
большинство подкастов — про общество и культуру, каждый месяц запускается по 400 шоу — Медиа на vc.ru
{«id»:14028,»url»:»\/distributions\/14028\/click?bit=1&hash=85004897ea0e0c5e718009dec7f74f5e3b5b4532d88da66769638100dd25e22b»,»title»:»\u041c\u043e\u0436\u0435\u0442 \u043b\u0438 \u0440\u043e\u0431\u043e\u043f\u0447\u0435\u043b\u0430 \u0437\u0430\u0434\u0430\u0432\u0438\u0442\u044c \u043f\u0430\u0441\u0435\u0447\u043d\u0438\u043a\u0430?»,»buttonText»:»\u0412\u044b\u044f\u0441\u043d\u0438\u0442\u044c»,»imageUuid»:»60ced7ea-cbe2-5119-8195-37f920cb466b»}
Самые длинные выпуски — об играх, самые короткие — об изучении языков.
4500 просмотров
«Яндекс» опубликовал исследование о подкастах в России на основе данных «Яндекс.Музыки» и собственного поиска: про их количество, жанры, среднюю длительность и слушателей.
За пять лет количество поисковых запросов о подкастах в «Яндексе» выросло в четыре раза. В 2020 году больше 16 млн жителей больших городов слушали подкасты хотя бы раз в месяц.
Поисковые запросы о подкастах «Яндекс»
Из 11,5 тысячи подкастов в «Яндекс.Музыке» пять тысяч запустились в 2020 году, а в 2021-м каждый месяц запускается в среднем по 400 шоу.
Около 3000 подкастов в каталоге обновлялись в течение последнего месяца. За три года количество шоу выросло в восемь раз.
Количество активных подкастов по месяцам «Яндекс»
Количество выпусков подкастов в действующих и неактивных шоу «Яндекс»
Медианная длительность выпуска — около 30 минут. За последние полтора года она сократилась на 10 минут. Из активных подкастов самые длинные выпуски у подкаста о настольной игре Dungeons & Dragons «Бесценный опыт» — в среднем четыре часа, самые короткие у проекта о значении использовании слов «Слова» — 30 секунд.
Подкасты до 30 минут за один раз дослушивают в четырёх случаях из пяти, до 60 минут — в два раза реже. Новые эпизоды публикуются в среднем раз в 10 дней.
Дослушивания подкаста за раз в зависимости от его длины «Яндекс»
Больше всего подкастов в категории «Общество и культура», к ней относится каждое четвёртое шоу. На втором месте — «Наука и образование», на третьем — «Бизнес и работа». У новостных подкастов выпуски выходят в несколько раз чаще, чем в других категориях.
Самые длинные выпуски — об играх (в среднем один час), про футбол и музыкальную индустрию. Самые короткие — в категориях «Детям» (в среднем девять минут), «Изучение языков» и «Фикшн и аудиосериалы».
Самые популярные категории по количеству подкастов «Яндекс»
Категории по общей длительности контента «Яндекс»
Темы подкастов в зависимости от пола и возраста слушателей «Яндекс»
Устройства, на которых чаще слушают подкасты «Яндекс»
В выходные публикуется меньше подкастов, чем в будни.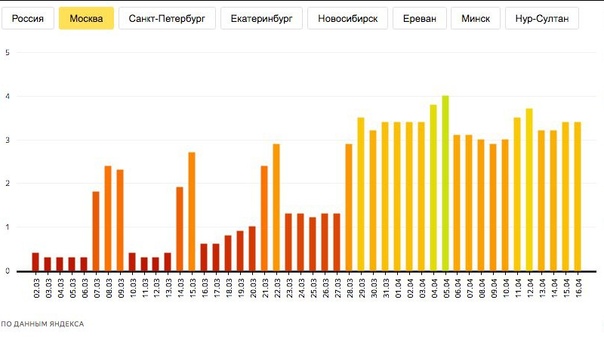 Но прослушиваний почти столько же. Самое популярное время для публикации выпуска — 12:00. С 21:00 до 23:00 происходит всплеск числа прослушиваний — родители ставят детям сказки на ночь, объяснили в «Яндексе».
Но прослушиваний почти столько же. Самое популярное время для публикации выпуска — 12:00. С 21:00 до 23:00 происходит всплеск числа прослушиваний — родители ставят детям сказки на ночь, объяснили в «Яндексе».
Количество публикаций подкастов и прослушиваний по дням недели «Яндекс»
Публикации по времени дня «Яндекс»
Количество прослушиваний по времени суток «Яндекс»
На Новый год пользователи будут покупать одежду и обувь — исследование Яндекса
2793 https://ppc.world/build/resources/img/logo-v2.png 6 из 10 пользователей ждут новогодних распродаж, а 88% из них уже составили список покупок 2022-12-12 2022-12-12 редакция ppc.world ppc.world https://ppc.world/build/resources/img/logo-v2.png 160 31 Новость 1- 12.
 12.2022
12.2022 - 117
 12.2022
12.2022Команда Яндекса опросила пользователей об ожиданиях от новогодних распродаж и изучила пользовательские запросы во время январских каникул. Результатами Яндекс поделился в пресс-релизе.
Результаты опроса. Исследователи выяснили, что 6 из 10 пользователей ждут новогодних распродаж. Из них 88% пользователей уже составили списки покупок. Почти 50% респондентов будут искать товары именно в интернете, а 36% совместят онлайн- и офлайн-шоппинг.
Самые популярные товары, которые хотят приобрести респонденты во время распродаж:
-
одежда и обувь — 63%;
-
косметика и парфюмерия — 42%;
-
техника и электроника — 21%.
Динамика запросов. Аналитики Яндекса сравнили, как отличается количество запросов в январские каникулы по сравнению с общими показателями января.
Аналитики Яндекса сравнили, как отличается количество запросов в январские каникулы по сравнению с общими показателями января.
Сильнее всего растет спрос на такие товары:
-
инвентарь для зимних видов спорта — на треть;
-
товары для детей — на 25%;
-
игровые приставки — на 20%;
-
телевизоры — на 17%;
-
умные гаджеты — на 16%;
-
парфюмерия — на 15%.
В январские каникулы пользователи также чаще интересуются мероприятиями и культурными учреждениями:
-
шоу — в четыре раза чаще;
-
кинотеатры — в три раза;
-
боулинг, аквапарк — в два раза;
-
путешествия на один день — на 85%;
-
парки развлечений — на 71%;
-
горнолыжные курорты — на 65%;
-
караоке — на 40%;
-
театры и экскурсии — на 25%.

Кроме того, в динамике запросов проявляется желание пользователей изменить свою жизнь с нового года.
Интерес к курсам и школам повышается в 2 раза, число запросов о натуральных продуктах растет на 107%, о правильном питании — на 78%.
Напоминаем, что согласно исследованию компании «Ашманов и партнеры», 8 из 10 пользователей уходят после маркетплейсов в поиск, онлайн-магазины и на другие площадки.
Подпишитесь, чтобы получать полезные материалы о платном трафике
Нажимая кнопку, вы даете согласие на обработку персональных данных
Ещё новости
Ко всем новостямНаправления исследований Яндекса
Компьютерное зрение
Исследовательская группа Яндекса регулярно вносит свой вклад в сообщество исследователей компьютерного зрения, в основном в области поиска изображений и генеративного моделирования.
32 публикации
2 публикации
1 набор данных
Обработка естественного языка
Язык — одна из ключевых форм общения. Мы изучаем методы представления и понимания языка, чтобы упростить взаимодействие человека с компьютером.
21 публикация
2 сообщения
2 набора данных
Крупномасштабное машинное обучение
Сегодня для обучения самых мощных моделей часто требуются значительные ресурсы. Наше исследование направлено на то, чтобы сделать крупномасштабное обучение более эффективным и доступным для всего сообщества машинного обучения.
6 публикаций
1 сообщение
Теория машинного обучения
Мы изучаем различные аспекты, связанные с теоретическим пониманием моделей и алгоритмов машинного обучения.
24 публикации
2 публикации
Машинное обучение на основе графов
Графики — это естественный способ представления данных из различных областей, таких как социальные сети, молекулы, текст, код и т.
д. Мы разрабатываем и анализируем алгоритмы для графически структурированных данных.11 публикаций
3 сообщения
1 набор данных
Вероятностное машинное обучение
Вероятностное машинное обучение описывает методы, позволяющие рассуждать и делать выводы относительно неизвестных величин. Обычно используется в генеративном моделировании, регрессии и количественной оценке неопределенности.
6 публикаций
Распределительный сдвиг
Распределительный сдвиг — это несоответствие между данными обучения и развертывания, повсеместно распространенное в реальном мире. Изучение этого явления может сделать системы машинного обучения более безопасными и надежными.
5 публикаций
3 публикации
1 набор данных
Оценка неопределенности
Оценка неопределенности позволяет обнаруживать, когда модели машинного обучения допускают ошибки. Это имеет решающее значение в приложениях машинного обучения с высоким риском, таких как автономные транспортные средства и медицинское машинное обучение.
8 публикаций
3 сообщения
1 набор данных
Повышение градиента
Повышение градиента итеративно объединяет слабых учеников (обычно деревья решений) для создания более сильной модели. Он достигает самых современных результатов на табличных данных с разнородными функциями.
11 публикаций
1 сообщение
Оптимизация
Большинство алгоритмов машинного обучения строят модель оптимизации и изучают ее параметры на основе заданных данных. Таким образом, разработка эффективных и действенных методов оптимизации имеет существенное значение.
13 публикаций
Машинный перевод
Языковые барьеры препятствуют глобальному общению и доступу к мировым знаниям. Улучшая системы машинного перевода, мы надеемся облегчить обмен культурой и информацией.
9 публикаций
1 набор данных
Обработка речи
Речь является важной модальностью данных и связана с такими приложениями, как распознавание речи и синтез речи, которые являются основными технологиями в таких продуктах, как голосовые помощники.
5 публикаций
Поиск ближайшего соседа
Поиск ближайшего соседа — давняя проблема, возникающая в большом количестве приложений машинного обучения, таких как службы рекомендаций, поиск информации и другие.
13 публикаций
2 сообщения
1 набор данных
Генеративные модели
Генеративные модели компьютерного зрения являются мощным инструментом для различных приложений.
9 публикаций
3 сообщения
Сегментация
Сегментация изображения — это давняя проблема на уровне пикселей в компьютерном зрении, которая также может служить испытательным стендом для других задач плотного прогнозирования.
1 публикация
Представления
Создание высококачественных представлений данных является необходимым компонентом обычных конвейеров машинного обучения.
8 публикаций
Ранжирование
Обучение ранжированию является центральной проблемой поиска информации.
Цель состоит в том, чтобы
ранжировать заданный набор элементов, чтобы оптимизировать общую полезность списка.16 публикаций
Табличные данные
Табличные данные включают двумерные таблицы с объектами (строки) и признаками (столбцы), которые используются в многочисленных прикладных задачах, таких как классификация, регрессия, ранжирование и многие другие.
5 публикаций
2 публикации
1 набор данных
Байесовские методы
Байесовские методы — это подмножество вероятностного МО, которое обеспечивает нормативную теорию МО и возможность рассуждать над субъективными неизвестными и справляться с эпистемологическими неопределенностями.
4 публикации
1 сообщение

 д. Мы разрабатываем и анализируем алгоритмы для графически структурированных данных.
д. Мы разрабатываем и анализируем алгоритмы для графически структурированных данных.

 Цель состоит в том, чтобы
ранжировать заданный набор элементов, чтобы оптимизировать общую полезность списка.
Цель состоит в том, чтобы
ранжировать заданный набор элементов, чтобы оптимизировать общую полезность списка.децентрализованный вывод и точная настройка больших языковых моделей
Большие языковые модели являются одними из самых значительных последних достижений в области машинного обучения. Тем не менее, использование этих моделей может быть затруднено: разгрузка и квантование имеют ограничения, а сторонние API менее гибкие. В качестве альтернативного решения мы предлагаем Petals, децентрализованную систему с открытым исходным кодом (демонстрированную на этой неделе на треке демонстраций ACL 2023), позволяющую любому запускать большие модели или даже адаптировать их, используя свободные ресурсы добровольцев. В этом посте вы узнаете мотивацию системы, лежащие в ее основе идеи и ее преимущества по сравнению с другими способами использования больших моделей.
В качестве альтернативного решения мы предлагаем Petals, децентрализованную систему с открытым исходным кодом (демонстрированную на этой неделе на треке демонстраций ACL 2023), позволяющую любому запускать большие модели или даже адаптировать их, используя свободные ресурсы добровольцев. В этом посте вы узнаете мотивацию системы, лежащие в ее основе идеи и ее преимущества по сравнению с другими способами использования больших моделей.
Лепестки были разработаны в рамках коллаборации BigScience инженерами и исследователями из Исследовательского центра Яндекса, НИУ ВШЭ, Университета Вашингтона, Hugging Face, ENS Paris-Saclay и Школы анализа данных Яндекса.
Предыстория: открытые LLM и методы их запуска Ссылка скопирована в буфер обмена
С 2020 года мы наблюдаем, как большие языковые модели (LLM), такие как GPT-3, быстро улучшают свои возможности, иногда приобретая новые свойства, такие как обучение в контексте. В 2022 и начале 2023 года было выпущено множество открытых альтернатив проприетарным LLM: яркими примерами этой тенденции являются BLOOM, OPT, LLaMA, а также YaLM, разработанный Яндексом. Однако использование этих моделей с высокой производительностью по-прежнему является сложной инженерной задачей: модели с более чем 170 миллиардами параметров требуют более 340 гигабайт памяти графического процессора для хранения с точностью FP16, что превышает возможности любого отдельного ускорителя.
Однако использование этих моделей с высокой производительностью по-прежнему является сложной инженерной задачей: модели с более чем 170 миллиардами параметров требуют более 340 гигабайт памяти графического процессора для хранения с точностью FP16, что превышает возможности любого отдельного ускорителя.
С точки зрения пользователя, простым решением является использование API, где модель размещается у внешнего поставщика, взимающего плату за запросы к этому LLM. Хотя этот подход не требует опыта обслуживания моделей, он также является наименее гибким: сопровождающие API обычно не позволяют проверять внутренние состояния нейронной сети, что может быть полезно для ее анализа. Кроме того, сама модель может быть постепенно выведена из эксплуатации поставщиком, что особенно затрудняет проведение воспроизводимых исследований с использованием таких API.
Напротив, выгрузка весов нейронной сети в более крупное локальное хранилище (такое как ОЗУ или твердотельный накопитель) обеспечивает полный контроль над моделью. Даже если на вашем персональном компьютере достаточно памяти, латентность при таком подходе значительно выше: генерация одного токена с помощью BLOOM-176B, выгрузка займет более 5 секунд из-за узкого места в передаче данных. Такая задержка может быть приемлемой для пакетной обработки, но не для интерактивных приложений: следовательно, нам нужно что-то прозрачное, но достаточно быстрое.
Даже если на вашем персональном компьютере достаточно памяти, латентность при таком подходе значительно выше: генерация одного токена с помощью BLOOM-176B, выгрузка займет более 5 секунд из-за узкого места в передаче данных. Такая задержка может быть приемлемой для пакетной обработки, но не для интерактивных приложений: следовательно, нам нужно что-то прозрачное, но достаточно быстрое.
Обзор подхода Ссылка скопирована в буфер обмена
На поверхностном уровне Petals работает как децентрализованный конвейер, предназначенный для быстрого вывода нейронных сетей. Он разбивает любую заданную модель на несколько блоков (или слоев), которые размещаются на разных серверах . Эти серверы могут быть разбросаны по континентам, и каждый может подключить свой собственный GPU! В свою очередь, пользователи могут подключаться к этой сети как клиент и применять модель к своим данным.
Когда клиент отправляет запрос в сеть, он направляется через цепочку серверов, построенную таким образом, чтобы минимизировать общее время прохождения вперед. При присоединении к системе каждый сервер выбирает наиболее оптимальный набор блоков, исходя из текущих узких мест в пайплайне. Ниже вы можете увидеть иллюстрацию Petals для нескольких серверов и клиентов с разными входными данными для модели.
При присоединении к системе каждый сервер выбирает наиболее оптимальный набор блоков, исходя из текущих узких мест в пайплайне. Ниже вы можете увидеть иллюстрацию Petals для нескольких серверов и клиентов с разными входными данными для модели.
Обзор Petals
Поскольку наша сеть состоит из добровольцев, а не серверов по требованию, каждый участник Petals может отключиться в любой момент. Чтобы устранить потенциальные сбои, клиент сохраняет промежуточные активации, отправленные каждому блоку, и перенаправляет их с автономного сервера на онлайн-узел, на котором размещен тот же блок.
Важно отметить, что прозрачность промежуточных состояний дает здесь дополнительное преимущество. Поскольку все входные и выходные данные блока отправляются по сети, между слоями модели можно вставлять адаптеры для конкретных задач, что позволяет проводить легкую точную настройку без изменения предварительно обученной модели, размещенной на серверах. В статье о Petals [1] система рассматривается более подробно, включая другие компоненты, такие как активация и весовое сжатие модели.
Лепестки на практике Ссылка скопирована в буфер обмена
Если вы просто хотите использовать Petals в качестве клиента, вам не нужно ничего знать о деталях системы. Интерфейс Petals намеренно очень похож на библиотеку Transformers: если вам нужно только получить сгенерированные выходные данные или адаптировать модель с быстрой настройкой, фрагмент ниже охватывает все необходимые шаги. Как видите, подключение к общедоступной сети Petals и любая сложная логика маршрутизации не видны конечному пользователю. Репозиторий Petals содержит несколько руководств и примеров, показывающих, как использовать его для разных задач.
Пример фрагмента кода для логического вывода и точной настройки с помощью Petals. В настоящее время система поддерживает модели BLOOM и LLaMA.
Конечно, волонтерская платформа работает только при наличии достаточного количества графических процессоров, обрабатывающих запросы клиентов. Предполагая, что у вас есть система Linux с установленными CUDA и PyTorch, подключение вашей собственной машины к публичному рою и превращение в сервер также зависит от двух команд терминала:
pip install -U лепесток.python -m лепесток.cli.run_server bigscience/bloom
В качестве альтернативы, если вы хотите создать свой собственный рой (например, для использования определенной модели внутри компании), мы предлагаем руководство по развертыванию собственной версии Petals.
Бенчмарки Ссылка скопирована в буфер обмена
Мы сравниваем производительность Petals с разгрузкой, так как это самый популярный метод использования моделей 100B+ на локальном оборудовании. Мы тестируем как однопакетный вывод в качестве интерактивной настройки, так и пропускную способность параллельного прямого прохода для сценария пакетной обработки. Наши эксперименты проводятся на BLOOM-176B и охватывают различные сетевые условия, от нескольких высокоскоростных узлов до реальных интернет-каналов. Как видно из приведенной ниже таблицы, Petals предсказуемо медленнее, чем разгрузка, с точки зрения пропускной способности, но в 3–25 раз быстрее с точки зрения задержки по сравнению с реалистичной настройкой. Это означает, что логический вывод (а иногда даже тонкая настройка) с помощью Petals выполняется намного быстрее, несмотря на то, что мы используем распределенную модель, а не локальную.