
Правильный пример robots txt | Как создать файл robots txt для wordpress?
Сегодня я расскажу, как создать файл robots txt для wordpress. Этот пост, будет очень важным для тех, у кого до сих пор нет файла robots txt.
Я постараюсь рассказать вам основные команды, которые используются в этом файле, чтобы вы могли составить самостоятельно robots txt а также покажу пример, каким должен быть правильный robots.txt для wordpress :smile:.
Дублированный контент является одной из причин всех санкций поисковых систем. Это, то же самое, что пойти на другой сайт, скопипастить оттуда статью и опубликовать на своем ресурсе. Таким образом, у вас появиться неуникальная информация, которую поисковики очень сильно не любят.
Но, самое страшное то, что многие новички даже не подозревают, что у них на блоге может быть дублированный контент. После создания блога, они просто начинают писать себе статьи. Пишут, пишут, а тут раз, и страницы вылетают из индексации :smile:. Потом они думают, почему мой сайт попал под АГС? Я же писал интересные, уникальные статьи для людей. (.*)$ http://vachevskiy.ru/$1 [R=301,L]
(.*)$ http://vachevskiy.ru/$1 [R=301,L]
Этот код будет перенаправлять сайт с www. vachevskiy.ru на vachevskiy.ru. Только не забудьте вместо vachevskiy.ru указать адрес своего сайта.
2. Лишние переменные.
Это когда страница открыта для индексации по такому адресу
Как легко узнать и проверить тиц сайта?
и по такому
Как легко узнать и проверить тиц сайта?
Это две разные страницы для поискового робота, и последнюю, нужно закрывать от индексации. Как правильно это сделать, я объясню немножко позже.
3. Анонс новостей.
Возможно, вы замечали на многих блогах, что идет анонс статьи, картинка, а потом, кнопка читать далее. Так вот, этот анонс будет как раз таки дублированным контентом. Я, например, вообще не делаю анонсов. У меня идет заголовок, картинка и кнопка читать далее. Если вы решили делать анонсы, но старайтесь чтобы они были небольшие, поскольку запретить их индексацию в файле robots. txt невозможно.
txt невозможно.
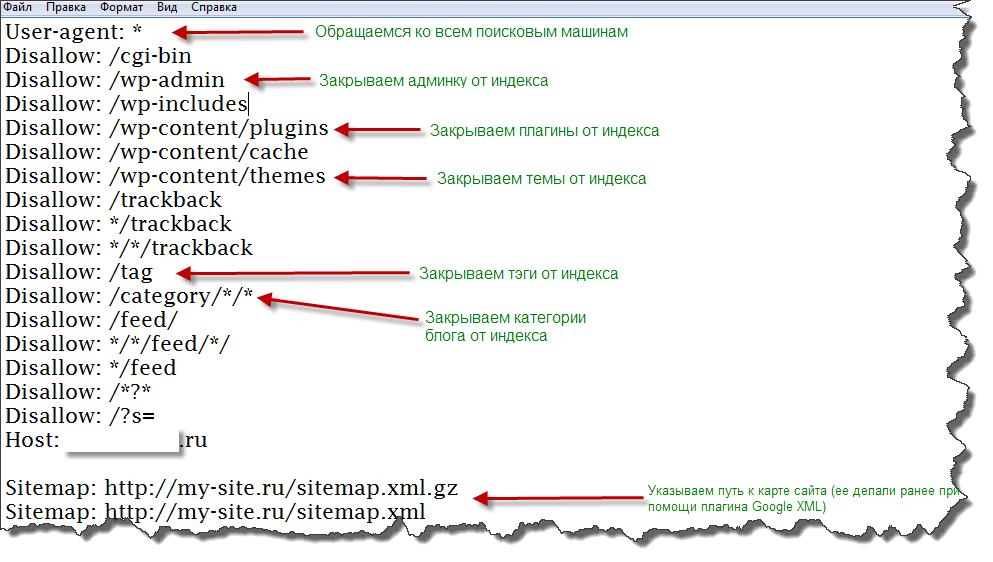
Ну а вообще, сейчас я вам покажу правильный robots.txt для wordpress, который стоит на моем сайте. Вот пример robots txt:
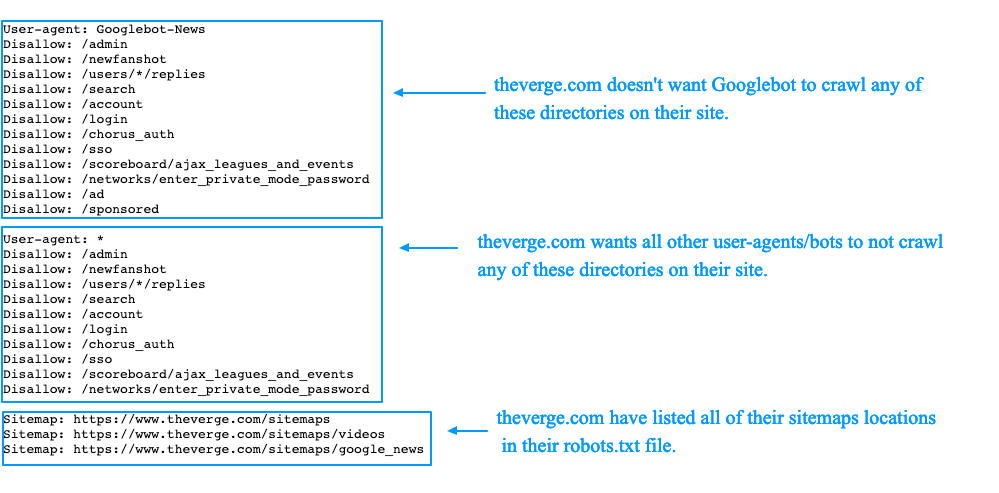
User-agent: Yandex
Disallow: /wp-register.php
Disallow: /wp-content/themes
Disallow: /*?
Disallow: /webstat/
Disallow: */comments
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: /*?*
Disallow: /comments
Disallow: /wp-content/plugins
Disallow: /wp-admin/
Disallow: /feed/
Disallow: /wp-login.php
Disallow: /category/*/*
Disallow: /wp-includes/
Host: vachevskiy.ruUser-agent: *
Disallow: /wp-login.php
Disallow: /webstat/
Disallow: /feed/
Disallow: */trackback
Disallow: /wp-register.php
Disallow: */feed
Disallow: */comments
Disallow: /*?*
Disallow: /*?
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /category/*/*
Disallow: /wp-admin/
Disallow: /trackback
Disallow: /wp-includes/
Disallow: /commentsSitemap: http://vachevskiy.
ru/sitemap.xml
Sitemap: http://vachevskiy.ru/sitemap.xml.gz
 ru/sitemap.xml
ru/sitemap.xmlЕсли у вас сайт на движке wordpress, и настроены ЧПУ, то можете смело ставить этот пример robots txt и не париться. Что значит, настроены ЧПУ? Если ссылка вод такая:
Как легко узнать и проверить тиц сайта?
то этот robots.txt подойдет. А если, например, такая (вот статья о том, как сделать ссылку):
http://www.mycharm.ru/articles/text/?id=2766
то нужно просто убрать из файла robots.txt вот эту строчку
Disallow: /*?*, поскольку она заблокирует индексацию всех страниц, где встречается знак вопроса «?». Ее нужно убрать в двоих местах.
Как составить правильный robots.txt самому?
Если у вас другая система управления сайтом, то я вам сейчас кратко расскажу основные команды для того, чтобы вы могли составить robots.txt для своего сайта самостоятельно. Итак, поехали.
Директива «User-agent» отвечает за то, к какому поисковому роботу вы обращаетесь.
- User-agent: * — ко всем поисковикам;
- User-agent: Yandex – только к Яндексу;
- User-agent: Googlebot – только к Гуглу;
Директива «Disallow» закрывает страницы, категории или сайт от индексации.
Например, у меня есть на сайте вод такая страница http://vachevskiy.ru/search/ и я хочу закрыть ее от индексации всех поисковиков. В таком случаи нужно прописать следующее.
User-agent: *
Disallow: /search/
Если вы хотите закрыть весь сайт от индексации гуглом, то нужно прописать так:
User-agent: Googlebot
Disallow: /
А если, наоборот, хотите, чтобы весь сайт индексировался гуглом, то нужно прописать в файле robots.txt вод так:
User-agent: Googlebot
Disallow:
Таким образом, мы можем запретить индексировать сайт или страницу, яндексу и гулу отдельно, или всем поисковикам сразу.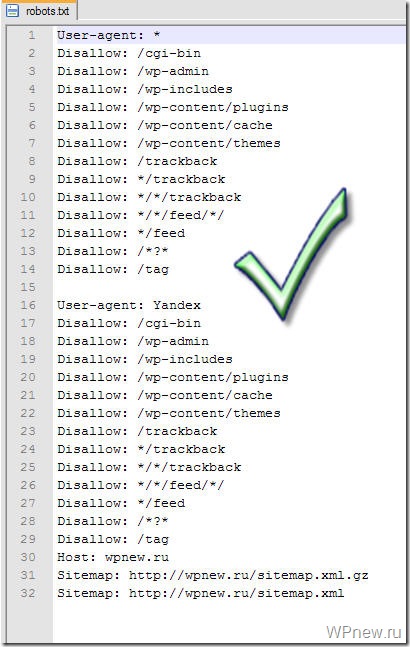
Директива «Allow» разрешает индексировать сайт, категории или страницы.
Например, вы хотите запретить индексировать папку wp-includes всем поисковикам, но в этой папке хотите разрешить индексировать файл compat.php, тогда нужно прописать следующее:
User-agent: *
Disallow: /wp-includes/
Allow: /wp-includes/compat.php
Директива «Sitemap» позволяет указать карту сайта поисковым роботам:
User-agent: *
Sitemap: http://vachevskiy.ru/sitemap.xml
Есть еще несколько директив, которые понимает только Яндекс.
Директива «Host» позволяет указать основной адрес сайта. С www или без www. Я указал без www.
User-agent: Yandex
Host: vachevskiy.ru
Директива «Crawl-delay» позволяет указать задержку, с которой поисковый робот будет отправлять вам команду. Если у вас большой сайт, то поисковик постоянным его штудированием может создать большую нагрузку на сервер. И чтобы этого не случилось, вы можете воспользоваться директивой «Crawl-delay»
И чтобы этого не случилось, вы можете воспользоваться директивой «Crawl-delay»
Вод пример:
User-agent: Yandex
Crawl-delay: 3
Это значит, что интервал между посылками команды будет 3 секунды. Но опять же, это актуально только для яндекса.
Для того, чтобы без проблем самому составить файл robots.txt, очень важно научиться понимать некоторые спецсимволы. Адрес начинается с третьего слеша.
- Символ * — любая, последовательность символов.
- Символ $ — конец строки.
Я сейчас объясню, что это значит, и как эти символы использовать при составлении файла robots.txt
Сначала разберем, как использовать «*». Например, у меня есть дублирована страница
http://vachevskiy.ru/page?replytocom=29#respond
Для того, чтобы убрать ее с индекса нужно прописать следующее:
User-agent: *
Disallow: /*?*
Таким образом, я говорю поисковому роботу: «Если в URL страницы встретишь знак вопроса «?» то не индексируй ее. И неважно, какие символы стоят до знака вопроса и после него».
И неважно, какие символы стоят до знака вопроса и после него».
Потому что перед знаком вопроса и после него мы поставили звездочку «*». А она, в свою очередь, означает любую последовательность символов.
Ну а теперь разберем, как использовать символ $. Например, у нас есть вод такая страница
http://vachevskiy.ru/index.php
и мы хотим запретить поисковому роботу ее индексировать.
Для этого нужно прописать следующее
User-agent: *
Disallow: /*index.php$
Я говорю поисковикам: «Если index.php конец строки и неважно какие символы до index.php – не индексируй». Пояснил, как мог, если что-то не понятно, то спрашивайте в комментариях ;-).
Таким образом, зная всего лишь эти два спецсимволы, можно запрещать от индексации любую страницу или раздел сайта.
Как убедиться в том, что мы составили правильный robots.txt?
Для этого, прежде всего, нужно добавить сайт в яндекс вебмастер. Потом, нужно зайти в раздел: «Настройка индексирования» — «Анализ robots. txt».
txt».
После этого нужно загрузить файл robots.txt и нажать на кнопку проверить. Если вы увидите примерно такое сообщения, как на картинке, без ошибок, значит у вас правильный robots.txt для wordpress или другой системы управления.
Но мы еще можем проверить конкретную страницу. Например, я копирую url статьи, которая должна быть открыта для индексации, и проверяю, так ли это на самом деле.
Ну вод и все, наверное, что касается вопроса, как создать файл robots txt для wordpress. Да и не только для wordpress. Теперь вы должны уметь составить правильный robots.txt для любой системы управления :smile:.
как создать, настройка, закрыть, индексация, правильный robots для Яндекса и Google, пример файла
Зачем сайту файл robots.txt и как его создать
Запускаете сайт? Поздравляем! Прежде чем устремиться к вершинам топа Яндекс или Google, проверьте, не забыта ли одна маленькая, но значительная деталь — файл robots.txt
Robots. txt — текстовый файл в главной директории веб-ресурса, который инструктирует роботов-поисковиков. В первую очередь, содержание файла подсказывает, какие страницы нужно индексировать, а какие — не стоит.
txt — текстовый файл в главной директории веб-ресурса, который инструктирует роботов-поисковиков. В первую очередь, содержание файла подсказывает, какие страницы нужно индексировать, а какие — не стоит.
Наличие файла robots.txt на сайте — непременное условие: он полезен для продвижения, кроме того, без него невозможно добиться высоких позиций в выдаче Яндекс, Google и других поисковых систем.
Зачем нужен файл robots.txt
Перед тем, как начать индексировать сайт, дружелюбный робот-поисковик сразу обратит внимание на robots.txt — прочитает инструкции и лишь затем приступит к работе. От того, как составлен файл, напрямую зависит успех или неудача кампании по продвижению, а также сохранность приватных данных на сайте.
Если robots.txt заполнен верно, ресурс получи:
- быструю и правильную индексацию страниц
Без файла robots.txt или при неверном его составлении поисковая машина может добавить в результаты выдачи нерелевантные страницы — например, экран авторизации и регистрации. Такой “мусор” будет конкурировать с целевыми страницами, и в поисковой выдаче окажется совсем не то, что хотелось бы видеть.
Такой “мусор” будет конкурировать с целевыми страницами, и в поисковой выдаче окажется совсем не то, что хотелось бы видеть.
К тому же, это негативно повлияет на поведенческие факторы, а значит, сайт “просядет” в выдаче.
- защиту приватной информации и личных данных
Чтобы администраторская панель сайта, а также личные данные и пароли, не оказались доступны всем пользователям интернета — закройте приватные страницы от индексации в файле robots.txt.
Как создать и настроить файл robots.txt
Создать файл robots.txt нетрудно, настроить — немного сложнее, однако это тоже можно сделать без специальных знаний.
Создание
Откройте текстовый редактор — стандартный Блокнот или, например, более продвинутый editor для программистов — Notepad++. Создайте файл в формате .txt, дайте ему имя “robots” и приступайте к заполнению.
Ещё один способ — создать robots.txt онлайн. Генератор предложит заполнить поля, сам пропишет синтаксис и позволит скачать уже готовый robots. txt. В сети множество инструментов для создания такого типа файлов. К примеру, сервис Seolib.
txt. В сети множество инструментов для создания такого типа файлов. К примеру, сервис Seolib.
Интерфейс генератора robots.txt
Редактирование
Если файл создан вручную, текст внутри придётся написать самостоятельно. Если скачан из онлайн-генератора — внимательно проверить и отредактировать содержимое.
Пример блока в файле robots.txt
User-agent — поисковый робот, которому даётся инструкция: например, Googlebot, Yandexbot или * (все роботы).
Allow — разрешающая директива, Disallow — запрещающая.
Host и Sitemap — также обязательные директивы для robots.txt. Первая подсказывает, какое из зеркал сайта следует индексировать, вторая — объясняет, “как пройти” к карте сайта.
В примере мы закрыли роботам доступ к панели администратора, разрешили индексировать содержимое страницы content, правда, исключая файл picture.png. Кроме того, указали основное зеркало сайта и путь к карте сайта.
Заполняя файл robots.txt, стремитесь к краткости — не путайте машину слишком подробными указаниями. Старайтесь сделать инструкцию смысловой и конкретной.
Следите за размером файла robots.txt — у бота Google, к примеру, есть ограничение для него в 500 кб.
Загрузка на сайт
Поместите файл robots.txt в корневую директорию сайта. Он должен отображаться по адресу: имя-сайта.ru/robots.txt. Если файл окажется в другом месте, поисковый робот не станет его искать и просто проигнорирует.
Чтобы загрузить файл robots.txt на сайт, как правило, требуется доступ к протоколу FTP. У популярных CMS также есть функция редактирования файла на панели администратора: по умолчанию или после установки специального модуля.
Проверяем robots.txt
Узнать, на месте ли файл robots.txt, проще простого — перейдите по адресу его расположения: имя-сайта.ru/robots.txt.
Хотите проверить синтаксис и структуру файла? На помощь придут специальные сервисы поисковых систем для вебмастеров: Яндекс. Вебмастер и Search Console Google.
Вебмастер и Search Console Google.
Анализ robots.txt в Яндекс.Вебмастер
Robots.txt — необходимый “винтик” в механизме веб-ресурса. Возможно, не потребуется он только сайтам-одностраничникам, которые почти не участвуют в seo. Но подстраховаться всё равно можно, тем более что создание файла для сайта с простейшей структурой займёт всего несколько минут.
Подписывайтесь на наш канал в Яндекс.Дзен!
Нажмите «Подписаться на канал», чтобы читать DigitalNews в ленте «Яндекса» .
Подводя итоги года, мы решили написать про самое яркое событие в мире соцсетей: конфликте «Аэрофлота…
Просмотров: 17,979
Бесплатные инструменты от Click.ruВ 2019 году еще есть люди, которые платят за связь и ЖКУ с комиссией, покупают товары и услуги тольк…
Просмотров: 29,917
Скликивание бюджета в Яндекс. Директ
ДиректДаже среди опытных пользователей Директа нет единого мнения о том, можно ли свернуть рекламную кампа…
Просмотров: 12,198
Яндекс для бизнеса: подключение диалоговЯндекс.Диалоги — новый сервис для разработчиков сайтов, при помощи которого можно наладить общение с…
Просмотров: 12,528
Пример файла txtRobots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots.txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду .
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает всех ботов
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц .
Что делать, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит
Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц. Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или . файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https://example.com/pink.xlsocks
Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots. txt:
txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter
Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots.txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.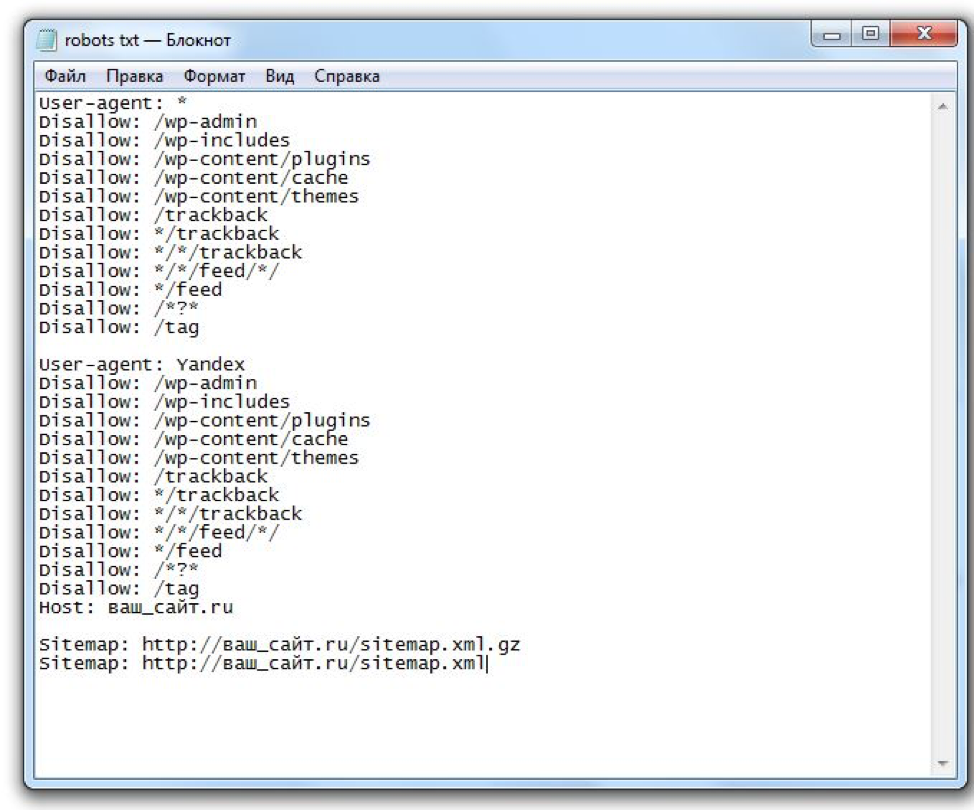 txt, которые вы можете использовать на своем сайте.
txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила. Чтобы проверить правильность robots.txt, вы можете использовать нашу программу проверки robots.txt.
Пример файла txtRobots: 10 шаблонов для использования
Мы рассмотрим 10 примеров файла robots.txt.
Вы можете либо скопировать их на свой сайт, либо объединить шаблоны, чтобы создать свой собственный.
Помните, что файл robots. txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
txt влияет на SEO, поэтому обязательно проверяйте вносимые вами изменения.
Начнем.
1) Запретить все
Первый шаблон не позволит всем ботам сканировать ваш сайт. Это полезно по многим причинам. Например:
- Сайт еще не готов
- Вы не хотите, чтобы сайт отображался в результатах поиска Google
- Это промежуточный веб-сайт, используемый для тестирования изменений перед добавлением в рабочую среду .
Какой бы ни была причина, именно так вы запретите всем поисковым роботам читать страницы:
Агент пользователя: * Запретить: /
Здесь мы ввели два «правила», а именно:
- User-agent — нацельтесь на определенного бота с помощью этого правила или используйте подстановочный знак *, что означает всех ботов
- Disallow — используется, чтобы сообщить боту, что он не может зайти в эту область сайта. Установив значение
/, бот не будет сканировать ни одну из ваших страниц .
Что делать, если мы хотим, чтобы бот просканировал весь сайт?
2) Разрешить все
Если на вашем сайте нет файла robots.txt, то по умолчанию бот будет сканировать весь сайт. Тогда один из вариантов — не создавать и не удалять файл robots.txt.
Но иногда это невозможно и нужно что-то добавить. В этом случае мы бы добавили следующее:
Агент пользователя: * Запретить:
Сначала это кажется странным, так как у нас все еще действует правило Disallow. Тем не менее, он отличается тем, что не содержит /. Когда бот прочитает это правило, он увидит, что ни один URL не имеет правила Disallow.
Другими словами, весь сайт открыт.
3) Заблокировать папку
Иногда бывают случаи, когда нужно заблокировать часть сайта, но разрешить доступ к остальным. Хорошим примером этого является административная область страницы.
Область администратора может позволять администраторам входить в систему и изменять содержимое страниц.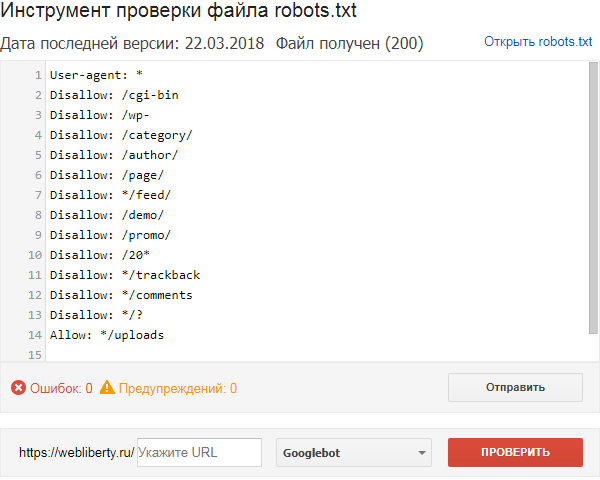 Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Мы не хотим, чтобы боты смотрели в эту папку, поэтому мы можем запретить это следующим образом:
Агент пользователя: * Запретить: /admin/
Теперь бот будет игнорировать эту область сайта.
4) Заблокировать файл
То же самое относится и к файлам. Может быть определенный файл, который вы не хотите показывать в поиске Google. Опять же, это может быть административная область или что-то подобное.
Чтобы заблокировать ботов от этого, вы должны использовать этот файл robots.txt.
Агент пользователя: * Запретить: /admin.html
Это позволит боту сканировать весь веб-сайт, кроме файла /admin.html .
5) Запретить расширение файла
Что делать, если вы хотите заблокировать все файлы с определенным расширением. Например, вы можете заблокировать файлы PDF на вашем сайте, чтобы они не попадали в поиск Google. Или у вас есть электронные таблицы, и вы не хотите, чтобы робот Googlebot тратил время на чтение.
В этом случае вы можете использовать два специальных символа для блокировки этих файлов:
-
*— это подстановочный знак, который будет соответствовать всему тексту . -
$— Знак доллара остановит сопоставление URL-адресов и представляет собой конец URL-адреса
При совместном использовании вы можете блокировать файлы PDF следующим образом:
Агент пользователя: * Запретить: /*.pdf$
или .xls файлы, подобные этому:
Агент пользователя: * Запретить: /*.xls$
Обратите внимание, что правило запрета имеет /*.xls$ . Это означает, что он будет соответствовать всем этим URL-адресам:
-
https://example.com/files/spreadsheet1.xls -
https://example.com/files/folder2/profit.xls -
https://example.com/users.xls
Тем не менее, он не будет соответствовать этому URL:
-
https://example. com/pink.xlsocks
 com/pink.xlsocks
com/pink.xlsocks Поскольку URL-адрес не заканчивается на .xls .
6) Разрешить только Googlebot
Вы также можете добавить правила, применимые к конкретному боту. Вы можете сделать это с помощью User-agent правило, до сих пор мы использовали подстановочный знак, который соответствует всем ботам.
Если бы мы хотели разрешить только Googlebot просматривать страницы на сайте, мы могли бы добавить этот robots.txt:
Агент пользователя: * Запретить: / Агент пользователя: Googlebot Запретить:
7) Запретить определенного бота
Как и в приведенном выше примере, мы можем разрешить всех ботов, но запретить одного бота. Вот как выглядел бы файл robots.txt, если бы мы хотели заблокировать только Googlebot:
Агент пользователя: Googlebot Запретить: / Пользовательский агент: * Запретить:
Существует множество пользовательских агентов ботов, вот список наиболее распространенных, с помощью которых вы можете создавать правила:
- Googlebot — используется для поиска Google
- Bingbot — используется для поиска Bing
- Slurp — поисковый робот Yahoo
- DuckDuckBot — используется поисковой системой DuckDuckGo
- Baiduspider — это китайский поисковик .
- YandexBot — это российская поисковая система
- фейсбот — используется Facebook
- Pinterestbot — используется Pinterest
- TwitterBot — используется Twitter

Когда бот посещает ваш сайт, ему необходимо найти все ссылки на странице. В карте сайта перечислены все URL-адреса вашего сайта. Добавляя карту сайта в файл robots.txt, вы облегчаете боту поиск всех ссылок на вашем сайте.
Для этого нужно использовать правило Sitemap :
Агент пользователя: * Карта сайта: https://pagedart.com/sitemap.xml
Вышеприведенное взято из файла PageDart robots.txt. Вы также можете указать более одной карты сайта, если у вас разные карты сайта для каждого языка.
URL-адрес карты сайта должен быть полным URL-адресом с https:// в начале, чтобы он работал.
9) Замедлите скорость сканирования
Можно контролировать скорость, с которой бот будет просматривать страницы вашего сайта. Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Это может быть полезно, если ваш веб-сервер борется с высоким трафиком.
Bing, Yahoo и Yandex поддерживают правило Crawl-delay . Это позволяет вам установить задержку между каждым просмотром страницы следующим образом:
Агент пользователя: * Задержка обхода: 10
В приведенном выше примере бот будет ждать 10 секунд, прежде чем запросить следующую страницу. Вы можете установить задержку от 1 до 30 секунд.
Google не поддерживает это правило, поскольку оно не является частью исходной спецификации robots.txt.
10) Нарисуй робота
Последний шаблон предназначен для развлечения. Вы можете добавить рисунок ASCII, чтобы добавить робота в файл robots.txt, например:
.# _ # [ ] # ( ) # |>| # __/===\__ # //| о=о |\\ # <] | о = о | [> # \=====/ # / / | \\ № <_________>
Если кто-то придет и взглянет на ваш файл robots.txt, это может вызвать у него улыбку.
Некоторые компании уже делают это, у Airbnb есть реклама в файле robots. txt:
txt:
https://www.airbnb.co.uk/robots.txt
У NPM есть робот в robots.txt:
https://www.npmjs.com/robots.txt
У Avvo.com есть рисунок Grumpy Cat в формате ASCII:
https://www.avvo.com/robots.txt
Но мне больше всего нравится Robinhood.com:
https://robinhood.com/robots.txt
Подведение итогов, пример файла txt для роботов
Мы рассмотрели 10 различных шаблонов robots.txt, которые вы можете использовать на своем сайте.
Эти примеры включают:
- Запретить всех ботов со всего сайта
- Разрешить всем ботам везде
- Заблокировать папку от сканирования
- Заблокировать файл от сканирования
- Разрешить одного бота
- Запретить все типы файлов
- Запретить определенного бота
- Ссылка на вашу карту сайта
- Уменьшите скорость, с которой бот сканирует ваш сайт
- В вашем файле robots.txt есть работа по рисованию
Помните, что вы можете комбинировать части этих шаблонов как угодно, пока действуют правила.