
О распространенных проблемах SEO, связанных с файлом Robots.txt
Файлы Robots.txt — это инструмент, ограничивающий для сканеров поисковых систем доступ к определенным страницам сайта. В этой статье мы поделимся рекомендациями, касающиеся файла robots.txt.
- Что такое файл Robots.txt?
- Почему файлы Robots.txt важны?
- Рекомендованные практики Google для файлов Robots.txt
- Блокировать определенные веб-страницы
- Медиа-файлы
- Файлы ресурсов
- Как работать с атрибутами Noindex
- Метатег Robots: <meta name=«robots» content=«noindex» />
- Настройте HTTP-заголовок X-Robots-Tag.
- 14 распространенных проблем с Robots.txt
- Отсутствует файл Robots.txt
- Добавление строк Disallow для блокировки конфиденциальной информации
- Добавление Disallow для предотвращения дублирования контента
- Добавление Disallow для кода, размещенного на стороннем сайте
- Использование абсолютных URL-адресов
- Robots.
 txt размещен не в корневой папке сайта
txt размещен не в корневой папке сайта - Обслуживание разных файлов Robots.txt
- Добавлена директива для блокировки всего содержимого сайта
- Добавление ALLOW вместо DISALLOW
- Неверное расширение типа файла
- Добавление Disallow для папки верхнего уровня, где размещаются веб-страницы, которые нужно индексировать
- Блокировка доступа ко всему сайту во время разработки
- Написание директив заглавными или прописными буквами
- Использование кодов состояния сервера (например, 403) для блокировки доступа
- Как проверить, используется ли сайте X-Robots-Tag?
- Заключение
 txt размещен не в корневой папке сайта
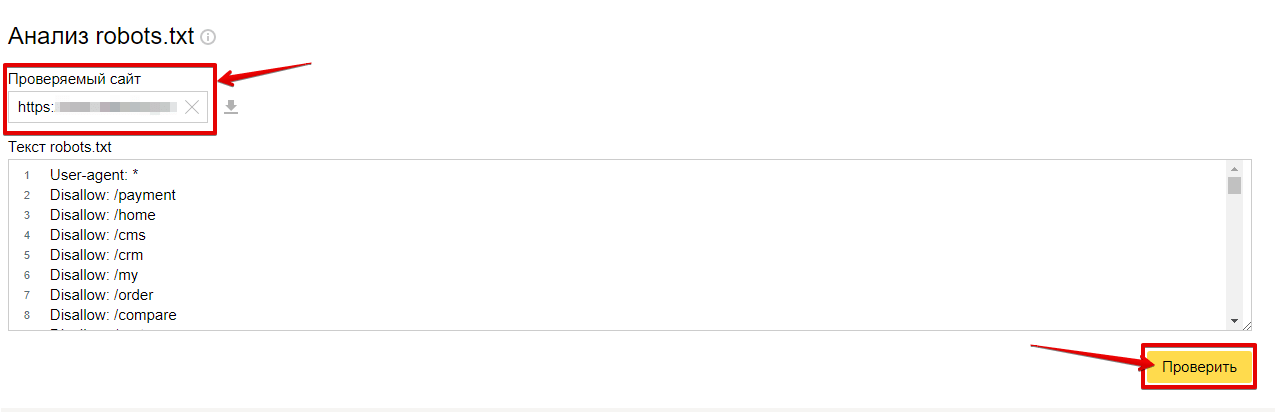
txt размещен не в корневой папке сайтаФайл robots.txt сообщает поисковым роботам, какие веб-страницы сайта они могут просматривать. Бот поисковой системы (например, Googlebot) читает файл robots.txt перед началом сканирования вашего сайта, чтобы узнать, с какими веб-страницами он должен работать.
Вот так выглядит файл robots.txt.
Когда боты и другие сканеры попадают на сайт, они могут использовать большой объем серверных мощностей. Это может замедлить ваш сайт. Robots.txt решает эту проблему.
Это может замедлить ваш сайт. Robots.txt решает эту проблему.
Ниже приведен пример файла Robots.txt от Google, в котором для Googlebot заблокирован доступ к определенным каталогам, разрешен доступ к /directory2/subdirectory1/. Но для других сканеров заблокирован весь сайт.
Пользовательские агенты перечислены в «группах». Каждая группа указана в отдельных строках по типу сканера. Она содержит перечень файлов, к каким он может и не может получить доступ.
Информирование поискового сканера о том, какие страницы сайта нужно сканировать, а какие нет, позволяет лучше контролировать краулинговый бюджет сайта, направляя поисковых роботов к наиболее важным его страницам.
Файла robots.txt также позволяет избежать перегрузки сервера сайта разнообразными запросами. Например, в приведенном выше примере robots.txt есть файлы, которые хранятся в папке /cgi-bin. Их блокировка в Robots.txt дает сканерам понять, что в этой папке нет ресурсов, которые нужно индексировать.
Предупреждение: веб-страницы, заблокированные в robots. txt, могут отображаться в результатах поиска Google, но без описания.
txt, могут отображаться в результатах поиска Google, но без описания.
Чтобы предотвратить отображение URL-адреса в результатах поиска Google, необходимо защитить файлы на сервере паролем, использовать метатег noindex или заголовок ответа.
Если веб-страницы заблокированы для сканирования в robots.txt, то любая информация об индексировании или служебных директивах не будет найдена и будет игнорироваться.
Поисковым роботам следует разрешить сканировать важные ресурсы, необходимые для отображения содержимого страниц сайта.
Файл Robots.txt можно использовать для блокирования доступа поисковых сканеров к определенным веб-страницам сайта.
Совет: для блокировки сканирования и индексации используйте директиву noindex на уровне конкретной веб-страницы. Но лучше добавить эту директиву глобально с помощью HTTP-заголовка X-Robots-Tag.
Используйте файл robots.txt для предотвращения отображения в поисковой выдаче изображений, видео и аудио файлов. Но это не помешает другим веб-страницам или пользователям ссылаться на эти ресурсы.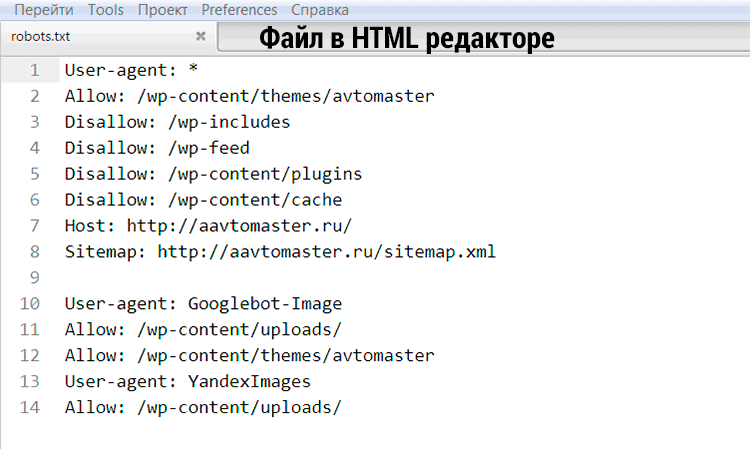 Если другие веб-страницы или сайты ссылаются на этот контент, он все равно может появиться в результатах поиска.
Если другие веб-страницы или сайты ссылаются на этот контент, он все равно может появиться в результатах поиска.
Используйте robots.txt, чтобы заблокировать второстепенные ресурсы. Но если их отсутствие затрудняет понимание краулером конкретных веб-страниц, то не следует их блокировать.
Приведенный выше пример тега указывает поисковым системам не показывать веб-страницу в результатах поиска. Значение атрибута name= «robots» указывает, что директива применяется ко всем сканерам. Чтобы обратиться к определенному сканеру, замените значение robots атрибута name на имя сканера.
Совет: данный метатег должен указываться в разделе <head>. Если нужно заблокировать определенные страницы сайта от сканирования или индексации, используйте директиву no index.
X-Robots-Tag можно использовать как элемент ответа HTTP-заголовка для конкретного URL-адреса. Любая директива метатега robots также может быть указана в X-Robots-Tag. Ниже приведен пример HTTP-ответа с X-Robots-Tag, который указывает поисковым сканерам не индексировать страницу:
Любая директива метатега robots также может быть указана в X-Robots-Tag. Ниже приведен пример HTTP-ответа с X-Robots-Tag, который указывает поисковым сканерам не индексировать страницу:
HTTP/1.1 200 OK Date: Tue, 25 May 2010 21:42:43 GMT (...) X-Robots-Tag: noindex (...)
Чтобы использовать одновременно несколько директив, их нужно указать через запятую.
Совет: мы рекомендуем использовать этот метод для блокировки любого контента. X-Robots-Tag с HTTP-ответами позволяют указать директивы сканирования, которые применяются на сайте глобально.
Сайт без файла robots.txt, метатегов robots или HTTP-заголовков X-Robots-Tag обычно сканируется и индексируется нормально.
Возможная причина проблемы: Файла robots.txt повышает уровень контроля над контентом и файлами сайта, которые может сканировать и индексировать поисковый бот. Его отсутствие означает, что Google будет индексировать весь контент сайта.
Добавление строки Disallow в файл robots. txt также представляет собой угрозу безопасности. Так как определяет, где хранится закрытый от пользователей контент.
txt также представляет собой угрозу безопасности. Так как определяет, где хранится закрытый от пользователей контент.
В чем проблема: Используйте проверку подлинности на стороне сервера, чтобы заблокировать доступ к личному контенту.
Сайты должны быть просканированы, чтобы определить их канонический индекс. Не блокируйте содержимое с помощью robots.txt вместо canonical.
В чем проблема: В некоторых CMS достаточно сложно добавлять пользовательские теги canonical. В этом случае можно попробовать другие методы.
Чтобы удалить контент со стороннего сайта, вам необходимо связаться с его владельцем.
В чем проблема: Это может привести к ошибке, когда сложно определить исходный сервер для конкретного контента.
Директивы в файле robots.txt (за исключением «Sitemap:») действительны только для относительных путей.
В чем проблема: Сайты с несколькими подкаталогами могут использовать абсолютные адреса, но действительны только относительные URL.
Файл Robots.
В чем проблема: Не помещайте файл robots.txt в какую-либо другую папку.
Не рекомендуется обслуживать различные файлы robots.txt в зависимости от агента пользователя или других атрибутов.
В чем проблема: сайты всегда должны использовать один и тот же файл robots.txt для международной аудитории.
Часто владельцы сайтов оставляют файл robots.txt, который может содержать строку disallow, блокирующую все содержимое сайта.
В чем проблема: Это происходит, когда на сайте используется версия robots.txt по умолчанию.
На сайтах не обязательно указывать директиву allow. Директива allow позволяет переопределять директивы disallow в том же файле robots.txt.
В чем проблема: В случаях, когда директивы disallow похожи, использование allow может помочь в добавлении нескольких атрибутов, чтобы их различать.
В разделе справки Google Search Console рассказывается, как создавать файлы robots.txt. После того, как вы создали этот файл, можно будет проверить его с помощью тестера robots.
В чем проблема: Файл должен иметь расширение .txt и создаваться в кодировке UTF-8.
Запрет на сканирование веб-страниц может привести к их удалению из индекса Google.
В чем проблема: При добавлении перед именем папки звездочки (*) это может означать что-то промежуточное. Когда она добавлена после, это указывает на необходимость заблокировать все, что включено в URL-адрес после /.
Можно временно приостановить поисковое сканирование, вернув код HTTP 503 для всех URL-адресов, включая файл robots.txt. Файл robots.txt будет периодически проверяться, пока он будет недоступен.
В чем может быть проблема: При перемещении сайта или массовых обновлениях robots.txt может быть пустым по умолчанию для блокировки всего сайта. В данном случае он должен оставаться на месте и не быть удален во время технического обслуживания.
Директивы в файле robots.txt являются чувствительными к регистру.
В чем проблема: Некоторые CMS автоматически устанавливают URL-адреса для отображения содержимого файла robots. txt в верхнем и нижнем регистре. Директивы должнысоответствовать фактической структуре URL-адресов со статусом 200.
txt в верхнем и нижнем регистре. Директивы должнысоответствовать фактической структуре URL-адресов со статусом 200.
Чтобы заблокировать сканирование сайта, файл robots.txt должен возвращаться в обычном режиме (то есть с HTTP-кодом «200» «ОК»).
В чем проблема: при перемещении сайта robots.txt может оказаться пустым или удаленным. Рекомендуется, чтобы он оставался на месте и не был удален во время технического обслуживания.
Чтоб проверить заголовки сервера, используйте инструмент просмотреть как робот Google в Search Console.
Проверьте весь сайт, чтобы определить веб-страницы, которые следует заблокировать с помощью директив disallow. Убедитесь в том, что на сайте не используется автоматическое перенаправление и не изменяется файл robots.txt. Оцените эффективность сайта до и после изменений.
Вадим Дворниковавтор-переводчик статьи «14 Common Issues with the Robots.txt File in SEO (and How to Avoid Them)»
Оптимизация файла robots.txt для лучшего ранжирования сайта в Яндексе
SEO продвижение сайтов
Привет, Друзья! В этой стате мы поговорим о том, как файл robots.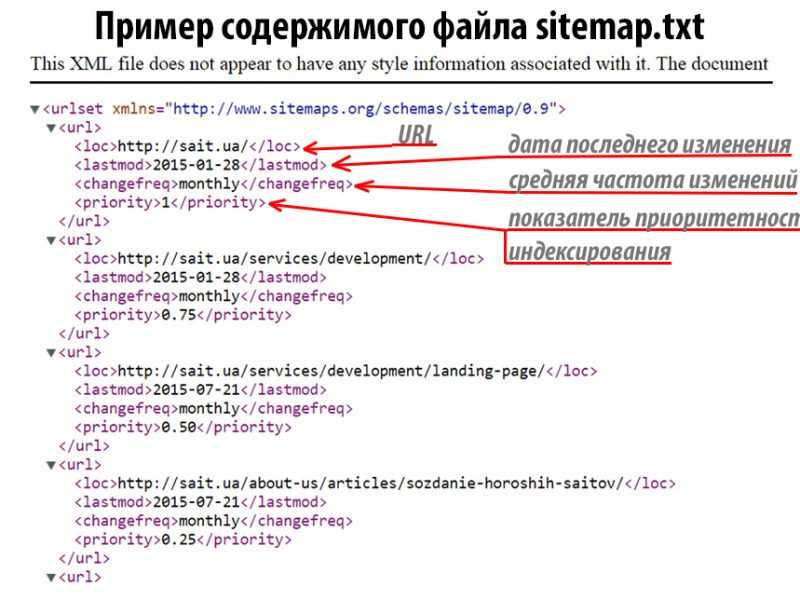 txt влияет на продвижение сайта. Итак поехали!
txt влияет на продвижение сайта. Итак поехали!
Как файл robots.txt влияет на продвижение сайта
Оглавление статьи
- 1 Как файл robots.txt влияет на продвижение сайта
- 2 Зачем нужен файл robots.txt
- 3 Файл robots.txt для wordpress
- 4 Важные моменты при составлении файла robots.txt
- 5 Вместо заключения
- 6 SEO продвижение сайта по России:
Самым важным инструментом во внутреннем SEO-продвижении сайта является файл robots.txt.
Многие веб-мастера недооценивают важность и значение этого файла и составляют его за несколько минут, не особо вникая в суть. И в итоге получают проблемы с индексацией сайта.
Поэтому вы должны уделить немного времени тому, чтобы разобраться, что это за файл, зачем он нужен и какие преимущества можно получить от его правильного заполнения.
Зачем нужен файл robots.txt
Самое главное, зачем составляют файл robots.txt — это более быстрая и полная индексация вашего сайта! Все дело в том, что в большинстве случаев на сайте существуют различные страницы, которые не должны попадать в индекс Яндекса и Google, но которые открыты для индексирования, и поисковым ботам ничего не остается, кроме как сканировать все эти страницы.
Вот пример подобных страниц, которые оказывают негативное влияние на индексацию всего вашего сайта в целом:
- Дубликаты страниц (например, это может быть одна и та же страница на вашем сайте, но доступная под разными url-адресами).
- Страницы с ошибкой 404 — если вы их не запретили, то поисковый бот может просканировать тысячи ненужных страниц.
- Низкокачественные и спамные страницы. Если вы знаете, что у вас на сайте есть подобные страницы, то их лучше запретить индексировать.
- Бесконечные страницы (простой пример — календарь. В нем может быть навигация по дням, неделям, месяцам, годам и т. д., и поисковый робот может просканировать тысячи ненужных страниц).
- Страницы поиска (например, если у вас есть несколько сотен материалов, то поисковые роботы могут начать индексировать все эти ненужные страницы с результатами поиска, что будет приводить к дублированию контента).
- Страницы корзины и оформления заказа. Это актуально исключительно для интернет-магазинов.
- Страницы с фильтрами, возможно даже страницы сравнения товаров — их может быть огромное количество (чем крупнее интернет-магазин, тем больше может существовать таких страниц) — от них нет никакой практической пользы, но все они по умолчанию индексируются поисковыми системами.
- Страницы с регистрацией и авторизацией. Их лучше запретить индексировать, потому что тем самым ваш сайт могут найти злоумышленники, для того чтобы попытаться его взломать.
- Версии для печати (если они существуют) содержат дублированный контент основного сайта, поэтому если у вас они есть, то их в обязательном порядке надо скрыть от индексации.

Естественно, что этот список ненужных страниц вы можете самостоятельно расширить, т. к. у вас на сайте, возможно, немного другая структура, и вы можете решить, что те или иные разделы поисковым роботам индексировать не нужно!
Файл robots.
 txt для wordpress
txt для wordpressUser-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest. xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.
xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т. д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно).
д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ru
Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команду Host понимает
# Яндекс и Mail.RU, Google не учитывает.
Host: www.site.ruВажные моменты при составлении файла robots.txt
Важно помнить о том, что чем меньше мусорных страниц, тем выше скорость индексации основных (важных) страниц вашего сайта. Поэтому если вы избавитесь от всего мусора, то индексация всех новых страниц, статей, записей, карточек товаров значительно ускорится, и ваш сайт, возможно, даже поднимется в поисковой выдаче за счет попадания большего количества целевых страниц в поисковую выдачу.
Важно также в файле robots.txt прописать главное зеркало и ссылку на xml-карту сайта (sitemap), потому что это поможет многократно улучшить индексацию вашего сайта!
Естественно, что составить файл надо правильно: после того как вы составили файл robots. txt, нужно зайти в панель «Вебмастера» Яндекса или «Гугла» и проверить, индексируется ли ваш сайт (все основные страницы, например главная страница, рубрики, каталог товаров, статьи и так далее). Кроме того, вы должны здесь же (в «Вебмастере») проверить, что вы запретили индексацию всех мусорных страниц.
txt, нужно зайти в панель «Вебмастера» Яндекса или «Гугла» и проверить, индексируется ли ваш сайт (все основные страницы, например главная страница, рубрики, каталог товаров, статьи и так далее). Кроме того, вы должны здесь же (в «Вебмастере») проверить, что вы запретили индексацию всех мусорных страниц.
Если же какие-то поисковые боты (например, от поиска mail.ru) нагружают ваш сервер, делают тысячи ненужных вам переходов по страницам вашего сайта, но пользователи из этих поисковых систем приходят на ваш сайт редко, то можете запретить вообще индексацию для всех поисковых роботов, кроме Yandex и Google. Но это делать нужно только в крайнем случае, например чтобы защититься от парсинга собственного сайта, или если нагрузка на хостинг достигает критических отметок.
Так как этот файл очень важен, то постарайтесь максимально подробно изучить структуру его составления, чтобы нужные вам страницы остались в выдаче поисковых систем, а не были заблокированы из-за того, что вы допустили какую-то ошибку.
Помните также, что составление robots.txt зависит также и от того, на каком движке (CMS) работает ваш сайт. Например, для блога на WordPress файл robots.txt будет значительно отличаться от того же файла для интернет-магазина на движке «1С-Битрикс».
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Записаться на SEO обучение
SEO продвижение сайта по России:
Как TXT-файлы роботов влияют на производительность сайта
На вашем сайте есть файл robots. txt? Правильно ли он настроен для повышения производительности вашего сайта? Вы знаете, что он делает или как и почему?
txt? Правильно ли он настроен для повышения производительности вашего сайта? Вы знаете, что он делает или как и почему?
Миллионы веб-сайтов используют текстовый файл robots для управления тем, как поисковые системы взаимодействуют с их веб-сайтом.
Google активно проверяет файл, чтобы убедиться, что он может сканировать ваши страницы. Однако не все сайты хотят, чтобы их страницы отображались в поисковой системе, но они хотят, чтобы их посетители получали максимальное количество посещений.
В этой статье предлагается простое руководство по файлам robotos.txt и тому, как они влияют на производительность вашего веб-сайта B2B.
Узнайте, как работает файл robots.txt и зачем он нужен. Узнайте о недостатках отсутствия файла или его неправильной настройки.
Читайте дальше, чтобы узнать, как увеличить количество трафика с помощью передовых методов SEO.
Что такое Txt-файл Robots?
Файл robots.txt или текстовый файл указывает поисковым системам и другим веб-роботам, как сканировать страницы вашего веб-сайта.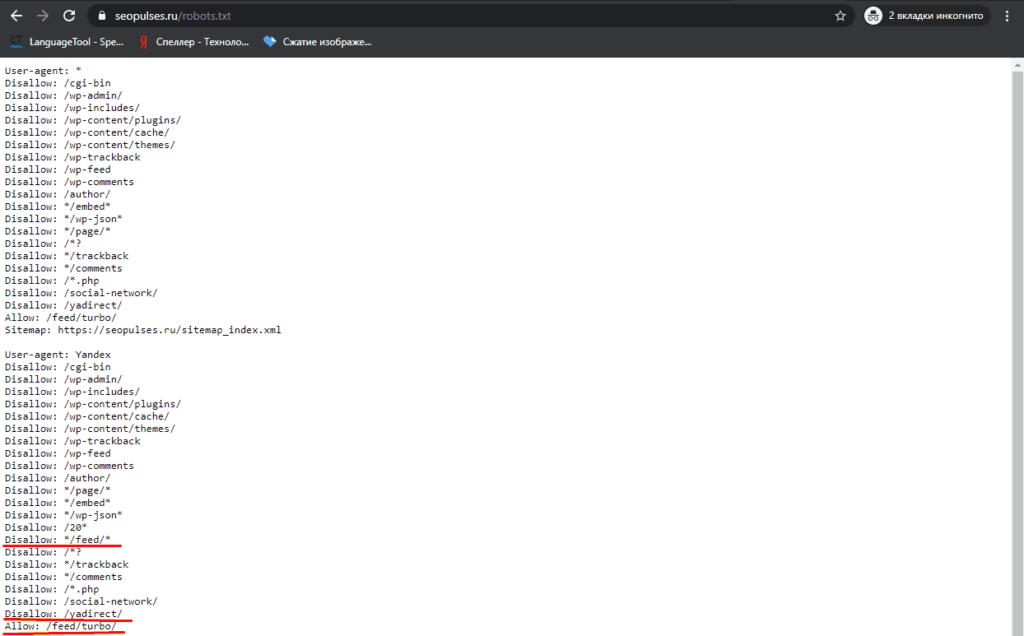
Он действует как часовой на вашем сайте и при желании может фактически заблокировать Google и другие поисковые системы от индексации контента. Например, текстовый файл robots в Facebook «запрещает» всем основным поисковым системам доступ к его содержимому.
Помимо запрета доступа ко всем страницам, вы можете указать ботам поисковых систем сканировать только определенные области. Подкаталоги, которые содержат информацию, которую вы не хотели бы показывать в Google, работают таким образом.
Зачем был изобретен файл robots.txt?
Стандарт файла robots txt является частью протокола исключения роботов (REP), который пытается контролировать доступ поисковых роботов.
Мартин Костер разработал стандарт в 1994 году, когда всемирная паутина только зарождалась. Его сайт был завален ботами поисковых систем. Это привело к созданию спецификации для направления автоматизированного трафика так, как того хотели веб-мастера.
REP не является официальным веб-стандартом.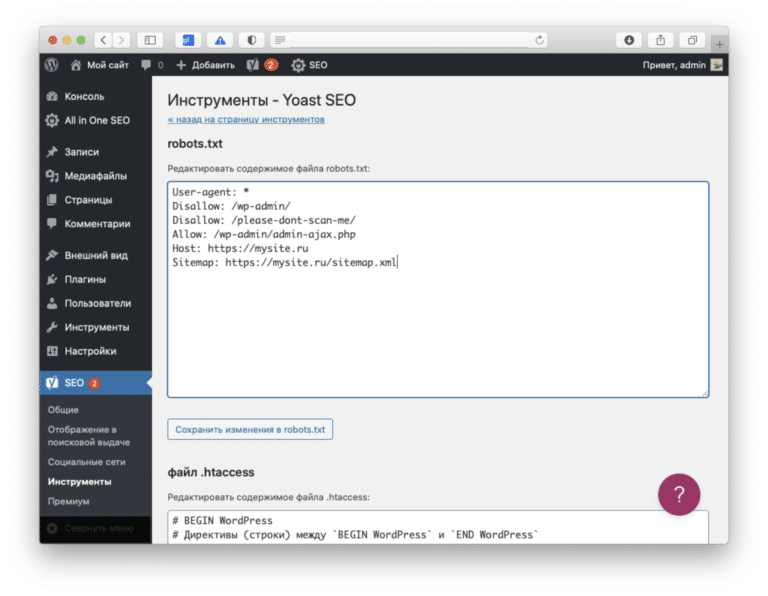 Это означает, что сканеры и веб-боты могут интерпретировать инструкции по своему усмотрению. Или полностью игнорировать их.
Это означает, что сканеры и веб-боты могут интерпретировать инструкции по своему усмотрению. Или полностью игнорировать их.
Основные поисковые системы, такие как Google и Bing, соответствуют основным спецификациям. Таким образом, включение файла robots.txt на ваш сайт повлияет на большую часть вашего органического входящего трафика.
Как работает robots.txt
Файл robots.txt представляет собой простой текстовый документ без форматирования.
Он должен находиться в корневой папке или папке верхнего уровня вашего веб-сайта. Например, текстовый файл Google robots.txt — https://www.google.com/robots.txt
. Основная предпосылка — разрешить или запретить доступ ботам к областям вашего сайта.
Боты, поисковые роботы, поисковые роботы и пользовательские агенты — все это одно и то же – автоматизированный трафик. Файл robot.txt не повлияет на обычных посетителей, поскольку они будут напрямую обращаться к вашим страницам.
Робот Google может посещать ваш сайт несколько раз в день и сначала проверяет файл robots. txt. Если вы укажете в качестве агента пользователя Googlebot , вы сможете запретить или заблокировать Google сканирование определенных разделов.
txt. Если вы укажете в качестве агента пользователя Googlebot , вы сможете запретить или заблокировать Google сканирование определенных разделов.
По умолчанию поисковые роботы могут получить доступ ко всем страницам вашего веб-сайта, которые они найдут. Файл robots.txt говорит им не делать этого.
Robots Txt Examples
Типичный текстовый файл robots выглядит следующим образом:
User-agent: Googlebot
Disallow: /assets
Обратите внимание на user-agent. В данном случае это Google, то есть Googlebot, но существуют и другие, в том числе:
- Bingbot — поисковая система Microsoft Bing .
- Baiduspider — китайский поисковик Baidu
- Googlebot-Image — собственный паук Google Images
- Яндекс – главная поисковая система России
Строка Disallow: должна содержать относительный путь к папке или файлам, которые вы хотите исключить из сканирования.
Вы можете запретить весь каталог, добавив начальный / или введя подкаталог, например. /изображения/декабрь-2020. Отдельные страницы работают одинаково, поэтому, например, Disallow: /contact.php исключит страницу контактов.
/изображения/декабрь-2020. Отдельные страницы работают одинаково, поэтому, например, Disallow: /contact.php исключит страницу контактов.
Выбор нескольких параметров
Подстановочный знак * — это эффективный способ разрешить или запретить пользовательские агенты и файлы. Например, чтобы запретить всем ботам сканировать вашу папку «файлы», используйте:
User-agent: *
Disallow: /files
Однако это сопровождается предупреждением. Используя подстановочные знаки, вы можете эффективно заблокировать весь свой SEO-трафик!
Будьте осторожны при использовании этих правил, так как это может повлиять на рейтинг вашего сайта в поиске Google. Робот Googlebot игнорирует любые ошибки, обнаруженные в вашем файле robots.txt, но будет следовать вашим указаниям.
Недостатки отсутствия файла robots.txt
Нужен ли вашему веб-сайту файл robots txt для работы?
Нет, это не так. Кроме того, исключение файла robots не помешает Google и т.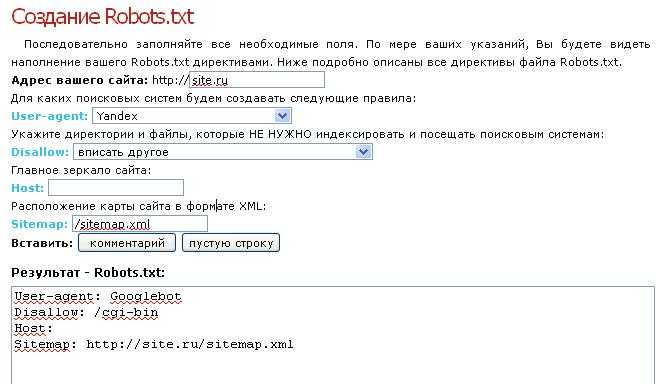 д. сканировать ваш веб-сайт. Тогда зачем иметь его на месте?
д. сканировать ваш веб-сайт. Тогда зачем иметь его на месте?
Добавьте файл robots.txt для управления страницами, которые будут отображаться в поиске Google.
Если у вас есть страница входа, доступ к которой вы хотите предоставить определенным посетителям, но не широкой публике, исключите ее в robots.txt. Возможно, у вас есть новый веб-сайт, который находится в папке /new-site. Запретите этот каталог тестирования в файле robots.
Корпоративные веб-сайты с тысячами страниц могут столкнуться с проблемой бюджета сканирования.
Это происходит, когда у робота Googlebot заканчивается время при индексировании вашего сайта. Он выделяет определенное количество ресурсов и может обходить страницы для перехода по другим ссылкам.
Запрещая каталоги с менее популярным содержимым, вы можете представить страницы, которые хотите проиндексировать первыми. Вы также можете указать Google не сканировать мультимедийные файлы, такие как PDF-файлы или изображения.
SEO и WordPress Robots Txt Files
WordPress создает файл robots по умолчанию. Содержимое выглядит так:
Содержимое выглядит так:
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Карта сайта: https://yoursite.com/wp-sitemap .xml
Вы заметите, что WordPress исключает область администрирования, за исключением страницы admin-ajax.php. Этот файл создает контент, который поисковые системы сочтут полезным, но который не должен оставаться закрытым.
Некоторые плагины также создают директиву Sitemap: , которая передает URL-адрес страницы карты сайта сканеру.
Как создать SEO-файл Google Robots Txt
Сначала проверьте файл с помощью Google Robots.txt Tester
Хотя создать файл robots.txt довольно просто, добавить его в корневую папку вашего сайта сложно.
Создание необходимых правил для исключения частного контента также может занять некоторое время. Ошибки могут случиться, и худшим результатом будет полное исчезновение из Google.
Создайте лучший файл robots. txt, чтобы увеличить продажи и квалифицированных потенциальных клиентов, сотрудничая со специалистом по поисковой оптимизации.
txt, чтобы увеличить продажи и квалифицированных потенциальных клиентов, сотрудничая со специалистом по поисковой оптимизации.
Продуктивное SEO и производительность сайта
Файл robots.txt направляет поисковую систему при сканировании вашего веб-сайта.
Он может блокировать поиск определенных каталогов, файлов и носителей. Тем не менее, одна ошибка может эффективно заблокировать Google и навредить результатам SEO.
Если у вас есть дополнительные вопросы, не стесняйтесь обращаться , чтобы сделать работу вашего сайта более продуктивной.
Имран Селимханов
Имран является основателем Productive Shop. Он пишет на темы формирования спроса B2B и стратегии SEO, чтобы помочь стартапам понять, как завоевать цифровую долю голоса.
До Productive Shop Имран руководил формированием спроса в консалтинговой компании Oracle, руководил сайтом электронной коммерции, обслуживающим команды LE, а до этого помогал создавать офисы PMO в технологических стартапах.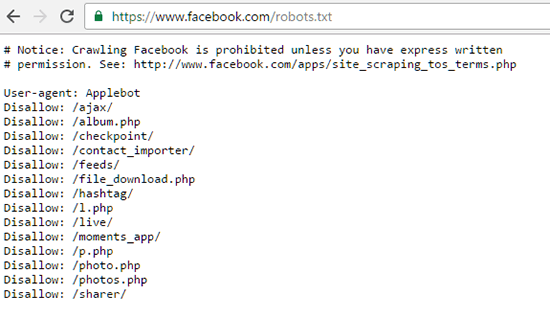 Когда он не на работе, Имрана можно увидеть путешествующим в Скалистых горах, оттачивающим свои навыки стрельбы по мишеням и падающим с лыжных трасс из черного алмаза из-за чрезмерной уверенности в своих лыжных способностях.
Когда он не на работе, Имрана можно увидеть путешествующим в Скалистых горах, оттачивающим свои навыки стрельбы по мишеням и падающим с лыжных трасс из черного алмаза из-за чрезмерной уверенности в своих лыжных способностях.
Получайте последние обновления блога от Productive Shop! Подпишитесь на наш блог:
Связанные ресурсы
Что такое robots.txt? Руководство для начинающих с примерами
А, robots.txt — один крошечный файл с большими последствиями. Это один технический элемент SEO, в котором вы не хотите ошибиться, ребята.
В этой статье я объясню, почему каждому веб-сайту нужен файл robots.txt и как его создать (без проблем для SEO). Я отвечу на часто задаваемые вопросы и приведу примеры того, как правильно выполнить это для вашего сайта. Я также дам вам загружаемое руководство, которое охватывает все детали.
Содержание:
- Что такое robots.txt?
- Почему файл robots.txt важен?
- Но нужен ли файл robots. txt?
- Какие проблемы могут возникнуть с robots.txt?
- Как работает файл robots.txt?
- Советы по созданию файла robots.txt без ошибок
- Тестер robots.txt
- Руководство по протоколу исключения роботов (скачать бесплатно)
 txt?
txt? Что такое robots.txt?
Robots.txt — это текстовый файл, который издатели веб-сайтов создают и сохраняют в корне своего веб-сайта. Его цель — сообщить автоматическим веб-краулерам, таким как боты поисковых систем, какие страницы на веб-сайте не сканировать. Это также известно как протокол исключения роботов.
Robots.txt не гарантирует, что исключенные URL-адреса не будут проиндексированы для поиска. Это потому, что пауки поисковых систем все еще могут узнать, что эти страницы существуют, через другие веб-страницы, которые ссылаются на них. Или страницы все еще могут быть проиндексированы из прошлого (подробнее об этом позже).
Robots.txt также не гарантирует, что бот не будет сканировать исключенную страницу, поскольку это добровольная система. Боты основных поисковых систем редко не придерживаются ваших указаний. Но другие, которые являются плохими веб-роботами, такие как спам-боты, вредоносные программы и программы-шпионы, часто не следуют приказам.
Помните, что файл robots.txt общедоступен. Вы можете просто добавить /robots.txt в конец URL-адреса домена, чтобы увидеть его файл robots.txt (как у нас здесь). Поэтому не включайте никакие файлы или папки, которые могут содержать важную для бизнеса информацию. И не полагайтесь на файл robots.txt для защиты личных или конфиденциальных данных от поисковых систем.
Хорошо, с учетом этих предостережений, давайте продолжим…
Почему robots.txt важен?
Боты поисковых систем имеют директиву сканировать и индексировать веб-страницы. С помощью файла robots.txt вы можете выборочно исключить страницы, каталоги или весь сайт из сканирования.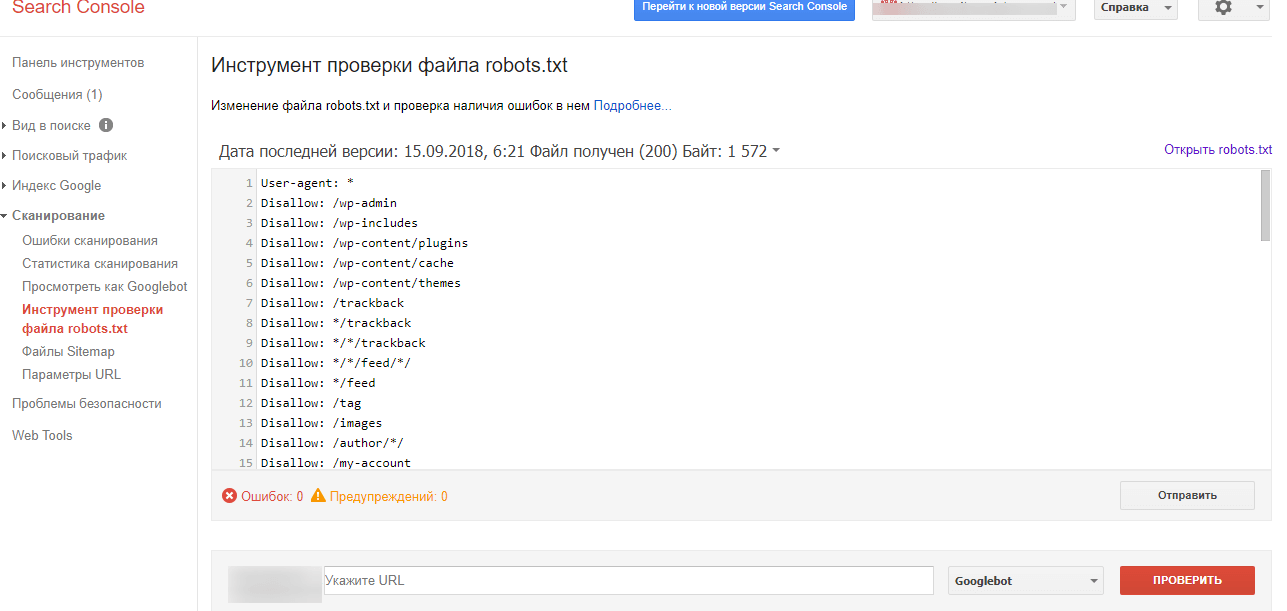
Это может быть удобно во многих различных ситуациях. Вот несколько ситуаций, в которых вы можете использовать файл robots.txt:
- Чтобы заблокировать определенные страницы или файлы, которые не следует сканировать/индексировать (например, неважные или похожие страницы)
- Чтобы прекратить сканирование определенных частей веб-сайта, пока вы их обновляете
- Чтобы сообщить поисковым системам о расположении вашей карты сайта
- Чтобы указать поисковым системам игнорировать определенные файлы на сайте, такие как видео, аудиофайлы, изображения, PDF-файлы и т. д., чтобы они не отображались в результатах поиска
- Чтобы ваш сервер не был перегружен запросами*
*Использование robots.txt для блокировки ненужного сканирования — один из способов снизить нагрузку на ваш сервер и помочь ботам более эффективно находить ваш хороший контент. Google предоставляет удобную диаграмму здесь. Кроме того, Bing поддерживает директиву Crawl-Delay, которая может помочь предотвратить слишком много запросов и избежать перегрузки сервера.
Конечно, у файла robots.txt есть множество применений, и я расскажу о них в этой статье.
Но нужен ли файл robots.txt?
На каждом веб-сайте должен быть файл robots.txt, даже если он пустой. Когда поисковые роботы заходят на ваш сайт, первое, что они ищут, это файл robots.txt.
Если ничего не существует, поисковые роботы получают ошибку 404 (не найдено). Хотя Google утверждает, что Googlebot может продолжать сканировать сайт, даже если файла robots.txt нет, мы считаем, что лучше загрузить первый файл, который запрашивает бот, чем выдавать ошибку 404.
Какие проблемы могут возникнуть с robots.txt?
Этот простой маленький файл может создать проблемы для SEO, если вы не будете осторожны. Вот несколько ситуаций, на которые стоит обратить внимание.
1. Случайная блокировка всего вашего сайта
Этот подвох случается чаще, чем вы думаете. Разработчики могут использовать robots.txt, чтобы скрыть новый или измененный раздел сайта во время его разработки, но затем забыть разблокировать его после запуска.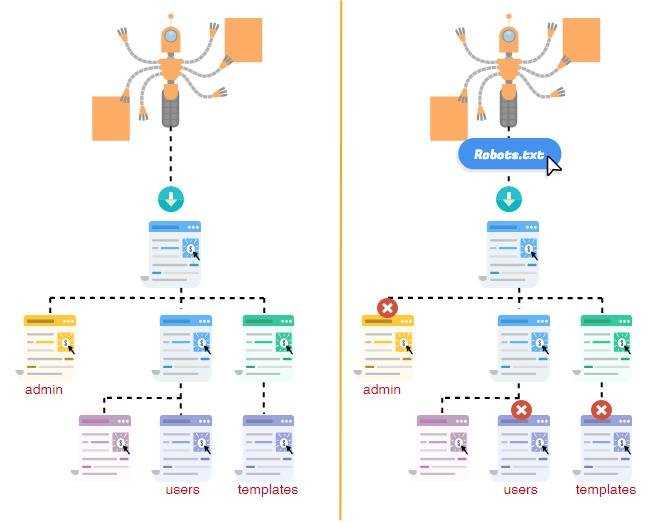 Если это уже существующий сайт, эта ошибка может привести к внезапному падению рейтинга в поисковых системах.
Если это уже существующий сайт, эта ошибка может привести к внезапному падению рейтинга в поисковых системах.
Удобно иметь возможность отключать сканирование на время подготовки нового сайта или раздела сайта к запуску. Просто не забудьте изменить эту команду в файле robots.txt, когда сайт заработает.
2. Исключение уже проиндексированных страниц
Блокировка проиндексированных страниц robots.txt приводит к тому, что они застревают в индексе Google.
Если исключить страницы, которые уже есть в индексе поисковой системы, они останутся там. Чтобы действительно удалить их из индекса, вы должны установить на самих страницах мета-тег robots «noindex» и позволить Google просканировать и обработать его. Как только страницы будут удалены из индекса, заблокируйте их в robots.txt, чтобы Google не запрашивал их в будущем.
Как работает robots.txt?
Чтобы создать файл robots.txt, вы можете использовать простое приложение, такое как Блокнот или TextEdit. Сохраните его с именем файла robots.txt и загрузите его в корень вашего веб-сайта как www.domain.com/robots.txt — здесь его будут искать пауки.
Сохраните его с именем файла robots.txt и загрузите его в корень вашего веб-сайта как www.domain.com/robots.txt — здесь его будут искать пауки.
Простой файл robots.txt будет выглядеть примерно так:
User-agent: *
Disallow: /directory-name/
Google дает хорошее объяснение того, что означают разные строки в группе в файле robots.txt файл в своем файле справки по созданию robots.txt:
Каждая группа состоит из нескольких правил или директив (инструкций), по одной директиве в строке.
Группа предоставляет следующую информацию:
- К кому относится группа (пользовательскому агенту)
- К каким каталогам или файлам может получить доступ агент
- К каким каталогам или файлам этот агент не имеет доступа
Я объясню подробнее о различных директивах в файле robots.txt далее.
Директивы robots.txt
Общий синтаксис, используемый в файле robots.txt, включает следующее:
User-agent
User-agent относится к боту, которому вы отдаете команды (например, Googlebot или Bingbot). У вас может быть несколько директив для разных пользовательских агентов. Но когда вы используете символ * (как показано в предыдущем разделе), это означает все пользовательские агенты. Вы можете увидеть список пользовательских агентов здесь.
У вас может быть несколько директив для разных пользовательских агентов. Но когда вы используете символ * (как показано в предыдущем разделе), это означает все пользовательские агенты. Вы можете увидеть список пользовательских агентов здесь.
Запретить
Правило Запретить указывает папку, файл или даже весь каталог для исключения из доступа веб-роботов. Примеры включают следующее:
Разрешить роботам сканировать весь сайт:
Агент пользователя: *
Запретить:
Запретить всем роботам со всего сайта:
Агент пользователя: *
Запретить: /
Запретить всем роботам из «/myfolder» /» и все подкаталоги «myfolder»:
User-agent: *
Disallow: /myfolder/
Запретить всем роботам доступ к любому файлу, начинающемуся с «myfile.html»:
User-agent: *
Disallow: /myfile.html
Запретить роботу Googlebot доступ к файлам и папкам, начинающимся с «мой»:
Агент пользователя: googlebot
Запретить: /my
Разрешить
Эта команда применима только к роботу Googlebot и сообщает ему, что он может получить доступ к подкаталогу или веб-странице, даже если его родительский каталог или веб-страница запрещены.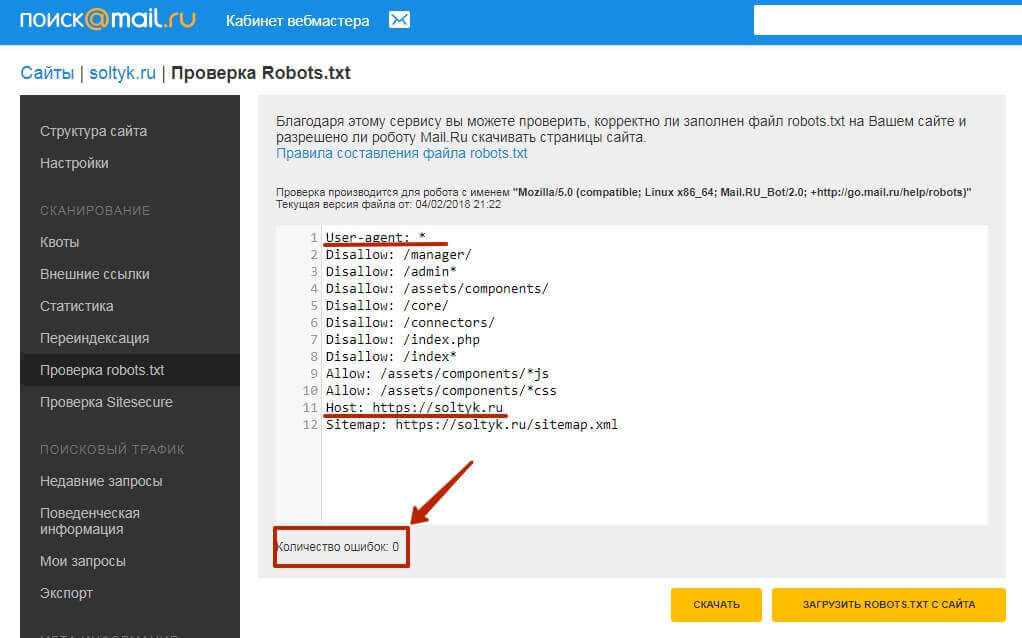
Возьмем следующий пример: Запретить всех роботов из папки /scripts/, кроме page.php:
Запретить: /scripts/
Разрешить: /scripts/page.php
Crawl-delay
Это сообщает ботам, как долго подождите, чтобы просканировать веб-страницу. Веб-сайты могут использовать это для сохранения пропускной способности сервера. Googlebot не распознает эту команду, и Google просит вас изменить скорость сканирования через консоль поиска. По возможности избегайте задержки сканирования или используйте ее с осторожностью, так как она может существенно повлиять на своевременное и эффективное сканирование веб-сайта.
Карта сайта
Сообщите роботам поисковых систем, где в файле robots.txt найти XML-карту сайта. Пример:
User-agent: *
Disallow: /directory-name/
Карта сайта: https://www.domain.com/sitemap.xml
Чтобы узнать больше о создании XML-карт сайта, см. это: Что такое Карта сайта в формате XML и как ее создать?
Подстановочные знаки
Есть два символа, которые могут указать роботам, как обрабатывать определенные типы URL:
Символ *.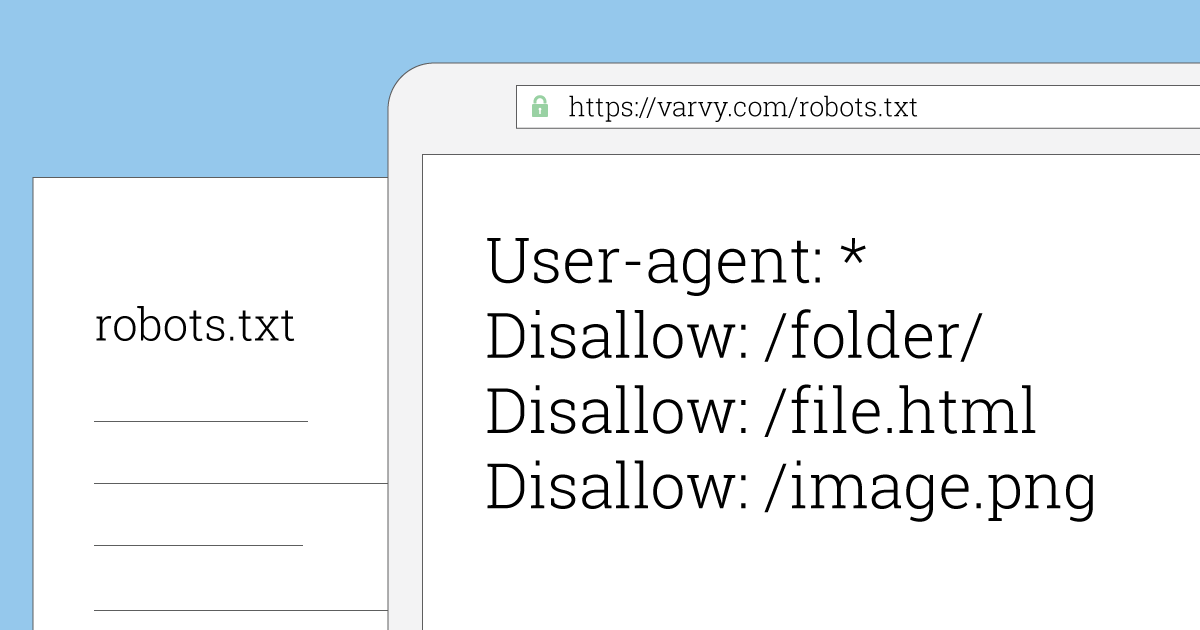 Как упоминалось ранее, он может применять директивы к нескольким роботам с одним набором правил. Другое использование — сопоставление последовательности символов в URL-адресе, чтобы запретить эти URL-адреса.
Как упоминалось ранее, он может применять директивы к нескольким роботам с одним набором правил. Другое использование — сопоставление последовательности символов в URL-адресе, чтобы запретить эти URL-адреса.
Например, следующее правило запрещает роботу Googlebot доступ к любому URL-адресу, содержащему «страницу»:
Агент пользователя: googlebot
Запретить: /*page
Символ $. Символ $ сообщает роботам, что им нужно сопоставить любую последовательность в конце URL-адреса. Например, вы можете заблокировать сканирование всех PDF-файлов на веб-сайте:
User-agent: *
Disallow: /*.pdf$
Обратите внимание, что вы можете комбинировать подстановочные знаки $ и *, и их можно комбинировать для разрешающих и запрещающих директив.
Например, Запретить все файлы asp:
Агент пользователя: *
Запретить: /*asp$
- Это не будет исключать файлы со строками запроса или папками из-за символа $, обозначающего конец
- Исключено из-за подстановочный знак перед asp – /pretty-wasp
- Исключено из-за подстановочного знака перед asp – /login. asp
- Не исключено из-за $ и URL-адреса, включающего строку запроса (?forgotten-password=1) – /login.asp?forgotten-password=1
 asp
aspНе сканируется или не индексируется
Если вы не хотите Google для индексации страницы, для этого есть другие средства, кроме файла robots.txt. Как Google указывает здесь:
Какой метод следует использовать для блокировки сканеров?
- robots.txt: используйте его, если сканирование вашего контента вызывает проблемы на вашем сервере. Например, вы можете запретить сканирование бесконечных сценариев календаря. Вы не должны использовать robots.txt для блокировки частного контента (вместо этого используйте аутентификацию на стороне сервера) или обработки канонизации. Чтобы убедиться, что URL-адрес не проиндексирован, используйте метатег robots или HTTP-заголовок X-Robots-Tag. 9Метатег robots 0063
- : используйте его, если вам нужно управлять тем, как отдельная HTML-страница отображается в результатах поиска (или убедиться, что она не отображается).
- X-Robots-Tag HTTP-заголовок: используйте его, если вам нужно управлять отображением не-HTML-контента в результатах поиска (или убедиться, что он не отображается).

А вот еще руководство от Google:
Блокировка Google от сканирования страницы, скорее всего, приведет к удалению страницы из индекса Google.
Однако запрет в robots.txt не гарантирует, что страница не будет отображаться в результатах: Google может решить, основываясь на внешней информации, такой как входящие ссылки, что она релевантна. Если вы хотите явно заблокировать страницу от индексации, вам следует вместо этого использовать метатег noindex robots или HTTP-заголовок X-Robots-Tag. В этом случае не следует запрещать страницу в robots.txt, потому что страницу необходимо просканировать, чтобы тег был виден и подчинялся.
Советы по созданию файла robots.txt без ошибок
Вот несколько советов, которые следует учитывать при создании файла robots. txt:
txt:
- Команды вводятся с учетом регистра. Например, вам нужна заглавная буква «D» в Disallow.
- Всегда добавляйте пробел после двоеточия в команду.
- При исключении всего каталога поставьте косую черту до и после имени каталога, например: /имя-каталога/
- Все файлы, не исключенные специально, будут включены для сканирования ботами.
Тестер robots.txt
Всегда проверяйте файл robots.txt. Чаще всего вы думаете, что издатели веб-сайтов ошибаются, что может разрушить вашу стратегию SEO (например, если вы запретите сканирование важных страниц или всего веб-сайта).
Используйте инструмент Google robots.txt Tester. Вы можете найти информацию об этом здесь.
Руководство по протоколу исключения роботов
Если вам нужна более подробная информация, чем эта статья, загрузите нашу Руководство по протоколу исключения роботов . Это бесплатный PDF-файл, который вы можете сохранить и распечатать для справки, чтобы получить подробную информацию о том, как создать файл robots. txt.
txt.
Заключение
Файл robots.txt на первый взгляд кажется простым, но он позволяет издателям веб-сайтов давать сложные указания о том, как они хотят, чтобы боты сканировали веб-сайт. Правильное получение этого файла имеет решающее значение, так как оно может уничтожить вашу программу SEO, если все сделано неправильно.
Поскольку существует множество нюансов использования robots.txt, обязательно прочитайте введение Google в robots.txt.
У вас есть проблемы с индексацией или другие проблемы, требующие технических знаний SEO? Если вы хотите получить бесплатную консультацию и расценки на услуги, свяжитесь с нами сегодня.
Брюс Клэй является основателем и президентом Bruce Clay Inc., глобальной фирмы цифрового маркетинга, предлагающей поисковую оптимизацию, оплату за клик, маркетинг в социальных сетях, оптимизированную для SEO веб-архитектуру, а также инструменты SEO и обучение. Свяжитесь с ним через LinkedIn или через веб-сайт BruceClay.