
Правильный файл robots.txt для сайта на WordPress в 2022
Файл robots.txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Пример;
- Где найти;
- Как создать;
- Инструкция по работе;
- Синтаксис;
- Директивы;
- Как проверить.
Пример правильного файла robots.txt для сайта на WordPress
- User-agent: *
- Disallow: /cgi-bin
- Disallow: /wp-admin/
- Disallow: /wp-includes/
- Disallow: /wp-content/plugins/
- Disallow: /wp-content/cache/
- Disallow: /wp-content/themes/
- Disallow: /wp-trackback
- Disallow: /wp-feed
- Disallow: /wp-comments
- Disallow: /author/
- Disallow: */embed*
- Disallow: */wp-json*
- Disallow: */page/*
- Disallow: /*?
- Disallow: */trackback
- Disallow: */comments
- Disallow: /*.php
- Host: https://seopulses.
 ru
ru - Sitemap: https://seopulses.ru/sitemap_index.xml
 ru
ruГде можно найти файл robots.txt и как его создать или редактировать
Чтобы проверить файл robots.txt сайта, следует добавить к домену «/robots.txt», примеры:
https://seopulses.ru/robots.txt
https://serpstat.com/robots.txt
https://netpeak.net/robots.txt
Как создать и редактировать robots.txt
Вручную
Данный файл всегда можно найти, подключившись к FTP сайта или в файлом редакторе хостинг-провайдера в корневой папке сайта (как правило, public_html):
Далее открываем сам файл и можно его редактировать.
Если его нет, то достаточно создать новый файл.
После вводим название документа и сохраняем.
Через модули/дополнения/плагины
Чтобы управлять данный файлом прямо в административной панели сайта следует установить дополнительный модуль:
- Для 1С-Битрикс;
https://dev.1c-bitrix.ru/learning/course/?COURSE_ID=139&LESSON_ID=5814
- WordPress;
https://ru. wordpress.org/plugins/pc-robotstxt/
wordpress.org/plugins/pc-robotstxt/
- Для Opencart;
https://opencartforum.com/files/file/5141-edit-robotstxt/
- Webasyst.
https://support.webasyst.ru/shop-script/149/shop-script-robots-txt/
Инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.

Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.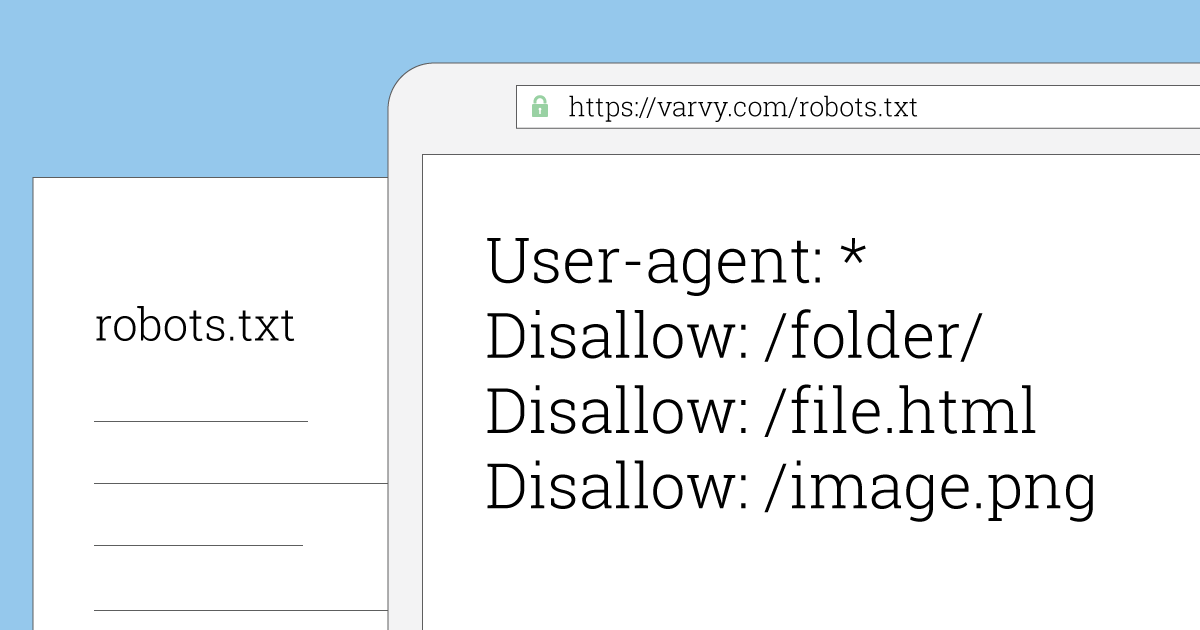 ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами.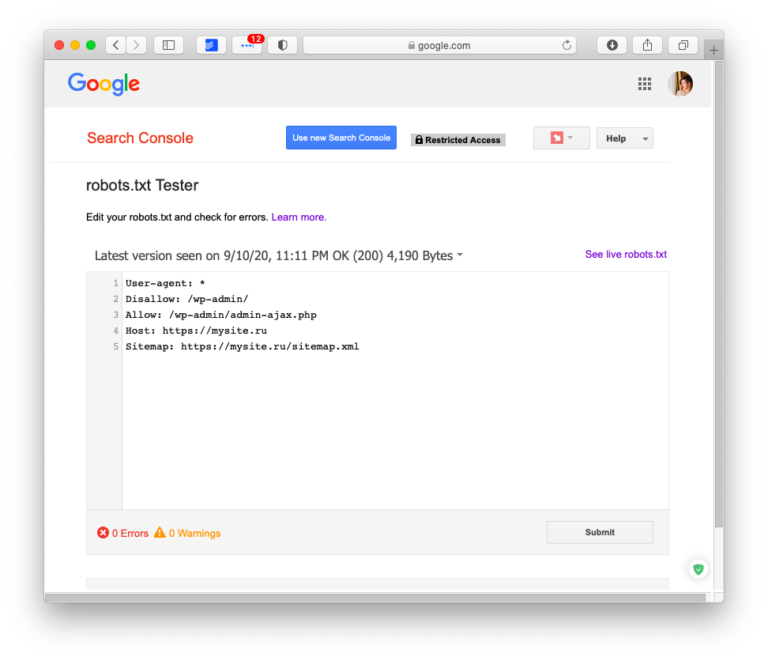 Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
что это такое, зачем нужен индексный файл и как его настроить – примеры роботс тхт
Если вы хоть немного интересовались вопросом внутренней оптимизации сайтов, то наверняка встречали термин robots txt. Как раз ему и посвящена наша сегодняшняя тема.
Сейчас вы узнаете, что такое robots txt, как он создается, каким образом веб-мастер задает в нем нужные правила, как обрабатывается файл robots. txt поисковыми роботами и почему отсутствие этого файла в корне веб-ресурса — одна из самых серьезных ошибок внутренней оптимизации сайта. Будет интересно!
txt поисковыми роботами и почему отсутствие этого файла в корне веб-ресурса — одна из самых серьезных ошибок внутренней оптимизации сайта. Будет интересно!
Что такое robots.txt
Технически robots txt — это обыкновенный текстовый документ, который лежит в корне веб-сайта и информирует поисковых роботов о том, какие страницы и файлы они должны сканировать и индексировать, а для каких наложен запрет. Но это самое примитивное описание. На самом деле c robots txt все немного сложнее.
Файл robots txt — это как «администратор гостиницы». Вы приходите в нее, администратор выдает вам ключи от номера, а также говорит, где ресторан, SPA, зона отдыха, кабинет управляющего и прочее. А вот в другие номера и помещения для персонала вход вам заказан. Точно так же и с robots txt. Только вместо администратора — файл, вместо клиента — поисковые роботы, а вместо помещений — отдельные веб-страницы и файлы. Сравнение грубое, но зато доступное и понятное.
Для чего нужен файл robots.
 txt
txtБез этого файла поисковики будут хаотично блуждать по сайту, сканировать и индексировать буквально все подряд: дубли, служебные документы, страницы с текстами «заглушками» (Lorem Ipsum) и тому подобное.
Правильный robots txt не дает такому происходить и буквально ведет роботов по сайту, подсказывая, что разрешено индексировать, а что необходимо упустить.
Существуют специальные директивы robots txt для данных задач:
- Allow — допускает индексацию.
- Disallow — запрещает индексацию.
Кроме того, можно сразу прописать, каким конкретно роботам разрешено или запрещено индексировать заданные страницы. Например, чтобы запретить индексацию директории /private/ поисковым роботам «Гугл», в роботс необходимо прописать User-agent:
User-agent: Google
Disallow: /private/
Также вы можете указать основное зеркало веб-сайта, задать путь к Sitemap, обозначить дополнительные правила обхода через директивы и прочее.
И вот мы разобрались, для чего нужен robots txt. Дальше сложнее — создание файла, его наполнение и размещение на сайте.
Как создать файл robots.txt для сайта?
Итак, как создать файл robots txt?
Создать и изменять файл проще всего в приложении «Блокнот» или другом текстовом редакторе, поддерживающим формат .txt. Специальное ПО для работы с robots txt не понадобится.
Создайте обычный текстовый документ с расширением .txt и поместите его в корень веб-ресурса. Для размещения подойдет любой FTP-клиент. После размещения обязательно стоит проверить robots txt — находится ли файл по нужному адресу. Для этого в поисковой строке браузера нужно прописать адрес:
имя_сайта/robots.txt
Если все сделано правильно, вы увидите во вкладке данные из robots txt. Но без команд и правил он, естественно, работать не будет. Поэтому переходим к более сложному — наполнению.
Символы в robots.txt
Помимо упомянутых выше функций Allow/Disallow, в robots txt прописываются спецсимволы:
- «/» — указывает, что мы закрываем файл или страницу от обнаружения роботами «Гугл» и т. д.;
- «*» — прописывается после каждого правила и обозначает последовательность символов;
 д.;
д.;- «$» — ограничивает действие «*»;
- «#» — позволяет закомментировать любой текст, который веб-мастер оставляет себе или другим специалистам (своего рода заметка, напоминание, инструкция). Поисковики не считывают закомментированный текст.
Синтаксис в robots.txt
Описанные в файле robots.txt правила — это его синтаксис и разного рода директивы. Их достаточно много, мы рассмотрим наиболее значимые — те, которые вы, скорее всего, будете использовать.
User-agent
Это директива, указывающая, для каких search-роботов будут действовать следующие правила. Прописывается следующим образом:
User-agent: * имя поискового робота
Примеры роботов: Googlebot и другие.
Allow
Это разрешающая индексацию директива для robots txt. Допустим, вы прописываете следующие правила:
Допустим, вы прописываете следующие правила:
User-agent: * имя поискового робота
Allow: /site
Disallow: /
Так в robots txt вы запрещаете роботу анализировать и индексировать весь веб-ресурс, но запрет не касается папки site.
Disallow
Это противоположная директива, которая закрывает от индексации только прописанные страницы или файлы. Чтобы запретить индексировать определенную папку, нужно прописать:
Disallow: /folder/
Также можно запретить сканировать и индексировать все файлы выбранного расширения. Например:
Disallow: /*.css$
Sitemap
Данная директива robots txt направляет поисковых роботов к описанию структуры вашего ресурса. Это важно для SEO. Вот пример:
User-agent: *
Disallow: /site/
Allow: /
Sitemap: http://site.com/sitemap1.xml
Sitemap: http://site. com/sitemap2.xml
com/sitemap2.xml
Crawl-delay
Директива ограничивает частоту анализа сайта и тем самым снижает нагрузку на сервер. Здесь прописывается время в сек. (третья строчка):
User-agent: *
Disallow: /site
Crawl-delay: 4
Clean-param
Запрещает индексацию страниц, сформированных с динамическими параметрами. Суть в том, что поисковые системы воспринимают их как дубли, а это плохо для SEO. О том, как найти дубли страниц на сайте, мы уже рассказывали. Вам нужно прописывать директиву:
Clean-param: p1[&p2&p3&p4&..&pn] [Путь к динамическим страницам]
Примеры Clean-param в robots txt:
Clean-param: kol_from1&price_to2&pcolor /polo.html # только для polo.html
или
Clean-param: kol_from1&price_to2&pcolor / # для всех страниц сайта
Кстати, советуем прочесть нашу статью «Как просто проверить индексацию сайта» — в ней много полезного по этой теме. Плюс есть информативная статья «Сканирование сайта в Screaming Frog». Рекомендуем ознакомиться!
Плюс есть информативная статья «Сканирование сайта в Screaming Frog». Рекомендуем ознакомиться!
Особенности настройки robots.txt для «Гугла»
На практике синтаксис файла robots.txt для этих систем отличается незначительно. Но есть несколько моментов, которые мы советуем учитывать.
Google не рекомендует скрывать файлы с CSS-стилями и JS-скриптами от сканирования. То есть правило должно выглядеть так:
User-agent: Googlebot
Disallow: /site
Disallow: /admin
Disallow: /users
Disallow: */templates
Allow: *.css
Allow: *.js
Host: www.site.com
Примеры настройки файла robots.txt
Каждая CMS имеет свою специфику настройки robots txt для сканирования и индексации. И лучший способ понять разницу — рассмотреть каждый пример robots txt для разных систем. Так и поступим!
Пример robots txt для WordPress
Роботс для WordPress в классическом варианте выглядит так:
User-agent: Googlebot
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Allow: *. css # открыть все файлы стилей
css # открыть все файлы стилей
Allow: *.js # открыть все с js-скриптами
User-agent: *
Disallow: /cgi-bin # служебная папка для хранения серверных скриптов
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # результаты поиска
Disallow: /search # результаты поиска
Disallow: */page/ # страницы пагинации
Disallow: /*print= # страницы для печати
Sitemap: http://site.ua/sitemap.xml
Sitemap: http://site.ua/sitemap1.xml
Пример robots.txt для «Битрикс»
Одна из главных проблем «Битрикс» — по дефолту поисковые системы считывают и проводят индексацию служебных страниц и дублей. Но это можно предотвратить, правильно прописав robots txt:
User-Agent: Googlebot
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Disallow: /bitrix/
Disallow: /login/
Disallow: /*?action=
Disallow: /?mySort=
Disallow: */filter/
Disallow: */clear/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/tools/conversion/ajax_counter. php
php
Allow: /bitrix/components/main/
Allow: /bitrix/css/
Allow: /bitrix/templates/comfer/img/logo.png
Allow: /personal/cart/
Sitemap: https://site.ua/sitemap.xml
Пример robots.txt для OpenCart
Рассмотрим пример robots txt для платформы электронной коммерции OpenCart:
User-agent: Googlebot
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Allow: *. css
css
Allow: *.js
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /*route=product/search
Disallow: /index.php
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=
Disallow: /*?page=
Disallow: /*&page=
Disallow: /wishlist
Disallow: /login
Sitemap: http://site. ua/sitemap.xml
ua/sitemap.xml
Пример robots.txt для Joomla
В «Джумле» роботс выглядит так:
User-agent: Googlebot
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Allow: *.css
Allow: *.js
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /component/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /*?start=*
Disallow: /xmlrpc/
Sitemap: http://www. site.ua/sitemap.xml
site.ua/sitemap.xml
Пример robots.txt для Drupal
Для Drupal:
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index. php
php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
Выводы
Файл robots txt — функциональный инструмент, благодаря которому веб-разработчик дает инструкции поисковым системам, как взаимодействовать с сайтом. Благодаря ему мы обеспечиваем правильную индексацию, защищаем веб-ресурс от попадания под фильтры поисковых систем, снижаем нагрузку на сервер и улучшаем параметры сайта для SEO.
Чтобы правильно прописать инструкции файла robots.txt, крайне важно отчетливо понимать, что вы делаете и зачем вы это делаете. Соответственно, если не уверены, лучше обратитесь за помощью к специалистам. В нашей компании настройка robots txt входит в услугу внутренней оптимизации сайта для поисковых систем.
Кстати, в нашей практике был случай, когда клиент обратился за услугой раскрутки сайта, в корне которого файл robots txt попросту отсутствовал и индексация происходила некорректно. Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
Почитайте, там много интересных моментов: «SEO-Кейс: Продвижение сайта медицинских справок».
FAQ
Что такое файл robots.txt?
Robots txt — это документ, содержащий правила индексации вашего сайта, отдельных его файлов или URL поисковиками. Правила, описанные в файле robots.txt, называются директивами.
Зачем нужен файл robots.txt?
Robots txt помогает закрыть от индексации отдельные файлы, дубли страниц, документы, не несущие никакой пользы для посетителей, а также страницы, содержащие неуникальный контент.
Где находится файл robots.txt?
Он размещается в корневой папке веб-ресурса. Чтобы проверить его наличие, достаточно в URL-адрес вашего веб-ресурса дописать /robots.txt и нажать Enter. Если он на месте, откроется его страница. Так можно просмотреть данный файл на любом сайте, даже на стороннем. Просто добавьте к адресу /robots.txt.
У Вас остались вопросы?
Наши эксперты готовы ответить на них.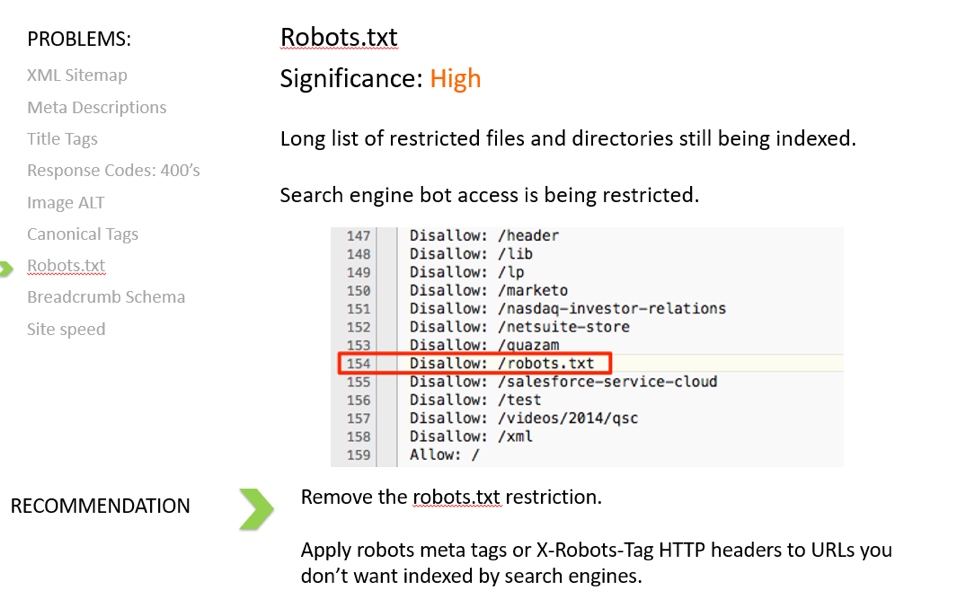 Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Оставьте ваши контактные данные. Будем рады обсудить ваш проект!
Получить консультацию
Наш менеджер свяжется с Вами в ближайшее время
Пример файла txtRobots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду .
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает все боты
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц .
 Установив значение
Установив значение Что, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google.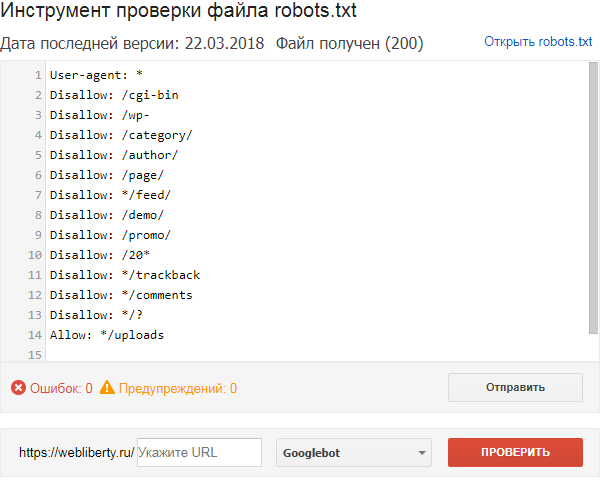 Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example. com/users.xls
 com/users.xls
com/users.xls Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter

Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила. Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Robots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду .
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает все боты
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц .
 Установив значение
Установив значение Что, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google.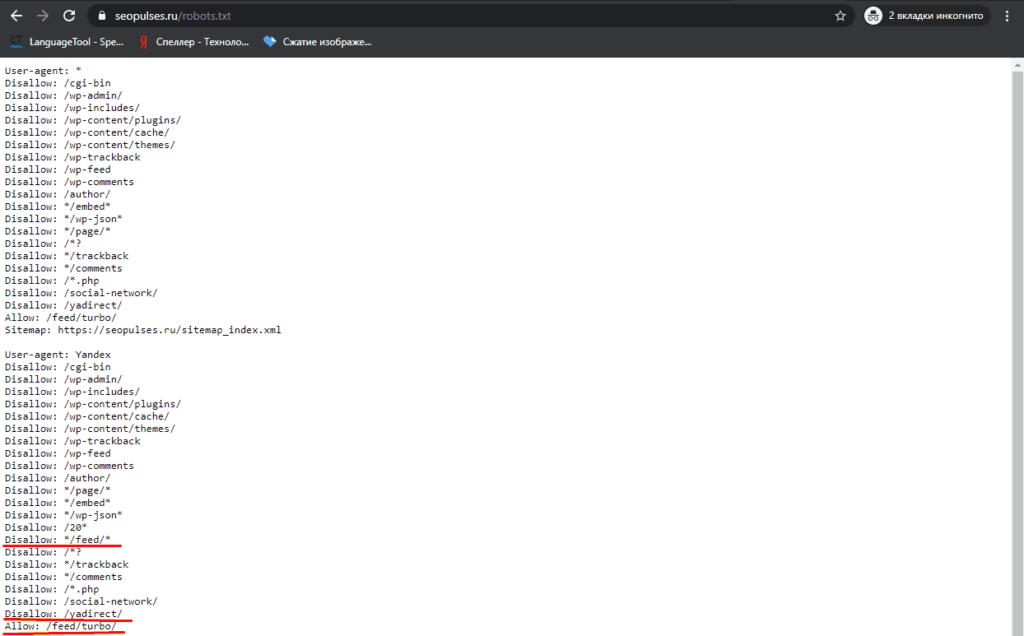 Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example. com/users.xls
 com/users.xls
com/users.xls Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter

Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта.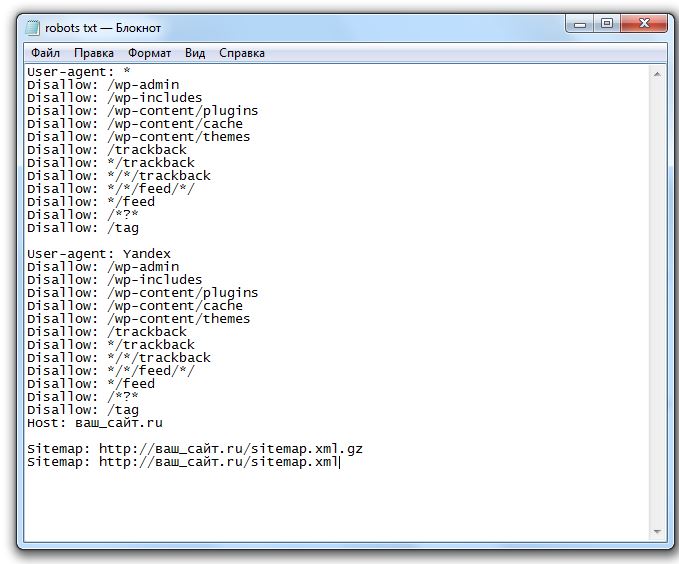 Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила.