных в векторы признаков. Эти векторы признаков затем передаются в модель, которая генерирует предсказанные теги (опять же, положительных , отрицательных или нейтральных ).
Извлечение признаков из текста
Первым шагом в классификаторе текста с машинным обучением является преобразование извлечения текста или векторизации текста, и классическим подходом был набор слов или набор энграмм с их частотой.
Совсем недавно были применены новые методы извлечения признаков, основанные на встраиваниях слов (также известных как векторы слов ). Этот тип представлений позволяет словам с похожим значением иметь одинаковое представление, что может повысить производительность классификаторов.
Алгоритмы классификации
На этапе классификации обычно используются статистические модели, такие как наивный байесовский метод, логистическая регрессия, метод опорных векторов или нейронные сети:
- Наивный байесовский алгоритм: семейство вероятностных алгоритмов, использующих теорему Байеса для предсказания категории текста.
- Линейная регрессия: очень известный алгоритм в статистике, используемый для прогнозирования некоторого значения (Y) с учетом набора признаков (X).
- Машины опорных векторов: невероятностная модель, использующая представление текстовых примеров в виде точек в многомерном пространстве. Примеры различных категорий (настроений) сопоставляются с отдельными областями в этом пространстве. Затем новым текстам присваивается категория на основе сходства с существующими текстами и областями, с которыми они сопоставлены.
- Глубокое обучение: разнообразный набор алгоритмов, которые пытаются имитировать человеческий мозг, используя искусственные нейронные сети для обработки данных.
Гибридные подходы
Гибридные системы объединяют желаемые элементы основанных на правилах и автоматических методов в одной системе. Одним из огромных преимуществ этих систем является то, что результаты часто являются более точными.
Проблемы анализа тональности
Анализ тональности — одна из самых сложных задач в обработке естественного языка, потому что даже люди испытывают трудности с точным анализом настроений.
Специалисты по обработке и анализу данных совершенствуются в создании более точных классификаторов настроений, но впереди еще долгий путь. Давайте внимательно рассмотрим некоторые из основных проблем анализа машин:
- Субъективность и тон
- Контекст и полярность
- Ирония и сарказм
- Сравнения
- EMOJIS
- Определяющие нейтральные
- 99969 AMOJIS
- .
Субъективность и тон
Есть два типа текста: субъективный и объективный. Объективные тексты не содержат явных чувств, тогда как субъективные тексты содержат. Скажем, например, вы собираетесь проанализировать настроение следующих двух текстов:
Посылка хорошая.
Упаковка красная.
Большинство людей сказали бы, что настроение положительное для первого и нейтральное для второго, верно? Все предикатов (прилагательные, глаголы и некоторые существительные) не должны рассматриваться одинаково в отношении того, как они создают настроение. В приведенных выше примерах приятный больше субъективный , чем красный .
Контекст и полярность
Все высказывания произносятся в какой-то момент времени, в каком-то месте, некоторыми людьми и для некоторых людей, вы поняли. Все высказывания произносятся в контексте. Анализировать настроение без контекста довольно сложно. Однако машины не могут узнать о контекстах, если они не упомянуты явно. Одной из проблем, возникающих из контекста, является изменение полярности. Посмотрите на следующие ответы на опрос:
Все об этом.
Абсолютно ничего!
Представьте, что приведенные выше ответы получены из ответов на вопрос Что вам понравилось на мероприятии? Первый ответ будет положительным, а второй отрицательным, верно? Теперь представьте, что ответы получены из ответов на вопрос . Что вам НЕ понравилось в мероприятии? Отрицательный ответ в вопросе полностью изменит анализ настроений.
Потребуется значительный объем предварительной или последующей обработки, если мы хотим принять во внимание хотя бы часть контекста, в котором были созданы тексты. Однако, как предварительно обработать или постобработать данные, чтобы зафиксировать фрагменты контекста, которые помогут проанализировать настроение, не так просто.
Ирония и сарказм
Когда дело доходит до иронии и сарказма , люди выражают свои негативные чувства, используя позитивные слова, которые машинам может быть трудно обнаружить без полного понимания контекста ситуации, в которой чувство выразилось.
Например, посмотрите на несколько возможных ответов на вопрос Вам понравилось у нас делать покупки?
Да, конечно. Так гладко!
Не один, а много!
Какое настроение вы бы приписали ответам выше? Первый ответ с восклицательным знаком может быть отрицательным, верно? Проблема в том, что нет текстовой подсказки, которая помогла бы машине научиться или, по крайней мере, подвергнуть сомнению это настроение, поскольку , да, и , конечно, , часто относятся к позитивным или нейтральным текстам.
Как насчет второго ответа? В этом контексте настроение положительное, но мы уверены, что вы можете придумать много разных контекстов, в которых один и тот же ответ может выражать отрицательное настроение.
Сравнения
Как обрабатывать сравнения в анализе настроений — еще одна проблема, которую стоит решить. Посмотрите на тексты ниже:
Этот продукт не имеет себе равных.
Это лучше, чем старые инструменты.
Это лучше, чем ничего.
Первое сравнение не требует контекстуальных подсказок для правильной классификации. Понятно, что положительный.
Второй и третий тексты классифицировать немного сложнее. Вы бы классифицировали их как нейтральный , положительный или даже отрицательный ? Еще раз, контекст может иметь значение. Например, если «старых инструментов» во втором тексте считались бесполезными, то второй текст очень похож на третий текст.
Emojis
Существует два типа смайликов согласно Guibon et al. 0004/¯) представляют собой более длинное сочетание знаков вертикального характера. Смайлики играют важную роль в настроении текстов, особенно в твитах.
При анализе тональности твитов вам необходимо уделять особое внимание уровню символов, а также уровню слов. Также может потребоваться много предварительной обработки. Например, вы можете захотеть предварительно обработать контент социальных сетей и преобразовать как западные, так и восточные смайлики в токены и внести их в белый список (т.
Вот довольно полный список эмодзи и их символов Юникода, которые могут пригодиться при предварительной обработке.
Определение нейтрального
Определение того, что мы подразумеваем под нейтральным , является еще одной проблемой, которую необходимо решить, чтобы выполнить точный анализ настроений. Как и во всех задачах классификации, определение ваших категорий — и, в данном случае, нейтрального тега — является одной из наиболее важных частей задачи. Что вы подразумеваете под нейтральным , положительный или отрицательный имеет значение при обучении моделей анализа настроений. Поскольку для маркировки данных требуется, чтобы критерии маркировки были непротиворечивыми, необходимо хорошее определение проблемы.
Вот несколько идей, которые помогут вам идентифицировать и определить нейтральные тексты:
- Объективные тексты . Так называемые объективные тексты не содержат явных настроений, поэтому такие тексты следует отнести к нейтральной категории.
- Неактуальная информация . Если вы не обработали свои данные предварительно, чтобы отфильтровать ненужную информацию, вы можете пометить их как нейтральные. Однако будьте осторожны! Делайте это только в том случае, если вы знаете, как это может повлиять на общую производительность. Иногда вы будете добавлять шум в свой классификатор, и производительность может ухудшиться.
- Тексты с пожеланиями . Некоторые пожелания типа Хотелось бы, чтобы в продукте было больше интеграций в целом нейтральны. Тем не менее, те, которые включают сравнения, такие как, Я хотел бы, чтобы продукт был лучше довольно сложно классифицировать
Точность аннотаторов
Анализ настроений — чрезвычайно сложная задача даже для людей. В среднем согласие между аннотаторами (показатель того, насколько хорошо два (или более) человека, размечающих метки, могут принять одно и то же решение по аннотации) довольно низкое, когда дело доходит до анализа тональности. А поскольку машины учатся на размеченных данных, классификаторы анализа настроений могут быть не такими точными, как другие типы классификаторов.
Тем не менее, анализ тональности стоит затраченных усилий, даже если ваши прогнозы анализа тональности время от времени неверны. Используя модель анализа настроений MonkeyLearn, вы можете рассчитывать на правильные прогнозы примерно в 70-80% случаев, когда вы отправляете свои тексты на классификацию.
Если вы новичок в анализе настроений, вы быстро заметите улучшения. В типичных случаях использования, таких как маршрутизация заявок, мониторинг брендов и анализ VoC, вы сэкономите много времени и денег на утомительных ручных задачах.
Примеры использования и приложения анализа настроений
Применения анализа настроений безграничны и могут применяться в любой отрасли, от финансов и розничной торговли до гостиничного бизнеса и технологий. Ниже мы перечислили некоторые из наиболее популярных способов использования анализа настроений в бизнесе:
- Мониторинг социальных сетей
- Мониторинг бренда
- Голос клиента (VoC)
- Служба поддержки клиентов
- Исследование рынка
Судьбоносным вечером 9 апреля 2017 года United Airlines насильно удалила пассажира с перебронированного рейса. Кошмарный инцидент был снят другими пассажирами на свои смартфоны и немедленно опубликован. Одним из видео, размещенным на Facebook, поделились более 87 000 раз и просмотрели 6,8 миллиона раз к 18:00 понедельника, всего через 24 часа.
Фиаско было только усугублено пренебрежительным ответом компании. В понедельник днем генеральный директор United написал в Твиттере заявление, в котором извинился за «необходимость повторного размещения клиентов».
Это именно та пиар-катастрофа, которой можно избежать с помощью анализа настроений. Это пример того, почему важно заботиться не только о том, говорят ли люди о вашем бренде, но и о том, как они говорят о нем. Больше упоминаний не означает положительных упоминаний.
Бренды всех форм и размеров взаимодействуют с клиентами, лидами и даже конкурентами во всех социальных сетях. Отслеживая эти разговоры, вы можете понять настроения клиентов в режиме реального времени и с течением времени, чтобы вы могли немедленно обнаруживать недовольных клиентов и реагировать как можно скорее.
Большинство отделов маркетинга уже настроены на онлайн-упоминания по объему — они измеряют больше болтовни как повышение узнаваемости бренда. Но компаниям нужно смотреть дальше цифр, чтобы получить более глубокое понимание.
Мониторинг бренда
Бренды располагают обширной информацией не только в социальных сетях, но и в Интернете, на новостных сайтах, в блогах, на форумах, в обзорах продуктов и т. д. Опять же, мы можем смотреть не только на количество упоминаний, но и на индивидуальное и общее качество этих упоминаний.
Например, в случае с United Airlines вспышка началась в социальных сетях нескольких пассажиров. Через несколько часов новость была подхвачена новостными сайтами и со скоростью лесного пожара распространилась по США, затем по Китаю и Вьетнаму, поскольку United обвинили в расовом профилировании пассажира китайско-вьетнамского происхождения. В Китае этот инцидент стал самой популярной темой на Weibo, сайте микроблогов с почти 500 миллионами пользователей.
И опять же, все это происходит в считанные часы после инцидента.
Мониторинг бренда позволяет получить ценную информацию из разговоров о вашем бренде со всего Интернета. Анализируйте новостные статьи, блоги, форумы и многое другое, чтобы оценить отношение к бренду и настроить таргетинг на определенные демографические группы или регионы по желанию. Автоматически классифицируйте срочность всех упоминаний бренда и мгновенно направляйте их назначенным членам команды.
Получите представление о чувствах и мнениях клиентов, помимо простых цифр и статистики. Поймите, как меняется имидж вашего бренда с течением времени, и сравните его с имиджем ваших конкурентов. Вы можете настроиться на определенный момент времени, чтобы следить за выпусками продуктов, маркетинговыми кампаниями, заявками на IPO и т. д. и сравнивать их с прошлыми событиями.
Анализ настроений в режиме реального времени позволяет выявить потенциальные кризисы в сфере PR и принять незамедлительные меры до того, как они перерастут в серьезные проблемы. Или определяйте положительные комментарии и отвечайте напрямую, чтобы использовать их в своих интересах.
Пример: Expedia Canada
В преддверии Рождества Expedia Canada провела классическую маркетинговую кампанию «Побег из зимы». Все было хорошо, за исключением визжащей скрипки, которую они выбрали в качестве фоновой музыки. Понятно, что люди обратились в социальные сети, блоги и форумы. Expedia сразу заметила и удалила рекламу.
Затем они создали серию дополнительных видеороликов: в одном было показано, как оригинальный актер разбивает скрипку; другой предложил реально негативно настроенному пользователю Твиттера вырвать скрипку из рук актера на экране. Хотя их первоначальная кампания потерпела неудачу, Expedia смогла искупить свою вину, прислушиваясь к своим клиентам и отвечая на них.
Анализ настроений позволяет вам автоматически отслеживать всю болтовню вокруг вашего бренда, а также выявлять и устранять потенциально взрывоопасные ситуации такого типа, пока у вас еще есть время их разрядить.
Голос клиента (VoC)
Мониторинг социальных сетей и брендов дает нам немедленную, нефильтрованную и бесценную информацию о настроениях клиентов, но вы также можете использовать этот анализ для работы в опросах и взаимодействиях со службой поддержки.
Опросы Net Promoter Score (NPS) — один из самых популярных способов получения обратной связи для предприятий с помощью простого вопроса: порекомендовали бы вы эту компанию, продукт и/или услугу другу или члену семьи? Это приводит к единому баллу по числовой шкале.
Предприятия используют эти оценки, чтобы идентифицировать клиентов как сторонников, пассивных или недоброжелателей. Цель состоит в том, чтобы определить общее качество обслуживания клиентов и найти способы поднять всех клиентов до уровня «промоутеров», где они, теоретически, будут покупать больше, оставаться дольше и направлять других клиентов.
Числовые (количественные) данные обследования легко агрегируются и оцениваются. Но следующий вопрос в опросах NPS, спрашивая, почему участники опроса оставили оценку, которую они набрали, ищет открытые ответы или качественные данные.
Ответы на открытые опросы раньше было намного сложнее анализировать, но с помощью анализа тональности эти тексты можно разделить на положительные и отрицательные (и везде между ними), предлагая более глубокое понимание голоса клиента (VoC).
Анализ настроений можно использовать в любом виде опроса — количественном и качественном — и при взаимодействии со службой поддержки, чтобы понять эмоции и мнения ваших клиентов. Отслеживание настроений клиентов с течением времени позволяет глубже понять, почему показатели NPS или отношение к отдельным аспектам вашего бизнеса могут измениться.
Вы можете использовать его во входящих опросах и обращениях в службу поддержки, чтобы выявлять клиентов, которые «сильно негативны», и немедленно нацеливаться на них, чтобы улучшить их обслуживание. Сосредоточьтесь на определенных демографических данных, чтобы понять, что работает лучше всего и как вы можете улучшить.
Анализ в режиме реального времени позволяет сразу же увидеть изменения в VoC и понять нюансы обслуживания клиентов с течением времени, помимо статистики и процентов.
Узнайте, как мы проанализировали настроение тысяч отзывов на Facebook и преобразовали их в полезную информацию.
Пример: проект McKinsey City Voices
В Бразилии федеральные государственные расходы выросли на 156% с 2007 по 2015 год, в то время как удовлетворенность государственными услугами неуклонно снижалась. Недовольный этим контрпродуктивным прогрессом, Департамент городского планирования нанял McKinsey, чтобы помочь им сосредоточиться на пользовательском опыте или «гражданской поездке» при предоставлении услуг. Этот ориентированный на граждан стиль управления привел к появлению того, что мы называем умными городами.
McKinsey разработала инструмент под названием City Voices, который проводит опросы граждан по более чем 150 показателям, а затем проводит анализ настроений, чтобы помочь лидерам понять, как живут избиратели и что им нужно, чтобы лучше информировать государственную политику. Используя этот инструмент, бразильское правительство смогло выявить самые насущные потребности — например, более безопасную автобусную систему — и улучшить их в первую очередь.
Если это может быть успешным в национальном масштабе, представьте, что это может сделать для вашей компании.
Служба поддержки клиентов
Мы уже рассмотрели, как мы можем использовать анализ настроений с точки зрения более широкого VoC, поэтому теперь мы наберем группы обслуживания клиентов.
Мы все знаем правило: высокий уровень клиентского опыта означает более высокий уровень возврата клиентов. Ведущие компании знают, что то, как они работают, так же, если не больше, важно, как и то, что они делают. Клиенты ожидают, что их взаимодействие с компаниями будет немедленным, интуитивно понятным, личным и беспроблемным. Если нет, они уйдут и займутся бизнесом в другом месте. Знаете ли вы, что каждый третий покупатель покидает бренд после всего лишь одного неудачного опыта?
Вы можете использовать анализ настроений и классификацию текста, чтобы автоматически упорядочивать входящие запросы в службу поддержки по темам и срочности, чтобы направлять их в нужный отдел и гарантировать, что самые срочные обрабатываются немедленно.
Проанализируйте взаимодействие со службой поддержки клиентов, чтобы убедиться, что ваши сотрудники следуют соответствующему протоколу. Повысьте эффективность, чтобы клиенты не оставались в ожидании поддержки. Снизить уровень оттока; в конце концов, удержать клиентов проще, чем привлечь новых.
Узнайте, как мы анализировали взаимодействие со службой поддержки в Twitter.
Исследование рынка
Анализ настроений расширяет возможности всех видов исследования рынка и конкурентного анализа. Независимо от того, изучаете ли вы новый рынок, предугадываете будущие тенденции или ищете преимущество в конкурентной борьбе, анализ настроений может иметь решающее значение.
Вы можете анализировать онлайн-обзоры своих продуктов и сравнивать их с конкурентами. Возможно, ваш конкурент выпустил новый продукт, который провалился. Узнайте, какие аспекты продукта оказались наиболее негативными, и используйте их в своих интересах.
Следите за своим брендом и конкурентами в режиме реального времени в социальных сетях. Найдите новые рынки, на которых ваш бренд может добиться успеха. Выявляйте тенденции по мере их появления или следуйте долгосрочным тенденциям рынка с помощью анализа официальных рыночных отчетов и деловых журналов.
Вы получите доступ к новым источникам информации и сможете количественно оценить качественную информацию. С помощью анализа социальных данных вы можете заполнить пробелы там, где общедоступных данных мало, например, на развивающихся рынках.
Узнайте, как анализировать настроения в отзывах об отелях на TripAdvisor или проводить анализ настроений в отзывах о ресторанах Yelp.
Инструменты и учебные пособия по анализу настроений
Анализ настроений — обширная тема, и начать ее изучение может быть пугающе. К счастью, существует множество полезных ресурсов, от полезных руководств до всевозможных бесплатных онлайн-инструментов, которые помогут вам сделать первые шаги.
Бесплатные онлайн-инструменты для анализа настроений
Хорошим началом вашего пути будет просто поиграть с инструментом для анализа настроений. Небольшой личный опыт поможет вам понять, как это работает
Далее, чтобы продолжить анализ тональности, вам нужно попробовать анализ тональности MonkeyLearn и шаблон ключевых слов. Сначала вам нужно зарегистрироваться, а затем выполнить следующие шаги:
1. Выберите шаблон ключевого слова + анализа тональности
2. Загрузите свои данные
Если у вас нет файла CSV, вы можете использовать наш образец набора данных.
3. Сопоставьте столбцы CSV с полями панели мониторинга
В этом шаблоне есть только одно поле: текст. Если в вашем наборе данных несколько столбцов, выберите столбец с текстом, который вы хотите проанализировать.
4. Назовите свой рабочий процесс
5. Дождитесь импорта данных
6. Изучите панель управления!
Вы можете:
- Фильтровать по настроению или ключевому слову.
- Поделитесь по электронной почте с другими коллегами.
Открытый исходный код и SaaS (программное обеспечение как услуга) Инструменты анализа тональности
Когда дело доходит до анализа тональности (и анализа текста в целом), у вас есть два варианта: создать собственное решение или купить инструмент.
Библиотеки с открытым исходным кодом на таких языках, как Python и Java, имеют особенно хорошие возможности для создания собственного решения для анализа тональности, поскольку их сообщества больше склоняются к науке о данных, например к обработке естественного языка и глубокому обучению для анализа тональности. Но вам понадобится команда специалистов по данным и инженеров, огромные первоначальные инвестиции и свободное время.
Инструменты SaaS позволяют сразу же внедрить предварительно обученные модели анализа настроений или настроить собственные, часто всего за несколько шагов. Эти инструменты рекомендуются, если у вас нет группы специалистов по обработке и анализу данных или инженеров, поскольку они могут быть реализованы с небольшим количеством кода или без него и могут сэкономить месяцы работы и денег (более 100 000 долларов США).
Еще одно ключевое преимущество инструментов SaaS заключается в том, что вам даже не нужно уметь программировать; они обеспечивают интеграцию со сторонними приложениями, такими как MonkeyLearn Zendesk, Excel и Zapier Integrations.
Если вы хотите начать работу с этими готовыми инструментами, ознакомьтесь с этим руководством по лучшим инструментам SaaS для анализа тональности, которые также поставляются с API для полной интеграции с вашими существующими инструментами.
Или начните учиться выполнять анализ тональности с помощью API MonkeyLearn и встроенной модели анализа тональности, написав всего шесть строк кода. Затем обучите свою собственную модель анализа настроений с помощью простого в использовании пользовательского интерфейса MonkeyLearn.
- Учебное пособие по анализу настроений в Python с использованием API MonkeyLearn.
Если вы все еще убеждены, что вам нужно создать собственное решение для анализа тональности, ознакомьтесь с этими инструментами и учебными пособиями на различных языках программирования:
Анализ тональности Python
- обучения и имеет полезные инструменты для векторизации текста. Обучить классификатор поверх векторизаций, таких как частотные или текстовые векторизаторы tf-idf, довольно просто. Scikit-learn имеет реализации для машин опорных векторов, наивного Байеса и логистической регрессии, среди прочего.
- NLTK была традиционной библиотекой НЛП для Python. Он имеет активное сообщество и предлагает возможность обучать классификаторы машинного обучения.
- SpaCy — это библиотека NLP с растущим сообществом. Как и NLTK, он предоставляет мощный набор низкоуровневых функций для НЛП и поддерживает обучение классификаторов текста.
- TensorFlow, разработанный Google, предоставляет низкоуровневый набор инструментов для построения и обучения нейронных сетей. Также есть поддержка векторизации текста, как при традиционной частоте слов, так и при более продвинутых сквозных встраиваниях слов.
- Keras предоставляет полезные абстракции для работы с несколькими типами нейронных сетей, такими как рекуррентные нейронные сети (RNN) и сверточные нейронные сети (CNN), и позволяет легко складывать слои нейронов. Keras можно запустить поверх Tensorflow или Theano. Он также предоставляет полезные инструменты для классификации текста.
- PyTorch — это новейшая платформа глубокого обучения, поддерживаемая некоторыми престижными организациями, такими как Facebook, Twitter, Nvidia, Salesforce, Стэнфордский университет, Оксфордский университет и Uber. Он быстро развил сильное сообщество.
Учебники, которые стоит попробовать:
Веб-скрапинг Python и анализ тональности: в этом туториале представлено пошаговое руководство о том, как анализировать 100 лучших субреддитов по тональности. В нем объясняется, как использовать Beautiful Soup, одну из самых популярных библиотек Python для просмотра веб-страниц, которая собирает имена самых популярных веб-страниц субреддитов (таких субреддитов, как /r/funny, /r/AskReddit и /r/todayilearned).
Используя библиотеку Praw, он демонстрирует, как взаимодействовать с Reddit API и извлекать комментарии из этих субреддитов. Затем узнайте, как использовать TextBlob для анализа тональности извлеченных комментариев.
Код: https://github.com/jg-fisher/redditSentimentАнализ настроений в Твиттере с использованием Python и NLTK. В этом пошаговом руководстве показано, как обучить свой первый классификатор настроений. Автор использует Natural Language Toolkit NLTK для обучения классификатора твитов. Упрощение анализа настроений с помощью Scikit-learn. В этом руководстве объясняется, как обучить модель логистической регрессии анализу настроений.
Упрощение анализа тональности с помощью Scikit-learn. В этом руководстве объясняется, как обучить модель логистической регрессии для анализа тональности.
Анализ настроений Javascript
Java — это еще один язык программирования с сильным сообществом, занимающимся наукой о данных, с замечательными библиотеками обработки данных для НЛП.
- OpenNLP: набор инструментов, который поддерживает наиболее распространенные задачи НЛП, такие как токенизация, сегментация предложений, маркировка частей речи, извлечение именованных сущностей, разбиение на фрагменты, синтаксический анализ, определение языка и разрешение кореференций.
- Stanford CoreNLP: набор основных инструментов NLP на Java, предоставленный The Stanford NLP Group.
- Lingpipe: набор инструментов Java для обработки текста с использованием вычислительной лингвистики. LingPipe часто используется для классификации текста и извлечения сущностей.
- Weka: набор инструментов, созданный Университетом Вайкато для предварительной обработки данных, классификации, регрессии, кластеризации, правил ассоциации и визуализации.
Исследования и курсы по анализу настроений
Изучив основы анализа настроений и поняв, как он может вам помочь, вы можете углубиться в тему:
Документы по анализу настроений
Литература по анализу настроений огромна; существует более 55 700 научных статей, статей, тезисов, книг и рефератов.
Ниже приведены наиболее часто цитируемые и читаемые статьи в сообществе специалистов по анализу настроений в целом:
- Изучение мнений и анализ настроений (Pang and Lee, 2008) и Хоффманн, 2005).
- Исследование мнений и анализ настроений (Лю и Чжан, 2012 г.)
- Анализ настроений и анализ мнений (Лю, 2012 г.) идейный лидер в области машинного обучения, написавший книгу об анализе настроений и анализе мнений.
Полезно для тех, кто начинает исследования в области анализа настроений. Лю проделывает замечательную работу, объясняя анализ настроений высокотехнологичным, но понятным способом. В книге он охватывает различные аспекты анализа настроений, включая приложения, исследования, классификацию настроений с использованием контролируемого и неконтролируемого обучения, субъективность предложений, анализ настроений на основе аспектов и многое другое.
Для тех, кто хочет узнать о подходах к анализу настроений, основанных на глубоком обучении, относительно новой и быстрорастущей области исследований, взгляните на Подходы к анализу настроений, основанные на глубоком обучении.
Курсы и лекции по анализу настроений
Еще один хороший способ углубиться в анализ настроений — овладеть знаниями и навыками в области обработки естественного языка (NLP) — области информатики, которая фокусируется на понимании «человеческого» языка.
Сочетая машинное обучение, компьютерную лингвистику и информатику, НЛП позволяет машине понимать естественный язык, включая чувства, оценки, отношения и эмоции людей из письменного языка.
Существует большое количество курсов, лекций и ресурсов, доступных в Интернете, но основным курсом НЛП является курс Stanford Coursera Дэна Джурафски и Кристофера Мэннинга. Пройдя этот курс, вы получите пошаговое введение в эту область от двух самых уважаемых имен в сообществе НЛП.
Если вам нужен более практический курс, вам следует записаться на курс Data Science: Natural Language Processing (NLP) в Python на Udemy. Этот курс дает вам хорошее представление о НЛП и его возможностях, но он также заставит вас создавать различные проекты на Python, включая детектор спама, анализатор настроений и счетчик статей. Большинство лекций очень короткие (около 5 минут), и курс обеспечивает правильный баланс между практическим и теоретическим содержанием.
Наборы данных для анализа тональности
Ключевой частью освоения анализа тональности является работа с различными наборами данных и экспериментирование с различными подходами.
Во-первых, вам нужно получить данные и получить набор данных, который вы будете использовать для проведения своих экспериментов.Ниже приведены некоторые из наших любимых наборов данных анализа тональности для экспериментов с анализом тональности и подходом машинного обучения. Они открыты и доступны для бесплатного скачивания:
- Обзоры продуктов: этот набор данных состоит из нескольких миллионов отзывов клиентов Amazon со звездными рейтингами, что очень полезно для обучения модели анализа настроений.
- Обзоры ресторанов: этот набор данных состоит из 5,2 миллионов обзоров Yelp со звездным рейтингом.
- Обзоры фильмов: этот набор данных состоит из 1000 положительных и 1000 обработанных отрицательных отзывов. Он также предоставляет 5331 положительное и 5331 отрицательное обработанное предложение / фрагмент.
- Обзоры изысканных блюд: этот набор данных состоит примерно из 500 000 отзывов о еде с Amazon. Он включает информацию о продукте и пользователе, рейтинги и текстовую версию каждого обзора.
- Отношение авиакомпаний к Kaggle в Твиттере: этот набор данных состоит из примерно 15 000 помеченных твитов (положительных, нейтральных и отрицательных) об авиакомпаниях.
- Первые дебаты Республиканской партии Отношение в Твиттере: этот набор данных состоит примерно из 14 000 помеченных твитов (положительных, нейтральных и негативных) о первых дебатах Республиканской партии в 2016 году.
список лексиконов анализа настроений, которые пригодятся. Эти лексиконы представляют собой набор словарей слов с метками, указывающими их отношение к разным предметным областям. Следующие словари действительно полезны для определения тональности текстов:
- Словари настроений для 81 языка: этот набор данных содержит как положительные, так и отрицательные словари настроений для 81 языка.
- SentiWordNet: этот набор данных содержит около 29 000 слов с оценкой тональности от 0 до 1.
- Лексикон мнений для анализа тональности: этот набор данных содержит список из 4 782 отрицательных слов и 2 005 положительных слов на английском языке.
- Словарь настроений Wordstat: этот набор данных включает ~4800 положительных и ~9000 отрицательных слов.
- Emoticon Sentiment Lexicon: этот набор данных содержит список из 477 смайликов, помеченных как положительные, нейтральные или отрицательные.
Напутствие
Анализ настроений может быть применен к бесчисленным аспектам бизнеса, от мониторинга бренда и аналитики продуктов до обслуживания клиентов и исследования рынка. Внедряя его в свои существующие системы и аналитику, ведущие бренды (не говоря уже о целых городах) могут работать быстрее и точнее для достижения более полезных целей.
Анализ настроений вышел за рамки просто интересной высокотехнологичной прихоти и скоро станет незаменимым инструментом для всех компаний современной эпохи. В конечном счете, анализ настроений позволяет нам получать новые идеи, лучше понимать наших клиентов и более эффективно расширять возможности наших собственных команд, чтобы они могли работать лучше и продуктивнее.
MonkeyLearn — это онлайн-платформа, упрощающая анализ текста с помощью инструментов машинного обучения и визуализации данных.
Если вам нужна помощь в создании системы анализа настроений для вашего бизнеса, посетите MonkeyLearn Studio и запросите демонстрацию.
Related Posts
- Лучшее бесплатное облако слов для визуализации ваших данных
- Визуализация настроений в облаке слов
- Извлечение ключевых слов: руководство по поиску ключевых слов в тексте
Методы расчета оценки тональности для текста
Расширенный НЛП Текст
Эта статья была опубликована в рамках блога по науке о данных.
Со временем объем данных увеличился в геометрической прогрессии. Цифровизация во всех областях генерирует большое количество данных в секунду. Сегодня этот большой объем данных относится к неструктурированному типу, т.е. нет предопределенных форматов. Сюда входят изображения, видео, аудио, текст и т. д. Среди них текст является наиболее генерируемым типом неструктурированных данных.
Изображение пользователя Ann H с сайта Pexels Будь то файл журнала машины или отзыв клиента о продукте, все основано в основном на тексте. Компании и предприятия используют эти данные для принятия решений. Эти решения могут включать в себя изменение существующих политик, создание новых продуктов, формулирование новых предложений для сообщества и т. д. Поскольку сгенерированный текст удобочитаем для человека, он не может быть понят машинами. Поэтому, чтобы сделать его более удобным для машин, была введена концепция обработки естественного языка или НЛП.В этой статье мы узнаем, как анализировать текст, чтобы найти его тональность. Поскольку мы хотим рассчитать оценку настроений, мы будем смотреть на текстовые данные, созданные людьми, такие как обзоры продуктов, рестораны и т. д., или твиты от известных личностей. С помощью этих оценок мы можем понять эмоции, стоящие за текстом, и классифицировать их для дальнейшего принятия решений.
Содержание1.
Потребность в чувствах 9 баллов00052. Метод 1: Использование количества положительных и отрицательных слов – с нормализацией
3. Метод 2: Использование количества положительных и отрицательных слов – с полунормализацией
4. Метод 3: Использование VADER SentimentIntensityAnalyser
5. Выводы
Need of Sentiment ScoreСегодня текстовые данные широко используются для понимания поведения клиентов и пользователей в отношении услуг. Например, компании используют обзоры продуктов, чтобы понять мнение клиентов о продуктах. На основе подобных анализов клиентов можно классифицировать по группам и принимать конкретные решения для клиентов, которые недовольны. Использование текстов бесконечно, и специалисты по обработке и анализу данных по всему миру помогли проанализировать тенденции использования текстов. Вы также можете использовать звездочки, чтобы понять мнение пользователей о продуктах или услугах. Тем не менее, чтобы понять реальную реакцию, анализ текстовой обратной связи является лучшим решением.
Чтобы понять эмоции, стоящие за текстом, мы можем проанализировать текст, используя методы НЛП, чтобы найти закономерности. Однако, если один и тот же процесс необходимо проделать с большим количеством текстов, это займет много времени, а до этого времени будут добавляться новые тексты. В этих случаях полезен расчет оценок тональности. Таким образом, положительная оценка показывает положительный текст, а отрицательная оценка показывает отрицательный текст. Автоматизация этого калькулятора оценки тональности поможет анализировать текст и принимать быстрые решения. Для расчета оценок настроений мы также будем использовать наши методы, а также некоторые предопределенные методы, основанные на правилах, для мгновенного расчета этих оценок.
Первый метод: использование положительного и отрицательного подсчета слов с нормализацией для расчета показателя тональности отношение разницы количества положительных и отрицательных слов и общего количества слов. Мы будем использовать набор данных Amazon Cell Phone Reviews от Kaggle.
Чтобы рассчитать настроение, здесь мы будем использовать формулу:
Давайте сначала импортируем библиотеки
импортируем pandas как pd из nltk.corpus импортировать стоп-слова из nltk.tokenize импортировать word_tokenize из nltk.stem импортировать WordNetLemmatizer import re
Теперь мы импортируем набор данных. Из всех столбцов, представленных в этом наборе данных, мы будем использовать столбец «тело», который содержит обзоры мобильных телефонов.
df = pd.read_csv('201-reviews.csv', usecols=['body'])
Далее мы создадим экземпляр WordNetLemmatizer, который будем использовать на следующем шаге. Также будем вызывать стоп-слова из библиотеки NLTK.
лемма = WordNetLemmatizer() stop_words = stopwords.words('english')Далее мы определим функцию для предварительной обработки текста. В этой функции мы сначала преобразовали входную строку в нижний регистр. Затем мы извлекли из этой строки только буквы. Эта задача выполняется с помощью регулярных выражений.
a-zA-Z]+’,’ ‘, corp).strip()
токены = word_tokenize(corp)
слова = [t для t в токенах, если t не в стоп-словах]
lemmatize = [lemma.lemmatize(w) для w словами]
вернуть лемматизировать Теперь мы применим эту функцию к каждому тексту в столбце « body ».
preprocess_tag = [text_prep(i) для i в df['body']] df["preprocess_txt"] = preprocess_tag
Далее мы посчитаем количество результирующих слов для каждого текста. Это будет полезно позже, когда мы вычислим Sentiment Score.
df['total_len'] = df['preprocess_txt'].map(lambda x: len(x))
На следующем этапе мы определили общий список отрицательных и положительных слов. Для этого мы взяли Positive-text.txt и Negative-text.txt файлы или общеизвестные как Opinion Lexicon соответствующими авторами. То же самое можно скачать отсюда.
файл = открыть ('negative-words.txt', 'r') neg_words = файл.read().split() файл = открыть ('positive-words. txt', 'r')
pos_words = file.read().split() Далее мы произведем подсчет положительных и отрицательных слов в тексте. Для этого посчитаем все слова в preprocess_txt которые присутствуют в списке положительных слов pos_words , и аналогичным образом будут подсчитаны все слова в списке preprocess_txt , которые присутствуют в списке отрицательных слов neg_words . Мы добавим эти значения в основной Pandas DataFrame.
num_pos = df['preprocess_txt'].map(лямбда x: len([i для i в x, если i в pos_words])) df['pos_count'] = число_поз num_neg = df['preprocess_txt'].map(лямбда x: len([i для i в x, если i в neg_words])) df['neg_count'] = num_neg
Наконец, посчитаем настроение. Мы создадим столбец « настроений » и выполним расчет для каждого текста.
df['sentiment'] = round((df['pos_count'] - df['neg_count']) / df['total_len'], 2)
Собираем все вместе:
импортируем панды как пд из nltk.corpus импортировать стоп-слова из nltk.
a-zA-Z]+',' ', corp).strip()
токены = word_tokenize(corp)
слова = [t для t в токенах, если t не в стоп-словах]
lemmatize = [lemma.lemmatize(w) для w словами]
вернуть лемматизировать
preprocess_tag = [text_prep(i) для i в df['body']]
df["preprocess_txt"] = preprocess_tag
df['total_len'] = df['preprocess_txt'].map(лямбда x: len(x))
файл = открыть ('негативные-слова.txt', 'r')
neg_words = файл.read().split()
файл = открыть ('positive-words.txt', 'r')
pos_words = файл.read().split()
num_pos = df['preprocess_txt'].map(lambda x: len([i для i в x, если i в pos_words]))
df['pos_count'] = число_поз
num_neg = df['preprocess_txt'].map(лямбда x: len([i для i в x, если i в neg_words]))
df['neg_count'] = num_neg
df['настроение'] = round((df['pos_count'] - df['neg_count']) / df['total_len'], 2)
дф.голова() При выполнении этого кода мы получаем:
Источник изображения — персональный компьютер
Метод 2: использование количества положительных и отрицательных слов — с полунормализацией для расчета оценки тональности
В этом методе оценка тональности рассчитывается путем оценки соотношения количества положительных слов и количества отрицательных слов + 1.
Поскольку нет никакой разницы в задействованных значениях, значение тональности всегда будет больше 0. Кроме того, добавление 1 в знаменателе избавит от ошибки деления на ноль. Начнем с реализации. Код реализации останется прежним до отрицательного и положительного количества слов из предыдущей части, с той разницей, что на этот раз нам не нужно общее количество слов, поэтому мы будем опускать эту часть. 9a-zA-Z]+’,’ ‘, corp).strip()
токены = word_tokenize(corp)
слова = [t для t в токенах, если t не в стоп-словах]
lemmatize = [lemma.lemmatize(w) для w словами]
вернуть лемматизировать
preprocess_tag = [text_prep(i) для i в df[‘body’]]
df[«preprocess_txt»] = preprocess_tag
файл = открыть (‘негативные-слова.txt’, ‘r’)
neg_words = файл.read().split()
файл = открыть (‘positive-words.txt’, ‘r’)
pos_words = файл.read().split()
num_pos = df[‘preprocess_txt’].map(lambda x: len([i для i в x, если i в pos_words]))
df[‘pos_count’] = число_поз
num_neg = df[‘preprocess_txt’]. a-zA-Z]+’,’ ‘, corp).strip()
токены = word_tokenize(corp)
слова = [t для t в токенах, если t не в стоп-словах]
lemmatize = [lemma.lemmatize(w) для w словами]
вернуть лемматизировать
preprocess_tag = [text_prep(i) для i в df[‘body’]]
df[«preprocess_txt»] = preprocess_tag
файл = открыть (‘негативные-слова.txt’, ‘r’)
neg_words = файл.read().split()
файл = открыть (‘positive-words.txt’, ‘r’)
pos_words = файл.read().split()
num_pos = df[‘preprocess_txt’].map(lambda x: len([i для i в x, если i в pos_words]))
df[‘pos_count’] = число_поз
num_neg = df[‘preprocess_txt’].map(лямбда x: len([i для i в x, если i в neg_words]))
df[‘neg_count’] = num_neg
df[‘настроение’] = round(df[‘pos_count’] / (df[‘neg_count’]+1), 2)
дф.голова() При выполнении этого кода получаем:
Источник изображения — персональный компьютер
Третий метод: Использование VADER SentimentIntensityAnalyser для расчета показателя тональностиВ этом методе мы будем использовать анализатор интенсивности настроений, который использует лексикон VADER.
VADER — это длинная форма Valence Aware и sEntiment Reasoner, инструмента анализа настроений на основе правил. VADER вычисляет текстовые эмоции и определяет, является ли текст положительным, нейтральным или отрицательным. Этот анализатор вычисляет тональность текста и выдает четыре различных класса выходных оценок: положительных , отрицательных , нейтральных и составных .Здесь мы будем использовать составной балл. Составная оценка — это совокупность оценок слова или, точнее, сумма всех слов в лексиконе, нормализованная между -1 и 1. Не рекомендуется использовать общие методы предварительной обработки текста перед вычислением, поскольку это может повлиять на VADER. полученные результаты. Используя эти результаты VADER, вы также можете классифицировать каждый текст по категориям в соответствии с вашими потребностями.
Теперь мы будем использовать VADER для расчета оценки тональности. Поскольку этот процесс отличается от предыдущих двух методов, мы будем реализовывать его с нуля.
Сначала мы импортируем библиотеки. Мы будем использовать библиотеку NLTK для импорта SentimentIntensityAnalyzer.
импортировать панд как pd из nltk.sentiment.vader импортировать SentimentIntensityAnalyzer
Далее мы создадим экземпляр SentimentIntensityAnalyzer.
отправлено = SentimentIntensityAnalyzer()
Далее мы прочитаем данные обзора сотового телефона, которые мы использовали ранее.
df = pd.read_csv('', usecols = ['тело'])Наконец, мы рассчитаем показатель комплексной оценки и добавим его в основной фрейм данных для каждого из текстов.
polarity = [round(sent.polarity_scores(i)['compound'], 2) for i in df['body']] df['sentiment_score'] = полярность
Собираем все вместе:
импортировать панд как pd из nltk.sentiment.vader импортировать SentimentIntensityAnalyzer отправлено = SentimentIntensityAnalyzer() df = pd.read_csv('', usecols = ['тело']) polarity = [round(sent. polarity_scores(i)['compound'], 2) для i в df['body']]
df['sentiment_score'] = полярность
дф.голова() При выполнении этого кода мы получаем:
Источник изображения — персональный компьютер ВыводыВ этой статье мы узнали о трех различных способах расчета показателей тональности для каждого из заданных обзоров мобильных телефонов. Первые два
Об авторе
метода вычисляются автоматически, в то время как третий метод основан на правилах, и оценка оценивается сама по себе. У каждого из этих методов есть свои плюсы и минусы. Существует множество способов, с помощью которых можно рассчитать оценку тональности. Можно даже определить свой собственный метод оценки баллов. ВЕЙДЕР более здравый и точный с точки зрения интернет-сленга, который широко используется сегодня. Можно попробовать создать новый и более сильный метод оценки, который мог бы охватывать более широкий диапазон слов.Свяжитесь со мной в LinkedIn.
Для любых предложений или запросов статьи, вы можете написать мне здесь.
Ознакомьтесь с другими моими статьями здесь и на Medium
Вы можете оставить мне ценный отзыв на LinkedIn.
Спасибо, что уделили время!
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора
blogathoncentment analysissentiment scorevader
Содержание
Лучшие ресурсы
Скачать приложение
Мы используем файлы cookie на веб-сайтах Analytics Vidhya для предоставления наших услуг, анализа веб-трафика и улучшения вашего опыта на сайте. Используя Analytics Vidhya, вы соглашаетесь с нашей Политикой конфиденциальности и Условиями использования. Принять
Политику конфиденциальности и файлов cookie
DataHour: день из жизни специалиста по данным
Дата : ПОНЕДЕЛЬНИК, 26 сентября 2022 г. | Время : 20:30 — 9:30 PM ISTRЗарегистрируйтесь БЕСПЛАТНО!Анализ тональности текста в НЛП. Проблемы, варианты использования и методы: от… | Арун Джагота
Фото Icons8 Team на UnsplashЛюдям нравится выражать чувства.
Счастливый или несчастный. Нравится или не нравится. Хвалить или жаловаться. Хорошо или плохо. То есть положительный или отрицательный.Анализ настроений в НЛП касается расшифровки таких настроений из текста. Это положительный , отрицательный, оба или ни один ? Если есть настроение, , который объектов в тексте, к которым относится настроение, и фактическая фраза настроения, такая как плохой , размытый , недорогой , … (не просто положительный или отрицательный .) Это также называется аспектом на основе анализа [1].
Как техника, анализ настроений интересен и полезен.
Сначала самое интересное. Не всегда легко сказать, по крайней мере, для компьютерного алгоритма, является ли тональность текста положительной, отрицательной, и той, и другой, или ни той, ни другой. Сигналы могут быть тонкими. Помимо общего настроения, еще труднее сказать, какие объекты в тексте являются предметом какого настроения, особенно когда задействованы как положительные, так и отрицательные чувства.
Далее, к полезной части. Это легко объяснить. Люди, которые продают вещи, хотят знать, как люди относятся к этим вещам. Он называется отзыв клиента 😊. Игнорировать это вредно для бизнеса.
Есть и другие применения. Такие как интеллектуальный анализ мнений , т.е. попытка выяснить, кто придерживается (или придерживался) каких мнений. Например, по словам Джона Смита, коронавирус просто исчезнет в течение шести месяцев . Эту задачу можно формализовать как поиск ( источник , цель , мнение ) утраивается. В нашем примере источник = Джон Смит , цель = коронавирус , мнение = просто уйдут в течение полугода .
(много) Примеры
Анализ настроений — это то, что можно назвать проблемой длинного хвоста. Множество различных сценариев и тонкостей. Такие проблемы часто лучше всего описываются примерами.
Во-первых, давайте рассмотрим несколько простых положительных моментов.
Превосходное обслуживание клиентов.
Очень нравится.
Хорошая цена.Далее некоторые плюсы и минусы различить немного сложнее.
Положительные стороны :
Что не нравится в этом продукте.
Неплохо.
Не проблема.
Не багги.
Негативы :
Не устраивает.
Неудобно для пользователя.
Не хорошо.
Определенно не положительный :
Это хорошо?Положительные стороны в приведенном выше списке не самые сильные. Тем не менее, они особенно хороши для обучения алгоритмов ML делать ключевые различия, поскольку мы определенно не хотим, чтобы эти положительные результаты предсказывались как отрицательные.
Положительные :
Низкая цена.
Негативы :
Низкое качество.Эти экземпляры особенно хороши для обучения алгоритмов ML делать ключевые различия.
Положительные :
Быстрый оборот .
Негативы :
Быстрый до отказа.Здесь действует то же самое.
Положительные :
Недорого.
Негативы :
дешево.Здесь действует то же самое.
Наконец, несколько негативов, которые немного сложнее расшифровать.
Я не получил обещанного.
Моя посылка еще не пришла.
Никто из вашей команды не смог решить мою проблему.
Меня задержали на час!
Почему это так сложно использовать?
Почему так легко выходит из строя?Сценарии использования
Легко представить множество. Вот некоторые из основных конкретных.
- Узнайте о негативных отзывах о вашем товаре или услуге. В сообщениях в блогах, на сайтах электронной коммерции или в социальных сетях. Более широко в любом месте в Интернете.
- Совокупное отношение к финансовым инструментам. Например, конкретные акции. Каковы недавние настроения рынка по акциям xyz? Кроме того, варианты на основе аспектов. Например, , по мнению аналитиков финансовой компании xyz, акции abc, вероятно, вырастут на 20% в следующем году . Выяснение того, чье мнение это, дает больше информации, которая может быть использована для оценки достоверности или ее отсутствия.
- Определите, на какие компоненты вашего продукта или услуги жалуются люди? Особенно сильно. Для приоритизации тактических или долгосрочных улучшений.
- Отслеживайте изменения настроений клиентов с течением времени для определенного продукта или услуги (или их линейки). Чтобы проверить, стало ли лучше…
- Отслеживайте изменение мнений политиков с течением времени. Отдельные лица или группы, такие как политические партии. Средства массовой информации любят это делать. Чтобы разжечь назойливые вопросы, такие как , вы сказали это тогда, но теперь это! .
Вычислительные задачи
То, что мы обсуждали до сих пор, можно свести к двум различным вычислительным задачам.
- Каково общее настроение текста: положительное , отрицательное , оба или ни ?
- Какое настроение к какой части текста относится. Это также называется анализом настроений на основе аспектов.
Начнем с первой проблемы, которую мы назовем классификация настроений .
Проблема классификации тональности
Вводится текст. Результат, который мы ищем, состоит в том, равно ли настроение положительный , отрицательный , оба или ни один . В одном из вариантов этой задачи, который мы здесь рассматривать не будем, нас интересует дополнительно предсказание силы положительных и отрицательных настроений. Вы можете себе представить, почему. телефон xyz действительно отстой гораздо более негативен, чем Я немного разочарован телефоном xyz .
Подход, основанный на словаре
Самый простой подход — создать два словаря терминов, несущих позитивную и негативную окраску соответственно.
Под термином мы подразумеваем слово или фразу. Текст классифицируется как положительный или отрицательный на основе попадания терминов в тексте в эти два словаря. Текст классифицируется как нейтральный, если он не попадает ни в один словарь. Текст классифицируется как положительный и отрицательный, если он попадает в оба словаря.Этот подход стоит рассмотреть, когда кто-то хочет быстро получить несколько эффективный классификатор тональности с нуля, а у вас нет достаточно богатого набора данных текста, помеченного тональностью. Простота — одна из причин. Более важная причина заключается в том, что у альтернативы машинного обучения есть свои препятствия, которые необходимо преодолеть. Мы подробно рассмотрим их, когда будем обсуждать эту тему.
Несмотря на препятствия машинного обучения, подход на основе словаря рано или поздно столкнется с проблемами качества. Поэтому, если в вашем случае важны высокая точность и высокая полнота различных классов тональности, вам следует заранее подумать о том, чтобы стиснуть зубы и инвестировать в ML.
Ваша задача станет намного проще, если вы сможете найти достаточно богатый набор размеченных данных или придумать несколько творческих способов его получения, возможно, после некоторого дополнительного легкого НЛП (обсуждается в следующем разделе).Контролируемые задачи обучения
Первая проблема заключается в необходимости иметь большой и разнообразный набор данных текстов, помеченных их классами настроений: положительные , отрицательные , оба или ни то, ни другое.
Проблема вот в чем. Представьте, что текст представлен вектором. Пока в обычной модели векторного пространства, т.е. в виде мешка слов. Тем не менее, проблема применима, хотя и в несколько меньшей степени, даже к встраиванию слов.
Векторное пространство огромно. Каждое слово в лексиконе имеет размерность.
Подавляющее большинство слов в этом пространстве не несет никакой смысловой нагрузки. Для обучения классификатора машинного обучения потребуется огромный обучающий набор.
Большая часть того, что он будет делать, — это узнавать, какие слова являются «неприятными». То есть разучивая предубеждения, которые он накопил по пути (см. пример ниже).Давайте посмотрим на пример, на котором классификатор может научиться ошибочно связывать нейтральные слова с положительным или отрицательным настроением.
xyz телефон отстой → отрицательный
Он научится связывать слово телефон с настроением отрицательным . Очевидно, мы этого не хотим. Чтобы забыть об этом, потребуются экземпляры обучающего набора со словом phone в них, которые не помечены ни , ни (т. е. нейтральный ).
При этом разбивая большой и разнообразный корпус (такой как Википедия) на предложения и маркируя каждое нейтральное , можно решить эту проблему. Интуиция здесь такая. Все слова изначально научатся быть нейтральными. Такие слова, как — отстой , которые неоднократно встречаются в тексте, помеченном как , отрицательный в конечном итоге «сбежит» из своего нейтрального ярлыка.
За рамками наборов слов Особенности
Из примеров с пометками, которые мы видели в предыдущем разделе, кажется, что знак «?» является предиктором настроений. Это интуитивно понятно. Скептики задают вопросы. Не истинно верующие.
Использование словарей в качестве функций
Если у нас уже есть словари фраз, связанных с положительными или отрицательными эмоциями (или их легко составить), почему бы не использовать их в качестве дополнительных функций. Они не должны быть полными. Просто куратор. Таким образом, мы можем воспользоваться их качеством.
Более подробно, вот как. Скажем, нехорошо, есть в словаре отрицаний. Мы создадим логическую функцию для этой записи. Значение этой функции равно 1, если в тексте появляется нехорошо , и 0, если нет. Мы также можем добавить запись ( нехорошо , отрицательный ) в наш обучающий набор. Обратите внимание, что здесь мы думаем о , а не о хорошем , как о полном тексте.
Использовать часть речи?
Слова, насыщенные чувствами, часто являются прилагательными. Это заставляет задуматься, может ли быть полезным использование информации о части речи каждого слова в тексте? В качестве дополнительных функций или для обрезки функций.
Давайте начнем с изучения частей речи слов в наших различных примерах. Этот анализ был выполнен с использованием онлайн-пост-тегера [2].
Части речи различных слов в предложениях, несущих чувстваКакие мысли это вызывает? Прилагательное в POS-теге , по-видимому, значительно коррелирует с полярностью настроений (положительной или отрицательной). POS-тег также наречие . Определители , предлоги и местоимения , кажется, предсказывают нейтральный класс.
Как мы можем воспользоваться этим? Мы могли бы задействовать особенности набора слов в их частях речи. Например, отфильтруйте все слова, POS-тег которых является определителем, предлогом или местоимением.
Это можно рассматривать как сложную форму удаления стоп-слов.Разработка характеристик: некоторые наблюдения
Хотя эти наблюдения являются общими, они особенно применимы к нашей проблеме (классификация настроений).
Во-первых, нам не нужны веские доказательства, прежде чем мы добавим новую функцию. Просто слабая вера в то, что это может помочь. Алгоритм машинного обучения определит, насколько предсказуема эта функция, возможно, в сочетании с другими функциями. По мере того, как обучающая выборка со временем становится богаче, машинное обучение автоматически научится использовать эту функцию более эффективно, если это возможно. Слабые черты могут суммироваться.
Единственным недостатком этого является то, что если мы переусердствуем, то есть добавим слишком много функций, взрыв пространства функций может снова преследовать нас. Подробнее об этом позже.
Давайте расширим понятие «слабая вера в то, что это может помочь». Здесь «помощь» просто означает, что функция предсказывает некоторый класс настроений.
Нам не нужно знать, какой. ML разберется с этим. То есть, какое значение признака предсказывает, какой класс тональности. Напротив, при настройке системы, основанной на правилах (специальным случаем которой являются словари), необходимо указать, какие комбинации значений признаков предсказывают, какой класс тональности.Есть ли в этом риске космический взрыв?
Мы уже приняли тот факт, что использование функций набора слов взорвет наше пространство функций. По причинам, обсужденным ранее, мы решили стиснуть зубы на этом фронте. Вопрос в том, не усугубят ли дело дополнительные функции, упомянутые в этом разделе?
На самом деле они сделают лучше. Давайте рассуждать об этом. Сначала функция со знаком вопроса . Имеет логическое значение. Здесь нет взрыва. Далее, функции на основе словаря. На самом деле они уменьшают шум в пространстве векторов слов, поскольку они выводят на поверхность слова и фразы, насыщенные эмоциями. Наконец, особенности частей речи.
Использование их, как было предложено, для фильтрации (т. е. удаления слов) сокращает пространство признаков.Word k-gram Возможности?
Мы намеренно поместили это после предыдущего раздела, потому что это увеличивает риск взрыва пространства функций, если не сделать это правильно. Пространство слова к -грамм даже с к = 2 огромно. Тем не менее, разумное сокращение этого пространства может потенциально увеличить соотношение выгод и затрат от этих функций.
Ниже приведены некоторые возможные идеи для рассмотрения. В обсуждении мы ограничимся k=2, т.е. биграммами, хотя это применимо и в более общем плане.
- Удалите из модели биграммы, которые не имеют достаточной поддержки в обучающем наборе. (Под поддержкой биграммы мы подразумеваем, сколько раз она встречается в обучающем наборе.)
- Для дополнительной обрезки учитывайте также части речи.
Подведение итогов …
Мы закончим этот раздел подведением итогов того, что мы здесь обсуждали, и их последствий.
Во-первых, мы видим, что подход ML может быть дополнен множеством функций. Мы просто добавляем функции в смесь. Пока есть правдоподобный случай для каждого включения. Мы не беспокоимся о корреляциях между функциями. Слишком сложно для анализа. Пусть МЛ разбирается. Цель оправдывает средства. Пока у нас есть достаточно богатый размеченный набор данных, который мы можем разбить на разбивки для обучения и тестирования и надежно измерить качество того, что мы называем «концом».Нам нужно подумать о расширении пространства функций. Мы уже сделали.
Теперь несколько слов об алгоритме обучения. У нас есть много вариантов. Наивный Байес. Логистическая регрессия. Древо решений. Случайный лес. Повышение градиента. Может быть, даже глубокое обучение. Ключевым моментом, на который стоит обратить внимание, является то, что эти варианты охватывают различные уровни сложности. Некоторые могут автоматически обнаруживать многомерные функции, которые особенно предсказывают настроение. Риск здесь заключается в том, что многие из многомерных признаков, которые они обнаруживают, также зашумлены.
Итак, теперь у нас есть множество вариантов выбора функций и множество вариантов алгоритмов обучения. Потенциально очень мощный. Но и рискованно. Как упоминалось ранее, мы можем снизить риск, помня о взрывном росте пространства функций.
В конечном счете, мы должны сосредоточиться на создании как можно большего количества размеченных наборов данных, даже если только постепенно. В долгосрочной перспективе это имеет большее значение, чем тактическая оптимизация функций, чтобы компенсировать отсутствие хорошего тренировочного набора. Это единственный наиболее важный аспект этой проблемы. Инвестируйте в это.
Целевые варианты
До этого момента мы думали о классификации настроений как о задаче с четырьмя классами: положительные , отрицательные , оба , ни . В некоторых настройках класс и можно игнорировать. В таких условиях мы интерпретируем и как нейтральный .
В большинстве случаев нас интересуют только первые два.
Таким образом, нейтральный — это неприятный класс. «Неприятность» означает, что ее необходимо учитывать, даже если это не то, что мы ищем. Почему это нужно учитывать? Ну, мы не хотим, чтобы нейтральный текст классифицировался как положительный или отрицательный. Другими словами, включая нейтральный класс (поддерживаемый достаточно богатым обучающим набором для него), улучшается точность положительных и отрицательных результатов.Это легко проиллюстрировать на примере. Вспомните экземпляр
xyz phone отстой → отрицательный
Нам не нужен вывод phone → отстой . Это означает, что каждый телефон отстой. При добавлении нейтрального класса вместе с достаточно богатым обучающим набором для него риск такого необоснованного вывода значительно снижается.
Вероятностная классификация
Независимо от того, какой алгоритм обучения мы в конечном итоге выберем — наивный байесовский алгоритм, логистическая регрессия, дерево решений, случайный лес, повышение градиента и т.
д. — мы должны рассмотреть возможность использования предсказанных вероятностей различных классов. Например, если прогнозируемые вероятности на входе составляют примерно 50% (положительные), 50% (отрицательные), 0% (0), то мы можем интерпретировать текст как имеющий как положительные, так и отрицательные настроения.Как эффективно построить обучающую выборку
Итак, теперь ясно, что подход ML является мощным. Теперь давайте посмотрим на «кормление зверя», т.е. на создание богатого тренировочного набора.
Вот идея, как быстро собрать большой набор текстов, которые можно эффективно размечать вручную.
- Выберите подходящий источник неструктурированного текста. Например, обзоры продуктов на сайте электронной коммерции.
- Создать два столбца в электронной таблице, один для текста , один для метка .
- Поместите каждый документ (например, каждый обзор продукта) в отдельную ячейку в столбце с меткой text .
- Добавьте метки вручную.
Давайте подробнее рассмотрим шаг 4. Рассмотрите возможность использования краудсорсинга. Или, по крайней мере, разделить работу между членами команды. Кроме того, примите соглашение, согласно которому пустая ячейка в столбце меток обозначает конкретную метку. Хороший выбор: и , то есть нейтральный .
Вы можете быть удивлены тем, как быстро вы можете создать богатую тренировочную выборку, используя этот процесс.
Если в наборе данных отзывов о продуктах к каждому отзыву прилагается звездочка, вы можете использовать эту оценку для автоматической маркировки положительных и отрицательных экземпляров. Это может ускорить процесс маркировки. Тем не менее, вы должны выполнить ручной проход после автоматической маркировки, чтобы просмотреть его и исправить те метки, которые неверны.
Предположение, лежащее в основе этой автоматической маркировки, заключается в том, что ее качество достаточно хорошее. Так что только небольшая часть этикеток нуждается в исправлении.
Вы должны посмотреть на них всех. Тем не менее, визуальное сканирование всех этикеток имеет гораздо более высокую производительность, чем редактирование отдельных.Детализация обучающего экземпляра
Вообще говоря, насколько это возможно, входные экземпляры должны быть более детализированными, чем более грубыми. Отзывы клиентов о продуктах, как правило, достаточно детализированы. Особенно, если они уже отмечены рейтингами, из которых мы можем автоматически получить целевое настроение. В этом случае разбивать более длинные обзоры на отдельные предложения и вручную помечать их соответствующим ярлыком тональности может оказаться слишком трудоемко, а польза от этого неясна.
Далее рассмотрим отправную точку для более длинных документов. Например, полноформатные обзорные статьи о классах продуктов. Например, 10 лучших телефонов на 2020 год или 10 лучших акций на 2020 год.
Доводы в пользу того, чтобы разбить их на более мелкие детали, такие как абзацы или даже предложения, более убедительны.
Очевидно, что если мы сможем ограничить текст областью, к которой применимо определенное настроение, это может помочь повысить точность алгоритма обучения.В качестве крайнего примера предположим, что у вас есть 20-страничный документ, весь из которого нейтрален, кроме одного предложения, в котором есть сильное настроение. Имеет смысл обозначить это предложение с настроением, а остальной текст как нейтральное. Это, вероятно, сработает лучше, чем маркировка 20-страничного документа настроением в одном предложении.
Детализация экземпляров в полевых условиях
Как обсуждалось выше, для обучающей выборки более мелкие экземпляры в обучающей выборке обычно лучше, чем более крупные. Это предпочтение не распространяется на время классификации, то есть на использование классификатора в поле. Мы должны идти вперед и предсказывать настроение любого текста, который нам дают, будь то предложение или глава.
В отличие от обучения, у прогнозирования тональности длинного документа нет недостатков.
Это всего лишь вопрос ожиданий. Если пользователь ищет тональность документа длиннее абзаца, на самом деле он имеет в виду, что ему нужно общее общее тональность всего текста. Является ли он положительным в целом, отрицательным в целом, обоими или ни одним (нейтральным)?Это нормально, иногда это то, что вам нужно. И как только вы обнаружите документы, которые несут некоторую тональность, вы всегда можете перейти к классификатору тональности для отдельных предложений или абзацев.
Ввиду этого следует иметь в виду, что оценка на тестовом наборе, извлеченном из размеченного набора данных, не даст точной оценки того, насколько хорошо классификатор работает в полевых условиях. Удерживаемый тестовый набор получается из помеченного набора данных, который состоит из отдельных экземпляров по причинам, обсуждавшимся ранее. Входные данные поля не обязательно всегда такие детализированные.
Аспектный анализ настроений
Здесь, помимо расшифровки различных настроений в тексте, мы также пытаемся выяснить, какое из них к чему относится.
Очевидно, что такой анализ может быть очень полезным, как показано в примере ниже.
Камера на моем телефоне
отстой. Кроме того, я счастлив. Вы явно хотите знать, на что жалуются и что нравится.
Часто нам также нужно извлечь фактические фразы настроения. Рассмотрим приведенный ниже пример из выдуманного целостного обзора нового телевизора.
Хорошая цена. Четкое изображение. Яркие цвета. Статика в аудио. Движение немного отстает.
В идеале мы хотели бы извлечь из него тройки (аспект, сентиментальная фраза, полярность).
Аспект: цена, изображение, цвета, звук, движение
Фраза настроения: хорошая резкость, яркость, статика, немного отстает
Полярность: + + + — -Полярность может помочь получить общую оценку качества (например, здесь 3 из 5). Может иметь и другое применение.
Извлечение аспектов и эмоциональных фраз
Давайте пропустим этот текст через POS-теггер в [2].
Вспомним, что легенда POS-тегов
Легенда POS-теговЧто бросается в глаза? В качестве первой попытки разбейте текст на предложения, запустите POS-tagger для каждого предложения и, если последовательность тегов равна
, сочтите прилагательное как фразу настроения, существительное как аспект, считая прилагательное фразой настроения и существительным, чтобы быть аспект работает на удивление хорошо. С точки зрения точности, т.е. Не вспомнить, потому что этот шаблон слишком специфичен. Например, он не распознает фразу аспекта тональности в Движение немного отстает .
Итак, как мы можем попытаться расширить идею предыдущего абзаца, чтобы попытаться улучшить запоминание? Сформулируйте это как задачу маркировки последовательностей. См. [3] для подробной формулировки маркировки последовательностей аналогичной задачи, распознавание именованных объектов .
Текст токенизирован как последовательность слов. С этой последовательностью связана последовательность меток, которая указывает, что такое аспект и что такое сентиментальная фраза .
Ниже приведен наш более ранний пример, переформулированный в соответствии с этим соглашением, где A обозначает аспект, S обозначает эмоциональную фразу, а N не обозначает ни то, ни другое. Мы разделили пару на две части, так как они не помещаются в горизонтальную линию.
слов Хорошая цена. Четкое изображение. Яркие цвета. Статика в аудио.
метки S A S A S A S N A слов Движение немного отстает.
labels A S S SВ [3] мы сосредоточились на скрытых марковских моделях для маркировки последовательностей. Здесь более естественно работать с условными марковскими моделями [4] по причинам, которые мы объясним ниже.
Во-первых, что такое условная марковская модель? Напомним, что наша задача логического вывода состоит в том, чтобы ввести последовательность слов и найти для нее наиболее вероятную последовательность меток. Для последовательности токенов [ Движение , отстает от , a , бит ] мы ожидаем, что наилучшей последовательностью меток будет [A, S, S, S].
Условная марковская модель (CMM) моделирует эту задачу вывода как задачу поиска последовательности меток L , которая максимизирует условную вероятность P ( L | T ) для данной последовательности токенов T . Модель Маркова делает определенные предположения, которые делают эту проблему вывода разрешимой. В частности, предполагается, что P ( L | T ) является факторированным как
P ( L | T ) = P ( L 1 | L 0, P T 1)* P ( L 2| L 1, T 2)*…* P ( L п| L _{n-1}, T n)
Вместо того чтобы объяснять, давайте проиллюстрируем это на нашем примере. Мы добавили метку B , обозначающую начало.
P( [B,A,S,S,S] | [B, Движение , отставание , a , бит ] ) = P(A|B, Движение )*P( S|A, отстает от )*P(S|S, a )*P(S|S, бит )
Алгоритм вывода описывать не будем.
Это слишком сложно для этого поста. Кроме того, это не наша тема. Однако мы объясним индивидуальные вероятности в приведенном выше примере качественно. Вооружившись таким объяснением, мы можем представить, как перебираем все возможные последовательности меток, вычисляем вероятность каждой и находим ту, которая имеет наибольшую вероятность.Начнем с P (A|B, Движение ). На это влияют два фактора и их взаимодействие. Во-первых, вероятность того, что первое слово является частью аспекта. Во-вторых, вероятность того, что Движение является аспектным словом.
Вероятность первого фактора значительно больше 0. Можно представить много реальных примеров, в которых первое слово является аспектным. Например, камера имеет низкое разрешение .
Вероятность второго фактора, на которой мы хотели бы остановиться подробнее. Рассмотрим P (A| Движение ), игнорируя влияние предыдущего состояния B. CMM позволяет нам смоделировать эту вероятность как находящуюся под влиянием любых характеристик по нашему выбору, полученных из комбинации A и Движения .
Возможно перекрытие. HMM, напротив, будет работать вместо P ( Motion |A). Он будет рассматривать Motion и A как символы, не позволяя нам использовать какие-либо функции, которые мы можем счесть полезными.Фактически, мы можем думать о P(A| Motion ) как задача обучения с учителем, в которой (A, Motion ) является входом, а P(A| Motion ) выходом. Сила этого подхода заключается в его способности изучать сложные отображения P ( L i | T i), в которых мы можем использовать любые признаки из пары ( L i, T i), которые мы сочту нужным.
На ум особенно приходят две особенности. Часть речи слова и помечено ли слово как принадлежащее распознанному именованному объекту. (См. [3], в котором рассматривается распознавание именованных объектов в НЛП со многими реальными вариантами использования и методами.)
Признак части речи уже упоминался в примерах, которые мы видели, в которых POS-тег существительное казался предиктором ярлыка аспекта , а прилагательное предиктором фразы настроения .