
Настройка файла robots.txt — Виртуальный хостинг
robots.txt — это служебный файл с инструкциями для поисковых роботов, размещаемый в корневой директории сайта (/public_html/robots.txt). С его помощью можно запретить индексирование отдельных страниц (или всего сайта), ограничить доступ для определенных роботов, настроить частоту запросов роботов к сайту и др. Корректная настройка robots.txt позволит снизить нагрузку на сайт, создаваемую поисковыми роботами.
Формат robots.txt
- Файл содержит набор правил (директив), каждое из которых записывается с новой строки в формате
имя_директивы: значение(пробел после двоеточия необязателен, но допустим). - Каждый блок правил начинается с директивы
User-agent. - Внутри блока правил не должно быть пустых строк.
- Новый блок правил отделяется от предыдущего пустой строкой.
- В файле можно использовать примечания, отделяя их знаком
#.
- Файл должен называться именно
robots.txt; написание Robots.txt или ROBOTS.TXT будет ошибочным.

Некоторые роботы могут игнорировать отдельные директивы. Например, GoogleBot не учитывает директивы Host и Crawl-Delay; YandexDirect игнорирует общие директивы (заданные как User-agent: *), но учитывает правила, заданные специально для него.
Проверить созданный robots.txt
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex
User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота
Disallow: /
Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота
Disallow: /catalog
Allow: /catalog/auto
Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot
User-agent: AhrefsBot
Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива
Disallow:равнозначнаAllow: /, то есть «не запрещать ничего». - В директивах может использоваться символ
$для обозначения точного соответствия указанному параметру. Например, записьDisallow: /catalogаналогичнаDisallow: /catalog *и запретит доступ ко всем страницам с/catalog
Использование$это изменит.Disallow: /catalog$запретит доступ к/catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: *
Disallow:
Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex
Disallow: /catalog1$
Host: https://mydomain.com
Примечания:
- Директива
Hostможет быть только одна; если в файле указано несколько, роботом будет учтена только первая. - Необходимо указывать протокол HTTPS, если он используется. Если вы используете HTTP, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил
User-agentпосле директивDisallowиAllow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил
User-agentпосле директивDisallowиAllow. - Для Яндекса максимальное значение в
Crawl-delay— 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер. - Для Google-бота установить частоту обращений можено в панели вебмастера Search Console.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2
www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www., при этом в URL присутствуют дополнительные динамические параметры. mydomain.ru/news.html
mydomain.ru/news.html
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex
Disallow:
Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
С более подробной информацией о настройке директивы Clean-param рекомендуем ознакомиться в справочнике Яндекса.
Изменение robots.txt в системе управления UralCMS
Изменение robots.txt | Иконки магазина | Управление шаблонами | Текстовые файлы | Водяные знаки
Печать
Вы можете самостоятельно редактировать файл robots.txt в системе управления UralCMS.
Для этого необходимо перейти в раздел:
1. Настройки и оформление
2. Настройки поисковых систем
3. Изменение robots.txt
Изменение robots.txt
Файл robots.txt – это текстовый файл, находящийся в корневой директории сайта, в котором записываются специальные инструкции для поисковых роботов. Данные функции дают поисковому роботу указания, какие страницы можно индексировать, а какие запрещены для индексации, также указывается расположение карты сайта, корректный адрес сайта и т.д.
В системе управления UralCMS файл robots.txt создается автоматически при активации нового сайта. При этом содержимое этого файла создается по умолчанию и разрешает индексировать все разделы сайта, за исключением системных разделов (раздела адиминистрирования).
Файл robots.txt может работать с двумя протоколами — http и https.
Пример файла robots.txt с сайтом на протоколе http:
Если сайт переехал на протокол https, измените файл robots.txt, заменив http на https в полях Host и Sitemap.
Обратите внимание, что в поле Host нужно добавлять адрес сайта без знака «/» на конце.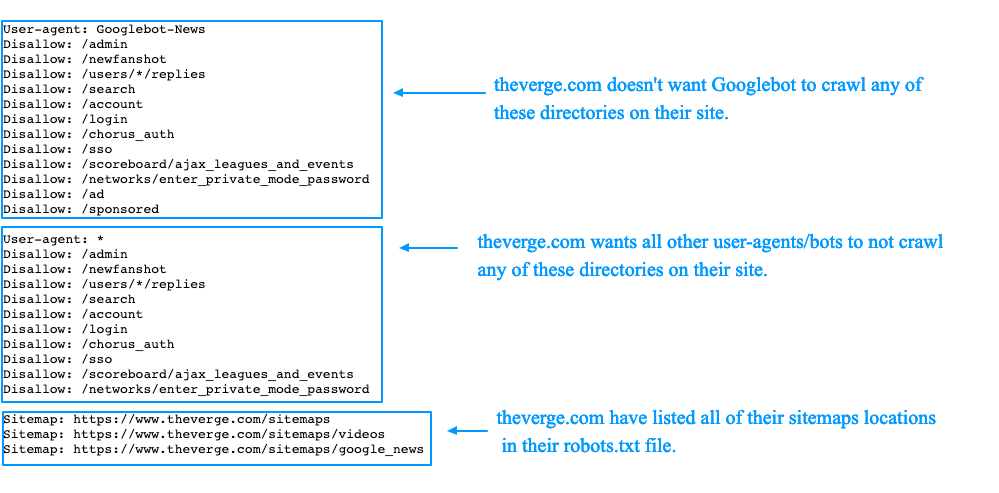
Описание основных функций для файла robots.txt:
Примечание: каждая функция указывается с новой строки.
User-agent — функция для указания ботов поисковых систем
Пример использования функции:
- User-agent: * (указание для любых ботов)
Disallow — функция для запрета индексирования отдельных категорий, рубрик, папок и т.д.
Пример использования функции:
- Disallow: (без указания — нет запрещенных для индексации страниц)
- Disallow:/editor/ (запрет индексирования раздела по адресу sitename.ru/editor/)
Host — функция для указания основного зеркала сайта (адреса сайта)
Пример использования функции:
- Host: sitename.ru (указание для поисковых ботов об основном домене сайта)
Sitemap — функция для указания адреса карты сайта
Пример использования функции:
- Sitemap: http://sitename. ru/?sitemap.xml (адрес карты сайта в формате xml)
 ru/?sitemap.xml (адрес карты сайта в формате xml)
ru/?sitemap.xml (адрес карты сайта в формате xml)# — знак решетки, расположенный в начале строки, указывает на принудительно игнорирование функции
Пример использования:
- #Sitemap: http://sitename.ru/?sitemap.xml (указание на игнорирование функции)
- #Host: sitename.ru (указание на игнорирование функции)
Корректное содержание файла robots.txt для UralCMS
User-agent: *
Crawl-delay: 2
Disallow: /editor/
Disallow: /basket/
Disallow: /registration/
Disallow: /enter/
Disallow: /sitesearch/
Disallow: /subscribe/
Disallow: /mycabinet/
Disallow: /passrecovery/
Disallow: */filter/
Disallow: /*producer=
Disallow: /*minprice=
Disallow: /*maxprice=
Disallow: /*f[
Disallow: /*sort=
Disallow: /*show_by=
Disallow: /*daily=
Disallow: /*print=1
Host: sitename. ru
ru
Sitemap: http://sitename.ru/?sitemap.xml
Где sitename.ru — адрес сайта вашей компании, просто замените его на свой.
Обращаем ваше внимание на то, что ошибки, допущенные при редактировании данного файла могут привести к некорректному индексированию сайта поисковыми системами. Поэтому, если вы сомневаетесь в том, что правильно внесли изменения в файл robots.txt, обратитесь в службу поддержки.
Управление поисковыми системами и поисковыми роботами с помощью файла robots.txt
Управление поисковыми системами и поисковыми роботами с помощью файла robots.txtВы можете указать, какие разделы вашего сайта должны индексироваться поисковыми системами и поисковыми роботами, а какие разделы они должны игнорировать. Для этого вы указываете директивы в файле robots.txt и помещаете файл robots.txt в корневой каталог вашего документа.
Директивы, указанные в файле robots.txt, являются только запросами. Хотя большинство поисковых систем и многие поисковые роботы соблюдают эти директивы, они , а не обязаны это делать. Таким образом, вы никогда не должны полагаться на файл robots.txt, чтобы скрыть контент, который вы не хотите индексировать.
Хотя большинство поисковых систем и многие поисковые роботы соблюдают эти директивы, они , а не обязаны это делать. Таким образом, вы никогда не должны полагаться на файл robots.txt, чтобы скрыть контент, который вы не хотите индексировать.
- Использование директив robots.txt
- Пример 1. Дайте всем сканерам указание получить доступ ко всем файлам
- Пример 2: указать всем программам-обходчикам игнорировать все файлы
- Пример 3. Указание всем программам-обходчикам игнорировать определенный каталог
- Пример 4. Указание всем программам-обходчикам игнорировать определенный файл
- Пример 5: Управление интервалом сканирования
- Дополнительная информация
Использование директив robots.txt
Директивы, используемые в файле robots.txt, просты и понятны. Наиболее часто используемые директивы: User-agent , Disallow и Crawl-delay . Вот несколько примеров:
Вот несколько примеров:
Пример 1: Дайте всем сканерам указание получить доступ ко всем файлам
Агент пользователя: * Disallow:
В этом примере любой поисковый робот (указанный параметром Директива User-agent и подстановочный знак звездочки) могут получить доступ к любому файлу на сайте.
Пример 2. Указание всем сканерам игнорировать все файлы
Агент пользователя: * Disallow: /
В этом примере всем поисковым роботам предписывается игнорировать все файлы на сайте.
Пример 3: Указание всем сканерам игнорировать определенный каталог
Агент пользователя: * Disallow: /scripts/
В этом примере всем программам-обходчикам предписывается игнорировать каталог scripts .
Пример 4: Указание всем поисковым роботам игнорировать определенный файл
Агент пользователя: * Disallow: /documents/index.html
В этом примере всем поисковым роботам предписывается игнорировать каталог documents/index. html .
html .
Пример 5: Управление интервалом сканирования
Агент пользователя: * Crawl-delay: 30
В этом примере все поисковые роботы получают указание ждать не менее 30 секунд между последовательными запросами к веб-серверу.
Дополнительная информация
Для получения дополнительной информации о файле robots.txt посетите веб-сайт http://www.robotstxt.org.
Подробнее о статье
- Уровень: Начальный
Другие статьи в этой категории
- MySQL
- PostgreSQL
- Веб-сервер Apache
- PHP
- Питон
- Перл
- Рубин
- Линукс
- Системы контроля версий
- Клиентские технологии
- Развертывание приложения
- Добавление защиты CAPTCHA на ваш веб-сайт
- Управление поисковыми системами и поисковыми роботами с помощью файла robots.txt
- Настройка переадресации кадра URL
- SQLite
- Луа
- Определение того, использует ли ваша учетная запись CageFS
- Настройка виртуальной машины для локального тестирования
- Веб-тестирование и разработка
- Создание постоянных приложений Node. js
- Включение общего доступа к ресурсам между источниками (CORS)
- Настройка фреймов с заголовком X-Frame-Options
- Разработка веб-сайтов, совместимых с ADA
- Веб-сервер Nginx
- Установка и настройка интерфейса командной строки (CLI) AWS
- Редактирование файла hosts на Mac
- Отключение автоматического создания файла robots.txt
 js
jsПоказать больше
Была ли эта статья полезной для вас? Тогда вам понравится наша поддержка. Испытайте преимущества хостинга A2 уже сегодня и получите предварительно защищенный и предварительно оптимизированный веб-сайт. Ознакомьтесь с нашими планами веб-хостинга сегодня.
Как установить robots.txt глобально в nginx для всех виртуальных хостов
спросил
Изменено 2 года, 8 месяцев назад
Просмотрено 69 тысяч раз
Я пытаюсь установить robots. для всех виртуальных хостов под http-сервером nginx.
Я смог сделать это в Apache, поместив следующее в main 9~ / robots.txt {
псевдоним /var/www/html/robots.txt;
}  txt
txt
Я пробовал использовать ‘=’ и даже поместил его на один из виртуальных хостов для проверки. Казалось, ничего не работает.
Что мне здесь не хватает? Есть ли другой способ добиться этого?
- nginx
- robots.txt
1 Местоположение
нельзя использовать внутри блока http . У nginx нет глобальных псевдонимов (т. е. псевдонимов, которые можно определить для всех виртуальных хостов). Сохраните свои глобальные определения в папке и включите их.
сервер {
слушать 80;
корень /var/www/html;
включить /etc/nginx/global.d/*.conf;
}
2
Вы можете установить содержимое файла robots.txt прямо в конфиге nginx:
location = /robots.
 txt { return 200 "User-agent: *\nDisallow: /\n"; }
txt { return 200 "User-agent: *\nDisallow: /\n"; }
Также можно добавить правильный Content-Type:
location = /robots.txt {
add_header Content-Type text/plain;
return 200 "Агент пользователя: *\nDisallow: /\n";
}
3
Определены ли другие правила? Возможно, включен common.conf или другой файл конфигурации, который переопределяет вашу конфигурацию. Один из следующих определенно должен работать.
местоположение /robots.txt { псевдоним /home/www/html/robots.txt; }
расположение /robots.txt { root /home/www/html/; }
- Nginx запускает все местоположения «регулярных выражений» в порядке их появления. Если какое-либо местоположение «regexp» окажется успешным, Nginx будет использовать это первое совпадение. Если местоположение «regexp» не удалось, Nginx использует обычное местоположение, найденное на предыдущем шаге.
- местоположения «regexp» имеют приоритет над местоположениями «prefix»
2
Вы также можете просто отправить файл robots. txt напрямую:
txt напрямую:
location /robots.txt {
return 200 "Агент пользователя: *\nDisallow: /\n"
}
У меня была такая же проблема с acme challanges, но тот же принцип применим и к вашему случаю.
Чтобы решить эту проблему, я переместил все свои сайты на нестандартный порт, я выбрал 8081 и создал виртуальный сервер, прослушивающий порт 80. Он проксирует все запросы на 127.0.0.1:8081 , кроме тех, что к .well-known. Это действует почти как глобальный псевдоним с одним дополнительным переходом, но это не должно вызывать значительного снижения производительности из-за асинхронной природы nginx.
восходящий неакме {
сервер 127.0.0.1:8081;
}
сервер {
слушать 80;
журнал_доступа /var/log/nginx/acme-access.log;
error_log /var/log/nginx/acme-error.log;
расположение /.известный {
корень /var/www/acme;
}
расположение / {
proxy_set_header Хост $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $ схема;
proxy_set_header X-Frame-Options SAMEORIGIN;
# Поддержка WebSocket (nginx 1.