
Что такое robots.txt ✔️ Блог Webpromo
20.10.2022
Редакция: Оля Сомова. Автор: Ольга Сомова
Результаты поисковой выдачи содержат релевантные ресурсы в ответ на пользовательский запрос. Перед тем как дать информацию, поисковые роботы сканируют сайт и отправляют в индекс. Как управлять Google ботами? В статье разбираем, что такое robots.txt, из чего он состоит и какие инструменты для составления файла существуют? Зачем нужен файл robots.txt?
Содержание:
- Как поисковые боты сканируют страницы?
- Что такое robots.txt?
- Структура файла robots.txt
- ТОП-6 ошибок в robots.txt
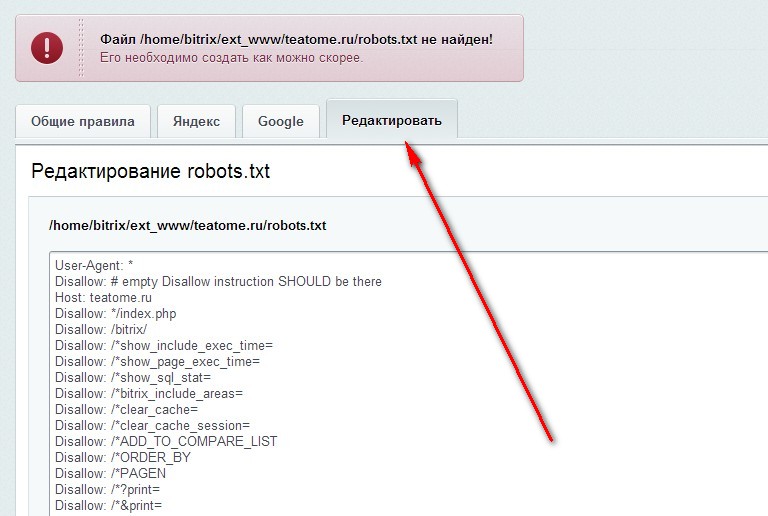
- Пример robots.txt
- Создание и валидация robots.txt
- Сервисы и инструменты для проверки robots.txt
- Что исключать из индекса с помощью robots.txt?
- Выводы
Читайте также: Веб-архив.
Поисковые роботы — это системные алгоритмы, которые проверяют доступные страницы в интернете. Google индексирует информацию, которую вы публикуете. Можно ли управлять ботами? Есть возможность направить системных ботов. Для этого необходимо создать файл robots.txt и показать, какие страницы стоит индексировать, а какие нет.
Как поисковые боты сканируют страницы?
Работа поисковых ботов заключается в поиске нового контента, которые они добавляют в поисковый индекс. Их также называют алгоритмами, краулерами. Боты переходят по ссылкам на страницах в интернете и сканируют содержащую информацию. Когда пользователь вводит запрос в строку, релевантные результаты извлекаются из индекса и ранжируются согласно рейтингу.
Задача поисковых роботов — предоставить пользователям лучшие варианты ответов на их запросы. Почему это важно? Понимание того, как боты находят, индексируют и ранжируют контент, поможет повлиять на позиции сайта в органических результатах поисковой выдачи.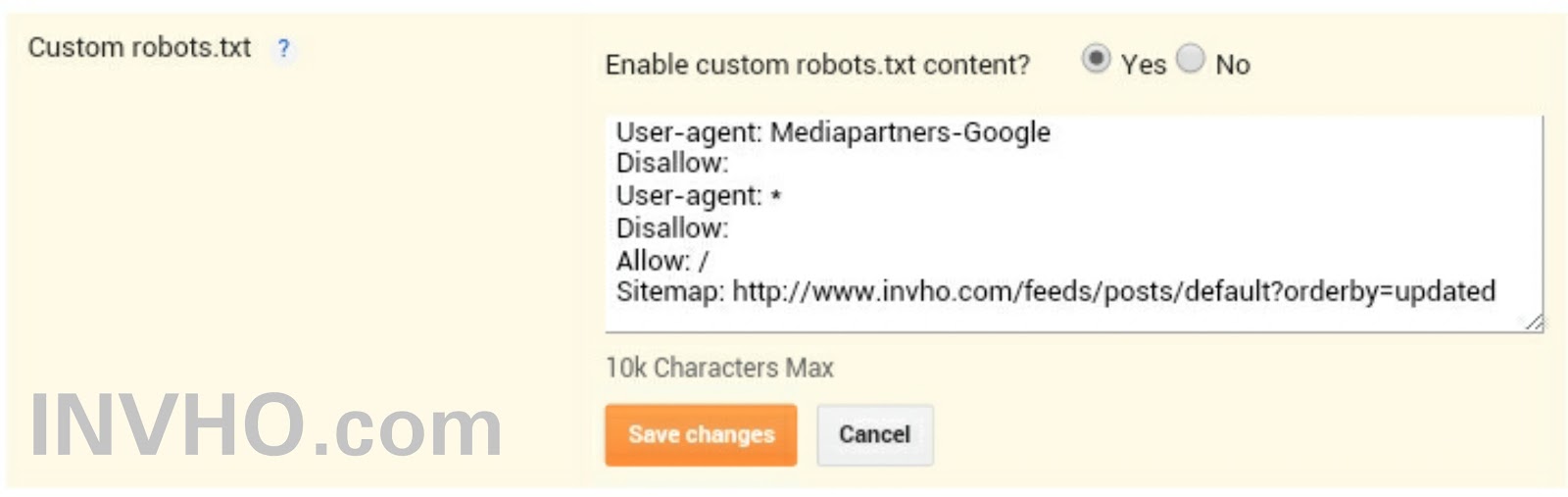
Как поисковики сканируют страницу? Рассмотрим самую популярную поисковую систему в мире Google, доля рынка которой составляет 92%.
Google содержит индекс, где находится больше триллиона веб-страниц. Поэтому система всегда сможет найти любую ссылку, ресурс и т.д. Алгоритмы начинают индексировать с URL-адреса. Далее Googlebot сканирует и обрабатывает страницы согласно прописанному алгоритму и после этого отправляет в цифровую библиотеку под названием поисковый индекс.
Существует понятие, как краулинговый бюджет. Это ограниченное количество страниц, которое боты могут проиндексировать за один раз, и определяется в индивидуальном порядке. Поэтому важно исключать ненужные данные и указывать, что именно необходимо отправить в индекс. Robots.txt это файл, с помощью которого это можно реализовать.
Что такое robots.txt?
Отвечая на вопрос, что такое robots.txt это инструкция, хранящийся в формате текста на сервере. Текст robots.txt это команды, созданные из латинских символов. С помощью этой информации поисковые роботы понимают, какие страницы можно индексировать. Если не прописывать robots.txt, система будет индексировать все страницы, включая дубли или другой «мусор». Каждая строка robots.txt несет одну команду в форме директивы.
Текст robots.txt это команды, созданные из латинских символов. С помощью этой информации поисковые роботы понимают, какие страницы можно индексировать. Если не прописывать robots.txt, система будет индексировать все страницы, включая дубли или другой «мусор». Каждая строка robots.txt несет одну команду в форме директивы.
Читайте также: Рейтинг популярных поисковых систем в мире и Украине за 2022. Сравниваем результаты прошлого и текущего года
Robots.txt можно редактировать по необходимости, чтобы закрыть отдельные страницы от индексации. Чаще это лендинги под временные акции и распродажи, версии для печати, системные файлы и каталоги, пустые страницы.
Важно! 500 кб — максимальный размер файла robots.txt, установленный Google.
При обработке robots.txt, роботы получают 3 правила для индексирования:
- Полный доступ дает разрешение для сканирования всего сайта.

- Частичный доступ позволяет сканировать отдельные элементы.
- При полном запрете Googlebot не сможет ничего просканировать.

Структура файла robots.txt
Robots.txt это текстовый файл, который прописывается в блокноте, любом текстовом редакторе (Notepad++, Sublime). Его добавляют в корневую часть сайта. Такие кодовые инструкции для роботов задаются с помощью директив с различными параметрами.
Структура robots.txt это:
- user-agent — название робота, который должен просканировать данную страницу
- allow/disallow — директивы (команды) для выполнения роботами
Что такое robots.txt и из чего он состоит? Разберем директивы robots.tx по отдельности.
User-agent
Указывает робота, для которого будут актуальны описанные правила robots.txt. К популярным относятся:
- Googlebot — основной бот Google.
- Googlebot-Image — бот картинок.
- Googlebot-Mobile — индексатор мобильной версии.
- Googlebot-Video — робот для сканирования видео.

Готовый текстовый документ robots.txt следует загрузить в корневую папку с названием сайта, где находится файл index.html и файлы движка.
Поисковая система каждый раз при сканировании будет обращаться к robots.txt. Это дает ей информацию и понимание, что можно индексировать, что нет.
Директива allow/disallow
Команда robots.txt разрешает или запрещает сканирование. Для каждого отдельного раздела, папки или URL нужно прописывать правила с помощью знака «/». Например:- Для запрета папки сайта указываем такую последовательность в robots.txt это:
Disallow: /folder/ - Для запрета только одного файла (в данном случае изображения):
Disallow: /folder/img.jpg
Директива sitemap
Директива Sitemap в robots.txt это направление ботам, где найти карту сайта в формате XML, что поможет им быстрее ориентироваться в структуре ресурса.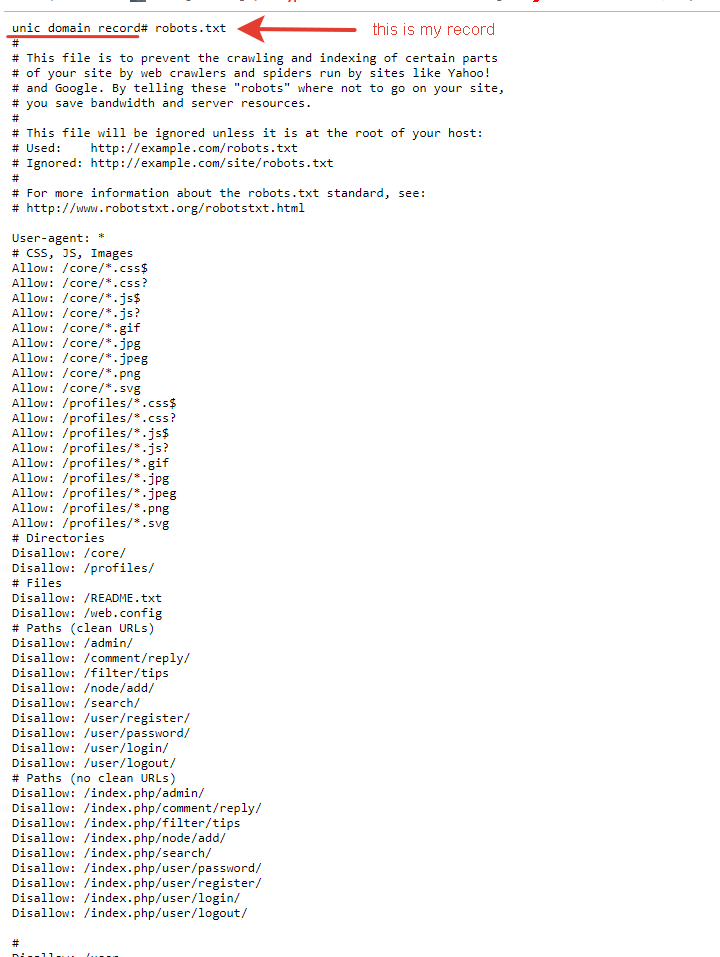
Читайте также: Как проверить индексацию сайта в Google и что делать, если страниц нет в выдаче?
Директива Clean-param
Правило robots.txt это запрет для индексации информации, которая содержит динамические параметры. Это страницы с одинаковым контентом — дубли, приводящие к понижению позиции сайта в выдаче.
Директива Crawl-delay
Команда robots.txt подходит для крупных сайтов с большим количеством страниц, что может влиять на скорость загрузки. Каждый раз когда роботы заходят на сайт, это также дает дополнительную нагрузку.
Чтобы снизить давление на сервер, следует использовать в robots.txt директиву Crawl-delay, которая ограничивает количество сканирований. Время в секундах — это параметр, который указывает роботам, сколько раз за определенный период следует сканировать сайт.
ТОП-6 ошибок в robots.txt
Ошибки в robots.txt это нарушения, которые приводят к последствиям.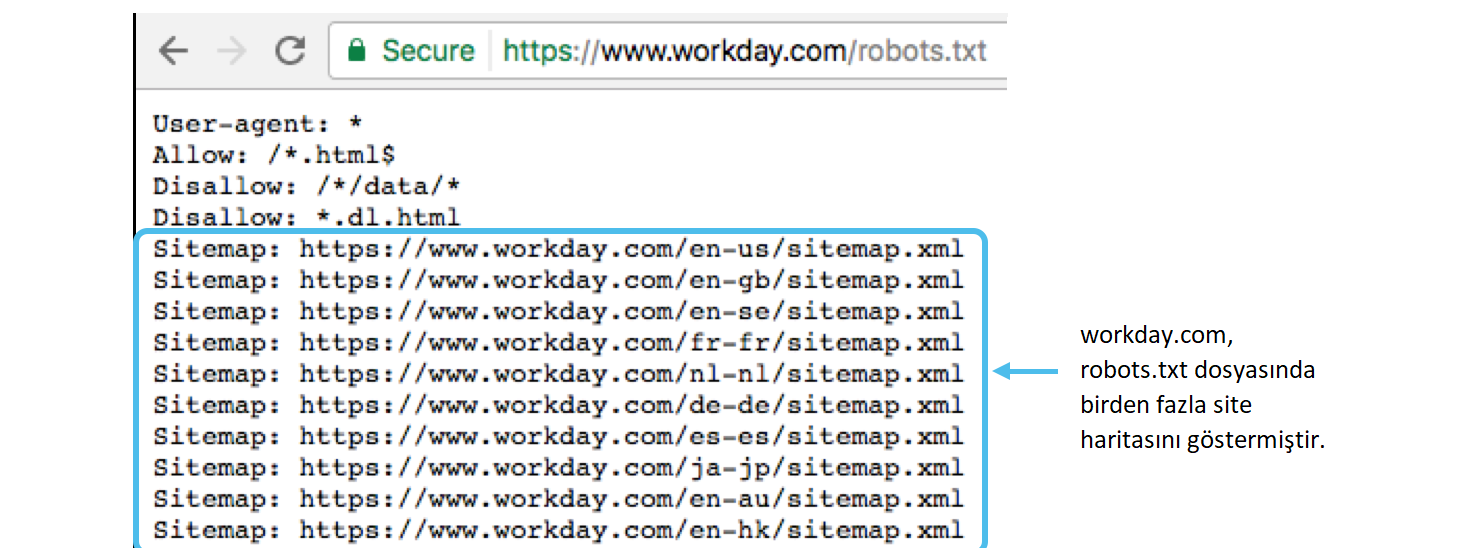 Как отмечает Google, у поисковых роботов гибкие алгоритмы, поэтому небольшие недочеты в robots.txt не сказываются на их работе. Однако если в robots.txt есть ошибки, лучше их исправить. Какие распространенные ошибки существуют в robots.txt?
Как отмечает Google, у поисковых роботов гибкие алгоритмы, поэтому небольшие недочеты в robots.txt не сказываются на их работе. Однако если в robots.txt есть ошибки, лучше их исправить. Какие распространенные ошибки существуют в robots.txt?
- Неправильное расположение robots.txt. Где находится robots.txt? Напомним, что robots.txt это файл, который должен быть расположен в корневой папке. В обратном случае роботы не смогут его найти.
- Ошибка названия. Всегда название следует писать с маленькой буквы — robots.txt.
- Перечисление папок через запятую. Каждое новое правило пишется с новой строки. При перечислении правил через запятую директива robots.txt не сработает.
- Отсутствие ссылки на файл sitemap.xml. С помощью него роботы получают информацию о структуре сайта и его главных разделах, которые Google сканируют в первую очередь. Данный пункт robots.txt особенно важен для SEO-продвижения сайта.
- Пустые команды в robots.txt это папки и файлы для индексирования или закрытия от индексации, которые нужно не забывать прописывать. Многие специалисты оставляют открытые (пустые) allow/disallow.
- Отсутствие проверок robots.txt. Если вы закрываете отдельные страницы, следует периодически проверять установленные правила. Для этого используйте валидатор.

Пример robots.txt
Приводим пример что такое robots.txt:
Создание и валидация robots.txt
Как сделать robots.txt? Потребуется обычный текстовый редактор, встроенный блокнот на компьютере или любой другой сервис. Robots.txt пишется вручную.
Чтобы знать, как правильно составить robots.txt, воспользуйтесь онлайн-генераторами. Это сервисы, с помощью которых можно автоматически быстро сгенерировать robots.txt. Такой способ подойдет для тех, кто имеет несколько сайтов. После автоматической генерации, robots.txt необходимо проверить вручную правильность его написания, чтобы избежать ошибок.
Еще один вариант как создать robots.txt это использовать готовые шаблоны. В интернете есть большое количество файлов для популярных CMS, например WordPress. Шаблон включает стандартные директивы, что упрощает процесс написания, нет необходимости создавать robots.txt с нуля.
Учитывайте, что для написания robots.txt важно владеть базовыми знаниями синтаксиса.
Как мы указывали выше в статье, проверить robots.txt можно несколькими способами. Обнаружить ошибки поможет Google Search Console, который показывает, какие страницы не прошли индексацию.
Сервисы и инструменты проверки robots.txt
Важно проверять правильность написания robots.txt, чтобы сайт корректно сканировался роботами и попадал в поисковый индекс. Для этого советуем использовать дополнительные сервисы:
Google Search Console — главный инструмент для проверки robots.txt, если говорить о системе Google. Сервис включает отдельный раздел как настроить robots.
Seositecheckup — сторонний инструмент для проверки robots.txt на ошибки.
Также можно проверить доступность robots.txt через браузер. Для этого к домену необходимо дописать /robots.txt. Следует провести проверку в нескольких браузерах.
Читайте также: Как Google ранжирует сайты? Ключевые слова как фактор
Что исключать из индекса с помощью robots.txt?
Robots.txt это возможность управлять поисковыми алгоритмами и направить их на главные страницы сайта, которые будут видеть пользователи. Правильный robots.txt не должен содержать следующие пункты:
- Дубли страниц. Каждая из них имеет индивидуальный URL с уникальным контентом;
- Страницы с неуникальным контентом;
- Данные с показателями сессий;
- Файлы, связанные с системой CMS и управлением сайтом (шаблоны, темы, панель администратора).

Исключать с помощью robots.txt это значит закрыть все, что не приносит пользу, а также то, что еще находится на стадии доработки или разработки, дублируется, нерелевантные страницы.
Выводы
Googlebot периодически сканирует и индексирует сайт, чтобы определить его позицию в поисковой выдаче. Алгоритмы знают, что такое robots.txt и считывают правила, указанные в файле. Текстовый документ robots.txt включает директивы или команды, с помощью которых роботы определяют какие страницы доступны для индексации.
Существует несколько вариантов, как создать robots.txt для сайта. Важно также понимать, где находится robots.txt и как его настроить. Не забываем делать проверки на ошибки через сервисы.
Robots.TXT — инструкция
Что такое robots.txt
Robots.txt — это стандартный текстовый файл в кодировке UTF-8 с расширением .txt, который содержит директивы и инструкции индексирования сайта, его страниц или разделов. Он необходим для роботов поисковых систем. В статье расскажем, зачем он нужен, какие инструменты используются для его проверки и настройки под Яндекс и Google, а также представим рекомендации по созданию.
Он необходим для роботов поисковых систем. В статье расскажем, зачем он нужен, какие инструменты используются для его проверки и настройки под Яндекс и Google, а также представим рекомендации по созданию.
Это первый файл, к которому обращаются поисковые системы, чтобы определить, может ли проводиться индексация сайта. Файл располагается в корневой директории сайта. Разместить его можно через FTP-клиент. Файл должен быть доступен в браузере по ссылке вида site.ru/robots.txt. На него нужно смотреть в первую очередь, если на сайт “упал трафик”.
Рассмотрим наиболее простой пример содержимого robots.txt (кстати, в названии должен быть строго нижний регистр букв), которое позволяет поисковым системам индексировать все разделы сайта:
User-agent: *
Allow: /
Эта инструкция дословно говорит: роботы, которые читают данную инструкцию (User-agent: *), могут индексировать весь сайт (Allow: /).
Зачем он вообще необходим? Чтобы это понять, достаточно представить, как работает поисковый робот. Им по умолчанию приходится просматривать миллиарды страниц по всему интернету, а затем определить для каждой страницы запросы, которым они могут соответствовать. В конце они ранжируют общую массу в поисковой выдаче. Конечно, это задача не из легких. Для работы поисковых алгоритмов задействуются колоссальные ресурсы, которые, конечно, ограничены.
Им по умолчанию приходится просматривать миллиарды страниц по всему интернету, а затем определить для каждой страницы запросы, которым они могут соответствовать. В конце они ранжируют общую массу в поисковой выдаче. Конечно, это задача не из легких. Для работы поисковых алгоритмов задействуются колоссальные ресурсы, которые, конечно, ограничены.
Если кроме страниц, которые содержат полезный контент и которые по задумке владельца сайта должны попадать в выдачу, роботу придется просматривать еще множество технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут растрачиваться впустую. Лишь один сайт может генерировать тысячи страниц результатов поиска по сайту, повторяющихся страниц или таких страниц, которые не содержат контента вообще. А если этот объем масштабировать на всю сеть, то получатся огромные цифры и соответствующие ресурсы, которые придется тратить поисковикам.
Наличие огромного количества бесполезного контента на сайте может отрицательно сказаться на его представлении в поиске.
Помимо этого, существует такое понятие, как краулинговый бюджет. Условно говоря, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, конечно, ограничен, хоть по мере роста проекта и повышения его качества краулинговый бюджет может увеличиваться. Главная мысль в том, в выдаче должны участвовать лишь страницы, которые содержат полезные записи, а весь технический «мусор» не должен засорять выдачу.
Зачем Robots.txt нужен для SEO?
Если на сайте нет robots.txt, то роботы из поисковых систем будут беспорядочно блуждать по всему сайту. Роботы могут попасть в корзину с мусором, после чего они «сделают вывод», что на сайте слишком грязно. А с помощью robots.txt можно скрыть определенные страницы от индексации. Его нужно создавать для каждого поддомена.
Правильно заполненный файл robots.txt с верной последовательностью позволит роботу создать представление, что на сайте всегда чисто и убрано. Важно регулярно проверять содержимое.
Где находится и как создать?
Файл robots.txt размещается в корневой директории сайта: путь к файлу robots станет таким: site.ru/robots.txt.
Принцип настройки и как редактировать. Техническая часть
После написания файла Robots его текст можно редактировать в процессе оптимизации ресурса, например, в Notepad. Делать это нужно в текстовом файле robots.txt с соблюдением правил и синтаксиса файла, но не в HTML редакторе. После редактирования на сайт можно выгрузить обновленную версию файла. Кстати, для определенны CMS есть специальные плагины и дополнения, которые дают возможность редактировать файл прямо в админ панели.
Подробнее рассмотрим список директив, используемые символы и принципы настройки.
User-Agent
Это обязательная директива, которая определяет, к какому роботу будут применяться прописанные ниже в файле правила. Иными словами, это обращение к конкретному роботу или всем поисковым ботам. Все файлы должны начинаться именно с этой строчки.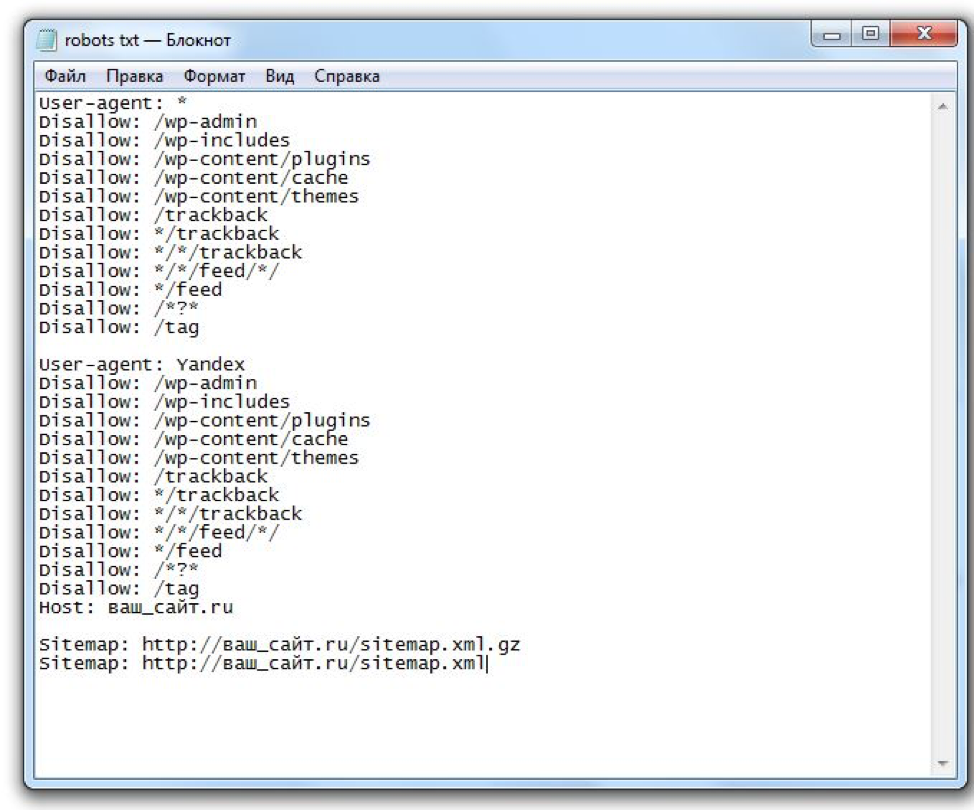 Пустой эту строку оставлять нельзя. Регистр символов в значениях директивы User-agent (пользовательский агент) не принимается во внимание.
Пустой эту строку оставлять нельзя. Регистр символов в значениях директивы User-agent (пользовательский агент) не принимается во внимание.
Disallow
Disallow. Наиболее распространенная директива, запрещающая индексировать определенные страницы или целые разделы веб-сайта. В этой строке можно использовать спец символы * и $. Точка с запятой не используются. Пробел в начале строки ставить можно, но не рекомендуется.
Что нужно исключить из индекса?
- В первую очередь роботу необходимо запретить включать в индекс любые дубли страниц. Доступ к странице должен осуществляться лишь по одному URL. Обращаясь к сайту, поисковый бот по каждому URL должен получить в ответ страницу строго с уникальным содержанием. Дубли нередко появляются у CMS в процессе создания страниц. Так, один и тот же документ можно найти по техническому домену в формате http:// site.ru/?p=391&preview=true и “человекопонятному” URL http:// site.ru/chto-takoe-seo. Часто дубли появляются и из-за динамических ссылок. Важно их все скрывать от индекса с помощью масок (писать каждую команду нужно с новой строки):
Disallow: /*?*
Disallow: /*%
Disallow: /index.php
Disallow: /*?page=
Disallow: /*&page=
2. Все страницы с неуникальным контентом, например, статьями, новостями, а также политикой конфиденциальности, картинками, изображениями и проч. Такие документы стоит скрыть от поисковых машин, прежде чем они начнут индексироваться.
3. Все страницы, которые используются при работе сценариев. К примеру, это те, где есть сообщения наподобие “Спасибо за ваш отзыв!”.
4. Страницы, которые включают индикаторы сессий. Для подобных страниц тоже рекомендуется использовать директиву Disallow с соответствующими символами. В строке указывается:
Disallow: *PHPSESSID=
Disallow: *session_id=
5. Все файлы движка управления сайтом. Это файлы шаблонов, администраторской панели, тем, баз и другие. Возможные исключения:
Все файлы движка управления сайтом. Это файлы шаблонов, администраторской панели, тем, баз и другие. Возможные исключения:
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
6. Бесполезные для пользователей страницы и разделы. К примеру, не имеющие какого-либо содержания, с неуникальным контентом, несуществующие и так далее. Их роботу видеть не стоит. Кроме этого, для робота Googlebot при необходимости можно заблокировать выдачу сайта в новостях через Googlebot-News, а через Googlebot-Image — запретить показ изображений в Гугл Картинках.
Рекомендуем держать файл robots.txt всегда в порядке и в чистоте, и тогда ваш сайт будет индексироваться значительно быстрее и лучше, а ранжироваться выше.
Запрет конкретного раздела сайта
User-agent: *
Disallow: /admin/
Запрет на сканирование определенного файла
User-agent: *
Disallow: /admin/my-embarrassing-photo.
 png
png
Полная блокировка доступа к хосту
User-agent: *
Disallow: /
Разрешить полный доступ
Разрешает полный доступ:
User-agent: *
Disallow:
Allow
С помощью такой директивы можно, напротив, допустить каталог или конкретный адрес для того, чтобы он индексировался. В некоторых случаях быстрее и легче запретить к сканированию весь сайт и с помощью строки Allow открыть роботу необходимые разделы.
User-agent: *#
Блокируем весь раздел /admin
Disallow: /admin#
Кроме файла /admin/css/style.css
Allow: /admin/css/style.css#
Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow: /admin/js/
Директива Crawl-delay
Директива, которая не актуальна в случае Goolge, но очень полезна для работы с другими поисковиками, например, Яндекс или даже Yahoo. .
.
С ее помощью можно замедлить сканирование, если сервер бывает перегружен. Она задает интервал времени для обхода страниц в секундах (актуально для Яндекса). Чем выше значение, тем медленнее краулер станет обходить страницы сайта.
User-agent: *
Crawl-delay: 5
Хотя Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Важно, что китайским Baidu тоже не учитывается наличие Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт лишь единожды.
Стоит учитывать: если установлено высокое значение Crawl-delay, самое главное — убедиться, что сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано менее 2880 страниц в день, и этот показатель не слишком велик для крупных сайтов.
Директива Clean-param
Директива Clean-param дает возможность запрещать поисковому роботу обход страниц с динамическими параметрами, контент которых не имеет отличий от основной страницы. Например, многие интернет-магазины используют параметры в url-адресах, которые отправляют данные по источникам сессий, в том числе персональные идентификаторы пользователей.
Например, многие интернет-магазины используют параметры в url-адресах, которые отправляют данные по источникам сессий, в том числе персональные идентификаторы пользователей.
Чтобы поисковые роботы не заходили на данные страницы и лишний раз не создавали нагрузку на сервер, можно использовать директиву Clean-param, которая поможет оставить в выдаче только исходный документ.
Давайте рассмотрим использование данной директивы на примере. Например, что сайт собирает информацию по пользователям на страницах:
https:// site.ru/get_book/?userID=1&source=site_2&book_id=3
https:// site.ru/get_book/?userID=5&source=site_4&book_id=5
https:// site.ru/get_book/?userID=9&source=site_11&book_id=2
Параметр userID, который есть в каждом url-адресе, показывает персональный идентификатор пользователя, а параметр source показывает источник, из которого посетитель попал на сайт.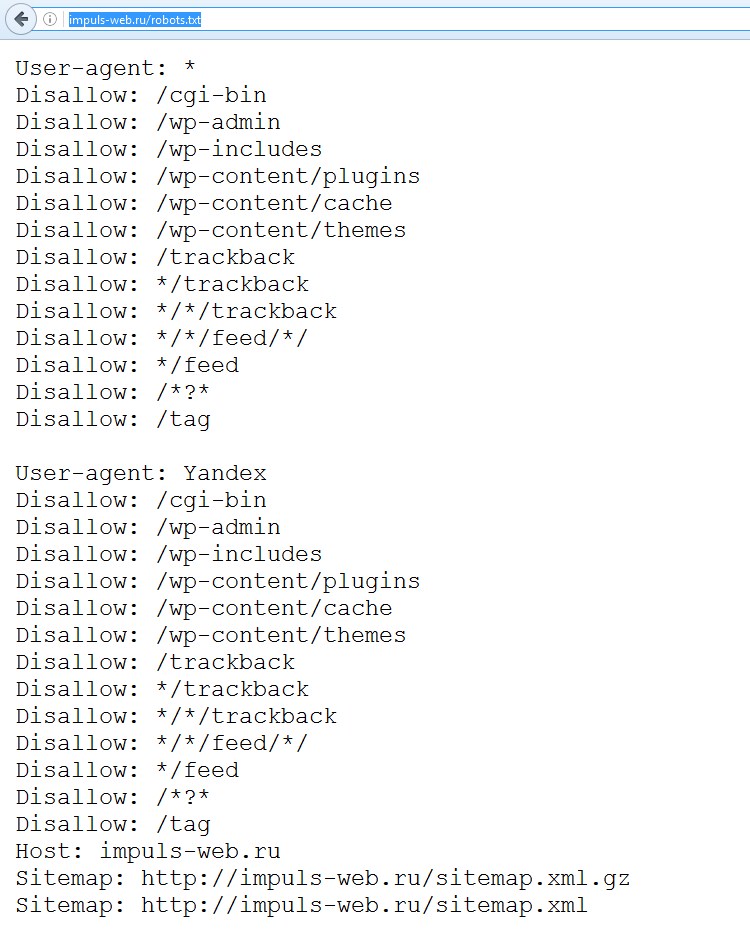 По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В этом случае нам необходимо использовать директиву Clean-param таким образом:
По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В этом случае нам необходимо использовать директиву Clean-param таким образом:
User-agent: Yandex
Clean-param: userID /books/get_book.pl
Clean-param: source /books/get_book.pl
Данные директивы позволяют поисковому роботу Яндекса свести все динамические параметры в единую страницу:
https:// site.ru/books/get_book.pl?&book_id=3
Если на сайте есть такая страница, то именно она станет индексироваться и участвовать в выдаче.
Главное зеркало сайта в robots.txt — Host
С марта 2018 года Яндекс отказался от директивы Host. Ее функции полностью перешли на раздел «Переезд сайта в Вебмастере» и 301-редирект.
Директива Host указывает поисковому роботу Яндекса на главное зеркало сайта. Если сайт был доступен сразу по нескольким разным URL адресам, например, с www и без www, требовалось настроить 301 редирект на главный URL адрес и указать его в директиве Host, поддержка Host прекращена.
Эта директива была полезна при установке SSL-сертификата и переезде сайта с http на https. В директиве Host адрес сайта при наличии SSL-сертификата указывался с https.
Директива Host указывалась в User-agent: Yandex только 1 раз. Например для нашего сайта это выглядело таким образом:
User-agent: Yandex
Host: https:// site.ru
В этом примере указано, что главным зеркалом сайта oparinseo.ru является ни www.oparinseo.ru, ни http://oparinseo.ru, а именно https://oparinseo.ru.
Для указания главного зеркала сайта в Google требуется использовать инструменты вебмастера в Google Search Console.
Комментарии в robots.txt
Комментарии в файле robots.txt можно оставлять после символа # — они будут игнорироваться поисковыми системами. Чаще всего они необходимы для обозначения причин открытия или закрытия для индексации определенных страниц, чтобы в будущем оптимизатор мог точно понять причины тех или иных правок в файле.
Один из примеров:
#Это файл robots.txt. Все, что прописывают в данной строке, роботы не прочтут
User-agent: Yandex #Правила для Яндекс-бота
Disallow: /pink #закрыл от индексации, т.к. на странице есть неуникальный контент
Карта сайта в robots.txt — Sitemap.xml
Директива Sitemap позволяет показать поисковому роботу путь на xml карту сайта. Этот файл очень важен для поисковых систем, так как при обходе сайта они в самом начале обращаются к нему. В этом файле представлена структура сайта со всем внутренними ссылками, датами создания страниц, приоритетами индексирования.
Пример robots.txt с указанием адреса карты сайта в строке:
User-agent: *
Sitemap: https:// site.ru/sitemal.xml
Благодаря наличию xml карты сайта представление сайта в поисковой выдаче улучшается. Она является стандартом, который должен использоваться на каждом сайте.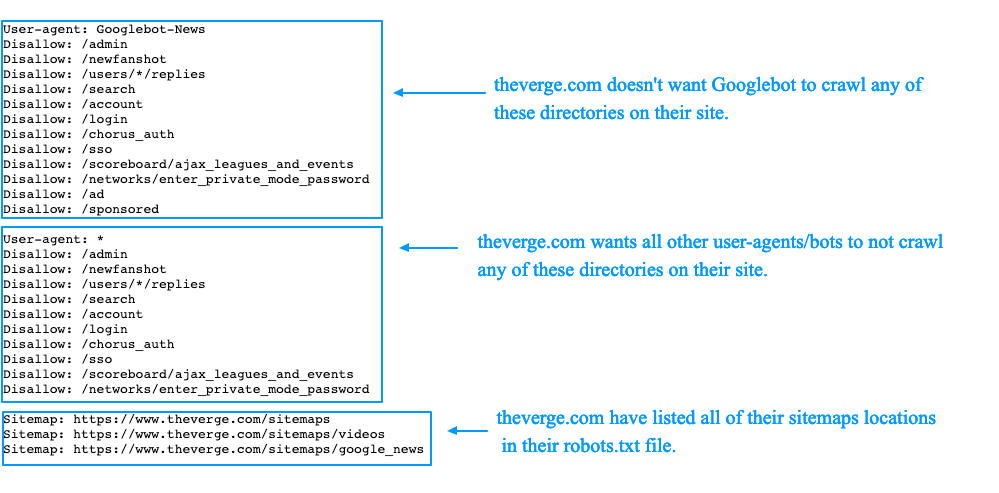 Частота обновления и актуальность поддержания sitemap.xml сможет значительно увеличить скорость индексирования страниц, особенно у относительно молодого сайта.
Частота обновления и актуальность поддержания sitemap.xml сможет значительно увеличить скорость индексирования страниц, особенно у относительно молодого сайта.
Как проверить Robots.txt?
После того, как готовый файл robots.txt был загружен на сервер, обязательно необходима проверка его доступности, корректности и наличия ошибок в нем.
Как проверить robots.txt на сайте?
Если файл составлен правильно и загружен в корень сервера, то после загрузки он будет доступен по ссылке типа site.ru/robots.txt. Он является публичным, поэтому посмотреть и провести анализ robots.txt можно у любого сайта.
Как проверить robots.txt на наличие ошибок — доступные инструменты
Можно провести проверку robots.txt на наличие ошибок, используя для этой цели специальные инструменты Гугл и Яндекс:
- В панели Вебмастера Яндекс — https://webmaster.yandex.ru/tools/robotstxt/
- В Google Search Console — https://www.google.com/webmasters/tools/robots-tes. ..
 ..
..Эти инструменты покажут все ошибки данного файла, предупредят об ограничениях в директивах и предложат провести проверку доступности страниц сайта после настройки robots.txt.
Частая ошибка Robots.txt
Обычной распространенной ошибкой является установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent соответствующий краулер будет следовать лишь тем правилам, что установлены именно для него, а остальные проигнорирует. Важно не забывать дублировать общие директивы для всех User-Agent.
Правильный robots.txt для WordPress
Внешний вид Robots.txt на платформе WordPress
Ниже представлен универсальный пример кода для файла robots.txt. Для каждого конкретного сайта его нужно менять или расширять, чтобы страницы могли проиндексироваться корректно.
В представленном варианте нет опасности запретить индексацию каких-либо файлов внутри ядра WordPress либо папки wp-content.
User-agent: *
# Нужно создать секцию правил для роботов. * означает для всех роботов. Чтобы указать секцию правил для отдельного робота, вместо * укажите его имя: GoogleBot (mediapartners-google), Yandex.
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /wp-admin/ # Закрываем админку.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed$ # Все встраивания. Символ $ — конец строки.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat #
Одна или несколько ссылок на карту сайта (файл Sitemap).
Sitemap: http:// example.com/sitemap.xml
Sitemap: http:// example.com/sitemap.xml.gz
 Это независимая
# директива и дублировать её для каждого User-agent не нужно. Например,
# Google XML Sitemap создает две карты сайта:
Это независимая
# директива и дублировать её для каждого User-agent не нужно. Например,
# Google XML Sitemap создает две карты сайта:
Правильный robots.txt для Joomla
Внешний вид Robots.txt на платформе Joomla
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /tmp/
Sitemap: https:// site.ru/sitemap.xml
Здесь указаны другие названия директорий, однако суть остается одной: таким образом закрываются мусорные и служебные страницы, чтобы показать поисковым системам лишь то, что они должны увидеть
Правильный robots.
 txt для Tilda
txt для TildaОба файла — роботс и карта сайта — генерируются Тильдой автоматически.
Чтобы просмотреть их, добавьте к вашему адресу сайта /robots.txt или /sitemap.xml, например:
http:// mysite.com/robots.txt
http:// mysite.com/sitemap.xml
Правда, единственный вариант внести кардинальные изменения в эти файлы для сайта на Тильде — экспортировать проект на собственных хостинг и произвести нужные изменения.
Правильный robots.txt для Bitrix
Внешний вид Robots.txt на платформе Bitrix
Код для Robots, который представлен ниже, является базовым, универсальным для любого сайта на Битриксе. В то же время важно понимать, что у каждого сайта могут быть свои индивидуальные особенности, и этот файл может потребоваться корректировать и дополнять в вашем конкретном случае. После этого его нужно сохранить.
User-agent: * # правила для всех роботов
Disallow: /cgi-bin # папка на хостинге
Disallow: /bitrix/ # папка с системными файлами битрикса
Disallow: *bitrix_*= # GET-запросы битрикса
Disallow: /local/ # папка с системными файлами битрикса
Disallow: /*index.
Disallow: /auth/ # авторизацияDisallow: *auth= # авторизация
Disallow: /personal/ # личный кабинет
Disallow: *register= # регистрация
Disallow: *forgot_password= # забыли пароль
Disallow: *change_password= # изменить пароль
Disallow: *login= # логин
Disallow: *logout= # выход
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url= # трекбеки
Disallow: *back_url_admin= # трекбеки
Disallow: *captcha # каптча
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открываем папку с файлами uploads
Allow: /bitrix/*.
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
# Укажите один или несколько файлов Sitemap
Sitemap: http:// site.ru/sitemap.xml
Sitemap: http:// site.ru/sitemap.xml.gz
 php$ # дубли страниц index.php
php$ # дубли страниц index.php js # здесь и далее открываем для индексации скрипты
js # здесь и далее открываем для индексации скриптыRobots.txt в Яндекс и Google
Многие оптимизаторы, делая только первые шаги в работе с robots.txt, задаются логичным вопросом о том, почему нельзя указать общий User-agent: * и не указывать роботу каждого поисковика — Яндекс и Google — одни и те же инструкции.
Все дело в том, что поисковая система Google более позитивно воспринимает директиву User-agent: Googlebot в файле robots, а Яндекс — отдельную директиву User-agent: Yandex.
Прописывая ключевые правила отдельно для Google и Яндекс, можно управлять индексацией страниц и разделов веб-ресурса посредством Robots. Кроме того, применение персональных User-agent, поможет запретить индексацию некоторых файлов Google, но при этом оставить их доступными для роботов Яндекса, и наоборот.
Кроме того, применение персональных User-agent, поможет запретить индексацию некоторых файлов Google, но при этом оставить их доступными для роботов Яндекса, и наоборот.
Максимально допустимый размер текстового документа robots составляет 32 КБ (если он больше, файл считается открытым и полностью разрешающим). Это позволяет почти любому сайту указать все необходимые для индексации инструкции в отдельных юзер-агентах для Google и Яндекс.. Поэтому лучше не проводить эксперименты и указывать правила, которые относятся к каждому поисковику.
Кстати, Googlebot-Mobile — робот, индексирующий сайты для мобильных устройств.
Правильно настроенный файл robots.txt может позитивно влиять на SEO-продвижение сайта в Яндекс и Google, улучшение позиций. Если вы хотите избавиться от “мусора” и навести порядок на сайте, улучшить его индексацию, в первую очередь нужно работать именно с robots.txt. И если самостоятельно справиться с этим из-за отсутствия опыта и достаточных знаний сложно, лучше доверить эту задачу SEO-специалисту.
— как проверить, работает ли robots.txt на локальном веб-сервере на локальном хосте?
спросил
Изменено 1 год, 7 месяцев назад
Просмотрено 4к раз
Я добавляю файл robots.txt в корневой каталог локального веб-сервера.
URL-адрес файла robots.txt на сервере: http://localhost/myserver/robots.txt .
Содержимое файла robots.txt:
User-agent: * Запретить: /
Как проверить, работает ли файл robots.txt для локального веб-сервера?
Нужно ли мне установить какой-нибудь веб-сканер или поисковую систему локально и запустить ее, чтобы убедиться в этом?
Спасибо.
- веб-сканер
- локальный хост
- веб-сервер
- поисковая система
Как проверить, работает ли файл robots.
 txt для локального веб-сервера?
txt для локального веб-сервера? Насколько мне известно, файл robots.txt не мешает поисковым роботам сканировать ваши сайты. Просто настаивает на том, чтобы этого не делать. Это означает, что вы не можете проверить, являются ли эти работы не таковыми.
Вместо этого вы можете и должны убедиться, что поисковые роботы могут читать ваш robots.txt , когда они посещают ваш сайт. Это можно обеспечить, следуя соглашениям.
Значит твой 9Файл 0013 robots.txt должен находиться в корневом каталоге.
Если вы собираетесь разместить свой сайт в домене xyz , то адрес должен быть http://xyz/robots.txt .
Для получения дополнительной информации см. здесь.
Если ваш сайт работает, вы можете использовать любой онлайн-инструмент, чтобы убедиться, что файл robots.txt доступен. Одним из таких инструментов является это.
2Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Что такое файлы WordPress robots.txt и как их использовать
Искусство и наука о том, как вывести ваш веб-сайт на высокие позиции в результатах различных поисковых систем, обычно называют SEO (поисковая оптимизация). И есть много разных аспектов, когда дело доходит до SEO, возможно, слишком много, чтобы охватить их в одной статье. Вот почему сейчас мы сосредоточимся только на одном — файле WordPress robots.txt. В этой статье мы углубимся в то, что такое файл robots.txt и как его использовать. Среди прочего, мы обсудим различные способы создания файла и рассмотрим лучшие практики в отношении его директив.
Что такое файл «robots.txt»
Robots.txt — это текстовый файл, расположенный в корневом каталоге WordPress. Вы можете получить к нему доступ, открыв URL-адрес your-website.com/robots.txt в браузере. Он служит для того, чтобы роботы поисковых систем знали, какие страницы вашего сайта следует сканировать, а какие нет. Строго говоря, сайту не обязательно иметь файл robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше всего сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать ваш сайт независимо от того, есть у вас файл robots.txt или нет.
Строго говоря, сайту не обязательно иметь файл robots.txt. Если вы находитесь в процессе создания своего веб-сайта, лучше всего сначала сосредоточиться на создании качественного контента. Боты поисковых систем будут сканировать ваш сайт независимо от того, есть у вас файл robots.txt или нет.
Однако наличие файла robots.txt с соответствующими директивами дает немало преимуществ после того, как ваш веб-сайт WordPress будет завершен. Оптимизированные директивы robots.txt не только не позволяют сканерам сканировать ненужный контент, но и гарантируют, что ваша квота сканирования (максимальное количество раз, которое сканер может сканировать ваш веб-сайт в течение заданного времени) не будет потрачена впустую.
Кроме того, хорошо написанные директивы WordPress robots.txt могут уменьшить негативные последствия плохих ботов, запретив им доступ. Это, в свою очередь, может улучшить общую скорость загрузки вашего сайта . Но имейте в виду, что директивы robots. txt не должны быть вашей единственной защитой. Плохие боты часто игнорируют эти директивы, поэтому настоятельно рекомендуется использовать хороший плагин безопасности, особенно если на вашем сайте возникают проблемы, вызванные плохими ботами.
txt не должны быть вашей единственной защитой. Плохие боты часто игнорируют эти директивы, поэтому настоятельно рекомендуется использовать хороший плагин безопасности, особенно если на вашем сайте возникают проблемы, вызванные плохими ботами.
Наконец, распространено заблуждение, что файл robots.txt может препятствовать индексации некоторых страниц вашего веб-сайта. Файл robots.txt может содержать директивы, запрещающие сканирование, а не индексирование . И, даже если страница не просканирована, ее все равно можно проиндексировать по внешним ссылкам, ведущим на нее. Если вы хотите избежать индексации конкретной страницы, вам следует использовать метатег noindex вместо директив в файле robots.txt.
Темы Qode: Лучшие темы
View CollectionBridge
Креативная многоцелевая тема WordPress
Stockholm
Действительно мультиконцептуальная тема
Startit
Fresh Startup Business Theme
Как использовать файл «robots.
 txt»
txt»Выяснив, что такое файл robots.txt WordPress и что он делает, мы можем рассмотреть, как он используется. В этом разделе мы расскажем, как создать и отредактировать файл robots.txt, о некоторых полезных практиках в отношении его содержимого и о том, как проверить его на наличие ошибок.
Как создать файл robots.txt
По умолчанию WordPress создает виртуальный файл robots.txt для любого веб-сайта. Такой файл может выглядеть примерно так, например:
Однако, если вы хотите отредактировать его, вам нужно будет создать настоящий файл robots.txt. В этом разделе мы объясним три способа, которыми вы можете это сделать. Два из них связаны с использованием плагинов WordPress, а третий основан на использовании FTP.
Йоаст SEO
С более чем 5 миллионами активных установок Yoast SEO является одним из самых популярных доступных SEO-плагинов. Он имеет множество инструментов для оптимизации сайта, в том числе функцию, которая позволяет пользователям создавать и редактировать файлы robots. txt.
txt.
После установки плагина нажмите на недавно созданный SEO раздел , а затем нажмите на Tools подраздел . На открывшейся странице нажмите на Редактор файлов ссылку вверху.
На следующей странице найдите раздел robots.txt . Оттуда, если вы еще не создали его раньше, вы должны нажать кнопку Создать файл robots.txt .
Будет создан файл, и вы сможете увидеть его содержимое в текстовой области. Используя ту же текстовую область, вы сможете редактировать содержимое вашего нового файла robots.txt. Когда вы закончите редактирование файла, нажмите кнопку Сохранить изменения в robots.txt ниже.
Все в одном SEO
All in one SEO — еще один очень популярный SEO-плагин, который поставляется с различными бесплатными функциями, включая те, которые позволяют пользователям создавать и редактировать файлы WordPress robots. txt.
txt.
После установки плагина щелкните новый раздел All in One SEO в меню панели инструментов, а затем щелкните параметр Feature Manager . На странице Feature Manager найдите Robots.txt функцию , а затем нажмите кнопку Activate рядом с ней.
Будет создан файл robots.txt. После этого вы также увидите сообщение об успешном завершении, в котором говорится, что параметры были обновлены . И появится новый подраздел под названием Robots.txt .
Нажав на опцию Robots.txt , вы увидите новый раздел. Там вы сможете добавить новые правила/директивы в файл robots.txt, а также посмотреть, как он выглядит на данный момент.
Помимо использования плагина WordPress, вы можете просто создать файл robots.txt вручную. Сначала создайте пустой файл типа .txt на своем компьютере и сохраните его как robots. txt .
txt .
Затем вам необходимо загрузить его на свой сервер с помощью FTP. Если вы не знакомы с FTP, вам следует узнать больше об использовании FTP, прежде чем продолжить.
Когда вы будете готовы, подключитесь к вашему серверу, используя ваши учетные данные FTP . Затем в правой части перейдите в корневой каталог WordPress , часто называемый public_html. В левой части вашего FTP-клиента (мы используем Filezilla) найдите файл robots.txt 9.0098, который вы ранее создали и сохранили на своем компьютере. Щелкните правой кнопкой мыши на нем и выберите Загрузить вариант .
Через несколько секунд файл будет загружен, и вы сможете увидеть его среди файлов в вашем корневом каталоге WordPress.
Если вы хотите впоследствии отредактировать загруженный файл robots.txt, найдите его в корневом каталоге WordPress, щелкните его правой кнопкой мыши и выберите параметр View/Edit .
Добавление правил в файл robots.txt
Теперь, когда вы знаете, как создавать и редактировать файл robots.txt, мы можем подробнее поговорить о директивах, которые может содержать этот файл. Чаще всего в robots.txt присутствуют две директивы: User-agent и Disallow .
Директива агента пользователя указывает, к какому боту применяются директивы, перечисленные под директивой агента пользователя. Вы можете указать одного бота (например, User-agent: Bingbot) или сделать директивы применимыми ко всем ботам, поставив звездочку (Агент пользователя: *).
Директива Disallow запрещает боту доступ к определенной части вашего веб-сайта. А еще есть директива Allow, которая просто делает противоположное . Вам не нужно использовать его так часто, как Disallow, потому что боты имеют доступ к вашему сайту по умолчанию. Директива Allow обычно используется в сочетании с директивой Disallow. Точнее, он служит для разрешения доступа к файлу или подпапке, принадлежащей запрещенной папке.
Точнее, он служит для разрешения доступа к файлу или подпапке, принадлежащей запрещенной папке.
Кроме того, есть еще две директивы: Crawl-delay и Карта сайта . Директива Crawl-delay используется для предотвращения перегрузки сервера из-за чрезмерных запросов на сканирование. Однако, эту директиву следует использовать с осторожностью, поскольку она не поддерживается некоторыми сканерами (например, Googlebot) и по-разному интерпретируется сканерами, которые ее поддерживают (например, BingBot). Директива Sitemap указывает поисковым системам на ваш XML-файл карты сайта. Настоятельно рекомендуется использовать эту директиву, так как она может помочь вам отправить созданную XML-карту сайта в Google Search Console или Bing Webmaster Tools. Но имейте в виду, что вы должны использовать абсолютный URL-адрес для ссылки на вашу карту сайта (например, Карта сайта: https://www.example.com/sitemap_index. xml) при использовании этой директивы.
xml) при использовании этой директивы.
В следующем разделе мы покажем вам два фрагмента кода, чтобы проиллюстрировать использование директив robots.txt, о которых мы упоминали выше. Однако это только примеры; в зависимости от вашего веб-сайта вам может понадобиться другое подмножество директив. С учетом сказанного давайте посмотрим на фрагменты.
Этот пример фрагмента кода запрещает доступ ко всему каталогу /wp-admin/ для всех ботов, за исключением файла /wp-admin/admin-ajax.php, который находится внутри.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Этот фрагмент открывает доступ к папке /wp-content/uploads/ для всех ботов. При этом запрещает доступ к папкам /wp-content/plugins/, /wp-admin/ и /refer/, а также к файлу /readme.html для всех ботов. Пример ниже показывает правильный способ написания нескольких директив; независимо от того, относятся ли они к одному или другому типу, обязательно по одному в ряду.
Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта.
 Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта.
Кроме того, в этом примере фрагмента кода вы можете сослаться на файл карты сайта, указав его абсолютный URL-адрес. Если вы решите использовать его, обязательно замените часть www.example.com фактическим URL-адресом веб-сайта. Агент пользователя: *
Разрешить: /wp-content/uploads/
Запретить: /wp-content/plugins/
Запретить: /wp-admin/
Запретить: /readme.html
Запретить: /refer/
Карта сайта: https://www.example.com/sitemap_index.xml
Тестирование файла robots.txt
После того, как вы добавите директивы, соответствующие требованиям вашего веб-сайта, вы должны протестировать файл robots.txt WordPress. Поступая таким образом, вы проверяете, что в файле нет синтаксических ошибок, и убедитесь, что соответствующие области вашего веб-сайта были правильно разрешены или запрещены.
Чтобы протестировать файл robots.txt вашего веб-сайта, перейдите на веб-сайт SEO-тестирования . Затем вставьте любой URL-адрес, управляемый вашим веб-сайтом (URL-адрес вашей домашней страницы, например), выберите пользовательский агент (например, Googlebot) и нажмите кнопку Test .
Если URL доступен для сканирования, вы увидите зеленый результат с надписью Разрешено . В противном случае будет указано Disallowed . Чтобы подтвердить правильность директив сканирования на своем веб-сайте, вы можете повторить тот же процесс для любого количества различных URL-адресов на своем веб-сайте.
Заключительные мысли
Файл robots.txt — это текстовый файл, расположенный в корневом каталоге каждого сайта WordPress. Он содержит директивы для сканеров, сообщающие им, какие части вашего веб-сайта они должны или не должны сканировать. Хотя этот файл по умолчанию является виртуальным, знание того, как создать его самостоятельно, может быть очень полезным для ваших усилий по SEO.
Вот почему мы рассмотрели различные способы создания физической версии файла и поделились инструкциями по его редактированию. Кроме того, мы коснулись основных директив, которые должен содержать файл WordPress robots.txt, и того, как проверить, правильно ли вы их установили.