
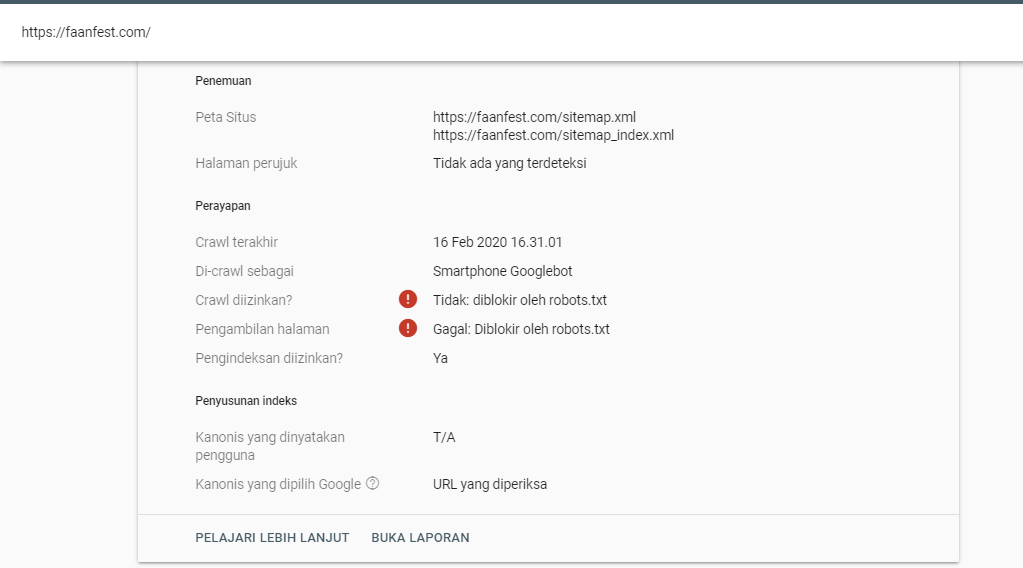
Robots txt: что это за файл
Файл текстового формата robots.txt содержит информацию, необходимую для индексации сайта поисковиками. Он размещается в корневом каталоге и разбит на директории, содержащие команды, при помощи которых ботам поисковиков открывается доступ к определенным местам на веб-ресурсе и закрывается. Причем роботы разных поисковиков обрабатывают этот файл при помощи собственных алгоритмов, у которых могут быть свои специфические особенности. Работа со ссылками с других площадок проводится независимо от того, как настроен robots.
Основные задачи robots.txt
У «роботс» главное назначение – это содержать правила, которые помогают ботам правильно индексировать ресурс. Основные из таких директив – Allow (разрешение индексировать раздел или конкретный файл), Disallow (обратная команда, то есть запрет на такую процедуру) и User-agent (адресация команд Allow и Disallow, то есть определение, какие боты должны им следовать). Следует учитывать, что содержащиеся в «роботс» инструкции имеют характер рекомендаций, а не обязательных предписаний. Поэтому роботы могут в разных ситуациях как использовать, так и игнорировать их.
Поэтому роботы могут в разных ситуациях как использовать, так и игнорировать их.
Создание и размещение «роботс»
Файл должен быть исключительно текстовым, то есть иметь расширение txt, и находиться в корневом каталоге соответствующего сайта. Размещение осуществляется при помощи клиента FTP. Дальше проводится проверка файла на предмет его доступности. С этой целью необходимо перейти на страницу site.com/robots.txt. Причем этот адрес должен отображаться в браузере полностью.
Требования к файлу
Следует учитывать, что при отсутствии «роботс» в корневом каталоге или неправильной его настройке есть риск того, что сайт не будет доступен в поисковике и его посещаемость будет низкой. В файле не может использоваться кириллица, поэтому , если домен кириллический, применяют Punycode. Важно при этом, чтобы поддерживалось соответствие между кодировкой страниц и структурой ресурса.
Дополнительные директивы
Кроме основных команд Allow, Disallow и User-agent, присутствующих в каждом файле «роботс», есть ряд директив специального назначения, которые используются в особых случаях.
Crawl-delay
Если роботы поисковых систем слишком сильно нагружают сервер, поможет эта директива. Она содержит информацию о минимальном интервале между завершением загрузки одной страницы и переходом бота к обработке следующей. Этот промежуток времени указывается в секундах. Причем робот «Яндекса» без проблем считывает не только значения в целых числах, но и дробные, к примеру 0,7 секунды. Но роботы поисковика Google директиву Crawl-delay пока не учитывают.
Clean-param
Эта директива используется поисковыми ботами «Яндекса». Структура названий сайтов может быть сложной, и нередко системы, управляющие контентом, создают в них динамические параметры. Они могут передавать дополнительные сведения о сессиях пребывания на сайте пользователей, реферерах и т. п. Директива Clean-param имеет такой синтаксис:
s0[&s1&s2&..&sn] [path].
Здесь два поля, в первом из которых перечисляются параметры, учитывать которые поисковые роботы не должны. Их необходимо разделять при помощи символа &. Во втором поле указываются адреса тех страниц, на которые распространяется данное правило. В качестве примера использования такой директивы можно привести форум, на котором при посещении пользователем страниц формируются ссылки с длинными названиями такого образца: http://forum.com/index.php?id=788987&topic=34. При этом у страниц одинаковое содержание, но у всех пользователей собственные идентификаторы. Чтобы предотвратить индексацию поисковыми роботами всего массива дублирующихся страниц с разными id, директива Clean-param должна выглядеть так: id /forum.com/index.php.
Их необходимо разделять при помощи символа &. Во втором поле указываются адреса тех страниц, на которые распространяется данное правило. В качестве примера использования такой директивы можно привести форум, на котором при посещении пользователем страниц формируются ссылки с длинными названиями такого образца: http://forum.com/index.php?id=788987&topic=34. При этом у страниц одинаковое содержание, но у всех пользователей собственные идентификаторы. Чтобы предотвратить индексацию поисковыми роботами всего массива дублирующихся страниц с разными id, директива Clean-param должна выглядеть так: id /forum.com/index.php.
Sitemap
Чтобы сайты индексировались правильно и быстро, создается Sitemap – файл (или несколько) с картой ресурса. Соответствующая директива прописывается в любом месте файла «роботс» и учитывается поисковыми ботами независимо от расположения. Однако, как правило, она находится в конце документа. Обрабатывая директиву, бот запоминает информацию и проводит ее переработку. Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Именно полученные таким образом данные становятся основой для проведения последующих сессий, в процессе которых для индексации загружаются страницы веб-ресурса.
Host
Боты всех поисковиков руководствуются этой директивой, которая позволяет прописать зеркало веб-ресурса, которое при индексации будет восприниматься как главное. Так можно избежать включения в индекс нескольких зеркал, то есть дублирования одного сайта в выдаче поисковой системы. Если значений Host несколько, робот, осуществляющий индексацию, принимает во внимание только первое, а все остальные игнорирует.
Специальные символы
Необходимо учитывать, что в конце каждой директивы по умолчанию прописывается специальный символ *. Его назначение – расширить зону действия правила на весь сайт, то есть на все его страницы или разделы, названия которых начинаются с определенного сочетания символов. Для отмены операции, которая проводится по умолчанию, используется символ $. По стандарту формирования «роботс» рекомендуется после каждого набора указаний User-agent прописывать пустую строку с переводом. Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Причем для комментирования используется символ #. Информацию, размещенную после него и до пустого перевода, поисковые боты не учитывают.
Запрет индексации ресурса или отдельных разделов
Чтобы весь сайт, определенные разделы или страницы не индексировались, можно использовать указание Disallow. Если проставить здесь символ /, будет заблокирован для индексации весь ресурс, а «/ bin» закроет доступ к тем страницам, названия которых начинаются с этого сочетания знаков.
Проверка robots.txt
Когда в файл «роботс» вносятся какие-либо изменения, его необходимо проверить. Это операция, которая проводится в обязательном порядке, так как ошибка в расстановке символов может вызвать немало проблем. Минимальную проверку можно провести при помощи инструментов веб-мастера от Google и «Яндекса». Для их использования следует пройти регистрацию и внести информацию о своем ресурсе.
|
Рейтинг 5, голосов 6 |
|||||||||
Настройка файла robots.
 txt — Документация startmedia
txt — Документация startmediaДокументация startmedia
GitLabPlanfix
Search…
Документация StartMedia
Регламент
📜
Регламент рабочего процесса
📋
Planfix — работа с задачами
Базовые статьи
🔧
Настройка рабочего окружения
🎆
Развертка локальной копии сайта
Обучающие материалы
Как создать Merge Request
Начальный уровень
Многосайтовость битрикс и Open Server
Структура шаблона
Верстка
Работа с Битриксом
Готовые решения
Решения для поисковой оптимизации
Миграции — Перенос инфоблоков с локальной копии на боевой сайт
Продвинутый уровень
Системное администрирование
Работа с веб-сервером
Настройка редиректов
Работа с доменами
Настройка SPF-записи
Работа с DNS записями
Настройка файла robots.txt
Создание копии битрикс в хранилище
Разворачивание dev версии
Конвертация сайта на bitrix из win1251 в utf8
Лечим сайт от вирусов и закрываем дыры
Gitlab
Перенос сайта на 1C-Bitrix на наш хостинг
Интеграции Битрикс со сторонними сервисами
Дебаггинг
Справочники
1C-Bitrix
Gitlab
Open Server
PhpStorm
Терминал
Apache (htaccess)
Автотесты кода
Работа с Базой Данных
Чек-лист Project менеджера
Добавление подарка в корзину при добавления каждого товара
ыфппывпывфпв
PhpStorm
Готовые команды консоли
Powered By GitBook
Настройка файла robots. txt
txt
robots.txt — это служебный файл с инструкциями для поисковых роботов, размещаемый в корневой директории сайта (/public_html/robots.txt). С его помощью можно запретить индексирование отдельных страниц (или всего сайта), ограничить доступ для определенных роботов, настроить частоту запросов роботов к сайту и др. Корректная настройка robots.txt позволит снизить нагрузку на сайт, создаваемую поисковыми роботами.
Файл содержит набор правил (директив), каждое из которых записывается с новой строки в формате имя_директивы: значение (пробел после двоеточия необязателен, но допустим). Каждый блок правил начинается с директивы User-agent; внутри него не должно быть пустых строк. Новый блок правил отделяется от предыдущего пустой строкой.
В файле можно использовать примечания, отделяя их знаком #.
Файл должен называться именно robots.txt; написание Robots.txt или ROBOTS.TXT будет ошибочным.
Некоторые роботы могут игнорировать отдельные директивы. Например, GoogleBot не учитывает директивы Host и Crawl-Delay; YandexDirect игнорирует общие директивы (заданные как User-agent: *), но учитывает правила, заданные через специально для него.
Проверить созданный robots.txt можно в вебмастер-сервисах Yandex или Google или в других подобных сервисах в сети.
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex
User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.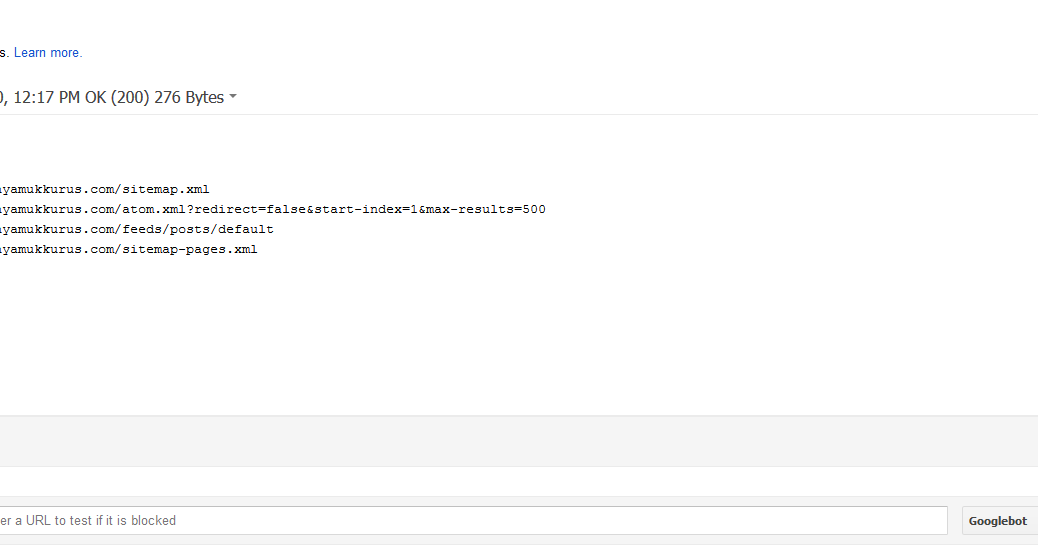
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота
Disallow: /
Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота
Disallow: /catalog
Allow: /catalog/auto
Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs. com — используйте:
com — используйте:
User-agent: MJ12bot
User-agent: AhrefsBot
Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
 ).
Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
).
Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
 ).
Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
).
Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
$Host: https://mydomain.com
Примечания:
Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.

Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Примечания:
Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Для Яндекса максимальное значение в Crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота установить частоту обращений можено в панели вебмастера Search Console.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2
www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex
Disallow:
Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
С более подробной информацией о настройке директивы Clean-param рекомендуем ознакомиться в справочнике Яндекса.
Previous
Работа с DNS записями
Next
Создание копии битрикс в хранилище
Last modified 3yr ago
Copy link
On this page
Формат robots.txt
Используемые директивы
Нужно ли прописывать директиву host в файле Robots.txt
Доброго всем времени суток! Кузнецов Анатолий на связи и сегодня я решил поделиться с вами информацией, которая еще несколько лет назад меня самого сильно интересовала. Вопрос у меня был следующий: «нужно ли прописывать директиву host в файле Robots. txt». И самое главное, что будет если директиву host прописать неправильно?
txt». И самое главное, что будет если директиву host прописать неправильно?Что такое директива host и зачем она нужна
Host — специально разработанная директива для поисковых роботов Яндекса, которая указывает им какое главное зеркало на сайте, а какое второстепенное.
Очень часто использовали директиву host во времена перехода сайтов на безопасное https соединение. До применения SSL сертификатов и https протоколов, сайты располагались по адресу http. Пример моего сайта:
- Было: https://hozyindachi.ru
- Стало: https://hozyindachi.ru
С добавлением буквы «S» сайт начинал работать через защищенное соединение и, по сути, становился новым, дублирующим сайтом. Но как мы все понимаем, дублирование и хорошее ранжирование понятия не совместимые в Яндекс. И чтобы избежать проблем, нужно один сайт делать зеркалом второго. Именно для этой процедуры и была создана директива host, которую прописывали в файле Robots.txt.
Как прописывать директиву host в robots.txt
Раньше её прописывали так:
User-agent:
Yandex Disallow: /page
Host: site.ru
Этот код говорил роботам Яндекса, что основной сайт находиться по адресу site.ru и он является главным зеркалом. В моем случае это был сайт https://hozyindachi.ru. Ну а тот, который был раньше https://hozyindachi.ru, подклеивался и не учитывался роботами. Так все и работало до 2018 года и вся эта процедура называлась «деликатный переезд» c http на https.
Уверен, что многие помнят те веселые времена, когда после безграмотного перехода на htpps протокол у сайта обваливался трафик и терялись позиции.
В 2018 году Яндекс отменил директиву host
12 марта 2018 в блоге вебмастера Платон Щукин опубликовал текст следующего характера, отменяющий директиву host по следующим причинам.
Информация из Яндекс Вебмастер:
Директива Host позволяла сохранить доступность старого сайта на период переезда, однако ее использование было также сопряжено с некоторыми неудобствами.
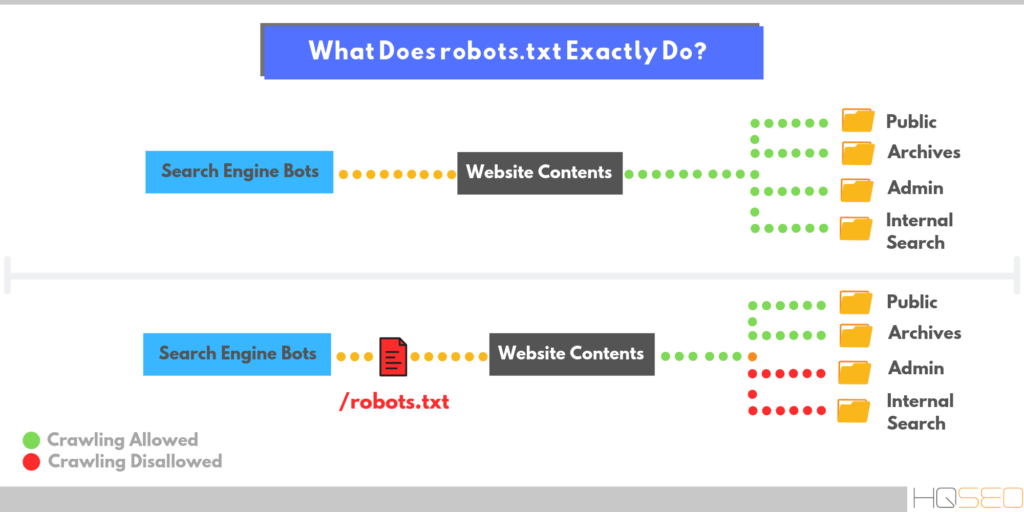 Например, необходимо было проверять, что в директиве Host всех зеркал указан один и тот же сайт, иначе переезд мог произойти некоректно. В связи с этим было решено отказаться от использования директивы Host — теперь переезд будет выполняться только при помощи редиректа HTTP-301. Это также упростит совмещение переезда в Яндексе и других поисковых системах.
Например, необходимо было проверять, что в директиве Host всех зеркал указан один и тот же сайт, иначе переезд мог произойти некоректно. В связи с этим было решено отказаться от использования директивы Host — теперь переезд будет выполняться только при помощи редиректа HTTP-301. Это также упростит совмещение переезда в Яндексе и других поисковых системах. Что теперь нужно делать?
Новый план работ рекомендованный Яндексом:
1. Добавьте новый домен в Вебмастер (в том числе сайт по протоколу HTTPS, если переезд выполняется на HTTPS) и убедитесь, что он не склеен в группу зеркал с другим сайтом. Если это так, воспользуйтесь инструментом «Отклейка зеркал», чтобы расклеить сайты. После окончания расклейки переходите ко второму пункту.2. Настройте редирект 301 со страниц старого сайта на аналогичные страницы нового. При этом я рекомендую учитывать несколько важных моментов:
— сайты должны совпадать между собой структурно, поэтому страницы старого сайта должны выполнять редирект именно на аналогичные страницы нового сайта.
— оба сайта должны быть доступны роботу. Проверьте, что в robots.txt обоих сайтов содержатся одинаковые правила, ведь если будут запрещены разные страницы, это может привести к различию контента. Если сайты используют один и тот же файл robots.txt, то файл sitemap лучше указать по адресу нового главного зеркала, так как после переезда индексироваться будет именно он.
— убедитесь, что большая часть страниц сайтов доступна и отвечает кодом HTTP-200 ОК или кодом редиректа 301. Если на доменах существенная доля страниц будет недоступна из-за кода ответа 404, это может помешать переезду. В таком случае недоступные страницы можно запретить к индексированию в файле robots.txt, чтобы робот-зеркальщик не посещал их при сверке контента.
3.
Когда все необходимые настройки будут внесены, в панели Яндекс.Вебмастера старого адреса отправьте заявку на переезд сайта. Если заявка была успешно принята, значит, настройки выполнены корректно и сайты смогут склеиться. Процесс склейки был значительно ускорен и сейчас может занимать от нескольких дней до 3 недель.
Замечу, что завершение переезда не означает, что все страницы сайта сразу попадут в поиск по адресу главного зеркала. Страницы неглавного зеркала будут участвовать в поиске какое-то время, пока аналогичные страницы главного зеркала не будут проиндексированы. Постепенно, по мере обхода нужного сайта, неглавное сможет пропасть из поиска.
Зачастую также возникает вопрос, почему в Яндекс.Вебмастере у неглавного зеркала большое число страниц в списке «Загруженных», и это число может даже увеличиваться, хотя в поиске страницы не появляются.
Не забудьте также, что для нового домена в Яндекс.Вебмастере необходимо добавить свой файл sitemap и установить региональность.
 Если же структура сайта при переезде изменилась, Вы можете установить редирект со страниц старого сайта на аналогичные страницы нового, а с них установить редирект на нужные адреса. Наши рекомендации по смене структуры сайта описаны в разделе Помощи.
Если же структура сайта при переезде изменилась, Вы можете установить редирект со страниц старого сайта на аналогичные страницы нового, а с них установить редирект на нужные адреса. Наши рекомендации по смене структуры сайта описаны в разделе Помощи. Проверьте, что все зеркала в группе выполняют редирект на желаемое главное зеркало. Это также относиться к версиям «с www» или «без www».
Проверьте, что все зеркала в группе выполняют редирект на желаемое главное зеркало. Это также относиться к версиям «с www» или «без www».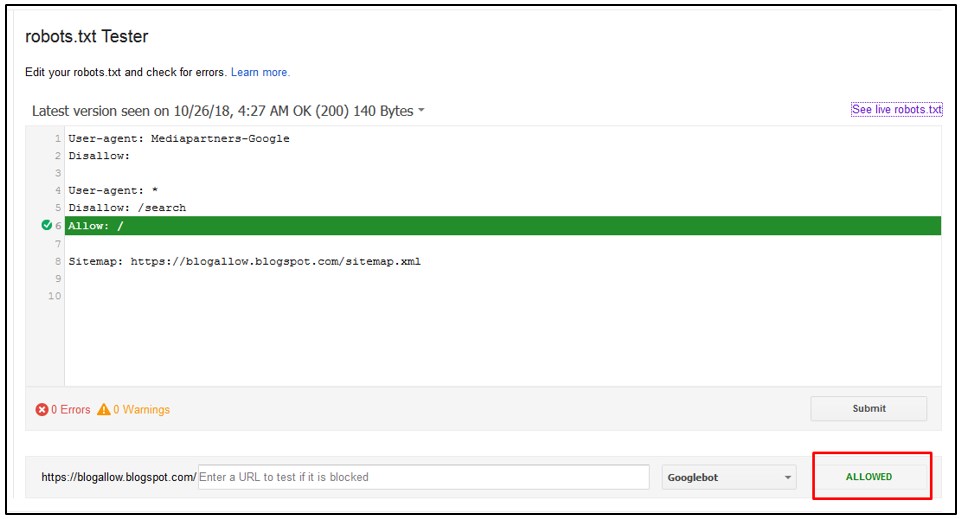 В этом нет какой-либо ошибки: в список загруженных входят все страницы, ссылки на которые известны индексирующему роботу, поэтому данные о таких страницах вполне могут храниться в базе робота. Попадать в поиск такие страницы не будут, так как принадлежат неглавному зеркалу.
В этом нет какой-либо ошибки: в список загруженных входят все страницы, ссылки на которые известны индексирующему роботу, поэтому данные о таких страницах вполне могут храниться в базе робота. Попадать в поиск такие страницы не будут, так как принадлежат неглавному зеркалу.Как теперь выглядит мой файл robots.txt
Я упростил максимально свой файл robots.txt. Многие SEO-шники бегают с ним как курица с яйцом. Я и сам раньше парился и пытался его прописывать отдельно для двух поисковых систем Яндекс и Google, в надежде на лучшее ранжирование и максимальное исключение возможных дублей и усложнений в работе для роботов.
Но все оказалось полной фигней и роботам похоже фиолетово, как вы его пропишите, лишь бы не перекрыли случайно то, что точно не стоит перекрывать. В общем мой файл в Robots теперь такой и в нем полностью отсутствует директива host:
Заключение
Про директиву host в файле Robots.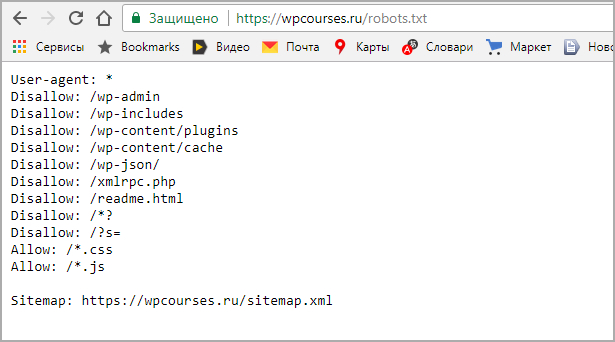 txt сегодня можно забыть!!! Тем более я получил официальный ответ на этот вопрос от Яндекса:
txt сегодня можно забыть!!! Тем более я получил официальный ответ на этот вопрос от Яндекса:
Ответ Яндекс:
Здравствуйте!Указывать директиву Host не нужно. Её поддержка была вовсе отключена, то есть при переезде на новое доменное имя учитывается только редирект со страниц предполагаемого неглавного зеркала на аналогичные страницы желаемого главного. Подробнее об этом можно прочитать в нашем блоге.
Оцените, пожалуйста, мой ответ ❤️
—
Платон Щукин
Поддержка Яндекса
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Записаться на SEO обучение
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс.
Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
Заказать SEO продвижение сайта
SEO продвижение сайта по России:
Как использовать Robots.
txt для управления поисковыми роботамиВведение
robots.txt — это текстовый файл, который содержит правила, предписывающие поисковым роботам и поисковым системам открывать или игнорировать определенные разделы вашего веб-сайта. Обычно называемые веб-роботами, поисковые роботы следуют директивам в файле robots.txt перед сканированием любой части вашего веб-сайта. Файл robots.txt должен находиться в корневом каталоге документов веб-сайта, чтобы любой поисковый робот мог получить к нему доступ.
В этой статье объясняется, как использовать файл robots.txt для управления поисковыми роботами на вашем веб-сайте.
Предварительные условия
- Разверните облачный сервер на Vultr.
- Укажите активное доменное имя на сервер.
- Войдите в систему через SSH как пользователь без полномочий root с привилегиями sudo.
- Разместите веб-сайт на сервере, таком как WordPress.
Структура файла Robots.txt
Действительный файл Robots.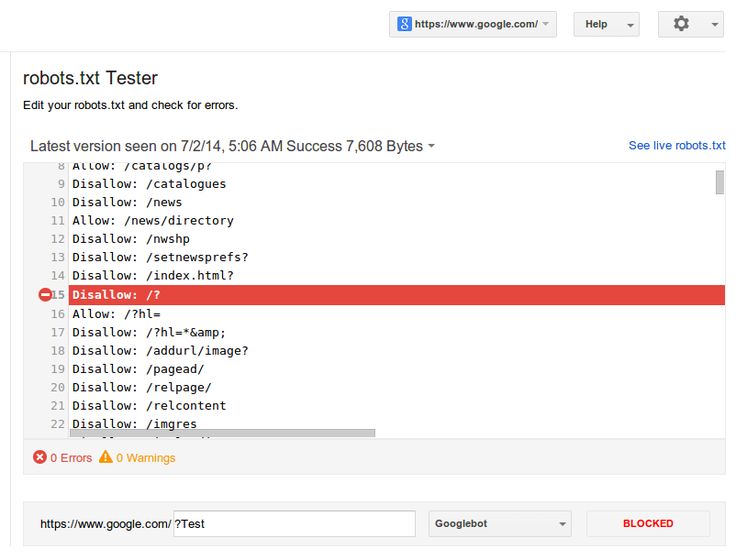 txt содержит одну или несколько директив, объявленных в формате: поле, двоеточие, значение.
txt содержит одну или несколько директив, объявленных в формате: поле, двоеточие, значение.
- User-agent: Объявляет поисковый робот, к которому применяется правило.
- Разрешить: Указывает путь, к которому должен обращаться поисковый робот.
- Disallow: Объявляет путь, к которому поисковый робот не должен обращаться.
- Карта сайта: Полный URL карты сайта структуры.
Значения должны включать относительные пути для полей разрешения/запрета, абсолютные пути (действительный URL-адрес) для карты сайта и имена поисковых роботов для поля агента пользователя. Общие имена пользовательских агентов и соответствующих поисковых систем, которые вы можете безопасно объявить в файле robots.txt, включают:
- Алекса
- ia_archiver
- АОЛ
- aolсборка
- Бинг
- Бингбот
- BingPreview
- УткаУткаГоу
- УткаДакБот
- Гугл
- Гуглбот
- Googlebot-Изображение
- Googlebot-видео
- Яху
- Хлеб
- Яндекс
- Яндекс
Необъявленные сканеры следуют директиве all * .
Общие директивы Robots.txt
Правила в файле robots.txt должны быть действительными, иначе поисковые роботы будут игнорировать недопустимые правила синтаксиса. Допустимое правило должно включать путь или полный URL-адрес. В приведенных ниже примерах показано, как разрешать, запрещать и контролировать поисковые роботы в файле robots.txt.
1. Предоставить веб-сканерам доступ к файлам веб-сайта
Разрешить одному веб-сканеру доступ ко всем файлам веб-сайта.
Агент пользователя: Bingbot Разрешать: /
Разрешить всем поисковым роботам доступ к файлам веб-сайта.
Агент пользователя: * Разрешать: /
Предоставьте поисковому роботу доступ к одному файлу.
Агент пользователя: Bingbot Разрешить: /documents/helloworld.php
Предоставить всем поисковым роботам доступ к одному файлу.
Агент пользователя: * Разрешить: /documents/helloworld.php
2. Запретить поисковым роботам доступ к файлам веб-сайта
Запретить поисковым роботам доступ ко всем файлам веб-сайта.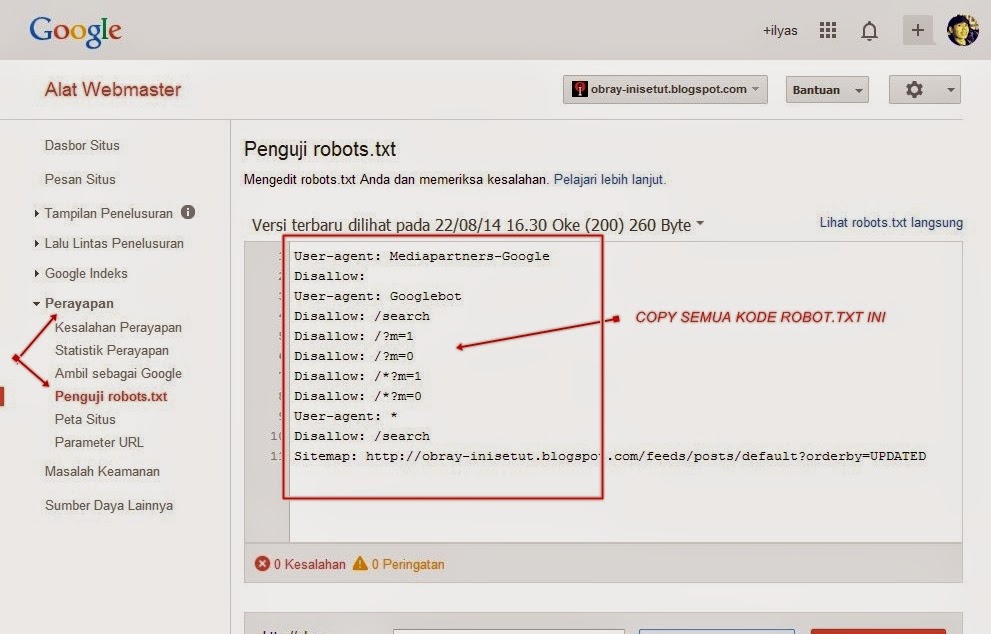
Агент пользователя: Googlebot Запретить: /
Запретить всем поисковым роботам доступ к файлам веб-сайта.
Агент пользователя: * Запретить: /
Запретить поисковому роботу доступ к одному изображению.
Агент пользователя: MSNBot-Media Запретить: /documents/helloworld.jpg
Запретить поисковому роботу доступ ко всем изображениям определенного типа.
Агент пользователя: MSNBot-Media Запретить: /*.jpg$
Вы также можете запретить определенному сканеру изображений доступ ко всем изображениям веб-сайта. Например, следующее правило предписывает изображениям Google игнорировать все и удалять проиндексированные изображения из своей базы данных.
Агент пользователя: Googlebot-Image Запретить: /
Запретить поисковым роботам доступ ко всем файлам, кроме одного.
Агент пользователя: * Запретить: /~documents/helloworld.php
Чтобы явным образом разрешить доступ к нескольким файлам, повторите правило Disallow :
User-agent: * Запретить: /~documents/hello.
 php
Запретить: /~documents/world.php
Запретить: /~documents/again.php
php
Запретить: /~documents/world.php
Запретить: /~documents/again.php
Указание всем поисковым роботам обращаться к файлам веб-сайта, но игнорировать определенный файл.
Агент пользователя: * Разрешать: / Запретить: /documents/index.html
Указание всем поисковым роботам игнорировать определенный каталог. Например: wp-admin .
Агент пользователя: * Запретить: /wp-admin/
3. Группирование директив robots.txt
Чтобы применить директивы robots.txt в группах, объявите несколько пользовательских агентов и примените одно правило.
Например:
Агент пользователя: Googlebot # Первая группа Агент пользователя: Googlebot-Новости Разрешать: / Запретить: /wp-admin/ Агент пользователя: Bing # Вторая группа Агент пользователя: Slurp Разрешать: / Запретить: /wp-includes/ Disallow: /wp-content/uploads/ # Игнорировать изображения WordPress
Приведенные выше директивы применяют одно и то же правило для каждой объявленной группы.
4. Управление интервалами сканирования веб-сканером
Запросы веб-сканера могут увеличить нагрузку на сервер, поэтому вам необходимо регулировать скорость, с которой сканеры сканируют ваш веб-сайт в секундах.
Например, следующая директива предписывает всем поисковым роботам ждать не менее 60 секунд между последовательными запросами к вашему серверу.
Агент пользователя: * Задержка сканирования: 60
Пример
Следующий пример файла robots.txt предписывает всем поисковым роботам обращаться к файлам веб-сайта, игнорировать важные каталоги и использовать карту сайта для понимания структуры веб-сайта.
Агент пользователя: * Разрешать: / Запретить: /cgi-bin/ Запретить: /wp-admin/ Запретить: /wp-includes/ Карта сайта: https://www.example.com/sitemap_index.xml
Чтобы протестировать и просмотреть файл robots.txt, посетите свой веб-сайт и загрузите файл после / . Например: http://example.com/robots. . txt
txt
Если ваш веб-сайт возвращает ошибку 404 , создайте новый файл robots.txt и загрузите его в корневой каталог вашего документа, обычно /var/www/html или /var/www/public_html .
Большинство поисковых роботов следуют вашим директивам robots.txt. Однако плохие боты и поисковые роботы могут игнорировать ваши правила. Чтобы обезопасить свой сервер, заблокируйте вредоносных ботов с помощью файла .htaccess , если вы используете стек LAMP на своем сервере, добавив в файл следующие строки:
SetEnvIfNoCase User-Agent ([a-z0-9]{2000 }) плохие_боты
SetEnvIfNoCase User-Agent (archive.org|binlar|casper|checkpriv|choppy|clshttp|cmsworld|diavol|dotbot|extract|feedfinder|flicky|g00g1e|harvest|heritrix|httrack|kmccrew|loader|miner|nikto|nutch|planetwork |postrank|purebot|pycurl|python|seekerspider|siclab|skygrid|sqlmap|sucker|turnit|vikspider|winhttp|xxxyy|youda|zmeu|zune) bad_bots
Заказать Разрешить, Запретить
Разрешить от всех
Запретить от env=bad_bots
Все, что вам нужно знать о robots.
 txt
txtМы говорим о robots.txt и о том, как заставить эти файлы работать на вашем сайте. С файлами robots.txt вы отвечаете за то, какие поисковые системы сканируют ваш сайт, что может привести к положительным изменениям.
Вы узнаете, что это такое, как их использовать и как убедиться, что вы все делаете правильно ! Если вы хотите получить более высокий рейтинг, вам нужно больше узнать о robots.txt.
Связанная ссылка: Полное руководство для начинающих по отображению на первой странице Google
Что такое файл robots.txt?
Проще говоря, файлы robots.txt либо разрешают, либо блокируют доступ сканеров к частям вашего веб-сайта.
При поиске определенной темы в поисковой системе некоторые боты рассредоточиваются, чтобы найти искомую информацию. Цель состоит в том, чтобы пользователи, выполняющие поиск, попадали на ваш сайт, но на вашем веб-сайте есть части, которые вы, возможно, не хотите сканировать . Вот где на помощь приходят файлы robots.txt.
Вот где на помощь приходят файлы robots.txt.
Дорожная карта была разработана специально для ботов, и обычно боты не отклоняются от дорожной карты.
Файлы robots.txt либо разрешают, либо блокируют поисковым роботам доступ к частям вашего веб-сайта. Они делают это с помощью директив, которые сообщают каждой поисковой системе, могут они или не могут выполнять поиск на странице. Как и в любом другом случае, есть ограничения на правила, но эти директивы работают очень хорошо, и применение этих файлов может быть очень полезным для вашего SEO.
Где находятся файлы robots.txt?
Если вы не знаете, где искать и редактировать файлы robots.txt, вам будет приятно узнать, что их относительно легко найти.
Файлы robots.txt хранятся в корневом каталоге. Просто введите базовый URL-адрес веб-страницы «/robots.txt». Вы перейдете на страницу с обычным текстом, где сможете просматривать и редактировать все файлы robots.txt на своем веб-сайте.
У вас его нет?
В этот момент вы можете спросить себя зачем нужны файлы robots. txt? Нужны ли они?
txt? Нужны ли они?
Возможно, вы считаете, что продвигаете свой блог хорошо, и вам не нужна дополнительная помощь.
Правда в том, что внедрение файлов robots.txt может быть полезным для SEO вашего веб-сайта несколькими способами.
Может быть конфиденциальная информация, которую вы не хотите видеть в поисковой выдаче, или, может быть, страница просто не представляет ценности. Какой бы ни была причина, использование файла robots.txt для управления сканированием вашего веб-сайта — это то, что должны учитывать все сайты. На самом деле это рекомендуется Google , чтобы веб-сайты включали эти файлы.
Как упоминалось ранее, файлы robots.txt блокируют сканирование определенных частей вашего сайта. Эти файлы можно изменить, чтобы определенные поисковые роботы не могли находить и индексировать вашу страницу. Если веб-сайт сканируют слишком много третьих лиц, это может замедлить работу вашего сайта.
Ссылка по теме: Лучшие плагины SEO для WordPress
Создайте свой собственный
Одна из прекрасных особенностей файла robots. txt — его простота создания. Возможно, вы заметили, что на вашем сайте их нет, и хотите их создать. Это относительно простая задача, которая можно сделать в текстовом редакторе .
txt — его простота создания. Возможно, вы заметили, что на вашем сайте их нет, и хотите их создать. Это относительно простая задача, которая можно сделать в текстовом редакторе .
Вам нужно будет создать новый файл в простом текстовом редакторе (например, Блокнот) и сохранить его как «robots’txt».
Далее вам потребуется получить доступ к корневому каталогу вашего сайта. Это можно сделать, войдя в cPanel и найдя папку public_html. Как только вы найдете это, вы можете перетащить файл Блокнота.
Наконец, вам нужно установить права доступа к файлу. Как владелец, вы хотите иметь полный доступ к файлу, и вы хотите заблокировать полный доступ для всех других сторон. Вы хотите иметь возможность «читать», «записывать» и «выполнять» файлы как владелец.
User-Agents
Когда вы идентифицируете пользовательский агент индивидуально, бот, сканирующий ваш сайт, будет привлечен к строкам, в которых он упоминается.
User-Agent звучит намного сложнее, чем есть на самом деле. По сути, это то, как каждая поисковая система идентифицирует себя. Если вы спуститесь в кроличью нору, вы найдете сотни пользовательских агентов, но лишь немногие из них полезны для практики SEO.
По сути, это то, как каждая поисковая система идентифицирует себя. Если вы спуститесь в кроличью нору, вы найдете сотни пользовательских агентов, но лишь немногие из них полезны для практики SEO.
То, что файл robots.txt делает с пользовательскими агентами, указывает им конкретно, что делать, когда он попадает на вашу страницу . Например, вы можете «разрешить» или «запретить» пользовательским агентам сканировать вашу страницу.
Если вы хотите обратиться сразу ко всем юзер-агентам, вы можете поставить символ «*», который называется подстановочным знаком. Это отличный способ решить одну функцию по всем направлениям.
Директивы
Директивы — это инструкции, которые вы записываете в файл robots.txt для каждого агента пользователя при сканировании вашей страницы. По сути, вы добавляете директивы, чтобы информировать сканеров о том, как взаимодействовать с вашей страницей. Хотите ли вы полностью заблокировать им доступ к странице или как взаимодействовать со страницей после ее открытия.
При создании директив будьте осторожны и не вводите противоречивые команды.
Поисковые системы будут пропускать директиву, если для них нет четкого пути.
Однако Google поддерживает не все директивы. Google просто не будет следовать некоторым командам, поэтому крайне важно быть в курсе, прежде чем писать свои директивы.
Карта сайта
Добавление карты сайта в файл robots.txt — невероятно важный совет, который нельзя упускать из виду.
По сути, XML-карты сайта предоставляют поисковым системам информацию, которую вы хотите, чтобы они искали на вашем веб-сайте . Благодаря XML-карте сайта поисковые системы могут видеть релевантные страницы и последние обновления вашего веб-сайта.
Файлы Sitemap важны, потому что они являются одними из самых популярных поисковых запросов, которые Google использует для поиска вашей страницы во время поиска.
Карты сайта могут быть мощным инструментом, поэтому добавление карты сайта в формате XML на страницу robots. txt может быть очень полезным.
txt может быть очень полезным.
Неподдерживаемые директивы
Поскольку мы говорим о директивах, важно знать, какие директивы не поддерживаются Google . Есть несколько директив, которые Google больше не поддерживает или никогда не поддерживал. Однако бывают случаи, когда у Google есть альтернатива.
Google не поддерживает директивы Nofollow, Noindex, Host Directive и Cawl Delay.
Nofollow
Первой неподдерживаемой директивой являются директивы Nofollow. Эти директивы были разработаны, чтобы указать агентам пользователя не переходить по ссылкам на страницы и файлы на указанной странице.
Единственный способ запретить Google переходить по ссылкам сейчас — использовать атрибут ссылки rel= «nofollow».
Noindex
Директивы Noindex — это вторая директива, не поддерживаемая Google. Эта директива позволяет Google сканировать и индексировать вашу страницу, но не будет включать ее в результаты поиска. Однако есть способы скрыть содержимое вашей страницы.
В качестве альтернативы вы можете использовать тег noindex, защиту паролем или код состояния HTTP 404 и 410.
Crawl-Delay
Crawl-Delays поддерживаются Яндексом и Bing, но, к сожалению, не Google. Crawl-delays — это директива, которая сообщает агентам пользователя о задержке во времени между каждым сканированием.
Host Directive
Яндекс поддерживает только эту директиву, поэтому не лучшая директива, чтобы полагаться на . Однако перенаправление 301 имени хоста, которое вам не нужно, на то, которое вам нужно, поддерживается всеми платформами.
Директива host позволяет пользователям настраивать, хотят ли они показывать «www». перед их URL. На практике это выглядит так:
Хост: example.com.
Ссылка по теме: Как настроить перенаправление NGINX 301
Директива запрета
Директивы запрета именно так и звучат. Они не позволяют поисковым системам получать доступ к страницам вашего веб-сайта, которые помечены как таковые.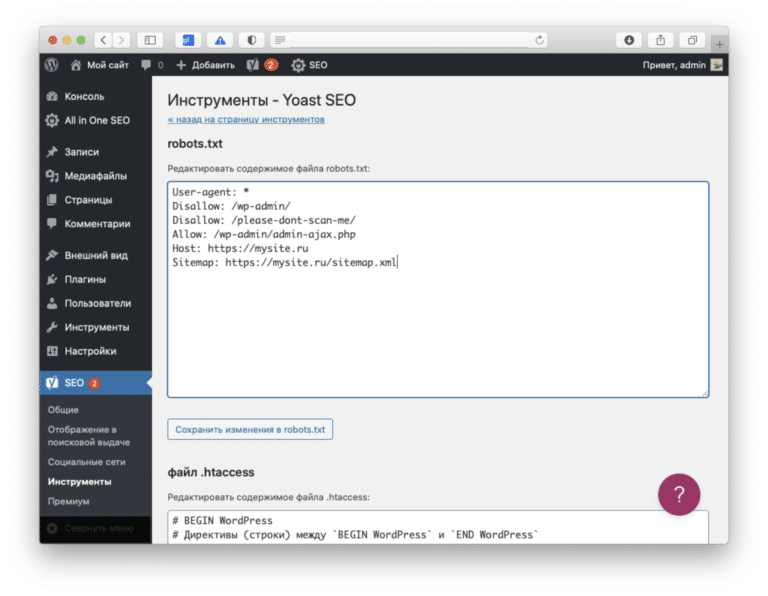 Google поддерживает эти директивы, но они могут быть немного сложными.
Google поддерживает эти директивы, но они могут быть немного сложными.
Запреты могут быть обманчивы, потому что они не работают со ссылками на эту страницу . Google все еще может найти их по исходящим ссылкам. Если по какой-то причине эти исходящие ссылки заставят Google добавить их в качестве страницы результатов, он сделает это, несмотря на то, что ему запрещено сканировать вашу страницу.
Для страниц, содержащих конфиденциальную информацию, или страниц, которые вы действительно не хотите видеть в результатах поиска, запрет может быть не лучшим вариантом.
Передовой опыт
Использовать пользовательские агенты только один раз
Использование и пользовательский агент только один раз является хорошим практическим правилом, в основном для того, чтобы пользователь не совершал ошибок. Google автоматически объединит все директивы, независимо от того, сколько раз указан пользовательский агент. Однако, если вы запутались во всех списках, это может быть дорого .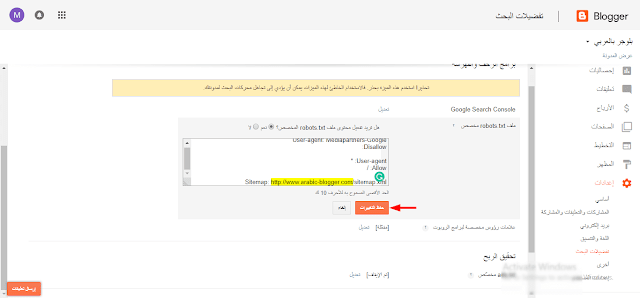 Лучшей практикой было бы перечислить ваш пользовательский агент, а затем поместить все команды, которые вы хотите применить, под этой записью.
Лучшей практикой было бы перечислить ваш пользовательский агент, а затем поместить все команды, которые вы хотите применить, под этой записью.
Используйте «$», чтобы показать конец URL-адреса
Используйте «$» в конце URL-адреса. Это полезный инструмент, чтобы сообщить Google, какие URL-адреса нельзя сканировать или индексировать. Например:
User-agent: *
Disallow: /*.jpg$
Это означает, что Google будет запрещено сканировать или индексировать любые URL-адреса, оканчивающиеся на «.jpg». Однако это не означает, что Google не может найти «.jpg?id=123».
Напишите , конкретно , какие URL-адреса вы хотите заблокировать.
Каждая директива на новой строке
При написании файла robots.txt убедитесь, что строки не перегружены информацией. Каждая директива должна располагаться на новой строке. Это позволит избежать путаницы для поисковых систем и предотвратит любые нежелательные ошибки.
Будьте конкретны
Конкретность — это ключ к избежанию ошибок.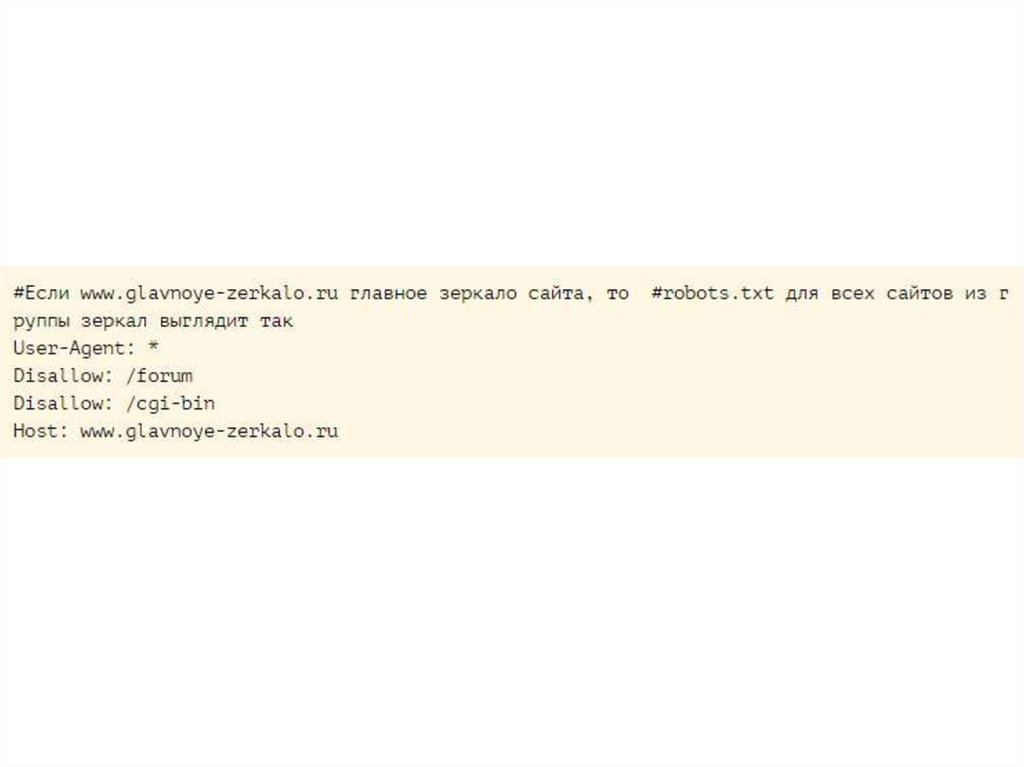 мельчайших деталей могут оказать существенное влияние на SEO 9.0027 . Убедитесь, что вы закрыли все записи с помощью «/», чтобы убедиться, что это не влияет на похожие страницы, или с помощью «$», чтобы закрыть URL-адреса, чтобы уберечь вас от проблем в будущем.
мельчайших деталей могут оказать существенное влияние на SEO 9.0027 . Убедитесь, что вы закрыли все записи с помощью «/», чтобы убедиться, что это не влияет на похожие страницы, или с помощью «$», чтобы закрыть URL-адреса, чтобы уберечь вас от проблем в будущем.
Быть организованным во время любых серьезных изменений на вашем веб-сайте очень важно для поддержания SEO на вашей странице.
Ссылки по теме: Контрольный список миграции веб-сайта: передовой опыт SEO
Упрощение инструкций с помощью подстановочных знаков
Подстановочные знаки могут сэкономить массу времени и путаница. Использование этой «*» — идеальный способ сделать ваши файлы robots.txt быстрыми и легкими. Подстановочные знаки — это, по сути, опция «выбрать все», когда речь идет о пользовательских агентах. Однако то же самое можно применить и к URL-адресам! Например:
User-agent: *
Disallow: /photos/*?
Используйте комментарии, чтобы объяснить себя
Если вы пишете файл robots.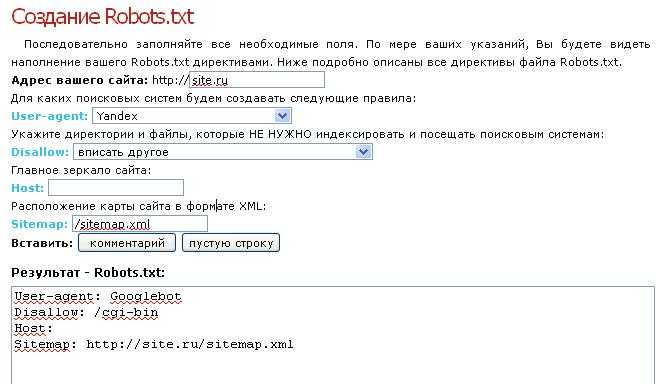 txt для кого-то другого или нервничаете, вы можете забыть, почему именно вы что-то поместили туда, где вы это сделали, оставляя комментарии — это приемлемый способ объяснить, почему вы написали раздел, как вы сделали. Просто напишите «#», а затем свое объяснение в отдельной строке, и все готово. Краулеры будут игнорировать все, чему предшествует «#».
txt для кого-то другого или нервничаете, вы можете забыть, почему именно вы что-то поместили туда, где вы это сделали, оставляя комментарии — это приемлемый способ объяснить, почему вы написали раздел, как вы сделали. Просто напишите «#», а затем свое объяснение в отдельной строке, и все готово. Краулеры будут игнорировать все, чему предшествует «#».
Каждый поддомен получает свой
К сожалению, вы не можете объединить файлы robot.txt в поддомен вашего веб-сайта. Например, если вы являетесь владельцем сайта example.com, но все ваши фотографии размещены на сайте photos.example.com, для них потребуются отдельные файлы robot.txt.
Не блокировать хороший контент
Редактируя файлы robot.txt, убедитесь, что вы не блокируете хороший контент по своей воле. Это может легко случиться с опечатка или просто опечатка . Поэтому обязательно проверяйте и перепроверяйте свои файлы! Целью является привлечение трафика на ваш сайт, а хороший контент — вот что делает это.
Чувствительность к регистру
Обратите внимание; в файлах robots.txt учитывается регистр. Если в вашем файле неправильный регистр заглавных букв, поисковые системы не будут следовать директивам, которые вы для него установили. Хорошее эмпирическое правило состоит в том, чтобы создать файл как можно скорее, во избежание ошибок. Еще одна хорошая практика — стараться всегда использовать строчные буквы. Таким образом, не составит труда запомнить, какая заглавная буква куда идет.
Не злоупотребляйте задержкой сканирования
Задержки сканирования могут быть полезны, чтобы убедиться, что ваш сайт не перегружен. Однако есть способ злоупотребить этой директивой. Если у вас большой или растущий сайт, задержка может стоить вам нескольких ценных поисков . Просто имейте в виду, что в будущем это может стоить вам органического трафика и ранжирования.
Проверка на наличие ошибок
Как вы видели, относительно легко допустить ошибки в файлах robots. txt. Вы захотите периодически проверять, все ли работает гладко, и, к счастью, есть довольно простой способ сделать это. Использование Google Seach Console , в отчете «Покрытие» вы сможете найти ошибки и устранить их.
txt. Вы захотите периодически проверять, все ли работает гладко, и, к счастью, есть довольно простой способ сделать это. Использование Google Seach Console , в отчете «Покрытие» вы сможете найти ошибки и устранить их.
Ошибка: отправленный URL-адрес заблокирован robots.txt
Если вы видите эту ошибку, это означает, что некоторые части вашей карты сайта заблокированы файлами robots.txt. Это может произойти, если в карту сайта включены перенаправленные, неиндексированные или канонизированные страницы.
Самый простой способ найти и решить проблему — использовать тестер Google robots.txt .
Ошибка: заблокировано robots.txt
Сообщение об ошибке «заблокировано ошибкой robots.txt» означает, что на вашем веб-сайте есть страница, которая заблокирована, но еще не проиндексирована Google. Вы можете снять блокировку, если эта информация важна и вы хотите, чтобы она была проиндексирована. Если страница намеренно заблокирована, вы можете использовать метатег robots или заголовок x-robots, чтобы удалить ошибку и скрыть содержимое.
Ошибка: проиндексировано, но заблокировано robots.txt
Эта ошибка означает, что Google все же проиндексировал часть заблокированного контента . Это похоже на решение предыдущей проблемы. Удаление блока сканирования и использование метатега или заголовка x-robots — лучшее решение, если вы все еще не хотите, чтобы он индексировался. Или, если это было непреднамеренно, снимите блокировку, чтобы восстановить видимость.
Заключение
Изучение особенностей файла robots.txt может повысить эффективность сканирования вашего веб-сайта поисковыми системами. Требуется некоторое время, чтобы привыкнуть, и ошибки могут быть существенными. Но если вы потратите время на изучение, нет сомнений, что ваше SEO может иметь очень позитивные изменения.
Полное руководство для начинающих по Robots.txt: рекомендации и примеры
У вас больше возможностей, чем вы думаете, когда дело доходит до контроля сканирования и индексации вашего сайта поисковыми роботами. И эта сила заключена в файле robots.txt.
И эта сила заключена в файле robots.txt.
В этом посте я покажу вам, что такое файл robots.txt, почему он важен и как вы можете легко создать его самостоятельно или с помощью нашего бесплатного генератора Txt для роботов. Вы также узнаете о метатегах robots, о том, как они соотносятся с файлом robots.txt и как оба они могут оказать большое влияние на SEO.
Знаете ли вы, что находится в вашем файле robots.txt?
На первый взгляд, «файл robots.txt» звучит как сложный кодовый термин, но на самом деле его концепция довольно проста для понимания.
Файл robots.txt сообщает роботам поисковых систем, какие части вашего сайта следует посещать, сканировать и индексировать, а от каких частей сайта следует держаться подальше. Это не заменяет защиту конфиденциальной или личной информации от отображения на страницах результатов поисковых систем или в поисковой выдаче. Если вам нужно защитить конфиденциальную или личную информацию, рассмотрите возможность защиты страницы паролем или блокировки индексации.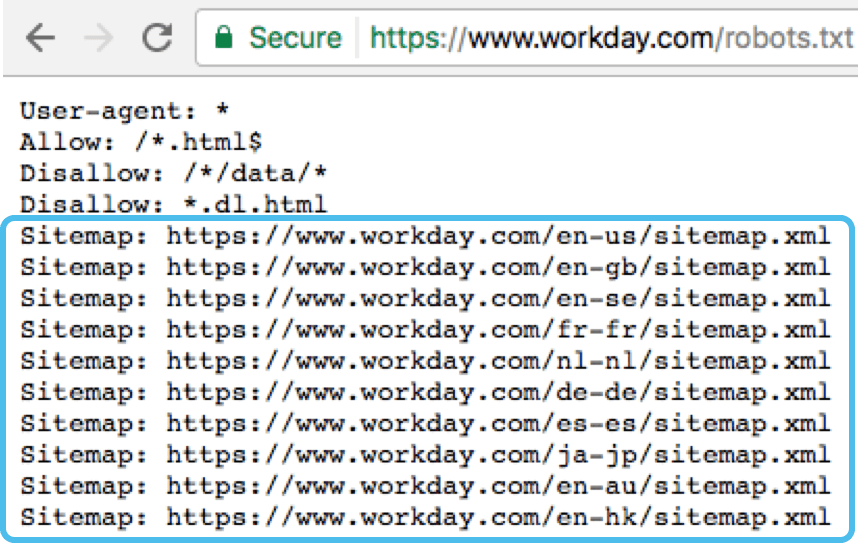
Думайте о своем веб-сайте как о музее, а файл robots.txt — это путеводитель, который позволяет вам узнать, какие экспонаты посетить, а какие места в настоящее время закрыты для посетителей.
В файле robots.txt есть директивы, сообщающие роботам поисковых систем, какие страницы разрешено сканировать, а какие нет. Бот поисковой системы или поисковый робот — это программа, которая сканирует и индексирует информацию о любом сайте в Интернете. Цель состоит в том, чтобы каталогизировать информацию, чтобы те, кто ищет ее, могли получить ее через результаты страницы поисковой системы.
В файле robots.txt вы можете обращаться ко всем ботам поисковых систем с помощью звездочки (*). Это будет выглядеть так:
User-Agent: *
Или вы можете поговорить конкретно с одним ботом, который будет выглядеть так:
User-Agent: GoogleBot
User-Agent: HaoSouSpider
После того, как вы определите, какие боты вы разговариваете, пришло время решить, что вы хотите разрешить или запретить. Для этого вы просто указываете «разрешить» или «запретить», а затем указать нужный URL-адрес. Вот пример нашей страницы robots.txt:
Для этого вы просто указываете «разрешить» или «запретить», а затем указать нужный URL-адрес. Вот пример нашей страницы robots.txt:
Как вы можете видеть здесь, мы обращаемся ко всем ботам поисковых систем, потому что у нас есть «User-Agent: *». content/uploads/, но мы не разрешаем ботам сканировать URL-адреса, заканчивающиеся на /wp-content/plugins/ и /wp-admin/.
Однако у Nike гораздо более сложный файл robots.txt. Посмотрите на пример ниже:
Nike обращается ко всем поисковым роботам из первой группы правил, а затем вызывает определенных ботов из второй и третьей групп правил.
Каждая группа правил в файле robots.txt имеет разные директивы: пользовательский агент, разрешить, запретить, карту сайта. Nike добавляет немного изюминки в свой файл robots.txt в начале: «просто сканируй это», отсылка к их культовому слогану «просто сделай это», а в конце они включают классическую галочку Nike, как показано ниже.
Вам не нужно настраивать файл robots. txt таким образом, чтобы он работал эффективно, так что не расстраивайтесь. Просто сосредоточьтесь на 4 основных директивах:
txt таким образом, чтобы он работал эффективно, так что не расстраивайтесь. Просто сосредоточьтесь на 4 основных директивах:
1. User-Agent: определяет, к какой поисковой системе применяется это правило
2. Разрешить: определяет, разрешено ли сканирование и индексирование сайта
4. Карта сайта: указывает местоположение карты сайта для сайта
Если вы просто хотите разрешить или запретить все части вашего сайта, просто используйте ‘/’ Это может выглядеть так:
User-agent: *
Разрешить: /
Если у вас по незнанию есть файл robots.txt, который блокирует поисковые роботы на вашем сайте, это может серьезно помешать вашим усилиям по SEO в долгосрочной перспективе, поэтому лучше иметь надежный файл robots.txt как можно раньше.
Понимание огромного влияния файла robots.txt на ваш сайт.
Наличие файла robots.txt для вашего сайта не обязательно, поэтому, если у вас его нет, не беспокойтесь. Сайты без файла robots.txt обычно сканируются и индексируются поисковыми роботами. Но если вы хотите иметь больший контроль над своим SEO-рейтингом, вот некоторые из преимуществ наличия файла robots.txt для вашего сайта.
Сайты без файла robots.txt обычно сканируются и индексируются поисковыми роботами. Но если вы хотите иметь больший контроль над своим SEO-рейтингом, вот некоторые из преимуществ наличия файла robots.txt для вашего сайта.
Блокировать повторяющийся контент: Дублированный контент может повредить вашему рейтингу в поисковых системах, поэтому убедитесь, что страницы с дублирующимся контентом недоступны для поисковых роботов. для всех веб-сайтов. Веб-сайты с высоким авторитетом получают более высокий краулинговый бюджет, поскольку содержат большое количество полезной и достоверной информации. Независимо от уровня авторитетности вашего сайта возможности сканирования поисковыми системами ограничены, поэтому наличие файла robots.txt позволяет поисковым роботам сосредоточиться на индексировании качественной информации.
Передача по ссылочному капиталу: Ссылочный капитал — это значение, которое «Сайт Б» получает, когда «Сайт А» ссылается на него. Когда «А» получает высокий трафик и передает часть этого трафика «Б», тогда «Б» получает увеличение трафика, и это пример передачи капитала. Идеально созданный файл robots.txt позволяет направлять трафик на ценные страницы и ограничивает видимость менее желательных страниц.
Когда «А» получает высокий трафик и передает часть этого трафика «Б», тогда «Б» получает увеличение трафика, и это пример передачи капитала. Идеально созданный файл robots.txt позволяет направлять трафик на ценные страницы и ограничивает видимость менее желательных страниц.
Любой может создать файл robots.txt — вам не нужно звонить в ИТ.
Каждый веб-сайт может иметь один файл roebots.txt, который находится в корневом каталоге вашего сайта. Итак, если ваш веб-сайт www.samplesite.com, ваш файл robots.txt будет находиться на www.samplesite.com/robots.txt/. Ваш файл robots.txt нельзя размещать в подкаталогах, подобных www.samplesite.com/plantcare/robots.txt.
Вы можете создать файл robots.txt в любом обычном текстовом редакторе, например, в Блокноте. Программное обеспечение для обработки текстов не идеально подходит для создания файлов такого типа, поскольку оно может добавлять ненужные символы, когда файл сохраняется в проприетарном формате. Вот 5 вещей, о которых следует помнить при создании файла robots.txt:
Вот 5 вещей, о которых следует помнить при создании файла robots.txt:
- Имя файла robots.txt
- Убедитесь, что файл находится в корневом каталоге вашего сайта
- Создайте одну или несколько групп правил
- В группе правил добавить директиву
- Агент пользователя
- Разрешить
- Запретить
- Карта сайта
- Помните, что поисковые роботы часто сканируют страницу по умолчанию, поэтому, если вы хотите заблокировать сканирование и индексирование, дайте директиву запрета .
Наш бесплатный генератор robots.txt упрощает творческий процесс.
Чтобы помочь вам создать идеальный файл robots.txt, у нас есть бесплатный генератор, который вы можете использовать в любое время. Просто введите информацию, и для вас будет создан файл robots.txt. Наш бесплатный генератор robots. txt прост и удобен в использовании.
txt прост и удобен в использовании.
После того, как вы создали файл robots.txt, пришло время загрузить его в соответствии с требованиями хоста вашего веб-сайта. Некоторые хосты веб-сайтов, такие как Wix, могут создать для вас файл robots.txt, и в этих случаях вы не сможете создавать, редактировать и загружать файл robots.txt вручную.
Не уверены, есть ли на вашем сайте файл robots.txt? Вот как вы можете это проверить.Возможно, на вашем сайте уже есть файл robots.txt, и вы можете легко это проверить. Просто введите свой URL-адрес и добавьте «/ robots.txt», и ваш файл robots.txt должен появиться.
Robots.txt и метатеги robots являются сестрами, а не близнецами.
Метатеги robots и файл robots.txt содержат инструкции для поисковых роботов, но метатеги robots предоставляют более конкретные параметры. Файл robots.txt содержит 4 директивы: User-Agent, Allow, Disallow и Sitemap.
Метатеги robots имеют 10 различных параметров: Noindex, Index, Follow, Nofollow, Noimageindex, None, Noarchive, Nocache, Nosnippet, Unavailable_after.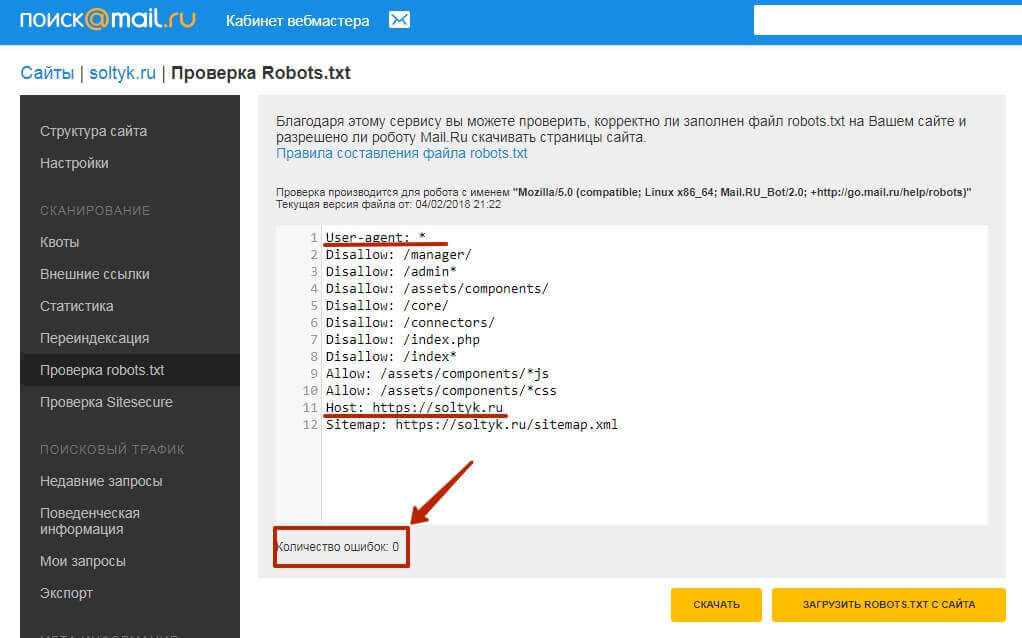 Каждый из этих параметров по-разному направляет поисковый робот. Позволь мне объяснить.
Каждый из этих параметров по-разному направляет поисковый робот. Позволь мне объяснить.
- Noindex : Вы не хотите, чтобы эта страница индексировалась.
- Индекс: Вы хотите, чтобы эта страница была проиндексирована. Сканирование и индексация выполняются автоматически, поэтому в большинстве случаев вам не нужно их использовать.
- Подписаться: Передайте ссылку на эквити, пожалуйста! Используйте этот параметр, если вы хотите передать доступ к связанным страницам, которые не проиндексированы.
- Nofollow: Пожалуйста, не переходите по этим ссылкам!
- Noimageindex: Лучше не включать изображения. Когда поисковые роботы видят это, они знают, что нельзя индексировать изображения на странице.
- Нет: Вы хотите объединить мощь Noindex и Nofollow.
- Noarchive : Вы не хотите отображать кешированную ссылку на эту страницу в поисковой выдаче.
- Nocache : Версия тега Noarchive для Internet Explorer и Firefox
- Nosnippet: Вам не нужно метаописание для этой страницы в поисковой выдаче.
- Unavailable_after: Вы хотите, чтобы поисковые системы прекратили индексировать эту страницу по истечении заданного времени.

Метатег robots находится в HTML-коде веб-страницы в разделе. Вот пример того, как это может выглядеть:
В этом примере, указав «роботы», мы обращаемся ко всем поисковым роботам, а указав «noindex», мы говорим им не сканировать и не индексировать эту страницу.
Если вы хотите указать пользовательский агент, вы можете заменить «роботы» на нужный пользовательский агент, например, Googlebot.
Итак, напомним, метатег robots находится в HTML-коде конкретной веб-страницы и дает четкие инструкции поисковым роботам.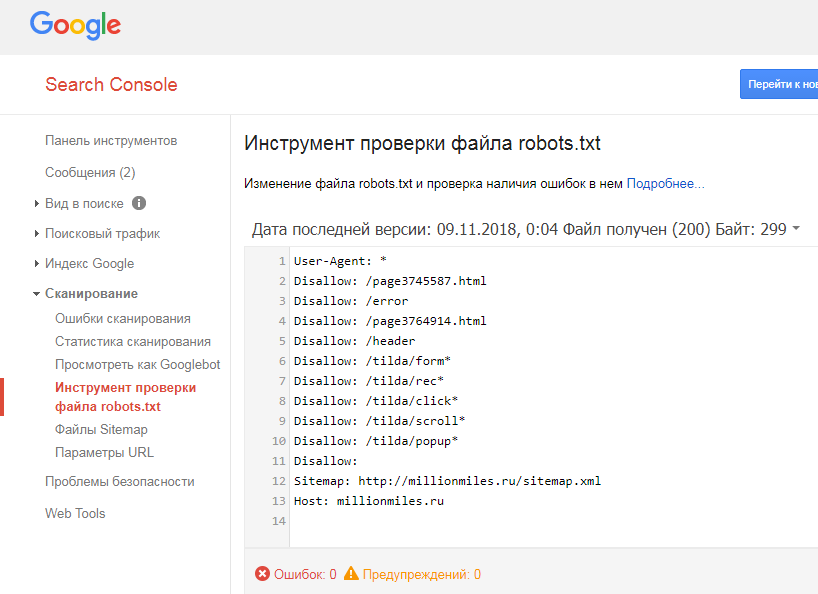 В отличие от файла robots.txt, который имеет отдельную страницу и говорит за весь веб-сайт, метатег robots говорит только за одну страницу. И robots.txt, и метатеги robots сообщают ботам поисковых систем, как сканировать и индексировать вашу страницу, что дает вам больше контроля над вашим SEO-путешествием — если вы используете их с умом.
В отличие от файла robots.txt, который имеет отдельную страницу и говорит за весь веб-сайт, метатег robots говорит только за одну страницу. И robots.txt, и метатеги robots сообщают ботам поисковых систем, как сканировать и индексировать вашу страницу, что дает вам больше контроля над вашим SEO-путешествием — если вы используете их с умом.
С большими метатегами роботов приходит большая ответственность.
Мета-теги robots могут иметь огромное влияние на SEO, как и файл robots.txt. Вы можете использовать метатеги robots вместо файла robots.txt или вместе с ним.
Если вы используете метатеги robots вместо файла robots.txt, вы можете упустить общую картину. Файл robots.txt позволяет вам увидеть, как вы направляете поисковых роботов через ваш сайт в целом, в то время как метатег robots влияет только на одну конкретную страницу. Но с другой стороны, мета-теги robots позволяют вам более конкретно указать, как вы хотите, чтобы поисковые роботы обрабатывали каждую страницу отдельно, что делает ее более настраиваемой.
Если вы используете файл robots.txt вместо мета-тегов robots, вы можете упустить мелкие детали, которые могут стоить вам денег. Хотя здорово видеть лес за деревьями, иногда вам нужны более четкие и конкретные директивы для страницы, чтобы обеспечить отображение качественного релевантного контента в поисковой выдаче, а менее релевантный контент может уйти на задний план.
Если вы решите использовать метатеги robots и файл robots.txt одновременно, вот несколько советов для достижения успеха.
- Воспринимайте файл robots.txt как путеводитель по всему сайту.
- Рассматривайте метатеги robots как путеводитель по определенной странице вашего сайта.
- И файлы robots.txt, и метатеги robots сканируются ботами поисковых систем, и оба имеют одинаковые полномочия.
- Будьте последовательны! Минимизируйте противоречия между файлом robots.txt и метатегами robots.
 txt
txt - Создавайте качественный контент. Убедитесь, что ваш контент привлекателен, заслуживает доверия и укрепляет ваш авторитет. Файлы robots.txt и метатеги robots указывают поисковым роботам, куда идти. Чем меньше вам придется прятаться, тем лучше.
- Не дублировать контент. Если на вашем сайте есть дублированный контент, обязательно скройте дубликаты с помощью robots.txt или метатегов robots. Дублированный контент может повредить вашему рейтингу SEO и снизить ваш рейтинг в поисковой выдаче.
- Не блокировать ссылочный вес. Создание ссылок — важная стратегия улучшения SEO, но она может работать только в том случае, если ссылочный капитал переносится с одного веб-сайта на другой. Если ваш файл robots.txt или метатеги robots созданы правильно, страницы, на которые вы хотите увеличить трафик, будут повышены, а менее желательные страницы отойдут на второй план и, скорее всего, останутся незамеченными.
