
Правильный robots.txt для WordPress | Как сделать robots.txt
Содержание:
- Что такое robots.txt
- Для чего нужен robots.txt
- Как редактировать robots txt
- Правильный robots.txt для CMS WordPress
- Проверка robots.txt
Вебмастера и маркетологи знают насколько важна индексация сайта поисковыми системами. Именно поэтому они делают все возможное, чтобы помочь поисковикам типа Google и Yandex правильно сканировать и индексировать свои сайты.
Большое количество времени и ресурсов тратятся на внутреннюю и внешнюю оптимизацию, такую как контент, ссылки, теги, оптимизация изображений и структуры сайта.
Всё это играет огромную роль в продвижении. Однако если вы забыли сделать техническую оптимизацию сайта, если вы не слышали о файлах robots.txt и sitemap.xml могут возникнуть проблемы с правильным сканированием и индексацией вашего сайта.
к содержанию ↑
Что такое robots.txt
Robots.txt – это текстовый файл, который используется в качестве инструкции для роботов поисковых систем (также известных как сканеры, боты или пауки), как сканировать и индексировать страницы сайта.
Простыми словами, robots.txt говорит роботам, какие страницы или файлы сайта мы хотим видеть в поиске, а какие нет.
В идеале файл robots.txt размещается в корневом каталоге вашего веб-сайта (https://site.com/robots.txt), чтобы роботы могли сразу получить доступ к его инструкциям.
Если вы используете CMS WordPress, то вы сможете увидеть ваш файл по вышеуказанному адресу, однако вы не найдете сам файл в общей папке с вашим сайтом. Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Это потому что WordPress автоматически создает виртуальный файл robots.txt (с параметрами по-умолчанию), если не находит данный файл в корневом каталоге сайта.
Виртуальный файл robots.txt CMS WordPress не решает всех необходимых задач, в связи с этим крайне желательно написать свой.
к содержанию ↑
Для чего нужен robots.txt
Файл robots.txt нужен, для того чтобы запретить поисковым роботам посещать определенные разделы вашего сайта, например:
- страницы пагинации;
- страницы с результатами поиска на сайте;
- административные файлы;
- служебные страницы;
- ссылки с utm-метками;
- данные о параметрах сортировки, фильтрации, сравнении;
- страница личного кабинета и т.п.
Важно! Файл robots.txt не является обязательным к исполнению поисковыми роботами. В связи с этим, если вы хотите на 100% быть уверенными в том что какая-либо из страниц вашего сайта не появится в поисковой выдаче – используйте мета-тег robots.
Согласно Cправке Google файл robots.txt не предназначен для того, чтобы запрещать показ веб-страниц в результатах поиска Google.
Если вы не хотите чтобы какая-то страница вашего сайта появилась в поиске вставьте в <head> страницы атрибут noindex:
<meta name=“robots” content=“noindex,nofollow”>
к содержанию ↑
Как редактировать robots txt
Редактировать файл robots.txt в CMS WordPress можно двумя способами. Добавить необходимый код в файл functions.php, или при помощи плагина.
В нашей компании мы предпочитаем второй способ.
Устанавливаем плагин Virtual Robots.txt из репозитория CMS WordPress, открываем его в админ. панеле во вкладке Настройки. В открывшееся поле плагина вносим необходимый код, жмем кнопку Save и вуаля – ваш файл robots.txt готов.
к содержанию ↑
Правильный robots.txt для CMS WordPress
Взял с сайта seogio.ru и немного подкорректировал. Вот что получилось:
Вот что получилось:
User-agent: * # общие правила для роботов всех поисковых систем
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск по сайту
Disallow: *&s= # поиск по сайту
Disallow: /search/ # поиск по сайту
Disallow: /author/ # архив автора
Disallow: /users/ # архив пользователей
Disallow: */trackback # трекбеки, уведомления в комментариях о ссылке на веб-документ
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Allow: /*/*.js # открываем файлы скриптов js
Allow: /*/*.css # открываем фалы css
Allow: /wp-*.png # разрешаем индексировать изображения
Allow: /wp-*.jpg # разрешаем индексировать изображения
Allow: /wp-*.jpeg # разрешаем индексировать изображения
Allow: /wp-*.gif # разрешаем индексировать гифки
Allow: /wp-admin/admin-ajax.php # разрешаем ajax
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail. RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz


к содержанию ↑
Проверка robots.txt
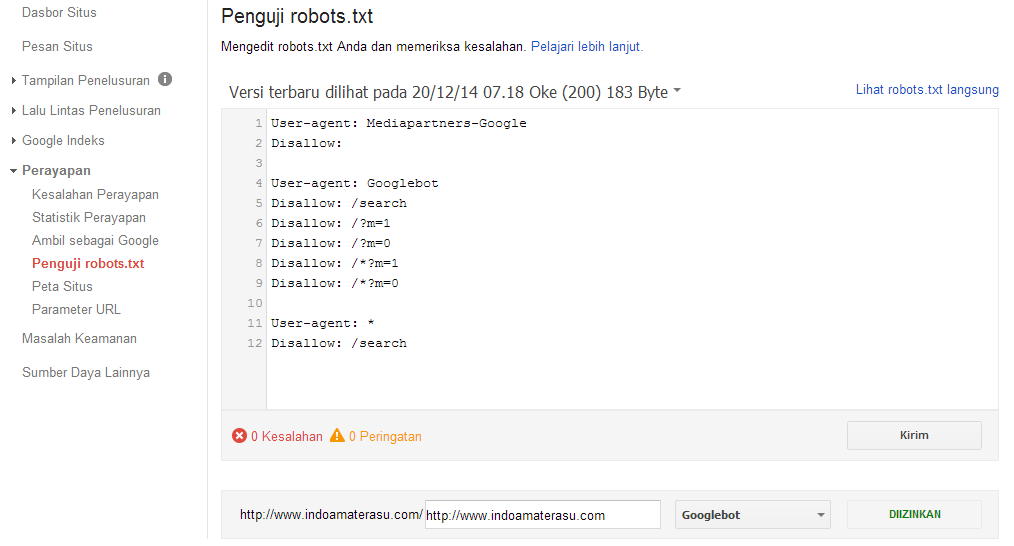
Если файл robots.txt настроен неправильно это может привести к множественным ошибкам в индексации сайта. Проверить правильность настройки вашего robots.txt можно с помощью бесплатного инструмента Google Robots Testing Tool
Выбираем наш сайт:
Вводим в строку путь к нашему файлу robots.txt и жмем кнопку Проверить:
В результате не должно быть ошибок и предупреждений и файл должен быть Доступен для роботов:
Если файл robots.txt настроен правильно, это значительно ускорит процесс индексации вашего сайта.
Правильный robots txt для сайта, инструкция новичкам Блог Ивана Кунпана
Оглавление:
- Что такое файл robots txt, зачем он нужен и за что он отвечает
- Где находится robots txt, как увидеть его?
- Как создать правильный robots txt для сайта
- Генераторы robots txt
- Плагины robots txt для WordPress
- Создать robots txt вручную
- Использовать правильный robots txt с чужого сайта
- Как залить на сайт файл robots txt в корневую папку сайта
- Проверка файла robots txt
- Заключение
Здравствуйте друзья! В статье показано, что такое правильный robots txt для сайта, где он находится, способы создания файла robots, как адаптировать под себя файл robots с другого сайта, как его залить к себе на блог.
к оглавлению ↑
Что такое файл robots txt, зачем он нужен и за что он отвечаетФайл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.

Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
к оглавлению ↑
Где находится robots txt, как увидеть его?Думаю, многие новички задают себе вопрос – где находится robots txt? Находится файл в корневой папке сайта, в папке public_html, его можно увидеть достаточно просто. Вы можете зайти на хостинг, открыть папку своего сайта и посмотреть есть там этот файл или нет. В прилагаемом ниже видео, показано, как это сделать. Можно посмотреть файл и с помощью Яндекс вебмастера и Google webmaster, но об этом поговорим позже.
В прилагаемом ниже видео, показано, как это сделать. Можно посмотреть файл и с помощью Яндекс вебмастера и Google webmaster, но об этом поговорим позже.
Есть вариант еще проще, который позволяет посмотреть не только свой robots txt, но и robots любого сайта, Вы можете robots скачать к себе на компьютер, а затем адаптировать его к себе и использовать на своём сайте (блоге). Делается это так – Вы открываете нужный Вам сайт (блог), и через слэш дописываете robots.txt (смотрите скрин)
и нажимаете Enter, открывается файл robots txt. В данном случае, Вы не можете видеть, где находится robots txt, но можете его посмотреть и скачать.
к оглавлению ↑
Как создать правильный robots txt для сайтаСоздать robots txt для сайта можно различными вариантами:
- использовать генераторы онлайн, которые быстро создадут файл robots txt, сайтов и сервисов, которые это умеют делать, достаточно много;
- использовать плагины для WordPress, которые помогут решить эту задачу;
- составить файл robots txt своими руками вручную в обычном блокноте или программе NotePad++;
- использовать готовый, правильный robots txt с чужого сайта (блога), заменив в нем адрес своего сайта.
.png)
к оглавлению ↑
Генераторы robots txtИтак, ранее генераторами создания файлов robots txt я не пользовался, но перед написанием данной статьи решил протестировать 4 сервиса по генерации файлов robots txt, получил определённые результаты, о них позже скажу. Вот эти сервисы:
- [urlspan]SEOlib[/urlspan];
- [urlspan]сервис PR-CY[/urlspan];
- [urlspan]сервис Raskruty.ru[/urlspan];
- seo café зайти сюда можно по этой ссылке — info.seocafe.info/tools/robotsgenerator.
О том, как использовать генератор robots txt на практике, подробно показано в прилагаемом ниже видео. В процессе испытания пришел к выводу, что они для этого новичкам не подходят, и вот почему? Генератор позволяет только оформить правильную запись без ошибок самого файла, а для составления правильного robots txt все равно нужно обладать знаниями, надо знать, какие папки закрыть, какие нет. По этой причине использовать генератор robots txt чтобы создать файл, новичкам не рекомендую.
По этой причине использовать генератор robots txt чтобы создать файл, новичкам не рекомендую.
к оглавлению ↑
Плагины robots txt для WordPressЕсть плагины, например, PC Robots.txt для создания файла. Этот плагин позволяет редактировать файл прямо в панели управления сайтом. Другой плагин iRobots.txt SEO – этот плагин с похожим функционалом. Вы можете найти кучу различных плагинов, которые позволяют работать с файлом robots txt. При желании Вы можете задать в поле «Поиск плагинов» словосочетание robots. txt и нажать кнопку «Поиск» и Вам будет предложено несколько плагинов. Конечно, о каждом из них надо прочитать, посмотреть отзывы.
Принцип работы плагинов robots txt для WordPress очень похож на работу генераторов. Чтобы получить правильный robots txt для сайта, нужны знания и опыт, а откуда он может быть у новичков? По моему мнению, от подобных сервисов можно получить больше вреда, чем пользы. А если устанавливать плагин, так он еще и хостинг нагрузит. По этой причине устанавливать плагин robots txt WordPress не рекомендую.
А если устанавливать плагин, так он еще и хостинг нагрузит. По этой причине устанавливать плагин robots txt WordPress не рекомендую.
к оглавлению ↑
Создать robots txt вручнуюМожно создать robots txt вручную, используя обычный блокнот или программу NotePad++, но для этого должны быть знания и опыт. Новичкам этот вариант тоже подходит мало. Но со временем, когда появится опыт, можно будет это делать, причем составить файл robots txt для сайта, прописать директивы Disallow robots, закрыть от индексации нужные папки, выполнить проверку robots и его корректировку можно всего за 10 минут. На приведенном скрине показан роботс тхт в блокноте:
Сам порядок создания файла robots txt здесь рассматривать не будем, об этом подробно написано во многих источниках, например, в Яндекс вебмастер. Перед составлением файла роботс тхт, необходимо зайти в Яндекс Вебмастер, где подробно расписана каждая директива, что за что отвечает и на основании этой информации составить файл. (смотрите скрин).
(смотрите скрин).
Кстати, новый Яндекс вебмастер предлагает подробную и развернутую информацию, статью о новом Яндекс вебмастере можно посмотреть на блоге. Точнее представлено две статьи, которые принесут большую пользу блоггерам и не только новичкам, советую прочитать.
Если Вы не новичок и хотите сделать robots txt самостоятельно, то нужно соблюдать ряд правил:
- Использование национальных символов в файле robots txt не допускается.
- Размер файла robots не должен превышать 32 Кбайт.
- В названии файла robots нельзя писать типа Robots или ROBOTS, файл нужно подписать именно так, как показано в статье.
- Каждую директиву нужно начинать с новой строки.
- В одной строке нельзя указывать больше одной директивы.
- Директива «Disallow» с пустой строкой равнозначна директиве «Allow» — разрешить, это надо помнить.
- Нельзя ставить пробел в начале строки.
- Если не сделать пробел между различными директивами «User-agent», то роботы воспримут только верхнюю директиву – остальные проигнорируют.
- Сам параметр директивы нужно прописать только одной строкой.
- Нельзя заключать параметры директивы в кавычки.
- Нельзя после директивы закрывать строку точкой с запятой.
- Если файл robots не будет обнаружен или будет пустой, то роботы будут это воспринимать, как «Всё разрешено».
- Можно делать комментарии в строке директивы (чтобы было понятно, что это за строка), но только после знака решетка #.
- Если сделать пробел между строками, то это будет означать конец директивы User-agent.
- В директивах «Disallow» и «Allow» должен быть указан только один параметр.
- Для директив, которые являются директорией ставится слэш, например – Disallow/ wp-admin.
- В разделе «Crawl-delay» нужно рекомендовать роботам временной интервал между скачиванием документов с сервера, обычно это 4-5 секунд.
- Важно — между директивами не должно быть пустых строк. Новая директива начинается через один пробел. Это означает конец правил для поискового робота, в прилагаемом видео это подробно показано. Звёздочки означают последовательность любых символов.
- Все правила я советую повторять отдельно для робота Яндекса, то есть все директивы, которые были прописаны для других роботов, повторить для Яндекса отдельно. В конце информации для робота Яндекса надо записать директиву хост (Host — она поддерживается только Яндексом) и указать свой блог. Хост указывает Яндексу, какое зеркало Вашего сайта главное с www или без.
- Кроме того в отдельной директории файла роботс тхт, то есть через пробел, рекомендуется указывать адрес карты вашего сайта. Создание файла можно сделать за несколько минут и начинается с фразы «User-agent:». Если Вы хотите закрыть от индексации, например, картинки, то надо прописать Disallow: /images/.

 Звёздочки означают последовательность любых символов.
Звёздочки означают последовательность любых символов.к оглавлению ↑
Использовать правильный robots txt с чужого сайтаИдеального файла не существует, периодически нужно пробовать экспериментировать и учитывать изменения в работе поисковых систем, учитывать те ошибки, которые со временем могут появиться на Вашем блоге. Поэтому для начала можно взять чужой проверенный файл robots txt и установить его к себе.
Поэтому для начала можно взять чужой проверенный файл robots txt и установить его к себе.
Обязательно надо изменить записи, которые отражают адрес Вашего блога в директории Host (смотрите скрин, смотрите также видео), а также заменить на свой адрес сайта в адресе карты сайта (две нижние строки). Со временем этот файл немного надо подкорректировать. Например, Вы обратили внимание, что у Вас начали появляться дубли страниц.
В разделе «Где находится robots txt, как увидеть», который находится выше, мы рассматривали, как посмотреть и скачать robots txt. Поэтому, нужно выбрать хороший трастовый сайт, у которого высокие показатели Тиц, высокая посещаемость, открыть и скачать правильный robots txt. Нужно сравнить несколько сайтов, выбрать для себя нужный файл роботс тхт и залить себе его на сайт.
к оглавлению ↑
Как залить на сайт файл robots txt в корневую папку сайтаКак уже писалось, после создания сайта на WordPress, по умолчанию, файл robots txt отсутствует. Поэтому его надо создать и закачать в корневую папку нашего сайта (блога) на хостинг. Закачать файл достаточно просто. На хостинге TimeWeb можно закачать напрямую, на других хостингах закачать можно либо через FileZilla, либо через FTP соединение с помощью Total Commander. В видео, которое расположено ниже, показан процесс закачки файла robots txt на хостинг TimeWeb.
Поэтому его надо создать и закачать в корневую папку нашего сайта (блога) на хостинг. Закачать файл достаточно просто. На хостинге TimeWeb можно закачать напрямую, на других хостингах закачать можно либо через FileZilla, либо через FTP соединение с помощью Total Commander. В видео, которое расположено ниже, показан процесс закачки файла robots txt на хостинг TimeWeb.
к оглавлению ↑
Проверка файла robots txtПосле закачки файла robots txt, нужно проверить его наличие и работу. Для этого можем посмотреть файл с браузера, как показано выше в разделе «Где находится robots txt, как увидеть». А проверить работу файла можно с помощью Яндекс вебмастера и Google webmaster. Помним, что для этого должны быть подтверждены права на управление сайтом, как в Яндексе, так и в Google.
Для проверки в Яндексе заходим в наш аккаунт Яндекс вебмастера, выбираем сайт, если у Вас их несколько. Выбираем «Настройка индексирования», «Анализ robots.![]() txt», а дальше следуем инструкциям.
txt», а дальше следуем инструкциям.
В Google вебмастер делаем аналогично, заходим в наш аккаунт, выбираем нужный сайт (если их несколько), нажимаем кнопку «Сканирование» и выбираем «Инструмент проверки файла robots.txt». Откроется файл robots txt, Вы можете его исправить или проверить.
На этой же странице находятся отличные инструкции по работе с файлом robots txt, можете с ними ознакомиться. В заключении привожу видео, где показано что представляет собой файл robots txt, как его найти, как его посмотреть и скачать, как работать с генератором файла, как составить robots txt и адаптировать под себя, показана другая информация:
к оглавлению ↑
ЗаключениеИтак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете [urlspan]зайти на него[/urlspan] и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
С уважением, Иван Кунпан.
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
 Продвижение блога статьями«.
Продвижение блога статьями«.Просмотров: 13748
Что такое файлы WordPress robots.txt и как их использовать
Искусство и наука о том, как вывести ваш веб-сайт на высокие позиции в результатах различных поисковых систем, обычно называют SEO (поисковая оптимизация). И есть много разных аспектов, когда дело доходит до SEO, возможно, слишком много, чтобы охватить их в одной статье. Вот почему сейчас мы сосредоточимся только на одном — файле WordPress robots.txt. В этой статье мы углубимся в то, что такое файл robots.txt и как его использовать. Среди прочего, мы обсудим различные способы создания файла и рассмотрим лучшие практики в отношении его директив.
Что такое файл «robots.txt»
Robots.txt — это текстовый файл, расположенный в корневом каталоге WordPress. Вы можете получить к нему доступ, открыв URL-адрес your-website.com/robots.txt в браузере. Он служит для того, чтобы роботы поисковых систем знали, какие страницы вашего сайта следует сканировать, а какие нет. Строго говоря, сайту не обязательно иметь файл robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше всего сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать ваш сайт независимо от того, есть у вас файл robots.txt или нет.
Строго говоря, сайту не обязательно иметь файл robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше всего сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать ваш сайт независимо от того, есть у вас файл robots.txt или нет.
Однако наличие файла robots.txt с соответствующими директивами дает немало преимуществ после того, как ваш веб-сайт WordPress будет завершен. Оптимизированные директивы robots.txt не только не позволяют сканерам сканировать ненужный контент, но и гарантируют, что ваша квота сканирования (максимальное количество раз, которое сканер может сканировать ваш веб-сайт в течение заданного времени) не будет потрачена впустую.
Кроме того, хорошо написанные директивы WordPress robots.txt могут уменьшить негативные последствия плохих ботов, запретив им доступ. Это, в свою очередь, может улучшить общую скорость загрузки вашего сайта . Но имейте в виду, что директивы robots. txt не должны быть вашей единственной защитой. Плохие боты часто игнорируют эти директивы, поэтому настоятельно рекомендуется использовать хороший плагин безопасности, особенно если на вашем сайте возникают проблемы, вызванные плохими ботами.
txt не должны быть вашей единственной защитой. Плохие боты часто игнорируют эти директивы, поэтому настоятельно рекомендуется использовать хороший плагин безопасности, особенно если на вашем сайте возникают проблемы, вызванные плохими ботами.
Наконец, распространено заблуждение, что файл robots.txt может препятствовать индексации некоторых страниц вашего веб-сайта. Файл robots.txt может содержать директивы, запрещающие сканирование, а не индексацию . И, даже если страница не просканирована, ее все равно можно проиндексировать по внешним ссылкам, ведущим на нее. Если вы хотите избежать индексации конкретной страницы, вам следует использовать метатег noindex вместо директив в файле robots.txt.
Темы Qode: Лучшие темы
View Collection
Bridge
Креативная многоцелевая тема WordPress
Stockholm
Действительно мультиконцептуальная тема
Startit
Fresh Startup Business Theme
Как использовать файл «robots.
 txt»
txt»Выяснив, что такое файл robots.txt WordPress и что он делает, мы можем рассмотреть, как он используется. В этом разделе мы расскажем, как создать и отредактировать файл robots.txt, о некоторых полезных практиках в отношении его содержимого и о том, как проверить его на наличие ошибок.
Как создать файл robots.txt
По умолчанию WordPress создает виртуальный файл robots.txt для любого веб-сайта. Такой файл может выглядеть примерно так, например:
Однако, если вы хотите отредактировать его, вам нужно будет создать настоящий файл robots.txt. В этом разделе мы объясним три способа, которыми вы можете это сделать. Два из них связаны с использованием плагинов WordPress, а третий основан на использовании FTP.
Йоаст SEO
С более чем 5 миллионами активных установок Yoast SEO является одним из самых популярных доступных SEO-плагинов. Он имеет множество инструментов для оптимизации сайта, в том числе функцию, которая позволяет пользователям создавать и редактировать файлы robots. txt.
txt.
После установки плагина нажмите на вновь созданный SEO раздел , а затем нажмите на Tools подраздел . На открывшейся странице щелкните ссылку редактора файлов вверху.
На следующей странице найдите раздел robots.txt . Оттуда, если вы еще не создали его раньше, вы должны нажать кнопку Создать файл robots.txt .
Будет создан файл, и вы сможете увидеть его содержимое в текстовой области. Используя ту же текстовую область, вы сможете редактировать содержимое вашего нового файла robots.txt. Когда вы закончите редактирование файла, нажмите кнопку Сохранить изменения в robots.txt ниже.
Все в одном SEO
All in one SEO — еще один очень популярный SEO-плагин, который поставляется с различными бесплатными функциями, включая те, которые позволяют пользователям создавать и редактировать файлы WordPress robots.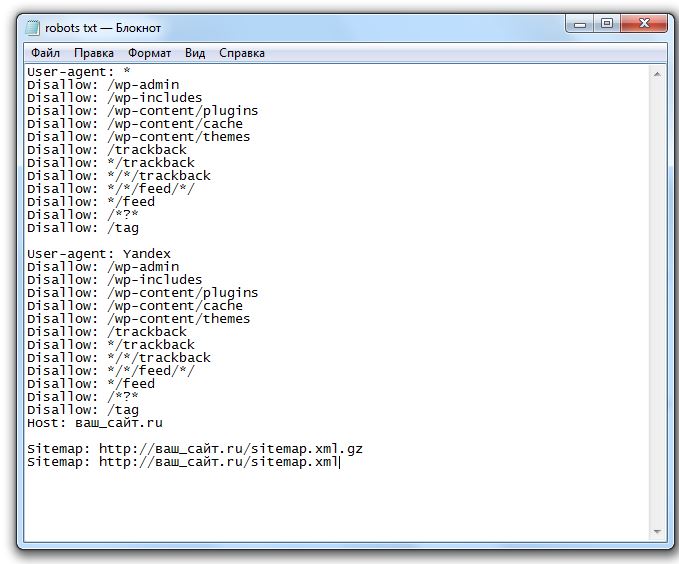 txt.
txt.
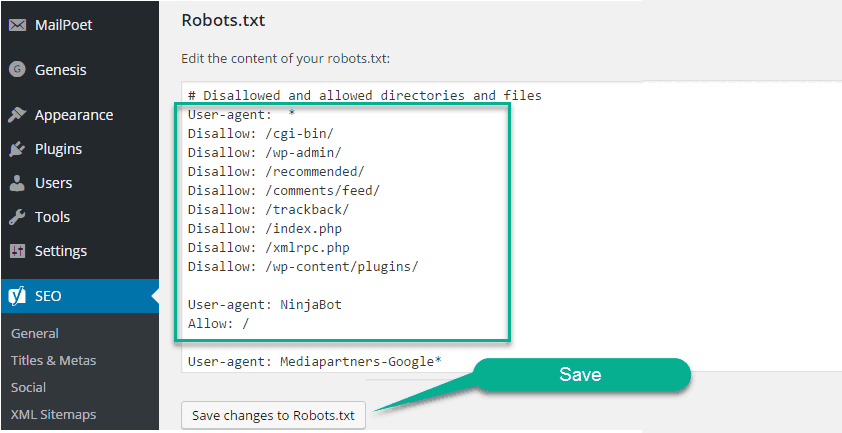
После установки плагина щелкните новый раздел All in One SEO в меню панели инструментов, а затем щелкните параметр Feature Manager . На странице Feature Manager найдите Robots.txt функцию , а затем нажмите кнопку Activate рядом с ней.
Будет создан файл robots.txt. После этого вы также увидите сообщение об успешном завершении, указывающее, что параметры были обновлены . И появится новый подраздел под названием Robots.txt .
Нажав на опцию Robots.txt , вы увидите новый раздел. Там вы сможете добавить новые правила/директивы в файл robots.txt, а также посмотреть, как он выглядит на данный момент.
Помимо использования плагина WordPress, вы можете просто создать файл robots.txt вручную. Сначала создайте пустой файл типа .txt на своем компьютере и сохраните его как robots.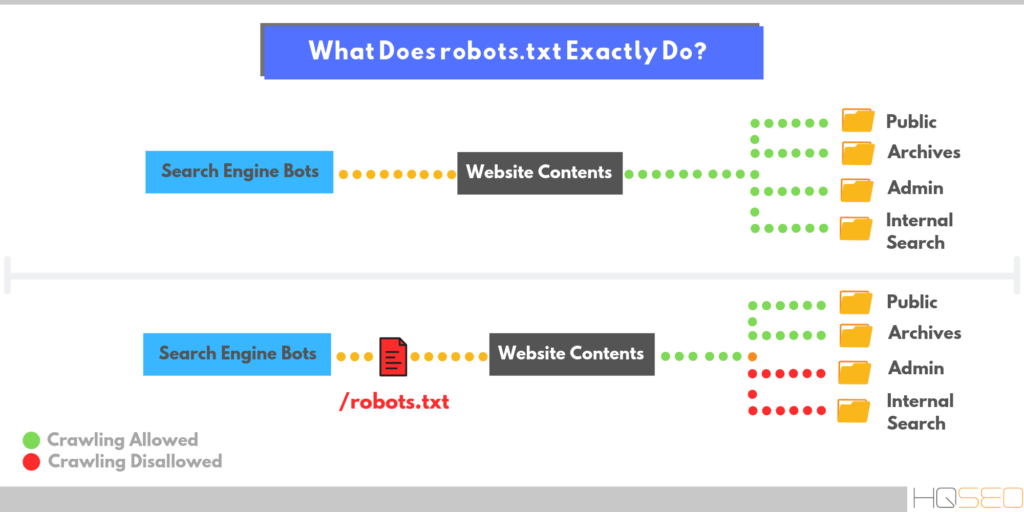 txt .
txt .
Затем вам нужно загрузить его на свой сервер с помощью FTP. Если вы не знакомы с FTP, вам следует узнать больше об использовании FTP, прежде чем продолжить.
Когда вы будете готовы, подключитесь к вашему серверу, используя ваши учетные данные FTP . Затем в правой части перейдите в корневой каталог WordPress , часто называемый public_html. В левой части вашего FTP-клиента (мы используем Filezilla) найдите файл robots.txt 9.0010, который вы ранее создали и сохранили на своем компьютере. Щелкните правой кнопкой мыши на нем и выберите опцию Загрузить .
Через несколько секунд файл будет загружен, и вы сможете увидеть его среди файлов в корневом каталоге WordPress.
Если вы хотите впоследствии отредактировать загруженный файл robots.txt, найдите его в корневом каталоге WordPress, щелкните его правой кнопкой мыши и выберите параметр View/Edit .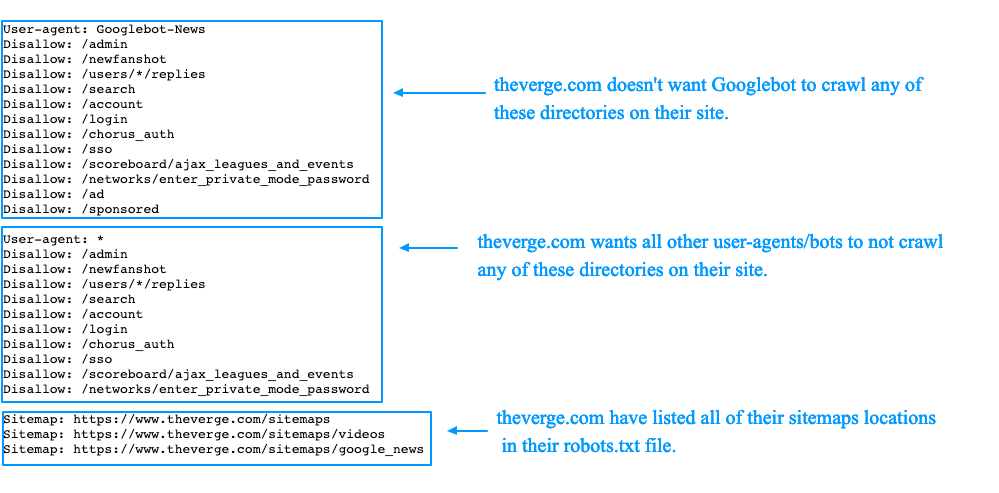
Добавление правил в файл robots.txt
Теперь, когда вы знаете, как создавать и редактировать файл robots.txt, мы можем подробнее поговорить о директивах, которые может содержать этот файл. Чаще всего в robots.txt присутствуют две директивы: User-agent и Disallow .
Директива агента пользователя указывает, к какому боту применяются директивы, перечисленные под директивой агента пользователя. Вы можете указать одного бота (например, User-agent: Bingbot) или сделать директивы применимыми ко всем ботам, поставив звездочку (Агент пользователя: *).
Директива Disallow запрещает боту доступ к определенной части вашего веб-сайта. А еще есть директива Allow, которая просто делает противоположное . Вам не нужно использовать его так часто, как Disallow, потому что боты имеют доступ к вашему сайту по умолчанию. Директива Allow обычно используется в сочетании с директивой Disallow.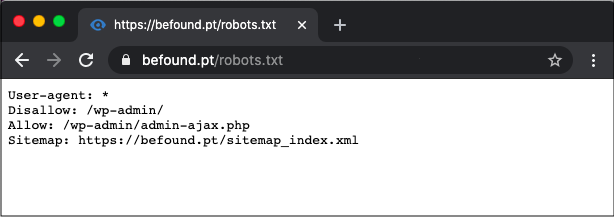 Точнее, он служит для разрешения доступа к файлу или подпапке, принадлежащей запрещенной папке.
Точнее, он служит для разрешения доступа к файлу или подпапке, принадлежащей запрещенной папке.
Кроме того, есть еще две директивы: Crawl-delay и Карта сайта . Директива Crawl-delay используется для предотвращения перегрузки сервера из-за чрезмерных запросов на сканирование. Однако, эту директиву следует использовать с осторожностью , поскольку она не поддерживается некоторыми поисковыми роботами (например, Googlebot) и по-разному интерпретируется сканерами, которые ее поддерживают (например, BingBot). Директива Sitemap служит для указания поисковым системам вашего XML-файла карты сайта. Настоятельно рекомендуется использовать эту директиву, так как она может помочь вам отправить созданную карту сайта в формате XML в консоль поиска Google или инструменты Bing для веб-мастеров. Но имейте в виду, что вы должны использовать абсолютный URL-адрес для ссылки на вашу карту сайта (например, Карта сайта: https://www. example.com/sitemap_index.xml) при использовании этой директивы.
example.com/sitemap_index.xml) при использовании этой директивы.
В следующем разделе мы покажем вам два фрагмента кода, чтобы проиллюстрировать использование директив robots.txt, о которых мы упоминали выше. Однако это только примеры; в зависимости от вашего веб-сайта вам может понадобиться другое подмножество директив. С учетом сказанного давайте посмотрим на фрагменты.
Этот пример фрагмента кода запрещает доступ ко всему каталогу /wp-admin/ для всех ботов, за исключением файла /wp-admin/admin-ajax.php, который находится внутри.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Этот фрагмент открывает доступ к папке /wp-content/uploads/ для всех ботов. При этом запрещает доступ к папкам /wp-content/plugins/, /wp-admin/ и /refer/, а также к файлу /readme.html для всех ботов. Пример ниже показывает правильный способ написания нескольких директив; независимо от того, относятся ли они к одному или другому типу, обязательно по одному в ряду.
Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта.
 Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта.
Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта. User-Agent: *
Разрешить: /wp-content/uploads/
Запретить: /wp-content/plugins/
Запретить: /wp-admin/
Запретить: /readme.html
Запретить: /refer/
Карта сайта: https://www.example.com/sitemap_index.xml
Тестирование файла robots.txt
После того, как вы добавите директивы, соответствующие требованиям вашего веб-сайта, вы должны протестировать файл robots.txt WordPress. Поступая таким образом, вы проверяете, что в файле нет синтаксических ошибок, и убедитесь, что соответствующие области вашего веб-сайта были правильно разрешены или запрещены.
Чтобы протестировать файл robots.txt вашего веб-сайта, перейдите на веб-сайт SEO-тестирования . Затем вставьте любой URL-адрес, управляемый вашим веб-сайтом (URL-адрес вашей домашней страницы, например), выберите пользовательский агент (например, Googlebot) и нажмите кнопку Test .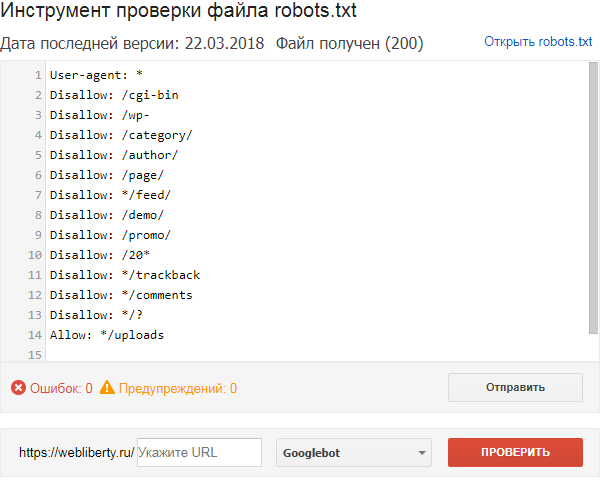
Если URL доступен для сканирования, вы увидите зеленый результат с надписью Разрешено . В противном случае будет указано Disallowed . Чтобы подтвердить правильность директив сканирования на своем веб-сайте, вы можете повторить тот же процесс для любого количества различных URL-адресов на своем веб-сайте.
Заключительные мысли
Файл robots.txt — это текстовый файл, расположенный в корневом каталоге каждого сайта WordPress. Он содержит директивы для сканеров, сообщающие им, какие части вашего веб-сайта они должны или не должны сканировать. Хотя этот файл по умолчанию является виртуальным, знание того, как создать его самостоятельно, может быть очень полезным для ваших усилий по SEO.
Вот почему мы рассмотрели различные способы создания физической версии файла и поделились инструкциями по его редактированию. Кроме того, мы коснулись основных директив, которые должен содержать файл WordPress robots.txt, и того, как проверить, правильно ли вы их установили.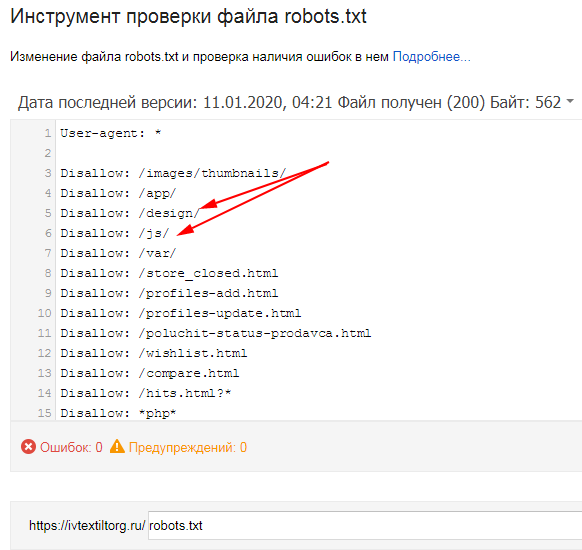 Теперь, когда вы освоили все это, вы можете подумать о том, как разобраться с другими аспектами SEO вашего сайта.
Теперь, когда вы освоили все это, вы можете подумать о том, как разобраться с другими аспектами SEO вашего сайта.
Как исправить ошибку «Веб-сканер не может найти файл robots.txt»
Robots.txt — важный файл для правильной работы сайта. Именно здесь сканеры поисковых систем находят информацию о страницах веб-ресурса, которые следует сканировать в первую очередь, а на какие вообще не стоит обращать внимание. Файл robots.txt используется, когда необходимо скрыть некоторые части сайта или весь сайт от поисковых систем. Например, место с личной информацией пользователя или зеркало сайта.
Что делать, если системный аудитор не видит этот файл? Об этом и других проблемах, связанных с файлом robots.txt, читайте в нашей статье.
Как работает файл robots.txt?
robots.txt — это текстовый документ в кодировке UTF-8. Этот файл работает для протоколов http, https и FTP. Тип кодировки очень важен: если файл robots.txt закодирован в другом формате, поисковая система не сможет прочитать документ и определить, какие страницы следует распознавать, а какие нет. Другие требования к файлу robots.txt следующие:
Другие требования к файлу robots.txt следующие:
- все настройки в файле актуальны только для сайта, на котором находится robots.txt;
- расположением файла является корневой каталог; URL-адрес должен выглядеть так: https://site.com.ua/robots.txt;
- размер файла не должен превышать 500 Кб.
При сканировании файла robots.txt поисковым роботам предоставляется разрешение на сканирование всех или некоторых веб-страниц; им также может быть запрещено это делать.
Об этом можно здесь.
Коды ответов поисковой системы
Поисковый робот сканирует файл robots.txt и получает следующие ответы:
- 5XX – разметка временной ошибки сервера, при которой сканирование останавливается;
- 4XX — разрешение на сканирование каждой страницы сайта;
- 3XX — перенаправлять до тех пор, пока сканер не получит другой ответ. После 5 попыток исправлена ошибка 404;
- 2XX – успешное сканирование; все страницы, которые необходимо прочитать, распознаются.
Если при переходе на https://site.com.ua/robots.txt поисковая система не находит или не видит файл, будет ответ «robots.txt не найден».
Причины ответа «robots.txt не найден»
Причины ответа поискового робота «robots.txt не найден» могут быть следующими:
- текстовый файл расположен по другому URL-адресу;
- файл robots.txt не найден на сайте.
Дополнительная информация об этом видео Джона Мюллера из Google.
Обратите внимание! Файл robots.txt находится в каталоге основного домена, а также в поддоменах. Если вы включили поддомены в аудит сайта, файл должен быть доступен; в противном случае сканер сообщит об ошибке о том, что файл robots.txt не найден.
Почему это важно?
Отсутствие исправления ошибки «robots.txt не найден» приведет к некорректной работе поисковых роботов из-за некорректных команд из файла. Это, в свою очередь, может привести к падению рейтинга сайта, некорректным данным о посещаемости сайта. Также, если поисковые системы не увидят robots.txt, будут просканированы все страницы вашего сайта, что нежелательно. В результате вы можете пропустить следующие проблемы:
Это, в свою очередь, может привести к падению рейтинга сайта, некорректным данным о посещаемости сайта. Также, если поисковые системы не увидят robots.txt, будут просканированы все страницы вашего сайта, что нежелательно. В результате вы можете пропустить следующие проблемы:
- перегрузка сервера;
- бесцельное сканирование страниц с одинаковым содержанием поисковыми системами;
- больше времени для обработки запросов посетителей.
От бесперебойной работы файла robots.txt зависит бесперебойная работа вашего веб-ресурса. Поэтому давайте рассмотрим, как исправить ошибки в работе этого тестового документа.
Как исправить файл robots.txt?
Чтобы поисковые роботы правильно реагировали на ваш файл robots.txt, он должен быть правильно отлажен. Проверьте текстовый документ безопасности на наличие следующих ошибок:
- Значения директив перепутаны. Запретить или разрешить должны быть в конце фразы.
- Несколько URL-адресов страниц в одной директиве.
