
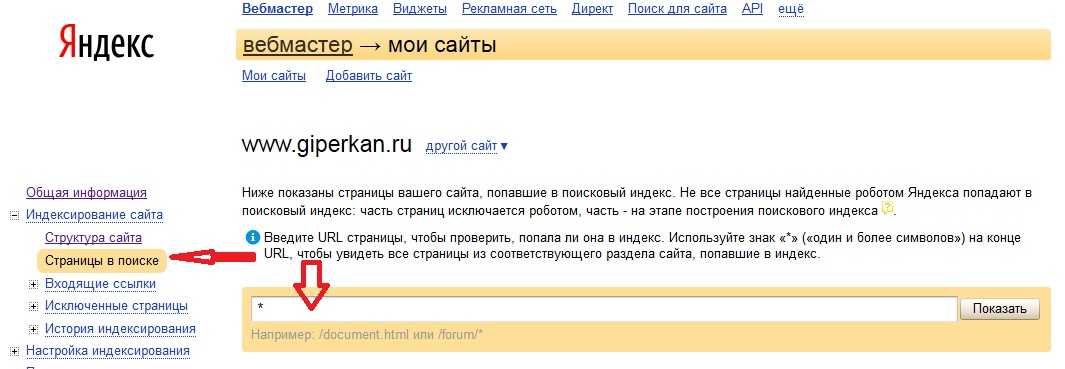
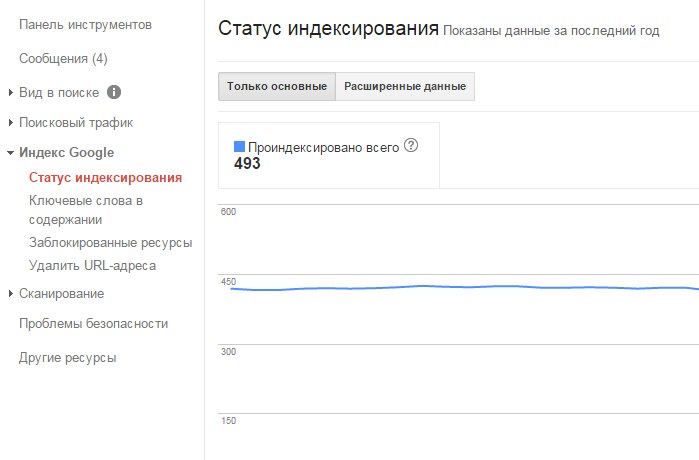
Получение истории индексирования сайта. Руководство разработчика
Возвращает количество проиндексированных страниц сайта, а также их HTTP-статус за определенный период. По умолчанию возвращаются данные за текущий день.
GET https://api.webmaster.yandex.net/v4/user/{ Тип: int64. ID пользователя. Необходим для вызова любых ресурсов API Яндекс Вебмастера. Чтобы получить его, используйте метод GET /v4/user."}}">}/hosts/{Тип: host id (string). ID сайта. Чтобы получить его, используйте метод GET /v4/user/{user-id}/hosts."}}">}/indexing/history
? [Начало диапазона дат."}}">=<datetime>]
& [Конец диапазона дат."}}">=<datetime>]user-id | Тип: int64. ID пользователя. Необходим для вызова любых ресурсов API Яндекс Вебмастера. Чтобы получить его, используйте метод GET /v4/user. |
host-id | Тип: host id (string). ID сайта. Чтобы получить его, используйте метод GET /v4/user/{user-id}/hosts. |
date_from | Начало диапазона дат. |
date_to | Конец диапазона дат. |
{
"indicators": {
"HTTP_2XX": [
{
"date": "2016-01-01T00:00:00,000+0300",
"value": 1
}
]
}
}<Data>
<indicators>
<HTTP_2XX>
<ОбязательныйДа
Тип
\n datetime\n
Описание
Дата и время загрузки страниц.
"}}">>2016-01-01T00:00:00,000+0300</date>
<ОбязательныйДа
Тип
\n int64\n
Описание
Количество страниц.
"}}">>1</value>
</HTTP_2XX>
</indicators>
</Data> | Имя | Обязательный | Тип | Описание |
|---|---|---|---|
| HTTP_2XX | Да | IndexingStatusEnum | Статус HTTP-кода. |
date | Да | datetime | Дата и время загрузки страниц. |
value | Да | Количество страниц. |
| Индикатор | Описание |
|---|---|
HTTP_2XX HTTP_3XX HTTP_4XX HTTP_5XX | Подробнее о статусах см. в Справке. |
| OTHER | Неподдерживаемый HTTP-код, ошибка соединения и др. |
Чтобы посмотреть структуру ответа подробнее, нажмите на причину.
| Код | Причина | Описание |
|---|---|---|
| 200 OK | ||
| 403 | INVALID_USER_ID | ID пользователя, выдавшего токен, отличается от указанного в запросе. В примерах ниже {
"error_code": "INVALID_USER_ID",
"available_user_id": 1,
"error_message": "Invalid user id. {user_id} should be used."
}<Data>
<Описание |
| 404 | HOST_NOT_VERIFIED | Не подтверждены права на управление сайтом. {
"error_code": "HOST_NOT_VERIFIED",
"host_id": "http:ya.ru:80",
"error_message": "some string"
}<Data> <Описание |
| HOST_NOT_INDEXED | Сайт еще не проиндексирован. {
"error_code": "HOST_NOT_INDEXED", //errorCode.
"host_id": "http:ya.ru:80", //id хоста. host id.
"error_message": "some string" //Error message.
}<Data> <Описание | |
Данные о сайте еще не загружены в Яндекс Вебмастер. {
"error_code": "HOST_NOT_LOADED",
"host_id": "http:ya.ru:80",
"error_message": "some string"
}<Data> <Описание |
 ru:80</host_id>
<Описание
ru:80</host_id>
<Описание
Была ли статья полезна?
Научный журнал «Вестник Новосибирского государственного университета. Серия: История, филология»
На данном сайте прием материалов остановлен. Для подачи статьи зарегистрируйтесь на новом сайте.
ISSN 1818-7919
Целью деятельности журнала является введение в научный оборот результатов новейших научных исследований в области истории, археологии, этнографии Сибири и прилегающих территорий Евразии, русской филологии, литературоведения и журналистики Сибири.
Редакционная политика издания направлена на отбор наиболее значимых публикаций, подготовленных по актуальной научной тематике. В задачи редакции журнала входят обеспечение этических норм в собственной деятельности и во взаимоотношениях со всеми участниками публикационного процесса (авторами, рецензентами, редакторами, издательством, распространителями и читателями), максимально объективного анонимного (обоюдно «слепого») рецензирования поступающих материалов, оценка достоверности и научной значимости представленной работы, ее соответствия тематике журнала и действующим юридическим нормам в отношении авторского права и плагиата, рассмотрение рукописи как конфиденциального документа, ознакомиться с которым имеют право лишь лица, уполномоченные ответственным секретарем выпуска журнала.
Учредитель журнала – Новосибирский государственный университет.
Журнал состоит из отдельных тематических выпусков:
– «История» (номера 1, 8),
– «Филология» (номера 2, 9),
– «Археология и этнография» (номера 3, 5, 7),
– «Востоковедение» (номера 4, 10),
– «Журналистика» (номер 6).
Журнал зарегистрирован Федеральной службой по надзору в сфере связи, информационных технологий и массовых коммуникаций (свидетельство о регистрации ПИ № ФС77-40144 от 04.06.2010 г.).
Журнал с 2002 г. входит в перечень ведущих рецензируемых научных изданий Российской Федерации, рекомендуемых Высшей аттестационной комиссией для публикации основных научных результатов диссертаций на соискание ученой степени кандидата и доктора наук.
Журнал включен в Российский индекс научного цитирования, в ядро РИНЦ. Полнотекстовые версии статей размещены в сети Интернет на странице журнала в научной электронной библиотеке по адресу: http://elibrary.ru
Журнал входит в базу данных Russian Science Citation Index на платформе Web of Science (с 2018 года), Scopus (с 2020 года).
Плата с авторов (в том числе с аспирантов) за публикацию рукописей не взимается. Периодичность: 10 выпусков в год.
Материалы публикуются в журнале под лицензией Creative Commons “Attribution” («Атрибуция») 4. 0 Всемирная.
0 Всемирная.
Контакты:
Выпуск «История» – Андрей Владимирович Дмитриев ([email protected]), ответственный редактор, Станислав Олегович Егоров ([email protected]), ответственный секретарь
Выпуск «Филология» – Ольга Георгиевна Щеглова ([email protected]), ответственный редактор, Людмила Николаевна Синякова ([email protected]), ответственный редактор, Мария Сергеевна Берендеева ([email protected]), ответственный секретарь
Выпуск «Востоковедение» – Елена Эдмундовна Войтишек ([email protected]), ответственный редактор, Сергей Александрович Комиссаров ([email protected]), ответственный редактор, Андрей Васильевич Варёнов ([email protected]), ответственный секретарь
Выпуск «Археология и этнография» – Андрей Иннокентьевич Кривошапкин ([email protected]), ответственный редактор, Дмитрий Вадимович Селин ([email protected]), ответственный секретарь
Выпуск «Журналистика» – Ольга Дмитриевна Журавель (olga_zhuravel@mail. ru), ответственный редактор, Юлия Сергеевна Елисеева ([email protected]), ответственный секретарь
ru), ответственный редактор, Юлия Сергеевна Елисеева ([email protected]), ответственный секретарь
Адрес редакции серии: Россия, 630090, г. Новосибирск, ул. Пирогова, 1, к. 1260
Сергей Григорьевич Скобелев, ответственный секретарь серии
E-mail: [email protected]
Адрес: Россия, 630090, г. Новосибирск, ул. Пирогова, 1, к. 1262
Дарья Владимировна Ильина, координатор серии (вопросы развития журнала, сотрудничества, работы сайта, индексации статей)
E-mail: [email protected]
Адрес: Россия, 630090, г. Новосибирск, ул. Пирогова, 1, к. 1260
Краткая история индексирования
Джона Симкина
До изобретения книгопечатания в пятнадцатом веке индексирование книг имело ограниченное применение, так как не было двух одинаковых экземпляров или с одинаковой нумерацией страниц. Индексы того времени бывают нескольких видов:
- списки терминов или словосочетаний
- согласований с Библией (с 7 века)
- предметных указателей канонического права (с XI века)
- «настоящие соответствия» или засекреченные списки ссылок на богословские концепции
- предметных указателей к трудам по этике, натурфилософии и логике.
 В некоторых рукописях заглавные слова и ссылки на полях служили проводниками к тексту.
В некоторых рукописях заглавные слова и ссылки на полях служили проводниками к тексту.
 В некоторых рукописях заглавные слова и ссылки на полях служили проводниками к тексту.
В некоторых рукописях заглавные слова и ссылки на полях служили проводниками к тексту.Печатные указатели книг появились в 1460-х годах, практически с началом эры книгопечатания. Развитию медицины способствовали указатели на медицинские тексты и травы. Первое печатное Библейское согласие было опубликовано в 1544 году; его составитель был сожжен за ересь. Из многих последующих конкордансов Александра Крудена — 9.0019 Полное соответствие Священному Писанию – впервые опубликовано в 1737 году, до сих пор издается. Словарь Сэмюэля Джонсона английского языка (1755 г.) был первым указателем английского языка.
В 19 веке были предприняты шаги по систематизации индексации. Индексное общество было основано в Лондоне в 1877 году с целью создания «общего указателя универсальной литературы». Доктор Генри Бенджамин Уитли, в честь которого названа медаль Уитли, написал Что такое индексатор? в 1878 году. Это общество просуществовало до 1890 года. Вскоре после этого женщины начали выходить на поле. В конце концов, в 1957 году в Великобритании было создано Общество индексаторов.
В конце концов, в 1957 году в Великобритании было создано Общество индексаторов.
Тем временем в Соединенных Штатах Уильям Фредерик Пул начал свой Индекс периодической литературы. Это был первый из многих печатных указателей, опубликованных компанией HW Wilson Company и другими.
В тот же период в Бельгии Поль Отле начал Универсальный библиографический реперторий — универсальный указатель всех знаний. К 1914 этот указатель содержал более одиннадцати миллионов записей, подкрепленных текстовыми файлами и иллюстрациями. В этом отлете предполагался Интернет. В 1934 году он написал «Трактат о документации: le livre sur le livre, théorie et pratique», в котором описывалась система, с помощью которой знание проецировалось на индивидуальный экран, так что «в своем кресле каждый мог созерцать все творение». или отдельные его части».
За обществом индексаторов последовало основание обществ индексаторов в США (American Society of Indexers, 1968), Австралии и Новой Зеландии (Австралийское общество индексаторов, 1976 г. ), Канады (Канадское общество индексации и реферирования, 1977 г.), Китая (Китайское общество индексаторов, 1991 г.) и Южной Африки (Ассоциация южноафриканских индексаторов и библиографов, 1994 г.). ). Тем временем был опубликован Британский стандарт индексации (BS3700:1976); с его последующими изменениями он до сих пор используется во всем англоязычном мире.
), Канады (Канадское общество индексации и реферирования, 1977 г.), Китая (Китайское общество индексаторов, 1991 г.) и Южной Африки (Ассоциация южноафриканских индексаторов и библиографов, 1994 г.). ). Тем временем был опубликован Британский стандарт индексации (BS3700:1976); с его последующими изменениями он до сих пор используется во всем англоязычном мире.
С самого начала компьютер помогал создавать существующие формы указателей и позволял создавать большие базы данных. К сожалению, Всемирная паутина, самое большое скопление баз данных, развивалась без какого-либо общего плана, поэтому, хотя некоторые сайты используют сложные методы индексации, большинство из них доступны только с помощью примитивного поиска по ключевым словам, что часто приводит к неуправляемому количеству «попаданий». Он также не подлежит какому-либо контролю качества, поскольку хорошо задокументированная и ложная информация существует бок о бок с рекламой и другими формами пропаганды.
В будущем нет насущной необходимости разрабатывать новые методы индексирования, а необходимо более эффективно применять уже существующие, особенно для обеспечения доступности постоянно растущего хранилища информации. В этом профессия индексации жизненно важна.
В этом профессия индексации жизненно важна.
Краткая история поисковой оптимизации
Поисковая оптимизация (SEO) во многом сегодня связана с Google.
Однако практика, которую мы теперь знаем как SEO, на самом деле появилась еще до появления самой популярной в мире поисковой системы, основанной Ларри Пейджем и Сергеем Брином.
Хотя можно утверждать, что SEO и все, что связано с поисковым маркетингом, началось с запуска первого веб-сайта, опубликованного в 1991 году, или, возможно, когда была запущена первая веб-поисковая система, история SEO «официально» начинается немного позже, около 1997.
По словам Боба Хеймана, автора книги Digital Engagement, мы можем поблагодарить не кого иного, как менеджера рок-группы Jefferson Starship за то, что он помог создать новую область, которую мы будем называть «поисковая оптимизация».
Видите ли, он был очень расстроен тем, что официальный веб-сайт Jefferson Starship в то время находился на 4-й странице какой-то поисковой системы, а не на 1-й позиции на первой странице. Ревизионистская история или стопроцентный факт, все признаки определенно указывают на то, что термин SEO возник примерно в 1997 году.
Ревизионистская история или стопроцентный факт, все признаки определенно указывают на то, что термин SEO возник примерно в 1997 году.
Поищите еще немного, и вы увидите, что Джон Одетт из Multimedia Marketing Group использовал этот термин еще 15 февраля 1997 года.
Высокий рейтинг в поисковых системах в 1997 году был довольно новой концепцией.
Кроме того, он был очень ориентирован на каталоги.
До того, как DMOZ подпитывала первоначальную классификацию Google, LookSmart работал на Zeal, Go.com был собственным каталогом, а Yahoo Directory был основным игроком в поиске Yahoo.
Если вы не знакомы с DMOZ, проектом открытого каталога Mozilla (помните, что Mozilla была компанией, а Moz — брендом задолго до SEOMoz), по сути, это были «Желтые страницы» для веб-сайтов.
Это то, на чем изначально была основана Yahoo; возможность найти лучшие веб-сайты, одобренные редакторами.
Я начал заниматься поисковой оптимизацией в 1998 году, когда это было нужно нашим клиентам, которые создали классные сайты, но получали мало трафика.
Я и не подозревал, что это станет стилем жизни.
Опять же, всемирная паутина в то время была довольно новой концепцией для большинства людей.
Сегодня? Все хотят управлять страницами результатов поисковой системы (SERP).
Оптимизация в поисковых системах и маркетинг в поисковых системах
До того, как оптимизация в поисковых системах стала официальным названием, использовались и другие термины:
- Размещение в поисковых системах.
- Позиционирование в поисковых системах.
- Ранжирование в поисковых системах.
- Регистрация в поисковой системе.
- Представление поисковой системы.
- Продвижение сайта.
Но обсуждение было бы неполным без упоминания еще одного термина…
Поисковый маркетинг.
В какой-то момент в 2001 году один известный отраслевой писатель предложил поисковый маркетинг в качестве преемника поисковой оптимизации.
Очевидно, этого не произошло.
Приготовьтесь сейчас же; вы увидите много ложных заявлений (например, «SEO мертв», «новый SEO») и попыток ребрендинга SEO (например, «оптимизация поискового опыта»).
Хотя SEO как термин не идеален — в конце концов, мы не оптимизируем поисковые системы, мы оптимизируем наше присутствие в Интернете — он остается предпочтительным термином в нашей отрасли уже более 20 лет и, вероятно, будет на обозримое будущее.
Что касается маркетинга в поисковых системах?
Он все еще используется, но теперь больше связан с платным поисковым маркетингом и рекламой.
Сегодня два термина мирно сосуществуют.
Хронология истории поисковых систем
Поисковые системы изменили то, как мы находим информацию, проводим исследования, покупаем товары и услуги, развлекаемся и общаемся с другими.
Практически за каждым онлайн-ресурсом — будь то веб-сайт, блог, социальная сеть или приложение — стоит поисковая система.
Поисковые системы стали связующим звеном и ориентиром в повседневной жизни.
Но как все это началось?
Мы составили хронологию важных вех в истории поисковых систем и поисковой оптимизации, чтобы понять корни этой технологии, которая стала такой важной частью нашего мира.
Рассвет SEO: эпоха Дикого Запада
В последнее десятилетие 1900-х годов конкуренция в поисковых системах была очень высокой.
У вас был выбор поисковых систем — как каталогов, созданных человеком, так и списков на основе поисковых роботов, включая такие, как AltaVista, Ask Jeeves, Excite, Infoseek, Lycos и Yahoo.
В самом начале единственным способом проведения SEO-оптимизации были действия на странице.
Это включало оптимизацию по таким факторам, как:
- Убедитесь, что контент качественный и актуальный.
- Текста было достаточно.
- Ваши теги HTML были точными.
- У вас были внутренние ссылки и исходящие ссылки.
Если вы хотите иметь хорошие позиции в этой эпохе, хитрость заключалась в том, чтобы просто повторять ваши ключевые слова достаточное количество раз на ваших веб-страницах и в метатегах.
Хотите в 100 раз превзойти страницу, использующую ключевое слово? Тогда вы использовали бы ключевое слово 200 раз!
Сегодня мы называем это спамом.
Вот некоторые основные моменты:
1994
Yahoo был создан студентами Стэнфордского университета Джерри Вангом и Дэвидом Фило в трейлере кампуса. Yahoo изначально был списком интернет-закладок и каталогом интересных сайтов.
Веб-мастерам приходилось вручную отправлять свои страницы в каталог Yahoo для индексации, чтобы Yahoo мог найти их, когда кто-то выполнит поиск.
Также запущены AltaVista, Excite и Lycos.
1996
Пейдж и Брин, два студента Стэнфордского университета, создали и протестировали Backrub, новую поисковую систему, ранжирующую сайты на основе релевантности входящих ссылок и популярности.
Backrub в конечном итоге станет Google. Также был запущен HotBot на базе Inktomi.
1997
Следуя успеху «Руководства для веб-мастеров по поисковым системам», Дэнни Салливан запустил Search Engine Watch — веб-сайт, посвященный новостям о поисковой отрасли, советам по поиску в Интернете и информации о том, как лучше ранжировать веб-сайты.
(Десять лет спустя, после ухода из SEW, Салливан основал еще одно популярное поисковое издание, Search Engine Land, и теперь он работает в Google.)
Также дебютировал Ask Jeeves и был зарегистрирован Google.com.
1998
Goto.com запущен со рекламными ссылками и платным поиском. Рекламодатели делают ставки на Goto.com, чтобы он занимал место выше обычных результатов поиска, которые были созданы Inktomi. В конечном итоге Goto.com был приобретен Yahoo.
DMOZ (проект Open Directory) стал самым популярным местом для SEO-практиков, где они могли разместить свои страницы.
MSN вошла в пространство с поиском MSN, изначально поддерживаемым Inktomi.
1999
Состоялась первая в истории конференция по поисковому маркетингу «Стратегии поисковых систем» (SES). Вы можете прочитать ретроспективу Салливана об этом событии здесь.
(Серия конференций SES продолжалась под разными названиями и материнскими компаниями до закрытия в 2016 г. )
)
Революция Google
Google использует свои органические результаты вместо Inktomi.
Раньше Google был малоизвестной поисковой системой. Вряд ли известно!
Конечный результат: в каждом результате поиска Yahoo было написано «При поддержке Google», и в итоге они представили миру своего крупнейшего конкурента, а имя Google стало нарицательным.
До этого момента поисковые системы в основном ранжировали сайты на основе содержимого страницы, доменных имен, способности попасть в вышеупомянутые каталоги и базовой структуры сайта (хлебные крошки).
Но поисковый робот Google и алгоритм PageRank были революционными для поиска информации.
Google рассмотрел как внутренние, так и внешние факторы — количество и качество внешних ссылок, указывающих на веб-сайт (а также используемый якорный текст).
Если задуматься, алгоритм Google был по сути следующим: «Если люди говорят о вас, вы должны быть важны».
Хотя ссылки были лишь одним из компонентов общего алгоритма ранжирования Google, специалисты по поисковой оптимизации ухватились за ссылки как за самый важный фактор — и была создана целая подотрасль линкбилдинга.
Следующее десятилетие превратилось в гонку за получением как можно большего количества ссылок в надежде на более высокий рейтинг.
Ссылки стали широко используемой тактикой, с которой Google придется бороться в ближайшие годы.
В том же 2000 году панель инструментов Google стала доступна в Internet Explorer, позволяя специалистам по поисковой оптимизации видеть свой показатель PageRank (число от 0 до 10).
Это открыло эру нежелательных электронных писем с запросами на обмен ссылками.
Таким образом, с помощью PageRank Google, по сути, ввел меру валюты для своих ссылок. Так же, как авторитет домена сегодня используется не по назначению.
Обычные результаты Google также получили некоторую поддержку в виде рекламы AdWords, начиная с 2000 года.
Эти платные поисковые объявления начали появляться выше, ниже и справа от естественных (то есть бесплатных) результатов Google.
Тем временем группа веб-мастеров неофициально собралась в лондонском пабе, чтобы начать делиться информацией обо всем, что связано с SEO в 2000 году. 0003
0003
Это неофициальное собрание со временем превратилось в Pubcon, большую серию поисковых конференций, которая проводится до сих пор.
В ближайшие месяцы и годы мир SEO привык к ежемесячному Google Dance или периоду времени, в течение которого Google обновлял свой индекс, что иногда приводило к значительным колебаниям рейтинга.
Хотя Брин из Google однажды сказал, что Google не верит в веб-спам, к 2003 году его мнение, вероятно, изменилось.
Поисковая оптимизация стала намного сложнее после таких обновлений, как Флорида, потому что это стало гораздо важнее, чем простое повторение ключевых слов Х раз.
Google AdSense: монетизация ужасного SEO-контента
В 2003 году, после приобретения Blogger.com, Google запустил AdSense, который размещает контекстно-таргетированные объявления Google на сайтах издателей.
Сочетание AdSense и Blogger.com привело к всплеску простых, монетизированных онлайн-публикаций и революции в блогах.
В то время Google, вероятно, не осознавал этого, но они создавали проблемы, которые им нужно было исправить в будущем.
AdSense породил тактику рассылки спама и сайты, созданные для AdSense, заполненные некачественным/плохим/украденным контентом, который существовал исключительно для того, чтобы иметь высокий рейтинг, получать клики и зарабатывать деньги.
Да, и еще кое-что важное произошло в 2003 году.
Я основал сайт, на котором вы находитесь, Search Engine Journal!
И я невероятно рад сообщить, что мы все еще здесь и становимся сильнее, чем когда-либо.
Локальная поисковая оптимизация и персонализация
Примерно в 2004 году Google и другие ведущие поисковые системы начали улучшать результаты запросов с географической целью (например, ресторан, сантехник или какой-либо другой вид бизнеса или поставщик услуг в вашем городе). .
К 2006 году Google выпустила Maps Plus Box, который меня в то время очень впечатлил.
Примерно в 2004 году Google и поисковые системы начали более широко использовать данные конечных пользователей, такие как история поиска и интересы, для персонализации результатов поиска.
Это означало, что результаты, которые вы видели, могли отличаться от того, что видел кто-то, сидящий рядом с вами в кафе, когда он или она выполнял поиск по тому же запросу.
Также в 2005 году теги nofollow были созданы как средство борьбы со спамом.
SEO-специалисты начали использовать этот тег как способ моделирования PageRank.
Компания Google также выпустила несколько заслуживающих внимания обновлений:
- Jagger, которые помогли снизить уровень незапрашиваемых обменов ссылками, а также возвестили о снижении важности анкорного текста как фактора из-за его коррумпированности. .
- Big Daddy (придуман Джеффом Мэнсоном из RealGeeks), который улучшил архитектуру Google, чтобы лучше понять ценность и взаимосвязь ссылок между сайтами.
YouTube, Google Analytics и инструменты для веб-мастеров
В октябре 2006 года Google приобрел созданную пользователями сеть обмена видео YouTube за 1,65 миллиарда долларов, которая в итоге стала второй по популярности поисковой собственностью в мире.
Сегодня у YouTube 2 миллиарда пользователей!
Из-за стремительного роста популярности видео SEO стало критически важным для брендов, компаний и частных лиц, которые хотели, чтобы их нашли.
В 2006 году Google также запустила два невероятно важных инструмента:
- Google Analytics. Этот бесплатный веб-инструмент был настолько популярен при запуске, что веб-мастера получали предупреждения о простоях и обслуживании.
- Инструменты Google для веб-мастеров. Инструменты Google для веб-мастеров, теперь известные как Search Console, позволяют веб-мастерам просматривать ошибки сканирования, видеть, по каким запросам появился ваш сайт, и запрашивать повторное включение.
Также в 2006 году XML-карты сайта получили всеобщую поддержку поисковых систем.
XML-карты сайта позволяют веб-мастерам отображать для поисковых систем каждый URL на своем веб-сайте, доступный для сканирования.
XML-карта сайта содержит не только список URL-адресов, но и ряд дополнительной информации, которая помогает поисковым системам выполнять более интеллектуальное сканирование.
Универсальный поиск
Начиная с 2007 года поиск начал развиваться новыми и захватывающими способами.
Все эти обновления были направлены на улучшение поиска для пользователей.
Начнем с универсального поиска Google.
До этого момента результаты поиска состояли из 10 синих ссылок.
Затем Google начал смешивать традиционные результаты органического поиска с другими типами вертикальных результатов, такими как новости, видео и изображения.
Это было самое большое изменение в поиске Google — и SEO — со времени обновления во Флориде.
Очистка выгребной ямы
В 2008 году тогдашний генеральный директор Google Эрик Шмидт сказал, что Интернет становится выгребной ямой, и что бренды являются решением. «Бренды — это то, как вы разбираете выгребную яму», — сказал он.
Менее чем через шесть месяцев после его комментария появилось обновление Google под названием Vince.
Крупные бренды внезапно оказались намного лучше в поисковой выдаче.
Но, по словам Google, на самом деле он не предназначался для поощрения брендов.
Google хотел придать большее значение доверию к алгоритму (а крупные бренды, как правило, вызывают больше доверия, чем более мелкие и менее известные бренды).
Вскоре после этого обновления Google выпустила еще одно обновление для повышения скорости индексации под названием Caffeine.
Как сообщал Search Engine Journal в то время, Caffeine был «поисковой архитектурой нового поколения для Google, которая должна быть быстрее и точнее, обеспечивать более качественные и релевантные результаты и сканировать большие части Интернета».
Говоря о скорости, в 2010 году Google объявил, что скорость сайта является фактором ранжирования.
Bing и The Search Alliance
В 2009 году Microsoft Live Search стал Bing.
Затем, в попытке бросить вызов почти 70-процентному захвату Google поискового рынка США, Yahoo и Microsoft объединили свои усилия, чтобы заключить 10-летнее соглашение о поиске (хотя пять лет спустя оно было переработано).
Поисковый альянс увидел, что Bing от Microsoft усиливает обычные и платные результаты поиска Yahoo.
Несмотря на то, что это сделало Bing чистой поисковой системой номер 2, они в конечном итоге не смогли сломить огромную власть Google в поиске в США и во всем мире. В октябре 2020 года Bing официально был переименован в Microsoft Bing.
Рост социальных сетей
В конце 2000-х появилось еще одно явление: социальные сети.
Google сделал большую ставку на YouTube (хотя он попытается снова с ныне несуществующим Google+).
Но другие сети, такие как Facebook, Twitter и LinkedIn, стали крупными игроками (а в последующие годы их станет еще больше).
Вместе с развитием социальных сетей появились слухи о том, что социальные сигналы могут влиять на ранжирование в поиске.
Да, социальные сети могут помочь SEO, но косвенно — точно так же, как другие формы маркетинга могут помочь привлечь больше трафика на ваш веб-сайт и повысить узнаваемость бренда и аффинити (что создает поисковый спрос).
Несмотря на то, что влияние социальных сетей (лайки, твиты, +1 и т. д.) неоднократно отрицалось Google на протяжении многих лет как фактор ранжирования, оно продолжало указываться как сильно коррелирующее с различными факторами ранжирования. исследования.
Если вы хотите узнать больше об этой теме, я настоятельно рекомендую прочитать Как социальные сети помогают SEO [Окончательный ответ].
Schema
Разметка Schema, форма микроданных, была введена в 2011 году, чтобы помочь поисковым системам интерпретировать контекст запроса. Вы можете просмотреть каждый тип разметки схемы на Schema.org.
Схема не является фактором ранжирования. И мало доказательств того, что это влияет на эффективность вашего поиска.
Тем не менее, схема поможет вам выделиться в поисковой выдаче с помощью расширенных и избранных фрагментов.
Например, на вебинаре Search Engine Journal компания Milestone сообщила, что после развертывания схемы количество показов в поиске для крупных сетей ресторанов быстрого питания увеличилось на 33–66%.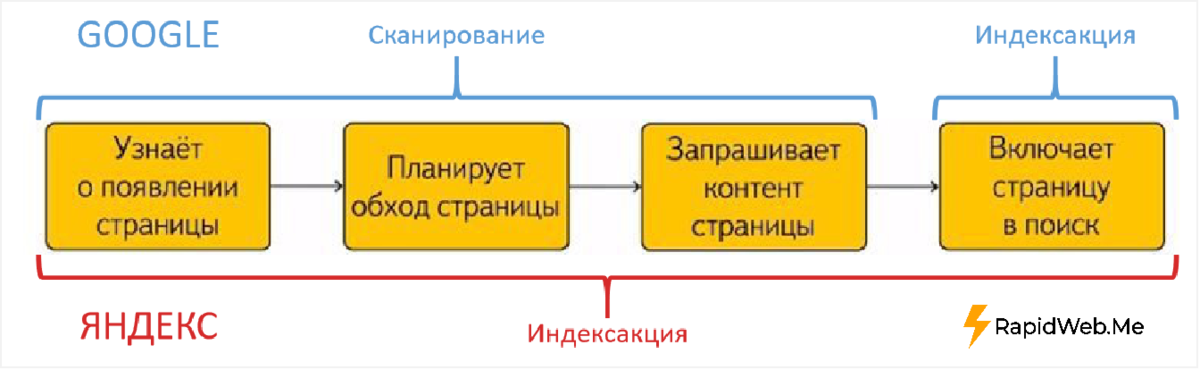
Другой эксперимент InLinks показал, что сайты со схемой повышают рейтинг после внедрения схемы.
Если вы не уверены, правильно ли вы внедрили структурированные данные, проверьте их в Инструменте тестирования структурированных данных Google.
The Google Zoo: Panda & Penguin
Два основных алгоритмических обновления — Panda в 2011 году и Penguin в 2012 году — оказали большое влияние на поисковую оптимизацию, которое ощущается до сих пор, поскольку Google снова попытался очистить результаты поиска. и поощряйте высококачественные сайты.
В 2011 году результаты поиска Google подверглись серьезной проверке, поскольку в результатах поиска преобладали так называемые «контент-фермы» (веб-сайты, создающие большие объемы контента низкого качества).
Поисковая выдача Google также была загромождена веб-сайтами с неоригинальным и автоматически сгенерированным контентом, и даже в некоторых случаях сайты-скрейперы превосходили создателей контента.
В результате эти сайты приносили огромные доходы от рекламы (помните, я упомянул проблему AdSense, которую Google создал самостоятельно?).
Эти сайты также жили и умирали за счет органического трафика от Google.
Но после того, как в 2011 году вышло обновление Google Panda, многие веб-сайты увидели, что большая часть, если не весь, этот трафик исчез в одночасье.
Компания Google предоставила некоторое представление о том, что считается высококачественным сайтом.
Panda, предназначенная для устранения низкокачественного (или некачественного) контента, периодически обновлялась в течение следующих лет и в конечном итоге стала интегрированной в основной алгоритм Google в 2016 году. алгоритм переоптимизации, предназначенный для исключения из его результатов «агрессивной тактики спама».
Этот алгоритм, впоследствии получивший название Penguin, нацелен на схемы ссылок (веб-сайты с необычными шаблонами ссылок, включая большое количество анкорного текста с точным соответствием, который соответствует ключевым словам, по которым вы
хотели ранжироваться) и наполнение ключевыми словами.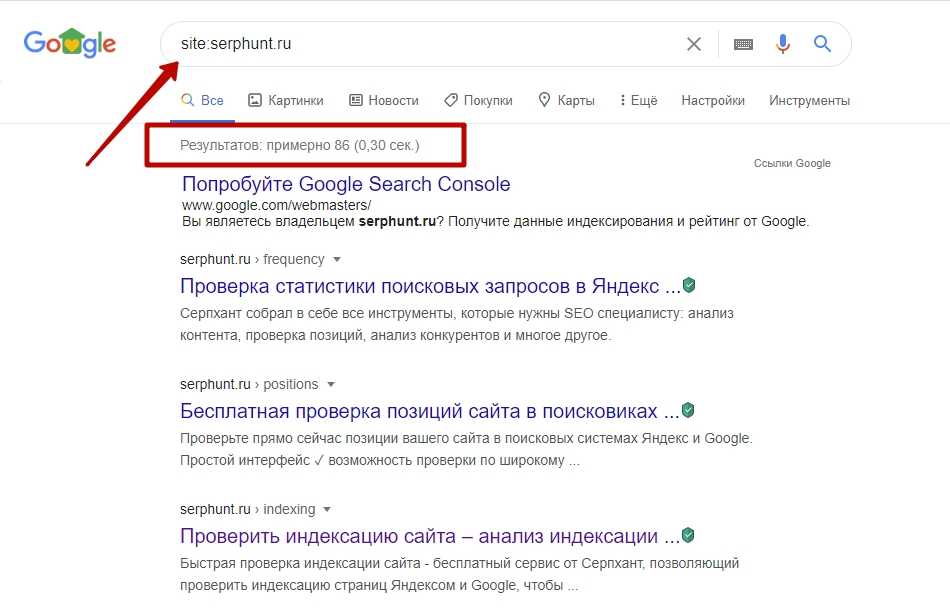
Penguin обновлялся не так часто, как Panda, и между некоторыми обновлениями проходило больше года. И, как и Panda, Penguin стал частью алгоритма реального времени Google в 2016 году.
Это был серьезный переход от интерпретации строк ключевых слов к пониманию семантики и намерений.
Вот как Амит Сингхал, бывший старший вице-президент Google по инженерным вопросам, описал его при запуске:
«График знаний позволяет вам искать вещи, людей или места, о которых знает Google — достопримечательности, знаменитости, города, спортивные команды, здания, географические объекты, фильмы, небесные объекты, произведения искусства и многое другое — и мгновенно получайте информацию, относящуюся к вашему запросу. Это важный первый шаг к созданию следующего поколения поиска, который использует коллективный разум Интернета и понимает мир немного лучше, чем люди».
Google расширил результаты поиска этой информацией.
Панели знаний, блоки и карусели могут появляться всякий раз, когда люди выполняют поиск одной из миллиардов сущностей и фактов в сети знаний.
Следующим шагом Google в поиске следующего поколения стал в сентябре 2013 года новый алгоритм Hummingbird, разработанный для более эффективного выполнения запросов на естественном языке и диалогового поиска.
С появлением мобильных устройств (и голосового поиска) Google необходимо было полностью перестроить работу своего алгоритма, чтобы удовлетворить потребности современных пользователей.
Hummingbird считается самым большим изменением в основном алгоритме Google с 2001 года. Очевидно, Google хотел предоставлять более быстрые и релевантные результаты, особенно для мобильных пользователей.
Mobile-First
Примерно с 2005 года в нашей отрасли постоянно задавали один вопрос:
Является ли это «Годом мобильных устройств»?
Ну получается, что не в 2005.
Или в 2006.
И не в 2007.
Или в 2008. Или в 2009.
Даже не в 2010 году, когда Google превратилась в компанию, ориентированную на мобильные устройства.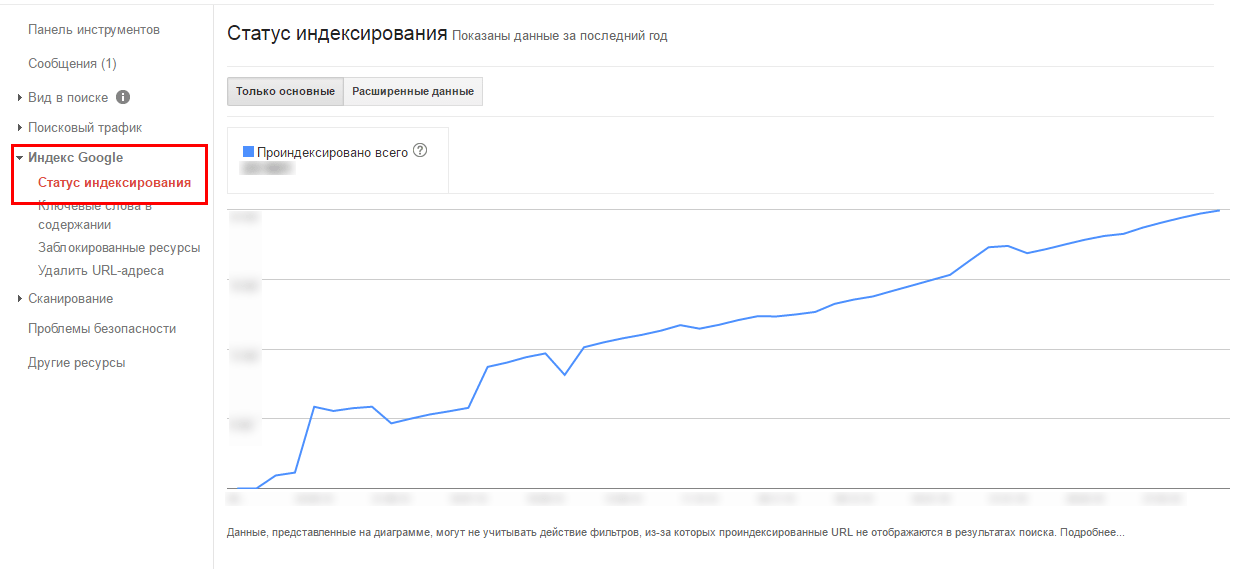
Затем пришли и ушли 2011, 2012, 2013 и 2014 годы.
О мобильной связи много говорили и ее активно разрекламировали, потому что все это время она росла как сумасшедшая.
По мере того, как все больше пользователей используют смартфоны, они все чаще ищут предприятия и вещи, находясь в пути.
Наконец, в 2015 году у нас был Год мобильных устройств — точка, в которой мобильные поиски впервые обогнали настольные поиски в Google. И хотя это верно с точки зрения необработанных поисковых чисел, также верно и то, что цель поиска совершенно иная, а коэффициент конверсии на мобильных устройствах остается намного ниже.
Это был также год, когда comScore сообщил, что количество интернет-пользователей, использующих только мобильные устройства, превысило количество пользователей, использующих только настольные компьютеры.
Также в 2015 году Google запустила долгожданное обновление алгоритма для мобильных устройств, предназначенное для предоставления пользователям «наиболее актуальных и своевременных результатов, независимо от того, находится ли информация на мобильных веб-страницах или в мобильном приложении».
Пытаясь ускорить работу страниц, в 2016 году Google также представил ускоренные мобильные страницы (AMP).
Идея AMP заключалась в мгновенной загрузке контента. Многие средства массовой информации и издатели быстро внедрили AMP и продолжают использовать его сегодня.
Возможно, вас это не удивит, но в январе 2017 года Google объявил, что скорость страницы теперь будет фактором ранжирования для мобильного поиска.
В том же месяце Google заявил, что начнет обесценивать страницы с навязчивыми всплывающими окнами.
В июле 2019 года для всех новых веб-сайтов было включено индексирование с приоритетом мобильных устройств. А к марту 2021 года все веб-сайты перейдут на индексацию для мобильных устройств.
Машинное обучение и интеллектуальный поиск
Ранее я упоминал, что Google, изначально построенный на поиске информации, стал компанией, ориентированной на мобильные устройства.
Ситуация изменилась в 2017 году, потому что генеральный директор Google Сундар Пичаи объявил Google первой компанией, занимающейся машинным обучением.
Сегодня поиск Google предназначен для информирования и помощи, а не для предоставления пользователям списка ссылок.
Вот почему Google встроил машинное обучение во все свои продукты, включая поиск, Gmail, рекламу, Google Assistant и другие.
Что касается поиска, мы уже начали замечать влияние машинного обучения с помощью Google RankBrain.
Объявленный в октябре 2015 года, RankBrain изначально использовался для интерпретации 15% поисковых запросов, которые Google никогда раньше не видел, на основе слов или фраз, которые ввел пользователь.
С тех пор Google расширил RankBrain, чтобы он запускался при каждом поиске.
Хотя RankBrain влияет на ранжирование, он не является фактором ранжирования в традиционном смысле, когда вы получаете вознаграждение за более высокий рейтинг за выполнение x, y и z.
В мире интеллектуального поиска скоро появится еще больше возможностей.
- Количество голосовых запросов увеличивается.
- Визуальный поиск стал невероятно хорош
- Пользователи (и бренды) все чаще используют чат-ботов и личных помощников (например, Siri от Apple, Alexa от Amazon и Cortana от Microsoft).

Эти достижения в области технологий означают, что тех, кто занимается SEO, ждут более захватывающие времена.
Основные обновления Google
Google ежедневно обновляет свой алгоритм.
Но в течение года Google выпускает основные обновления, когда в его алгоритм вносятся изменения.
Существуют также обширные обновления основного алгоритма.
Целью этих основных обновлений является создание более удобного поиска для пользователей с более релевантными и надежными результатами поиска.
Эти основные обновления Google не нацелены на определенную страницу или сайт, а направлены на улучшение того, как система отслеживает контент.
Вот как Google описал эти основные обновления:
«Один из способов понять, как работает основное обновление, — представить, что вы составили список из 100 лучших фильмов в 2015 году. Несколько лет спустя, в 2019 году, вы обновляете список. Это естественно изменится. Некоторые новые и замечательные фильмы, которых раньше никогда не было, теперь будут кандидатами на включение. Вы также можете переоценить некоторые фильмы и понять, что они заслуживают более высокого места в списке, чем раньше».
Вы также можете переоценить некоторые фильмы и понять, что они заслуживают более высокого места в списке, чем раньше».
В марте 2018 года Google подтвердил, что развернуто масштабное обновление основного алгоритма, предназначенное для страниц с недостаточным вознаграждением.
Чуть больше месяца спустя Google выпустила еще одно крупное обновление основного алгоритма, направленное на релевантность контента.
Затем в августе было выпущено еще одно масштабное обновление ядра (иногда ошибочно и неточно называемое «обновлением для медиков»), нацеленное на сайты с некачественным контентом.
В марте 2019 года в качестве расширения основного обновления за август 2018 года Google подтвердил, что основное обновление (также известное как Florida 2) было здесь, и оно должно было быть большим.
Но SEO-сообщество посчитало, что это скорее откат к предыдущим алгоритмам.
В июне 2019 года произошло еще одно масштабное обновление ядра, которое выявило слабые места E-A-T на веб-сайтах, сосредоточив внимание на авторитетности и надежности входящих ссылок.
Время от времени Google выпускает масштабное обновление ядра, которое влияет на все результаты поиска по всему миру.
Например, в сентябре 2019 года было выпущено масштабное обновление ядра, направленное на повышение общей оптимальной производительности сайтов. И еще одно широкое основное обновление в январе 2020 года, нацеленное на категории YMYL (ваши деньги, ваша жизнь).
В этом ключевое отличие широких основных обновлений от основных обновлений — вам нужно анализировать сайт в целом, а не конкретную страницу.
Совсем недавно, в мае 2020 года, Google выпустила основное обновление, которое нацелено на целевые страницы с тонким контентом и повышает результаты локального поиска.
BERT
BERT — крупнейшее обновление алгоритма Google со времен RankBrain.
BERT расшифровывается как представления двунаправленного кодировщика от преобразователей, используемых для обработки естественного языка.
По сути, это помогает Google лучше понимать контекст поисковых запросов.
Например, слово «летучая мышь» может означать ночное крылатое животное, часто ассоциирующееся с Бэтменом. Или его можно использовать, когда бейсболист идет на биту.
С помощью BERT Google может анализировать контекст для предоставления более качественных результатов поиска.
Что делает BERT еще лучше, так это то, что Google теперь может использовать слова, окружающие ваши ключевые слова, чтобы помочь своим паукам переварить ваш контент.
Например, «Я был в пещере летучих мышей». Или: «После своей биты я пошел в землянку». Теперь Google может генерировать контекстную модель вокруг других слов в предложении. Это решающий фактор в том, как обработка естественного языка идентифицировала человеческое общение.
Как сказал Дэнни Салливан из Google:
«С помощью BERT нечего оптимизировать, и никто не должен ничего переосмысливать. Основы нашего стремления вознаграждать отличный контент остаются неизменными».
Если вы все еще хотите узнать больше о BERT, Дон Андерсон расскажет здесь все, что вам нужно знать о BERT.
Избранные сниппеты
Возможно, вы уже видели избранные сниппеты, но не понимали, что это такое.
Избранные сниппеты — это короткие тексты, маркеры, числа или таблицы, которые появляются в верхней части поиска Google.
Цель избранного фрагмента — ответить на запрос пользователя непосредственно в поисковой выдаче без необходимости переходить на веб-сайт.
Но избранные фрагменты могут быть чрезвычайно изменчивыми, поэтому действуйте осторожно.
В избранных фрагментах нет ничего нового. Их заметили еще в 2014 году.
Избранные фрагменты дали толчок привлекательности желанной «нулевой позиции». Это означает, что ваш результат поиска отображается выше всех других отвлекающих факторов в поисковой выдаче, плюс вы также будете отображаться в обычных результатах.
В январе 2020 года Google обновил эту функцию, чтобы удалить дубликаты результатов поиска избранного фрагмента, чтобы вы были включены либо в избранный фрагмент, либо в обычный результат, а не в оба.