
Файл robots.txt — примеры использования для сайта, закрытие от индексации сайта
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого описания:
Robots.txt – текстовой файл, размещенный на сервере (в корне сайта), который сообщает поисковым ботам, что нужно индексировать, а что нет.
Типичная конфигурация файла robots.txt, ниже я объясню, что это значит.
User-agent: *<br /> Disallow:<br /> User-agent: *<br /> Disallow: /<br /> User-agent: *<br /> Disallow: /folder/<br /> User-agent: *<br /> Disallow: /page.html
Зачем нам знать о файле robots.
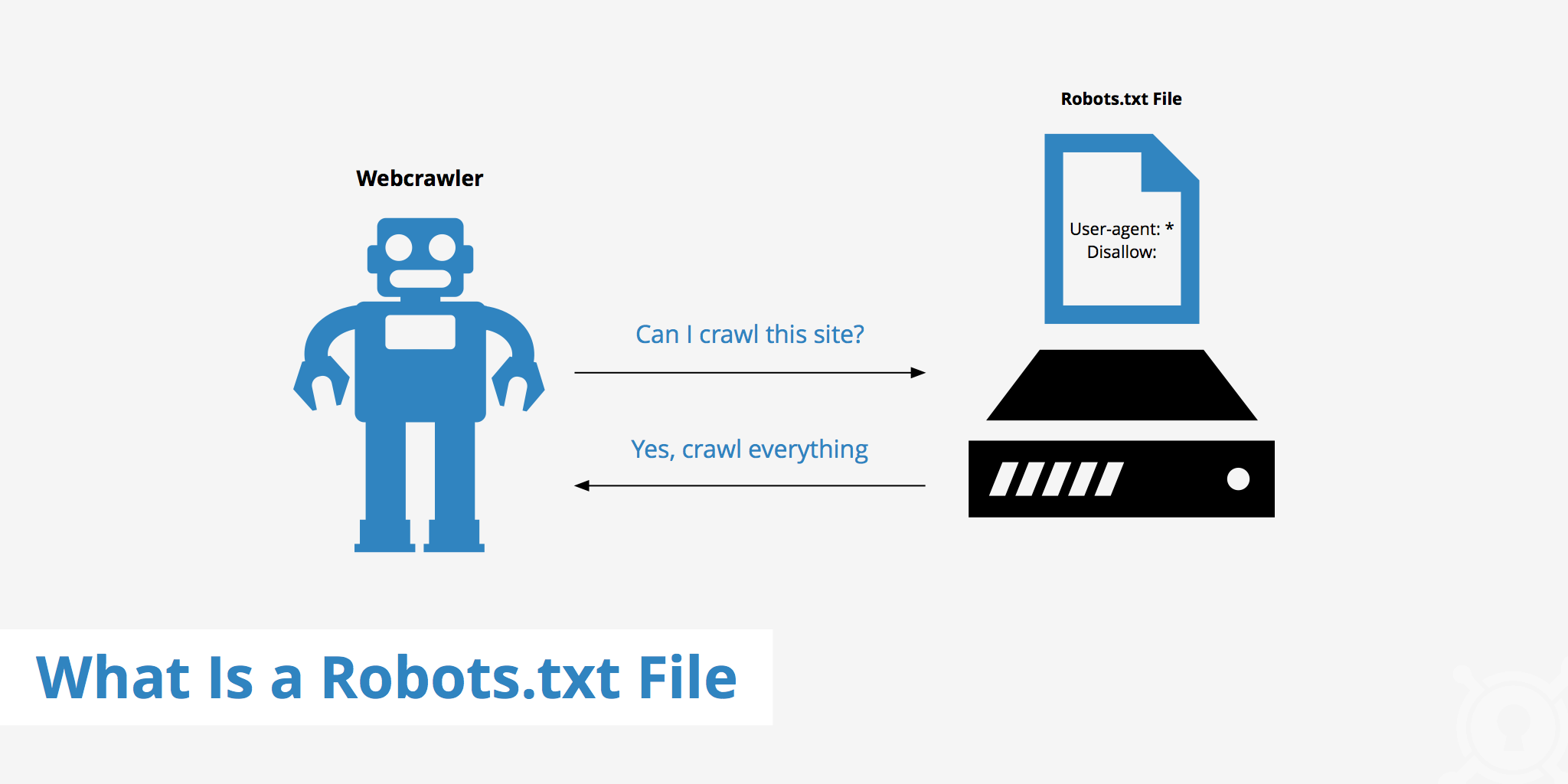 txt?
txt?- Незнание и непонимание того, как работает файл robots.txt, может иметь негативное влияние на рейтинг вашего сайта.
- Файл robots.txt контролирует то, как поисковые алгоритмы индексируют ваш сайт.
Алгоритм работы
Первое, что сделает поисковый бот, когда посетит ваш сайт – это обращение к файлу robots.txt. С какой целью? Робот хочет знать, имеет ли полномочия, проиндексировать сайт или ту или иную страницу сайта. Если нет явного запрета на обход страниц, то робот продолжает свою работу. Если существуют запреты, то робот покинет сайт. Поэтому, если вы хотите использовать какие-либо инструкции для поисковых роботов, то файл robots.txt – это тот самый инструмент.
Внимание! Существуют два важных нюанса, которые вебмастер должен проверить, если речь идет о файле robots.txt:
- Определить существует ли этот файл;
- Убедиться, что он не вредит индексации сайта.
Как проверить, что robots.
Проверить существует ли такой файл можно с помощью любого веб-браузера. Файл должен быть размещен в корневой папке сайта. Достаточно просто в адресную строку ввести site.ru/robots.txt (site.ru заменив вашим доменным именем) и отобразиться содержимое этого файла. Если такого файла не существует или он пуст, то вы увидите просто белый фон или 404 ошибку.
Проверить не мешают ли директивы файла robots.txt можно через Яндекс.Вебмастер во вкладке «Инструменты -> Анализ robots.txt.
В поле «Разрешены ли URL?» достаточно вставить адреса ваших страниц и нажать «проверить». Результат будет ниже
Аналогичную процедуру можно проделать и в Google Search Console.
Зачем нам нужен файл robots.txt?
Итак, мы знаем, где искать файл robots.txt и то, что он нужен, но зачем он нужен, какие конкретные причины?
- На сайте есть страницы, которые вы не хотите показывать поисковым системам;
- Необходимо, чтобы доступ к сайту имели только определенные роботы, например, сканеры Google и Яндекс;
- Вы создаете новый раздел и планируете новую структуру. Для того, чтобы ваши «тесты» не попадали в поисковую выдачу, лучше закрыть эти разделы от индексации;
- У вас многожество дублей страниц и вы хотите исключить эти дубли из поиска.
Как создать файл robots.txt?
Очень просто. Robots.txt – простой текстовой файл. Достаточно создать такой файл у себя на компьютере и закачать его на сайт через FTP-клиент, либо, если платформа позволяет это сделать, то создать такой файл прямо на хостинге.
Инструкции robots.txt – тут уже сложнее
Теперь необходимо разобраться, как этот файл правильно использовать.
User-agent
Синтаксис User-agent определяет в отношении каких ботов действуют правила. Есть два способа это сделать:
- User-agent: * — такой способ говорит, что, любой робот должен придерживаться следующих «правил».
- User-agent: GoogleBot – этот способ говорит, что данный «правила» касаются только и исключительно для робота GoogleBot.
Disallow
Инструкция «Disallow» — запрещает роботам индексировать те или иные элементы (файлы, страницы, папки, изображения). Таким образом, если вы не хотите, чтобы содержимое папки «temp» не было проиндексировано, нужно указать это в файле robots.txt следующим образом:
User-agent: *<br /> Disallow: /temp
Allow
Все что не закрыто по-умолчанию — открыто. Поэтому «allow» часто используется в сочетании с «disallow». Например.
В предыдущем примере мы закрыли от индексации папку temp, однако через некоторое время мы решили, что мы хотим открыть доступ роботам к файлу my.docx, который находиться в папке temp, но только к нему, а не к другим файлам в это папке. Запись allow позволяет нам предоставить доступ к этому файлу (или группе файлов\папок), таким образом:
User-agent: *<br /> Disallow: /temp<br /> Allow: /temp/my.docx
Что еще должно быть в файле robots.txt?
Кроме деректив поисковым роботам о том, что нужно или не нужно индексировать, в файл robots.txt желательно прописать путь до карты сайты, делается это следующим образом:
Sitemap: https://ex-pl.com/sitemap.xml
Как проверить, что файл robots.txt работает правильно?
Правильность вашего файла вы можете проверить в Яндекс.Вебмастере или Google Search Console.
Важные замечания
Закрытие страниц, папок, файлов от поисковых роботов через файл robots.txt не гарантирует не попадания этих элементов в поисковую выдачу. Все же директивы в этом файле имеют рекомендательный характер для ботов и они могут воспользоваться этими рекомендациями, а могут не воспользоваться. Для того, чтобы на 100% исключить из индекса ту или иную страницу, можно воспользоваться тегами noindex\nofollow.
Примеры robots.txt
Пример 1
User-agent: *<br /> Disallow:
Все роботы могут посещать и индексировать все файлы и страницы сайта.
Пример 2
User-agent: *<br /> Disallow: /
Закрыть сайт от индексации через robots.txt полностью. Это значит, что ваш сайт не будет отображаться в результатах поиска.
Пример 3
User-agent: *<br /> Disallow: /cgi/<br /> Disallow: /private/<br /> Disallow: /tmp/
Ни один из роботов не будет индексировать папки: cgi, private, tmp.
Пример 4
User-agent: Googlebot-Image<br /> Disallow: /photos/
Картиночному боту Google запрещен доступ к папке photos.
Пример 5
User-agent: *<br /> Disallow: /directory/file.html
Все роботам запрещено индексировать файл file.html в папке directory.
Пример 6
User-agent: WebStripper<br /> Disallow: /
User-agent: WebCopier<br /> Disallow: /
User-agent: TeleportPro<br /> Disallow: /
User-agent: HTTrack<br /> Disallow: /
User-agent: wget<br /> Disallow: /
Данные директивы запрещают некоторым программам доступ к сайту.
Файл robots txt для сайта
Robots.txt – это служебный файл, инструкция для поисковых роботов для индексации сайта. В файле указываются каталоги, которые не требуется индексировать. Обычно это администраторская панель, кеш, служебные файлы. Размещается в корневой папке веб-ресурса. Его использование необходимо для лучшей индексации страниц, защиты приватной информации и повышения безопасности сайта.
Часто используется веб-мастерами вместе с другим служебным файлом, предусмотренным протоколом sitemap ( написанном на языке XML), который действует наоборот, предоставляя карту сайта с разрешенными к чтению роботами страницами.
Robots.txt и его влияние на индексацию сайта
На индексацию сайта также влияют скорость и надежность хостинга. Быстрый и надежный хостинг со скидкой до 30%!
После создания сайта его корневая папка на хосте становится доступной для поисковых систем. Роботы читают все, что найдут, без разбора.
В каталогах динамических сайтов, находящихся под управлением CMS, они не найдут никакой информации, ведь она хранится в базах данных MYSQL. Роботы, если им этого не запретить, беспрепятственно перебирают файлы в директориях, которые закрыты для посещения всем, кроме администратора. Это опасно для сайта и отнимает время у поисковиков, снижая скорость индексации веб-ресурса.
Для хакеров и прочих компьютерных злоумышленников доступные к чтению служебные файлы – это еще не дверь, но замочная скважина, в которую они обязательно залезут с электронной отмычкой для получения контроля над всем сайтом. Если в файле robots.txt указать, что читать надо только индексные файлы, то знакомство поисковой системы с динамическим сайтом произойдет быстрее, а его безопасность повысится.
Для статических веб-ресурсов этот файл станет небольшой гарантией, что хранящиеся конфиденциальные данные (телефоны, адреса электронной почты и другие) не окажутся в открытом доступе.
Веб-мастер, создавая файл robots.txt, может запретить роботам поисковых систем посещение всего сайта или дать доступ к его индексации только одной из категорий или страниц сайта.
Какие страницы стоит запретить и закрыть в robots.txt?
Если на хосте, где размещен сайт, есть панель управления, то этот файл можно создать, открыв корневую папку и нажав кнопку «новый файл» (бывают варианты в названиях). Но лучше создать файл на домашнем компьютере, а для загрузки воспользоваться каналом FTP.
Самой удобной программой для создания файла robots.txt является Notepad++. Но не возбраняется использовать обычный блокнот из набора Windows или текстовый редактор Word. Сохранять файл надо с расширением .txt.
Даже если он написан неправильно, это не приведет к потере работоспособности сайта, как это происходит с неправильным файлом .htaccess.
— Если не хочется ни изучать синтаксис файла, ни создавать его самостоятельно, то можно обратиться, например на http://pr-cy.ru/robots/, где его сгенерируют автоматически.
Директивы файла — user agent, host и т.д.
Директивы (команды) файла пишутся на латинице, после каждой из них ставится двоеточие и указывается объект управления.
Директивы бывают стандартные:
- User-agent – имя поискового робота;
- Allow – разрешить;
- Disallow – запретить;
- Sitemap – адрес, где находится sitemap.xml;
- * – для всех.
И расширенные:
- Craw-delay– промежуток времени между чтением директорий;
- Request-rate – количество страниц, просмотренных за одну секунду;
- Visit-time – желаемое время посещения сайта роботом.
Расширенные директивы снижают нагрузку на сервер и защищают сайт от слишком назойливых парсеров.
Google, Яндекс и настройка роботс
Поисковые системы Гугл и Яндекс одинаково хорошо читают этот файл, но рассчитывать, что его наличие послужит установлению каких-либо особенных отношений поисковых систем с сайтом – это ненужный романтизм, лишенный оснований. Есть некоторые отличия в том как можно обратиться к поисковому роботу, ведь у каждой системы их целый набор:
- YandexBot и Googlebot – это обращение к основным поисковым роботам;
- YandexNews и Googlebot-news – роботы, специализирующиеся на новостном контенте;
- YandexImages и Googlebot-image – индексаторы картинок.
У Яндекса поисковых роботов девять, а у Google восемь. Если требуется общая индексация, то после директивы User-agent пишется Yandex или Googlebot.
У Яндекса есть еще одна особенность: его роботы читают директиву Host, указывающую на «зеркало» сайта. Гугл ее не понимает.
Нужен красивый домен для Вашего проекта? Проверить и купить домен дешево болеее чем в 300 зонах!
Как составить robots.txt для Joomla
Вот как может выглядеть этот файл для новостного сайта на CMS Joomla.
User-agent: YandexNews
Disallow: /administrator
Disallow: /components
Disallow: /libraries
Allow: /index1.php
Allow: /index2.php
Request-rate: 1/20
Visit-time: 0200-0600
В нем для индексации «приглашен» новостной бот Яндекса, которому запрещено читать директории administrator, components и libraries (папка, где собственно и содержится «движок»). Индексировать можно 1 страницу за 20 секунд, а посещать сайт с двух ночи до шести утра по Гринвичу.
Проверить правильность написания файла robots.txt можно обратившись в Яндексе к сервису «Вебмастеру». Такой же Центр Веб-мастеров есть и у Google.
Не нужно использовать этот файл как основу – в нем просто показано использование директив.
Пример правильного файла robots.txt для WordPress — как запретить все лишнее
А это – рабочий файл robots.txt для CMS WordPress.
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
User-agent: Yandex
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Disallow: /*?*
Disallow: *?replytocom
Disallow: /wp-*
Disallow: /comments/feed/
Host: http://вашсайт.ру
Sitemap: http://вашсайт.ру/sitemap.xml
В первом блоке написаны директивы для всех поисковых роботов, они же дублируются для Яндекса, только с уточнением основной версии сайта. Как видно, из индекса исключена пагинация, служебные файлы и каталоги.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Мы предлагаем:
Что такое Robots.txt, карта сайта, 301 редирект?
В данной статье рассмотрим:
Что такое robots.txt
Robots.txt — текстовый файл, расположенный на сайте, который предназначен для роботов поисковых систем. В этом файле владелец сайта может указать параметры индексирования своего сайта (как страницы включать в индекс поисковых систем, а какие — нет) как для всех поисковых систем сразу, так и для каждой поисковой системы в отдельности.
Файл robots.txt на платформе AdvantShop
Файл robots.txt уже изначально есть в административной части вашего интернет-магазина. В нем указаны стандартные настройки robots.txt интернет-магазина для поисковой системы Яндекс (отдельно) и для всех остальных поисковых систем. Вы можете самостоятельно вносить в него изменения в соответствии с вашими индивидуальными требованиями к индексированию сайта.
Как настроить файл robots.txt на платформе AdvantShop
Чтобы перейти к редактированию файла robots.txt, перейдите в административную часть вашего магазина. В меню выберите «Настройки» — «SEO и счётчики» (см. рис. 1), а затем перейдите на вкладку «Robots.txt«. Вы увидите поле, в котором можно редактировать текст файла (см.рис. 2).
Рисунок 1.
Рисунок 2.
После внесения изменений, нажмите кнопку «Сохранить».
Как правильно заполнить файл robots.txt и проверить его корректность?
Правила настройки файла robots.txt для поисковых систем прописаны на страницах помощи соответствующих поисковых систем:
Яндекс — Использование robots.txt
Google — Спецификации файла robots.txt
Внимание
В большинстве случаев стандартный текст файла robots.txt, уже заданный платформой AdvantShop, является достаточным и не требует внесения каких-либо изменений. Во избежание каких-либо ошибок, мы рекомендуем вам обратиться к SEO-специалисту для внесения каких-либо правок в данный файл.
Также, обратите внимание на регистр букв, к примеру, директивы
Disallow: /registration.aspx
и
Disallow: /Registration.aspx
обрабатываются поисковыми системами как разные страницы.
Корректность файла robots.txt для поисковой системы Яндекс Вы можете проверить в панели Вебмастер Yandex (в сервисе необходимо авторизоваться под своим логином и паролем). Для других поисковых систем используйте соответствующие панели (также с предварительной авторизацией), к примеру, Google Webmaster Tools и Bing Webmaster.
Закрытие от индексации дублей страниц
Дубли страниц в каталоге, которые могут появиться при фильтрации или постраничном просмотре (пагинации), по-умолчанию уже закрыты от индексации следующими директивами:
Disallow: *?type=*
Disallow: *?letter=*
Disallow: *brandid=*
Disallow: *pricefrom=*
Disallow: *priceto=*
Disallow: *prop=
Пример файла robots.txt для полного закрытия сайта от индексации:
User-agent: *
Disallow: /
Внимание
Мы настоятельно не рекомендуем Вам закрывать сайт от индексации без консультации SEO-специалиста, так как это может очень негативно сказаться на индексации сайта и его позициях в поисковых системах.
Директива Sitemap
Директива Sitemap служит для указания адреса карты сайта в формате xml для поисковых роботов. При её указании необходимо прописать полный адрес карты сайта xml, с указанием протокола http (или https). Данная директива должна располагаться после всех директив в файле robots.txt, с отступом в одну строку. Пример:
…
Disallow: /preorder
Sitemap: http://site.ru/sitemap.xml
Пример файла robots.txt для обычной работы интернет-магазина на платформе AdvantShop:
User-agent: Yandex
Disallow: *?type=*
Disallow: *?letter=*
Disallow: *brandid=*
Disallow: *pricefrom=*
Disallow: *priceto=*
Disallow: *prop=
Disallow: /newscategory$
Disallow: /fogotpassword
Disallow: /compare
Disallow: /myaccount
Disallow: /checkout
Disallow: /registration
Disallow: /cart
Disallow: /wishlist
Disallow: /checkout/billing
Disallow: /tools/
Disallow: /login
Disallow: /preorder
User-agent: *
Disallow: *?type=*
Disallow: *?letter=*
Disallow: *brandid=*
Disallow: *pricefrom=*
Disallow: *priceto=*
Disallow: *prop=
Disallow: /newscategory$
Disallow: /fogotpassword
Disallow: /compare
Disallow: /myaccount
Disallow: /checkout
Disallow: /registration
Disallow: /cart
Disallow: /wishlist
Disallow: /checkout/billing
Disallow: /tools/
Disallow: /login
Disallow: /preorder
Sitemap: http://{имя домена}/sitemap.xml
Обратите внимание
Запись вида {имя домена} необходимо заменить (вместе с фигурными скобками) на адрес вашего магазина.
Например:
- «Sitemap: http://{имя домена}/sitemap.xml», после замены получится вот так «Sitemap: http://mysite5.ru/sitemap.xml»
Карта сайта (Sitemap)
Карта сайта (sitemap) – это файл, который необходим для корректной и своевременной индексации сайта в поисковых системах. С помощью карты сайта Вы можете сообщить поисковой системе, какие страницы Вашего сайта нужно индексировать, как часто обновляется информация на сайте, а также индексирование каких страниц наиболее важно.
В магазине карта сайта автоматически формируется в формате HTML и в формате XML.
В формате HTML карта сайта создается для посетителей, чтобы облегчить им поиск необходимой информации. В формате XML карта сайта создается для поисковых роботов, чтобы поисковый робот увидел ссылки на все страницы, которые есть на сайте.
Рассмотрим, как сгенерировать в магазине карту сайта в формате HTML и XML, и как сообщить поисковым системам о наличии карты сайта в интернет магазине
-
Формирование карты сайта HTML
-
Формирование карты сайта XML
-
Регистрация карты сайта в поисковых системах
Формирование карты сайта XML и карты сайта HTML
Чтобы сгенерировать карты сайта, необходимо перейти в панель администрирования, пункт меню «Настройки» — «Системные настройки» (см. рис. 3).
Рисунок 3.
На открывшейся странице необходимо выбрать вкладку «Карта сайта» и нажать на кнопку «Обновить карты» (см. рис.4, п.2), Ваши карты сайта будут обновлены.
Рисунок 4.
Для перехода к сгенерированным картам сайта в строках «Адрес карты XML» и «Адрес карты HTML» нажмите ссылку карты (см. рис.3, п.3-4).
Обновление карт сайта XML и HTML происходит раз в сутки в автоматическом режиме.
Регистрация карты сайта в поисковых системах
После формирования карты сайта, необходимо сообщить поисковым системам о наличии файла sitemap. Для этого нужно совершить следующие действия:
-
Добавить директиву sitemap в файл robots.txt. Данная директива имеет вид Sitemap: http://site.ru/sitemap.xml (где site.ru – адрес вашего веб-сайта) и прописывается (предпочтительно) в конце документа с новой строки.
-
Указать URL файла sitemap в Yandex.Вебмастере и Google.Вебмастере.
Чтобы перейти к редактированию файла robots.txt, необходимо в панели администрирования выбрать пункт меню «Настройки» — «SEO и счетчики«. Затем перейти на вкладку Robots.txt (см. рис. 5).
Рисунок 5.
Вставьте в файл robots.txt, предпочтительно в конце, строку, указывающую на местоположение файла Sitemap (см. рис. 6):
Sitemap: http://site.ru/sitemap.xml.
Рисунок 6.
После внесения изменений, нажмите кнопку «Сохранить» в правом верхнем углу.
Чтобы указать URL карты сайта для поисковых систем, совершите следующие действия:
-
Для ПС Яндекс – Зайдите в раздел «Индексирование» — «Файлы Sitemap» сервиса Яндекс.Вебмастер, после чего укажите ссылку на ваш файл Sitemap в строку и нажмите кнопку «Добавить».
Рисунок 7.
-
Для ПС Google – Зайдите в раздел «Сканирование»- «Файлы Sitemap» сервиса Google Webmaster Tools, после чего нажмите на кнопку «добавление/проверка файла sitemap» и укажите путь к своему файлу sitemap.xml. Обратите внимание, что адрес самого домена уже будет указан в соответствующей строке.
После этого нажмите кнопку «Тест», и если ошибок не будет обнаружено – кнопку «Отправить».
Рисунок 8.
Готово, мы рассмотрели, как настроить карты сайта.
301 редирект
Суть «301-го» редиректа (перенаправления с кодом ответа 301) в том, чтобы сообщить пользователю или поисковому роботу информацию о том, что страница, которую он открывает по определённому URL-адресу, перемещена на другой URL-адрес. На практике это выглядит так: пользователь вводит URL-адрес, для которого настроен 301 редирект, и попадает на другой URL-адрес (необходимый Вам).
В каких случаях нужен 301 редирект?
Зачастую происходит следующая ситуация: сайт существовал по определённому URL, и все ссылки на его страницы хорошо проиндексировались поисковыми системами; пользователи находили через поиск страницы сайт и переходили на них. Однако однажды владелец решил изменить свой сайт и переехал на новую CMS, которая формирует ссылки на статьи, товары и категории по новому алгоритму.
Если, к примеру, раньше условная статья об условном продукте «Продукт 1» была вида:
mysite.com/category111/product222/product1/
то на новом, условном, сайте новая ссылка условно стала:
mysite.com/product/superduperproduct1/
Получается, что в поисковой системе сохранилась старая ссылка, и при переходе по ней пользователь видит страницу 404 (не найдена).
В таком случае, как и в ряде других, нужна переадресация с одной ссылки на другую, или, как это называется, «301 редирект».
Итак, переадресация с кодом 301 обычно нужна в следующих случаях:
1) У Вас есть статья, товар или категория, которая изменила свой URL
2) Хотите настроить переадресацию с «www» на «без www» или наоборот
3) У Вас есть ещё один домен, и вы хотите, чтобы посетители с него перенаправлялись на «основной домен» (важно для SEO)
4) Любой из пунктов 1-3, но при этом у вас ещё и кириллический домен (мойсуперсайт.рф или подобный)
Где находится настройка 301 редиректа?
Настройки редиректов находятся в панели администрирования — пунт меню «Настройки — SEO и счётчики«, вкладка «301 редирект» (см. рис. 9).
Рисунок 9.
В магазине на базе AdvantShop 301 редирект представлен в виде таблицы, с колонкой «Откуда» и колонкой «Куда». Указываем старый URL, указываем новый URL, после чего перенаправление работает.
В таблице также представлена ещё третья, необязательная, колонка «Артикул товара (необязательно)». О ней расскажем отдельно ниже.
Важно
Чтобы включить работу редиректов, поставьте галочку «Активность 301 редиректа» (рис. 9).
Рисунок 10.
Как добавить/редактировать/удалить 301 редирект?
Для добавления нажимаем кнопку «+ Добавить 301 редирект». Возникает всплывающее окно. Вносим данные (поле «Артикул» можно оставить пустым), нажимаем на кнопку «Сохранить» — всё готово.
Рисунок 11.
Для редактирования записи кликните на неё один раз. Строчка превратится в поля для редактирования. Внесите изменения и кликните на любом пустом месте страницы, чтобы сохранить изменения.
Чтобы удалить запись, нажмите на кнопку крестика и подтвердите удаление.
Далее рассмотрим несколько примеров.
Пример 1. У Вас есть статья, товар или категория, которая изменила свой URL
Например, мы сменили CMS интернет-магазина, и теперь нужно как-то направить пользователей со старых ссылок на новые. Со старой ссылки настроим редирект на новую.
У нас есть ссылка:
http://site5.ru/staraya-ssilka
Нужно направить на:
http://site5.ru/novaya-ssilka
Так и добавим данные в таблицу (рис. 12).
Рисунок 12.
Готово.
Если мы работаем в рамках одного сайта, мы можем использовать относительные ссылки(рис 5.1).
Мы можем не писать адрес сайта, а указать сразу фрагмент ссылки, которая идет за адресом.
В поле «откуда» вместо «http://site5.ru/staraya-ssilka» мы можем написать лишь «staraya-ssilka».
В поле «куда» вместо «http://site5.ru/novaya-ssilka» мы можем написать лишь «novaya-ssilka».
Внимание
Знак «/» в начале указывать не нужно. Вариант «/novaya-ssilka» неверный, вариант «novaya-ssilka» — верный.
Рисунок 13.
Готово.
В обоих случаях при переходе по старой ссылке http://site5.ru/staraya-ssilka нас «перебросит» на новую ссылку.
Обратите внимание, что одна запись работает для одной ссылки, и если нужно перенаправить ссылки для 10 товаров, нужно добавить 10 записей, аналогично той, которую мы добавили выше.
Пример 2. Переадресация с «www» на «без www» или наоборот
Если допустить, чтобы сайт открывался и по www.site5.ru, и по (просто) site5.ru, поисковые системы увидят в этом дубликат сайта, т.к. для поисковой машины адрес без www и с www — это два разных сайта с одинаковым содержимым.
Для решения этой проблемы Вам нужно определить, какой адрес будет главным, и со второстепенного настроить 301 редирект на основной.
Если мы решили, что www.site5.ru будет главным, то настраиваем запись так:
с http://site5.ru* на http://www.site5.ru (с сайта без WWW переходить на сайт с WWW)
Рисунок 14.
Если решили, что site5.ru (без WWW) будет главный, то настраиваем запись так:
с http://www.site5.ru* на http://site5.ru (с записи с WWW переходить на сайт без WWW)
Рисунок 15.
Готово.
Знак звездочки » * » в конце домена означает, что все URL, которые начинаются с домена, будут перенаправлены на новый домен.
Пример 3. У Вас есть синоним домена и нужно перенаправить пользователя на «основной домен»
Бывают ситуации, когда у Вас есть 2 разных доменных имени, которые подключены к одному и тому же сайту. Т.е. по обоим доменам открывается один и тот же магазин. Такое бывает, когда владельцы сайта докупают домен, к примеру, с тире в названии (например, moysait.ru и moy-sait.ru), чтобы пользователи, набравшие адрес с тире, также попали на Ваш сайт.
Либо бывают ситуации, когда один домен зарегистрирован в зоне *.ru, а другой — в зоне *.com.
Для поискового продвижения важно, чтобы сайт был доступен по «основному домену», и с остальных доменов был настроен 301 редирект.
Итак, мы определились, что условный адрес «http://site5.ru» (без www) будет нашим главным доменом, и будем ссылаться на него.
Чтобы настроить редирект вида http://site5.com на http://site5.ru , Вам необходимо сделать следующее:
1) В поле «откуда» написать адрес сайта с http:// и добавить знак звездочки » * » в конце.
Чтобы получилось: http://site5.com*
2) В поле «куда» написать адрес сайта, куда направлять, также с http://, но без звездочки.
Чтобы получилось http://site5.ru
Выглядит это так:
Рисунок 16.
Такой же вариант подходит, если нужно сделать пренаправление с http://site-5.ru на http://site5.ru (с домена «с тире» на домен «без тире»).
Рисунок 17.
Пример 4. У Вас кириллический домен. Как в этом случае настроить редирект?
В случае если в имени домена встречаются кириллические или другие нелатинские символы, нужно зайти на сайт https://www.nic.ru/whois/ , ввести в текстовое поле русский адрес, нажать «Показать». Внизу серым крупным шрифтом выведется (в скобках) адрес русского сайта символами:
Рисунок 18.
Нужно скопировать содержимое из скобок и вставить в поле «откуда». Впереди символов указывается «http://», в конце также пишется » * » (звездочка), если редирект нужен для всех страниц сайта(рис. 19).
Кириллическая ссылка выглядеть будет так:
http://XN—80AAIRFBUBOC.XN—P1AI
Ссылка на страницу соответственно:
http://XN—80AAIRFBUBOC.XN—P1AI/pages/page1
Т.е. все настройки производятся так же, как и с обычным доменом, но вместо кириллицы указывается определённый набор символов.
Рисунок 19.
Пример 5. Переадресация с «http» на «https»
В ситуации, когда на Вашем сайте установлен SSL сертификат, т.е. на сайте есть https-соединение, достаточно создать три записи редиректа.
1) Первое правило:
— В поле «откуда» написать адрес сайта с http:// и добавить знак звездочки » * » в конце. Чтобы получилось: http://site.ru*
— В поле «куда» написать адрес сайта, для которого установлен SSL сертификат. Если это домен без www, то нужно написать https://, но без звездочки, чтобы получилось https://site.ru
2) Второе правило. Аналогично создаем вторую запись, уже с http://www.домен на https:
— В поле «откуда» написать адрес сайта с http:// и добавить знак звездочки » * » в конце. Чтобы получилось: http://www.site.ru*
— В поле «куда» написать адрес сайта, для которого установлен SSL сертификат. Если это домен без www, то нужно написать https://, но без звездочки, чтобы получилось https://site.ru
3) Третье правило. Большинство новых сертификатов поддерживают как просто «https://site.ru» так и вариант «https://www.site.ru» (с www), то получится, что для поисковых машин у нас есть 2 одинаковых сайта. Чтобы избежать дублирования, добавим ещё одно правило.
— В поле «откуда» написать адрес сайта с https:// и добавить знак звездочки » * » в конце. Чтобы получилось: https://www.site.ru*
— В поле «куда» написать адрес сайта, для которого установлен SSL сертификат. Если это домен без www, то нужно написать https://, но без звездочки, чтобы получилось https://site.ru
Рисунок 20.
Внимание
Если Вы приобретаете SSL-сертификат только для платёжных систем или для работы в соц. сетях, настраивать подобный редирект в большинстве случаев нет необходимости.
Заметка
После перехода сайта на https и настройке 301 редиректа с http на https позиции сайта в поисковых системах понижаются на некоторый период времени. К сожалению, это неизбежный эффект, который зависит от работы самих поисковых систем.
Для чего нужна необязательная колонка «Артикул товара»?
Дополнительная третья колонка добавлена для замены, в некоторых случаях, колонки «куда».
Пример:
Если на Вашем новом сайте у товара сменится URL (по сравнению с URL на старом сайте), то, чтобы регулярно не «следить» за новыми ссылками на товар и корректировать их в таблице 301-го редиректа, можно использовать колонку «Артикул товара».
В ней достаточно указать артикул товара, и старая ссылка всегда будет ссылаться на актуальный текущий URL товара.
Настройка выглядит так:
Рисунок 21.
Первая запись — Относительная ссылка (без домена)
Вторая запись — Полная ссылка (с доменом и http:// )
Третья запись — Полная ссылка с кириллическим доменом.
Все три ссылки работают по принципу «направить нашу ссылку на URL товара, при условии, что мы знаем только артикул товара».
Массовая загрузка 301 редиректа
Рассмотрим, как можно осуществить экспорт или импорт 301 редиректа в интернет-магазине.
Наша задача — показать, как можно массово изменить или загрузить 301 редирект на сайт.
Формат файла
Файл в формате CSV представлен на рисунке ниже (рис.22).
Рисунок 22.
В файле 3 столбца, которые дублируют 3 колонки в панели администрирования:
RedirectFrom – столбец «Откуда», т.е. ссылка, которую требуется заменить, переадресовать.
RedirectTo – столбец «Куда», актуальная ссылка, на которую требуется сделать редирект (перенаправление страницы).
ProductArtNo – артикул товара, добавлена для замены, в некоторых случаях, колонки «куда».
Импорт
Вы можете создать файл CSV (разделители — точка с запятой) формата, описанного выше, заполнить столбцы необходимыми ссылками и импортировать на сайт.
Для того чтобы осуществить импорт файла, перейдите в панель администрирования, пункт меню «Настройки — SEO и счётчики«, вкладка «301 редирект» , и нажмите на кнопку «Добавить файл«.
Рисунок 23.
Рисунок 24.
Рисунок 25.
В открывшемся окне выберите файл для импорта, нажмите «Открыть», и данные из файла автоматически появляются в списке 301 редиректа (рис. 26).
Рисунок 26.
Экспорт
С сайта можно экспортировать файл с 301 редиректом, внести в файл изменения и вновь загрузить на сайт. Для этого перейдите в панель администрирования, пункт меню «Настройки — SEO и счётчики«, вкладка «301 редирект«, и нажмите на кнопку «Экспорт«.
Рисунок 27.
Рисунок 28.
Файл скачивается на Ваш компьютер в формате, описанном выше.
Примечание.
Обновление данных или добавление новых строк из файла происходит по столбцу «RedirectFrom» («Откуда»).
При загрузке файла на сайт происходит проверка: если ссылка из RedirectFrom уже присутствует на сайте в столбце «Откуда», то она обновляется теми данными, которые пришли в новом файле; если ссылки из RedirectFrom нет на сайте в столбце «Откуда», то строка с данными из файла добавляется в качестве новой строки со значениями на сайт.
Рассмотрим на примере.
В файле строка вида (рис.29):
Рисунок 29.
При импорте файла на сайт проверяется столбец RedirectFrom (на сайте “Откуда”) — есть ли в столбце “Откуда” значение из файла столбца “RedirectFrom”? В нашем примере проверяется значение “login.aspx”(рис.30).
Рисунок 30.
Если значение есть (как в нашем примере “login.aspx”), строка обновляется. А именно: в столбец “Куда” записывается значение из файла “RedirectTo” (рис.31).
Рисунок 31.
Если значения нет, то строка добавляется (рис.32,33).
Рисунок 32.
Рисунок 33.
Готово. Мы рассмотрели основные настройки файла Robots. карты сайта и 301 -ого редиректа.
Тэги: Robots, робот, редирект, 301 редирект, карта сайта,sitemap, битые ссылки, закрытие страниц от индексации, сайт открывался с www, главное зеркало, перенаправление, http на https
Файл robots txt — основные директивы и инструкция по редактированию в Нубексе
Robots.txt — это текстовый файл, который содержит специальные инструкции для роботов-поисковиков, исследующих ваш сайт в интернете. Такие инструкции — они называются директивами — могут запрещать к индексации некоторые страницы сайта, указывать на правильное «зеркалирование» домена и т.д.
Для сайтов, работающих на платформе «Нубекс», файл с директивами создается автоматически и располагается по адресу domen.ru/robots.txt, где domen.ru — доменное имя сайта. Например, с содержанием файла для сайта nubex.ru можно ознакомиться по адресу nubex.ru/robots.txt.
Изменить robots.txt и прописать дополнительные директивы для поисковиков можно в админке сайта. Для этого на панели управления выберите раздел «Настройки», а в нем — пункт «SEO».
Найдите поле «Текст файла robots.txt» и пропишите в нем нужные директивы. Желательно активировать галочку «Добавить в robots.txt ссылку на автоматически генерируемый файл sitemap.xml»: так поисковый бот сможет загрузить карту сайта и найти все необходимые страницы для индексации.
Не забудьте сохранить страницу после внесения необходимых изменений.
Основные директивы для файла robots txt
Загружая robots.txt, поисковый робот первым делом ищет запись, начинающуюся с User-agent: значением этого поля должно являться имя робота, которому в этой записи устанавливаются права доступа. Т.е. директива User-agent — это своего рода обращение к роботу.
1. Если в значении поля User-agent указан символ «*», то заданные в этой записи права доступа распространяются на любых поисковых роботов, запросивших файл /robots.txt.
2. Если в записи указано более одного имени робота, то права доступа распространяются для всех указанных имен.
3. Заглавные или строчные символы роли не играют.
4. Если обнаружена строка User-agent: ИмяБота, директивы для User-agent: * не учитываются (это в том случае, если вы делаете несколько записей для различных роботов). Т.е. робот сначала просканирует текст на наличие записи User-agent: МоеИмя, и если найдет, будет следовать этим указаниям; если нет — будет действовать по инструкциям записи User-agent: * (для всех ботов).
Кстати, перед каждой новой директивой User-agent рекомендуется вставлять пустой перевод строки (Enter).
5. Если строки User-agent: ИмяБота и User-agent: * отсутствуют, считается, что доступ роботу не ограничен.
Запрет и разрешение индексации сайта: директивы Disallow и Allow
Чтобы запретить или разрешить поисковым ботам доступ к определенным страницам сайта, используются директивы Disallow и Allow соответственно.
В значении этих директив указывается полный или частичный путь к разделу:
- Disallow: /admin/ — запрещает индексацию всех страниц, находящихся внутри раздела admin;
- Disallow: /help — запрещает индексацию и /help.html, и /help/index.html;
- Disallow: /help/ — закрывает только /help/index.html;
- Disallow: / — блокирует доступ ко всему сайту.
Если значение Disallow не указано, то доступ не ограничен:
- Disallow: — разрешена индексация всех страниц сайта.
Для настройки исключений можно использовать разрешающую директиву Allow. Например, такая запись запретит роботам индексировать все разделы сайта, кроме тех, путь к которым начинается с /search:
User-agent: *
Allow: /search
Disallow: /
Неважно, в каком порядке будут перечислены директивы запрета и разрешения индексации. При чтении робот все равно рассортирует их по длине префикса URL (от меньшего к большему) и применит последовательно. То есть пример выше в восприятии бота будет выглядеть так:
User-agent: *
Disallow: /
Allow: /search
— разрешено индексировать только страницы, начинающиеся на /search. Таким образом, порядок следования директив никак не повлияет на результат.
Директива Host: как указать основной домен сайта
Если к вашему сайту привязано несколько доменных имен (технические адреса, зеркала и т.д.), поисковик может решить, что все это — разные сайты. Причем с одинаковым наполнением. Решение? В бан! И одному боту известно, какой из доменов будет «наказан» — основной или технический.
Чтобы избежать этой неприятности, нужно сообщить поисковому роботу, по какому из адресов ваш сайт участвует в поиске. Этот адрес будет обозначен как основной, а остальные сформируют группу зеркал вашего сайта.
Сделать это можно с помощью директивы Host. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы Host нужно указать основной домен с номером порта (по умолчанию 80). Например:
User-Agent: *
Disallow:
Host: test-o-la-la.ru
Такая запись означает, что сайт будет отображаться в результатах поиска со ссылкой на домен test-o-la-la.ru, а не www.test-o-la-la.ru и s10364.nubex.ru (см. скриншот выше).
В конструкторе «Нубекс» директива Host добавляется в текст файла robots.txt автоматически, когда вы указываете в админке, какой домен является основным.
В тексте robots.txt директива host может использоваться только единожды. Если вы пропишите ее несколько раз, робот воспримет только первую по порядку запись.
Директива Crawl-delay: как задать интервал загрузки страниц
Чтобы обозначить роботу минимальный интервал между окончанием загрузки одной страницы и началом загрузки следующей, используйте директиву Crawl-delay. Ее нужно добавить в запись, начинающуюся с User-Agent, непосредственно после директив Disallow и Allow. В значении директивы укажите время в секундах.
User-Agent: *
Disallow:
Crawl-delay: 3
Использование такой задержки при обработке страниц будет удобным для перегруженных серверов.
Существуют также и другие директивы для поисковых роботов, но пяти описанных — User-Agent, Disallow, Allow, Host и Crawl-delay — обычно достаточно для составления текста файла robots.txt.
Robots.txt — инструкция для SEO ➤ Что значит robots.txt
Файл robots.txt часто не замечают. Или действуют по принципу «не знал, не знал, да и забыл».
Хотя именно robots.txt – важная часть любого набора инструментов SEO, независимо от того, новичок вы в этой отрасли или уже матерый ветеран-оптимизатор.
Что такое файл robots.txt?
Файл robots.txt показывает важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как проверить все страницы вашего сайта, поисковые роботы проверяют данный файл.
Robots.txt еще указывает поисковой системе на то, какие страницы сканировать, а какие нет. А еще это отличный инструмент для управления краулингового бюджета вашего сайта.
Вы, наверное, спрашиваете себя: «Минуточку, а что вообще такое краулинговый бюджет?» Краулинговый бюджет – это то, что использует Google для эффективного сканирования и индексации сайта. Как бы ни был велик Google, у него все еще маловато ресурсов для сканирования и индексирования контента такого количества сайтов, которое есть сейчас.
Если у вашего сайта есть всего лишь несколько сотен URL, то Google без проблем сможет сканировать и индексировать страницы вашего сайта.
Но если ваш сайт большой (как, например, интернет-магазин), и у вас тысячи страниц с огромным количеством автоматически сгенерированных URL, тогда Google может не сканировать все эти страницы, и вы потеряете кучу потенциального трафика.
Это именно тот момент, когда нужно подсказать, что, когда и сколько нужно сканировать.
В Google сообщили, что «наличие множества url-адресов с низким качеством наполнения плохо влияет на сканирование и индексацию сайта». Вот где наличие файла robots.txt может помочь с факторами, влияющими на краулинговый бюджет вашего сайта.
Вы можете использовать этот файл для управления краулинговым бюджетом, будучи уверенным, что поисковые системы используют время на вашем сайте настолько эффективно (особенно если у вас большой сайт), насколько это возможно, и что они сканируют только важные страницы и не теряют время на такие страницы, как страница входа, регистрации или страница благодарности.
Для чего нужен robots.txt?
Прежде чем поисковый робот, такой, как Googlebot, Bingbot и др., сканирует веб-страницу, он сначала проверяет, существует ли на самом деле файл robots.txt. А уж если такой файл есть, то поисковый робот, как правило, будет следовать указаниям из этого файла.
Файл robots.txt может быть мощным инструментом в любом арсенале SEO, поскольку это отличный способ контролировать то, как именно поисковые роботы/боты получают доступ к определенным областям вашего сайта.
Важно! Вы должны быть уверены, что понимаете, как работает файл robots.txt, иначе вы случайно запретите роботу Googlebot или любому другому боту сканировать весь ваш сайт, и тогда ваш веб-ресурс не будет отражаться в результатах поиска.
Но когда все сделано правильно, вы можете контролировать такие вещи, как:
- Блокировка доступа ко всем разделам вашего сайта (среда разработки, промежуточная среда и т. д.).
- Предотвращение сканирования, индексации или отображения страниц результатов внутреннего поиска на ваших сайтах.
- Указание местоположения вашей карты или карт сайта.
- Оптимизация бюджета сканирования путем блокировки доступа к страницам низкого качества (вход в систему, благодарности, корзины покупок и т. д.).
- Предотвращение индексирования определенных файлов на вашем сайте (изображений, PDF-файлов и т. д.).
Примеры robots.txt
Ниже приведу парочку примеров того, как вы можете использовать файл robots.txt на вашем сайте.
Разрешение всем поисковым системам/роботам на доступ ко всему контенту вашего сайта:
Блокировка доступа всех поисковых систем/роботов ко всему контенту вашего сайта:
User-agent: *
Disallow: /
Вы можете увидеть, что очень легко допустить ошибку при создании robots.txt для веб-ресурса, когда различием между блокировкой целого сайта от разрешения полного доступа является лишь слеш в директиве disallow (Disallow: /).
Блокировка доступа определенной поисковой системе/роботу к определенной папке:
User-agent: Googlebot
Disallow: /
Блокировка доступа поисковым системам/роботам к определенной странице на вашем сайте:
User-agent:
Disallow: /thankyou.html
Запрет на доступ к определенным папкам сайта для всех поисковых систем/роботов:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /junk/
Вот пример того, как выглядит файл robots.txt на сайте theverge.com:
Вот так корректнее:
1 – theverge.com не хочет, чтобы Googlebot News сканировал любой из этих каталогов на сайте.
2 – theverge.com блокирует доступ всем роботам к сканированию этих каталогов на сайте.
3 – theverge.com перечислил размещение всех карт сайта в их файле robots.txt.
Этот же пример файла можно найти здесь: www.theverge.com/robots.txt.
В примере видно, как The Verge использует файл robots.txt, чтобы ограничить сканирование определенных каталогов на сайте новостным роботом Google «Googlebot-News».
Важно помнить, что если вы хотите быть уверены, что боты не сканируют определенные страницы или каталоги на сайте, то их нужно перечислить в описании «Disallow» в вашем файле robots.txt, как в примере выше.
Также вы можете больше узнать, как Google работает с robots.txt в их руководстве по спецификации robots.txt. Google имеет максимальный лимит на размер файла robots.txt – 500KB, так что важно помнить о размере robots.txt на вашем сайте.
Как создать robots.txt
Создание файла – достаточно простой процесс, но в нем очень легко допустить ошибку. Не позволяйте этому препятствовать вам создавать или модифицировать robots для вашего сайта. Эта справка от Google расскажет о процессе создания файла от и до, и поможет с легкостью создать вам свой собственный robots.txt.
Если вы освоили правила создания и редактирования robots, у Google есть также рекомендации, которые объяснят, как протестировать ваш файл robots.txt и проверить, правильно ли он настроен.
Проверьте, есть ли у вас файл robots.txt
Если вы новичок в robots.txt, или не уверены, есть ли у вашего сайта такой файл, вы можете сделать быструю проверку. Все, что вам нужно, это перейти к домену вашего сайта и добавить /robots.txt в конец вашего URL. Например: www.yoursite.com/robots.txt
Если ничего не происходит, значит, у вас его нет. То есть сейчас самое время заняться его созданием.
Возьмите на заметку:
- Убедитесь, что все важные страницы можно просканировать, а контент, не представляющий реальной ценности, заблокирован.
- Не блокируйте JavaScript и файлы CSS.
- Всегда проверяйте файл, чтобы удостовериться, что в нем ничего не изменилось.
- Используйте правильный регистр каталогов, подкаталогов и файловых имен.
- Поместите файл robots.txt в корневой каталог сайта, чтобы его можно было найти.
- Robots.txt чувствителен к регистру, он должен быть записан только как «robots.txt» и никак иначе.
- Не используйте файл robots.txt, чтобы скрыть персональную информацию, потому что она все еще будет видима.
- Добавьте в файл адрес размещения карты сайта.
- Убедитесь, что вы не блокируете контент или страницы, которые вы хотите сканировать.
На что обратить внимание:
Если у вас есть субдомен или несколько субдоменов на сайте, тогда вам нужно иметь файл robots.txt на каждом из них, так же, как и в основном домене. Выглядит это примерно так: store.yoursite.com/robots.txt и yoursite.com/robots.txt.
Важно помнить, что лучше не использовать robots.txt для предотвращения сканирования такой информации, как персональная информация пользователей.
Причиной является то, что другие страницы могут ссылаться на эту информацию, и тогда появится обратная прямая ссылка, которая обойдет правила файла robots.txt, и тогда контент все равно может быть проиндексирован.
Если вам нужно заблокировать ваши страницы от индексации в результатах поиска, используйте разные методы, такие, как защита паролем или добавления мета-тега «noindex» на эти страницы. Google не пройдет на страницу или сайт, защищенный паролем, поэтому не сможет сканировать или индексировать эти страницы.
Если не можете сделать сами, делегируйте
Если вы все еще немного нервничаете, что никогда раньше не работали с файлом robots.txt, расслабьтесь – он достаточно прост в использовании. Когда вы освоите правила работы с файлом, вы сможете улучшить SEO вашего сайта, а также помочь посетителям и роботам поисковых систем.
А если у вас не получается, то всегда есть СПРАВА. Поможем улучшить видимость важных страниц вашего сайта! Обращайтесь!
Используя robots.txt правильно, вы поможете роботам поисковых систем расходовать их краулинговый бюджет с умом и сканировать только важные страницы. Тогда роботы не будут тратить время и ресурсы на страницы, которые не нужно сканировать. Это поможет роботам организовать и показывать ваш контент в поисковой выдаче, что, в свою очередь, означает, что у вас будет лучшая видимость.
Не забывайте, что установка файла не всегда требует много времени. По большей части сделать это нужно только один раз, а потом уже редактировать файл в зависимости от ваших нужд.
Надеюсь, что практики, советы и предложения, описанные в этой статье, помогут вам быть более уверенными в создании/изменении robots.txt для вашего сайта, а также упростят процесс работы с файлом.
Файл robots.txt — шпаргалка для начинающих
Любой человек, тем более тот, который только начинает свой путь вебмастера, не может сделать идеальный сайт для раскрутки в интернете и получения прибыли с него, если не знает предназначения основных файлов движка, который он использует. Однако существуют однотипные файлы, которые используют все CMS — системы.
Один из таких файлов является robots.txt. Именно ему и посвящена данная статья. Здесь мы рассмотрим правильное составление этого файла и расскажем о некоторых нюансах упрощения составления списка запрещенных страниц для собственного сайта.
Robots.txt – текстовый файл, открываемый обычным блокнотом. Находится он в корневом каталоге любого движка и состоит из списка запрещенных для отображения в поисковой выдаче страниц.
Каждая строка этого файла представляет собой ссылку на запрещенную к индексации поисковыми системами страничку. Иногда приходится запретить к показу несколько однотипных страничек.
Допустим, что у вас на сайте присутствуют теги, которые создаются как отдельная страничка с выдачей. Естественно, поисковым системам незачем отображать эту информацию, так как вы не только задублируете информацию, но и создадите совсем ненужную ссылку в поисковой выдаче.
Для более наглядного понимания стоит привести пример:
Site.com/tags/1 Site.com/tags/2 …
Таких тегов могут быть тысячи, чтобы не дублировать каждый тег новой строкой, можно ввести всего одну строку следующего вида:
Это значит, что в вашем домене будут заблокированы для выдачи в поиске все странички, имеющие в своем адресе фразу «tags» на втором уровне (сразу после доменного имени).
Главная идея этого файла состоит в том, чтобы запретить роботам поисковых систем отображать в поиске странички, которые будут либо дублировать информацию, либо отображать личную информацию пользователей сайта без предварительной регистрации.
Во-первых, это не позволяет получить пользователям интернета личную информацию пользователей ресурса, во-вторых, в поиске будут отображаться только необходимые вам страницы.
Это основные принципы, которыми руководствуются создатели сайтов, редактируя текстовый файл robots. Правильно оформив данный файл, вы позволите поисковым роботам индексировать только качественный контент со своего сайта.
Проверка на правильность оформления файла robots.txt для поисковых систем – одно из необходимых правил, если вы до этого ни разу не пользовались движком, не знаете всей его структуры или просто хотите лишний раз проверить свои знания, и убедиться в том, что ваш robots.txt правильный.
Провести проверку можно в специальных разделах для вебмастеров в самих поисковых системах. В Google Webmaster подобный инструмент находится во вкладке «Состояние» —> «Заблокированные URL». В окно вставьте строки вашего файла robots.txt и в нижнем окне введите ссылки на различные данные на вашем сайте для проверки блокировки.
На самом деле данная проверка не так проста, как вам кажется, ведь по сути придется проверить элементы «разных типов» сайта, например: категории, теги, странички, странички с параметрами и т.д. В результатах проверки вы увидите, какие странички разрешены для отображения в поисковых системах, а какие запрещены.
В Яндекс Вебмастере все абсолютно аналогично, за исключением того, что можно не вставлять строки в поле, а выгрузить сам файл непосредственно с сайта.
Как вариант, можно просмотреть карту сайта и с карты сайта «повытаскивать» несколько примеров ссылок для проверки на блокировку.
Если у вас нет времени на составление собственного файла robots.txt для поисковиков, можете воспользоваться стандартным списком и по необходимости дополнить его.
Пример правильного файла robots для wordpress:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Host: site.com
Также в конце файла не забудьте указать ссылку на карту сайта:
Sitemap: http://site.com/sitemap.xml
Также в конце файла не забудьте указать ссылку на карту сайта:
Sitemap: http://site.com/sitemap.xml
Обратите внимание! Данный список является самым оптимальным вариантом, но подходит только для типичных сайтов без вмешательства в глобальный код движка/шаблона.
Учитывая факт, что идеальный вариант этого файла нужен каждому сайту, многие разработчики модулей и плагинов уже позаботились об его автоматическом создании. Сейчас вы можете без проблем найти специальный генератор в интернете. Один из наиболее простых и удобных в использовании находится здесь.
Сервисы подобные этому проводят тщательный анализ вашей карты сайта и составляют список дублей и ненужных страничек, делая идеальный robots.txt для вашего сайта. После генерации вам остается лишь скопировать строки в ваш файл, расположенный на сервере и все.
Обратите внимание! Файл Robots.txt не предназначен для полного сокрытия страниц от поисковых систем! Google, Yandex и прочие поисковые системы просто не выносят запрещенные страницы в поиск и не добавляют их в количество проиндексированных, но все равно сканируют их.
Если, к примеру, вы решите загнать в скрытую от индексации страницу какой-нибудь вирус или вредоносный скрипт, поисковая система все равно признает сайт вредоносным и возможно заблокирует доступ к нему.
Хотим обратить ваше внимание на то, что даже самый лучший генератор не способен сделать список блокируемых страниц идеальным. Максимально правильно может составить список блокируемых ссылок только владелец сайта или опытный специалист по SEO.
Поэтому, если в индексе поисковых систем появились нежелательные страницы вашего ресурса или вы не знаете, как правильно их скрыть, лучше всего обратиться за помощью к SEO-специалистам или попросить помощи на специализированном форуме, предоставив всю необходимую информацию.
Напоследок хотелось бы добавить, что действующие в данный момент алгоритмы Google проверяют правильное создание файла robots.txt, это в свою очередь влияет на релевантность выдачи сайта по запросам в поисковой системе Google.
Если вы начинающий вебмастер, не стоит спешить с оформлением или тупым копированием строк. Для начала изучите как можно больше информации и только потом приступайте к составлению файла robots.txt.
Удачного продвижения!
FAQ robots.txt: часто задаваемые вопросы
Robots.txt — что это?
Файл robots.txt — это индексный файл в текстовом формате, который рекомендует поисковым роботам (например, Google, Yandex) какие страницы сканировать, а какие нет.
Нужен или нет robots.txt?
Однозначно да. Он помогает поисковым роботам быстрее разобраться какие страницы нужно индексировать, а какие нет.
Где находится файл robots.txt?
Файл располагается в корневой папке сайта и доступный для просмотра по адресу: https://site.ua/robots.txt
Как выглядит стандартный robots.txt?
Robots.txt пример:
Что должно быть в robots.txt?
Атрибуты robots.txt:
- User-agent — описывает каким именно роботам нужно смотреть инструкцию. Существует около 300 поисковых роботов (Googlebot, Yandexbot и т.д.). Чтобы указать инструкции сразу для всех роботов следует прописать:
Другие роботы:- Ahrefsbot;
- Exabot;
- SemrushBot;
- Baiduspider;
- Mail.RU_Bot.
- Disallow — указывает роботу, что не нужно сканировать.
Открыть для сканирования весь сайт (robots.txt разрешить все):
Запретить сканирование всего сайта (robots.txt запретить все):
Robots.txt запретить индексацию папки:
Запретить индексацию страницы в robots.txt:
Запретить индексацию конкретного файла:
Запрет индексации всех файлов на сайте с расширением .pdf:
Запретить индексацию поддомена в robots.txt:
Каждый поддомен имеет свой файл robots.txt. Если его нет — создайте и добавьте в корневую папку поддомена.
Закрыть все кроме главной в robots.txt: - Allow — разрешает роботу сканировать сайт/папку/конкретную страницу.
Например, чтобы разрешить роботу сканировать страницы каталога, а все остальное закрыть:
Как выглядит Robots.txt для Гугла и Яндекса?
Как указать главное зеркало в robots.txt?
Для обозначения главного зеркала (копии сайта, доступной по разным адресам) используют атрибут Host.
Host в robots.txt:
Как прописать карту сайта в robots.txt?
Карта сайта (sitemap.xml) сообщает поисковым роботам приоритетные страницы для индексации. Она находится по адресу: https://site.com/sitemap.xml.
Sitemap в robots.txt:
Что обозначают символы в robots.txt?
Наиболее часто используются следующие символы:
- “/” — закрытие от робота весь сайт/папку/страницу;
- “*” — любая последовательность символов;
- “$” — ограничение действия знака “*”;
- “#” — комментарии, которые не учитываются роботами.
Как настроить robots.txt?
В файле обязательно нужно отдельно для каждого робота прописать, что открыто для сканирования и что закрыто, прописать хост и карту сайта.
Файлы robots.txt различаются между собой в зависимости от используемой CMS.
Рекомендуем закрывать от индексации страницы: авторизации, фильтрации, поиска, страницу 404, вход в админку.
Пример идеального robots.txt:
Как проверить robots.txt?
Чтобы проверить валидность robots.txt (правильно ли заполнен файл) — используйте инструмент для вебмастеров Google Search Console. Для этого достаточно ввести код файла в форму, указать сайт и Вы получите отчет о корректности файла:
Ошибки в robots.txt
- Перепутали местами инструкции.
Неправильно:
Правильно: - Записали пару директорий сразу в одной инструкции:
- Не правильное название файла — не Robot.txt и не ROBOTS.TXT, а robots.txt!
- Правило User-agent не должно быть пустым, обязательно нужно указывать для каких роботов оно действует.
- Следите, чтобы не указать лишних символов в файле (“/”, “*”, “$” и т.д.).
- Не открывайте для сканирования страницы, которые не нужны в индексе.
Подойдите со всей ответственностью к формированию файла robots.txt — и будет Вам счастье 😉
Как Google интерпретирует спецификацию robots.txt | Центр поиска
Автоматизированная система Google краулеры поддерживают Протокол исключения роботов (REP). Это означает, что перед сканированием сайта сканеры Google загружают и анализируют Файл robots.txt для извлечения информации о том, какие части сайта можно сканировать. REP неприменимо к сканерам Google, которые контролируются пользователями (например, фид подписки) или поисковые роботы, которые используются для повышения безопасности пользователей (например, вредоносное ПО анализ).
На этой странице описывается интерпретация REP в Google. Для оригинала проект стандарта, проверьте IETF Data Tracker. Если вы новичок в robots.txt, начните с нашего введение в robots.txt. Вы также можете найти советы по созданию файла robots.txt и обширный список часто задаваемые вопросы и ответы на них.Что такое файл robots.txt
Если вы не хотите, чтобы сканеры получали доступ к разделам вашего сайта, вы можете создать файл robots.txt файл с соответствующими правилами. Файл robots.txt — это простой текстовый файл, содержащий правила, в отношении которых сканеры могут получить доступ к каким частям сайта.
Местоположение файла и срок действия
Вы должны поместить файл robots.txt в каталог верхнего уровня сайта на поддерживаемом
протокол. В случае поиска Google поддерживаемые протоколы: HTTP,
HTTPS и FTP. По HTTP и HTTPS поисковые роботы получают файл robots.txt с помощью HTTP
безусловный запрос GET ; на FTP сканеры используют стандартный RETR (RETRIEVE) команда с использованием анонимного входа в систему.
Правила, перечисленные в файле robots.txt, применяются только к хосту, протоколу и номеру порта. где размещен файл robots.txt.
URL-адрес файла robots.txt (как и другие URL-адреса) чувствителен к регистру.Примеры действительных URL-адресов robots.txt
| Robots.txt Примеры URL | |
|---|---|
http://example.com/robots.txt | Годен до:
|
http://www.example.com/robots.txt | Годен до: Недействительно для:
|
http://example.com/folder/robots.txt | Недействительный файл robots.txt. Сканеры не проверяют файлы robots.txt в подкаталогах. |
http://www.exämple.com/robots.txt | Годен до:
Не действует для: |
ftp://example.com/robots.txt | Годен до: Не действует для: |
http://212.96.82.21/robots.txt | Годен до: Не действует для: |
http://example.com:80/robots.txt | Действительно для:
Не действует для: 80 для HTTP, 443 для HTTPS, 21 для FTP) эквивалентны своим именам хостов по умолчанию. |
http://example.com:8181/robots.txt | Годен до: Не действует для: |
Обработка ошибок и кодов состояния HTTP
При запросе файла robots.txt код статуса HTTP ответа сервера влияет на то, как файл robots.txt будет использоваться поисковыми роботами Google.
| Обработка ошибок и кодов состояния HTTP | |
|---|---|
2xx (успешно) | Коды состояния HTTP, которые сигнализируют об успехе, побуждают сканеры Google обрабатывать файл robots.текст файл, предоставленный сервером. |
3xx (перенаправление) | Google выполняет не менее пяти переходов переадресации, как определено
RFC 1945, а затем
останавливает и обрабатывает его как Google не выполняет логические перенаправления в файлах robots.txt (фреймы, JavaScript или переадресация типа мета-обновления). |
4xx (ошибки клиента) | Сканеры Google обрабатывают все ошибки 401 (неавторизованный) и 403 (запрещенный) HTTP
коды состояния. |
5xx (ошибка сервера) | Поскольку сервер не смог дать однозначного ответа на запрос Google robots.txt,
Google временно интерпретирует ошибки сервера, как если бы сайт был полностью запрещен. Google
будет пытаться сканировать файл robots.txt до тех пор, пока не получит HTTP-статус, не связанный с ошибкой сервера.
код. Ошибка 503 Код состояния HTTP для каждого URL-адреса на сайте. Если мы можем определить, что сайт неправильно настроен для возврата |
| Прочие ошибки | Файл robots.txt, который невозможно получить из-за проблем с DNS или сетью, например таймауты, недопустимые ответы, сброс или прерванные соединения и ошибки фрагментации HTTP, рассматривается как ошибка сервера. |
Кэширование
Google обычно кэширует содержимое файла robots.txt на срок до 24 часов, но может кэшировать его.
дольше в ситуациях, когда обновление кэшированной версии невозможно (например, из-за
таймауты или ошибки 5xx ). Кешированный ответ может использоваться разными сканерами.
Google может увеличить или уменьшить время жизни кеша в зависимости от
Максимальный возраст Cache-Control
Заголовки HTTP.
Формат файла
Роботы.txt должен быть
Простой текст в кодировке UTF-8
файл и строки должны быть разделены символами CR , CR / LF или LF .
Google игнорирует недопустимые строки в файлах robots.txt, включая Unicode. Знак порядка байтов (BOM) в начале файла robots.txt и используйте только допустимые строки. Например, если загруженный контент представляет собой HTML, а не правила robots.txt, Google попытается проанализировать контент и извлекать правила, а все остальное игнорировать.
Точно так же, если кодировка файла robots.txt отличается от UTF-8, Google может игнорировать символы, не входящие в диапазон UTF-8, потенциально могут отображать правила robots.txt неверный.
В настоящее время Google применяет ограничение на размер файла robots.txt, равное 500. кибибайт (KiB). Содержание после того, как максимальный размер файла игнорируется. Вы можете уменьшить размер файла robots.txt файл, объединив директивы, которые могут привести к слишком большому размеру файла robots.txt файл. Для Например, поместите исключенный материал в отдельный каталог.
Синтаксис
Допустимые строки robots.txt состоят из поля, двоеточия и значения. Пробелы необязательны, но
рекомендуется для улучшения читаемости. Пробел в начале и в конце строки равен
игнорируется. Чтобы включить комментарии, поставьте перед комментарием символ # . Держать в
Имейте в виду, что все, что находится после символа # , будет проигнорировано.Общий формат <поле>: <значение> <# необязательный-комментарий> .
Google поддерживает следующие поля:
-
user-agent: определяет, к какому искателю применяются правила. -
разрешить: путь URL-адреса, который можно сканировать. -
disallow: путь URL, сканирование которого невозможно. -
карта сайта: полный URL карты сайта.
Поля allow и disallow также называются директивами .
Эти директивы всегда указываются в виде
Директива : [путь] , где [путь] является необязательным. По умолчанию нет
ограничения на сканирование для указанных сканеров. Сканеры игнорируют директивы без [путь] .
Значение [путь] , если указано, относится к корню веб-сайта, откуда
роботы.txt был получен (с использованием того же протокола, номера порта, имени хоста и домена).
Значение пути должно начинаться с / для обозначения корня, а значение —
деликатный случай. Узнать больше о
Соответствие URL-адресов на основе значений пути.
агент пользователя Строка пользовательского агента определяет, к каким правилам искателя применяются. Видеть
Сканеры Google и строки пользовательского агента
для получения исчерпывающего списка строк пользовательских агентов, которые вы можете использовать в своих файлах robots.txt файл.
Значение строки пользовательского агента нечувствительно к регистру.
запретить Директива disallow указывает пути, к которым не должны обращаться сканеры.
идентифицированная строкой user-agent, с которой сгруппирована директива disallow .
Сканеры игнорируют директиву без пути.
Google не может индексировать содержание страниц, сканирование которых запрещено, но все же может
проиндексировать URL-адрес и показать его в результатах поиска без фрагмента.Узнайте, как
блочная индексация. Значение директивы disallow чувствительно к регистру.
использование:
запретить: [путь]
разрешить Директива allow определяет пути, к которым могут получить доступ указанные
краулеры. Если путь не указан, директива игнорируется.
Значение директивы allow чувствительно к регистру.
использование:
разрешить: [путь]
карта сайта Google, Bing и другие основные поисковые системы поддерживают поле карты сайта в
robots.txt, как определено sitemaps.org.
Значение поля карты сайта чувствительно к регистру.
использование:
карта сайта: [absoluteURL]
Строка [absoluteURL] указывает на расположение файла карты сайта или файла индекса карты сайта.Это должен быть полный URL-адрес, включая протокол и хост, и не обязательно
В кодировке URL. URL-адрес не обязательно должен находиться на том же хосте, что и файл robots.txt. Вы можете
укажите несколько полей карты сайта . Поле карты сайта не привязано к какому-либо конкретному
пользовательский агент, и за ним могут следить все сканеры, если он не запрещен для сканирования.
Например:
пользовательский агент: otherbot
запретить: / капуста
карта сайта: https://example.com/sitemap.xml
карта сайта: https://cdn.example.org/other-sitemap.xml
карта сайта: https://ja.example.org/ テ ス ト - サ イ ト マ ッ プ .xml
Группировка строк и правила
Вы можете сгруппировать правила, которые применяются к нескольким пользовательским агентам, повторяя пользовательский агент строк для каждого поискового робота.
Например:
пользовательский агент: a
запретить: / c
пользовательский агент: b
запретить: / d
пользовательский агент: e
пользовательский агент: f
запретить: / г
пользовательский агент: h
В этом примере есть четыре отдельные группы правил:
- Одна группа для пользовательского агента «а».
- Одна группа для пользовательского агента «b».
- Одна группа для пользовательских агентов "e" и "f".
- Одна группа для пользовательского агента "h".
Техническое описание группы см.
раздел 2.1 РЭП.
Порядок приоритета для пользовательских агентов
Для конкретного поискового робота действительна только одна группа. Сканеры Google определяют правильный
группу правил, найдя в файле robots.txt группу с наиболее конкретным пользовательским агентом
который соответствует пользовательскому агенту поискового робота.Остальные группы игнорируются. Весь несоответствующий текст
игнорируются (например, googlebot / 1.2 и googlebot * являются
эквивалент googlebot ). Порядок групп в файле robots.txt:
не имеющий отношения.
Если для определенного пользовательского агента объявлено несколько групп, все правила из
группы, применимые к конкретному пользовательскому агенту, внутренне объединяются в одну группу.
Примеры
Сопоставление
пользовательского агента полейпользовательский агент: googlebot-news
(группа 1)
пользовательский агент: *
(группа 2)
пользовательский агент: googlebot
(группа 3)
Вот как поисковые роботы выбирают соответствующую группу:
Группа отслеживаемых на гусеничном ходу Googlebot News googlebot-news следует за группой 1, потому что группа 1 является наиболее специфической группой. Googlebot (Интернет) googlebot следует за группой 3. Изображения робота Googlebot googlebot-images следует за группой 2, потому что нет конкретного googlebot-images группа. Googlebot News (при сканировании изображений) При сканировании изображений за группой 1 следует googlebot-news . googlebot-news не сканирует изображения для Картинок Google, поэтому только
следует за группой 1. Другой бот (Интернет) Другие сканеры Google следуют за группой 2. Otherbot (новости) Другие сканеры Google, которые сканируют новостной контент, но не идентифицируют себя как googlebot-news следуйте за группой 2. Даже если есть запись для связанной
поисковый робот, он действителен только в том случае, если он специально соответствует.
Группировка правил
Если в файле robots.txt есть несколько групп, относящихся к определенному пользовательскому агенту,
Сканеры Google внутренне объединяют группы. Например:
пользовательский агент: googlebot-news
запретить: / рыба
пользовательский агент: *
запретить: / морковь
пользовательский агент: googlebot-news
запретить: / креветка
Сканеры внутренне группируют правила на основе пользовательского агента, например:
пользовательский агент: googlebot-news
запретить: / рыба
запретить: / креветка
пользовательский агент: *
запретить: / морковь
Соответствие URL на основе значений пути
Google использует значение пути в директивах allow и disallow как
основа для определения того, применяется ли правило к определенному URL-адресу на сайте.Это работает
сравнение правила с компонентом пути URL-адреса, который поисковый робот пытается получить.
Не 7-битные символы ASCII в пути могут быть включены как символы UTF-8 или как экранированные с помощью процентов
Символов в кодировке UTF-8 на
RFC 3986.
Google, Bing и другие основные поисковые системы поддерживают ограниченную форму подстановочных знаков для
значения пути. Эти:
-
* обозначает 0 или более экземпляров любого допустимого символа. -
$ обозначает конец URL-адреса.
Пример совпадения пути / Соответствует корневому URL-адресу и любому URL-адресу нижнего уровня. / * Эквивалент /. Завершающий подстановочный знак игнорируется. / Соответствует только корню.Любой URL нижнего уровня разрешен для сканирования. / рыба Соответствует любому пути, который начинается с / fish .
Матчей:
-
/ рыба -
/fish.html -
/fish/salmon.html -
/ рыбья голова -
/ рыбные головы / вкуснятина.HTML -
/fish.php?id=anything
Не соответствует:
-
/Fish.asp -
/ сом -
/? Id = рыба -
/ пустыня / рыба
Примечание. При сопоставлении учитывается регистр. / рыба * Эквивалент / рыба .Завершающий подстановочный знак игнорируется.
Матчей:
-
/ рыба -
/fish.html -
/fish/salmon.html -
/ рыбья голова -
/fishheads/yummy.html -
/fish.php?id=anything
Не соответствует:
-
/ Рыба.asp -
/ сом -
/? Id = рыба
/ рыба / Соответствует чему-либо в папке / fish / .
Матчей:
-
/ рыба / -
/ животные / рыба / -
/ fish /? Id = что-нибудь -
/ рыба / лосось.htm
Не соответствует:
-
/ рыба -
/fish.html -
/Fish/Salmon.asp
/*.php Соответствует любому пути, который содержит .php .
Матчей:
-
/ индекс.php -
/filename.php -
/folder/filename.php -
/folder/filename.php?parameters -
/folder/any.php.file.html -
/filename.php/
Не соответствует:
-
/ (даже если он отображается в /index.php) -
/ окна. филиппинских песо
/*.php $ Соответствует любому пути, который заканчивается на .php .
Матчей:
-
/filename.php -
/folder/filename.php
Не соответствует:
-
/filename.php?parameters -
/ имя файла.php / -
/filename.php5 -
/ windows.PHP
/fish*.php Соответствует любому пути, который содержит / fish и .php в указанном порядке.
Матчей:
-
/fish.php -
/ рыбные головы / сом.php? параметры
Не совпадает: /Fish.PHP
Порядок приоритета правил
При сопоставлении правил robots.txt с URL-адресами сканеры используют наиболее конкретное правило на основе
длина его пути. В случае противоречивых правил, в том числе с использованием подстановочных знаков, Google использует
наименее ограничительное правило.
Следующие примеры демонстрируют, какое правило поисковые роботы Google будут применять к заданному URL-адресу.
Примеры ситуаций http://example.com/page разрешить: / p
запретить: /
Применимое правило : allow: / p , потому что оно более конкретное.
http://example.com/folder/page разрешить: / папка
disallow: / папка
Применимое правило : allow: / folder , потому что в случае
правила соответствия, Google использует наименее ограничительное правило.
http://example.com/page.htm разрешить: / страница
запретить: /*.htm
Применимое правило : disallow: /*.htm , потому что оно соответствует
больше символов в URL-адресе, чтобы он был более конкретным.
http://example.com/page.php5 разрешить: / страница
запретить: / *.ph
Применимое правило : allow: / page , потому что в случае
правила соответствия, Google использует наименее ограничительное правило.
http://example.com/ разрешить: / $
запретить: /
Применимое правило : allow: / $ , потому что оно более конкретное.
http: // example.com / page.htm разрешить: / $
запретить: /
Применимое правило : disallow: / , потому что разрешить Правило применяется только к корневому URL-адресу.
Пример текстового файла Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете скопировать их на свой сайт или объединить шаблоны, чтобы создать свои собственные.
Помните, что файл robots.txt влияет на ваше SEO, поэтому обязательно проверяйте вносимые вами изменения.
Приступим.
1) Запретить все
Первый шаблон остановит сканирование вашего сайта всеми ботами. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду.
Какой бы ни была причина, как вы запретите всем поисковым роботам читать страницы:
Агент пользователя: *
Disallow: /
Здесь мы ввели два «правила»:
- User-agent - Настройте таргетинг на конкретного бота, используя это правило, или используйте * в качестве подстановочного знака, что означает всех ботов
- Disallow - Используется, чтобы сообщить боту, что он не может перейти в эту область сайта.Установив для него значение
/, бот не будет сканировать ни одну из ваших страниц.
Что, если мы хотим, чтобы бот сканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Один из вариантов - не создавать и не удалять файл robots.txt.
Тем не менее, иногда это невозможно, и нужно что-то добавить. В этом случае мы бы добавили следующее:
На первый взгляд это кажется странным, поскольку у нас все еще действует правило Disallow.Тем не менее, он другой, поскольку он не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL-адрес не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда вам нужно заблокировать часть сайта, но разрешить доступ остальным. Хорошим примером этого является админка страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты просматривали эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: *
Запретить: / admin /
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое и с файлами. Возможно, существует конкретный файл, который вы не хотите, чтобы он попал в поиск Google. Опять же, это может быть админка или что-то подобное.
Чтобы заблокировать это для ботов, используйте файл robots.txt.
Агент пользователя: *
Запрещено: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением.Например, вы можете заблокировать PDF-файлы на вашем сайте, чтобы они попадали в поиск Google. Или у вас есть электронные таблицы, на чтение которых робот Googlebot не должен тратить время зря.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
* - Это подстановочный знак и будет соответствовать всему тексту -
$ - Знак доллара остановит сопоставление URL-адресов и представляет конец URL-адреса
При совместном использовании вы можете заблокировать PDF-файлы следующим образом:
Агент пользователя: *
Запретить: / *.pdf $
Или .xls файлов, например:
Агент пользователя: *
Disallow: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https: // пример.com / pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это, используя правило User-agent , до сих пор мы использовали подстановочный знак, соответствующий всем ботам.
Если бы мы хотели разрешить просмотр страниц сайта только роботу Googlebot, мы могли бы добавить этот файл robots.txt:
Агент пользователя: *
Запретить: /
Пользовательский агент: Googlebot
Disallow:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота.Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Пользовательский агент: Googlebot
Запретить: /
Пользовательский агент: *
Disallow:
Есть много пользовательских агентов-ботов, вот список общих, с которыми вы можете создавать правила:
- Googlebot - используется для поиска Google
- Bingbot - используется для поиска Bing
- Slurp - поисковый робот Yahoo
- DuckDuckBot - используется поисковой системой DuckDuckGo
- Baiduspider - это китайская поисковая система
- ЯндексБот - это русская поисковая машина
- facebot - используется Facebook
- Pinterestbot - используется Pinterest
- TwitterBot - используется Twitter
8) Ссылка на вашу карту сайта
Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице.В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы упрощаете ботам поиск всех ссылок на вашем сайте.
Для этого вам нужно использовать Sitemap правило:
Агент пользователя: *
Карта сайта: https://pagedart.com/sitemap.xml
Вышеупомянутый файл взят из файла robots.txt PageDart. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https: // в начале, чтобы он работал.
9) Снизьте скорость ползания
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер испытывает трудности при высоком трафике.
Bing, Yahoo и Яндекс поддерживают правило Crawl-delay . Это позволяет вам установить задержку между просмотром каждой страницы следующим образом:
Агент пользователя: *
Задержка сканирования: 10
В приведенном выше примере бот будет ждать 10 секунд перед запросом следующей страницы.Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуйте робота
Этот последний шаблон предназначен для развлечения. Вы можете добавить искусство ASCII, чтобы добавить робота в файл robots.txt, например:
# _
# []
# ()
# |> |
# __ / === \ __
# // | о = о | \\
# <] | о = о | [>
# \ ===== /
# / / | \ \
№ <_________>
Если кто-нибудь придет посмотреть на ваш robots.txt, то он может заставить их улыбнуться.
Некоторые компании уже делают это, у Airbnb есть реклама в их файле robots.txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в своем robots.txt:
https://www.npmjs.com/robots.txt
На Avvo.com есть рисунок Grumpy Cat в кодировке ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Заключение, пример txt файла для роботов
Мы рассмотрели 10 разных роботов.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить конкретного бота
- Ссылка на вашу карту сайта
- Понизьте скорость, с которой бот сканирует ваш сайт
- Нарисуйте какие-то работы в ваших роботах.txt файл
Помните, что вы можете комбинировать части этих шаблонов любым удобным вам способом, пока действуют правила. Чтобы проверить, действителен ли файл robots.txt, вы можете использовать нашу программу проверки robots.txt.
Страницы веб-роботов
О /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для получения инструкций по
их сайт для веб-роботов; это называется Исключение роботов
Протокол .
Это работает так: робот хочет перейти по URL-адресу веб-сайта, скажем,
http: // www.example.com/welcome.html. Прежде чем он это сделает, он первым
проверяет http://www.example.com/robots.txt и находит:
Агент пользователя: *
Запретить: /
«User-agent: *» означает, что этот раздел применим ко всем роботам. "Disallow: /" сообщает роботу, что он не должен посещать никакие
страницы на сайте.
При использовании /robots.txt следует учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, которые сканируют
Интернет на наличие уязвимостей в системе безопасности и сборщики адресов электронной почты, используемые спамерами
не обращаю внимания.
- файл /robots.txt является общедоступным. Все могут видеть, какие разделы
вашего сервера вы не хотите, чтобы роботы использовали.
Так что не пытайтесь использовать /robots.txt для сокрытия информации.
Смотрите также:
Детали
/Robots.txt является стандартом де-факто и не принадлежит никому
орган по стандартизации. Есть два исторических описания:
Вдобавок есть внешние ресурсы:
Файл / robots.txt активно не развивается.
См. Как насчет дальнейшего развития /robots.txt?
для более подробного обсуждения.
Остальная часть этой страницы дает обзор того, как использовать /robots.txt в
ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, см. Также FAQ.
Как создать файл /robots.txt
Куда девать
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет "/ robots.txt "для URL, он удаляет
компонент пути из URL-адреса (все, начиная с первой косой черты),
и помещает на его место "/robots.txt".
Например, для "http://www.example.com/shop/index.html" будет
удалите "/shop/index.html" и замените его на
"/robots.txt", и в итоге будет
"http://www.example.com/robots.txt".
Итак, как владельцу веб-сайта вам необходимо разместить его в нужном месте на своем
веб-сервер для работы полученного URL. Обычно это то же самое
место, куда вы помещаете основной "index" вашего веб-сайта.html "добро пожаловать
страница. Где именно он находится и как туда поместить файл, зависит от
программное обеспечение вашего веб-сервера.
Не забудьте использовать строчные буквы для имени файла:
robots.txt, а не Robots.TXT.
Смотрите также:
Что туда класть
Файл «/robots.txt» - это текстовый файл с одной или несколькими записями.
Обычно содержит одну запись следующего вида:Пользовательский агент: *
Disallow: / cgi-bin /
Запретить: / tmp /
Запретить: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что для каждого префикса URL-адреса вам нужна отдельная строка "Disallow".
хотите исключить - нельзя сказать "Disallow: / cgi-bin / / tmp /" на
одна линия. Кроме того, в записи может не быть пустых строк, так как они
используются для разграничения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается ни в User-agent, ни в Disallow
линий. '*' В поле User-agent - это специальное значение, означающее "любой
робот ". В частности, у вас не может быть таких строк, как" User-agent: * bot * ",
«Запрещать: / tmp / *» или «Запрещать: *.gif ".
Что вы хотите исключить, зависит от вашего сервера.
Все, что явно не запрещено, считается справедливым
игра для извлечения. Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
Пользовательский агент: *
Запретить: /
Разрешить всем роботам полный доступ
Пользовательский агент: *
Запретить:
(или просто создайте пустой файл "/robots.txt", или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользовательский агент: *
Disallow: / cgi-bin /
Запретить: / tmp /
Запретить: / мусор /
Исключить одного робота
Пользовательский агент: BadBot
Запретить: /
Чтобы позволить одному роботу
Пользовательский агент: Google
Запретить:
Пользовательский агент: *
Запретить: /
Для исключения всех файлов, кроме одного
В настоящее время это немного неудобно, поскольку нет поля «Разрешить».В
простой способ - поместить все файлы, которые нельзя разрешить, в отдельный
каталог, скажите "вещи" и оставьте один файл на уровне выше
этот каталог:Пользовательский агент: *
Запретить: / ~ joe / stuff /
В качестве альтернативы вы можете явно запретить все запрещенные страницы:Пользовательский агент: *
Запретить: /~joe/junk.html
Запретить: /~joe/foo.html
Запретить: /~joe/bar.html
Как добавить файл Robots.txt
Как добавить файл robots.txt на свой сайт
Текстовый файл robots или robots.txt (часто ошибочно называемый файлом robot.txt) необходим на каждом веб-сайте. Добавление файла robots.txt в корневую папку вашего сайта - очень простой процесс, и наличие этого файла на самом деле является «признаком качества» для поисковых систем. Давайте посмотрим на параметры файла robots.txt, доступные для вашего сайта.
Что такое текстовый файл роботов?
Файл robots.txt - это просто файл в формате ASCII или простой текстовый файл, который сообщает поисковым системам, где им не разрешено заходить на сайт - также известный как стандарт исключения для роботов.Любые файлы или папки, перечисленные в этом документе, не будут сканироваться и индексироваться пауками поисковых систем. Наличие даже пустого файла robots.txt показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь свободный доступ к нему. Мы рекомендуем добавить текстовый файл роботов к вашему основному домену и всем поддоменам на вашем сайте.
Параметры форматирования файла robots.txt
Создание robots.txt - простой процесс. Выполните следующие простые шаги:
- Откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «robots» в нижнем регистре, не забудьте выбрать.txt в качестве расширения типа файла (в Word выберите «Обычный текст»).
- Затем добавьте в файл следующие две строки текста:
Пользовательский агент: *
Disallow:
«Пользовательский агент» - это другое слово для роботов или пауков поисковых систем. Звездочка (*) означает, что эта строка относится ко всем паукам. Здесь нет файла или папки, перечисленных в строке Disallow, что означает, что любой каталог на вашем сайте может быть доступен. Это базовый текстовый файл для роботов.
- Блокирование "пауков" поисковых систем со всего вашего сайта также является одним из роботов.txt варианты. Для этого добавьте в файл эти две строчки:
Пользовательский агент: *
Disallow: /
- Если вы хотите заблокировать доступ пауков к определенным областям вашего сайта, ваш файл robots.txt может выглядеть примерно так:
User-agent: *
Disallow: / database /
Disallow: / scripts /
. Эти три строки говорят всем роботам, что им не разрешен доступ к чему-либо в базе данных и каталогах или подкаталогах сценариев. Помните, что в строке Disallow можно использовать только один файл или папку.Вы можете добавить столько строк Disallow, сколько вам нужно.
- Не забудьте добавить удобный для поисковых систем XML-файл карты сайта в текстовый файл robots. Это гарантирует, что "пауки" найдут вашу карту сайта и легко проиндексируют все страницы вашего сайта. Используйте этот синтаксис:
Карта сайта: http://www.mydomain.com/sitemap.xml
- После завершения сохраните и загрузите файл robots.txt в корневой каталог вашего сайта. Например, если ваш домен www.mydomain.com, вы разместите файл по адресу www.mydomain.com/robots.txt.
- После того, как файл будет размещен, проверьте файл robots.txt на наличие ошибок.
Search Guru может помочь реализовать этот и другие технические элементы SEO. Свяжитесь с нами сегодня чтобы начать!
Создание файла robots.txt Блок
Цели обучения
После завершения этого раздела вы сможете:
- Опишите основные функции внешней поисковой системы.
- Перечислить, что содержится в файле robots.txt файл.
- Опишите два способа создания файла robots.txt.
- Объясните, как проверить файл robots.txt.
- Опишите, как настроить кеширование при создании файла robots.txt.
Внешние поисковые системы
Брэндон Уилсон, мерчендайзер Cloud Kicks, хочет узнать о файле robots.txt, чтобы использовать его для повышения своего рейтинга во внешнем поиске и минимизации посторонних посещений своего сайта. Он начинает с внешних поисковых систем, которые выполняют три основные функции.
- Crawl: Ищите в Интернете контент, просматривая код / контент для каждого найденного URL.
- Индекс: Храните и систематизируйте контент, найденный в процессе сканирования. Как только страница попадает в индекс, Google может отображать ее в результате соответствующих запросов.
- Рейтинг: Предоставляйте фрагменты контента, которые лучше всего отвечают на запрос пользователя, с результатами, отсортированными в порядке от наиболее релевантного к наименее релевантному.
Сканер ищет / robots.txt URI на вашем сайте, где сайт определяется как HTTP-сервер, работающий на определенном хосте и номере порта. На сайте может быть только один /robots.txt . Из этого файла поисковый робот определяет, какие страницы или файлы он может или не может индексировать, используя параметр Disallow. Торговцы, такие как Брэндон, используют этот файл, чтобы ограничить индексируемую информацию важной информацией и предотвратить перегрузку своих сайтов нерелевантными запросами.
Давайте вместе с Брэндоном исследуем, что такое роботы.txt и как их сгенерировать и проверить.
Что находится в файле robots.txt?
Когда сканер посещает веб-сайт, например https://www.cloudkicks.com/ , он сначала проверяет файл robots.txt, расположенный в https://www.cloudkicks.com/robots.txt . Если файл существует, он анализирует содержимое, чтобы увидеть, какие страницы он может проиндексировать. Вы можете настроить файл robots.txt для применения к определенным роботам и запретить доступ к определенным каталогам или файлам. Вы можете записать в этот файл в Бизнес-менеджере до 50 000 символов.
Формат файла
Вот основной формат файла robots.txt.
User-agent: [имя user-agent]
Disallow: [строка URL, которую нельзя сканировать]
Вот пример.
Пользовательский агент: man-bot
Задержка сканирования: 120
Disallow: /category/*.xml$
Disallow: / mobile
Пользовательский агент: Googlebot
Запретить: / cloudkicks-test = new-products /
URI, начинающийся с указанного значения, не посещается. Например:
Disallow: / help - Disallow / help.html и /help/index.html.
Disallow: / help / - запрещает /help/index.html, но разрешает /help.html.
URL уточнения поиска
Если у вас уже есть записи в robots.txt, рекомендуется добавить эти строки внизу, чтобы запретить URL-адреса для уточнения поиска. Внешним поисковым системам не нужно их индексировать, и они могут рассматривать эти URL как дублированный контент, что вредит SEO.
# Параметры URL уточнения поиска
Запретить: / * pmin *
Запрещение: / * pmax *
Disallow: / * prefn1 *
Disallow: / * prefn2 *
Disallow: / * prefn3 *
Disallow: / * prefn4 *
Disallow: / * prefv1 *
Disallow: / * prefv2 *
Disallow: / * prefv3 *
Disallow: / * prefv4 *
Disallow: / * srule *
Скорость сканирования
Установите для робота Googlebot скорость сканирования Низкая в консоли поиска Google, поскольку Google игнорирует строку задержки сканирования в robots.текст. Термин скорость сканирования означает, сколько запросов в секунду робот Googlebot отправляет сайту при сканировании, например 5 запросов в секунду.
Вы не можете изменить частоту сканирования вашего сайта Google, но если вы хотите, чтобы Google сканировал новое или обновленное содержание на вашем сайте, вы можете запросить повторное сканирование.
Предотвратить сканирование
Когда поисковый робот посещает веб-сайт, например https://www.cloudkicks.com/ , он сначала проверяет файл robots.txt и определяет, разрешено ли ему индексировать сайт.В некоторых случаях вы этого не хотите. Например, Брэндон не хочет, чтобы поисковые роботы смотрели на его разработки и демонстрационные экземпляры, потому что они не предназначены для покупателей.
Вот пример файла robots.txt, который запрещает поисковым роботам индексировать сайт:
User-agent: * # относится ко всем роботам
Disallow: / # запретить индексирование всех страниц
Защита витрины паролем
Разработчики на одном из сайтов Cloud Kicks используют функцию защиты паролем витрины магазина, когда готовятся к запуску сайта.Эта функция ограничивает доступ к витрине для людей, участвующих в проекте. Это ограничение также не позволяет сканерам и роботам поисковых систем индексировать эту витрину и делать ее доступной для поисковых систем. Он защищает как динамический контент, например страницы, так и статический контент, например изображения.
Создайте файл robots.txt
Вы можете использовать практически любой текстовый редактор для создания файла robots.txt. Например, Блокнот, TextEdit, vi и emacs могут создавать допустимые файлы robots.txt. Не используйте текстовый процессор; текстовые процессоры часто сохраняют файлы в проприетарном формате и могут добавлять неожиданные символы, такие как фигурные кавычки, что может вызвать проблемы для поисковых роботов.Обязательно сохраните файл в кодировке UTF-8, если появится запрос в диалоговом окне сохранения файла.
Для использования файла robots.txt в Salesforce B2C Commerce Брэндон должен сначала настроить псевдоним своего имени хоста. Затем он может создать свой файл robots.txt в Бизнес-менеджере.
Если для экземпляра включено кэширование, он должен сделать недействительным кеш статического содержимого для создания или обслуживания нового файла robots.txt. Когда кеширование отключено на промежуточном экземпляре, B2C Commerce немедленно обнаруживает любые изменения в robots.txt файл.
Используйте Business Manager, чтобы создать файл robots.txt для одного или нескольких сайтов по отдельности. Сервер приложений обслуживает файл robots.txt, который хранится в качестве предпочтения сайта и может быть реплицирован с одного экземпляра на другой. Брэндон использует этот метод для существующих сайтов, чтобы разрешить сканирование только для производственного экземпляра, а не для разработки или промежуточного этапа.
Вот как создать файл robots.txt в Бизнес-Менеджере.
- Менеджер по открытому бизнесу.
- Выберите сайт > Инструменты продавца> SEO> Роботы .
- Выберите экземпляр: Staging
- Выберите Определите robots.txt для конкретного типа экземпляра.
- Выберите тип доступа: Всем паукам разрешен доступ к любым статическим ресурсам
- Используйте этот параметр для производственного экземпляра, если вы хотите, чтобы он просматривался и был доступен для внешних поисковых систем.
- Нажмите Применить .
- Недействительный кеш.
- Выберите Администрирование> Сайты> Управление сайтами> сайт> вкладку Кэш .
- В разделе «Статическое содержимое и кеши страниц» щелкните Сделать недействительным .
Для типа доступа вы также можете выбрать:
- Всем паукам запрещен доступ к любым статическим ресурсам
Используйте этот параметр для разрабатываемого или промежуточного экземпляра, если вы не хотите, чтобы они сканировались и были доступны для внешних поисковых систем. - Пользовательский файл robots.txt Определение (рекомендуется)
Используйте этот параметр, если вы хотите контролировать, какие части вашего магазина будут сканироваться и доступны для внешних поисковых систем.
Чтобы использовать файл robots.txt в производственном экземпляре, создайте его на промежуточном экземпляре, а затем реплицируйте настройки сайта из промежуточного в производственный.
Загрузите файл robots.txt
Если вы создаете файл robots.txt во внешнем файле, вы должны загрузить файл в каталог картриджей / static / default в пользовательском картридже витрины на вашем сервере B2C Commerce. Используйте вашу интегрированную среду разработки (IDE), такую как CodeJS или Eclipse.
Вы должны скопировать роботов.txt от экземпляра к экземпляру с помощью репликации кода, потому что картридж / static / default зависит от картриджа, а не для сайта.
Проверьте файл robots.txt
Для проверки правильности размещения файла robots.txt:
- Сделать недействительным кеш страницы статического содержимого (при необходимости).
- В браузере введите имя хоста экземпляра, косую черту, а затем
robots.txt . Например: http://www.cloudkicks.com/robots.txt - Если вы получили пустую страницу, значит файла там нет.
Давай подведем итоги
В этом модуле вы узнали, что находится в файле robots.txt и как его создавать, загружать и проверять. Вы также узнали, как предотвратить сканирование. Ранее в этом модуле вы изучали XML-карты сайта и способы уведомления о них поисковые системы. Теперь пройдите финальную викторину и получите новый значок.
использованная литература
Пользовательский агент: *
Запретить: / поиск
Разрешить: / search / about
Разрешить: / search / static
Разрешить: / search / howsearchworks
Disallow: / sdch
Disallow: / groups
Запретить: / index.html?
Запретить: /?
Разрешить: /? Hl =
Запретить: /? Hl = * &
Разрешить: /? Hl = * & gws_rd = ssl $
Запретить: /? Hl = * & * & gws_rd = ssl
Разрешить: /? Gws_rd = ssl $
Разрешить: /? Pt1 = true $
Запретить: / imgres
Запретить: / u /
Запретить: / предпочтения
Запретить: / setprefs
Запретить: / по умолчанию
Disallow: / м?
Disallow: / m /
Разрешить: / м / финансы
Запретить: / wml?
Запретить: / wml /?
Запретить: / wml / search?
Запретить: / xhtml?
Запретить: / xhtml /?
Запретить: / xhtml / search?
Запретить: / xml?
Disallow: / imode?
Запретить: / imode /?
Запретить: / imode / search?
Disallow: / jsky?
Запретить: / jsky /?
Запретить: / jsky / search?
Disallow: / pda?
Запретить: / pda /?
Запретить: / pda / search?
Запретить: / sprint_xhtml
Запретить: / sprint_wml
Disallow: / pqa
Disallow: / palm
Запретить: / gwt /
Disallow: / покупки
Disallow: / local?
Запретить: / local_url
Disallow: / shihui?
Запретить: / shihui /
Disallow: / products?
Запретить: / product_
Запрещено: / products_
Disallow: / products;
Запретить: / print
Disallow: / books /
Запретить: / bkshp? * Q = *
Disallow: / books? * Q = *
Запретить: / books? * Output = *
Disallow: / books? * Pg = *
Запретить: / books? * Jtp = *
Запретить: / books? * Jscmd = *
Disallow: / books? * Buy = *
Запретить: / books? * Zoom = *
Разрешить: / books? * Q = related: *
Разрешить: / books? * Q = editions: *
Разрешить: / books? * Q = subject: *
Разрешить: / books / about
Разрешить: / правообладатели
Разрешить: / books? * Zoom = 1 *
Разрешить: / books? * Zoom = 5 *
Разрешить: / books / content? * Zoom = 1 *
Разрешить: / books / content? * Zoom = 5 *
Disallow: / ebooks /
Disallow: / ebooks? * Q = *
Запретить: / ebooks? * Output = *
Disallow: / ebooks? * Pg = *
Запретить: / ebooks? * Jscmd = *
Disallow: / ebooks? * Buy = *
Disallow: / ebooks? * Zoom = *
Разрешить: / электронные книги? * Q = related: *
Разрешить: / ebooks? * Q = editions: *
Разрешить: / электронные книги? * Q = subject: *
Разрешить: / ebooks? * Zoom = 1 *
Разрешить: / ebooks? * Zoom = 5 *
Запретить: / патенты?
Запретить: / патенты / скачать /
Запрещено: / патенты / pdf /
Запретить: / патенты / связанные /
Запретить: / ученый
Disallow: / citations?
Разрешить: / citations? User =
Disallow: / citations? * Cstart =
Разрешить: / citations? View_op = new_profile
Разрешить: / citations? View_op = top_hibited
Разрешить: / scholar_share
Disallow: / s?
Разрешить: / maps? * Output = classic *
Разрешить: / maps? * File =
Разрешить: / maps / d /
Disallow: / maps?
Запретить: / mapstt?
Запретить: / mapslt?
Запретить: / maps / stk /
Запретить: / maps / br?
Запретить: / mapabcpoi?
Запретить: / maphp?
Запретить: / mapprint?
Запретить: / maps / api / js /
Разрешить: / maps / api / js
Запретить: / maps / api / place / js /
Запретить: / maps / api / staticmap
Запретить: / maps / api / streetview
Запретить: / maps / _ / sw / manifest.json
Disallow: / mld?
Запретить: / staticmap?
Запретить: / maps / preview
Запретить: / карты / место
Запретить: / maps / timeline /
Запретить: / help / maps / streetview / partners / welcome /
Запретить: / help / maps / Indoormaps / partners /
Disallow: / lochp?
Disallow: / center
Disallow: / ie?
Запретить: / blogsearch /
Запретить: / blogsearch_feeds
Запретить: / advanced_blog_search
Запретить: / uds /
Disallow: / chart?
Disallow: / transit?
Разрешить: / calendar $
Разрешить: / calendar / about /
Запретить: / календарь /
Запретить: / cl2 / feeds /
Запретить: / cl2 / ical /
Запретить: / coop / directory
Запретить: / coop / manage
Disallow: / Trends?
Запретить: / тенденции / музыка?
Disallow: / Trends / hottrends?
Запретить: / тенденции / viz?
Запретить: / тенденции / встраивать.js?
Запретить: / тенденции / fetchComponent?
Запретить: / тенденции / бета
Запретить: / тенденции / темы
Запретить: / musica
Запретить: / musicad
Запретить: / musicas
Запретить: / musicl
Запретить: / музыка
Запретить: / musicsearch
Запретить: / musicsp
Запретить: / musiclp
Запретить: / urchin_test /
Disallow: / movies?
Запретить: / wapsearch?
Разрешить: / безопасный просмотр / диагностика
Разрешить: / safebrowsing / report_badware /
Разрешить: / safebrowsing / report_error /
Разрешить: / safebrowsing / report_phish /
Запретить: / обзоры / поиск?
Запретить: / orkut / альбомы
Disallow: / cbk
Disallow: / подзарядка / приборная панель / автомобиль
Disallow: / recharge / dashboard / static /
Запретить: / profiles / me
Разрешить: / profiles
Запретить: / s2 / profiles / me
Разрешить: / s2 / profiles
Разрешить: / s2 / oz
Разрешить: / s2 / photos
Разрешить: / s2 / search / social
Разрешить: / s2 / static
Disallow: / s2
Запретить: / transconsole / portal /
Запретить: / gcc /
Запретить: / aclk
Disallow: / cse?
Запретить: / cse / home
Запретить: / cse / panel
Запретить: / cse / manage
Запретить: / tbproxy /
Запретить: / imesync /
Запретить: / shenghuo / search?
Запретить: / поддержка / форум / поиск?
Запретить: / reviews / polls /
Запретить: / hosted / images /
Запретить: / ppob /?
Disallow: / ppob?
Запретить: / accounts / ClientLogin
Запретить: / accounts / ClientAuth
Disallow: / accounts / o8
Разрешить: / accounts / o8 / id
Запретить: / topicsearch? Q =
Запретить: / xfx7 /
Запрещено: / в квадрате / api
Запретить: / в квадрате / поиск
Запрещено: / в квадрате / таблица
Disallow: / qnasearch?
Запретить: / приложение / обновления
Запретить: / sidewiki / entry /
Запретить: / quality_form?
Запретить: / labs / popgadget / search
Запретить: / buzz / post
Запретить: / сжатие /
Запретить: / analytics / feeds /
Запретить: / аналитика / партнеры / комментарии /
Запретить: / analytics / portal /
Запретить: / analytics / uploads /
Разрешить: / предупреждения / управление
Разрешить: / alerts / remove
Запретить: / alerts /
Разрешить: / alerts / $
Запретить: / ads / search?
Запретить: / ads / plan / action_plan?
Запретить: / ads / plan / api /
Disallow: / ads / hotels / partners
Запретить: / phone / compare /?
Запретить: / путешествия / clk
Запретить: / hotelfinder / rpc
Disallow: / hotels / rpc
Запретить: / commercesearch / services /
Запретить: / оценка /
Запретить: / chrome / browser / mobile / tour
Запретить: / сравнить / * / применить *
Запретить: / forms / perks /
Запретить: / покупки / поставщики / поиск
Запретить: / ct /
Запретить: / edu / cs4hs /
Запретить: / доверенные магазины / с /
Disallow: / доверенные магазины / tm2
Запретить: / доверенные магазины / проверить
Запретить: / adwords / offer
Disallow: / shopping? *
Запретить: / shopping / product /
Запрещено: / покупка / продавец
Запретить: / покупки / рейтинги / аккаунт / метрики
Запретить: / покупки / рейтинги / продавец / immersivedetails
Disallow: / shopping / reviewer
Disallow: / о / карьера / приложения /
Запретить: / приземление / выход.html
Запретить: / webmasters / sitemaps / ping?
Запретить: / ping?
Запретить: / галерея /
Disallow: / Landing / Now / ontap /
Разрешить: / searchhistory /
Разрешить: / карты / резерв
Разрешить: / карты / резерв / партнеры
Запретить: / карты / резерв / api /
Запретить: / карты / резерв / поиск
Disallow: / карты / резерв / бронирования
Запретить: / карты / резерв / настройки
Запретить: / карты / резерв / управлять
Запретить: / карты / резерв / оплата
Запретить: / карты / резерв / квитанция
Запретить: / карты / резерв / продавцы
Запретить: / карты / резерв / платежи
Запретить: / карты / резерв / обратная связь
Запретить: / карты / резерв / условия
Disallow: / maps / reserve / m /
Запретить: / maps / reserve / b /
Запретить: / карты / резерв / партнерская панель управления
Запретить: / about / views /
Запретить: / intl / * / about / views /
Disallow: / local / cars
Disallow: / local / cars /
Disallow: / местный / дилерский центр /
Disallow: / местный / обеденный /
Запретить: / local / place / products /
Запретить: / местное / место / отзывы /
Disallow: / local / place / rap /
Запретить: / local / tab /
Запретить: / localservices / *
Разрешить: / finance
Разрешить: / js /
Запретить: / nonprofits / account / # AdsBot
Пользовательский агент: AdsBot-Google
Запретить: / maps / api / js /
Разрешить: / maps / api / js
Запретить: / maps / api / place / js /
Запретить: / maps / api / staticmap
Запретить: / maps / api / streetview # Сканеры некоторых социальных сетей могут получать доступ к разметке страницы при использовании google.com / imgres * ссылки являются общими. Чтобы узнать больше, свяжитесь с images-robots-allowlist@google.com.
Пользовательский агент: Twitterbot
Разрешить: / imgres Пользовательский агент: facebookexternalhit
Разрешить: / imgres Карта сайта: https://www.google.com/sitemap.xml
Использование и настройка Robots.txt в 2021 году
Истоки протокола robots.txt, или «протокола исключения роботов», можно проследить до середины 1990-х годов, когда веб-пауки начали путешествовать по Интернету. читать сайты. Некоторых веб-мастеров беспокоило, какие пауки посещают их сайты.Файл, содержащий указания, по каким разделам сайта следует сканировать и который не должен предлагать владельцам сайтов обещание иметь больший контроль над тем, какие сканеры могут посещать их URL-адреса и какой объем ресурсов им разрешено использовать. С тех пор файл robots.txt расширился, чтобы удовлетворить потребности современных веб-дизайнеров и владельцев веб-сайтов.
Текущие версии протокола будут приняты пауками и основными поисковыми системами для отправки для сбора информации для их соответствующих алгоритмов ранжирования.Это общее соглашение между различными поисковыми системами, что делает команды потенциально ценным, но часто упускаемым из виду инструментом для брендов в их отчетах по SEO.
Что такое robots.txt?
Robots.txt - это серия команд, которые сообщают веб-роботам, обычно поисковым системам, какие страницы сканировать, а какие нет. Когда поисковая система попадает на сайт, она просматривает команду для получения инструкций. Для сайта может показаться нелогичным указать поисковой системе не сканировать его страницы, но это также может дать веб-мастерам мощный контроль над своим краулинговым бюджетом.
При записи файла протокола вы будете использовать простые двухстрочные команды. В первой строке написано «пользовательский агент». Эта часть протокола определяет, к кому применяются инструкции, а звездочка « * », обычно называемая подстановочным знаком, будет означать, что команда применяется ко всем веб-роботам. Под «агентом пользователя» будет написано «запретить». Это говорит роботам, что они не могут делать. Если есть "\", это означает, что пауки не должны ничего сканировать по сайту. Если эта часть остается пустой, пауки могут сканировать весь сайт.
Зачем мне использовать robots.txt?
Понимание того, как Google сканирует веб-сайты, поможет вам понять ценность использования протокола robots.txt. У Google есть краулинговый бюджет. Это описывает количество времени, которое Google будет посвящать сканированию определенного сайта. Google рассчитывает этот бюджет на основе ограничения скорости сканирования и потребности в сканировании. Если Google видит, что их сканирование сайта замедляет этот URL и, таким образом, ухудшает взаимодействие с пользователем в любых обычных браузерах, они замедляют скорость сканирования.Это означает, что если вы добавите новый контент на свой сайт, Google не увидит его так быстро, что может нанести ущерб вашему SEO.
Вторая часть расчета бюджета, спрос, диктует, что URL-адреса с большей популярностью будут получать больше посещений от пауков Google. Другими словами, как заявил Google, «вы не хотите, чтобы ваш сервер был перегружен поисковым роботом Google или тратил краулинговый бюджет на сканирование неважных или похожих страниц вашего сайта». Протокол позволит вам лучше контролировать, куда и когда отправляются поисковые роботы, помогая вам избежать этой проблемы.Robots.txt не только помогает вам направлять роботов поисковых систем с менее важных или повторяющихся страниц вашего сайта, но и служить другим важным целям:
- Это может помочь предотвратить появление дублированного контента. Иногда вашему веб-сайту может потребоваться более одной копии контента. Например, если вы создаете версию для печати части контента, у вас могут быть две разные версии. У Google есть хорошо известное наказание за дублирование контента. Это позволит вам этого избежать.
- Если вы переделываете части своего веб-сайта, вы можете использовать robots.txt, чтобы скрыть незавершенные страницы от индексации до того, как они будут подготовлены.
- У вас также, вероятно, есть страницы на вашем веб-сайте, которые вы не хотите показывать широкой публике. Например, это может быть страница с благодарностью после того, как кто-то совершил покупку или отправил страницу входа. Эти страницы не должны появляться в поисковой системе, что делает бесполезным их индексирование для Google или других поисковых систем.
По данным Google, вот некоторые из наиболее распространенных наборов правил для протокола:
- Важно отметить при этом различные полезные функции robots.txt, вы не пытаетесь использовать протокол для сохранения конфиденциальности конфиденциальной информации. Думайте о протоколе как о запросе, а не о команде.
- Хотя «хорошие» пауки, которыми управляют такие авторитетные организации, как Google или Bing, будут прислушиваться к командам протокола, поисковые роботы, разработанные с более гнусными намерениями, по-прежнему могут игнорировать команду и сканировать страницу независимо от код указан. Страницы также можно проиндексировать другими способами. Например, если другой сайт или другая страница вашего собственного сайта ссылается на эту страницу, ваша скрытая страница может быть проиндексирована.
- При планировании инфраструктуры сайта важно различать личные страницы. Являются ли эти страницы частными и недоступными для обнаружения исключительно по причинам SEO, или содержание этих страниц вдали от поисковых роботов является проблемой безопасности - например, раскрытие конфиденциальных данных клиентов? Ценность robots.txt заключается в стратегии SEO, а не в сохранении конфиденциальности конфиденциальной информации.
Как настроить robots.txt?
Настройка протокола может быть несложной, но сначала давайте рассмотрим, что означают две части протокола:
- Агент пользователя : относится к поисковым роботам, на которые ссылается текст
- Disallow : указывает, что вы хотите заблокировать, что сканер не должен читать
В дополнение к этим двум основным частям вы также можете использовать третью часть, помеченную как «разрешить», если вам это нужно.Этот раздел будет использоваться, если у вас есть подкаталог, который находится в заблокированном каталоге. Например, если вы хотите заблокировать большую часть каталога, но у вас есть один небольшой подкаталог, самый быстрый способ настроить его - это сказать: user-agent: * (помните, что звездочка указывает, что протокол применяется к все пауки) disallow: / directory allow: / subdirectory1
Это укажет поисковым роботам искать этот единственный подкаталог, даже если он находится в более крупном заблокированном каталоге.Если вы хотите разрешить поисковым роботам просматривать сайт целиком, оставьте поле «Запрещать» пустым. Если вы хотите настроить robots.txt на блокировку определенных страниц, таких как страница входа или страница благодарности, то в разделе «запретить» протокола вы поместите часть своего URL-адреса, которая идет после '. com '. Когда вы думаете о страницах, которые вы можете захотеть заблокировать, подумайте об этих типах контента и посмотрите, есть ли у вас на вашем сайте.
- Страницы входа
- Страницы благодарности за то, что кто-то что-то скачает или купил
- Требуется дублированный контент, например PDF-файл или версия веб-страницы для печати
- Новые страницы, которые вы начали разрабатывать, но пока не хотите, чтобы поисковые системы их индексировали
Хотя robots.txt выглядит просто, есть несколько правил, которые необходимо соблюдать, чтобы код был правильно интерпретирован.
- Используйте все строчные буквы в имени файла, "robots.txt"
- Протоколы должны находиться в каталоге верхнего уровня веб-сервера.
- У вас может быть только один запрет для каждого URL на сайте
- Поддомены с общим корневым доменом нуждаются в разных файлах протокола
После настройки протокола вам следует протестировать свой сайт с помощью учетной записи Google Webmasters.В меню будет опция «Сканирование». При нажатии на нее откроется раскрывающееся меню, в котором будет опция тестера протокола.