
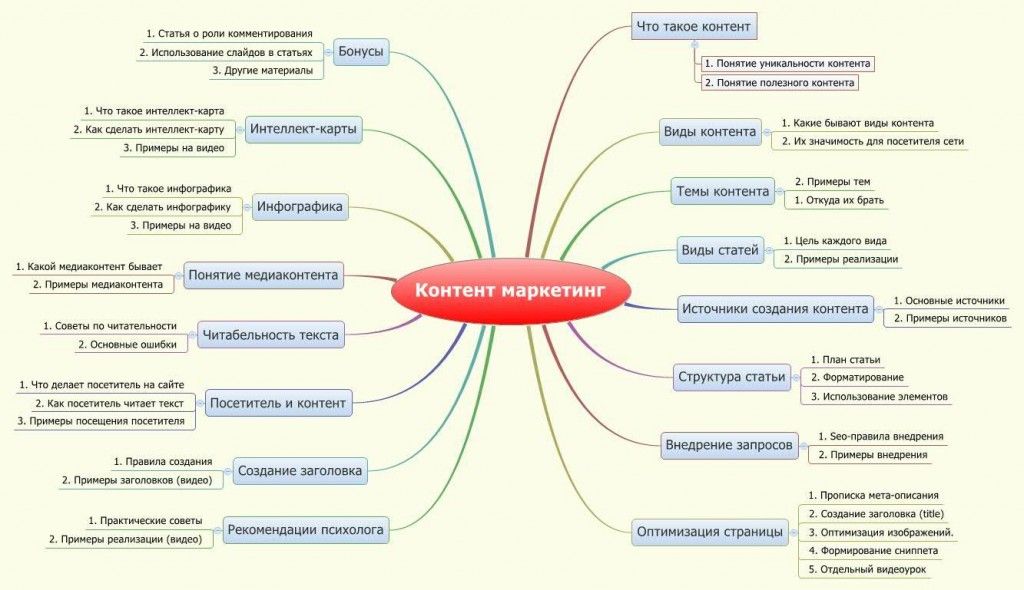
Виды контента в контент-маркетинге. | Университет СИНЕРГИЯ
Содержание
Контент — это любая информация, опубликованная на сайте компании или в социальных сетях. С помощью контента можно повышать вовлеченность аудитории, формировать репутацию бренда и побуждать к покупке. Мы расскажем про важность контента в интернет-маркетинге, виды контента и особенностях создания публикаций.
Важность контента
Контент-маркетинг — это стратегия продвижения сайтов и групп в соцсетях, которая основана на на публикации записей, интересных читателям. Какие площадки и виды контента лучше подходят для продвижения, решает маркетолог. Выбор стратегии зависит от особенностей товара, состава целевой аудитории и стратегии позиционирования бренда.
Преимущества использования контент-маркетинга:
- Повышение позиций сайта компании в поисковой выдаче. При подготовке контента можно использовать методы SEO-продвижения и повысить видимость домена в интернете.

- Расширение воронки продаж. Публикация постов в соцсетях помогает привлечь внимание к товару или услуге. Благодаря «умной ленте» посты смогут увидеть даже пользователи, не подписанные на страницу компании. Часть из них станет лояльными подписчиками.
- Повышение узнаваемости бренда. Оригинальный контент помогает компании выделиться среди конкурентов и запомниться целевой аудитории. Чтобы достичь цели, важно выбрать единый стиль оформления материалов и тон общения с пользователями.
- Изучение целевой аудитории. Анализ комментариев и проведение активностей в соцсетях помогает составить портрет потенциального клиента. Владея информацией о потребностях аудитории, можно улучшать продукты или услуги.
- Работа с возражениями. В социальных сетях можно публиковать посты, которые отвечают на типичные вопросы пользователей. Этот формат контента помогает развеять сомнения у читателей, им становится легче принять решение о покупке.


Контент-маркетинг основан на обмене ресурсами. Вы публикуете материалы, которые развлекают аудиторию или дают полезную информацию. Взамен вы получаете лояльность аудитории, заявки на покупку и отклик в социальных сетях (подписки, лайки, репосты, комментарии).
Виды контента
Маркетологи выделяют основные типы контента:
- Информационный.
- Развлекающий.
- Продающий.
- Интерактивный.
Информационный контент содержит информацию, полезную читателям. Он помогает расширить уровень кругозора, приобрести новые знания и навыки. Виды материалов: новостные публикации, инструкции, мануалы, мастер-классы, рецензии, иллюстрации со статистикой.
Развлекательный контент вызывает положительные эмоции у подписчиков, повышает лояльность, мотивирует заходить на страницу бренда. Виды развлекательного контента: мемы, коллажи, фото, видео, несерьезные заметки, статьи и подборки.
Продающие записи напрямую призывают читателей совершить покупку. Виды материалов: посты про акции и скидки, презентации новинок в ассортименте, лендинги, кейсы, сторителлинг.
Виды материалов: посты про акции и скидки, презентации новинок в ассортименте, лендинги, кейсы, сторителлинг.
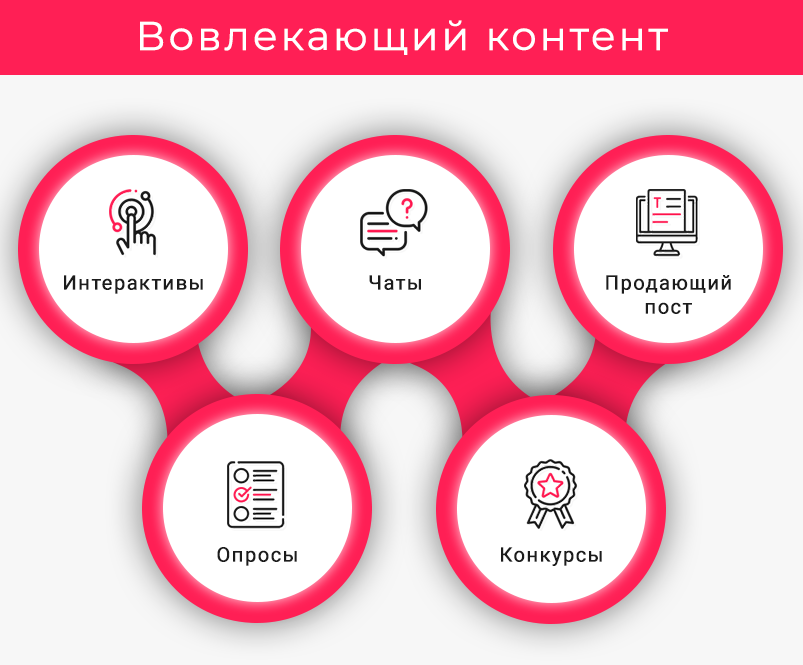
Интерактивные посты увеличивают активность целевой аудитории. К данной категории относятся опросы, тесты и розыгрыши. Интерактивным контентом будет и пост, где в комментариях читатели смогут оставлять предложения по работе компании.
Кейс
Кейс — это один из видов информационного контента. Кейс рассказывает историю возникновения проблемы клиента, план решения задачи, потраченные ресурсы и полученный результат. Контент рассказывает о методах работы, подсвечивает сильные стороны компании и укрепляет репутацию бренда.
Сторителлинг
Сторителлинг также представляет собой рассказ. У сторителлинга, в отличие от кейса, есть автор — сотрудник компании или довольный клиент. В статье содержится больше эмоций, подробностей и фотографий. Сторителлинг привлекает внимание к проекту и хорошо запоминается. При чтении пользователь ставит себя на место клиента, что помогает принять решение о покупке.
Лендинг
Лендинг — не только вид контента, но и эффективный инструмент увеличения продаж. Лендингом называется одностраничный сайт с минимумом информации. У лендинга есть определенная цель. Продающая страница мотивирует пользователей совершить конкретное действие:
- оставить заявку на покупку продукта;
- оставить заявку на бесплатную консультацию;
- указать контактную информацию и получить бонус.
Разбор
Разбор содержит подробное описание характеристик товара или опыта использования услуги. Он отвечает на незаданные вопросы клиента и помогает принять решение о покупке. В начале статьи должно быть содержание, чтобы читатель мог перейти к интересному пункту. Текст разбора может содержать личное мнение составителя или нейтральное перечисление свойств продукта.
Инструкция
Инструкция рассказывает о правилах использования товара или программного продукта. В тексте содержатся ответы на распространенные вопросы пользователей. Инструкция зачастую включает описание процесса сборки или подключения товара. В сложных случаях рекомендуется дополнять текст инструкции фото и видео. Качественная инструкция снижает нагрузку на службу поддержки клиентов.
Инструкция зачастую включает описание процесса сборки или подключения товара. В сложных случаях рекомендуется дополнять текст инструкции фото и видео. Качественная инструкция снижает нагрузку на службу поддержки клиентов.
Новость
Новостные посты помогают сформировать репутацию компании. Они показывают читателям, что вы стремитесь идти в ногу со временем и следите за ключевыми событиями отрасли и мировыми трендами. Это универсальный формат, подходящий для сайта, блога, соцсетей или рассылки.
Стандартная подача материалов подразумевает нейтральное описание событий. Но если новость хорошая, в статье можно выразить положительные эмоции. Важно следить за качеством постов и не публиковать информацию без проверки источника.
Инфографика
Хорошим дополнением к новостным статьям, записям в блоге или письмам в рассылке являются наглядные иллюстрации. Формат контента подразумевает информативность и красивый дизайн. Выбранный стиль позволяет компактно разместить большой объем данных на малой площади.
Подборка
Подборка — вид контента, содержащий перечисление однотипных материалов. Этот может быть список продуктов, подходящих под определенные критерии, обзор модных трендов или полезных советов для покупателей.
Например, компания, продающая товары для ремонта, может публиковать подборки идей дизайна интерьера. В группе магазина, продающего материалы для творчества, можно описывать способы их применения. Подборки часто используют при написании рассылок.
Колонка
Колонка — раздел на сайте журнала или газеты, где публикуются заметки от главного редактора. На сайте организации колонку должен вести человек, пользующийся авторитетом. Это может быть владелец бизнеса, представитель ТОП-менеджмента или специалист с признанным авторитетом.
В формате колонки можно рассказывать о важных событиях отрасли, нововведениях в компании, расширении ассортимента, открытии новых филиалов и других инфоповодах. Отличие колонки от других жанров заключается в том, что все публикации принадлежат одному человеку.
Интервью
Этот вид контента предполагает беседу с экспертом в формате вопрос-ответ. Экспертное мнение повышает доверие к бренду и продукту. Чтобы текст получился интересным читателям, у беседы должна быть цель и план, расписанный по пунктам. При редактировании полученного материала важно сохранить стиль общения рассказчика, тогда текст получится увлекательным.
Фотографии
Публикация качественных фотографий помогает демонстрировать продукты и вызывает желание сделать покупку. Наполнять сайты и группы фотографиями особенно важно для тех направлений деятельности, где принятие решения о покупке зависит от внешнего вида товара. К этим сферам относится:
- работа кафе и ресторанов;
- торговля одеждой и обувью;
- торговля предметами декора;
- реализация недвижимости;
- организация туристических поездок;
- услуги гостиниц и отелей.
Опросы
Проведение интерактивов помогает бренду напомнить о себе и поднять активность подписчиков, что полезно для продвижения группы или паблика. Простой формат опроса предполагает выбор одного из вариантов или просьбу поставить лайк, если читатель согласен с утверждением. Другим решением для интерактива будет просьба написать свое мнение в комментариях. Проведя анализ полученных отзывов, можно совершенствовать линейку продукции и уровень сервиса.
Простой формат опроса предполагает выбор одного из вариантов или просьбу поставить лайк, если читатель согласен с утверждением. Другим решением для интерактива будет просьба написать свое мнение в комментариях. Проведя анализ полученных отзывов, можно совершенствовать линейку продукции и уровень сервиса.
Квизы
Квиз — это короткое интерактивное развлечение. Участник квиза должен выполнить ряд простых действий, чтобы получить результат. Запуск квиза улучшает эмоциональный контакт с аудиторией. Во время прохождения сюжета участники узнают больше о продуктах компании.
Конкурсы
Для повышения активности подписчиков в соцсетях можно проводить розыгрыши призов. Самой распространенной стратегией является выбор победителя из участников, которые поставили лайк или сделали репост записи. Но чтобы повысить эмоциональную вовлеченность аудитории, стоит дать подписчикам возможность проявить себя и проводить творческие конкурсы.
Мемы и шутки
В некоторых случаях уместна публикация мемов — популярных шуток из интернета. Эта стратегия применяется в нишах, где целевая аудитория состоит по большей части из школьников, студентов и молодых людей. Чтобы успешно пользоваться мемами для продвижения группы, важно следить за модными трендами и «быть на одной волне» с подписчиками.
Эта стратегия применяется в нишах, где целевая аудитория состоит по большей части из школьников, студентов и молодых людей. Чтобы успешно пользоваться мемами для продвижения группы, важно следить за модными трендами и «быть на одной волне» с подписчиками.
При выборе типа контента следует ориентироваться на интересы целевой аудитории. Например, людям старшего поколения нравятся аналитические статьи и новости, а молодежь предпочитает короткие посты и видеоролики.
Самым эффективным каналом для продвижения с помощью контента являются социальные сети. Но подписчики в соцсетях ожидают увидеть в первую очередь развлекательный контент: смешные фото и видео, сторителлинг. Многим пользователям интересна информация о скидках и акциях, а также розыгрыши призов.
В постах важно чередовать виды контента, чтобы поддерживать интерес у целевой аудитории. Не стоит часто публиковать продающие посты, это вызывает негатив. Более эффективной стратегией будет вызвать доверие у читателя, создать положительные ассоциации с брендом и ненавязчиво подвести к покупке.
Понятие информационного содержания (контента) -Управление информационным содержанием (контентом) Интернет-ресурсов
Кто не делится найденным, подобен свету в дупле секвойи (древняя индейская пословица)
Библиографическая запись: Понятие информационного содержания (контента). — Текст : электронный // Myfilology.ru – информационный филологический ресурс : [сайт]. – URL: https://myfilology.ru//192/ponyatie-informaczionnogo-soderzhaniya-kontenta/ (дата обращения: 5.01.2023)
Содержание
Контентом называется всё информационное наполнение интернет-сайта, газеты, журнала. В переводе с английского языка слово контент означает «содержание». К нему относятся текст, фотографии, картинки, видео и аудио-файлы. Если говорить о контенте сайта, то к нему относится все, что пользователь видит при просмотре страницы.
В основном под контентом в первую очередь подразумевают текст, а изображения и остальные составляющие являются дополнительной информацией, которая украшает сайт и приводит его к такому виду, при котором информация может быть усвоена гораздо легче. Так же контентом принято называть ту часть информационной составляющей сетевого ресурса (или сайта), которую пользователь может использовать по своему усмотрению, в частности загрузить на собственный компьютер и сохранить для личного использования.
Но при этом необходимо понимать, что любой контент сайта является интеллектуальной собственностью автора этого контента и охраняется законом об авторских правах.
Любой контент имеет автора и владельца. Причем далеко не всегда владелец контента является его автором. Вот, к примеру, допустим, владелец ресурса приобретает на бирже статей, готовую статью по интересующей его теме и публикует её на своем сайте.
Не смотря на то, что автором этого контента он не является, все права на данный объект интеллектуальной собственности принадлежат именно владельцу сайта. В процессе покупки статьи к нему так же переходят авторские права на контент. Воровство контента или любой его части являются незаконным.
Содержание информационного ресурса, рассматриваемое вне формы его визульного представления, называется контентом. Понятия «форма» и «содержание» относятся к философским категориям: форма отражает способы существования содержания. Во взаимосвязи «форма — содержание», содержание является ведущей, то есть определяющей характеристикой объекта. Поэтому оно активнее влияет на форму, по сравнению обратного влияния формы на содержание.
В ходе развития объекта неизбежно возникает конфликт между ними, разрешением которого является замена формы, более адекватной новому содержанию.
Содержание (контент) может быть различным: экономическим, правовым, техническим и т.д. Оно может находиться в Интернете, и тогда он носит название Web-контент, либо на предприятии, и тогда оно называется корпоративным контентом.
Web-контент в основном не структурирован (тексты, аудио и видеоматериалы и т.д.). Корпоративный контент, как правило, сохраняется в структурированных формах (таблицы, базы данных и знаний, хранилища данных и т д.).
Задача специалистов по управлению контентом состоит в выборе или разработке такой формы его хранения, которая с наибольшей эффективностью позволит достичь поставленные цели управления. Управление контентом осуществляется с помощью интегрированных сервисов. Они максимально отделяют пользователя и администратора от технологической и программной среды реализации.
Это особенно важно для электронного бизнеса, где контент и форма играют важную роль в маркетинговой и рекламной стратегии предприятия.
Системы управления веб-контентом (WCMS – WEB Content Menedgment Servis) предназначены для выполнения операций с ним на сайте:
Кроме того, необходимо администрирование веб-ресурсов — изменение структуры веб-сайта, разграничение прав доступа, а также разработка новых веб-ресурсов.
Системы управления корпоративным контентом включают системы документооборота масштаба предприятия, в которых имеются функции работы с веб-документами через веб-интерфейс.
Развитие систем управления корпоративным контентом осуществляется в направлении использования специализированных программных систем класса (ECM — Enterprise Content Management).
Так как контент не может существовать отдельно от бизнес-процессов предприятий, эти системы интегрируются с системами управления бизнес-процессами (business process management, BPM).
Структура контента
Контент состоит из множества фрагментов, которые могут быть представлены пользователю в различных последовательностях (постоянных или изменяемых). Такие последовательности фрагментов контента могут быть определены как структура контента. В практике проектирования мультимедийного издания используются следующие виды структур контента.
Такие последовательности фрагментов контента могут быть определены как структура контента. В практике проектирования мультимедийного издания используются следующие виды структур контента.
Линейная. Линейная структура свидетельствует о том, что один фрагмент информации следует за другим. Если необходимо, чтобы пользователь прошел шаг 1 перед шагом 2, это должно быть отражено в структуре содержания.
Иерархическая. Иерархическая структура применяется в случае, если контент имеет категории с подкатегориями.
Примеры: организационные диаграммы, дерево родословной, файловая система, структура управления.
Сетевая структура. Используется, когда необходимо перемещаться от одного фрагмента контента другому либо по ассоциации, либо по заданному условию. При реализации нелинейной схемы навигации появляется возможность перехода от каждой страницы к каждой.
Примеры: игры, семантические сети (структура для представления знаний в виде узлов, соединенных дугами), Интернет.
Параллельная структура. Такая структура используется при демонстрации в презентации двух взаимосвязанных частей информации одновременно.
Примеры: фильмы с субтитрами, презентации со звуковым сопровождением.
Матрица. Матрицы хороши для использования при представлении больших объемов повторяющихся данных.
Примеры: таблицы, диаграммы, графики, индексы.
Наложение (Overlay). Оверлейная структура может использоваться, если есть необходимость пользователю запомнить или напомнить частью чего-либо.
информационный интернет контент
Пространственные расширения. Пространственный масштаб структуры используются для направления пользователя к другому источнику информации.
Пример: энциклопедии, словари, библиотеки, боковые панели в журналах.
Смешанная схема. Структуры контента (навигации) представляет собой комбинацию приведенных выше структур.
17.1: Представление мотива и информационное содержание
- Последнее обновление
- Сохранить как PDF
- Идентификатор страницы
- 41014
- Manolis Kellis et al.
- Массачусетский технологический институт через MIT OpenCourseWare
Вместо матрицы профиля мы также можем представить мотивы, используя теорию информации. В теории информации информация об определенном событии передается посредством сообщения. Количество информации, переносимой сообщением, измеряется в битах. Мы можем определить биты информации, переносимые сообщением, наблюдая за распределением вероятностей события, описанного в сообщении. По сути, если мы ничего не знаем об исходе события, сообщение будет содержать много битов.
Энтропия Шеннона — это мера ожидаемого количества информации, содержащейся в сообщении. Другими словами, это информация, содержащаяся в сообщении о каждом событии, которое может произойти, взвешенное по вероятности каждого события. Энтропия Шеннона определяется уравнением:
\[ H(X)=-\sum_{i} p_{i} \log _{2} p_{i} \nonumber \]
Энтропия максимальна, когда все события имеют одинаковую вероятность возникновения. Это потому, что энтропия сообщает нам ожидаемый объем информации, которую мы узнаем. Даже если у каждого из них есть одинаковая вероятность наступления, мы знаем о событии как можно меньше, поэтому ожидаемый объем информации, которую мы узнаем, максимален. Например, бросок монеты имеет максимальную энтропию только тогда, когда монета честная. Если монета нечестная, то мы знаем больше о событии подбрасывания монеты, а ожидаемое сообщение об исходе подбрасывания монеты будет содержать меньше информации.
Даже если у каждого из них есть одинаковая вероятность наступления, мы знаем о событии как можно меньше, поэтому ожидаемый объем информации, которую мы узнаем, максимален. Например, бросок монеты имеет максимальную энтропию только тогда, когда монета честная. Если монета нечестная, то мы знаем больше о событии подбрасывания монеты, а ожидаемое сообщение об исходе подбрасывания монеты будет содержать меньше информации.
Мы можем смоделировать мотив, исходя из того, сколько информации у нас есть о каждой позиции после применения Выборки Гибса или EM. На следующем рисунке высота каждой буквы представляет количество битов информации, которую мы узнали об этой базе. Более высокие стеки соответствуют большей уверенности в том, что является основанием в этом положении мотива, в то время как более низкие стеки соответствуют более высокой степени неопределенности. С четырьмя кодонами на выбор энтропия Шеннона каждой позиции составляет 2 бита. Другой способ взглянуть на этот рисунок состоит в том, что высота буквы пропорциональна частоте основания в этой позиции.
С четырьмя кодонами на выбор энтропия Шеннона каждой позиции составляет 2 бита. Другой способ взглянуть на этот рисунок состоит в том, что высота буквы пропорциональна частоте основания в этой позиции.
Рисунок 17.12: Высота каждого стека представляет собой количество битов информации, которую выборка Гиббса или EM сообщила нам о позиции в мотиве
Существует метрика расстояния в вероятностных распределениях, известная как расстояние Кульбака-Лейблера. Это позволяет нам сравнить дивергенцию распределения мотивов с некоторым истинным распределением. Расстояние K-L равно
\[ D_{K L}\left(P_{\text {мотив}} \mid P_{\text {фон}}\right)=\Sigma_{A, T, G, C} P_{\text {мотив} } (i) \ log \ underset {P \ text {фон} (i)} {P _ {\ text {мотив}} (i)} \ nonumber \]
В Plasmodium более низкое содержание G-C. Если мы предположим, что содержание GC равно 20%, то мы получим следующее представление для вышеуказанного мотива. Основания C и G гораздо более необычны, поэтому их распространенность весьма необычна. Обратите внимание, что в этом представлении мы использовали расстояние K-L, так что стек может быть больше 2,9.0032
© источник неизвестен. Все права защищены. Этот контент исключен из нашей лицензии Creative Commons. Для получения дополнительной информации см. http://ocw.mit.edu/help/faq-fair-use/.
Если мы предположим, что содержание GC равно 20%, то мы получим следующее представление для вышеуказанного мотива. Основания C и G гораздо более необычны, поэтому их распространенность весьма необычна. Обратите внимание, что в этом представлении мы использовали расстояние K-L, так что стек может быть больше 2,9.0032
© источник неизвестен. Все права защищены. Этот контент исключен из нашей лицензии Creative Commons. Для получения дополнительной информации см. http://ocw.mit.edu/help/faq-fair-use/.
Рисунок 17.13: Сайт связывания lexA при низком содержании GC и использовании расстояния K-L
Библиография
- [1] Тимоти Л. Бейли. Подгонка модели смеси путем максимизации ожидания для обнаружения мотивов в биополимерах. В материалах Второй Международной конференции по интеллектуальным системам для молекулярной биологии, стр. 28–36. АААИ Пресс, 1994.
- [2] К. Э. Лоуренс и А. А. Рейли. Алгоритм максимизации ожидания (em) для идентификации и характеристики общих сайтов в последовательностях невыровненных биополимеров. Белки, 7(1):41–51, 1990.
 Белки, 7(1):41–51, 1990.
Белки, 7(1):41–51, 1990.Эта страница под названием 17.1: Представление мотива и информационное содержание распространяется в соответствии с лицензией CC BY-NC-SA 4.0 и была создана, изменена и/или курирована Manolis Kellis et al. (MIT OpenCourseWare) через исходный контент, отредактированный в соответствии со стилем и стандартами платформы LibreTexts; подробная история редактирования доступна по запросу.
- Наверх
- Была ли эта статья полезной?
- Тип изделия
- Раздел или Страница
- Автор
- Манолис Келлис и др.
- Лицензия
- CC BY-NC-SA
- Версия лицензии
- 4,0
- Программа OER или Publisher
- MIT OpenCourseWare
- Теги
- source@https://ocw. mit.edu/courses/6-047-computational-biology-fall-2015/
- source@https://ocw.
 mit.edu/courses/6-047-computational-biology-fall-2015/
mit.edu/courses/6-047-computational-biology-fall-2015/| Вольфрам Постскриптумы Дембски |
| |||||||||||||||
Три года спустя я все еще думаю, что здесь есть несоответствие, но генератор случайных чисел — не лучший пример, чтобы его проиллюстрировать. Генератор случайных чисел не описывает конкретная случайная строка вообще, и поэтому не может быть кратчайшим описанием конкретной случайной строки. Он описывает набора всех случайных строк. Генератор случайных чисел не является воспроизводимым описанием конкретной строки, поскольку каждая сгенерированная строка уникальна. Это еще более верно для настоящей случайной последовательности, основанной на радиоактивном распаде или любом другом естественном источнике истинной случайности (8). Это еще более верно для настоящей случайной последовательности, основанной на радиоактивном распаде или любом другом естественном источнике истинной случайности (8). Однако есть и другие системы, такие как π (пи) и клеточные автоматы (9), которые воспроизводимо и однозначно описывают произвольную длинную случайную последовательность. Парадокс заключается в том, что длина этих простых алгоритмов вообще ничего не говорит нам об «информационном содержании» или сложности последовательности, которую они производят/описывают, потому что «информационное содержание» может иметь любое значение в зависимости от длины вывода. Поскольку π бесконечной длины, его информативность должна быть бесконечной. Информация и значениеВид «информации», производимой бездумной компьютерной программой или естественным физическим бездумным процессом. это дешевая, бесполезная, бессмысленная информация. Просто дайте ему работать вечно, и он будет производить бесконечный поток «информации»! это , а не то, что люди называют информацией. Вот настоящий парадокс. Вот настоящий парадокс. Другой способ сформулировать парадокс таков: длинная случайная последовательность букв имеет более высокое информационное содержание, чем книга той же длины. Это связано с тем, что случайная строка вообще практически не поддается сжатию, в то время как содержимое книги сжимается легко (как известно всем, кто использует программы для сжатия на ПК, такие как pkzip, winzip и т. д.). На самом деле случайная строка содержит максимум информации. Это определение информации придумал не Пол Дэвис, а Шеннон, Чайтин и Колмогоров. Следующие 3 блока, серый блок, содержащий «информацию», следующий с добавлением небольшого количества шума и один с максимальным количеством добавленного шума, показывать возрастающую информативность по математическому определению:
«Информационное содержание» отражается в размере файлов jpeg, поскольку jpeg является алгоритмом сжатия (все три имеют размер 50×75 пикселей и имеют одинаковый коэффициент сжатия [14]).  Таким образом, ранжирование человеческой информации (книг) и случайных строк (шума) на основе критерия сжимаемости дает результат, явно противоречащий здравому смыслу. Дело в том, что слово «информационное содержание» вне математического контекста вводит в заблуждение. Предлагаю называть такой Информационный Контент именно тем, чем он является: сжимаемость и только. В чем разница между случайной строкой и книгой? Слова в книге тщательно отобраны по их смыслу . Неудивительно, что определение сжимаемости информационного содержания приводит к таким парадоксальным результатам, потому что сжимаемость игнорирует значение символов. Другой читатель New Scientist Тони Кастальдо написал: «Противоположно только то, что книга будет использоваться человеком в человеческих целях, и, конечно, повседневное использование (в вашем мире) будет о людях для людей». целях. Для компьютера книга будет иметь меньше информации». Однако программа, написанная на Fortran, C++, Visual Basic и т. Хьюберт Йоки«Я указал выше в обсуждении нахождения определения и меры « информации », что математическое определение не охватывает все значения, которые интуитивно связаны с этим словом. Точно так же сложность Колмогорова-Чайтина может точно так же не уловить всего, о чем думают, в слове сложность ‘, тем не менее, он окажется очень полезным в молекулярной биологии» [12]. Джон Мейнард Смит«Теоретики информации используют фразу «информация — это данные плюс значение»» [11]. Это именно то, что я имею в виду. Но кто эти «теоретики информации»?Раду Попа«Теория информации Шеннона является чисто математической и заставляет информацию не обращать внимания на функционирование, поэтому она не может отличить значимые (учебные) сигналы от шума». [13] [13]Ричард Фейнман«Как случайная строка может содержать любой информации, не говоря уже о максимальном количестве? Конечно, мы должны использовать неправильное определение «информации»? …» [3]Этикетки! Эти случайные строки являются метками, а не сообщениями! Без метки каждая случайная строка — это просто случайная строка и ничего более. Ярлыки создают смысл. Эти случайные строки могут быть помечены разными способами. Должна быть создана таблица кодов, такая как таблица кодов ASCII, таблица кодов Морзе или таблица генетических кодов. Но зато есть информация в кодовой таблице. Этот тип информации должен выходить за рамки исходного набора случайных строк. Ян СтюартЛюди говорят очень много чепухи о ДНК как об «информации» для организма — как будто информация имеет какое-то значение вне четко определенного контекста. […] Однако в сообщении действительно важно не количество информации, а ее качество. «Два плюс два будет семнадцать» длиннее, чем «2+2=4», но тоже ерунда. Уоррен Уивер«Слово информация в теории Шеннона используется в особом смысле, который не следует путать с его обычным употреблением. В частности, информацию не следует путать со значением…» [5] Пол Дэвис«Все случайные последовательности одинаковой длины кодируют примерно одинаковое количество информации, но решающее значение имеет качество этой информации…» [6]Полезное понимание Дэвиса состоит в том, что значимая информация должна быть очень конкретным и небольшим подмножеством всех случайных последовательностей. Однако: как мы определяем «качество»? Как определить подмножество? Джеймс Глейк«Рождение теории информации произошло с безжалостной жертвой смысла — того самого качества, которое придает информации ее ценность и предназначение».из The Information A History, a Theory, a Flood (2011), цитируемого Эндрю Робинсоном в журнале Science 30 сентября 2011 г.  :
«Представляя свою «Математическую теорию коммуникации», основатель теории информации Клод Шеннон прямо заявил, что значение «не имеет отношения к инженерной проблеме». :
«Представляя свою «Математическую теорию коммуникации», основатель теории информации Клод Шеннон прямо заявил, что значение «не имеет отношения к инженерной проблеме».Джим КратчфилдПозже я обнаружил, что Кратчфилд заметил упомянутый выше парадокс: чистая случайность порождает большое количество шенноновской информации, а также высокую алгоритмическую сложность Колмогорова.«Теория информации в изложении Шеннона — это не теория содержания информации. Это количественная теория информации».Кратчфилд разработал меру значимой информации, которая позволяет избежать этого парадокса. Он назвал это статистической сложностью . Статистическая сложность низкая, когда случайность очень высока. высокая , но и низкая, когда случайность очень низкая (закономерности). Но в среднем диапазоне там, где случайность смешана с регулярностью, статистическая сложность высока [7]. Я не уверен, удалось ли Крачфилду, но он пытается избежать парадокса.  ПредложениеКак отмечалось выше, я предлагаю называть математическую концепцию информации Чайтина-Колмогорова «сжимаемостью», чтобы предотвратить смешение «математической информации» с «человеческой информацией». Более того, вдохновленный идеей спецификации Уильяма Дембски [2], я предлагаю следующее. Подмножество случайных строк, которые люди называют информацией, определяется «словарем слов». На самом деле словарь определяет то интересное подмножество, которое мы называем информацией. Количество значимой информации в строке символов зависит от количества совпадений со строками в установленном словаре. Это справедливо как для человеческого языка, так и для языка ДНК. Генетики определяют значение фрагмента ДНК путем поиска в установленном «генном словаре» (установленном по многим другим видам). Остальную часть строки ДНК можно считать случайной, пока не будет найдено совпадение со словом из словаря. Этот метод недавно был продемонстрирован командой, которая использовала более крупный «генетический словарь» человеческого генома (11 баз данных вместо 2) и нашла 65 000–75 000 совпадений (вместо 30 000). Конечно, есть связь с наличием «словарных слов» и сжимаемостью. Но между сжимаемостью и значением нет линейной зависимости. Мое предложение: Информационное содержание на основе словаря : информационное содержание на основе словаря, указанного заранее. Это не максимальная сжимаемость, к которой стремятся инженеры по коммуникациям и дизайнеры веб-графики, однако она определенно не является субъективной или произвольной, потому что ее легко реализовать и выполнить с помощью компьютерной программы, и она будет улавливать «значение» количественным образом. Кроме того, это показывает, что значение относится к словарю. Французский текст, проверенный с помощью голландского словаря, даст очень низкие значения. Само программное обеспечение может проверить, какой словарь дает наилучший результат. Недостатком этого предложения является то, что текст, содержащий случайные, но правильно написанные слова или даже сам словарь, имеет наивысший балл, а это не то, что нам нужно. Необходимо добавить проверку грамматики.  Чем больше грамматических ошибок, тем меньше информативности. Но тогда текст без орфографических или грамматических ошибок может быть тарабарщиной, потому что такой «текст» может быть создан компьютерной программой! [это было сделано и отправлено в научный журнал]. Хуже того, текст с некоторыми орфографическими и грамматическими ошибками может быть очень содержательным. Чем больше грамматических ошибок, тем меньше информативности. Но тогда текст без орфографических или грамматических ошибок может быть тарабарщиной, потому что такой «текст» может быть создан компьютерной программой! [это было сделано и отправлено в научный журнал]. Хуже того, текст с некоторыми орфографическими и грамматическими ошибками может быть очень содержательным. Вывод: для обнаружения значимой ДНК (генов!) в геноме метод словаря работает отлично. Метод словаря работает также для отделения строки случайных букв от строки слов, но он не может обнаружить осмысленные тексты. Утешение: даже люди могут не распознать смысл в правильно написанных текстах. ПостыИюль 2001 г. Для меня большая честь, что д-р Huen YK, Исследовательский центр Cah, Сингапур, сослался на версию 1 этой статьи в своей книге Mathematical Properties of DNA: Algebraic Sequence Analysis , Интернет-журнал биоинформатики, том 1: 42-59, 2001 г. [эта статья была удалена].
Примечания:
| ||||||||||||||||
 Есть парадокс. Кажется очевидным, что эта мера «информационного содержания» не соответствует сути. Он измеряет сжимаемость последовательности, а не «информационное содержание».
Для захвата информационного содержания необходимо значение последовательности.
Есть парадокс. Кажется очевидным, что эта мера «информационного содержания» не соответствует сути. Он измеряет сжимаемость последовательности, а не «информационное содержание».
Для захвата информационного содержания необходимо значение последовательности. д., будет иметь более низкое информационное содержание, чем случайная строка.
д., будет иметь более низкое информационное содержание, чем случайная строка.  [4]
[4] )
) 
 1067). Но как может алгоритмическая теория информации быть неактуальной для любого набора данных, если она является окончательной и общей теорией случайности? Удивительно, что Вольфрам хранит молчание по этому ключевому моменту (с).
1067). Но как может алгоритмическая теория информации быть неактуальной для любого набора данных, если она является окончательной и общей теорией случайности? Удивительно, что Вольфрам хранит молчание по этому ключевому моменту (с). Их можно запускать бесконечно долго, поэтому вывод может расти до бесконечной длины. В частности, правило 30 может создать сложный и несжимаемый шаблон произвольного размера (d). Измерять сложность такого вывода длиной его кратчайшего описания определенно бессмысленно, потому что независимо от того, насколько длинный вывод, алгоритм, который его произвел, остается одним и тем же. Клеточные автоматы по правилу 30 всегда выдают один и тот же результат при одних и тех же начальных условиях (это детерминировано). Так что на самом деле это простое описание/предписание этого конкретного вывода.
Их можно запускать бесконечно долго, поэтому вывод может расти до бесконечной длины. В частности, правило 30 может создать сложный и несжимаемый шаблон произвольного размера (d). Измерять сложность такого вывода длиной его кратчайшего описания определенно бессмысленно, потому что независимо от того, насколько длинный вывод, алгоритм, который его произвел, остается одним и тем же. Клеточные автоматы по правилу 30 всегда выдают один и тот же результат при одних и тех же начальных условиях (это детерминировано). Так что на самом деле это простое описание/предписание этого конкретного вывода. Но я хотел бы также отметить, что интуитивные понятия часто бывают зачаточными и непоследовательными; уточнение этих понятий часто показывает, как наша интуиция может ошибаться. Еще никому не удалось заменить алгоритмическую теорию информации более подходящим понятием.
Но я хотел бы также отметить, что интуитивные понятия часто бывают зачаточными и непоследовательными; уточнение этих понятий часто показывает, как наша интуиция может ошибаться. Еще никому не удалось заменить алгоритмическую теорию информации более подходящим понятием. Например, никто не доказал, что они проходят все полиномиальные статистические тесты.
Например, никто не доказал, что они проходят все полиномиальные статистические тесты. [ГК]
[ГК] Числа, выбранные людьми, вовсе не случайны, и псевдослучайные числа, созданные компьютерами, тоже не очень случайны. Теперь ученые разработали способ генерировать случайные числа из подлинный источник случайности — непредсказуемая стадия того, когда, где и как кристалл начинает расти в растворе.
Числа, выбранные людьми, вовсе не случайны, и псевдослучайные числа, созданные компьютерами, тоже не очень случайны. Теперь ученые разработали способ генерировать случайные числа из подлинный источник случайности — непредсказуемая стадия того, когда, где и как кристалл начинает расти в растворе. 239.
239.