
Дубли страниц сайта — поиск и удаление
Что такое дубли страниц
В рамках одного доменного имени очень может такое быть, что один и тот же контент доступен по разным адресам.
Вполне вероятно, что на разных страницах сайта опубликован очень похожий или же полностью дублированный контент. Это может быть одинаковые (или очень похожие) описания meta name="description" content="", заголовки h2, title страницы. Если после проверки на наличие дубликатов выяснилось, что они присутствуют в вашем приложении, то необходимо устранить ненужные дубли страниц.
Дубли — это страницы, которые или очень похожи или являются полной копией (дублем) основной (продвигаемой вами) страницы.
Причины появления дублей страниц на сайте
- Не указано главное зеркало сайта. Одна и та же страница доступна по разным URL (с www. и без | с http и с https).
- Версии страниц сайта для печати, не закрытые от индексации.
- Генерация страниц с одними и теми же атрибутами, расположенными в разном порядке. Например,
/?cat=2&id=1. - Автоматическая генерация дубликатов движком приложения (CMS). Из-за ошибок в системе управления контентом (CMS), так же могут появляются дубли страниц.
- Ошибки веб-мастера при разработке (настройке) приложения.
- Дублирование страницы (статьи, товара…) веб-мастером или контент-маркетологом.
- Изменение структуры сайта, после которого страницам присваиваются новые адреса, а старые не удаляются.
- На сайте используются «быстрые» мобильные версии страниц, с которых не выставлен
Canonicalна основные версии. - Сознательное или несознательное размещение ссылок третьими лицами на ваши дубли с других ресурсов.
Виды дублей
Дубликаты различают на 3 вида:
- Полные — с полностью одинаковым контентом;
- Частичные — с частично повторяющимся контентом;
- Смысловые, когда несколько страниц несут один смысл, но разными словами.
Полные
Полные дубли ухудшают факторы всего сайта и осложняют его продвижение в ТОП, поэтому от них нужно избавиться сразу после обнаружения.
- Версия с/без
www. Возникает, если пользователь не указал зеркало в панели Яндекса и Google. - Различные варианты главной страницы:
- site.com
- site.com/default/index
- site.com/index
- site.com/index/
- site.com/index.html
- Страницы, появившиеся вследствие неправильной иерархии разделов:
- site.com/products/apple/
- site.com/products/category/apple/
- site.com/category/apple/
- UTM-метки. Метки используются, чтобы передавать данные для анализа рекламы и источника переходов. Обычно они не индексируются поисковиками, но бывают исключения.
- GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес страницы:
- site.com/products/apple/page.php?color=green
- Страницы, сгенерированные реферальной ссылкой. Обычно они содержат специальный параметр, который добавляется к URL. С такой ссылки должен стоять редирект на обычный URL, однако часто этим пренебрегают.
- Неправильно настроенная страница с ошибкой 404, которая провоцирует бесконечные дубли. Любой случайный набор символов в адресе сайта станет ссылкой и без редиректа отобразится как страница 404.
Избавиться от полных дубликатов можно, поставив редирект, убрав ошибку программно или закрыв документы от индексации.
Частичные
Частичные дубликаты не так страшны для на сайта, как полные. Однако, если их много — это ухудшает ранжирование веб-приложения. Кроме того, они могут мешать продвижению и по конкретным ключевым запросам. Разберем в каких случаях они возникают.
Характеристики в карточке товара
Нередко, переключаясь на вкладку в товарной карточке, например, на отзывы, можно увидеть, как это меняет URL-адрес. При этом большая часть контента страницы остаётся прежней, что создает дубль.
Если CMS неправильно настроена, переход на следующую страницу в категории меняет URL, но не изменяет Title и Description. В итоге получается несколько разных ссылок с одинаковыми мета-тегами:
- site.com/fruits/apple/
- site.com/fruits/apple/?page=2
Такие URL-адреса поисковики индексируют как отдельные страницы. Чтобы избежать дублирования, проверьте техническую реализацию вывода товаров и автогенерации.
Также на каждой странице пагинации необходимо указать каноническую страницу, которая будет считаться главной.
Подстановка контента
Часто для повышения видимости по запросам с указанием города в шапку сайта добавляют выбор региона. При нажатии которого на странице меняется номер телефона. Бывают случаи, когда в адрес добавляется аргумент, например
Версия для печати
Версии для печати полностью копируют контент и нужны для преобразования формата содержимого. Пример:
- site.com/fruits/apple
- site.com/fruits/apple/print – версия для печати
Поэтому необходимо закрывать их от индексации в robots.txt.
Смысловые
Смысловые дубли — контент страниц, написанный под запросы из одного кластера. Чтобы их обнаружить (смысловые дубли страниц), нужно воспользоваться результатом парсинга сайта, выполненного, например, программой Screaming Frog. Затем скопировать заголовки всех статей и добавить их в любой Hard-кластеризатор с порогом группировки 3,4. Если несколько статей попали в один кластер – оставьте наиболее качественную, а с остальных поставьте 301 редирект.
Чем опасны дубли страниц на сайте
Наличие дубликатов на сайте — один ключевых факторов внутренней оптимизации (или её отсутствия), который крайне негативно сказывается на позициях сайта в органической поисковой выдаче. Дубли служат причиной нескольких проблем, связанных с оптимизацией:
- Индексация сайта. При большом количестве дублей поисковые роботы в силу ограниченного краулингового бюджета могут не проиндексировать нужные страницы. Также есть риск того, что сайт будет пессимизирован, а его краулинговый бюджет — урезан.
- Проблемы с выдачей приоритетной страницы в органическом поиске. За счет дублей в поисковую выдачу может попасть не та страница, продвижение которой планировалось, а её копия. Есть и другой вариант: обе страницы будут конкурировать между собой, и ни одна не окажется в выдаче.
- «Распыление» ссылочного веса. Вес страницы сайта — это своеобразный рейтинг, выраженный в количестве и качестве ссылок на неё с других сайтов или других страниц внутри этого же сайта. При наличии дублей ссылочный вес может переходить не на единственную версию страницы, а делиться между ее дубликатами. Таким образом, все усилия по внешней оптимизации и линкбилдингу оказываются напрасными.
Как найти дублирующиеся страницы? Это можно сделать с помощью специальных программ и онлайн сервисов. Часть из них платные, другие – бесплатные, некоторые – условно-бесплатные (с пробной версией или ограниченным функционалом).
Яндекс Вебмастер
Чтобы посмотреть наличие дубликатов в панели Яндекса, необходимо зайти: Индексирование -> Страницы в поиске -> Исключённые.
Страницы исключаются из индекса по разным причинам, в том числе из-за повторяющегося контента (дублирования). Обычно конкретная причина прописана под ссылкой.
Google Search Console
Посмотреть наличие дублей страниц в панели Google Search Console можно так: Покрытие -> Исключено.
Netpeak Spider
Netpeak Spider – платная программа с 14-дневной пробной версией. Если провести поиск по заданному сайту, программа покажет все найденные ошибки и дубликаты.
Xenu
Xenu — бесплатная программа, в которой можно проанализировать даже не проиндексированный сайт. При сканировании программа найдет повторяющиеся заголовки и мета-описания.
Сайт Репорт
Сайт Репорт — это неплохой сервис, предоставляющий пользователю инструмент диагностики внутренних и внешних факторов с целью оптимизации сайта. Поиск дубликатов — это один из множества инструментов сервиса по оптимизации сайта или другого приложения. Сервис предоставляет бесплатный анализ до 25 страниц. Если у вас на сайте большее количество страниц, то (при необходимости) придётся немного потратиться. Но оно того стоит.
Screaming Frog Seo Spider
Screaming Frog Seo Spider является условно-бесплатной программой. До 500 ссылок можно проверить бесплатно, после чего понадобится платная версия. Наличие дублей программа определяет так же, как и Xenu, но быстрее и эффективнее.
Как начать пользоваться бесплатно:
- Скачать программу Screaming Frog Seo Spider и установить её на свой ПК. Скачать ключ-активатор для программы. Пароль к архиву:
prowebmastering.ru - Запустить
keygen.exe, задать имя пользователя и ключ (ключ можно сгенерировать) - В самой программе Screaming Frog Seo Spider выбрать вкладку «Licence» -> «Enter Licence»
- В появившемся окне указать то, что указали (или сгенерировали) при запуске
keygen.exe, жмём «OK», перезапускаем программу.
Документация по работе с программой Screaming Frog Seo Spider здесь.
Небольшой видео-обзор и основные настройки Screaming Frog Seo Spider:
Поисковая выдача
Результаты поиска могут отразить не только нужный нам сайт, но и некое отношение поисковой системы к нему. Для поиска дублей в Google можно воспользоваться специальным запросом.
site:mysite.ru -site:mysite.ru/&
site:mysite.ru — показывает страницы сайта mysite.ru, находящиеся в индексе Google (общий индекс).
site:mysite.ru/& — показывает страницы сайта mysite.ru, участвующие в поиске (основной индекс).
Таким образом, можно определить малоинформативные страницы и частичные дубли, которые не участвуют в поиске и могут мешать страницам из основного индекса ранжироваться выше. При поиске обязательно кликните по ссылке «повторить поиск, включив упущенные результаты», если результатов было мало, чтобы видеть более объективную картину.
Варианты устранения дубликатов
При дублировании важно не только избавиться от копий, но и предотвратить появление новых.
Физическое удаление
Самым простым способом было бы удалить повторяющиеся страницы вручную. Однако перед удалением нужно учитывать несколько важных моментов:
- Источник возникновения. Зачастую физическое удаление не решает проблему, поэтому ищите причину
- Страницы можно удалять, только если вы уверены, что на них не ссылаются другие ресурсы
Настройка 301 редиректа
Если дублей не много или на них есть ссылки, настройте редирект на главную или продвигаемую страницу. Настройка осуществляется через редактирование файла .htaccess либо с помощью плагинов (в случае с готовыми CMS). Старый документ со временем выпадет из индекса, а весь ссылочный вес перейдет новой странице.
Создание канонической страницы
Указав каноническую страницу, вы показываете поисковым системам, какой документ считать основным. Этот способ используется для того, чтобы показать, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Для этого на всех дублях в теге прописывается следующая строчка со ссылкой на оригинальную страницу:
<link rel="canonical" href="http://site.com/original.html">
Например, на странице пагинации главной должна считаться только одна страница: первая или «Показать все». На остальных необходимо прописать атрибут rel="canonical", также можно использовать теги rel=prev/next:
// Для 1-ой страницы: <link rel="next" href="http://site.com/page/2"> <link rel="canonical" href="http://site.com"> // Для второй и последующей: <link rel="prev" href="http://site.com"> <link rel="next" href="http://site.com/page/3"> <link rel="canonical" href="http://site.com">
Запрет индексации в файле Robots.txt
Файл robots.txt — это своеобразная инструкция по индексации для поисковиков. Она подойдёт, чтобы запретить индексацию служебных страниц и дублей.
Для этого нужно воспользоваться директивой Disallow, которая запрещает поисковому роботу индексацию.
Disallow: /dir/ – директория dir запрещена для индексации Disallow: /dir – директория dir и все вложенные документы запрещены для индексации Disallow: *XXX – все страницы, в URL которых встречается набор символов XXX, запрещены для индексации.
Внимательно следите за тем какие директивы вы прописываете в robots.txt. При некорректном написании можно заблокировать не те разделы либо вовсе закрыть сайт от поисковых систем.
Запрет индексировать страницы действует для всех роботов. Но каждый из них реагирует на директиву Disallow по-разному: Яндекс со временем удалит из индекса запрещенные страницы, а Google может проигнорировать правило, если на данный документ ведут ссылки..
Вывод
Дублирующиеся h2, title, description, а также некоторые части контента вроде отзывов и комментариев очень нежелательны и осложняют продвижение сайта. Поэтому обязательно проверяйте ресурс на дубликаты, как сгенерированные, так и смысловые и применяйте описанные в статье методы для их устранения.
prowebmastering.ru
Поиск дублей страниц сайта: программы, сервисы, приёмы
От автора
О теории дублирования контента на сайте я писал стать тут, где доказывал, что дубли статей это плохо и с дубли страниц нужно выявлять и с ними нужно бороться. В этой статье я покажу, общие приемы по выявлению повторяющегося контента и акцентирую внимание на решение этой проблемы на WordPress и Joomla.
Еще немного теории
Я не поддерживаю мнение о том, что Яндекс дубли страниц воспринимает нормально, а Google выбрасывает дубли из индекса и за это может штрафовать сайт.
На сегодня я вижу, что Яндекс определяет дубли страниц и показывает их в Яндекс.Вебмастере на вкладке «Индексация». Более того, ту страницу, которую Яндекс считает дублем, он удаляет из индекса. Однако я вижу, что Яндекс примет за основную страницу первую, проиндексированную и вполне возможно, что этой страницей может быть дубль.
Также понятно и видно по выдаче, что Google выбрасывает из поиска НЕ все страницы с частичным повторением материала.
Вместе с этим, отсутствие дублей на сайте воспринимается поисковыми системами, как положительный фактор качества сайта и может влиять на позиции сайта в выдаче.
Теперь от теории к практике: как найти дубли страниц.
Поиск дублей страниц сайта
Перечисленные ниже способы поиск дублей страниц не борются с дублями, а помогают их найти в поиске. После их выявления, нужно принять меры по избавлению от них.
Программа XENU (полностью бесплатно)
Программа Xenu Link Sleuth (http://home.snafu.de/tilman/xenulink.html), работает независимо от онлайн сервисов, на всех сайтах, в том числе, на сайтах которые не проиндексированы поисковиками. Также с её помощью можно проверять сайты, у которых нет накопленной статистики в инструментах вебмастеров.
Поиск дублей осуществляется после сканирования сайта программой XENU по повторяющимся заголовкам и мета описаниям. Читать статью: Проверка неработающих, битых и исходящих ссылок сайта программой XENU
Программа Screaming Frog SEO Spider (частично бесплатна)
Адрес программы https://www.screamingfrog.co.uk/seo-spider/. Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Статья: SEO анализ сайта программой Scrimimg Seo Spider
Программа Netpeak Spider (платная с триалом)
Сайт программы https://netpeaksoftware.com/spider. Еще один программный сканер для анализа ссылок сайта с подробным отчетом. Статья Программа для SEO анализа сайта Netpeak Spider
Яндекс.Вебмастер
Для поиска дублей можно использовать Яндекс.Вебмастер после набора статистики по сайту. В инструментах аккаунта на вкладке Индексирование >>>Страницы в поиске можно посмотреть «Исключенные страницы» и выяснить причину их удаления из индекса. Одна из причин удаления это дублирование контента. Вся информация доступна под каждым адресом страницы.
поиск дублей страниц в Яндекс.ВебмастерЯзык поисковых запросов
Используя язык поисковых запросов можно вывести список всех страниц сайта, которые есть в выдаче (оператор «site:» в Google) и поискать дубли «глазами». Как это сделать читать в статье Простые способы проверить индексацию страниц сайта.
Сервисы онлайн
Есть онлайн сервисы, который показывают дубли сайта. Например, сервис Siteliner.com (http://www.siteliner.com/) На нём можно найти битые ссылки и дубли. Можно проверить до 25000 страниц по подписке и 250 страниц бесплатно.
Российский сервис Saitreport.ru, может помочь в поиске дублей. Адрес сервиса: https://saitreport.ru/poisk-dublej-stranic
Google Search Console
В консоли веб-мастера Google тоже есть инструмент поиска дублей. Откройте свой сайт в консоли Гугл вебмастер. На вкладке Вид в поиске>>>Оптимизация HTML вы увидите, если есть, повторяющиеся заголовки и мета описания. Вероятнее всего это дубли (частичные или полные).
поиск дублей страниц в консоли веб-мастера GoogleЧто делать с дублями
Найденные дубли, нужно удалить с сайта, а также перенастроить CMS, чтобы дубли не появлялись, либо закрыть дубли от поисковых ботов мета-тегами noindex, либо добавить тег rel=canonical в заголовок каждого дубля.
Как бороться с дублями
Здесь совет простой, бороться с дублями нужно всеми доступными способами, но прежде всего, настройкой платформы (CMS) на которой строится сайт. Уникальных рецептов нет, но для Joomla и WordPress есть практичные советы.
Поиск и удаление дублей на CMS Joomla
CMS Joomla «плодит» дубли, «как крольчиха». Причина дублирования в возможностях многоуровневой вложенности материалов, размещения материалов разных пунктах меню, в различных макетах для пунктов меню, во встроенном инструменте пагинации (листания) и различной возможности сортировки материалов.
Например, одна и та же статья, может быть в блоге категории, в списке другого пункта меню, может быть, в сортировке по дате выпуска и вместе с тем, быть в сортировке по количеству просмотров, дате обновления, автору и т.д.
Встроенного инструмента борьбы с дублями нет и даже появление новой возможности «Маршрутизация URL» не избавляет от дублирования.
Решения проблемы
Решить проблему дублирования на сайтах Joomla помогут следующие расширения и приёмы.
Бесплатный плагин «StyleWare Content Canonical Plugin». Сайт плагина: https://styleware.eu/store/item/26-styleware-content-canonical-plugin. Плагин фиксирует канонические адреса избранных материалов, статей, категорий и переадресовывает все не канонические ссылки.
SEO Компоненты Joomla, Artio JoomSEF (бесплатный) и Sh504 (платный). У этих SEO «монстров» есть кнопка поиска и удаления дублей, а также есть легкая возможность добавить каноническую ссылку и/или закрыть страницы дублей от индексации.
Перечисленные расширения эффективно работают, если их ставят на новый сайт. Также нужно понимать, что при установке на рабочий сайт:
- На сайте со статьями в индексе эти расширения «убьют» почти весь индекс.
- Удаление дублей компонентами не автоматизировано и дубли всё равно попадают в индекс.
- Хотя управлять URL сайта этими компонентами очень просто.
Если дубль страницы попадет в индекс, то поисковики, не умея без указателей определять, какая страница является основной, могут дубль принять за основную страницу, а основную определить, как дубль. Из-за этого важно, не только бороться с дублями внутри сайта, но и подсказать поисковикам, что можно, а что нельзя индексировать. Сделать это можно в файле robots.txt, но тоже с оговорками.
Закрыть дубли в robots.txt
Поисковик Яндекс, воспринимает директиву Disallow как точное указание: материал не индексировать и вывести материал из индекса. То есть, закрыв на Joomla , страницы с таким url: /index.php?option=com_content&view=featured&Itemid=xxx, а закрыть это можно такой директивой:
Disallow: /*?
вы уберете, из индекса Яндекс все страницы со знаком вопроса в URL.
В отличие от Яндекс, поисковик Google не читает директиву Disallow так буквально. Он воспринимает директиву Disallow как запрет на сканирование, но НЕ запрет на индексирование. Поэтому применение директивы [Disallow: /*?] в блоке директив для Google файла robots.txt, на уже проиндексированном сайте, скорее приведет к негативным последствиям. Google перестанет сканировать закрытые страницы, и не будет обновлять по ним информацию.
Для команд боту Google нужно использовать мета теги <meta name=»robots» content=»noindex»/>, которые можно добавить во всех редакторах Joomla, на вкладке «Публикация».
Например, вы создаете на сайте два пункта меню для одной категории, один пункт меню в виде макета блог, другой в виде макета список. Чтобы не было дублей, закройте макет список мета-тегом noindex, nofollow, и это избавит от дублей в Google выдаче.
Также рекомендую на сайте Joomla закрыть в файле robots.txt страницы навигации и поиска от Яндекс на любой стадии индексации и от Google на новом сайте:
- Disallow: /*page*
- Disallow: /*search*
Стоит сильно подумать, об индексации меток, ссылок и пользователей, если они используются на сайте.
Поиск и удаление дублей на CMS WordPress
На WordPress создаваемый пост попадает на сайт как статья, и дублируется в архивах категории, архивах тегов, по дате, по автору. Чтобы избавиться от дублей на WordPress, разумно закрыть от индексации все архивы или, по крайней мере, архивы по дате и по автору.
Использовать для этих целей можно файл robots.txt с оговорками сделанными выше. Или лучше, установить SEO плагин, который, поможет в борьбе с дублями. Рекомендую плагины:
- Yast SEO (https://ru.wordpress.org/plugins/wordpress-seo/)
- All in One SEO Pack (https://ru.wordpress.org/plugins/all-in-one-seo-pack/)
В плагинах есть настройки закрывающие архивы от индексации и масса других SEO настроек, который избавят от рутинной работы по оптимизации WordPress.
Вывод
По практике скажу, что побороть дубли на WordPress можно, а вот с дублями на Joomla поиск дублей страниц требует постоянного контроля и взаимодействия с инструментами веб-мастеров, хотя бы Яндекс и Google.
©SeoJus.ru
Еще статьи
(Всего просмотров 2 198)
Поделиться ссылкой:
Похожее
seojus.ru
как найти и удалить дубли страниц
Автор Алексей На чтение 7 мин. Опубликовано
Поисковые алгоритмы постоянно развиваются, часто уже сами могут определить дубли страницы и не включать такие документы в основной поиск. Тем не менее, проводя экспертизы сайтов, мы постоянно сталкиваемся с тем, что в определении дублей алгоритмы еще далеки от совершенства.
Что такое дубли страниц?
Дубли страниц на сайте – это страницы, контент которых полностью или частично совпадает с контентом другой, уже существующей в сети страницы.
Адреса таких страниц могут быть почти идентичными.
Дубли:
- с доменом, начинающимся на www и без www, например, www.site.ru и site.ru.
- со слешем в конце, например, site.ru/seo/ и site.ru/seo
- с .php или .html в конце, site.ru/seo.html и site.ru/seo.php
Одна и та же страница, имеющая несколько адресов с указанными отличиями восприниматься как несколько разных страниц – дублей по отношению друг к другу.
Какими бывают дубликаты?
Перед тем, как начать процесс поиска дублей страниц сайта, нужно определиться с тем, что они бывают 2-х типов, а значит, процесс поиска и борьбы с ними будет несколько отличным. Так, в частности, выделяют:
- Полные дубли — когда одна и та же страница размещена по 2-м и более адресам.
- Частичные дубли — когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress обычно дублей страниц нет, а вот Joomla генерирует огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Влияние дублей на продвижение сайта
- Дубли нежелательны с точки зрения SEO, поскольку поисковые системы накладывают на такие сайты санкции, отправляют их в фильтры, в результате чего понижается рейтинг страниц и всего сайта вплоть до изъятия из поисковой выдачи.
- Дубли мешают продвижению контента страницы, влияя на релевантность продвигаемых страниц. Если одинаковых страниц несколько, то поисковику непонятно, какую из них нужно продвигать, в результате ни одна из них не оказывается на высокой позиции в выдаче.
- Дубли снижают уникальность контента сайта: она распыляется между всеми дублями. Несмотря на уникальность содержания, поисковик воспринимает вторую страницу неуникальной по отношении к первой, снижает рейтинг второй, что сказывается на ранжировании (сортировка сайтов для поисковой выдачи).
- За счет дублей теряется вес основных продвигаемых страниц: он делится между всеми эквивалентными.
- Поисковые роботы тратят больше времени на индексацию всех страниц сайта, индексируя дубли.
Как найти дубли страниц
Исходя из принципа работы поисковых систем, становится понятно, что одной странице должна соответствовать только одна ссылка, а одна информация должна быть только на одной странице сайта. Тогда будут благоприятные условия для продвижения нужных страниц, а поисковики смогут адекватно оценить ваш контент. Для этого дубли нужно найти и устранить.
Программа XENU (полностью бесплатно)

Программа Xenu Link Sleuth (http://home.snafu.de/tilman/xenulink.html), работает независимо от онлайн сервисов, на всех сайтах, в том числе, на сайтах которые не проиндексированы поисковиками. Также с её помощью можно проверять сайты, у которых нет накопленной статистики в инструментах вебмастеров.
Поиск дублей осуществляется после сканирования сайта программой XENU по повторяющимся заголовкам и метаописаниям.
Программа Screaming Frog SEO Spider (частично бесплатна)
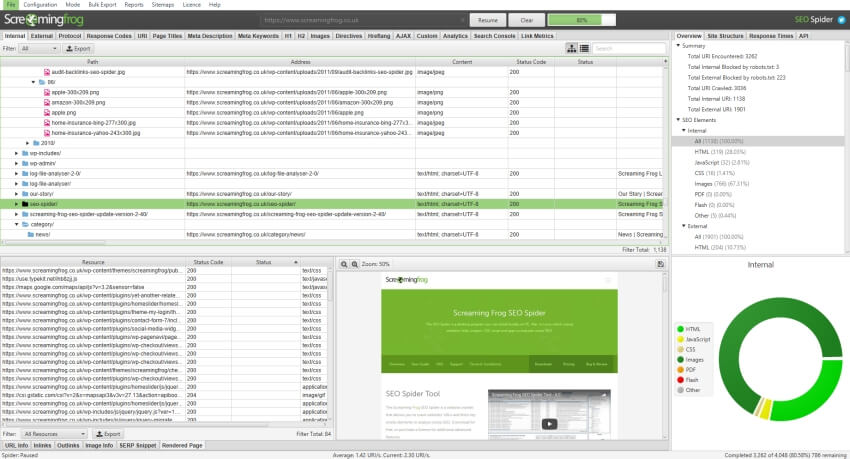
Адрес программы https://www.screamingfrog.co.uk/seo-spider/. Это программа работает также как XENU, но более красочно. Программа сканирует до 500 ссылок сайта бесплатно, более объемная проверка требует платной подписки. Сам ей пользуюсь.
Программа Netpeak Spider (платная с триалом)

Ссылка на программу Netpeak Spider. Еще один программный сканер для анализа ссылок сайта с подробным отчетом.
Яндекс Вебмастер
Для поиска дублей можно использовать Яндекс.Вебмастер после набора статистики по сайту. В инструментах аккаунта на вкладке Индексирование > Страницы в поиске можно посмотреть «Исключенные страницы» и выяснить причину их удаления из индекса. Одна из причин удаления это дублирование контента. Вся информация доступна под каждым адресом страницы.

Google Search Console
В консоли веб-мастера Google тоже есть инструмент поиска дублей. Откройте свой сайт в консоли Гугл вебмастер. На вкладке Вид в поиске > Оптимизация HTML вы увидите, если есть, повторяющиеся заголовки и метаописания. Вероятнее всего это дубли (частичные или полные).

Язык поисковых запросов
Используя язык поисковых запросов можно вывести список всех страниц сайта, которые есть в выдаче (оператор «site:» в Google и Yandex) и поискать дубли «глазами».

Сервисы онлайн
Есть сервисы, который проверяют дубли страниц на сайте онлайн. Например, сервис Siteliner.com (http://www.siteliner.com/). На нём можно найти битые ссылки и дубли. Можно проверить до 25000 страниц по подписке и 250 страниц бесплатно.

Российский сервис Saitreport.ru, может помочь в поиске дублей. Адрес сервиса: https://saitreport.ru/poisk-dublej-stranic

Удаление дублей страниц сайта
Способов борьбы с дубликатами не так уж и много, но все они потребуют от вас привлечения специалистов-разработчиков, либо наличия соответствующих знаний. По факту же арсенал для «выкорчевывания» дублей сводится к:
- Их физическому удалению — хорошее решение для статических дублей.
- Запрещению индексации дублей в файле robots.txt — подходит для борьбы со служебными страницами, частично дублирующими контент основных посадочных.
- Настройке 301 редиректов в файле-конфигураторе «.htaccess» — хорошее решение для случая с рефф-метками и ошибками в иерархии URL.
- Установке тега «rel=canonical» — лучший вариант для страниц пагинации, фильтров и сортировок, utm-страниц.
- Установке тега «meta name=»robots» content=»noindex, nofollow»» — решение для печатных версий, табов с отзывами на товарах.
Чек-лист по дублям страниц
Часто решение проблемы кроется в настройке самого движка, а потому основной задачей оптимизатора является не столько устранение, сколько выявление полного списка частичных и полных дублей и постановке грамотного ТЗ исполнителю.
Запомните следующее:
- Полные дубли — это когда одна и та же страница размещена по 2-м и более адресам. Частичные дубли — это когда определенная часть контента дублируется на ряде страниц, но они уже не являются полными копиями.
- Полные и частичные дубли могут понизить позиции сайта в выдаче не только в масштабах URL, а и всего домена.
- Полные дубликаты не трудно найти и устранить. Чаще всего причина их появления зависит от особенностей CMS сайта и навыков SEO разработчика сайта.
- Частичные дубликаты найти сложнее и они не приводят к резким потерям в ранжировании, однако делают это постепенно и незаметно для владельца сайта.
- Чтобы найти частичные и полные дубли страниц, можно использовать мониторинг выдачи с помощью поисковых операторов, специальные программы-парсеры, поисковую консоль Google и ручной поиск на сайте.
- Избавление сайта от дублей сводится к их физическому удалению, запрещению индексации дублей в файле «robots.txt», настройке 301 редиректов, установке тегов «rel=canonical» и «meta name=»robots» content=»noindex, nofollow»».
webmaster-seo.ru
Как правильно искать и удалять дубли страниц на сайте

13 июля Яндекс провел очередной вебинар для вебмастеров, посвященный одной из самых распространенных проблем при работе с сайтом с точки зрения поисковой оптимизации —выявлению и удалению дублей страниц и других ненужных документов. Александр Смирнов рассказал и показал, как работать со «Статистикой обхода» и архивами загруженных страниц, которые помогают находить дубли и служебные страницы. Также объяснил, как составлять robots.txt для документов такого типа.
Перед тем, как начать говорить о дублях, Александр дал определение дублирующей странице сайта:
Дубли – две или более страниц одного сайта, которые содержат идентичный или в достаточной мере похожий текстовый контент.
Довольно часто дубли – это одна и та же страница сайта, доступная по разным URL-адресам.
Причин появления дублей на сайте – множество и все они связаны с различными ошибками. Например:
Ошибки в содержимом страниц:
• некорректные относительные ссылки
• отсутствие текста
Некорректные настройки:
• HTTP-200 вместо HTTP-404
• доступность служебных страниц
Ошибки в CMS:
• особенности структуры
Большое количество возможных причин возникновения дублей обычно очень гнетет вебмастеров и они откладывают их поиск в долгий ящик, не желая тратить на это время. Делать этого не стоит, так как наличие дублей страниц на сайте зачастую приводит к различным проблемам.
01 | Опасность дублей на сайте
Проблемы, к которым приводят дубли:
• Смена релевантной страницы в результатах поиска
• Обход дублирующих страниц
• Затруднение сбора статистики
Смена релевантной страницы
Например, на сайте есть бухгалтерские услуги, описание которых доступно по двум адресам:
site.ru/uslugi/buhgalterskie-uslugi/
site.ru/buhgalterskie-uslugi/
Первый адрес находится в разделе «Услуги», а второй адрес – это страничка в корне сайта. Контент обеих страниц абсолютно одинаков.
Робот не хранит в своей базе несколько идентичных документов, поэтому в поиске остается только один из них – на усмотрение робота. Кажется, что в этом нет ничего плохого, ведь страницы идентичны. Однако опытные вебмастера знают, что позиции конкретной страницы по запросам рассчитываются на основании нескольких сотен показателей, поэтому при смене страницы в поисковой выдаче, позиции могут измениться.
Именно так и произошло в случае с бухгалтерскими услугами – по конкретному запросу [услуги бухгалтерского учета] в середине июня произошло конкретное проседание позиций, чтобы было связано со сменой релевантной страницы в поисковой выдаче.

Через некоторое время релевантная страница вернулась в выдачу, однако совершенно очевидно, что даже такое небольшое изменение может повлиять на количество трафика на ресурс.
Обход дублирующих страниц
При наличии большого количества дублей на ресурсе, поисковому роботу приходится постоянно посещать большое количество страниц. Поскольку количество запросов со стороны индексирующего робота ограничено (производителем сервера или CMS сайта, вебмастером с помощью директивы Crawl-delay), он, при наличии большого количества дублирующих страниц, начинает скачивать именно их, вместо того чтобы индексировать нужные страницы сайта. В результате в поисковой выдаче могут показываться какие-то неактуальные данные и пользователи не смогут найти нужную им информацию, хоть она и размещена на сайте.
Пример из практики по обходу дублирующих страниц, из которого видно, что до конца мая робот ежедневно скачивал чуть меньше миллиона страниц интернет-магазина. После обновления ресурса и внесения изменений на сайт, робот резко начинает увеличивать нагрузку на ресурс, скачивая по несколько миллионов страниц в день:

Большая часть этих страниц – дубли, с некорректными GET-параметрами, которые появились из-за некорректной работы CMS, используемой на сайте.
Проблемы со сбором статистики в Яндекс.Вебмастере и Яндекс.Метрике
Если говорить о Вебмастере, то в разделе «Страницы в поиске» можно наблюдать вот такую картину:

При каждом обновлении поисковой базы, количество страниц в поиске остается практически неизменным, но видно, что робот при каждом обновлении добавляет и удаляет примерно одинаковое количество страниц. То есть какой-то процесс происходит, постоянно что-то удаляется и добавляется, при этом количество страниц в поиске остается неизменным. Если посмотреть статистику обхода, то мы увидим, что ежедневно робот посещает несколько тысяч новых страниц сайта, при этом эти новые страницы в поисковую выдачу не попадают. Это как раз-таки и связано с обходом роботом дублирующих страниц, которые потом в поисковую выдачу не включаются.
Если смотреть статистику посещаемости конкретной страницы в Яндекс. Метрике, то может возникнуть следующая ситуация: данная страница показывалась ранее по конкретному запросу и на нее были переходы из результатов поиска, которые почему-то прекратились в начале мая:

А произошло следующее – включилась в поисковую выдачу дублирующая страница, и пользователи с поиска начали переходить на нее, а не на нужную страницу сайта.
Казалось бы, эти три большие проблемы, вызываемые наличием дублей страниц на сайте, должны мотивировать вебмастеров к их устранению. А чтобы удалить дубли с сайта, сначала их нужно найти.
02 | Поиск дублей
— Видишь дублирующие страницы?
— Нет.
— И я нет. А они есть.
Самый простой способ искать дублирующие страницы – это с помощью раздела «Страницы в поиске» в Яндекс.Вебмастере:
Страницы в поиске -> Исключенные страницы -> Сортировка: Дубль -> Применить

В результате можно увидеть все страницы, которые исключил робот, посчитав их дублирующими.
Если таких страниц много, например, несколько десятков тысяч, можно полученную страницу выгрузить из Вебмастера и дальше использовать ее по своему усмотрению.
Второй способ – с помощью раздела «Статистика обхода»:
Статистика обхода -> Сортировка: 200 (ОК)

В этом разделе можно увидеть не только страницы, которые посещает робот, не только дубли, но и различные служебные страницы сайта, которые в поиске видеть бы не хотелось.
Третий способ – с применением фантазии.
Берем любую страницу сайта и добавляем к ней произвольный GET-параметр (в нашем случае это /?test=123. При помощи инструмента «Проверка ответа сервера», проверяем код ответа от данной страницы:

Если данная страница доступна и отвечает, как на скриншоте, кодом ответа 200, то это может привести к появлению дублирующих страниц на сайте. Например, если робот найдет где-то такую ссылку в интернете, он ее проиндексирует и потенциально она может стать дублирующей.
Четвертый способ – это проверка статуса URL.
В ситуации, когда нужная страница уже пропала из результатов поиска, при помощи этого инструмента можно проверить, по каким именно причинам это произошло:

В данном случае видно, что страница была исключена из поиска поскольку является дублем.
Кроме этих четырех способов можно использовать еще какие-то свои способы, например: посмотреть логи своего сервера, статистику Яндекс.Метрики, в конце концов, посмотреть поисковую выдачу, там тоже можно выявить дублирующие страницы.
03 | Устранение дублей
Все возможные дубли страниц можно разделить на две категории:
• Явные дубли (полностью идентичный контент)
• Неявные дубли (страницы с похожим содержимым)
Внутри этих двух категорий представлено большое количество видов дублей, на которых сейчас мы остановимся подробней и разберемся, как их можно устранить.
1. Страницы со слэшом в конце адреса и без
Пример:
site.ru/page
site.ru/page/
Что делаем:
— HTTP-301 перенаправление с одного вида страниц на другие с помощью .hitacces/CMS
Какие именно страницы нужно оставлять для робота решает сам вебмастер в каждом конкретном случае. Можно посмотреть на страницы своего сайта в поиске, какие из них присутствуют в нем в данный момент, и принимать решение, исходя из этих данных.
2. Один и тот же товар в нескольких категориях
Пример:
site.ru/игрушки/мяч
site.ru/мяч
Что делаем:
— Используем атрибут rel=”canonical” тега <link>
Оставлять для робота лучше те страницы, формат адресов которых наиболее удобен для посетителей сайта.
3. Страницы версий для печати
Пример:

Что делаем:
Используем запрет в файле robots.txt, который укажет роботу, что все страницы с подобными адресами индексировать нельзя —
Disallow://node_print.php*
4. Страницы с незначащими параметрами
Пример:
site.ru/page
site.ru/page?utm_sourse=adv
site.ru/page?sid=e0t421e63
Что делаем:
Прибегаем к помощи специальной директивы Clean-param в robots.txt и указываем все незначащие параметры, которые используются на сайте –
Clean-param: sis&utm_sourse
5. Страницы действий на сайте
Пример:
site.ru/page?add_basket=yes
site.ru/page?add_compare=list
site.ru/page?comment_page_1
Что делаем:
Запрет в robots.txt –
Disallow:* add_basket=* Disallow:* add_compare=* Disallow:* comment_*Или
Disallow:*?*
6. Некорректные относительные адреса
Пример:
site.ru/игрушки/мяч
site.ru/игрушки/ игрушки/ игрушки/ игрушки/мяч
Что делаем:
1. Ищем источник появления
2. Настраиваем HTTP-404 на запросы робота
7. Похожие товары
Пример:
— товары отличаются характеристиками (размером, цветом)
— похожие товары одной категории
Что делаем:
— Оставляем товар на одном URL и используем селектор (возможность выбора нужного цвета и размера)
— Добавляем на такие страницы дополнительное описание, отзывы
— Закрываем ненужное в noindex
8. Страницы с фотографиями без описания
Пример:
Страницы фотогалерей, фотобанков
Что делаем:
— Добавляем дополнительное описание, теги
— Открытие комментариев на странице
9. Страницы фильтров и сортировки
Пример:
site.ru/shop/catalog/podarki/?sort=minimum_price&size=40
site.ru/shop/catalog/filter/price-from-369-to-804/pr_material-f22-or-c5/
Что делаем:
— Определяем востребованность и полезные оставляем
— Для бесполезных прописываем запрет в robots.txt –Disallow:*sort=* Disallow:*size=* Disallow:*/filter/*
10. Страницы пагинации
Пример:
site.ru/shop/catalog/podarki/
site.ru/shop/catalog/podarki/?page_1
site.ru/shop/catalog/podarki/?page_2
Что делаем:
Используем атрибут rel=”canonical” тега <link>
04 | Выводы:
Причины возникновения и виды дублей разнообразны, поэтому различными и должны быть подходы к ним с точки зрения поисковой оптимизации. Не нужно их недооценивать. Почаще нужно заглядывать в Вебмастер и своевременно вносить соответствующие изменения на сайт.
Шпаргалка по работе с дублями:

www.searchengines.ru
Все о том, как найти дубли страниц на сайте… и убрать
Все, что вы хотели найти про дубли страниц на сайте и дублирование контента. Узнайте 7 методов, чтобы проверить, найти и убрать все, что мешает развитию.
Неважно какой движок у вашего сайта: Bitrix, WordPress, Joomla, Opencart… Проверка сайта на дубли страниц может выявить эту проблему и её придется срочно решать.
Дублирование контента, равно как и дубли страниц на сайте, является большой темой в области SEO. Когда мы говорим об этом, то подразумеваем наказание от поисковых систем.
Этот потенциальный побочный эффект от дублирования контента едва ли не самый важный. Даже с учетом того, что Google по сути почти никогда не штрафует сайты за дублирование информации.
Наиболее вероятные проблемы для SEO из-за дублей:
Потраченный краулинговый бюджет.
Если дублирование контента происходит внутри веб-ресурса, гарантируется, что вы потратите часть краулингового бюджета (выделенного лимита на количество индексируемых за один заход страниц) при обходе дублей страниц поисковым роботом. Это означает, что важные страницы будут индексироваться менее часто.
Разбавление ссылочного веса.
Как для внешнего, так и для внутреннего дублирования контента разбавление ссылочного веса является самым большим недостатком для SEO. Со временем оба URL-адреса могут получить обратные ссылки. Если на них отсутствуют канонические ссылки (или 301 редирект), указывающие на исходный документ, вес от ссылок распределится между обоими URL.
Только один вариант получит место в поиске по ключевой фразе.
Когда поисковик найдет дубли страниц на сайте, то обычно он выберет только одну в ответ на конкретный поисковый запрос. И нет никакой гарантии, что это будет именно та, которую вы продвигаете.
Любые подобные сценарии можно избежать, если вы знаете, как найти дубли страниц на сайте и убрать их. В этой статье представлено 7 видов дублирования контента и решение по каждому случаю.
Стоит заметить, что дубли контента могут быть не только у вас на сайте. Ваш текст могут просто украсть. Начнем разбор с этого варианта.
1 Копирование контента
Скопированное содержание в основном является неоригинальной частью контента на сайте, который был скопирован с другого сайта без разрешения. Как я уже говорилось ранее, Google не всегда может точно определить, какая часть является оригинальной. Так что задачей владельца сайта является поиск фактов копирования контента и принятие мер, если обнаружится факт кражи контента.
Увы, это не всегда легко и просто. Но иногда может помочь маленькая хитрость.
Отслеживайте сохранение уникальности ваших документов (если у вас есть блог, желательно это контролировать) с помощью каких-либо сервисов (например, text.ru) или программ. Скопируйте текст своей статьи и запустите проверку уникальности.
Конечно, если сайт содержит сотни статей, то проверка займет много времени. Поэтому я установил на данный сайт комментарии «Hypercomments» и включил функцию фиксации цитирования. Каждый раз, как кто-то скопирует кусок текста, он появляется во вкладке цитаты. Мне сразу видно, что был скопирован весь текст такой-то статьи. Это повод проверить её уникальность через некоторое время.
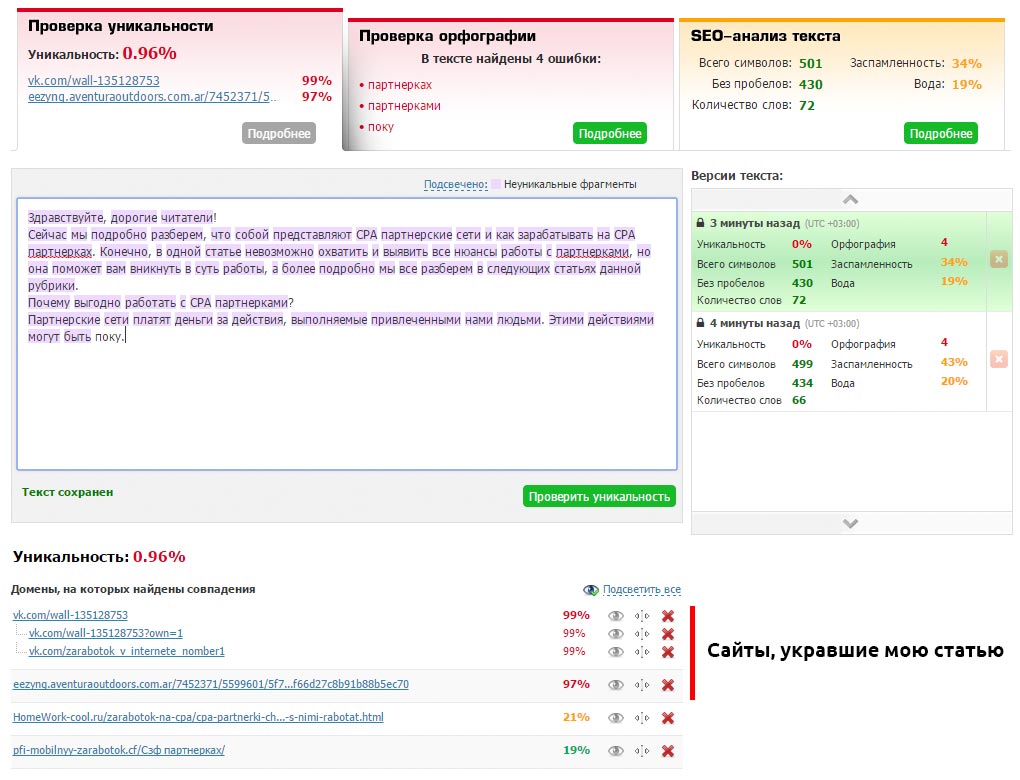
Таким образом вы найдет все сайты, которые содержат текст полностью или частично взятый с вашего сайта. В таком случае необходимо первым делом обратиться к веб-мастеру с просьбой удалить позаимствованный контент (или поставить каноническую ссылку, если это для вашего бизнеса работает и его сайт не слишком плохой в плане SEO). Если консенсус не будет достигнут, вы можете сообщить о копии в Google: отчет о нарушении авторских прав.
2 Синдикация контента
Синдикация – это переиздание содержания на другом сайте с разрешения автора оригинального произведения. И хотя она является законным способом получения вашего контента для привлечения новой аудитории, важно установить рекомендации для издателей, чтобы синдикация не превратилась в проблемы для SEO.
В идеале, издатель должен использовать канонический тег на статью, чтобы указать, что ваш сайт является первоисточником. Другой вариант заключается в применении тега noindex к синдицированному контенту.
Вариант 1: <link rel=»canonical» href=»http://site.ru/original-content» />
Вариант 2: <div rel=»noindex»>Синдицированный контент</div>
Всегда проверяйте это вручную каждый раз, когда разрешаете дублирование вашего контента на других сайтах.
3 HTTP и HTTPS протоколы
Одной из наиболее распространенных внутренних причин дублирования страниц на сайте является одновременная работа сайта по протоколам HTTP и HTTPS. Эта проблема возникает, когда перевод сайта на HTTPS реализован с нарушением инструкции, которую можно прочитать по ссылке. Две распространенные причины:
Отдельные страницы сайта на протоколе HTTPS используют относительные URL
Это часто актуально, если использовать защитный протокол только для некоторых страниц (регистрация/авторизация пользователя и корзина покупок), а для всех остальных – стандартный HTTP. Важно иметь в виду, что защищенные страницы могут иметь внутренние ссылки с относительными URL-адресами, а не абсолютными:
Абсолютный: https://www.homework-cool.ru/category/product/
Относительный: /product/
Относительные URL не содержат информацию о протоколе. Вместо этого они используют тот же самый протокол, что и родительская страница, на которой они расположены. Если поисковый бот найдет такую внутреннюю ссылку и решит следовать по ней, то перейдет по ссылке с HTTPS. Затем он может продолжить сканирование, пройдя по нескольким относительным внутренним ссылкам, а может даже просканировать весь сайт с защитным протоколом. Таким образом в индекс попадут две совершенно одинаковые версии ресурса.
В этом случае необходимо использовать абсолютные URL-адреса вместо относительных для внутренних ссылок. Если боту уже удалось найти дубли страниц на сайте, и они отобразились в панели вебмастера в Яндексе или Google, то установите 301 редирект, перенаправляя защищенные страницы на правильную версию с HTTP. Это будет лучшим решением.
Вы полностью перевели сайт на HTTPS, но HTTP версия все еще доступна
Это может произойти, если есть обратные ссылки с других сайтов, указывающие на HTTP версию, или некоторые из внутренних ссылок на вашем ресурсе по-прежнему содержат старый протокол.
Чтобы избежать разбавления ссылочного веса и траты краулингового бюджета используйте 301 редирект с HTTP и убедитесь, что все внутренние ссылки указаны с помощью относительных URL-адресов.
Чтобы быстро проверить дубли страниц на сайте из-за HTTP/HTTPS протокола, нужно проконтролировать работу настроенных редиректов.
4 Страницы с WWW и без WWW
Одна из самых старых причин для появления дублей страниц на сайте, когда доступны версии с WWW и без WWW. Как и HTTPS, эта проблема обычно решается за счет включения 301 редиректа. Также необходимо указать ваш предпочтительный домен в панели вебмастера Google.
Чтобы проверить дубли страниц на сайте из-за префикса WWW, так же редирект должен корректно работать.
5 Динамически генерируемые параметры URL
Динамически генерируемые параметры часто используются для хранения определенной информации о пользователях (например, идентификаторы сеансов) или для отображения несколько иной версии той же страницы (например, сортировка или корректировка фильтра продукции, поиск информации на сайте, оставление комментариев). Это приводит к тому, что URL-адреса выглядят следующим образом:
URL 1: https:///homework-cool.ru/position.html?newuser=true
URL 2: https:///homework-cool.ru/position.html?older=desc
Несмотря на то, что эти страницы будут содержать дубли контента (или очень похожую информацию), для поисковых роботов это повод их проиндексировать. Часто динамические параметры создают не две, а десятки различных версий страниц, которые могут привести к значительному количеству напрасно проиндексированных документов.
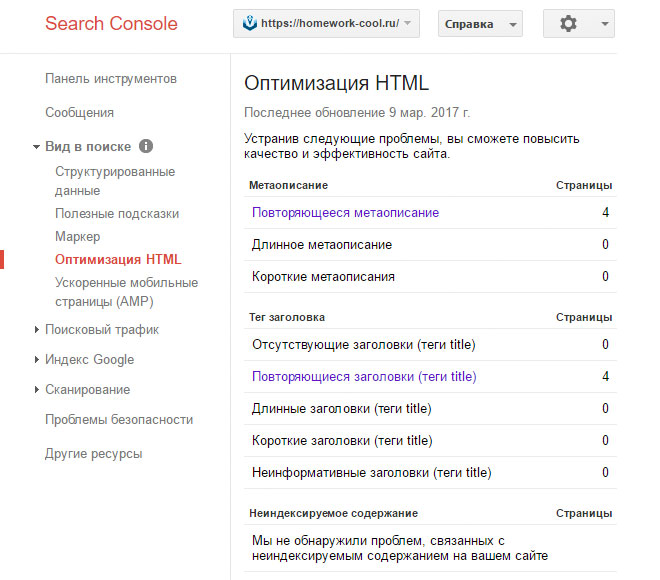
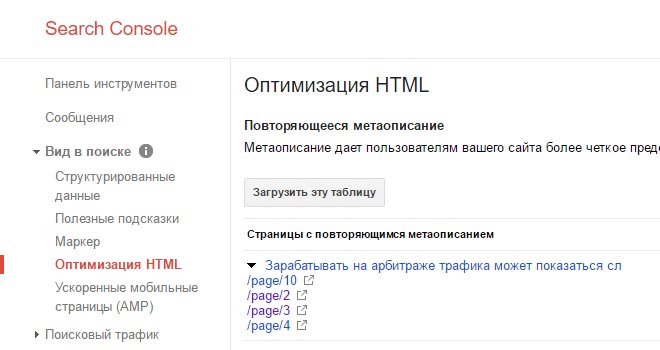
Найти дубли страниц на сайте можно с помощью панели вебмастера Google в разделе «Вид в поиске — Оптимизация HTML»
Яндекс Вебмастер покажет их в «Индексирование – Страницы в поиске»
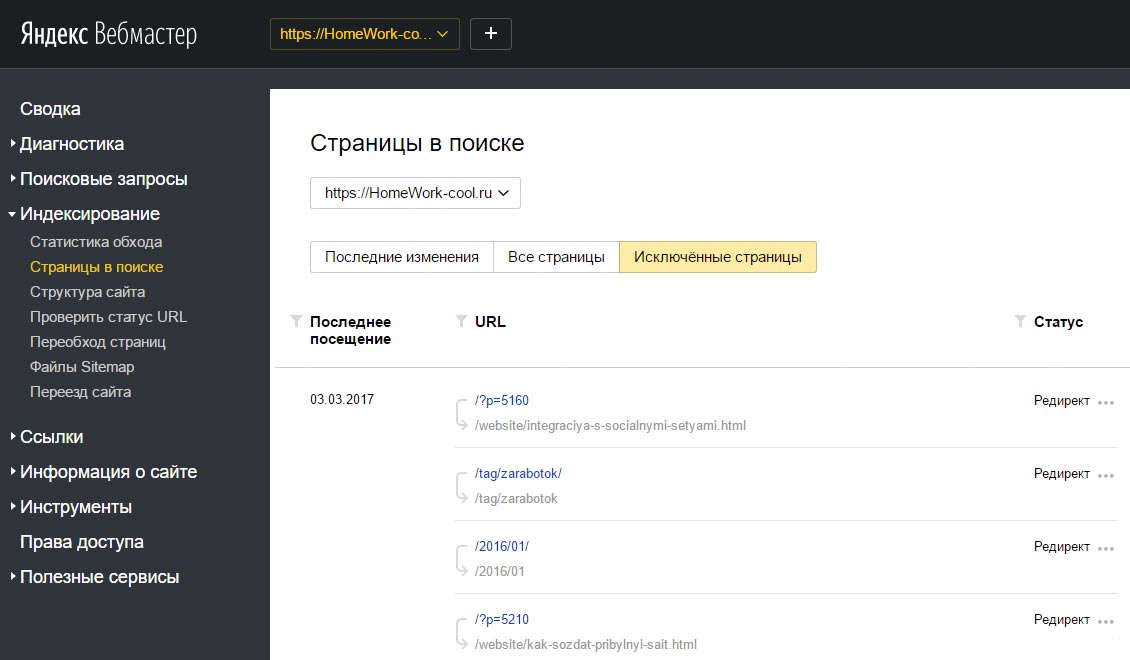
Для конкретного случая в индексе Google находятся четыре страницы пагинации с одинаковым метаописанием. А скриншот из Яндекса наглядно показывает, что на все «лишние» атрибуты в ссылках настроен редирект, включая теги.
Еще можно прямо в поисковике ввести в строку:
site:domen.ru -site:domen.ru/&
Таким образом можно найти частичные дубли страниц на сайте и малоинформативные документы, находящиеся в индексе Google.
Если вы найдете такие страницы на вашем сайте, убедитесь, что вы правильно классифицируете параметры URL в панели вебмастера Google. Таким образом вы расскажите Google, какие из параметров должны быть проигнорированы во время обхода.
6 Подобное содержание
Когда люди говорят про дублирование контента, они подразумевают совершенно идентичное содержание. Тем не менее, кусочки аналогичного содержания так же попадают под определение дублирования контента на сайте от Google:
«Если у вас есть много похожих документов, рассмотрите вопрос о расширении каждого из них или консолидации в одну страницу. Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но информация на них одинакова, вы можете либо соединить страницы в одну о двух городах или добавить уникальное содержание о каждом городе»
Такие проблемы могут часто возникать с сайтами электронной коммерции. Описания для аналогичных продуктов могут отличаться только несколькими специфичными параметрами. Чтобы справиться с этим, попробуйте сделать ваши страницы продуктов разнообразными во всех областях. Помимо описания отзывы о продукте являются отличным способом для достижения этой цели.
На блогах аналогичные вопросы могут возникнуть, когда вы берете старую часть контента, добавите некоторые обновления и опубликуете это в новый пост. В этом случае использование канонической ссылки (или 301 редиректа) на оригинальный пост является лучшим решением.
7 Страницы версий для печати
Если страницы вашего сайта имеют версии для печати, доступные через отдельные URL-адреса, то Google легко найдет их и проиндексирует через внутренние ссылки. Очевидно, что содержание оригинальной статьи и её версии для печати будет идентичным – таким образом опять тратится лимит индексируемых за один заход страниц.
Если вы действительно предлагаете печатать чистые и специально отформатированные документы вашим посетителям, то лучше закрыть их от поисковых роботов с помощью тега noindex. Если все они хранятся в одном каталоге, таком как https://homework-cool.ru/news/print/, вы можете даже добавить правило Disallow для всего каталога в файле robots.txt.
Disallow: /news/print
Подведем итоги
Дублирование контента и скрытые дубли страниц на сайте могут обернуться головной болью для оптимизаторов, так как это приводит к потере ссылочного веса, трате краулингового бюджета, медленной индексации новых страниц.
Помните, что вашими лучшими инструментами для борьбы с этой проблемой являются канонические ссылки, 301 редирект и robots.txt. Не забывайте периодически проверять и обновлять контент вашего сайта с целью улучшения индексации и ранжирования в поисковых системах.
Какие случаи дублей страниц вы находили на своем сайте, какие методы используете, чтобы предотвратить их появление? Я с нетерпением жду ваших мыслей и вопросов в комментариях.
homework-cool.ru
Как найти дубли страниц на сайте
Содержание статьи
Наличие дублей страниц в индексе — это такая страшная сказка, которой seo-конторы пугают обычно владельцев бизнеса. Мол, смотрите, сколько у вашего сайта дублей в Яндексе! Честно говоря, не могу предоставить примеры, когда из-за дублей сильно падал трафик. Но это лишь потому, что эту проблему я сразу решаю на начальном этапе продвижения. Как говорится, лучше перебдеть, поэтому приступим.
Что такое дубли страниц?
Дубли страниц – это копии каких-либо страниц. Если у вас есть страница site.ru/bratok.html с текстом про братков, и точно такая же страница site.ru/norma-pacany.html с таким же текстом про братков, то вторая страница будет дублем.
Могут ли дубли плохо сказаться на продвижении сайта
Могут, если у вашего сайта проблемы с краулинговым бюджетом (если он маленький).
Краулинговый бюджет — это, если выражаться просто, то, сколько максимум страниц вашего сайта может попасть в поиск. У каждого сайта свой КБ. У кого-то это 100 страниц, у кого-то — 25000.
Если в индексе будет то одна страница, то другая, в этом случае они не будут нормально получать возраст, поведенческие и другие «подклеивающиеся» к страницам факторы ранжирования. Кроме того, пользователи могут в таком случае ставить ссылки на разные страницы, и вы упустите естественное ссылочное. Наконец, дубли страниц съедают часть вашего краулингового бюджета. А это грозит тем, что они будут занимать в индексе место других, нужных страниц, и в итоге нужные вам страницы не будут находиться в поиске.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress такой херни обычно нету, а вот всякие Джумлы генерируют огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Способы поиска дублирующего контента
Можно искать дубли программами или онлайн-сервисами. Делается это по такому алгоритму — сначала находите все страницы сайта, а потом смотрите, где совпадают Title.
XENU
XENU – это очень олдовая программа, которая издавна используется сеошниками для сканирования сайта. Лично мне её старый интерфейс не нравится, хотя задачи свои она в принципе решает. На этом видео парень ищет дубли именно при помощи XENU:
Screaming Frog
Я лично пользуюсь либо Screaming Frog SEO Spider, либо Comparser. «Лягушка» — мощный инструмент, в котором огромное количество функций для анализа сайта.
Comparser
Comparser – это все-таки мой выбор. Он позволяет проводить сканирование не только сайта, но и выдачи. То есть ни один сканер вам не покажет дубли, которые есть в выдаче, но которых уже нет на сайте. Сделать это может только Компарсер.
Поисковая выдача
Можно также и ввести запрос вида site:vashsite.ru в выдачу поисковика и смотреть дубли по нему. Но это довольно геморройно и не дает полной информации. Не советую искать дубли таким способом.
Онлайн-сервисы
Чтобы проверить сайт на дубли, можно использовать и онлайн-сервисы.
Google Webmaster
Обычно в панели вебмастера Google, если зайти в «Вид в поиске — Оптимизация HTML», есть информация о страницах с повторяющимся метаописанием. Так можно найти часть дублей. Вот видеоинструкция:
Sitereport
Аудит сайта от сервиса Sitereport также поможет найти дубли, помимо всего прочего. Хотя дублированные страницы можно найти и более простыми/менее затратными способами.
Решение проблемы
Для нового и старого сайта решения проблемы с дублями — разные. На новом нам нужно скорее предупредить проблему, провести профилактику (и это, я считаю, самое лучшее). А на старом уже нужно лечение.
На новом сайте делаем вот что:
- Сначала нужно правильно настроить ЧПУ для всего ресурса, понимая, что любые ссылки с GET-параметрами нежелательны;
- Настроить редирект сайта с www на без www или наоборот (тут уж на ваш вкус) и выбрать главное зеркало в инструментах вебмастера Яндекс и Google;
- Настраиваем другие редиректы — со страниц без слеша на страницы со слешем или наоборот;
- Завершающий этап – это обновление карты сайта.
Отдельное направление – работа с уже имеющимся, старым сайтом:
- Сканируем сайт и все его страницы в поисковых системах;
- Выявляем дубли;
- Устраняем причину возникновения дублей;
- Проставляем 301 редирект и rel=»canonical» с дублей на основные документы;
- В обязательном порядке 301 редиректы ставятся на страницы со слешем или без него. Обязательная задача – все url должны выглядеть одинаково;
- Правим роботс — закрываем дубли, указываем директиву Host для Yandex с заданием основного зеркала;
- Ждем учета изменений в поисковиках.
Как-то так.
znet.ru
Дубликаты страниц сайта. Простой поиск дублей
Проверка сайта на дубликаты страниц
Ваш сайт продвигается слишком медленно? Постоянно случаются откаты на более низкие позиции? И это при том что внутренняя и внешняя оптимизация веб-ресурса выполнена на высшем уровне?
Подобное случается по нескольким причинам. Самая частая из них –дубликаты страниц на сайте, имеющих разные адреса и полное или частичное повторение содержания.
Чем опасны дубли страниц на сайте
Дубликаты страниц на сайте делают текст, размещенный на них неуникальным. К тому же снижается доверие к подобному веб-ресурсу со стороны поисковых систем.
Чем же еще опасны дубли страниц на сайте?
- Ухудшение индексации. Если веб-ресурс достаточно объемный и по каким-либо причинам регулярно происходит дублирование контента на сайте (бывают случаи, когда у каждой страницы существует по 4–6 дублей), это достаточно негативно влияет на индексацию поисковиками.
Во-первых, из-за того, что роботы поисковиков расходуют время при индексации лишних страничек.
Во-вторых, поисковики постоянно выполняют поиск дублей страниц. При обнаружения таковых они занижают позиции веб-ресурса и увеличивают интервалы между заходами своих роботов на его страницы.
- Ошибочное определение релевантной страницы. На сегодняшний день алгоритмы поисковых систем обучены распознавать дублирование контента на сайте, который индексируется. Но выбор поисковых роботов не всегда совпадает с мнением владельца веб-ресурса.
В итоге в результатах поиска может оказаться совсем не та страничка, продвижение которой планировалось. При этом внешняя ссылочная масса может быть настроена на одни странички, а в выдачу будут попадать дубликаты страниц на сайте.
В результате ссылочный профиль будет неэффективным и поведенческие факторы будут колебаться из-за распределения посетителей по ненужным страницам. Другими словами, будет путаница, которая крайне негативно скажется на рейтинге Вашего сайта.
- Потеря естественных ссылок. Посетитель, которому понравилась информация с Вашего веб-ресурса, может захотеть кому-нибудь ее рекомендовать. И если эту информацию он почерпнул на странице- дубликате, то и ссылку он будет распространять не ту, которая требуется.
Такие ценные и порой дорогие естественные ссылки будут ссылаться на дубли страниц на сайте, что в разы снижает эффективность продвижения.

Дублирование контента на сайте. Причины
Чаще всего дубли страниц на сайте создаются по одной из причин:
- Не указано главное зеркало сайта. То есть одна и та же страница доступна по разным URL — с www. и без.
- Автоматическая генерация движком веб-ресурса. Такое довольно часто происходит при использовании новых современных движков. Поскольку у них в теле заложены некоторые правила, которые делают дубликаты страниц на сайте и размещают их под другими адресами в своих директориях.
- Случайные ошибки веб-мастера, вследствие которых происходит дублирование контента на сайте. Результатом таких ошибок часто становится появление нескольких главных страничек, имеющих разные адреса.

- Изменение структуры сайта, которое влечет за собой присваивание новых адресов старым страницам. При этом сохраняются их копии со старыми адресами.

Как найти дубликаты страниц
Проверить сайт на дубли страниц поможет один из несложных методов:
- Анализ данных в сервисах поисковых систем для вебмастеров. Добавляя свой веб-ресурс в сервис Google Webmaster, Вы получаете доступ к данным раздела «Оптимизация HTML». В нем по дублируемым мета-данным можно найти страницы, на которых есть дублирование контента.
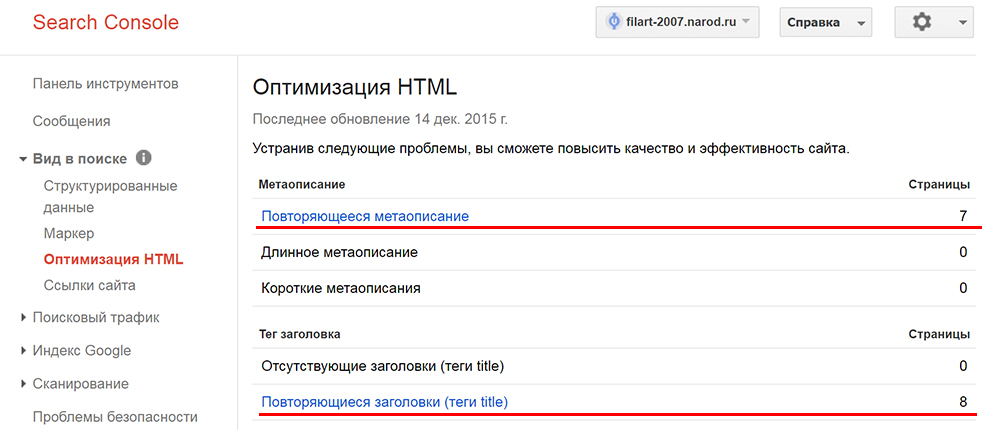
В Яндекс.Вебмастере дубли страниц можно проверить в разделе «Индексирование» > «Вид в поиске». На этой странице сделайте сортировку «Исключенные страницы» > «Дубли».
- Анализ проиндексированных страниц. Для получения их списка используется специальные операторы поисковых систем:
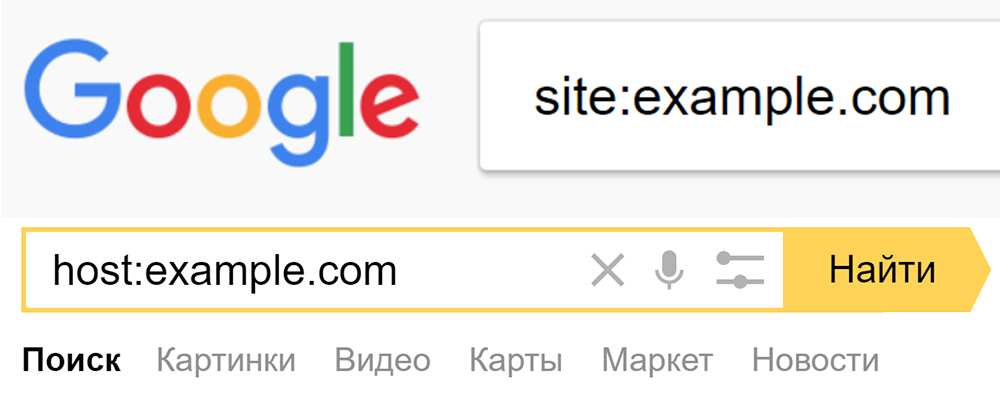
Полученная в результате выдача поможет проверить сайт на дубли страниц, у которых будут повторяться заголовки и сниппеты.
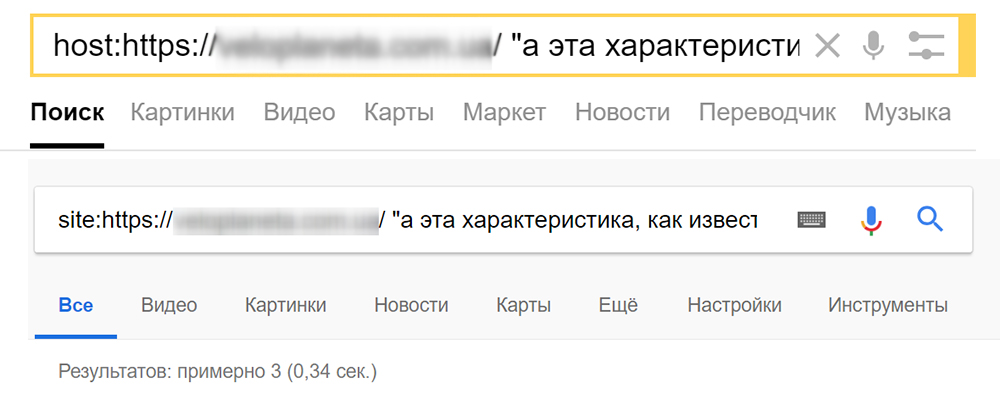
3. Поиск дублей фрагментов текста. Для получения их списка используются уже знакомые операторы (site: — для Google и hosh: — для Яндекса) , после которых указываем адрес сайта и в кавычках фрагмент текста. В результате мы можем получить либо полные дубли страниц, либо же частичное дублирование контента.
4. С помощью специальных программ и сервисов. Например, воспользовавшись программой Netpeak Spider, можно определить дубликаты страниц, текста, мета-тегов и заголовков. Все обнаруженные дубли необходимо будет удалить.
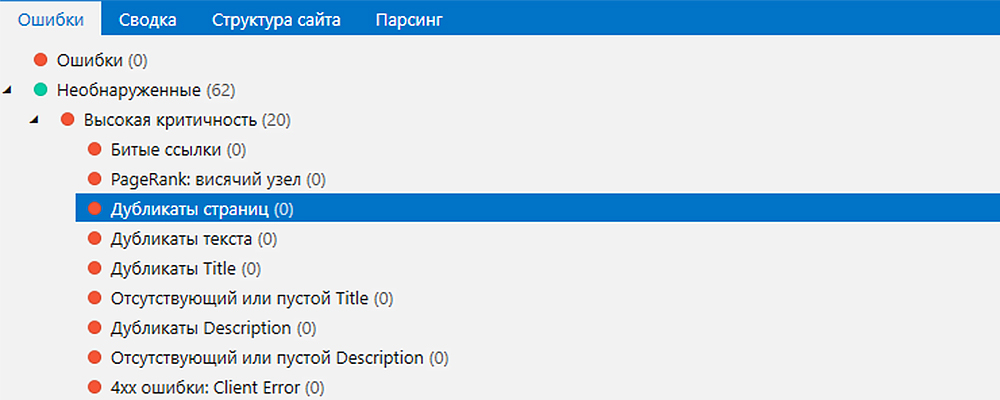
Если вы не хотите покупать десктопную программу Netpeak Spider, найти дубли страниц поможет многофункциональная seo-платформа Serpstat, которая работает онлайн + есть мобильная версия.
Сервис находит дублирующиеся тайтлы, дескрипшны, h2 дубль тайтла, больше чем 1 тайтл на странице, больше чем 1 заголовок h2 на странице.
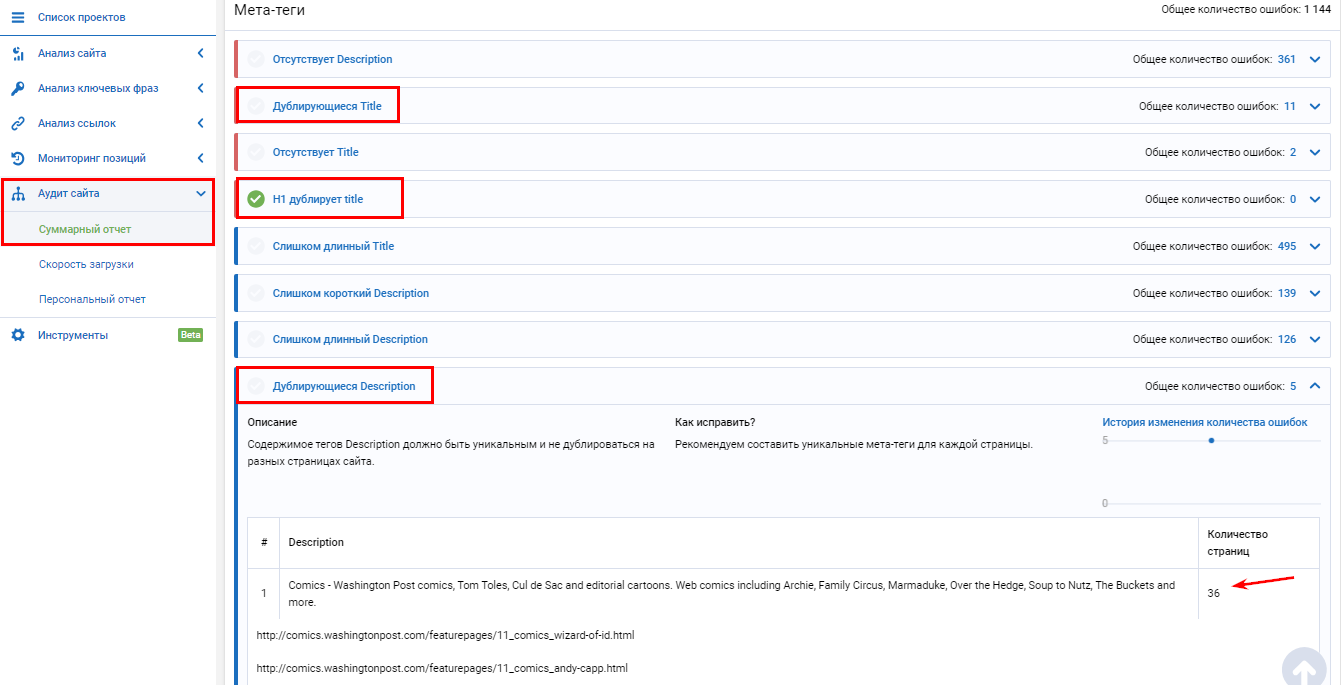

Выводы
Желательно время от времени выполнять вышеперечисленные проверки, чтобы дублирование контента на сайте не стало неожиданной причиной падения его рейтингов. При этом нужно не забывать, что полные дубликаты страниц не являются единственной проблемой.
Дублирующиеся h2, title, description, а также некоторые части контента вроде отзывов и комментариев также очень нежелательны.
Надеемся, что эта статья была для Вас полезной. Не забудьте поделиться ссылкой на нее с теми, кому она также может быть интересной!
seo-akademiya.com