
Hypertext Markup Language (HTML) / Язык гипертекстовой разметки (HTML)
Что такое HTML? — Глоссарий по аналитике посетителейTL;DRHTML (язык гипертекстовой разметки) — это язык, используемый для создания веб-страниц. Некоторые страницы могут быть написаны непосредственно в HTML, в то время как другие могут использовать конструкторы страниц или другие инструменты для создания веб-страниц, которые также производят HTML-выход, который, в свою очередь, может быть прочитан браузерами.
Что означает HTML?HTML расшифровывается как Hypertext Markup Language (язык гипертекстовой разметки) и является языком, используемым для создания веб-страниц. Он использует разметку для определения и стилистики элементов. Например, он может определять шрифты, цвета, положение, ссылки и т.д. Несмотря на то, что большинство создателей веб-сайтов не пишут непосредственно в HTML, конечные результаты, которые читаются и интерпретируются веб-браузерами, находятся в формате HTML. Поэтому при щелчке правой кнопкой мыши на любой веб-странице и нажатии кнопки «просмотреть исходную страницу», первая строка текста в результирующем окне должна быть <!doctype html>.
Поэтому при щелчке правой кнопкой мыши на любой веб-странице и нажатии кнопки «просмотреть исходную страницу», первая строка текста в результирующем окне должна быть <!doctype html>.
Хотя структуры могут различаться, некоторые из элементов, которые вы должны найти в любом HTML, являются следующими (с пояснениями, выделенными курсивом). Проверьте это на любой веб-странице, щелкнув правой кнопкой мыши в любом месте на ней и нажав «просмотреть источник страницы»:
<!DOCTYPE html> — это показывает веб-браузеру, что это HTML-файл, который он может прочитать.
<html lang=»en»> — это показывает язык, на котором написана веб-страница.
<head> — обозначает начало головной секции, в которой размещены общие коды.
<title>Заголовок страницы</title> — это метатег, показывающий заголовок страницы, который отображается во вкладке браузера
<meta name=»description» content=». ..» /> — используется для описания того, о чем страница, для поисковых систем.
..» /> — используется для описания того, о чем страница, для поисковых систем.
<meta name=»viewport» content=»width=device-width, initial scale=1, minimum scale=1, user-scalable=0″ /> — это команда, рассказывающая, как веб-страница должна отображаться на экране различного размера.
<meta name=»роботы» content=»index,follow» /> — это говорит роботам, которые ползают по странице, что они могут проиндексировать ее и добавить в результаты поиска.
<link rel=»таблица стилей» type=»текст/css» href=»/css/style/style.css»> — соединяет HTML с CSS-файлом, в котором размещена более подробная стилистика текста.
<script src=»/js/random.js» type=»text/javascript»></script> — соединяется с файлом Javascript, используемым для выполнения действия на веб-странице.
<link rel=»canonical» href=»https://yourpage.com»/> — если есть страницы со схожим содержанием или страница может быть найдена по более чем одному URL, это показывает ползунки, какие URL должны быть приняты во внимание в целях авторизации.
</head> — это закрывает головную секцию.
<body> — открывается раздел тела, в котором размещается фактическое содержимое страницы.
<div> — открывается секция, называемая контейнером, которая обычно устанавливает кадр для некоторого содержимого
<a href=»https://yoursiteshomepage.com»><img src=»/images/logo.svg» alt=»alt text»></a> — это один из способов размещения изображения логотипа, которое ссылается на вашу домашнюю страницу.
<div>Это первые слова, которые фактически отображаются на вашем сайте</div> — некоторый текст, который можно стилизовать в подключенном CSS-файле.
…
</тело>
Коды языков | htmlbook.ru
Код языка применяется для атрибутов, задающих язык, на котором написан весь документ или отдельные его блоки. В HTML язык обычно задается через атрибут lang.
В табл. 1 приведены некоторые распространенные языки и их коды, которые используются в качестве значений.
| Язык | Код |
|---|---|
| Абхазский | ab |
| Азербайджанский | az |
| Аймарский | ay |
| Албанский | sq |
| Английский | en |
| Американский английский | en-us |
| Арабский | ar |
| Армянский | hy |
| Ассамский | as |
| Африкаанс | af |
| Башкирский | ba |
| Белорусский | be |
| Бенгальский | bn |
| Болгарский | bg |
| Бретонский | br |
| Валлийский | cy |
| Венгерский | hu |
| Вьетнамский | vi |
| Галисийский | gl |
| Голландский | nl |
| Греческий | el |
| Грузинский | ka |
| Гуарани | gn |
| Датский | da |
| Зулу | zu |
| Иврит | iw |
| Идиш | ji |
| Индонезийский | in |
| Интерлингва (искусственный язык) | ia |
| Ирландский | ga |
| Исландский | is |
| Испанский | es |
| Итальянский | it |
| Казахский | kk |
| Камбоджийский | km |
| Каталанский | ca |
| Кашмирский | ks |
| Кечуа | qu |
| Киргизский | ky |
| Китайский | zh |
| Корейский | ko |
| Корсиканский | co |
| Курдский | ku |
| Лаосский | lo |
| Латвийский, латышский | lv |
| Латынь | la |
| Литовский | lt |
| Малагасийский | mg |
| Малайский | ms |
| Мальтийский | mt |
| Маори | mi |
| Македонский | mk |
| Молдавский | mo |
| Монгольский | mn |
| Науру | na |
| Немецкий | de |
| Непальский | ne |
| Норвежский | no |
| Пенджаби | pa |
| Персидский | fa |
| Польский | pl |
| Португальский | pt |
| Пуштунский | ps |
| Ретороманский | rm |
| Румынский | ro |
| Русский | ru |
| Самоанский | sm |
| Санскрит | sa |
| Сербский | sr |
| Словацкий | sk |
| Словенский | sl |
| Сомали | so |
| Суахили | sw |
| Суданский | su |
| Тагальский | tl |
| Таджикский | tg |
| Тайский | th |
| Тамильский | ta |
| Татарский | tt |
| Тибетский | bo |
| Тонга | to |
| Турецкий | tr |
| Туркменский | tk |
| Узбекский | uz |
| Украинский | uk |
| Урду | ur |
| Фиджи | fj |
| Финский | fi |
| Французский | fr |
| Фризский | fy |
| Хауса | ha |
| Хинди | hi |
| Хорватский | hr |
| Чешский | cs |
| Шведский | sv |
| Эсперанто (искусственный язык) | eo |
| Эстонский | et |
| Яванский | jw |
| Японский | ja |
Что такое HTML? Что нужно знать о популярном языке разметки
- HTML означает язык разметки гипертекста и представляет собой язык кодирования, управляющий структурой веб-сайта.

- HTML составляет основу крупнейших веб-сайтов в Интернете и является основной частью создания веб-сайтов.
- HTML в основном отвечает за управление отображением текста, будь то гиперссылки, маркированные списки или другие параметры форматирования.

Почти каждый веб-сайт, который вы посещаете, был создан с использованием различных языков кодирования. Но когда дело доходит до Интернета, пожалуй, самым важным является HTML.
HTML, также известный как «язык гипертекстовой разметки», отвечает за настройку структуры и макета веб-сайта, определение размера шрифта, цвета и стиля, а также создание гиперссылок и определение того, где и как должны отображаться изображения.
Короче говоря, ключевые слова и теги HTML определяют внешний вид и поведение веб-сайта. Без HTML мы бы видели обычный текст на пустых страницах.
HTML существует с 1989 года и несколько лет назад получил серьезное обновление в виде HTML5.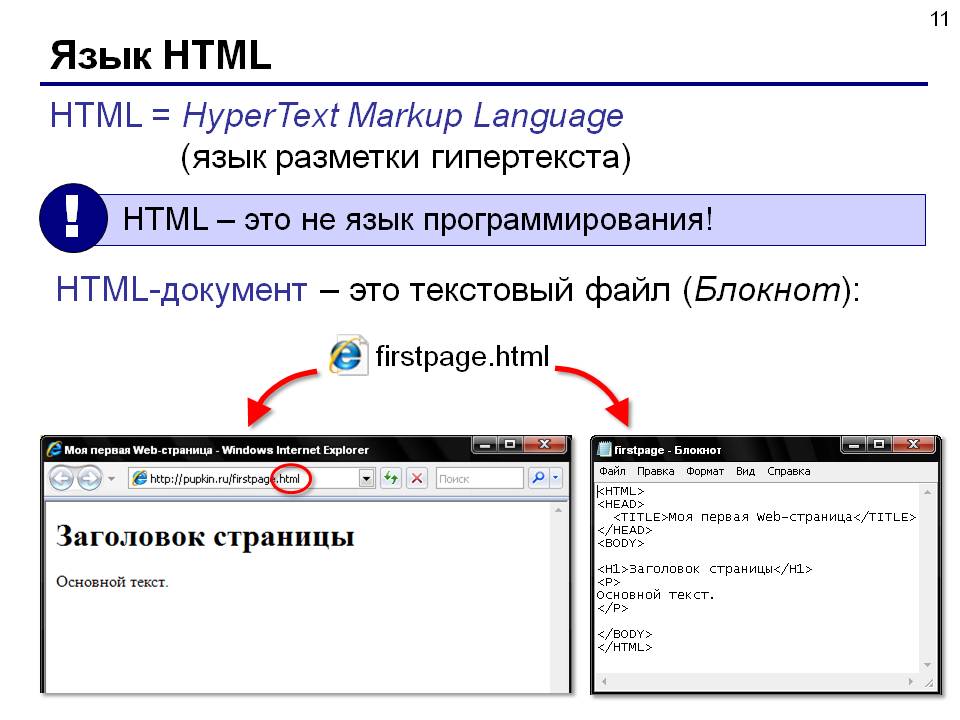 Если вы хотите создать свой собственный веб-сайт, вы должны знать, как использовать HTML.
Если вы хотите создать свой собственный веб-сайт, вы должны знать, как использовать HTML.
Вот основное руководство по HTML.
Что такое HTML?
Теги языка программирования используются для идентификации и стилизации конкретных структурных элементов веб-страницы. Дженнифер Стилл/Business Insider Из всех языков программирования HTML, пожалуй, самый простой. Это связано с тем, что он не использует «динамическую функциональность», как другие языки, такие как Ruby, JavaScript и PHP. Другими словами, HTML нельзя использовать для автоматического обновления контента на определенном веб-сайте или предоставления целевой информации, например определения местоположения пользователя, чтобы показать ему местную погоду. При этом его ограниченные возможности не делают HTML менее полезным — он остается неотъемлемой частью почти всех веб-сайтов в Интернете.
При этом его ограниченные возможности не делают HTML менее полезным — он остается неотъемлемой частью почти всех веб-сайтов в Интернете.
Вот некоторые общие теги:
и
и : Все, что появляется в этом теге, будет выделено полужирным шрифтом .
и : Этот тег выделяет все в нем курсивом .
и : Это тег гиперссылки, который позволяет создателям создавать гиперссылки на все, что содержится внутри.
и : Этот тег отображает изображения, загруженные на сервер или имеющие внешние ссылки.
Если вы посмотрите на исходный код веб-сайта, вы увидите HTML-теги в действии. Каждая часть почти каждого веб-сайта, который вы посещаете, так или иначе связана с HTML.
Как работает HTML?
Вы можете быстро составить код и создать простую веб-страницу. Дженнифер Стилл/Business Insider Вышеупомянутые теги и все другие, включенные в язык HTML, можно использовать так часто, как вы хотите. Вам просто нужно убедиться, что тег закрыт — другими словами, если вы начинаете абзац с, вам нужно обязательно заканчивать его с помощью
. Если вы этого не сделаете, весь ваш код может быть испорчен. HTML является открытым исходным кодом, что означает, что его можно бесплатно использовать и развивать по своему усмотрению.
Однако у него есть свои недостатки. Поскольку HTML настолько прост, сложно создать эстетически приятную или продвинутую веб-страницу, используя только его. Он отлично подходит в качестве основы для веб-страницы, но не для всей структуры.
Поскольку он настолько распространен, любой, кто интересуется веб-дизайном, должен знать, как его использовать и читать.
Что такое кодирование? Краткое руководство по компьютерному программированию
Что такое ошибка 404? Как бороться с веб-ошибкой на разных сайтах или исправить ошибку на своем сайте
Что такое кеш? Полное руководство по кешам и их важному использованию на вашем компьютере, телефоне и других устройствах
«Какой у меня IP?»: вот что делает IP-адрес и как найти свой
Что такое просмотр веб-страниц? Вот что вам нужно знать о процессе автоматического сбора данных с веб-сайтов и его использовании
Дженнифер Стилл
Дженнифер — писательница и редактор из Бруклина, Нью-Йорк.
до 540 миллиардов параметров для достижения прорывной производительности — Блог Google AI
Авторы: Шаран Наранг и Ааканкша Чоудери, инженеры-программисты, Google Research В последние годы большие нейронные сети, обученные понимать и генерировать языки, добились впечатляющих результатов в широком спектре задач. GPT-3 впервые показал, что большие языковые модели (LLM) можно использовать для нескольких выстрелов 9.0042 обучение и может достигать впечатляющих результатов без крупномасштабного сбора данных для конкретных задач или обновления параметров модели. Более поздние LLM, такие как GLaM, LaMDA, Gopher и Megatron-Turing NLG, добились передовых результатов за несколько попыток во многих задачах за счет масштабирования размера модели, использования редко активируемых модулей и обучения на больших наборах данных из более разнообразные источники.
В прошлом году Google Research объявила о нашем видении Pathways, единой модели, которая может обобщать домены и задачи и при этом быть высокоэффективной. Важной вехой на пути к реализации этого видения стала разработка новой системы Pathways для организации распределенных вычислений для ускорителей. В «PaLM: масштабируемое языковое моделирование с помощью Pathways» мы представляем модель Pathways Language Model (PaLM), 540-миллиардную модель Transformer с плотным декодированием, обученную с помощью системы Pathways, которая позволила нам эффективно обучать одну модель в нескольких Модули TPU v4. Мы оценили PaLM на сотнях задач понимания и генерации языка и обнаружили, что он обеспечивает современную производительность за несколько шагов в большинстве задач, во многих случаях со значительным отрывом.
По мере увеличения масштаба модели повышается производительность задач, а также открываются новые возможности. |
Обучение языковой модели с 540 миллиардами параметров с использованием путей
PaLM демонстрирует первое крупномасштабное использование системы Pathways для масштабирования обучения до 6144 микросхем, что является самой большой конфигурацией системы на основе TPU, используемой для обучения на сегодняшний день. Обучение масштабируется с использованием параллелизма данных на уровне модуля в двух модулях Cloud TPU v4 с использованием стандартного параллелизма данных и моделей в каждом модуле. Это значительное увеличение масштаба по сравнению с большинством предыдущих LLM, которые либо обучались на одном модуле TPU v3 (например, GLaM, LaMDA), либо использовали конвейерный параллелизм для масштабирования до 2240 графических процессоров A100 в кластерах графических процессоров (Megatron-Turing NLG), либо использовал несколько модулей TPU v3 (Gopher) с максимальным масштабом 4096 чипов ТПУ v3.
PaLM достигает эффективности обучения на уровне 57,8% использования аппаратных FLOP, , самого высокого показателя, достигнутого для LLM в этом масштабе . Это связано с комбинацией стратегии параллелизма и переформулировкой блока Transformer, который позволяет параллельно вычислять уровни внимания и прямой связи, что позволяет ускориться за счет оптимизации компилятора TPU.
Это связано с комбинацией стратегии параллелизма и переформулировкой блока Transformer, который позволяет параллельно вычислять уровни внимания и прямой связи, что позволяет ускориться за счет оптимизации компилятора TPU.
PaLM был обучен с использованием комбинации английских и многоязычных наборов данных, которые включают высококачественные веб-документы, книги, Википедию, разговоры и код GitHub. Мы также создали словарь «без потерь», который сохраняет все пробелы (особенно важно для кода), разбивает символы Unicode, не входящие в словарь, на байты и разбивает числа на отдельные токены, по одному на каждую цифру.
Прорывные возможности в языковых, логических и кодовых задачах
PaLM демонстрирует прорывные возможности в решении множества очень сложных задач. Ниже мы выделяем несколько примеров для понимания и генерации языка, рассуждений и задач, связанных с кодом.
Понимание языка и генерация
Мы оценили PaLM на 29 широко используемых задачах обработки естественного английского языка (NLP). PaLM 540B превзошел производительность нескольких предыдущих крупных моделей, таких как GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla и LaMDA, в 28 из 29 случаев.задач, которые охватывают задачи на ответы на вопросы (вариант закрытой книги с открытым доменом), задачи на закрытие и завершение предложений, задачи в стиле Винограда, задачи на понимание прочитанного в контексте, задачи на рассуждение здравого смысла, задачи SuperGLUE и вывод естественного языка задания.
PaLM 540B превзошел производительность нескольких предыдущих крупных моделей, таких как GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla и LaMDA, в 28 из 29 случаев.задач, которые охватывают задачи на ответы на вопросы (вариант закрытой книги с открытым доменом), задачи на закрытие и завершение предложений, задачи в стиле Винограда, задачи на понимание прочитанного в контексте, задачи на рассуждение здравого смысла, задачи SuperGLUE и вывод естественного языка задания.
| Улучшение производительности PaLM 540B по сравнению с предыдущей версией (SOTA) в 29 задачах НЛП на английском языке. |
В дополнение к задачам НЛП на английском языке PaLM также демонстрирует высокую производительность в многоязычных тестах НЛП, включая перевод, хотя только 22% учебного корпуса не на английском языке.
Мы также изучаем возникающие и будущие возможности PaLM в тесте Beyond the Imitation Game Benchmark (BIG-bench), недавно выпущенном наборе из более чем 150 новых задач языкового моделирования, и обнаруживаем, что PaLM достигает прорывной производительности. Мы сравниваем производительность PaLM с Gopher и Chinchilla, усредненную по общему подмножеству из 58 таких задач. Интересно, что мы отмечаем, что производительность PaLM в зависимости от масштаба следует логарифмически линейному поведению, аналогичному предыдущим моделям, предполагая, что повышение производительности за счет масштабирования еще не достигло плато . PaLM 540B 5-shot также лучше, чем средняя производительность людей, которым было предложено решить те же задачи.
Мы сравниваем производительность PaLM с Gopher и Chinchilla, усредненную по общему подмножеству из 58 таких задач. Интересно, что мы отмечаем, что производительность PaLM в зависимости от масштаба следует логарифмически линейному поведению, аналогичному предыдущим моделям, предполагая, что повышение производительности за счет масштабирования еще не достигло плато . PaLM 540B 5-shot также лучше, чем средняя производительность людей, которым было предложено решить те же задачи.
| Масштабирование PaLM на подмножестве из 58 задач BIG-bench. |
PaLM демонстрирует впечатляющие возможности понимания и генерации естественного языка на нескольких БОЛЬШИХ лабораторных задачах. Например, модель может различать причину и следствие, понимать концептуальные комбинации в соответствующих контекстах и даже угадывать фильм по эмодзи.
Примеры, демонстрирующие однократную производительность PaLM 540B при выполнении БОЛЬШИХ настольных задач: маркировка причин и следствий, концептуальное понимание, угадывание фильмов по смайликам, поиск синонимов и контрфактуалов. |
Рассуждение
Сочетая масштаб модели с подсказками по цепочке мыслей , PaLM демонстрирует революционные возможности в задачах рассуждения, требующих многошаговой арифметики или рассуждений на основе здравого смысла. Предыдущие LLM, такие как Gopher, видели меньше пользы от масштаба модели в повышении производительности.
| Стандартные подсказки в сравнении с подсказками по цепочке мыслей для примера математической задачи начальной школы. Подсказка по цепочке мыслей разбивает подсказку для многоэтапной задачи рассуждения на промежуточные шаги (выделены желтым цветом), аналогично тому, как человек подошел бы к ней. |
Мы наблюдали высокую производительность PaLM 540B в сочетании с подсказками по цепочке размышлений на трех наборах арифметических данных и двух наборах данных на основе здравого смысла. Например, с 8-кратной подсказкой PaLM решает 58% проблем в GSM8K, эталоне из тысяч сложных математических вопросов школьного уровня, превосходя предыдущий максимальный результат в 55%, достигнутый путем точной настройки модели GPT-3 175B. с обучающим набором из 7500 задач и совмещением его с внешним калькулятором и верификатором.
с обучающим набором из 7500 задач и совмещением его с внешним калькулятором и верификатором.
Этот новый показатель особенно интересен, поскольку он приближается к среднему показателю 60% задач, решенных 9-12-летними детьми, которые являются целевой аудиторией для набора вопросов. Мы подозреваем, что отдельное кодирование цифр в словаре PaLM помогает добиться таких улучшений производительности.
Примечательно, что PaLM может даже генерировать явные объяснения для сценариев, требующих сложного сочетания многоэтапного логического вывода, знания мира и глубокого понимания языка. Например, он может предоставить высококачественные объяснения новых шуток, которых нет в Интернете.
| PaLM объясняет оригинальный анекдот двумя подсказками. |
Генерация кода
Также было показано [1, 2, 3, 4], что LLM хорошо обобщаются для задач кодирования, таких как написание кода с учетом описания на естественном языке (текст в код), перевод кода с одного языка на другой и исправление ошибок компиляции.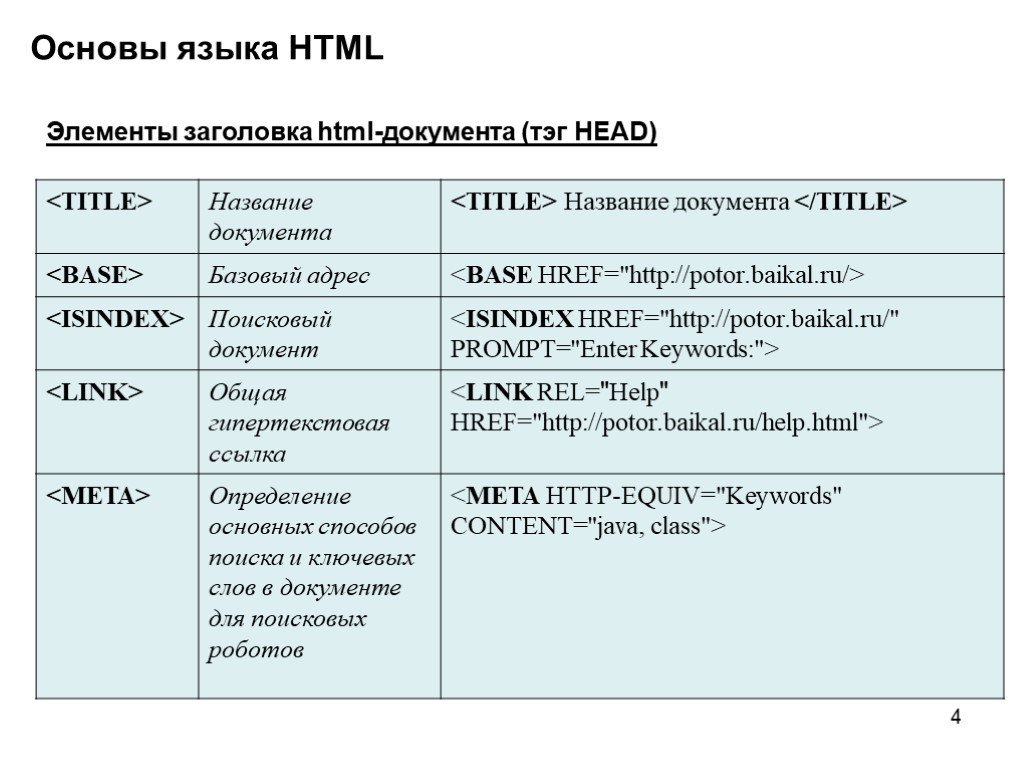 (код в код).
(код в код).
PaLM 540B демонстрирует высокую производительность в задачах кодирования и задачах на естественном языке в одной модели, даже несмотря на то, что в наборе данных перед обучением у него всего 5% кода. Его производительность при малом количестве выстрелов особенно примечательна, потому что он находится на одном уровне с точно настроенным Codex 12B при использовании В 50 раз меньше кода Python для обучения. Этот результат подтверждает более ранние выводы о том, что более крупные модели могут быть более эффективными с точки зрения выборки, чем более мелкие модели, потому что они более эффективно передают знания как из других языков программирования, так и из данных на естественном языке.
Примеры точно настроенной модели PaLM 540B для задач преобразования текста в код, таких как GSM8K-Python и HumanEval, и задач преобразования кода в код, таких как Transcoder. |
Мы также видим дальнейшее увеличение производительности за счет тонкой настройки PaLM для набора данных кода только для Python, который мы называем PaLM-Coder. Для примера задачи исправления кода под названием DeepFix, где целью является модификация изначально поврежденных программ на C до их успешной компиляции, PaLM-Coder 540B демонстрирует впечатляющую производительность, достигая скорости компиляции 82,1%, что превосходит предыдущий уровень техники 71,7%. . Это открывает возможности для исправления более сложных ошибок, возникающих при разработке программного обеспечения.
| Пример из задачи DeepFix Code Repair. Тонко настроенный PaLM-Coder 540B исправляет ошибки компиляции ( слева, , выделено красным) в версии кода, который компилируется ( справа, ). |
Этические соображения
Недавние исследования выявили различные потенциальные риски, связанные с LLM, обученными веб-тексту. Крайне важно анализировать и документировать такие потенциальные нежелательные риски с помощью прозрачных артефактов, таких как карты моделей и таблицы данных, которые также включают информацию о предполагаемом использовании и тестировании. С этой целью в нашем документе представлены таблица данных, карточка модели и результаты тестов Responsible AI, а также отчеты о тщательном анализе набора данных и выходных данных модели на предмет предвзятости и рисков. Хотя анализ помогает определить некоторые потенциальные риски модели, анализ предметной области и конкретной задачи необходим для правильной калибровки, контекстуализации и смягчения возможного вреда. Дальнейшее понимание рисков и преимуществ этих моделей является предметом текущих исследований, наряду с разработкой масштабируемых решений, которые могут защитить от злонамеренного использования языковых моделей.
Крайне важно анализировать и документировать такие потенциальные нежелательные риски с помощью прозрачных артефактов, таких как карты моделей и таблицы данных, которые также включают информацию о предполагаемом использовании и тестировании. С этой целью в нашем документе представлены таблица данных, карточка модели и результаты тестов Responsible AI, а также отчеты о тщательном анализе набора данных и выходных данных модели на предмет предвзятости и рисков. Хотя анализ помогает определить некоторые потенциальные риски модели, анализ предметной области и конкретной задачи необходим для правильной калибровки, контекстуализации и смягчения возможного вреда. Дальнейшее понимание рисков и преимуществ этих моделей является предметом текущих исследований, наряду с разработкой масштабируемых решений, которые могут защитить от злонамеренного использования языковых моделей.
Заключение и будущая работа
PaLM демонстрирует возможность масштабирования системы Pathways до тысяч чипов-ускорителей в двух модулях TPU v4 путем эффективного обучения модели с 540 миллиардами параметров с помощью хорошо изученного и хорошо зарекомендовавшего себя рецепта плотной модели Transformer, состоящей только из декодера. Расширение границ масштаба модели обеспечивает революционную производительность PaLM за несколько шагов в различных задачах обработки естественного языка, рассуждений и кода.
Расширение границ масштаба модели обеспечивает революционную производительность PaLM за несколько шагов в различных задачах обработки естественного языка, рассуждений и кода.
PaLM прокладывает путь к еще более совершенным моделям, сочетая возможности масштабирования с новыми архитектурными решениями и схемами обучения, и приближает нас к видению Pathways:
| «Позволить одной системе ИИ обобщать тысячи или миллионы задач, понимать различные типы данных и делать это с поразительной эффективностью». 021 PaLM — результат большой совместной работы многих команд в рамках Google Research и Alphabet. Мы хотели бы поблагодарить всю команду PaLM за их вклад: Джейкоба Девлина, Мартена Босму, Гаурав Мишра, Адама Робертса, Пола Бархама, Хён Вон Чанга, Чарльза Саттона, Себастьяна Германна, Паркера Шу, Кенсена Ши, Сашу Цвященко, Джошуа Майнеза. , Абхишек Рао, Паркер Барнс, Йи Тай, Ноам Шазир, Винодкумар Прабхакаран, Эмили Рейф, Нан Ду, Бен Хатчинсон, Райнер Поуп, Джеймс Брэдбери, Джейкоб Остин, Майкл Айсард, Гай Гур-Ари, Пэнчен Инь, Тоджу Дьюк, Ансельм Левская , Санджай Гемават, Сунипа Дев, Хенрик Михалевски, Ксавье Гарсия, Ведант Мисра, Кевин Робинсон, Лиам Федус, Денни Чжоу, Дафна Ипполито, Дэвид Луан, Хёнтак Лим, Баррет Зоф, Александр Спиридонов, Райан Сепасси, Дэвид Дохан, Шивани Агравал, Марк Омерник, Эндрю Дай, Танумалаян Санкаранараяна Пиллаи, Мари Пелла, Айтор Левкович, Эрика Морейра, Ревон Чайлд, Александр Полозов, Кэтрин Ли, Цзунвэй Чжоу, Сюэчжи Ван, Бреннан Саэта, Марк Диаз, Орхан Фират, Мишель Катаста и Джейсон Вей. |
