Настройка редиректа htaccess для ваших сайтов и robot txt
Мы поговорили про редиректы и индексирование в нашей статье “какие нужно сделать первые шаги для оптимизации сайта”. Еще раз это проговорим здесь как настройка редиректа htaccess осуществляется для ваших сайтов. Огромная ошибка многих сайтов, которые приходят к нам на аудит, заключается в том, что они доступны как с WWW, так и без WWW. Например, наш сайт доступен по адресу https://adieusovok.com/ и когда я пытаюсь набрать в адресной строке http://www.adieusovok.com/, то он тоже доступен, но у меня при наборе такого адреса автоматически происходит переадресация на https://adieusovok.com/ (без WWW).
Нужно понимать, что сайт с WWW и без WWW – это две абсолютно разные вещи. То есть, это два разных сайта. Поэтому в корне неверно иметь сайт, который доступен по обоим вариантам адреса. Должен быть доступен только один вариант. Обязательно нужно настроить 301 редирект с WWW на без WWW
В случае с WordPress проблем нет. Там по умолчанию все грамотно настроено, и вы будете иметь только один вариант адреса. А вот на других движках такая проблема наблюдается.
Там по умолчанию все грамотно настроено, и вы будете иметь только один вариант адреса. А вот на других движках такая проблема наблюдается.
Содержание страницы
- 1 Настройка редиректа htaccess
- 1.1 Резюме по настройке редиректа htaccess
- 2 Настройка главного зеркала сайта
- 3 Отличие 301 и 302 редиректа
- 4 Настройка Robots.txt
- 4.1 Правило «Allow» – это наоборот открытие
- 4.2 Правило «Disallow» – это наоборот закрытие
- 5 Добавление в панели вебмастеров Robots.txt
- 6 Тег rel=canonical
- 6.1 Пример для тега rel=canonical
- 7 Настройка 404 страница
- 7.1 Код 200
- 7.2 Видео по создание страницы 404
- 7.3 Удаление ненужных страниц из индекса
- 8 Через редиректы для работы с CPA
- 8.1 Резюме по настройке редиректов для CPA сайтов
- 9 Что делать с ненужные внешними ссылками?
- 9.1 Тег rel=”nofollow”
- 9.2 Пример с тегом rel=nofollow
- 9.
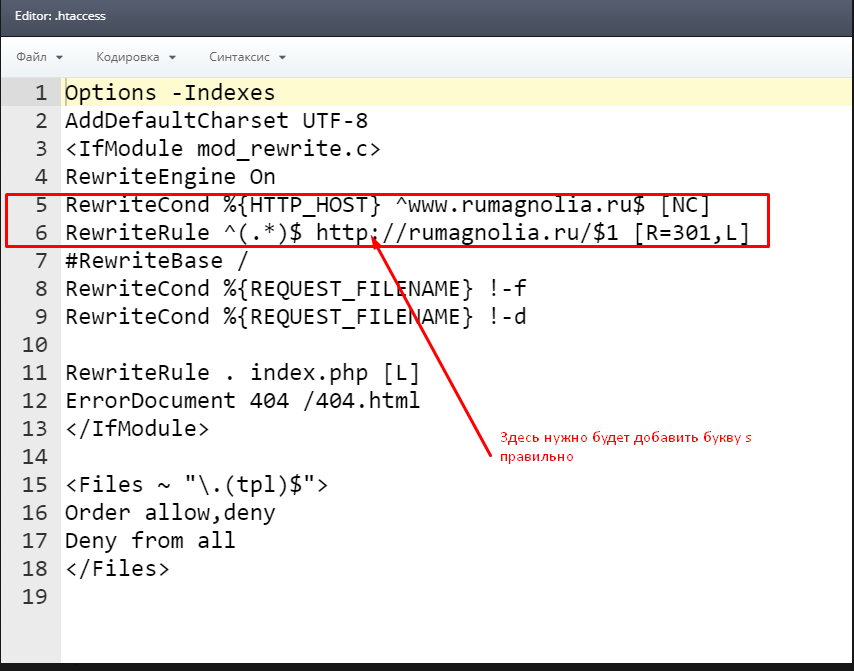
 (.*)$ http://site.ru/$1 [R=301,L]
(.*)$ http://site.ru/$1 [R=301,L]Его нужно добавить в файл .htaccess и вы получите редирект с WWW на без WWW.Сразу отмечу, что лучше выбрать – самым правильным будет вариант, который находится в индексе. Есть код (на примере моего блога):
url:www.adieusovok.com* | url:adieusovok.com.ru*
Мы вбиваем его в Яндексе и видим проиндексированные страницы нашего сайта. Даже если сайт проиндексирован с WWW, то в выдаче вы этого не увидите. Чтобы это проверить нужно навести курсор мышки на заголовок статьи и посмотреть в левый нижний угол экрана: Впереди WWW нет. Если бы он там был, то это означало бы, что Яндекс проиндексировал мой сайт с WWW. Аналогично и с Гуглом. Там уже другой код: site:adieusovok.com
проверяем как сайт проиндексировался в поисковикахОпять же, при наведении на заголовок мы видим в нижнем углу наши реальные URL адреса. На основе этого мы и принимаем решение – какой вариант должен быть у сайта.
Я считаю, что если сайт молодой, то лучше задать основное зеркало сайта без WWW. Почему? Потому что это укорачивает наш домен. Если же ваш сайт уже имеет историю и доступен по 2-м вариантам, то нужно выбрать тот, который находится в индексе.Резюме по настройке редиректа htaccess
Бывают такие случаи, когда сайт доступен по обоим вариантам (в Яндексе – один, а в Гугле – другой). Как быть в такой ситуации? Ориентируемся на тот поисковик, который вам более дорог. Если основной трафик у вас идет с Яндекса, то корректируемся под Яндекс. Что произойдет с другим поисковиком, когда вы пропишете редиректы (301 редирект)? Так мы даем понять поисковикам, что наш сайт навсегда переехал на определенный домен (c WWW или без) и все страницы, которые не отвечают этому требованию выпадут из индекса и останется только то, что нам нужно. Это называется склейка. В Гугле это происходит обычно довольно быстро (неделя-две), Яндексу потребуется месяца два. Вот и вся настройка редиректа htaccess в двух словах.
Все просто!Настройка главного зеркала сайта
В Я.Вебмастер и Google Webmaster указываем главное зеркало. Это находится вот здесь:
настройка главного зеркала сайтаЕсли необходимо задать домен с WWW, то ставим внизу галочку:
Демонстрация кнопки настройки реддиректа в панели Явебмастерс с wwwПо поводу Гугла, то здесь нужно добавить сайт в Гугл Вебмастерс, далее зайти в “Управление ресурсом”, там выбрать “Настройки” (значок “шестеренки” в правом верхнем углу), далее “Настройки сайта” и выиграем в пункте “Основной домен” то, что нас интересует.
Демонстрация кнопки настройки реддиректа в панели Гуглвебмастерс с wwwЧтобы выбрать один из двух вариантов, надо добавить оба варианта в панель Вебмастера и только потом выбрать правильный.
Отличие 301 и 302 редиректа
Расскажу теперь отличие 301 редиректа от 302. Я говорил, что нужен именно 301 редирект, потому что 302 редирект говорит поисковикам о том, что сайт временно переехал. В этом случае ссылочный вес и все остальное не передается.
Сайт будет как новый. Поэтому, если делаем редиректы, то прописываем 301 редирект.Настройка Robots.txt
Это файл, который в первую очередь показывает поисковикам – какие директории не следует индексировать. Находится он в корне сайта. Если его нет – его надо создать. Обычно это .txt документ. Назвать его необходимо “Robots” и загрузить в корень сайта. Здесь есть такое правило, как Disallow, которое показывает, что указанную директорию не нужно индексировать.
То есть, поисковики должны игнорировать эту директорию. Обычно это какие-то служебные директории (страницы с метками, страницы пагинации, feed и т.д.). Но, очень часто Гугл игнорирует этот файл. Мы покажем как по-другому исключать страницы из индекса Гугла.
Robots.txt обязательно должен быть на каждом сайте. Также обязательно должен быть прописан Host – это основное зеркало, которое у нас должно быть проиндексировано.
Он прописывается единожды, обычно в конце. Прописывайте так, как вам нужно, чтобы индексировался сайт – просто site.ru, либо с www, либо c https. Это обязательно! Обязательно в Robots.txt надо прописать адрес до sitemap.xmlUser-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= Host: ВАШ САЙТ Sitemap: http://ВАШ САЙТ/sitemap.
xml.gz Sitemap: http://ВАШ САЙТ/sitemap.xmlЭто касается только карты формата .xml
Далее, можно посмотреть, что находится в индексе и добавить ненужные разделы. Я уже давал код, который выводит все ваши проиндексированные страницы:
url:www.site.ru* | url:site.ru*
Просто забиваете его в Яндекс и смотрите, что в индексе. Все мусорные страницы обычно в конце выдачи. Чтобы попасть на самые последние страницы выдачи, вы вот тут:
Проверка индексации сайта в ЯндексеПишете какую-нибудь цифру побольше (например, 99) и внизу вы увидите самые последние проиндексированные страницы. Походите там, посмотрите, может что-то нужно закрыть от индексации.
Правило «Allow» – это наоборот открытие
Прописываем команду allow для индексацииНапример, Гугл сейчас требует, чтобы мы открывали .css и .js файлы, чтобы он понимал из чего состоит наш сайт. Для Гугла я прописал открытие вот этих папок:
Прописываем команду allow для индексацииЭто касается Вордпресс.
Если у вас другой движок, то у вас все тут будет по-другому.Правило «Disallow» – это наоборот закрытие
Здесь, стандартно то, что надо закрыть у Вордпресса:
Прописываем команду disallow для закрытия индексацииВ конце – страница поиска:
Прописываем команду disallow для закрытия индексации поискаУ вас, скорее всего, такого нет. У меня поиск есть.
Добавление в панели вебмастеров Robots.txtЧасто вижу ошибки и опечатки в Robots.txt. Обязательно рекомендую прочекать этот файл в панели вебмастера. У Яндекса это можно сделать в «Инструментах» à «Анализ Robots.txt»
Добавление в панели вебмастеров Robots.txt для проверки валидности кодаВы нажимаете «Проверить» и сервис укажет вам на ошибки, если они есть. Файл должен проходить валидацию и давать ответ, что ошибок нет.
Если вы при просмотре выдачи заметили страницу или категорию, которую хотите исключить, вручную прописали правило и сомневаетесь правильно вы это сделали или нет, то ниже есть поле «Разрешены ли URL», в которое вы вставляете необходимый адрес и нажимаете кнопку «Проверить»:
Проверки валидности кода robot txt в ручном режимеВ результате, ниже вы можете увидеть, что категория подчеркнута красным
На фото результат проверки валидности кодаЭто значит, что она запрещена к индексированию и вы все сделали правильно.
Если цвет – зеленый, значит индексация разрешена и у вас где-то ошибка.Обязательно проверьте свой Robots на ошибки, потому что они закрадываются довольно часто.
То же самое в Google Webmasters – во вкладке «Сканирование» à «Инструменты проверки файла Robots.txt»
На фото результат проверки валидности кода в ГуглвебмастерсПрописываем нашу страницу. Справа можно выбрать бота, если это необходимо (например, мобильного). В нашем случае, оставляем все как есть и нажимаем «Проверить». В итоге сервис подсветит красным – какое именно правило запрещает для индексирования проверяемую страницу. Повторюсь, Гуглу обычно все-равно за эти правила и он может проиндексировать сайт. Я не раз такое наблюдал.
Если вы хотите, что весь ваш сайт полностью не индексировался, вставьте, до закрывающегося </head> в шапке сайта, вот такой код:
<meta name=”robots” content=”none”/>
Это самый действенный способ.Если же вам необходимо закрыть какую-то конкретную страницу от индекса, то тогда вот такой код:
<meta name=”robots” content=”noindex,follow”/>
Робот будет ходить по ссылкам (follow), но не будет индексировать эту страницу (noindex).
Это касается того момента, как закрыть страницы для Гугла. В плагине Yoast SEO это все автоматизировано. Например, у нас есть страница пагинации номер 2. При переходе на нее в адресной строке появляется url:site.ru/page2Не нужно, чтобы он попадал в индекс, потому что это мусорная страница. Поэтому в Robots.txt прописано вот такое правило, которое исключает данные страницы из индекса:
На фото видно как закрыть мусорные страницы в robot txtТо же самое касается страниц с тегами. Если их не оптимизировать, то лучше вообще закрыть от индексации. Такие страницы создают дубли, на них выводится контент с других страниц. Поэтому я закрываю их в Robots.txt
На фото видно как закрыть мусорные страницы в robot txt с тегамиНо, Гугл их все-равно индексирует. Поэтому, в плагине Yoast SEO, во вкладке «Таксономия», например, на странице с метками передвигаем рычажок на «noindex»
На фото видно как закрыть мусорные страницы одной кнопкой в плагине YoastseoИ плагин автоматически на все страницы с метками ставит “noindex,follow”.
На фото исходный код любой страницы с метками, Если мы посмотрим исходный код любой страницы с метками, то увидим следующую картину:То есть, просто одна кнопочка позволяет выкинуть из индекса все страницы с метками.
Тег rel=canonical
Это вообще опасный тег. Если пользоваться им неправильно – можно жестко накосячить. Настоятельно рекомендую им лишний раз не пользоваться. Я видел несколько раз, как люди неправильно им пользовались и у них кошмар творился на сайте.
Что это за тег? Когда одна и та же страница находится на разных url-адресах (например, одна и та же статья находится в 2 разных категориях), мы не можем один из них исключить из индекса (это физически сложно реализовать). Я вообще рекомендую, если такая ситуация есть на сайте, например, в интернет магазине, где один и тот же товар относится к разным рубрикам, то лучше не выводит в url рубрику. Но, если такое уже есть и сайт у вас проиндексирован, то тут нас и выручает тег rel=canonical. Он указывает нашу основную страницу.
И дальше идет ссылка на самую основную страницу.Пример для тега rel=canonical
Например, товар «стул» располагается в приоритетной для него категории «Мягкая мебель» и на всех других страницах сайта (на страницах других рубрик) прописан тег rel=canonical ведущий на основную рубрику, которую мы сами выбрали (на рубрику «Мягкая мебель»). Таким образом у нас не будет дублей, поисковики будут видеть, что rel=canonical прописан на ту страницу, они будут засовывать в индекс только ту страницу, которая является канонической, и эта страница будет забирать весь вес со страниц-дублей. Если, например, у нас будут покупаться ссылки на другие рубрики, где располагается товар «стул», а на этих страницах будет стоять тег rel=canonical, то вес будет перетекать на основную страницу.
Повторюсь, что использовать этот тег стоит в очень редких случаях, потому что велика вероятность, что вы все сделаете неправильно. Более подробно почитайте у меня на блоге. Там разобраны разнообразные примеры.
Настройка 404 страница
Все несуществующие страницы должны отдавать 404 ошибку, и поисковики должны это видеть. Один из примеров – конкуренты понаставили огромное количество ссылок на несуществующие страницы и в индексе все это повылезало. Все это потому, что сайт не отдавал ошибку 404. По факту в магазине было 200 страниц, а в индексе 500.000 страниц. Чем это чревато? Когда много ненужных страниц в индексе их ценность падает для поисковиков. Поисковики смотрят на количество полезных страниц в индексе. И все страницы, которые есть в индексе – должны быть полезными.
Я проверяю в Яндекс Вебмастере. Инструмент “Проверка ответа сервера”. Вбиваете туда какую-нибудь несуществующую страницу и смотрите отдается ли 404 ошибка.
Проверка ответа сервераКод 200
Если же вбиваете нормальную существующую страницу, то должен отдаваться код 200.
На фото код 200Видео по создание страницы 404
Удаление ненужных страниц из индекса
Удалить из индекса поисковых систем можно только те страницы, которые отдают 404 ошибку или запрещены для индексирования.
Обычные страницы вы не удалите никак. Запретить для индексирования можно через Robots.txt, с помощью <meta name=”robots”>, который прописывается в шапке сайта, либо запретить можно страницу, которая отдает 404 ошибку. Потом, чтобы ускорить удаление, можно воспользоваться сервисом ЯндексаЕсли я захочу удалить обычную страницу сайта, то сервис даст мне ответ, что «Нет оснований для удаления…». Это сделано для того, чтобы конкуренты не пытались удалить страницы из индекса.
На фото показано как удалить страницу на сайте в ЯвебмастрсЕсли же у сервиса будут основания, то страницу он удалит. У Гугла тоже есть подобный инструмент. Он работает более эффективно и более быстро. Во вкладке «Индекс Google» à «Удалить URL-адреса».Вместо “site.ru” вам нужно будет добавить свой сайт.
На фото показано как удалить страницу на сайте в гуглвебмастрсУдалить можно не просто страницу, а целую рубрику. Мы просто пишем рубрику, слеш и ставим звездочку. И это будет означать, что удалить необходимо будет всю директорию.
Вообще, это делать не обязательно. Это нужно, чтобы ускорить вылет страниц из индекса. Если страница отдает 404 ошибку или она запрещена для индексирования – она сама со временем вылетит из индекса.
Через редиректы для работы с CPA
Не знаю кто нас читает, но сейчас сайты создают с внедрением разных механик для монетизации. Формат работы CPA -это когда есть партнерская программа, которая выплачивает вам комиссионные за выполнение условие посетителем вашего сайта. основное условие это покупка или заказа услуги рекламодателя.
Этот раздел статьи сейчас особенно касается тех, чьи ссылки идут на CPA сети. Поисковики борются с сайтами, которые созданы исключительно для заработка на партнерских программах. Если сайт заточен под партнерку, то поисковик думает, что такой сайт не приносит пользу. Тут надо быть аккуратными – если на сайте всего 30 страниц и 20-30 ссылок, которые ведут на партнерские сети, такие сайты могут быть зафильтрованы Яндексом. Сейчас это практикуется довольно часто.
Многие ребята, зарабатывающие на партнерках, сталкивались с этим – количество ссылок на их сайтах относительно общего количества страниц было слишком большим и Яндекс накладывал на них фильтры, потому что считал, что такие ресурсы не приносят пользу.Резюме по настройке редиректов для CPA сайтов
В таких случаях главное – подстраховаться. Если вы хотите зарабатывать через те же СРА, у вас должно быть большое количество страниц в индексе. Например, 1000 страниц в индексе и 5-10 ссылок на товар. Таким образом мы будем демонстрировать поисковикам, что наш сайт приносит пользу, но мы иногда зарабатываем. А когда у нас 20 страниц и 20 ссылок – мы демонстрируем, что мы создали сайт, чтобы зарабатывать на партнерках и все.
Вообще, когда мы ставим ссылки на сомнительные ресурсы, типа СРА сетей, либо тизерных сетей, то лучше всего использовать не “nofollow”, а редирект.
Лучше всего используйте не “nofollow”, а редирект для вашего сайтаКак это выглядит? Ссылка в статье ссылается на свою внутреннюю страницу, а та автоматически редиректит на внешний сайт.
И тут можно на всякий случай прописать «nofollow»Для упрощения всего этого есть плагин WordPress WP No External Links. Кто интересуется СРА сетями, можно через этот плагин все реализовать. Но, не нужно делать лишних редиректов без надобности. Если вы ссылаетесь на нормальные сайты – ссылайтесь на них напрямую. Если что-то сомнительное – лучше через редиректы. Это только в крайних случаях.
Что делать с ненужные внешними ссылками?
Да мы пишем контент для создания сайта под бурж трафик. Но не известно кто нас сейчас читает, поэтому обязательно рекомендую удалять ненужные внешние ссылки с сайта. Особенно не тематические. Сейчас есть фильтр, который называют “новый АГС”, который накладывается Яндексом за продажу ссылок. Если у вас много ссылок и они на сайты разной тематики, если ссылки содержат в анкоре ключевые слова, то это все признаки коммерческих ссылок и Яндекс такие сайты чаще всего фильтрует и полностью режет трафик. Поэтому, все те, кто ссылками торгует – снимаем их обязательно.
Если кто-то торговал вечными ссылками, тоже лучше лишний раз подстраховаться и снять. Если все-таки хотите продавать – делайте это аккуратно, подавайте заявки только на тематические ресурсы и в условиях пропишите, что ссылки должны быть безанкорными.Внешние ссылки на сайте можно проверять разными способами. Когда мы с вами будем разбирать сео-софт, который я использую в работе, я вам покажу все возможные автоматические способы. А так, конкретную страницу можно проверить, например, здесь
Вводите URL, нажимаете “Проверить” и он все ссылки на эту страницу покажет.
Тег rel=”nofollow”
Я считаю, что тегом “nofollow” нужно закрывать только те ссылки, которые ведут на низкокачественные ресурсы. Обычно это в комментариях, потому что там люди оставляют вообще иногда какие-то непонятные сайты. Что касается меня – я вообще от этого ушел и сделал так, чтобы ссылки, оставляемые комментаторами, были неактивными. Если вы так не делаете, то пропишите тег rel=”nofollow”, если у вас его еще нет.
Обычно, на современных шаблонах это автоматически прописывается, но вот раньше не было такого.Тег прописывается пододобным образом:
<a href=”url” rel=”nofollow“>текст ссылки</a>
Если ссылки только на качественные ресурсы, Вы не продаете ссылки, то можно не использовать rel=”nofollow” (я так считаю).
В моем случае, я закрыл в rel=”nofollow” ссылки в подвале, ссылки на соц.сети. Дело в том, что раньше я продавал ссылки. И обычно у покупателей есть требование – чтобы со страницы ссылалось не более 3-4 ссылок. Если бы я не продавал ссылки, то закрывать бы все это не стал. В этом нет смысла. Поисковики прекрасно понимают, что ссылки на соц.сеть – это нормально. Ссылки на нормальные сайты – это тоже нормально. Я во всех своих статьях не ставлю rel=”nofollow” на ссылки.
На Западе все уже давно пиарят друг друга, не ставя rel=”nofollow”, тем самым раскручиваются очень хорошо. Именно поэтому я часто ставлю даже на своих конкурентов ссылки без rel=”nofollow”. В итоге эти ребята часто становятся не моими конкурентами, а моими друзьями. Итак, ставить ссылки на авторитетные ресурсы – скорее плюс, чем минус. Например, когда я пишу статью про Яндекс Метрику, то я и ссылаюсь на Яндекс Метрику, потому что это логично. И Яндекс это видит. Это же касается всех сервисов. Вес по ссылке не передается, адресат ее не получает, но вес на нашей странице теряется.Пример с тегом rel=nofollow
Раньше, если, например, мы ставили ссылку с rel=”nofollow” что происходило? Никакого веса со страницы не уходило, он весь оставался на нашей странице. Где-то года 2 назад Гугл изменил принцип работы тега rel=”nofollow”. Сейчас, если бы я его поставил в своей статье, то сайт, на который я ссылаюсь, веса бы не получил, но вес моей страницы утек бы. Он бы просто растворился в воздухе.
Если мы представим, что условно вес нашего сайта =1 и мы ставим 3 внешние ссылки (2 без rel=”nofollow” и 1 с rel=”nofollow”).
Инфографика работы редиректа для вашего сайтаПолучится, что после первой ссылки 0,33 веса нашей ссылки ушло, после второй ссылки 0,33 веса еще ушло, после третей 0,33 веса все-равно ушло, но тот сайт этого веса не получил. Мы просто-напросто обделяем человека весом нашей ссылки, хотя сами мы его теряем. Вообще никакого смысла в rel=”nofollow” в данном случае нет. В последних докладах Гугл рекомендует ставить rel=”nofollow” в статьях, когда мы делаем платные обзоры.
Повторюсь, что если вы ставите ссылку без rel=”nofollow” на какой-нибудь авторитетный ресурс, например, Википедию, то это наоборот для вас плюс. Допустим, есть интернет магазин кондиционеров и у него есть поставщики, мы сделали страницы, на которые посадили запросы «купить кондиционер Samsung». Вполне логично поставить на это странице ссылку на официальный сайт Samsung. Это увеличит доверие к нам, потому что мы ссылаемся на кого нужно и ничего плохого в этом нет.
Noindex
Noindex воспринимается только Яндексом. Гугл вообще не знает, что это такое и он ему вообще не нужен. Noindex можно прописывать двумя способами – <noindex> и <!–noindex–>. Последний способ он более современный и он делает код валидным. Noindex запрещает индексирование определенного блока для Яндекса. Когда я применяю его? Например, у меня есть клиентский сайт и там на каждой странице небольшое количество контента (500-1000 знаков), а в футере сайта стоит форма онлайн заявки и там описаны преимущества этого сайта, т.е. стоит некий текст, но он дублируется на всех страницах. Для того, чтобы придать больше уникальности всей странице, я текст, который стоит в футере закрываю тегом Noindex. Можно еще закрыть счетчики или блоки с метками.
Рекомендую особо с этим тегом не напрягаться. Многие из-за невнимательности могут наделать проблем с сайтом. Если у вас все еще остались вопросы как настройка редиректа htaccess прописывается для вашего сайта, пожалуйста задавайте вопросы в комментариях.
SEO
Решение, как сделать автоматическое добавление номера страницы в мета-теги Title и Description для страниц пагинации в «1С-Битрикс»
Категории: Битрикс SEO SEO
Решение, как убрать в конце URL знак вопроса и сделать 301 редирект на URL без вопроса, чтобы не было дублей страниц
Категории: Сервер SEO .htaccess 301
Решение, как обернуть ссылки в формат Java Script + span, то есть осуществлять переход по ним, посредством скрипта jQuery
Категории: JS SEO jQuery
Решение, как запретить отдельную страницу к индексации поисковыми системами на 1С-Битрикс при помощи тегов noindex и nofollow через API
Категории: Битрикс SEO API
Решение, как настроить 301 редирект (переадресация) с протокола HTTP на HTTPS через файл .
htaccessКатегории: SEO .htaccess 301
Решение, как настроить 301 редирект (переадресация) с адреса без WWW на адрес с WWW через файл .htaccess
Категории: SEO .htaccess 301
Решение, как настроить 301 редирект (переадресация) с WWW на адрес без WWW через файл .htaccess
Категории: SEO .htaccess 301
Правило для .htaccess — чтобы убрать .php в конце адреса каждой веб-страницы сайта
Категории: SEO .htaccess 301
Правило для .
htaccess — чтобы убрать .html в конце адреса каждой веб-страницы сайтаКатегории: SEO .htaccess 301
Категории: SEO
Настройка в .htaccess, 301 редирект с заглавных букв на прописные в части адреса страницы URL
Категории: SEO .htaccess 301
Решение, как в .htaccess убрать несколько повторяющихся слешей в конце URL
Категории: SEO .htaccess 301
Правило в htaccess для слэша в конце УРЛ для Битрикс
Категории: SEO .
htaccess 301Решение, как не пускать поисковых роботов на сайт или его копию
Категории: SEO
Проблема с 301 редиректом в htaccess, добавляется окончание от старой ссылки.
Категории: SEO .htaccess 301
.htaccess — Использование X-Robot-Tag в.htaccess — WordPress для строки запроса без индекса
спросил
Изменено 4 года, 5 месяцев назад
Просмотрено 2к раз
Я рассмотрел здесь другие вопросы, касающиеся использования X-Robot-Tag для запрета индексации определенной страницы в .
У меня аналогичный вопрос, хотя я хотел бы не индексировать группу страниц и не знаю, как это сделать.
Я использую wordpress и подключаемый модуль фильтра многоуровневой навигации, который поставляется с woocommerce.
Мне удалось не индексировать большинство страниц с помощью плагина Yoast, однако каждый параметр в многоуровневом навигационном фильтре создает страницу для отображения отфильтрованных параметров. эти страницы имеют форму
https://www.mysite.co.uk/brand/brand1/?filter_cats1=cat1каждый фильтр имеет похожий URL-адрес, заканчивающийся аналогично
?filter_cats1=cat1Есть ли способ отфильтровать эти URL-адреса с помощью X-robot-Tag? Как уже упоминалось, я видел только способы запретить индексирование определенных страниц, мне еще предстоит найти способ запретить индексирование групп страниц с похожими URL-адресами
Вы должны поместить новый .htaccess в каталог user/uploaded/. В этом файле вы сможете указать свое правило . htaccess 9|&)filter_cats1= [NC]
Правило перезаписи .* : [E=DO_SEO_HEADER:1]
Набор заголовков X-Robots-Tag «noindex, nofollow» env=DO_SEO_HEADER Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как защитить один подкаталог — форум веб-сервера Apache на WebmasterWorld
- Дом
- Индекс форумов
- Код, контент и презентация/веб-сервер Apache
00:07 15 декабря 2022 г.
Для этой страницы требуется JavaScript.
Сообщение слишком старое, нет ответов
Как защитить один подкаталог
запретить Google индексировать и следовать подкаталогу
мбойднв22:27 22 декабря 2015 г. (GMT 0)
Я не очень разбираюсь в htaccess. Было интересно, может ли кто-нибудь сэкономить быструю строку кода.
Google проиндексировал мою форму бронирования, что недопустимо. У меня был метатег в шаблоне, и они все равно сделали это. Он заблокирован в моем файле robots.txt, но они все равно его проиндексировали. Это загадка для меня.
Итак, при дальнейшем копании я просмотрел свой файл htaccess в подкаталоге. http s://mydomain.com/secured-booking/.htaccess
и первая строка кода:
1. Options All -IndexesЧтение сети, я думаю, что это должно было быть (потому что это подкаталог): Options -Indexes
Дальнейшее чтение привело меня к мысли заменить строку 1 на:
Набор заголовков X -Robots-Tag "noindex, noarchive, nosnippet"Все, что я хочу сделать, это чтобы все файлы в подкаталоге не отслеживались и не индексировались.
Что я могу сделать, если я заблокировал его в файле robot.txt, поместил метатег… я не могу защитить паролем эти каталоги..
будет (в подкаталоге htaccess)
Заголовок установить X-Robots-Tag "noindex, noarchive, nosnippet"поможет?
[ отредактировано : Ocean10000 в 1:00 (UTC) 23 декабря 2015 г.]
[причина редактирования] не привязано [/ редактировать]Присоединяйтесь к беседе
- Зарегистрируйтесь бесплатно! — Стать профессиональным участником!
- Просмотр категорий форума — Войдите на форумi>
Модераторы и ведущие участники
- Список модераторов | Ведущие участники: на этой неделе Этот месяц, ноябрь, Октябрь, Архив, 100 лучших за все время, Участники с наибольшим количеством голосов
Горячие темы на этой неделе
- Обновления Google и изменения в поисковой выдаче — май 2022 г.
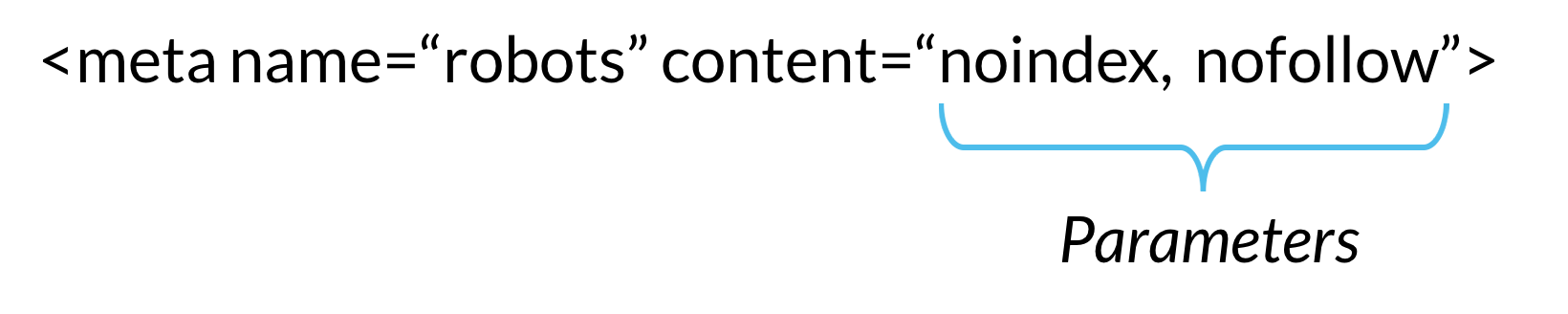 (.*)$ http://site.ru/$1 [R=301,L]
(.*)$ http://site.ru/$1 [R=301,L] Я считаю, что если сайт молодой, то лучше задать основное зеркало сайта без WWW. Почему? Потому что это укорачивает наш домен. Если же ваш сайт уже имеет историю и доступен по 2-м вариантам, то нужно выбрать тот, который находится в индексе.
Я считаю, что если сайт молодой, то лучше задать основное зеркало сайта без WWW. Почему? Потому что это укорачивает наш домен. Если же ваш сайт уже имеет историю и доступен по 2-м вариантам, то нужно выбрать тот, который находится в индексе. Все просто!
Все просто!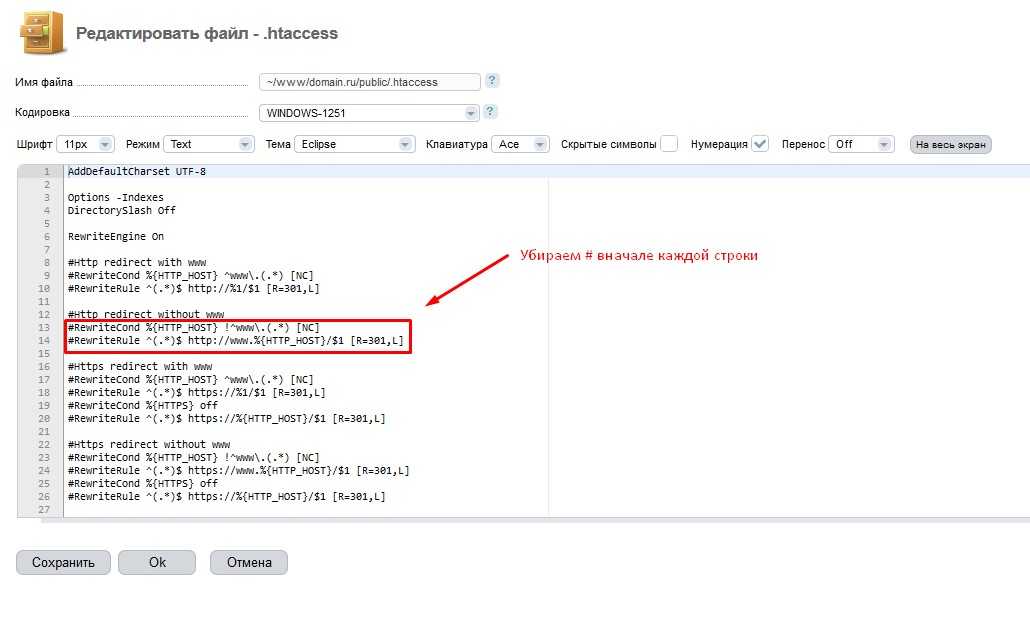 Сайт будет как новый. Поэтому, если делаем редиректы, то прописываем 301 редирект.
Сайт будет как новый. Поэтому, если делаем редиректы, то прописываем 301 редирект. Он прописывается единожды, обычно в конце. Прописывайте так, как вам нужно, чтобы индексировался сайт – просто site.ru, либо с www, либо c https. Это обязательно! Обязательно в Robots.txt надо прописать адрес до sitemap.xml
Он прописывается единожды, обычно в конце. Прописывайте так, как вам нужно, чтобы индексировался сайт – просто site.ru, либо с www, либо c https. Это обязательно! Обязательно в Robots.txt надо прописать адрес до sitemap.xml xml.gz Sitemap: http://ВАШ САЙТ/sitemap.xml
xml.gz Sitemap: http://ВАШ САЙТ/sitemap.xml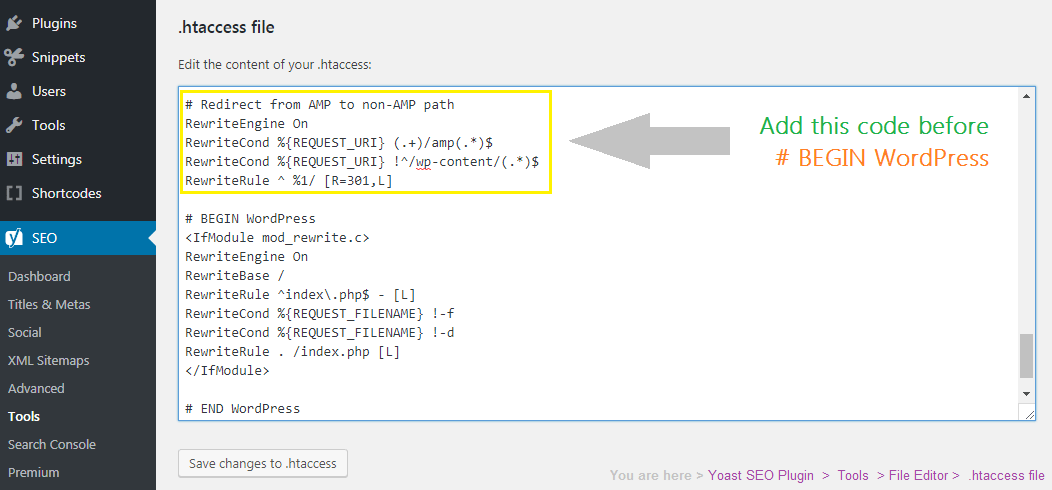 Если у вас другой движок, то у вас все тут будет по-другому.
Если у вас другой движок, то у вас все тут будет по-другому. Если цвет – зеленый, значит индексация разрешена и у вас где-то ошибка.
Если цвет – зеленый, значит индексация разрешена и у вас где-то ошибка. Это касается того момента, как закрыть страницы для Гугла. В плагине Yoast SEO это все автоматизировано. Например, у нас есть страница пагинации номер 2. При переходе на нее в адресной строке появляется url:site.ru/page2
Это касается того момента, как закрыть страницы для Гугла. В плагине Yoast SEO это все автоматизировано. Например, у нас есть страница пагинации номер 2. При переходе на нее в адресной строке появляется url:site.ru/page2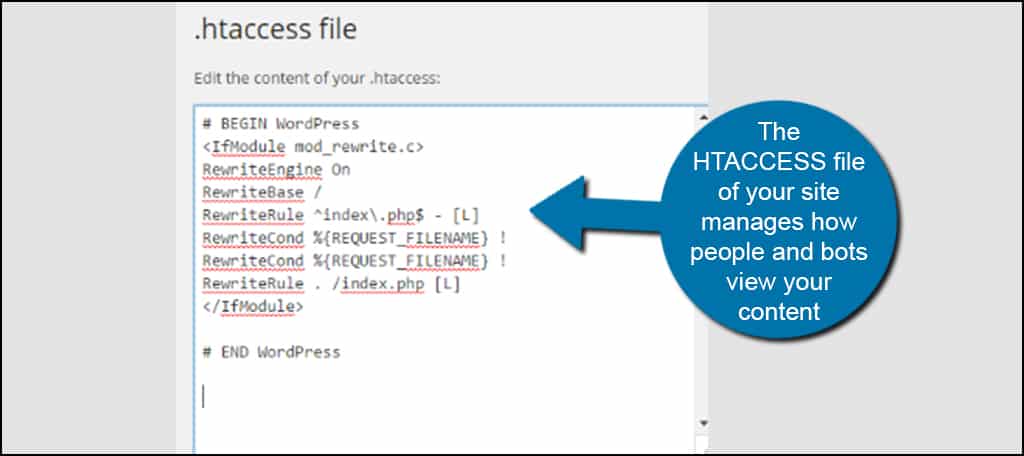 Если мы посмотрим исходный код любой страницы с метками, то увидим следующую картину:
Если мы посмотрим исходный код любой страницы с метками, то увидим следующую картину: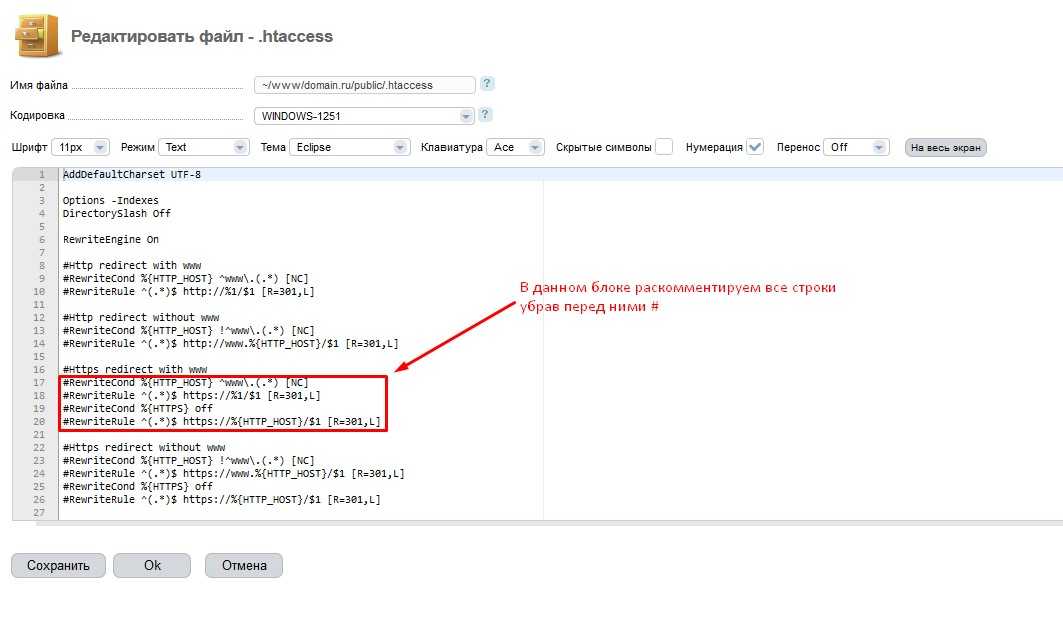 И дальше идет ссылка на самую основную страницу.
И дальше идет ссылка на самую основную страницу.
 Обычные страницы вы не удалите никак. Запретить для индексирования можно через Robots.txt, с помощью <meta name=”robots”>, который прописывается в шапке сайта, либо запретить можно страницу, которая отдает 404 ошибку. Потом, чтобы ускорить удаление, можно воспользоваться сервисом Яндекса
Обычные страницы вы не удалите никак. Запретить для индексирования можно через Robots.txt, с помощью <meta name=”robots”>, который прописывается в шапке сайта, либо запретить можно страницу, которая отдает 404 ошибку. Потом, чтобы ускорить удаление, можно воспользоваться сервисом Яндекса
 Многие ребята, зарабатывающие на партнерках, сталкивались с этим – количество ссылок на их сайтах относительно общего количества страниц было слишком большим и Яндекс накладывал на них фильтры, потому что считал, что такие ресурсы не приносят пользу.
Многие ребята, зарабатывающие на партнерках, сталкивались с этим – количество ссылок на их сайтах относительно общего количества страниц было слишком большим и Яндекс накладывал на них фильтры, потому что считал, что такие ресурсы не приносят пользу. И тут можно на всякий случай прописать «nofollow»
И тут можно на всякий случай прописать «nofollow» Если кто-то торговал вечными ссылками, тоже лучше лишний раз подстраховаться и снять. Если все-таки хотите продавать – делайте это аккуратно, подавайте заявки только на тематические ресурсы и в условиях пропишите, что ссылки должны быть безанкорными.
Если кто-то торговал вечными ссылками, тоже лучше лишний раз подстраховаться и снять. Если все-таки хотите продавать – делайте это аккуратно, подавайте заявки только на тематические ресурсы и в условиях пропишите, что ссылки должны быть безанкорными. Обычно, на современных шаблонах это автоматически прописывается, но вот раньше не было такого.
Обычно, на современных шаблонах это автоматически прописывается, но вот раньше не было такого. На Западе все уже давно пиарят друг друга, не ставя rel=”nofollow”, тем самым раскручиваются очень хорошо. Именно поэтому я часто ставлю даже на своих конкурентов ссылки без rel=”nofollow”. В итоге эти ребята часто становятся не моими конкурентами, а моими друзьями. Итак, ставить ссылки на авторитетные ресурсы – скорее плюс, чем минус. Например, когда я пишу статью про Яндекс Метрику, то я и ссылаюсь на Яндекс Метрику, потому что это логично. И Яндекс это видит. Это же касается всех сервисов. Вес по ссылке не передается, адресат ее не получает, но вес на нашей странице теряется.
На Западе все уже давно пиарят друг друга, не ставя rel=”nofollow”, тем самым раскручиваются очень хорошо. Именно поэтому я часто ставлю даже на своих конкурентов ссылки без rel=”nofollow”. В итоге эти ребята часто становятся не моими конкурентами, а моими друзьями. Итак, ставить ссылки на авторитетные ресурсы – скорее плюс, чем минус. Например, когда я пишу статью про Яндекс Метрику, то я и ссылаюсь на Яндекс Метрику, потому что это логично. И Яндекс это видит. Это же касается всех сервисов. Вес по ссылке не передается, адресат ее не получает, но вес на нашей странице теряется.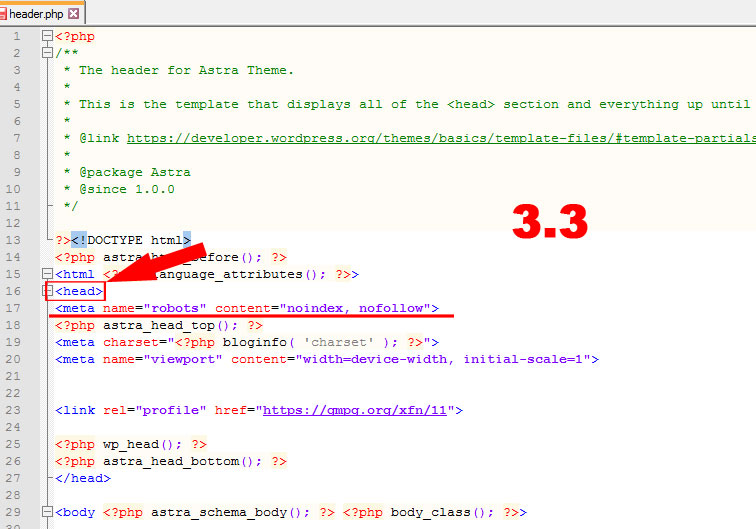

 htaccess
htaccess htaccess — чтобы убрать .html в конце адреса каждой веб-страницы сайта
htaccess — чтобы убрать .html в конце адреса каждой веб-страницы сайта

 htaccess 9|&)filter_cats1= [NC]
Правило перезаписи .* : [E=DO_SEO_HEADER:1]
Набор заголовков X-Robots-Tag «noindex, nofollow» env=DO_SEO_HEADER
htaccess 9|&)filter_cats1= [NC]
Правило перезаписи .* : [E=DO_SEO_HEADER:1]
Набор заголовков X-Robots-Tag «noindex, nofollow» env=DO_SEO_HEADER