
Генератор Robots.txt — Создать robots.txt для сайта и настроить бесплатно – Онлайн сервис
| По умолчанию — All Robots are: | AllowedRefused | |
| Crawl-Delay: | По умолчанию — No Delay5 Seconds10 Seconds20 Seconds60 seconds120 Seconds | |
| Карта сайта (Sitemap): (оставить чистым, если нет) | ||
| Поисковые роботы: | Как по умолчаниюAllowedRefused | |
| Google Image | Как по умолчаниюAllowedRefused | |
| Google Mobile | Как по умолчаниюAllowedRefused | |
| Yandex | Как по умолчаниюAllowedRefused | |
| MSN Search | Как по умолчаниюAllowedRefused | |
| Yahoo | Как по умолчаниюAllowedRefused | |
| Yahoo MM | Как по умолчаниюAllowedRefused | |
| Yahoo Blogs | Как по умолчаниюAllowedRefused | |
| Ask/Teoma | Как по умолчаниюAllowedRefused | |
| GigaBlast | Как по умолчаниюAllowedRefused | |
| DMOZ Checker | Как по умолчаниюAllowedRefused | |
| Nutch | Как по умолчаниюAllowedRefused | |
| Alexa/Wayback | Как по умолчаниюAllowedRefused | |
| Baidu | Как по умолчаниюAllowedRefused | |
| MSN PicSearch | Как по умолчаниюAllowedRefused | |
| Закрыть каталоги от индексирования: | Путь относится к корню и должен содержать в конце слеш (/). «/» «/» | |
Далее: Создайте файл ‘robots.txt’ в корне Вашего сайта. Скопируйте полученное и вставьте в файл.
Robots.txt — специальный текстовый файл, размещаемый в корне каждого сайта. Данный документ содержит подробные инструкции для поисковых роботов относительно того, что им надо индексировать, а что — нет. Правильная настройка Robots.txt обязательна, если Вам необходима корректная индексация Вашего сайта.
Как создать правильный Robots.txt? Эффективное и быстрое решение для создания и настройки Robots. txt – воспользоваться онлайн сервисом на нашем сайте. В результате работы генератора Robots.txt Вы получите текст, который необходимо сохранить в файл под названием robots.txt и загрузить в корневой каталог Вашего сайта.
txt – воспользоваться онлайн сервисом на нашем сайте. В результате работы генератора Robots.txt Вы получите текст, который необходимо сохранить в файл под названием robots.txt и загрузить в корневой каталог Вашего сайта.
Создайте правильный файл robots.txt для Вашего сайта
Создайте правильный файл robots.txt для Вашего сайтаКонсалтинг и аналитикаSEO инструменты и сервисы
- SEO инструменты
- Генерация robots.txt
Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Файл должен находиться в корне сайта (то есть иметь путь относительно имени сайта /robots.txt). При наличии нескольких поддоменов файл должен располагаться в корневом каталоге каждого из них. Данный файл дополняет стандарт Sitemaps.
Файл robots.txt используется для частичного управления индексированием сайта поисковыми роботами. Этот файл состоит из набора инструкций для поисковых машин, при помощи которых можно задать файлы, страницы или каталоги сайта, которые не должны индексироваться.
Файл robots.txt может использоваться для указания расположения файла и может показать, что именно нужно, в первую очередь, проиндексировать поисковому роботу.
Поставьте к себе на сайт
Эффективным способом создания robots.txt является онлайн генератор, предоставленный нашим сервисом. С его помощью можно быстро и качественно создать необходимый файл. Скачайте созданный robots.txt и загрузите в корневую директорию вашего сайта.
Генератор robots.txt
Индексировать сайт всем роботам?
разрешитьзапретитьГлавное зеркало сайта (директива host):
Установить задержку (в сек.)
05102060120Карта сайта находится по адресу:
Запретить скачивание сайта программами (оффлайн браузерами)
robots.txt для WordPress
Запретить индексировать файл или путь:
Пример: /admin.html или /admin/
Разрешить этим роботам индексировать сайт:
- Яндекс
- Яндекс Картинки
- Mail.
 Ru
Ru - Rambler
- Google Картинки
- Google Мобильный
- Aport
- MSN Поиск
- MSN Картинки
- Yahoo
- Yahoo Картинки
 Ru
Rurobots.txt для Вашего сайта
Особенности robots.txt для Яндекс и Google
Для корректной индексации вашего сайта Яндексом, крайне желательно использовать директиву host. Это позволит избежать проблем с индексированием зеркала сайта и дублей его страниц.
Для Google, файл robots.txt ничем не существенно не отличается. Единственным ограничением, о которой Google сообщает веб-мастерам, это ограничение (500 Кб) на размер файла.
robots.txt для WordPress
Одной из особенностью CMS WordPress является то, что в ней создается много дублей страниц. Например, опубликованная Вами статья попадает сразу в несколько мест на сайте. Она попадает на страницу категорий, в поиск, анонсы на главной и т.д. Таким образом, создаются дубли страниц, что в конечном счете снижает значимость сайта в глазах поисковых роботов.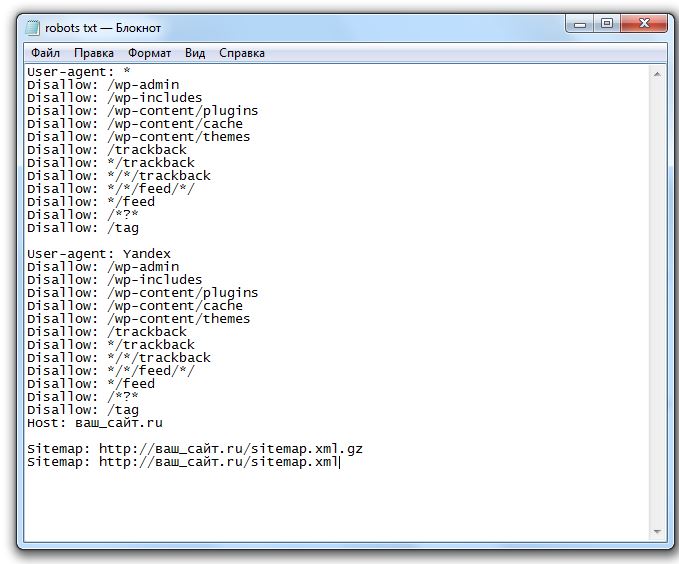 Это легко исправить с помощью robots.txt.
Это легко исправить с помощью robots.txt.
© 2022 SEO-AUDITOR
Бесплатные SEO инструменты и сервисы для веб-мастеров, оптимизаторов и копирайтеров, администраторов сайтов, серверов и сисадминов — все для OnLine анализа, оптимизации, продвижения, разработки и мониторинга сайта.
Все материалы этого сайта могут использоваться, перепечатываться, распространяться и цитироваться только с указанием ссылки на первоисточник.
Дизайн сайта “СириусВеб”
Следите за нами:
Читать @SEOAuditorRu в Twitter
Обратная связь
Мы будем рады ответить на любые ваши вопросы, просьбы и пожелания. Просто заполните форму, и наш представитель свяжется с вами в кратчайшие сроки.
Ваше имя*E-mail*
Тема
Сообщение*
Бесплатный генератор robots.txt | Создать файл Robotx.txt | SEO Image
Генератор Robots.txt
Используйте форму ниже, чтобы сгенерировать файл robots. txt для вашего веб-сайта. Форма позволит «паукам» или запретит (откажет) им индексировать содержимое ваших страниц.
txt для вашего веб-сайта. Форма позволит «паукам» или запретит (откажет) им индексировать содержимое ваших страниц.
Всегда помните, что Allow:/ должен быть последним на странице, если он вообще добавлен.
| По умолчанию — все роботы: | Алловдисаллоу | |
| Задержка сканирования: | По умолчанию — без задержки5 секунд10 секунд20 секунд60 секунд120 секунд | |
| Карта сайта: (оставьте поле пустым, если его нет) | ||
| Поисковые роботы: | Гугл | То же, что и DefaultAllowDisallow |
| Изображение Google | То же, что и DefaultAllowDisallow | |
| Google для мобильных устройств | То же, что и DefaultAllowDisallow | |
| MSN-поиск | То же, что и DefaultAllowDisallow | |
| Яху | То же, что и DefaultAllowDisallow | |
| Яху ММ | То же, что и DefaultAllowDisallow | |
| Блоги Yahoo | То же, что и DefaultAllowDisallow | |
| Аск/Теома | То же, что и DefaultAllowDisallow | |
| Гигавзрыв | То же, что и DefaultAllowDisallow | |
| Проверка ДМОЗ | То же, что и DefaultAllowDisallow | |
| Орех | То же, что и DefaultAllowDisallow | |
| Алекса/Обратный путь | То же, что и DefaultAllowDisallow | |
| Байду | То же, что и DefaultAllowDisallow | |
| Навер | То же, что и DefaultAllowDisallow | |
| MSN PicSearch | То же, что и DefaultAllowDisallow | |
| Запрещенные каталоги: | Путь указан относительно корня и должен содержать завершающую косую черту «/» | |
Теперь создайте файл robots. txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
Генератор контента Robots.txt Следующие шаги:
Здесь вы добавляете файл sitemap.xml и блокируете страницы, которые вы не хотите индексировать поисковыми системами. Наш инструмент сделает всю работу за вас, это довольно просто. Файлы Robotx.txt помогут поисковым системам найти вашу карту сайта. Блокировка страниц считается «рекомендуемой», поисковая система все еще может в некоторой степени отслеживать дату и, возможно, обслуживать страницы с низким уровнем поиска. Если вы действительно хотите, чтобы он был заблокирован, защитите паролем свои каталоги.
Генератор Robots.txt — Мгновенное создание файла Robots.txt
Об инструменте создания файла Robots.txt
Вы хотите разрешить всем поисковым роботам доступ к вашему веб-сайту или заблокировать доступ к нему некоторых поисковых роботов? Если да , используйте наш генератор файлов Google Robots.
Что такое файл robots.txt?
Хотите повысить SEO-рейтинг своего сайта? Если да, то сделать это не сложно. Вы можете сделать это естественным образом с помощью крошечного файла robots.txt.
Файл robots.txt, также известный как протокол или стандарт исключения роботов, представляет собой файл, содержащий следующие инструкции.
- Как сканировать веб-сайт.
- Каким поисковым роботам разрешен или заблокирован доступ к веб-сайту?
- Как получить доступ и индексировать содержимое веб-сайта.
- Как предоставлять этот контент пользователям.
Подводя итог, можно сказать, что файл robots.txt является стандартом, принятым веб-администраторами для инструктирования сканеров/ботов.
- Какая часть их веб-сайта нуждается в индексации.
- Какая часть их веб-сайта не нуждается в индексации. Это включает в себя страницу входа на веб-сайт, панель инструментов, дублированный контент и страницы, находящиеся в разработке.

Примечание: Сканеры/боты, такие как детекторы вредоносных программ и сборщики электронной почты, не следуют этому стандарту и пытаются сканировать слабые места на вашем веб-сайте. После обнаружения этой слабости существует значительная вероятность того, что они могут начать индексировать те части, которые вы не хотите индексировать.
SEO и robots.txt
Вы хотите занять более высокое место в результатах поиска Google и других поисковых систем? Ответ прост «Да», как и все хотят. Затем сосредоточьтесь на файле robots.txt. Я не говорю, что это единственный фактор, который может поставить вас выше. Но нет никаких сомнений в том, что это способствует повышению рейтинга SEO.
Когда сканеры/боты поисковых систем сканируют ваш сайт, они сначала ищут файл robots.txt в корне домена. Если он не будет найден, велика вероятность того, что они либо неправильно просканируют ваш веб-сайт, либо не просканируют все страницы, которые вам нужно просканировать.
Бюджет сканирования и robots.txt
Google использует краулинговый бюджет, и этот бюджет основан на краулинговом лимите. Предел сканирования — это время, которое сканеры Google проводят на вашем сайте. Но если Google считает, что сканирование вашего веб-сайта приводит к ухудшению пользовательского опыта, он будет медленно сканировать ваш веб-сайт. Медленное сканирование означает, что роботы Google будут придавать значение только основным или основным страницам вашего веб-сайта. Все новые страницы, которые вы хотите проиндексировать, либо проиндексируются со временем, либо будут проигнорированы поисковыми роботами Google.
Таким образом, чтобы решить эту проблему, каждый веб-сайт должен иметь карту сайта и файл robots.txt, чтобы сообщать поисковым роботам Google и другим поисковым системам, какая часть их веб-сайта требует большего внимания.
Характеристики файла robots.txt
- Это текстовый файл (.txt).
- Всегда в корневой папке.
- Всегда называется «robots.txt», вы не можете использовать заглавную букву «R».
- URL-адрес должен быть https://abcdomain.com/robots.txt.
- Поисковые роботы не обязаны следовать за ним.

Синтаксис robots.txt
Базовый синтаксис файла robots.txt:
.Агент пользователя: [имя агента пользователя]
Запретить: [строка URL не сканируется]
Может показаться, что создать файл robots.txt с помощью синтаксиса несложно. Но небольшая ошибка может привести к разрушительным последствиям, если какая-либо из ваших основных страниц будет исключена из индексации.
Поэтому, прежде чем создавать файл robots.txt в качестве веб-администратора или эксперта по поисковой оптимизации, вы должны знать следующие термины, используемые в файле robots.txt.
User-agent относится к определенным поисковым роботам, для которых вы хотите дать инструкции. Например, в случае паука Google, называемого ботом Google, вы можете использовать
.
Агент пользователя: Googlebot .
Запретить указывает поисковому роботу не индексировать конкретный URL-адрес. Для каждого URL разрешена только одна строка запрета. Например,
Запретить: /myfile1.html
Запретить: /myfile2.html
Разрешить указывает поисковому роботу индексировать конкретный URL-адрес. Даже если основная папка запрещена для бота Google, вы можете разрешить индексацию подпапки с помощью команды allow.
Crawl-delay указывает время в миллисекундах, которое сканеры должны ждать перед загрузкой и сканированием содержимого страницы. Например,
Задержка сканирования: 10
Однако каждый поисковый бот интерпретирует его по-своему. В Bing это временное окно, в течение которого бот посещает сайт только один раз. В Яндексе это время между последовательными посещениями. Однако вы также можете установить задержку сканирования для бота Google, но он не подтверждает эту команду.
XML Sitemap вызывает карты сайта, связанные с URL-адресом. Все ведущие поисковые системы, такие как Google, Yahoo и Bing, поддерживают эту функцию.
Как создать файл robots.txt с помощью генератора файлов Google robots.txt?
Создание файла robots.txt занимает много времени, и небольшая ошибка может привести к разрушительным последствиям. Поэтому лучше использовать какой-нибудь надежный онлайн-инструмент для создания файла robots.txt в соответствии с вашими требованиями.
Чтобы создать файл robots.txt с помощью генератора файлов Google robots.txt, выполните следующие действия.
- Откройте генератор файла robots.txt.
- Здесь вы найдете несколько вариантов. Это зависит от того, какой вариант вы хотите использовать. Однако не все параметры являются обязательными.
- Первая строка содержит значения по умолчанию для всех роботов и задержку сканирования.
- Вторая строка предназначена для URL-адреса XML-карты сайта. Упомяните его, если у вас есть. В противном случае оставьте это поле пустым.
- Следующие несколько строк содержат названия ботов поисковых систем. Предположим, вы хотите, чтобы специальный бот поисковой системы (Google) сканировал ваш сайт. Затем выберите «Разрешено» в раскрывающемся списке для бота Google или наоборот.
- Последняя строка предназначена для каталогов с ограниченным доступом.
 Упомяните его, если у вас есть. В противном случае оставьте это поле пустым.
Упомяните его, если у вас есть. В противном случае оставьте это поле пустым.Примечание: Обязательно добавьте косую черту перед заполнением поля адресом каталога или страницы.
Часто задаваемые вопросы
Как проверить, есть ли у вас файл robots.txt?
Введите имя своего домена, а затем добавьте «/robots.txt» в конец URL-адреса. Например, для домена «abcdomain.com» URL-адрес должен быть https://abcdomain.com/robots.txt.
Можем ли мы использовать robots.txt, чтобы предотвратить появление конфиденциальных данных в результатах поисковой выдачи?
В этом случае не используйте robots.![]()