
Яндекс вносит изменения в индексирование AJAX-сайтов
Оксана Мамчуева
1214
Яндекс сообщил об изменениях в обходе роботами AJAX-сайтов. Теперь вместо проверки HTML-версий страниц роботы будут исполнять скрипты на AJAX-сайтах.
Страницы с параметром #! больше не поддерживаются. Чтобы контент сайта не пропал из результатов поисковой выдачи, необходимо:
- Изменить в карте сайта структуру ссылок так, чтобы в их содержании не было символа #
- Настроить на важных для состояния сайта страниц редирект 301 на новые с корректными адресами (а именно — без параметра #!). При этом переадресацию нужно настроить как со страниц по адресам вида http://www.example.com/?_escaped_fragment_=blog, так и со страниц http://www.example.com/#!blog.


Страницы с тегом meta name=«fragment» content=«!» также скоро перестанут поддерживаться. Но никакие дополнительные настройки для спасения контента в этом случае не нужны: метатег будет проигнорирован, а оригинальная страница — проиндексирована с исполнением JavaScript.
«Яндекс перестает поддерживать индексацию страниц с такими параметрами в связи с тем, что технология рендеринга более удобна и эффективна для передачи поисковому роботу контента сайта в полном объеме», – поясняется в блоге Яндекса для вебмастеров.
Напомним, проверить, как будет проиндексирован сайт при исполнении JS и сравнить с исходным вариантом обхода роботами можно в разделе Рендеринг страниц JavaScript Яндекс Вебмастера.
Вместо фрагментов в адресах ссылок рекомендуется использовать History API. Он позволяет управлять историей браузера в пределах сессии — посещенными страницами в пределах вкладки или фрейма, который загружен внутри страницы. Подробнее об этом можно прочитать в Справке.
- Новости
- SEO
- Яндекс
Google позволил указывать плюсы и минусы продукта в сниппетах товарных обзоров
При помощи микро-разметки
Google приравнял к спаму дублирование контента в бизнес-профилях
Это касается фото, постов, видео и логотипов
Шторм в выдаче Google
Из-за пожара в одном из дата-центров
Яндекс пессимизирует сайты за сходство с популярными ресурсами
Позиции понижаются за «мимикрию»
Google улучшил поиск по запросам в кавычках
Однако не рекомендует им пользоваться
Яндекс Вебмастер сообщит о наличии на сайте страниц со статусами 5XX
В разделе Диагностика
индексация js сайтов — CMS Magazine
Мы решили провести эксперимент и проверить это в боевых условиях, создав сайты на javascript, а именно на фреймоворке vue js и проверив их индексацию.
Реактивные фреймворки используются для создания реактивных страниц и на данный момент завоевали большую популярность среди разработчиков. Самыми популярными на данный момент являются Angular.js, React.js, Vue.js. У каждого есть свои преимущества и недостатки, но работают они все в принципе одинаково. При загрузке страницы имеется некоторый root элемент (Примечание: root — корневой элемент — то есть элемент, внутри которого будет отрисовываться контент. ), относительно которого рендерится приложение, и содержимое изначальной верстки, например такое
будет отрисовано и превратится в полноценную страницу, между подставится содержимое переменной content. При этом при любом изменении переменной content страница сразу же перерисуется и содержимое внутри блока изменится. Такая связь называется реактивной.
Если просмотреть исходный html-код страницы, которая использует js фреймворк, можно увидеть весь ее изначальный шаблон с разметкой, например:
Для функционала, не критичного к индексированию, например, личным кабинетам, административным панелям, проблема индексирования не важна, и там давно используются реактивные фреймворки, но очень заманчиво использовать их преимущества и на сайтах с контентом. Поэтому у многих возникает вопрос, как поисковый робот будет видеть данную страницу: как пользователь, с уже подставленными значениями переменных, или будет видеть весь ее исходный код.
Поэтому у многих возникает вопрос, как поисковый робот будет видеть данную страницу: как пользователь, с уже подставленными значениями переменных, или будет видеть весь ее исходный код.
Первое время поисковики не умели индексировать js. Но уже несколько лет как эта проблема была ими решена. В 2014 году Google объявил, что может «лучше понимать веб (т.е. JavaScript)». В 2015 году Яндекс сообщил в своих новостях: «Мы начали использовать JavaScripts и CSS при обходе некоторых ресурсов для того, чтобы получить больше данных о страницах сайтов и увидеть содержимое таких сайтов в том виде, в каком оно отображается в современном браузере. Это позволяет оценить удобство интерфейса, получить контент, который ранее был недоступен роботу, и сравнить эти данные с уже используемыми при ранжировании в поиске.»
В разделе помощи поисковых систем можно найти информацию, посвященную особенностям индексации. Например, про сайты на ajax Яндекс сообщает: «Робот Яндекса может проиндексировать AJAX-сайт, если у каждой страницы сайта есть HTML-версия.
AJAX, или «асинхронный JavaScript и XML» — это набор техник по веб-разработке , совмещающий JavaScript и XML, что позволяет веб-приложениям взаимодействовать с сервером в фоновом режиме. Асинхронный означает, что другие функции или линии кода могут запускаться, когда запущен скрипт async. XML некогда был основным языком передачи данных; однако AJAX используется для всех типов передачи данных (включая JSON).
Также к распространенным ошибкам поисковые системы относят навигацию через скрипты. «Наиболее распространенным способом размещения ссылки является HTML тег . Но существуют и другие способы навигации между страницами. Например, можно использовать технологии JavaScript или Flash. Робот Яндекса не переходит по таким ссылкам, поэтому следует дублировать ссылки, реализованные при помощи скриптов, обычными текстовыми ссылками.»
Второй — загрузить значение пременных по API. После того, как страница будет полностью загружена, отправляется запрос на получение данных c помощью ajax, и с сервера возвращаются данные в формате json.
Признаки отсутствия асинхронной загрузки:
Переменные инициализированы в коде, если просмотреть исходный код, то можно увидеть, чему они равны, например
Соответственно мы хотели проверить индексацию страницы в обоих этих случаях. Если в первом случае поисковом роботу нужно просто загрузить страницу, во втором — нужно еще дождаться результата ajax запроса, который, возможно, повлияет на итоговое отображение страницы. соответственно сразу возникает вопрос, сколько же робот будет ожидать ответа от сервера и будет ли он вообще его ждать, или решит, что страница пустая и не добавит ее в индекс. В теории, когда страница загружена полностью, поисковому боту нечего делать на ней, и он мог выйти, не дождавшись, пока придет результат запроса данных, а без данных страница была бы пустая. Но бот дожидается результата запроса, как оказалось
Поэтому мы подготовили два варианта текстов для тестирования, охватывающих оба этих случая.
Проверяем индексацию js сайтов поисковыми системами
Для проверки индексации мы подготовили уникальные тексты для страниц. Тексты наши копирайтеры готовили связные, осмысленные, чтобы исключить влияние индексации некачественных текстов. В каждый текст добавили уникальные термины, придуманные нами. Предварительно слова были проверены в поисковых системах: по ним не должно было быть ничего найдено в результатах поиска, а также поисковики не должны были предлагать заменить их похожими словами. Такая уникальность и подробное раскрытие темы должна была помочь поисковым системам однозначно классифицировать интент при формировании поисковой выдачи по ключевикам наших страниц. Для чистоты эксперименты мы не прописали мета-теги для страниц — поисковики должны были ориентироваться только на содержимое страниц.
Для пользователей размещенные тексты на страницах выглядят как обычно. Дополнительно мы разметили заголовок и подзаголовки с тегами h2, h3, h4.
Если Вы посмотрите на такие страницы через привычный seo специалистам просмотр кода страницы, то в случае синхронной загрузки Вы увидите текст в коде, а вот в случае асинхронной загрузки — только код без видимого текста.
Код страницы с синхронной загрузкой
Код страницы с асинхронной загрузкой
Советы по технической оптимизации от представителя Google Джона Мюллера рекомендуют тестировать JS-фреймворки с помощью функции Rich Snippets в Search Console и использовать инструмент проверки структурированных данных, чтобы убедиться, что веб-сайт правильно сканируется и отображается.
Аналогично показывает видимость кода страницы и Яндекс Вебмастер.
В Яндекс Вебмастере один из вариантов увидеть страницу как Яндекс — посмотреть на содержимое страницы в Инструменты — Проверка ответа сервера. Здесь при синхронной загрузке видим отображение текста в содержимом. А вот для асинхронной загрузки видим только код.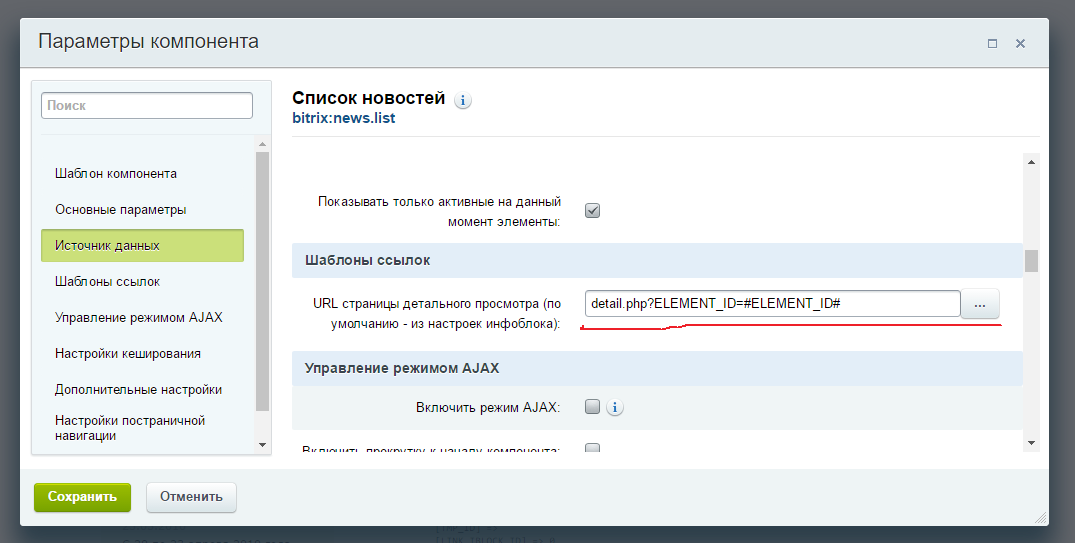
Второй вариант — посмотреть как Яндекс видит страницу — в Инструменты-Проверка мобильных страниц. И здесь уже на скриншоте видно, что Яндекс видит текст и для синхронной и для асинхронной загрузки. Для того, чтобы убедиться, что текст индексируется решаем продолжить эксперимент до его появления в поисковой выдачи.
При использовании vue.js заголовок страницы в коде можно указать как
При генерации страницы сформируется вывод нужного заголовка. Дополнительно мы решили проверить, видят ли поисковики такие конструкции. Для этого мы создали дополнительную страницу с обычным текстом и добавили ей уникальный заголовок со словами, которые больше нигде не встречаются.
Реализация проверки seo на vue.js
Таймлайн проверки индексации сайтов поисковиками:
26 апреля
Сайты добавлены нами в Яндекс Вебмастер и Google Search Console, страницы отправлены в переобход.
Уже на следующий день мы получили от Яндекса уведомление об отсутствии у поддоменов фавиконов и региональной привязки.
28 апреля
В Вебмастере появилось сообщение о добавлении страниц в поиск. Проверяем поисковую выдачу.
По запросу с асинхронной загрузкой по прежнему Яндекс не находит. По запросу с синхронной загрузкой получаем страннный результат — вместо сообщения, что слово не найдено, сообщение, о том, что запросы скрыты в связи с соблюдением законодательства РФ. Делаем скрины, отправляем вопрос поддержке Яндекса.
1 мая
Информация по поисковым запросам в Яндексе не появилась, однако предупреждение о нарушении законодательства об авторских правах исчезло.
Мы, кстати, не первый раз сталкиваемся с тем, что при первоначальной индексации сайтов робот Яндекса может сделать самые неожиданные выводы,не имеющие с действительностью ничего общего. Решается всё обычно быстро через отправку запроса в поддержку Яндекса.
5 мая
В поиске Яндекс по запросу «брозперит» наконец появился сайт с асинхронной загрузкой. По первому сайту опять нет изменений. На всякий случай, обе его страницы несколько раз с начала эксперимента отправлялись в переобход.
Получен ответ от поддержки Яндекса по выдаче результатов:
Получаем через несколько дней ответ Яндекса:
«Указанная вами поисковая выдача по заданному поисковому запросу могла содержать в качестве единственного релевантного результата поиска ссылку на сайт, доступ к которому был ограничен по решению уполномоченных органов власти, в связи с чем ссылка на сайт перестала отображаться в поиске.
Ваш сайт пока не включен в результаты поиска, он должен появится через какое-то время после переиндексации страниц поисковым роботом.»
Если Яндекс считает, что сайты, релевантные ранее несуществующему и придуманному слову могут быть заблокированы предусмотрительно Роскомнадзором, не будем с ним спорить.
8 мая
Обе главных страницы сайтов появились в поиске по запросам, с ними связанными Внутренняя страница так и не появилась в Яндексе, очевидно это связано с тем, что поисковик намного медленнее Гугла добавляет страницы в поиск.
Через несколько дней после очередного апдейта в поиске Яндекса появилась и внутренняя страница.
Сниппеты для запросов
С точки зрения seo, нам было также интересно, что используют поисковики в качестве сниппета для нового для них запроса, если не указывать тег description. В текстах мы использовали подзаголвки h2-h4.
Дополнительно по обоим сайтам в Вебмастере мы запросили подбор «Рекомендованных запросов». Во-первых, мы надеялись, это быстрее покажет, что именно видит поисковик и какую семантику считает релевантной. Во-вторых, интересен был список запросов для сайта с асинхронной загрузкой.
В итоге через несколько дней по обеим сайтам выдал сообщение, что недостаточно данных для формирования рекомендованных запросов.
Рекомендации по seo для js
Поисковые работы не имеют проблем с индексацией js, если выполнены рекомендации (см. ниже). Роботы Яндекса и Google могут проиндексировать сайт с синхронной и с асинхронной загрузкой js.
Рекомендации Google по оптимизации js сайтов, в том числе сайтов на ajax
Как и Flash, AJAX может затруднить индексирование сайтов поисковыми системами, если эта технология реализована с ошибками. В основном AJAX вызывает две проблемы при использовании поисковых систем. Роботы поисковых систем должны «видеть» ваше содержание. Необходимо также убедиться, что они распознают правила навигации и следуют им.
Разрабатывайте сайты на основе принципа доступности. При разработке сайта с применением AJAX подумайте, что нужно пользователям, включая тех, кто не использует браузеры с поддержкой JavaScript (например, людей, работающих с программами чтения с экрана или мобильными устройствами). Один из самых простых способов проверить доступность сайта – предварительно просмотреть его в браузере с отключенной поддержкой JavaScript или в текстовом браузере (например, Lynx). Просмотр сайта в текстовом режиме может также оказаться полезным, если необходимо выявить другое содержание, которое сложно обнаружить роботу Googlebot, например, текст, внедренный в изображения или ролики в формате Flash.
Просмотр сайта в текстовом режиме может также оказаться полезным, если необходимо выявить другое содержание, которое сложно обнаружить роботу Googlebot, например, текст, внедренный в изображения или ролики в формате Flash.
Избегайте использования окон iFrame или создавайте отдельные ссылки на их содержание. Содержание, отображаемое с помощью iFrame, не индексируется и не показывается в результатах поиска Google. Использовать окна
iFrame для отображения содержания не рекомендуется. Если вы применяете эту технологию, не забудьте добавить дополнительные текстовые ссылки на их содержание, чтобы робот Googlebot мог просканировать его и внести в индекс.
Если вы начинаете создавать сайт с нуля, бывает полезно построить структуру сайта и систему навигации, используя только HTML. После того как страницы, ссылки и содержание сайта примут упорядоченный вид, можно улучшить внешний вид и интерфейс сайта с помощью AJAX. Робот Googlebot просканирует HTML, тогда как пользователи с современными браузерами смогут оценить ваши дополнения на языке AJAX.
При создании ссылок следует выбрать формат, позволяющий наряду с вызовом функции JavaScript предлагать статическую ссылку. Таким образом, пользователи, включившие поддержку JavaScript, смогут применять функциональные возможности AJAX, а те, у кого нет поддержки JavaScript, смогут перейти по ссылке, не обращая внимания на сценарий. Пример.
Обратите внимание, что URL статической ссылки содержит параметр (?foo=32), а не фрагмент (#foo=32), используемый в коде AJAX. Это важно, поскольку поисковые системы распознают параметры URL, но часто не учитывают наличие фрагментов. Теперь вы применяете статические ссылки, так что пользователи и поисковые системы могут переходить именно к тому содержанию, к которому нужно открыть общий доступ или на которое нужно сослаться.
Использование HTML-ссылок по-прежнему значительно помогает нам (а также другим поисковым системам, мобильным устройствам и пользователям) распознать структуру вашего сайта.
Ознакомиться с Руководством для веб-мастеров, чтобы получить дополнительную информацию о том, как повысить привлекательность вашего сайта для Google и посетителей. В этом руководстве приводится также список методов, которые следует избегать, включая скрытую переадресацию с помощью Javascript. Общее правило заключается в том, что нужно обеспечивать неизменность содержания и вместе с тем предлагать пользователям различные функции, которые зависят от их возможностей.
В этом руководстве приводится также список методов, которые следует избегать, включая скрытую переадресацию с помощью Javascript. Общее правило заключается в том, что нужно обеспечивать неизменность содержания и вместе с тем предлагать пользователям различные функции, которые зависят от их возможностей.
Еще лучше сделать так, чтобы один и тот же текст появлялся независимо от того, включена поддержка JavaScript или нет. В идеальном случае у пользователей, отключивших JavaScript, должен быть доступ к HTML-версии слайд-шоу.
Используйте атрибут rel=»canonical» для указания канонических URL, если контент размещается на нескольких URL-ах.
Избегайте использования AJAX-подобных механизмов сканирования. Это — самая распространенная ошибка, которую допускают специалисты при смене подходов к программированию сайтов. Не забудьте удалять тег «meta fragment» из копии HTML AJAX страниц. Никогда не используйте данный тип тегов, если на странице применяется тег «escaped fragment».
Не используйте в URL-ах символ «#», Google очень редко индексирует такие адреса. Структура «стандартного» адреса страницы должна строиться по принципу: путь/имя файла/параметры запроса, за исключением тех случаев, когда для расширения возможностей навигации используется объект History API.
Чаще применяйте инструмент «Сканер Google для сайтов», доступный в Search Console. Он позволит вам лучше понять, какими видят страницы сайта алгоритмы поискового робота Googlebot. Имейте в виду инструмент не поддерживает URL-ы, содержащие символы «#!» или «#».
Убедитесь в том, что все запрашиваемые ресурсы, включая файлы javascript, фреймворки, ответы сервера, сторонние API и т.д., не закрыты в файле robots.txt. «Сканер Google для сайтов» покажет вам список ресурсов, закрытых от индексации. Если они были закрыты в файле robots.txt (это часто происходит со сторонними API) или временно недоступны по другим причинам, важно дополнительно убедиться в том, что код работает страницы исполняется корректно.
Google поддерживает использование javascript для создания тайтлов, метаописаний и мета-тегов robots, структурированных данных, и других видов мета-данных. Во всех случаях использования формата AMP страница AMP HTML должна быть статической. В то же время, при создании веб-страниц допустимо использовать элементы JS/PWA. Не забывайте создавать файлы sitemap с применением тега тег — это укажет поисковому роботу, что на сайте производились изменения.
Рекомендации Яндекса для Ajax сайтов
Робот Яндекса может проиндексировать AJAX-сайт, если у каждой страницы сайта есть HTML-версия.
Обычно, чтобы указать роботу предпочитаемую для использования в результатах поиска версию, нужно добавить в HTML-код страницы, которая не должна участвовать в поиске, ссылку на нужную страницу с атрибутом rel=»canonical». Этот атрибут может помешать роботу корректно проиндексировать HTML-версию AJAX-страницы, поэтому не используйте его для страниц, которые должны участвовать в поиске.
Вы можете сообщить роботу о HTML-версии страницы с помощью:
1) Метатега
Добавьте в код AJAX-страницы метатег meta name=»fragment» content=»!». В итоге HTML-версия этой страницы должна быть доступна по адресу с добавлением параметра ?_escaped_fragment_=(значение параметра пустое).
Например: http://www.example.com/?_escaped_fragment_=.
Не размещайте метатег в HTML-версии страниц сайта — робот не сможет проиндексировать ее.
2) Параметра в адресе страницы
Добавьте в адрес AJAX-страницы параметр #!. В итоге HTML-версия этой страницы должна быть доступна по адресу, в котором сочетание #!заменено на параметр ?_escaped_fragment_=. Например: адрес http://www.example.com/#!blog должен измениться на адрес http://www.example.com/?_escaped_fragment_=blog.
Cсылки, содержащие #!, также можно использовать в карте сайта.
Чтобы робот быстрее узнал о страницах сайта, отправьте на переобход HTML-версии страниц. Когда HTML-страницы появятся в результатах поиска, ссылки будут перенаправлять пользователей на AJAX-страницы сайта.
Когда HTML-страницы появятся в результатах поиска, ссылки будут перенаправлять пользователей на AJAX-страницы сайта.
Дополнительные особенности индексации
Обфускация js
Влияние не тестировалось в ходе эксперимента, но можно предположить, что обфускация js не будет влиять на индексацию (теоретически, конечно, могут быть исключения). Обфускация — это приведение исходного текста программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции. Цель обфускации js — затруднениe изучения/понимания javascript-кода. JavaScript выполняется на стороне браузера. Даже на довольно старых (более 2х лет назад) форумах можно найти сообщения о том, что поисковики индексируют обфусцированный код.
Сжатие js
Сжатие js не влияет на индексацию. Скорее наоборот — это приведет к ускорению загрузки страницы и положительно повлияет на индексирование поисковыми системами. Сжатие js — постоянная рекомендация для сайтов в Google PageSpeed.
Сжатие js — постоянная рекомендация для сайтов в Google PageSpeed.
Ускорение индексации сайта на js
— лайфхак от Дэвида Кюннена
В январе 2019 года Дэвид Кюннен, специалист из Германии, опубликовал итоги своего тестирования по ускорению индексации сайта на js — «Как добавить 250 тысяч страниц в индексацию Google» («How to get 250k+ pages indexed by Google»). Сайт, о котором речь в статье, был разработан с React App на фронтенде.
В ходе тестирования вначале был настроен SSR — серверный рендеринг. Кюннен исходил из предположения, что рендеринг для SPA-сайтов (Single Page Applications) помогает роблотам сразу видеть все ссылки в коде без двойного прохода по коду. Внедрение рендеринга на сайте позволило ему увеличить скорость обхода страниц Google, но незначительно. В комментариях к публикации также рассматривается альтернатива SSR — использование пререндерера.
Значительного, в несколько раз, увеличения скорости индексирования удалось добиться отключением js для бота.
Поисковик выделяет ограниченное количество ресурсов для индексации конкретного сайта. Несмотря на то, что Google видит все ссылки в начальном HTML, но он все равно отправляет все в свой рендерер, чтобы убедиться, ничего ли не осталось для индексации — из-за наличия в коде JavaScript не понимая, все ли находится в начальном HTML. Сразу же после этих изменений скорость обхода Google увеличилась до 5-10 страниц в секунду.
Оказывается, нет. https://developers.google.com/search/docs/guides/dynamic-rendering В статье Google рекомендует использовать динамическое отображение контента. Оно дает возможность предоставлять некоторым агентам пользователя контент страницы, предварительно обработанный на сервере. Для работы динамического отображения ваш сервер должен распознавать поисковых роботов (например, проверяя агент пользователя). Запросы от роботов передаются средству отображения, а запросы от пользователей обрабатываются обычным образом. При необходимости средство динамического отображения возвращает версию контента, которая может быть обработана роботом, например статическую HTML-страницу.
Динамическое отображение рекомендуется применять для индексируемого контента, который создается пользователями с помощью JavaScript и часто изменяется, а также для контента, в котором есть функции JavaScript, не поддерживаемые нужными роботами. Не все сайты требуют динамического отображения, оно нужно лишь для корректной работы поисковых роботов.
Как и ожидалось, Google индексирует и выводит страницы в поисковой выдаче в несколько раз быстрее Яндекса.
Несмотря на то, что индексация страниц нового сайта производится автоматически, лучше проконтролировать этот процесс для исключения ошибок со стороны поисковиков.
Страницы js сайтов корректно индексируются поисковыми системами независимо от синхронной или асинхронной загрузки.
На индексацию влияют также корректность чпу и их соответствие правилам поисковых систем.
Специалисты APRIORUM всегда помогут вам выполнить грамотную оптимизацию любого сайта с учетом особенностей кода сайта и задач бизнеса.
Опасности «гуглинга» вашего сайта
Оптимизируя свой сайт для Google, вы можете саботировать свой сайт для Baidu в Китае и Яндекса в России и Восточной Европе.
Это неоспоримый факт, что Google имеет самое большое присутствие на рынке поиска в мире. В результате существует бесконечный запас ресурсов и информации о том, как оптимизировать поиск для Google. Таким образом, я понимаю, насколько важно для владельцев веб-сайтов убедиться, что их сайты оптимизированы и хорошо работают в результатах поиска Google.
Однако, оптимизируя сайт исключительно на основе изменений и возможностей алгоритма Google, вы фактически деоптимизируете сайт для других поисковых систем. Эта деоптимизация может снизить производительность вашего сайта на некоторых важных рынках.
Если такой рынок, как Китай, важен для вашего бизнеса, вам необходимо убедиться, что изменения, которые вы вносите для повышения производительности Google, также хорошо работают для такой поисковой системы, как Baidu.
Для России и некоторых стран Восточной Европы он должен работать на Яндекс.
Существует много различий в передовых методах SEO среди поисковых систем, включая местные правила, домен и местоположение хостинга.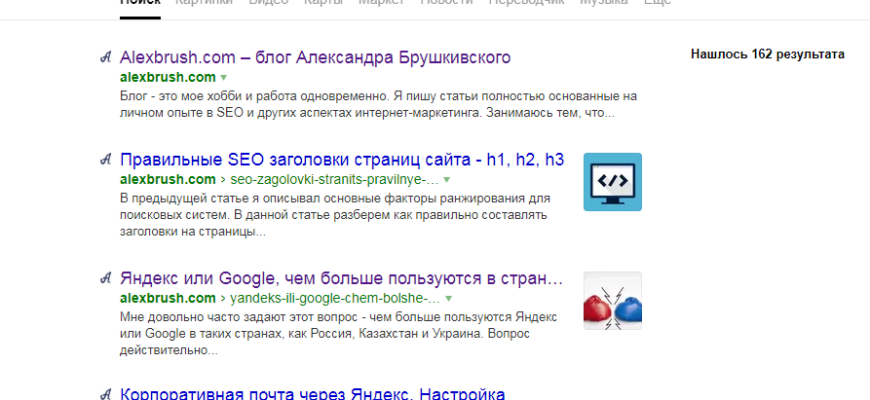 Ниже приведены некоторые из обновлений, которые вы, возможно, внедрили или планируете внедрить на свой сайт, и которые могут разрушить ваш обычный поисковый трафик с Baidu.
Ниже приведены некоторые из обновлений, которые вы, возможно, внедрили или планируете внедрить на свой сайт, и которые могут разрушить ваш обычный поисковый трафик с Baidu.
JavaScript и AJAX
В прошлом году Google подтвердил, что может сканировать и индексировать ссылки и контент с помощью JavaScript и AJAX. Это, конечно, было хорошей новостью для многих владельцев веб-сайтов, поскольку это помогло бы улучшить их работу с сайтом.
К сожалению, Baidu пока не умеет сканировать и индексировать контент с помощью JavaScript и AJAX. Использование JavaScript для навигации по сайту убивает трафик с Baidu сразу после запуска нового сайта. В одном примере мы видели, как вскоре после запуска нового сайта количество китайских страниц, проиндексированных Baidu, уменьшилось с 86 300 до 174 страниц.
В ноябре прошлого года Яндекс объявил, что начнет сканировать JavaScript и AJAX, и предупредил владельцев сайтов, чтобы они не блокировали свои файлы JavaScript и CSS. Однако то, что Яндекс теперь может сканировать и индексировать эти ссылки и контент, не означает, что страницы начнут отображаться выше в результатах поиска. Яндекс измеряет ценность страниц не только по содержанию, но и по входящим ссылкам и другим статистическим данным.
Яндекс измеряет ценность страниц не только по содержанию, но и по входящим ссылкам и другим статистическим данным.
Ресурсы
Рекомендация:
По возможности не используйте JavaScript и AJAX для навигации и контента, который Baidu должен сканировать и индексировать. Если вы все еще хотите использовать JavaScript и AJAX, создайте отдельный китайский сайт со статическими ссылками в навигации и важным контентом в HTML.
Яндекс создал специальные механизмы для большей видимости в результатах поиска для страниц с JavaScript и AJAX.
Мета-ключевые слова, мета-описание и теги заголовков
Контент, введенный в мета-ключевые слова, мета-описание и теги заголовков, возможно, не считается таким важным, как раньше для Google, но он по-прежнему играет важную роль в поисковой оптимизации для Baidu.
Рекомендация:
Поэтому размещайте мета-ключевые слова и мета-теги описания в разделе
на всех страницах. Вы можете оставить их пустыми для сайтов других стран/языков, но обязательно заполните их на китайских страницах. Также используйте теги
Вы можете оставить их пустыми для сайтов других стран/языков, но обязательно заполните их на китайских страницах. Также используйте теги~
на страницах. Они могут не так сильно помочь против Google, но и не повредят. Лучше всего использовать их в шаблонах веб-страниц, чтобы помочь вашим китайским страницам.
Субдомен против подкаталога
Хотя большинство тестов производительности показывают, что сегментация страны или языка с использованием подкаталога работает лучше для сайта без домена верхнего уровня с кодом страны, некоторые международные эксперты по поисковой оптимизации по-прежнему выступают за использование поддоменов.
Справочное руководство Google для веб-мастеров позволяет компаниям использовать любой метод. Однако Baidu специально предлагает использовать подкаталоги.
Рекомендация:
Если вы хотите, чтобы ваш китайский сайт хорошо отображался в результатах поиска Baidu, вам необходимо установить китайский сайт в качестве подкаталога, например «Yourdomain. com/cn/» или «Yourdomain.com/». zh-cn/, а не как субдомен, например, «cn.yourdomain.com».
com/cn/» или «Yourdomain.com/». zh-cn/, а не как субдомен, например, «cn.yourdomain.com».
Размещение контента на веб-странице
Google и большинство основных поисковых систем стали действительно хорошо сканировать и индексировать целые страницы контента.
Тем не менее, Baidu еще не так хорошо справляется со своей задачей. Также известно, что когда Baidu повторно сканирует страницы, которые были проиндексированы ранее, он сканирует только первые 1000 байт или около того контента, чтобы увидеть, есть ли в нем новая информация. Если он не находит ничего нового, он прекращает индексацию остальной части страницы и переходит к следующей.
Рекомендация:
Всегда размещайте важный контент (включая ключевые слова) в начале страницы. Если вы обновите какой-либо контент в нижней половине страницы, отправьте URL-адреса этих страниц в Baidu, используя инструмент Baidu для веб-мастеров, для переиндексации.
У Яндекса также есть собственные Инструменты для веб-мастеров, где вы можете проверить эффективность своего веб-сайта, отправить карты сайта в формате XML и предпринять другие действия для улучшения своего веб-сайта.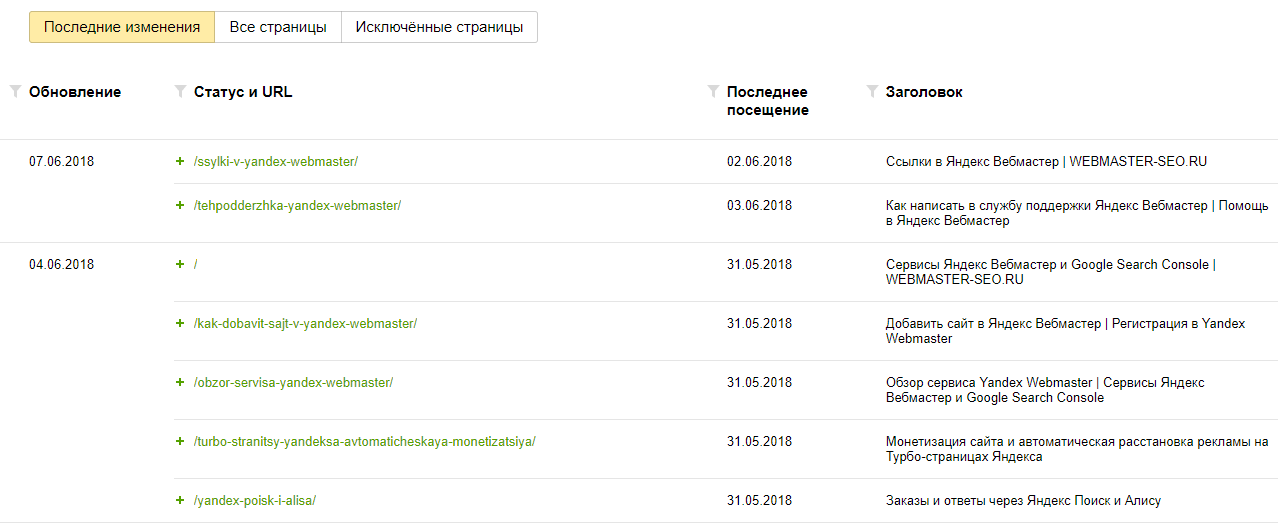
Есть много других алгоритмических различий между поисковыми системами Google, Baidu и Yandex. Если Китай и Восточная Европа являются важными рынками для вашего бизнеса, убедитесь, что вы используете сбалансированные стратегии SEO, которые работают для всех ваших целевых поисковых систем.
Подробнее о:
Как JavaScript и AJAX влияют на индексацию в Google?
Автор: Ramón Saquete
Содержание
- 1 Проблемы CSR при начальной загрузке страницы
- 1.1 Проблемы в результате медленного рендеринга
- 1.2 Проблемы с индексированием: 900 88
- 2 Проблемы КСО в отношении переход на следующую страницу
- 2.1 Проблемы с индексированием
- 2.2 Что происходит с фрагментами теперь, когда Google может индексировать AJAX?
- 3 Блокировка индексации частичных ответов с помощью AJAX
- 4 Заключение
Со временем Google значительно улучшил индексацию JavaScript и AJAX . Вначале он ничего не индексировал и не переходил ни по каким ссылкам, появляющимся в контенте, загруженном через эти фреймворки. Но затем мало-помалу он начал индексировать некоторые реализации и улучшать свои возможности. В настоящее время он может индексировать множество различных реализаций и переходите по ссылкам, загруженным через AJAX или API Fetch . Тем не менее, все равно будут случаи, когда он может не сделать это .
Вначале он ничего не индексировал и не переходил ни по каким ссылкам, появляющимся в контенте, загруженном через эти фреймворки. Но затем мало-помалу он начал индексировать некоторые реализации и улучшать свои возможности. В настоящее время он может индексировать множество различных реализаций и переходите по ссылкам, загруженным через AJAX или API Fetch . Тем не менее, все равно будут случаи, когда он может не сделать это .
Чтобы проанализировать случаи, когда Google может не индексировать наш сайт, сначала нам нужно понять концепцию рендеринга на стороне клиента (CSR). Это означает, что HTML-код нарисован на стороне клиента с помощью JavaScript , обычно с использованием AJAX в избытке. Первоначально веб-сайты всегда отображали HTML-код на стороне сервера ( Server Side Rendering или SSR), но с некоторых пор стал популярным CSR с появлением фреймворков JavaScript, таких как Angular, React и Vue . Однако CSR отрицательно влияет на индексацию , производительность рендеринга веб-сайтов и, следовательно, на SEO .
Однако CSR отрицательно влияет на индексацию , производительность рендеринга веб-сайтов и, следовательно, на SEO .
Как мы уже объясняли ранее, для обеспечения индексации во всех поисковых системах и ситуациях , помимо достижения хорошей производительности, лучшим решением является использование универсального фреймворка , так как с этими мерами мы получаем нечто под названием Hybrid Rendering . Он заключается в прорисовке веб-сайта на сервере при первой загрузке, а затем на клиенте через JavaScript и AJAX по мере перехода навигации к ссылкам, следующим за . Хотя на самом деле существует больше ситуаций, когда использование термина «гибридный рендеринг» также допустимо.
Иногда компания-разработчик использует CSR и не предлагает нам вариант использования универсального фреймворка. это Веб-разработка на основе CSR вызовет у нас проблемы , в большей или меньшей степени , в зависимости от сканера и его алгоритмов ранжирования . В этом посте мы собираемся проанализировать, что это за проблемы с поисковым роботом Google и как их решить .
В этом посте мы собираемся проанализировать, что это за проблемы с поисковым роботом Google и как их решить .
Проблемы CSR при первоначальной загрузке страницы
Во-первых, мы собираемся проанализировать проблемы индексации, возникающие , как только мы вводим URL-адрес за пределами веб-сайта , и когда HTML отображается на стороне клиента с помощью JavaScript.
Проблемы из-за медленного рендеринга
Процесс индексации Google проходит следующие этапы:
- Сканирование : Googlebot запрашивает URL-адрес на сервере.
- Первая волна индексации : она мгновенно индексирует содержимое, созданное на сервере, и получает новые ссылки для сканирования.
- Генерирует HTML-код на стороне клиента, запуская JavaScript . Этот процесс требует значительных вычислительных ресурсов (это можно сделать сразу или даже занять несколько дней, ожидая получения необходимых для этого ресурсов).
- Вторая волна индексации : с раскрашенным HTML на стороне клиента оставшееся содержимое индексируется и получаются новые ссылки для обхода.

Помимо того факта, что для полного индексирования страниц может потребоваться больше времени, что приведет к задержке индексации последующих страниц, связанных с ними, если рендеринг страницы выполняется медленно, средство визуализации Googlebot может оставлять незакрашенные части . Мы проверили это, используя вариант «Получить как Google», предоставленный Google Search Console , и созданный им снимок экрана не рисует ничего, что занимает более 5 секунд для отображения. Однако он генерирует HTML, который занимает больше времени, чем эти 5 секунд. Чтобы понять, почему это происходит, мы должны иметь в виду, что средство визуализации Google Search Console сначала создает HTML-код, запускающий JavaScript, с помощью средства визуализации Googlebot, а затем рисует пиксели страницы . Первая задача — та, которую необходимо учитывать для индексации, к которой мы относим термин CSR. В Google Search Console мы видим HTML-код, созданный во время первой волны индексации, а не тот, который был сгенерирован модулем визуализации Googlebot .
Первая задача — та, которую необходимо учитывать для индексации, к которой мы относим термин CSR. В Google Search Console мы видим HTML-код, созданный во время первой волны индексации, а не тот, который был сгенерирован модулем визуализации Googlebot .
В Google Search Console мы не видим HTML-код, нарисованный JavaScript, запускаемый роботом Googlebot 🕷 и используемый на последнем этапе индексации. Для этого мы должны использовать этот инструмент: https://search.google.com/test/mobile-friendly 😲Нажмите, чтобы твитнуть
https://search.google.com/test/mobile-friendlyВ проведенные нами тесты, когда рендеринг HTML занимал более 19секунд, он ничего не проиндексировал . Хотя это долгое время, в некоторых случаях его можно превзойти, особенно если мы интенсивно используем AJAX, и в этих случаях рендерер Google, как и любой рендерер, действительно должен ждать выполнения следующих шагов:
- HTML загружается и обрабатывается для запроса связанных файлов и создания DOM .
- CSS загружается и обрабатывается, для запроса связанных файлов и создания CSSOM .
- JavaScript загружается, компилируется и запускается для запуска запросов AJAX .
- Запрос AJAX перемещается в очередь запросов и ожидает ответа вместе с другими запрошенными файлами.
- Запущен AJAX-запрос , который должен пройти по сети на сервер.
- Сервер отвечает на запросы через сеть, и, наконец, мы должны дождаться запуска JavaScript, чтобы отрисовать содержимое HTML-шаблона страницы .
Время запроса и загрузки процесса, который мы только что описали, зависит от загрузки сети и сервера в это время . Более того, Googlebot использует только HTTP/1.1 , что медленнее, чем HTTP/2, потому что запросы обрабатываются один за другим, а не все одновременно. Необходимо, чтобы и клиент, и сервер разрешали использование HTTP/2, поэтому Googlebot будет использовать только HTTP/1. 1, даже если наш сервер разрешает HTTP/2 . Подводя итог, это означает, что Googlebot ждет завершения каждого запроса, чтобы запустить следующий, и, возможно, он не будет пытаться распараллелить определенные запросы, открывая различные соединения, как это делают браузеры (хотя мы точно не знаем, как это происходит). Имеет ли это). Таким образом, мы находимся в ситуации, когда мы можем превысить эти 19 секунд, которые мы оценили ранее .
1, даже если наш сервер разрешает HTTP/2 . Подводя итог, это означает, что Googlebot ждет завершения каждого запроса, чтобы запустить следующий, и, возможно, он не будет пытаться распараллелить определенные запросы, открывая различные соединения, как это делают браузеры (хотя мы точно не знаем, как это происходит). Имеет ли это). Таким образом, мы находимся в ситуации, когда мы можем превысить эти 19 секунд, которые мы оценили ранее .
Представьте, например, что с запросами изображений, CSS, JavaScript и AJAX запускается более 200 запросов, каждый из которых занимает 100 мс. Если запросы AJAX отправляются в конец очереди, мы, вероятно, превысим время, необходимое для индексации их содержимого .
С другой стороны, из-за этих проблем с производительностью CSR, мы получим худшую оценку по показателю FCP (First Contentful Paint) в PageSpeed с точки зрения рендеринга и его WPO, и, как следствие, худший рейтинг .
🕸Чистый подход CSR вредит индексированию и ранжированию, потому что генерация HTML обходится дороже как для робота Google, так и для браузеров 😕Нажмите, чтобы твитнуть
Проблемы с индексированием:
При индексировании контента, окрашенного на стороне клиента, Googlebot может столкнуться со следующим проблемы, которые препятствуют индексированию HTML-кода, сгенерированного JavaScript :
- Они используют версию JavaScript , которую сканер не распознает.
- Они используют JavaScript API не распознается роботом Googlebot (в настоящее время мы знаем, что веб-сокеты, WebGL, WebVR, IndexedDB и WebSQL не поддерживаются — дополнительная информация доступна на странице https://developers.google.com/search/docs/guides/rendering).
- Файлы JavaScript заблокированы robots.txt .
- Файлы JavaScript обслуживаются через HTTP, в то время как веб-сайт использует HTTPS .
- Есть ошибки JavaScript .
- Если приложение запрашивает разрешение пользователя на что-то, и от этого зависит рендеринг основного контента, то оно не будет отрисовываться, т.к. Googlebot по умолчанию отклоняет любое запрашиваемое им разрешение.

Чтобы узнать, страдаем ли мы от какой-либо из этих проблем, мы должны использовать тест Google для мобильных устройств . Он покажет нам скриншот того, как страница отрисовывается на экране, подобно Google Search Console, но также он покажет нам HTML-код, сгенерированный средством визуализации (как упоминалось ранее), лог-регистров ошибок в JavaScript. код и Функции JavaScript, которые визуализатор еще не может интерпретировать . Мы должны использовать этот инструмент для проверки всех URL-адресов, которые представляют каждый шаблон страницы на нашем веб-сайте, чтобы убедиться, что веб-сайт индексируется.
Мы должны иметь в виду, что в HTML , сгенерированном предыдущим инструментом, все метаданные (включая канонический URL-адрес) будут игнорироваться роботом Googlebot, поскольку он принимает во внимание информацию только тогда, когда она отображается на сервере .
Проблемы CSR с переходом на следующую страницу
Теперь давайте посмотрим, что происходит, когда мы используем ссылку для навигации, когда мы уже находимся на веб-сайте и HTML-код нарисован на стороне клиента.
Проблемы индексации
В отличие от CSR при начальной загрузке, переход на следующую страницу с переключением основного контента через JavaScript быстрее, чем SSR . Но у нас будут проблемы с индексацией, если:
- Ссылки не имеют действительного URL-адреса, возвращающего 200 OK в атрибуте href .
- Сервер возвращает ошибку при прямом доступе к URL-адресу без JavaScript или с включенным JavaScript и удалении всех кешей . Будьте осторожны с этим: если мы перейдем на страницу, нажав на ссылку, может показаться, что она работает, потому что она загружается JavaScript. Даже при прямом доступе, если веб-сайт использует Service Worker, веб-сайт может имитировать правильный ответ, загружая свой кэш. Но Googlebot — это поисковый робот без сохранения состояния, поэтому он не принимает во внимание кеш Server Worker или любые другие технологии JavaScript, такие как локальное хранилище или хранилище сеансов, поэтому он получит сообщение об ошибке.
 Будьте осторожны с этим: если мы перейдем на страницу, нажав на ссылку, может показаться, что она работает, потому что она загружается JavaScript. Даже при прямом доступе, если веб-сайт использует Service Worker, веб-сайт может имитировать правильный ответ, загружая свой кэш. Но Googlebot — это поисковый робот без сохранения состояния, поэтому он не принимает во внимание кеш Server Worker или любые другие технологии JavaScript, такие как локальное хранилище или хранилище сеансов, поэтому он получит сообщение об ошибке.
Будьте осторожны с этим: если мы перейдем на страницу, нажав на ссылку, может показаться, что она работает, потому что она загружается JavaScript. Даже при прямом доступе, если веб-сайт использует Service Worker, веб-сайт может имитировать правильный ответ, загружая свой кэш. Но Googlebot — это поисковый робот без сохранения состояния, поэтому он не принимает во внимание кеш Server Worker или любые другие технологии JavaScript, такие как локальное хранилище или хранилище сеансов, поэтому он получит сообщение об ошибке.Кроме того, чтобы веб-сайт был доступен, URL-адрес должен измениться с помощью JavaScript с API истории .
Что происходит с фрагментами теперь, когда Google может индексировать AJAX?
Фрагменты — это часть URL-адреса, которая может стоять в конце, перед которой ставится решетка # . Например:
http://www.humanlevel.com/blog.html#example
Этот тип URL-адресов никогда не достигает сервера , они управляются только на стороне клиента. Это означает, что при запросе вышеуказанного URL-адреса на сервер он получит запрос «http://www.humanlevel.com/blog.html», а в клиенте браузер прокрутит до фрагмента документа, который упоминается. Это обычное и изначально предполагаемое использование для этих URL-адресов , широко известных как привязки HTML . А анкором, на самом деле, является любая ссылка (тег «а» в HTML происходит от анкора ). Однако в прежние времена фрагменты также использовались для изменения URL-адресов через JavaScript на загруженных AJAX страницах , чтобы позволить пользователю перемещаться по истории просмотров. Это было реализовано таким образом, потому что тогда фрагмент был единственной частью URL, которую мы могли изменить с помощью JavaScript, поэтому разработчики воспользовались этим, чтобы использовать их не по назначению. Это изменилось с появлением API-интерфейса истории, поскольку он позволял изменять весь URL-адрес с помощью JavaScript.
Это означает, что при запросе вышеуказанного URL-адреса на сервер он получит запрос «http://www.humanlevel.com/blog.html», а в клиенте браузер прокрутит до фрагмента документа, который упоминается. Это обычное и изначально предполагаемое использование для этих URL-адресов , широко известных как привязки HTML . А анкором, на самом деле, является любая ссылка (тег «а» в HTML происходит от анкора ). Однако в прежние времена фрагменты также использовались для изменения URL-адресов через JavaScript на загруженных AJAX страницах , чтобы позволить пользователю перемещаться по истории просмотров. Это было реализовано таким образом, потому что тогда фрагмент был единственной частью URL, которую мы могли изменить с помощью JavaScript, поэтому разработчики воспользовались этим, чтобы использовать их не по назначению. Это изменилось с появлением API-интерфейса истории, поскольку он позволял изменять весь URL-адрес с помощью JavaScript.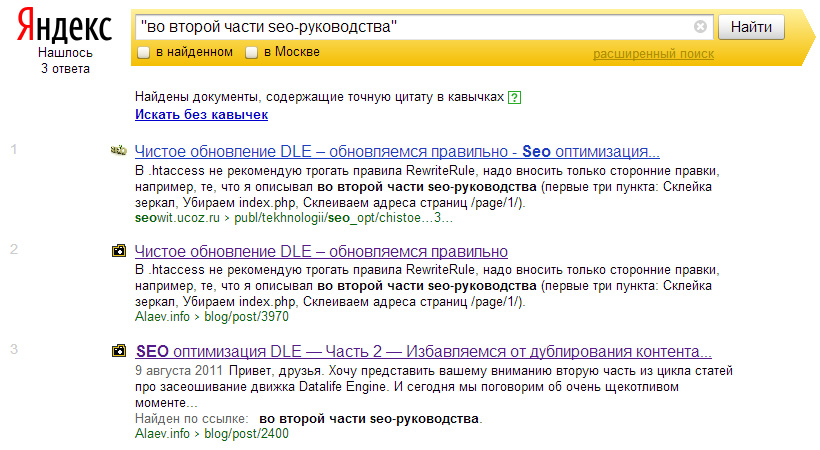
Раньше, когда Google не мог индексировать AJAX, если URL-адрес изменял свое содержимое через AJAX на основе части фрагмента, мы знали, что он будет индексировать только URL-адрес и содержимое без учета фрагмента. Итак… что происходит со страницами с фрагментами теперь, когда Google может индексировать AJAX? Поведение точно такое же. Если мы свяжем страницу с фрагментом, и она изменит свое содержимое при доступе через фрагмент, она проиндексирует содержимое, игнорируя фрагмент, и популярность пойдет на этот URL , поскольку Google считает, что фрагмент будет использоваться в качестве привязки, а не для изменения содержимого, как следует.
Однако в настоящее время Google индексирует URL-адреса с хэш-бангом (#!). Это можно реализовать, просто добавив восклицательный знак или bang , и Google заставит это работать, чтобы поддерживать обратную совместимость с устаревшей спецификацией, чтобы сделать AJAX индексируемым. Такая практика, однако, не рекомендуется, так как теперь она должна реализовываться с API истории, к тому же Google может внезапно прекратить индексацию URL-адресов hashbang в любое время .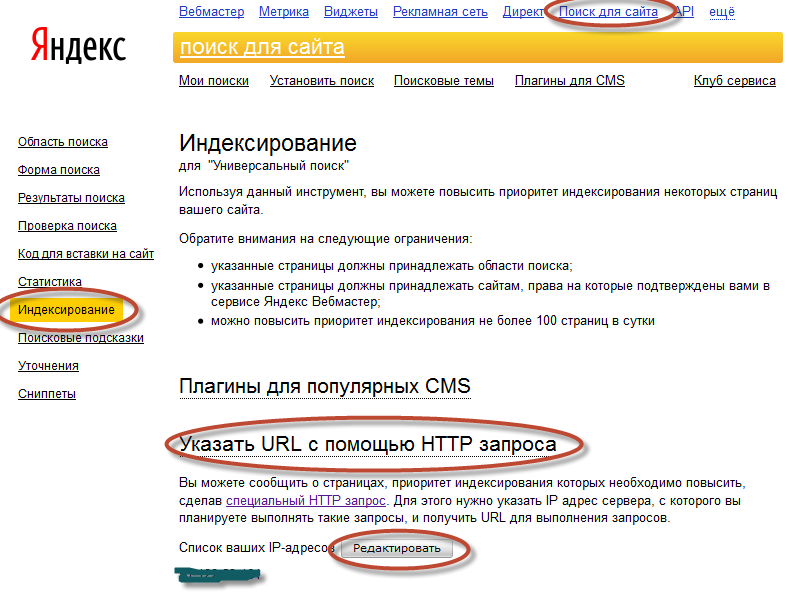
Блокировка индексации частичных ответов через AJAX
Когда запрос AJAX отправляется на URL-адреса REST или GraphQL API , нам возвращается JSON или часть страницы, которую мы не хотим индексировать . Поэтому мы должны заблокировать индексацию URL-адресов, на которые направлены эти запросы .
Когда-то мы могли заблокировать их с помощью robots.txt , но с тех пор, как появился рендерер Googlebot, мы не можем заблокировать какой-либо ресурс, используемый для рисования HTML.
В настоящее время Google немного умнее и обычно не пытается индексировать ответы с помощью JSON, но если мы хотим убедиться, что они не будут проиндексированы, универсальное решение, применимое ко всем поисковым системам, заключается в следующем: заставить все URL-адреса, используемые с AJAX, принимать только запросы, сделанные с помощью метода POST , потому что он не используется сканерами. Когда запрос GET достигает сервера, он должен возвращать ошибку 404. С точки зрения программирования это не заставляет нас удалять параметры из QueryString URL.
Когда запрос GET достигает сервера, он должен возвращать ошибку 404. С точки зрения программирования это не заставляет нас удалять параметры из QueryString URL.
Существует также возможность добавления HTTP-заголовка «X-Robots-Tag: noindex» (придуманный Google) к ответам AJAX или чтобы эти ответы возвращались с кодом 404 или 410. Если мы используем эти методы для загруженного контента непосредственно из HTML, он не будет проиндексирован, как если бы мы заблокировали его через файл robots.txt. Однако, учитывая, что это JavaScript, рисующий ответ на странице, Google не устанавливает связь между этим ответом и JavaScript, рисующим контент , поэтому он делает именно то, что мы от него ожидаем. А именно: не индексировать частичный ответ и полностью индексировать сгенерированный HTML. Будьте осторожны с этим, потому что это поведение может когда-нибудь измениться, как и весь наш контент, загружаемый через AJAX, если мы применим этот метод.
Заключение
Теперь Google может индексировать JavaScript и AJAX, но это неизбежно влечет за собой более высокую стоимость индексации уже обработанного HTML на сервере .