
Как спарсить любой сайт? / Хабр
Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
Найдите официальное API,
Найдите XHR запросы в консоли разработчика вашего браузера,
Найдите сырые JSON в html странице,
Отрендерите код страницы через автоматизацию браузера,
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте.
Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
 Пример: http://techcrunch.com/sitemap.xml
Пример: http://techcrunch.com/sitemap.xmlПоищите XHR запросы в консоли разработчика
Кабина моего самолетаВсе современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).
Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
Открывайте вебстраницу, которую хотите спарсить
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
Открывайте вкладку Network и кликайте на фильтр XHR запросов
Обновляйте страницу, чтобы в логах стали появляться запросы
Найдите запрос, который запрашивает данные, которые вам нужны
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!Алгоритм действий такой:
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
Внизу ищите длинную длинную строчку с данными.
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get.Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_source
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile. password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driver
password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driverЗаметьте фложок enableVNC. Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
фреймворк для парсинга сайтов — Документация Grab 0.6.22
Grab — фреймворк для парсинга сайтов — Документация Grab 0.6.22Предупреждение
Документация на русском языке устарела и может содержать ошибки.
Пожалуйста, используйте английскую документацию для получения
актуальной информации о библиотеке Grab.
Grab — библиотека для работы с сетевыми документами. Основные области использования Grab:
- извлечение данных с веб-сайтов (site scraping)
- работа с сетевыми API
- автоматизация работы с веб-сайтами, например, регистратор профилей на каком-либо сайте
Grab состоит из двух частей:
- Главный интерфейс Grab для создания сетевого запроса и работы с его результатом. Этот интерфейс удобно использовать в простых скриптах, где не нужна большая многопоточность, или непосредственно в python-консоли.
- Интерфейс Spider, позволяющий разрабатывать асинхронные парсеры. Этот интерфейс позволяет, во-первых, более строго описать логику парсера, во-вторых, разрабатывать парсеры с большим числом сетевых потоков.
Grab сайты
- Официальный сайт: http://grablib.org
- Репозиторий на github: http://github.com/lorien/grab
- Группа рассылки: http://groups.google.com/group/python-grab
Документация Grab
- Введение в Grab
- Установка библиотеки Grab
- Установка под Linux
- Установка под Windows
- Настройка Grab-объекта
- Клонирование
- Отладка запросов
- Использование logging-системы
- Нумерация запросов
- Сохранение запросов и ответов в файлы
- Полный список настроек
- Настройки
- Настройка HTTP-заголовков
- Изменение HTTP-заголовков
- Настройка User-Agent заголовка
- Настройка Referer заголовка
- Методы HTTP-запросов
- Выбор метода
- POST-запрос
- Отправка файлов
- Прочие возможности
- Ограничение тела ответа
- Сжатие ответа
- HTTP-Авторизация
- Работа с pycurl-дескриптором
- 301 и 302 редиректы
- Meta Refresh редиректы
- Кодировка документа
- Для чего нужно знать кодировку
- Алгоритм определения кодировки
- Опция задания кодировки
- Работа с кукисами
- Настройка кукисов
- Работа с файлом кукисов
- Обработка сетевых ошибок, таймауты
- Сетевые ошибки
- Таймауты
- Режим повторных запросов
- Работа с прокси-серверами
- Настройка прокси-сервера
- Работа со списками прокси
- Работа с ответом
- Объект Reponse
- Технические детали устройства Grab
- Используемые библиотеки
- Структура расширений
- Поддержка python 3
- Работа с формами
- Автоматическая обработка форм
- Отправка формы
- Отправка файлов
- Работа с DOM-деревом
- Интерфейс к LXML библиотеке
- DOM-дерево
- XPATH-методы
- CSS-методы
- Обработка исключений
- Поиск в тексте документа
- Поиск строк
- Поиск регулярных выражений
- Другие расширения
- PyQuery расширение
- BeautifulSoup расширение
- Cетевые транспорты
- Что такое транспорт
- Транспорт pycurl
- Транспорт urllib
- Транспорт selenium
- Полезные утилиты
- Пул заданий
- Блокировка файла
- Логирование Grab-активности в файл
- Фильтрация строк в файле
- Обработка HTML
- Работа с LXML-элементами
- Работа с регулярными выражениями
- Работа с текстом
- Работа с http-заголовками
Документация Grab:Spider
Асинхронный модуль для разработки сложных парсеров.
- Что такое Spider
- Способы создания заданий
- initial_urls
- task_generator
- add_task
- yield
- Резюме
- Задания
- Конструктор Task объекта
- Task-объект как хранилище данных
- Клонирование Task-объекта
- Очередь заданий
- Приоритеты заданий
- Бэкенды хранилищ
- Генератор заданий
- Обработка ошибок
- Правила обработки запросов
- Сетевые ошибки
- Повторно выполнение заданий
- Статистика ошибок
- Система кэширования сетевых запросов
- Бэкенды системы кэширования
- Исползование кэша
- Сжатие кэшируемых данных
API
Вся нижеследующая информация сгенерирована из комментариев в исходном коде. Поэтому она на английском языке. Документы из раздела API полезны тем, что они показывают описания всех аргументов каждого метода и класса библиотеки Grab.
Базовый интерфейс:
- grab. base: API базового класса
- grab.error: классы исключений
- grab.response: класс ответа сервера
 base: API базового класса
base: API базового классаУтилиты:
- grab.upload
Всякая фигня
- Алфавитный указатель
- Состав модуля
- Поиск
Read the Docs v: latest
- Versions
- latest
- stable
- Downloads
- htmlzip
- epub
- On Read the Docs
- Project Home
- Builds
Free document hosting provided by Read the Docs.
Загрузчик веб-сайтов | Копир сайта | Загрузчик сайта
Загрузчик сайта | Копир сайта | Загрузчик сайта | Website RipperЭто приложение лучше всего работает с включенным JavaScript.
6k
Акции
Загрузите весь исходный код и активы любого веб-сайта
Основные преимущества
Самый простой способ
загрузить веб-сайт .Независимость от платформы
Веб-интерфейс позволяет использовать риппер веб-сайтов прямо в браузере в любой операционной системе, без загрузки или настройки какого-либо программного обеспечения. Используйте его, когда вам нужно быстро скачать сайт .
Fast Previews
Website Downloader предлагает быстрый предварительный просмотр результатов загрузки, размещенных на наших серверах, без использования драгоценного дискового пространства вашего компьютера. После предварительного просмотра вы можете загрузить веб-страницу или загрузить весь веб-сайт .
Простота
Загрузчик веб-сайтов очень прост и удобен в использовании, но при этом обладает расширенными функциями, такими как загрузка только подкаталога или определенных страниц с веб-сайта (как загрузчик веб-страницы ). Веб-граббер — самый простой способ скачать веб-сайт .
Веб-граббер — самый простой способ скачать веб-сайт .
Что говорят о нас
Опыт работы с лучшим
Копир веб-сайтов . Реувен Коэн@rUv
Украсть полный исходный код любого веб-сайта? Websitedownloader.io pic.twitter.com/ko6KO9T1eF
620:55 — 12 августа 2016 г.
justin barbour@jus10barbour
Полезный инструмент для работы с локальными копиями сайтов: DL всего исходного кода HTML и ресурсов любого сайт с WebsiteDownloader.io bit.ly/website-downloader
510:05 — 11 августа 2016
Raul L Cruz@iamRaulCruz
Быстро загружайте исходный код любого веб-сайта в легко редактируемый формат (включая все активы) | Websitedownloader.io
48:19 — 9 августа 2016
Тиффани Уордл@typegirl
Еще один полезный способ недорого получить визуальный архив вашей учетной записи @flickr. Websitedownloader.io
Websitedownloader.io
16:35 — 19 ноября 2018 г.
Аманда Дональдсон@AMDesignlovin
Нашел этот классный инструмент для загрузки ресурсов веб-страницы. bit.ly/website-downloader
416:00 — 9 августа 2016
Кейси Оуэнс@clowens3
Ознакомьтесь с этим новым загрузчиком веб-сайтов – buff.ly/2aZufqw #web #design #dev #FrontEnd #css #html #js #php pic.twitter.com/K2W4JAfljJ
116:54 — 19 августа 2016
Джонатан Паски@jonathanpasky
Очень круто: загрузите исходный код и активы любого веб-сайта: bit.ly/ загрузчик веб-сайтов
29:53:00 — 11 августа 2016 г.
John-Bunya Klutse@JBKlutse
Ищете инструмент для загрузки всего исходного кода HTML и ресурсов любого веб-сайта. Попробуйте Websitedownloader.io #jbklutse #websitedownloader
29:43 — 11 августа 2016
Ben Novak@novakben
Загрузите весь исходный HTML-код и активы любого веб-сайта с WebsiteDownloader. io, посетите bit.ly/website -downloader
io, посетите bit.ly/website -downloader
3:15 — 10 августа 2016
Ларри Сивиц@larrysivitz
Вы не работаете со службой, которая загружает весь исходный код HTML и активы любого веб-сайта? WebsitedOwnloader.io
217:46 — 8 августа 2016
Cesar Razuri@ceasetheday
Pretty Nifty: New Websity Downloader Websitownloader.io
38:18 — 9 августа 2016
. surajbarthyИсходный код кто-нибудь? fb.me/1lG7V0FyX
222:00 — 8 августа 2016
Нравится Загрузчик веб-сайтов? Голосуйте за нас на RankedByVotes
Функции загрузчика веб-сайтов
Загрузчик веб-сайтов,
Копир веб-сайтов или Ripper веб-сайтов позволяет загружать веб-сайты из Интернета на локальный жесткий диск вашего компьютера. Загрузчик веб-сайтов упорядочивает загруженный сайт по исходной относительной структуре ссылок веб-сайтов. Загруженный веб-сайт можно просмотреть, открыв одну из HTML-страниц в браузере.
Загруженный веб-сайт можно просмотреть, открыв одну из HTML-страниц в браузере.HTML
Веб-граббер берет каждый файл HTML, загружает и клонирует его на локальный жесткий диск. Вы можете использовать HTML-редактор для внесения изменений в каждый HTML-файл локально или использовать онлайн-редактор HTML. Если вы не кодер, вы можете вместо этого использовать редактор WYSIWYG-HTML.
Преобразование ссылок
Мы преобразуем все ссылки в HTML-файлах, чтобы они работали локально, в автономном режиме, а не указывали на онлайн-сайт.
CSS и JavaScript
Файлы CSS и JavaScript загружаются в простую структуру папок и правильно ссылаются в файлах HTML.
Изображения
Как и другие активы, изображения также загружаются и используются локально.
Варианты использования популярного загрузчика веб-сайтов
После клонирования веб-сайта на жесткий диск вы можете открыть исходный код веб-сайта с помощью редактора кода или просто просмотреть его в автономном режиме с помощью выбранного вами браузера.
 Site Downloader можно использовать для разных целей. Это действительно просто использовать программное обеспечение для загрузки веб-сайта , ничего не загружая.
Site Downloader можно использовать для разных целей. Это действительно просто использовать программное обеспечение для загрузки веб-сайта , ничего не загружая.Резервные копии
Если у вас есть веб-сайт, у вас всегда должна быть свежая резервная копия веб-сайта на случай, если сервер сломается или вас взломают. Загрузчик веб-сайтов — это самый быстрый и простой способ сделать резервную копию вашего веб-сайта, он позволяет вам загрузить весь веб-сайт .
Автономный загрузчик веб-сайтов
Загрузите веб-сайт в автономном режиме для дальнейшего использования, к которому вы можете получить доступ, скажем, даже без подключения к Интернету. когда вы в полете или на отдыхе на острове!
Миграция сайта
Если вы привязаны к своему хостинг-провайдеру или по какой-либо другой причине не имеете доступа к исходным файлам вашего веб-сайта, просто используйте копировальный аппарат веб-сайта для загрузки файлов и переноса вашего веб-сайта на новый сервер. Не забудьте установить правильные права доступа к файлам с помощью калькулятора chmod при миграции.
Не забудьте установить правильные права доступа к файлам с помощью калькулятора chmod при миграции.
Обучение
Если вы веб-дизайнер или разработчик, поднимите свои навыки на новый уровень, реконструировав исходный код веб-сайта по , загрузите полный веб-сайт и изучите новые шаблоны UX и передовые методы кодирования. Загрузите полную версию веб-сайта , чтобы начать обучение.
Очистка экрана
Онлайн-загрузчик веб-сайтов позволяет извлекать полезные данные, информацию и знания из содержимого веб-страницы. Запуская ваши алгоритмы парсинга локально, они работают быстрее и плавнее!
Интернет-архив
Забыли оплатить продление хостинга? Не волнуйтесь, ваш сайт не потерян. Вы можете восстановить свои веб-сайты из Интернет-архива с помощью Wayback Machine Downloader
Машинное обучение
Интеллектуальный анализ веб-контента: вы можете получить несколько веб-сайтов и запустить анализ текста или алгоритмы машинного обучения на локальных данных вместо того, чтобы каждый раз извлекать новую веб-страницу. время, для новых данных.
время, для новых данных.
Сеть блогов
Интернет-маркетологи могут использовать Wayback Machine Downloader для создания сетей блогов из доменов с истекшим сроком действия, не платя ни копейки за контент, загружая веб-сайты из Интернет-архива!
Готовы начать использовать загрузчик веб-сайтов?
Использование загрузчика Wayback Machine | Читайте наш блог | Конфиденциальность | Условия | Файлы cookie
Копирование веб-сайтов | Сайты загрузки | Website Ripper
Этот бесплатный инструмент прекрасно работает примерно до 50 страниц. Чтобы загрузить все файлы с полных веб-сайтов, мы используем наш премиальный загрузчик веб-сайтов.
Узнайте, как загрузить веб-сайт
Это лучший онлайн-копировщик веб-сайтов, бесплатный онлайн-инструмент, который позволяет бесплатно загружать сайты со всем исходным кодом. Введите URL-адрес веб-сайта, и этот инструмент Site Downloader начнет сканирование веб-сайта и загрузит все ресурсы веб-сайта, включая изображения, файлы Javascript, файлы CSS и изображения Favicon. Как только он скопирует все активы веб-сайта, он предоставит вам ZIP-файл с исходным кодом. Этот загрузчик веб-сайтов представляет собой онлайн-сканер, который позволяет загружать полные веб-сайты без установки программного обеспечения на свой компьютер.
Как только он скопирует все активы веб-сайта, он предоставит вам ZIP-файл с исходным кодом. Этот загрузчик веб-сайтов представляет собой онлайн-сканер, который позволяет загружать полные веб-сайты без установки программного обеспечения на свой компьютер.
Примечание. Скопируйте точный и правильный URL-адрес веб-сайта. Откройте целевой веб-сайт и скопируйте ссылку из адресной строки, а затем вставьте ее сюда вместо того, чтобы вводить URL-адрес самостоятельно. Если у вас возникнут какие-либо проблемы, звоните по номеру , свяжитесь со мной . Я сделаю это вручную и отправлю вам файлы
Обновлено 15 АПРЕЛЯ 2020 г. [ Улучшено ]
Вышло новое обновление Website Copier. Ниже приведены изменения, которые я внес в это обновление.
- Просмотр процента завершения вашего любимого веб-сайта с помощью ProgressBar
- Проверить состояние процесса загрузки
Обновлено 08 ЯНВАРЯ 2020 г. [ Ошибка исправлена и улучшена]
Выпущено новое обновление копировщика веб-сайтов.
- Исправлена проблема с заменой ссылок на ресурсы и файлы HTML
- Загрузки шрифтов CSS
- Загрузка изображений (включенных в таблицы стилей)
- Более эффективные и точные результаты
- Исправлены мелкие ошибки
Обновлено 28 ИЮЛЯ 2019 г. [ Загрузить полный веб-сайт ]
Теперь он загружает полный веб-сайт со своими активами. Если вы обнаружите какую-либо ошибку, не стесняйтесь обращаться ко мне по телефону
. Почему это БЕСПЛАТНОЕ копирование веб-сайтов?
Как вы знаете, все другие загрузчики с веб-сайтов являются премиальными, но они совершенно бесплатны. Вам не кажется, что это так? Вот ответ. Будучи программистом, мой главный приоритет — автоматизировать все для меня и других людей БЕСПЛАТНО с по ПОМОГИТЕ людям и сэкономьте их драгоценное время.
Почему это лучший копировщик сайтов?
Существуют десятки других онлайн-инструментов, которые позволяют вам загружать сайт онлайн, но почти все автономные загрузчики веб-страниц не являются полностью бесплатными.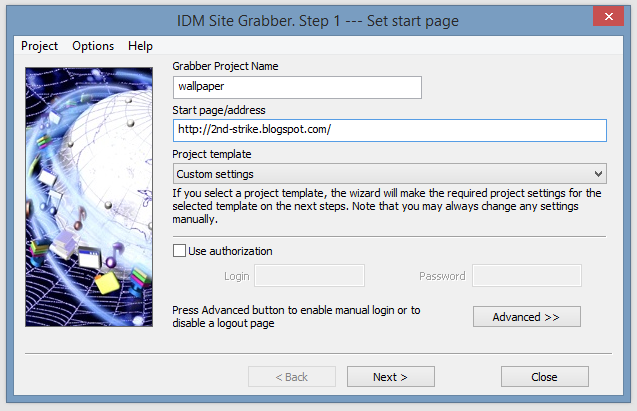 Некоторые из них дают вам попробовать загрузить сайт. Некоторые из них не предоставляют вам точный клон веб-сайта из-за их премиум-членства. Если говорить об этом рипере веб-сайтов, то вы можете совершенно бесплатно загрузить любой веб-сайт, не открывая новую вкладку.
Некоторые из них дают вам попробовать загрузить сайт. Некоторые из них не предоставляют вам точный клон веб-сайта из-за их премиум-членства. Если говорить об этом рипере веб-сайтов, то вы можете совершенно бесплатно загрузить любой веб-сайт, не открывая новую вкладку.
Online Features Ripper для веб-сайтов
Этот копировщик веб-сайтов не требует времени для загрузки или создания копии любого сайта. Если вы ищете копировщик веб-сайтов, который не требует слишком много времени для регистрации/входа в систему и чего-то еще, то этот инструмент вам определенно понравится.
Веб-сайт содержит JS/CSS и изображения в качестве своих активов веб-сайта, и они называют свои активы. Несколько других инструментов для копирования веб-сайтов переименовывают свои активы, когда они дают вам zip-файл, но в этом инструменте вы получите исходное имя активов.
Вам не нужно ничего устанавливать, чтобы просто скопировать веб-сайт, например, процесс регистрации, решение Recaptcha. Вам нужно всего лишь скопировать ссылку на веб-сайт для скачивания в буфер обмена, вставить в раздел веб-сайта и нажать кнопку «Копировать». Вот и все
Вам нужно всего лишь скопировать ссылку на веб-сайт для скачивания в буфер обмена, вставить в раздел веб-сайта и нажать кнопку «Копировать». Вот и все
Как я уже говорил об активах, он загружает все активы веб-сайта, включая изображения (jpg, jpeg, png), файлы CSS, файлы Javascript.
Почему для загрузки сайта следует использовать онлайн-копировщик веб-сайтов?
Давайте немного поговорим о причинах использования загрузчика с сайта. Если у вас есть веб-сайт конкурента, и вы хотите следовать его дизайну и не хотите посещать их веб-сайт снова и снова, тогда этот инструмент лучше всего подходит для вас. Это даст вам автономный HTML-сайт вашего конкурента, и вы сможете легко следить за их дизайном со своего компьютера, не посещая их веб-сайт. Другая причина: скажем, вы хотите сделать резервную копию своего сайта, чтобы сохранить контент для использования в автономном режиме, и вы не хотите загружать свой сайт, копируя каждый файл, тогда этот инструмент очень поможет вам и сэкономит ваше время.