
Обзор сервиса JustMagic — Анализ текстов и многое другое
Последнее время все гуру SEO-индустрии в один голос кричат о необходимости работы над текстовыми факторами. Ссылочное теряет позиции (нет, не умирает, ибо бред), поведенческие крутить стрём, а вот работа с текстовыми факторами дело благородное и полезное.
Сегодня речь пойдёт о сервисе JustMagic, объединившем в себя множество инструментов, часть которых и призвана облегчить жизнь SEO-специалистам, а также позволяет «капнуть погублже» и получить максимум отдачи от текстов, которые мы размещаем на сайтах. Под отдачей я подразумеваю траф и позиции, естественно, сервис исключительно аналитический с соответствующим подходом. Иными словами — результаты работы с сервисом это сухие числа, которые выражают качество текстов и позволяют сделать текст максимально качественным с точки зрения SEO.
Маркетинговые трюки, речевые обороты, тавтологию, косноязычные изречения, литературный слог и прочий «гуманитарный изыск» данный сервис в расчет не берет.
Так что, если вы SEOшник и верите в силу текстовых факторов ранжирования — этот сервис, а соответственно и обзор части его функционала — для вас.
Начнем с небольшой предыстории. Автор программы — Алексей Чекушин, хорошо известный в профессиональных кругах SEO-специалист. Очевидно, что сперва ряд наработок сервиса использовался Алексеем для внутренних задач и лишь позднее перерос в открытый сервис. Just Magic позиционируется как сервис для опытных SEO-специалистов, а не широких масс.
Появился Just Magic лишь в прошлом году, однако за это время он сумел существенно подрости и обзавестись довольно богатым функционалом. Алексей активно развивает свой сервис и, я думаю, Just Magic спрятал еще не мало карт в рукаве.
Ну что, достаточно лирики — перейдем к обзору.
Возможности Just Magic
- Подбор семантики
- Расширение семантики
- Кластеризация запросов
- Оценка качества тематичности текстов «Акварель».
- Анализатор текстов
Функционал сервиса довольно широк, мы остановимся на каждом пункте и рассмотрим их в отдельности.
Удобство работы и внешний вид
Нет — это не прикол, сервис выглядит именно так. Первые минуты знакомства с Just Magic вызывали у меня щенячий восторг. Четко, модно, молодежно! Однако при более длительном контакте левый глаз начал подергиваться, пальцы отбивать чечетку по столу, а зубы скрежетать друг о друга… «Уау, как оригинально!» сменилось на «Да е…ы в …т, вы серьезно!? Где кнопка — нормальный интерфейс?». В общем, я искренне надеюсь, что Алексей услышит меня, и хотя бы в качестве сплит-теста попробует прикрутить к своему сервису более спокойный дизайн.
Удобство работы так же не порадует новичков, т.к. если вы не понимаете зачем это, не знаете злополучных регулярок и не в состоянии понять и применить, полученные результаты — то, вам не по пути.
Иными словами — к новичкам сервис не дружелюбен, и даже сам интерфейс намекает об этом, нарочито выкрикивая:»Школоло, когда все сидели под DOS-ом ты еще даже не ползал под столом!»
Сервис не очень интуитивен, но задавшись целью и покурив маны в течение 10-20 минут вам все покажется простым, понятным и разложенным по своим местам (это не умиляет того факта, что дизайн «вырвиглаз»).
Скриншот JustMagic
Раздел «Текстовый анализатор»
Вот, как в самом Just Magic описан раздел анализа текстов
В общем, на вход нам нужно подать Экселевский файл с расширением .xlsx, в котором будут содержаться URL наших посадочных и ключи напротив. Вот, как это выглядит на примере:
Лимит бесплатных проверок ограничен 5-ью страницами в месяц. Иными слвами на шару вы можете проверить 5 фраз по 10 ключам каждую.
Отчет/результат высылается на почту, указанную при регистрации и содержит 2 файла. Архив и .xlsx отчёт. В архиве файл с аналогичным содержимым, однако в формате .tsv
Открыв отчет в первый раз возникает ощущение, что структуру документа делали люди, при
Just-Magic — онлайн сервис для работы с ключевыми словами, семантикой
Обзор Just-Magic
Just-Magic — сервис, предназначенный для составления семантического ядра нового сайта, а также расширения семантики существующего ресурса. Генерация производится на основе собственных баз данных сервиса, популярных запросов поисковых систем и статистических данных портала. Бесплатный тариф включает в себя 100 лимитов в месяц.Инструмент подойдёт SEO-специалистам, поскольку позволяет группировать автоматически фразы при составлении структуры сайта. Платформой могут воспользоваться вебразработчики для создания нового ресурса. Доступны пакетные тарифы и расчёты за разовый анализ, что делает сервис удобным как для больших, так и маленьких компаний.
Для начала кластеризации необходимо залить список запросов — это можно сделать через окно браузера или загрузив таблицу в формате .XLS. Just-Magic анализирует слова и выводит результаты с рекомендованными рубриками и url’ами. При желании можно указать сайт-конкурент с желаемой структурой. Тематический классификатор определяет тематику страницы или фразы. Программа позволяет проверять тексты на наличие ключей и их видимость для поисковых роботов, а также находить лишние слова, которые могут способствовать пессимизации. Подключив инструмент к Яндекс.Метрике, можно получить данные о том, по каким запросам приходит аудитория сайта и какими фразами можно дополнить страницы для увеличения поискового трафика. Доступна проверка частотности ключей. Сгенерированный отчёт можно отправить по электронной почте.
Ключевые особенности
- Составление семантического ядра сайта
- Проверка текстов на наличие ключевых фраз
- Тематический классификатор
- Интеграция с Яндекс.Метрикой
- Бесплатно 100 лимитов после регистрации
JustMagic | Тематический классификатор — зачем он нужен, и как его правильно применять.
Что такое тематический классификатор?
Тематический классификатор — это еще один способ поменьше работать для оптимизатора. Попробуйте решить «простую» задачку. Вы напарсили запросы, и у вас получились вот такие:
- аквамарин
- аквамарин 2
- аквамарин 3
- аквамарин 4
- аквамарин 5
- аквамарин сочи
- аквамарин владивосток
- аквамарин казань
И вам нужно понять, что из них относится к вашей тематике, а что — лишнее. Допустим, ваша тематика — отели. Что вы будете делать? Скорее всего — зайдете в выдачу и посмотрите. Но так вы поступите, если запросов у вас десяток или два. А если их тысячи? Или — десятки тысяч? Метод «зайти и проверить каждый» работать перестаёт. И тут на помощь приходит тематический классификатор, который распределит эти запросы за вас. Вот как он справляется с представленным выше списком:

Как видим, отельной тематике соответствуют всего 3 запроса. «Аквамарин 3» — это бизнес-центр, «Аквамарин Владивосток» — это строящийся ЖК. А «аквамарин казань» — и вовсе ювелиры. Можете самостоятельно сходить в выдачу и проверить. Каким образом классификатор понимает, какой запрос к чему относится? Он делает то же самое, что и человек — идет в выдачу и смотрит что в ней есть. Затем сравнивает найденное в выдаче с некоторыми «эталонными» коллекциями. При этом анализируются не урлы сайтов или какая-то информация по ним, а сами текстов заголовков и сниппетов. В общем случае процесс выглядит так:
Запрос выдачи → Разбиение на слова → Построение вектора → Сравнение с векторами тематик.
Как это применимо на практике? Когда мы начинаем разбор какой-то новой ниши, или сбор семантики для сайта, мы всегда начинаем с массового парсинга запросов. Запросы мы эти получаем из вордстата, подсказок, вебмастера, метрики или баз. При любом методе сбора, мы всегда будем получать как соответствующие нашему сайту запросы, так и нет. Рассмотрим на достаточно хардокрном примере. Допустим, у нас есть автопортал, и мы хотим сделать раздел про BMW ALPINA. Мы обращаемся к вордстату, подавая к нему запросы alpina и альпина. И получаем вот такой интересный результат:
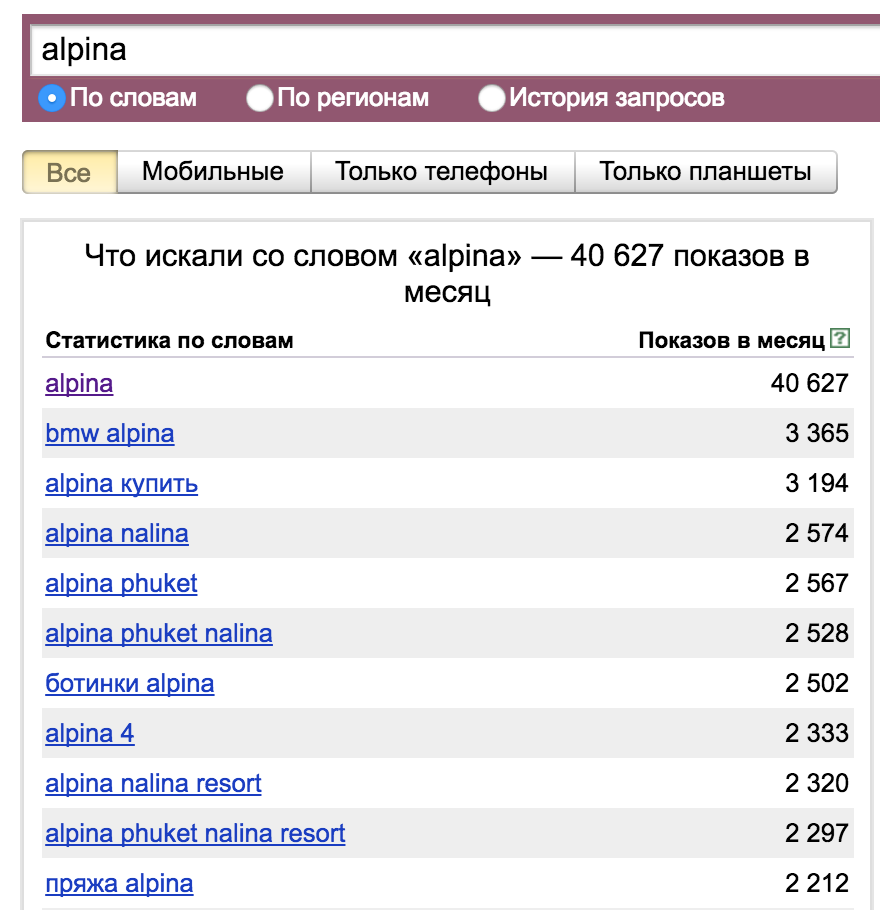
Оказывается, помимо BMW, alpina может быть чем угодно. Ботинками, отелем, даже пряжей. Посмотрим, как с такой задачей справится классификатор. Загружаем в него спарсенные запросы, фильтруем по вхождению «BMW» в тематике и получаем вот такой список:

Как видно, качество очень хорошее. Может показаться, что один запрос там лишний — а именно «вино альпина». Но если открыть выдачу и почитать, то станет понятно что нет, он очень даже к месту:
А в багажнике — еще один маленький штрих — вы найдете пристегнутый ремешками, деревянный ящичек. Внутри несколько бутылок вина. Компания Alpina всем клиентам обязательно дарит несколько бутылок с собственных виноградников. Вино — хобби хозяина фирмы Буркарта Бовенсайпена.
Если бы мы искали не «бмв», а что-то другое, то классификатор нам опять же помог бы. Например, мотоциклы:

Или автохимию:
(оказывается, альпина — это еще и бренд моторного масла).

Таким образом, в классический метод сбора семантики добавляется ещё один элемент. После первичного сбора ядра мы выполняем тематическую классификацию запросов и отсеиваем нетематичные:
Первичный сбор запросов → Тематическая классификация → Кластеризация/постраничное.
Ещё одно применение — это почистить текущее ядро. Причем классификатор справляется даже с теми случаями, где человек запрос оставит. Например, если мы продвигаем сайт про гостиницы, то казалось бы что криминального в запросе «гостиница чайка ярославль»? Однако, классификатор упрямо относит его в «/Бизнес/Недвижимость/Аналитика». Почему так происходит? Давайте заглянем в выдачу:
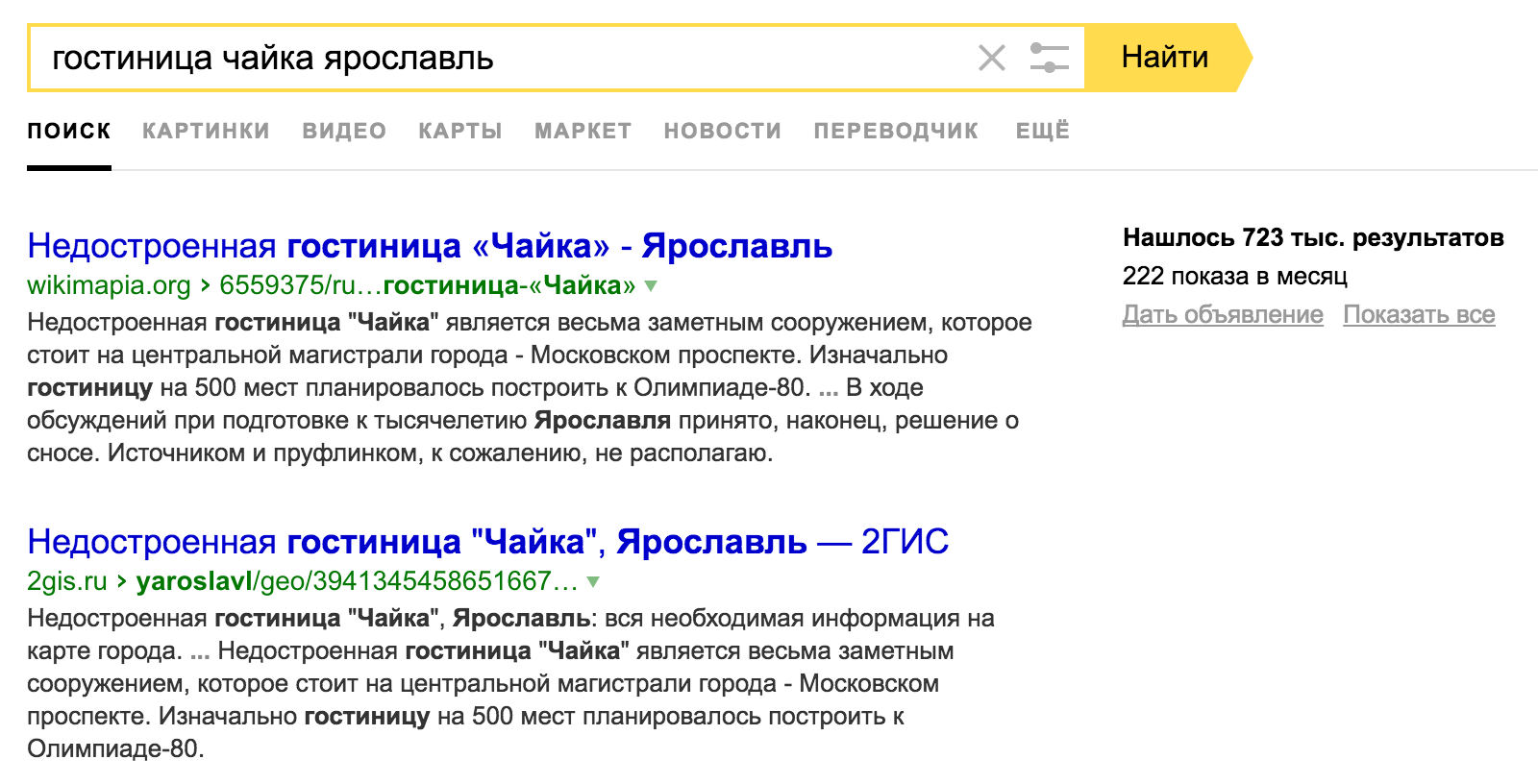
Оказывается, это недостроенная гостиница и для сайта бронирований отелей она совершенно не подходит. И такой пример далеко не единичный. Что может быть не так с запросом «давидыч гостиница самары»? А почему «отель двух миров уфа» лучше выкинуть из ядра? Ответы на эти вопросы можно получить только зайдя в выдачу. Или же — воспользовавшись классификатором.
Где пощупать тематический классификатор самому?
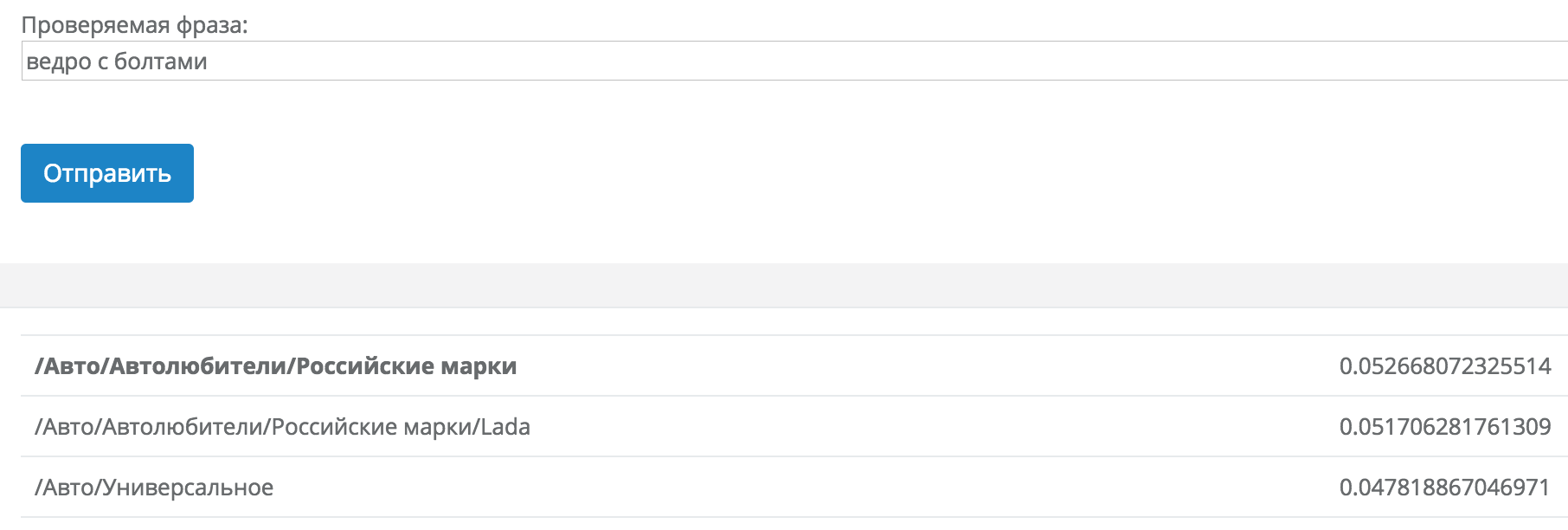
1) У нас есть шикарная полностью бесплатная демка классификатора: https://just-magic.org/serv/demo_temakl.php
Можно погонять отдельные запросы и посмотреть как классификатор справляется с вашей тематикой (работает только с запросами, урлы не разбирает).
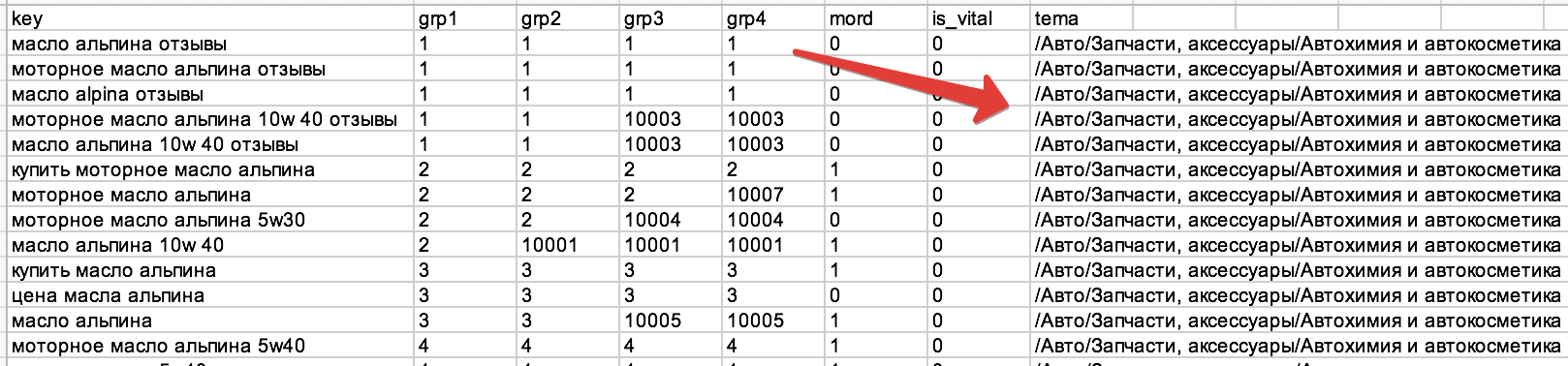
2) Тематический классификатор встроен в кластеризатор: https://just-magic.org/serv/grp_onl.php
В столбце «tema» выводится результат классификации:
3) Тематический классификатор есть отдельным модулем: https://just-magic.org/serv/temakl.php
Зачем он нужен отдельным модулем, если уже встроен в кластеризатор?
1. Он дешевле. Ровно в 2 раза дешевле, чем кластеризация. Что очень актуально для чистки ядра перед кластеризацией или расширением.
2. У него есть опция выгрузки расширенных данных. Это очень актуально для запросов, которые могут быть отнесены сразу к нескольким категориям. Например, куда отнести запрос «диета для фитнеса»?
/Дом/Кулинария/Диеты?
/Дом/Мода и красота/Фитнес?
/Дом/Здоровье/Здоровый образ жизни?
Все три темы подходят для запроса. Расширенные данные выгружают не только 1, наиболее релевантную тему, а 10 релевантных с их условными весами, что упрощает работу с подобными запросами.
3. Он умеет работать не только с запросами, но и с урлами (этой опции нет и в демке). Допустим, вы хотите пробить своих/потенциальных доноров на тематичность. Просто загрузите список урлов (с http/https), анализатор сам распознает в них урлы и присвоит тематику:

Внимание! Анализатор определяет тематику не сайта, а конкретной страницы. Как пример — анализ трех разных категорий с Яндекс.Маркета:

Подведем итог. Тематический классификатор — очень удобный инструмент для массовой фильтрации запросов. Он может эффективно применяться как при фильтрации запросов при подборе ядра, так и для проверки текущего. Пользуйтесь классификатором, и ваши волосы будут мягкими и шелковистыми ядра станут лучше и чище.
JustMagic | Группы
Данные раздел служит для групповой работы над проектами, например, владелец веб-студии, может подключать к своей учетной записи произвольных пользователей.
Нормальную страницу с документацией всё руки не доходят сделать, поэтому краткая схема работы будет описана прямо тут.
Термины. Master — тот, кто управляет учёткой и подключает к себе пользователей. Slave — пользователь, который находясь в этом режиме, использует ресурсы учётки Master. Задачи, отправленные в этом режиме, принадлежат учётке Master и при ограничении доступа Masterом, Slave-юзер теряет к ним доступ. Будучи одобренным Master(ом/ами), Slave юзер может переключатся между ними или своей учёткой в любой момент времени. Например, утром, придя на работу, оптимизатор подключается к Master-записи основной компании, а вечером, придя домой, выключает режим Slave и работает с личными проектами тратя ресурсы своей учётной записи.
Как происходит добавление Slave-юзеров:
- Slave-юзер должен зарегаться в системе и сообщить Masterу свой email. Пока пользователя нет в системе, Master не сможет его добавить.
- Master, убеждается, что у него активен режим Master, и добавляет Slave-юзера через форму, используя его email.
- Slave-юзер переключает основной режим системы в Slave.
- После выполнения предыдущего пункта, в нижней части страницы управления группами, у Slave-юзера появляется список тех Master, которые разрешили ему доступ. Их может быть несколько, т.к. одного юзера в теории могут добавить к себе несколько компаний. Slave-юзер должен выбрать из этого списка своего Master на текущий момент.
После этого, всё должно заработать. Если что-то не работает, то в разделе управления группами, и у Master, и у Slave выводится информация, кто в каком режиме находится и на каком основании. Если ничего не получается — пишем в саппорт. Кроме того, не забываем, что у Master должен быть тариф с поддержкой групповой работы.
JustMagic | Документация API
Оглавление
Введение
Если вы не обладаете достаточным опытом программирования и не понимаете принципов работы сетевых протоколов — просьба использовать веб-интерфейс и не трогать API. Система и документация сделаны на скорую руку и рассчитаны на более-менее опытных кодеров, которым не нужно разжёвывать элементарные вещи.
Вся архитектура серверов JustMagic построена по принципу KISS. Некоторые вещи, которые могут показаться нелогичными, неудобными или устаревшими, сделаны таким образом в угоду производительности и унификации. Например, 100млн строк, переданных в json формате, потребует относительно много памяти для распаковки. Если же эти строки передать в простом текстовом формате, разделив их символом перевода строки ‘\n’, то любой объем можно последовательно обработать с общим расходом памяти в несколько килобайт.
Любимые ОС, язык программирования и среда разработки архитектора системы — Linux, Си (без++) и Vim, а консоль bash — это воплощение удобства и красоты дизайна. Думаю, эти вкусовые предпочтения заранее ответят на возникающие вопросы вида «А почему всё так неудобно? А где готовая объектная библиотека под основные языки? Таки шо, всё нужно самим с использованием Curl писать?»
Общая информация
- Ключ доступа для API можно получить в личном кабинете.
- API доступно только для тарифов от Эцилоппа и выше.
- Система в стадии тестирования, при обнаружении багов, просьба проинформировать админа по адресу [email protected]. За найденные баги отсыпаем чатлов.
- Настоятельно рекомендую подписаться на рассылку новостей API в личном кабинете, т.к. через неё будет происходить информирования об изменениях API.
- Описание выходных данных пока не описано в документации из-за нехватки времени и их очевидности. Если что-то совсем непонятно — спрашивайте в группе telegram, и эти данные будут немедленно описаны в документации.
- Пример кода, выполняющий простейшие операции можно скачать ТУТ. Рекомендую взять его за основу.
- Пример должен корректно работать на версиях PHP 5.5.0, PHP 7 и выше.
- Подразумевается консольный запуск командой ‘./api_ex.php‘, либо ‘/usr/bin/php api_ex.php‘
- В debian, для корректного консольного запуска нужен пакет php-cli. Ну и php-curl не помешает.
Базовые принципы:
- Все запросы отправляются на адрес https://api.just-magic.org/api_v1.php . Протокол строго https, http отвечать не будет.
- Данные отправляются в формате JSON в POST запросе. Кодировка UTF-8.
- Ответы возвращаются в формате json, за исключением случаев, когда был запрошен csv или xlsx файл результата.
- HTTP код ответа должен быть 200. Если это не так, значит что-то пошло не так.
- Все ответы имеют параметр err, который содержит короткий текстовый код ошибки и errtxt, который содержит подробное русское описание ошибки. При успешной работе err равно 0.
- Обязательные параметры модуля постановки задач отмечены красным цветом, все остальные параметры можно игнорировать, т.к. они заполнятся значениями по умолчанию.
- По некоторым простым параметрам, обработчика ошибок нет, при кривом значении оно будет автоматом заменено значением по умолчанию. Например, параметры search_engine или lang. Это сделано из-за нехватки времени. Чуть позже будет дописан нормальный обработчик ошибок, а пока просьба не ошибаться в параметрах.
- Особенности типа bool: Логическим false обладают следующие значения 0, ‘0’, », ‘false’. Всё остальное считается true. Лучше всего юзать 0 и 1.
- Для всех запросов должны быть обязательно переданы параметры action и apikey.
Ограничения системы:
Ограничения на число запросов: сервер не будет обслуживать больше 2 одновременных запросов с одного ip. Просьба отправлять задачи последовательно, а не параллельно. При кривом коде, который будет бессмысленно долбить сервер нон-стопом без пауз, доступ к API будет приостановлен. Интервал проверки готовности задач, просьба делать не меньше 30 секунд.
Типы запросов.
Тип запроса передаётся через параметр action. Допустимые значения info, put_task, get_task, list_tasks.
Тип info.
Выводит общую информацию об учётной записи, типа тарифа, стоимости операций, срок действия подписки итп. Дополнительных параметров не имеет.
Тип put_task.
Команда постановки задач. Все её параметры описаны в разделе модулей постановки задач. Подробное описание параметров можно смотреть на странице веб-интерфейса. Ядро обработки постановки задач у веб-морды и данного обработчика одно и то же. Красные параметры обязательные, всё остальное ставится по умолчанию если не передано.
Единственный дополнительный параметр, не описанный в таблицах и единый для всех модулей — это justask типа bool. При его установки в true, задача валидируется, считается её стоимость, но сама задача в работу не уходит и деньги не списываются. Этот модуль нужен для расчёта стоимости и валидации задач. Или для отладки.
Как и в веб-морде, так и в АПИ, система чистит входные данные. Удаляются все кривые непечатные символы, дубликаты строк итп. Предупреждений не выводится. Давным-давно, при первых стартах системы, мы не чистили входные данные сами, а выдавали предупреждения об ошибках и их месте. Люди были недовольны и просили просто всё фиксить автоматом и отправлять в работу. С тех пор так и повелось. ))
Описание выходных данных
- err — код ошибки, если 0, всё ок.
- errtxt — подробное описание ошибки
- tid — id поставленной задачи
- size — размер задачи в условных единицах. Для некоторых модулей это строки, для некоторых слова итп
- lim_price — цена одной единицы
- lim_plan — стоимость задачи
- lim_need — сколько не хватает денег. Если 0 — баланса достаточно
- just_ask — если true, то задача не отправлена, а только валидирована и рассчитана стоимость
Тип list_tasks
Выводит общий список задач пользователя, их статусы и дополнительные данные. Задачи сортируются в обратном порядке по убыванию. Т.е. первыми идут самые свежие.
Принимает необязательные параметры limit, по умолчанию равный 10, максимально 100 и offset по умолчанию 0. Эти параметры эквиваленты аналогичным в SQL запросах. Если вы не знаете, для чего они нужны, то пользуйтесь веб-интерфейсом. ))
Тип get_task
Служит для получения информации о конкретной задаче и выгрузке результата. Описание доп. параметров:
- tid — id задачи, с которой нужно работать
- mode — режим выдачи. Допустимо info, xlsx, csv. По умолчанию info.
- info — выдёт общие json данные о задаче, заголовки сервера:
- Content-Type: application/json;charset=utf-8
- xlsx — отдаёт результат в xlsx формате, заголовки сервера:
- Content-type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
- Content-disposition: attachment; filename=123_label.xlsx
- csv — выдёт данные в просто текстовом формате вида csv, html или txt, в зависимости от типа задачи. Выдаваемый файл сжат gzip. Заголовки сервера:
- Content-type: application/gzip
- Content-disposition: attachment; filename=123_label.csv.gz
- info — выдёт общие json данные о задаче, заголовки сервера:
- system — допустимо unix и win, по дефолту win. Имеет значение только для выдачи вида csv. При режиме unix выдаёт чистые данные с символом перевода строки «\n» в utf-8. Если режим выбран win, то перевод строки будет «\r\n», а в начале файла будет дописана BOM-метка юникодной кодировки.
Для режимов xlsx и csv используется не json, а бинарный формат данных, эквивалентный режиму сохранения файла в браузере.
Модули постановки задач
Модуль «Регулярки»
Тип задачи — rexp
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | rexp | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| base | int | Локальная база для выборки. Смотрим доступные базы в справочнике | 3 | |
| rexpa | string | POSIX совместимое регулярное выражение по которому будет сделана выборка | кот\(ы\|ам\) | |
| rexpd | string | POSIX совместимое регулярное выражение совпадения с которым будут ИСКЛЮЧЕНЫ из выборки | ^злые\s | NULL |
Модуль «Акварель»
Тип задачи — aqua
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | aqua | |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| key | string | Ключевое слово, по которому будет проходить проверка | купить ноутбук | |
| data | string | Проверяемый текст | В нашем магазине можно купить отличный ноутбук. | |
| lang | string | Язык задачи. Возможные варианты — ru/en | ru | ru |
Модуль «Акварель-генератор»
Тип задачи — aqua_gen
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | aqua_gen | |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\nрозовый слон | |
| lang | string | Язык задачи. Возможные варианты — ru/en | ru | ru |
Модуль «Частотность WordStat»
Тип задачи — wsfreq
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | wsfreq | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| ya_lrws | int | Код региона по системе кодов Яндекса. | 213 | NULL |
| device | string | Тип устройства пользователя согласно справочной таблице. | desktop | all |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\nрозовый слон | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. | ||
| s_std | bool | Собирать данные вида: (купить слона) | true | false |
| s_q | bool | Собирать данные вида: («купить слона») | true | false |
| s_qv | bool | Собирать данные вида: («!купить !слона») | true | false |
| s_qs | bool | Собирать данные вида: («[купить слона]») | true | false |
| s_qvs | bool | Собирать данные вида: («[!купить !слона]») | true | false |
Модуль «Подсказки WordStat»
Тип задачи — wssug
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | wssug | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| ya_lrws | int | Код региона по системе кодов Яндекса. | 213 | NULL |
| device | string | Тип устройства пользователя согласно справочной таблице. | desktop | all |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\nрозовый слон | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. | ||
| page | int | Число собираемых страниц вордстата. (увеличивает стоимость фразы) Допустимы целые числа от 1 до 40. При заказе 40 страниц, ценник равен 30 страницам. (скидка за объём) | 40 | 1 |
Модуль «Текстовый анализатор»
Тип задачи — txt_anlz
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | txt_anlz | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| ya_lr | int | Код региона по системе кодов Яндекса. | 213 | 213 |
| f_type | bool | Соответствие по типу страниц | true | false |
| f_per | bool | Анализировать только пересечения | true | false |
| stop | string | Стоп-лист доменов. Список фраз, разделённых символом перевода строки «\n». Не более 10 доменов. |
yandex.ru\nwikipedia.org\n |
yandex.ru\nwikipedia.org\n |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». Столбцы разделены символом «\t». Формат аналогичен формату xlsx файла. | url1\tкупить кота\n | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. |
Модуль «Тематический классификатор»
Тип задачи — temakl
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | temakl | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| f_gall | bool | Выводить 10 категорий и их условные веса. | true | false |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\n | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. |
Модуль «Маркеры-онлайн»
Тип задачи — mark_onl
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | mark_onl | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| ya_lr | int | Код региона по системе кодов Яндекса. | 213 | 213 |
| mode | string | Режим работы «hard» или «soft» | soft | hard |
| min_pwr | int | минимальный порог привязки. Допускается от 3 до 9. | 3 | 3 |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». Столбцы разделены символом «\t». Формат аналогичен формату xlsx файла. | url1\tкупить кота\n | |
| data_base | string | База для распределения. Список фраз, разделённых символом перевода строки «\n». | купить кота\nрозовый слон | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. | ||
| file_b | file | Файл xlsx формата, альтернатива полю data_base. Максимум — 14мб. Если загружен файл, то поле data_base игнорируется. |
Модуль «Маркеры»
Тип задачи — mark
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | mark | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| base | int | Локальная база для выборки. Смотрим доступные базы в справочнике | 3 | |
| mode | string | Режим работы «hard» или «soft» | soft | hard |
| min_pwr | int | минимальный порог привязки. Допускается от 3 до 9. | 3 | 3 |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». Столбцы разделены символом «\t». Формат аналогичен формату xlsx файла. | url1\tкупить кота\n | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. |
Модуль «Расширение семанитики»
Тип задачи — grp_deep
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | grp_deep | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| base | int | Локальная база для выборки. Смотрим доступные базы в справочнике | 3 | |
| deep | int | Число итераций расширения. От 0 до 9. | 2 | 1 |
| min_pwr | int | минимальный порог привязки. Допускается от 3 до 9. | 3 | 3 |
| f_delsrc | bool | Удалить исходные ключи из финальной группировки | true | false |
| f_alter | bool | Альтернативный формат нумерации групп. | false | false |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\n | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. |
Модуль «Парсер подсказок»
Тип задачи — sug_par
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | sug_par | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| lang | string | Язык задачи. Возможные варианты — ru/en | ru | ru |
| ya_lr | int | Код региона по системе кодов Яндекса. | 213 | 213 |
| mode | string | Режим работы стандартный («std«), валидация («check«), отладка («debug«). | debug | std |
| iter | int | Число итераций. От 1 до 3. | 2 | 1 |
| f_porno | bool | Искать порно-подсказки. | false | false |
| f_rus | bool | Перебор русского алфавита. | false | false |
| f_eng | bool | Перебор английского алфавита | false | false |
| f_num | bool | Перебор цифр. | false | false |
| f_space | bool | Добавлять пробел к базовой фразе | false | true |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\n | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. |
Модуль «Кластеризация семантики.»
Тип задачи — grp_onl
| Название параметра | Тип | Описание | Пример | По умолчанию |
| task | string | Тип задачи | grp_onl | |
| label | string | Метка задачи, для удобства | для озона | NULL |
| f_mail | bool | Необходимость отправки email, после завершения задачи | true | false |
| search_engine | string | Движок ПС, допустимо yandex или google | yandex | yandex |
| lang | string | Язык задачи. ru или en | ru | ru |
| ya_lr | int | Код региона по системе кодов Яндекса для выдачи ПС! | 213 | 213 |
| ya_lrws | int | Код региона по системе кодов Яндекса для сбора частотности. | 213 | NULL |
| google_lr | string | Регион гугла. Копипастим со страницы кластеризатора английское название региона до табулятора целиком, как в примере. Если будет устойчивый спрос на гугл через АПИ — открою доступ к нашей структурированной базе регионов гугла, а пока так, ибо спрос низкий, а времени мало, есть более приоритетные задачи. | Saratov Oblast,Russia | Moscow,Moscow,Russia |
| device | string | Тип устройства пользователя согласно справочной таблице для сбора частотности. | desktop | all |
| data | string | Основная задача. Список фраз, разделённых символом перевода строки «\n». | купить кота\nрозовый слон | |
| file_t | file | Файл xlsx формата, альтернатива полю data. Максимум — 14мб. Если загружен файл, то поле data игнорируется. | ||
| f_temakl | bool | Тематическая классификация запросов. Бесплатно, но требует сильно больше времени на выполнение задачи. | false | false |
| f_alter | bool | Альтернативный формат нумерации групп. | false | false |
| f_is_geo | bool | Определить ГЕО-зависимость запроса | false | false |
| f_is_comm | bool | Определение коммерческости запроса | false | false |
| s_std | bool | Собирать частотность вида: (купить слона) | true | false |
| s_q | bool | Собирать частотность вида: («купить слона») | true | false |
| s_qv | bool | Собирать частотность вида: («!купить !слона») | true | false |
| s_qs | bool | Собирать частотность вида: («[купить слона]») | true | false |
| s_qvs | bool | Собирать частотность вида: («[!купить !слона]») | true | false |
| domain | string | Домен для поиска релевнтных страниц | lib.ru | NULL |
Особенности модуля:
- f_temakl может быть установлен только для языка ru, в остальных случаях он будет сброшен.
- f_is_geo и f_is_comm может быть установлен только для языка ru и ПС yandex, в остальных случаях он будет сброшен.
Справочники
Типы устройств пользователя
| Id | Описание |
| all | Все типы устрйоств |
| desktop |
Десктопы |
| tablet_phone |
Мобильные (Планшеты и Телефоны) |
| tablet |
Планшеты |
| phone |
Телефоны |
Базы данных ключей
Из-за низкой популярности локальных модулей, обновление базы для нас нерентабельно, поэтому, новые локальные базы собираться не будут.
| Id | Год | Размер | Описание |
| 3 | 2016 | 185 млн | Коммерческо-информационная база широкого спектра |
История изменений
Тут будет публиковаться история изменений и обновлений API.
23.12.2018
Запуск первой версии API.