
Делаем правильно кластеризацию семантического ядра

Важным этапом продвижения сайта является сбор семантического ядра и кластеризация ключевых поисковых запросов. Ошибки при группировке будут стоить драгоценного времени, денег и других проблем. В этой статье я хочу рассказать главные принципы и правила группировки, а также показать примеры сервисов и программ.
Кластеризация ключевых фраз
Я выделяю 2 основных момента при группировке:
- запросы должны подходить друг к другу по логическому смыслу
- запросы должны показывать одинаковую выдачу в Яндексе
С логическим смыслом все понятно — нельзя поместить на одну страницу ключи “купить телефон” и “покраска авто в Омске”. Так или иначе запросы должны подходить друг к другу по смыслу. Если у нас страница про отделка потолков в квартире, то все запросы должны быть про отделку потолков.
Вот с проверкой по выдаче все не так однозначно. В целом суть следующая — вводим запросы в Яндекс в режиме “инкогнито”, выбираем регион продвижения и смотрим, насколько пересекается выдача.
Допустим, есть 2 запроса “отделка потолков в квартире” и “отделка потолков в ванной”, нужно понять, подойдут ли эти ключи на одну страницу или нет. Открываем 2 окна в Яндексе и вводим эти запросы.


Сразу видно, что в первом случае четко говорится про отделку потолков в квартире, а во втором — в ванной. Значит, запросы ведут на разные страницы и объединять их нельзя.
А вот еще один пример: фразы “купить батареи отопления” и “купить радиаторы отопления”. Вроде кажется, что запросы разные, но посмотрим выдачу.


Как видим, выдача одинаковая — и там и там присутствуют и батареи и радиаторы. Поэтому эти 2 запроса можно смело помещать на одну страницу.
Программы и сервисы для кластеризации ключевых слов
Кластеризация семантического ядра в Excel делается достаточно просто — загоняете все запросы в программу и начинаете группировать руками. Сам принцип группировки используете, как я написал выше. То есть сначала группируем по смыслу, потом проверяем выдачу Яндекса.
Но, кстати, бывает так, что выдача “мутная” по двум или более запросам, не понятно, куда их поместить вместе или врозь. Это означает, что конкуренция здесь маленькая и выдача четко не сформирована, значит, не будет ошибкой или поместить запросы вместе или на разные страницы, как вам будет удобнее.
Вот пример кластеризации семантического ядра в программе Excel.

Этот способ я сам часто использую, если тематика не сложная и ни много ключевых слов, 100-200 ключей вполне подойдет.
Посмотрите видео, как кластеризовать ядро в программе Эксель.
Можно еще как альтернативу excel использовать бесплатный онлайн сервис ручной кластеризации kg.ppc-panel.ru.
Автоматическая кластеризация
Если семантическое ядро очень большое, то я пользуюсь сервисом автоматической кластеризации поисковых запросов promopult.ru. Это ОЧЕНЬ дешевый сервис по сравнению с аналогами.
Единственным его минусом является не совсем точная группировка, так как все равно нужно в итоге пересматривать кластеризацию.
Хотя, я думаю, что нет НИ ОДНОГО сервиса, который бы делал 100% правильную группировку. Даже конторы, которые занимаются только сбором и кластеризацией семантики, все равно проверяют и правят вручную конечный результат.
Вот краткий обзор по настройке проекта.



Сервис посчитает, сколько стоит кластеризация ядра и предложит запустить проект. Это вариант платной кластеризации, которым я пользуюсь, он меня вполне устраивает.
А вот подробное видео, как пользоваться инструментом:
Кластеризация в Just-magic
Тоже хороший способ кластеризации, который я иногда использую. Он более точный, чем сервис PromoPult, но более дорогой. Вот посмотрите видео, как делать кластеризацию в этом сервисе.
Кластеризация запросов в key collector
Этот способ тоже достаточно широко используется, но как и везде, дорабатывать все равно нужно вручную.
Загружаете семантическое ядро в программу, выбираете регион продвижения.


Далее по шагам:
- Выбираете вкладку “Данные”
- Раздел “Анализ групп”
- Группировка по поисковой выдаче
- Сила по SERP — 6
- Нажимаете “Вычислить группировку”
- И экспортируете готовый файл в Excel
Получается вот такая штука на выходе.

Но я повторюсь, что при кластеризации запросов в кей коллектор, все равно результат нужно чистить вручную, так как НИ ОДИН сервис или программа не делает 100% правильной группировки ключевых слов.
Заключение
Итак, еще раз общий вывод, как можно делать кластеризацию:
- Вручную в программе Excel
- Использовать автоматические сервисы (я пользуюсь promopult и just-magic)
- В программе Key Collector
P.S. Если вам понравилась статья или она была полезной для вас, то поделитесь ею с друзьями в соц. сетях, а также пишите ваши вопросы или замечания в комментариях.
 Загрузка…
Загрузка…mydaoseo.ru
Как проработать семантическое ядро с помощью Key Collector. Часть 2. Читайте на Cossa.ru
Минусовка
Работать с группой — значит отминусовать её (избавиться от ненужных и нерелевантных стоп-слов) и сгруппировать. Рассмотрим вопрос минусовки. В Key Collector есть «окно стоп-слов», которое позволяет:
- редактировать слова, например, фиксировать их словоформу;
- создавать списки и отправлять каждое минус-слово в свой список;
- отмечать фразы, содержащие стоп-слова.
Сперва отмечаем галочкой слово «купить» (в Key Collector автоматический выделяются все фразы, содержащие «купить»), а затем их удаляем:
Слова можно закинуть в окно стоп-слов разными способами.
Первый. Отправляем фразы по одной. Это точечный подход, и используется он редко. Кликните по значку щита слева от нужной фразы, чтобы отправить её в окно стоп-слов:
Второй способ. Выделяем группу запросов и жмём «Отправить в окно стоп-слов». Подход уже более массовый, но всё ещё не очень удобный.
Третий способ. Самый удобный и в то же время массовый — минусовка через анализ групп. Для этого выбираем нужную группу и во вкладке «Данные» заходим в «Анализ групп»:
Анализ групп — очень крутой инструмент. Советую потратить 10 минут, чтобы изучить все его возможности: поиграть с различными типами группировки (не забывайте про кнопку «Вычислить группировку»), посмотреть, как работает экспорт (он пригодится, например, для составления отчёта о чистоте трафика).
Для минусовки выбираем тип группировки «по отдельным словам»:
В этой группировке Key Collector разбивает всё семантическое ядро и группирует его по словам, имеющим одинаковую исходную словоформу.
В колонке «Количество фраз» показано, в скольких фразах ядра встречается то или иное слово. В «Сумме» — сумма значений для сгруппированных слов из выбранной вами колонки. Колонки
Чтобы начать минусовать, сортируем список по убыванию количества фраз (так удобнее, через пару строк покажу, почему) и начинаем закидывать в окно стоп-слов нерелевантные:
Если вы выберете указанные ниже настройки, то при отправке слова в минус-список в вашей группе галочками отметятся все фразы, содержащие этот минус:
Это удобно, если вам нужно немного ускорить процесс минусации, причём вы можете заминусовать сразу несколько слов, которые содержатся в большом количестве фраз. Именно поэтому мы сортируем список по количеству фраз. В данном примере я добавил в минуса три первых нерелевантных слова — а в таблице выделились сразу 1257 нерелевантных фраз:
Теперь мы можем удалить эти фразы и заново запустить анализ групп.
Таким образом, за 20 секунд мы на 15% уменьшили количество фраз, с которыми нам предстоит работать. Это ускоряет процесс, но сказывается на качестве минусовки. Ведь внутри тех 1200 фраз, которые мы выделили и удалили, могли сидеть другие минуса (их мы теперь не увидим).
Пример: мы не уверены, стоит ли минусовать слово «ручка»:
Мы можем расхлопнуть группу и посмотреть, в каких фразах используется это слово:
Ага, велосипеды с ручкой — это детские велосипеды, у которых есть ручка, видимо, чтобы родители могли катать своих детей. Однако на сайте у нас в принципе нет раздела с детскими велосипедами. Закидываем «ручки» в минуса.
Бывает и так, что одна форма слова является минусом, а другая — нет. Благо, при клике по щиту в окно стоп-слов отправляются все словоформы, причём мы их можем редактировать. В данном случае — приписать восклицательный знак и отправить в минуса только одну словоформу:
То есть мы проходимся по всему списку слов в «Анализе групп» и выбираем минуса. Если у нас мало времени, можем ограничиться какими-то порогом. Например, минусовать до частотности 10.
Кстати, если мы не удаляли фразы по ходу, под конец анализа в списке будут выделены все фразы, содержащие минус-слова. Мы можем удалить их, а можем перенести в отдельную группу для мусорных слов:
Это удобно, если вы собираетесь добирать дополнительную семантику в тот же проект, пользуясь настройкой «Не добавлять фразу, если она уже есть в какой-то другой группе». Тогда вам не придётся повторно анализировать фразы, которые вы уже обработали.
Сам же полученный список минус-слов можно экспортировать как и куда угодно:
Итак, мы отминусовали группу «Велосипед», переходим к группе «Велик». Эта группа масок оказалась супермусорной! Оказывается, велик — это не только сленговый синоним велосипеда, но и словоформа «большого». Поэтому вместе с масками типа «купить велик» и «заказать велик» подобрались и фразы «купить большой», «заказать большой».
Из-за этого у нас почти 15 тысяч слов всякой фигни. Прикиньте, если бы мы изначально собирали все маски в одну группу, а не разбивали на подгруппы! Пришлось бы вычищать эти 15 тысяч среди всех собранных фраз. Но, к счастью, мы придерживались правила «если ядро незнакомое, и ты не знаешь, как поведут себя маски, раскидай их на парсинге по разным группам». Поэтому сейчас просто удалим группу «велик» и заново соберем её, зафиксировав словоформу «!велик».
«И настроение улучшилось» ©Минусация через анализ групп — это очень удобный способ, который здорово ускоряет процесс. Вам не надо копаться в списке из всех фраз на 7000 строк — достаточно просмотреть группу на 1500 строк.
P. S.
И ещё пара мыслей в тему минусации. В начале статьи мы говорили о том, что иногда удобно отправлять на парсинг маски, уже уточненные минус-словами.
В KC есть возможность сформировать список минусов на уровне инструмента «Стоп-слова» и использовать его при составлении запроса к Wordstat.

Если активировать эту функцию, то в списке для парсинга будет отображаться, например, «купить велосипед», а в Wordstat отправится расширенный запрос вида «купить велосипед -бу -детский».
Итого, если вы уже на входе знаете нежелательные для себя слова — применяйте их при составлении запроса. Составить список минусов до начала парсинга можно руководствуясь личным опытом, интуицией, здравым смыслом или готовыми списками.
Группировка
После того, как у нас готово чистое отминусованное ядро, его нужно группировать.
Группировка — это распределение слов по группам (по-умному называется «кластеризация»). Далее можно написать под каждую группу слов свой вариант объявления. Или — вы решите написать одно объявление для всего ядра, но сгруппированные фразы всё равно раскидать по разным группам объявлений. Или — каждой группе слов прописать объявление, а потом всё это дело раскидать по принципу «один ключевик — одно объявление». Впрочем, это самый долгий способ.
Чаще всего мы раскидываем слова по разным группам и прописываем каждой своё объявление. Однако решение, как именно дробить ядро, зависит только от вас. Два основных ограничения, которые можно использовать — это максимальное/минимальное число слов в группе плюс максимальная/минимальная частотность слов.
Мы уже познакомились с инструментом Key Collector «Анализ групп». Он помогает не только при минусовке, но и при группировке. Ниже я опишу алгоритм, по которому мы группируем слова через анализ групп. Возможно, он кажется слишком замороченным, но жизнь вообще штука тяжёлая.
Сперва нужно понять, стоит ли «сливать» в одну собранные группы. То есть является ли нынешняя разбивка по группам для парсинга равносильной первому этапу семантической группировки. Ведь группы для парсинга мы разбивали, чтобы не нарваться на ситуацию, как со словом «велик». На данном этапе логика разбивки по семантическим группам может измениться.
Что мы имеем:
Три группы: велосипед, велик, велек.
Чего я хочу добиться группировкой: разбить слова на группы, которым затем пропишу индивидуальные объявления с максимальным вхождением ключевых слов в заголовок. Получается, что названия семантических групп должны содержать слова, которые я затем использую в заголовке.
Буду ли я использовать в заголовках слова «велек» и «велик»? Нет, здесь я поступлюсь вхождением, но сделаю объявления более естественным. Для фраз «купить велек» напишу заголовки «Купить велосипед». В данном случае «велек» и «велик» — группы не семантические, потому я не буду использовать в объявлениях слова из названий этих групп.
Итого: в этом случае нужно «слить» все группы в одну, а затем переразбить на группы по другой логике.
Сделаем это:
Теперь необходимо узнать реальные частотности полученного списка слов — эта информация нам пригодится позже.
По идее, при парсинге масок мы уже получили частотности слов:
С ними можно работать, но здесь частотности по многим словам завышенные, ведь список не откроссминусован. Давайте пойдём по хардкору: скопируем этот список, откроссминусуем, зальём заново и соберём реальные частотности.
Копируем ключевики:
Проводим кроссминусовку:
Удаляем старый список слов, добавляем откроссминусованный (не забудьте убрать символ «-» в настройках парсинга):
Кстати, это очень полезная настройка, так как вы можете парсить сразу уточнённые ВЧ-минусами фразы — и тем самым экономить время. То есть вместо списка
«велосипед москва»
«велосипед купить»
…
отправлять на парсинг
«велосипед москва -б -у -бу -авито -прокат»
«велосипед купить -трехколесный -б -у -бу»
…
Таким образом, получаем список для парсинга частотности:
Частотность парсится с помощью инструмента «Сбор с Yandex. Direct»:
После получения частотностей приступаем к группировке. Для этого нужно определиться с глубиной группировки и порогом высокочастотности (ВЧ).
Порог ВЧ — частота, начиная с которой мы считаем слово высокочастотным. Это нужно для того, чтобы выделить ВЧ-слова в отдельные группы. В конкретном примере подразумеваем под ВЧ ключевик с 300+ показами в месяц (хотя это может быть и 1000, и 5000 — зависит от ситуации).
Глубина группировки определяет, насколько подробно мы разбиваем группы на подгруппы. Также это порог, после которого слова уже не нужно выделять в отдельную группу. В нашем примере возьмём глубину от двух слов и от 30 показов в месяц (в сумме по группе).
Начнём. Выбираем исходную группу, заходим в анализ групп, сортируем по убыванию количества фраз:
Обратите внимание: сейчас в анализ групп попали минус-слова — с ними на данном этапе не работаем.
Начинаем двигаться сверху вниз по первому кругу, выделяя в отдельные группы фразы с общим «продуктовым» признаком (белые велосипеды, трёхколесные велосипеды, велосипеды в москве, велосипеды недорогие). На втором круге мы будем выделять в группы фразы с «непродуктовыми» добавками (велосипеды купить, магазин велосипедов).
У «продуктовых» добавок больший приоритет, так как они определяют посадочную страницу и вероятнее включаются в заголовок объявления (из ключевика «купить детский трёхколесный велосипед» на 37 символов мы возьмём в заголовок «Детские трёхколесные велосипеды»).
Выделяем группу слов и переносим её в новую группу:
Вуаля, в исходной группе создана подгруппа, в которую перенеслись все фразы, содержащие слово «Москва» и его словоформы:
Так мы проходимся сверху вниз, выделяя группы, содержащие от двух слов и 30 показов. Например, выделим группу «велосипеды мужчины»:
Но при этом не станем выделять «велосипеды склад» (не хватает частотности):
Также не будем выделять «велосипеды кама» (не хватает количества фраз в группе). Возможно, пример с «камой» не самый удачный, так как этой фразе можно написать объявление с суперрелевантной посадочной. Но на то он и пример.
После того как мы выделили все «продуктовые» группы, переходим на второй «непродуктовый» круг. После его завершения получим иерархию с первым уровнем вложенности. Это исходная группа и подгруппы — «велосипеды москва», «велосипеды недорого» и т. д.
После этого необходимо выделить группу ВЧ-слов. Дело в том, что после первых двух кругов в исходной группе «велосипеды» остались слова, которые не попали ни в одну из подгрупп. Но среди них есть ВЧ, под которые нужно написать индивидуальные объявления. Выделим их в отдельную подгруппу и назовем её «велосипеды_ВЧ». Как и условились ранее, под ВЧ мы подразумеваем фразы от 300 показов:
Окончательный список подгрупп на первой ступени иерархии выглядит так:
Далее повторяем те же шаги, с теми же ограничениями, но уже на уровне подгрупп. И так несколько раз. То есть после полной группировки у нас получается иерархическая структура семантического ядра с большим уровнем вложенности.
- Исходная группа «велосипеды» разбивается на «велосипеды москва», «велосипеды купить», «велосипеды ВЧ».
- «Велосипеды москва» разбивается на «велосипеды москва магазин», «велосипеды москва стелс», «велосипеды москва ВЧ».
- «Велосипеды москва магазин» — на «велосипеды москва магазин интернет».
Окончательная иерархия выглядит как-то так:
Для удобства можно цветом отмечать группы и подгруппы, которые вы уже полностью проработали:
Перенос сгруппированного ядра в Excel-файл
После того как мы проработали всю иерархию — когда она «полностью зелёная», — нужно перенести её в Excel для создания заливочного файла.
К сожалению, в Key Collector нет опции, позволяющей разом выгрузить все ключевики с сохранением структуры в том виде, в котором нам это нужно (ну, или я плохо искал). Придётся работать в «ручном» режиме.
Здесь всё просто: берём по очереди каждую группу из нашей иерархии, копируем ключевики и вставляем в Excel. Группы в Excel называем в соответствии со структурой ядра:
При переносе ВЧ-групп мы обычно дублируем фразы в точном соответствии:
Для массового добавления операторов точного соответствия можно использовать интернет-сервисы или формулы в Еxcel. Для массового удаления минус-слов — инструментом Еxcel «Найти и заменить» (найти «-*» и заменить на » «).
ВЧ-группы удобно выделять цветом (например, синим отмечать группы с несколькими ВЧ-фразами, а красным — с одной). Это поможет на этапе написания объявлений.
Группы с несколькими ВЧ-словами также стоит разбить. Это легко сделать через формулу сцепки в Excel:
Вообще, отмечать группы цветом удобно на каждом этапе работы. Например, отминусовали группу — отметили жёлтым. Сгруппировали — отметили зелёным. Перенесли в Excel — отметили синим. Это поможет при групповой работе над проектом.
После того, как мы полностью скопировали наше сгруппированное семантическое ядро из Кey Collector в Excel, можно приступать к объявлениям.
Добавим вторые варианты объявлений. Для этого копипастим строки, содержащие название группы и само объявление:
После добавления доп. объявлений заполняем копипастами все недозаполненные строки — и наши группы объявлений под заливку почти готовы. Останется доработать файлы в соответствии с форматами «Яндекса» или Google. Победа!
Спасибо всем, кто дочитал до конца. Если статья оказалась для вас полезной, смело делитесь материалом со своими коллегами. Если бесполезной — тоже не держите в себе, пишите. Остались вопросы? Спрашивайте в комментариях.
Авторы статьи:
Анастасия Якунина, production-менеджер в Adventum,
Артур Семикин, performance-менеджер в Adventum.
Первую часть руководства — Как проработать семантическое ядро с помощью Key Collector (подбор масок, добавление и парсинг в Key Collector) — читайте тут.
Мнение редакции может не совпадать с мнением автора. Если у вас есть, что дополнить — будем рады вашим комментариям. Если вы хотите написать статью с вашей точкой зрения — прочитайте правила публикации на Cossa.
www.cossa.ru
Семантическое ядро с помощью Key Collector ☝ SEO оптимизация
Раз вы читаете эту статью, значит, вы уже знаете какую роль играет для сайта правильно подобранная семантика. А если нет, то скажу коротко — семантика это фундамент любого продвижения.
Кто не хочет читать статью, может посмотреть это видео.
Итак, мы переходим к созданию нашего ядра запросов, с чего начать?
А начинаем мы со сбора основных ключевых фраз, хотя бы 10-15 начальных придётся составить самим, ну или взять их с конкурентов в ТОПе. Как это сделать, я описал в этой статье — Простое семантическое ядро за 5 минут.
Дальше мы переходим к программе Key Collector. И да — она платная, но я буду рассказывать на её примере. Почему именно эта платная программа? Потому что эта одна из немногих программ, которая окупила каждый потраченный на себя рубль. Если хотите собрать ядро бесплатно, то переходите по ссылке выше, но качество ядра будет соответствующее.
Переходим к обязательным настройкам Key Collector, что нужно сделать в первую очередь, чтобы сбор ядра и статистики по нему вообще был возможен?
Мои настройки

Настройки Яндекс Директа. Сюда лучше добавить хотя бы 5-6 левых аккаунтов, а лучше 10, чтобы процесс сбора статистики по Директу не занимал много времени.

Настройки Google.Adwords. Сюда мы вписываем любой тестовый аккаунт, который создадим в гугл.

Так же предлагаю купить антикапчу — это не дорогой и эффективный способ сэкономить ваше время на распознавание изображений, я использую сервис anti-captcha.com

Ну и для полноты счастья, чтобы максимально ускорить свой процесс сбора, я использую ещё прокси, их покупаю на proxy6.net. Мест где приобрести прокси в интернете достаточно, так что вы можете найти и дешевле, но не покупайте прокси, которыми пользуется кто-то ещё — толку от них не будет.

- Формулы KEI можете взять в сети или придумать свою. У меня есть и те и другие, из сети я взял от Семёна Ядрёна.
KEI = ( KEI_YandexMainPagesCount * 6 ) + ( KEI_YandexTitlesCount + KEI_GoogleTitlesCount ) + ( KEI_YandexDocCount / 73000 )
- Как происходит сбор, с чего начать?
Основные этапы сбора запросов
- Начинаем с пакетного сбора слов из левой колонки Яндекс.Wordstat по заданному списку, о подготовки которого я писал выше.
- Когда Левая колонка собрана, то по тому же списку собираем правую колонку
- Далее переходим к пакетному сбору поисковых подсказок
- Сбор с Google.Adwords
- Пакетный сбор похожих поисковых запросов
- Данные с Яндекс.Метрики. Логинимся в Яндекс, можно левого аккаунта, но на него нужно передать доступ к Метрики и Вебмастеру.
- И на последок выгружаем данные с Яндекс.Вебмастера.

Лучше использовать именно эту последовательность, чтобы потом было проще отсеять мусорные фразы, а они обычно обильнее идут начиная с 4 пункта.
После того, как мы собрали кучу ключевых слов, их нужно очистить от мусора. Для этого используем фильтры и стоп слова.

Через фильтры мы можем найти как по исключающим словам, так и по включающим лишние(для отсева) или нужные(для перемещения в новую группу) нам ключи.
Но чтобы найти стоп-слова нам нужно отметить галочками именно лишние слова, которые нам не подходят.
Для определения стоп-слов используем вкладку Данные => Анализ групп. Выбираем Тип: по отдельным словам. Жмём правой клавишей мыши на любом выделенном слове и выбираем к пункт Отправить все слова из определений целиком отмеченных групп в окно стоп-слов.

После того как мы очистили от мусора все ключи мы можем опять пойти по второму кругу и закинуть уже все наши очищенные ключевые фразы в сбор по левой колонке, правой и т.д., пока не придём к нужному нам количеству ключевых фраз для работы.
Обычно хорошее ядро идёт от 100 тысяч фраз перед отсевом.
После чего лучше распределить все запросы по группам, используя фильтрацию, в идеале, чтобы группы были равны разделам сайта.
Все разделы можно обозначить разными цветами, нажав на них правой клавишей мыши и выбрав нужный цвет, и отсортировать их таким же путём.
Перед сбором статистических данных лучше совместить все разделы в одну большую мульти-группу, для этого выделяем все разделы используя клавишу shift или ctrl и нажимаем на иконку включения мульти-группы.

Сбор статистических данных
Остался последний этап сбора данных по СЯ.

- Сбор статистики Яндекс.Директ
- Сбор статистики Google.Adwords
- Сбор позиций Яндекса
- Сбор позиций Гугла
- Сбор релевантных страниц по Яндексу или Гуглу
- Сбор данных SERP, и нашего значения KEI
И рассчитываем KEI по имеющимся данным.

Анализ данных СЯ и выгрузка результатов
И вот мы подошли к самому интересному!
Для анализа данных мы будем использовать раздел Данные.
В нём переходим в Градиент по значениям и выставляем ту калонку, по которой нам нужен будет этот градиент, например KEI 1(если вы задали формулу), выбираем Окрасить всю строку и нажимаем ОК.

Аллилуйя! Теперь мы видим зелёным цветом самые легко продвигаемые запросы, а красным за которые может и браться не стоит!
Но этого ещё не достаточно, давайте отсортируем колонки по тем значениям, которые нам нужны, например по частотности «!» и отсутствие релевантных страниц на нашем сайте или позиций.
Теперь, когда самые частотные запросы будут сверху и мы исключили все страницы, по которым у нас есть позиции или релевантность, мы можем смело брать их для дальнейшего анализа.
Но это ещё не всё! Нам нужно понять какие ещё запросы мы можем продвигать вместе с выбранными нами на одной странице?
Для этого переходим в раздел Анализ групп и выбираем тип: По поисковой выдачи и выставляем там силу SERP и ТОП в зависимости от типа запроса.
Например для информационных страниц выставляем SERP = 2 или 3 и ТОП10 или даже ТОП20, а для коммерческих SERP = 4 или 5 и ТОП10.

Далее нажимаем вычислить группировку и экспортируем всё это дело в XLS.
Теперь у нас есть кластеры с которыми мы можем работать, используя ключевые слова из каждой группы для продвижения на одной странице.
А чтобы найти самые вкусные кластеры нам нужно будет анализировать наше ядро, для этого снимаем режим мультигруппы и выделяем с зажатой клавишей ctrl те группы, которые мы будем выгружать и выгружаем их опять же с зажатой клавишей ctrl.

Или для выгрузки всех групп просто зажимаем клавишу Shift и жмём на ту же кнопку выгрузки в XLS.

P.S.: Не забываем, что колонки выгрузки у нас будут совпадать с теми, которые отображаются в программе, поэтому можно создать в настройках Вид => Шаблон вида тот шаблон, который мы будем использовать и в дальнейшем в своих проектах.
artur2k.ru
Фильтрация крупного семантического ядра в Key Collector
Начал писать эту статью довольно давно, но перед самой публикацией оказалось, что меня опередили соратники по профессии и выложили практически идентичный материал.
Поначалу я решил, что публиковать свою статью не буду, так как тему и без того прекрасно осветили более опытные коллеги. Михаил Шакин рассказал о 9-ти способах чистки запросов в KC, а Игорь Бакалов отснял видео об анализе неявных дублей. Однако, спустя какое-то время, взвесив все за и против, пришел к выводу, что возможно моя статья имеет право на жизнь и кому-то может пригодиться – не судите строго.
Если вам необходимо отфильтровать большую базу ключевых слов, состоящую из 200к или 2 миллионов запросов, то эта статья может вам помочь. Если же вы работаете с малыми семантическими ядрами, то скорее всего, статья не будет для вас особо полезной.
Рассматривать фильтрацию большого семантического ядра будем на примере выборки, состоящей из 1 миллиона запросов по юридической теме.
Что нам понадобится?
- Key Collector (Далее KC)
- Минимум 8гб оперативной памяти (иначе нас ждут адские тормоза, испорченное настроение, ненависть, злоба и реки крови в глазных капиллярах)
- Общие Стоп-слова
- Базовое знание языка регулярных выражений
Если вы совсем новичок в этом деле и с KC не в лучших друзьях, то настоятельно рекомендую ознакомиться с внутренним функционалом, описанным на официальных страницах сайта. Многие вопросы отпадут сами собой, также вы немножечко разберетесь в регулярках.
Итак, у нас есть большая база ключей, которые необходимо отфильтровать. Получить базу можно посредством самостоятельного парсинга, а также из различных источников, но сегодня не об этом.
Всё, что будет описано далее актуально на примере одной конкретной ниши и не является аксиомой! В других нишах часть действий и этапов могут существенно отличаться! Я не претендую на звание Гуру семантика, а лишь делюсь своими мыслями, наработками и соображениями на данный счет.
Оглавление
Шаг 1. Удаляем латинские символы
Удаляем все фразы, в которых встречаются латинские символы. Как правило, у таких фраз ничтожная частотка (если она вообще есть) и они либо ошибочны, либо не относятся к делу.
Все манипуляции с выборками по фразам проделываются через вот эту заветную кнопку
Далее выставляем настройки, указанные на скриншоте, и жахаем «применить».
Если вы взяли миллионное ядро и дошли до этого шага – то здесь глазные капилляры могут начать лопаться, т.к. на слабых компьютерах/ноутбуках любые манипуляции с крупным СЯ могут, должны и будут безбожно тормозить.
Выделяем/отмечаем все фразы и удаляем.
Вернуться к оглавлению
Шаг 2. Удаляем спец. Символы
Операция аналогична удалению латинских символов (можно проводить обе за раз), однако я рекомендую делать все поэтапно и просматривать результаты глазами, а не «рубить с плеча», т.к. порой даже в нише, о которой вы знаете, казалось бы, все, встречаются вкусные запросы, которые могут попасть под фильтр и о которых вы могли попросту не знать.
Небольшой совет, если у вас в выборке встречается множество хороших фраз, но с запятой или другим символом, просто добавьте данный символ в исключения и всё.
Еще один вариант (самурайский путь)
- Выгрузите все нужные фразы со спецсимволами
- Удалите их в KC
- В любом текстовом редакторе замените данный символ на пробел
solutionsseo.ru
Методика правильного сбора данных в Кей Коллекторе
Парсинг ключевых слов для семантического ядра через Кей Коллектор на текущий день является одним из лучших решений в этой области. Программа представляет собой мощнейший инструмент для работы с СЯ и ключевыми фразами, начиная от их сбора, заканчивая группировкой. Сбор данных играет ключевую роль, так как именно от него зависит насколько полное семантическое ядро мы соберем. После настройки КК приступим к подготовке программы для сбора данных. Вся подготовка и настройка в данной статье производится без привязки к региону.
Выбор источников
Источников для сбора семантики существует немало и Кей Коллектор может похвастаться работой с большинством из них. Собирая ключевые фразы из разных баз и ресурсов мы имеем возможность получить максимально полное семантическое ядро. Однако в то же время есть возможность насобирать столько всего, что на одну чистку и обработку уйдет не один день. В идеале требуется соблюдать некий баланс между полнотой ядра и скоростью работы с ним. Основываясь на практике работы с разными ядрами, оптимальный список источников будет выглядеть так:
Пакетный сбор фраз из левой колонки Yandex.Wordstat.
Когда речь идет о сборе ключевых слов, первым в большинстве случаев вспоминается Яндекс.Вордстат. Добавление данного источника позволит нам спарсить левую колонку сервиса по маркерным словам, то есть не только само слово, но и все, что с ним упоминается.
Плюсы источника:
Большое количество реальных запросов от пользователей, которые пользуются поисковой системой.
Актуальные запросы, обновление раз в месяц.
Возможность на этапе отбора маркерных слов оценить объем семантики по фразе.
Минусы источника:
2. Пакетный сбор слов из Rambler.Adstat.
Этот источник скорее является дополнением к первому. Поисковая система Rambler не пользуется большой популярностью, но, как показывает практика и из нее есть возможность получить ряд интересных фраз для добавления в СЯ.
Плюсы источника:
Дополнение к фразам, собранным из Вордстата.
Независимая и уникальная база слов поисковой системы.
Минусы источника:
Небольшое количество слов в базе.
Большинство фраз не будет добавлено, так как они уже “приедут” из Вордстата.
3. Пакетный сбор поисковых подсказок.
Этот инструмент позволяет получать поисковые подсказки из ряда поисковых систем и ресурсов. То есть мы можем получить “предложения” поисковой системы к фразе, которые вбивает пользователь, основываясь на прошлых запросах и их частоте. Подсказки очень актуальны, так как их обновление происходит чаще, чем баз. Это обусловлено желанием предлагать пользователю только свежую и популярную информацию. Например, ПС Яндекс обновляет подсказки примерно раз в день.
Хороший результат показывают отмеченные на картинке источники подсказок: Yandex, Google (SAFE), YouTube (SAFE), Yandex.Direct (SAFE). В источниках Google, YouTube и Yandex.Direct необходимо установить режим SAFE (безопасный), так как в противном случае будут использоваться перебор подсказок, что может привести к санкциям от этих ресурсов.
Важно! Не советуем использовать подсказки Mail.ru в работе с большими ядрами. Система, использующая сбор подсказок работает по принципу перебора букв алфавита к каждой предложенной фразе. В Mail.ru, если подсказок не найдено, то парсится запрошенная системой буква, то есть сбор подсказок по фразе “окна” будет иметь вид “окна а”, “окна б” и так далее. На 1 000 фраз мы получим как минимум 5 000 таких мусорных запросов. Это потратит время и на парсинг и на их чистку.
Плюсы источника:
Актуальная информация, частое обновление.
Поисковая система сама подбирает нам самые популярные поисковые запросы.
Минусы источника:
Система работает по принципу перебора букв, в некоторых случаях по принципу перебора популярных окончаний к фразе. В итоге мы получаем неестественные фразы с одинаковыми окончаниями. В Яндексе часто попадается окончание “5 лучших моделей”. Да, можно найти рабочую фразу, но когда данная подсказка добавляется к “как вылечить простуду 5 лучших моделей”, то это не более, чем мусор. Еще одним вариантом является “отзывы сотрудников” и “N букв”, где N — цифра от 1 до 10 (решение кроссвордов). В больших проектах данные словосочетания можно заранее включить в список стоп-слов, так как их будет много, а ценности они практически не несут, разве что это наша тематика и найдется рабочая фраза.
4. Сбор расширений ключевых фраз.
Расширения ключевых фраз предлагают работу со статистикой сервисов Rookee. Инструмент на выходе дает неплохое количество фраз, которые не всегда есть возможность зацепить при парсинге из предыдущих источников.
Плюсы источника:
Уникальные фразы, которые не получить из парсинга ПС.
Довольно чистый итоговый результат, без мусора, так как сервис Rookee имеет хорошие базы и статистики.
Минусы источника:
5. Следующий источник, который используется для создания полного семантического ядра не входит в инструменты КК. Речь идет о базах ключевых слов. Хорошим вариантом будет бесплатная база Букварикс (www.bukvarix.com). В базе находится более 2 млрд слов и фраз, которые можно добавить в свое семантическое ядро.
Обратите внимание! Убедитесь, что у вас хватает памяти на жестком диске для скачивания базы, так как она занимает 170 гигабайт.
Плюсы инструмента:
Очень большое количество ключевых фраз.
Отдельным плюсом базы в целом является наличие больших списков минус-слов, которые можно позаимствовать для чистки СЯ.
Минусы инструмента:
Часто бывает, что многие фразы баз неактуальны, так как хранятся там долгое время, а обновление таких объемов может проводиться порой раз в 6 месяцев.
Большое количество фраз является и минусом баз, так как собраны все тематики и есть возможность зацепить много мусора при сборе. Поэтому всегда добавляйте стоп-слова как в самой базе, так и после добавления в КК, потому что система изменения словоформы базы работает хуже, чем та же система в КК.
Это основные источники, которые показывают хороший результат и позволяют сохранить баланс качество / скорость в сборе семантического ядра.
Подготовка папок
С источниками познакомились, теперь необходимо настроить рабочую область папок, с которыми мы будем работать на этапе сбора данных. Стандартный вариант при создании нового проекта в КК выглядит так:
В соответствии с нашей методикой сбора, которая будет описана далее, необходимо подготовить проект следующим образом.
Немного комментариев к этому непонятному “дереву”. Для простоты использования мы пронумеровали папки по типу “001, 002” и так далее и отсортировали их в алфавитном и числовом порядке.
Такой запас чисел необходим в том случае, если группировка будет проходить в Кей Коллекторе, а в работе с большими ядрами количество папок может доходить до сотни.
Создание подпапки 7+ в каждом источнике необходимо для того, чтобы перенести полученные фразы которые состоят из более чем 7 слов. Дело в том, что при сборе частоты, сбор через Яндекс.Директ не может работать с фразами, которые состоят из более чем 7 слов и для получения точной частоты по ним необходимо проводить сбор через Вордстат. Чтобы ускорить процесс и проводить сбор параллельно, лучшим способом будет разделить все фразы на “до 8 слов” и “8 и более”. Это позволит Директу не “спотыкаться” при сборе об такие фразы, а Вордстату не обрабатывать то, что в разы быстрее сделает Директ.
Папка “ДУБЛИ” потребуется для чистки фраз по типу “купить квартиру”, “квартиру купить”. Те фразы, которые меньше употребляются пользователями отправятся сюда.
Итерации сбора
Итак, рабочая область готова, источники выбраны, теперь можно приступить к самому главному — сбору данных.
Сразу стоит отметить, что мы будем описывать сбор максимально полного семантического ядра, ведь именно такое ядро даст понять намерения пользователя и узнать все стороны вопроса, который его интересует.
Почему в подготовке папок мы указали 3 источника? Дело в следующем: в большинстве случаев сбор СЯ даже через Кей Коллектор происходит по сценарию — собрал фразы из левой колонки вордстата, почистил / обработал, пустил в работу. Этот вывод основан на анализе инструкций по сбору данных представленных в Рунете.
Некоторые используют бОльшее количество источников, однако все отталкиваются только от маркерных слов. Это абсолютно неправильно. Минусом такого подхода является то, что мы теряем большую часть ядра, если проводим сбор данных только по маркерным словам.
Представьте, что мы собрали фразы по ключевому слову “пластиковые окна”. Получили фразы по типу “купить пластиковые окна”, “пластиковые окна дешево” и другие популярные расширения ключевой фразы. Однако на этом ядро ни в коем случае не заканчивается, более того, основная его часть проявится только когда мы соберем данные по собранным фразам. То есть, если мы проведем сбор по фразам “купить пластиковые окна” и “пластиковые окна дешево”, мы увидим большое количество рабочих фраз, которые невозможно получить при сборе данных по маркерной фразе “пластиковые окна”. Одно это понимание уже может расширить наше семантическое ядро по отношению к конкурентам.
Именно исходя из этих соображений на этапе подготовки папок мы сделали 3 источника. Первый из них будет для сбора данных по подготовленным маркерным фразам. Во второй мы проведем сбор данных по фразам, которые получили на первом этапе. И в третий сбор данных по фразам второй итерации (лат. iteratio — повторяю).
Количество итераций выбрано исходя из практики. Как правило, самое большое количество фраз появляется в ходе второй итерации. Третья уже “выжимает соки” из наших фраз и является самой маленькой, но не менее ценной.
Теперь непосредственно к сбору данных. Рассмотрим настройку на примере фразы “кондиционеры”.
Первая итерация
Сбор
Рабочая область готова, выбираем ИСТОЧНИК 1 в правой части окна программы.
Нажимаем на первый источник “Пакетный сбор фраз из левой колонки Yandex.Wordstat”.
Настройки: “Добавить в текущую группу” (выделенная) и “Не добавлять фразу, если она уже есть в любой другой группе”. Вторая настройка требуется для избегания дублей, так как одна и та же фраза может прийти из разных источников. Чтобы не перебирать одинаковые фразы и ускорить процесс сбора данных выставляем эту настройку.
В программе есть функция “Распределить по группам”. Так мы можем сразу определить, в какую папку пойдут фразы по тому или иному маркерному запросу. С одной стороны, это очень удобно, так как упростит последующую группировку, с другой стороны, при работе с большими проектами нередки случаи, что в ходе итераций запросы одной тематики подмешиваются к запросам другой тематики. В этом время уйдет на сортировку запросов по нужным группам, если они попали не туда. Поэтому мы советуем загружать все данные в “Текущую папку”, а после проведения всех итераций производить группировку и распределение по группам. Инструменты КК помогут сделать это быстро и без лишних усилий.
Запускаем «Начать сбор».
Пакетный сбор слов из Rambler.Adstat. Настройки идентичны настройкам в предыдущем источнике.
Пакетный сбор поисковых подсказок. Настраиваем сбор в текущую группу, “Не добавлять фразу если она есть в любой другой группе”.
Сбор расширений ключевых фраз сервиса Roostat. Для данного источника требуется указать регион сбора, глубину сбора (ТОП) и для какой поисковой системы стоит собирать данные. Если нас интересуют информационные запросы без привязки к региону, то лучшим решением будет оставить регион “Москва”.
После окончания сбора по всем итерациям нам необходимо очистить группу от мусорных запросов.
Чистка
Эффективная чистка подробно рассмотрена в отдельной статье, так как заслуживает особого внимания. В данном примере можно отметить несколько быстрых способов:
Используем фильтрацию фраз.
Выбираем “содержит прочие символы”.
Жмем “Применить”. Кей Коллектор отфильтрует все фразы, которые содержат какие-либо спец символы или символы, которые не были указаны в настройках КК на замену или удаление. В 99% случаев это мусор, который не сыграет роли.
Выделяем все отфильтрованные фразы и переносим их в папку МУСОР.
Настройки переноса следующие
Есть возможность настроить параметры оптимизации, но по опыту работы с большими проектами это не столь необходимо и лучше оставим настройки стандартными.
Важно! Не удаляйте фразы, которые считаете мусорными! Переносите их в папку “МУСОР”. Так как предложенная методика предлагает несколько повторений сбора, в случае если мы удалим фразы они снова будут собраны. Если перенести их в папку “МУСОР”, сработает настройка “Не добавлять фразу, если она есть в любой другой группе” и мы сэкономим много времени, сил и финансов.
Вторым вариантом быстрой чистки является “содержит латинские символы”. Однако в этом случае все зависит исключительно от тематики. Если мы готовим ядро для интернет магазина, то данная настройка вычеркнет 30% ядра, а то и больше.
Следующий кропотливый, но эффективный способ. Переходим во вкладку “Данные”, жмем “Анализ групп”.
Этот инструмент полезен тем, что позволяет быстро выделить необходимые слова и все схожие с ним словоформы. Допустим, нам не нужны фразы “ремонт кондиционера”, которые мы получили в ходе сбора. Мы используем быстрый фильтр и вбиваем фразу “ремонт”
Выделяем все полученные результаты и сразу переносим их в МУСОР.
Третий способ — использование стоп-слов.
Если часто работать с СЯ, то постепенно наберется свой постоянный список стоп-слов, которые применяются в различных случаях. В любом случае можно легко найти готовые списки стоп-слов (или еще их называют минус слова) в интернете и добавить их в свой список, если они подходят по тематике. С помощью стоп-слов можно вычистить большое количество мусорных фраз сразу после сбора.
Сбор частот
После чистки собранных фраз от мусора можно запускать сбор частот для наших фраз. Выгодно изначально почистить фразы от мусора, а затем запускать сбор, так как это позволит сэкономить бюджет на антикапче и ускорить процесс сбора.
Сбор частот нужен нам для определения того, насколько часто пользователи вводят в поисковую систему тот или иной запрос и для определения их типа запроса. Соответственно, этим будет определяться приоритетность использования той или иной фразы.
Прежде чем запускать сбор необходимо разделить фразы на состоящие из 7 слов и фразы, состоящие из более чем 7 слов. Как описывалось ранее, это необходимо из-за того, что Директ не может обрабатывать запросы более 7 слов.
Используем фильтрацию по фразам.
Можно сохранить настройки фильтрации в шаблоны, чтобы иметь быстрый доступ к нужным настройкам.
Переносим полученные фразы в подготовленную папку 7+
Теперь всё готово для сбора частот. В папке ИСТОЧНИК 1 (не 7+), запускаем сбор данных из Яндекс.Директ.
Рекомендуемые настройки:
В последующем, после сбора всех итераций мы можем собрать информацию о конкурентах в Директе, если это необходимо для проекта.
Обратите внимание! В ходе обработки следите за сбором частот, так как на 1 аккаунт Яндекс.Директ приходится 100 капч, после чего необходимо перезапустить сбор. Также следите за общим количеством капч, если они достигли порога в 5 000 (выставленного в настройках) необходимо перезапустить Кей Коллектор.
В папке 7+, в которой находятся фразы из 8 слов и более запускаем сбор частот через Яндекс.Вордстат.
Яндекс.Директ обрабатывает частоты в разы быстрее “лупы” (Вордстата).
После того, как оба процесса закончатся переносим обратно фразы из папки 7+ в папку ИСТОЧНИК 1, так как теперь ничего не помешает работе с данными фразами в одной папке.
Для того, чтобы использовать только актуальные фразы с потенциальным трафиком необходимо провести чистку по частотностям. Порог, который можно оставить зависит от объема проекта. Если есть возможность и желание работать для каждого пользователя, то порог можно ставить и в 1 запрос в месяц. Однако в большинстве случаев порога частоты равным 5 более чем хватает. Для уточнения — речь идет не о СЯ для Директа, где в некоторых случаях используются и так называемые “пустышки”.
Для фильтрации по частоте используем инструмент фильтрация фраз, но в этот раз запускаем его в колонке “!” WS (или Частота “!” [YW], если вы не меняли стандартное название).
Выставляем порог “меньше 5” (или другое значение, в зависимости от предпочтений).
Отмечаем полученные фразы и переносим их в “МУСОР”.
Первая итерация очищена и готова к дальнейшей работе.
Вторая и третья итерации
Вторая итерация ничем не отличается от первой по последовательности действий. Но для сбора данных мы используем фразы, которые получили в ходе первой итерации. Для этого мы берем и выделяем все фразы в папке ИСТОЧНИК 1: выделили первую фразу, перешли в конец списка, с зажатым SHIFT’ом выделили последнюю фразу. Копируем: CTRL + C или правой кнопкой и “Копировать” (последний пункт выпадающего окна). После этого выделяем папку ИСТОЧНИК 2 и по очереди запускаем сбор из источников, как это проводилось в первой итерации.
Таким образом мы повторяем все пункты: Сбор, Чистка, Сбор частот, но используем фразы с первой итерации.
Третья итерация как понятно из логики — это сбор по фразам второй итерации.
Выделяем, копируем фразы, переходим на ИСТОЧНИК 3 и повторяем пункты: Сбор, Чистка, Сбор частот для фраз второй итерации.
В итоге, у нас должно получиться 3 папки с фразами, где следующая дополняет предыдущую. Практика показывает, что по объему от большего к меньшему чаще всего бывает так: ИСТОЧНИК 2, ИСТОЧНИК 1, ИСТОЧНИК 3. Если вдруг получилась друга ситуация, ничего страшного в этом нет, главное, чтобы все фразы соответствовали нашему ядру и тематике.
Работа с базами
На следующем этапе необходимо подключить базы. Как и описывали, мы используем базы Букварикс.
Интерфейс программы выглядит достаточно просто и не составит труда в нем разобраться. Берем нашу маркерную фразу “кондиционер” и добавляем её в левый столбец программы и жмем кнопку “Найти”.
Пример того, что показывает база изначально:
Цифра очень большая, 729 тысяч, но как видно из результатов кондиционер в данном случае рассматривается и как средство для волос, поэтому необходимо добавить в стоп слова такие запросы как: волос, орифлейм, питание, увлажнение и другие, которые не связаны с кондиционером как прибором. Постепенно выйдет адекватное количество фраз, а для баз это может быть порядка 80-120 тысяч.
Данные можно экспортировать в двух вариантах: текстовый файл и excel, это указывается в настройках.
После экспорта необходимо добавить полученные фразы в КК. Для этого необходимо нажать кнопку “Добавить фразы”
Можно добавить фразы обычным копированием, либо же загрузить их из файла
После добавления фраз необходимо провести для них такие пункты как: Чистка и Сбор частот.
При работе с базами часто бывает, что порядок действий выстраивается так: быстрая чистка по анализу групп, затем сбор частот и повторная чистка. Так как базы собираются за долгое время, при сборе частот большинство из запросов будет иметь месячную частоту 0 и их можно будет быстро отсеять фильтрацией по “!” WS, не тратя времени (но тратя деньги на антикапчу) вручную разбирая эти 80-120 или более фраз.
Этап сбора по базам дает как правило небольшой прирост в количестве фраз нашего СЯ, однако базы содержат большое количество запросов из 8 и более слов, которые редко встретишь в других источниках семантики.
Совмещение итераций
После того, как мы собрали все итерации, почистили их на мусор, собрали для них частоту и почистили фразы с частотой менее 5 необходимо совместить все полученные итерации и базы в одну группу. Это необходимо для последующей очистки на дубли, которые как правило разбросаны по итерациям.
Чтобы правильно сделать сборку необходимо копировать, не перемещать фразы из папки в папку. Копирование поможет нам восстановить прежний вариант, если вдруг мы случайно удалим фразы или сделаем что-то не так.
Для того, чтобы копировать фразы необходимо выполнить следующее:
Данную процедуру необходимо повторить для других итераций и баз, чтобы в папке “СБОРКА” мы получили все фразы нашего проекта (кроме мусорных).
Чистка на дубли
Чистка на дубли представляет собой очищение наших фраз от дубликатов, которые отличаются лишь перестановкой слов, например “купить кондиционер”, “кондиционер купить”. Частота у них будет показана одна и та же, однако в проекте будет использоваться только более правильная формулировка с точки зрения русского языка и восприятия человека. Кей Коллектор берет этот анализ на себя и делает это вполне качественно.
Для того, чтобы почистить фразы на дубли нам необходимо собрать частоту по маске “[!QUERY]” WS. Эта частота показывает маску фразы, а именно, то как пользователи вбивали данный запрос в зависимости от постановки слов. Допустим, после сбора этих частот фразы “гель для душа” и “для душа гель” будут иметь примерное соотношение 145 к 5, то есть первая фраза употребляется гораздо чаще второй. Нередко бывает, что частота QUERY по значению больше, чем “!” WS, однако это обуславливается тем, что она включает в себя сумму частот “!” WS разных формулировок фразы. Например, если фраза одинаково часто используется в обоих вариантах, а их точная частота (“!”) выглядит как 150 и 10, то их частота QUERY будет выглядеть как 80 и 80. Этот пример редко можно встретить, но он “на пальцах” и четко описывает отображаемые в программе данные.
Как же программа чистит подобные дубли? Система собирает данные по маске QUERY и делает “умную отметку”, а именно выделяет и предлагает оставить фразы с наиболее высоким показателем QUERY.
Для того, чтобы собрать частоту QUERY необходимо сделать следующее:
Выделяем папку СБОРКА.
На панели инструментов выбираем “лупу” и функцию “Собрать частоты по маске “[!QUERY]””.
После окончания сбора проведем саму чистку дублей.
Переходим во вкладку Данные и включаем инструмент “Анализ неявных дублей”
После подсчета перед нами откроется окно с предложенными неявными дублями.
Проводим следующую настройку
Такая настройка, как “Не учитывать словоформы при поиске неявных дублей” отвечает за то, что дублями будут признаваться формулировки с разными окончаниями и словоформами. Например, при включенной опции программа посчитает фразы “купить кондиционер” и “купить кондиционеры” дублями. В целом, эта опция оправдывает себя, так как в большинстве случаев, склонения которые предлагаются как дубли таковыми и являются, поскольку поисковые системы самостоятельно меняют словоформы запроса и сопоставляют с заголовками страниц. Поэтому, после ряда тестов мы посчитали, что эта функция полезна и стоит ее включать.
После того, как система обработала дубли в нашем проекте необходимо выполнить “умную отметку”.
Кей Коллектор отметит в таблице все фразы, которые он считает дублями. В зависимости от объема рекомендуется проверить взглядом предложенную отметку. Если вдруг нам кажется, что какая-то фраза звучит неестественно, но показатель QUERY выше, чем у более “правильной” фразы, то стоит посмотреть источник фразы, так как в большинстве случаев такие варианты возникают при подсказках поисковых систем. То есть пользователь вбил “шины”, Яндкс предложил ему “купить” и он выбрал, соответственно будет подсчитано, что эта формулировка используется часто. Такие фразы стоит оставлять, так как они не меняют семантического смысла, а переставить слова в заголовке в будущем не составить труда.
Отмеченные фразы переносим (не забудьте поменять настройки с копирования) в папку дубли.
Нередко бывает так, что при сборе попадаются фразы с повторением слов, допустим “как приготовить кашу как”. При этом у них есть точная частота и они не определяются как дубли системой КК. Для этого есть следующее решение, настраиваем фильрацию фраз следующим образом:
Фраза содержит повторы слов
Добавляем второе условие — QUERY равно 0. Для того, чтобы добавить условие жмем на “…” на верхнем уровне.
И добавляем второе условие
Нажимаем применить. При данном фильтре мы задаем условие: во фразе содержатся повторы слов и частота написания пользователями фразы в таком варианте равняется 0. Таким образом мы исключаем фильтрацию слов с повторением предлогов, которые могут попасться если мы просто оставим фильтр “содержит повторы слов”. Для более тщательной чистки, QUERY можно поставить не равным 0, а меньше 5 или меньше 10. Чтобы не получилось так, что мы выделим фразу с точной частотой 5 и QUERY 4, можно добавить третье условие, что “!” WS более 10. С помощью этих фильтров можно максимально очистить семантическое ядро от подобного мусора.
Полученные фразы переносим в подпапку дублей “ПОВТОРЫ”.
На этом этапе можно сказать, что наше ядро готово к работе и группировке.
Итоги
Предложенный вариант сбора семантического ядра в Кей Коллекторе подходит для проектов любого масштаба. Разве что для мелких проектов возможно не использовать базы, если количество фраз оттуда будет слишком большим.
Мы рассмотрели сбор максимально полного семантического ядра. Этот способ заключается в нескольких итерациях, которые собирают все варианты и тематики связанные с нашими маркерными словами. В данной методике не использовалась привязка к региону, что часто требуется для локальных коммерческих проектов и практически не рассматривались особенности сбора СЯ для контекстной рекламы.
Если обобщить преимущества и недостатки такой методики, то выйдет примерно следующее:
Плюсы методики:
Максимально полное ядро. Мы на голову обойдем конкурентов, которые не используют несколько итераций в сборе СЯ.
Эффективная чистка на дубли и повторы слов.
Эффективная чистка на мусор (основные моменты), которая также является частью этой методики.
Использование баз, как дополнительного источника семантики.
Минусы методики:
Возможно, продолжительный по времени анализ и ход всех итераций. Однако результат того стоит.
Сложность в первоначальном следовании “инструкции” и понимании всех методик.
Необходимость бОльшего бюджета на антикапчу, так как объем фраз для обработки больше, чем в сборе данных с одной итерацией.
semyadro.pro
Как работать с Key Collector и Key Assort?
Сегодня будет проведен обзор совместной работы лучшей программы для сбора семантики Key Collector и лучшей программы для кластеризации запросов Key Assort.
Key Collector
Заходим в программу.
1. Здесь уже собрались какие-то запросы и у нас получилось 383 фразы. Уже есть определенные данные.

Например, мы работаем с поисковой выдачей, с частотами и т.д, и нам нужно здесь распределить эти фразы по страницам. И алгоритм, который встроен в Key Collector, нас по какой-то причине не устраивает.
Мы можем уже здесь собрать данные – они нужны будут нам в Key Collector (доля главных страниц, количество вхождений в заголовки). Эти данные нужно будет еще раз собирать и в KeyAssort.
И вот чтобы не делать это дважды, мы соберем эти данные только в Key Collector. Открываем вкладку «Парсинг/Собрать данные из ПС Yandex»

Идет парсинг

Далее видим, что собрались данные по поисковой выдаче.

Что делаем дальше?
Переходим во вкладку «Файл/Экспорт/Поисковая выдача».
Выбираем Яндекс. Сниппеты не загружаем. Выбираем Экспортировать.

Выпадает вкладка, в которой нужно ввести имя файла – назовем «экспорт» (он в Excel).
Key Assort
Далее идем в KeyAssort.
-
Создаем проект (у нас он уже создан).
-
Выбираем следующее: «Файл/Импорт/С данными о поисковой выдаче».
-
В выпавшем меню о запросе безвозвратно удалить все данные нажимаем «да».
-
В появившемся окне выбираем «Выдача».
-
Появилась вкладка «Параметры импорта». Проверяем: столбец «А» — это запрос; столбец «N» — конкретные сайты.
-
Теперь выбираем в настройках тип кластеризации: «Сервис/Настройки программы/Кластеризация».

Запросы добавились. Собирать данные не нужно, они есть (в нижней строке экрана написано «Собрано данных 384 из 384»)

Здесь делаем все настройки, которые нам нужны, индивидуально.
В данном случае выбираем Силу – 4; вид кластеризации – Hard, сохраняем.
Далее в верхней панели жмем вкладку «Кластеризовать». Получаем результат.

Здесь дополнительно ничего парсить не нужно. Напомним, что эту кластеризацию нужно проверять, т.е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
Часто бывает так, что наша стандартная кластеризация – и тип, и сила – могут для конкретных проектов показать себя не очень хорошо. И тогда мы будем играться с силой: уменьшать, увеличивать. Допустим, получились слишком маленькие группы и слишком много несгруппированных запросов, тогда можно силу уменьшить.
Итак, все сгруппировано.
Дальше нам нужно перетащить все проекты направо. Для этого переходим в правую часть экрана, там во вкладке «Группа/Форма» вводим название – не важно, как это называется, назовем, к примеру, «категория».
Клавишей «Shift» выделяем все файлы левой части экрана и тащим направо.

Если мы не хотим никак дополнительно называть эти группы ключей, тогда назовем их как один из запросов этой группы. Если хотим, чтобы группы более осмысленно уже на этом этапе назывались, тогда здесь их просто переименовываем.
Все.
Что делаем дальше?
Экспорт. И здесь нужно экспортировать не как обычно в Excel, а экспортировать в Key Collector. Для этого в правой части экрана в верхней вкладке выбираем «Экспорт/Key Collector». Жмем, делаем файл – даем ему название в выпавшем меню.

Все, экспортировали.
Возвращаемся в Key Collector и выбираем «Файл/Импорт/Проект KeyAssort». В выпавшем меню выбираем наш файл.
В предлагаемом меню выбираем «не проверять дубли фраз» и «проверять статистику». Жмем импортировать. И он сейчас эти фразы сразу распределит по вкладкам, так же, как у нас это было в Key Assort.
Получаем категории и фразы, уже распределенные по категориям.

И дальше можно с ними работать, собирать по ним дальше данные и можно также переименовывать здесь эти группы, назвать их как-то по другому.
И если у нас получилась слишком большая группа, можно еще раз выгрузить это в Key Assort, там сгруппировать и утащить это обратно, если это вдруг для каких-то целей понадобится.
Вот такая связка. Сейчас последняя версия Key Assort и последняя версия Key Collector очень удобны для этого. И рекомендуется для этого их и использовать.
Представляем вашему вниманию бесплатные видеоуроки по SEO от Андрея Буйлова — руководителя веб-студии Муравейник, с 15 летним опытом работы. Здесь вы узнаете всё о продвижении сайтов — внутренняя техническая оптимизация, каким должен быть контент, как продвигать интернет-магазины, как прорабатывать ссылочный профиль и многое другое.
www.anthome.ru
Key Collector – обзор мощнейшего инструмента для SEO, часть 2
СОДЕРЖАНИЕ
Стандартная формула расчета KEI в KeyCollector
KEI: вычисление эффективности ключевой фразы по шкале 0 до 100
KEI: прогноз объёма трафика
KEI: вычисление уровня конкуренции по ключу
Key Collector для YouTube
Сбор рекомендаций на внутреннюю перелинковку с помощью Key Collector
Играемся с интерфейсом
Выводы
Итак, продолжаем разбирать программу KeyCollector. В прошлой части мы достаточно много внимания уделили сбору семантического ядра и его очистке. В этой же части мы уделим большое внимание формулам KEI.
Для тех, кто не в курсе, KEI расшифровывается как Keyword Effectiveness Index, т.е. индекс эффективности ключа. Хотя, если посмотреть правде в глаза, то формулы KEI можно конфигурировать как угодно, т.е. какого-либо универсального рецепта формулы здесь нет и быть не может.
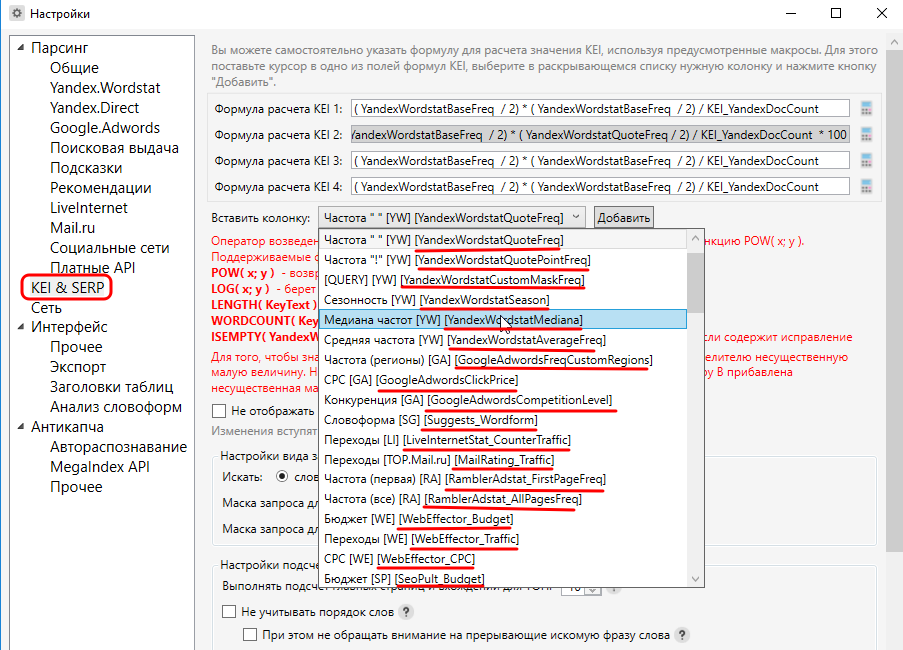
Для начала давайте рассмотрим, где вообще хранятся формулы для вычисления KEI. Заходим в Настройки – KEI & SERP и видим вот это:

Здесь мы видим 4 поля, в которых хранится одна и та же «штатная» формула для расчета KEI. Справа от этих четырех полей есть 4 калькулятора, с помощью которых можно вычислить KEI не по всем формулам сразу, а по какой-то одной конкретной формуле.
Данные, полученные в результате вычислений, выводятся в таблицу в соответствующие колонки:
Чуть ниже мы будем рассматривать несколько формул и у Вас наверняка возникнет вопрос, «А откуда Вы переменные-то берёте? И откуда Вы знаете, какая переменная за что отвечает?». Вот отсюда:
Стандартная формула расчета KEI в KeyCollector
Выглядит эта формула — вот таким образом:
( YandexWordstatBaseFreq / 2) * ( YandexWordstatBaseFreq / 2) / KEI_YandexDocCount
Расшифруем переменные:
YandexWordstatBaseFreq – это базовая частота по Яндексу
KEI_YandexDocCount – сколько документов ранжируется в Яндексе по данному запросу.
Т.е. в переводе на русский язык получаем следующую формулу: базовая частота по Яндексу делится пополам, полученное число возводится в квадрат, а затем делится на количество ранжируемых документов. Следовательно, чем выше базовая частота – тем выше KEI, а чем выше конкурентность (т.е. количество документов в поисковой выдаче) – тем ниже KEI. Тот случай, когда «чем больше – тем лучше». Или нет? Ведь другие 2 вида частот не учитываются, а потому запрос вполне может оказаться накрученным, верно?
К тому же, стандартная формула вполне может выдать нули, т.е. по данным запросам якобы продвигаться нет смысла. Давайте посчитаем вручную. Для этого возьмём первую строку. Базовая частота запроса составляет 1293 показов.
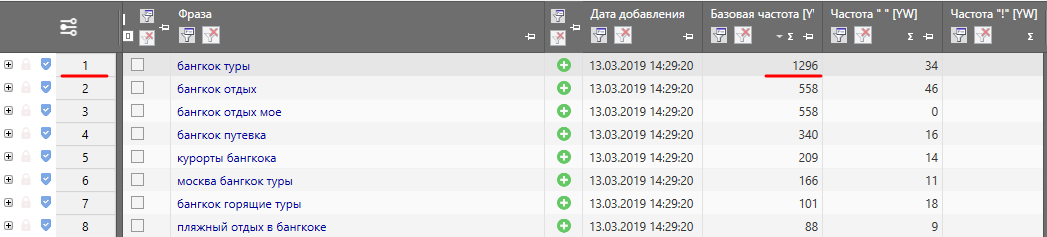
Считаем по формуле:
1) 1293 / 2 = 646,5
2) 646,5 * 646,5 = 417962,25
3) 417962,25 / 98000000 = 0,004264921
Откуда мы взяли 98000000? Очень просто – мы пробили позиции по сайту, а Вы уже знаете, что помимо позиций Key Collector собирает еще ряд данных.

Т.е. то что KEI в итоге равен 0,00 – мы по сути то же самое и получили. Но при этом мы с Вами понимаем, что «что-то тут не то, не может быть такого, чтобы по этому ключу не было смысла продвигаться».
Отсюда простейший вывод – от стандартной формулы, которая указана в Кей Коллекторе, толку крайне мало. Однако, никто не мешает нам разработать более информативную формулу, верно? Верно. Этим и займёмся.
Для начала во вторых скобках заменим базовую частоту на частоту в кавычках, а количество документов в поисковой выдаче разделим на 1 миллион, чтобы у нас не получались слишком маленькие числа. Новая формула теперь выглядит вот так (изменения отмечены красным):
( YandexWordstatBaseFreq / 2) * ( YandexWordstatQuoteFreq / 2) / ( KEI_YandexDocCount / 1000000)
Считаем:

Эффективность по-прежнему измеряется по принципу «чем больше – тем лучше», плюс в вычислении KEI задействовано больше величин. Да и KEI перестал быть нулевым, теперь можно хотя бы чуть-чуть сориентироваться в том, какие ключи наиболее эффективны для продвижения.
Можно модифицировать формулу еще раз, добавив домножение на половину «!частот», и т.д. Можно модифицировать формулы как угодно на своё усмотрение.
В качестве примера рассмотрим еще несколько формул.
KEI: вычисление эффективности ключевой фразы по шкале 0 до 100
Вот таким образом выглядит формула:
((YandexWordstatBaseFreq + YandexWordstatQuotePointFreq) / (YandexWordstatBaseFreq + 0.01) — 1 ) * 100, где:
YandexWordstatBaseFreq – базовая частота
YandexWordstatQuotePointFreq – «!частота»

Соответственно, чем выше KEI – тем эффективнее ключевая фраза. Минус формулы в том, что в ней не учитывается сезонозависимость (у сезонозависимых запросов эффективность меняется от сезона к сезону) и количество документов в поисковой выдаче. Но зато помогает буквально в 1 клик выявить запросы, по которым продвигаться бессмысленно.
KEI: прогноз объёма трафика
ВАЖНО!!! Сейчас речь идет именно об органической выдаче, а не о рекламной! Следовательно, и трафик будет поисковый, а не рекламный. В данном подразделе статьи мы рассмотрим сразу 2 формулы.
Начнём вот с этой — (YandexWordstatQuotePointFreq) * X + 0.01, где:
YandexWordstatQuotePointFreq – «!частота» по Яндексу
X – значение, которое будет меняться в зависимости от позиции сайта:
ТОП-1 (т.е. самая высокая позиция сайта) = 0,25
ТОП-2 = 0,15
ТОП-3 = 0,1
ТОП-4 = 0,08
ТОП-5, ТОП-6, ТОП-7 = 0,04
ТОП-8, ТОП-10 = 0,03
ТОП-9 = 0,02
Почему именно эти цифры? Очень просто – если домножить эти коэффициенты на 100, то мы получим приблизительный среднестатистический процент распределения посетителей по ТОП-10. Т.е. если необходимо спрогнозировать трафик по какой-то конкретной позиции, то просто подставляем вместо X нужный коэффициент и получаем приблизительный прогноз трафика.
Данную формулу, как Вы уже поняли, нельзя назвать точной, т.к. при попадании в ТОП-1 далеко не всегда на сайт приходит именно 30% посетителей, может быть и меньше. Например, когда на странице выдачи большое количество рекламы, из-за чего ТОП-1 физически не помещается на экран. Взгляните вот на этот скриншот. Он сделан при разрешении экрана 1920х1080 пикселей.

Если перенастроить разрешение на 1366х768 (а это самое популярное на сегодня десктопное разрешение экрана), то на первый экран НЕ попадёт, то, что находится ниже красной черты. Не верите? С помощю браузера Opera сэмулировать такое разрешение не составит труда.
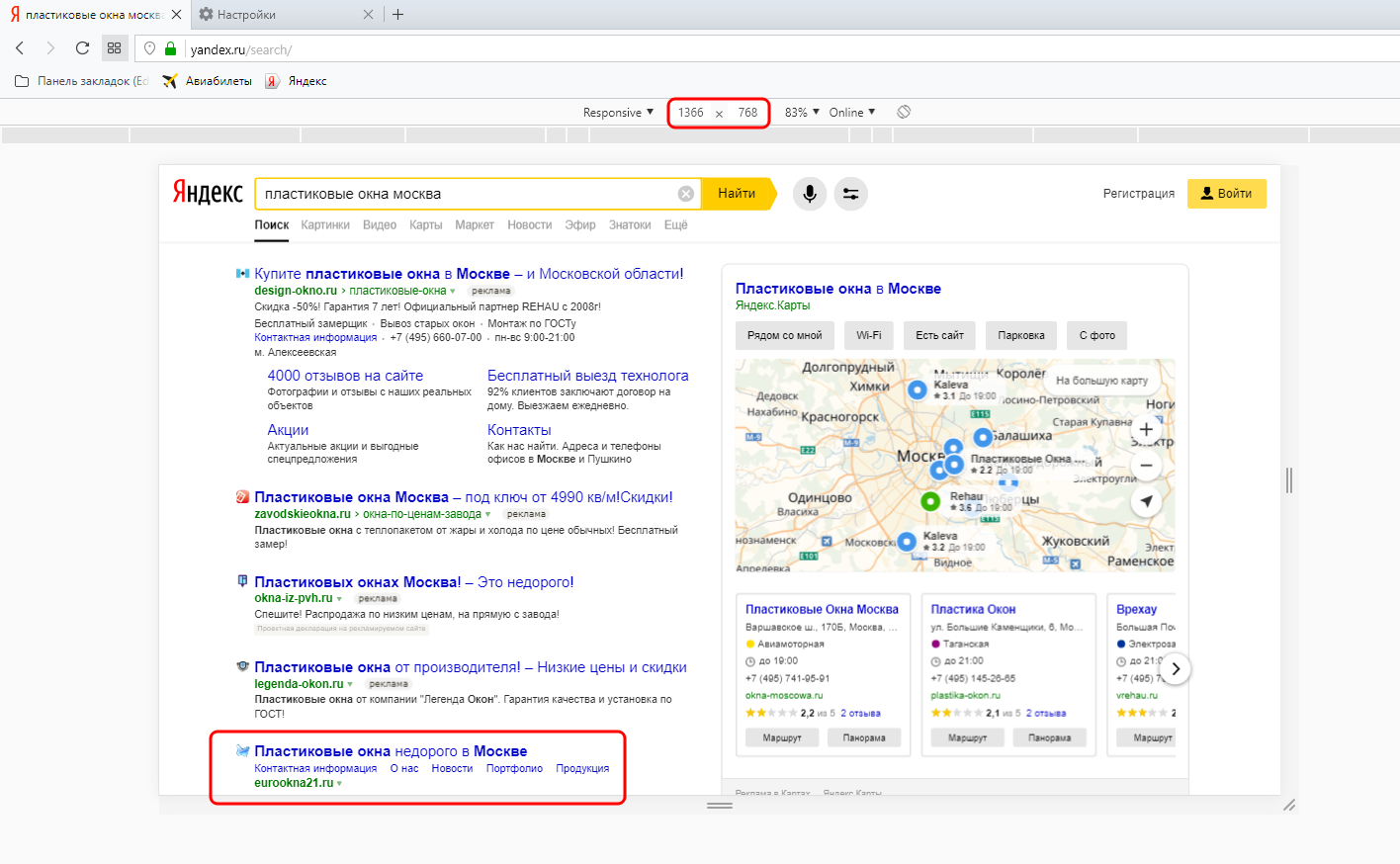
Т.е. в большинстве случаев на первый экран у нас попадает только ТОП-1, и то сниппет помещается не полностью (не попали Description и кнопка онлайн-чата). Становится очевидно, что почти 60% трафика отхапают себе именно рекламные объявления, а потому гораздо правильнее полученный KEI домножить на оставшиеся 40%. Т.е. конкретно для запроса «пластиковые окна москва» формула расчета прогноза посещаемости будет выглядеть не вот так:
( YandexWordstatQuotePointFreq ) * 0,25 + 0.01
а вот так:
(( YandexWordstatQuotePointFreq ) * 0,25 + 0.01 ) * 40 / 100
Результаты будут в корне отличаться:
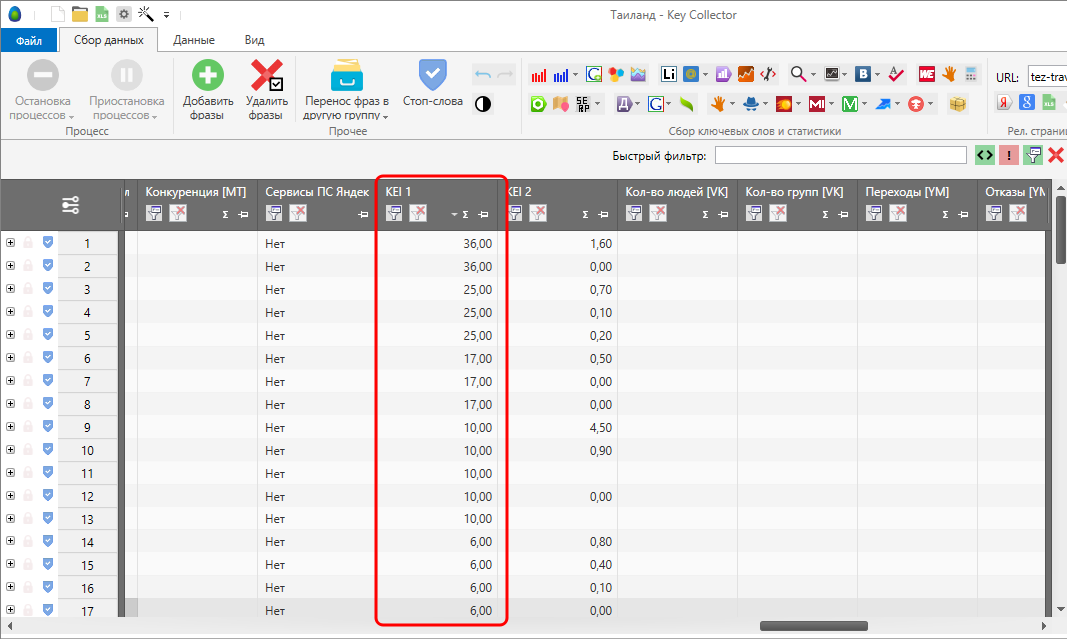
(первая формула – KEI 1, вторая – KEI 2)

Теперь переходим к другой формуле:
( YandexWordstatQuotePointFreq ) * (((15 + 10 + 8 + 4 + 0.01 ) / 4 ) / 100 )
С ее помощью можно спрогнозировать трафик, если сайт по запросу попадёт в ТОП-5 (за исключением первой позиции). Естественно, если по ключу вылезает куча рекламных объявлений, практически вытесняющих органическую выдачу вниз, то результат тоже имеет смысл домножить на 40% для более точного прогноза.
KEI: вычисление уровня конкуренции по ключу
Здесь рассмотрим сразу две формулы.
Для Яндекса – (( KEI_YandexMainPagesCount * KEI_YandexMainPagesCount * KEI_YandexMainPagesCount ) + ( KEI_YandexTitlesCount * KEI_YandexTitlesCount * KEI_YandexTitlesCount )) / 20
Для Google – (( KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount ) + ( KEI_GoogleTitlesCount * KEI_GoogleTitlesCount * KEI_GoogleTitlesCount )) / 20.
Т.е. главные страницы в кубе + количество точных вхождений фраз в заголовки в кубе.
Кстати, в куб потребовалось возводить для более высокой точности. Откуда взялось 20? Очень просто. Допустим у нас в ТОП-10 находится 10 главных страниц, на каждой из которых есть точное вхождение ключа. 10 в кубе = 1000, итого 1000+1000=2000 – это максимальное значение результата вычислений. Если же разделить на 20, значение будет варьироваться от 0 до 100. Можно сказать, что уровень конкуренции в этом случае будет вычисляться в процентах.
Key Collector для YouTube
На данный момент Key Collector для YouTube-блогеров не особо полезен. Во-первых, невозможно отмониторить позиции своего видео по тому или иному поисковому запросу, поскольку выдача формируется индивидуально для каждого с учётом интересов, к тому же она не является единственным источником просмотров.
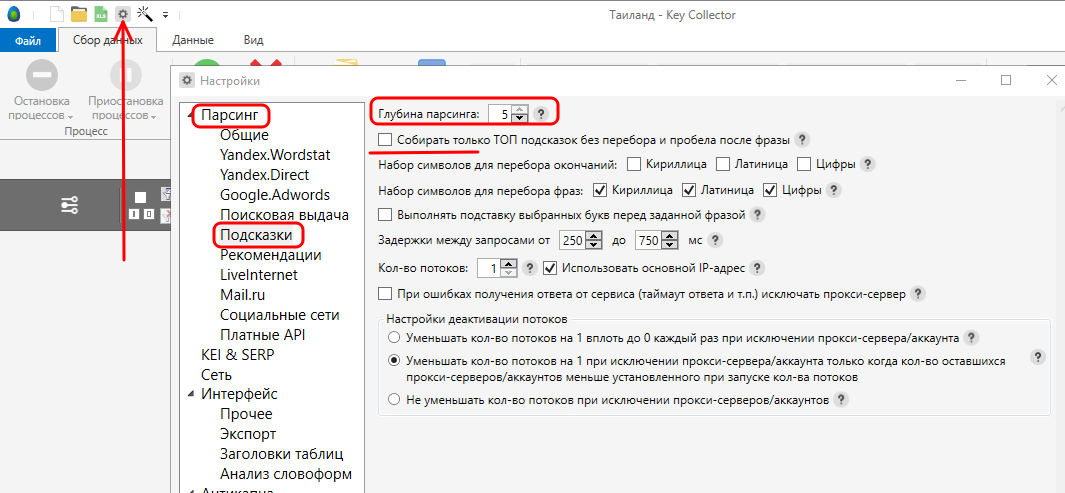
Поэтому самый максимум, чем может быть полезен Key Collector для YouTube-блогеров – помощь в парсинге поисковых подсказок. Для этого надо Key Collector немного перенастроить.
Заходим в Настройки – Парсинг — Подсказки, выставляем максимальную глубину (5) и снимаем галочку «Собирать только ТОП».
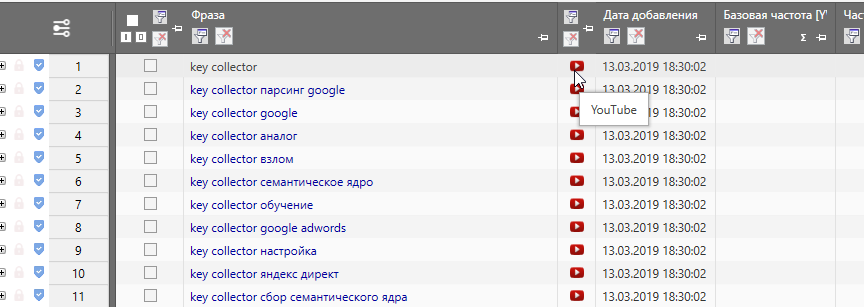
Затем заходим в Поисковые подсказки, из галочек оставляем только YouTube и Safe-режим, прописываем интересующие ключи и запускаем парсинг.

На выходе Вы получите список поисковых подсказок от YouTube.
За счет данных подсказок можно быстро сформировать заголовок, описание и теги продвигаемого видео и получить хороший прирост просмотров.
Сбор рекомендаций на внутреннюю перелинковку с помощью Key Collector
Да, с помощью Key Collector’а можно собирать рекомендации на внутреннюю перелинковку. Собственно, кроме списка ключей и УРЛ сайта для этих целей больше ничего не требуется. Т.е указываем УРЛ сайта, нажимаем кнопку сбора рекомендаций, в открывшемся окне (при необходимости) добавляем список «обрезков» и запускаем сбор рекомендаций.
На счет «обрезков» сейчас объясним. Если в список добавить blog, то будут игнорироваться все УРЛ, в которых присутствует данный «обрезок».
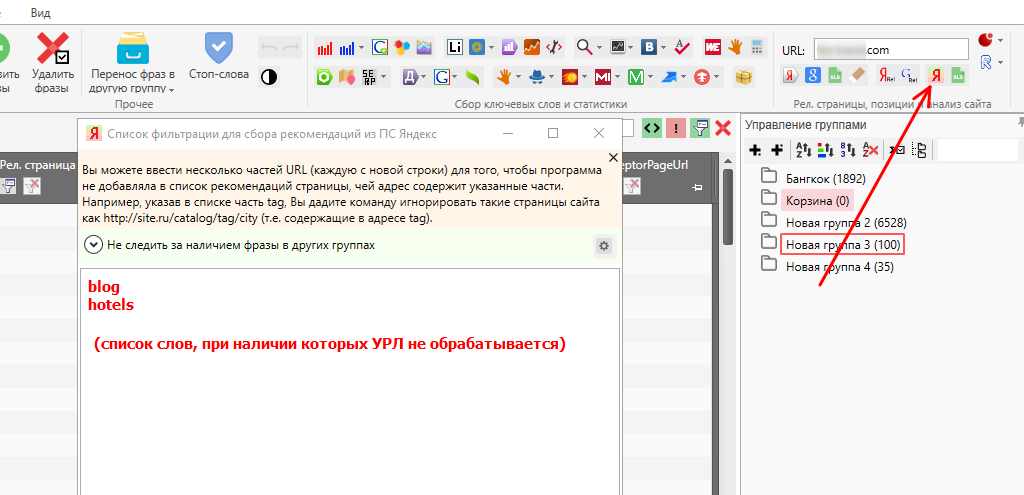
На выходе мы получим список УРЛ, наиболее подходящих в качестве акцептора (приемника), т.е. именно на эти страницы лучше всего ссылаться по соответствующим ключам (1 страница = 1 ключ). Список этих УРЛ будет находиться в таблице в столбце AcceptorPageURL.

НО… Эти данные НЕ панацея, т.е. это рекомендации, сделанные на основе поисковой выдачи. Т.е. эти данные необходимо проверять, т.к. не факт, что на сайте вообще существует релевантная данному запросу страница. Если ее на самом деле на сайте нет, то и ссылаться, соответственно, не на что. Однако, это не значит, что поле в этом случае будет пустым.
Играемся с интерфейсом
По умолчанию в таблице Key Collector’а находится более 50 столбцов, большая часть которых, обычно, вообще пустует, а потому только мешает. Что делать?
Ответов на этот вопрос может быть несколько.
Пожалуй, самый оптимальный вариант – зайти на вкладку Вид и кликнуть на «Автонастройку видимости колонок». Как видите, пустые колонки просто скрылись.
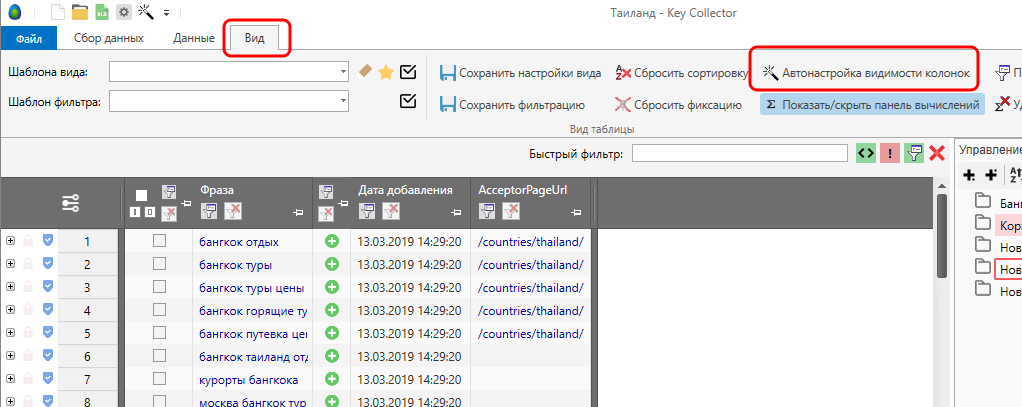
Плюс в том, что Вам больше не будут мешать столбцы с пустыми данными. Минус – столбцы, которые ЗАПОЛНЕНЫ данными тоже иногда могут мешать, т.к. эти данные в данный момент могут быть и вовсе не нужны. Что делать? Правильно – сделать несколько собственных шаблонов «под себя» и при необходимости менять их.
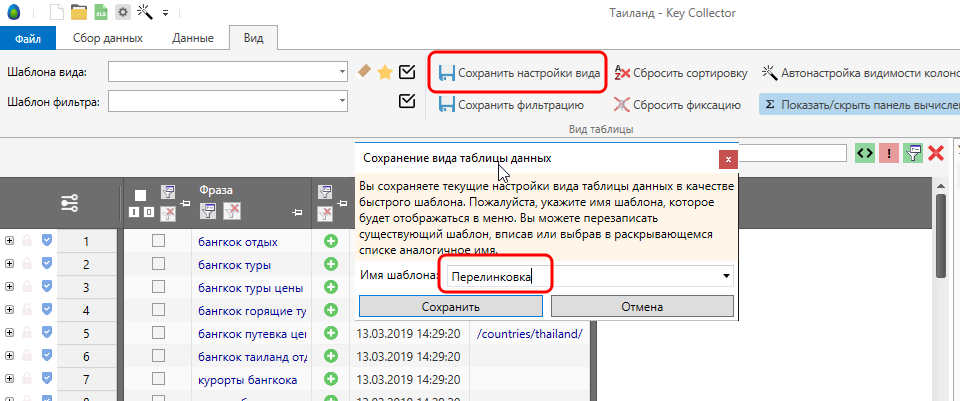
И начнём с сохранения шаблонов. Если взглянуть на скриншот выше, то у нас получился практически готовый шаблон на рекомендации по внутренней перелинковке. Именно так мы его и сохраним.
Теперь давайте его чуточку подправим, удалив столбец с датой добавления и столбец с указанием источника добавления. Для этого кликаем на настройку столбцов, листаем список и убираем лишние галочки.
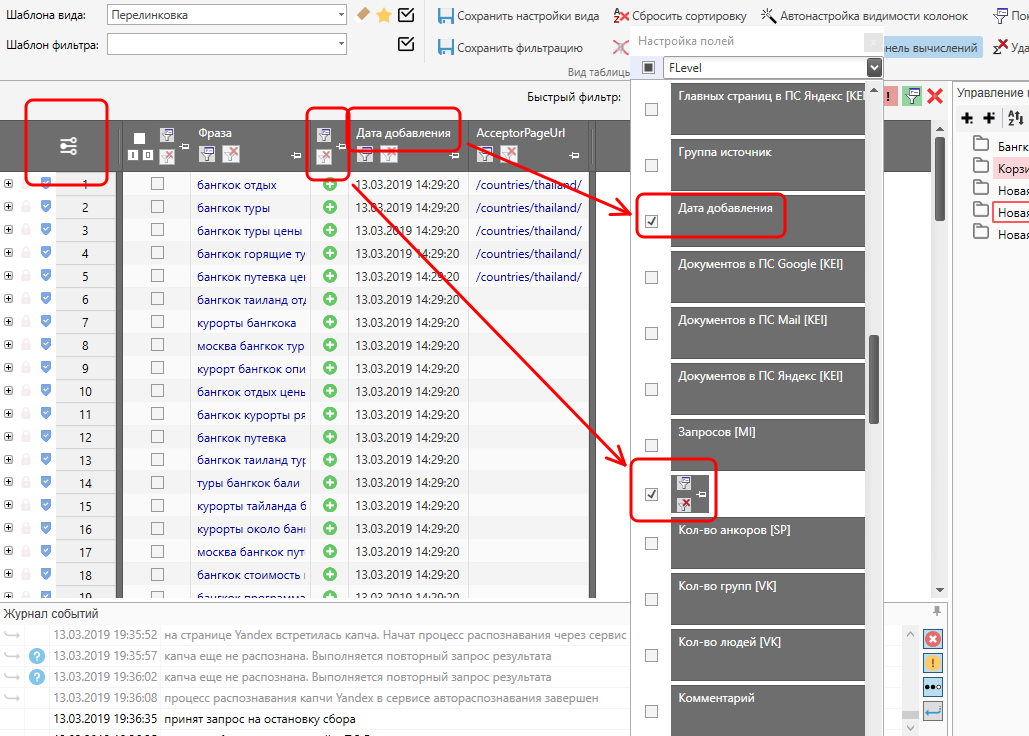

Как видите, таблица снова видоизменилась. Если такой вариант больше устраивает – его вполне можно сохранить как шаблон (причем вместо уже имеющегося).
Теперь давайте сконструируем шаблон, в котором будут отображаться только частоты по Яндексу. Снова заходим в настройки, удаляем столбец с УРЛ и открываем столбцы с частотами.

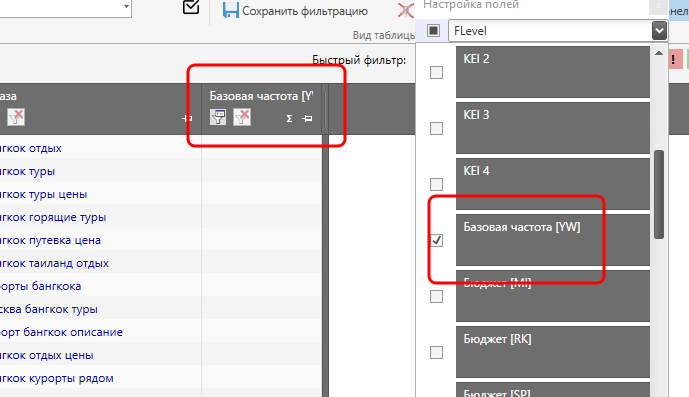
Да, столбцы на данный момент пустые, но это временно и в данном случае неважно. Важно другое. Мы удалили из таблицы столбец с УРЛами, которые получили в качестве рекомендованных акцепторов для перелинковки. И, несмотря на то, что столбец удалён, данные никуда не потерялись. Т.е. если столбец восстановить, то и собранные данные тоже восстановятся.
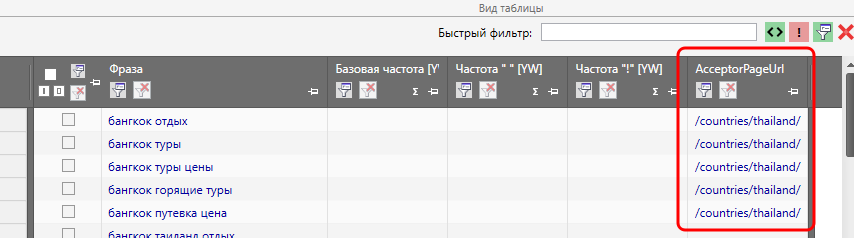
Таким образом, Вы можете сделать «под себя» несколько шаблонов и переключаться между ними по мере необходимости. В крайнем случае у Вас всегда есть возможность настроить отображение ВСЕХ столбцов.
По аналогии можно настроить и шаблоны фильтров. Например, в данном случае настроен фильтр на одновременное соблюдение двух условий – наличие слова «тур» в ключе + наличие ссылки в AcceptorPageURL.
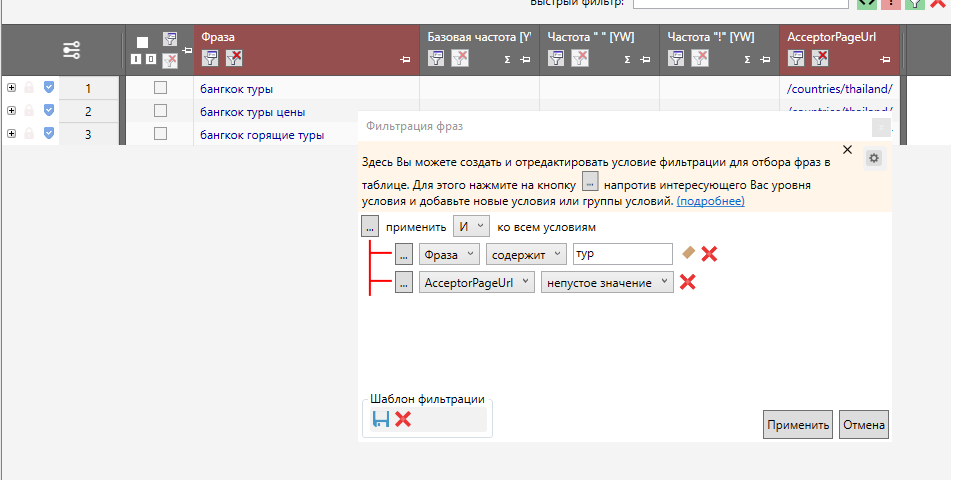
Этот шаблон фильтров тоже можно сохранить:

Данная фишка крайне полезна тем, кому периодически приходится задавать однотипные сложные условия, т.е. тоже сводит к минимуму всю возню.
Выводы
Итак, что же мы выяснили?
Мы выяснили, что даже с помощью бесплатных инструментов Вы можете собрать огромное семантическое ядро для дальнейшего продвижения, достаточно быстро очистить его от мусорных запросов, выявить накрученные и «пустые» запросы, выяснить, какие из поисковых запросов являются сезонозависимыми. Разобрались, как спрогнозировать посещаемость сайта и прикинуть уровень конкуренции на основе собранных данных.
Также мы разобрались с интерфейсом, а также с тем, как данный программный комплекс может быть полезен для продвижения YouTube-канала.
А потому можно смело сказать, что программный комплекс Key Collector однозначно мастхэв для каждого SEO-шника, заказчика, YouTube-блогера, а в некоторых случаях – даже для фрилансера.
Ну а самое главное, мы выяснили, что с ТАКИМ функционалом 1800р за пожизненную лицензию –это очень и очень мало – некоторые фрилансеры столько за 1 день зарабатывают.
stokrat.org