
динамическая сетка в Яндекс.Клавиатуре / Хабр
Нельзя быть полностью довольным своей клавиатурой. Кажется, абсолютное большинство людей недолюбливает этот инструмент и мечтает печатать быстрее. Особенно достаётся клавиатурам мобильных устройств: в набранных с их помощью текстах в два-три раза больше ошибок, чем при десктопном вводе. Неудивительно: попробуй попади с первого раза по всем нужным кнопкам, когда они такие маленькие и никак не отделены друг от друга тактильно. А если ещё и печатать на ходу?
На связи Антон Дворкович. Вы можете помнить меня по постам о тонкостях чувашского языка и технологиях машинного перевода. Почему сегодня я рассказываю о Клавиатуре? Потому что в её основе — технологии и опыт Яндекс.Переводчика. Именно они помогают пользователям меньше ошибаться и печатать быстрее.
Из этой статьи вы узнаете не только о «классическом» подходе к исправлению опечаток с помощью подсказок и автокорректора, но и о динамической сетке, которая позволяет исправлять ошибки ещё до того, как человек их совершит.
Чуть-чуть предыстории
Сейчас довольно сложно восстановить точную хронологию превращения Яндекс.Клавиатуры из экспериментального проекта в одно из самых быстрорастущих приложений компании. Особенно если задаться целью упомянуть всех, кто приложил к ней руку, и никого не забыть. Поэтому не стану и пытаться. Скажу лишь, что в какой-то момент мы пришли к неожиданной мысли: основная функция любой клавиатуры — это набор текста. И хорошая клавиатура должна помогать пользователям печатать быстро и без ошибок. Это главное предназначение клавиатуры — на нём и нужно сфокусироваться.
Идея-то простая, но вот задачка сложная. Повлиять на размер клавиатуры мы не в силах, он ограничен габаритами мобильных устройств. А вот уменьшить количество ошибок, чтобы пользователям не приходилось тратить время на исправления, — вполне. И вот тут-то и начинается самое интересное, потому что способов их уменьшить — вагон и маленькая тележка. Кажется, мы попробовали всё и даже кое-что новое.
Подсказки и автокорректор
Когда-то давно подсказки Клавиатуры для исправления набранных слов базировались на опенсорсном компоненте из проекта AOSP. Работало шустро, просто, но не особо точно для русского языка. Затем с этой задачей пришли к нам — команде машинного перевода. На тот момент мы уже собрали внушительный Опечаточник для своих задач (снаружи он отчасти известен под названием Яндекс.Спеллер). Эта штука умеет предлагать вероятное продолжение слова, используя технологии машинного обучения. Звучит как готовое решение, но нет.
Мобильная версия накладывает много ограничений, в том числе на объём памяти и вычислительные мощности. Для масштаба: исходный Опечаточник — сервис на сотнях серверов, с тяжёлыми моделями и огромными базами данных. Для нас же было важно уместить всё на смартфоне, выполнять операции локально, не отправляя введённые символы на сервер. Чтобы всё это заработало, мы ужали модели до единиц мегабайт и ускорили их применение.
Понятно, что никакая локальная логика пока что не сравнится в качестве с серверной, поэтому мы решили дать возможность включить в настройках и «облачные» подсказки. Причём так, чтобы они работали, только когда пользователь подключён к Wi-Fi (экономим трафик и батарейку). Пришлось повозиться с HTTP/2, чтобы тормоза сети не приводили к тормозам подсказок. Всё работает бесшовно: если «дозвониться» до сервера за отведённое время (150 мс) не удалось, включатся локальные подсказки.
Свайп
Считается, что свайп — это лучший способ набирать текст быстро. Отчасти это так: по нашим данным, опытные пользователи с помощью свайпа могут набирать сообщения до двух с половиной раз быстрее, чем с использованием точечного ввода. На самом деле можно вводить текст даже быстрее. А именно — так, как задумано человеческой природой: голосом. Для этого мы добавили в Клавиатуру распознавание речи с помощью SpeechKit, но, будем честны, свайп пока что популярнее, поэтому его мы тоже решили поддержать.
Но не всё так просто. Поддержка свайпа далась нам с трудом. Первый подход и вовсе оказался неуспешным: кривые, сопоставленные словам, распределены не нормально (по Гауссу), а в общем-то очень хаотично, поэтому нужно применять хитрые модели, чтобы понимать намерения пользователей. В итоге мы добавили свайп в Яндекс.Клавиатуру, но для этого потребовалось собрать дополнительно около двух миллионов примеров с помощью Толоки. Мы даже начали экспериментировать с нейросетями, хотя в итоге победил старый добрый noisy channel.
Теперь ввод свайпом работает хорошо, хоть и не избавлен от врождённых болезней. Свайпом нельзя ввести слово, которого нет в языковой модели. Какую бы кривую вы ни нарисовали, модель подберёт слово, максимально соответствующее её рисунку из тех, что она знает. Так что для новых или придуманных слов придётся понажимать по старинке.
Подсказки и автокорректор, свайп и голосовой ввод — кажется, что это исчерпывающий список способов ускорить ввод текста на клавиатуре? Но нет, мы попробовали кое-что ещё.
Динамическая сетка
Эта идея основана на двух тезисах.
Во-первых, на смартфонах мы знаем не только какую букву выбрал пользователь Клавиатуры, но и на какую именно точку пришлось касание пальца. Если место контакта находится подозрительно близко к границе между буквами, то высока вероятность, что человек просто промахнулся.
Во-вторых, если человек набирает «ПРИВЕ», то вряд ли следующим касанием он попытается нажать Ь. Мы можем незаметно изменить размеры хитбоксов букв так, чтобы у буквы Т площадь оказалась больше, чем у мягкого знака.
Взгляните на скриншоты ниже, для подготовки которых мы включили визуальный режим отладки. Каждой клавише соответствует цветная область — хитбокс, или «мощность» клавиши. Не ищите закономерностей в оттенках, они нужны только для наглядного разделения участков. Важен размер: чем больше площадь хитбокса, тем выше вероятность, что именно туда нажмёт пользователь после текущей буквы.
Следите за мягким знаком: при наборе слова «привет» ему соответствует совсем маленький участок. В слове «приятель» — существенно больший.
В слове «приятель» — существенно больший.
То же самое, но в динамике:
Каждый введённый символ подаётся на вход двум моделям.
Языковой. Её задача — на основе истории нажатий предсказывать вероятность выбора следующих букв, независимо от геометрии. Именно в этой модели учитываются слова, которые не встречаются в наших библиотеках. Если вы систематически набираете что-то специфическое, модель запомнит, как это пишется, и перестанет исправлять на знакомые ей слова.
Геометрической. Будем честны, мы не первые, кто догадался до этого, но мы нашли, что улучшить: используем более умные двухмерные гауссовы распределения для координат, параметризованные предыдущими нажатиями. Качественно это работает так: чем ближе координата нажатия к геометрическому центру клавиши, тем выше вероятность, что ошибки нет. И наоборот.
Чтобы обучить языковую модель, достаточно машинного обучения без учителя. Алгоритм сам распознаёт, какие слова и какие буквы чаще следуют друг за другом. Но для обучения геометрической модели мы опять обратились за помощью к толокерам. Им предлагались задания, в которых следовало нажимать на определённые буквы, а мы отслеживали координаты точек касаний. Разумеется, задания были более завуалированы — мы предлагали набирать на клавиатурах мобильных устройств определённые предложения.
Но для обучения геометрической модели мы опять обратились за помощью к толокерам. Им предлагались задания, в которых следовало нажимать на определённые буквы, а мы отслеживали координаты точек касаний. Разумеется, задания были более завуалированы — мы предлагали набирать на клавиатурах мобильных устройств определённые предложения.
Языковой и геометрической моделью дело не ограничивается. Допустим, человек вводит «Пр». Что это может значить? Если он пишет кому-то сообщение, скорее всего, он собирается написать «Привет», а если хочет что-то найти на карте — «Проспект». Поэтому динамическая сетка подстраивается под специфику приложения, в котором она открыта. Для этого есть четыре режима: общий, карты, электронные магазины и мессенджеры.
Но, несмотря на все преимущества динамической сетки, если хитбокс клавиши достиг 50% от изначальной «мощности», Клавиатура никогда не подменяет её. Это важно, чтобы у нас была возможность ввести любую букву. Кроме того, если стереть последнюю букву, заработает обычная сетка, не динамическая.
Заключение
С помощью динамической сетки удаётся исправлять около 60% промахов гладко и незаметно для пользователей. Как следствие, пользователи начинают считать, что это именно они наловчились так метко попадать в клавиши, и подвох замечают только при отключении Клавиатуры. Иногда это даже обидно 🙂
Планов меньше у нас не стало. Например, люди набирают сообщения разными способами: кто-то большим пальцем, кто-то указательным, кто-то левой рукой, кто-то правой, кто-то двумя руками. В будущем, возможно, мы добавим в клавиатуру функцию преднастройки под стиль конкретного пользователя.
Кроме того, в части новых моделей телефонов есть возможность регистрировать не точки касания, а овалы, которые показывают, как палец ложится на экран. Мы собираемся с этим поэкспериментировать, и, возможно, такой подход позволит сделать Яндекс.Клавиатуру ещё полезнее.
«Яндекс» научил почту писать письма под диктовку и читать их вслух
Новости
Новости
Анастасия Марьина
Руководитель новостного отдела RB.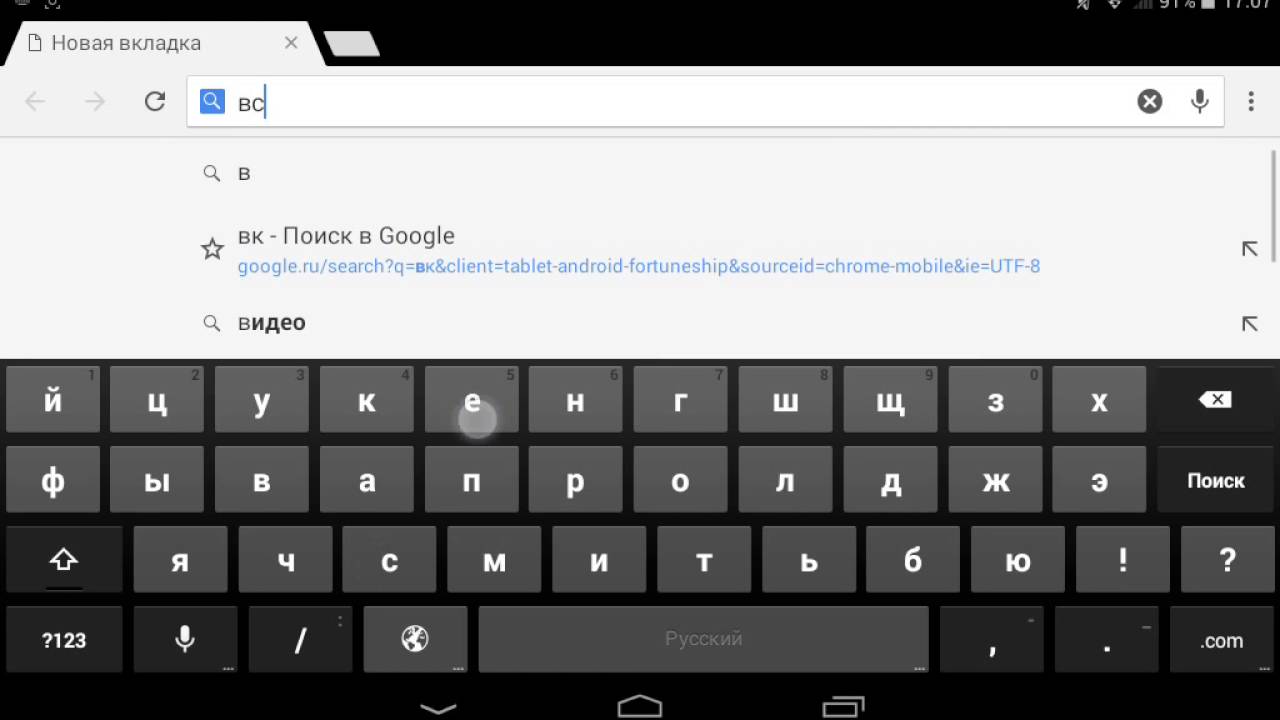 ru
ru
Анастасия Марьина
«Яндекс.Почта» запустила в приложении для iOS функцию голосового ввода текста. Об этом Rusbase рассказали в пресс-службе «Яндекса».
Анастасия Марьина
К письму также можно прикрепить аудиозапись собственного голоса — на случай, если в распознанный текст закралась ошибка, а исправлять ее не с руки.
Одновременно с голосовым вводом в почте появилось озвучивание входящих писем. Приложение может прочесть вслух тему и текст письма.
Для распознавания и озвучивания речи «Яндекс» использует комплекс технологий Yandex SpeechKit. В него входят технологии распознавания, семантического анализа и синтеза речи и технология голосовой активации. SpeechKit также используется в поиске, картах, браузере, навигаторе и других сервисах «Яндекса».
Сейчас голосовой ввод и озвучивание доступны части пользователей «Яндекс. Почты» для iOS. В течение двух недель обновление получат все пользователи iOS-приложения. О планах создать такой сервис на Android не сообщается.
Почты» для iOS. В течение двух недель обновление получат все пользователи iOS-приложения. О планах создать такой сервис на Android не сообщается.
Фото: Primakov / Depositphotos.
- Полезные сервисы
- Мобайл
- Технологии
- Яндекс
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 И советы, и реклама: как продавать товары с высоким чеком с помощью «Яндекс.Дзена»
- 2 Курьерская доставка: как настроить и использовать
- 3
Как удвоить трафик на сайт с помощью «Яндекс.
 Дзена»: кейс телеканала RU.TV
Дзена»: кейс телеканала RU.TV - 4 «Яндекс» открыл набор на оплачиваемую стажировку в Москве
- 5 Тестируем «Яндекс.Станцию Мини»: с чувством юмора все в порядке
 Дзена»: кейс телеканала RU.TV
Дзена»: кейс телеканала RU.TVВОЗМОЖНОСТИ
05 мая 2023
E-world.prototype.club
05 мая 2023
«Еда будущего»
06 мая 2023
Онлайн-программа менторства и бизнес-акселерации для предпринимательниц
Все ВОЗМОЖНОСТИ
Списки и рейтинги
Самые интересные нейросети: топ-14 сервисов для раскрашивания изображений, генерации текста и не только
Колонки
Как законно уволиться без отработки?
Истории
5 cпособов защитить себя от конкуренции с ИИ
Истории
Подборка: 10 самых популярных ИИ-генераторов изображений
Архив rb. ru
ru
Как получить больничный, если вы не больны
Переносим голосовые технологии туда, где их еще не было
Компания Kardome рада поделиться своими достижениями за прошлый год. Мы добились огромных успехов с нашей технологией голосового пользовательского интерфейса (VUI), и мы хотим воспользоваться этой возможностью, чтобы подумать о том, что значит быть в авангарде голосовых технологий. Для нас все сводится к одному: нашей миссии.
Миссия Kardome состоит в том, чтобы развивать технологию распознавания речи, которая изменит то, как люди общаются, подключаются и взаимодействуют с машинами и друг с другом.
Чтобы добиться успеха, нам нужны партнерские отношения с замечательными людьми и организациями, которые так же увлечены инновациями, как и мы. И это то, над чем мы работали в прошлом году — налаживание отношений с ключевыми людьми из ведущих организаций, которые разделяют нашу философию.
Мы также расширили нашу технологию VUI, включив в нее идентификатор голоса , анализ трехмерного звука и специфичный для предметной области ASR . Эти новые технологии обеспечат превосходное распознавание речи и голоса для потребительской электроники, автомобилей и предприятий.
Далее вы узнаете больше о нашем новом программном пакете Spatial Listening Software Suite , о некоторых наших заметных достижениях за последний год и о новых партнерских отношениях, которые мы установили, которые помогут нам выполнить нашу миссию — голос превыше всего.
Представляем программное обеспечение Kardome для пространственного прослушиванияВ этом году мы представили пакет программного обеспечения для пространственного прослушивания. Пространственное прослушивание позволяет разработчикам бытовой электроники, автомобилей и корпоративного оборудования создавать устройства распознавания речи следующего поколения, которые:
- Понять, кто говорит (голосовая идентификация)
- Где они находятся (анализ 3D-аудио)
- Что они говорят (автоматическое распознавание речи [ASR]) 9 0026
Этот улучшенный возможность распознавания речи возникает даже в самых сложных голосовых средах. В то же время конфиденциальность, оперативность и независимость пользователя поддерживаются за счет пространственного прослушивания, реализованного с использованием граничных технологий.
В то же время конфиденциальность, оперативность и независимость пользователя поддерживаются за счет пространственного прослушивания, реализованного с использованием граничных технологий.
Ниже приведен пример нашего нового пакета программного обеспечения для пространственного прослушивания в действии:
Создание новых партнерских отношений для продвижения VUI KardomeМы установили несколько новых партнерских отношений с крупными технологическими компаниями, которые проложили путь к расширению. Голосовые технологии Kardome в ближайшие годы.
От Renault Group и Hyundai в автомобильной промышленности и крупных технологических гигантов, таких как Intel и Яндекс, до компаний-разработчиков звуковых решений, таких как Knowles, Kardome прокладывает путь к созданию превосходного распознавания голоса для интеллектуальных устройств.
Kardome также представила свои голосовые технологии на Viva Tech, одном из крупнейших европейских мероприятий в области стартапов и технологий, 19-й ежегодной Шанхайской международной выставке промышленной автоматизации и робототехники и Саммите инноваций самообслуживания во Флориде.
Значимые упоминания и наградыВыдающиеся достижения Kardome включают первое место в конкурсе стартапов Reinhold Cohn Group из группы из более чем 160 стартапов.
Группа Reinhold Cohn проводит ежегодный конкурс стартапов, чтобы найти масштабируемые технологические решения для решения различных задач путем объединения глобальных организаций и инновационных стартапов.
Компания Kardome заняла первое место в конкурсе благодаря своей технологии разделения источников и шумоподавления, управляемой искусственным интеллектом, которая обеспечивает точный ввод голосовых команд в режиме реального времени и вывод звука в любой среде.
Компания Kardome также выиграла конкурс Huawei Moving Audio Tech Forward Challenge. Участникам было предложено предложить инновационные аппаратные или программные технологические решения для захвата и передачи звука, защиты и воспроизведения звука, а также рендеринга и адаптации аудиоконтента к пользователю и окружающей среде.
Участникам было предложено предложить инновационные аппаратные или программные технологические решения для захвата и передачи звука, защиты и воспроизведения звука, а также рендеринга и адаптации аудиоконтента к пользователю и окружающей среде.
Компания Kardome решила эту задачу, разработав технологию, улучшающую качество звука и разборчивость речи для устройств VUI, таких как голосовые помощники, устройства распознавания речи и приложения для преобразования речи в текст.
Кроме того, Startup Pill включил Kardome в число 30 качественных стартапов в реальном времени, на которые стоит обратить внимание в 2021 году. самый естественный и эффективный способ взаимодействия людей с машинами — то, как люди взаимодействуют друг с другом.
Проблема заключается в том, что человеко-машинное взаимодействие по-прежнему в основном осуществляется вручную (нажатие кнопок), несмотря на то, что голосовые интерфейсы существуют уже несколько десятилетий. Так почему же голосовые технологии все еще отстают от сенсорного управления и интерфейсов?
Есть две основные причины: существующие современные VUI плохо работают в шумной среде и громоздки.
Сегодня существует два важных типа VUI:
Голосовые помощникиВо-первых, это хорошо известные голосовые помощники, предоставляемые Amazon, Google, Apple и другими поставщиками облачных услуг.
Эти голосовые устройства отлично подходят для поиска, навигации и потоковой передачи.
Однако использование голосовой помощи для функционального интерфейса, т. е. открытие окна или регулировка громкости телевизора, приводит к очень громоздкому двухэтапному запросу. Например: «Привет, Алекса, уменьши громкость моего телевизора Hisense в моей гостиной».
Этот громоздкий интерфейс приводит к практически нулевому взаимодействию с клиентами.
Пользовательские VUIВторым широко используемым VUI являются те, которые производители интеллектуальных устройств, будь то автомобили или телевизоры, создают и интегрируют со своими периферийными системами.
Обычно они строят эти интерфейсы из готовых компонентов, которые лишь частично подходят друг другу. В результате эти VUI могут обслуживать клиентов только в относительно спокойной обстановке.
В результате эти VUI могут обслуживать клиентов только в относительно спокойной обстановке.
Мы в Kardome решили, что наша миссия состоит в том, чтобы оснастить машины пониманием речи на уровне человека для решения существующих проблем VUI. Поэтому мы собрали невероятно талантливую команду экспертов по речевому искусственному интеллекту, которые разработали нашу запатентованную технологию пространственного прослушивания для достижения этой цели.
Наша передовая технология пространственного прослушивания решит самые сложные проблемы VUI, позволяя машинам понимать, кто говорит, где они находятся и о чем они говорят — в любой среде. Spatial Listening Suite от Kardome предоставит пользователям конфиденциальность, оперативность и независимость.
Что ждет Kardome в будущем? Для Kardome наша цель — быть в авангарде голосовых технологий. Что это значит? Это означает делать что-то, чем никто другой не занимается — создавать технологию голосового пользовательского интерфейса, не похожую ни на что другое.
Мы хотим, чтобы люди могли легко использовать свой голос для управления своими устройствами, получения информации и взаимодействия с семьей и коллегами через видео- и аудиоплатформы.
Благодаря нашему новому набору программного обеспечения для пространственного прослушивания, новым партнерским отношениям и другим интересным разработкам, мы поднимем голосовые технологии на новый уровень в Новом году и в последующие годы.
Хотите узнать больше о Kardome?Заполните форму, чтобы записаться на прием:
Документация Voximplant | Voximplant.com
Вы можете распознавать живую речь во время активного звонка или конференции.
Копирование URL-адреса
Использование распознавания речи
Расшифровка звонка
Использование бета-функций STT Google
9002 6Передача параметров напрямую провайдеру
Есть два режима распознавания речи в Воксимплант. Подсказка фразы 9Режим 0010 распознает ввод пользователя из списка предустановленных фраз и может быть полезен в IVR и диалогах с голосовым взаимодействием. Режим Freeform распознает все вводимые пользователем данные и преобразует их в текст, что может быть полезно при преобразовании человеческого разговора в текстовый файл.
Подсказка фразы 9Режим 0010 распознает ввод пользователя из списка предустановленных фраз и может быть полезен в IVR и диалогах с голосовым взаимодействием. Режим Freeform распознает все вводимые пользователем данные и преобразует их в текст, что может быть полезно при преобразовании человеческого разговора в текстовый файл.
Вы можете использовать различные системы распознавания речи, такие как Google, Amazon, Microsoft, Яндекс или Тинькофф. Вы можете найти имена профилей здесь.
Режим Фразовая подсказка поддерживается только профилем Google. Google не ограничивает результаты указанным списком, но слова в указанном вами списке имеют более высокий шанс быть выбранными.
- Импортируйте модуль ASR в ваш сценарий с помощью метода require:
требуется (модули.ASR)
- Используйте метод VoxEngine.createASR для создания объекта ASR .
- Подпишитесь на события объекта ASR , такие как ASREvents. Result.
- Отправка мультимедиа из объекта вызова в объект ASR с помощью метода sendMediaTo
- Получить результаты через события
 Result.
Result.Если вы хотите использовать Режим Phrasehint для распознавания речи, укажите параметр PhraseHints после профиля распознавания речи. См. следующий пример кода, чтобы понять, как это работает:
ASR с подсказками
Режим Фразовая подсказка поддерживается только профилем Google.
Если вы хотите использовать режим Freeform , событие Result срабатывает каждый раз, когда распознается голос. Между захватом и распознаванием всегда есть задержка, поэтому спланируйте взаимодействие с пользователем соответствующим образом.
Используйте следующий пример кода, чтобы понять, как работает этот режим:
ASR без подсказок
Используйте метод записи, чтобы расшифровать вызов или конференцию в текстовый файл. Установите для параметра Transcribe значение true , а для параметра language — один из поддерживаемых языков.
Установите для параметра Transcribe значение true , а для параметра language — один из поддерживаемых языков.
См. следующий пример кода, чтобы понять, как это работает:
Расшифровка звонка
В отличие от аудио- и видеозаписи, результаты расшифровки доступны только после завершения звонка, поэтому их следует получать с помощью метода GetCallHistory API HTTP. . Вы должны вызвать этот метод с with_records=true указан параметр.
В ответе JSON есть записи с полем transaction_url. Значение этого поля возвращает транскрипцию в виде обычного текста:
GetCallHistory
Каждая строка в файле транскрипции имеет префикс «Левая» для аудиопотока от конечной точки вызова в облако Voximplant и «Правая» для аудиопотока из Облако Voximplant на конечную точку вызова (та же логика, что и с левым и правым аудиоканалом для стереозаписи).
Имена «Левая» и «Правая» могут быть изменены с помощью параметра labels. Параметр dict позволяет указать массив слов, которым транскрибатор пытается сопоставиться в случае проблем с распознаванием. Указание специфичных для домена слов может значительно улучшить результаты транскрипции.
Параметр dict позволяет указать массив слов, которым транскрибатор пытается сопоставиться в случае проблем с распознаванием. Указание специфичных для домена слов может значительно улучшить результаты транскрипции.
Поскольку Google предоставляет доступ к своим функциям Speech API v1p1beta1, мы также его поддерживаем.
В настоящее время распознавание речи Voximplant поддерживает следующие функции:
enableSeparateRecognitionPerChannel
alterLanguageCodes
enableWordTimeOffsets
enableWordConfidence
enableAutomaticPunctuation
diarizationConfig
метаданные
экземпляр ASR:
Экземпляр ASR с v1p1beta1
Дополнительные сведения о параметрах см. в справочнике по API.
Вот как выглядит результат запроса:
Результат ASR
С бета-функциями Google событие ASREvents.result обновляется с resultEndTime , channelTag и languageCode 900 10 свойств.